making sense of email addresses on drives
TRANSCRIPT

Journal of Digital Forensics, Journal of Digital Forensics,
Security and Law Security and Law
Volume 11 Number 2 Article 10
2016
Making Sense of Email Addresses on Drives Making Sense of Email Addresses on Drives
Neil C. Rowe U.S. Naval Postgraduate School
Riqui Schwamm U.S. Naval Postgraduate School
Michael R. McCarrin U.S. Naval Postgraduate School
Ralucca Gera U.S. Naval Postgraduate School
Follow this and additional works at: https://commons.erau.edu/jdfsl
Part of the Computer Engineering Commons, Computer Law Commons, Electrical and Computer
Engineering Commons, Forensic Science and Technology Commons, and the Information Security
Commons
Recommended Citation Recommended Citation Rowe, Neil C.; Schwamm, Riqui; McCarrin, Michael R.; and Gera, Ralucca (2016) "Making Sense of Email Addresses on Drives," Journal of Digital Forensics, Security and Law: Vol. 11 : No. 2 , Article 10. DOI: https://doi.org/10.15394/jdfsl.2016.1385 Available at: https://commons.erau.edu/jdfsl/vol11/iss2/10
This Article is brought to you for free and open access by the Journals at Scholarly Commons. It has been accepted for inclusion in Journal of Digital Forensics, Security and Law by an authorized administrator of Scholarly Commons. For more information, please contact [email protected].
(c)ADFSL

Making Sense of Email Addresses on Drives JDFSL V11N2
© 2016 ADFSL Page 153
MAKING SENSE OF EMAIL ADDRESSES ONDRIVES
Neil C. Rowe1, Riqui Schwamm1, Michael R. McCarrin1 and Ralucca Gera2
U.S. Naval Postgraduate School1Computer Science Department
2Applied Mathematics DepartmentMonterey, California 93943 USA
1-831-656-2462, fax 1-831-656-2814, [email protected]
ABSTRACTDrives found during investigations often have useful information in the form of email addresses,which can be acquired by search in the raw drive data independent of the file system. Using thesedata, we can build a picture of the social networks in which a drive owner participated, evenperhaps better than investigating their online profiles maintained by social-networking services,because drives contain much data that users have not approved for public display. However,many addresses found on drives are not forensically interesting, such as sales and support links.We developed a program to filter these out using a Naïve Bayes classifier and eliminated 73.3% ofthe addresses from a representative corpus. We show that the byte-offset proximity of theremaining addresses found on a drive, their word similarity, and their number of co-occurrencesover a corpus are good measures of association of addresses, and we built graphs using this data ofthe interconnections both between addresses and between drives. Results provided several newinsights into our test data.
Keywords: digital forensics, electronic mail, email, addresses, users, filtering, networks,visualization
INTRODUCTIONFinding social networks is important ininvestigating organized crime and terrorism.Social networks can be learned fromconnections recorded by social-networkingservices and discussion-forum Web pages.However, this is public information, and isoften of limited value in a criminalinvestigation in which subjects conceal keyinformation about their contacts.Furthermore, license agreements often prohibitautomated analysis of such data withoutpermission, and much user data may not beaccessible without the cooperation of the
service or page owner. A better source couldbe the contacts users store on their computersand devices in the form of electronic-mail(email) addresses, telephone numbers, streetaddresses, and personal names. Some may beinformation of which users are not awarebecause it was stored by software or left inunallocated space after deletions.
This work focuses on email-address data.Such data can indicate personal connections bythe nearby placement of pairs of addresses on adrive, similarity of words in address pairssuggesting aliases, or repeated association ofaddress pairs on a set of drives. We may thus

JDFSL V11N2 Making Sense of Email Addresses on Drives
Page 154 © 2016 ADFSL
be able to infer networks of contacts of varyingconnection strengths from the data on onedrive alone. We can then use several methodsto build visualizations of the networks to makethem easier to understand. A key obstacle isthat many addresses on a drive areuninteresting because businesses andorganizations put contact addresses into theirWeb pages and software, so we must firstexclude these. Note that seeking addresses ondrives has advantages over inspecting therecords of a mail server because it can findolder addresses removed from a server orpotential contacts never used to send mail.
LITERATURE REVIEWMost work on visualizing social networks hasfocused on social-networking sites where linksbetween people are made explicit through avariety of friend and contact links (Holzer,Malin, and Sweeney, 2005; Zhou et al, 2006;Polakis et al, 2010). They can also beextracted from text by nearby mentions ofnames of people (Laclavik et al, 2012), thoughnearness may be coincidental. So far there hasbeen little attention to the mining of addressesfrom drives, their classification, or theirconnection to social networks. There has beenwork on the classification of email messagesfrom their message headers (Lee, Shishibori,and Ando, 2007), but headers providesignificantly richer contextual information thanlists of email addresses found scattered over adrive.
TEST SETUPThis work primarily used the Real DataCorpus (Garfinkel et al, 2009), a collection ofcurrently 2401 drives from 36 countries afterexcluding 961 empty or unreadable drives.These drives were purchased as usedequipment and represent a range of business,government, and home users. We ran theBulk Extractor tool (Bulk Extractor, 2013) to
extract all email addresses, their offsets on thedrive, and their preceding and followingcharacters. Email addresses consist of ausername of up to 64 characters, a “@”, and aset of domain and subdomain names delimitedby periods. Bulk Extractor bypasses the filesystem and searches the raw drive bytes forpatterns appearing to be email addresses, so itcan find addresses in deleted files and slackspace. On our corpus, this resulted in292,347,920 addresses having an average of28.4 characters per address, of which therewere 17,544,550 distinct addresses. Thenumber of files on these drives was 61,365,153,so addresses were relatively infrequent, thoughthey were more common for mobile devices.
Sample output of Bulk Extractor:65484431478 [email protected]>\x0A> To: "'ttfaculty@cs
69257847997 [email protected]\x1E\x06\x09*\x86H\x86\xF7\x0D\x01\x09\x01\x16\[email protected]\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00
Bulk Extractor’s email-address scannerseeks domain/subdomain lists containing atleast one period and punctuating delimiters infront and behind the address. Currently, BulkExtractor handles common compressed formatsbut cannot recognize non-ASCII addresses.Recent standards for international email in theIETF’s RFC 6530 allow the full Unicodecharacter set in both usernames and domains(Klensin and Ko, 2012) so that must beconsidered in the future. Most of our corpuspredates the standard.
This work primarily used an “emailstoplist” provided by the U.S. NationalInstitute of Standards and Technology (NIST)by running Bulk Extractor on a portion oftheir software collection. Email addressesfound inside software are likely softwarecontact information and unlikely to be

