istra ivanje podataka - nikolaajzenhamer.rs
TRANSCRIPT

ISTRAŽIVANJE PODATAKAAjzenhamer NikolaBukurov AnjaStanković Vojislav
0 5 10 15 200
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
0 5 10 15 200
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
0 5 10 15 200
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
0 5 10 15 200
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9

2

Ajzenhamer NikolaBukurov AnjaStankovic Vojislav
Istrazivanje podataka
3. oktobar 2017.


Sadrzaj
Predgovor iii
1 Uvod u istrazivanje podataka 11.1 Motivacija i pojam istrazivanja podataka . . . . . . . . . . . . . . . . . . 11.2 Pojam modela . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.3 Primeri podoblasti istrazivanja podataka . . . . . . . . . . . . . . . . . . . 31.4 Izazovi u procesu istrazivanja podataka . . . . . . . . . . . . . . . . . . . 61.5 Metrika istrazivanja podataka . . . . . . . . . . . . . . . . . . . . . . . . . 8
2 Podaci 92.1 Tipovi podataka . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.1.1 Vrednosti atributa . . . . . . . . . . . . . . . . . . . . . . . . . . . 102.1.2 Tipovi atributa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.2 Tipovi skupova podataka . . . . . . . . . . . . . . . . . . . . . . . . . . . 132.2.1 Tabelarni podaci . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132.2.2 Grafovski podaci . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152.2.3 Podaci sa poretkom . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.3 Kvalitet podataka . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 182.3.1 Greske pri merenju i prikupljanju podataka . . . . . . . . . . . . . 192.3.2 Sum i elementi van granica . . . . . . . . . . . . . . . . . . . . . . 192.3.3 Nedostajuce vrednosti . . . . . . . . . . . . . . . . . . . . . . . . . 202.3.4 Duplirani (multiplicirani) podaci . . . . . . . . . . . . . . . . . . . 21
2.4 Pretprocesiranje podataka . . . . . . . . . . . . . . . . . . . . . . . . . . . 212.4.1 Agregacija . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 222.4.2 Uzorcenje . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 222.4.3 Dimenzionalna redukcija . . . . . . . . . . . . . . . . . . . . . . . . 252.4.4 Izbor podskupa atributa . . . . . . . . . . . . . . . . . . . . . . . . 252.4.5 Izbor skupa atributa . . . . . . . . . . . . . . . . . . . . . . . . . . 262.4.6 Diskretizacija i binarizacija . . . . . . . . . . . . . . . . . . . . . . 262.4.7 Transformacija atributa . . . . . . . . . . . . . . . . . . . . . . . . 29
2.5 Mere slicnosti i razlicitosti . . . . . . . . . . . . . . . . . . . . . . . . . . . 312.5.1 Osnove . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 312.5.2 Slicnost i razlicitost izmedu jednostavnih atributa . . . . . . . . . 312.5.3 Razlicitosti izmedu objekata . . . . . . . . . . . . . . . . . . . . . . 312.5.4 Slicnosti izmedu objekata . . . . . . . . . . . . . . . . . . . . . . . 332.5.5 Primeri mera bliskosti . . . . . . . . . . . . . . . . . . . . . . . . . 33
i

ii SADRZAJ
3 Istrazivacka analiza i vizualizacija 393.1 Sumarne statistike . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
3.1.1 Frekvencija i modus . . . . . . . . . . . . . . . . . . . . . . . . . . 393.1.2 Percentili . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 403.1.3 Mere pozicije: srednja vrednost i medijana . . . . . . . . . . . . . 403.1.4 Mere razmere: rang i varijansa . . . . . . . . . . . . . . . . . . . . 403.1.5 Sumarne statistike za podatke sa vise atributa . . . . . . . . . . . 41
3.2 Vizualizacija . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 423.2.1 Opsti koncepti . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 423.2.2 Tehnike vizualizacije . . . . . . . . . . . . . . . . . . . . . . . . . . 44
4 Klasifikacija 534.1 Osnovni pojmovi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 534.2 Opsti pristup resavanju problema klasifikacije . . . . . . . . . . . . . . . . 544.3 Stablo odlucivanja . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
4.3.1 Konstruisanje stabla odlucivanja . . . . . . . . . . . . . . . . . . . 554.3.2 Metodi podele test atributa . . . . . . . . . . . . . . . . . . . . . . 564.3.3 Kriterijumi zaustavljanja algoritama za konstrukciju stabala odlucivanja 624.3.4 Karakteristike stabala odlucivanja . . . . . . . . . . . . . . . . . . 62
4.4 Prakticni problemi pri klasifikaciji . . . . . . . . . . . . . . . . . . . . . . 644.4.1 Preprilagodavanje i potprilagodavanje modela . . . . . . . . . . . . 644.4.2 Evaluacija performansi . . . . . . . . . . . . . . . . . . . . . . . . . 69
5 Dodatni metodi klasifikacije 735.1 Klasifikatori zasnovani na pravilima . . . . . . . . . . . . . . . . . . . . . 73
5.1.1 Mere kvaliteta pravila . . . . . . . . . . . . . . . . . . . . . . . . . 745.1.2 Karakteristike klasifikatora zasnovanih na pravilima . . . . . . . . 745.1.3 Seme odredivanja uredenja . . . . . . . . . . . . . . . . . . . . . . 755.1.4 Formiranje pravila klasifikacije . . . . . . . . . . . . . . . . . . . . 755.1.5 Od stabla odlucivanja do pravila . . . . . . . . . . . . . . . . . . . 785.1.6 Uproscavanje pravila . . . . . . . . . . . . . . . . . . . . . . . . . . 785.1.7 Prednosti klasifikatora zasnovanih na pravilima . . . . . . . . . . . 79
5.2 Modeli zasnovani na instancama . . . . . . . . . . . . . . . . . . . . . . . 795.2.1 Klasifikacija pomocu najblizih suseda . . . . . . . . . . . . . . . . 79
5.3 Bajesov klasifikator . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 825.3.1 Koriscenje Bajesove teoreme za klasifikaciju . . . . . . . . . . . . . 835.3.2 Naivni Bajesov klasifikator . . . . . . . . . . . . . . . . . . . . . . 83
6 Procena kvaliteta i izbor modela 876.1 Tehnike evaluacije . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
6.1.1 Nekonfigurabilan slucaj . . . . . . . . . . . . . . . . . . . . . . . . 886.1.2 Konfigurabilan slucaj . . . . . . . . . . . . . . . . . . . . . . . . . 906.1.3 Pitanje kvaliteta modela . . . . . . . . . . . . . . . . . . . . . . . . 93
7 Regresija 957.1 Grebena linearna regresija . . . . . . . . . . . . . . . . . . . . . . . . . . . 967.2 Mere kvaliteta . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97

SADRZAJ iii
8 Logisticka regresija 998.1 Matematicka formulacija . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100
9 Metod potpornih vektora 1039.1 Resenje optimizacionog problema . . . . . . . . . . . . . . . . . . . . . . . 1059.2 Kernel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
9.2.1 Dejstvo Gausovog kernela . . . . . . . . . . . . . . . . . . . . . . . 1079.3 Primene . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 108
10 Neuronske mreze 10910.0.1 Neuronske mreze sa propagacijom unapred . . . . . . . . . . . . . 10910.0.2 Konvolutivne neuronske mreze . . . . . . . . . . . . . . . . . . . . 114
11 Pravila pridruzivanja 11711.1 Osnovni pojmovi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11811.2 Metrika za procenu kvaliteta . . . . . . . . . . . . . . . . . . . . . . . . . 11811.3 Formiranje pravila pridruzivanja . . . . . . . . . . . . . . . . . . . . . . . 119
11.3.1 Apriori algoritam . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12011.3.2 Razmatranje slozenosti algoritma . . . . . . . . . . . . . . . . . . . 122
11.4 Formiranje pravila pridruzivanja . . . . . . . . . . . . . . . . . . . . . . . 12211.5 Mere kvaliteta . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123
11.5.1 Mere koje uzimaju u obzir statisticku zavisnost . . . . . . . . . . . 12511.5.2 Osobine dobre mere . . . . . . . . . . . . . . . . . . . . . . . . . . 126
12 Klasterovanje 12712.1 Uvod u klaster analizu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 127
12.1.1 Primena klaster analize . . . . . . . . . . . . . . . . . . . . . . . . 12712.1.2 Tipovi klasterovanja . . . . . . . . . . . . . . . . . . . . . . . . . . 12812.1.3 Tipovi klastera . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 130
12.2 Algoritmi klasterovanja . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13212.3 K-sredine . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13312.4 Hijerarhijsko klasterovanje . . . . . . . . . . . . . . . . . . . . . . . . . . . 13512.5 DBSCAN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 138
13 Analiza glavnih komponenti 140
Literatura 151

iv SADRZAJ

Predgovor
Ovaj tekst predstavlja skriptu iz kursa’’Istrazivanje podataka”, na Matematickom
fakultetu Univerziteta u Beogradu, zasnovanu na materijalima prof. dr Nenada Mitica ibeleskama sa predavanja prof. dr Mladena Nikolica iz istog predmeta. Skripta je pratecimaterijal pre svega studentima koji ovaj kurs slusaju u okviru svojih studija, ali i svimaVama koji biste zeleli da se upoznate sa ovom tematikom.
Ovaj materijal ne moze zameniti pohadanje nastave niti drugu preporucenu litera-turu. U tekstu se cesto referise na osnovne pojmove iz vestacke inteligencije i, posebno,iz masinskog ucenja. Savet je da se citalac prvo upozna sa pojmovima iz vestacke inte-ligencije, za sta autori preporucuju [4].
Ovaj materijal je u ranoj fazi formiranja, te autori upozoravaju na postojanostgresaka u tekstu. Ukoliko ste pazljivi citalac ove skripte, i ukoliko uocite bilo kakvugresku ili propust, molimo Vas da nam to javite na [email protected]. Svikomentari, sugestije, kritike, ali i pohvale vezane za ovaj materijal su dobrodosli.
Autori
v


Glava 1
Uvod u istrazivanje podataka
Kada bi Vam sada neko postavio pitanje’’Sta je istrazivanje podataka”, sta biste
odgovorili? Sa druge strane, ako bi Vas neko pitao za misljenje o’’Data Mining”, vero-
vatno bi Vam se upalila sijalica iznad glave. Zapravo, pojam’’Istrazivanje podataka” na
srpskom jeziku u potpunosti odgovara pojmu’’Data Mining” na engleskom jeziku. To
je samo jedan od pojmova koji oznacavaju disciplinu koja je u stalnom napretku, a kojaje poslednjih godina posebno popularna u svetu, a i kod nas.
1.1 Motivacija i pojam istrazivanja podataka
Zasto razmisljamo da se bavimo istrazivanjem podataka? Istrazivanje podataka imarazne primene, pre svega u poslovnim okruzenjima, ali i u medicini, inzenjerstvu, naucii drugim delatnostima. U poslovnim primenama rukujemo velikom kolicinom podatakakoje treba obraditi. Iako snaga racunara sve vise raste, takode raste i kolicina poda-taka koja se prikuplja. Uz to, rastu i nasa ocekivanja, odnosno, zelimo da dobijamo stokvalitetnije informacije. One nam omogucavaju da steknemo prednost u odnosu na kon-kurenciju. U drugim navedenim oblastima, stalno se prikuplja velika kolicina podataka.Naucne simulacije veoma lako umeju da generisu i terabajte podataka. Zbog kolicine iprostorno-vremenske prirode podataka tradicionalne metode za analizu nisu pogodne zaupotrebu.
Kada razmatramo istrazivanje podataka, uvek polazimo od jedne osnovne pretpo-stavke, a to je da cesto postoje
’’sakrivene” informacije koje nisu odmah (lako) uocljive.
Analiticari mogu da izgube nedelje ili mesece dok ne uoce pravilnost. Primenom tra-dicionalnih metoda veliki deo podataka nikada i ne stize do analize, pogotovo ako su upitanju tzv. sirovi podaci (engl. raw data). Navedimo primere nekih sirovih podatakau razlicitim disciplinama:
• U bioinformatici radimo sa sekvencama genetskog materijala, sto je zapravo pred-stavljeno tekstom. Na primer, ATGACGTGGGGA. Dakle, ulaz je tekst (engl. string).
• Jos jedan primer je analiza socijalnih mreza koja se bavi proucavanjem socijalnihstruktura koriscenjem teorije grafova. U ovoj oblasti se intenzivno koriste grafovi,na primer, graf kolaboracije. Drugim recima, ulaz je graf (engl. graph).
1

2 GLAVA 1. UVOD U ISTRAZIVANJE PODATAKA
Svi navedeni primeri sirovih podataka, ali i mnogi drugi, nisu pogodni za tradicio-nalne metode analize. Oni se ne uklapaju u, na primer, statisticke okvire jer nije jasno(ili moguce) kako pretvoriti takve podatke u numericke vrednosti sa kojima statistikarukuje. Zbog toga su nam potrebne nove, naprednije tehnike. Ovim dolazimo do jedneod najcescih definicija pojma istrazivanja podataka.
Istrazivanje podataka je disciplina koja se bavi pronalazenjem skrivenih informacijau podacima.
Dakle, u istrazivanju podataka, bavicemo se netrivijalnim izdvajanjem implicitnih,prethodno nepoznatih i potencijalno korisnih informacija iz podataka. Iz ove definicijemozemo primetiti da je za istrazivanje podataka neophodno imati podesne algoritme,iskustvo i dobre podatke. Neki od alternativnih naziva su
’’istrazivacka analiza poda-
taka” (engl. exploratory data analysis) i’’podacima vodeno otkrivanje” (engl. data-
driven knowledge discovery). Napomenimo da u istrazivanju podataka nema mesta zadeduktivno ucenje. Zakljucivanje koje se koristi u istrazivanju podataka je verovatnosnozakljucivanje.
1.2 Pojam modela
Istrazivanje podataka je u velikoj meri zasnovano na algoritmima, tj. postoji ve-liki broj razlicitih algoritama koji se koriste. Neki od njih ce biti detaljno obradeni upoglavljima koji slede. Ono sto je zajednicko za te algoritme jeste da svaki algoritampokusava da ukalupi (engl. fit) podatke u neki model.
Model je matematicka reprezentacija zavisnosti izmedu kvantitativno reprezentova-nih promenljivih u fenomenu koji izucavamo.
Ukalupljivanje zapravo predstavlja postupak odabira modela. Na Slici 1.1 prikazanisu podaci (u obliku crnih kruzica), i dva potencijalna modela (1.885x + 1.333, plavombojom na slici levo, i 8 ln(x), crvenom bojom na slici desno). Za odabir modela bira semodel koji je najblizi karakteristikama podataka. Sva je prilika da je model na slici levoblizi podacima od modela na slici desno.
Navedimo neke primere zadataka za cije resavanje se koristi istrazivanje podataka ipridruzimo ih odgovarajucim podoblastima istrazivanja podataka:
• Identifikovati sve uslove koje je potrebno staviti u ugovor da bi se izbegli rizicnikrediti (klasifikacija).
• Pronaci grupe piksela na slici koji su’’slicne boje” (klasterovanje). Ovo je korak
koji prethodi redukciji palete slike. Nakon sto smo pronasli grupe piksela, mozemopronaci
’’srednju boju” (sto se naziva centroid) te grupe i zameniti sve piksele u
grupi upravo pronadenim centroidom.
• Za nekog kupca odredenog proizvoda, izdvojiti njegove Facebook’’prijatelje” koji
’’vole” slicne stvari koji upadaju u kategoriju kupljenog proizvoda, a zatim im
ponudi reklamu za taj proizvod (predvidanje).

1.3. PRIMERI PODOBLASTI ISTRAZIVANJA PODATAKA 3
0 2 4 6 8 100
10
20
0 2 4 6 8 10
0
10
20
Slika 1.1: Odabir modela.
• Odrediti sve izlete koje treba ponuditi turistima koji izaberu odredenu destinaciju(pravilo pridruzivanja).
Poreklo istrazivanja podataka mozemo naci u disciplinama kao sto su masinskoucenje, vestacka inteligencija, i statistika. Obratimo paznju na razlike izmedu ovihdisciplina. Masinsko ucenje se bavi generalizacijom nad podacima, pod kojim uslovimaje generalizacija aplikabilna, kao i konstrukcijom algoritama koji uce iz podataka. Zarazliku od toga, istrazivanje podataka se ne bavi toliko dizajnom koliko primenom al-goritama, zatim pripremanjem i vizualizacijom podataka. Vestacka inteligencija se bavikontrolom kombinatorne eksplozije. Statistika nam je znacajna zbog brojnih velicinakao sto su prosek, kvantili, i drugo. Tradicionalne tehnike su nekorisne zbog kolicinepodataka, dimenzionalnosti podataka, i heterogenosti i distribuiranosti podataka.
Svi modeli i zadaci istrazivanja podataka mogu se svrstati u dve grupe metoda:
Metode predvidanja. Metode predvidanja formiraju predvidanje o vrednostima po-dataka na osnovu poznatih rezultata dobijenih iz drugih podataka ili istorijskihpodataka. Atribut koji se predvida je cilj ili zavisna promenljiva, dok se atributikoji se koriste u predvidanju nazivaju nezavisne promenljive. Primeri su: klasifi-kacija, regresija, itd.
Opisne metode. Opisne metode identifikuju obrasce i odnose izmedu podataka. Istrazujuse ispitivane osobine podataka, a ne predvidaju se vrednosti promenljivih. Primerisu: korelacije, trendovi, klasteri, trajektorije, anomalije, itd.
1.3 Primeri podoblasti istrazivanja podataka
U ovoj sekciji cemo obratiti kratku paznju na neke podoblasti istrazivanja podatakasa kojima cemo se susreti nadalje. Medu podoblastima kojima cemo obratiti paznjunalaze se: klasifikacija (engl. classification), regresija (engl. regression), klasterovanje(engl. clustering) i pravila pridruzivanja (engl. associtation rules).
U klasifikaciji podatke koje istrazujemo (nadalje cemo ih nazivati instance ili vektori)imaju odredene atribute (ili koordinate). Od svih atributa, neki od njih odreduje klasu.
4 GLAVA 1. UVOD U ISTRAZIVANJE PODATAKA
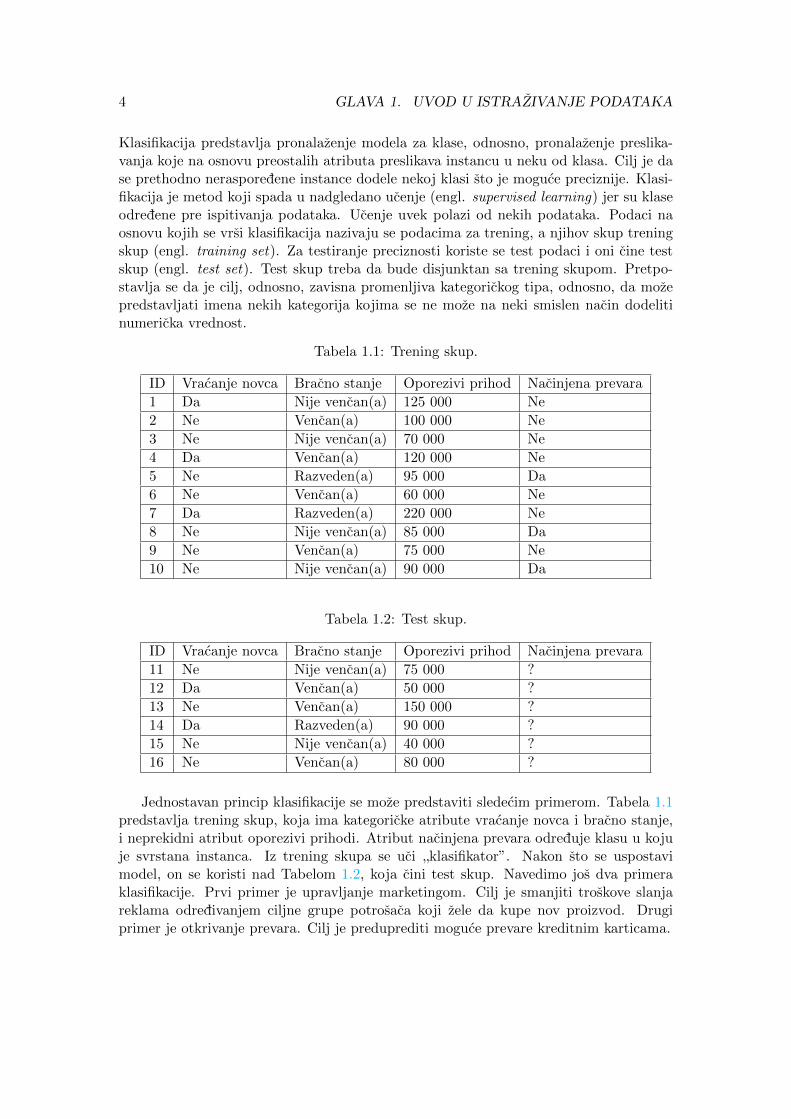
Klasifikacija predstavlja pronalazenje modela za klase, odnosno, pronalazenje preslika-vanja koje na osnovu preostalih atributa preslikava instancu u neku od klasa. Cilj je dase prethodno nerasporedene instance dodele nekoj klasi sto je moguce preciznije. Klasi-fikacija je metod koji spada u nadgledano ucenje (engl. supervised learning) jer su klaseodredene pre ispitivanja podataka. Ucenje uvek polazi od nekih podataka. Podaci naosnovu kojih se vrsi klasifikacija nazivaju se podacima za trening, a njihov skup treningskup (engl. training set). Za testiranje preciznosti koriste se test podaci i oni cine testskup (engl. test set). Test skup treba da bude disjunktan sa trening skupom. Pretpo-stavlja se da je cilj, odnosno, zavisna promenljiva kategorickog tipa, odnosno, da mozepredstavljati imena nekih kategorija kojima se ne moze na neki smislen nacin dodelitinumericka vrednost.
Tabela 1.1: Trening skup.
ID Vracanje novca Bracno stanje Oporezivi prihod Nacinjena prevara
1 Da Nije vencan(a) 125 000 Ne
2 Ne Vencan(a) 100 000 Ne
3 Ne Nije vencan(a) 70 000 Ne
4 Da Vencan(a) 120 000 Ne
5 Ne Razveden(a) 95 000 Da
6 Ne Vencan(a) 60 000 Ne
7 Da Razveden(a) 220 000 Ne
8 Ne Nije vencan(a) 85 000 Da
9 Ne Vencan(a) 75 000 Ne
10 Ne Nije vencan(a) 90 000 Da
Tabela 1.2: Test skup.
ID Vracanje novca Bracno stanje Oporezivi prihod Nacinjena prevara
11 Ne Nije vencan(a) 75 000 ?
12 Da Vencan(a) 50 000 ?
13 Ne Vencan(a) 150 000 ?
14 Da Razveden(a) 90 000 ?
15 Ne Nije vencan(a) 40 000 ?
16 Ne Vencan(a) 80 000 ?
Jednostavan princip klasifikacije se moze predstaviti sledecim primerom. Tabela 1.1predstavlja trening skup, koja ima kategoricke atribute vracanje novca i bracno stanje,i neprekidni atribut oporezivi prihodi. Atribut nacinjena prevara odreduje klasu u kojuje svrstana instanca. Iz trening skupa se uci
’’klasifikator”. Nakon sto se uspostavi
model, on se koristi nad Tabelom 1.2, koja cini test skup. Navedimo jos dva primeraklasifikacije. Prvi primer je upravljanje marketingom. Cilj je smanjiti troskove slanjareklama odredivanjem ciljne grupe potrosaca koji zele da kupe nov proizvod. Drugiprimer je otkrivanje prevara. Cilj je preduprediti moguce prevare kreditnim karticama.

1.3. PRIMERI PODOBLASTI ISTRAZIVANJA PODATAKA 5
Regresija je podoblast istrazivanja podataka u kojoj se na osnovu vrednosti nekihpromenljivih predvida vrednost promenljive ciji je domen skup realnih brojeva. Izmedupromenljivih cije su vrednosti poznate i promenljive cija se vrednost predvida postojelinearne ili nelinearne zavisnosti.
Navedimo neke primere regresije. Prvi primer je predvidanje kolicine prodaje novogartikla na osnovu utrosenih sredstava u reklamnoj kampanji. Drugi primer je predvidanjebrzine vetra kao funkcija temperature, vlaznosti, vazdusnog pritiska, kolicine oblaka, idrugih parametara. Treci primer je predvidanje cene akcija na berzi u zavisnosti odvremenskog perioda.
Klasterovanje podrazumeva da se slicni podaci (u odnosu na odgovarajuce atribute)grupisu zajedno u grupe koje nazivamo klasteri. Dok su elementi unutar klastera slicni,klasteri se medu sobom razlikuju. Klasterovanje je vid nenadgledanog ucenja (engl. un-supervised learning) jer klasteri nisu odredeni pre ispitivanja podataka. Problem kojise javlja u klasterovanju jeste to sto je obicno potrebno znanje eksperta da bi se pro-tumacilo znacenje formiranih klastera. Vec smo pominjali primer sa pikselima kao primerklasterovanja koji ima znacaja u redukciji velicine slika (klasterovanje je vazan korak kojiprethodi kompresiji slike).
Odredivanje pravila pridruzivanja (ili analiza pridruzivanja, analiza veza, analizaafiniteta) oznacava otkrivanje obrazaca koji opisuju medusobno cvrsto povezane osobinepodataka. Obicno se predstavljaju preko implikacije ili osobina podskupova na sledecinacin: ako za neki skup instanci vazi skup osobina X, onda za taj skup verovatno vazii skup osobina Y . Kako prostor koji se pretrazuje raste eksponencijalno, cilj je izdvojitinajinteresantnije obrasce na najefikasniji nacin.
Navedimo neke primere pravila pridruzivanja. Prvi primer je nalazenje grupe genakoji imaju slicne funkcionalnosti u bioinformatici. Drugi primer je identifikacija Vebstranica kojima se pristupa zajedno. Treci primer koji cemo nesto detaljnije razmatratijeste primer sa potrosackom korpom. Na osnovu kupovina (skupa transakcija) u nekojprodavnici, analizom pridruzivanja mozemo pronaci artikle koji se cesto kupuju uz nekedruge artikle. Na primer, na osnovu skupa transakcija prikazanih Tabelom 11.1 mozemoprimetiti pravilo {Pelene} −→ {Mleko}, sto sugerise da kupci koji kupuju pelene imajutendenciju da kupe i mleko.
Tabela 1.3: Podaci o potrosackim korpama.
1 {Hleb, Margarin, Pelene, Mleko}2 {Kafa, Secer, Kolaci, Loso}3 {Hleb, Margarin, Kafa, Pelene, Mleko, Jaja}4 {Hleb, Margarin, Losos, Piletina}5 {Jaja, Hleb, Margarin}6 {Losos, Pelene, Mleko}7 {Hleb, Caj, Secer, Jaja}8 {Kafa, Secer, Piletina, Jaja}9 {Hleb, Pelene, Mleko, So}10 {Caj, Jaja, Kolaci, Pelene, Mleko}

6 GLAVA 1. UVOD U ISTRAZIVANJE PODATAKA
1.4 Izazovi u procesu istrazivanja podataka
Izazova (citaj, problema) u procesu istrazivanja podataka ima mnogo. U nastavkuteksta cemo se baviti nekim izazovima i diskutovati o njima.
Istrazivanje podataka treba da bude dostupno i ljudima koji nisu tehnicki strucni, od-nosno, koji mozda nemaju formalno obrazovanje iz racunarskih nauka. Zbog toga trebaobezbediti interfejse preko kojih ljudi mogu komunicirati sa sistemima za istrazivanjepodataka. Izrada takvih interfejsa nije nimalo lak posao.
Problem ukalupljivanja predstavlja fundamentalni problem istrazivanja podataka.Na primer, za skup podataka sa Slike 1.1, mozemo pronaci model ciji grafik ce sigurnoprolaziti kroz sve tacke koje predstavljaju date podatke. Na Slici 1.2, model desnopredstavlja Langranzov polinom konstruisan nad tackama koji predstavljaju podatke.Taj model, iako sjajno modelira pocetne podatke, veoma je nestabilan (obratiti paznjuna amplitude polinoma visokog stepena).
0 2 4 6 8 100
10
20
0 2 4 6 8 10
0
10
20
30
Slika 1.2: Problem preteranog ukalupljivanja podataka u model.
Veoma cesto se moze desiti da se u skupu podataka nadu tzv. atipicni podaci (engl.outliers), odnosno, elementi van granica modela. Ukoliko prilikom izbora modela uvr-stamo i takve podatke, sva je prilika da cemo doci do neprirodnih modela. Jedanocigledan primer loseg modela do kojeg se doslo prikazan je na Slici 1.3. Pretposta-vimo da se u skupu podataka predstavljenom na Slici 1.1 (kao i na Slici 1.2) nasaojos jedan podatak (x, y) = (2.5, 100). Uvrstavanjem i tog podatka pri ukalupljavanju,dobijamo iskrivljenu sliku podataka (slika desno).
Kao sto smo pomenuli, interpretacija rezultata je tezak posao. Na primer, klasterikoje dobijamo nad nekim podacima umeju da budu veoma cudni ako nismo dobro upo-znati sa domenom problema koji istrazujemo.
Interpretacija rezultata se cesto svodi na vizualizaciju rezultata (ili barem bude pot-pomognuta njome). Neke rezultate je moguce pogodno vizualizovati, ali ne i sve. Vizu-alizacija je posebno teska u slucajevima sa visokim dimenzijama.
Zbog brzog rasta kolicine podataka, algoritmi istrazivanja podataka moraju da buduu stanju da izdrze kolicine koje se mere gigabajtima i terabajtima podataka. Dakle,oni moraju da budu skalabilni. Posebno treba obratiti paznju na cinjenicu da mnogialgoritmi istrazivanja podataka koriste neku vrstu pretrage koja ima tendenciju da ek-sponencijalno raste. Skalabilnost se moze poboljsati uzimanjem uzoraka (engl. sampling)

1.4. IZAZOVI U PROCESU ISTRAZIVANJA PODATAKA 7
0 2 4 6 8 10
0
50
100
0 2 4 6 8 10
0
50
100
Slika 1.3: Problem atipicnih elemenata.
ili razvijanjem paralelnih i distribuiranih algoritama [1].Dimenzionalnost predstavlja broj atributa neke instance. Nije retko susreti se sa
podacima koji imaju stotine i hiljade atributa. Opisivanje zavisnosti medu tim atri-butima moze da bude nezgodno sto za racunarsko izracunavanje to i za interpretaciju.Na primer, kao rezultat odredivanja zavisnosti medu deset hiljada atributa (promenlji-vih) nekih instanci dobija se hiljadu linearnih jednacina. Sta uraditi sa tim rezultatom?Takode, za neke algoritme, slozenost raste sa povecavanjem dimenzionalnosti [1].
Tradicionalne metode analize cesto su radile nad podacima koji sadrze atribute istogtipa, i koji su na neki nacin bili uredeni (na primer, slogovi u bazama podataka). Saporastom uloge istrazivanja podataka u poslovanju, nauci, medicini i drugim oblastima,javila se potreba za rukovanjem heterogenim i slozenim podacima. Primeri takvih po-dataka su kolekcije polustruktuiranih i hiperlinkovima povezanih Veb stranica, DNKpodaci sa sekvencijalnim i trodimenzionalnom strukturom, klimatski podaci koji zaviseod vremena, i drugi. Ovi podaci sadrze mnoge veze o kojima treba voditi racuna.
Kvalitet podataka sa kojima se radi u istrazivanju podataka nije ni priblizno nalikna podatke sa kojima tradicionalne metode rukuju. Skoro uvek imamo problema sanedostajucim i irelevantnim podacima, te ih treba pazljivo analizirati, dolaziti do njihuz pomoc dostupnih atributa, i odstranjivati one koji
’’smetaju”.
Istrazivanje podataka ima veoma bitne drustvene posledice. Diskutovacemo o tri ta-kve posledice: narusavanje privatnosti, profilisanje i neautorizovano koriscenje. Narusavanjeprivatnosti se ogleda u dolazenju do informacija koje nam nisu prvobitno bile dostupne.Na primer, u popisu stanovnistva neko moze da se ne izjasni o drzavljanstvu, a da mi touspemo da dobijemo koriscenjem ostalih atributa koje smo sakupili. Profilisanje mozedovesti do problema pogresne klasifikacije. U zakonskim sistemima ovo moze da imaozbiljne posledice. Na primer, ako sistem konstantno savetuje policajcu nekog okrugada motri na ljude tamnije boje koze zato sto medu podacima stoji da ima vise prestup-nika sa tamnijom bojom koze. Medutim, dodatnim privodenjem takvih osoba, sistempostaje sve vise stereotipan. Neautorizovano koriscenje predstavlja pristup podacima zakoje ne postoji dovoljni nivo privilegija. Zastita tajnosti informacija predstavlja bitnutemu u istrazivanju podataka.

8 GLAVA 1. UVOD U ISTRAZIVANJE PODATAKA
1.5 Metrika istrazivanja podataka
Kao sto smo rekli, glavni cilj svakog istrazivanja podataka jeste dobijanje informacijakoje nam prevashodno nisu bile ocigledne. Medutim, prvo pitanje koje se postavlja jestepitanje kvaliteta dobijenih informacija. Za to nam sluzi metrika istrazivanja podataka.
Metrika istrazivanja podataka je merenje efikasnosti i korisnosti upotrebe istrazivanjapodataka.
Metrika istrazivanja podataka zavisi od interesovanja, odnosno zeljenog cilja. Naprimer, za poslovne aplikacije se kao mera cesto koristi povracaj investicija. Za drugeprimene mogu da posluze tradicionalne metrike zasnovane na utrosenom prostoru i vre-menu i analizi slozenosti. U nekim slucajevima, metrika istrazivanja podataka moze dabude tacnost klasifikacije, i sl. Bitno je napomenuti da metrika istrazivanja podatakanije nas primarni cilj, vec samo predstavlja posrednu informaciju o onome sto je predmetistrazivanja.

Glava 2
Podaci
Kao sto smo videli u prethodnom poglavlju, podaci igraju kljucnu ulogu u istrazivanjupodataka. Naizgled nam se moze uciniti da podaci uglavnom imaju pogodne oso-bine, medutim, u stvarnosti oni nose sa sobom mnostvo problema. Zapravo, u procesuistrazivanja podataka, prvo mesto zauzima pretprocesiranje podataka (engl. data prepro-cessing), odnosno, skup tehnika kojima se dobijaju pogodni podaci koji ce predstavljatiulaz algoritama istrazivanja podataka. Ovo poglavlje zapocecemo nekim od problemavezanih za podatke koji su vazni za uspesno istrazivanje podataka:
Tipovi podataka. Skupovi podatka se razlikuju na mnogo nacina. Na primer, atributikoji se koriste da opisu objekte podataka mogu biti razlicitih tipova – kvalitativnii kvantitativni – i skupovi podataka mogu imati specijalne karakteristike. Tippodataka odreduje koje alate i tehnike mozemo koristiti za njihovu analizu.
Kvalitet podataka. Podaci su cesto daleko od savrsenih. Iako vecina tehnika zaistrazivanje podataka moze da tolerise odreden nivo nesavrsenosti podataka, po-svecivanje paznje razumevanju i poboljsanju kvaliteta podataka obicno poboljsavarezultat analize.
Pretprocesiranje podataka. Sirovi podaci cesto moraju biti pretprocesirani kako bise ucinili pogodnijim za analize. Jedan pogled na pretprocesiranje moze biti po-boljsanje podataka, dok drugi ciljevi mogu biti fokusirani na promenu podatakakako bi se bolje prilagodili konkretnoj tehnici ili alatu za istrazivanje podataka.
Analiza podataka u smislu njhovih odnosa. Jedan pristup analizi podataka je pro-nalazenje odnosa medu objektima podataka i onda primeniti ostale analize zasno-vane na tim odnosima umesto koriscenja samih objekata.
2.1 Tipovi podataka
Skup podataka (engl. data set) moze se posmatrati kao skup objekata (engl. dataobjects) i njihovih atributa (engl. features). Atributi su svojstvo ili karakteristikaobjekta. Primeri atributa su: temperatura grada, boja automobila, velicina ekrana, idrugi. Druga imena za atribute su promenljive, polja, osobine, karakteristike, itd. Skupatributa opisuje objekat. Objekat je takode poznat i kao slog, tacka, slucaj, primer,entitet, instanca, itd.
9

10 GLAVA 2. PODACI
2.1.1 Vrednosti atributa
Opisimo atribute nesto detaljnijom definicijom. Atribut je svojstvo ili karakteristikaobjekta koja moze da varira, bilo od objekta do objekta, ili zavisno od vremena.
Na primer, boja ociju varira od coveka do coveka, dok temperatura grada variratokom vremena. Primetimo da je boja ociju simbolicki atribut sa malim brojem mogucihvrednosti {plave, zelene, braon, crne, itd.}, dok je temperatura numericka vrednost sapotencijalno beskonacno mnogo mogucih vrednosti.
Na najosnovnijem nivou, atributi nisu samo brojevi i simboli. Ali, kako bismo disku-tovali i preciznije analizirali karakteristike objekata, dodeljujemo im brojeve i simbole.Da bismo to ucinili na dobro definisan nacin, potrebna nam je merna skala (engl. mea-surement scale).
Merna skala je preslikavanje koje pridruzuje brojcanu ili simbolicku vrednost atributujednog objekta.
Dakle, svaki atribut ima neku vrednost (govoricemo i o slucajevima kada nam vred-nosti atributa nisu poznate ili dostupne, ali uvek cemo se truditi da ipak postoji nekavrednost za sve atribute). Vrednosti atributa su brojevi ili simboli koji su pridruzeniatributu.
Bitno je napomenuti razliku izmedu atributa i njihovih vrednosti. Naime, isti atributimogu da budu preslikani u razlicite vrednosti atributa. Na primer, visina moze da se meriu metrima ili kilometrima. Sa druge strane, razliciti atributi mogu da budu preslikaniu isti skup vrednosti, pri cemu osobine atributa mogu da budu razlicite. Na primer,vrednosti za broj godina i tezinu su celobrojne (dakle, ta dva atributa dele isti domen),ali broj godina ne moze da se smanjuje dok tezina moze.
Osobine atributa ne moraju da budu iste kao osobine vrednosti koje se koriste pri me-renju tog atributa. Na slici 2.1 prikazano je merenje razlicitih duzi (A do E), kao i merekoje su im pridruzene, koriscenjem dve vrednosne skale. Primeticemo da koriscenjemskale levo imamo uvid samo u poredak, dok koriscenjem skale desno pored poretkaimamo informaciju i o umnosku. Dakle, vrednosti atributa ne moraju da oslikavajupunu informaciju nekog atributa.
2.1.2 Tipovi atributa
Jedan tipican nacin razlikovanja tipova atributa je da se tipovi karakterisu operaci-jama koje se mogu, i koje ima smisla, primeniti na vrednosti tog atributa. Pri tome,koristimo sledece osobine i operacije koje se najcesce koriste radi odredivanja tipa atri-buta:
1. Razlicitost = i 6=
2. Uredenje <, ≤, > i ≥
3. Aditivnost + i −
4. Multiplikativnost ∗ i /

2.1. TIPOVI PODATAKA 11
Slika 2.1: Merenje duzine duzi koriscenjem dve razlicite skale. Levo: samo poredak.Desno: poredak i umnozak.
Pomocu ovih svojstava, mozemo da definisemo cetiri tipa atributa. Svaki naredni tipposeduje svojstva i operacije svih prethodnih tipova. Oni su:
Imenski (engl. Nominal). Vrednost imenskog (cesto cemo reci i kategorickog) atributasu upravo razlicita imena, odnosno, imenski atributi pruzaju samo mogucnost razli-kovanja jednog od drugog objekta (=, 6=). Primeri imenskih atributa su: postanskikodovi, identifikacije zaposlenih, boja ociju, pol i drugi. Nad ovim atributimamogu se primeniti sledece statisticke operacije: modus (engl. mode), entropija(engl. entropy), korelacija (engl. contingency correlation), i χ2 test. Modus pred-stavlja tacku u kojoj dolazi do maksimuma modela, odnosno, najcescu vrednost.Entropija je mera neuredenosti. Korelacija podrazumeva analizu jacine i smerapovezanosti. χ2 test se koristi za ispitivanje nezavisnosti medu promenljivama.
Redni (engl. Ordinal). Vrednosti rednih atributa pruzaju dovoljno informacija za uredenjeobjekata (<, ≤, >, ≥). Primeri rednih atributa su: tvrdoca minerala (dobra, bolja,najbolja), ocene, redni brojevi zgrada u ulici. Statisticke operacije koje se moguprimeniti su: medijana (engl. median), percentil (engl. percentile), i korelacijaranga (engl. rank correlation). Medijana je vrednost koja se nalazi na srediniuredenog poretka. Percentil je vrednost ispod koje upada odreden procenat po-smatranja u grupi posmatranja. Medijana zapravo predstavlja 50-i percentil. Ko-relacija ranga, ili Spirmanov koeficijent korelacije (engl. Spearman’s correlation),meri stepen asocijacije medu promenljivama.
Intervalni (engl. Interval). Za intervalne atribute, najvise ima smisla praviti razlikeizmedu vrednosti, odnosno, postoji jedinica mere takvih atributa (+, −). Primerisu: datumi u kalendaru, temperatura u stepenima Celizijusa. Statisticke operacijekoje mozemo izvoditi su: srednja vrednost (engl. mean), standardna devijacija(engl. standard deviation), i Pirsonova korelacija (engl. Pearson’s correlation).Srednja vrednost je aritmeticka sredina vrednosti. Standardna devijacija namgovori koliko u proseku elementi skupa odstupaju od srednje vrednosti skupa.Pirsonova korelacija meri stepen linearne povezanosti medu promenljivim.

12 GLAVA 2. PODACI
Razmerni (engl. Ratio). Kod razmernih atributa imaju smisla i proizvod i kolicnik(∗, /). Za razmerne atribute kljucni su kolicnici (odnosi). Primeri su: tempe-ratura u Kelvinima, kolicina novca, godine, masa, duzina. Statisticke operacijekoje mozemo izvoditi su: geometrijska sredina, harmonijska sredina, koeficijentvarijacije.
Jedan pogodan nacin za razlikovanje razmernih od intervalnih podataka jeste sto urazmernim podacima postoji
’’prirodna nula”. Naime, ako pogledamo razliku izmedu
’’nula” stepeni Celzijusove i Kelvinove skale, postoji jedna bitna razlika.
’’Nula” Kelvi-
nove skale predstavlja fizicko svojstvo odsustva energije, dok’’nula” Celzijusove skale ne
donosi nikakav realni smisao osim oznake 0.Imenski i redni atributi spadaju u kvalitativne atribute, dok su intervalni i razmerni
kvantitativni atributi. Kvalitativni atributi nemaju vecinu svojstava brojeva. Cak iakosu predstavljeni brojem, treba ih tretirati kao simbole. Za razliku od njih, kvantitativniatributi su predstavljeni brojevima i imaju vecinu svojstava brojeva.
Tipovi atributa mogu se opisati i u smislu transformacija koje ne menjaju znacenjeatributa. Zaista, Stenli Smit Stivens (Stanley Smith Stevens), psiholog koji je definisaoprethodno opisane tipove atributa, definisao ih je i u smislu ovih dozvoljenih transfor-macija. Na primer, smisao atributa duzine se ne menja ako se meri u incima umestocentimetrima.
Operacije koje imaju smisla za odreden tip atributa su one koje ce davati isti rezultatkada je atribut transformisan koriscenjem transformacije koja cuva znacenje atributa.Na primer, prosecna duzina objekta je drugacija kad se meri u centimetrima u odnosuna merenje u incima, ali obe prosecne vrednosti predstavljaju istu duzinu. U tabeli 2.1prikazane su dozvoljene transformacije za cetiri, prethodno opisana, tipa atributa.
Tabela 2.1: Transformacije koje definisu nivoe atributa
Tipatributa
Transformacija Komentar
Imenski Bilo koje bijektivno preslikavanje.Ako svi zaposleni dobiju
nove identifikacije, to necedoneti bilo kakve razlike.
Redni
Promena vrednosti kojacuva uredenje:
nova vrednost = f(stara vrednost),gde je f monotona funkcija.
Atribut koji sadrzi poredenje{dobar, bolji, najbolji}podjednako dobro biva
predstavljen vrednostima{1, 2, 3} ili {0.5, 1, 10}.
Intervalninova vrednost = a ∗ stara vrednost+ b,
gde su a i b konstante.
Celizijusova i Farenhajtovatemperaturna skala se
razlikuju u velicini stepenai u tome gde je nula.
Razmerninova vrednost = a ∗ stara vrednost
gde je a konstantaDuzina moze da se meri u
metrima ili stopama.
Atributi mogu da budu opisani i preko broja vrednosti koje sadrze. U tom slucajurazlikujemo dve vrste atributa:

2.2. TIPOVI SKUPOVA PODATAKA 13
Diskretni atributi. Imaju konacan (ili prebrojivo beskonacan) skup vrednosti. Cestose prikazuju kao celobrojne promenljive upravo zbog osobine da se bilo kakav skupdiskretnih vrednosti moze bijektivno preslikati u neki podskup skupa prirodnih (ilicelih) brojeva. Binarni atributi su specijalan slucaj diskretnih atributa, kod kojihmozemo imati tacno dve vrednosti u skupu, na primer, {tacno, netacno}, {da, ne},{musko, zensko}, {0, 1}. Primeri diskretnih atributa su: postanski brojevi, racunii skup reci u nekom dokumentu.
Neprekidni atributi. Skup vrednosti ovih atributa cine realni brojevi. Realne vredno-sti mogu da se mere i predstavljaju samo preko konacnog broja cifara. Uobicajennacin predstavljanja je u obliku realnih brojeva u pokretnom zarezu. Primeri ne-prekidnih atributa su: temperatura, visina, tezina, pritisak i brzina.
Prakticno bilo koji tip merne skale – imenski, redni, intervalni i razmerni – mozebiti kombinovan sa bilo kojim tipom zasnovanim na broju vrednosti atributa – binarni,diskretni i neprekidni. Ipak, neke kombinacije se javljaju veoma retko ili nemaju smisla.Tipicno, imenski i redni atributi su binarni ili diskretni, dok su intervalni i razmernineprekidni. Ipak, prebrojivi atributi, koji su diskretni, takode su i razmerni.
Asimetricni atributi su oni atributi kod kojih se jedino prisustvo ne-nula vrednostismatra znacajnim. Na primer, neka je objekat student ciji su atributi informacija dali je student slusao neki od kurseva koji se drze na celom univerzitetu. Za konkretnogstudenta vrednost atributa 1 znaci da je on slusao kurs pridruzen tom atributu, a 0 danije slusao. Postavlja se pitanje – kada su dva studenta slicna po kursevima koje suslusali? Zbog toga sto studenti slusaju samo mali deo svih dostupnih kurseva, vecinavrednosti u takvih podacima ce biti 0. Zbog toga, ukoliko poredimo studente na osnovukurseva koje nisu slusali, onda ce vecina studenata biti veoma slicna, naravno, ukoliko jebroj dostupnih kurseva veliki. Binarni atributi kod kojih su bitne ne-nula vrednosti sezovu asimetricni binarni atributi. Videcemo kasnije zbog cega su ovi atributi znacajni.
2.2 Tipovi skupova podataka
Postoji veliki broj razlicitih tipova skupova podataka, i kako se oblast istrazivanjapodataka razvija i sazreva, tako ce sve vise biti dostupni razlicitiji tipovi skupova poda-taka. Tipove skupova podataka cemo grupisati u tri grupe: tabelarni podaci, grafovskipodaci i podaci sa poretkom.
2.2.1 Tabelarni podaci
U tabelarnim podacima podaci se sastoje od skupa objekata, pri cemu se svaki sa-stoji od fiksiranog skupa atributa. U najjednostavnijem obliku ne postoji eksplicitnapovezanost izmedu objekata i svaki objekat ima isti skup atributa. Najcesce se ovakviskupovi cuvaju u datotekama ili u relacionim bazama podataka. Napomenimo da seistrazivanje podataka ne oslanja na dodatne informacije koje su dostupne u relacionojbazi podataka, vec da ona sluzi kao pogodno mesto za cuvanje objekata. Tabela 2.2prikazuje primer najjednostavnijeg oblika tabelarnih podataka.
Transakcioni podaci predstavljaju specijalnu vrstu tabelarnih podataka gde vazi dasvaki objekat (koji predstavlja jednu transakciju) sadrzi skup stavki koje idu zajedno.

