introduction to applied statistics chapter 1 bct2053
TRANSCRIPT

Introduction to Introduction to Applied StatisticsApplied Statistics
CHAPTER 1
BCT2053

CONTENTCONTENT
1.1 Statistical Terminologies
1.2 Statistical Problem-Solving Methodology
1.3 Review of Descriptive Statistics
1.3.1 Measures of Central Tendency
1.3.2 Measures of Variation
1.3.2.1 Game of Darts
1.4 Exploratory Data Analysis
1.4.1 Stem and Leaf Plot
1.4.2 Boxplots

OBJECTIVE
By the end of this chapter, you should be able to
Define the meaning of statistics, population, sample, parameter, statistic, descriptive statistics and inferential statistics.
Understand and explain why a knowledge of statistics is needed Outline the 6 basic steps in the statistical problem solving methodology. Identifies various method to obtain samples. Discuss the role of computers and data analysis software in statistical
work. Summarize data using measures of central tendency, such as the mean,
median, mode, and midrange. Describe data using measures of variation, such as the range, variance,
and standard deviation. Identify the position of a data value in a data set, using various measures
of position, such as percentiles, deciles, and quartiles. Analyze accuracy and precision of data using game of darts. Draw and interpret a stem and leaf plot. Draw and interpret a boxplot.

1.1 OVERVIEW1.1 OVERVIEW
• Define the meaning of statistics, population, sample, parameter, statistic, descriptive statistics and
inferential statistics.
• Understand and explain why a knowledge of statistics is needed

What is What is Statistics?Statistics?
Most people become familiar with probability and statistics through radio, television, newspapers, and magazines. For example, the following statements were found in newspapers:
• Ten of thousands parents in Malaysia have chosen StemLife as their trusted stem cell bank.
• The death rate from lung cancer was 10 times for smokers compared to nonsmokers.
• The average cost of a wedding is nearly RM10,000.
• In USA, the median salary for men with a bachelor’s degree is $49,982, while the median salary for women with a bachelor’s degree is $35,408.
• Globally, an estimated 500,000 children under the age of 15 live with Type 1 diabetes.
• Women who eat fish once a week are 29% less likely to develop heart disease.

is the sciences of conducting studies to collect, organize, summarize, analyze, present, interpret and draw conclusions from data.
Any values (observations or measurements) that have been collected
Statistics

The basic idea behind all statistical methods of data analysis is to make inferences about a population by studying small
sample chosen from it
PopulationThe complete collection of
measurements outcomes, object or individual under study
SampleA subset of a population,
containing the objects or outcomes that are actually observed
ParameterA number that describes a population characteristics
StatisticA number that describes a
sample characteristics
TangibleAlways finite & after a population is sampled,
the population size decrease by 1The total number of members is fixed &
could be listed
ConceptualPopulation that consists of all the
value that might possibly have been observed & has an unlimited number
of members

EXERCISE 1.1EXERCISE 1.1
1. The freshman class at IT College has 317 students and an IQ pre-test is given to all of them in their first week. The dean of admission collected data on 27 of them and found their mean score on the IQ pre-test was 51. The mean for the entire freshman class was therefore estimated to approximately 51 on this test. A subsequent computer analysis of all freshmen showed the true mean to be 52.Based on the above problem,
a) What is the population?b) Is the population tangible or conceptual?c) What is the sample?d) What number is a parameter?e) What number is a statistic?

Descriptive & Inferential StatisticsDescriptive & Inferential Statistics
Inferential statistics consists of generalizing from
samples to populations, performing estimations hypothesis testing, determining relationships among variables, and making predictions.
Used to describe, infer, estimate, approximate the characteristics of the target population
Used when we want to draw a conclusion for the data obtain from the sample
Descriptive statistics consists of the collection,
organization, classification, summarization, and presentation of data obtain from the sample.
Used to describe the characteristics of the sample
Used to determine whether the sample represent the target population by comparing sample statistic and population parameter

EXERCISE 1.1EXERCISE 1.1
2. In each of these statements, tell whether descriptive or inferential statistics have been used.
a) Ten of thousands parents in Malaysia have chosen StemLife as their trusted stem cell bank. (Descriptive)
b) The death rate from lung cancer was 10 times for smokers compared to nonsmokers. (Inferential)
c) The average cost of a wedding is nearly RM10,000.
d) In USA, the median salary for men with a bachelor’s degree is $49,982, while the median salary for women with a bachelor’s degree is $35,408.
e) Globally, an estimated 500,000 children under the age of 15 live with Type 1 diabetes.
f) A researcher claim that a new drug will reduce the number of heart attacks in men over 70 years of age.