Making Sense of Email Addresses on Drives JDFSL V11N2
© 2016 ADFSL Page 155
interesting, but this is not guaranteed becausesoftware developers may have inadvertentlyleft personal addresses, or deliberately putthem in to enable unauthorized data leakage.We supplemented this list with three othersources: known “blackhole” addresses used forforwarding spam(gist.github.adamloving/4401361, 482 items),known scam email addresses(www.sistersofspam.co.uk, 2030 items), andaddresses found by us using Bulk Extractor onfresh installs of standard Windows andMacintosh operating systems (332 items).After eliminating duplicates, the stoplist had496,301 addresses total.
We also created four important word listsfor use in interpreting the words withinaddresses:
809,858 words of the online dictionariesused in (Rowe, Schwamm, andGarfinkel 2013). The English word listwas 223,525 words from two dictionarysources and included morphologicalvariants. 587,258 additional wordswere from Croatian, Czech, Dutch,Finnish, French, German, Greek,Hungarian, Italian, Norwegian, Polish,Portuguese, Romanian, Serbian,Spanish, Swedish, and Turkishdictionaries and transliterated toASCII. We did not consider languageslike Arabic and Chinese whosetransliteration to ASCII wasproblematic. We converted words tolower case, eliminated those that werealso personal names and genericusernames, and eliminated non-Englishone-letter and two-letter words sincethey caused too many false matches tocode strings. Unlike in our previouswork, we did not include abbreviations,acronyms, and words found only insidesoftware.
102,426 personal names including bothgiven names and surnames. Weobtained international coverage byusing a variety of resources includingproposed baby names. Anotherapproximately 15,000 were found byinspecting the training set and stop list.
3,515 names of email and messagingservers. Some had words like “mail”and “chat” in their domains, but othersrequired Web research to determinetheir function.
2,813 “generic usernames” representinggeneric addresses such as businesscontacts. These we identified bymanually inspecting the training setand stoplist. Table 1 gives examples.
Table 1Example generic usernamesauctions backup beautycallcenter conference downloadeditor feedback grouphomepage ideas jobsindialinux marketinfo nobodyoutlet passwords registrationresponse save testingtickets update yourmatches
ELIMINATINGUNINTERESTING
ADDRESSESA first step is to remove addresses unlikely tobe interesting in a forensic investigation. Wehave clues in both the username and thedomain/subdomain names. For instance,[email protected] uses two humannames in the username, and a domain namethat includes “mail” to suggest a mail server;these clues suggest it is an interesting address.On the other hand, [email protected] uses the frequentgeneric term “sales” in the username, and thedomain is a “.com” without indication of a

JDFSL V11N2 Making Sense of Email Addresses on Drives
Page 156 © 2016 ADFSL
server; so mail to or from this address isunlikely to be interesting, and the addressshould be removed from further analysis. Caseusually does not matter in addresses, so weconverted all to lower case after the caseanalysis described in section 4.4.
Training/test setsWe obtained data for training and testing ouruser-address identification by first taking arandom sample of 6638 of the 17 milliondistinct addresses in our corpus, manuallyinspecting them to assess whether they werelikely to be personal user addresses, andlabeling them accordingly. Most were easy toassess, but some required research on the Webto determine the nature of their sites. A fewcases in the random sample (about 50 or so)about which we could not reach a cleardetermination were excluded. We needed toexclude these because it is not ethical to justtry sending mail to an address, and manyaddresses are no longer valid since our corpusspans twenty years. We supplemented thisrandom sample with a random sample of 1000items from the NIST address stoplist, markingthem as nonusers. This resulted in 7638distinct addresses of which 3061 were labeledas users and 4577 were labeled as nonusers.We used this test for both training and testing,choosing disjoint subsets from it.
Clues to interesting anduninteresting addresses
The stoplist matched 27.5% of the addresses inour corpus, and missed many obviouslynonuser addresses. Thus it was important touse evidence from multiple other clues for theremaining addresses. We compiled a set ofclues from a number of sources for testing:
Whether the address was in ourcombined stoplist.
The number of drives on which theaddress occurred in our corpus.
Addresses that occur on many drivesare likely to be contact addresses ofsoftware vendors, which we consideruninteresting. (That reflects therandom-sample nature of our corpus; inother corpora, addresses occurring onmany drives may well be interesting.)Note that it is important to count thenumber of drives rather than thenumber of occurrences of the addressbecause addresses can occur repeatedlyon a drive when it is used for automaticcontact. Figure 1 shows thedistribution of the logarithm of thenumber of drives on which an addressoccurred, ignoring the approximately 14million addresses that occur on onlyone drive so the leftmost bar is for 2drives.
The occurrence of automatic-contactpatterns in the characters preceding theaddress. Table 2 shows the patterns weused, found by analysis of our trainingsets.
The number of times in succession theaddress occurred on the drive withoutintervening addresses; repeatedoccurrences suggest automated logging.
Figure 1. Histogram of number of drives on which anemail address occurs in the full corpus, versus thenatural logarithm of the number of drives

