ibm research lab in haifa architectural and design issues in the general parallel file system benny...
Post on 20-Dec-2015
214 views
TRANSCRIPT

IBM Research Lab in HaifaIBM Research Lab in Haifa
Architectural and Design Issues in Architectural and Design Issues in the General Parallel File Systemthe General Parallel File System
Benny Mandler - [email protected] Mandler - [email protected]
May 12, 2002

HRL
AgendaAgenda
What is GPFS?? a file system for deep computing
GPFS usesGeneral architectureHow does GPFS meet its challenges - architectural issues
? performance? scalability? high availability? concurrency control

HRL
RS/6000 SP Scalable Parallel ComputerRS/6000 SP Scalable Parallel Computer1-512 nodes connected by high-speed switch1-512 nodes connected by high-speed switch1-16 CPUs per node (Power2 or PowerPC)1-16 CPUs per node (Power2 or PowerPC)>1 TB disk per node>1 TB disk per node500 MB/s full duplex per switch port500 MB/s full duplex per switch port
Scalable parallel computing enables I/O-intensive applicationsScalable parallel computing enables I/O-intensive applications::Deep computing - simulation, seismic analysis, data miningDeep computing - simulation, seismic analysis, data miningServer consolidation - aggregating file, web servers onto a centrally-managed machineServer consolidation - aggregating file, web servers onto a centrally-managed machineStreaming video and audio for multimedia presentationStreaming video and audio for multimedia presentationScalable object store for large digital libraries, web servers, databases, ...Scalable object store for large digital libraries, web servers, databases, ...
Scalable Parallel ComputingScalable Parallel Computing
What is GPFS?

HRL
High Performance - High Performance - multiple GB/s to/from a single filemultiple GB/s to/from a single fileconcurrentconcurrent reads and writes, parallel data access - within a file and across filesreads and writes, parallel data access - within a file and across files
Support fully parallel access both to file data and metadataSupport fully parallel access both to file data and metadataclient caching client caching enabled by distributed lockingenabled by distributed lockingwide striping, large data blocks, prefetchwide striping, large data blocks, prefetch
ScalabilityScalabilityscales up to 512 nodes (N-Way SMP). Storage nodes, file system nodes, disks, scales up to 512 nodes (N-Way SMP). Storage nodes, file system nodes, disks, adapters...adapters...
High AvailabilityHigh Availability
fault-tolerancefault-tolerance via logging, replication, RAID supportvia logging, replication, RAID supportsurvives node and disk failuressurvives node and disk failures
Uniform access Uniform access via shared disks - Single image file systemvia shared disks - Single image file system
High capacityHigh capacity multiple TB per file system, 100s of GB per file.multiple TB per file system, 100s of GB per file.
Standards compliant Standards compliant (X/Open 4.0 "POSIX") with minor exceptions(X/Open 4.0 "POSIX") with minor exceptions
GPFS addresses SP I/O requirementsGPFS addresses SP I/O requirements
What is GPFS?

HRL
Native AIX File System (JFS)No file sharing - application can only access files on its own node
Applications must do their own data partitioning
DCE Distributed File System (follow-up of AFS)Application nodes (DCE clients) share files on server nodeSwitch is used as a fast LANCoarse-grained (file or segment level) parallelismServer node is performance and capacity bottleneck
GPFS Parallel File SystemGPFS Parallel File SystemGPFS file systems are striped across GPFS file systems are striped across multiple disks on multiple storage nodesmultiple disks on multiple storage nodes
Independent GPFS instances run on each Independent GPFS instances run on each application nodeapplication node
GPFS instances use storage nodes as GPFS instances use storage nodes as "block servers" - all instances can access all "block servers" - all instances can access all disksdisks
GPFS vs. local and distributed file systems on the SP2GPFS vs. local and distributed file systems on the SP2

HRL
Video on Demand for new "borough" of TokyoVideo on Demand for new "borough" of TokyoApplications: movies, news, karaoke, education ...Applications: movies, news, karaoke, education ...Video distribution via hybrid fiber/coaxVideo distribution via hybrid fiber/coaxTrial "live" since June '96Trial "live" since June '96Currently 500 subscribersCurrently 500 subscribers
6 Mbit/sec MPEG video streams6 Mbit/sec MPEG video streams100 simultaneous viewers (75 MB/sec)100 simultaneous viewers (75 MB/sec)200 hours of video on line (700 GB)200 hours of video on line (700 GB)12-node SP-2 (7 distribution, 5 storage)12-node SP-2 (7 distribution, 5 storage)
Tokyo Video on Demand TrialTokyo Video on Demand Trial