An overview of descriptive statistics An overview of descriptive statistics and statistical inferenceand statistical inference
START
Gathering of Data
Classification, Summarization, and Processing of data
Presentation and Communication of
Summarized information
Is Information from a sample?
Use cencus data to analyze the population
characteristic under study
Use sample information to make inferences about
the population
Draw conclusions about the population
characteristic (parameter) under study
STOP
Yes
No
Statistical Inference
Descriptive
Statistics

Need for StatisticsNeed for Statistics
It is a fact that, you need a knowledge of statistics to help you:
1. Describe and understand numerical relationship between variables There are a lot of data in this world so
we need to identify the right variables.
2. Make better decision Statistical methods allow people to
make better decisions in the face of uncertainty.

Describing relationship between variablesDescribing relationship between variables
1. A management consultant wants to compare a client’s investment return for this year with related figures from last year. He summarizes masses of revenue and cost data from both periods and based on his findings, presents his recommendations to his client.
2. A college admission director needs to find an effective way of selecting student applicants. He design a statistical study to see if there’s a significance relationship between SPM result and the gpa achieved by freshmen at his school. If there is a strong relationship, high SPM result will become an important criteria for acceptance.

Aiding in Decision MakingAiding in Decision Making
1. Suppose that the manager of “Big-Wig Executive Hair Stylist”, Alvin Tang, has advertised that 90% of the firm’s customers are satisfied with the company’s services. If Pamela, a consumer activist, feels that this is an exaggerated statement that might require legal action, she can use statistical inference techniques to decide whether or not to sue Alvin.
2. Students and professional people can also use the knowledge gained from studying statistics to become better consumers and citizens. For example, they can make intelligent decisions about what products to purchase based on consumer studies about government spending based on utilization studies, and so on.

1.2: STATISTICAL 1.2: STATISTICAL PROBLEM SOLVING PROBLEM SOLVING
METHODOLOGYMETHODOLOGY
• Outline the 6 basic steps in the statistical problem solving methodology.
• Identifies various method to obtain samples.
• Discuss the role of computers and data analysis software in statistical work.

STATISTICAL PROBLEM STATISTICAL PROBLEM SOLVING METHODOLOGY SOLVING METHODOLOGY
6 Basic Steps
1. Identifying the problem or opportunity
2. Deciding on the method of data collection
3. Collecting the data
4. Classifying and summarizing the data
5. Presenting and analyzing the data
6. Making the decision

STEP 1STEP 1Identifying the problem or opportunityIdentifying the problem or opportunity
Must clearly understand & correctly define the objective/goal of the study If not, time & effort are waste
Is the goal to study some population?
Is it to impose some treatment on the group & then test the response?
Can the study goal be achieved through simple counts or measurements of the group?
Must an experiment be performed on the group?
If sample are needed, how large?, how should they be taken? – the larger the better (more than 30)

Characteristics of Sample Size
The larger the sample, the smaller the magnitude of sampling errors.
Survey studies needed large sample because the returns of the survey is voluntary based.
Easy to divide into subgroups.
In mail response the percentage of response may be as low as 20%-30%, thus the bigger number of samples is required.
Subject availability and cost factors are legitimate considerations in determining appropriate sample size.

STEP 2STEP 2Deciding on the Method of Data CollectionDeciding on the Method of Data Collection
Data must be gathered that are accurate, as complete as possible & relevant to the problem
Data can be obtained in 3 ways
1. Data that are made available by others (internal, external, primary or secondary data)
2. Data resulting from an experiment (experimental study)
3. Data collected in an observational study (observation, survey, questionnaire, interview)

STEP 3STEP 3Collecting the dataCollecting the data
A. Nonprobability data Is one in which the judgment of the experimenter, the
method in which the data are collected or other factors could affect the results of the sample
3 basic methods: Judgment samples, Voluntary samples and Convenience samples
B. Probability data Is one in which the chance of selection of each item in
the population is known before the sample is picked
4 basic methods : random, systematic, stratified, and cluster.