Making Sense of Email Addresses on Drives JDFSL V11N2
© 2016 ADFSL Page 157
Figure 2 plots the fraction of useraddresses as a function of the naturallogarithm of successive occurrences, forthe addresses of the training set usingcounts from our full corpus. From thiswe chose a threshold of 3.91 (50occurrences) for a Boolean clue.
The length in characters of the domainsand subdomains.
The domain type. The categories weused were mail or messaging server, oneof {.com, .co, .biz, .coop}, one of {.edu,.ac, .pro}, one of {.org, .gov, .govt, .gv,.gouv, .gob, .mil, .int, .museum, .arpa},one of {.net, .info, .aero}, and anyother domain. Mail and messagingservers were defined by occurrence of aknown server name in any of the wordsdelimited by periods following the “@”or any inclusion of the string “mail.”The other domain categories weredefined by the subdomain on the rightend after removing any two-lettercountry codes. This means that“yahoo.com” was considered a serverbut “legalsoftware.co.uk” was considereda “.com.”
Table 2Patterns we seek in immediately previous characters toindicate automated-contact addresses.“ for <” “> from:”“>from: cab <” “return-path: <”“internet:” “email=”“mailto:” “fromid=”“set sender to” “email address:”“/Cookies/”
The type of country in the domainname (assuming U.S. if none). Thecategories we used were U.S., developedworld, developing world, and other.
Whether a word in the domain-subdomain list matched a word in theusername, e.g.“[email protected].”
The length in characters of theusername.
Whether the first character of theusername was a digit.
Whether the last character of theusername was a digit.
The assessed likelihood of the usernamebeing a human name once split asnecessary into recognizablecomponents, as will be explained insection 4.4.
The type of file, if any, in which theemail address occurred based on itsextension and directory. This requiresrunning a different tool to calculateoffset ranges of files (we used the
Figure 2. Fraction of user addresses versus the naturallogarithm of the number of times they occurred insuccession in our training set