HRL
Major aircraft manufacturer
Using CATIA for large designs, Elfini for structural modeling and analysis
SP used for modeling/analysisUsing GPFS to store CATIA designs and structural modeling dataGPFS allows all nodes to share designs and models
Engineering DesignEngineering Design
GPFS uses

HRL
File systems consist of one or more shared disks? Individual disk can contain data, metadata, or both ? Disks are designated to failure group ? Data and metadata are striped to balance load and maximize parallelism
Recoverable Virtual Shared Disk for accessing disk storage
? Disks are physically attached to SP nodes? VSD allows clients to access disks over the SP switch? VSD client looks like disk device driver on client node? VSD server executes I/O requests on storage node.? VSD supports JBOD or RAID volumes, fencing, multi-pathing (where physical hardware permits)
GPFS only assumes a conventional block I/O interface
Shared Disks - Virtual Shared Disk architectureShared Disks - Virtual Shared Disk architecture
General architecture

HRL
Implications of Shared Disk Model? All data and metadata on globally accessible disks (VSD)? All access to permanent data through disk I/O interface? Distributed protocols, e.g., distributed locking, coordinate disk access from multiple nodes
? Fine-grained locking allows parallel access by multiple clients? Logging and Shadowing restore consistency after node failures
Implications of Large Scale? Support up to 4096 disks of up to 1 TB each (4 Petabytes)The largest system in production is 75 TB? Failure detection and recovery protocols to handle node failures? Replication and/or RAID protect against disk / storage node failure? On-line dynamic reconfiguration (add, delete, replace disks and nodes; rebalance file system)
GPFS Architecture OverviewGPFS Architecture Overview
General architecture

HRL
Three types of nodes: file system, storage, and manager? Each node can perform any of these functions? File system nodes
run user programs, read/write data to/from storage nodesimplement virtual file system interfacecooperate with manager nodes to perform metadata operations
? Manager nodes (one per “file system”)global lock managerrecovery managerglobal allocation managerquota managerfile metadata manageradmin services fail over
? Storage nodesimplement block I/O interfaceshared access from file system and manager nodesinteract with manager nodes for recovery (e.g. fencing)file data and metadata striped across multiple disks on multiple storage nodes
GPFS Architecture - Node RolesGPFS Architecture - Node Roles
General architecture

HRL
GPFS Software StructureGPFS Software Structure
General architecture

HRL
Large block size allows efficient use of disk bandwidthFragments reduce space overhead for small filesNo designated "mirror", no fixed placement function:
Flexible replication (e.g., replicate only metadata, or only important files)Dynamic reconfiguration: data can migrate block-by-blockMulti level indirect blocks ? Each disk address:
list of pointers to replicas? Each pointer:disk id + sector no.
Disk Data Structures: FilesDisk Data Structures: Files
General architecture

HRL
Conventional file systems store data in small blocks to pack data more densely
GPFS uses large blocks (256KB default) to optimize disk transfer speed
Large File Block SizeLarge File Block Size
Performance
0 128 256 384 512 640 768 896 1024
I/O Transfer Size (Kbytes)
0
1
2
3
4
5
6
7
Th
rou
gh
pu
t (M
B/s
ec)

HRL
Parallelism and consistencyParallelism and consistency
Distributed locking - acquire appropriate lock for every operation - used for updates to user data
Centralized management - conflicting operations forwarded to a designated node - used for file metadata
Distributed locking + centralized hints - used for space allocationCentral coordinator - used for configuration changes
I/O slowdown effectsAdditional I/O activity rather than token serveroverload

HRL
GPFS allows parallel applications on multiple nodes to access non-overlapping ranges of a single file with no conflict
Global locking serializes access to overlapping ranges of a fileGlobal locking based on "tokens" which convey access rights to an object (e.g. a file) or subset of an object (e.g. a byte range)
Tokens can be held across file system operations, enabling coherent data caching in clients
Cached data discarded or written to disk when token is revokedPerformance optimizations: required/desired ranges, metanode, data shipping, special token modes for file size operations
Parallel File Access From Multiple NodesParallel File Access From Multiple Nodes
Performance