A) Nonprobability Data SamplesA) Nonprobability Data Samples
1. Judgment samples
Base on opinion of one or more expert person Ex: A political campaign manager intuitively picks certain voting
districts as reliable places to measure the public opinion of his candidate
2. Voluntary samples
Question are posed to the public by publishing them over radio or tv (phone or sms)
3. Convenience samples
Take an ‘easy sample’ (most conveniently available) Ex: A surveyor will stand in one location & ask passerby their
questions

B) Probability Data Samples
1. Random samples
Selected using chance method or random methods
Example: A lecturer wants to study the physical fitness levels
of students at her university. There are 5,000 students enrolled at the university, and she wants to draw a sample of size 100 to take a physical fitness test. She obtains a list of all 5,000 students, numbered it from 1 to 5,000 and then randomly invites 100 students corresponding to those numbers to participate in the study.

B) Probability Data Samples
2. Systematic samples Numbering each subject of the populations and data is
selected every kth number.
Example: A lecturer wants to study the physical fitness levels of
students at her university. There are 5,000 students enrolled at the university, and she wants to draw a sample of size 100 to take a physical fitness test. She obtains a list of all 5,000 students, numbered it from 1 to 5,000 and randomly picks one of the first 50 voters (5000/100 = 50) on the list. If the pick number is 30, then the 30th student in the list should be invited first. Then she should invite the selected every 50th name on the list after this first random starts (the 80th student, the 130th student, etc) to produce 100 samples of students to participate in the study.

B) Probability Data Samples
3. Stratified samples
Dividing the population into groups according to some characteristics that is important to the study, then sampling from each group
Example: A lecturer wants to study the physical fitness levels of students at
her university. There are 5,000 students enrolled at the university, and she wants to draw a sample of size 100 to take a physical fitness test. Assume that, because of different lifestyles, the level of physical fitness is different between male and female students. To account for this variation in lifestyle, the population of student can easily be stratified into male and female students. Then she can either use random method or systematic methods to select the participants. As example she can use random sample to chose 50 male students and use systematic method to chose another 50 female students or otherwise.

B) Probability Data Samples
4. Cluster samples Dividing the population into sections/clusters, then
randomly select some of those cluster and then choose all members from those selected cluster
Using a cluster sampling can reduce cost and time.
Example: A lecturer wants to study the physical fitness levels of students at
her university. There are 5,000 students enrolled at the university, and she wants to draw a sample to take a physical fitness test. Assume that, because of different lifestyles, the level of physical fitness is different between freshmen, sophomores, juniors and seniors students. To account for this variation in lifestyle, the population of student can easily be clustered into freshmen, sophomores, juniors and seniors students. Then she can choose any one cluster such as freshmen and take all the freshmen students as the participant.

EXERCISE 1.2EXERCISE 1.21. In each of these statements, identify the type of sample obtain.
a) A quality engineer wants to inspect rolls of wallpaper in order to obtain information on the rate at which flows in the printing are occurring. She decides to draw a sample of 50 rolls of wallpaper from a day’s production. Each hour for 5 hours, she takes the 10 most recently produced rolls and counts the number of flaws on each.
b) Suppose a researcher have a list of 1000 registered voters in a community and he want to pick a probability sample of 50. He use a random number table to pick one of the first 20 voters (1000/50 = 20) on our list. The table gave him the number of 16, so he select the 16th voter on the list as the first selected number. Then he pick every 20th name after this random start (the 36th voter, the 56th voter, etc) to produce a sample.
c) A researcher wanted to survey students in 100 homerooms in secondary school in a large school district. They randomly select 10 schools from all the secondary schools in the district. Then from a list of homerooms in the 10 schools they randomly select 100 homerooms.

EXERCISE 1.2EXERCISE 1.21. In each of these statements, identify the type of sample obtain.
d) In a consumer surveys of large cities the procedure is to divide a map of the city into small blocks. Each blocks containing a cluster are surveyed. A number of clusters are selected for the sample, and all the households in a cluster are surveyed. Using a cluster sampling can reduce cost and time. Less energy and
money are expended if an interviewer stays within a specific area rather than traveling across stretches of the cities.
e) Suppose our population is a university student body. We want to estimate the average annual expenditures of a college student for non school items. Assume we know that, because of different lifestyles, juniors and seniors spend more than freshmen and sophomores, but there are fewer students in the upper classes than in the lower classes because of some dropout factor. To account for this variation in lifestyle and group size, the population of student can easily be stratified into freshmen, sophomores, junior and seniors. A sample can be stratum and each result weighted to provide an overall estimate of average non school expenditures.