JDFSL V11N2 Making Sense of Email Addresses on Drives
Page 158 © 2016 ADFSL
Fiwalk tool in SleuthKit), andmatching address offsets to theseranges. Only 1673 of the 7638addresses in our training set occurredeven once within a file, so we ignoredthis clue in tests although it may helpon occasion.
Evidence combinationTo combine clues in these experiments, weused Naïve Bayes inference in the odds form:│ & &…&= ( | ) ( | ) … ( | ) ( )
Here U represents the identification as auser address, represents the occurrence ofthe ith clue, o means odds, and “|” means“given.” Linear weighted sums such as withartificial neural networks and support vectorsare a mathematically similar alternativerelated logarithmically to the above formula.Decision trees are not appropriate for this taskbecause few of the clues are binary, and case-based reasoning is not appropriate because itcould require considerable computation time tofind the nearest match for this task whichincludes many nonnumeric attributes. We didnot use any weighting on the clues other thanthat provided by the computed oddsthemselves, an approach to weighting whichwe have found sufficient in previousexperiments.
To smooth for clues with low counts, weincluded the Laplacian addition constant :( | ) = ( ( | ) + ( ))/( (~ | ) + )
where ( ) means the count of X, and ~Xmeans not X. In the experiments we willdiscuss with 100 random runs with the samerandom seed before each group of 100, wecalculated the F-score when varying theconstant as shown in Table 3. (F-score isdefined as the reciprocal of 1 plus the ratio ofthe total of false positives and false negatives
to twice the total of true positives.) So itappeared that a constant of 1 was sufficient,and we used that in the experiments describedbelow. We could not use 0 because randomsubsets might miss the clues.
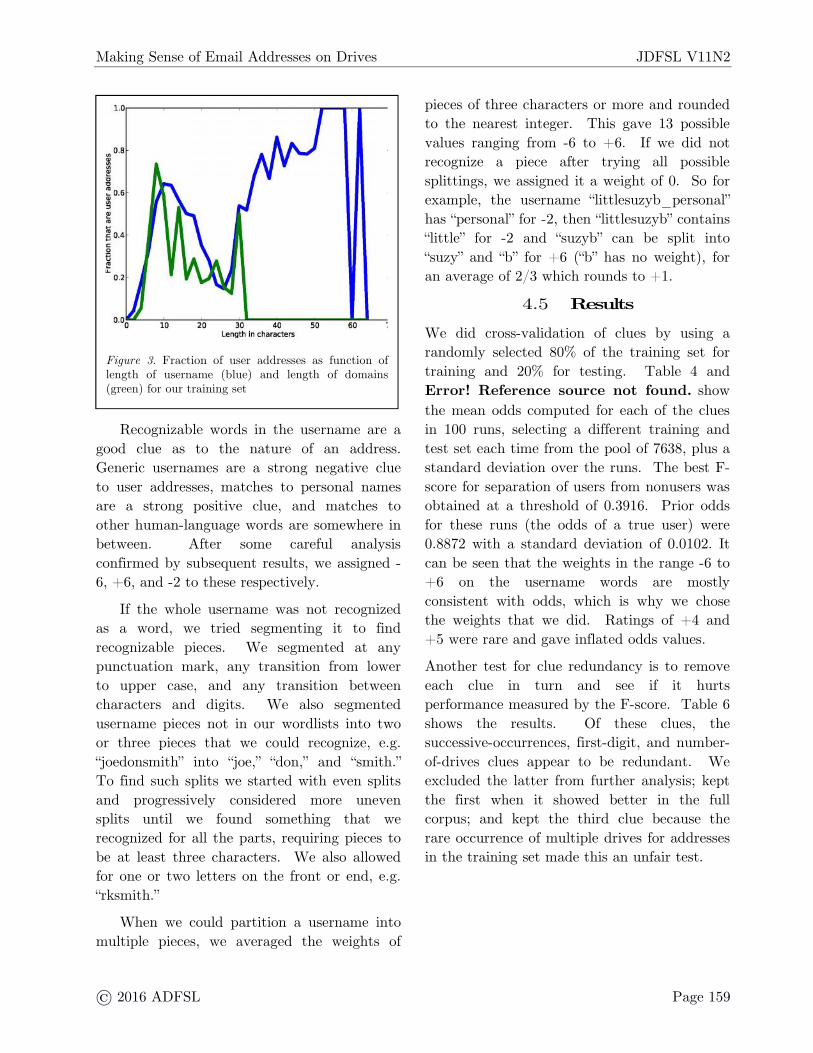
Handling difficult cluesSeveral clues are numeric and we must mapthe numbers to probabilities. For example,Figure 3 plots the fraction of user addresses inthe training set as a function of length of theusername (blue curve with larger input range)and length of the domain and subdomains(green), averaging each adjacent pair oflengths. The dip in the middle of theusername curve is interesting; to the left areusernames that are short enough for users tocomfortably type themselves; to the right areautomated reporting addresses about userssent by software, and in between are lengthstoo long for users but too short for automatedreporting. Note there are username lengthsright up to the SMTP-protocol maximum of 64characters. To model these data, we split theusername lengths into four ranges (at 8, 15,and 30) and domain-name lengths into threeranges (at 8 and 15).Table 3Results on varying the additive constant in the oddscalculation
Best F-score1 0.946593 0.9458710 0.94284100 0.94086
Making Sense of Email Addresses on Drives JDFSL V11N2
© 2016 ADFSL Page 159
Recognizable words in the username are agood clue as to the nature of an address.Generic usernames are a strong negative clueto user addresses, matches to personal namesare a strong positive clue, and matches toother human-language words are somewhere inbetween. After some careful analysisconfirmed by subsequent results, we assigned -6, +6, and -2 to these respectively.
If the whole username was not recognizedas a word, we tried segmenting it to findrecognizable pieces. We segmented at anypunctuation mark, any transition from lowerto upper case, and any transition betweencharacters and digits. We also segmentedusername pieces not in our wordlists into twoor three pieces that we could recognize, e.g.“joedonsmith” into “joe,” “don,” and “smith.”To find such splits we started with even splitsand progressively considered more unevensplits until we found something that werecognized for all the parts, requiring pieces tobe at least three characters. We also allowedfor one or two letters on the front or end, e.g.“rksmith.”
When we could partition a username intomultiple pieces, we averaged the weights of
pieces of three characters or more and roundedto the nearest integer. This gave 13 possiblevalues ranging from -6 to +6. If we did notrecognize a piece after trying all possiblesplittings, we assigned it a weight of 0. So forexample, the username “littlesuzyb_personal”has “personal” for -2, then “littlesuzyb” contains“little” for -2 and “suzyb” can be split into“suzy” and “b” for +6 (“b” has no weight), foran average of 2/3 which rounds to +1.
ResultsWe did cross-validation of clues by using arandomly selected 80% of the training set fortraining and 20% for testing. Table 4 andError! Reference source not found. showthe mean odds computed for each of the cluesin 100 runs, selecting a different training andtest set each time from the pool of 7638, plus astandard deviation over the runs. The best F-score for separation of users from nonusers wasobtained at a threshold of 0.3916. Prior oddsfor these runs (the odds of a true user) were0.8872 with a standard deviation of 0.0102. Itcan be seen that the weights in the range -6 to+6 on the username words are mostlyconsistent with odds, which is why we chosethe weights that we did. Ratings of +4 and+5 were rare and gave inflated odds values.Another test for clue redundancy is to removeeach clue in turn and see if it hurtsperformance measured by the F-score. Table 6shows the results. Of these clues, thesuccessive-occurrences, first-digit, and number-of-drives clues appear to be redundant. Weexcluded the latter from further analysis; keptthe first when it showed better in the fullcorpus; and kept the third clue because therare occurrence of multiple drives for addressesin the training set made this an unfair test.
Figure 3. Fraction of user addresses as function oflength of username (blue) and length of domains(green) for our training set