HRL
GPFS stripes successive blocks across successive disksDisk I/O for sequential reads and writes is done in parallel GPFS measures application "think time" ,disk throughput, and cache state to automatically determine optimal parallelism
Prefetch algorithms now recognize strided and reverse sequential accessAccepts hintsWrite-behind policy
Application reads at 15 MB/secEach disk reads at 5 MB/sec
Three I/Os executed in parallel
Deep Prefetch for High ThroughputDeep Prefetch for High Throughput
Performance
HRL
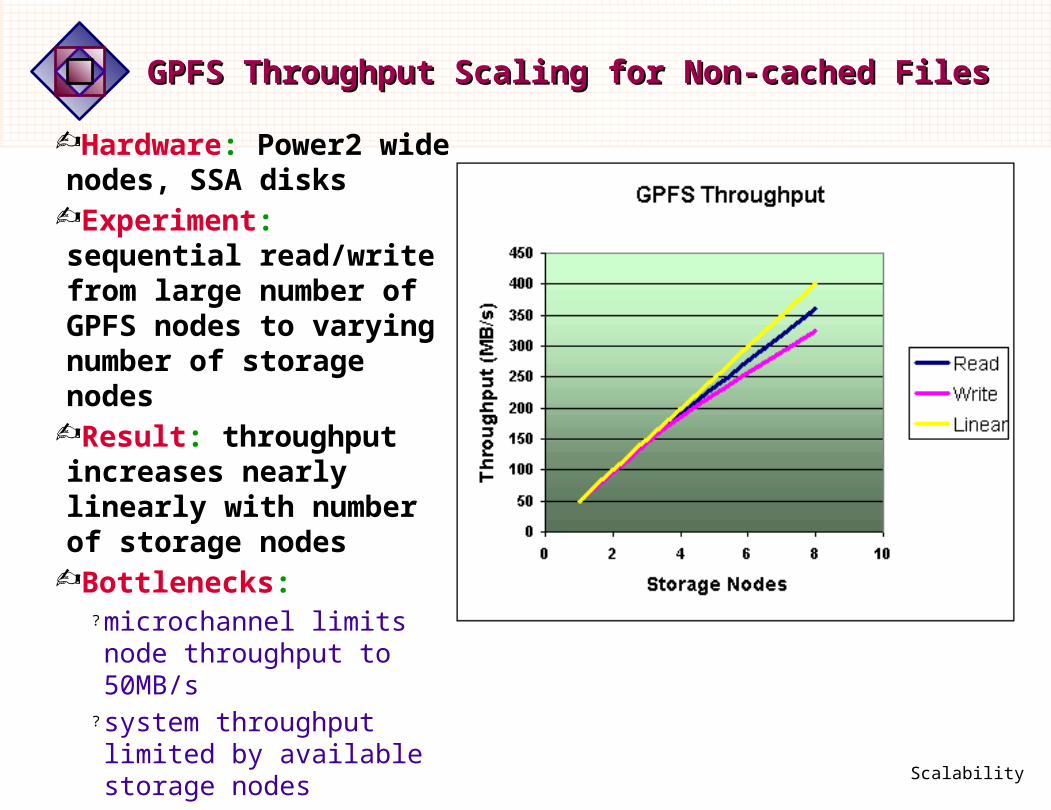
Hardware: Power2 wide nodes, SSA disks
Experiment: sequential read/write from large number of GPFS nodes to varying number of storage nodes
Result: throughput increases nearly linearly with number of storage nodes
Bottlenecks:? microchannel limits node throughput to 50MB/s
? system throughput limited by available storage nodes
GPFS Throughput Scaling for Non-cached FilesGPFS Throughput Scaling for Non-cached Files
Scalability
HRL
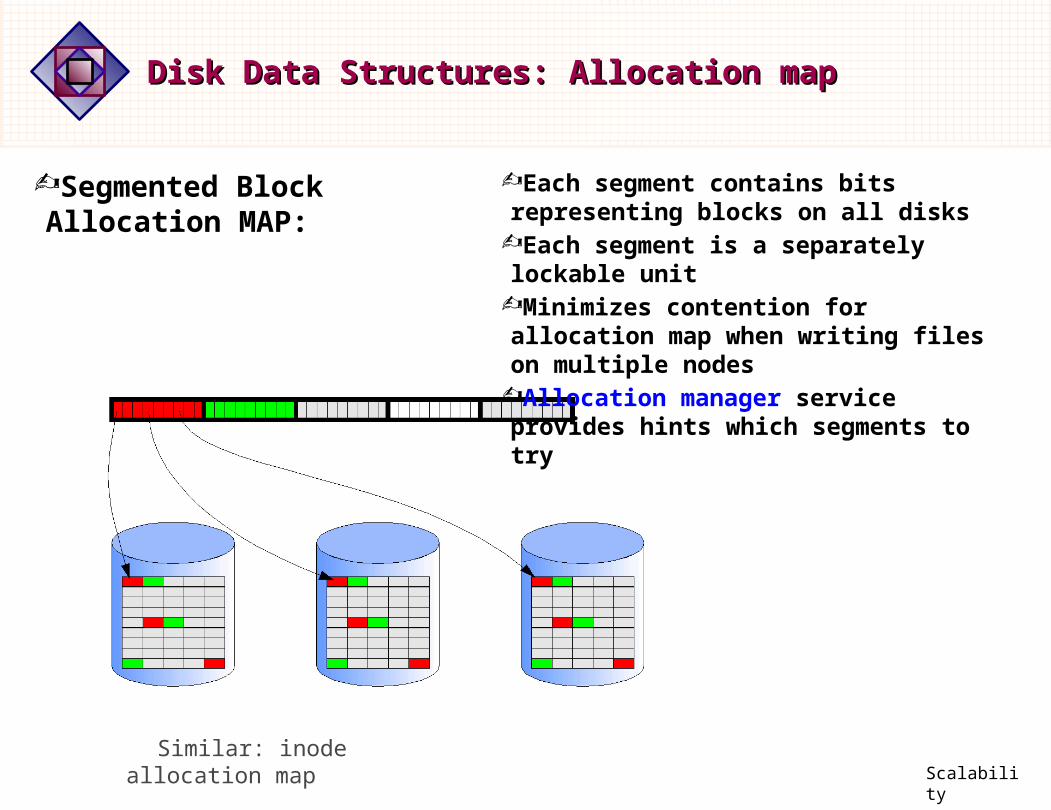
Segmented Block Allocation MAP:
Each segment contains bits representing blocks on all disks
Each segment is a separately lockable unitMinimizes contention for allocation map when writing files on multiple nodes
Allocation manager service provides hints which segments to try
Similar: inode allocation map
Disk Data Structures: Allocation mapDisk Data Structures: Allocation map
Scalability