STEP 4Classifying and Summarizing the Data
Organize or group the facts/sample raw data for study and investigation
Classifying- identifying items with like characteristics & arranging them into groups or classes.
Ex: Production data (product make, location, production process,…)
Data can be classified as Qualitative (categorical/Attributes) data and Quantitative (Numerical) data.
Summarization Graphical & Descriptive statistics ( tables, charts, measure of
central tendency, measure of variation, measure of position)

Data ClassificationData Classification
Variables can be classified
By how they are categorized, counted or measured
- Level of measurements of data
As Quantitative and Qualitative
Data are the values that variables can assume Variables is a characteristic or attribute that can assume different
values. Variables whose values are determined by chance are called random
variables

Types of
Data
Qualitative (categorical/Attributes) 1* Data that refers only to name classification (done
using numbers)2* Can be placed into
distinct categories according to some
characteristic or attribute.
Quantitative (Numerical)
1* Data that represent counts or measurements
(can be count or measure)
2* Are numerical in nature and can be ordered or
ranked.
Nominal Data (can’t be rank)Gender, race, citizenship. etc
Ordinal Data (can be rank)Feeling (dislike – like),
color (dark – bright) , etcLikert scale
Discrete Variables Assume values that can be
counted and finiteEx : no of “something”
Continuous variables 1. Can assume all values between any two specific values & it obtained by measuring2. Have boundaries and must be rounded because of the limits of measuring device
Ex: weight, age, salary, height, temperature, etc
Use code numbers (1, 2,…)

EXERCISE 1.2EXERCISE 1.22. The Lemon Marketing Corporation has asked you for information about
the car you drive. For each question, identify each of the types of data requested as either attribute data or numeric data. When numeric data is requested, identify the variable as discrete or continuous.
a) What is the weight of your car?b) In what city was your car made?c) How many people can be seated in your car?d) What’s the distance traveled from your home to your school?e) What’s the color of your car?f) How many cars are in your household?g) What’s the length of your car?h) What’s the normal operating temperature (in degree Fahrenheit) of
your car’s engine?i) What gas mileage (miles per gallon) do you get in city driving?j) Who made your car?k) How many cylinders are there in your car’s engine?l) How many miles have you put on your car’s current set of tyres?

Level of Measurements of DataLevel of Measurements of Data
Nominal-level data
Ordinal-level data
Interval-level data
Ratio-level data
classifies data into mutually exclusive (non overlapping), exhausting categories in which no order or ranking can be imposed on the data
classifies data into categories that can be ranked; however, precise differences between the ranks do not exist
ranks data, and precise differences between units of measure do exist; however, there is no meaningful zero
Possesses all the characteristics of interval measurement, and there exists a true zero.
Examples

EXERCISE 1.2EXERCISE 1.23. The chart shows the number of job-related injuries for each of the
transportation industries for 1998.I
a) What are the variables under study?b) Categorize each variable as qualitative or quantitative.c) Categories each quantitative variables as discrete or continuous.d) Identify the level of measurement for each variable.
Industry Number of injuries
Railroad 4520
Intercity bus 5100
Subway 6850
Trucking 7144
Airline 9950

STEP 5STEP 5Presenting and Analyzing the dataPresenting and Analyzing the data
Summarized & analyzed information given by the graphical statistics (graph and chart) descriptive statistics (refer topic 1.3)
Identify the relationship of the information
Making any relevant statistical inferences hypothesis testing confidence interval ANOVA control charts, …

Types of Graph & ChartTypes of Graph & Chart
The purpose of graphs in statistics is to convey the data
to the viewer in pictorial form.
Graphs are useful in getting the audience’s attention in a
publication or a presentation.