14 GLAVA 2. PODACI
Tabela 2.2: Tabelarni podaci.
ID Vracanje novca Bracno stanje Oporezivi prihod Nacinjena prevara1 Da Nije vencan(a) 125 000 Ne2 Ne Vencan(a) 100 000 Ne3 Ne Nije vencan(a) 70 000 Ne4 Da Vencan(a) 120 000 Ne5 Ne Razveden(a) 95 000 Da6 Ne Vencan(a) 60 000 Ne7 Da Razveden(a) 220 000 Ne8 Ne Nije vencan(a) 85 000 Da9 Ne Vencan(a) 75 000 Ne10 Ne Nije vencan(a) 90 000 Da
Na primer, Tabela 2.3 sadrzi podatke o prodavnici prehrambene robe. Transakcija pred-stavlja skup proizvoda koje je neki kupac kupio, a stavke su individualni proizvodi.
Tabela 2.3: Transakcioni podaci.
TID Proizvodi
1 Hleb, sok, mleko
2 Pivo, hleb
3 Pivo, sok, pelene, mleko
4 Pivo, hleb, pelene, mleko
5 Sok, pelene, mleko
U tabelarne podatke spadaju i podaci koji se cuvaju u obliku matrica podataka.Ako objekti imaju identican skup fiksiranih numerickih atributa, tada mozemo da ihposmatramo kao da su u pitanju tacke u visedimenzionalnom prostoru u kome svaka di-menzija odgovara jednom od razlicitih atributa. Takvi skupovi podataka se predstavljajumatricama gde su objekti predstavljeni u vrstama, a atributi u kolonama. S obziromda su podaci u matricama numericki, nad matricama se mogu primenjivati standardneoperacije sa matricama. Tabela 2.4 prikazuje primer matrice podataka.
Tabela 2.4: Matrica podataka.
Projekcija x Projekcija y Udaljenost Opterecenje Debljina
10.23 5.27 15.22 27 1.2
12.65 6.25 16.22 22 1.1
13.54 7.23 17.34 23 1.2
14.27 8.43 18.45 25 0.9
Jos jedan tip skupova podataka je matrica reci. Ona predstavlja pogodan tip zapredstavljanje dokumenata ako zanemarimo redosled reci u tekstu. Svaki dokument jepredstavljen vektorom reci, pri cemu moguce reci u dokumentima su reci koje se navodekao komponente vektora, a vrednost svake komponente je broj pojavljivanja te reci udokumentu. Tabela 2.5 prikazuje primer matrice reci. Dokumenti su smesteni u vrste,a reci u kolone matrice. U praksi se cuvaju samo ne-nula vrednosti.

2.2. TIPOVI SKUPOVA PODATAKA 15
Tabela 2.5: Matrica reci.
tim trener igra lopta rezultat pobeda
dokument 1 3 0 5 0 2 6
dokument 2 0 7 0 2 1 0
dokument 3 0 1 0 0 1 2
2.2.2 Grafovski podaci
Graf ume ponekad da bude pogodna i mocna reprezentacija podataka. Razmatramodva slucaja: graf opisuje odnose izmedu objekata i sami objekti su predstavljeni grafom.
Kada odnosi izmedu objekata saopstavaju vazne informacije, tada se podaci cestopredstavljaju grafom. Preciznije, objekti se predstavljaju cvorovima grafa, a odnosimedu objektima se predstavljaju granama izmedu odgovarajucih cvorova. Dodatno semogu prikazati osobine odnosa, kao sto su usmerenost i tezina. Tipican primer je Veb,koji se (u svom najjednostavnijem prikazu) sastoji od stranica sa tekstom i linkovima kadrugim stranicama. Slika 2.2 prikazuje primer povezanih Veb stranica (svaka stranica jecvor, a linkovi ka drugim stranicama su usmerene grane).
AB
C D
E
<a href=’B.html’></a>
<a href=’C.html’></a><a href=’B.html’></a>
<a href=’D.html’></a>
<a href=’E.html’></a>
Slika 2.2: Povezane Veb stranice.
Sa druge strane, ako objekti imaju strukturu, odnosno, ako se sadrze od podobje-kata izmedu kojih postoje odnosi, onda se upravo struktura takvih objekata predstavljagrafovima. Tipican primer su hemijska jedinjenja ciji se atomi predstavljaju cvorovima,a grane izmedu cvorova su hemijske veze. Slika 2.3 prikazuje strukturu hemijskog jedi-njenja benzen (hemijska formula za benzen je C6H6), koji sadrzi atome ugljenika (crno)i vodonik (sivo).

16 GLAVA 2. PODACI
Slika 2.3: Molekul benzena.
2.2.3 Podaci sa poretkom
Za neke tipove podataka atributi mogu imati odnose koje obuhvataju vremenski iliprostorni redosled. Takvi podaci se jednim imenom nazivaju podaci sa poretkom (engl.ordered data). U nastavku teksta sledi opis tipova podataka sa poretkom.
Redni podaci (engl. sequential data), ili vremenski podaci (engl. temporal data),mogu se posmatrati kao produzetak tabelarnih podataka gde svaki objekat ima odredenovreme koje se asocirano sa tim objektom. Na primer, ako uz transakcione podatke nekeprodavnice imamo i informaciju o vremenu izvodenja transakcije, onda bismo mogli dauocavamo neke obrasce poput
’’prodaja slatkisa je najveca pred Noc Vestica”. Tabela
2.6 prikazuje primer podataka sa poretkom. U opticaju su pet razlicitih vremena {t1, t2,..., t5}, tri razlicita kupca {C1, C2, C3} i pet razlicitih stavki {A, B, ..., E}. U gornjojtabeli, svaki red predstavlja spisak stavki koje je kupac kupio u odredenom vremenu.U donjoj tabeli su predstavljene iste informacije, ali sada svaki red predstavlja jednogkupca. Svaki red sadrzi informacije o svakoj transakciji koja je vezana za kupca, pricemu transakciju cini skup kupljenih stavki i vreme kupovine.
Tabela 2.6: Podaci sa poretkom.
Vreme Kupac Stavke
t1 C1 A, B
t2 C3 A, C
t2 C1 C, D
t3 C2 A, D
t4 C2 E
t5 C1 A, E
Kupac Vreme i stavke
C1 (t1: A, B) (t2: C, D) (t5: A, E)
C2 (t3: A, D) (t4: E)
C3 (t2: A, C)
2.2. TIPOVI SKUPOVA PODATAKA 17
Sekvencijalni podaci (engl. sequence data) sastoje se od skupa koji predstavlja se-kvencu individualnih objekata, kao sto je sekvenca reci ili slova. Ovo veoma lici na rednepodatke, ali kod sekvencijalnih podataka nema vremenskih odrednica. Umesto toga po-stoje pozicije koje odreduju red u sekvenci. Na primer, genetska informacija se mozepredstaviti u obliku sekvenci nukleotida koji su poznati kao geni. Slika 2.4 predstavljadeo ljudskog genetskog koda izrazenog preko sekvence cetiri nukleotida od kojih je savDNK sastavljen: A (adenin), T (timin), G (guanin) i C (citozin).
GGTTCCGCCTTCAGCCCCGCGCC
CGCAGGGCCCGCCCCGCGCCGTC
GAGAAGGGCCCGCCTGGCGGGCG
GGGGGAGGCGGGGCCGCCCGAGC
CCAACCGAGTCCGACCAGGTGCC
CCCTCTGCTCGGCCTAGACCTGA
GCTCATTAGGCGGCAGCGGACAG
GCCAAGTAGAACACGCGAAGCGC
TGGGCTGCCTGCTGCGACCAGGG
Slika 2.4: Sekvencijalni podaci.
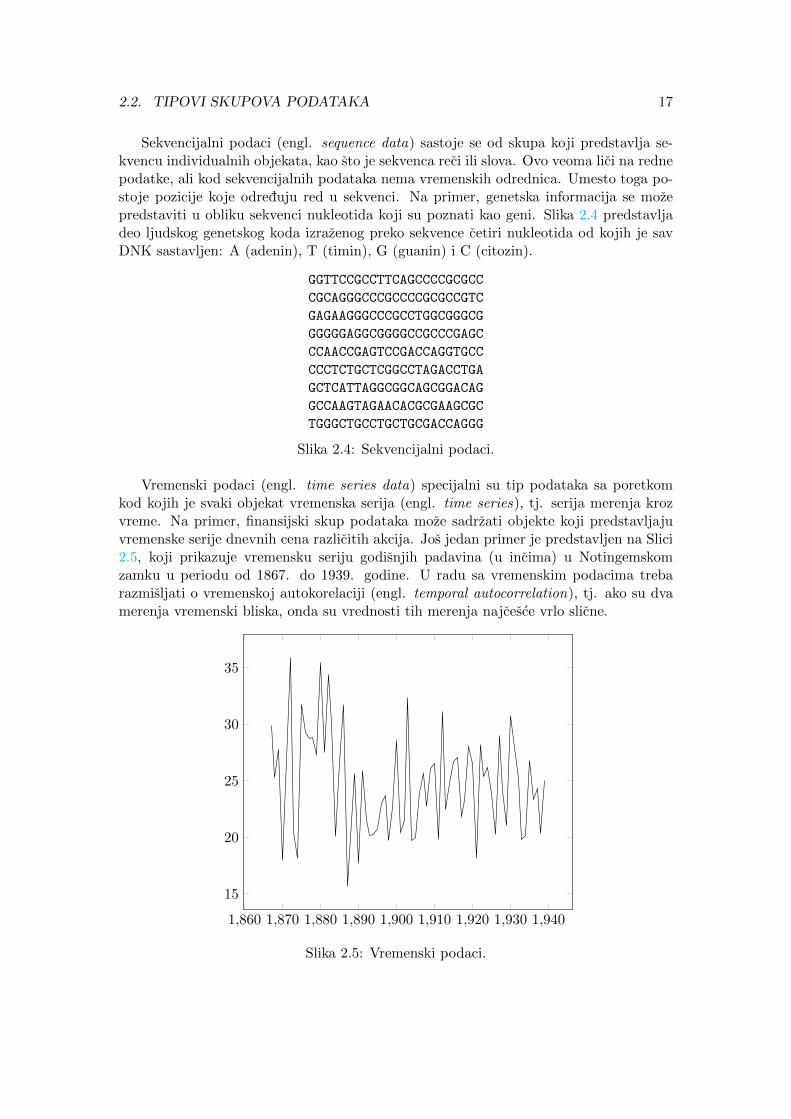
Vremenski podaci (engl. time series data) specijalni su tip podataka sa poretkomkod kojih je svaki objekat vremenska serija (engl. time series), tj. serija merenja krozvreme. Na primer, finansijski skup podataka moze sadrzati objekte koji predstavljajuvremenske serije dnevnih cena razlicitih akcija. Jos jedan primer je predstavljen na Slici2.5, koji prikazuje vremensku seriju godisnjih padavina (u incima) u Notingemskomzamku u periodu od 1867. do 1939. godine. U radu sa vremenskim podacima trebarazmisljati o vremenskoj autokorelaciji (engl. temporal autocorrelation), tj. ako su dvamerenja vremenski bliska, onda su vrednosti tih merenja najcesce vrlo slicne.
1,860 1,870 1,880 1,890 1,900 1,910 1,920 1,930 1,940
15
20
25
30
35
Slika 2.5: Vremenski podaci.

18 GLAVA 2. PODACI
U prostornim podacima (engl. spatial data) objekti imaju atribute koji se odnosena lokaciju, kao sto su pozicija na mapi ili povrsina. Primer prostornih podataka sumeteoroloski podaci (padavine, temperatura, pritisak) koji se sakupljaju sa razlicitihlokacija. I ovde imamo aspekt prostorne autokorelacije (engl. spatial autocorrelation)koji je slican kao vremenska autokorelacija samo se odnosi na fizicku (prostornu) bliskostumesto na vremensku. Na Slici 2.6 prikazan je primer prostornih podataka koji prikazujeprosecnu godisnju temperaturu godine 1998.
Slika 2.6: Prostorni podaci.
2.3 Kvalitet podataka
U istrazivanju podataka cesto baratamo podacima koji su prikupljeni za neke drugesvrhe ili za
’’buduce potrebe”. Na primer, model predvidanja se konstruise nad po-
dacima koje dobijamo, pa samim tim ukoliko su podaci losi, onda ce i model sigurnobiti los. Zbog toga cesto ne mozemo da brinemo o problemima kvaliteta tokom rada,vec je pre same upotrebe algoritama i resavanja zadataka potrebno na neki nacin pri-premiti podatke. Tu se postavljaju naredna tri pitanja:
’’Koje su vrste problema pri
odredivanju kvaliteta podataka?”,’’Kako odrediti probleme sa podacima?”, i
’’Sta raditi
sa uocenim problemima?”. Kako sprecavanje problema kvaliteta podataka cesto nije op-cija, istrazivanje podataka se fokusira na: (1) detekciju i ispravljanje problema kvalitetapodataka i (2) koriscenje algoritama koji umeju da tolerisu podatke slabog kvaliteta, kojisu robusni. Prvi korak, detekcija i ispravljanje, cesto se naziva preciscavanje podataka(engl. data cleaning).
U ovoj sekciji cemo se baviti narednim problemima kvaliteta podataka: greske primerenju i prikupljanju podataka, sum i elementi van granica, nedostajuce vrednosti iduplirani (multiplicirani) podaci.
2.3. KVALITET PODATAKA 19
2.3.1 Greske pri merenju i prikupljanju podataka
Greska pri merenju (engl. measurement error) se odnosi na bilo koji problem kojise moze javiti u procesu merenja. Cest je problem da se vrednost koja je izmerenarazlikuje od stvarne vrednosti do neke mere. Za neprekidne atribute, numericka razlikau izmerenoj i stvarnoj vrednosti se naziva greska (engl. error). Termin greska podataka(engl. data collection error) odnosi se na greske kao sto su izostavljanje objekata ilivrednosti atributa ili neprikladnog ukljucivanja objekta u skup podataka. Greske primerenju ili greske podataka mogu biti bilo sistematicne ili nasumicne.
2.3.2 Sum i elementi van granica
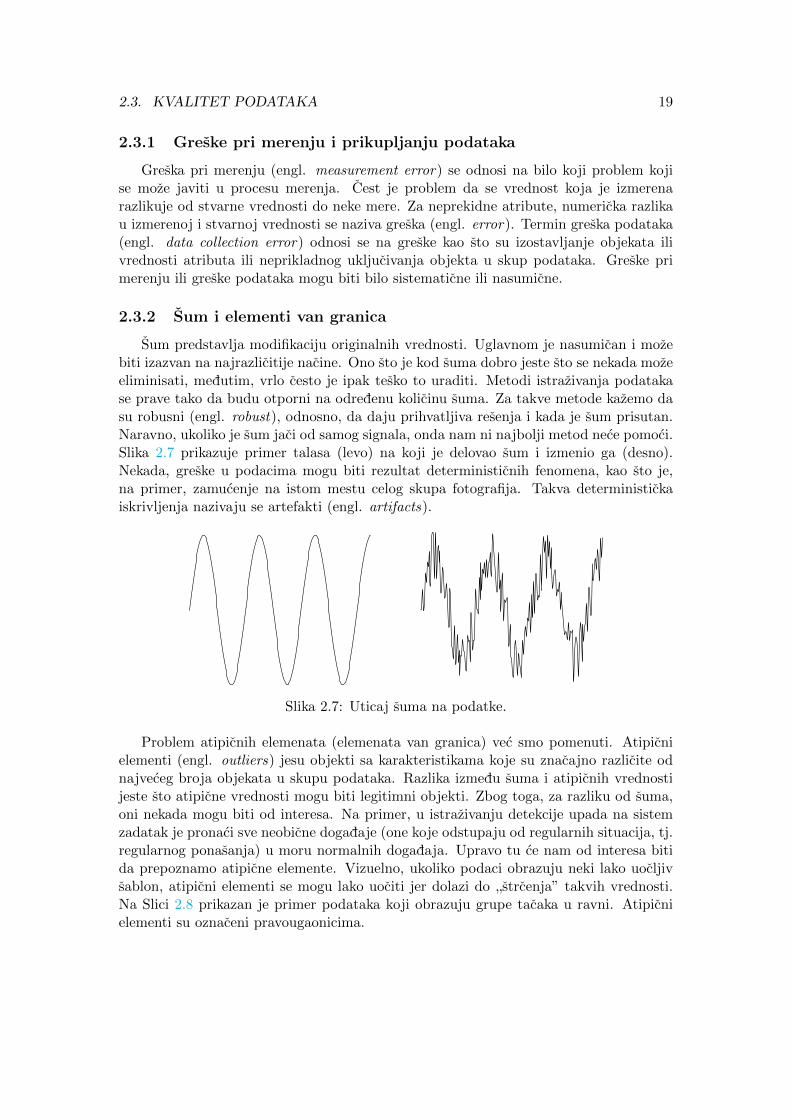
Sum predstavlja modifikaciju originalnih vrednosti. Uglavnom je nasumican i mozebiti izazvan na najrazlicitije nacine. Ono sto je kod suma dobro jeste sto se nekada mozeeliminisati, medutim, vrlo cesto je ipak tesko to uraditi. Metodi istrazivanja podatakase prave tako da budu otporni na odredenu kolicinu suma. Za takve metode kazemo dasu robusni (engl. robust), odnosno, da daju prihvatljiva resenja i kada je sum prisutan.Naravno, ukoliko je sum jaci od samog signala, onda nam ni najbolji metod nece pomoci.Slika 2.7 prikazuje primer talasa (levo) na koji je delovao sum i izmenio ga (desno).Nekada, greske u podacima mogu biti rezultat deterministicnih fenomena, kao sto je,na primer, zamucenje na istom mestu celog skupa fotografija. Takva deterministickaiskrivljenja nazivaju se artefakti (engl. artifacts).
Slika 2.7: Uticaj suma na podatke.
Problem atipicnih elemenata (elemenata van granica) vec smo pomenuti. Atipicnielementi (engl. outliers) jesu objekti sa karakteristikama koje su znacajno razlicite odnajveceg broja objekata u skupu podataka. Razlika izmedu suma i atipicnih vrednostijeste sto atipicne vrednosti mogu biti legitimni objekti. Zbog toga, za razliku od suma,oni nekada mogu biti od interesa. Na primer, u istrazivanju detekcije upada na sistemzadatak je pronaci sve neobicne dogadaje (one koje odstupaju od regularnih situacija, tj.regularnog ponasanja) u moru normalnih dogadaja. Upravo tu ce nam od interesa bitida prepoznamo atipicne elemente. Vizuelno, ukoliko podaci obrazuju neki lako uocljivsablon, atipicni elementi se mogu lako uociti jer dolazi do
’’strcenja” takvih vrednosti.
Na Slici 2.8 prikazan je primer podataka koji obrazuju grupe tacaka u ravni. Atipicnielementi su oznaceni pravougaonicima.

20 GLAVA 2. PODACI
−2 −1 0 1 2 3 4 5−4
−3
−2
−1
0
1
2
Slika 2.8: Atipicni elementi.
2.3.3 Nedostajuce vrednosti
Nije neobicno da za neke objekte u skupu podataka ne znamo vrednosti jednog ilivise atributa. Stavise, ovo je mozda najcesci problem sa kojim se mozemo susresti uistrazivanju podataka. U nekim slucajevima mozda jednostavno nismo uspeli da priku-pimo podatke, na primer, neki ljudi odbijaju da daju informaciju o broju licne karte. Unekim drugim slucajevima atributi nisu primenljivi za sve objekte, na primer, prilikompopunjavanja formulara, za popunjavanje narednog polja mora se odgovoriti sa
’’da” na
prethodno polje. Sta ako je osoba odgovorila sa’’ne”? Drugi primer je da plata nije pri-
menljiva na decu. Rukovanje nedostajucim vrednostima se moze uraditi na vise nacina.U nastavku dajemo neke metode za to.
Eliminacija objekata predstavlja jednostavan i efektivan nacin resavanja problemanedostajucih vrednosti. Jednostavno odbacimo sve objekte kojima nesto
’’fali” i zavrsili
smo posao. Mana ovog pristupa je da cak i parcijalni objekti nose neke informacijekoje nam mogu biti od znacaja. Takode, ukoliko je veliki broj objekata koji imajunedostajuce vrednosti, onda cemo izgubiti na pouzdanosti analize. Sa druge strane, akoje takvih objekata malo, onda ovaj metod moze biti od koristi. Metod slican ovome jesteda se eliminisu svi atributi koji imaju nedostajuce vrednosti. Jasno je da ovde treba bitioprezan jer mozemo doci u situaciju da eleminisemo atribute koji mogu biti kriticni zaanalizu.
Procena nedostajucih vrednosti podrazumeva procenjivanje vrednosti jednog (nepo-znatog) atributa na osnovu drugih (poznatih) atributa. Ako je atribut neprekidan, ondaga mozemo proceniti koriscenjem prosecne vrednosti tog atributa najblizih suseda, a akoje atribut kategoricki, onda ga mozemo proceniti koriscenjem vrednosti tog atributa kojise najvise puta pojavljuje u ostalim objektima.

2.4. PRETPROCESIRANJE PODATAKA 21
Mnogi pristupi istrazivanja podataka se mogu modifikovati tako da ignorisu nedo-stajuce vrednosti pri obradi. Na primer, neka se objekti klasteruju i neka treba izracunatislicnost izmedu parova objekata. Ako barem jedan od objekata u paru ima nedostajucevrednosti za neke atribute, onda se slicnost racuna na osnovu onih atributa koji nemajunedostajuce vrednosti. Slicnost ce biti aproksimirana, ali osim ako je broj atributa maliili broj nedostajucih vrednosti veliki, stepen odstupanja aproksimacije mozda nece imativelikog uticaja. Naravno, ignorisanje nekada nije moguce.
Zamena svim mogucim vrednostima (poredanim tezinski prema verovatnoci poja-vljivanja) predstavljena je sledecim principom. Neka instanca a ima atribut X komenedostaje vrednost i neka atribut X moze uzeti vrednost iz skupa {x1, x2, ..., xn} saverovatnocom {p1, p2, ..., pn}, redom. Tada cemo u skup podataka dodati instancu akoja ce imati vrednost xi, i = 1, n za atribut X onoliko puta tako da raspodela vred-nosti xi, i = 1, n odgovara raspodeli definisanoj skupom {p1, p2, ..., pn}. Jasno je daumnozavanje instance a raste eksponencijalno sa brojem atributa kojima nedostaje vred-nost, pa samim tim se i skup podataka veoma brzo siri.
2.3.3.1 Nekonzistentne vrednosti
Pojava nekonzistentnih vrednosti predstavlja zaseban problem u kojem vrednosti ne-kih atributa izlaze iz domena tih atributa. Na primer, u podacima o adresama moze sedesiti da se za jedan grad navede postanski broj koji ne pripada tom gradu. Nekonzi-stentne vrednosti se mogu dobiti na razne nacine, na primer, greskama u unosu podataka(na primer, zamenom dve cifre prilikom unosa sa tastature).
Neki tipovi nekonzistentnosti se jednostavno detektuju. Na primer, visina covekanikako ne bi trebalo da bude negativna. U nekim slucajevima je moguce konsultovatise sa eksternim izvorom podataka i eventualno ispraviti gresku. Ipak, ne postoje opsti
’’recepti” za resavanje problema nekonzistentnih vrednosti.
2.3.4 Duplirani (multiplicirani) podaci
Skupovi podataka mogu da ukljuce duplikate ili skoro identicne podatke. Najcescese javljaju kod spajanja podataka iz heterogenih izvora. Za detekciju i eliminaciju du-plikata treba adresirati dva glavna pitanja. Prvo, ako postoje dva objekta koja zapravopredstavljaju jedan objekat, onda vrednosti nekih atributa mogu da se razlikuju i svenekonzistentnosti treba da se rese. Drugo, treba voditi racuna da slucajno ne proglasimojednakost dva slicna objekta, koji zapravo nisu duplikati. Primer duplikata je pojavlji-vanje iste osobe sa vise elektronskih adresa. Proces obrade (eliminacije) duplikata senaziva ciscenje podataka.
2.4 Pretprocesiranje podataka
Pretprocesiranje podataka (engl. data preprocessing) podrazumeva pripremu po-dataka pre primene metoda istrazivanja podataka. Ono se primenjuje radi dobijanjapodataka koji vise odgovaraju razlicitim svrhama i potrebama istrazivanja podataka.Pretprocesiranje podataka se sastoji od mnogo razlicitih strategija i tehnika, a mi cemose baviti: agregacijom, uzorcenjem, smanjenjem dimenzije, izborom podskupa atributa,formiranjem atributa, diskretizacijom i binarizacijom i transformacijom atributa.

22 GLAVA 2. PODACI
2.4.1 Agregacija
Agregacija (engl. aggregation) predstavlja kombinovanje dva ili vise objekata (iliatributa) u jedan objekat (atribut). Ocigledan problem je nacin agregiranja podataka,tj. na koji nacin se kombinuju vrednosti atributa agregiranih podataka. Kvantitativniatributi, kao sto je, na primer, cena proizvoda, tipicno se agregiraju sumiranjem iliuprosecavanjem. Kvalitativni atributi, kao sto je naziv proizvoda, moze biti izostavljenili sakupljen u skup svih naziva proizvoda objekata koji se agregiraju.
Postoje razne svrhe agregacije. Prvo, redukcija podataka (smanjivanje broja atributaili objekata) dovodi do mogucnosti koriscenja skupljih tehnika istrazivanja podataka.Drugo, agregacija moze dovesti do promene skale (na primer, umesto 365 dana dobijamo12 meseci). Trece, agregirani podaci su obicno i
’’stabilniji” (odnosno, imaju tendenciju
da imaju manja odstupanja nego pojedinacni objekti).Naravno, agregacija ima i svojih mana. Najociglednija i najznacajnija od njih je
moguci gubitak interesantnih detalja. Na primer, ako u prodavnici koja cuva podatke osvakoj kupovini na dnevnom nivou agregiramo podatke po mesecu, onda cemo izgubitipodatak o tome koji dan u nedelji ima najvecu prodaju.
Slika 2.9 prikazuje standardnu devijaciju prosecnih mesecnih i godisnjih padavina uAustraliji u periodu od 1982. do 1993. godine. Prosecne godisnje padavine imaju manjuvarijabilnost od prosecnih mesecnih padavina. Mere padavina (i njihove standardnedevijacije) izrazene su u centimetrima.
Slika 2.9: Histogrami standardne devijacije za mesecne (levo) i godisnje (desno) padavineu Australiji u periodu od 1982. do 1993. godine.
2.4.2 Uzorcenje
Uzorcenje (engl. sampling), ili izbor uzoraka, predstavlja cesto koriscenu tehnikukoja podrazumeva izdvajanje podskupa podataka koji ce biti analizirani iz celokup-nog skupa dostupnih podataka. U statistici, uzorcenje se cesto koristi kako za prelimi-narna istrazivanja tako i za konacne analize podataka. Uzorcenje moze biti korisno i uistrazivanju podataka.
Medutim, razlikujemo motivaciju uzorcenja u statistici i istrazivanju podataka. Sta-tisticari biraju uzorke jer je dobijanje kompletnog skupa podataka koji su od interesajako skupo i vremenski zahtevno. Izbor uzoraka se koristi u istrazivanju podataka jer jeobrada kompletnog skupa podataka koji je od interesa jako skupa ili vremenski zahtevna.

2.4. PRETPROCESIRANJE PODATAKA 23
Kljucni princip za efektivno uzorcenje glasi: Koriscenjem uzoraka koji su reprezen-tativni dobija se efekat skoro isti kao da je radeno na kompletnom skupu podataka. Zauzorak kazemo da je reprezentativan ako ima aproksimativno iste osobine (od interesa)kao i originalni skup podataka. U nastavku cemo diskutovati razne strategije uzorcenja.
2.4.2.1 Tipovi uzorcenja
Postoji veliki broj nacina na koje mozemo birati uzorke, pa samim tim postoji i velikibroj tipova uzoraka. Mi cemo diskutovati cetiri jednostavna tipa. To su:
1. Jednostavno slucajno uzorcenje (engl. simple random sampling). Ovaj tip uzorcenjakarakterise postojanje jednake verovatnoce za izbor bilo koje stavke.
2. Uzorcenje bez zamene (engl. sampling without replacement). Pri svakom odabirustavke ona se uklanja iz skupa svih objekata koji grade tzv. populaciju (engl.population).
3. Uzorcenje sa zamenom (engl. sampling with replacement). Pri svakom odabirustavke ona se ne uklanja iz populacije. Posledica ovakvog pristupa je da isti objekatmoze da bude izabran vise puta. Uzorcenje sa zamenom je jednostavnije za analizuod uzorcenja bez zamene jer verovatnoca izbora svake stavke ostaje ista u procesuizbora uzorka.
4. Stratifikovano uzorcenje (engl. stratified sampling). Pri ovom tipu uzorcenja po-daci se dele u vise delova (koje nazivamo strate ili slojevi), a zatim se vrsi jed-nostavno slucajno uzorcenje iz svakog od delova. Objasnimo motivaciju za ovimtipom uzorcenja.
Kada se populacija sastoji od razlicitih tipova objekata pri cemu svaki tip mozeda broji veoma razlicit broj objekata, jednostavan slucajni uzorak ima tenden-ciju da neadekvatno reprezentuje one tipove objekata koji se retko javljaju. Ovomoze uzrokovati problemima kada analiza zahteva pravu reprezentaciju svih tipovaobjekata. Na primer, pri izgradnji klasifikacionog modela za retke klase, kriticnoje pitanje da li ce te retke klase biti adekvatno reprezentovane u uzorku ili ne.Stratifikovano uzorcenje je dizajnirano tako da se cuva raspodela tipova objekata.
U najjednostavnijoj varijanti, bira se jednak broj objekata iz svake grupe bez obzirana razlicitost velicina grupa. U nekoj drugoj varijanti metoda, broj objekata kojise izvlaci iz svake grupe je proporcijalan velicini te grupe.
2.4.2.2 Uzorcenje i gubitak informacija
Jednom kada je odabran tip uzorcenja, jos uvek nam ostaje pitanje velicine uzorka.Veca velicina uzorka nam povecava verovatnocu da uzorak bude reprezentativan, alitakode eliminise dosta prednosti uzorcenja. Sa druge strane, ukoliko je uzorak premali,moguce je izgubiti sablone u podacima, ali i detektovati sablone koji su pogresi (engl.erroneous).
Slika 2.10 prikazuje skup podataka koji sadrzi 5000 dvodimezionalnih tacaka, dokSlike 2.11 i 2.12 prikazuju uzorke ovog skupa velicine 1250 i 250, redom. Vidimo da jeveci deo strukture skupa podataka ocuvan u uzorku velicine 1250, dok je sablon skupapodataka potpuno izgubljen u uzorku velicine 250.

24 GLAVA 2. PODACI
Slika 2.10: 5000 tacaka. Slika 2.11: 1250 tacaka. Slika 2.12: 250 tacaka.
2.4.2.3 Odredivanje pogodne velicine uzorka
Radi ilustrovanja da odredivanje pogodne velicine uzorka zahteva metodoloski pri-stup, obratimo paznju na naredni primer.
Neka je dat skup podataka koji se sastoji od malog broja grupaskoro identicno jednakih velicina. Pronaci makar jednu reprezenta-tivnu tacku za svaku od grupa. Pretpostaviti da su objekti u svakojgrupi veoma slicni medu sobom, ali da nisu slicni objektima iz drugihgrupa. Slika 2.13 prikazuje idealni skup klastera (grupa) iz kojih seizvlace trazene tacke.
Ovaj problem se moze efikasno resiti uzorcenjem. Jedan pristup je da se uzme maliuzorak tacaka, izracuna se slicnost svaka dva para, a zatim se formiraju grupe tacaka kojesu jako slicne. Trazeni skup tacaka se dobija uzimanjem jedne tacke iz svake dobijenegrupe. Odavde vidimo da nam je potrebna velicina uzorka koja garantuje da ce se savelikom verovatnocom dobiti zeljeni rezultat, tj. da ce barem jedna tacka biti izabranaiz svakog klastera. Slika 2.14 prikazuje verovatnocu uzimanja jednog objekta iz svake of10 grupa za velicinu uzorka od 10 do 60.
Slika 2.13: Deset grupa tacaka.
0 10 20 30 40 50 60 700
0.2
0.4
0.6
0.8
1
Slika 2.14: Verovatnoca da uzoraksadrzi tacke iz svake od 10 grupa.

2.4. PRETPROCESIRANJE PODATAKA 25
2.4.3 Dimenzionalna redukcija
Dimenzionalna redukcija (engl. dimensionality reduction) predstavlja tehniku sma-njenja broja atributa. Skupovi podataka mogu da imaju veliki broj atributa. Na primer,skup dokumenata, pri cemu je svaki dokument reprezentovan vektorom cije su kompo-nente frekvencije reci koje se pojavljuju u tom dokumentu. U takvih slucajevima postojehiljade ili desetine hiljada atributa (komponenti vektora).
Svrha dimenzionalne redukcije ima mnogo. Kljucni dobitak je smanjenje kolicinevremena i memorije potrebnih za rad metoda istrazivanja podataka. Ovo ima uzrokedelom u otklanjanju irelevantnih atributa i smanjenju suma, ali i u
’’kletvi dimenzio-
nalnosti” (engl. curse of dimensionality), koja je objasnjena ispod. Takode, redukcijadimenzionalnosti dovodi do jednostavnijih modela, lakse vizuelizacije itd.
’’Kletva dimenzionalnosti” se odnosi na fenomen da mnogi tipovi podataka za analizu
postaju znacajno tezi uz porast dimenzionalnosti podataka. Posebno, kada se dimenzi-onalnost povecava, podaci postaju sve proredeniji u prostoru koji zauzimaju. Definicijegustine i rastojanja izmedu tacaka koje su kriticne za klasterovanje i otkrivanje eleme-nata van granica postaju manje znacajne.
Tehnike za redukciju dimenzionalnosti koje cemo navesti su: analiza glavnih kompo-nenata (engl. principle component analysis), dekompozicija singularne vrednosti (engl.singular value decomposition), druge nelinearne tehnike i tehnike sa nadzorom.
2.4.4 Izbor podskupa atributa
Izbor podskupa atributa (engl. feature subset selection) predstavlja tehniku koriscenjasamo (pravog) podskupa svih atributa. Ova tehnika predstavlja jos jedan nacin sma-njenja dimenzionalnosti. Iako se mozda cini da ovakav postupak dovodi do gubitkainformacija, ovo ipak nije slucaj ukoliko postoje redundantni atributi i atributi sa irele-vantnim vrednostima.
Redundantni atributi (engl. redundant features) jesu oni atributi kod kojih dolazi doponavljanja jedne, vise od jedne ili svih informacija sadrzanih u jednom ili vise atributa.Na primer, uglavnom je suvisno cuvati i cenu proizvoda i PDV. Atributi sa irelevantnimvrednostima (engl. irrelevant features) jesu oni atributi koji sadrze informacije kojenisu korisne za proces istrazivanja podataka. Na primer, pri predvidanju prosecne ocenestudenta broj indeksa je potpuno irelevantan podataka. Redundantnost i irelevantnostu podacima mogu da smanjuju preciznost klasifikacije i kvaliteta klastera.
Tehnike za izbor podskupa atributa su (uredene po kvalitetu):
• Gruba sila. Probaju se svi moguci podskupovi atributa kao ulaz u algoritamistrazivanja podataka, a zatim se izabere najbolji. Iako predstavlja idealan pristupproblemu, neprikladan zbog velikog broja podskupova (broj podskupova n atributaje 2n).
• Pristupi pomocu omotaca (engl. wrapper approaches). Koristi se algoritam istrazivanjapodataka kao crna kutija koja pronalazi najbolji podskup skupa atributa. Slicnoprimeni grube sile, ali se ne uzimaju u obzir bas svi podskupovi. Ovi pristupispadaju u pohlepne algoritme kvadratne slozenosti.

26 GLAVA 2. PODACI
• Pristupi zasnovani na filterima (engl. filter approaches). Atributi se biraju prepocetka rada algoritma istrazivanja podataka nekim pristupom koji je nezavisanod procesa istrazivanja podataka. Na primer, mozemo birati skupove atributa cijesu korelacije po parovima (engl. pairwise) sto manje moguce.
• Ugnjezdeni pristupi (engl. embedded approaches). Izbor podskupova atributaje deo algoritma istrazivanja podataka. Posebno, tokom izvrsavanja algoritmaistrazivanja podataka, algoritam sam odlucuje koji ce atribute koristiti, a koje ceodbaciti.
2.4.5 Izbor skupa atributa
Izbor skupa atributa (engl. feature creation) podrazumeva formiranje novih atributakoji sadrze najvaznije informacije iz skupa podataka na mnogo efikasniji nacin negooriginalni atributi.
Opste metodologije za pristup ovom problemu su: izdvajanje atributa, preslikavanjeatributa u novi prostor i konstrukcija atributa.
Sastavljanje novog skupa atributa iz originalnih, sirovih podataka naziva se izdvaja-nje atributa (engl. feature extraction). Na primer, neka je dat skup fotografija takvih dasvaku fotografiju treba klasifikovati prema tome da li sadrzi covekovo lice ili ne. Sirovipodaci nisu nista drugo do pikseli, i kao takvi, oni nisu pogodni za mnoge klasifikacionealgoritme. Ipak, ako su podaci procesuirano tako da iz njih dobijamo atribute visokognivoa, kao sto su posebne vrste ivica i povrsina koje su visoko korelirane sa postoja-njem covekovog lica, onda mozemo koristiti veci skup klasifikacionih tehnika. Nazalost,izdvajanje atributa ima jednu veoma znacajnu manu – veoma mnogo zavisi od domena.
Totalno drugaciji pogled na podatke moze da otkrije informacije i interesantne atri-bute. Na primer, vremenske serije cesto sadrze periodicne obrasce. Ako imamo jedanobrazac i ne mnogo suma, lako ga je detektovati. Sa povecanjem broja obrazaca i kolicinesuma, ovaj zadatak postaje znacajno tezi. Takvi obrasci se mogu cesto otkriti primenomFurijeove transformacije (engl. Fourier transformation) na vremensku seriju. Za svakuvremensku seriju, Furijeova transformacija daje novi objekat ciji su atributi u odnosusa frekvencijama. Ovaj pristup predstavlja jednu tehniku preslikavanja atributa u noviprostor (engl. mapping the data to a new space). Slika ?? prikazuje primer opisanog fe-nomena. Pored Furijeove transformacije, pokazuje se da transformacije talasicima (engl.wavelet transformation) takode umeju biti korisne za vremenske serije, ali i druge tipovepodataka.
Ponekad atributi u originalnim podacima imaju neophodne informacije, ali one nisu uformi koja je prilagodena algoritmu istrazivanja podataka. U ovakvim situacijama jedanili vise novih atributa koji se konstruisu iz postojecih atributa mogu biti vise korisninego originalni atributi. Ovaj princip se naziva konstrukcija atributa (engl. featureconstruction).
2.4.6 Diskretizacija i binarizacija
Neki algoritmi istrazivanja podataka, a pogotovo neki klasifikacioni algoritmi, za-htevaju da podaci budu u formi kategorickih atributa. Analize zasnovane na pravi-lima pridruzivanja zahtevaju da podaci budu u formi binarnih atributa. Dakle, cesto

2.4. PRETPROCESIRANJE PODATAKA 27
Slika 2.15: Primena Furijeove transformacije radi identifikovanja frekvencija koje lezeispod u vremenskim serijama: talas sa dve sinusoide (levo), talas sa dve sinusoide + sum(sredina), frekvencija (desno).
je neophodno transformisati neprekidne atribute1 u atribute koje broje diskretan brojvrednosti2, sto je poznato kao diskretizacija (engl. discretization), ali je i neophodnotransformisati neprekidne i diskretne atribute u jedan ili vise binarnih atributa, sto jepoznato kao binarizacija (engl. binarization).
2.4.6.1 Binarizacija
Jednostavna tehnika binarizacije se zasniva na sledecem: ako ima m kategorickihvrednosti, tada se svakoj dodeljuje jedinstven prirodan broj u intervalu [0,m − 1], azatim se konvertuje svaki od tih brojeva u binarnu vrednost. Ako je atribut redni, ondase poredak mora odrzati postupkom dodele. Kako je n = dlog2me bitova potrebno zareprezentaciju ovih brojeva, to se ti brojevi reprezentuju pomocu n binarnih atributa.Radi ilustracije, redna promenljiva sa 5 vrednosti {uzasno, slabo, OK, dobro, sjajno}zahteva tri binarne promenljive x1, x2 i x3. Konverzija je prikazana Tabelom 2.7.
2.4.6.2 Diskretizacija neprekidnih atributa
U opstem slucaju, najbolja diskretizacija zavisi od algoritma koji se koristi, kao i odostalih atributa koji se posmatraju. Ipak, tipicno je da se diskretizacija atributa radi uizolaciji.
Transformacija neprekidnih atributa u diskretne se sastoji iz dve faze: odabiranjebroja kategorija i odredivanje kako preslikati vrednosti neprekidnih atributa u te kate-gorije. U prvoj fazi, posle sortiranja vrednosti neprekidnog atributa, oni se dele u nintervala navodenjem n − 1 tacke razdvajanja (engl. split points). U drugoj fazi, svevrednosti iz jednog intervala se preslikavaju u istu kategoricku vrednost.
1Naravno, u racunarima nije moguce sadrzati informacije koje su neprekidne, tj. realne brojeve.Umesto toga, koriste se brojevi u pokretnom zarezu. Medutim, ta podela realne ose na brojeve upokretnom zarezu je toliko fina, da prakticno mozemo da razmisljamo kao da baratamo neprekidnimvelicinama.
2Cesto su ove vrednosti kategoricke, mada ne mora uvek to da vazi. Na primer, broj studenata uucionici je razmerni atribut, ali je i diskretan.

28 GLAVA 2. PODACI
Tabela 2.7: Konverzija rednog atributa u tri binarna atributa.
Redna vrednost Vrednost prirodnog broja x1 x2 x3uzasno 0 0 0 0
slabo 1 0 0 1
OK 2 0 1 0
dobro 3 0 1 1
sjajno 4 1 0 0
2.4.6.3 Diskretizacija bez koriscenja informacija o klasama
Jednostavna razlika izmedu diskretizacionih metoda za klasifikaciju je da li se koristeinformacije o klasama (nadgledana diskretizacija) ili ne (nenadgledana diskretizacija).Ako se informacije o klasama ne koriste, onda se koriste relativno jednostavni pristupi.
Na primer, pristup jednakih sirina (engl. equal width approach) deli interval atri-buta na korisnicki definisan broj jednakih intervala (Slika 2.17). Ovakav pristup se loseponasa sa atipicnim elementima, pa se preferira pristup jednakih frekvencija (engl. equalfrenquency approach ili equal depth approach), koji pokusava da smesti isti broj objekatau svaki interval (Slika 2.18). Jos jedan primer nenadgledane diskretizacije je K-sredine(engl. K-means), koji predstavlja metod za klasterovanje (Slika 2.19). Konacno, vizuelnoispitivanje podataka moze biti efektivan pristup.
2.4.6.4 Diskretizacija koriscenjem informacija o klasama
Iako je nenadgledana diskretizacija bolja od nikakve diskretizacije, ako imamo naumu postavljeni cilj, koriscenje dodatnih informacija (oznake klasa) cesto proizvodi boljerezultate. Pristupi zasnovani na entropiji dosta dobro pristupaju problemu diskretizacije,i mi cemo predstaviti jedan takav, jednostavan pristup.
Neka je dat skup podataka kao na Slici ?? koji se opisuje dvama atributima X iY . Dve klase su oznacene bojama plavo i crveno. Cilj je diskretizovati atribute X i Ytako da podela ravni podataka daje sto je cistije moguce pravougaonike (koji se dobijajutom podelom). Ta
’’cistoca”, odnosno, slicnost prema bojama, meri se entropijom (engl.
entropy). Dakle, biramo podelu koja treba da minimizuje srednju entropiju po razlicitimpravougaonicima.
Ovaj jednostavan primer ilustruje dva aspekta diskretizacije. Prvo, klase tacaka udvema dimenzijama su dobro razdvojene, ali u jednoj dimenziji ovo nije slucaj. Gene-ralno, diskretizacija svakog atributa zasebno cesto daje podoptimalne rezultate. Drugo,pet intervala daju bolje rezultate nego tri, ali sest intervala nece poboljsati diskretiza-ciju, bar ne u terminima entropije. (Vrednosti entropija i rezultati za sest intervala nisuprikazani.) Posledica je da je pozeljno imati kriterijum zaustavljanja koji automatskipronalazi najbolji broj particija.

