hirdb技術解説 hirdbによる データレプリケーショ …...xdm/rd xdm/xt hirdb...
TRANSCRIPT

© Hitachi, Ltd. 2012, 2019. All rights reserved.
HiRDBによるデータレプリケーションの解説
HiRDB技術解説
株式会社 日立製作所 サービス&プラットフォームビジネスユニットサービスプラットフォーム事業本部 DB部
2019/7

© Hitachi, Ltd. 2012, 2019. All rights reserved. 1
Contents
2. 概要
3. 機能説明
4. 適用事例
5. システム設計のポイント
6. 環境構築のポイント
7. 運用のポイント
8. HiRDB Datareplicatorの運用例
9. 障害時の対処方法
10. おわりに
1. はじめに

© Hitachi, Ltd. 2012, 2019. All rights reserved.
1. はじめに
2

© Hitachi, Ltd. 2012, 2019. All rights reserved.
1-1 HiRDBとは:社会インフラを支え続けるデータベース
3
データベースの信頼性が社会インフラの信頼性につながる
世の中の重要な社会インフラは
IT基盤なしには支えられない
IT基盤の要はデータベース
公共・教育
医療
金融
産業・流通
『止めない・止まらない』
基幹系RDBMSとして
HiRDBは20年以上、社会インフラを支えてきました。
そして、これからも支え続けます!
交通・運輸
通信

© Hitachi, Ltd. 2012, 2019. All rights reserved.
1-2 本資料の概要
4
■本資料の内容
◆HiRDB Datareplicatorの機能について解説します。2章: 概要3章: 機能説明
◆データ連携の適用事例について解説します。4章: 適用事例
◆システム設計、環境構築、運用のポイントについて解説します。5章: システム設計のポイント6章: 環境構築のポイント7章: 運用のポイント
◆HiRDB Datareplicatorの運用方法・手順について解説します。8章: HiRDB Datareplicatorの運用例
◆障害時の対処方法についてFAQを織り交ぜて解説します。9章: 障害時の対処方法
解説
広域災害に備えた遠隔地へのデータベースの保管、システム移行時のデータ移行、新規システム追加時に既存システムのデータを参照する場合、基幹系システムから情報系システムへフレッシュなデータを渡す場合など、さまざまな場面にてデータレプリケーションが必要とされています。本資料では、HiRDBのデータレプリケーション製品であるHiRDB Datareplicatorについて、わかりやすく解説します。ディザスタリカバリシステムの適用業務事例をはじめとして、HiRDBのデータレプリケーション製品を使用したシステムの設計・運用上の注意事項、運用手順やトラブルシュート関連情報についても、解説します。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
2. 概要
5

© Hitachi, Ltd. 2012, 2019. All rights reserved.
2-1 今注目を集めるデータレプリケーション技術
6
業務データ基幹業務データ
Web 文書・メールERP
統合データ
情報統合 ディザスタリカバリシステム
マイグレーション
MF環境 オープン環境
メインサイト
リモートサイト
解説データレプリケーション技術は、ディザスタリカバリシステムでリモートサイトへのバックアップに
利用されるなど、様々な場面で活用されています。
© Hitachi, Ltd. 2012, 2019. All rights reserved.
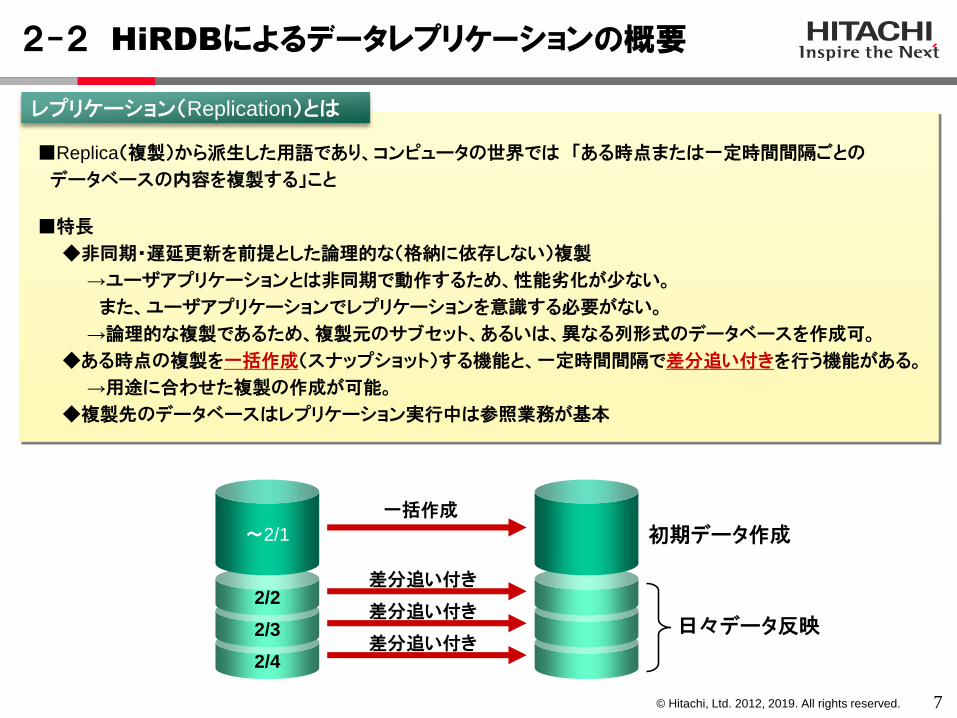
2-2 HiRDBによるデータレプリケーションの概要
7
■Replica(複製)から派生した用語であり、コンピュータの世界では 「ある時点または一定時間間隔ごとの
データベースの内容を複製する」こと
■特長
◆非同期・遅延更新を前提とした論理的な(格納に依存しない)複製
→ユーザアプリケーションとは非同期で動作するため、性能劣化が少ない。
また、ユーザアプリケーションでレプリケーションを意識する必要がない。
→論理的な複製であるため、複製元のサブセット、あるいは、異なる列形式のデータベースを作成可。
◆ある時点の複製を一括作成(スナップショット)する機能と、一定時間間隔で差分追い付きを行う機能がある。
→用途に合わせた複製の作成が可能。
◆複製先のデータベースはレプリケーション実行中は参照業務が基本
2/4
2/3
2/2
~2/1 初期データ作成
日々データ反映
一括作成
差分追い付き
差分追い付き
差分追い付き
レプリケーション(Replication)とは