Types of Graph & ChartTypes of Graph & Chart

Distribution Shapes for HistogramDistribution Shapes for Histogram
Bell Shaped Has a single
peak & tapers off at either end
Approximately symmetry
It is roughly the same on the both sides of a line running through the center
J-Shaped Has a few data
values on the left side & increase as one move to the right
Uniform Basically
flat/rectangular
Reverse J-Shaped
Opposite J-Shaped
Has a few data values on the right side & increase as one move to the left

Distribution Shapes for HistogramDistribution Shapes for Histogram
Right Skewed The peak is to
the left The data value
taper off to the right
Bimodal Have 2 peak at
the same height
Left Skewed The peak is to
the right The data value
taper off to the left
U-Shaped The shape is U

STEP 6STEP 6Making the decisionMaking the decision
The researchers can make a list of all the options and decisions which can achieve the objective and goal of the research, weighs the options and choose the best options which represents the ‘best’ solution to the problem.
The correctness of this choice depends on the analytical skill and the quality of the information.

Statistical Problem Solving Methodology
START
Identify the problem or opportunity
Gather available internal and external facts relevant to the
problem
Gather new data from populations and samples using instruments, interviews,
questionnaire, etc
Classify, summarize, and process data using tables,
charts, and numerical descriptive measure
Present and communicate summarized information in form of tables, charts and
descriptive measure
Use cencus information to evaluate alternative courses of
action and make decisions
Use sample information to 1. Estimate value of parameter 2. Test assumptions about parameter
Interpret the results, draw conclusions, and make decisions
STOP
Are available facts sufficient?
Is information from a sample?
No
No
Yes
Yes

Role of the Computer in StatisticsRole of the Computer in Statistics
Two software tools commonly used for data
Analysis:
1. Spreadsheets Microsoft Excel & Lotus 1-2-3
2. Statistical Packages MINITAB, SAS, SPSS and SPlus

Data Analysis Aplication in EXCELData Analysis Aplication in EXCEL
• Graph and chart• Formulas• Add in – Analisis Tool Park – Data Analysis

1.3: REVIEW OF 1.3: REVIEW OF DESCRIPTIVE DESCRIPTIVE
STATISTICSSTATISTICS• Summarize data using measures of central tendency, such as the mean, median, mode, and midrange.
• Describe data using measures of variation, such as the range, variance, and standard deviation.
• Identify the position of a data value in a data set, using various measures of position, such as percentiles, deciles, and quartiles.

Summary Statistics (Data Description)Summary Statistics (Data Description)
Statistical methods can be used to summarize data.
Measures of average are also called measures of central tendency and include the mean, median, mode, and midrange.
Measures that determine the spread of data values are called measures of variation or measures of dispersion and include the range, variance, and standard deviation.
Measures of position tell where a specific data value falls within the data set or its relative position in comparison with other data values. The most common measures of position are percentiles, deciles, and quartiles.
The measures of central tendency, variation, and position are part of what is called traditional statistics. This type of data is typically used to confirm conjectures about the data.

TIPS: INSERT & CLEAR DATA by using Scientific Calculator
Casio fx-570MS Insert data
MODE SD data M+ Shift 1 Shift 2 Clear data
Shift CLR 1
Casio fx-570W Insert data
MODE SD data M+ Shift 1 Shift 2 Shift 3 Shift 4 Clear data
Shift AC/ON =
ROUNDING RULE: The value of statistic/parameter should be rounded to one more decimal place than occurs in the raw data

1.3.1 Measures of Central Tendency1.3.1 Measures of Central Tendency
Mean
the sum of the values divided by the total number of values.
Population Mean Sample Mean
1 , population size
N
ii
xN
N
1 , sample size
n
ii
xx n
n
Example: 9 2 1 4 3 3 7 5 8 6 , 4.8x

Properties of Mean
The mean is compute by using all the values of the data.
The mean varies less than the median or mode when samples are taken
from the same population and all three measures are computed for
these samples.
The mean is used in computing other statistics, such as variance.
The mean for the data set is unique, and not necessarily one of the data
values.
The mean cannot be computed for an open-ended frequency
distribution.
The mean is affected by extremely high or low values and may not be
the appropriate average to use in these situations

1.3.1 Measures of Central Tendency1.3.1 Measures of Central Tendency
Median
the middle number of n ordered data (smallest to largest)
If n is odd If n is even
1
2
Median(MD) nx 12 2Median(MD)
2
n nx x
Example: 9 2 1 4 3 3 7 5 8 6
MD = 4.5
Example: 9 2 1 3 3 7 5 8 6
MD = 5