2.4. PRETPROCESIRANJE PODATAKA 29
0 5 10 15 200
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
Slika 2.16: Originalni podaci (tackesu regularni podaci, pravougaonici suatipicni elementi).
0 5 10 15 200
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
Slika 2.17: Intervali jednake sirine.
0 5 10 15 200
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
Slika 2.18: Intervali jednakih frekven-cija.
0 5 10 15 200
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
Slika 2.19: K-sredine.
0 1 2 3 4 50
1
2
3
4
5
Slika 2.20: Diskretizacija atributa X iY za cetiri klase podataka, koriscenjemtri intervala podele.
0 1 2 3 4 50
1
2
3
4
5
Slika 2.21: Diskretizacija atributa X iY za cetiri klase podataka, koriscenjempet intervala podele.
2.4.7 Transformacija atributa
Transformacija atributa oznacava transformaciju koja se primenjuje na sve vrednostitog atributa. Drugim recima, za svaki objekat, transformacija se primenjuje na vrednostiatributa za taj objekat. Na primer, ako je bitna jedino velicina objekta, promenljiva moze

30 GLAVA 2. PODACI
da se transformise uzimanjem apsolutne vrednosti. U daljem tekstu razmatramo dvevrste transformacija atributa: transformacije elementarnim funkcijama i normalizacija.
2.4.7.1 Elementarne funkcije
Ovaj tip transformacije podrazumeva primenu elementarnih matematickih funkcijana svaku vrednost pojedinacno. Ako je x atribut, onda bi primeri takvih funkcija moglibiti xk, log x, ex, 1/x, sinx, |x|, i sl.
U statistici se cesto koriste funkcije√x, log x i 1/x radi transformacije podataka
koji nemaju Gausovu (normalnu) raspodelu u podatke koji imaju tu raspodelu. Uistrazivanju podataka ima i drugih razloga. Na primer, ako je vrednost atributa izmedu1 i 1 milijarda, primenom log10 funkcije se dobijaju bolji odnosi kod poredenja (naprimer, 108:109 i 10:1000).
Transformaciju promenljivih koriscenjem elementarnih funkcija treba primenjivati saoprezom jer moze doci do promene prirode podataka. Jasno je da je ovo cilj primeretransformacije, ali postoje problemi ako je priroda transformacije takva da nije u pot-punosti pozeljna. Na primer, transformacija 1/x smanjuje velicinu vrednosti koje su 1ili vise, ali povecava velicinu vrednosti izmedu 0 i 1. Ovo se fino ilustruje primerom:transformacijom 1/x vrednosti {1, 2, 3} postaju {1, 12 , 13}, ali vrednosti {1, 12 , 13} postaju{1, 2, 3}, tj. obrce se poredak.
2.4.7.2 Normalizacija ili standardizacija
Cilj standardizacije ili normalizacije (u zajednici istrazivanja podataka se ova dvatermina koriste ravnopravno, dok u statistici normalizacija se odnosi na transformacijukojom se dobija normalna raspodela) jeste da kompletan skup vrednosti treba da do-bije neku zeljenu osobinu. Na primer, ako je x prosek vrednosti atributa i sx njihovastandardna devijacija, onda transformacija
x′ =x− xsx
proizvodi novi atribut koji ima prosek 0 i standardnu devijaciju 1.Ako se razliciti atributi kombinuju na neki od nacina, tada je ovakva transformacija
neophodna da bi se izbegla dominacija u izracunavanjima promenljive koja ima vecuvrednost. Na primer, potrebno je porediti osobe uzimajuci u obzir atribute starost iprihod. Ako se ne uzme u obzir razlicita priroda atributa, razlika u prihodima dve osobeje mnogo veca (u apsolutnim jedinicima) nego razlika u godinama.
Sredina i standardna devijacija su jako osetljive na atipicne elemente, pa se pomenutatransformacija cesto modifikuje. Umesto srednje vrednosti se uzima medijana, a stan-dardna devijacija se zamenjuje apsolutnom standardnom devijacijom. Ako je x atribut,onda se apsolutna standardna devijacija od x racuna kao
σA =
m∑i=1
|xi − µ|,
gde xi predstavlja i-tu vrednost atributa x, m je broj objekata i µ je ili prosek ilimedijana.

2.5. MERE SLICNOSTI I RAZLICITOSTI 31
2.5 Mere slicnosti i razlicitosti
Slicnost i razlicitost su znacajni zato sto se koriste u razlicitim tehnikama istrazivanjapodataka, kao sto su klasterovanje, algoritam najblizih suseda, i detekcija anomalija. Umnogim slucajevima, inicijalni skup podataka nije potreban jednom kada se slicnosti ilirazlike izracunaju.
2.5.1 Osnove
Neformalno, slicnost (engl. similarity) izmedu dva objekata, u oznaci s, je numerickamera stepena koliko su dva objekta slicni. Sto dva objekta vise lice jedan na drugog,to im je slicnost veca. Slicnost se cesto meri vrednostima u intervalu [0, 1], pri cemu0 oznacava da slicnost ne postoji, a 1 da je slicnost potpuna. Vazno je napomenutida slicnost od 1 ne mora da znaci da su dva objekta
’’ista” jer, na primer, mozda ne
raspolazemo svim atributima tih objekata.Razlicitost (engl. dissimilarity) izmedu dva objekata, u oznaci d, je numericka
mera stepena koliko su dva objekta razliciti. Sto dva objekta vise lice jedan na dru-gog, razlicitost im je manja. Cesto se kao sinonim koristi i termin rastojanje, mada,kako cemo videti, rastojanje se cesto odnosi na specijalnu klasu razlicitosti. Najmanjarazlicitost je cesto 0, dok gornja granica varira, odnosno, cesto se uzima vrednost 1 ili∞.
Radi udobnosti, uvodimo pojam blizine (engl. proximity) koji oznacava ili slicnostili razlicitost.
Transformacije se cesto koriste radi konverzije iz slicnosti u razlicitost, ili obratno, iliradi transformisanja mere blizine da upada u odredeni interval, najcesce [0, 1]. U opstemslucaju transformacija slicnosti u interval [0, 1] se vrsi izrazom
s′ = (s−mins)/(maxs −mins),a transformacija razlicitosti u interval [0, 1] se vrsi izrazom
d′ = (d−mind)/(maxd −mind),gde su s i d pocetne vrednosti, s′ i d′ su nove vrednosti, max i min su najvece, odnosno,najmanje vrednosti slicnosti i razlicitosti, redom.
2.5.2 Slicnost i razlicitost izmedu jednostavnih atributa
Bliskost objekata sa vecim brojem atributa se tipicno definise kao kombinacija bli-skosti pojedinacnih atributa, pa cemo zbog toga prvo opisati bliskost izmedu objekatasa jednim atributom. Neki nacini odredivanja slicnosti i razlicitosti za jednostavne (po-jedinacne) atribute su prikazani Tabelom 2.8. U ovoj tabeli, x i y su dva objekta kojiimaju atribut naznacenog tipa. Takode, d(x, y) i s(x, y) su razlicitost i slicnost izmedux i y, redom. Iako su razliciti pristupi moguci, ovi su neki od najcescih.
2.5.3 Razlicitosti izmedu objekata
U ovoj podsekciji diskutovacemo razlicite mere razlicitosti. Pocinjemo sa rastoja-njima (engl. distance), sto su razlicitosti sa odredenim svojstvima, a zatim dajemoprimere opstijih tipova razlicitosti.

32 GLAVA 2. PODACI
Tabela 2.8: Slicnost i razlicitost jednostavnih atributa.
Tip atributa Razlicitost Slicnost
Imenski d =
{0, x = y
1, x 6= ys =
{1, x = y
0, x 6= y
Redni d =|x− y|n− 1
s = 1− d
Kvantitativni d = |x− y|s = −d, s =
1
1 + d, s = e−d
s = 1− d−mindmaxd −mind
2.5.3.1 Rastojanja
Euklidsko rastojanje (engl. Euclidean distance) izmedu dva objekata x i y, u n-dimenzionom prostoru, dato je Formulom 2.1,
d(x, y) =
√√√√ n∑k=1
(xk − yk)2, (2.1)
gde su xk i yk k-ti atributi objekata x i y, redom. Ako se skale razlikuju, neophodno jeizvrsiti njihovu standradizaciju.
Rastojanje Minkovskog (engl. Minkowski distance) izmedu dva objekata x i y, un-dimenzionom prostoru, predstavlja uopstenje Euklidskog rastojanja dato Formulom2.1, i prikazano je Formulom 2.2,
d(x, y) =
(n∑k=1
|xk − yk|r) 1
r
, (2.2)
gde je r parametar. Neki poznati primeri rastojanja Minkovskog se dobijaju za sledecevrednosti parametra r:
• r = 1. Menhetn rastojanje. Tipican primer je Hamingovo rastojanje, sto predsta-vlja broj razlicitih bitova izmedu dva objekta koji imaju iskljucivo binarne atribute,tj. izmedu dva binarna vektora.
• r = 2. Euklidsko rastojanje.
• r = ∞.’’Supremum” rastojanje. Predstavlja maksimum razlike izmedu odgova-
rajucih komponenti vektora. Formalnije,’’supremum” rastojanje se definise For-
mulom 2.3
d(x, y) = limr→∞
(n∑k=1
|xk − yk|r) 1
r
. (2.3)
Napomenimo da treba praviti razliku izmedu parametra r i broja dimenzija (atributa)n. Menhetn, Euklidsko i
’’supremum” rastojanja su definisana za sve vrednosti n ∈ N.
Rastojanja, poput Euklidskog rastojanja, imaju neke dobro poznate osobine. Akoje d(x, y) rastojanje izmedu tacaka x i y, onda, ako rastojanje d ispunjava naredne triosobine:

2.5. MERE SLICNOSTI I RAZLICITOSTI 33
1. Pozitivna odredenost (engl. positivity):
(a) d(x, x) ≥ 0,∀x, y,
(b) d(x, y) = 0, samo ako x = y.
2. Simetrija (engl. symmetry):d(x, y) = d(y, x),∀x, y.
3. Nejednakost trougla (engl. triangle inequality):d(x, z) ≤ d(x, y) + d(y, z), ∀x, y, z.
naziva se metrika (engl. metric).
2.5.4 Slicnosti izmedu objekata
Slicnost takode ima neke dobro poznate osobine. Ako je s(x, y) slicnost izmedutacaka x i y, onda su tipicne naredne osobine slicnosti:
1. s(x, y) = 1, samo ako x = y. (0 ≤ s ≤ 1)
2. Simetrija:s(x, y) = s(y, x),∀x, y.
2.5.5 Primeri mera bliskosti
U ovoj podsekciji bice prikazani primeri mera bliskosti.
2.5.5.1 Mere slicnosti za binarne podatke
Mere slicnosti izmedu objekata koji imaju samo binarne atribute se nazivaju koefi-cijenti slicnosti (engl. similarity coefficients), i tipicno imaju vrednosti iz opsega [0, 1].Neka su x i y dva objekta koji se sastoje od n binarnih atributa. Poredenje dvaju takvihobjekata, tj. binarnih vektora, dovodi do narednih cetiri vrednosti:
f00 = broj atributa koji su 0 u x i 0 u yf01 = broj atributa koji su 0 u x i 1 u yf10 = broj atributa koji su 1 u x i 0 u yf11 = broj atributa koji su 1 u x i 1 u y
Jedan cesto koriscen koeficijent slicnosti je koeficijent jednostavnog uparivanja (engl.simple matching coefficient), u oznaci SMC, koji se definise kao
SMC =broj uparenih vrednosti atributa
broj atributa=
f11 + f00f00 + f01 + f10 + f11
.
Ova mera broji prisustva i odsustva jednako. Kao posledica toga, SMC moze da sekoristi da pronade studente koji su odgovorili slicno na testu koji se sastoji iskljucivo od
’’tacno/netacno” pitanja.
Kod asimetricnih podataka, SMC bi nam rekao da su svi objekti slicni. Zato seumesto toga koristi Zakarov koeficijent (engl. Jaccard coefficient). Zakarov koeficijent,u oznaci J , racuna se po narednoj formuli:
J =broj uparenih prisustva
broj atributa koji nisu 00 uparenja=
f11f01 + f10 + f11
.

34 GLAVA 2. PODACI
2.5.5.2 Kosinusna slicnost
Vec smo diskutovali da se dokumenti cesto reprezentuju kao vektori u kojima svakiatribut predstavlja frekvenciju kojom se odgovarajuca rec pronalazi u dokumentu. Ovosu najcesce asimetricni podaci, pa zelimo da izbegnemo uvrstavanje 00 uparivanja kakobismo izbegli problem da svi dokumenti budu slicni. Dakle, potrebna nam je mera slicnaZakarovom koeficijentu, ali takva da moze da barata ne-binarnim vektorima.
Neka su x i y dva vektora. Kosinusna slicnost (engl. cosine similarity) izmeduvektora x i y, u oznaci cos(x, y), racuna se po sledecoj formuli:
cos(x, y) =x ◦ y
||x|| · ||y|| , (2.4)
gde je ◦ operacija skalarnog proizvoda vektora, odnosno,
x ◦ y =n∑k=1
xkyk,
i ||x|| norma vektora x, odnosno,
||x|| =
√√√√ n∑k=1
x2k =√x ◦ x.
Geometrijska reprezentacija kosinusne slicnosti je zapravo vrednost kosinusa uglaizmedu vektora x i y. Zato, ako je kosinusna slicnost jednaka 1, tada je ugao izmedu xi y jednak 0, tj. vektori x i y su kolinearni. Ako je kosinusna slicnost 0, tada je ugaoizmedu x i y jednak π
2 , tj. oni nemaju zajednicke vrednosti odgovarajucih atributa.
2.5.5.3 Prosireni Zakarov koeficijent (koeficijent Tanimotoa)
Prosireni Zarakov koeficijent moze se koristiti za dokumenta i u slucaju binarnihatributa predstavlja Zakarov koeficijent. Ovaj koeficijent, koji se oznacava EJ , definisanje sledecom formulom:
EJ(x, y) =x ◦ y
||x||2 + ||y||2 − x ◦ y .
2.5.5.4 Korelacija
Korelacija izmedu dva objekta koji imaju binarne ili neprekidne atribute je meralinearnog odnosa izmedu njihovih atributa. Preciznije, Pirsonov koeficijent korelacijeizmedu dva objekta, x i y, definise se sledecom formulom:
corr(x, y) =covariance(x, y)
standard deviation(x) · standard deviation(y)=
sxysx · sy
,
pri cemu se koriste sledece standardne statisticke notacije i definicije:
covariance(x, y) = sxy =1
n− 1
n∑k=1
(xk − x)(yk − y) (2.5)

2.5. MERE SLICNOSTI I RAZLICITOSTI 35
standard deviation(x) = sx =
√√√√ 1
n− 1
n∑k=1
(xk − x)2
standard deviation(y) = sy =
√√√√ 1
n− 1
n∑k=1
(yk − y)2
x =1
n
n∑k=1
xk je prosek od x
y =1
n
n∑k=1
yk je prosek od y
Vrednost korelacije je uvek u intervalu [−1, 1]. Korelacija vrednosti 1 znaci da xi y imaju savrsenu pozitivnu, a -1 savrsenu negativnu linearnu korelaciju, tj. da jexk = ayk + b, gde su a i b konstante. Na primer, savrsenu pozitivnu korelaciju imaju
x = (3, 6, 0, 3, 6) i y = (1, 2, 0, 1, 2),
dok savrsenu negativnu korelaciju imaju
x = (−3, 6, 0, 3,−6) i y = (1,−2, 0,−1, 2).
Ako je korelacija 0, onda ne postoji linearna zavisnost izmedu atributa dvaju obje-kata. Ipak, moguce je da postoji neka nelinearna zavisnost. Objekti
x = (−3,−2,−1, 0, 1, 2, 3) i y = (9, 4, 1, 0, 1, 4, 9)
imaju nelinearnu zavisnost yk = x2k, ali je njihova korelacija 0. Jedan test koji se mozeprimeniti u ovakvim slucajevima jeste Spirmanov test korelacije. Izracunavanje ovogkoeficijenta podrazumeva da se atributima pridruze rangovi (dakle, podaci treba dabudu barem redni), pa da se nad tim rangovima izracuna Pirsonov koeficijent korelacije.
Ocenjivanje korelacije izmedu x i y moze biti lako ukoliko se vizualizuju parovi od-govarajucih vrednosti vektora x i y. Slika 2.22 prikazuje nekoliko ovakvih vizualizacijapri cemu x i y imaju po 30 atributa i vrednosti ovih atributa su nasumicno generisani(sa normalnom raspodelom) tako da korelacija izmedu x i y varira od −1 do 1.
2.5.5.5 Mahalanobisovo rastojanje
Predstavlja uopstenje Euklidskog rastojanja koje se koristi kada postoji korelacijanekih atributa, uz eventualni dodatak u razlikama opsega vrednosti atributa (mozemoreci – kada atributi imaju razlicite skale). Mahalanobisovo rastojanje je korisno kadavazi: (1) atributi su u korelaciji, (2) imaju razlicite opsege vrednosti (razlicite varijanse),i (3) raspodela podataka je priblizno normalna (Gausova). Mahalanobisovo rastojanjedva objekta (vektora) x i y je
mahalanobis(x, y) = (x− y)Σ−1(x− y)T ,
gde je Σ−1 inverzna matrica matrici kovarijansi podataka. Napomenimo da je matricakovarijansi Σ matrica ciji je element na poziciji (i, j) kovarijansa i-tog i j-tog atributa,definisano Formulom 2.5.

36 GLAVA 2. PODACI
Slika 2.22: Tackasti dijagrami koji ilustruju korelacije od −1 do 1.
Slika 2.23 prikazuje skup od 1000 tacaka ciji atributi x i y imaju korelaciju 0.6. Ma-halanobisovo rastojanje izmedu dve velike tacke je 6, a Euklidsko je 14.7. U praksi,racunanje Mahalanobisovog rastojanja je skupo, ali je korisno ako su atributi koreli-rani. Ako su atributi relativno nekorelirani, ali imaju razlicite opsege, onda je dovoljnostandardizovati promenljive.
2.5.5.6 Opsti pristup kombinovanju slicnosti
Prethodne definicije slicnosti su bazirane na pristupima koji pretpostavljaju da su sviatributi istog tipa. Slicnost je potrebna i u slucaju da ima vise atributa koji su razlicitogtipa. Jedan od pristupa je da se posebno izracunaju slicnosti izmedu svakog od atributaTabelom 2.8, a zatim kombinuju koristeci metod koji daje rezultat u intervalu [0, 1].Uobicajeno je da se ukupna slicnost racuna kao prosek slicnosti pojedinacnih atributa.
Nazalost, ovaj pristup ne radi dobro ako su neki atributi asimetricni. Na primer, uslucaju asimetricnih binarnih atributa, preporuceno merenje slicnosti se svodi na SMCkoji nije odgovarajuci za njih. Najjednostavnije resenje ovog problema je da asimetricnibinarni atributi mogu da se izostave kada su njihove vrednosti 0 za oba objekta. Slicanpristup radi dobro za nedostajuce vrednosti.
Algoritam 1 predstavlja efektivan nacin racunanja ukupne slicnosti izmedu objekatax i y, sa razlicitim tipovima atributa. Ova procedura se lako menja da radi sa meramarazlicitosti.

2.5. MERE SLICNOSTI I RAZLICITOSTI 37
Slika 2.23: Skup dvodimenzionalnih tacaka. Mahalanobisovo rastojanje izmeduoznacenih tacaka je 6, a Euklidsko je 14.7.
Algoritam 1 Slicnost heterogenih objekata.
1: procedure Slicnost(x, y)2: Za k-ti atribut izracunati slicnost sk(x, y) u opsegu [0, 1]3: Za k-ti atribut definisati indikator promenljivu δk kao
δk =
0, ako je k-ti atribut asimetrican i oba objekta imaju vrednost 0,
ili jedan od objekata ima nedostajucu vrednost za k-ti atribut1, inace
4: Izracunati ukupnu slicnost dva objekta pomocu formule
slicnost(x, y) =
n∑k=1
δksk(x, y)
n∑k=1
δk
(2.6)
5: return slicnost(x, y)6: end procedure
2.5.5.7 Koriscenje atributa sa tezinama
U prethodnim diskusijama, svi atributi su tretirani jednako pri racunanju blisko-sti. Ovo nije zeljeno kada su neki atributi znacajniji za bliskost od drugih. U ovakvimslucajevima formule za bliskost mogu biti modifikovane dodeljivanjem tezina odgova-rajucim atributima.

38 GLAVA 2. PODACI
Ako je suma tezina wk jednaka 1, onda Formula 2.6 postaje
slicnost(x, y) =
n∑k=1
δkwksk(x, y)
n∑k=1
δk
.
Definicija rastojanja Minkovskog se moze modifikovati na sledeci nacin:
d(x, y) =
(n∑k=1
wk|xk − yk|r) 1
r
.

Glava 3
Istrazivacka analiza i vizualizacija
Ovo poglavlje daje uvod u istazivacku analizu podataka, koja predstavlja prelimi-narno istrazivanje podataka radi boljeg razumevanja njihovih karakteristika. Istrazivackaanaliza moze pomoci u odabiru odgovarajucih tehnika za pretprocesiranje i analizu po-dataka. Neke tehnike koje se koriste u okviru istrazivacke analize, kao sto je vizualizacija,mogu se koristiti i za razumevanje i interpretiranje rezultata istrazivanja podataka.
3.1 Sumarne statistike
Sumarne statistike su brojevi, kao na primer medijana i standardna devijacija, kojiopisuju razlicite karakteristike potencijalno velikog skupa vrednosti koriscenjem jednogbroja ili malog skupa brojeva. Primeri sumarnih statistika iz svakodnevnog zivota suprosecna zarada u domacinstvu ili procenat studenata koji zavrse osnovne studije zacetiri godine. Sumarne osobine ukljucuju frekvenciju, poziciju i rasirenost. Vecina su-marnih statistika moze da bude izracunata u jednom prolazu (kroz podatke).
3.1.1 Frekvencija i modus
Kada nam je dat neureden skup kategorickih vrednosti, ne mozemo mnogo togauciniti kako bismo dalje karakterizovali vrednosti osim da izracunamo frekvenciju kojomse svaka od vrednosti pojavljuje u odredenom skupu podataka. Za dati kategorickiatribut x, koji moze uzimati vrednosti {v1, v2, . . . , vi, . . . , vk}, i skup od m objekata,frekvencija (engl. frequency) vrednosti vi definise se kao
frequency(vi) =broj objekata sa atributima vrednosti vi
m.
Modus (engl. mode) kategorickog atributa je vrednost koja ima najvecu frekvenciju.Kategoricki atributi cesto, ali ne uvek, imaju mali broj vrednosti, zbog cega modus ifrekvencija mogu biti interesantni i korisni. Za neprekidne podatke, modus cesto nijekoristan jer moze da se desi da se jedna vrednost ne pojavi vise od jednog puta. Poredtoga, u nekim slucajevima, modus moze ukazati na vazne informacije o prirodi vrednostiili postojanju nedostajucih vrednosti. Na primer, visine 20 ljudi merene u milimetrimanece se ponavljati, ali ako visine merimo u centimetrima, moze se desiti da neki ljudiimaju iste visine. Takode, ako se koristi jedinstvena vrednost za isticanje nedostajucevrednosti, onda ce ta vrednost cesto biti modus.
39

40 GLAVA 3. ISTRAZIVACKA ANALIZA I VIZUALIZACIJA
3.1.2 Percentili
Za uredene podatke, mnogo je korisnije razmotriti precentile skupa vrednosti. Za datiuredeni ili neprekidan atribut x i broj p izmedu 0 i 100, p-ti percentil (engl. percentile)xp je vrednost atributa x takva da je p% posmatranih vrednosti atributa x manje odxp. Na primer, 50. percentil je vrednost x50% takva da je 50% vrednosti od x manje odx50%. Ovaj percentil se naziva i medijana. Obicno je min(x) = x0% i max(x) = x100%.
3.1.3 Mere pozicije: srednja vrednost i medijana
Za neprekidne podatke, dve najsire koriscene sumarne statistike su srednja vrednost(engl. mean) (ili, uzoracka sredina) i medijana (engl. median), koje predstavljaju merepozicije skupa vrednosti. Razmotrimo skup {x1, x2, . . . , xm} od m objekata, na primer,visina m ljudi. Neka {x(1), x(2),...,x(m)
} predstavljaju vrednosti od x nakon sortiranja
u neopadajucem poretku. Tako, x(1) = min(x) i x(m) = max(x). Onda se srednjavrednost i medijana definisu na sledeci nacin:
mean(x) = x =1
m
m∑i=1
xi
median(x) =
xr+1, m = 2 · r + 1
12(x(r) + x(r+1)), m = 2 · r
Iako se srednja vrednost ponekad interpretira kao sredina skupa vrednosti, to je tacnosamo ako su vrednosti podeljene na simetrican nacin. Ako je raspodela vrednosti iskri-vljena, onda je medijana bolji pokazatelj sredine. Takode, srednja vrednost je osetljivijana postojanje elemenata van granica. Za podatke sa elementima van granica, medijanaponovo daje robusniju procenu sredine skupa vrednosti.
3.1.4 Mere razmere: rang i varijansa
Jos jedan skup cesto koriscenih sumarnih statistika za neprekidne podatke su onekoje mere disperziju ili razmere skupa vrednosti. Takve mere ukazuju na to da li suvrednosti atributa siroko raspostranjene ili su relativno koncentrisane oko jedne tackekao sto je srednja vrednost.
Najjednostavnija mera razmere je rang (engl. range), koji se, za dati atribut x saskupom m vrednosti {x1, . . . , xm}, definise kao
range(x) = max(x)−min(x) = x(m) − x(1).
Iako rang odreduje najvecu razmeru, moze biti varljiv ako je vecina vrednosti koncen-trisana u malom opsegu vrednosti, ali takode postoji relativno mali broj ekstremnihvrednosti. Zato je varijansa (engl. variance) pozeljnija pri merenju razmere. Varijansaposmatranih vrednosti atributa x se obicno obelezava oznakom s2x i definisana je formu-lom ispod. Standardna devijacija (engl. standard deviation), koja predstavlja kvadratnikoren varijanse, obelezava se oznakom sx, i ima iste jedinice mere kao x.
variance(x) = s2x =1
m− 1
m∑i=1
(xi − x)2.

3.1. SUMARNE STATISTIKE 41
Kako se varijansa racuna pomocu srednje vrednosti, ona je takode osetljiva na elementevan granice, posebno zbog kvadrirane razlike srednje vrednosti i drugih vrednosti. Kaorezultat, robusnije procene razmere skupa atributa se cesto koriste. Koriste se tri takvemere: apsolutna prosecna devijacija (engl. absolute average deviation), koja se oznacavaAAD, srednja apsolutna devijacija (engl. median absolute deviation), koja se oznacavaMAD i interkvartilni opseg (engl. interquartile range), koja se oznacava IQR. Ove merese definisu narednim formulama.
AAD(x) =1
m
m∑i=1
|xi − x|
MAD(x) = median(|x1 − x|, . . . , |xm − x|)IQR(x) = x75% − x25%
3.1.5 Sumarne statistike za podatke sa vise atributa
Mere pozicije za podatke koji se sastoje od vise atributa mogu se dobiti racunanjemsrednje vrednosti ili medijane posebno za svaki atribut. Tako, za dati skup n-dimenzionihpodataka, srednja vrednost x je data kao
x = (x1, . . . , xn)
gde je xi srednja vrednost i-tog atributa xi.Za podatke koji se sastoje od vise atributa, razmera svakog atributa moze se dobiti
racunanjem nezavisnim od drugih atributa nekim od pristupa opisanih u podsekciji 3.1.4.Medutim, za podatke sa neprekidnim promenljivama, razmera podataka se najcesceprikazuje matricom kovarijanse (engl. covariance matrix ) S, ciji element sij na poziciji(i, j) predstavlja kovarijansu i-tog i j-tog atributa podataka. Tako, ako su xi i xj redomi-ti i j-ti atribut, onda je
sij = covariance(xi, xj).
Vazi
covariance(xi, xj) =1
m− 1
m∑k=1
(xki − xi)(xkj − xj),
gde su xki i xkj vrednosti i-tog i j-tog atributa k-tog objekta. Primetimo da jecovariance(xi, xi) = variance(xi), pa matrica kovarijanse ima varijanse atributa naglavnoj dijagonali.
Kovarijansa dva atributa je mera stepena u kom dva atributa variraju zajedno i zavisiod magnitude promenljivih. Vrednost blizu 0 ukazuje da atributi nemaju (linearnu) vezu,ali nije moguce odrediti stepen veze izmedu dva atributa posmatranjem samo vrednostikovarijanse. Korelacija dva atributa odmah daje nagovestaj koliko jako su dva atributa(linearno) povezana i zato je korelacija pozeljnija od kovarijanse za istrazivacku analizu.Element rij na poziciji (i, j) matrice korelacije (engl. correlation matrix ) R predstavljakorelaciju izmedu i-tog i j-tog atributa podataka. Ako su xi i xj redom i-ti i j-ti atributi,onda
rij = correlation(xi, xj) =covariance(xi, xj)
si · sj,
gde su si i sj varijanse od xi i xj , redom. Elementi na glavnoj dijagonali matrice R sucorrelation(xi, xi) = 1, dok su ostale vrednosti izmedu −1 i 1.

42 GLAVA 3. ISTRAZIVACKA ANALIZA I VIZUALIZACIJA
3.2 Vizualizacija
Vizualizacija podataka je prikazivanje informacija u vidu grafika ili tabela. Uspesnavizualizacija zahteva da se podaci prebace u vizualni format kako bi karakteristike po-dataka ili veze izmedu pojedinacnih podataka ili atributa mogle da se analiziraju. Ciljvizualizacije je interpretacija vizualiziranih informacija od strane neke osobe i formiranjeumnog modela informacija.
Najvazniji razlog za koriscenje vizualizacije je taj sto ljudi mogu brzo da usvoje velikibroj vizualnih informacija, pronalaze sablone i otkriju elemente van granica.
3.2.1 Opsti koncepti
Sada cemo se pozabaviti opstim konceptima vezanim za vizualizaciju, konkretno,opstim pristupima za vizualizaciju podataka i njihovih atributa. Pretpostavlja se upo-znatost citaoca sa osnovnim tehnikama izrade nacrta (engl. plots), kao sto su: linijskigrafici, stubicasti dijagrami i tackasti nacrti.
3.2.1.1 Reprezentacija: preslikavanje podataka u graficke elemente
Prvi korak u vizualizaciji je preslikavanje informacija u vizualni format, tj. preslika-vanje objekata, atributa i veza u skupu informacija u vizualne objekte, atribute i veze.Objekti, atributi i njihovi odnosi se prevode u graficke elemente kao sto su tacke, linije,oblici i boje.
Objekti se obicno predstavjaju na jedan od tri nacina. Prvi, ukoliko se u obzir uzimasamo jedan kategoricki atribut, onda se objekti cesto spajaju u kategorije na osnovuvrednosti atributa, i ovi kategoricki atributi su prikazani kao unos u tabeli ili kao oblastna ekranu. Drugi nacin je da, ako objekat ima vise atributa, onda se on moze predstavitikao red (ili kolona) tabele ili kao linija na grafiku. Konacno, treci nacin, objekat se cestomoze interpretirati kao tacka u dvodimenzionalnom ili trodimenzionalnom prostoru, gdese graficki, tacka moze predstaviti kao geometrijska figura, poput kruga, krsta ili kutije.Dakle, objekti se predstavljaju tackama.
Kod atributa, reprezentacija zavisi od tipa atributa. Redni i neprekidni (intervalni irazmerni) atributi mogu se preslikati u neprekidne, uredene graficke karakteristike kaosto su lokacija duz x, y ili z ose, intenzitet, boja ili velicina (dijametar, sirina, visina,itd.). Za kategoricke atribute, svaka kategorija moze se preslikati u posebnu poziciju,boju, oblik, orijentaciju ili kolonu u tabeli. Medutim, za imenske atribute, cije su vred-nosti neuredene, graficke karakteristike, kao sto su boja i pozicija koje imaju svojstvenouredenje povezano sa njihovim vrednostima, moraju se koristiti pazljivo. Drugim recima,graficki elementi koji se koriste za predstavljanje rednih vrednosti cesto imaju redosled,dok ga redne vrednosti nemaju. Dakle, vrednosti atributa se mogu predstaviti kao po-zicija tacke ili njene karakteristike (boja, velicina, oblik).
Predstavljanje odnosa medu objektima grafickim elementima moze se javljati biloeksplicitno ili implicitno. Za grafovske podatke, standardna graficka reprezentacija –skup cvorova sa granama izmedu njih – cesto se koristi. Ako cvorovi (objekti) ili grane(odnosi) imaju svoje atribute ili karakteristike, onda se oni predstavljaju graficki. Naprimer, ako cvorovi predstavljaju gradove, a grane autoputeve izmesu njih, onda dija-metar cvora moze da predstavlja populaciju, dok sirina grane moze predstaviti gustinu

3.2. VIZUALIZACIJA 43
saobracaja. Ako se za predstavljanje koristi pozicija tada se lako uocavaju odnosi izmedutacaka, odnosno da li tacke formiraju neku grupu ili neki oblik, da li ima elemenata vangranica, itd.
3.2.1.2 Uredenje
Podesan izbor vizualne reprezentacije objekata i atributa je od sustinske vaznosti zadobru vizualizaciju. Uredenje (engl. arrangement) elemenata u okviru vizualnog prikazaje takode presudno. Predstavicemo ovo pomocu primera.
Ovaj primer ilustruje vaznost preuredenja tabele podataka. U Tabeli 3.1, koja pri-kazuje devet objekata sa sest binarnih atributa, ne postoji jasna veza izmedu objekatai atributa, bar na prvi pogled. Ako se redovi i kolone permutuju, kao sto je prikazanou Tabeli 3.2, onda je jasno da postoje dva tipa objekta u tabeli – jedan koji ima svejedinice za prva tri atributa i drugi koji ima sve jedinice za poslednja tri atributa.
Tabela 3.1: Tabela devet objekata sa sest binarnih atributa.
1 2 3 4 5 6
1 0 1 0 1 1 02 1 0 1 0 0 13 0 1 0 1 1 04 1 0 1 0 0 15 0 1 0 1 1 06 1 0 1 0 0 17 0 1 0 1 1 08 1 0 1 0 0 19 0 1 0 1 1 0
Tabela 3.2: Tabela devet objekata sa sest binarnih atributa permutovanih tako da sejasno vide odnosi redova i kolona.
6 1 3 2 5 4
4 1 1 1 0 0 02 1 1 1 0 0 06 1 1 1 0 0 08 1 1 1 0 0 05 0 0 0 1 1 13 0 0 0 1 1 19 0 0 0 1 1 11 0 0 0 1 1 17 0 0 0 1 1 1
3.2.1.3 Izbor
Jos jedan kljucni koncept u vizualizaciji je izbor (engl. selection). Izbor je elimina-cija ili smanjenje naglasenosti odredenih objekata i atributa. Objekti koji imaju mali

44 GLAVA 3. ISTRAZIVACKA ANALIZA I VIZUALIZACIJA
broj dimenzija cesto se mogu preslikati u dvodimenzionalne ili trodimenzionalne grafickereprezentacije na jednostavan nacin, ali ne postoji potpuno zadovoljavajuci nacin i opstipristup da se predstave podaci sa vise atributa. Takode, ako imamo previse objekata,vizualizacija svih objekata moze rezultirati prikazom koji je prenatrpan. Ako imamomnogo objekata i mnogo atributa onda je situacija jos izazovnija.
Najopsti pristup rukovanja vise atributa jeste da se izabere podskup atributa (obicnodva) koji ce biti prikazani. Alternativno, mogu se posmatrati parovi atributa. Taj nacinse koristi u nadi da ce kolekcija parova atributa dati kompletniji prikaz podataka.
Kada je broj tacaka veliki, na primer, vise hiljada, ili ako je opseg podataka veliki,tesko je prikazati dovoljno informacija o svakom objektu. Neke tacke mogu nacinitidruge tacke nerazumljivim ili objekat moze da ne zauzima dovoljno piksela za jasanprikaz svojih karakteristika. Na primer, oblik objekta se ne moze iskoristiti za otkrivanjekarakteristika objekta ako imamo samo jedan piksel. U ovakvim situacijama, korisnoje da mozemo da eliminisemo neke objekte, ili zumiranjem na odreden deo podataka iliuzimanjem uzorka tacaka.
3.2.2 Tehnike vizualizacije
Tehnike vizualizacije cesto su specijalizovane za tip podataka koji se analizira. Zaista,nove tehnike vizualizacije i pristupi, kao i specijalizovane varijacije postojecih tehnika,neprekidno se stvaraju, obicno kao odgovor stvaranju novih vrsta podataka i zadatakavizualizacije.
Bez obzira na specijalizaciju i ad hoc prirodu vizualizacije, postoje neki generickinacini da se klasifikuju tehnike vizualizacije. Jedna takva klasifikacija je zasnovana nabroju ukljucenih atributa (1, 2, 3 ili vise) ili na tome da li atribut ima neke specijalnekarakteristike, kao sto su hijerarhija ili grafovska struktura. Tehnike vizualizacije semogu klasifikovati i prema tipu ukljucenih atributa. Jos jedna klasifikacija zasnovana jena tipu aplikacije: naucna, statisticka i informaticka vizualizacija.
U daljem tekstu koristicemo sledece tri kategorije: vizualizacija malog broja atributa,vizualizacija podataka sa prostornim ili vremenskim atributima i vizualizacija podatakasa vise atributa.
3.2.2.1 Vizualizacija malog broja atributa
Histogrami Histogrami prikazuju raspodelu vrednosti deljenjem mogucih vrednostina podeoke (engl. bins) i prikazivanjem broja objekata koji upadaju u svaki podeok.Za kategoricke podatke, svaka vrednost je jedan podeok. Ako ovaj rezultat ima previsevrednosti, onda se vrednosti kombinuju na neki nacin. Za neprekidne atribute, opsegvrednosti je obicno, ali ne nuzno, podeljen na podeoke jednakih sirina i vrednosti usvakom podeoku su prebrojane. Na Slici 3.1 prikazan je primer histograma.
Jednom kada su dostupne vrednosti za svaki podeok, iscrtavaju se pravougaonicitako da svaki podeok bude predstavljen jednim pravougaonikom i povrsina svakog pra-vougaonika treba da bude proporcionalna broju vrednosti (objekata) koji upadaju uodgovarajuci opseg. Ako su svi intervali jednakih sirina, onda su svi pravougaonici istihsirina, a visina je proporcijalna broju vrednosti odgovarajuceg podeoka.
Dvodimenzionalni histogrami su takode moguci. Svaki atribut se deli na intervalei dva skupa intervala definisu dvodimenzionalne pravougaonike vrednosti. Iako dvodi-
3.2. VIZUALIZACIJA 45
Slika 3.1: Histogram sirine latica u skupu podataka Iris.
menzionalni histogrami mogu da se koriste za otkrivanje zanimljivih cinjenica o tomekako se vrednosti dva atributa zajedno pojavljuju, oni su vizualno komplikovaniji. Naprimer, lako je zamisliti situaciju u kojoj su neke kolone skrivene od drugih. Na Slici3.2 prikazan je primer dvodimenzionalnog histograma. Posto je svaki atribut podeljenna tri podeoka, ukupno ima devet dvodimenzionalnih pravougaonika.
Slika 3.2: Dvodimenzionalni histogram duzine i sirine latica u skupu podataka Iris.
Kutije-nacrti Kutije-nacrti (engl. box plots) predstavljaju jos jedan metod prikazi-vanja raspodele vrednosti jednog numerickog atributa. Slika 3.3 prikazuje obelezenekutije-nacrte za duzinu casicnog listica. Donji i gornji kraj pravougaonika predstavljaju,redom, 25. i 75. percentil, dok linija unutar pravougaonika predstavlja vrednost 50.percentila. Vrh i dno linije repa predstavljaju 90. i 10. percentil. Vrednosti van granica

46 GLAVA 3. ISTRAZIVACKA ANALIZA I VIZUALIZACIJA
predstavljeni su znakom +. Kutije-nacrti su relativno kompaktni, i tako, mnogi od njihmogu biti prikazani na jednom nacrtu. Pojednostavljene verzije, koje zauzimaju manjeprostora, takode se mogu koristiti. Kutije-nacrti mogu se koristiti za poredenje atributa,kao sto je prikazano na Slici 3.4.
Slika 3.3: Opis box plot-a za duzinu casicnog listica.
Slika 3.4: Opis box plot-a za duzinu casicnog listica.
Tackasti nacrti Vecina ljudi je donekle upoznata sa tackastim nacrtima (engl. scatterplots). Jedan takav je koriscen na Slici 2.22 za ilustrovanje linearne korelacije. Svakiobjekat prikazan je kao tacka u ravni pomocu vrednosti dvaju atributa kao x i y koordi-nate. Pretpostavlja se da su atributi celi ili realni brojevi. Na Slici 3.5 je prikazana semaza svaki par atributa skupa podataka Iris. Razlicite vrste Irisa su oznacene razlicitimmarkerima. Uredenje tackastih nacrta parova atributa u ovaj tip tabelarnog prikaza,koji je poznat kao matrica tackastih nacrta (engl. scatter plot matrix ), omogucava or-ganizovan nacin razmatranja vise tackastih dijagrama u isto vreme.