© Hitachi, Ltd. 2012, 2019. All rights reserved.
2-3 レプリケーション製品一覧
8
レプリケーション機能の種類 一括作成(表単位) 差分追い付き(行単位)
データ抽出・反映機能 データ連動機能
製品名 MF系 XDM/XT XDM/DS、DATABASE DATAREPLICATOR
オープン系 HiRDB Dataextractor HiRDB Datareplicator
稼働OS MF系 VOS3/ES1、VOS3/AS、VOS3/FS、VOS3/LS 、VOS1、VOSK
オープン系(*1) HP-UX、AIX、Windows、 Red Hat Enterprise Linux
ソースDB MF系 XDM/RD E2、XDM/SD E2、ADM、PDMII E2、RDB1 E2、TMS-4V/SP/DB
オープン系(*1) HiRDB、Oracle、Microsoft SQL Server
ターゲットDB MF系 XDM/RD E2
オープン系(*1) HiRDB、Oracle、Microsoft SQL Server
レプリケーション方式 アンロード方式(SQL抽出) ログ転送方式(トランザクション抽出)
通信経路 TCP/IP
提供製品一覧
※1 稼働OS、ソースDB、ターゲットDBのバージョンの詳細は、HiRDBのホームページでご確認ください。
https://www.hitachi.co.jp/Prod/comp/soft1/hirdb/info/platform/index.html
適用OS情報のURL

© Hitachi, Ltd. 2012, 2019. All rights reserved.
2-4 データ抽出・反映機能 HiRDB Dataextractor
9
抽出機能送信
受信機能反映
inetd
HiRDB HiRDB
Dataextractor
HiRDB
Dataextractor
pdload
HiRDB
SQL
HiRDB Dataextractorの構造
(パイプ)
◇データの抽出、転送、反映(ロード)までをひとつのジョブで実行できることが特長(抽出側からコマンド起動)
◇ジョブ/コマンド起動すると、リモートホスト側では(inetdの機能により)自動的にプロセス
が起動され必要な処理を行う。連携の結果は、ジョブ/コマンドを起動したところのリターンコードを見ることにより判る。
◇文字コード、バイトオーダの差異もプログラムで変換◇SQLで抽出するために、フレキシブルな条件の設定が可能(JOIN、副問合せも可)。
◇失敗時には表全体をロードして作成しなおす
◇中間ファイル生成までのみも可能
HiRDB Dataextractorの連携方式
DB 中間ファイル DB
コマンド

© Hitachi, Ltd. 2012, 2019. All rights reserved.
2-5 データ連動機能 HiRDB Datareplicator
10
◇抽出、送信、反映機能をコマンドで個別に起動
◇事前に定義された表の更新差分のみを、HiRDBのシステムログから抽出◇一定時間間隔で送信◇文字コード、バイトオーダの差異もプログラムで変換◇反映側でSQLを組み立ててDB更新
HiRDB Datareplicatorの連携方式
HiRDB Datareplicatorの構造
受信機能
HiRDB
Datareplicator
DB
HiRDB
反映機能
反映情報キューファイル
制御機能
UOC
アプリケーション
DB
HiRDB
LOG
抽出機能
HiRDB
Datareplicator
送信機能
抽出情報キューファイル
制御機能
SQL
コマンド コマンド
© Hitachi, Ltd. 2012, 2019. All rights reserved.
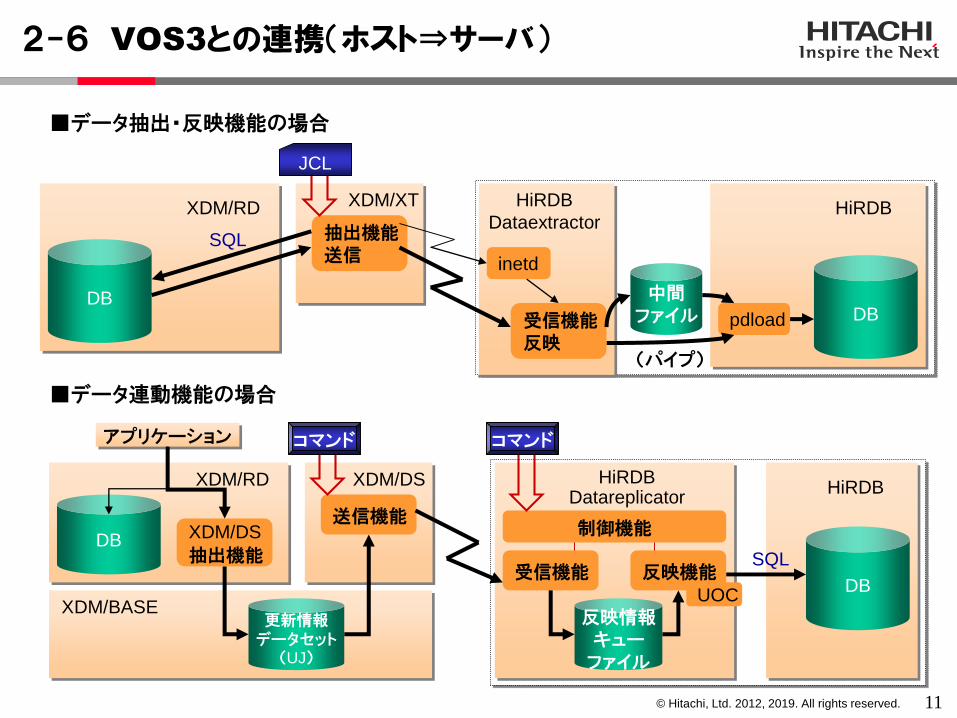
2-6 VOS3との連携(ホスト⇒サーバ)
11
DB 中間ファイル
抽出機能送信
受信機能反映
inetd
XDM/RD XDM/XT HiRDB
Dataextractor
DBpdload
HiRDB
SQL
(パイプ)
DB
XDM/RD
アプリケーション
XDM/DS
抽出機能
更新情報データセット
(UJ)
送信機能
XDM/DS
受信機能
HiRDBDatareplicator
DB
HiRDB
反映機能
反映情報キューファイル
制御機能
UOCXDM/BASE
SQL
■データ抽出・反映機能の場合
■データ連動機能の場合
コマンド コマンド
JCL