Properties of Median
The median is used when one must find the center or middle value of a data set.
The median is used when one must determine whether the data values fall into the upper half or lower half of the distribution.
The median is used to find the average of an open-ended distribution.
The median is affected less than the mean by extremely high or extremely low values.
Try this data: 19 2 1 4 3 3 7 5 8 6

1.3.1 Measures of Central Tendency1.3.1 Measures of Central Tendency
Mode
the most commonly occurring value in a data series
The mode is used when the most typical case is desired.
The mode is the easiest average to compute.
The mode can be used when the data are nominal, such as religious preference, gender, or political affiliation.
The mode is not always unique. A data set can have more than one mode, or the mode may not exist for a data set.
Example: 9 2 1 4 3 3 7 5 8 6 Mode = 3

Midrange is a rough estimate of the middle & also a very rough
estimate of the average and can be affected by one extremely high or low value.
lowest value highest valueMR
2
1.3.1 Measures of Central Tendency1.3.1 Measures of Central Tendency
Example: 9 2 1 4 3 3 7 5 8 6
MR = 5

Types of Distribution
Symmetric
Positively skewed or right-skewed Negatively skewed or left-skewed

EXERCISE 1.3.1EXERCISE 1.3.11. Determine the type of distribution of the following dataI
9 2 1 4 3 3 7 5 8 6
123 195 138 115 179 119 148 147 180 146 179 189 175 108 193 114 179 147 108 128 164 174 128 159 193 204 125 133 115 168 123 183 116 182 174 102 123 99 161 162 155 202 110 132
Mean = Mode = Median = 11
Mean = 25, Mode = 13, Median = 17
Mean = 5, Mode = 73, Median = 17

1.3.2 Measures of Variation / Dispersion 1.3.2 Measures of Variation / Dispersion
Used when the central of tendency doesn't mean anything or not needed (ex: mean are same for two types of data) If the mean of x and y are same and dispersion x < dispersion y,
then population x is better than population y
One that measure the variability that exists in a data set
To form a judgment about how well the average value illustrate/ depict the data
To learn the extent of the scatter so that steps may be taken to control the existing variation

1.3.2 Measures of Variation / Dispersion 1.3.2 Measures of Variation / Dispersion
Range
is the different between the highest value and the lowest value in a data set.
The symbol R is used for the range.
R = highest value - lowest value
Example: 9 2 1 4 3 3 7 5 8 6
R = 8

1.3.2 Measures of Variation / Dispersion 1.3.2 Measures of Variation / Dispersion
Variance
is the average of the squares of the distance each value is from the mean.
Population Variance Sample Variance
2
2 1 , population size
N
ii
xN
N
2
2 1 , sample size1
n
ii
x xs n
n
Example: 9 2 1 4 3 3 7 5 8 62
2
6.4
7.1s

1.3.2 Measures of Variation / Dispersion 1.3.2 Measures of Variation / Dispersion
Standard Deviation is the square root of the variance
Population standard deviation , Sample standard deviation, s
2.5
2.7s
2
1 , population size
N
ii
xN
N
2
1 , sample size1
n
ii
x xs n
n
Example: 9 2 1 4 3 3 7 5 8 6

Properties of Variance Properties of Variance & Standard Deviation & Standard Deviation
Variances and standard deviations can be used to determine the spread of the data. If the variance or standard deviation is large, the data are more dispersed. The information is useful in comparing two or more data sets to determine which is more variable.
The measures of variance and standard deviation are used to determine the consistency of a variable.
The variance and standard deviation are used to determine the number of data values that fall within a specified interval in a distribution.
The variance and standard deviation are used quite often in inferential statistics.
The standard deviation is used to estimate amount of spread in the population from which the sample was drawn.