3.2. VIZUALIZACIJA 47
Postoje dve glavne upotrebe ovih nacrta. Prvo, oni graficki prikazuju odnose izmedudva atributa. Drugo, kada su dostupne oznake klasa, oni mogu da se koriste za otkrivanjedo kog stepena dva atributa razdvajaju klase. Ako je moguce povuci liniju (ili nekukomplikovaniju krivu) koja deli ravan definisanu pomocu dva atributa u odvojene regionekoji sadrze uglavnom objekte jedne klase, onda je moguce napraviti precizan klasifikatorzasnovan na tom paru atributa. Ako nije moguce provuci liniju, onda je potrebno koristitivise atributa ili upotrebiti sofisticiranije metode kako bi se napravio klasifikator.
Slika 3.5: Matrica sema sa razbacanim elementima skupa podataka Iris.
3.2.2.2 Vizualuzacija sa prostornim i/ili vremenskim atributima
Podaci cesto imaju prostorne ili vremenske atribute. Na primer, podaci se mogusastojati od skupa posmatranja na prostornoj resetki, kao sto su posmatranja pritiskana Zemljinoj povrsini. Ova posmatranja mogu biti napravljena u razlicitim vremen-skim trenucima. Dodatno, podaci mogu imati samo vremensku komponentu, kao sto suvremenske serije podataka koje prikazuju dnevne cene akcija.
Nacrt sa konturama Za neke trodimenzionalne podatke, dva atributa odreduju po-ziciju u ravni, dok treci ima neprekidne vrednosti, kao sto su temperatura ili nadmorskavisina. Korisna vizualizacija za takve podatke je nacrt sa konturama (engl. contourplot), koji razbija ravan na razdvojene delove u kojima su vrednosti treceg atributa pri-

48 GLAVA 3. ISTRAZIVACKA ANALIZA I VIZUALIZACIJA
blizno iste. Tipican primer je mapa kontura koja prikazuje nadmorske visine lokacija.Na Slici 3.6 prikazana je toplota vode pomocu seme sa konturama.
Slika 3.6: Toplota vode.
3.2.2.3 Vizualizacija visedimenzionih podataka
U ovom delu bavimo se tehnikama vizualizacije koje mogu da prikazu vise dimenzijakoje mogu biti posmatrane prethodno opisanim tehnikama. Medutim, cak i ove tehnikesu ogranicene jer mogu da prikazu samo neke aspekte podataka.
Matrice Slika se moze posmatrati kao pravougaoni niz piksela, gde se svaki pikselodlikuje bojom i svetlinom. Matrica podataka je pravougaonik niza vrednosti. Tako,matrica podataka moze biti vizualizovana kao slika povezujuci svaki unos podataka umatrici pikselom na slici. Svetlina ili boja piksela odredene su vrednoscu odgovarajucegunosa u matrici.
Postoje neka vazna prakticna razmatranja kada se vizualizuju matrice podataka. Akosu poznate klase, onda je korisno preurediti matricu tako da svi objekti jedne klase buduzajedno. Ovo cini jednostavnijim, na primer, otkrivanje da li svi objekti jedne klaseimaju slicne vrednosti za neke atribute. Ako razliciti atributi imaju razlicite opsege,onda se atributi standardizuju tako da imaju srednju vrednost 0 i standardnu devijaciju1. Ovo sprecava da atributi sa najvecim magnitudnim vrednostima dominiraju slikom.Primer matrice za skup podataka Iris prikazan je na Slici 3.7.
Moze biti korisno posmatranje strukture u nacrtu matrice bliskosti za skup podataka.Ponovo, korisno je da se redovi i kolone matrice bliskosti sortiraju (kada su poznateoznake klasa) tako da su svi objekti jedne klase zajedno. Ovo omogucava vizualnuprocenu kohezivnosti svake klase i njene odvojenosti od drugih klasa. Primer matricekorelacije prikazan je na Slici 3.8.
Ako nisu poznate klase, mogu se koristiti razlicite tehnike (na primer, reorganizacijamatrice) kako bi se preuredili redovi i kolone matrice slicnosti tako da grupe veoma slicnih
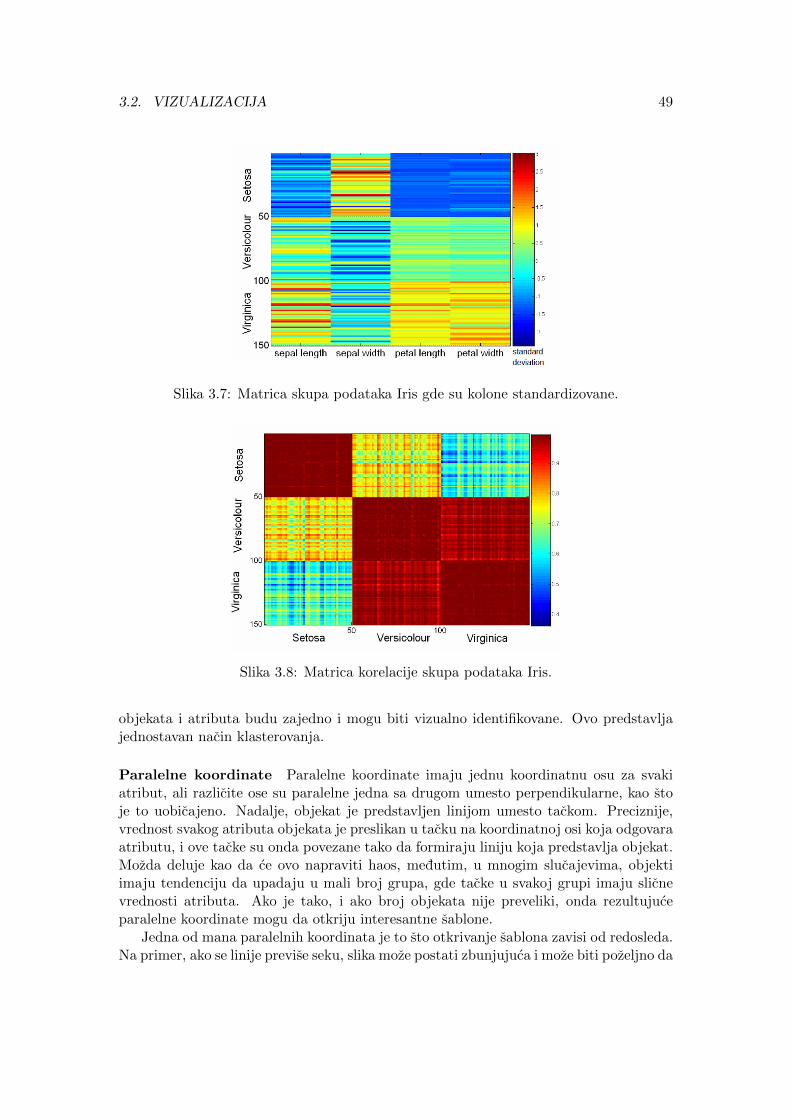
3.2. VIZUALIZACIJA 49
Slika 3.7: Matrica skupa podataka Iris gde su kolone standardizovane.
Slika 3.8: Matrica korelacije skupa podataka Iris.
objekata i atributa budu zajedno i mogu biti vizualno identifikovane. Ovo predstavljajednostavan nacin klasterovanja.
Paralelne koordinate Paralelne koordinate imaju jednu koordinatnu osu za svakiatribut, ali razlicite ose su paralelne jedna sa drugom umesto perpendikularne, kao stoje to uobicajeno. Nadalje, objekat je predstavljen linijom umesto tackom. Preciznije,vrednost svakog atributa objekata je preslikan u tacku na koordinatnoj osi koja odgovaraatributu, i ove tacke su onda povezane tako da formiraju liniju koja predstavlja objekat.Mozda deluje kao da ce ovo napraviti haos, medutim, u mnogim slucajevima, objektiimaju tendenciju da upadaju u mali broj grupa, gde tacke u svakoj grupi imaju slicnevrednosti atributa. Ako je tako, i ako broj objekata nije preveliki, onda rezultujuceparalelne koordinate mogu da otkriju interesantne sablone.
Jedna od mana paralelnih koordinata je to sto otkrivanje sablona zavisi od redosleda.Na primer, ako se linije previse seku, slika moze postati zbunjujuca i moze biti pozeljno da

50 GLAVA 3. ISTRAZIVACKA ANALIZA I VIZUALIZACIJA
se koordinatne ose rasporede tako da se dobije redosled osa sa manje preseka. Uporeditigrafike na Slici 3.9 – levo, gde je sirina casicnog listica (atribut koji je najvise izmesan)i desno, gde je ovaj atribut u sredini.
Slika 3.9: Paralelne koordinate skupa podataka Iris.
Zvezdaste koordinate Drugi pristup prikazivanju visedimenzionalnih podataka jestekodiranje objekata glifovima (engl. glyphs) ili ikonicama (engl. icons), simbolima kojipruzaju informacije na neverbalni nacin. Preciznije, svaki atribut objekta je mapiranodredenom karakteristikom glifa, tako da vrednost atributa odreduje tacnu prirodu ka-rakteristike. Time nam je omoguceno da na prvi pogled odredimo na koji nacin se dvaobjekta razlikuju.
Slika 3.10: Zvezdaste koordinate za 15 odabranih cvetova Irisa.
Jedan primer ovakvog pristupa su zvezdaste koordinate (engl. star coordinates).Ova tehnika koristi jednu osu za svaki atribut. Sve ose se granaju iz centralne tacke iravnomerno su rasporedene. Obicno su sve vrednosti atributa preslikane u opseg [0, 1].
Objekat se preslikava u skup osa u obliku zvezde na sledeci nacin: Svaka vrednostatributa se pretvara u razlomak koji predstavlja njegovo rastojanje od minimuma i mak-
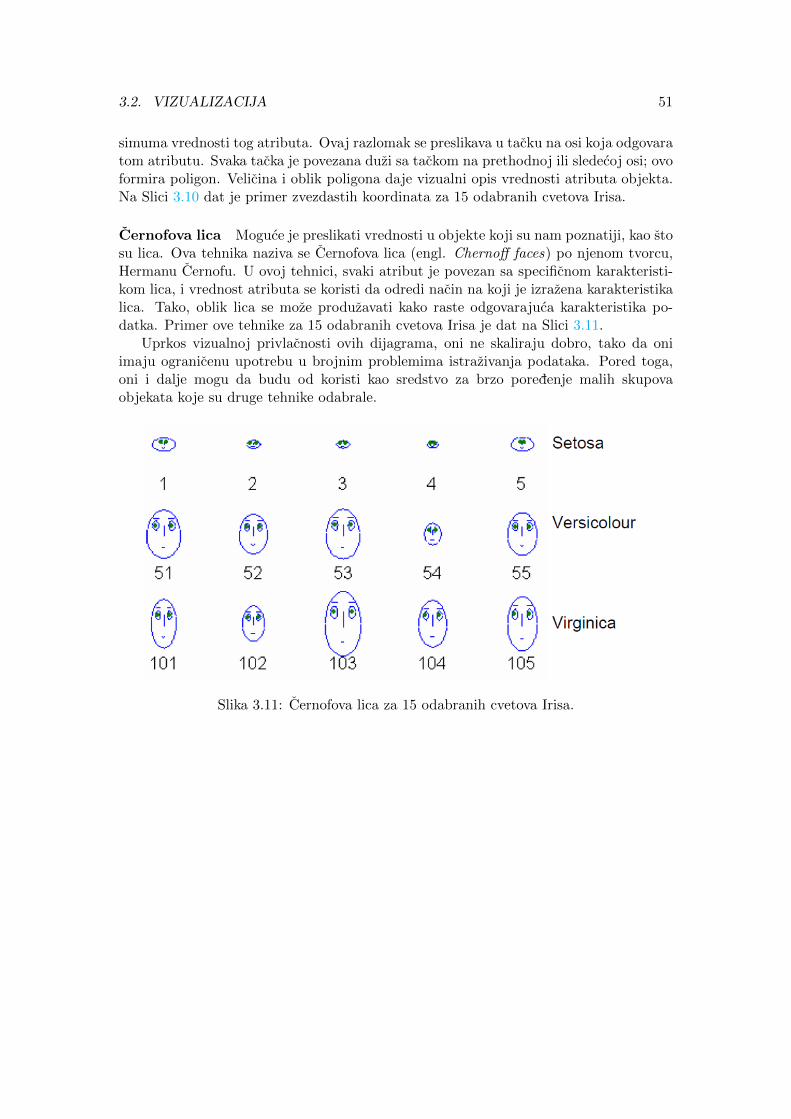
3.2. VIZUALIZACIJA 51
simuma vrednosti tog atributa. Ovaj razlomak se preslikava u tacku na osi koja odgovaratom atributu. Svaka tacka je povezana duzi sa tackom na prethodnoj ili sledecoj osi; ovoformira poligon. Velicina i oblik poligona daje vizualni opis vrednosti atributa objekta.Na Slici 3.10 dat je primer zvezdastih koordinata za 15 odabranih cvetova Irisa.
Cernofova lica Moguce je preslikati vrednosti u objekte koji su nam poznatiji, kao stosu lica. Ova tehnika naziva se Cernofova lica (engl. Chernoff faces) po njenom tvorcu,Hermanu Cernofu. U ovoj tehnici, svaki atribut je povezan sa specificnom karakteristi-kom lica, i vrednost atributa se koristi da odredi nacin na koji je izrazena karakteristikalica. Tako, oblik lica se moze produzavati kako raste odgovarajuca karakteristika po-datka. Primer ove tehnike za 15 odabranih cvetova Irisa je dat na Slici 3.11.
Uprkos vizualnoj privlacnosti ovih dijagrama, oni ne skaliraju dobro, tako da oniimaju ogranicenu upotrebu u brojnim problemima istrazivanja podataka. Pored toga,oni i dalje mogu da budu od koristi kao sredstvo za brzo poredenje malih skupovaobjekata koje su druge tehnike odabrale.
Slika 3.11: Cernofova lica za 15 odabranih cvetova Irisa.


Glava 4
Klasifikacija
Klasifikacija, odnosno, zadatak dodeljivanja objekata jednoj od vise predefinisanihkategorija, rasprostranjen je problem koji obuhvata mnostvo razlicitih primena. Pri-meri ukljucuju otkrivanje spam poruka na osnovu zaglavlja poruke i njenog sadrzaja,kategorisanje celija kao maligne ili beningne na osnovu rezultata magnetne rezonance,klasifikacija galaksija na osnovu njihovog oblika, itd.
Ovo poglavlje uvodi osnovne koncepte klasifikacije, opisuje neke od kljucnih problemakao sto su preprilagodavanje modela (engl. model overfitting), i predstavlja metode zaocenu i uporedivanje performansi tehnika klasifikacije.
4.1 Osnovni pojmovi
Ulazni podaci za klasifikaciju su skup slogova, tzv. podaci za trening (engl. trainingset). Svaki slog je oblika (x, y), gde je x skup atributa, a y specijalni atribut odredenza oznaku klase. Kljucna karakteristika koja razdvaja klasifikaciju od regresije je tipatributa y. Klasifikacija koristi diskretne, dok regresija koristi neprekidne atribute.
Klasifikacija (engl. classification) predstavlja ucenje ciljne funkcije f koja preslikavasvaki atribut skupa x u jednu od predefinisanih oznaka klasa y.
Ciljna funkcija je takode poznata kao model klasifikacije. Model klasifikacije je kori-stan za sledece ciljeve.
Opisno modeliranje Klasifikacioni model moze da sluzi kao sredstvo za razlikovanjeobjekata razlicitih klasa.
Intuitivno modeliranje Klasifikacioni model se moze koristiti i za predvidanje oznakeklase nepoznatih slogova.
Tehnike klasifikacije su najpogodnije za predvidanje ili opisivanje skupa binarnih iliimenskih kategorija. Manje su efikasne za redne kategorije zato sto ne uzimaju u obzirimplicitni poredak medu kategorijama. Ostali oblici veza, kao sto su potklasa–natklasa,takode se ignorisu. Ostatak poglavlja fokusira se samo na binarne i imenske oznakeklasa.
53

54 GLAVA 4. KLASIFIKACIJA
4.2 Opsti pristup resavanju problema klasifikacije
Tehnika klasifikacije (ili klasifikator) sistematican je pristup pravljenju klasifikacionogmodela od ulaznog skupa podataka. Svaka tehnika upotrebljava algoritam za ucenjekako bi odredila model koji najbolje odgovara vezi izmedu skupa atributa i klase ulaznihpodataka. Model koji algoritam generise trebalo bi da odgovara ulaznim podacima kaoi da tacno predvida klasu slogova koje ranije nije video.
Slika 4.1: Opsti pristup pravljenju klasifikacionog modela.
Na Slici 4.1 prikazan je opsti pristup resavanju klasifikacionih problema. Prvo morabiti obezbeden trening skup koji se sastoji od slogova cije su klase poznate. On se koristiza pravljenje klasifikacionog modela, koji se zatim koristi nad test skupom (engl. testset), koji se sastoji od slogova cije klase nisu poznate.
4.3 Stablo odlucivanja
Problem klasifikacije resavamo postavljanjem pazljivo sastavljenih pitanja o atribu-tima iz test skupa. Svaki put kad dobijemo odgovor, postavljamo sledece pitanje dok nedodemo do zakljucka o klasi datog sloga. Niz pitanja i odgovora organizovan je u oblikustabla odlucivanja, hijerarhijske strukture koja se sastoji iz cvorova i direktnih grana.Drvo ima tri razlicita tipa cvorova:
• koreni cvor, koji nema ulaznih grana i ima 0 ili vise izlaznih grana,
• unutrasnji cvorovi, od kojih svaki ima tacno jednu ulaznu granu i dve ili viseizlaznih grana,
• listovi ili zavrsni cvorovi, od kojih svaki ima tacno jednu ulaznu granu i nemaizlaznih grana.
Svaki list u stablu ima dodeljenu klasu. Unutrasnji cvorovi i koren sadrze uslove kojirazdvajaju slogove koji imaju razlicite karakteristike.
Jednom kada je napravljeno stablo odlucivanja, klasifikacija test sloga je jedno-smerna. Pocevsi od korenog cvora, primenjujemo test uslove na slog i pratimo odgo-varajuce grane na osnovu izlaza testa. Ovo ce nas odvesti ili do drugog unutrasnjeg

4.3. STABLO ODLUCIVANJA 55
cvora, za koji se primenjuje novi test uslov, ili do lista. Klasa koja je dodeljena listudodeljuje se slogu.
4.3.1 Konstruisanje stabla odlucivanja
U sustini, postoji eksponencijalno mnogo stabala odlucivanja koji mogu da se napravena osnovu datog skupa atributa. Dok su neka stabla preciznija od drugih, pronalazenjenajoptimalnijjeg stabla je racunski neizvodljivo zbog eksponencijalne velicine prostorapretrage. Ipak, razvijeni su efikasni algoritmi za konstruisanje prihvatljivo tacnog, iakomanje optimalnog, stabla odlucivanja za razumno vreme. Ovi algoritmi obicno kori-ste pohlepne strategije koja stvara stablo odluke pravljenjem niza lokalno optimalnihodluka o tome koji atribut iskoristiti za razdvajanje podataka. Jedan takav algoritam jeHantov algoritam, koji je osnova za mnoge postojece algoritme za konstruisanje stablaodlucivanja, ukljucujuci ID3, C4.5 i CART.
4.3.1.1 Hantov algoritam
U Hantovom algoritmu, stablo se pravi rekurzivno particionisanjem trening slogovana cistije podgrupe. Neka je Dt skup trening slogova koju su povezani sa cvorom t iy = {y1, y2, . . . , yc} skup oznaka klasa. U nastavku je rekurzivna definicija Hantovogalgoritma.
K1: Ako svi slogovi skupa Dt pripadaju istoj klasi yt, onda je list t oznacen klasom yt.
K2: Ako Dt sadrzi slogove koji se nalaze u vise od jedne klase, onda se bira test atributradi podele podataka u manje podskupove. Dete cvor se pravi za svaki izlaz testuslova i slogovi u Dt se rasporeduju deci na osnovu izlaza. Algoritam se, zatim,rekurzivno primenjuje na svaki od dece cvorova.
4.3.1.2 Problemi pri pravljenju stabala odlucivanja
Algoritam ucenja za konstrukciju stabala odlucivanja mora da se pozabavi sledecimpitanjima.
1. Kako treba podeliti trening slogove? Svaki rekurzivan korak pravljenja stablamora odabrati test atribut za deljenje slogova na manje podskupove. Da bi se ovajkorak implementirao, algoritam mora da obezbedi metod za odredivanje test uslovaza razlicite tipove atributa, kao i objektivne mere odredivanja toga koliko je svakiod test uslova dobar.
2. Kada treba stati sa deobom? Uslov zaustavljanja je potreban kako bi se pro-ces pravljenja stabla odlucivanja zaustavio. Jedna moguca strategija je nastavitisa prosirivanjem cvora sve dok se svi slogovi ne pripadaju istoj klasi ili dok svislogovi imaju identicne vrednosti atributa. Iako su oba uslova dovoljna da se zau-stavi algoritam, mogu se nametnuti i drugi kriterijumi kako bi se omogucilo ranijezaustavljanje.

56 GLAVA 4. KLASIFIKACIJA
4.3.2 Metodi podele test atributa
Algoritam za pravljenje stabla odlucivanja mora obezbediti metod za izrazavanjeuslova test atributa i njegovih izlaza za razlicite tipove atributa.
Binarni atributi Test uslov za binarni atribut proizvodi dva potencijalna izlaza.
Slika 4.2: Test uslovi za binarne atribute.
Imenski atributi Posto imenski atributi mogu imati vise vrednosti, njihovi test uslovimogu se izraziti na dva nacina – podela na vise grana i binarna podela. Kod podele navise grana, broj izlaza zavisi od broja razlicitih vrednosti odgovarajuceg atributa. Sdruge strane, binarna podela, koju koriste algoritmi kao sto je CART, razmatra svih2k−1 − 1 nacina za pravljenje binarne particije od k vrednosti atributa. Na Slici 4.3prikazani su opisani nacini podela vrednosti atributa bracno stanje u dva podskupa.
Slika 4.3: Test uslovi za imenske atribute. Podela na vise grana (gore) i binarna podela(dole).
Redni atributi Redni atributi takode mogu proizvesti binarne ili visestruke izlaze.Vrednosti se mogu grupisati sve dok im se ne narusava redosled. Slika 4.4 prikazujerazlicite nacine razdvajanja na osnovu atributa velicina majice. Podele (a) i (b)

4.3. STABLO ODLUCIVANJA 57
cuvaju redosled, dok podela (c) narusava redosled zato sto kombinuje vrednosti malo iveliko u jednu particiju, a vrednosti srednje i ekstra veliko u drugu.
Slika 4.4: Test uslovi za redne atribute.
Neprekidni atributi Za neprekidne atribute, test uslov moze se izraziti kao testporedenje (A < v) ili (A ≥ v) sa binarnim izlazima, ili razmerni upit sa izlazima oblikavi ≤ A < vi+1, za i = 1, . . . , k. Razlika ova dva pristupa prikazana je na Slici 4.5.U slucaju binarne podele, algoritam stabla odlucivanja mora da razmotri sve mogucevrednosti za v i bira onu koja proizvodi najbolju podelu. Za podelu na vise grana,algoritam mora da razmotri sve moguce raspone neprekidnih vrednosti. Jedan pristupje primena diskretizacije, a nakon toga, nove redne vrednosti ce biti dodeljene svakomdiskretizovanom intervalu. Susedni intervali se takode mogu spajati u vece intervale svedok je redosled ocuvan.
Slika 4.5: Test uslovi za neprekidne atribute.
4.3.2.1 Mere za odabir najbolje podele
Postoji mnogo mera koje se mogu koristiti za odlucivanje najboljeg nacina za podeluslogova. Ove mere definisu se u smislu klasne distribucije slogova pre i posle podele.Pohlepni pristup daje prednost cvorovima sa homogenom distribucijom klasa.
Neka p(i|t) oznacava deo slogova koji pripadaju klasi i u datom cvoru t. Ponekadizostavljamo referencu na cvor t i deo slogova oznacavamo kao pi. Mere razvijene zaodabir najbolje podele cesto su zasnovne na stepenu necistoce cvorova dece. Sto jemanji stepen necistoce, to je vise iskriljvena (engl. skewed) distribucija klasa. Na primer,
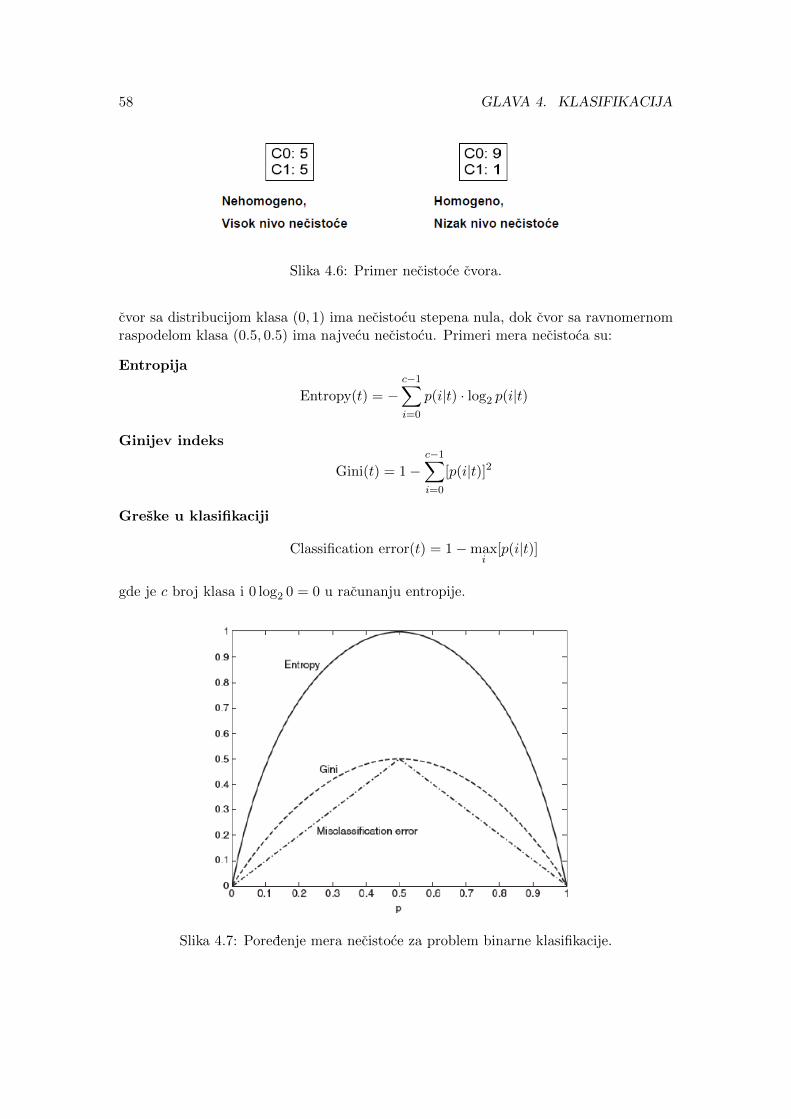
58 GLAVA 4. KLASIFIKACIJA
Slika 4.6: Primer necistoce cvora.
cvor sa distribucijom klasa (0, 1) ima necistocu stepena nula, dok cvor sa ravnomernomraspodelom klasa (0.5, 0.5) ima najvecu necistocu. Primeri mera necistoca su:
Entropija
Entropy(t) = −c−1∑i=0
p(i|t) · log2 p(i|t)
Ginijev indeks
Gini(t) = 1−c−1∑i=0
[p(i|t)]2
Greske u klasifikaciji
Classification error(t) = 1−maxi
[p(i|t)]
gde je c broj klasa i 0 log2 0 = 0 u racunanju entropije.
Slika 4.7: Poredenje mera necistoce za problem binarne klasifikacije.

4.3. STABLO ODLUCIVANJA 59
Slika 4.7 poredi vrednosti pomenutih mera necistoca za problem binarne klasifikacije.Vrednost p se odnosi na deo slogova koji pripada jednoj od dve klase. Primetimo dasve tri mere dostizu svoj maksimum kada je raspodela klasa ravnomerna (tj. kada jep = 0.5). Minimalne vrednosti se dostizu kada sve vrednosti pripadaju jednoj klasi (tj.kada je p jednako 0 ili 1). Primeri izracunavanja opisanih mera dati su u nastavku.
Da bismo ispitali koliko je dobar test uslova, treba da poredimo stepen necistoceroditeljskog cvora (pre razdvajanja) sa stepenima necistoce cvorova dece (nakon razdva-janja). Sto je njihova razlika veca, to je test uslov bolji. Dobitak (engl. gain), u oznaci∆, predstavlja kriterijum koji se moze koristiti za proveru kvaliteta razdvajanja:
∆ = I(roditelj)−k∑j=1
N(vj)
NI(vj),
gde je I funkcija koja racuna meru necistoce u zadatom cvoru, N ukupan broj slogovau roditeljskom cvoru, k broj vrednosti atributa i N(vj) broj slogova u cvoru deteta vj .
4.3.2.2 Razdvajanje binarnih atributa
Posmatrajmo dijagram na Slici 4.8. Pretpostavimo da postoje dva nacina razdvajanjaskupa na podskupove. Pre razdvajanja, Ginijev indeks je 0.5 jer je jednak broj slogovaiz obe klase. Ako odaberemo atribut A da razdvojimo podatke, Ginijev indeks cvoraN1 je 0.4898, a cvora N2 je 0.480. Tezinski prosek Ginijevog indeksa za decu cvorove je712 ·0.4898+ 5
12 ·0.480 = 0.486. Slicno se pokazuje da je tezinski prosek Ginijevog indeksapri razdvajanju po atributu B jednak 0.375. Posto podela po atributu B proizvodi manjiGinijev indeks, atribut B ima prednost u odnosu na atribut A.
4.3.2.3 Razdvajanje imenskih atributa
Kao sto smo diskutovali, imenski atribut moze proizvesti binarnu ili visestrukupodelu, sto je prikazano na Slici 4.9. Racunanje Ginijevog indeksa za binarnu po-delu slicna je onoj za binarne atribute. Za prvo grupisanje (Slika 4.9(a), levo) atri-buta tip automobila, Ginijev indeks {sportski, luksuzni} je 0.4922 i Ginijev indeks{porodicni} je 0.3750. Tezinski prosek Ginijevog indeksa u ovom slucaju je
16
20· 0.4922 +
4
20· 0.3750 = 0.468.

60 GLAVA 4. KLASIFIKACIJA
Slika 4.8: Razdvajanje binarnih atributa.
Slicno, za drugo grupisanje (Slika 4.9(a), desno) atributa tip automobila, {sportski}i {luksuzni, porodicni}, tezinski prosek Ginijevog indeksa je 0.167.
Kod visestruke podele (Slika 4.9(b)), Ginijev indeks se racuna za svaku vrednostatributa. Kako je Gini(porodicni) = 0.375,Gini(sportski) = 0 i Gini(luksuzni) =0.219, tezinski prosek Ginijevog indeksa iznosi
4
20· 0.375 +
8
20· 0 +
8
20· 0.219 = 0.163.
Odavde vidimo da visestruka podela ima manji Ginijev indeks od svih binarnih podela.
Slika 4.9: Razdvajanje imenskih atributa.
Visestruka podela je ocekivano bolja od binarne jer deljenjem heterogenost ne opada,vec samo raste. Posledica ovoga je da ce algoritmi konstruisanja stabala odlucivanjakoji su zasnovani na merama heterogenosti, pri biranju atributa po Ginijevom indeksu,biti odabrani oni atributi koji imaju mnogo vrednosti, a sa druge strane, mozda bas

4.3. STABLO ODLUCIVANJA 61
ti atributi nisu kljucni za odredivanje klase. Zbog toga cemo nekada zeleti da vrsimobinarnu podelu.
4.3.2.4 Razdvajanje neprekidnih atributa
Za razdvajanje neprekidnih atributa koriste se binarne pitalice zasnovane na jednojvrednosti (A ≤ v, odnosno, A > v). Postoji vise izbora za vrednost v po kojoj se deli,pri cemu je broj mogucih vrednosti za podelu jednak broju razlicitih vrednosti atributapo kojem se vrsi podela.
Svaka vrednost po kojoj se deli ima pridruzenu matricu brojanja. U svakoj od par-ticija se prebrojavaju klase. Jednostavan nacin za izbor najbolje vrednosti za v jesteda se za svako v skeniraju podaci da bi se dobila matrica brojeva i izracunao Ginijevindeks. Ovakav pristup grube sile zahteva ponavljanje posla i neefikasno je sa stanovistaizracunljivosti i slozenosti je O(n2).
Da bi se smanjila kompleksnost, za svaki atribut se vrsi sortiranje po vrednostima.Zatim se dobijene vrednosti linearno skeniraju uz azuriranje matrice brojanja i izracunavanjeGinijevog indeksa. Nakon toga se bira pozicija za podelu sa najmanjim Ginijevim in-deksom. Slozenost ovakvog postupka je O(n log n). Primer ovakvog racunanja dat je naSlici 4.10. Za vrednost v je izabrana vrednost 97, jer pri toj podeli Ginijev indeks imanajmanju vrednost (0.300).
Slika 4.10: Razdvajanje neprekidnih atributa.
4.3.2.5 Jos o merama po kojima se vrsi podela
Entropija je mera koja je nesto osetljivija na heterogenost od Ginijevog indeksa. Tose direktno zakljucuje na osnovu Slike 4.7. Kako heterogenost raste, to entropija brzeraste od Ginijevog indeksa.
Greska klasifikacije je najjednostavnija mera heterogenosti. Na primer, ako u nekomcvoru imamo tri klase cije su zastupljenosti p1 = 0.25, p2 = 0.50, i p3 = 0.25, prirodnoje za taj cvor izabrati onu klasu koja ima najvecu zastupljenost, tj. klasu 2. Zatimse zapitamo koliko ima instanci drugih klasa. Dakle, greska klasifikacije predstavljaprocenat nesaglasnih instanci u skladu sa odlukom koju smo doneli.
Vec smo konstatovali da, koriscenjem ovih mera, algoritmi konstruisanja stabalaodlucivanja biraju atribute sa visokim stepenom grananja, tj. sa velikim brojem vredno-sti. Zbog toga koristimo dodatne mere da bismo normirali dobitak. Normiranje dobitka

62 GLAVA 4. KLASIFIKACIJA
kod entropije se vrsi formulom
∆split = Entropy(p)−(
k∑i=1
nin
Entropy(i)
),
gde se roditeljski cvor p deli na k particija, a ni je broj slogova u particiji i. Ova merase naziva informaciona dobit.
4.3.3 Kriterijumi zaustavljanja algoritama za konstrukciju stabala odlucivanja
Na samom pocetku smo napomenuli da su algoritmi za konstrukciju stabala odlucivanjarekurzivni. Ostalo nam je da razmotrimo pitanje zaustavljanja ovih algoritama.
Jedan siguran kriterijum jeste da se sirenje (stabla) zaustavlja kada svi slogovi pripa-daju istoj klasi. Jasno je da tada nema sta da se razvrstava, pa algoritam staje. Slicno,ukoliko svi slogovi imaju iste vrednosti svih atributa, takode nemamo sta dalje da raz-vrstavamo. Ova dva kriterijuma predstavljaju prirodna zaustavljanja. U ovom slucaju,moguce je da ostanemo sa neheterogenim podacima, a da pritom ostanemo bez uslovaza grananje. To je nesto sto se regularno desava, bilo zbog gresaka, bilo zbog toga stonismo uzimali u obzir sve atribute (ili nam nisu bili dostupni).
Ranije zaustavljanje predstavlja kriterijum koji dovodi do prekida algoritma pre pri-rodnog zaustavljanja. Vise reci o ovome ce biti u daljem tekstu. Napomenimo da ovajkriterijum nije jednostavno odrediti.
4.3.4 Karakteristike stabala odlucivanja
U nastavku dajemo sazetak bitnih karakteristika algoritama za konstrukciju stabalaodlucivanja, a dodatne karakteristike se mogu pronaci u [1].
1. Tehnike koje su razvijene za izgradnju stabala odlucivanja su efikasne, pa su stablaodlucivanja jevtina za konstruisanje. Konstruisanje modela je brzo, cak i kada jevelicina trening skupa veoma velika. Dalje, jednom kada je stablo konstruisano,klasifikacija novih instanci je veoma brza. U najgorem slucaju, klasifikacija novihinstanci je slozenosti O(h), gde je h najveca dubina stabla. Ipak, napomenimoda su vecina metoda klasifikacije u istrazivanju podataka brzi u klasifikaciji novihinstanci, tako da ovde stavljamo akcenat na brzu konstrukciju modela.
2. Stabla odlucivanja manjih dubina se relativno lako interpretiraju. Ovo je jednood glavnih prednosti stabala odlucivanja u odnosu na druge metode klasifikacije.Stablo odlucivanja, prilikom klasifikacije nove instance, osim odgovora kojoj klasipripada daje i spisak uslova na osnovu cega je ta instanca klasifikovana bas u tojklasi. Ovo predstavlja argumentaciju koju mozemo da interpretiramo.
3. Jedna od najvecih mana stabala odlucivanja jeste sto preciznost dobijena njihovomprimenom nije uporediva (preciznije, slabija je) u odnosu na preciznost drugih me-toda klasifikacije, kao sto su neuronske mreze, metod potpornih vektora, i drugi.Unapredenje stabla odlucivanja predstavljaju tzv. nasumicne sume (engl. randomforests). Ukratko, skup podataka se podeli na nezavisno izabrane podskupove (i uodnosu na vrste i u odnosu na kolone) i nad svakim od podskupova se konstruise

4.3. STABLO ODLUCIVANJA 63
jedno stablo odlucivanja. Nova instanca se daje kao ulaz u svako dobijeno stablo,rezultat svih izlaza se agregira tako sto se odabere klasa koja je najvise zastupljena(’’glasanje”), i to predstavlja konacni rezultat. Zbog nezavisnosti u biranju podsku-
pova, stabla prave nekorelirane greske, pa se moze pokazati da verovatnoca greske
’’glasanja” eksponencijalno opada sa brojem modela koji
’’glasaju”. Problem je sto
nasumicne sume gube prednosti koje su stabla imala, odnosno, konstrukcija nijejednostavna, a i interpretacija je gotovo nemoguca.
4. Pronalazenje optimalnog stabla odlucivanja je NP-kompletan problem. Zbog togamnogo algoritama stabala odlucivanja koriste pristupe zasnovane na heuristikamaza usmeravanje pretrage u sirokom prostoru pretrage.
5. Jedno podstablo se moze pojaviti vise puta u raznim delovima stabla odlucivanja.Ovaj problem se naziva problem replikacije stabla. Ovaj problem cini stabloodlucivanja kompleksnijim nego sto je neophodno i potencijalno tezim za inter-pretaciju.
6. Test uslovi koji su opisani do sada u ovom poglavlju koriste samo jedan atribut.Posledica toga je da procedura izgradnje stabla moze da se posmatra kao pro-ces particionisanja prostora atributa u disjunktne regione sve dok svaki region nesadrzi instance iz iste klase (videti Sliku 4.11). Granica izmedu dva susedna regionarazlicitih klasa se naziva granica odlucivanja (engl. decision boundary). Kako testuslov koristi samo jedan atribut, to su granice odlucivanja rektilinearne (engl. rec-tilinear) hiperravni, tj. hiperravni koje su paralelne
’’koordinatnim osama”. Ovo
ogranicava ekspresivnu moc reprezentacije stabla odlucivanja prilikom modeliranjaodnosa izmedu neprekidnih atributa.
Slika 4.11: Primer stabla odlucivanja i njegovih granica odlucivanja za dvodimenzionalniskup podataka.
Slika 4.12 ilustruje skup podataka koji ne moze biti efektivno klasifikovan algorit-mom drveta odlucivanja koji se bazira na test uslovima koji koriste samo jedanatribut. Bilo da li je granica odlucivanja paralelna apscisi ili ordinati, veliki brojinstanci jedne ili druge klase ce biti pogresno klasifikovano. U ovom slucaju, stabloodlucivanja mora da kombinuje oba atributa pri cemu vazi da, iako ne moze da

64 GLAVA 4. KLASIFIKACIJA
postigne trazenu pravu, stablo moze cik-cak aproksimacijom da relativno dobropostigne efekat trazene prave, koja zaista deli instance dveju klasa. Medutim, ovajpostupak je veoma zahtevan i stabla malih dubina ne mogu nikako ovo da postignu.
Slika 4.12: Primer skupa podataka koji se ne moze particionisati optimalno koriscenjemtest uslova koji koriste jedan atribut.
7. Prisustvo redundantnih atributa nema stetnih efekata na preciznost stabla odlucivanja.Za atribut kazemo da je redundantan ukoliko je visoko koreliran sa drugim atribu-tom u podacima. Jedan od dva atributa nece biti koriscen za razdvajanje jednomkada je drugi atribut odabran. Ipak, ako skup podataka sadrzi mnogo irelevantnihatributa, tj. atributa koji nisu koristi za proces klasifikacije, onda postoji sansada neki od irelevantnih atributa bude izabran tokom izgradnje stabla, sto dovodido visoke, a nepotrebne dubine stabla. Tehnike za odabir atributa mogu povisitipreciznost stabla tako sto eliminisu itelevantne atribute tokom faze preprocesiranjapodataka.
4.4 Prakticni problemi pri klasifikaciji
U ovoj sekciji ce biti reci o nekim prakticnim problemima koji vaze za sve metodeklasifikacije, a ne samo za stabla odlucivanja. Ipak, treba imati u glavi makar jedankonkretan metod klasifikacije prilikom razmatranja ovih problema.
4.4.1 Preprilagodavanje i potprilagodavanje modela
Greske u klasifikaciji se najcesce dele u dve grupe: (1) greske pri treniranju i (2)greske u uopstavanju. Greska pri treniranju je broj gresaka u klasifikaciji za dati skuppodataka za trening, a greska u uopstavanju je ocekivana greska modela u odnosu naunapred nepoznate instance.

4.4. PRAKTICNI PROBLEMI PRI KLASIFIKACIJI 65
Dobar model mora korektno da klasifikuje i trening podatke i unapred nepoznatepodatke (ili test podatke). Drugim recima, dobar model mora da ima nisku greskupri treniranju, ali i nisku gresku pri generalizaciji. Ovo je bitno zato sto model kojivrsi ukalupljivanje trening podataka previse dobro moze imati veoma veliku gresku priuopstavanju nego model sa vecom greskom pri treniranju. Ovaj fenomen je poznat kaopreprilagodavanje (engl. overfitting).
Preprilagodavanje modela je fenomen koji se veoma cesto javlja u praksi. Ukolikone znamo kako da rukujemo njime, gotovo je sigurno da nista korisno necemo postici uistrazivanju podataka. Nadalje govorimo o kontroli fleksibilnosti modela.
Neka imamo model koji je vrlo fleksibilan. Na primer, za skup dvodimenzionalnihtacaka na Slici 1.2, interpolacioni polinom je bio veoma fleksibilan. To sto je on uspeo dase savrseno prilagodi trening podacima je uzrokovalo vrlo lose ponasanje u predvidanju.Ukoliko bismo tacke iz posmatranog primera samo malo izmenili, koeficijenti regresioneprave bi toliko bili slicni da bismo dobili prakticno istu pravu. Sa druge strane, sva jeprilika da bi interpolacioni polinom postao neprepoznatljiv. To nam dosta govori o losojuslovljenosti preprilagodljivog modela. Fleksibilni modeli prilicno variraju u odnosu naveoma male promene u podacima. Posledica toga je da takvi modeli prirodno izazivajusumnju.
Jedan nacin resavanja preprilagodenosti jeste smanjivanje fleksibilnosti modela. Druginacin jeste da imamo velike kolicine podataka. Naravno, veoma nam je znacajno da zapocetak umemo da identifikujemo da je doslo do preprilagodavanja. Za to nam sluzeadekvatni pristupi dijagnostici ustanovljavanja da li je model dobar ili ne, kao i evaluacijamodela. Dijagnostika se radi na osnovu evaluacije.
Sa druge strane, ako je model isuvise jednostavan tada i greska pri treniranju igreska pri generalizaciji mogu biti velike. Ovaj fenomen je poznat kao potprilagodavanje(engl. underfitting). Na primer, Slika 4.13 predstavlja primer u kojem podatke, kojiopisuju nekakvu sinusnu aktivnost pokusavamo da ukalupimo u pravu y = 0. Ovimsmo zanemarili gotovo sve karakteristike podataka, pa ce greske i na trening i na testpodacima biti velike. Iako je i ovaj problem postojan, on je veoma manje izrazen zbogizuzetne fleksibilnosti modela i algoritama u istrazivanju podataka, pa stoga gotovo danemamo problem na pitanje
’’kako se dovoljno prilagoditi podacima?”.
0 2 4 6
−1
−0.5
0
0.5
1
Slika 4.13: Problem potprilagodavanja modela.
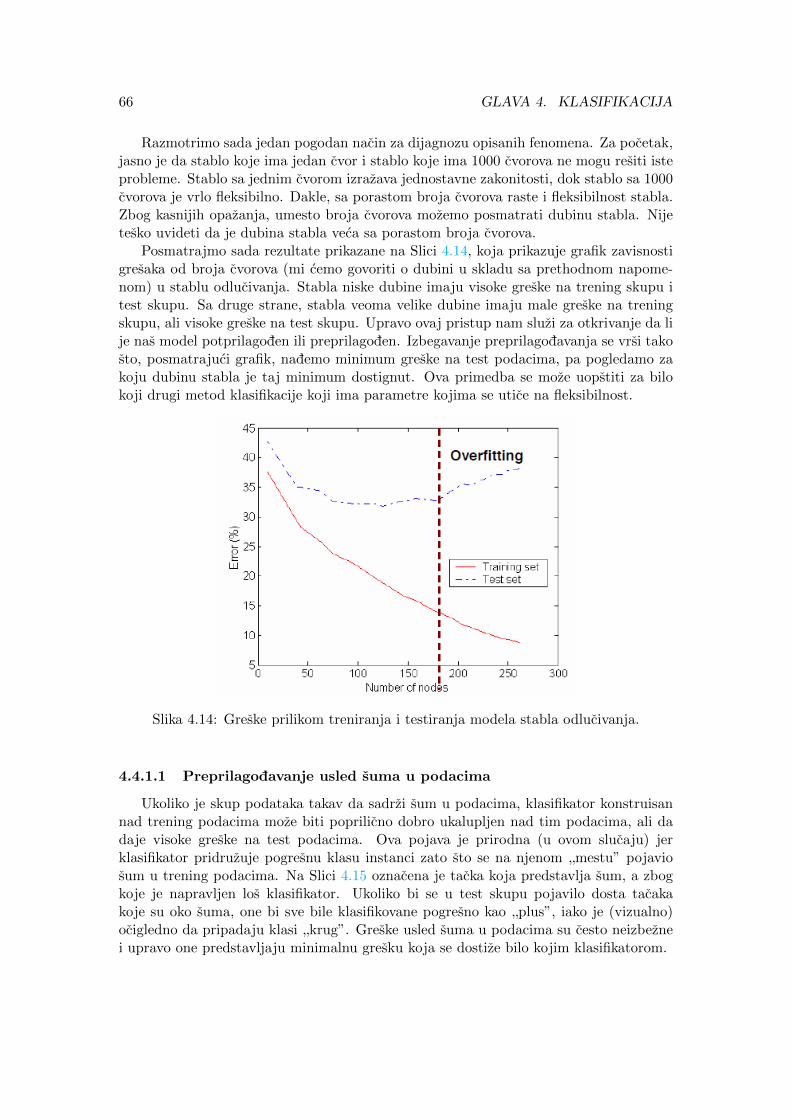
66 GLAVA 4. KLASIFIKACIJA
Razmotrimo sada jedan pogodan nacin za dijagnozu opisanih fenomena. Za pocetak,jasno je da stablo koje ima jedan cvor i stablo koje ima 1000 cvorova ne mogu resiti isteprobleme. Stablo sa jednim cvorom izrazava jednostavne zakonitosti, dok stablo sa 1000cvorova je vrlo fleksibilno. Dakle, sa porastom broja cvorova raste i fleksibilnost stabla.Zbog kasnijih opazanja, umesto broja cvorova mozemo posmatrati dubinu stabla. Nijetesko uvideti da je dubina stabla veca sa porastom broja cvorova.
Posmatrajmo sada rezultate prikazane na Slici 4.14, koja prikazuje grafik zavisnostigresaka od broja cvorova (mi cemo govoriti o dubini u skladu sa prethodnom napome-nom) u stablu odlucivanja. Stabla niske dubine imaju visoke greske na trening skupu itest skupu. Sa druge strane, stabla veoma velike dubine imaju male greske na treningskupu, ali visoke greske na test skupu. Upravo ovaj pristup nam sluzi za otkrivanje da lije nas model potprilagoden ili preprilagoden. Izbegavanje preprilagodavanja se vrsi takosto, posmatrajuci grafik, nademo minimum greske na test podacima, pa pogledamo zakoju dubinu stabla je taj minimum dostignut. Ova primedba se moze uopstiti za bilokoji drugi metod klasifikacije koji ima parametre kojima se utice na fleksibilnost.
Slika 4.14: Greske prilikom treniranja i testiranja modela stabla odlucivanja.
4.4.1.1 Preprilagodavanje usled suma u podacima
Ukoliko je skup podataka takav da sadrzi sum u podacima, klasifikator konstruisannad trening podacima moze biti poprilicno dobro ukalupljen nad tim podacima, ali dadaje visoke greske na test podacima. Ova pojava je prirodna (u ovom slucaju) jerklasifikator pridruzuje pogresnu klasu instanci zato sto se na njenom
’’mestu” pojavio
sum u trening podacima. Na Slici 4.15 oznacena je tacka koja predstavlja sum, a zbogkoje je napravljen los klasifikator. Ukoliko bi se u test skupu pojavilo dosta tacakakoje su oko suma, one bi sve bile klasifikovane pogresno kao
’’plus”, iako je (vizualno)
ocigledno da pripadaju klasi’’krug”. Greske usled suma u podacima su cesto neizbezne
i upravo one predstavljaju minimalnu gresku koja se dostize bilo kojim klasifikatorom.
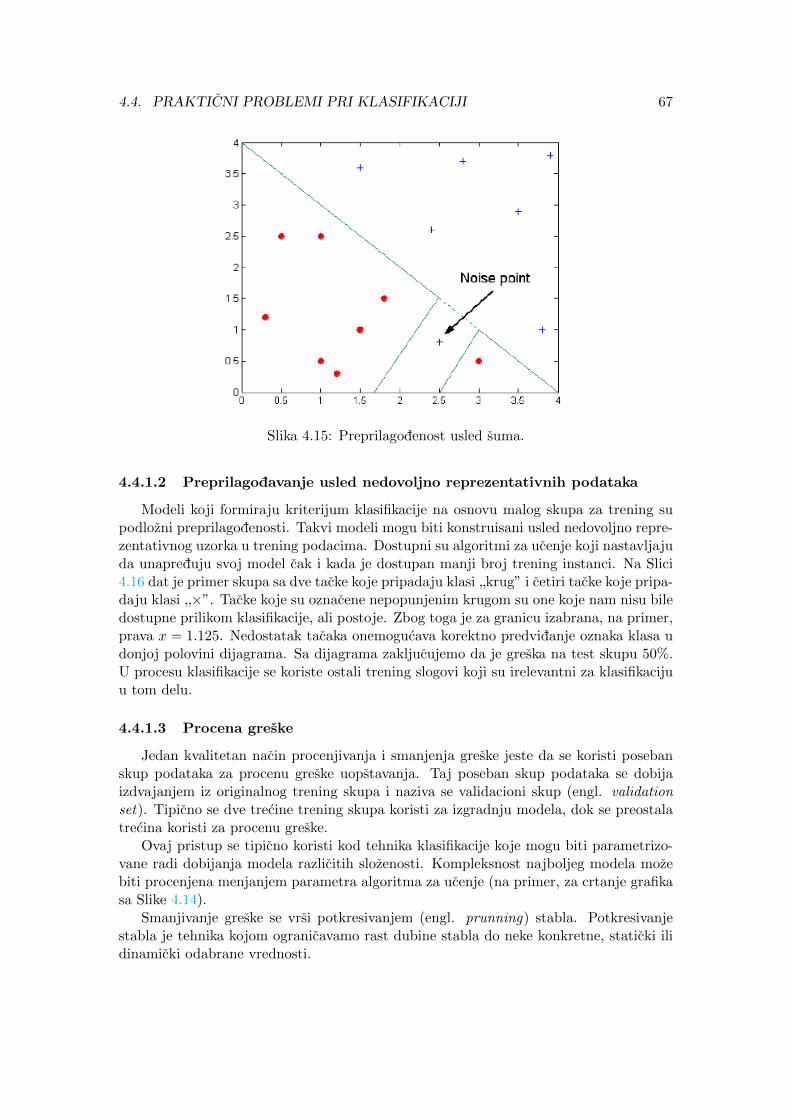
4.4. PRAKTICNI PROBLEMI PRI KLASIFIKACIJI 67
Slika 4.15: Preprilagodenost usled suma.
4.4.1.2 Preprilagodavanje usled nedovoljno reprezentativnih podataka
Modeli koji formiraju kriterijum klasifikacije na osnovu malog skupa za trening supodlozni preprilagodenosti. Takvi modeli mogu biti konstruisani usled nedovoljno repre-zentativnog uzorka u trening podacima. Dostupni su algoritmi za ucenje koji nastavljajuda unapreduju svoj model cak i kada je dostupan manji broj trening instanci. Na Slici4.16 dat je primer skupa sa dve tacke koje pripadaju klasi
’’krug” i cetiri tacke koje pripa-
daju klasi’’×”. Tacke koje su oznacene nepopunjenim krugom su one koje nam nisu bile
dostupne prilikom klasifikacije, ali postoje. Zbog toga je za granicu izabrana, na primer,prava x = 1.125. Nedostatak tacaka onemogucava korektno predvidanje oznaka klasa udonjoj polovini dijagrama. Sa dijagrama zakljucujemo da je greska na test skupu 50%.U procesu klasifikacije se koriste ostali trening slogovi koji su irelevantni za klasifikacijuu tom delu.
4.4.1.3 Procena greske
Jedan kvalitetan nacin procenjivanja i smanjenja greske jeste da se koristi posebanskup podataka za procenu greske uopstavanja. Taj poseban skup podataka se dobijaizdvajanjem iz originalnog trening skupa i naziva se validacioni skup (engl. validationset). Tipicno se dve trecine trening skupa koristi za izgradnju modela, dok se preostalatrecina koristi za procenu greske.
Ovaj pristup se tipicno koristi kod tehnika klasifikacije koje mogu biti parametrizo-vane radi dobijanja modela razlicitih slozenosti. Kompleksnost najboljeg modela mozebiti procenjena menjanjem parametra algoritma za ucenje (na primer, za crtanje grafikasa Slike 4.14).
Smanjivanje greske se vrsi potkresivanjem (engl. prunning) stabla. Potkresivanjestabla je tehnika kojom ogranicavamo rast dubine stabla do neke konkretne, staticki ilidinamicki odabrane vrednosti.