© Hitachi, Ltd. 2012, 2019. All rights reserved.
2-7 VOS3との連携(サーバ⇒ホスト)
12
■データ抽出・反映機能の場合
■データ連動機能の場合
DB
受信機能反映
抽出機能送信
inetd
XDM/RD XDM/XT HiRDB
Dataextractor
DBJXZOLOD
HiRDB
中間ファイル
SQL
DB
XDM/RD
アプリケーション
反映機能
更新情報データセット
(UJ)
受信機能
XDM/DS
送信機能
HiRDBDatareplicator
DB
HiRDB
抽出機能
抽出情報キューファイル
制御機能
XDM/BASE
LOG
SQL
JCLコマンド
JCL
コマンド

© Hitachi, Ltd. 2012, 2019. All rights reserved.
2-8 VOS1との連携
13
VOS1 RDB1、PDMII E2とは、HiRDBへの連携のみが可能です。ファイル転送を介在した方式を採用しています。
ファイル入力機能
HiRDB Datareplicator
DB
HiRDB
反映情報キューファイル
制御機能
アプリケーション
DB
RDB1、PDMII E2
LOG
SQL反映機能
UOC
SAM
ファイル
SAM
ファイル
ftp
SAM作成機能(ユティリティ)
DB
HiRDB
DB
RDB1、PDMII E2
SAM
ファイル
SAM
ファイル
ftp
抽出機能
RDB1 Dataextractor
PDMII E2 Dataextractor
pdload
■データ抽出・反映機能の場合
■データ連動機能の場合

© Hitachi, Ltd. 2012, 2019. All rights reserved.
2-9 Hitachi Advanced Data Binder との連携
14
◇HiRDBからは更新データ(INSERTは挿入値、UPDATEは更新後の値、DELETEは削除したキー値)を抽出◇データの発生順序がわかるようにタイムスタンプを付与してHADBサーバ上のCSVファイルとして出力◇CSVファイルは、 HADBユティリティを使用してHADBへインポート
HiRDBからHADBへのデータ連携方式(更新履歴データの連携)
HiRDBからHitachi Advanced Data Binder (以下HADB)へのデータ連携(更新履歴データの連携)
受信機能
HiRDB
Datareplicator
DB
HADB
反映機能
CSV
時系列の更新履歴データ
制御機能
アプリケーション
DB
HiRDB
LOG
抽出機能
HiRDB
Datareplicator
送信機能
抽出情報キューファイル
制御機能
コマンド コマンド
HADB連携機能(時系列情報出力機能)
HADB連携定義情報
CSV
インポートファイル
インポートジョブ
インポートジョブ
インポートジョブ
反映情報キューファイル
UOC提供
JP1/AJS3が定期的にHADBのバックグラウンドインポートを実行
Linux
※1
※1 内閣府の最先端研究開発支援プログラム「超巨大データベース時代に向けた最高速データベースエンジンの開発と当該エンジンを核とする戦略的社会サービスの実証・評価」(中心研究者:喜連川東大教授/国立情報学研究所所長)の成果を利用。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
3. 機能説明
15

© Hitachi, Ltd. 2012, 2019. All rights reserved.
3-1 HiRDB Datareplicatorの前提条件
16
◇抽出側DBMSと反映側DBMSの行を一意に対応付けるためのキー項目が必須・非NULLでユニークとなる列の集合(最大16列)・連動対象となる表にはユニークインデクス定義がされていること・マッピングキーは更新(UPDATE)されないことが基本
◇レプリケーションの方向は、行単位にみると、常に片方向・同一行を双方向でレプリケーションすることは不可能(DB不一致となる)
・多段階のレプリケーションにおいて、ループとなる方向(A→B→C→Aに戻るようなレプリケーションはデータがループする)
◇反映対象の表は参照業務(No Wait検索)に使用すること・反映側の表をユーザアプリケーションで更新した場合、正しい結果とならない
◇データ連動の単位はトランザクション・COMMITされたトランザクションが対象・HiRDBからの抽出では、更新(前)後ログが出力されていること・HiRDB/Parallel Serverの場合、バックエンドサーバ単位のトランザクションとなる
マッピングキー
レプリケーションの方向
トランザクション

© Hitachi, Ltd. 2012, 2019. All rights reserved.
3-2 データ連動機能 表の選択
17
抽出表は抽出側システムの抽出定義、反映表は反映側システムの反映定義で定義する。ただし、抽出表と反映表が全く同じ構成である場合には反映定義は省略できる。抽出定義と反映定義における表の対応は、「更新情報名」にて行う。◇抽出定義
・データ連動対象とする抽出表、列(全列の場合には*)をすべて定義する・表のサブセット(行の選択)を反映側で作成する場合には、送信する条件を指定する・抽出定義は事前にユティリティにてプリプロセスし、内部形式に変換しておく
◇反映定義・反映対象の表と列を指定する・複数の表に対応させることも可能であるが、行の選択は不可能・反映定義は、反映機能起動時に解析される
■抽出表と反映表の対応例 -表選択-
TABLE-A TABLE-B
TABLE-C TABLE-D
TABLE-A TABLE-DXDM/DS、
HiRDB Datareplicator
-条件-TABLE-AとTABLE-Dのみを
抽出するEXTRACT * FROM TABLE-A TO UPD1 KEY(A1)
EXTRACT * FROM TABLE-D TO UPD2 KEY(D1)
SEND 送信先識別子 FROM UPD%
<抽出定義>
A1 B1
C1 D1
A1 D1
抽出側DB 反映側DB