EXERCISE 1.3.2EXERCISE 1.3.21. Which of the following set of data is more disperseI
A: 9 2 1 4 3 3 7 5 8 6B: 3 4 5 4 3 3 8 6 7 5
Group 1:123 195 138 115 179 119 148 147 180 146 179 189 175 108 193 114 179 147 108 128 164 174
Group 2128 159 193 204 125 133 115 168 123 183 116 182 174 102 123 99 161 162 155 202 110 132
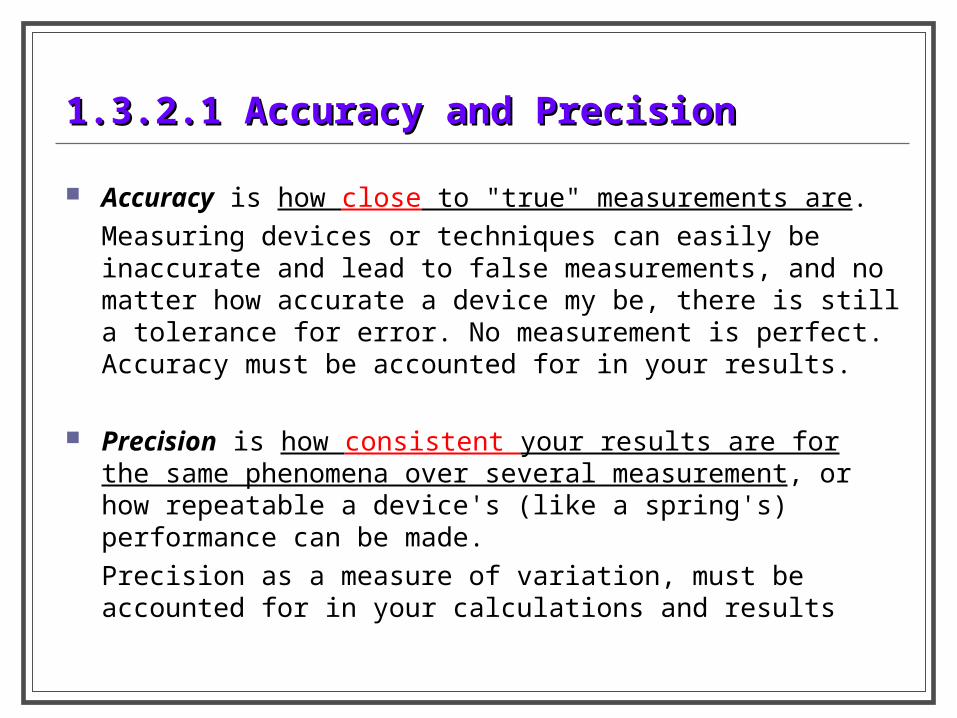
1.3.2.1 Accuracy and Precision1.3.2.1 Accuracy and Precision
Accuracy is how close to "true" measurements are.
Measuring devices or techniques can easily be inaccurate and lead to false measurements, and no matter how accurate a device my be, there is still a tolerance for error. No measurement is perfect. Accuracy must be accounted for in your results.
Precision is how consistent your results are for the same phenomena over several measurement, or how repeatable a device's (like a spring's) performance can be made.
Precision as a measure of variation, must be accounted for in your calculations and results

Game of DartsGame of Darts Picture A, very accurate (close
to the mark), but not very precise, since the darts are spread out everywhere.
Picture B shows an example of precision without accuracy (very consistent, but not near the mark).
Picture C shows both inaccuracy and imprecision.
Picture D shows both accuracy and precision.
Picture C Picture D

1.3.3 Measures of Position1.3.3 Measures of Position
Describing the position of the data value (increasing order)
Percentiles Quartiles
100
i in cP x x 4
i in cQ x x
15 3 22, 3, 4.5P D Q Example: 9 2 1 4 3 3 7 5 8 6
DecilesSplit data into
100 equal partsSplit data into 4 equal parts
Split data into 10 equal parts
10
i in cD x x
TIPS: If c is not a whole number, round it up to the next whole number
If c is a whole number, then use 1 2c cx x

EXERCISE 1.3.3EXERCISE 1.3.31. Given 9 2 1 4 3 7 5 4 6 .
a) What percentile is the value of 8?
b) Find the value correspond to 4th deciles.
c) Find the value correspond to 3rd quartiles.
2. Given 9 22 11 14 13 3 7 15 18 16
a) Find the value correspond to 20th percentiles.
b) What percentile is the value of 20?
c) Find the value correspond to 7th deciles.
TIPS: The percentile correspond to a given value of x is computed by:
number of values below 0.5100%
total number of values
xPercentile

OutliersOutliers An outlier is an extremely high or an extremely low data value when
compared with the rest of the data values.
Outliers can be the result of measurement or observational error.
When a distribution is normal or bell-shaped, data values that are beyond three standard deviations of the mean can be considered suspected outliers.
Example: 9 22 11 14 13 3 7 15 18 16 no outliers

EXERCISE 1.3.3EXERCISE 1.3.3
3. Given 19 2 1 4 3 7 5 4 6 . Find outliers.
4. Given 19 6 2 11 4 3 7 7 5 8 6 21 12
Find outliers

1.4: EXPLORATORY 1.4: EXPLORATORY DATA ANALYSISDATA ANALYSIS
• Draw and interpret a stem and leaf plot. • Draw and interpret a boxplot.

