m sc thesis_presentation_
TRANSCRIPT

Research Project for the degree of Master of Science in Computer Engineering
Mohamad Dia ABDULKARIM.
Supervisior: Assoc. Prof. Dr. Zekeriya TÜFEKÇİ
May , 2015

OutlineIntroduction Speaker VerificationCommon issues for Speaker VerificationVoice Activity DetectionParallel Model CombinationMethodVQVADMMSEResultsConclusion and Future work

Introduction

IntroductionSpeech is considered to be the most popular way of
communication that exist today.Technically, speech is a signal that carries dataThe processing of this data can be divided into three main
types: Speech recognition, Speaker recognition and language recognition.
Speech recognition is the process in which a given speech signal is converted to a group of words by implementing specific algorithms.
Many techniques and implementations are used in the development of speech recognition.
Speech recognition identifies the speech that the speaker produce.

Introduction ContinuedSpeaker recognition recognizes person producing an
utterance.Speech recognition and speaker recognition has some
similar intermediate stages.Speaker recognition has two approaches: Speaker identification; recognizing a specific person given
a database “closed” set identification or “open” set identification if the speaker is out of the database
Speaker verification.

Speaker Verification

Speaker VerificationSpeaker verification or authentication can be defined as
the process of verifying that the utterance produced by a speaker is identical to the id claimed.
Speaker verification systems can be classified into text-dependent or text-independent systems
For text-dependent systems the text or phrase is known, thus this can improve the system performance.
For text-independent systems the text is not known so there is no restrictions on users

Speaker Verification Continued.. This study focuses on text-independent speaker
verification.Speaker verification of text- independent systems perform
reasonably well when spoken utterances are free of any kind of distortions.
Performance degrades in the case of any external factors i.e., background noise.

Common Issues for Speaker Verification

Common Issues for Speaker VerificationThere are many issues that are considered a challenge for
speaker recognition systems and especially Speaker Verification systems
Mismatch between training and testing conditions, this occurs due to differences in backgrounds, recording devices and channels etc., this is considered the most challenging issue for speaker verification systems.
Background noise is a distinguished factor which is responsible for the degrading of the performance between the matched and mismatched conditions.
A lot of strategies were proposed to handle background noise.

Common Issues for Speaker Verification continued..
These strategies can be categorized into two methodsFirst method involves Adaptation or compensation Adaptation where estimated speaker model parameters
are adapted or altered in the training to reflect the test environment.
Compensation where feature that are extracted in the test environment are compensated or denoised to match with the training environment.
Second method involves modifying the pattern matching stage in order to account for the interfering noise.

Voice Activity Detection (VAD)

VADDue to the background conditions or noise, performance
of the speaker verification system degrades as mentioned earlier , VAD is an algorithm that estimate the noise statistics.
Generally, voice activity detection plays a good role in speech and speaker recognition assuming that the noise and speech are additive rather than correlated with one another.
It estimates the speech accordingly classifies the noisy signal into speech and non-speech segments

VAD Continued…Non-speech segments can be used to estimate the noise
model.Many VAD algorithms fail in High Signal to Noise ratios
(SNR) Energy based VAD improves the performance by making
the speaker verification system noise robust in noisy environments.
The selection of an adequate feature vector along with a robust decision rule considered a big challenge for VAD under adverse conditions.

Parallel Model Combination (PMC)

PMCParallel Model Combination is considered to be one of the
most efficient approach to achieve noise robustnessThis kind of approach attempts to modify the pattern
matching step so it can account for the interfering noisePMC estimates the noisy speech model given information
about both, noise and clean speech models, and that is achieved regarding some function.
The model used in PMC is a standard Hidden Markov Model with Gaussian output probability distributions.
Speaker verification systems works best when no mismatch exist between the training and test conditions.

PMC Continued..Mismatch occurs either in variations in the channel
conditions or in the form of additive noise.PMC attempts to decrease the mismatch happening
between the train and test modelsIn order to describe the effect of noise on the clean
speech parameters some assumption by Gales and Young were made :
The noise and speech are independent

PMC Continued…It is assumed that noise and speech are additive in the
linear domain, and for noise and speech to be additive at the power spectrum level it is assumed that spectral estimate includes sufficient smoothing.
In order for the observation vectors to be represented in the log domain assumptions about Gaussian mixtures including sufficient information should be made.
The additive noise does not alter the frame state allocationFor large data sets dynamic coefficients are used A new mismatch function must be used to implement
delta coefficients compensation to the PMC framework .