JDFSL V11N2 Making Sense of Email Addresses on Drives
Page 160 © 2016 ADFSL
Table 4Odds of a user address given various general anddomain clues based on the training setMeanodds
Standarddeviation
Description
0.001 0.00001 Address in stoplist1.301 0.0158 Address not in stoplist0.0688 0.0094 Software-suggesting
preceding characters0.8910 0.0102 No software-suggesting
preceding characters1.0669 0.0128 Occurs only on one
drive0.4563 0.0228 Two drives0.1518 0.0115 3-10 drives0.0056 0.0002 >10 drives0.9053 0.0113 Occurs 10 times or less
in succession0.2348 0.0274 Occurs more than 10
times in succession0.3741 0.0145 Domains length < 81.2228 0.0156 Domains length 8-150.3406 0.0105 Domains length > 155.0111 0.0948 Server name in
domains0.0148 0.0013 .com domain0.2586 0.0182 .edu domain0.0085 0.0019 .org domain0.3251 0.0268 .net domain0.0293 0.0032 Other domain0.0383 0.0087 Username word
matches domain words0.8898 0.0103 Username word does
not match domainwords
1.0246 0.0141 U.S. domain0.3844 0.0120 Developed non-U.S.
world domain3.6160 0.1447 Developing world
domain0.3756 0.0165 Rest of the world
domain
Table 5Odds of a user address given various username cluesbased on the training setMeanodds
Standarddeviation
Description
0.2453 0.0057 Username < 8characters
1.3546 0.0209 Username 8-15characters
0.8023 0.0263 Username 16-29characters
3.5833 0.169 Username > 29characters
0.8858 0.0354 First usernamecharacter is digit
0.8874 0.0110 First usernamecharacter is not adigit
2.1489 0.0560 Last usernamecharacter is digit
0.6931 0.0088 Last usernamecharacter is not adigit
0.0377 0.0053 Username weight -60.0744 0.0084 Username weight -50.2754 0.0316 Username weight -40.2171 0.0272 Username weight -30.6291 0.0235 Username weight -20.7464 0.0587 Username weight -10.6352 0.0167 Username weight 01.5080 0.1253 Username weight 11.4634 0.0530 Username weight 21.7459 0.0978 Username weight 35.6721 0.6841 Username weight 416.400 1.6673 Username weight 51.1881 0.0208 Username weight 6
Figure 4 shows the overall histogram ofaddress ratings for the corpus. The blue curveis our full corpus, and the green curve is forour stoplist with counts multiplied by 5 foreasier comparison (with the stop-list matchclue omitted in calculating the rating). Thereare peaks at both ends of the blue curve, somost addresses appear unambiguous to therater. Note that the stoplist had a few highly-rated addresses like “[email protected]”

Making Sense of Email Addresses on Drives JDFSL V11N2
© 2016 ADFSL Page 161
which were uninteresting software contacts butprovide no obvious clue. By setting thethreshold to 0.3916, the average of those forthe best F-scores on the training set, weidentified 78,029,211 address references as user-related, 26.7% of the total.
Table 6Effects on performance of removing each clue in turn inanalyzing the training setClue removed Best F-
scoreNone 0.9433Address in stoplist 0.9244Software-suggesting previouscharacters
0.9430
Number of drives on which itoccurs
0.9436
Number of occurrences insuccession
0.9433
Length of domains in characters 0.9411Domain type 0.7810Type of country of origin 0.9335Match between domain andusername
0.9416
Length of username incharacters
0.9330
Whether first character is digit 0.9433Whether last character is digit 0.9334Username weight 0.9287
Figure 5 plots precision versus recall forour training set. (Recall is the fraction of useraddresses above the threshold of all thosemanually identified as user addresses; precisionis the fraction of user addresses above thethreshold of all those above the threshold.) Itcan be seen that many addresses areunambiguously nonusers, but there were asmall number of difficult cases. Thus theprecision, while generally greater than 0.95,improves only gradually with increasingthreshold whereas recall improves quickly withdecreasing threshold. This means that falsepositives (nonusers identified as users) aremore difficult to eliminate than false negatives(users identified as nonusers). Fortunately,
false positives just add a little to thesubsequent workload, which is primarilyfocused on studying users, whereas falsenegatives represent potentially valuableinformation lost to investigators.
The processing time on our corpus wasaround 10,000 hours (a total across multipleprocessors) to run Bulk Extractor on 63.6terabytes of image data, and 4 hours for thesubsequent address analysis.
Figure 4. Distribution of ratings of user-relatedness onour corpus (blue) and for our stop list (green), thelatter multiplied by 5)
Figure 5. Precision versus recall for our training set

JDFSL V11N2 Making Sense of Email Addresses on Drives
Page 162 © 2016 ADFSL
VISUALIZING EMAILNETWORKS
Once we have excluded uninteresting emailaddresses, we can see more clearly theconnections between users. Even though mostusers of drives in our corpus employed mailservers, we saw many email addresses on ourdrives.
Measuring the dissimilaritybetween addresses
A key idea that will help visualize connectionsbetween email addresses is the notion of theirdissimilarity. Using this, we can approximatea metric space of all addresses wheredissimilarities are shown as distances, and thenseek clusters in it.
Several ways to measure dissimilarity wereexplored in this work:
Absolute value of the difference inoffsets in the storage in which theaddresses were found (McCarrin,Green, and Gera, 2016), or , =| − | . The difference in offsetswould seem to be a good measure ofdissimilarity since addresses foundnearby are likely to be within the sameline of the same file and thus related.
Dissimilarity of the words in the twoaddresses when they are split using themethods of section 4.4. Address pairswith shared domain/subdomain listsare weakly associated. Address pairswith shared username words are morestrongly associated since they suggestaliases and human relatives. Aliasesare increasingly common online aspeople manage multiple mail services(Gross and Churchill, 2007). Weestimated word dissimilarity by aweighted sum of the Jaccard metricvalues on the username and domains
separately, as, = 60 , , , +20 ( , , , ) where , means thewords of the username part of addressi, , means the domains andsubdomains of address i, and j is 1minus the number of words in theintersection of the two word listsdivided by the number of words in theunion of the two word lists. Weexcluded country codes and the finalsubdomain from the domain word listssince they are broad in their referents,and we excluded integers and one andtwo-character words from the usernamewordlists. For example, between“[email protected]” and“[email protected]” we computeda dissimilarity of 60 1 −+ 20 1 − = 43.3 . Theweights 60 and 20 were picked to beconsistent with the offset differences,and say that similarities in usernamesare three times more important thansimilarities in domains.
Dissimilarity based on lack of co-occurrences over a set of drives. Weused , = .( ) where isthe number of drives with the pair ofaddresses i and j. Again, this wasfitted to be consistent with the degreesof association in the offset differences.The rationale is that pairs that occurtogether more than once on drives havesome common cause. Note this formulaneeds to be adjusted for differences inthe size of corpora.
Whether two addresses were not withinthe same file, as a better way ofscoping a relationship than using offsetdifference alone. We used the Fiwalktool as mentioned in section 4.2. As