68 GLAVA 4. KLASIFIKACIJA
Slika 4.16: Preprilagodavanje usled nedovoljno reprezentativnih podataka.
Kao sto je razmatrano, sansa za preprilagodavanjem modela raste uz rast komplek-snosti modela. Upravo iz ovog razloga trebalo bi da biramo jednostavnije, sto predstavljastrategiju koja je u vezi sa pojmom iz filozofije nauke poznatim kao Okamova ostrica.
Okamova ostrica kaze da je najbolje ono objasnjenje koje je najprostije od svihobjasnjenja koja su saglasna sa opazanjima.
Kroz istrazivanje o masinskom ucenju, na cijim metodima pociva istrazivanje po-dataka, dato je opravdanje za ovaj princip. U masinskom ucenju je jasno objasnjenozasto od dva modela sa slicnom greskom generalizacije, a koji su saglasni sa podacima,treba izabrati onaj koji je jednostavniji. Napomenimo da, kod slozenijih modela, veca jesansa da se slucajno uklope zbog gresaka u podacima. Dakle, pri proceni modela, trebaukljuciti i njegovu slozenost.
Slika 4.17: Princip MDL.
Postoji jos jedan pristup evaluacije greske modela bez odvajanja podataka na posebneskupove. Ovaj informaciono-teorijski pristup se naziva princip najmanje duzine opisa(engl. minimum description length, zbog cega cemo ga mi obelezavati skracenicom MDLu daljem tekstu). Opis se odnosi na opis u proizvoljnom jeziku. Na primer, kompresijateksta pri binarnom kodiranju. Posmatrajmo primer prikazan na Slici 4.17. U ovomprimeru, i osoba A i osoba B imaju skup instanci sa poznatim vrednostima atributa x.Dodatno, osoba A zna tacne klase za svaku instancu, dok osoba B nema ove informacije.

4.4. PRAKTICNI PROBLEMI PRI KLASIFIKACIJI 69
B moze da dobije klasifikaciju zahtevajuci da osoba A posalje oznake klasa sekvencijalno.Ovakva poruka bi zahtevala Θ(n) bitova informacija, pri cemu je n ukupan broj instanci.
Alternativno, A moze da konstruise klasifikacioni model koji sumira odnos izmedu xi y. Model moze biti kodiran u kompaktan zapis pre slanja osobi B. Ako je preciznostmodela 100%, onda je cena prenosenja jednaka ceni kodiranja modela. Na primer, akoje model prava, jasno je da je slanje koeficijenata prave brze od slanja svih podataka.Inace, A mora dodatno da posalje informacije koje su instance klasifikovane pogresno.Ukupna cena prenosenja je
Cena(model,podaci) = Cena(model) + Cena(podaci|model),
pri cemu prvi sabirak na desnoj strani jednakosti oznacava cenu kodiranja modela, adrugi sabirak oznacava cenu kodiranja pogresno klasifikovanih instanci. Prema principuMDL, treba traziti model koji minimizira ukupnu funkciju cene.
4.4.1.4 Rukovanje preprilagodavanjem
Nakon sto imamo pogodnu procenu greske generalizacije, algoritam za ucenje mozeda krene u pretragu za dobrim modelom koji nece preprilagoditi trening podatke. Udaljem tekstu diskutujemo o dve strategije za izbegavanje preprilagodavanja modela ukontekstu stabala odlucivanja.
Prepotkresivanje (pravilo ranijeg zaustavljanja) Algoritam se zaustavlja prenego sto stablo naraste do maksimalne velicine. Tipicni uslovi zaustavljanja za odredenicvor su:
’’zaustavi se ako sve instance pripadaju istoj klasi” ili
’’zaustavi se ako su sve
vrednosti atributa iste”. Dodatna ogranicenja mogu biti, na primer,’’zaustavi se ako
je broj instanci manji od neke unapred zadate granice”,’’zaustavi se ako je raspodela
instanci nezavisna od raspodele atributa” (na primer, vidi se primenom χ2 testa) ili
’’zaustavi se ako sirenje tekuceg cvora ne poboljsava meru cistoce” (na primer, Ginijev
indeks ili informaciona dobit).
Potkresivanje po zavrsetku Drvo odlucivanja raste do krajnjih granica, pa se zatimiseku cvorovi u drvetu od dna ka vrhu. Ako se greska generalizacije poboljsa posleodsecanja poddrvo se zameni sa cvorom koji je list. Oznaka klase lista se odredujuprema vecini klasa instanci poddrveta. Za potkresivanje po zavrsetku se moze koristitii MDL.
4.4.2 Evaluacija performansi
Evaluacija performansi je veoma vazna stvar. Do sada je bilo reci o tome da jedanmodel bolje ili losije predvida u odnosu na drugi model, ali nije bilo reci o tome kako setacno meri
’’bolje”, odnosno,
’’losije”. Cilj nam je da kvantifikujemo koliko dobro nas
model predvida.
Matrica konfuzije Matrica konfuzije (engl. confusion matrix ) formira se od cetirivelicine SP , SN , LP i LN , sto je prikazano Tabelom 4.1. Vrednosti u matrici imajusledeca znacenja (pretpostavimo da imamo dve klase jedne kategorije, C+ i C−, koje

70 GLAVA 4. KLASIFIKACIJA
posmatramo kao’’pozitivno” i
’’negativno”, redom). Stvarno pozitivni, u oznaci SP ,
broj je instanci koje su klasifikovane kao pozitivne i one zaista jesu pozitivne. Stvarnonegativni, u oznaci SN , broj je instanci koje su klasifikovane kao negativne i one zaistajesu negativne. Lazno pozitivni, u oznaci LP , broj je instanci koje su klasifikovane kaopozitivne, ali su one zapravo negativne. Lazno negativni, u oznaci LN , broj je instancikoje su klasifikovane kao negativne, ali su one zapravo pozitivne. U slucaju dobrogklasifikatora, na glavnoj dijagonali matrice konfuzije se nalaze visoki brojevi, a u ostalihpoljima niske (pozeljno, nula).
Tabela 4.1: Matrica konfuzije.
Predvidena klasa
Prava klasaC+ C−
C+ SP LNC− LP SN
Preciznost Osnovna mera za procenu kvaliteta klasifikacije je preciznost (engl. accu-racy). Preciznost se meri formulom
Preciznost =SP + SN
SP + LP + SN + LN.
Interpretacija je jasna – preciznost predstavlja udeo tacno klasifikovanih instanci u ukup-nom broju instanci.
Pitanje da li je preciznost niska ili visoka zavisi od problema klasifikacije. Posma-trajmo, na primer, problem prepoznavanja vrste reci. Kod onih reci kod kojih nemahomonimije (a takvih je vecina), vrsta reci je jednoznacno odredena. Preciznost mo-dela od 90% kod ovog problema ne bi trebalo da nas impresionira jer je dovoljno dapogledamo u recnik i da vidimo koja je vrsta reci. Ukoliko bi nas model razresavao ihomonimije, onda bismo mogli da kazemo da je model visoko precizan.
Sa druge strane, posmatrajmo, na primer, predvidanje nekakvih klasa iz problemakoji imaju domene berzi. Preciznost od 90% je u vecini takvih problema nezamisliva.Tu bismo, mozda, bili zadovoljni i sa preciznoscu reda 30%.
Evo jos jednog primera. Na primer, prilikom klasifikacije avionskih putnika kaoteroriste, zapitajmo se koliki je broj takvih slucajeva koji zaista jesu teroristi. Odgovorje da je izrazito mali. Dakle, ako jedna klasa broji, na primer, 99% instanci, a drugaklasa 1% instanci, onda model cija je preciznost 99% nam prakticno ne sluzi nicemu.
Nemojmo biti obeshrabreni, preciznost je mera koja se itekako koristi u praksi. Po-trebno je samo dobro porazmisliti da li je ta mera prikladna u odnosu na nase podatke.Zbog ovih primedbi, cesto ce nam biti potrebna mera koja uzima u obzir i raspodeluinstanci po klasama.
Matrica cene Matrica cene (engl. cost matrix ) moze biti vrlo informativna ukolikoje pojam
’’cene” dovoljno jasan u domenu koji istrazujemo. Na primer, neka imamo
podatke sa informacijama o kupcima, pri cemu je 99% kupaca zadovoljno, a 1% ku-paca nezadovoljno. Zbog toga cemo podstaci da je pogresna klasifikacija kupca kojinije zadovoljan, na primer, deset puta skuplja za nas nego pogresna klasifikacija kupca

4.4. PRAKTICNI PROBLEMI PRI KLASIFIKACIJI 71
koji je zadovoljan. Tabela 4.2 prikazuje opstiji primer matrice cene, pri cemu vred-nost Cena(i|j) oznacava cenu pogresne klasifikacije instance klase j kao instanca klasei. U nastavku je dat primer izracunavanja koriscenjem matrice cene. Napomenimo dasu brojevi iz ovog primera proizvoljni, i da stvarne cene zavise od domena konkretnogproblema.
Tabela 4.2: Matrica cene.
Predvidena klasa
Prava klasaC+ C−
C+ Cena(C + |C+) Cena(C − |C+)C− Cena(C + |C−) Cena(C − |C−)
Dodatne mere evaluacije performansi U nastavku govorimo o merama koje uzi-maju u obzir disbalans klasa. Uvodimo dve pomocne mere, preciznost3 (engl. precision)i odziv (engl. recall), sledecim formulama
Preciznost = p =SP
SP + LP,
Odziv = r =SP
SP + LN.
Preciznost zapravo predstavlja udeo onih instanci koje su tacno klasifikovane kao po-zitivne u odnosu na sve instance koje su klasifikovane kao pozitivne. Ipak, ova merasama za sebe nije idealna. Neka imamo podatke o prevarama kreditnih kartica. Zapretpostaviti je da se prevare javljaju veoma retko, pa ako klasifikator stalno klasifikujetransakcije da nisu prevare, onda on ima savrsenu preciznost, jer posmatramo od onihza koje je rekao da su prevare, da li su zaista bile prevare. Samim tim, ako nikad nijerekao da je neka transakcija bila prevara, onda on nikada nije pogresio.
3Obratimo paznju da se isto ime koristi za ovu i prethodno opisanu meru performansi klasifikacije.Na engleskom jeziku je terminologija srecnija jer pravi razliku izmedu mera accuracy i precision. Upoglavljima koji slede, pod preciznoscu ce biti podrazumevana mera accuracy, osim ukoliko se posebnone naglasi drugacije.

72 GLAVA 4. KLASIFIKACIJA
Odziv predstavlja udeo onih instanci koje su tacno klasifikovane kao pozitivne odsvih instanci koje jesu pozitivne (bilo da li smo ih klasifikovali ispravno ili ne). Odziv jemera koja je komplementarna preciznosti, te zbog toga i ona sama za sebe nije idealna.
Nasa je priroda takva da bismo voleli da kao rezultat, tj. zakljucak nekog merenjauvek dobijamo jednu numericku vrednost. Dakle, potrebno je pronaci nacin na koji cemokombinovati prethodno opisane mere. Pritom, zelimo da i preciznost i odziv budu visokiukoliko je kombinovana mera visoka. Rezultat ovih zahteva je tzv. F -mera i ona je dataformulom4
F -mera = F =2
1p + 1
r
=2SP
2SP + LN + LP.
F -mera predstavlja harmonijsku sredinu mera p i r. U odnosu na ostale numerickesredine (aritmeticke i geometrijske), harmonijska sredina je najostrija. Posledica toga jeda cim krene da opada preciznost ili odziv, to se veoma znacajno odrazava na F -meru.Upravo to je efekat koji smo zeleli da postignemo.
4F -mera ovako definisana se naziva jos i F1-mera.

Glava 5
Dodatni metodi klasifikacije
U prethodnom poglavlju opisana je jednostavna tehnika klasifikacije, stablo odlucivanja,kao i neki problemi koji nastaju pri klasifikaciji, kao sto je preprilagodavanje modela.U ovom poglavlju predstavicemo jos neke tehnike klasifikacije. Metode predstavljene uovom poglavlju ne treba smatrati dodatnim u smislu neznacajnim. Stavise, ovi metodipredstavljaju naprednije tehnike klasifikacije, koji su cesto vazniji od stabala odlucivanja.Stabla odlucivanja su opisana u prethodnom poglavlju jer opisuju proces klasifikacije naverovatno najjednostavniji nacin (u poredenju sa nekim drugim tehnikama klasifikacije).Takode, zbog raznih problema do kojih dolazi u procesu klasifikacije, vazno nam je biloda imamo na umu barem jedan konkretan metod klasifikacije. Naravno, svi opisaniproblemi vaze i za druge metode. Ovo poglavlje zapocecemo jednostavnom tehnikomklasifikacije zasnovane na pravilima.
5.1 Klasifikatori zasnovani na pravilima
Klasifikator zasnovan na pravilima predstavlja tehniku kojom se instance klasifikujupomocu skupa pravila oblika
’’ako...onda...”. Pravila modela se zapisuju u disjunktivnoj
normalnoj formi, R = (r1∨r2∨. . .∨rk), gde je R skup pravila, a ri su pravila klasifikacijeodnosno disjunkti. Svako pravilo se predstavlja na sledeci nacin:
ri : (uslovi) −→ y
gde je uslovi konjunkcija atributa i y oznaka klase. Leva strana pravila se naziva(pred)uslov (engl. rule antecedent ili precondition) i sastoji se od konjunkcija testovanad atributima:
Conditioni = (A1 op v1) ∧ (A2 op v2) ∧ (Ak op vk)
gde je (Ai, vi) par atribut–vrednost, a op je logicki operator iz skupa {=, 6=, <,≤, >,≥}.Desna strana pravila naziva se posledica (engl. rule consequent) i ona sadrzi klasu yikoju je predvideo model. Primeri pravila za klasifikaciju mogu izgledati:
• (Tip krvi=Topla) ∧ (Nosi jaja=Da) −→ Ptica
• (Oporezivi prihod < 50K) ∧ (Vraca=Da) −→ izbegava=Ne
73

74 GLAVA 5. DODATNI METODI KLASIFIKACIJE
Kazemo da pravilo r pokriva ili obuhvata (engl. cover) instancu x ako atribut in-stance x zadovoljava uslov pravila r. Kaze se jos i da je pravilo r okinuto (engl. fired ilitriggered) kad god pokrije neku instancu.
5.1.1 Mere kvaliteta pravila
Kako bismo odredili prioritet pravilima ili tezinu glasovima, potrebne su nam merekvaliteta tih pravila. Odziv pravila (engl. coverage) predstavlja procenat instanci kojizadovoljavaju levu stranu pravila, tj. na koliko instanci je pravilo primenljivo. Preciznostpravila (engl. accuracy ili confidence factor) predstavlja procenat broja instanci kojizadovoljavaju desnu stranu pravila od instanci koji zadovoljavaju levu stranu pravila,tj. da je pravilo primenljivo i da tacno odreduje klasu. Primetimo da kod preciznostigovorimo samo o instancama na koje je pravilo primenljivo. Pravilo je sjajno ako ima ivisoku preciznost i visok odziv.
5.1.2 Karakteristike klasifikatora zasnovanih na pravilima
Postoje dve vazne karakteristike skupa pravila generisanog od strane klasifikatorazasnovanih na pravilima.
Uzajamno iskljuciva pravila Klasifikator sadrzi uzajamno iskljuciva pravila ako suona medusobno nezavisna, tj. svaki slog je pokriven najvise jednim pravilom. Ovaosobina iskljucuje potrebu za sortiranjem pravila i glasanjem. Ukoliko prilikomklasifikovanja naidemo na pravilo koje je primenljivo na datu instancu, to je onopravilo koje ce biti primenjeno i nema potrebe da nastavljamo sa pretragom.
Iscrpnost skupa pravila Klasifikator poseduje potpuno pokrivanje ako sadrzi kombi-naciju pravila za sve moguce vrednosti atributa. Ovo podrazumeva da je svakainstanca pokrivena bar jednim pravilom, tj. za svaku instancu klasifikator mozeda da odgovor kojoj klasi pripada.
Zajedno, ovim dveju karakteristikama se osigurava da je svaka instanca pokrivenatacno jednim pravilom. Idealno je da je skup pravila uzajamno iskljuciv i iscrpan. Akoskup pravila nije iscrpan, onda mu se moze dodati pravilo oblika rd : () −→ yd, sto senaziva podrazumevano pravilo (engl. default rule) koje ce pokriti preostale slucajeve.Podrazumevano pravilo se okida kada su sva preostala pravila u skupu promasena. Klasayd se naziva podrazumevana klasa (engl. default class) i za podrazumevanu klasu setipicno bira ona klasa koja se javlja najcesce, cime se dobija najmanja gresku u slucajunepristrasnog uzorka.
Postoje dva nacina za prevazilazenje problema kada skup pravila nije uzajamno is-kljuciv. Jedna mogucnost je da se uvede prioritet. U ovom slucaju se pravila poredajuu opadajucem redosledu po prioritetu, koji se moze definisati na vise nacina. Uredeniskup pravila se jos naziva i lista odluka (engl. decision list). Kada dobijemo test in-stancu, klasifikujemo je pomocu najbolje rangiranog pravila koje pokriva tu instancu.Drugi nacin je glasanje. Ovaj pristup omogucava da se primene sva primenljiva pravilana datu instancu i posledicu svakog od tih pravila koristimo kao glas za tu klasu. Naosnovu glasova se odlucuje koja ce klasa biti dodeljena instanci (klasa koja ima najviseglasova je ona koja se bira). Takode, mozemo dodati tezinu glasovima prema preciznostipravila.

5.1. KLASIFIKATORI ZASNOVANI NA PRAVILIMA 75
5.1.3 Seme odredivanja uredenja
Seme odredivanja uredenja mogu se implementirati pomocu principa pravilo-po-pravilo ili pomocu principa klasa-po-klasa.
Uredenje zasnovano na pravilima Ovaj pristup ureduje pravila prema merama kva-liteta. Ova sema obezbeduje da ce svaki test slog biti klasifikovan najboljim pra-vilom koje ga pokriva. Ako je broj pravila veliki, interpretiranje znacenja pravilapri dnu liste moze biti veoma tezak posao.
Uredenje zasnovano na klasama U ovom pristupu, pravila koja pripadaju istoj klasise grupisu jedno do drugog. Ova pravila se kolektivno sortiraju na osnovu infor-macije njihove klase. Ovaj pristup olaksava interpretaciju, ali moguce je da seprevidi neko visoko kvalitetno pravilo zbog manje sjajnog pravila koje predvidavisoko rangiranu klasu.
5.1.4 Formiranje pravila klasifikacije
Kako bismo formirali pravila klasifikacije potrebno je da izvucemo skup pravila kojiodreduje kljucnu vezu izmedu atributa skupa podataka i klasa. Postoje dve opste klasemetoda za izvlacenje pravila klasifikacije. To su direktni i indirektni metodi. Direktnimetodi izvlace pravila direktno iz podataka, dok indirektni metodi izvlace pravila izdrugih klasifikacionih modela, kao sto su stabla odlucivanja i neuronske mreze.
5.1.4.1 Direktan metod: sekvencijalno pokrivanje
Sekvencijalno pokrivanje (engl. sequential covering) cesto se koristi za izvlacenjepravila direktno iz podataka. Skup pravila se pravi pohlepno zasnovano na odredenojmeri evaluacije. Algoritam izvlaci pravila za jednu klasu u jednom trenutku, kada imamoskup podataka sa vise od dve klase. Bira se klasa za koju ce se izvlaciti pravila. Slogovikoji pripadaju toj klasi posmatraju se kao pozitivni, a svi ostali su negativni i takodobijamo binarni skup. Zatim se koristi funkcija koja moze da nauci jedno pravilo. Ucise pravilo za prepoznavanje pozitivne klase i ono se dodaje u skup pravila. Sve instancekoje su pokrivene tim pravilom se uklanjaju. Postupak se onda ponavlja za sledecuklasu.
Algoritam 2 Sekvencijalno pokrivanje
1: Neka je E trening skup i A skup parova atribut-vrednost, {Aj , vj}2: Neka je Yo uredena lista klasa {y1, y2, . . . , yk}3: Neka je R = {} inicijalni skup pravila4: for all y ∈ Yo − {yi}, i = 1, k do5: while kriterijum zaustavljanja nije dostignut do6: r ← Learn-One-Rule(E,A, y)7: Ukloni trening instance koji su pokriveni pravilom r8: R← R ∨ r . Dodaj r na kraj skupa pravila9: end while
10: end for11: R← R ∨ ({} −→ yk) . Dodaj podrazumevano pravilo na kraj skupa pravila

76 GLAVA 5. DODATNI METODI KLASIFIKACIJE
Slika 5.1: Primer algoritma sekvencijalno pokrivanje
Na Slici 5.1 prikazano je kako radi Algoritam 2. Prvo se uoci skup pozitivnih instanci,zatim se uci pravilo R1 koje pokriva te instance i onda se izbacuju pokrivene instance.Postupak se ponavlja nad sledecim skupom instanci i pravilom R2.
Porast skupa pravila Pravila ima eksponencijalno mnogo. Pri izgradnji pravila, ni-smo uvek u stanju da isprobamo sve mogucnosti, pa da vidimo koja je najbolja od njih.Stoga, kako bismo izbegli eksponencijalnu eksploziju, koristimo pohlepni pristup. Po-stoje dve strategije za povecavanje pravila klasifikacije: opste prema specificnom (engl.general-to-specific) i specificno prema opstem (engl. specific-to-general). U prvoj stra-tegiji, pravi se inicijalno pravilo r : {} −→ y, u kom je leva strana prazan skup, a desnastrana sadrzi ciljnu klasu. Ovo pravilo je loseg kvaliteta jer pokriva sve instance treningskupa. Novi konjunkti se postepeno dodaju i time se poboljsava kvalitet pravila. Drugastrategija podrazumeva da se nasumicno bira jedna pozitivna instanca od koje se krecesa porastom skupa. Pravilo se uopstava uklanjanjem konjukata tako da ono pokrije stovise instanci.
RIPPER algoritam RIPPER algoritam je jedan primer prve strategije. Ovaj al-goritam gradi jedno pravilo tako sto pocinje od prazne konjunkcije sa leve strane:{} −→ class. Zatim, on dodaje konjunkte koji maksimizuju FOIL-ovu meru dobitikvaliteta informacije zadatu formulom
FOIL = p1 ·(
log2p1
p1 + n1− log2
p0p0 + n0
),

5.1. KLASIFIKATORI ZASNOVANI NA PRAVILIMA 77
pri cemu vazi da pravilo r : A −→ + pokriva p0 pozitivnih (tj. p0 je broj instancikoje su pokrivene pravilom r pri cemu je klasa pogodena) i n0 (tj. n0 je broj instancikoje su pokrivene pravilom r pri cemu klasa nije pogodena) negativnih instanci, a nakondodavanja konjunkta B, prosireno pravilo r′ : A ∧ B −→ + pokriva p1 pozitivnih i n1negativnih instanci. Vrsi se poredenje novog pravila sa starim i razmatra se koliko jenovo pravilo poboljsalo performanse starog pravila.
Uklanjanje instanci Uklanjanje instanci se vrsi, pre svega, zato sto ako bi ostalesve instance, uvek bismo izvlacili isto pravilo. Mogli bismo da trazimo drugo rangiranopravilo, ali time se stvari dodatno komplikuju. Ako pogledamo Sliku 5.2, vidimo zastoje bitno da se instance uklanjaju.
Slika 5.2: Uklanjanje instanci trening skupa sekvencijalnim pokrivanjem. R1, R2 i R3predstavljaju pravila koja pokrivaju odgovarajuce podskupove instanci.
Slika prikazuje tri moguca pravila, R1, R2 i R3, koja su izvucena iz skupa podatakakoji sadrzi 29 pozitivnih instanci i 21 negativnu instancu. Pravilo R1 ima najvecupreciznost (12/15 instanci je pozitivno, tj. 80%), zatim R2 (7/10, odnosno, 70%) i nakraju R3 (8/12, tj. 66.7%). Pravilo R1 je napravljeno prvo jer ima najvecu preciznost.Nakon toga, jasno je da se pozitivne instance moraju ukloniti kako bi sledece pravilo bilorazlicito od R1. Pretpostavimo da algoritam ima izbor izmedu R2 i R3. Iako R2 imavecu preciznost od R3, R1 i R3 zajedno pokrivaju 18 pozitivnih i 5 negativnih (ukupnapreciznost je 78.3%) dok R1 i R2 zajedno pokrivaju 19 pozitivnih i 6 negativnih instanci(ukupna preciznost je 76%). Inkrementalni uticaj pravila R2 ili R3 na preciznost jeocigledniji kada se uklone sve instance pokrivene pravilom R1. Ako ne bismo uklonilipozitivne instance pokrivene pravilom R1, precenili bismo efektivnu preciznost pravilaR3, a ako ne bismo uklonili negativne instance, mogli bismo da potcenimo preciznostpravila R3. Na kraju bismo radije uzeli R2 nego R3 iako je polovina lazno pozitivnihinstanci pravila R3 vec uracunato u pravilu R1. Dobijamo manje kolerana pravila.

78 GLAVA 5. DODATNI METODI KLASIFIKACIJE
Provera pravila Za proveru pravila koriste se sledece metrike:
Preciznost =ncn
Laplas =nc + 1
n+ k
m-procenat =nc + kp
n+ k
gde je n broj instanci pokrivenih pravilom, nc broj pozitivnih instanci pokrivenih pra-vilom, k broj klasa i p prethodna verovatnoca za pozitivne klase.
Potkresivanje pravila Rekli smo da se algoritam zasniva na pohlepnoj pretrazi. Po-hlepna pretraga ima nekoliko izbora. Mozemo da dodamo jedan konjunkt, ili drugi ilimozda treci. Recimo da je prvi najbolji, prema svemu sto mozemo da zakljucimo u tre-nutnoj situaciji. Zatim treba izabrati sledeci konjunkt, i opet imamo vise izbora. Timedobijamo nekoliko konjunkata u pravilu. Moze da se desi da smo odbacili neki konjunktranije jer u datom trenutku nije obecavao, ali kasnije, kada je dodat jos neki, onda jetaj odbacen bolji u kombinaciji sa novim, nego onaj koji je odabran kao najbolji u tomtrenutku. Mozda mozemo da doradimo pravila da budu bolja i to se radi potkresivanjem.U nekom trenutku dobicemo dugacko pravilo, zato sto radimo pohlepno, a mozda namneki konjunkti smetaju i ako bismo ih izbacili, dobili bismo i bolje pravilo. Potkresivanjeradimo na sledeci nacin. Izbacimo jedan konjunkt i uporedimo novo pravilo sa starim.Ako dobijemo bolje performanse, znaci da nam taj konjunkt smeta i ne vracamo ga.Medutim, ako su performanse losije, onda vracamo taj konjunkt u pravilo, izbacujemosledeci i ponavljamo postupak.
5.1.5 Od stabla odlucivanja do pravila
Pravila mozemo dobiti iz stabla odlucivanja. U cvorovima su postavljana pitanja iodgovaranjem na ta pitanja dolazi se do listova gde dobijamo klasu. Upravo ta pitanjamogu da posluze kao pravila, odnosno, pravila cine skup pitanja i odgovora (put odkorena do lista u stablu) koji vodi do konkretne klase. Test uslovi na koje nailazimo uputu kroz stablo cine preduslov, dok oznaka klase u listu cini posledicu pravila. Kvalitetovog pristupa je sto se dobija skup pravila koji je medusobno iskljuciv i iscrpni. Manaje sto mozemo dobiti veliki broj pravila koji dele veliki broj uslova, a da se samo nestomalo razlikuje u njima. Ipak, neki uslovi se mogu uprostiti.
5.1.6 Uproscavanje pravila
Na Slici 5.3 vidimo da je, prema stablu odlucivanja, jedno od pravila koja vaze zaklasu NO sledece:
(Refund=No) ∧ (Status=Married) −→ NO.
Medutim, u tabeli podataka vidimo da je svim instancama kojima je vrednost atributaStatus jednaka Married pridruzena klasa NO i da atribut Refund uopste ne utice nakrajnji ishod, pa se pravilo moze uprostiti, cime se dobija pravilo
(Status=Married) −→ NO.

5.2. MODELI ZASNOVANI NA INSTANCAMA 79
Slika 5.3: Test skup i odgovarajuce stablo odlucivanja
5.1.7 Prednosti klasifikatora zasnovanih na pravilima
Ukratko cemo navesti neke dobre strane klasifikatora zasnovanih na pravilima, bezdubljeg ulazenja u detalje.
Prvo, ovi klasifikatori imaju istu izrazajnu moc kao i drveta odlucivanja. Drugo,njihova interpretacija je jednostavna, sve dok broj pravila nije veliki. Trece, njihovoformiranje je jednostavno.
5.2 Modeli zasnovani na instancama
Kod modela zasnovanih na instancama ne pravi se eksplicitan model. Na primer, kodstabala odlucivanja, upravo je stablo sa test uslovima bio eksplicitan model. Nasuprottome, kod modela zasnovanih na instancama instance se koriste za davanje odgovorakojoj klasi pripada nova instanca. Potrebno je da se analizira trening skup instancikako bismo dosli do ovog odgovora. Cena treninga ne postoji jer nema modela, ali cenapredvidanja je velika. Kod stabala odlucivanja cena treninga je bila veca, ali proveravanjeinstance je trivijalno. Kod modela zasnovanih na instancama uvek se analizira ceo skupi to je skupo.
Primeri modela zasnovanih na instacama su: ucenje napamet i najblizi susedi. Ucenjenapamet (engl. Rote classifier) cuva celokupan skup instanci za trening i sprovodi kla-sifikaciju samo ako se atributi novih instanci potpuno poklope sa atributima treninginstanci. Metod najblizih suseda ili k-najblizih suseda (engl. k-nearest neighbors), kaosto mu ime sugerise, ne koristi ceo trening skup, vec samo k
’’najblizih” tacaka (u na-
stavku teksta cemo videti sta znaci da je neka tacka’’najbliza” drugoj tacki) za obavljanje
klasifikacije.
5.2.1 Klasifikacija pomocu najblizih suseda
Osnovna ideja je da na osnovu k najblizih suseda date instance odredimo klasu teinstance. Vrsi se odredivanje suseda, zatim susedi glasaju, pa se vrsi prebrojavanje

80 GLAVA 5. DODATNI METODI KLASIFIKACIJE
glasova. Ona klasa koja je dobila najvise glasova se bira za finalni odgovor. Vec mozemoda primetimo da nije svejedno koliki ce biti broj k.
Slika 5.4: Skup najblizih suseda instance x za k ∈ {1, 2, 3}.
Posmatrajmo primer na Slici 5.4. Zelimo da klasifikujemo instancu x. Ukoliko uz-memo jednog najblizeg suseda, vidimo da joj je najbliza tacka koja pripada klasi minus,pa zakljucujemo da je to klasa instance x. Medutim, ako uzmemo dva suseda, ondanismo sigurni koja je klasa jer imamo instance obe klase (plus i minus). Na kraju, akouzmemo tri suseda, onda nekako vise lici da je klasa plus, a ne minus. Dakle, bitno jedobro odrediti k.
Biranje vrednosti za k se najlakse postize isprobavanjem razlicitih vrednosti. Poredtrening skupa, koristimo i validacioni skup (koji je disjunktan trening i test skupovima;sustinski, on se dobija deljenjem pocetnog trening skupa na dva dela, cime se dobija novitrening skup i validacioni skup). Odredimo neku vrednost za k i testiramo tu vrednost.Za instance iz validacionog skupa trazimo k najblizih suseda iz trening skupa. Na osnovutoga mozemo zakljuciti da li je odabrana dobra vrednost i ako nije, biramo sledecu i naisti nacin testiramo.
Sto je k vece, model je manje fleksibilan. Razmotrimo sta fleksibilnost oznacava umetodu k-najblizih suseda. Vratimo se na primer sa Slike 5.4. Ako bismo uzeli k = 14,odgovor za bilo koju instancu bi uvek bio minus jer imamo ukupno 14 instanci u skupu,a negativnih instanci ima vise nego pozitivnih. Sa druge strane, manje vrednosti brojak povecavaju fleksibilnost modela.
Za klasifikatore kazemo su lenji (engl. lazy) ukoliko se proces modeliranja podatakaza trening odlaze do procesa klasifikacije podataka za test. Klasifikatori zasnovani nametodu k-najblizih suseda su primer lenjih klasifikatora.
Vec smo rekli da se ne izgraduju eksplicitni modeli, ali grade se implicitni modeli.U primeru na Slici 5.5, implicitan model je upravo jedan od poligona. Svaka tacka uokviru nekog poligona najbliza je plavoj tacki u tom poligonu. Ovakav, implicitan modelprikazan na slici se naziva Voronoj dijagram. Za dati skup tacaka Voronoj dijagram jepodela prostora u regione unutar kojih su sve tacke blize nekom pojedinacnom cvorunego bilo kom drugom cvoru. Jasno je da je Voronoj dijagram primer metoda 1-najblizegsuseda. Na Slici 5.6 prikazan je primer tacaka u ravni koji se klasifikuju metodom k-najblizih suseda za dve vrednosti k; levo, za k = 1 i desno, za k = 10.
Najblizeg suseda biramo, na primer, u odnosu na Euklidsko rastojanje 2.1. Ipak,treba voditi racuna o sledecem: da bismo koristili Euklidsko rastojanje, moramo dastandardizujemo podatke, odnosno, merne jedinice moraju biti uporedive. Podsetimo se
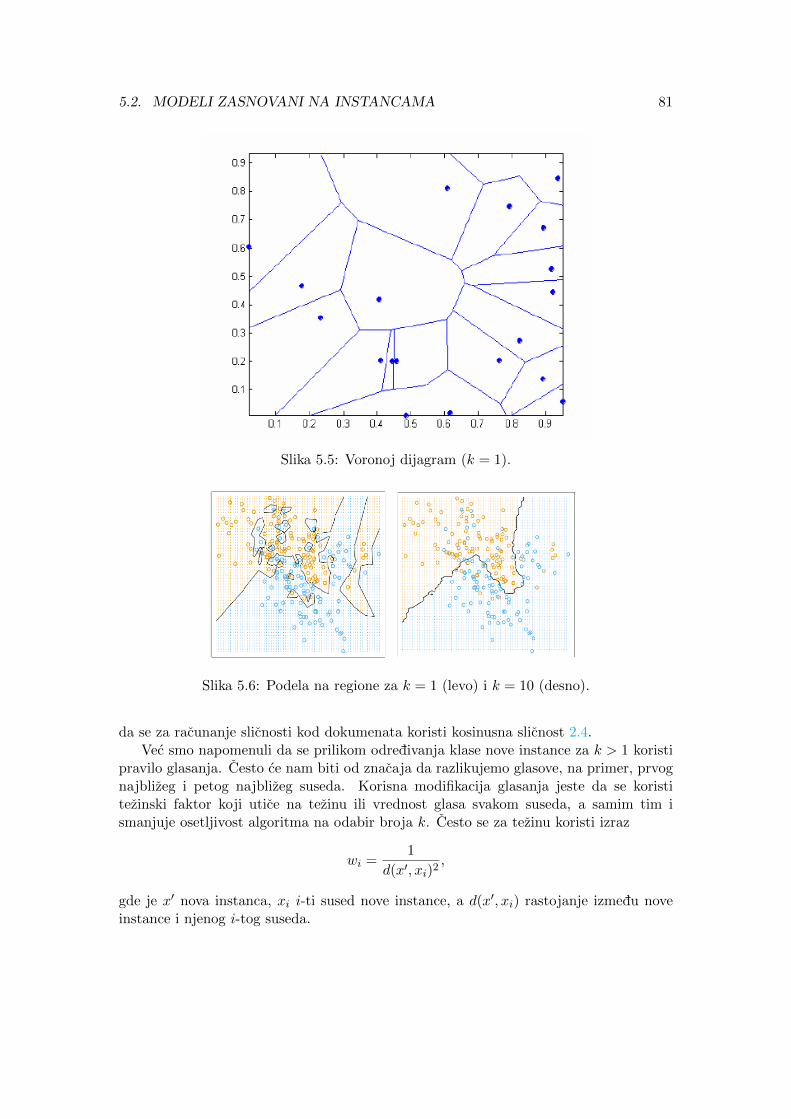
5.2. MODELI ZASNOVANI NA INSTANCAMA 81
Slika 5.5: Voronoj dijagram (k = 1).
Slika 5.6: Podela na regione za k = 1 (levo) i k = 10 (desno).
da se za racunanje slicnosti kod dokumenata koristi kosinusna slicnost 2.4.Vec smo napomenuli da se prilikom odredivanja klase nove instance za k > 1 koristi
pravilo glasanja. Cesto ce nam biti od znacaja da razlikujemo glasove, na primer, prvognajblizeg i petog najblizeg suseda. Korisna modifikacija glasanja jeste da se koristitezinski faktor koji utice na tezinu ili vrednost glasa svakom suseda, a samim tim ismanjuje osetljivost algoritma na odabir broja k. Cesto se za tezinu koristi izraz
wi =1
d(x′, xi)2,
gde je x′ nova instanca, xi i-ti sused nove instance, a d(x′, xi) rastojanje izmedu noveinstance i njenog i-tog suseda.

82 GLAVA 5. DODATNI METODI KLASIFIKACIJE
5.2.1.1 Visokodimenzionalni prostori
Visokodimenzionalni prostori predstavljaju problem i kod k-najblizih suseda. Kakobismo odrzali reprezentativnost skupa i gustinu, potrebno nam je eksponencijalno mnogoinstanci kako dimenzija raste. Gustina se odnosi na to da pored svake tacke imamo josneku koja je blizu. Upravo to je potrebno da bi metod k-najblizih suseda radio, jer nezelimo da zakljucujemo na osnovu tacaka koje su daleko. Posmatrajmo n-dimenzionalnelopte sa poluprecnikom duzine 1 i poluprecnikom duzine 0.99. Razlika u poluprecnikuje veoma mala, pa bismo rekli da su te lopte slicne. Medutim, iz jednacine
limn→∞
V n0.99
V n1
= limn→∞
0.99n
1n= 0
vidimo da nije tako. Ako bismo manju loptu stavili u vecu, zakljucili bismo da jeunutrasnjost velike lopte prazna, jer je zapremina manje lopte 0. To znaci da su svetacke koncentrisane na obodu lopte. U visokodimenzionalnim prostorima prakticno svetacke lopte su vrlo daleko od centra, a rastojanja se ponasaju nesto drugacije nego stoocekujemo. Nekoliko radova ukazuje na malu varijaciju distanci u visokodimenzionalnimprostorima, sto je nepovoljno za algoritam k-najblizih suseda.
5.2.1.2 Prednosti i mane
I u ovom delu cemo se kratko zadrzati na prednostima i manama, te cemo ih samonapomenuti, bez iznodenja detalja.
Prednosti metoda k-najblizih suseda su: jednostavnost, lokalnost (nije potrebno gra-diti model za ceo skup podataka u kojem mozda ne vazi isti trend), kao i pojava proi-zvoljnih oblika granica izmedu klasa.
Ovaj metod ima i svojih mana, a neki od njih su: standardizacija podataka je neop-hodna, neotporan je na ponovljene atribute, na njega utice prokletestvo dimenzionalnostii nepostojanje modela donosi nedostatak interpretabilnosti.
5.3 Bajesov klasifikator
U mnogim aplikacijama, veza izmedu skupa atributa i klasa nije deterministicka.Drugim recima, oznaka klase test instanci se ne moze predvideti sa sigurnoscu iakoje skup atributa identican nekim instancama trening skupa. Ovo se moze desiti zbogsumova u podacima ili zbog prisustva nekih zbunjujucih faktora koji uticu na klasifi-kaciju, a nisu ukljuceni u analizu. Na primer, razmotrimo predvidanje da li je coveku opasnosti da oboli od srcane bolesti na osnovu njegove dijete i ucestalosti trenira-nja. Iako vecina ljudi koji jedu zdravo i redovno vezbaju imaju manje sanse da oboleod srcanih bolesti, one i dalje mogu biti izazvane nekim drugim faktorima kao sto sunaslednost, prekomerno pusenje ili konzumiranje alkohola.
U ovoj sekciji predstavljamo pristup modeliranju probabilistickih veza izmedu skupaatributa i klasa. Neka su X i Y par slucajno odabranih promenljivih. Njihova za-jednicka verovatnoca (engl. joint probability), u oznaci P (X = x, Y = y), odnosi se naverovatnocu da ce X uzeti vrednost x i da ce Y uzeti vrednost y. Uslovna verovatnocaje verovatnoca da ce slucajna promenljiva uzeti zadatu vrednost kada je vrednost druge

5.3. BAJESOV KLASIFIKATOR 83
promenljive poznata. Na primer, uslovna verovatnoca P (Y = y|X = x) odnosi se na ve-rovatnnocu da ce Y uzeti vrednost y onda kada X ima vrednost x. Zajednicka i uslovnaverovatnoca su povezane na sledeci nacin:
P (X,Y ) = P (Y |X) · P (X) = P (X|Y ) · P (Y ).
Iz ove jednacine dobijamo formulu, koja je poznata kao Bajesova teorema:
P (Y |X) =P (X|Y ) · P (Y )
P (X).
Bajesova teorema moze se koristiti za resavanje problema predvidanja, opisanog napocetku sekcije.
5.3.1 Koriscenje Bajesove teoreme za klasifikaciju
Pre nego sto objasnimo kako se Bajesova teorema koristi za klasifikaciju, formali-zujmo problem klasifikacije iz statisticke perspektive. Neka X oznacava skup atributa,a Y klasu promenljive. Ako klasa promenljive ima nedeterministicku vezu sa atribu-tima, onda mozemo da tretiramo X i Y kao slucajne promenljive i opisati njihov odnosprobabilisticki pomocu P (Y |X).
Tokom trening faze, potrebno je da naucimo uslovne verovatnoce P (Y |X) za svakukombinaciju X i Y na osnovu informacija prikupljenih iz trening podataka. Znajuci oveverovatnoce, trening skup X ′ se moze klasifikovati pronalazenjem klase Y ′ za koju jeuslovna verovatnoca P (Y ′|X ′) najveca.
Precizno procenjivanje uslovnih verovatnoca za svaku mogucu kombinaciju klasa ivrednosti atributa je tezak problem jer zahteva veliki trening skup, cak i za ogranicenbroj atributa. Bajesova teorema je korisna jer nam omogucava da izrazimo uslovnuverovatnocu pomocu verovatnoce P (Y ), uslovne verovatnoce klase P (X|Y ) i dokazaP (X).
Vrednost P (X) ne predstavlja problem u jednodimenzionalnim prostorima, ali uvisedimenzionalnim prostorima je potrebno eksponencijalno mnogo podataka da bi seodrzala gustina. Medutim, kada se porede uslovne verovatnoce za razlicite vrednostipromenljive Y , P (X) je uvek konstantan i zbog toga se moze zanemariti. VerovatnocaP (Y ) se lako procenjuje iz trening skupa, a za procenu uslovne verovatnoce P (X|Y )koristi se Naivni Bajesov klasifikator.
5.3.2 Naivni Bajesov klasifikator
Naivni Bajesov klasifikato procenjuje uslovnu verovatnocu tako sto pretopstavljauslovnu nezavisnost atributa za datu klasu y. Pretpostavka uslovne nezavisnosti seformalno zapisuje na sledeci nacin:
P (X|Y = y) =n∏i=1
P (Xi|Y = y),
gde svaki skup atributa X = {X1, X2, . . . , Xn} ima n atributa.