PMC Continued……

Method

MethodThe main goal of this study is to increase the performance
of a speech recognition system under noisy environments Many approaches have been proposed to improve the
recognition performance of the speaker recognition system for noisy speech
VAD methods are used for estimating the noise model, and PMC is proposed for estimating the noisy speech model given both the clean speech and the noise model, which is estimated using a VAD method
two well-known VAD methods are implemented and compared, for the noisy Speaker Verification issue

Method Continued…PMC is used to estimate the noisy speech model.

VQVAD

VQVADVAD has a vital influence on robust speaker verification,
specifically energy-based VADEnergy-based VAD calculates the energy of each short-
frame and correspondingly considers low and high frames, refer to non-speech and speech respectively
The decision made for the energy threshold can be related to average or maximum energy utterance
The threshold could also be adjusted based on GMM parameters which can be fit to the energy distribution
the frames of the utterance are labeled as speech or non speech according to some likelihood ratio indicator

VQVAD Continued…..The energy based VAD works well, for high SNRs,
however, it usually marks most frames as speech, in low SNRs.
The adaptive VAD uses spectral subtraction method to overcome such problem.
Kinnunen and Rajan, proposed a VAD that does not rely on pre-trained acoustic models and two Gaussian mixture models one for speech and the other for non speech are trained.
Likelihood ratio is used to label all frames as speech or non speech

VQVADThe proposed self-Adaptive VAD can be outlined as
follows:Extract MFCCs from the noisy signalDenoise the speech signal Compute frame energies of the enhanced signalFind indices of low/high energy frames Train speech and nonspeech models from the frame
subsetsFor all frames, pick the more likely hypothesis with
minimum energy constraint

MMSE

MMSE As mentioned earlier VAD is considered a very good
algorithm in terms of speech enhancementMost systems depend on the Minimum Mean-Squared
Error (MMSE) estimate of the noise power spectrumThe higher the noise power the higher the variance MMSE estimate might not be close to the noise spectrum
in the current observationLee an Johnson purposes an MMSE a posteriori estimation
of noise based on an MMSE a priori estimation of the noise, combined with the current noisy observation

MMSE Continued…. A MMSE a posteriori noise estimation method is
explained by considering the instantaneous noise spectrum as sampled values from an underlying noise process.
a posteriori MMSE estimate of the noise power can evaluate this noise spectrum estimation method in the recent frame, when the noise process is stationary with high variance.
According to experiments this noise estimation approach gives higher accuracy specifically for low-SNR situations

Results

ResultsNIST 1998 and NOISEX-92 databases were used for
evaluating the MFCCs using parallel model combination approach.
In this study only male speakers were used for evaluationThis study focuses on the two- session training conditionthe total numbers existing for the trails is 13080noises were downsampled to 8kHz in order to have the
exact sampling rate of the NIST databasespeech STITEL and F16 were used and added to the test
speaker signals as background noise in order to attain the noisy speech signal at SNR levels of -06dB, 0dB, +06dB

Results Continued…speech signal was sampled at 8 kHz, and analyzed with 25
ms hamming windows every 10 ms.there were 13 MFCCs and 13 delta MFCCs for each feature
vector extracted from each frame.64 mixtures for modelling each speaker were used,
additionally, 3 Gaussian mixture models were used for estimating the noise.
Two VAD techniques were used, the VQ-VAD and the MMSE mentioned in the previous section, were used to generate the noise models using the noisy speech signal.
The speaker recognition system was built and tested using a Hidden Markov Model tool kit HTK

Results Continued…Comparison of equal error rates of the speech noise for all
SNR levels.
SPE
EC
H N
OIS
E
EER (Equal Error Rate)
SNR (dB)
MMSE VQ-VAD BASELINE METHOD
-6 dB 25.99 24.46 19.26
-0 dB 15.21 15.59 12.30
6 dB 9.86 9.25 8.94