Making Sense of Email Addresses on Drives JDFSL V11N2
© 2016 ADFSL Page 163
noted, few addresses were within files,which limits the applicability of thismeasure. Nonetheless, there werecorrelations for certain kinds of files butnot others. This will be a subject offuture work.
Whether two addresses were not in thesame message. This idea has been usedto distinguish legitimate addresses fromspam addresses (Chirita, Diederich, andNejdl, 2005).
The first three methods are useful for ourcorpus. The fourth and fifth require additionalinformation not always easy to get. Note thatonly the first two of these dissimilaritymeasures are metrics (distances) because thelast three can violate the triangle inequality( , ) ≤ ( , ) + ( , ) . Nonetheless, wecan still get useful visualizations from the lastthree.
Testing the dissimilaritymeasures
An important question is how well thesedissimilarity measures represent the associationof two addresses. This is a challengingquestion for our corpus because we do notknow the people that used nearly all theaddresses. Nonetheless, one simple indicator isthe correlation of the dissimilarity measureswith the ratings of user-relatedness obtainedby the methods of part 4, since similar ratingssuggest association. Figure 6 plots theabsolute value of the difference in our ratingsagainst the absolute value of the difference inoffsets for our full corpus; Figure 7 plots thesame against our measure for worddissimilarity; and Figure 8 plots the sameagainst our measure of co-occurrencedissimilarity. Though the data is noisy, thereare correlations up to 25 on offset deviation,up to 50 on word distance, and up to 25(representing 7 co-occurrences) on co-occurrence dissimilarity. So it appears that
these three measures are useful measures ofassociation at low values and can be plausiblytreated as distances.
Based on these results, we formulated acombined dissimilarity measure for addresseson the same drive. We did not include the co-occurrence dissimilarity because we saw fewinstances of co-occurrence in our corpus oncewe eliminated nonuser addresses. But wecould use the offset difference and worddissimilarity. They should be combined so a
Figure 6. Ratings deviation versus offset deviation forthe full corpus
Figure 7. Ratings deviation versus word distance forthe full corpus

JDFSL V11N2 Making Sense of Email Addresses on Drives
Page 164 © 2016 ADFSL
low value on one overrides a high value on theother since a low value usually has a reason.That suggests a “consensus dissimilarity”between address i and address j:= min( , , , )
where is offset dissimilarity and isthe word dissimilarity, provided either< 28 or < 50.
Figure 9 shows the distribution of thecombined dissimilarities we found between allpairs of email addresses in our corpus. Tolimit computation, we only computed wordsimilarity for addresses within an offset of1000. Note the curve is concave upwards,which suggests a relatively even spacing ofpoints in a metric hyperspace. Beforecalculating this, it was important to eliminateduplicate successive addresses in the BulkExtractor output to prevent theiroverweighting, since there are many of thesedue to automated software contacts: The most
common such address, [email protected], occurred 1.2 milliontimes total in successive entries due to thefrequency of certificate stores.
Experiments with familiardata
To get a better understanding of theeffectiveness of our methods, we took driveimages of 11 drives of people at our schoolwhere the drive owners agreed to explain theirconnections. We used dissimilarities computedusing the methods of the last section and thenplaced addresses in a two-dimensional space ina way most consistent with the dissimilarities.Two-dimensional space was used for ease ofvisualization. Many algorithms can fitcoordinates to distances, and visualization doesnot need an optimal solution. We thus usedan attraction-repulsion method to find x and yvalues that minimize:
⎣⎢⎢⎡ ( − ) + ( − )
⎦⎥⎥⎤
{ }for the consensus dissimilarity valuesdescribed the last section, and with = 50.We used a log ratio error rather than the least-squares dissimilarity error so as to not unfairlyweight points with a big dissimilarity fromothers (a weakness of much software for thisproblem). There are an infinite number ofequally optimal solutions to this minimizationdiffering in translation and rotation.
Figure 8. Ratings deviation versus sharing dissimilarity(distance) for the full corpus

Making Sense of Email Addresses on Drives JDFSL V11N2
© 2016 ADFSL Page 165
We show here data from a drive of one ofthe authors that had been used from 2007 to2014 for routine academic activities and alsohad files copied from previous machines goingback to 1998. It was a Windows 7 machineand had 1.22 million email addresses on it, ofwhich only 52,328 were unique. Manyaddresses were not user-related (76 of the 100
most common, for instance), so it wasimportant to exclude them to see explicit useractivity.
Figure 10 and Figure 11 show the resultsof position optimization for a subset ofaddresses on this drive, those of the firstauthor or addresses connected to the firstauthor by a fewer than 50.
Figure 9. Histogram of all calculated dissimilarities ≤ for pairs of addresses in our corpus