84 GLAVA 5. DODATNI METODI KLASIFIKACIJE
Uslovna nezavisnost Neka X, Y i Z oznacavaju tri skupa slucajnih promenljivih.Promenljive u skupu X su uslovno nezavisne od Y , kada je zadato Z, ako vazi sledeciuslov:
P (X|Y,Z) = P (X|Z).
Ova pretpostavka je slabija od nezavisnosti atributa. Poenta nezavisnosti je da jednapromenljiva ne moze da kaze nista o drugoj.
Razmotrimo sledeci primer, radi boljeg razumevanja uslovne nezavisnosti. Posma-trajmo vezu izmedu duzine ruke jednog coveka i njegove vestine citanja. Neko bi mogaoprimetiti da ljudi koji imaju duze ruke bolje citaju. Ova veza se moze objasniti pomocuzbunjujuceg faktora, a to su godine. Deca obicno imaju krace ruke i losije citaju od od-raslih. Ako fiksiramo vrednost atributa godine, onda veza izmedu duzine ruke i vestinecitanja nestaje. Tako, mozemo da zakljucimo da su ova dva atributa uslovno nezavisnakada je vrednost za godine fiksirana, tada jedno o drugom nista ne moze da kaze sto nijesadrzano u godinama.
Razmotrimo jos jedan primer, dat Tabelom 5.1. Verovatnoca da osoba ima grippod uslovima Hladnoca=Da, Curenje iz nosa=Ne, Glavobolja=Blaga i Groznica=Ne,racuna se na sledeci nacin:
p(Da|Da,Ne,Blaga,Ne) =3
5· 1
5· 2
5· 1
5· 5
8=
3
500.
Verovatnoca da osoba nema grip, pod istim uslovima, racuna se na sledeci nacin:
p(Ne|Da,Ne,Blaga,Ne) =1
3· 2
3· 1
3· 2
3· 3
8=
1
54.
Verovatnoca da je osobi hladno ako ima grip racuna se na sledeci nacin:
p(Hladno = Da|Grip = Da) =3
5.
Preciznije, od onih osoba koji imaju grip, brojimo koliko ima onih kojima je hladno.
Tabela 5.1: Podaci o simptomima i bolestima.
Hladnoca Curenje iz nosa Glavobolja Groznica Grip
Da Ne Blaga Da NeDa Da Ne Ne DaDa Ne Jaka Da DaNe Da Blaga Da DaNe Ne Ne Ne NeNe Da Jaka Da DaNe Da Jaka Ne NeDa Da Blaga Da Da
5.3.2.1 Prednosti i mane
Prednosti naivnog Bajesovog klasifikatora su razne. Prvo, efikasni su trening (prebro-javanje) i predvidanje (imamo sve verovatnoce samo izracunamo verovatnocu po formuli).

5.3. BAJESOV KLASIFIKATOR 85
Ovaj klasifikator nije osetljiv na prisustvo irelevantnih atributa (imaju iste raspodele usvim klasama). Ne zavisi od vrste atributa (kategoricki ili neprekidni). Ipak, lakse jeracunati za kategoricke jer njih jednostavno brojimo. Neprekidne prvo diskretizujemo,pa prebrojavamo ili pronademo normalnu raspodelu ili neku drugu raspodelu koja imodgovara. Takode, lako se azurira kako pristizu podaci (ne mora da se broji ispocetka).
Naravno, i ovaj klasifikator ima i svoje mane. Naime, naivni Bajesov klasifikatorpretpostavlja uslovnu nezavisnost atributa. Takode, ako se neke vrednosti atributa nepojavljuju u trening skupu, klasifikator im dodeljuje verovatnocu 0, sto nije realisticno.Poslednji problem se ipak moze resiti.
5.3.2.2 M-ocena uslovne verovatnoce
Ako se neke vrednosti atributa ne pojavljuju u trening skupu, naivni Bajesov klasi-fikator ne moze da ih klasifikuje i dodeljuje im verovatnocu 0. Ovaj problem se mozeresiti koriscenjem m-ocene uslovne verovatnoce:
P (Xi|Y ) =nc +mp
n+m,
gde je n ukupan broj instanci klase Y , nc je broj trening instanci klase Y koje uzimajuvrednost Xi, m je parametar poznat kao ekvivalentna velicina uzorka (engl. equivalentsample size), a p je korisnicki definisan parametar. Ako nema trening skupa onda jeP (Xi|Y ) = p. Zato se p moze smatrati verovatnocom posmatrane vrednosti Xi meduinstancama klase Y . Parametar m odreduje kompromis izmedu apriorne verovatnoce pi posmatrane verovatnoce nc/n. Parametar m kontrolise koliko cemu verujemo. Ako jeveliki trening skup, onda biramo malo m, a ako je mali trening skup, onda uzimamoveliko m jer je mali skup nepouzdan.


Glava 6
Procena kvaliteta i izbor modela
U prethodnim poglavljima smo videli da uz pomoc razlicitih algoritama dobijamorazlicite modele, kao sto su stablo odlucivanja, frekvencije koje aproksimiraju vero-vatnoce ili regresiona prava. Procena kvaliteta i izbor modela imaju ogroman znacaju istrazivanju podataka. Na prvi pogled mogu delovati jednostavno, ali ispostavlja seda ovo nije trivijalan posao. Nije cudno primetiti da cak i neko ko se profesionalno baviistrazivanjem podataka pravi greske u proceni kvaliteta modela. Zbog toga je dobrovladati ovih tehnikama savrseno.
Procena kvaliteta modela se bavi ocenom greske predvidanja modela. Izbor modelase bavi izborom jednog od vise mogucih modela.
Izbor modela se zasniva na proceni kvaliteta modela. Preciznije, biracemo modelekoji su najkvalitetniji u zavisnosti od procene kvaliteta koju smo izvrsili. Ipak, veza nemora biti trivijalna zbog raznih prakticnih problema. Upravo zbog netrivijalnosti vezeizmedu procene kvaliteta i izbora dolazi do prethodno pomenutih gresaka.
Procena kvaliteta i izbor modela se zasnivaju na merama kvaliteta (na primer, pre-ciznost) i tehnikama evaluacije i izbora (na primer, unakrsna validacija). Vrlo cestose pravi greska pri izjednacavanju tehnika evaluacije i tehnika izbora. Mi cemo pravitirazliku izmedu njih u daljem tekstu. S obzirom da smo diskutovali o merama kvalitetau Podsekciji 4.4.2, na ovom mestu cemo se samo podsetiti da mere kvaliteta zavise odproblema. Na primer, za problem klasifikacije mozemo koristiti preciznost ili F -meru,dok za regresiju imamo srednjekvadratnu gresku i koeficijent determinacije (R2). Poza-bavimo se detaljnije tehnikama evaluacije i izbora.
6.1 Tehnike evaluacije
Tehnike evaluacije variraju po slozenosti. Varijabilnost zavisi od: (1) konfigurabil-nosti algoritma i (2) zeljenog kvaliteta ocene. Konfigurabilnost algoritma se odnosi namenjanje parametara od kojih zavisi odabir konkretnog algoritma. Na primer, broj k ualgoritmu k-najblizih suseda, maksimalna dubina ili odabir mere necistoce kod stabalaodlucivanja, i sl. Sto se tice zeljenog kvaliteta ocene, naravno da bismo uvek zeleli naj-bolji kvalitet ocene. Medutim, vrlo cesta je situacija da jednostavniji modeli ne dajudovoljnu pouzdanost ocene. Ponavljanjem eksperimenta nad malo izmenjenim podacimadobijaju se greske koje jako variraju, tj. nisu stabilne.
87

88 GLAVA 6. PROCENA KVALITETA I IZBOR MODELA
Primarno nacelo procene kvaliteta Glavno nacelo procene kvaliteta modela glasi:
’’Podaci korisceni za procenu kvaliteta modela ni na koji nacin ne smeju biti upotrebljeni
prilikom treninga”. Deluje jednostavno, ali se u praksi ispostavlja kao vrlo pipavo. Presvega zbog toga sto postoje nacini na koje je moguce prekrsiti ovo nacelo, a da uopstenismo svesni da smo to uradili.
6.1.1 Nekonfigurabilan slucaj
Pretpostavlja se da algoritam nije konfigurabilan ili da je konfiguracija fiksirana.Jedan primer bi bila regresiona prava, ali bez regularizacije. Vec nam je jasno da ne-konfigurabilan algoritam nije realistican scenario. Ako se nauceni model pokaze lose, uiskusenju smo da vrsimo neke izmene i u tom slucaju naredni metodi procene kvalitetanisu validni, i to predstavlja osnovnu gresku, odnosno, koriscenje tehnika za nekonfigu-rabilne algoritme kod konfigurabilnih algoritama je zabranjeno.
Izbor modela Posto nema razlicitih konfiguracija, nema ni veceg broja modela izkojeg se moze birati, pa je izbor prakticno trivijalan. Jednostavno, dajemo celokupanskup podataka kao ulaz u algoritam i dobijamo model M . On ima svoju gresku E kojucemo probati u fazi evaluacije da aproksimiramo. Ipak, postavlja se pitanje na kojimpodacima treba trenirati?
Procena kvaliteta Podaci se dele na dva skupa: trening skup i test skup (videtiTabelu 6.1). Trening skup, posto je blizak ukupnim podacima, koristi se za treniranjemodela M0 koji sluzi kao aproksimacija modela M . Test skup se koristi za procenugreske E0 koju model M0 pravi prilikom predvidanja. Smatra se da je ta greska dobraaproksimacija greske E modela M .
Tabela 6.1: Podela skupa podataka na trening skup (plavo) i test skup (crveno).
x1 x2 x3 y
1 9 0 80 6 2 11 3 1 54 9 7 61 1 6 77 2 3 42 9 9 93 3 4 67 2 1 76 5 1 5
Problemi vezani za procenu pomocu trening i test skupa Sve je u redu ukolikoje skup podataka vrlo veliki i reprezentativan, ali u suprotnom, postavljaju se pitanjapoput
’’Kako izvrsiti podelu?”,
’’Sta ako su raspodele trening i test skupa razlicite?” i
’’Sta raditi usled velike varijanse ocene greske”.

6.1. TEHNIKE EVALUACIJE 89
6.1.1.1 Procena kvaliteta K-strukom unakrsnom validacijom
Procena kvaliteta modela se moze izvrsiti tehnikom unakrsne validacije (engl. crossvalidation). Algoritam 3 prikazuje ovu tehniku.
Algoritam 3 K-struka unakrsna validacija.
1: procedure UnakrsnaValidacija(k)2: Podaci se dele na k slojeva . Slojevi su disjunktni podskupovi3: for all sloj ∈ slojevi do4: Trenira se model na prestalih k − 1 slojeva5: Vrse se predvidanja dobijenim modelom na izabranom sloju6: end for7: Racuna se ocena greske8: end procedure
Tabela 6.2 predstavlja primer podele skupa podataka u prvom koraku Algoritma3. Nadalje, postupak se moze opisati sledecim: odaberemo prvi crveni sloj, izvucemoga iz skupa podataka, treniramo koriscenjem preostalih slojevima (zuti, plavi, zeleni ibraon), izvrsimo predvidanje koriscenjem crvenog sloja, vratimo nazad crveni sloj. Ovajpostupak (za crveni sloj) se ponavlja za slojeve zuti, plavi, zeleni i braon. Mozemoprimetiti da smo ovim postupkom, za razliku od podele na trening i test skupove, zatreniranje i testiranje koristili sve podatke, ali uz veoma bitnu napomenu da smo svakiput razdvajali trening skup i test skup, tako da nismo prekrsili primarno nacelo procenekvaliteta.
Tabela 6.2: Primer podele skupa podataka unakrsnom validacijom za k = 5.
x1 x2 x3 y
1 9 0 80 6 2 11 3 1 54 9 7 61 1 6 77 2 3 42 9 9 93 3 4 67 2 1 76 5 1 5
Problemi vezani za procenu unakrsnom validacijom Pre svega, posmatrajuciAlgoritam 3 trebalo bi odmah da dodemo do zakljucka da je taj algoritam racunskiveoma zahtevan. Drugo pitanje koje se postavlja je biranje broja slojeva. U praksi senajcesce koriste vrednosti k = 5 i k = 10. Preporuka je da se ne koriste jednoclani slojevi(engl. leave one out), posto je takva ocena greske optimisticna. Dodatno, ne racunatiocene greske za svaki sloj, pa ih uprosecavati (ne radi za nelinearne mere poput R2).Umesto toga, treba dati sva predvidanja, pa onda racunati gresku. Konacno, kao sto

90 GLAVA 6. PROCENA KVALITETA I IZBOR MODELA
smo primetili, sve instance se koriste u proceni kvaliteta, pa tehnika jeste pouzdanija, alii dalje jedan sloj ne mora imati istu raspodelu kao preostali slojevi. Poslednji problemce biti detaljnije razmatran u narednom tekstu.
6.1.1.2 Stratifikacija
Sekundarno nacelo procene kvaliteta Jos jedno nacelo procene kvaliteta modelaglasi:
’’Trening i test skup treba da imaju istu raspodelu kao i buduca opazanja”. Iz
ovoga je jasno da trening i test skup medu sobom treba da imaju istu raspodelu. Delujepipavo i jeste pipavo. Ublazenje ovog problema moze se postici koriscenjem velike kolicinepodataka, koriscenjem naprednijih tehnika uzorkovanja i stratifikacijom.
Stratifikacija podrazumeva da se prilikom deljenja podataka obezbeduje da deloviimaju istu raspodelu kao i ceo skup podataka.
Stratifikacija celokupnog skupa podataka je teska za male skupove podataka. Zbogtoga se moze koristiti njena pojednostavljena varijanta, odnosno, cilj je ocuvati raspodeluciljne promenljive. Algoritam 4 pokazuje kako se vrsi stratifikacija u odnosu na ciljnupromenljivu.
Algoritam 4 Stratifikacija u odnosu na ciljnu promenljivu.
1: procedure Stratifikacija(k)2: Sortirati podatke u odnosu na ciljnu promenljivu3: for all i← 1, k do4: for all j ← 1, . . . do5: Pi ← Pi ∪ (i+ j · k) . Pi je i-ti deo u stratifikaciji6: end for7: end for8: return P9: end procedure
Tabela 6.3 prikazuje primer rezultata Algoritma 4 za k = 5. Primecujemo da suvrednosti atributa y (koja predstavlja ciljnu promenljivu) sortirane. Samim tim, slojevise izgraduju tako sto redom uzimamo svaku k-tu instancu (u ovom slucaju, svaku petu) iumecemo je u odgovarajuci sloj. Time dobijamo da su instance u svakom sloju pribliznoisto rasporedene.
Dodatno treba razmotriti slucaj kada je ciljna promenljiva kategoricka (tj. kadaje klasa). Resenje je jednostavno: razlicitim klasama dodeliti proizvoljne numerickevrednosti, sortirati po dodeljenim vrednostima, pa zatim ponovo uraditi kao u slucajunumericke ciljne promenljive.
Napomenimo da stratifikacija ne resava problem reprezentativnosti buducih predvidanja,vec da raspodele slojeva budu priblizno iste.
6.1.2 Konfigurabilan slucaj
Algoritmi masinskog ucenja se obicno navode vrednostima metaparametara. Nave-dimo nekoliko primera metaparametara. Linearna i logisticka regresija imaju regulari-zacioni parametar. Metod potpornih vektora ima cenu gresaka, parametre kernela, itd.

6.1. TEHNIKE EVALUACIJE 91
Tabela 6.3: Primer rezultata stratifikacije u odnosu na ciljnu promenljivu za k = 5.
x1 x2 x3 y
0 6 2 17 2 3 41 3 1 56 5 1 54 9 7 63 3 4 61 1 6 77 2 1 71 9 0 82 9 9 9
Neuronske mreze imaju regularizacioni parametar, parametar vezan za metodu inercije,itd. Pre ucenja, moguce je izabrati podskup atributa. Neuronske mreze mogu imatirazlicite arhitekture. Algoritam k najblizih suseda moze koristiti razlicite distance. Da-kle, postoje razliciti nacini za konfigurisanje razlicitih algoritama, stoga uzimamo u ob-zir algoritamske konfiguracije (vrednosti metaparametara, atributi, arhitekture, kerneli,itd.).
Skup svih algoritamskih konfiguracija je odreden svim mogucim vrednostima svakogod parametara nekog algoritma (odnosno, svakog od delova algoritma koji moze davarira). Algoritamska konfiguracija je jedna konkretna torka iz tog skupa.
Izbor modela Razlicite konfiguracije kada se primene da iste podatke daju razlicitemodele. Primetimo sledece: izborom konfiguracije se bira model. Dakle, na izbor modelauticu podaci i algoritam koji je voden konfiguracijom.
Pitanje je’’Kako izabrati adekvatnu konfiguraciju, a time i model?”. Odgovor je
– jednostavno! Izvrsiti evaluaciju modela dobijenih za razlicite konfiguracije i izabratinajbolji. Postavlja se pitanje izbora ocena greske predvidanja tog modela. Ovaj problemnije jednostavan.
Procena kvaliteta i izbor modela na pogresan nacin Prikazimo prvo pogresanpristup koji predstavlja jedan od osnovnih nacina na koje ljudi grese kada se bave ovimproblemom. Pristup glasi: evaluira se svaka konfiguracija unakrsnom validacijom. Za-tim, bira se najbolja konfiguracija i prijavljuje se upravo dobijena procena kvaliteta mo-dela. Konacno, trenira se finalni model pomocu najbolje konfiguracije na celom skupupodataka. Pokazimo ovaj pristup na jednostavnom primeru. Neka imamo algoritam cijakonfiguracija se sastoji samo od jednog parametra λ. Za svaku od izabranih vrednostiλi parametra λ dobijamo greske Ei evaluiranjem na test skupu:
λ : 10k1 · · · 10ki · · · 10kn
E : E1 · · · Ei · · · En

92 GLAVA 6. PROCENA KVALITETA I IZBOR MODELA
Neka je Ei = minEk, k = 1, n. Dakle, treba da izaberemo parametar λi = 10ki naosnovu cega dobijemo finalni model, treniran na osnovu celog skupa podataka, koji imagresku Ei.
U cemu je greska? Uobicajeno opravdanje datog postupka bi bilo: posto se koristiunakrsna validacija, nikad se ne vrsi trening na instancama koji se koriste za testiranje.Medutim, da li je zaista tako? Vidimo da u izboru nije greska, unakrsna validacija radidobro, onako kako smo je opisali. To znaci da bi greska mogla da se potkrade u evalua-ciji. Ako malo bolje razmotrimo opisani pristup, dolazimo do sledeceg: Prilikom izboranajbolje konfiguracije, oslonili smo se na informaciju dobijenu koriscenjem celog skupapodataka, a izbor najbolje konfiguracije je deo treninga, posto se direktno odrazava narezultujuci model! Iz prethodnog primera, biranje parametra λi je zapravo deo treninga,a mi smo taj odabir vrsili na osnovu gresaka Ei, koje smo dobili iz test skupa. Etopreklapanja trening i test podataka.
6.1.2.1 Pojam validacionog skupa
Kao resenje prethodno opisanog problema, javlja se potreba za novim skupom kojice biti disjunktan i trening i test skupu. Takav skup se naziva validacioni skup (engl.validation set). Pogledajmo kako se menja izbor modela i ocena greske uvodenjemvalidacionog skupa.
Izbor modela pomocu validacionog skupa Podaci se dele na trening i validacioniskup. Za svaku konfiguraciju se radi sledece: (1) trenira se model za tu konfiguracijuna trening skupu i (2) vrsi se ocena greske predvidanja modela na validacionom skupu.Zatim, bira se konfiguracija koja daje najmanju gresku na validacionom skupu. Konacno,trenira se finalni model pomocu najbolje konfiguracije na celom skupu podataka.
Tabela 6.4: Podela skupa podataka na trening skup (plavo), validacioni skup (zeleno) itest skup (crveno).
x1 x2 x3 y
1 9 0 80 6 2 11 3 1 54 9 7 61 1 6 77 2 3 42 9 9 93 3 4 67 2 1 76 5 1 5
Ocena greske pomocu validacionog i test skupa Podaci se dele na trening itest skup (u okviru trening skupa se pravi podela na skup za treniranje i validacioniskup; videti Tabelu 6.4). Na celom trening skupu se izvrsi izbor modela i pridruzenekonfiguracije pomocu validacionog skupa. Za tu konfiguraciju se trenira model na celom

6.1. TEHNIKE EVALUACIJE 93
trening skupu. Vrsi se ocena greske tog modela na test skupu i ona se prijavljuje kaoocena kvaliteta modela.
Izbor modela pomocu unakrsne validacije Za svaku konfiguraciju se vrsi ocenagreske predvidanja modela unakrsnom validacijom. Zatim, bira se konfiguracija kojadaje najmanju gresku pri unakrsnoj validaciji. Konacno, trenira se finalni model pomocunajbolje konfiguracije na celom skupu podataka.
6.1.2.2 Procena kvaliteta ugnezdenom K-strukom unakrsnom validacijom
Uopstenje Algoritma 3 u slucaju nekonfigurabilnog algoritma dato je Algoritmom 5za konfigurabilne algoritme.
Algoritam 5 Ugnezdena K-struka unakrsna validacija.
1: procedure UgnezdenaUnakrsnaValidacija(k)2: Podeliti podatke na k slojeva3: for all sloj ∈ slojevi do4: for all konfiguracija ∈ konfiguracije do5: Vrsiti ocenu greske konfiguracije na preostalih k− 1 slojeva Algoritmom 36: end for7: Odabrati konfiguraciju sa najmanjom greskom8: Trenirati model pomocu te konfiguracije na preostalih k − 1 slojeva9: Izvrsiti predvidanje dobijenim modelom na izabranom sloju
10: end for11: Racunati ocenu greske12: end procedure
6.1.3 Pitanje kvaliteta modela
Uzroci niskog kvaliteta modela mogu biti razni. Jedno osnovno pitanje je da li jedobro odradena stratifikacija prilikom evaluacije. Ako smo ustanovili da je stratifikacijadobro odradena, onda moze doci do: (1) nedovoljne prilagodenosti modela i (2) preprila-godenosti modela. Nedovoljna prilagodenost modela je, na primer, ukoliko podaci dolazeiz funkcije f(x) = x2, a mi ih ukalupljujemo pravom f(x) = k · x+ n. Preprilagodenostmodela je ako bismo tacke koje imaju linearnu zavisnost ukalupljivali u interpolacionipolinom kroz te tacke.
Nagodba izmedu potprilagodenosti i preprilagodenosti Ako je model nedo-voljno prilagoden, onda neki od nacina resavanja problema su: koristiti prilagodljivijemodele, koristiti nize vrednosti regularizacionog parametra i konstruisati nove atribute.Sa druge strane, ako je model preprilagoden, onda treba: koristiti manje prilagodljivemodele, koristiti tehnike za izbor atributa, koristiti vise vrednosti regularizacionog para-metra i koristiti vise podataka. Slika 6.1 zavisnost greske predvidanja od kompleksnostimodela.
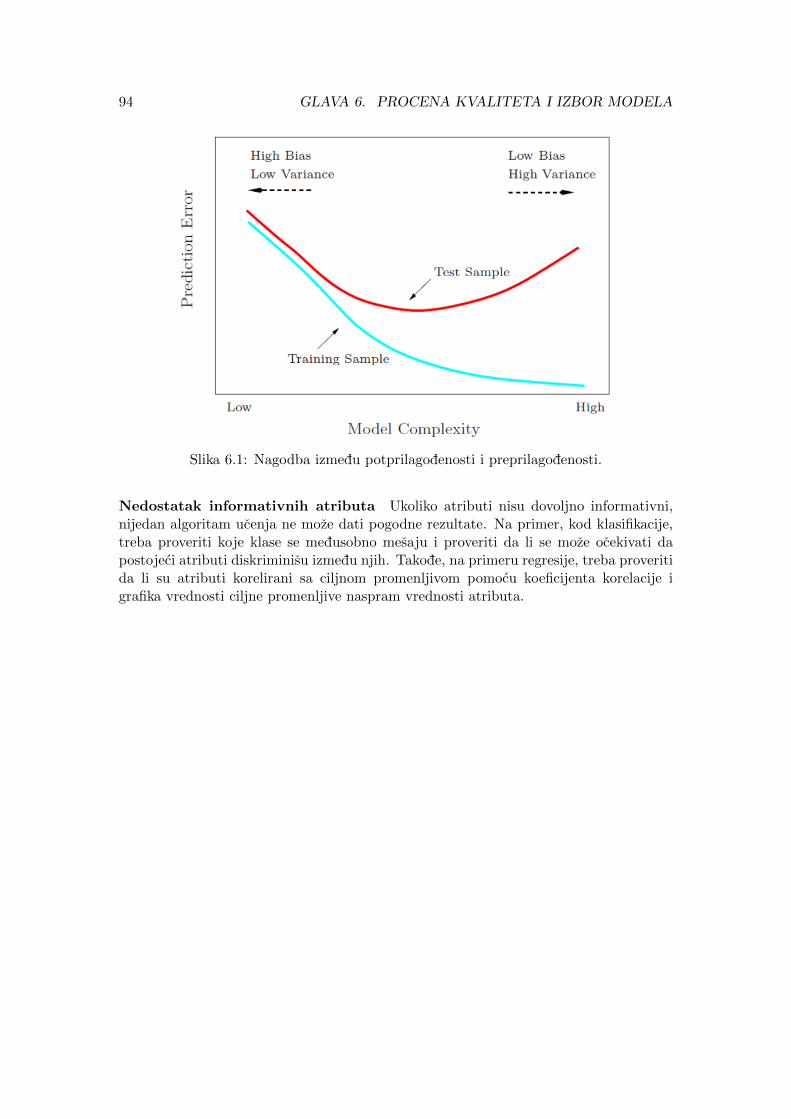
94 GLAVA 6. PROCENA KVALITETA I IZBOR MODELA
Slika 6.1: Nagodba izmedu potprilagodenosti i preprilagodenosti.
Nedostatak informativnih atributa Ukoliko atributi nisu dovoljno informativni,nijedan algoritam ucenja ne moze dati pogodne rezultate. Na primer, kod klasifikacije,treba proveriti koje klase se medusobno mesaju i proveriti da li se moze ocekivati dapostojeci atributi diskriminisu izmedu njih. Takode, na primeru regresije, treba proveritida li su atributi korelirani sa ciljnom promenljivom pomocu koeficijenta korelacije igrafika vrednosti ciljne promenljive naspram vrednosti atributa.

Glava 7
Regresija
Regresija je predvidanje neprekidnih atributa. Neki od modela su: linearna regresija,neuronske mreze, itd. Linearna regresija je linearna u odnosu na parametre, a neuronskamreza je nelinearna u odnosu na parametre. Logisticka regresija i analiza diskriminantise zapravo koriste za klasifikaciju, a nisu modeli regresije.
Regresiona analiza je:
• ukalupljivanje jednacina u podatke (Balke),
• proces izracunavanja izraza koji predvidaju numericke kolicine (Witten i Frank),
• statisticka alatka za istrazivanje odnosa izmedu promenljivih (Sykes),
• tehnika modeliranja predvidanja gde su promenljive cija se procena vrsi nepre-kidne.
Regresija je proces pronalazenja ciljne funkcije f koja preslikava vektor x u izlaz y
sa neprekidnim vrednostima. Cilj regresije je naci ciljnu funkciju koja moze da ukalupiulazne podatke sa minimalnom greskom. Greska moze biti izrazena preko apsolutnegreske ili kvadrata greske.
Jednacine koje se koriste u regresiji za predstavljanje modela su:
Empirijske jednacine Dobijene su na osnovu matematickih razmatranja. Ne razma-traju sta je potrebno za formiranje podataka. Koriste se jedino za interpolaciju,pri cemu primena za ekstrapolaciju daje neizvesne rezultate. Primeri su linearnaregresija i neuronske mreze.
Mehanisticke jednacine Dobijaju se iz analize situacije koju generisu podaci. Znamonesto o modelu i onda pravimo jednacinu.
Jedan od primera kako mozemo formirati linearnu jednacinu: polinom reda n i ste-pena r
y = β0 + β1x+ β2x2 + . . .+ βnx
r
Ako imamo β0 + β1x onda mozemo da povucemo pravu, a ako dozvolimo i vecestepene onda polinomima aproksimiramo tacke. Obicno kada razmisljamo o lineranojregresiji pomislimo na pravu, ali to ne mora da bude samo prava! Moze da bude ipolinom. To mozda zvuci cudno jer ocekujemo prave, ali moze se koristiti i hiperravan.
95

96 GLAVA 7. REGRESIJA
Primeri nelinearnog modela:
y = β0exp(−β1x)
y = β0exp(−β1x) + β2exp(−β3x)
Vidimo da je prva jednacina linearna po β0 ali nije po β1 jer se ono nalazi u ekspo-nentu. Druga jednacina je lineatna po β0 i β2 ali nije po β1 i β3.
Ako imamo linearan model na osnovu njega mozemo da zakljucimo koje su nampromenljive bitne, a koje ne. Ako je neki koeficijent jednak nuli, taj sigurno nije bitan.Ako je neki koeficijen veliki i pozitivan on je pozitivno korelisan sa ciljnom promenljivom,i obrnuto.
Forma linearnog modela je:
fw = w0 +n∑i=1
wi · xi.
Vrsimo minimizaciju
minw
N∑i=1
(yi − fw(xi))2,
gde su yi stvarne vrednosti, a fw(xi) su vrednosti koje model predvida. To mozemozapisati i na sledeci nacin:
minw||y −Xw||,
gde je y vektor svih izlaza. Odatle izvodimo cemu je jednako w:
w = (XTX)−1XTY.
7.1 Grebena linearna regresija
Ako su kolone matrice X linearno zavisne, matrica (XTX) nece biti invertibilan i toje problem. U takvoj situaciji, ne mozemo da se oslonimo na obicnu linearnu regresiju.Male promene u ulaznim podacima prouzrokovace velike promene u modelu i to je onosto ne zelimo. Zato se minimizuje drugaciji izraz:
minw
N∑i=1
(yi − fw(xi))2 + λ||w||22.
Sta se sada desava? Koeficijenti ne smeju biti nula nego uzimaju neke nenula vred-nosti, nekad cak i velike vrednosti. Nacin na koji se ovaj model stvarno prilagodavapodacima je taj da se koeficijenti odlepe od nule, jer ako je nula to je ravna linija.Medutim, kako krece da se prilagodava, tako se greska minimizuje, sto moze dovesti dopreprilagodavanja. Zato dodajemo λ||w||22. Greska opada kako dozvoljamo koeficijen-tima da rastu, ali tako raste norma i onda se model nece preprilagoditi. λ konstrolisekoliko ce se model prilagoditi podacima. Ono pridaje tezinu normi vektora w. Za velikoλ, model ce gledati da svede normu na nulu i zanemarice gresku. To nije dobro jer senismo uopste prilagodili, dobijamo ravnu liniju. Medutim, ako λ = 0 dobijamo vrlo

7.2. MERE KVALITETA 97
fleksibilan model koji moze potpuno da se prilagodi podacima, sto opet nije dobro jerdolazi do preprilagodavanja. Vrednost izmedu ta dva ekstremuma ce dati dobar model.Ovakva regresija se naziva grebena regresija.
Ispostavlja se da je i u ovom slucaju lako naci matricno resenje:
w = (XTX + λI)−1XTY.
Primene se nalaze svuda. Uvek se prvo proba sa linearnom regresijom. Ako ne ide, ondase pokusava sa neuronskim mrezama itd.
7.2 Mere kvaliteta
Koren srednjekvadratne greske
RMSE =
√√√√ 1
N
N∑i=1
(fw(xi)− yi)2
Posmatramo odstupanja pravih vrednosti od onoga sto model kaze. Uprosecavamokvadrate gresaka i onda korenujemo zbog kvadrata. Veoma je osteljivo na netipicneelemente (elemente van granica). Poput standardne devijacije, ali ne u odnosu na prosek,vec u odnosu na model. Izrazava se u istim jedinicama kao i ciljna promenljiva. Koristise da kvantifikuje velicinu greske. Posebno korisna ukoliko znamo prihvatljivu velicinugreske u razmatranoj primeni.
Koeficijent determinacije R2
R2 = 1− MSE
V ar= 1−
∑Ni=1(fw(xi)− yi)2∑N
i=1(y − yi)2
Najjednostavnije je da uvek predvidamo prosek. Kvadriramo prosek i delimo gavarijansom jer to predstavlja srednjekvadratna greska u odnosu na prosek. x objasnjavavarijaciju u y. x i y menjanju vrednosti nekako tj. variraju. Ako ostane vrlo malo greskemozemo da kazemo ovaj model objasanja kako se y menja u odnosu na x, a to sto ostaneje neobjasnjena varijacija.
MSE je greska u odnosu na model. To je ono sto jos uvek nije objasnjeno. Var jeukupna varijacija. Kako je MS udeo neobjasnjene varijacije tako je R2 udeo objasnjenevarijacije. Tako da nam ova mera govori koliki deo varijacije smo uspeli da objasnimomodelom.
Izrazava se na skali [−∞, 1]. 1 znaci da smo uspeli sve da objasnimo. Vrednostje negativna kad je model gori od proseka. Linearni model bi uvek mogao da simuliraprosek tako sto bi rekao da su svi clanovi osim slobodnog nula, a slobodni clan je upravoprosek. Ako zanemarimo slucajeve koji su gori od proseka, R2 se izrazava na skali [0, 1].To nam govori koliko je dobar metod u ucenju tj. koliko je naucio od onoga sto je mogaoda nauci. 1 znaci da je naucio svu varijaciju, onoliko koliko je mogao.
Ove mere treba da se koriste zajedno. Mozemo dobiti za R2 0,9. To zvuci poprilicnodobro - model je uspeo da nauci 90% onoga sto je mogao da nauci. Medutim, da li jetih 90% zaista dobro za nas model? Da bismo to proverili ipak moramo da pogledamo

98 GLAVA 7. REGRESIJA
i srednjekvadratnu gresku. Obrnuto isto vazi. Ne mozemo se osloniti samo na srednje-kvadratnu gresku. Ona nam npr. kaze da je za neki posao potrebno 5 sekundi i namato zvuci dobro, ali mozda je u startu varijansa bila 5 sekundi. Ako je tako, to znaci dasmo mi naucili prosek tj. nismo nista naucili. Ako smo zadovoljni sa 5 sekundi ondanismo morali nista da ucimo, mogli smo samo da koristimo prosek. Dakle, koristimo R2
da proverimo da li je model nesto ucio da bi dosao do te greske kojom smo zadovoljni.Ako se nista nije naucilo, bolje da koristimo sam prosek nego da trosimo vreme na skupealgoritme masinskog ucenja.
Ako model ne moze da uci onda trazimo drugaciji model - neki fleksibilniji, nelinea-ran. Moze se ispostaviti da imamo takve podatke koje ne nude potencijal da se iz njihnesto nauci. Mozda su prazni ili neki sum i ne mogu se nauciti.

Glava 8
Logisticka regresija
Jedan od osnovnih algoritama klasifikacije koji se cesto koristi za evaluaciju drugihalgoritama jeste logisticka regresija. To je relativno jednostavan model, intuitivan, mozese analizirati. Sta je osnovna postavka logisticke regresije?
Slika 8.1: Tacke koje pripadaju dvema klasama – plus i krug – razdvojene pravom.
Jedan nacin razdvajanja ovih klasa je prava. fw(x) je funkcija sa parametrom w i onarazdvaja klase. Vidimo da je to linearna kobminacija koordinata tj. prava. U opstemslucaju to je hiperravan, a u nasem, dvodimenzionalnom slucaju, to je prava. Ovakvuhiperravan nazivamo razdvajajuca hiperravan. Sve tacke duz prave postuju jednacinufw(x) = 0. Sta je sa ostalim tackama? Sa jedne strane imaju pozitivnu vrednost, asa druge negativnu to je za njih bitno! Svi plusici ce npr. imati pozitivnu vrednost, asvi kruzici npr. negativnu vrednost. Jos jedna zanimljiva stvar je da sto je tacka daljeod prave, to ce po apsolutnoj vrednosti imatu vecu vrednost. Funkcija je monotona ineprekidna i ocekujemo da sto se vise odaljavamo da ce vrednosti funkcije monotonorasti. Dakle, sto je tacka dalja od razdvajajuce hiperravni to smo sigurniji da je odgovorklasifikacije tacan. Veca vrednost funkcije pruza nam vecu pouzdanost. Tacke sa manjimvrednostima funkcije su nesigurne, mozda se desio neki sum pa je plusic zavrsio medukruzicima, a mozda je pogresna prava odabrana pa nam oni predstavljaju gresku. Ali,ako bi se desio plusic medu kruzicima daleko od prave, onda je model los.
Moze se desiti da su podaci takvi da ne postoji prava (ili hiperravan) koja ih mozesavrseno razdvojiti. Mi smo svesni toga da ce nam model praviti gresku jos na treningpodacima, ali biramo pravu tako da nam preciznost i dalje bude velika. Podaci kojepogresno klasifikujemo su mozda neki izuzeci ili specijalni slucajevi koji ne moraju dabudu bitni za model i mozemo da ih zanemarimo.
99

100 GLAVA 8. LOGISTICKA REGRESIJA
Slika 8.2: Tacke koje pripadaju dvema klasama – plus i krug – pri cemu prava ne mozeda ih razdvoji savrseno.
Logisticka regresija u odnosu na stabla odlucivanja Stabla odlucivanja su izrazajnijau odnosu na logisticku regresiju jer stabla mogu da opisuju podatke sa proizvoljnim gra-nicama. U prethodnom primeru, stablo bi bilo duboko da bi poptuno razdvojilo plusiceod kruzica. Stablo odlucivanja bi moglo da klasifikuje na osnovu funkcije - ako je vred-nost funkcije pozitivna, onda je plusic, ako je negativna onda je kruzic. Medutim, ononije u stanju da govori ni o cemu osim o pojedinacnim atributima. Dakle, stablo bi mo-ralo da gradi kompleksniju granicu, samim tim moralo bi da bude dublje. Sto je dubljeto je manje interpretabilno, a vidimo da nam je ova prava poprilicno interpretabilna.Iako je manje izrazajan model ima druge prednosti kao sto je interpretabilnost.
8.1 Matematicka formulacija
Neka je y ∈ {0, 1} i zelimo da modelujemo verovatnocu p(y, x). Razmotrimo lineranuformu modela:
fw(x) = w0 +
n∑i=1
wi · xi
Vidimo da sto je tacka dalje od razdvajajuce hiperravni, to je verovatnoca pripadanjaodgovarajucoj klasi veca. Medutim, fw(x) nije u intervalu [0, 1] i to nam smeta. Moramoda nekako prepodesimo funkciju tako da ipak upada u interval [0, 1]. Realni brojevi,se mogu preslikati u interval [0, 1], a nama je jos potrebno da to preslikavanje budemonotono. Sto je vise negativna vrednost zelim da budem blize nuli, a sto je visepozitivna vrednost zelim da budem blizi jedinici i time zapravo modelujemo verovatnocuda ce y biti 1. Kada dobijemo 0.75 to je verovatnoca da je klasa 1, a kad je 0.25 to jeverovatnoca da je klasa 1 odnosno to nam govori da je 0.75 verovatnoca da je klasa 0.Na osnovu toga cemu je blizi broj koji dobijemo zakljucujemo koja je klasa. Dodatno,postavimo prag na 0.5 i kad je broj preko 0.5 onda se klasifikuje kao 1, a ispod seklasifikuje kao 0.
Sigmoidna funkcija (slika 8.3) nam daje upravo monotono preslikavanje u interval[0, 1], a njen analiticki oblik je sledeci:
σ(x) =1
1 + exp(−x).
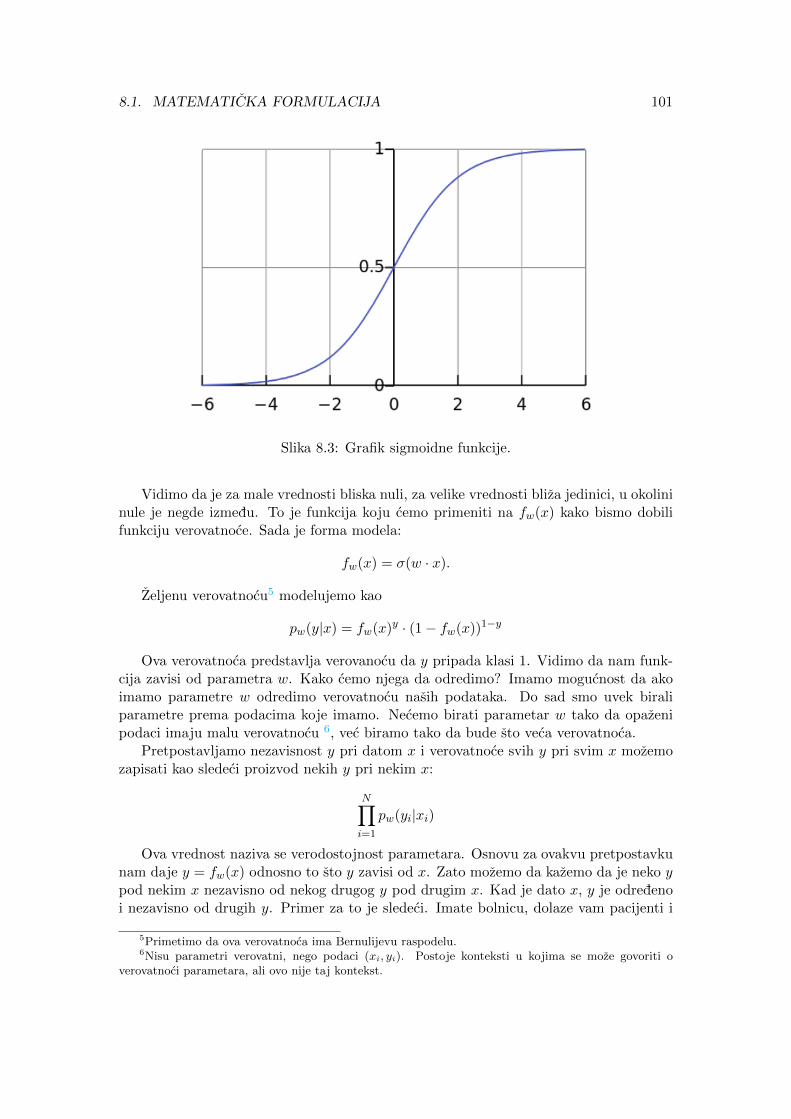
8.1. MATEMATICKA FORMULACIJA 101
Slika 8.3: Grafik sigmoidne funkcije.
Vidimo da je za male vrednosti bliska nuli, za velike vrednosti bliza jedinici, u okolininule je negde izmedu. To je funkcija koju cemo primeniti na fw(x) kako bismo dobilifunkciju verovatnoce. Sada je forma modela:
fw(x) = σ(w · x).
Zeljenu verovatnocu5 modelujemo kao
pw(y|x) = fw(x)y · (1− fw(x))1−y
Ova verovatnoca predstavlja verovanocu da y pripada klasi 1. Vidimo da nam funk-cija zavisi od parametra w. Kako cemo njega da odredimo? Imamo mogucnost da akoimamo parametre w odredimo verovatnocu nasih podataka. Do sad smo uvek biraliparametre prema podacima koje imamo. Necemo birati parametar w tako da opazenipodaci imaju malu verovatnocu 6, vec biramo tako da bude sto veca verovatnoca.
Pretpostavljamo nezavisnost y pri datom x i verovatnoce svih y pri svim x mozemozapisati kao sledeci proizvod nekih y pri nekim x:
N∏i=1
pw(yi|xi)
Ova vrednost naziva se verodostojnost parametara. Osnovu za ovakvu pretpostavkunam daje y = fw(x) odnosno to sto y zavisi od x. Zato mozemo da kazemo da je neko ypod nekim x nezavisno od nekog drugog y pod drugim x. Kad je dato x, y je odredenoi nezavisno od drugih y. Primer za to je sledeci. Imate bolnicu, dolaze vam pacijenti i
5Primetimo da ova verovatnoca ima Bernulijevu raspodelu.6Nisu parametri verovatni, nego podaci (xi, yi). Postoje konteksti u kojima se moze govoriti o
verovatnoci parametara, ali ovo nije taj kontekst.