Results Continued…Comparison of equal error rates of the STITEL noise for all
SNR levels.
STIT
EL
EER (Equal Error Rate)
SNR (dB)
MMSE VQ-VAD BASE-LINE METHOD
-6 dB 18.42 16.20 14.98
-0 dB 11.39 10.16 10.47
6 dB 8.18 8.40 8.10
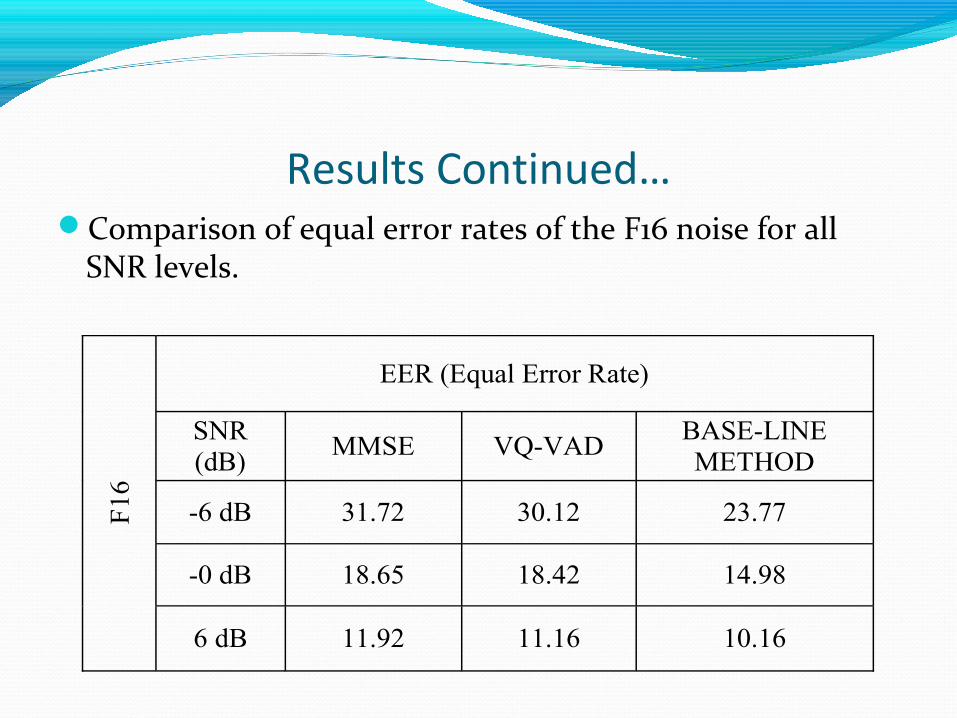
Results Continued…Comparison of equal error rates of the F16 noise for all
SNR levels.
F16
EER (Equal Error Rate)
SNR (dB)
MMSE VQ-VAD BASE-LINE METHOD
-6 dB 31.72 30.12 23.77
-0 dB 18.65 18.42 14.98
6 dB 11.92 11.16 10.16

Results Continued…For high SNR levels, the EER results of the implemented
VAD techniques were similar to the baseline method.For low SNR levels (-6 dB), the performance of the
baseline method was significantly better than the applied VAD techniques.
The implemented VAD techniques are good in estimating the noise for high SNR levels.
In the case of low SNR levels they are not that good.VQ-VAD method slightly outperforms the MMSE method
almost for all SNR cases.The VAD techniques estimated the noise models from the
noisy speech signal

Conclusion and Further work

Conclusion and Further workMany researches assumed that the noise signal is known
in advanceIn this study a new approach was proposedNoise is estimated from the noisy speech using VAD
techniquesestimated noise was used to estimate the noise modelthe estimated noise model along with the speech model
were combined using PMC to estimate the noisy speech model
the noise model was estimated directly from the noisy speech

Conclusion and Further work Continued…The results were compared with the baseline approachThe baseline approach yielded better performance than
the other two VAD-based techniques as expectedThe performance of the VAD techniques implemented
was similar to one another for all SNR levels as mentioned earlier
The EER results for the VAD based methods are not lower than the baseline method for high SNR levels
Additionally the EER for VAD implemented techniques are significantly lower than the baseline for low SNRs.

Conclusion and Further work Continued…Exploring or adjusting more reliable noise estimation
approaches to achieve optimal results for the speaker verification under adverse conditions especially for low SNR, can be a future research topic.
Project Files

THANK YOU FOR LISTENING!

Feature Extraction

The equal-error rate (EER) is a commonly accepted overall measure of system performance. It corresponds to the threshold at which the false acceptance rate is equal to the false rejection rate