JDFSL V11N2 Making Sense of Email Addresses on Drives
Page 166 © 2016 ADFSL
Figure 10. Visualization on a sample drive of addresses of first author and directly-connectedother addresses
Figure 11. Visualization on a sample drive of addresses of first author and directly-connectedother addresses, after filtering to eliminate nonuser addresses

Making Sense of Email Addresses on Drives JDFSL V11N2
© 2016 ADFSL Page 167
Usernames have been replaced withnumbers to preserve privacy. Figure 10 showsthe graph found on the complete subset ofaddresses (1646 in total), and Figure 11 showsthe graph after elimination of the nonuseraddresses from the subset (313 in total).Nonuser elimination did help clarify the data,and enables us to better distinguish theauthors’ aliases and close associates centered at(10,10) from other members of the authors’department to the right and above, and fromother contacts that are outliers below andabove. The tendency to form circular arcs isdue to the limited amount of distance databelow the threshold for users other than theauthor. This processing took around 70 hourson our full corpus.
VISUALIZINGSIMILARITIES
BETWEEN DRIVESUSING ADDRESSES
Besides graphing connections betweenindividual email addresses, it is useful to graphconnections between drives based on the countof their shared email addresses. Now thenodes will be drives and the counts provide ameasure of drive-owner association since usersthat share many addresses are likely to besimilar. This should provide more reliability inassociating drive owners since the comparisoncan draw on thousands or millions of datapoints. It can also provide an alternate way tosee hidden social networks not apparent fromexplicit links. We can do this for the full set ofaddresses on drives to see shared software, orwe can eliminate nonuser addresses first usingthe methods of section 4 to see just thepersonal contacts.
Fitting drive distancesOne simple approach to measuring drivesimilarity based on shared email addresses is to
let be the number of addresses on eachdrive, and be the number of addresses theyhave in common. Treat the set of addresses onthe drives as an independent random samplefrom some large population of N. Then fordrives i and j, counts and , andintersection count , the independenceassumption implies that = , allowingus to estimate a virtual = . A simpleadditional assumption we can use to estimatedissimilarity is that points of the population ofaddresses are evenly spaced in some region ofhyperspace. Here we want to visualize thedissimilarities in two dimensions, so assumethe points of the population are evenly spacedwithin a circle or square. Then if we increasethe area of the circle or square by a factor ofK, the radius of the circle or the side of thesquare increases by a factor of √ , and thedissimilarities between random points in thecircle or square increase by the same factor.Hence, the dissimilarity between two drivescan be estimated as = / . Thisdoes not become zero when the two sets areidentical, but overlaps between drive addresseswere quite small in our corpus so this case wasnever approached. This becomes infinite when= 0, and is unreliable when is small, sodistances need to be left undefined in thosecases. Then we can use the same optimizationformula in section 5.3 for finding coordinatesfrom distances. Figure 12 shows results fordrive similarity using the filtered (user-related)addresses where ≤ 10 ; we used the K-Means algorithm with K=13 to assign drives toclusters, and then colored the clusters. Thedifferences between clusters were subtle frominspection of their addresses, so we appear tohave discovered some new groupings in thedata. This processing only took a few minutesonce we had the shared-address datareferenced in section 5.

JDFSL V11N2 Making Sense of Email Addresses on Drives
Page 168 © 2016 ADFSL
A social-network approachAn alternative visualization technique is tocalculate a containment score (Broder, 1997)based on the size of the intersection of sets offeatures divided by the number of features ofthe smaller set, or = ( , ) where n isthe count of features on a drive. We can thencreate a topological view of the connectionsbetween drives in which drives are representedas nodes and the weight of the edges betweennodes denotes the value of the containmentscore between the drives to which theycorrespond. Figure 13 shows an example ofthis method for the email address-basedconnections on an example drive.
To display and manipulate the resultinggraphs we used the open-source graph analysis
and visualization tool Gephi(http://gephi.org). Visualization makes iteasier to identify clusters of related items; thetool also provides a variety of filteringstrategies and layout algorithms.
To reduce noise, we focused on the core ofthe networks (BORGATTI AND EVERETT,2000). Generally, the k-core is defined as asubgraph whose nodes have at least
connections to each other and fewer thanto any of the other nodes in the network. Thecore is the non-empty k-core with themaximum value of k. It often identifies thekey players in a social network. Furtherfiltering by degree centrality highlights themost connected nodes within the core.
Figure 12. Drive clustering (colors) using count of shared addresses, for distance≤

Making Sense of Email Addresses on Drives JDFSL V11N2
© 2016 ADFSL Page 169
Results of the social-networkapproach
To establish a baseline picture of relationshipsbetween drives, we calculated shared-addresscounts between drives using addresses asfeatures and eliminating the addresses belowthe 0.3916 probability. Table 7 shows thedistribution of sharing counts between drivepairs. The frequencies do not follow a Zipf’sLaw 1/k trend at higher counts but reflectmeaningful associations.
Table 7Sharing counts of addresses between drives and theirfrequencies of occurrenceSharedcount
Frequency Sharedcount
Frequency
1 401201 2 278883 8089 4 41695 2130 6 12887 1270 8 15639 1955 10-14 280115-19 963 20-29 87030-99 2167 100-999 6671000-9999
126 ≥10000 45
The graph of drive similarity based oncommon email addresses has 3248 nodes and447,292 edges. Its degree distribution followsthe expected power law that we see in big data
Figure 13. The degree distribution for emails on a drive