102 GLAVA 8. LOGISTICKA REGRESIJA
zelite da predvidite da li imaju neku bolest (koja se ne prenosi neposrednom bliskoscu).y1 predstavlja da li prvi pacijent ima ili nema tu bolest, yk da li k-ti pacijenti ima ilinema bolest. Promenljiva x predstavlja njihove godine, visinu, tezinu, procenat necegau krvi, dakle vrsili smo razne testove nad njima i imamo podatke za sve. Da li ce prvipacijent imati bolest ne zavisi od toga da li drugi pacijenti imaju bolest ili ne vec odnjegovih godina, visine, tezine itd.
Potrebno je pronaci vrednost parametra w cija je vrednost najveca. Kako su sumenumericki i analiticki pogodnije od proizvoda, razmatra se logaritam ovog proizvoda.Numericki, sume su pogodnije jer kod proizvoda postoji problem potkoracenja i pre-koracenja. Ovde mnozimo verovatnoce, to su mali brojevi pa se lako moze dogoditipotkoracenje. Analiticki, sume su pogodnije zbog diferenciranja. Logaritam je mono-tona funkcija i zato mozemo da ga primenimo na proizvod i onda to maksimizujemo.Obicno se umesto maksimizacije koristi minimizacija, pa se razmatra negativna vrednostlogaritma. Negativna vrednost logaritma verodostojnosti:
L(w) = −N∑i=1
log pw(yi|xi) = −N∑i=0
[yi log fw(xi) + (1− yi) log(1− fw(xi))].
Optimizacioni problem postaje:
minw−
N∑i=0
[yi log fw(xi) + (1− yi) log(1− fw(xi))].
Ova funkcija je konveksna, pa ima jedinstven globalni minimum. Primetimo da sadaako nam se javi neki plusic medu kruzicima ili obrnuto, i dalje imamo pravu. Istina,ona ne razdvaja klase savrseno, ali postoji i visoke su verovatnoce da ce pogoditi. Zaoptimizaciju se mogu koristiti numericke metode, obicno koristi Njutnova metoda.
Ako su atributi intervalni nemamo problem, medutim ako su kategoricki potrebno jeda ih kodiramo. Najbolje je koristiti dummy coding. Ne treba davati neke napamet, kojimozda imaju poredak i otvara mogucnost da se koriste neke operacije koje nema smislaprimenjivati nad kategorickim atributima.
Primene Predvidanje 30-dnevnog mortaliteta od infarkta na osnovu zdravstvenih po-dataka (pol, visina, tezina, pusenje, krvni pritisak, itd.). Posebna popularnost u medic-niskim primenama zbog interpretabilnosti i verovatnoca koja je mera pouzdanosti. Stose tice interpretabilnosti, ako je neko fw(x) jednako nuli, to nam znaci da taj atributnije bitan, a ako je neka velika vrednost to nam znaci da je mnogo bitan. Bitno namje da znamo koji su atributi nebitni jer time stedimo vreme i novac. To nam govorida nema potrebe da se bavimo dolazenjem do podataka vezanih ze te atribute. Ako jepozitivno, znaci da je x pozitivno korelirano sa vrednoscu funkcije, tj. sto je vece x vecaje i vrednost funkcije i obrnuto. Ako je negativno onda je x negativno korelirano savrednoscu funkcije odnosno sto je x vece vrednost funkcije je manja i obrnuto. To namomogucava da proverimo da li nam je model dobar, na osnovu medicinske teorije. Ako izteorije znamo da je nesto pozitivno korelirano, a model nam kaze da je negativno, jasnoje da model ne valja. Ako nemamo neku teoriju, model nam moze pomoci da dodemodo novih znanja, da otkrijemo neke korelacije za koje nismo znali ranije. Predstavljastandardni model za poredenje prilikom klasifikacije.
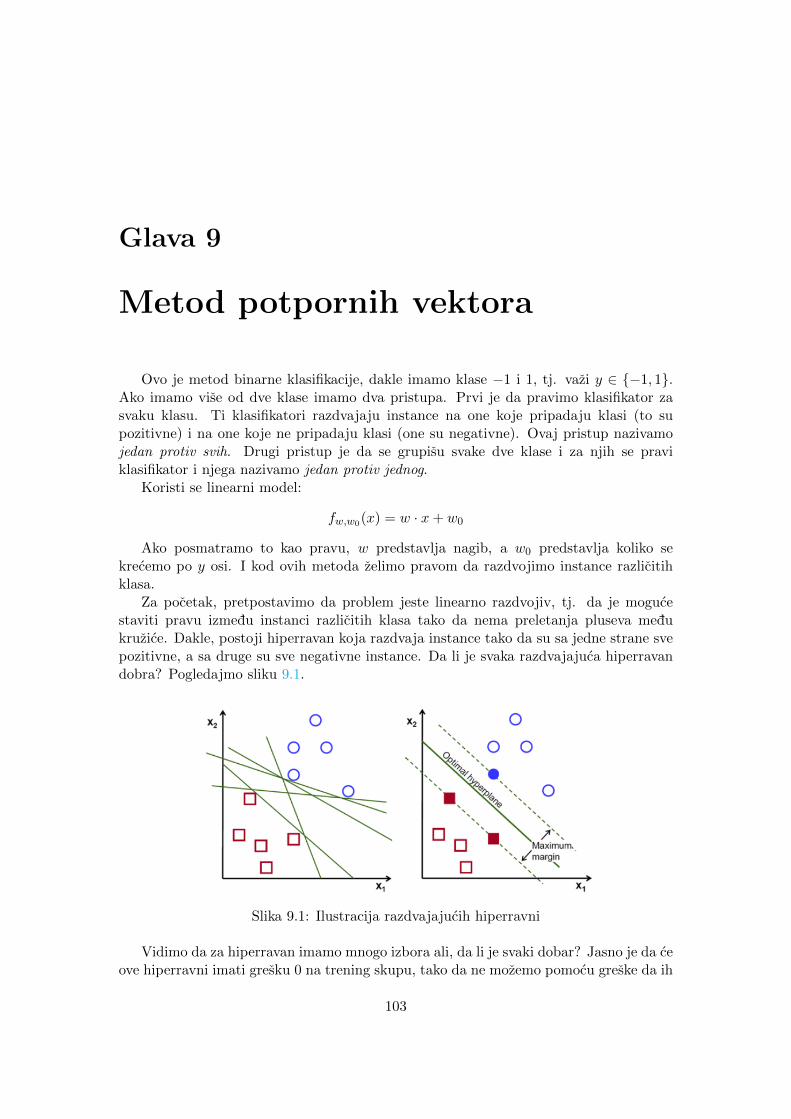
Glava 9
Metod potpornih vektora
Ovo je metod binarne klasifikacije, dakle imamo klase −1 i 1, tj. vazi y ∈ {−1, 1}.Ako imamo vise od dve klase imamo dva pristupa. Prvi je da pravimo klasifikator zasvaku klasu. Ti klasifikatori razdvajaju instance na one koje pripadaju klasi (to supozitivne) i na one koje ne pripadaju klasi (one su negativne). Ovaj pristup nazivamojedan protiv svih. Drugi pristup je da se grupisu svake dve klase i za njih se praviklasifikator i njega nazivamo jedan protiv jednog.
Koristi se linearni model:
fw,w0(x) = w · x+ w0
Ako posmatramo to kao pravu, w predstavlja nagib, a w0 predstavlja koliko sekrecemo po y osi. I kod ovih metoda zelimo pravom da razdvojimo instance razlicitihklasa.
Za pocetak, pretpostavimo da problem jeste linearno razdvojiv, tj. da je mogucestaviti pravu izmedu instanci razlicitih klasa tako da nema preletanja pluseva medukruzice. Dakle, postoji hiperravan koja razdvaja instance tako da su sa jedne strane svepozitivne, a sa druge su sve negativne instance. Da li je svaka razdvajajuca hiperravandobra? Pogledajmo sliku 9.1.
Slika 9.1: Ilustracija razdvajajucih hiperravni
Vidimo da za hiperravan imamo mnogo izbora ali, da li je svaki dobar? Jasno je da ceove hiperravni imati gresku 0 na trening skupu, tako da ne mozemo pomocu greske da ih
103

104 GLAVA 9. METOD POTPORNIH VEKTORA
poredimo. Ne zelimo one koje su previse blizu nekim instancama, tako da se naslanjajuna njih, vec zelimo one koje su podjednako udaljene od predstavnika obe klase. Da bismo ovo resenje formalizovali uvodimo pojam margine.
Margina razdvajajuce hiperravni je minimum rastojanja od te hiperravni do nekeod tacaka iz skupa podataka. Medu svim razdvajajucim hiperavnima, potrebno je nacioptimalnu - onu sa najvecom marginom. Potrebno je da ta optimalna ravan bude nasredini, podjednako udaljena od predstavnika obe klase. Za svaku od tacaka x, rastojanjedo hiperravni je
|w · x+ b|||w|| .
Slika 9.2: Ilustracija optimalne razdvajajuce hiperravni
Jednacina optimalne hiperravni je:
|w · x+ b| − b = 0.
sto mozemo videti sa slike 9.2. Zelimo optimalnu hiperravan koja maksimizuje2
||w||i da su pozitivne instance sa pozitivne strane a negativne sa negativne strane. Takodobijamo optimizacioni problem:
minw,w0
||w||2
yi(w · xi + w0) ≥ 1zai = 1, . . . , N
Posmatrajmo sada tezi slucaj – kada podaci nisu linearno separabilni. U ovom slucajupotrebno je dozvoliti greske, jer je jasno da ne postoji prava koja ce savrseno razdvojitiinstance razlicitih klasa, ali uz teznju da se njihov broj i intenzitet minimizuju:

9.1. RESENJE OPTIMIZACIONOG PROBLEMA 105
minw,w0
||w||22
+ C(
N∑i=1
ξi)
yi(w · xi + b) ≥ 1− ξi, i = 1, . . . , N
ξi ≥ 0, i = 1, . . . , N
Oznaka ξi predstavlja koliko je neka instanca duboko otisla na pogresnu stranu ravni.C nam kontrolise sta je vaznije. Ukoliko je C = 0 onda nam greska nije bitna i ξi biramokakve god zelimo. U tom slucaju ce w biti nula-vektor jer je tad minimalna normavektora, a nemamo ogranicenja za w. U slucaju kad C −→ ∞ pridajemo veliki znacajgreski tj. zelimo da greska bude sto manja, a margina nije preterano bitna. Zelimosto vecu marginu, ali i sto manju gresku i to je optimizacioni problem neradvajajucegslucaja.
9.1 Resenje optimizacionog problema
Problem kvadratnog programiranja 7, a postoje specijalizovani metodi za njegovoresavanje. Resenje je oblika:
w =N∑i=1
αyixi,
gde su αi Lagranzovi mnozioci za koje vazi 0 ≤ αi ≤ C. Vidimo da αi zavise od C.Kada je C = 0 tada imamo nula-vektor i sve αi = 0. Nekada nisu sve αi jednaki nuli,ali oni koji jesu predstavljaju one vektori koji nisu bitni za resenje. Oni vektori kojidodiruju obodne prave zapravo imaju αi > 0, i samo oni. Ti vektori podupiru prave tj.cine im potporu i zato se ovo naziva metoda potpornih vektora, a ove vektore nazivamopotporni vektori. To su zaista jedini podaci koji su bitni. Ovo resenje predstavljalinearnu kombinaciju svih podataka (xi su podaci, yi su klase, dakle -1 ili 1).
Model je onda oblika
fw,w0(x) =
N∑i=1
αyixi · x+ b,
pri cemu se klasa odreduje funkcijom sgn(fw,w0(x)).
9.2 Kernel
Postavlja se novo pitanje. Sta ako granica izmedu klasa nije hiperravan? Hiperravannije uvek pogodna granica izmedu klasa. U nekim situacijama je pogodnija kriva umestoprave (slika 9.3 desno). Ali mi ne zelimo krivu. Do sad smo se mucili da sve definisemoza pravu a sad nam odjednom vise odgovara kriva. Dodatno, ne mozemo da koristimoproizvoljne krive. Neke nisu linearne po w pa necemo doci do kvadratnog problema, aako ne dodemo do kvadratnog problema ne mozemo da resavamo sve to jednako efikasno
7Kvadratno prgramiranje nije pravo programiranje u smislu pisanja koda, vecc je to matematickoporgramiranje, odnosi se na optimizacije. Bavi se nalazenjem nekakvih optimuma tj. minimuma imaksimuma. To sto je kvadratno znaci da je cilja funkcija kvadratna i da su svi uslovi kvadratne ililinearne funkcije po parametrima.

106 GLAVA 9. METOD POTPORNIH VEKTORA
kao sto je sve do sad bilo. Resenje je se podaci preslikaju u neki visokodimenzionalniprostor.
Slika 9.3: Preslikavanje u visokodimenzionalni prostor
Pogledajmo sliku 9.3. Vidimo da na slici desno krug savrseno razdvaja klasu krugovaod klase kruzica. Bilo kakvu pravu da smislimo nece moci da razdvoji sve instance.Ukoliko izvrsimo preslikavanje
(x1, x2) −→ (x1, x2, x21 + x22)
primeticemo da su se instance koje se nalaze u centru kruga na desnoj slici nasle ni-sko na levoj, a one van kruga su visoko na slici levo. Zbog toga ce postojati prazanprostor koji cemo poseci pomocu hiperravni. Ispostavlja se da je to mesto preseka baskrug. To sto je hiperravan u visokodimenzionalnom prostoru moze biti pogodna kriva udvodimenzionalnom prostoru. Ovaj fenomen ima svoje osnove u necemu sto nazivamokernel.
Da bismo definisali sta je kernel, moramo uvesti pojam pozitivne semidefinitne ma-trice.
Matrica K je pozitivno semidefinitna ukoliko za svako x vazi xTKx ≥ 0.
Ako to svedemo na jednodimenzionalni slucaj, dobijamo da je x2 ≥ 0 sto uvek vazi,pa je ovo zapravo uopstenje nenegativnosti na matrice.
Neka je X neprazan skup (to ce biti skup instanci). Neka je k funkcija k : X ×X −→R. Ako je za svako n ∈ N i svako x1, . . . , xn ∈ X matrica dimenzija n×n sa elementimak(xi, xj) pozitivno semidefinitna, funkcija k je (pozitivno semidefinitan) kernel.
Dakle, funkcija k uzima dve instance i pridruzuje im neki broj. Primer je skalarniproizvod. On uzima dva vektora i pridruzuje im broj. Funkcija k je zapravo uopstenjeskalarnog proizvoda.
Za svaki kernel k postoji preslikavanje Φ iz X u neki prostor H sa skalarnim proi-zvodom tako da vazi k(u, v) = Φ(u) · Φ(v).
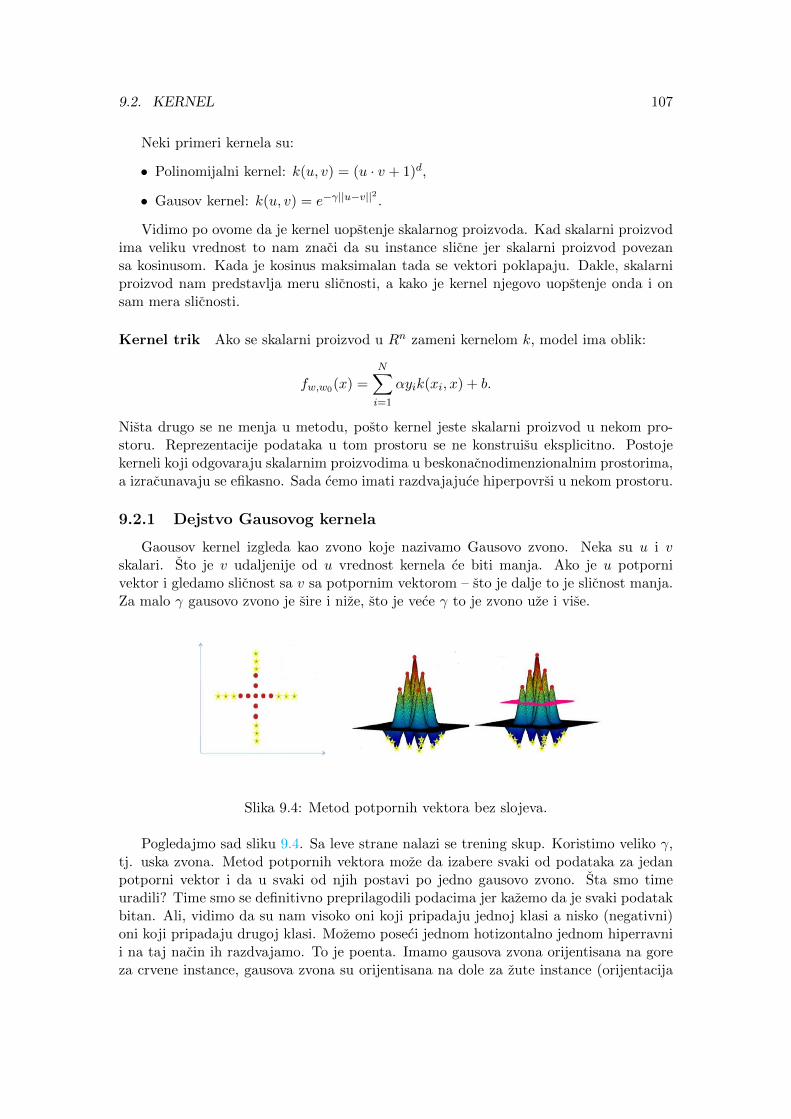
9.2. KERNEL 107
Neki primeri kernela su:
• Polinomijalni kernel: k(u, v) = (u · v + 1)d,
• Gausov kernel: k(u, v) = e−γ||u−v||2.
Vidimo po ovome da je kernel uopstenje skalarnog proizvoda. Kad skalarni proizvodima veliku vrednost to nam znaci da su instance slicne jer skalarni proizvod povezansa kosinusom. Kada je kosinus maksimalan tada se vektori poklapaju. Dakle, skalarniproizvod nam predstavlja meru slicnosti, a kako je kernel njegovo uopstenje onda i onsam mera slicnosti.
Kernel trik Ako se skalarni proizvod u Rn zameni kernelom k, model ima oblik:
fw,w0(x) =
N∑i=1
αyik(xi, x) + b.
Nista drugo se ne menja u metodu, posto kernel jeste skalarni proizvod u nekom pro-storu. Reprezentacije podataka u tom prostoru se ne konstruisu eksplicitno. Postojekerneli koji odgovaraju skalarnim proizvodima u beskonacnodimenzionalnim prostorima,a izracunavaju se efikasno. Sada cemo imati razdvajajuce hiperpovrsi u nekom prostoru.
9.2.1 Dejstvo Gausovog kernela
Gaousov kernel izgleda kao zvono koje nazivamo Gausovo zvono. Neka su u i vskalari. Sto je v udaljenije od u vrednost kernela ce biti manja. Ako je u potpornivektor i gledamo slicnost sa v sa potpornim vektorom – sto je dalje to je slicnost manja.Za malo γ gausovo zvono je sire i nize, sto je vece γ to je zvono uze i vise.
Slika 9.4: Metod potpornih vektora bez slojeva.
Pogledajmo sad sliku 9.4. Sa leve strane nalazi se trening skup. Koristimo veliko γ,tj. uska zvona. Metod potpornih vektora moze da izabere svaki od podataka za jedanpotporni vektor i da u svaki od njih postavi po jedno gausovo zvono. Sta smo timeuradili? Time smo se definitivno preprilagodili podacima jer kazemo da je svaki podatakbitan. Ali, vidimo da su nam visoko oni koji pripadaju jednoj klasi a nisko (negativni)oni koji pripadaju drugoj klasi. Mozemo poseci jednom hotizontalno jednom hiperravnii na taj nacin ih razdvajamo. To je poenta. Imamo gausova zvona orijentisana na goreza crvene instance, gausova zvona su orijentisana na dole za zute instance (orijentacija

108 GLAVA 9. METOD POTPORNIH VEKTORA
zavisi od y, ono moze biti 1 ili −1). Tako da, ako postavimo po jedno zvono za u svakutacku one koje pripadaju negativnoj klasi bice orijentisana na dole, a pozitivna na gorei lako ih razdvajamo jednom horizontalnom hiperravni.
Sa velikim brojem potpornih vektora i velikim vrednostima za γ, tj. uskim zvonimase preprilagodavamo. Da se ne bismo previse prilagodili koristimo sira zvona, tj. manjevrednosti za γ. Pomocu unakrsne validacije mozemo odrediti pogodnu vrednost za γ.
9.3 Primene
SVM je jedan od algoritama sa najboljim kvalitetom predvidanja u najrazlicitijimdomenima. Neke pogodne primene metoda potpornih vektora ukljucuju:
• kategorizacija teksta,
• prepoznavanje objekata na slikama,
• prepoznavanje rukom pisanih cifara,
• dijagnoza raka dojke,
• i mnoge druge.

Glava 10
Neuronske mreze
Neuronske mreze (eng. neural networks) predstavljaju najpopularniju i verovatnonajprimenjeniju metodu masinskog ucenja. Njihove primene su mnogobrojne i pome-raju domete vestacke inteligencije, racunarstva i primenjene matematike. Neke od njihsu kategorijzacija teksta, medicinska dijagnostika, prepoznavanje objekata na slikama,autonomna voznja, igranje igara poput igara na tabli (tavla i go) ili video igara, masinskoprevodenje prirodnih jezika, modelovanje semantike reci prirodnog jezika i slicno. Neu-ronske mreze zapravo predstavljaju parametrizovanu reprezentaciju koja moze posluzitiza aproksimaciju drugih funkcija. Pronalazenje odgovarajucih parametara se vrsi mate-matickom optimizacijom nekog kriterijuma kvaliteta aproksimacije i moze biti racunaskivrlo izazovno.
Postoje razlicite vrste neuronskih mreza. Osnovnu varijantu predstavljaju neuronskemreze sa propagacijom unapred (eng. feed forward neural networks). U obradi slika idrugih vrsta signala, pa i teksta, vrlo su popularne konvolutivne neuronske mreze (eng.convolutional neural networks). Za obradu podataka nalik nizovima promenljive duzine,najcesce se koriste rekurentne neuronske mreze (eng. recurrent nerual networks), zaobradu podataka koji se mogu predstaviti stablima koriste se rekuzivne neuronske mreze(eng. recursive neural networks), a za obradu podataka koji se predstavljaju grafovimakorsite se grafovske neuronske mreze (egn. graph neural networks). U nastavku ce bitidiskutovane prve dve vrste neuronskih mreza. Poslednje dve su novije od ostalih, pa jei obim njihovih primena manji, ali su vrlo zanimljive zbog svoje izrazajne moci.
10.0.1 Neuronske mreze sa propagacijom unapred
Neuronska mreza sa propagacijom unapred (u nastavku samo – neuronska mreza) sesastoji od osnovnih racunskih jedinica koje se nazivaju samo jedinicama ili neuronima,koje predstavljaju jednostavne parametrizovane funkcije. Svaka jedinica racuna line-arnu kombinaciju svojih argumenata i nad njom racuna neku nelinearnu transformaciju(u nastavku aktivacionu funkciju). Ove jedinice su organizovane u slojeve, tako da jedi-nice jednog sloja primaju kao svoje argumente (u nastavku ulaze) vrednosti (u nastavkuizlaze) svih jedinica prethodnog sloja i sve jedinice prosleduju svoje izlaze samo jedini-cama narednog sloja. Svi slojevi cije jedinice prosleduju svoje izlaze drugim jedinicamase nazivaju skrivenim slojevima. Ulazi jedinica prvog sloja se nazivaju ulazima mreze.Izlazi jedinica poslednjeg sloja se nazivaju izlazima mreze. Formalno, model se definise
109

110 GLAVA 10. NEURONSKE MREZE
na sledeci nacin:h0 = x
ai = Wihi−1 + ωi0 i = 1, 2, . . . , Lhi = g(ai) i = 1, 2, . . . , L
gde je x vektor ulaznih promenljivih, L je broj slojeva, Wi je matrica cija j-ta vrstapredstavlja vektor vrednosti parametara jedinice j u sloju i, wi0 predstavlja vektor slo-bodnih clanova linearnih kombinacija koje jedinice i-tog sloja izracunavaju, a g je neline-arna aktivaciona funkcija. Za vektor ai, g(ai) predstavlja vektor (g(ai1), g(ai2), . . . , g(aim))T ,gde je m broj jedinica u jednom sloju. Skup svih parametara modela ce se ukratkooznacavati sa w. Vazi fw(x) = hL. Shema neuronske mreze, prikazana je na slici 10.1.
Slika 10.1: Struktura neuronske mreze sa propagacijom unapred.
Postoji teorema koja izrazava vazno svojstvo neuronskih mreza – da se svaka ne-prekidna funkcija moze proizvoljno dobro aproksimirati neuronskom mrezom sa jednimskrivenim slojem i konacnim brojem neurona. Odnosno, skup svih neuronskih mreza sajednim skrivenim slojem je svuda gust na skupu funkcija neprekidnih na intervalu [0, 1]n.Ova teorema predstavlja osnovno teorijsko opravdanje za koriscenje neuronskih mreza uaproksimaciji funkcija.
U datoj formulaciji modela neuronske mreze nije precizirano koja aktivaciona funkcijase koristi. Moguce je izabrati razlicite funkcije, ali se u praksi najcesce koristi nekolikonarednih funkcija:
σ(x) =1
1 + e−x
tanh(x) =e2x − 1
e2x + 1
rlu(x) = max(0, x)
Prva, sigmoidna funkcija je siroko koriscena u masinskom ucenju i dugo je bilanajcesce koriscena aktivaciona funkcija u neuronskim mrezama. Druga, tangens hi-perbolicki je takode u sirokoj upotrebi. Treca, ispravljacka linearna jedinica predstavljatrenutno najcesce koriscenu aktivacionu funkciju. Razlog za njenu popularnost su pogod-nija svojstva pri optimizaciji, uprkos svojoj nediferencijabilnosti. Grafici sve tri funkcijesu prikazani na slici 10.2.

111
Slika 10.2: Najcesce koriscene aktivacione funkcije – sigmoidna, tangens hiperbolicki iispravljacka linearna jedinica.
Ukoliko neuronska mreza ima vise od jednog skrivenog sloja, naziva se dubokomneuronskom mrezom (eng. deep neural network). Koordinate ulaznih vektora se umasinskom ucenju nazivaju atributima, cesto zato sto stvarno opisuju objekte koje ulaznivektori predstavljaju. Vrednosti neurona skrivenih slojeva mreze se mogu smatrati novimatributima tih objekata. Drugim recima, neuronska mreza konstruise nove atribute usvojim skrivenim slojevima. Svaki sloj je u stanju da nadograduje nad prethodnim i takogradi slozenije i slozenije atribute. Ovo svojstvo je posebno uocljivo kod konvolutivnihneuronskih mreza i smatra se da je ova mogucnost konstrukcije novih atributa jedan odglavnih razloga za uspesnost dubokih neuronskih mreza.
Neuronske mreze se mogu koristiti kako za aproksimaciju funkcija sa vrednostimaiz Rn, tako i za aproksimaciju funkcija koje uzimaju kategoricke vrednosti. Pod kate-gorickim vrednostima se podrazumavaju vrednosti medu kojima nema uredenja, poputimena, tema tekstova, itd. Pretpostavlja se da ih ima konacno mnogo.
U slucaju aproksimacije neprekidne funkcije, govori se o problemu regresije. Tadajedinice poslednjeg nivoa ne koriste aktivacionu funkciju (kao sto je predvideno i u for-mulaciji teoreme o univerzalnoj aproksimaciji). Uz pretpostavku da je dat skup parovaD = {(xi, yi)|i = 1, . . . , N}, gde su xi argumenti, a yi vrednosti aproksimirane funkcije,aproksimacija se sprovodi resavanjem narednog optimizacionog problema:
minw
N∑i=1
(fw(xi)− yi)2 + λ||w||2.
Regularizacija formalno nije neophodna, ali se u praksi uvek koristi, jer su neuronskemreze vrlo fleksibilni modeli, sto znaci da je problem lose uslovljen.
Ako se aproksimira funkcija kategorickih vrednosti, govori se o problemu klasifikacije.U tom slucaju se na linearne kombinacije jedinica poslednjeg nivoa primenjuje takozvanafunkcija mekog maksimuma (eng. softmax) koja preslikava vektor dimenzije C u vektoriste dimenzije:
softmax(x) = (ex1∑Ci=1 e
xi, . . . ,
exC∑Ci=1 e
xi).
Vrednosti novog vektora se ocigledno sumiraju na 1 i stoga se mogu koristiti kaoraspodela verovatnoce. Takode, ova funkcija naglasava razlike medu koordinatama po-laznog vektora. Najveca pozitivna vrednost ce biti transformisana u novu vrednost kojajos vise odskace od drugih. Za vrednost aproksimacije se uzima kategorija koja odgovara

112 GLAVA 10. NEURONSKE MREZE
izlazu sa najvisom vrednoscu. Minimizacija srednjekvadratne greske nije najbolji pri-stup ovom problemu, posto nad kategorickim vrednostima oduzimanje nema smisla, caki kada su kategorije predstavljene brojevima. Stoga se pribegava verovatnosnoj formu-laciji zasnovanoj na raspodeli definisanoj mekim maksimumom i principu maksimalneverodostojnosti. Potrebno je maksimizovati verovatnocu opazenih vrednosti yi za datevrednosti xi. Uz pretpostavku uslovne nezavisnosti vrednosti yi za date vrednosti xi,vazi:
Pw(y1, . . . , yN |x1, . . . , xN ) =N∏i=1
Pw(yi|xi),
gde w predstavlja vektor parametara neuronske mreze od kojeg vrednosti na izlazu,koje predstavljaju verovatnoce, ocigledno zavise. Za verovatnocu jednog podataka vazi
Pw(yi|xi) =C∏j=1
(eai∑Ck=1 e
ai)tij ,
gde promenljiva tij ima vrednost 1 ako vrednosti yi odgovara kategoriji j, a 0 usuprotnom. Sume su analiticki pogodnije od proizvoda zbog linearnosti izvoda. Takodesu pogodnije i numericki jer mnozenjem malih brojeva lako dolazi do potkoracenja, amnozenjem velikih, do prekoracenja. Stoga se, umesto maksimizacije date verovatnoce,vrsi minimizacije negativne vrednosti logaritma te verovantoce
− logPw(y1, . . . , yN |x1, . . . , xN ) = −N∑i=1
logPw(yi|xi) = −N∑i=1
C∑j=1
tij logeai∑Ck=1 e
ak.
U oba slucaja, za resavanje ovog problema potrebno je koristiti metode matematickeoptimizacije. Problem optimizacije neuronske mreze je tezak zbog svoje nekonveksnosti,sto znaci da je moguce zavrsiti u lokalnim optimumima i da neke metode optimizacijekoje nisu primenljive ili da sporije rade. Sve metode za optimizaciju neuronske mrezezasnivaju se na konceptu gradijenta – vektora parcijalnih izvoda funkcije – i cinjenici dase vrednost funkcije najbrze smanjuje u suprotnom smeru.
Kao sto je na pocetku receno, neuronske mreze su se izvanredno pokazale u resavanjuprakticnih problema. Ipak, imaju i znacajne mane. Za kvalitetnu aproksimaciju jepotrebna velika kolicina podataka. Vreme potrebno za optimizaciju mreze moze bitivrlo veliko (npr. moze se meriti danima) i mogu zahtevati specijalizovani hardver dabi optimizacija bila izvrsena u prihvatljivom vremenu. Postoji veliki broj izbora kojeje potrebno uciniti pre resavanja optimizacionog problema, poput broja nivoa mreze,broja jedinica u nivou, izbora vrednosti regularizacionog parametra, izbora algoritmaza optimizaciju, itd. Za pravljenje ovih izbora cesto ne postoje jasne smernice, pa secesto odreduju empirijski – velikim brojem resavanja optimizacionog problema dok sene postignu zadovoljavajuci rezultati, sto je vremenski vrlo zahtevno. Zbog izrazitefleksibilnosti modela, moguce je da se model preterano prilagodi podacima na kojimaje vrsena optimizacija i da njegove performanse pri upotrebi budu nezadovoljavajuce.Zbog svega ovoga upotreba neuronskih mreza zahteva i veliko iskustvo.

113
Kao primer primene neuronske mreze, posluzio bi bilo koji problem regresije ili klasi-fikacije u kojem je za svaki vektor podataka x data vrednost y koju treba aproksimirati.Ipak, neki primeri, poput primena u prepoznavanju govora, su posebno zanimljivi.
Primer 45 Prepoznavanje govora, odnosno identifikacije reci koje su izgovoreneje izazovan problem iz mnogo razloga, kao sto su razlicite boje glasa razlicitih ljudi,razlicita brzina govora, razlicit intenzitet glasa, razlicit akcenat i artikulacija, prisustvosuma prilikom snimanja, itd. Ljudi nisu svesni tezine ovog problema u svakodnevnomgovoru, posto se u velikoj meri oslanjaju na razumevanje konteksta, koje vodi tomeda ocekuju pojavljivanje nekih reci, pre nego nekih drugih. Analogno tome, sistem zaprepoznavanje govora bi mogao znacajno poboljsati svoje performanse ukoliko bi mubila dostupna makar priblizna informacija o verovatnocama pojavljivanja reci, recimona osnovu prethodne dve koje su vec identifikovane. Naime, ukoliko sistem koji analiziragovor pridruzuje priblizne verovatnoce dvema recima samo na osnovu njihovog zvucnogzapisa, ali se na osnovu prethodne dve reci moze zakljuciti da je verovatno ca poja-vljivanja jedne od njih nakon prethodne dve priblizna nuli, to je vazan indikator da jeizgovorena druga rec.
Predvidanje trece reci na osnovu prve dve u principu nije neizvodljivo ukoliko jepoznat ogroman korpus teksta, iz kojeg se verovatnoce pojavljivanja razlicitih trojkimogu oceniti na osnovu njihovih frekvencija. Ovo se moze uraditi birajuci rec koja imanajvisu uslovnu verovatnocu, koja se ocenjuje iz frekvencija f kombinacija reci u korpusu:
P (w3|w2, w1) =P (w3, w2, w1)
P (w2, w1)∼ f(w3, w2, w1)
f(w2, w1)
U danasnjem dobu, veliki korpusi teksta su dostupni, ali odredivanje verovatno catrojki reci nije pouzdano zbog toga sto se mnoge trojke i u velikim korpusima mogu javitivrlo retko ili ne uopste, zbog toga sto je velicina vokabulara koji se koristi u nekom jezikuvrlo velika. Na primer ako se broj reci koje osoba koristi meri desetinama hiljada, ondase broj svih trojki tih reci meri hiljadama milijardi. Zbog toga bi verovantoce mnogihtrojki bile verovatno netacno ocenjene kao izuzetno male ili cak jednake nuli. Osnovnamana ovog pristupa je da tretira reci kao potpuno razlicite nedeljive celine i ne uocavapotencijalne slicnosti medu njima, poput recimo sinonimije ili srodnosti po smislu. Naprimer, ukoliko covek na osnovu prethodnog konteksta ocekuje da se u nastavku recenicejavi rec novac, lakse ce prepoznati i rec pare. Ukoliko ocekuje da se u nastavku recenicejavi kucni ljubimac, lakse ce prepoznati reci poput psa i macke. Ukoliko ocekuje da sejavi dan u nedelji, lakse ce prepoznati reci poput ponedeljka i utorka.
Ako se umesto ovog pristupa, pretpostavi da je svaka rec okarakterisana numerickimvektorom atributa odredene dimenzije n, koji opisuje njena sintaksna i semanticka svoj-stva, dolazi se do mnogo kompaktnije reprezentacije reci jer broj n moze biti drasticnomanji od ukupnog broja reci. Dodatno, ukoliko se model predvidanja formulise nad ta-kvim reprezentacijama, on moze da nauci da se nakon reci sa nekim svojstvima ocekujerec koja oznacava kucnog ljubimca i da na osnovu toga pridruzi visu verovatnocu recimapas i macka koje ce imati visoku vrednost atributa kucni ljubimac. Ovakav pristupomogucava i koriscenje dosta duzeg konteksta reci nego sto je moguce u pristupu kojise oslanja na same reci. Razlog za to je sto se smisao kucnog ljubimca, predstavljennekom od reci koje oznacavaju kucne ljubimce, mnogo cesce javlja u tekstovima od bilokoje pojedinacne reci koja ga oznacava, pa su i ocene verovatnoca pouzdanije. Naravno,

114 GLAVA 10. NEURONSKE MREZE
postavlja se pitanje, otkud dolaze sintaksna i semanticka svojstva reci. Da li ih je po-trebno osmisliti unapred i koliko to kosta u terminima vremena i novca? Odgovor je dace atributi koji opisuju reci biti definisani u procesu optimizacije, tako sto ce u tom pro-cesu biti odredeni parametri jedinica u skrivenim slojevima mreze, a izlazi tih jedinicace predstavljati vrednosti tih atributa. Vrlo je verovatno da ce biti tesko ili nemoguceodrediti znacenje tako konstruisanih atributa, ali to nije mnogo vazno ako je glavni ciljpogoditi narednu rec. Ukoliko je broj reci u vokabularu m, reci se predstavljaju baznimvektorima v1, v2, . . . , vm, prostora Rm, takvima da je vrednost i-te koordinate vektoravj , 1 ukoliko je i = j, a 0 u suprotnom.
10.0.2 Konvolutivne neuronske mreze
Konvolutivne neuronske mreze se intenzivno koriste u obradi signala poput zvuka islike, ali takode i teksta. Zasnivaju se upravo na pomenutoj sposobnosti mreza da kon-struisu atribute, ali ne nuzno samo iz vec datih atributa, vec i iz sirovog signala. Nazivajuse konvolutivnim upravo zato sto uce filtere, cijom konvolutivnom primenom detektujuodredena svojstva signala. Njihov znacaj je upravo u tome sto ne zahtevaju ljudskiangazman u definisanju relevantnih svojstava signala, vec u zavisnosti od problema kojije potrebno resiti same ustanovljavaju koja svojstva su bitna, kroz ucenje adekvatnih fil-tera. Ipak, ovakva vrsta fleksibilnosti podrazumeva izazove pri optimizaciji, kao i velikukolicinu podataka.
Konvolutivne mreze su prakticno uvek duboke neuronske mreze, jer je potrebnood sitnijih detalja, poput uspravnih, kosih i horizontalnih linija, iskonstruisati slozenijeoblike poput delova lica. Uobicajena struktura konvolutivne mreze podrazumeva sme-njivanje dve vrste slojeva – konvolutivnih slojeva (eng. convolution layer) i slojevaagregacije (eng. pooling layer), pri cemu je moguce i da se ista vrsta sloja ponovi viseputa. Na izlaze poslednjeg od tih slojeva se obicno nadovezuje mreza sa propagacijomunapred, koja uci nad atributima koje prethodni slojevi konstruisu. Konvolutivni slojima ulogu konstrukcije novih atributa, poput detekcije nosa, ukoliko je poznato gde sudetektovane uspravne, kose i horizontalne linije, sto ustanovljava prethodni konvolutivnisloj, recimo na osnovu samih ulaznih podataka. Pritom, vrlo cesto se na istom nivou de-finise vise paralelenih konvolutivnih slojeva. Naime, ako jedan sloj detektuje vertikalnelinije, prirodno je imati paralelno, nad istim prethodnim slojem (ili ulazom) i sloj kojidetektuje horizontalne linije. Jedinice u konvolutivnom sloju su organizovane u niz (uslucaju jednodimenzionih signala poput zvuka) ili matricu (u slucaju dovodimenzionihsignala poput slike) i dele vrednosti parametara. Obicno kao ulaze uzimaju vrednostisusednih jedinica iz prethodnog sloja. Na primer, u slucaju slike, to mogu biti vredno-sti 3 × 3 jedinice iz prethodnog sloja. Na taj nacin, imajuci u vidu da sve jedinice ujednom sloju imaju iste koeficijente, dejstvo konvolutivnog sloja se moze razumeti kaokonvolucija prethodnog sloja sa jedinicom definisanom parametrima tekuceg sloja ili ujednostavnijim terminima, kao prevlacenje filtera duz slike i izracunavanje vrednosti kojufilter daje na svakoj poziciji.
Sloj agregacije ukrupnjuje informacije koje dobija iz prethodnog sloja, obicno tako storacuna neku jednostavnu funkciju agregacije susednih jedinica prethodnog sloja, poputmaksimuma ili proseka. Ukoliko agregira, na primer, 3 × 3 piskela, onda je broj izlazaovog sloja 9 puta manji od broja izlaza prethodnog. Maksimum je najpopularniji izborfunkcije agregacije. Ukoliko 3 × 3 jedinice prethodnog sloja predstavljaju ulaz u jednu

115
jedinicu sloja agregacije i ako ona racuna njihov maksimum, dolazi do zanemarivanjeinformacije o tome gde je precizno neko svojstvo (poput uspravne linije) pronadeno, alise ne gubi informacija da je pronadeno. Ovakva vrsta zanemarivanja informacije cestone steti cilju koji treba postici. Na primer, ako je na slici pronadeno oko, uvo, usta inos, informacija o tacnoj pozicjiji najverovatnije nije bitna za odlucivanje da li se na slicinalazi lice. Naime, u realnosti, sanse da slika koja sadrzi navedene elemente, ne sadrzi licesu izuzetno male. Uloga agregacije je smanjenje broja parametara u visim slojevima, izcega proizilazi smanjenje racunske zahtevnosti pri optimizaciji i smanjenje fleksibilnostimodela, sto otezava njegovo preterano prilagodavanje ulaznim podacima i vodi boljimperformansama u predvidanju, upravo poput razlike u aproksimaciji polinomima visokogi niskog stepena.
Primer 46 Najcesca primena konvolutivnih neuronskih mreza je u obradi slika. Po-kazale su se izuzetno uspesnim u prepoznavanju objekata na slikama. Kao sto je receno,nizi slojevi konvolutivne mreze detektuju jednostavne oblike. Vrlo je lako ustanoviti kojioblik detektuju jedinice prvog konvolutivnog nivoa. To je oblik za koji one daju najvisevrednosti na izlazima. Kako je aktivaciona funkcija monotona, to je oblik koji dajenajvisu vrednost linearne kombinacije koju jedinica racuna. Ako su koeficijenti jedinicew, oblik je dat kao resenje problema
max||x||=1
w · x
Normiranje je vazno posto bi u slucaju da je skalarni proizvod pozitivan, povecavanjemintenziteta vektora x, uvek mogla biti dostignuta proizvoljna vrednost skalarnog proi-zvoda. Pod tim uslovom, lako se ustanovljava (recimo, postavljanjem parcijalnih izvodapo x na 0) da se maksimalna vrednost dostize za vrednost w = /||w||. Stoga, da bise prikazao oblik koji jedinica najnizeg konvolutivnog sloja prepoznaje, dovoljno je vi-zualizovati njene koeficijente u vidu slike cije dimenzije odgovaraju dimenzijama filterakoji ta jedinica predstavlja. Vizualizacija oblika koje prepoznaju visi nivoi konvolutivnemreze je komplikovanija i zahteva neki vid optimizacije, kako bi se nasli ulazi u mrezuza koje ove jedinice daju najvise vrednosti. Ova vrsta analize je vazna zbog toga sto po-kazuje koja svojstva analiziranih objekata, u ovom slucaju slika, su vazna za obavljanjeposla koji mreza obavlja. Ova informacija ne mora uvek biti poznata korisniku i mozepredstavljati novo saznanje.