© Hitachi, Ltd. 2012, 2019. All rights reserved.
3-3 データ連動機能 列の選択
18
■抽出表と反映表の対応例 -列選択-
TABLE-A TABLE-A
-条件-TABLE-AのA1、A3、A5列
を抽出する EXTRACT A1,A3,A5 FROM TABLE-A TO UPD1 KEY(A1)SEND 送信先識別子 FROM UPD1
■抽出表と反映表の対応例 -列選択(反映表)-
TABLE-A TABLE-X
-条件-TABLE-Aの全列を抽出し、
反映側でTABLE-XとTABLE-Yに振り分ける
EXTRACT * FROM TABLE-A TO UPD1 KEY(A1)
SEND 送信先識別子 FROM UPD1
A1 A2 A3 A4 A5A1 A3 A5
A1 A2 A3 A4 A5
<抽出定義>
A1 A3 A5 A1 A2 A4
TABLE-Y
LOAD A1,A3,A5 FROM UPD1 TO TABLE-X
LOAD A1,A2,A4 FROM UPD1 TO TABLE-Y
<抽出定義>
<反映定義>
抽出側DB
抽出側DB
反映側DB
反映側DB
XDM/DS、HiRDB Datareplicator
XDM/DS、HiRDB Datareplicator

© Hitachi, Ltd. 2012, 2019. All rights reserved.
3-4 データ連動機能 行の選択
19
■抽出表と反映表の対応例 -行選択(1)-■抽出表と反映表の対応例 -行選択(1)-
TABLE-A
-条件-TABLE-AのA1列の値が
101以上200以下のものを抽出する EXTRACT * FROM TABLE-A TO UPD1 KEY(A1)
SEND 送信先識別子 FROM UPD1 WHERE A1>=101 AND A1 <= 200
■抽出表と反映表の対応例 -行選択(2)-
-条件-TABLE-AのA1列の値が
100または200のものを抽出する EXTRACT * FROM TABLE-A TO UPD1 KEY(A1)
SEND 送信先識別子 FROM UPD1 WHERE A1 IN (100,200)
注:行選択の条件はマッピングキー列にのみ設定可能です。
<抽出定義>
<抽出定義>
抽出側DB
抽出側DB
反映側DB
反映側DB
XDM/DS、HiRDB Datareplicator
XDM/DS、HiRDB Datareplicator
A1TABLE-AA1
TABLE-AA1 TABLE-A
A1

© Hitachi, Ltd. 2012, 2019. All rights reserved.
3-5 データ連動機能 階層型DBとの対応
20
■抽出表と反映表の対応例 -階層型(構造型)DBとリレーショナルDBでの対応-
構造型DBからリレーショナルDBへ連動する場合、最上位のレコードから抽出対象とするレコードまでのすべての階層のレコードから抽出した情報をマージし、1つの反映表に反映する
SYAIN
社員表
EXTRACT BUSYO.NAME,SYAIN.ID,SYAIN.NAME
FROM BUSYO,SYAIN(SETBS) TO UPD1
EXTRACTKEY BUSYO.NAME,SYAIN.ID TO UPD1
LOAD * FROM UPD1 TO 社員表
<抽出定義>
<反映定義>
☆運用上の留意事項☆構造型DBから抽出する場合、最上位のレコードから抽出対象とするレコードまでのすべての階層のレコードからマッピングキーとなる構成要素の情報を抽出しなければならない。また、そのマッピングキーとなる構成要素はその親子集合内でユニークとならなければならない。
ID NAME
DB1G
10人
761189004
鈴木一郎333196157
佐藤次郎333195025
田中三郎
<DB実体>
<スキーマ定義>
333198841
高橋史郎……
DB2G
15人
BUSYO
NAME NINZU 部署名 社員ID 社員名
DB1G 761189004 鈴木一郎
DB1G 333196157 佐藤次郎DB2G 333195025 田中三郎
333198841 高橋史郎DB2G
…
…
… …
… …
抽出側DB
反映側DB
XDM/DS、HiRDB Datareplicator

© Hitachi, Ltd. 2012, 2019. All rights reserved.
3-6 データ連動機能 時系列表
21
通常のレプリケーションでは、抽出側DBMSの更新と同じ順序で、反映側DBMSにSQLを発行していくことで、複製を作成していきます。しかし、HiRDB Datareplicatorでは、反映側DBMSに、更新データを履歴として蓄積していくことができます。この履歴を蓄積する表を時系列表と呼びます。
品目番号 製品名 単価 在庫量
A101 鉛筆(黒) ¥50 200
A102 鉛筆(赤) ¥80 120
B201 万年筆 ¥500 30
C221 ペン(赤) ¥100 80
品目番号 製品名 単価 在庫量
A101 鉛筆(黒) ¥50 50
A102 鉛筆(赤) ¥80 150
B201 万年筆 ¥500 30
C221 ペン(赤) ¥100 60
C222 ペン(青) ¥100 50
以下の操作を実施①「鉛筆(黒)」を50本売上(在庫を更新[減らす])②「ペン(赤)」を20本売上(在庫を更新[減らす])③新商品「ペン(青)」を50本入荷(行追加)④「鉛筆(黒)」を100本売上(在庫を更新[減らす])⑤「鉛筆(赤)」を30本入荷(在庫を更新[増やす])
品目番号 製品名 単価 在庫量
A101 鉛筆(黒) ¥50 50
A102 鉛筆(赤) ¥80 150
B201 万年筆 ¥500 30
C221 ペン(赤) ¥100 60
C222 ペン(青) ¥100 50
品目番号 製品名抽出日 在庫量
A101 鉛筆(黒)'2008-02-01' 150
C221 ペン(赤)'2008-02-01' 60
C222 ペン(青)'2008-02-01' 50
A101 鉛筆(黒)'2008-02-01' 50
A102 鉛筆(赤)'2008-02-01' 150
商品在庫表
商品在庫表
商品在庫表
商品在庫履歴表
☆運用上の留意事項☆時系列表はユーザ運用で削除することが必要です。時系列表はリフレッシュ(再作成)できません。障害発生時はアンロードログ回復が必要です。
同一形式での複製
時系列表への複製
反映定義のload文にTimestampキーワードを指定
抽出側DB 反映側DB
反映側DB
操作
upd
upd
ins
upd
upd