Exploratory Data AnalysisExploratory Data Analysis The purpose of exploratory data analysis is to examine data in
order to find out what information can be discovered.
For example: Are there any gaps in the data? Can any patterns be discerned?

Stem-and-Leaf PlotsStem-and-Leaf Plots A stem-and-leaf plot is a data plot
that uses part of a data value as the stem (the leading digit) and part of the data value as the leaf (the trailing digit) to form groups or classes.
It has the advantage over grouped frequency distribution of retaining the actual data while showing them in graphic form.
Sometime we can construct a mixture model.
Arranging the data in order is not essential, but the leaves must be arrange in order.
Stem leaf
Leaf Stem Leaf

EXERCISE 1.4EXERCISE 1.4
1. An insurance company researcher conducted a survey on the number of car thefts in a large city for a period of 30 days last summer. The raw data are shown below.Construct a stem and leaf plot.
52 62 51 50 6958 77 66 53 5775 56 55 67 7379 59 68 65 7257 51 63 69 7565 53 78 66 55

EXERCISE 1.4EXERCISE 1.42. The data shown represents the percentage of unemployed males and
females in 1995 for a sample of countries of the world. Using the whole numbers as stems and the decimals as leaves, construct a back-to-back (mixture) stem and leaf plot and compare the distribution of the two groups.
Females Males
8.0 3.7 8.6 5.0 8.8 1.9 5.6 4.67.0 3.3 8.6 3.2 1.5 6.6 5.6 0.38.8 6.8 9.2 5.9 2.2 5.6 3.1 5.97.2 4.6 5.6 5.3 9.8 8.7 6.0 5.27.7 8.0 8.7 0.5 4.4 9.6 6.6 6.06.5 3.4 3.0 9.4 4.6 3.1 4.1 7.7

BoxplotsBoxplots
Boxplots are graphical representations of a five-number summary of a data set and outliers. The five-number summary are: The lowest value of data set (minimum) Q1 (or 25th percentile) The median (or 50th percentile) Q3 (or 75th percentile) The highest value of data set (maximum)

STEP to Construct a BoxplotSTEP to Construct a Boxplot STEP1 : Arrange the data STEP2 : Find the Median STEP3 : Find Q1 and Q3 STEP4 : Find Outliers
Points that lying more than 1.5 times the interquartile range above Q3 or below Q1
STEP5 : Draw a scale for the data on the x axis. STEP6 : Locate the lowest value, Q1, the median, Q3, the
highest value and outliers on the scale. STEP7 : Draw a box around Q1 and Q3, draw a vertical line
through the median, and connect the upper and lower values
1 3 1 3 3 11.5 and 1.5 x Q Q Q x Q Q Q
Example: Refer EXERCISE 1.4 (3)

Summarize the BoxplotsSummarize the Boxplots
EXTRA INFO:
1. If the boxplots for two or more data sets are graphed on the same axis, the distributions can be compared.
2. To compare the averages, use the location of the medians.
3. To compare the variability, use the location of the interquartile range.

EXERCISE 1.4EXERCISE 1.4
3. Plot a boxplot for the following data. Then describe the data.
a) 9 22 11 14 13 3 7 15 18 16
b) 19 2 1 7 5 8 6
4. A dietician is interested in comparing the sodium content of real cheese with the sodium content of a cheese substitute. Te data for two random samples are shown. Compare the distributions using boxplots
Real Chese 310, 420, 45, 40, 220, 240, 180, 90
Cheese Subtitute 270, 180, 250, 290, 130, 260, 340, 310

ConclusionConclusion The applications of statistics
are many and varied. People encounter them in everyday life, such as in reading newspapers or magazines, listening to the radio, or watching television.
By combining all of the descriptive statistics techniques discussed in this chapter together, the student is now able to collect, organize, summarize and present data.
Thank YouNEXT: Chapter 2 Commonly Used Probability Distributions