Glava 11
Pravila pridruzivanja
Za dati skup transakcija (slogova) naci pravila koja predvidaju pojavljivanje stavke(objekta) na osnovu pojavljivanja ostalih stavki (objekata) u transakciji. Tipican primerje potrosacka korpa.
Tabela 11.1: Transakcije potrosacke korpe
TID Stavke
1 Hleb, Mleko2 Hleb, Pelene, Pivo, Jaja3 Mleko, Pelene, Pivo, Kola4 Hleb, Mleko, Pelene, Pivo5 Hleb, Mleko, Pelene, Kola
U tabeli 11.1 je dat primer potrosackih korpi. Sta je pitanje? Da li mi iz ovih poda-taka mozemo nekako da donosimo zakljucke? Npr. da ce neko ko kupuje hleb kupiti imleko. Iz ovih podataka vidimo da ima ljudi koju su kupili hleb a nisu mleko i obrnuto.Ali mozemo reci da relativno cesto kupuju mleko oni koji kupuju hleb.
Primeri pravila pridruzivanja:{Pelene} −→ {Pivo},{Mleko, Hleb} −→ {Jaja, Kola}.
Na koji nacin mozemo da dodemo do ovakvih pravila? Kako da znamo koja odtih pravila su zapravo korisna? Primena je jasna. Na konkretnom primeru potrosackekorpe, recimo da zelimo da stavimo neke proizvode na snizenje. Na osnovu pravilapridruzivanja cemo odrediti koje. Ako znamo da ljudi koji kupuju hleb kupuju i mlekona osnovu pravila, onda necemo staviti i jedno i drugo na snizenje, vec samo jedno jerce drugo svakako kupiti.
Pravila pridruzivanja opisuju relacije izmedu skupova elemenata u podacima, i oblikasu
A −→ B,
gde su A i B skupovi elemenata predstavljeni u skupu podataka.
117

118 GLAVA 11. PRAVILA PRIDRUZIVANJA
Na primer, pravilo pridruzivanja {hleb, mleko} −→ {pelene} tumaci se na sledecinacin:
’’ako kupac kupi hleb i mleko, (verovatno) ce kupiti i pelene”. Stavke (engl.
items) su hleb, mleko, pelene. Skup stavki (engl. itemset) sadrzi jednu ili vise stavki.K-skup stavki je skup koji sadrzi K stavki.
11.1 Osnovni pojmovi
Brojac podrske (engl. support count) (σ) je broj pojavljivanja skupa stavki. Npr. utabeli 11.1, σ({Mleko, Hleb, Pelene}) = 2.
Podrska je ucestalost pojavljivanja skupa stavki u transakcijama. Npr. σ({Mleko,Hleb, Pelene}) = 2/5.
Cest skup stavki je skup stavki cija je podrska veca ili jednaka od navedenog praga(minsup).
Pravilo pridruzivanja je implikacija oblika X −→ Y , gde su X i Y skupovi stavki.Npr. {Mleko, Pelene} −→ {Pivo}.
11.2 Metrika za procenu kvaliteta
Podrska je kolicnik broja transakcija koje sadrze i X i Y i ukupnog broja transakcijatj. govori nam koliko se puta X i Y zajedno javljaju podeljeno sa ukupnim brojempravila. Podrska nam govori koliko je to pravilo korisno.
s(X −→ Y ) =σ(X ∪ Y )
N.
Pouzdanost (poverenje, engl. confidence) meri koliko cesto se stavka Y javlja utransakcijama koje sadrze X tj. ako je X u transakciji onda je i Y u transakciji. Bitnesu nam samo one transakcije u kojima se javlja X. Pouzdanost nam govori koliko jepravilo precizno.
c(X −→ Y ) =σ(X ∪ Y )
σ(X).
Obicno ocekujemo visoko poverenje jer da li nam je zaista potrebno pravilo koje jeu pravu u 10% slucajeva? Naravno da nije. I 50% je malo, bacacemo novcic pre negoda odredujemo pravila. Znaci zaista nas zanimaju pravila koja su vrlo cesto tacna stoznaci da im je visoka pouzdanost.
’’Jako” pravilo, ukazuje na visok nivo uzrocnosti,
pridruzivanja, asocijacije izmedu elemenata i ovakva pravila su od interesa. Sa drugestrane, visoka podrska znaci da se pojavljuje cesto, manje je verovatno da se praviloslucajno pojavilo. Primetimo da ako trazimo visoku pouzdanost, ne mozemo da trazimoi visoku podrsku zato sto je mozda fenomen koji se ispituje veoma komplikovan. Jednopravilo je jednostavna stvar, ali ne mozemo ocekivati da ce ljudi uvek kupiti sve te stvarisa leve strane pravila. Zato mozemo da koristimo mnogo malih pravila koja su podrskenpr. 5-10% i neko ce sigurno da upali.
Za dati skup transakcija (slogova) T cilj istrazivanja pravila pridruzivanja je pronacisva pravila koja imaju podrsku vecu od nekog praga (minsup) i pouzdanost vecu odnekog praga (minconf). Na primer, potrebna su nam pravila koja se korista u najmanje

11.3. FORMIRANJE PRAVILA PRIDRUZIVANJA 119
10% slucajeva i cija je preciznost najmanje 90%. Kako naci pravila koja zadovoljavajute pragove?
Prvi nacin je, naravno, gruba sila. Izlistamo sva moguca pravila pridruzivanja, zatimizracunamo podrsku i pouzdanost za svako od pravilo. Na kraju potkresemo pravila kojane zadovoljavaju minsup i minconf prag. Ovo je racunarski vrlo zahtevan proces i obicnose to ne radi tako.
11.3 Formiranje pravila pridruzivanja
Formiranje pravila pridruzivanja sastoji se iz dva koraka:
1. formiranje podrzanih (cestih) skupova stavki: Formirati sve skupove stavki kodkoijh je podrska ≥ minsup,
2. formiranje pravila iz cestih skupova: Formirati pravila sa visokom pouzdanoscu izsvakog skupa stavki, pri cemu je svako pravilo binarna podela cestog skupa stavki.
Kako nalazimo cest skup i koja cemo pravila napraviti od tog skupa? Koristi se Apri-ori algoritam koji realizuje jedan vrlo vazan princip, tzv. anti-monotonost. Sta principkaze? Ako je skup stavki cest, tada su i svi njegovi podskupovi takode cesti. Ako seneki od podskupova ne javlja cesto onda se ni skup ne javlja cesto tj. ako neki skup nijecest onda ni njegovi nadskupovi nisu cesti. To nazivamo anti-monotonost. Sta nam togovori? To nam govori da mozemo nekako da nademo nacin da sistematizujemo generi-sanje skupova stavki i onda cim vidimo neki skup koji nije cest ne generisemo njegovenadskupove. Tako donekle kontrolisemo eksponencijalnu eksploziju koja se javlja.
Slika 11.1: Resetka skupa pravila
Na slici 11.1 prikazana je resetka skupa pravila sa primenom anti-monotonosti. Kakose pravi resetka? Polazi se od praznog skupa. Zatim se dodaju skupovi pojedinacnihstavki, pa se od svakog prave dvoclani, troclani, ..., n-toclani skupovi stavki. Ako skupAB nije cest, onda sigurno i njegovi nadskupovi (obelezeni sivom bojom na slici) nisu

120 GLAVA 11. PRAVILA PRIDRUZIVANJA
cesti. Cim taj jedan nije cest, on povlaci da nisu cesti ni svi njegovi nadskupovi, uokvirenicrvenom isprekidanom linijom, i to je vrlo mocan mehanizam odsecanja.
11.3.1 Apriori algoritam
U nastavku je dat apriori algoritam, a na slici 11.2 je graficki prikazan apriori algo-ritam. Algoritam glasi:
• Na pocetku uzeti k = 1
• Formirati ceste skupove stavki kardinalnosti 1
• Ponavljati proces sve dok se prestane sa pronalazenjem cestih skupova stavki
• Formirati skupove stavki duzine (k + 1) iz skupova stavki duzine k
• Potkresati kandidatske skupove stavki koji sadrze podskup kardinalnosti k koji nijecest (jeftino odsecanje)
• Prebrojati podrsku za svakog kandidata pregledanjem baze
• Ukloniti kandidate koji su retki (tj. ostaviti samo one koji su cesti) (skupo odse-canje jer smo prvo morali da prodemo celu bazu i prebrojavamo da bismo utvrdilida kandidat nije cest)
Slika 11.2: Apriori algoritam

11.3. FORMIRANJE PRAVILA PRIDRUZIVANJA 121
Ilustracija Apriori principa Na slici 11.3 prikazana je primena apriori principa.Transakcije su zadate u prvoj tabeli. Zelimo da minimalna podrska bude strogo vecaod 1. U prvom prolazu inicijalizujemo jednoclane skupove. U ovom trenutku mozemoda vrsimo samo skupa odsecanja jer smo tek na pocetku i ovi skupovi nemaju nekepodskupove koji nisu cesti. Zato vrsimo prebrojavanje i dolazimo do zakljucka da {D}nije cest pa ga izbacujemo. Ostaju nam {A}, {B}, {C} i {E} i od njih generisemo veceskupove, dimenzije 2. Za dobijene skupove vrsimo prebrojavanje i izbacujemo one cijaje podrska 1, to su {A, B} i {A, E}. Ostaju nam skupovi: {A, C}, {B, C}, {B, E} i {C,E}. Od njih mozemo napraviti jedan troclani skup koji se javlja u transakcijama, a toje {B, C, E}
Slika 11.3: Primer primene apriori principa
Sad se postavlja pitanje, kako od skupova formiramo nadskupove? Jedan nacin jevrlo jednostavan – dodajemo po jedan element u svaki od njih. Medutim, tako ce selako desiti da dva puta napravimo isti nadskup i trosimo vise vremena za prebrojavanje.Npr. imamo skupove {A,B} i {B,C}. Od prvog skupa dobicemo nadskup {A,B,C}dodavanjem elementa C, a od drugog dobijamo isti nadskup dodavanjem elementa A.Ovo se naziva Fk−1 × F1 metoda (na k − 1 dodajemo jos 1). Potrebno je da su stavkeuvek leksikografski uredene u skupu. Dakle, nece postojati skup {B,A} nego {A,B}.Drugi, bolji, nacin je Fk−1 × Fk−1 metod, koja zahteva leksikografsko uredenje stavki.Neka su A = {a1, a2, ..., ak−1} i B = {b1, b2, ..., bk−1} par cestih k-skupova stavki. A iB mogu da se kombinuju ako zadovoljavaju uslov ai = bi za svako i = 1, 2, . . . , k − 2, iak−1 6= bk−1. Dakle, ideja je da se dva skupa koja se razlikuju samo po jednom elementuspoje u jedan.
Primer formiranja Fk−1 × Fk−1 metodom Neka imamo skup cestih skupova C3 ={abc, abd, acd, ace, bcd} (podrzani 3-skupovi). Spajanjem skupova iz C3 dobijamo noveskupove:
• abcd iz abc i abd

122 GLAVA 11. PRAVILA PRIDRUZIVANJA
• acde iz acd i ace
Potkresivanje (izostavljanje nepodrzanih skupova) radimo na sledeci nacin: Primecujemoda acde ima podskup ade koji nije u C3 pa ga izostavljamo i jedini kandidat koji namostaje je C4 = {abcd}, ali za njega treba izvrsiti prebrojavanje kako bi se utvrdilo da lije cest.
11.3.2 Razmatranje slozenosti algoritma
Faktori koji uticu na slozenost su:
Izbor praga podrske Smanjenje praga podrske daje veci broj cestih skupova stavki.Ovim se povecava broj kandidata i najveca duzina cestih skupova stavki. Sto jezahtevana podrska veca, to cemo ranije krenuti da odsecamo.
Dimenzionalnost (broj stavki) skupa stavki Broj stavki utice na velicinu resetke,ona eksponencijalno raste u odnosu na broj stavki. Potrebno je vise prostora zacuvanje brojaca podrske za sve stavke. Ako se broj cestih skupova stavki poveca,povecava se i cena izracunavanja i izvodenja U/I operacija.
Velicina baze podataka Posto Apriori pravi vise prolaza, sa povecanjem broja trans-akcija raste i vreme izvrsavanja algoritma
Prosecna velicina (sirina) transakcije Velicina transakcije povecava ucestalost skupastavki. Ovim se povecava najveca duzina cestih skupova stavki i skupova koji seobilaze u hes drvetu (broj podskupova transakcije se povecava sa povecanjem njenevelicine).
11.4 Formiranje pravila pridruzivanja
Zapocnimo ovaj deo narednom definicijom.
Skup stavki je maksimalno cest ako ni jedan od njegovih neposrednih nadskupovanije cest.
Na slici 11.4 dat je primer skupova stavki koji su maksimalno cesti.Svaki cest k-skup stavki moze da proizvede do 2k − 2 pravila pridruzivanja (ignorisu
se pravila sa praznom levom ili desnom stranom).Pravilo se izdvaja deljenjem skupa stavki Y na dva neprazna podskupa X i Y −X,
takve da X −→ Y −X ima vecu pouzdanost od zadatog praga.Svako takvo pravilo mora da zadovoljava i uslov da je vece od praga podrske.Za dati cest skup stavki L, naci sve neprazne podskupove f ⊂ L takve da f −→ L–f
zadovoljava minimum zahteva za pouzdanoscu. Ako je {A,B,C,D} cest skup stavki,pravila kandidati su:
ABC −→ D,ABD −→ C,ACD −→ B,BCD −→ A,
A −→ BCD,B −→ ACD,C −→ ABD,D −→ ABC
AB −→ CD,AC −→ BD,AD −→ BC,BC −→ AD,

11.5. MERE KVALITETA 123
Slika 11.4: Primer maksimalno cestih skupova stavki
BD −→ AC,CD −→ AB,
Ako je |L| = k, tada postoji 2k–2 kandidata za pravila pridruzivanja (zanemaruju seL −→ ∅ i ∅ −→ L)
Postavlja se pitanje, kako efikasno formirati pravila iz cestih skupova stavki? Naosnovu podrske smo organizovali pretragu resetke koja se odnosi na sve skupove stavki,a sada kad imamo jedan skup stavki iz njega mozemo da generisemo gomilu pravila. Dali nekako mozemo da se oslonimo na pouzdanost da organizujemo pretragu tog skupapravila? Odgovor je da, mozemo. U opstem slucaju, pouzdanost nema osobinu antimo-notonosti: c(ABC −→ D) moze da bude vece ili manje od c(AB −→ D)
Medutim, pouzdanost pravila izvedenih iz istog skupa pravila poseduje osobinu an-timonotonosti. Npr. L = {A,B,C,D} : c(ABC −→ D) ≥ c(AB −→ CD) ≥ c(A −→BCD). Dakle, ako nam pravilo AB −→ C nije pouzdano, onda sva pravila koja sedobijaju smanjivanjem leve strane i povecavanjem desne takode nisu pouzdana. Na slici11.5 dat je primer formiranja pravila za apriori algoritam.
Pravila kandidati se formiraju uparivanjem dva pravila koja dele isti prefiks na desnojstrani. Vrsi se spajanje (CD −→ AB, BD −→ AC) i to proizvodi kandidata za praviloD −→ ABC. Potkresati pravilo D −→ ABC ako njegov podskup AD −→ BC nemavisoku pouzdanost.
11.5 Mere kvaliteta
Pored pouzdanosti i podrske korisitimo jos neke mere za odredivanje kvaliteta. Zadefinisanje razlicitih mera koristi se tabela kontigenata.

124 GLAVA 11. PRAVILA PRIDRUZIVANJA
Slika 11.5: Primer formiranja pravila za apriori algoritam
Tabela 11.2: Tabela kontigenata za pravilo X −→ Y
Y Y
X f11 f10 f1+X f01 f00 f0+
f+1 f+0 |T |
U tabeli 11.2, f11 predstavlja podrsku za X i Y odnosno predstavlja koliko putase javljaju zajedno u transakcijama, f10 govori koliko puta se javlja X a ne javlja seY tj. to podrska za X i Y , f01 je podrska za X i Y odnosno koliko puta se Y javljau transakcijama bez X i f00 je podrska za X i Y tj. broj transakcija u kojima se nejavljaju ni X ni Y .
Zasto nismo zadovoljni time da imamo pravila sa relativno visokom podrskom ivisokom pouzdanoscu? Ispostavlja se da pouzdanost moze da nam da neka pravila kojanas mozda i ne zanimaju. Pogledajmo sledeci primer:
Tabela 11.3: Primer tabele kontigenata
Kafa Kafa
Caj 15 5 20
Caj 75 5 80
90 10 100
Neka je dato pravilo Caj −→ Kafa. Ako neko pije caj onda pije i kafu. Pouzdanostpravila je P (Kafa|Caj) = 0.75, a znamo da P(Kafa) = 0.9. Ako vecina ljudi piju kafuonda ovo pravilo nista pametno ne govori. Visoka je pouzdanost da ce onaj ko pije cajpiti i kafu, a zapravo svi piju kafu. Poenta je da su pravila koja su vrlo pouzdana mogubiti pouzdana ne zbog uzajamne veze X i Y nego zato sto Y ionako skoro uvek vazi.Tako da nam ovakva pravila nisu zanimljiva.

11.5. MERE KVALITETA 125
11.5.1 Mere koje uzimaju u obzir statisticku zavisnost
Prikazimo prvo formule za racunanje ovih mera, a zatim cemo reci nesto o nekimaod njih.
Lift =P (Y |X)
P (Y )
Interest =P (X,Y )
P (X) · P (Y )
PS = P (X,Y )− P (X) · P (Y )
φ-coefficient =P (X,Y )− P (X) · P (Y )√
P (X)[1− P (X)]P (Y )[1− P (Y )]
11.5.1.1 Lift
Lift se dobija deljenjem pouzdanosti podrskom. Pouzdanost i podrska itekako imajuveze sa verovatnocama, one aproksimiraju ove dve verovatnoce. Ukoliko je verovatnocaprilicno visoka onda se moze desiti P (Y |X) < P (Y ) i dobicemo brojeve manje od 1,tj. obaramo vrednost. Lift moze biti u intervalu [0,∞]. Ako se dobije vrednost uintervalu [0, 1], to je nezanimljivo pravilo. U primeru sa kafom i cajem upravo imamotakvo pravilo:
Lift =0.75
0.9= 0.8333 < 1.
Sa druge strane, imamo zanimljiva pravila, za vrednosti preko 1. Lift modelujeiznenadenje. Recimo, Y se javlja cesto, ali kad imamo X onda se javlja jos cesce.
Moze se desiti da to sto Lift daje nije uvek zanimljivo. Pogledajmo primer:
Za tabelu levo, vazi da je pouzdanost vrlo visoka jer se X i Y javljaju zajedno ili seuopste ne javljaju, nema slucaja kad se X pojavljuje a Y nema i obrnuto. Pouzdanost
je 100%, a Lift =0.1
(0.1) · (0.1)= 10, dakle, pravilo je zanimljivo. Za tabelu desno
su stvari obrnute. X i Y se cesce javljaju zajedno. Pouzdanost ostaje ista, 100%,
a Lift =0.9
(0.9) · (0.9)= 1.11. Desilo se da je Lift mnogo manji. P (Y ) je vece, tj.
podrska je veca, imamo visoku preciznost, a pravilo nam je postalo manje zanimljivo.Zakljucujemo da ni ova mera nije savrsena. Zapravo, nijedna nije savrsena!

126 GLAVA 11. PRAVILA PRIDRUZIVANJA
11.5.1.2 φ-koeficijent
φ-koeficijent je analogan koeficijentu korelacije za neprekidne promenljive. Prime-timo da ako su X i Y nezavisni, onda je P (X,Y ) = P (X) · P (Y ), pa ce mera dativrednost 0 kao sto i treba da bude, u suprotnom se ove verovatnoce razlikuju. Dodatno,normiramo razliku verovatnoca, kao sto i kod korelacije to radimo. Izraz pod korenomje izraz za disperziju Bernulijeve raspodele (kod korelacije se takode deli korenom izdisperzije). Pogledajmo sledeci primer:
Slika 11.6: Primer tabele kontigenata
Na slici ?? imamo dve tabele sa obrnutim vrednostima, kao sto smo to imali ikod Lift mere. Mozemo primetiti da obrtanjem vrednosti ne menjamo vrednost φ-
koeficijenta. Za tabelu levo, φ =0.6− 0.7 · 0.7√
0.7 · 0.3 · 0.7 · 0.3= 0.5238, a za tabelu desno,
φ =0.2− 0.3 · 0.3√
0.7 · 0.3 · 0.7 · 0.3= 0.5238, dakle, isti su. Naravno, ni ova mera ne modeluje
intuiciju u potpunosti.
11.5.2 Osobine dobre mere
Dobra mera mora da zadovoljava sledece tri osobine:
1. M(A,B) = 0 ako su A i B statisticki nezavisne.
2. M(A,B) se monotono povecava sa P (A,B) kada P (A) i P (B) ostaju neprome-njene.
3. M(A,B) se monotono smanjuje sa P (A) [ili P (B)] kada P (A,B) i P (B) [ili P (A)]ostaju nepromenjene.

Glava 12
Klasterovanje
12.1 Uvod u klaster analizu
Cilj klasterovanja (ili klaster analize) jeste pronalazenje grupa objekata takvih da suobjekti u grupi medusobno slicni (ili povezani), a da su objekti u razlicitim grupamamedusobno razliciti (ili nepovezani). Mozemo reci da su rastojanja unutar klasteraminimizovana dok su rastojanja izmedu klastera velika.
12.1.1 Primena klaster analize
Osvrnimo se na neke primene klasterovanja:
• Razumevanje
◦ pregledanje dokumenata iz iste grupe – neke reci su karakteristicnije za neketeme, nego za neke druge
◦ grupisanje gena i proteina koji imaju iste funkcionalnosti
◦ grupisanje akcija sa slicnim promenama cena
• Za upotrebu u drugim metodima
◦ Sumarizacija – kada imamo veliki broj podataka i ne mozemo da ih pregle-damo tako lako, mozemo da uradimo klasterovanje i dobijemo grupe i ondarazmatramo samo jedan podatak iz svake grupe a ne sve podatke
◦ Kompresija – redukcija palete boja, ustanovimo grupe boja, sve piksele iz istegrupe obojimo istom bojom.
◦ Efikasno nalazenje najblizih suseda – poredimo sa pojednim predstavnikomiz svakog klastera, klasteri su medusobno dobro razdvojeni i nije bitno kogpredstavnika izaberemo kao najblizeg suseda, ili da suzimo pretragu na jedanklaster
Treba razmisliti sta nije klaster analiza. Pogledajmo naredne primedbe:
• Klasifikacija pod nadzorom (nadgledana klasifikacija) nije klasterovanje jer klaste-rovanje nema nikakvu dodatnu informaciju koja nam je relevantna (prisetimo seda u klasifikaciji pod nadzorom postoje informacije o oznakama klasa).
127

128 GLAVA 12. KLASTEROVANJE
• Jednostavna podela podataka, kao sto je, na primer, podela studenata po prvomslovu prezimena, nije klasterovanje jer nisu studenti nista slicniji zbog toga sto imprezime pocinje istim slovom.
• Rezultat upita (odnosi se na GROUP BY i slicne efekte) nije klasterovanje jer je takvogrupisanje rezultat spoljasnje specifikacije.
Sa druge strane, podela grafa i te kako moze biti klasterovanje jer pociva na idejislicnosti, bliskosti. Na primer, na Facebook-u smo sa nekim ljudima bolje povezani, sanekima manje povezani. U smislu marketinga ili neceg relevantnog Facebook-u boljepovezani ljudi su slicniji te se mogu klasterovati.
Pojam klastera je nesto sto nije lako definisati. Gotovo uvek smo i mi sami u ne-doumici koliko klastera se moze pronaci u podacima. Primer na slici 12.1 ilustruje ovajfenomen.
Slika 12.1: Dvosmislenost pojma klastera.
12.1.2 Tipovi klasterovanja
Tipovi metoda klasterovanja su:
• hijerarhijsko/particiono;
• ekskluzivno/neekskluzivno – da li tacke mogu da se nalaze u vise klastera (neek-skluzivno) ili ne mogu (ekskluzivno);
• rasplinuto/nerasplinuto – u kojoj meri tacka pripada nekom klasteru. U rasplinu-tom klasterovanju tacka pripada svakom klasteru sa nekom tezinom izmedu 0 i 1.Zbir svih tezina je jednak 1;
• delimicno/kompletno – nekada se moze delimicno klasterovati skup, odnosno, unekim slucajevima moze se klasterovati samo deo podataka (na primer, ako podacine pripadaju dobro definisanim grupama);
• heterogeno/homogeno – da li su klasteri razlicitog oblika, velicine ili gustine.

12.1. UVOD U KLASTER ANALIZU 129
Hijerarhijsko i particiono su dve najzastupljenije grupe. Postoji znacajna razlikaizmedu hijerarhijskog i particionog skupa klastera. Particiono klasterovanje je podelaskupa podataka u nepreklapajuce (disjunktne) podskupove (klastere) takve da je svakipodatak tacno u jednom podskupu. Hijerarhijsko klasterovanje je skup ugnezdenih kla-stera organizovan u obliku hijerarhijskog stabla (koje nazivamo dendogram) i daje namdublje informacije o samoj strukturi podskupova. Broj klastera zavisi od dubine na ko-joj posmatramo stablo. Odnosno, sekuci dendogram na nekom nivou dobijamo raliciteklastere. Slike 12.2 i 12.3 ilustruju primere particionog i hijerarhijskog klasterovanja,redom.
Slika 12.2: Particiono klasterovanje.
Slika 12.3: Hijerarhijsko klasterovanje.

130 GLAVA 12. KLASTEROVANJE
12.1.3 Tipovi klastera
Tipovi klastera se razlikuju po principima koje koristimo da definisemo sta je klaster:
• Dobro razdvojeni klasteri (engl. well-separated),
• Klasteri zasnovani na centru (engl. center-based, prototype-based),
• Klasteri zasnovani na grafovima (engl. graph-based),
• Klasteri zasnovani na gustini (engl. density-based),
• Konceptualni klasteri (engl. conceptual)
• Opisani ciljnom funkcijom (engl. described by an objective function)
Dobro razdvojeni klasteri Klaster je skup tacaka takvih da je bilo koja tacka uklasteru blize (ili vise slicna) ostalim tackama u klasteru nego tackama koje nisu uklasteru. Jedan primer je dat na slici 12.4. Bitno je napomenuti da su rastojanjaizmedu krugova veca nego precnici krugova. Time se dobija da je svaka crvena tackabliza bilo kojoj crvenoj tacki nego plavoj ili zelenoj. Naravno, to je idealna situacija.U praksi podaci verovatno nikada nece biti dobro razdvojeni pa samim tim cemo tezedobijati dobro razdvojene klastere.
Slika 12.4: Tri dobro razdvojena klastera.
Klasteri zasnovani na centru Klaster je skup objekata takvih da je bilo koji obje-kat u klasteru blize (ili vise slican) centru (tzv. prototipu) klastera u odnosu na centre(prototipove) ostalih klastera. Centar klastera je cesto centroid (prosek svih tacaka uklasteru) ili medioid (najreprezentativnija tacka u klasteru). Elementi jednog klasterace biti blizi centru svog klastera nego centrima drugih klastera, ali mogu biti blizi ele-mentima drugog klastera nego svom centru.
Klasteri zasnovani na susedstvu Klaster je skup tacaka takvih da je tacka u kla-steru bliza (ili vise slicna) jednoj ili vise tacaka u svom klasteru nego bilo kojoj tackikoja nije u njenom klasteru. Susednost moze biti najblizi sused ili tranzitivnost. Ondamogu da se dese mnogo komplikovaniji oblici, da nisu centricni, ili dobro razdvojeni, aliu svakom slucaju postoje bliske tacke u okviru klastera.

12.1. UVOD U KLASTER ANALIZU 131
Slika 12.5: Cetiri klastera zasnovana na centru.
Slika 12.6: Osam susednih klastera.
Klasteri zasnovani na gustini Klasteri su oblasti sa velikom gustinom tacaka koje surazdvojene oblastima sa malom gustinom tacaka. Koriste se kada su klasteri nepravilniili isprepleteni, i kada je prisutan sum ili elementi van granica. Regioni male gustine sedozivljavaju kao neki pozadinski sum.
Slika 12.7: Sest klastera zasnovanih na gustini.
Konceptualni klasteri Klasterovanje na osnovu zajednickih osobina, kada je klasterdefinisan nekim svojstvom. Elementi dele neko svojstvo koje definise klaster. Zadatakje naci klastere koji dele neku zajednicku osobinu ili predstavljaju pojedinacni koncept.To je najapstraktnija metoda. Nemamo metode koje nalaze najrazlicitije vrste koncep-tualnih klastera onako kako bi ih covek prepoznao.
Klasteri opisani ciljnom funkcijom Prethodni tipovi su bili eksplicitno predsta-vljeni, odnosno, mogli smo precizno da vidimo koje tacke pripadaju kom klasteru. Opisi-vanje klastera ciljnom funkcijom predstavlja implicitan metod, tj. treba pronaci klasterekoji minimizuju/maksimizuju ciljnu funkciju.
Mozemo razlicitno klasterovati tacke na jedan nacin i dobiti jednu vrednost ciljnefunkcije, a na drugi nacin dobiti drugu vrednost, a zatim da odaberemo onaj nacinkoji daje najvisu vrednost ciljne funkcije. Neke od dobijenih ciljnih funkcija mogu daodgovaraju nekom od prethodno definisanih klastera.
Mogu da postoje lokalni ili globalni ciljevi. Algoritmi hijerarhijskog klasterovanjaobicno imaju lokalne ciljeve. Algoritmi particionog klasterovanja obicno imaju globalneciljeve.

132 GLAVA 12. KLASTEROVANJE
Slika 12.8: Dva konceptualna klastera.
Varijanta pristupa sa globalnom ciljnom funkcijom je ukalupiti podatke u parametri-zovani model. Parametri modela su izvedeni iz podataka. Mesani modeli pretpostavljajuda su podaci mesavina nekoliko statistickih raspodela. Na slici 12.9 dat je primer skupapodataka u kojem podaci dolaze iz dve razlicite raspodele.
Slika 12.9: Primer modela mesavine raspodela. Crveni podaci poticu iz normalne ras-podele N(−10, 5.5), a plavi podaci iz normalne raspodele N(10, 5.5).
12.2 Algoritmi klasterovanja
U ovom poglavlju govoricemo o tri jednostavnim, ali vaznim tehnikama klasterovanja.Preciznije, bice reci o:
• K-sredine. Ovo je tehnika zasnovana na centru i particionisanju, koja pokusavada pronade korisnicki definisan broj klastera (K), koji su reprezentovani svojimcentrima.
• Hijerarhijsko klasterovanje. Ovaj pristup proizvodi hijerarhijsko klasterovanjetako sto pocinje od svake tacke kao singltonski klaster, a zatim nadalje spaja dvanajbliza klastera u jedan, sve dok se ne dobije tacno jedan, sveobuhvatni klaster.
• DBSCAN. Ovo je pristup klasterovanju zasnovan na gustinama koji proizvodiparticionisane klastere, pri cemu je broj klastera automatski odreden od stranealgoritma. DBSCAN ne proizvodi kompletno klasterovanje.

12.3. K-SREDINE 133
12.3 K-sredine
K je broj klastera koji zelimo da nademo. Tradicioalno nam se to kod njega ne svida,jer obicno ne znamo koliko klastera ima u podacima, a algoritam jos manje zna. Zato ceda K predstavlja broj sredina (centroida) i da se tih K sredina azurira u svakom koraku.
Formulacija algoritma Osnovni algoritam K-sredine prikazan je algoritmom 6.
Algoritam 6 Osnovni algoritam K-sredine.
1: procedure OsnovniAlgoritamKSredine(K)2: Odabrati K instance za inicijalne centroide3: repeat4: Obrazuj K klastera dodeljivanjem svih tacaka najblizim centroidama5: Preracunaj centroide svakog klastera6: until Centroide se ne menjaju7: end procedure
Nasumice izaberemo K instanci iz nasih podataka i one ce predstavljati polaznecentroide. Klastere dobijamo tako sto preraspodelimo instance najblizim centroidama.Sledeci korak je da izracunamo centroide tako dobijenih klastera. Te centroide ne morajuodgovarati polaznim. A onda ponovo uradimo preraspodelu.
Primetimo da se smenjuju dva koraka: izracunavanje centroida i preraspodela in-stanci po klasterima. Ovo radimo sve dok se sredine menjaju. To ce posle nekog vremenasigurno iskonvergirati. Obicno broj iteracija nije veliki i brzo iskonvergira te slozenostnije velika.
U formulaciji prethodnog algoritma pominje se pojam bliskosti. Najblize rastoranjese meri kao Euklidsko rastojanje, kosinusno rastojanje, korelacija, itd. K-sredine kon-vergiraju ka prethodno pomenutim merama slicnosti. Moze se pokazati da se najvecideo konvergencije desava u prvih nekoliko iteracija. Cesto se uslov zaustavljanja menjana
’’sve dok relativno malo tacaka ne promeni klaster”.
Slozenost algoritma Za slozenost prethodnog algoritma razmatramo sledece: n jebroj tacaka, K je broj klastera, I je broj iteracija i d je broj atributa. Vremenskaslozenost je reda O(n · K · I · d), dok je prostorna slozenost reda O((n + K) · d). Akoje broj tacaka preveliki, mozemo da uzmemo uzorak. Broj klastera mi kontrolisemo.Broj iteracija nije veliki zbog brze konvergencije. Broj atributa utice u poredenju kadracunamo rastojanje, pri cemu mi mozemo smanjiti dimenzionalnost. Zakljucak kojimozemo izvesti je da je ovaj algoritam ipak racunski efikasan (iako nam se izraz n·K ·I ·dinicijalno moze uciniti velikim).
Evaluacija K-sredine klastera Zanima nas matematicka pozadina algoritma. Mo-ramo da odredimo ciljnu funkciju i mere kvaliteta koje opisuju sta je dobro. Moramo daminimizujemo funkciju greske.
Za podatke u Euklidskom prostoru se najcesce kao mera koristi zbir kvadrata gresaka(engl. sum of squared errors (SSE )). Za svaku tacku, greska je rastojanje do najblizeg

134 GLAVA 12. KLASTEROVANJE
centroida (klastera). Dobijene greske se kvadriraju i sabiraju. Formula je data sa
SSE =
k∑i=1
∑x∈Ci
dist2(mi, x),
gde je x tacka u klasteru Ci , mi je reprezentativna tacka u klasteru Ci. Moze se pokazatida mi odgovara centru (srednjoj vrednosti) klastera.
Od dva data klastera bira se onaj sa manjom greskom. Naivan nacin za smanjenjeSSE je povecanje broja klastera K. Dobra klasterizacija sa malim K moze da imamanju SSE gresku od lose klasterizacije sa velikim K. Ali ne treba to raditi na silu.SSE zapravo predstavlja funkciju greske, tj. cilju funkciju koja se minimizuje.
Karakteristike algoritma Na osnovu razmatranja samo formule ciljne funkcije kojualgoritam K-sredine minimizuje (SSE), mozemo doci do nekih zakljucaka. Prva osobinaje da se ovim algoritmom dobijaju globularni klasteri. Takode, ako je gustina ista, ondasu kalsteri jednake velicine. Mana kvadratnog rastojanja su atipicni elementi, jer uticuna kvalitet klastera. Takode, algoritam je osetljiv na velicinu prirodnih klastera, kao ina gustinu.
Slika 12.10: Ogranicenje K-sredina – razlicite velicine. Levo su prikazane originalnetacke, a desno tri klastera dobijena algoritmom K-sredina.
Slika 12.11: Ogranicenje K-sredina – razlicite gustine. Levo su prikazane originalnetacke, a desno tri klastera dobijena algoritmom K-sredina.
Problem u izboru pocetnih centroida Ako postoji K’’realnih” klastera, tada je
sansa da se izabere po jedan centroid u svakom od njih relativno mala. Ako je K veliko,

12.4. HIJERARHIJSKO KLASTEROVANJE 135
Slika 12.12: Ogranicenje K-sredina – neglobularni oblici. Levo su prikazane originalnetacke, a desno dva klastera dobijena algoritmom K-sredina.
sansa za dobar izbor je mala. Ako klasteri imaju istu velicinu n, tada vazi
P =broj nacina da se izabere centroid iz svakog klastera
broj nacina da se izabere K centroida=
K!nK
(Kn)K=K!
Kk.
Na primer, ako je K = 10, tada je P = 10!/1010 = 0.00036. Ponekad se inicijalnicentroidi sami poravnaju na
’’pravi” redosled, a ponekad ne.
Rad sa praznim klasterima Osnovni algoritam K-sredina moze da proizvede prazneklastere. Strategija za eliminaciju je zamena centroida. Postupak je sledeci: izabrati in-stancu koja najvise ucestvuje u SSE (tj. koja daje najveci doprinos kvadratnoj greski).Izabrati instancu koja je najdalje od tekucih centroida (ako je ona najdalja od tekucihcentroida, mozemo reci da mozda tekuce centroide nisu reprezentativne za taj deo pro-stora, pa pridruziti tom delu prostora novu centroidu koja ce biti reprezentativna zanjega). Ako ima vise praznih klastera ponoviti postupak.
Procesiranje podataka Kako bismo smanjili greske mozemo uraditi pretprocesira-nje: da normalizujemo podatke (zbog rastojanja), odstranimo elemente van granica ismanjimo dimenzionalnost. Za postprocesiranje takode imamo nekoliko opcija. Ako je-dan klaster ima veliku vrednost za SSE, a ostali malu, uzrok je mala vrednost za K, pataj klaster verovatno treba da se podeli na bar dva dela (predlog je podeliti primenomklasterovanja na tom klasteru). Moguce je vrsiti objedinjavanje klastera koji su
’’blizu”
i imaju relativno mali SSE.
12.4 Hijerarhijsko klasterovanje
Kao sto smo vec napomenuli, hijerarhijsko klasterovanje formira skup ugnezdenihklastera organizovanih u obliku drveta. Vizuelizuje se u obliku dendrograma, koji pred-stavlja redosled spajanja. Na slici 12.13 dat je primer dendograma i odgovarajuceghijerarhijskog klasterovanja. Na apscisi su date instance, a ordinate predstavljaju ra-stojanja na kojem su klasteri spojeni. Na primer, instance 1 i 3 su na rastojanju 0.05.Sto je rastojanje medu tackama vece, to je klaster heterogeniji, ako je rastojanje malo,spojili smo tacke koje su vrlo slicne. To dodatno pomaze u vizualizaciji.

136 GLAVA 12. KLASTEROVANJE
Slika 12.13: Primer dendograma (levo) i odgovarajuceg hijerarhijskog klasterovanja (de-sno).
Nije potrebno davati pretpostavke o broju klastera. Medutim, ako stvarno zelimo danademo odreden broj klastera, moramo navesti taj broj. Zeljeni broj klastera se dobijaskracivanjem dendograma na odgovarajucem nivou.
Tipovi hijerarhijskog klasterovanja Postoje dva glavna tipa hijerarhijskog klaste-rovanja. To su:
• Klasterovanje spajanjem (engl. agglomerative). U pocetku je svaka tacka jedanklaster. U svakom koraku se sakuplja najblizi par tacaka u klaster, pa par klasterau novi klaster, i tako sve dok ne ostane jedan klaster (ili K klastera).
• Klasterovanje razdvanjanjem (engl. divisive). Pocinje se sa jednim klasteromkoji ukljucuje sve tacke. U svakom koraku se klaster deli sve dok se ne dode dotoga da svaki klaster sadrzi samo jednu tacku ili dok se ne javi K klastera.
Formulacija algoritma Tradicionalno se u algoritmima klasterovanja koristi matricaslicnosti instanci. Element si,j matrica slicnosti instanci S govori koliko su instance i ij slicne. Vec odavde je jasno da je prostorna slozenost kvadratna (O(n2)).
Nadalje ce biti reci samo o hijerarhijskom klasterovanju spajanjem. Osnovni algori-tam hijerarhijskog klasterovanja dat je algoritmom 7.
Algoritam 7 Osnovni algoritam hijerarhijskog klasterovanja.
1: procedure OsnovniAlgoritamHijerarhijskogKlasterovanja2: Izracunati matricu slicnosti3: Neka je svaka tacka klaster4: repeat5: Objediniti dva najbliza klastera u odnosu na matricu slicnosti6: Azurirati matricu slicnosti7: until Ne ostane samo jedan klaster8: end procedure
Definisanje slicnosti izmedu klastera i azuriranje matrice slicnosti U pocetnomkoraku prethodnog algoritma u matrici slicnosti su se nalazile slicnosti izmedu instanci.

12.4. HIJERARHIJSKO KLASTEROVANJE 137
Medutim, svaki put kada se radi objedinjavanje dve instance, kolone i vrste koje odgo-varaju tim instancama se uklanjaju iz matrice slicnosti, a dodaje se nova vrsta i kolonakoje odgovaraju novom klasteru, sa vrednostima slicnosti izmesu tog klastera i drugihklastera. Algoritam se zavrsava sa matricom slicnosti klastera. Dakle, kljucna operacijaje izracunavanje slicnosti dva klastera.
Slika 12.14: Razne definicije slicnosti klastera: MIN ili’’jedna veza” (levo), MAX ili
’’kompletna veza” (sredina), prosek grupe (desno).
Na slici 12.14 prikazane su tri definicije slicnosti klastera: MIN, MAX i prosek grupe.Takode, moguce je razmatrati slicnost klastera kao rastojanje izmedu centroida. Recimonesto o predstavljenim trima slicnostima:
• MIN. Slicnost izmedu dva klastera se odreduje na osnovu dve najslicnije (najblize)tacke u razlicitim klasterima. Odreduje se jednim parom tacaka, tj. jednom vezomna grafu slicnosti. Ako koristimo MIN kao slicnost, onda mozemo da hvatamoproizvoljne oblike, ali je MIN osetljiv na sum i atipicne elemente.
• MAX. Slicnost izmedu dva klastera se odreduje na osnovu dve najmanje slicne(najdalje) tacke u razlicitim klasterima. Odreduju se parovi svih tacaka u razlicitimklasterima. Ako koristimo MAX kao slicnost, onda mozemo da hvatamo globularneoblike (koriscenje MAX za slicnost dovodi do toga da algoritam lici na K-sredine).Takode, postoji tendencija ka razbijanju velikih klastera. Ipak, osetljivost na sumi atipicne elemente je manja nego u slucaju MIN slicnosti.
• Prosek grupe. Slicnost dva klastera je prosecna vrednost slicnosti parova tacakau dva klastera. Predstavlja kompromis izmedu MIN i MAX. Manje je osetljivna sum i atipicne elemente zato sto su MIN i MAX osetljivi iz razlicitih razloga.Naklonost ka globularnim klasterima.
Slozenost algoritma Vec smo napomenuli da algoritam zahteva O(N2) prostora jerkoristi matricu slicnosti (pri cemu je N broj tacaka). Sto se tice vremenske slozenosti,algoritam zahteva O(N3) vremena u najvecem broju slucajeva: postoji N koraka i usvakom od njih se matrica slicnosti azurira i pretrazuje. Koristeci modifikovan pristupkompleksnost vremenskih zahteva moze da se redukuje na O(N2 log(N)). Naravno, jasnoogranicenje je da ne mogu da se koriste veliki skupovi podataka.
Ogranicenja algoritma Veoma bitna mana je da nema ciljne funkcije koja zahtevaminimizaciju, pa ne mozemo analizom da dodemo do zakljucaka, kao sto smo mogli kodalgoritma K-sredine. Vec smo videli da razlicite sheme imaju jedan ili vise problema sa:osetljivoscu na sum i elemente van granica, rukovanjem sa klasterima razlicite velicine,radom sa klasterima koji imaju konkveksan oblik i razbijanjem velikih klastera.

138 GLAVA 12. KLASTEROVANJE
12.5 DBSCAN
DBSCAN algoritam (skracenica od Density-Based Spatial Clustering of Applicationwith Noise) predstavlja klasterovanje zasnovano na gustini, odnosno, prepoznaje regionevisoke gustine koji su medusobno razdvojeni regionima niske gustine. Gustina je brojtacaka unutar odredenog poluprecnika (Eps).
Klasifikacija tacaka u odnosu na gustinu Instance mogu biti: (1) tacka u jezgru(engl. core point), (2) tacka na granici (engl. border point) i (3) sum (engl. noise point).Tacka A je tacka u jezgru ako je vise od zadatog broja tacaka (MinPts) unutar njeneEps okoline. U pitanju su tacke unutar klastera. Tacka A je tacka na granici ako imamanje od MinPts unutar svoje Eps okoline, ali je susedna sa tackom u jezgru, tj. onasama se nalazi u Eps okolini neke tacke u jezgru. Tacka A je sum ako nije ni tacka ujezgru ni tacka na granici. Ilustracija ove klasifikacije data je na slici 12.15.
Slika 12.15: DBSCAN – tacke u jezgru, na granici i sum. Parametri su Eps = 1 iMinPts = 4.
Formulacija algoritma Algoritam DBSCAN prikazan je algoritmom 8.
Algoritam 8 DBSCAN.
1: procedure DBSCAN(Eps, MinPts)2: Posmatramo tacke u jezgru (to su cvorovi grafa)3: if Ako su te tacke na rastojanju manjeg od Eps then4: Povezemo te tacke granama . Dobijamo komponente povezanosti grafa5: end if6: Dodamo tim tackama sve njihove granicne tacke i time dobijamo klaster(e) .
Ali ne spajamo granama granicne tacke, vec samo pridruzujemo komponentamapovezanosti
7: Eliminisemo preostale tacke . Odnosno, klasifikujemo ih kao sum8: end procedure

12.5. DBSCAN 139
Napomena za formulaciju prethodnog algoritma: ukoliko neka tacka na granici mozeda se pridruzi vecem broju tacaka u jezgru, onda biramo nasumicno kojoj tacki u jezgruse pridruzuje ta tacka na granici.
Na slici 12.16 dat je primer izvrsavanja algoritma DBSCAN. Levo su prikazane ori-ginalne tacke, u sredini klasifikacije instanci, a desno prepoznati klasteri. Parametrialgoritma su Eps = 10 i MinPts = 4. U sredini vidimo klasifikacije tacaka i to: zele-nom su oznacene tacke u jezgru, plavom tacke na granici i crvenom sum. Na slici desnosu razliciti klasteri prikazani razlicitim bojama.
Slika 12.16: Primer izvrsavanja algoritma DBSCAN.
Karakteristike algoritma Vec na slici 12.16 mozemo uociti da DBSCAN moze daprepoznaje klastere razlicitih oblika i velicina. Takode, otporan je na sum. Problemse javlja u situacijama kada su klasteri razlicitih gustina. Tada se odabirom razlicitihparametara Eps i MinPts mogu pogodno uhvatiti klasteri jedne gustine, ali ne i klasteridrugih gustina, a takode i da u odnosu na jedan klaster koji je vrlo gust neki drugi klaster(koji je redak) moze izgledati kao sum. U takvoj situaciji, DBSCAN nije otporan na sum.Na slici 12.17 date su originalne tacke, levo, i prepoznati klasteri za razlicite vrednostiparametara, desno (parametri za ishod desno gore su Eps = 9.75 i MinPts = 4, a zaishod desno dole su Eps = 9.92 i MinPts = 4).
Slika 12.17: Primer nezadovoljavajuceg ishoda izvrsavanja algoritma DBSCAN.
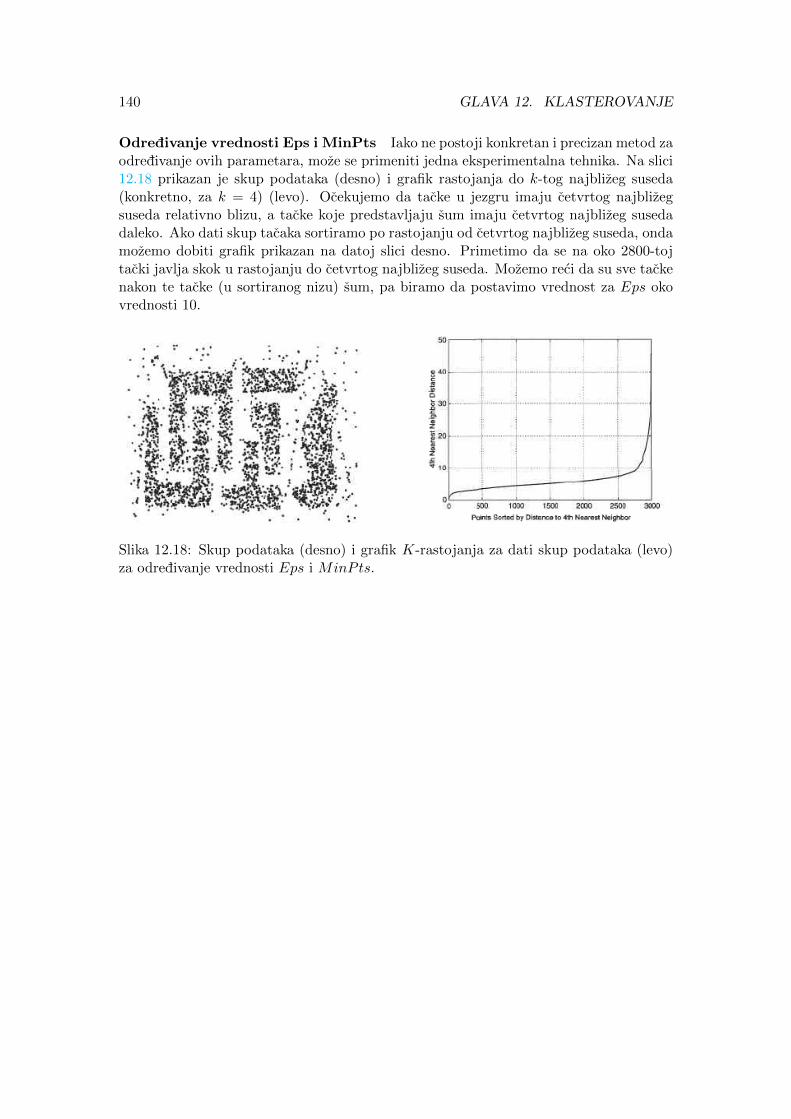
140 GLAVA 12. KLASTEROVANJE
Odredivanje vrednosti Eps i MinPts Iako ne postoji konkretan i precizan metod zaodredivanje ovih parametara, moze se primeniti jedna eksperimentalna tehnika. Na slici12.18 prikazan je skup podataka (desno) i grafik rastojanja do k-tog najblizeg suseda(konkretno, za k = 4) (levo). Ocekujemo da tacke u jezgru imaju cetvrtog najblizegsuseda relativno blizu, a tacke koje predstavljaju sum imaju cetvrtog najblizeg susedadaleko. Ako dati skup tacaka sortiramo po rastojanju od cetvrtog najblizeg suseda, ondamozemo dobiti grafik prikazan na datoj slici desno. Primetimo da se na oko 2800-tojtacki javlja skok u rastojanju do cetvrtog najblizeg suseda. Mozemo reci da su sve tackenakon te tacke (u sortiranog nizu) sum, pa biramo da postavimo vrednost za Eps okovrednosti 10.
Slika 12.18: Skup podataka (desno) i grafik K-rastojanja za dati skup podataka (levo)za odredivanje vrednosti Eps i MinPts.

140

141
Glava 13
Analiza glavnih komponenti

142 GLAVA 13. ANALIZA GLAVNIH KOMPONENTI

143

144 GLAVA 13. ANALIZA GLAVNIH KOMPONENTI

145

146 GLAVA 13. ANALIZA GLAVNIH KOMPONENTI

147

148 GLAVA 13. ANALIZA GLAVNIH KOMPONENTI


150 GLAVA 13. ANALIZA GLAVNIH KOMPONENTI

Literatura
[1] Tan Pang-Ning, Steinbach Michael, Kumar Vipin. Introduction to Data Mining.Pearson Education. 2006.
[2] Wu Xindong, Kumar Vipin. The Top Ten Algorithms in Data Mining. CRC Press.2009.
[3] Nikolic Mladen, Zecevic Andelka. Naucno izracunavanje. 2017.
[4] Janicic Predrag, Nikolic Mladen. Vestacka inteligencija. 2016.
[5] Climate Research Unit, Univ. of East Anglia. Average Annual Temperature.http://nelson.wisc.edu/sage/data-and-models/atlas/maps.php?datasetid=35&includerelatedlinks=1&dataset=35
151