© Hitachi, Ltd. 2012, 2019. All rights reserved.
3-7 データ連動機能 マージ表
22
抽出側の複数の表から、反映側では1個の表に統合することをマージ表作成と呼びます。マージ表の作成は、抽出側の複数の表のマッピングキーが同じであること、また、マッピングキーが更新されないことが前提です。HiRDB Datareplicatorの反映機能で実現します。
品目番号 製品名 単価
A101 鉛筆(黒) ¥50
A102 鉛筆(赤) ¥80
B201 万年筆 ¥500
C221 ペン(赤) ¥100
商品マスタ表
品目番号 在庫量
A101
A102
B201
C221
200
120
30
80
商品在庫表
品目番号 製品名 単価 在庫量
A101 鉛筆(黒) ¥50 200
A102 鉛筆(赤) ¥80 120
B201 万年筆 ¥500 30
C221 ペン(赤) ¥100 80
商品在庫表
マージ形式での複製
EXTRACT * FROM 商品マスタ表 TO UPD1 KEY(品目番号)
EXTRACT * FROM 商品在庫表 TO UPD2 KEY(品目番号)
SEND 送信先識別子 FROM UPD%
LOAD * FROM UPD1 TO sqlconvopt1 商品在庫表LOAD * FROM UPD2 TO sqlconvopt2 商品在庫表
<抽出定義>
<反映定義>
☆運用上の留意事項☆1表で定義するとUPDATE→INSERT変換となります。3表以上のマージはお勧めできません(複雑になるので)。マージ表は、表間の主従関係を明確にしておかなければなりません。マージ表はDataextractorのJOINを用いてリフレッシュ(再作成)します。
抽出側DB 反映側DB

© Hitachi, Ltd. 2012, 2019. All rights reserved.
3-8 データ連動機能 UOC
23
以下のような場合には、データ連動が標準で提供する機能では抽出側と反映側が対応できません。・異なるデータ型(SQLレベルの互換がないもの)に対応させる場合・列の値により、行を複数の表に振り分ける場合・複数の列を纏めたり、別の列の値を参照して列の値を加工する場合
このような場合には、反映側でUOCを作成することで、対応させます。
品目番号 製品名 単価
A101 鉛筆(黒) ¥50
A102 鉛筆(赤) ¥80
B201 万年筆 ¥500
C221 ペン(赤) ¥100
商品マスタ表
商品受注表
商品マスタ表
同一形式での複製
EXTRACT * FROM 商品マスタ表 TO UPD1 KEY(品目番号)
EXTRACT * FROM 商品受注表 TO UPD2 KEY(顧客番号)
SEND 送信先識別子 FROM UPD%
LOAD * FROM UPD1 TO 商品マスタ表LOAD * FROM UPD2 BY 'UOC'
<抽出定義> <反映定義>
顧客番号 品目番号 個数
A101
K100101 A101
B201K100101
K314405
50
20
35
商品受注表
顧客番号 品目番号 金額
A101
K100101 A101
B201K100101
K314405
¥2500
¥10000
¥1750
品目番号 製品名 単価
A101 鉛筆(黒) ¥50
A102 鉛筆(赤) ¥80
B201 万年筆 ¥500
C221 ペン(赤) ¥100
UOCで個数を金額(単価×個数)に変換
☆UOC作成上の留意事項☆UOCを作成するに当たっては、エラー時の処理を十分考慮願います。(HiRDB Datareplicatorでは70%がエラー処理)
☆運用上の留意事項☆UOCでは、SQLの組み立て・発行を行います。UOCを使用する場合、リフレッシュ(再作成)できません。
抽出側DB 反映側DB

© Hitachi, Ltd. 2012, 2019. All rights reserved.
3-9 データ連動機能 暗号化DB連動
24
☆運用上の留意事項☆抽出システム定義と反映システム定義のdblocaleの指定は同一である必要があります。暗号化列を選択条件に使った送信行の選択はできません。送信データUOCは使用できません。暗号化列に対して列データ編集UOCは使用できません。暗号化列を含む表に対して反映情報編集UOCは使用できません。暗号化列を分割条件に使ったキーレンジ単位分割での反映はできません。更新SQL出力機能は使用できません。
HiRDBのDBデータ暗号化機能を使用する場合、HiRDBのシステムログに出力される更新情報も暗号化されるため、暗号化されたDBの更新情報を連動する機能を提供します。以下のいずれかの運用を選択できます。■平文送信方式(抽出側Datareplicatorで復号して送信します。)
Datareplicatorの使用方法に変更はありません。従来どおりの運用で使用できます。■暗号文送信方式(抽出側Datareplicatorで復号せず送信し反映側Datareplicatorで復号します)
暗号文送信方式を使用する場合、抽出システム定義のplus_data_sendオペランドにtrueを指定します。hdeprepコマンドで鍵情報ファイルを生成した後、反映側Datareplicatorのホストにコピーして連動します。※コピーが終了したら、抽出側Datareplicatorにある鍵情報ファイルを削除してください。
■暗号文送信方式の留意事項
☆系切り替え機能利用時の留意事項☆系切り替え機能を使用する場合、鍵情報ファイルは、反映側Datareplicatorの現用系マシン上と予備系マシン上の同じディレクトリにあらかじめコピーしてください。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
3-10 データ連動機能 暗号化DB連動
25
☆運用上の留意事項☆抽出側Datareplicatorで一つの鍵情報ファイルを作成します。各反映側Datareplicatorの$HDSPATHディレクトリ下に鍵ファイルをコピーします。
①抽出側Datareplicator:反映側Datareplicatorが1:mの場合の鍵情報ファイルの運用
☆運用上の留意事項☆抽出側Datareplicatorごとに一つの鍵ファイルを作成します。各抽出側Datareplicatorで作成した鍵情報ファイルを全て反映側Datareplicatorの$HDSPATH
ディレクトリ下に鍵情報ファイルをコピーしてください。この場合、抽出側Datareplicator識別子は、システム全体で一意にしてください。
②抽出側Datareplicator:反映側Datareplicatorがn:1の場合の鍵情報ファイルの運用
-条件-鍵情報ファイルはhdeprepコマンドにより、hde_prpaf_XXの名称で作成します。
(XXは抽出側Datareplicator識別子)
抽出側Datareplicator 反映側Datareplicator
ユーザによるファイルコピー
鍵情報ファイル(hde_prpaf_01)
鍵情報ファイル(hde_prpaf_01)
抽出システム定義hdeid=01
反映システム定義hdsid=11
■暗号文送信方式の鍵情報ファイルの運用例