HRL
Problem: detect/fix file system inconsistencies after a failure of one or more nodes
? All updates that may leave inconsistencies if uncompleted are logged? Write-ahead logging policy: log record is forced to disk before dirty metadata is written
? Redo log: replaying all log records at recovery time restores file system consistency
Logged updates:? I/O to replicated data? directory operations (create, delete, move, ...)? allocation map changes
Other techniques: ? ordered writes? shadowing
High Availability - Logging and RecoveryHigh Availability - Logging and Recovery
High Availability

HRL
Application node failure:? force-on-steal policy ensures that all changes visible to other nodes have been written to disk and will not be lost
? all potential inconsistencies are protected by a token and are logged ? file system manager runs log recovery on behalf of the failed nodeafter successful log recovery tokens held by the failed node are released? actions taken: restore metadata being updated by the failed node to a consistent state, release resources held by the failed node
File system manager failure:? new node is appointed to take over? new file system manager restores volatile state by querying other nodes? New file system manager may have to undo or finish a partially completed configuration change (e.g., add/delete disk)
Storage node failure:? Dual-attached disk: use alternate path (VSD)? Single attached disk: treat as disk failure
Node Failure RecoveryNode Failure Recovery
High Availability

HRL
When a disk failure is detected? The node that detects the failure informs the file system manager? File system manager updates the configuration data to mark the failed disk as "down" (quorum algorithm)
While a disk is down? Read one / write all available copies? "Missing update" bit set in the inode of modified files
When/if disk recovers? File system manager searches inode file for missing update bits ? All data & metadata of files with missing updates are copied back to the recovering disk (one file at a time, normal locking protocol)
? Until missing update recovery is complete, data on the recovering disk is treated as write-only
Unrecoverable disk failure? Failed disk is deleted from configuration or replaced by a new one? New replicas are created on the replacement or on other disks
Handling Disk FailuresHandling Disk Failures

HRL
Cache ManagementCache Management
Total CacheGeneral Pool: Clock list, merge, re-map
Block Size pool: Clock list
Block Size pool: Clock list
Block Size pool: Clock list
StatsSeq / randomoptimal, totalSeq / randomoptimal, totalSeq / randomoptimal, totalSeq / randomoptimal, total
Balance dynamically according to usage patternsAvoid fragmentation - internal and externalUnified stealPeriodical re-balancing

HRL
EpilogueEpilogue
Used on six of the ten most powerful supercomputers in the world, including the largest (ASCI white)
Installed at several hundred customer sites, on clusters ranging from a few nodes with less than a TB of disk, up to 512 nodes with 140 TB of disk in 2 file systems
IP rich - ~20 filed patentsState of the artTeraSort
? world record of 17 minutes ? using 488 node SP. 432 file system and 56 storage nodes (604e 332 MHz)? total 6 TB disk space
References? GPFS home page: http://www.haifa.il.ibm.com/projects/storage/gpfs.html? FAST 2002: http://www.usenix.org/events/fast/schmuck.html? TeraSort - http://www.almaden.ibm.com/cs/gpfs-spsort.html? Tiger Shark: http://www.research.ibm.com/journal/rd/422/haskin.html