JDFSL V11N2 Making Sense of Email Addresses on Drives
Page 170 © 2016 ADFSL
(see Figure 14). It shows that while there aresome drives with high degree of 850, there areover 90 drives of degree 0, meaning that they
have no shared email addresses with any otherdrives. However, the average degree is 260.96,so there are enough correlations.
Screening the network of drives having atleast one address in common, by k-core withk=298, we obtain a hairball of 1214 nodes and226,180 edges, and at k=299 the whole corevanishes. The 298-core is therefore the core ofthe graph and identifies the most connectedsubgraph (with each node having 298connections or more to the other 1214 nodes inthe core). The nodes in this set all have asimilar position in the network and a similarrelative ranking to the other nodes in the core.
However, further analyzing the 298-core ofthe network, we identified three key drivesthat all share email addresses with the leftover43 drives as shown in Figure 15. Each of thesedrives has at least 439 connections. Such acomplete bipartite graph is an unusual patternof correlation in real networks, since the threedrives do not have a high correlation to eachother, but a similar high correlation to theother 43 drives.
Figure 14. The degree distribution of the drive image similarity network, where connections are shared emailaddresses

Making Sense of Email Addresses on Drives JDFSL V11N2
© 2016 ADFSL Page 171
Figure 16 shows the neighborhood of thehighest 5 degree nodes in the core. Weincluded a few other high degree nodes to see ifthey showed an interesting pattern, which wasindeed observed for the top 9 nodes of thecore.
Degree centrality does not necessarilyequate to importance, and the more central
nodes in a network can be the most redundantas has been observed here. Nonetheless, thesetopological visualizations can be helpful inseeing a network in a different way, screeningdata when there is too much, and analyzingthe important nodes. This makes a usefulsupplement to analysis based on individualnode properties.
Figure 15. The neighborhood of the highest three degrees in the core (with “communities” or key subgraphsindicated by colors)

JDFSL V11N2 Making Sense of Email Addresses on Drives
Page 172 © 2016 ADFSL
CONCLUSIONElectronic mail addresses alone can provideuseful information in a forensic investigationeven without the associated mail. Nonetheless,many email addresses are uninteresting fornearly all investigations, and we have shownsome simple methods that can exclude themreliably. We have shown this significantlyimproves the ability to see connectionsbetween email addresses on a diverse corpus,and enables us to see new phenomena in theconnections between addresses and drivesviewed in two different ways. Suchinformation can be combined with other kindsof connection information found on a drivesuch as telephone numbers, Internet addresses,
and personal names to get a good picture ofthe social context of its user.
ACKNOWLEDGEMENTSJanina Green collected the data described insection 5.3. The views expressed are those ofthe authors and do not represent the U.S.Government.
Figure 16. The neighborhood of the highest five degrees in the core

Making Sense of Email Addresses on Drives JDFSL V11N2
© 2016 ADFSL Page 173
REFERENCES
Borgatti, S., & Everett, M. (2000). Models ofcore/periphery structures. Social Networks21 (4), 375-395.
Broder, A. (June). On the resemblance andcontainment of documents. Paperpresented at the IEEE Conference onCompression and Complexity of Sequences,Positano, Italy, June (pp. 21-29), June1997.
Bulk Extractor 1.5. (2013). Digital corpora:Bulk Extractor [software]. Retrieved onFebruary 6, 2015 from digitalcorpora.org/downloads/bulk_extractor.
Chirita, P.-A., Diederich, J., & Nejdl, W.(2005). MailRank: Using ranking for spamdetection. Paper presented at theConference on Information and KnowledgeManagement, Bremen, Germany, October-November (pp. 373-380).
Garfinkel, S., Farrell, P., Roussev, V., &Dinolt, G. (2009). Bringing science todigital forensics with standardized forensiccorpora. Digital Investigation 6 (August),S2-S11.
Gross, B., & Churchill, E. (2007). Addressingconstraints: Multiple usernames, taskspillage, and notions of identity. Paperpresented at the Conference on HumanFactors in Computing Systems, San Jose,CA, US, April-May (pp. 2393-2398).
Holzer, R., Malin, B., & Sweeney, L. (2005).Email alias detection using social networkanalysis. Paper presented at the ThirdInternational Workshop on Link Discovery,Chicago, IL US, August (pp. 52-57).
Klensin, J, & Ko, Y. (2012, February). RFC6530 proposed standard: Overview andframework for internationalized email.Retrieved February 4, 2016 fromhttps://tools.ietf.org/html/rfc6530.
Lee, S., Shishibori, M., & Ando, K. (2007). E-mail clustering based on profile and multi-attribute values. Paper presented at theSixth International. Conference onLanguage Processing and Web InformationTechnology, Luoyang, China, August (pp.3-8).
McCarrin, M., Green, J., & Gera, R. (2016).Visualizing relationships among emailaddresses. Forthcoming.
Newman, M. (2004). Fast algorithm fordetecting community structure innetworks. Physical Review E, 69, (7), p.066133.
Polakis, I., Kontaxs, G., Antonatos, S.,Gessiou, E., Petsas, T., & Markatos, E.(2010). Using social networks to harvestemail addresses. Paper presented at theWorkshop on Privacy in the ElectronicSociety, Chicago, IL, US, October (pp. 11-20).
Rowe, N., Schwamm, R., & Garfinkel, S.(2013). Language translation for file paths.Digital Investigation, 10S (August), S78-S86.
Zhou, D., Manavoglu, E., Li, J., Giles, C., &Zha, H. (2006). Probabilistic models fordiscovering e-communities. Paperpresented at the World Wide WebConference, Edinburgh, UK, May (pp. 173-182).

JDFSL V11N2 Making Sense of Email Addresses on Drives
Page 174 © 2016 ADFSL