© Hitachi, Ltd. 2012, 2019. All rights reserved.
4. 適用事例
26

© Hitachi, Ltd. 2012, 2019. All rights reserved.
4-1 レプリケーションの適用業務
27
レプリケーションの代表的な使用目的
(1)ディザスタリカバリ
災害に備えたバックアップシステム
(2)データ移行
システム移行を行なう際の一時的な
データ連携
(3)業務垂直分散
システムの負荷分散
(4)業務水平分散
複数システム間でデータを共用するシステム
(5)分析用DB作成
分析業務へのデータ提供

© Hitachi, Ltd. 2012, 2019. All rights reserved.
4-2 ディザスタリカバリへの適用
28
広域災害(震災など)により、センタ(メインサイト)が全く機能しなくなることに備えるシステム
構成。遠隔地に副センタ(リモートサイト)を構築して、正センタへの更新データを転送しておき、
正センタ被災時には副センタに切り替えて業務を続行する。
メインサイト
リモートサイト
リモートサイトへのバックアップに、HiRDB Datareplicatorを利用することでコストを抑えたディザスタリカバリシステムを実現できます。
HiRDB Datareplicator
HiRDB Datareplicator
ディザスタリカバリとは

© Hitachi, Ltd. 2012, 2019. All rights reserved.
4-3
29
導入コストが安価HiRDB Datareplicatorの導入※だけで構築できます。(ディスクなどのハードウェア機種に依存しません)
※HiRDB Serverにバンドルされています。
リモートサイト側の縮小構成にも対応可能
リモートサイト側は、災害発生時に稼働するだけなので、メインサイト側に比べてのマシン台数を絞るなど、異なる構成にすることも可能です。
データ欠損の可能性 非同期・遅延方式のデータ連動であるため、メインサイト被災時
にトランザクションの欠損が発生する可能性があります。
特徴 説明
HiRDB Datareplicatorによる
ディザスタリカバリシステムの特徴

© Hitachi, Ltd. 2012, 2019. All rights reserved.
4-4 データ連携方法 ディザスタリカバリ
30
考慮事項
その他
メインサイトに障害発生時に短時間で切り替えて業務を継続するための(レプリカ)サイト構築
非同期遅延送信・反映方式のため、メインサイト障害時に未送信データ(グレーデータ)が存在パラレルの場合、コミット保証はバックエンドサーバ(BES)単位に同期される
24時間365日業務運用のために、定期的にメインサイトとリモートサイトを切り替え(入れ替え)る運用もある
目的
項 目 内 容 設計すべき事項
リモートサイトマシンのクラス、回線容量、切り替え後の業務要件により範囲を決定する
グレーデータの存在を認識し業務的な対処方法を決める反映トランザクション同期機能の適用を検討する
メインサイト⇔リモートサイト切り替え時の停止時間が最小となる運用手順要
連携方向 通常、メインサイトからリモートサイトへの1方向。ただし、相互バックアップの事例がある
連携数 メインサイトとリモートサイトの関係は1:1
表構成 メインサイトとリモートサイトでの表の構成は同一。すべての表を連携する場合とリモートサイトで最小限の業務を実行するのに必要なもののみを連携する場合がある
反映遅延 メインサイトの障害により切り替え実施時に喪失するデータを最小にしたいとのニーズがある
送信間隔を短く設計する(5~10秒、データ量との兼ね合いも考慮要)
同一行の双方向は不可。
-
-

© Hitachi, Ltd. 2012, 2019. All rights reserved.
4-5 適用事例 ディザスタリカバリ
3131
AIX6.1
HiRDB/Single Server 08-05
オンライン業務
AIX6.1
HiRDB/Single Server 08-05
HiRDB Datareplicator
SQL
HiRDB Datareplicator
LOG
LOG
メインサイト
リモートサイト
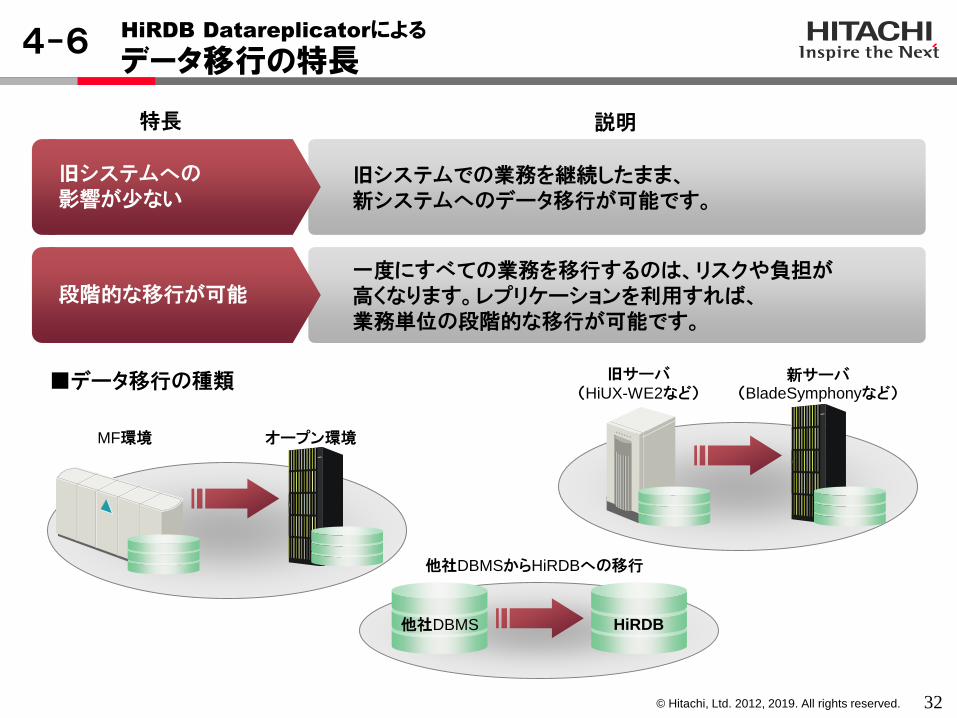
◇構成◇・メインサイトとリモートサイトのサイト間距離は
150km。・通常はメインサイトで本番業務を実施。
メインサイト被災により業務継続不可能となった場合に、リモートサイトに本番を切り替える。
・機器構成サーバ:EP8000
ストレージ:Universal Storage Platform
◇特長◇・レプリケーションを使用したディザスタリカバリ・更新データ量は 3.1MB/秒更新データ件数だとピーク時INSERT 1400件/秒+UPDATE 1200件/秒
◇方式◇・正副同一データ形式のフルレプリケーション・正副の同期間隔をできるだけ短くするために
5秒間隔での送信・反映処理の方式は表単位反映方式の
ハッシュ分割方式採用
某銀行の振替システム
DB
DB
© Hitachi, Ltd. 2012, 2019. All rights reserved.
4-6
32
旧システムへの影響が少ない
旧システムでの業務を継続したまま、新システムへのデータ移行が可能です。
段階的な移行が可能一度にすべての業務を移行するのは、リスクや負担が高くなります。レプリケーションを利用すれば、業務単位の段階的な移行が可能です。
MF環境 オープン環境
旧サーバ(HiUX-WE2など)
新サーバ(BladeSymphonyなど)
他社DBMS HiRDB
■データ移行の種類
他社DBMSからHiRDBへの移行
特長 説明
HiRDB Datareplicatorによる
データ移行の特長

© Hitachi, Ltd. 2012, 2019. All rights reserved.
4-7 データ連携方法 データ移行
33
考慮事項
その他
旧システムから新システムへの移行期間中に、旧システムで発生したデータを新システムへ反映する
旧システムから、新システムで表構成が異なる場合、障害時のデータ回復が複雑になる
UOCを適用せざるを得ないケースもある
目的
項 目 内 容 設計すべき事項
回復方法をよく検討する(回復不能となる場合もあり得る)
UOCの適用に当っては作業量をよく見積もること(難しいため)
連携方向 通常、マスタサイトからレプリカサイトへの1方向
連携数 マスタとレプリカの関係はM:N
表構成 新システムの表構成に依存
反映遅延 業務要件に依存 送信間隔は業務要件時間の半分程度から考慮する
M、Nは5程度におさえる
-
-
回線容量とデータ量からサブセット/フルセットを検討

© Hitachi, Ltd. 2012, 2019. All rights reserved.
4-8 適用事例 MFからの移行
34
VOS3
XDM/RDなど
<マスタ表>
業務A
Linux
HiRDB/Single Server
バッチ高速化機能(*1)
HiRDB Datareplicator
SQL
XDM/DS
更新情報データセット
<複製表>LOG
◇構成◇・MFのシステムをオープン化するため、
MF上DBのデータをサーバ上のHiRDBに送信。・参照主体の業務から段階的に移行する。
数ヶ月におよぶ移行期間に対応。
◇特長◇・旧システムでの本番業務を続けながら、
長期間のデータ移行作業が可能・HiRDBのバッチ高速化機能(*1)を使用して、
移行の影響によるバッチ実行時間の長大化を解消。
・uCosminexus Batch Job Execution Serverの導入により、ジョブ定義の移行作業を軽減
◇方式◇・反映側の表は、抽出側の表とデータ連動可能な
データ型で定義する。(場合によっては、UOCで対応する)
業務B
業務C
uCosminexus Batch Job
Execution Server
(*1):HiRDBのバッチ高速化機能は、HiRDB Acceleratorという製品で提供しています 。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
4-9 適用事例 旧サーバからの移行
35
新システム:Linux
旧システム1:Hi-UX/WE2 旧システム2:Hi-UX/WE2
HiRDB
HiRDB HiRDB
新システム情報
Replication
◇構成◇・2つの異なるシステムを1つの新システムに
統合する。・旧システムから新システムへのデータ移行は数ヶ月を要する。
・データ移行期間中は、旧システムをそのまま運用する。
・データ移行は複数回に分けて実施する。
◇特長◇・旧システムでの本番業務を続けながら、
長期間のデータ移行作業が可能・旧システムに影響あたえることなく、
移行作業が可能
◇方式◇・旧システムから新システムに反映する際、反映データは新システムに合わせて列を選択する。
・新システムで不足しているデータは、バッチで追加する。
旧システム情報(1)
旧システム情報(2)
列選択 列選択
データ編集バッチ

© Hitachi, Ltd. 2012, 2019. All rights reserved.
4-10 適用事例 他社DBMSからの移行
36
HP-UX
他社DBMS(Oracleなど)
<マスタ表>
オンライン業務
Linux
HiRDB/Single Server
HiRDB Datareplicator
SQL
HiRDB Datareplicator
<時系列表>
<複製表>
◇構成◇・他社DBのデータをHiRDBに送信。・旧システムから新システムへのデータ移行は数ヶ月を要する。
・データ移行期間中は、旧システムをそのまま運用する。
・データ移行は複数回に分けて実施する。
◇特長◇・旧システムでの本番業務を続けながら、
長期間のデータ移行作業が可能・新システムにおけるデータ構造の変更に
対応可能
◇方式◇・HiRDB Datareplicatorによる反映処理実行時に、複製表と時系列表の2表に反映
・時系列表のデータをアプリケーションで加工し、新システムに合わせたデータを作成
HiRDB Datareplicator Extension (※)
(※)HiRDB Datareplicator Extensionは、他社DB連携を行うために必要なオプション製品です。
アプリケーション
<新システム表>

© Hitachi, Ltd. 2012, 2019. All rights reserved.
4-11 データ連携方法 業務垂直分散
37
考慮事項
その他
マスタサイトの業務を分割し(例えば更新業務と参照業務)、レプリカサイトで一部の業務を行い、マスタサイトの負荷を分散する
送信サイト数が多い場合、一部サイトの障害により他のサイトまで影響が起きないようにする
上記分散型の他、集約型の連携例もある
目的
項 目 内 容 設計すべき事項
回線容量とデータ量からサブセット/フルセットを検討
縮退方式を決め定義に入れる業務APも接続先を切り替えできるように設計する
分散と集約を相互に行うことは避けるように設計する(障害時の回復が複雑になる)
連携方向 通常、マスタサイトからレプリカサイトへの1方向
連携数 マスタとレプリカの関係は1:N (事例としては1:130があり)要件によっては多段階の連携もある
表構成 マスタとレプリカ側での表の構成は同一かもしくは一部の列。送信先毎にデータを振り分けるサブセット型と全データを送るフルセット型がある
反映遅延 業務要件に依存 送信間隔は業務要件時間の半分程度から考慮する
運用を考えるとNをできるだけ少なくし、且つ、多段階も避ける方向とする
-
-

© Hitachi, Ltd. 2012, 2019. All rights reserved.
4-12 適用事例 業務垂直分散
38
センタサーバ:Windows
支店サーバ:Windows 支店サーバ:Windows
HiRDB
HiRDB HiRDB
Replication
(約25箇所)
◇構成◇・センタホストにある情報をセンタサーバにレプリケーションし、更に各支店サーバに配布
・センタホスト→サーバは、UOCで対応をマッピング・センタサーバ→支店サーバは、
FULLレプリケーション・センタサーバおよび支店サーバは全く同じ構成・各支店では、自サーバDBを参照し、業務を実行
◇特長◇・既存ホストを生かしたサーバ業務連携・自支店サーバを参照するため、レスポンス良・センタホスト不稼動の時間帯(定時後、休日)でも業務を実行でき、サービス時間増
・各支店サーバ障害時でも、センタサーバ参照可能なため、業務停止が少ない
◇方式◇□センタホスト-サーバ間・PDMII(構造型)とリレーショナルのマッピング
を行う為にUOCを使用(コーディットレコード対応)・PDMIIのログSWAPのタイミングでサーバに
ログ転送しファイル入力機能を使用してサーバに反映
□サーバ-サーバ間・常設コネクション方式で全データを送信
PDMII E2
センタホスト:VOS3
センタ情報
センタ情報
<CHAR、…>
<CHAR、…>
Replication
(+UOC)
センタ情報
<CHAR、…>
<CHAR、…>センタ情報
<CHAR、…>
<CHAR、…>

© Hitachi, Ltd. 2012, 2019. All rights reserved.
4-13 適用事例 業務垂直分散
39
センタサーバ:Windows
支店サーバ:Windows 支店サーバ:Windows
HiRDB
HiRDB HiRDB
全支店情報
<CHAR、VARCHAR…>
Replication
(約80箇所)
◇構成◇・各支店にあるサーバの情報を、本部センタの
サーバに集約・本部センタのHiRDBはすべての支店情報を持つ
支店サーバでは、自支店データのみを持つ・各支店では、自支店分については自サーバDBを
参照。他支店分はセンタサーバDBを参照・データ登録は各支店が必要に応じて実行
◇特長◇・自支店情報については、ローカルDBアクセスに
より、高速レスポンスを保証・センタサーバへの参照も、他支店分のみとなり、
トラフィックの分散となっておりレスポンス良し
◇方式◇・各支店からは、全データ送信・センタサーバでは、各支店番号をキーに集約
しており、全支店分を一括管理
支店情報
<CHAR、VARCHAR…>
支店情報
<CHAR、VARCHAR…>

© Hitachi, Ltd. 2012, 2019. All rights reserved.
4-14 データ連携方法 業務水平分散
40
考慮事項
その他
既存システムにアドオンしたシステムでの既存システムとのデータ共有 (複数システムでのデータ共有)
障害時のデータ回復が複雑になる
マスタとレプリカの業務特性からデータの属性を変更する(UOCを適用せざるを得ない)ケースもある
目的
項 目 内 容 設計すべき事項
回線容量とデータ量からサブセット/フルセットを検討
回復方法をよく検討する(他システムへの影響も考慮する)
UOCの適用に当っては作業量をよく見積もること(難しいため)
連携方向 通常、マスタサイトからレプリカサイトへの1方向だが、要件により双方向がある
連携数 マスタとレプリカの関係はM:N (M、N<5程度)要件によっては多段階の連携もある
表構成 マスタとレプリカ側での表の構成は同一かもしくは一部の列。送信先毎にデータを振り分けるサブセット型と全データを送るフルセット型がある
反映遅延 業務要件に依存 送信間隔は業務要件時間の半分程度から考慮する
マスタを決めること、またできるだけ絞ること。多段階も避ける方向とする
同一表の双方向は不可。別表でもできるだけ避けることを考える
-

© Hitachi, Ltd. 2012, 2019. All rights reserved.
4-15 適用事例 業務水平分散
41
DBDB
DBDB
DB
TMS-4V/SP
オンライン
APJ
LGJ
更新情報DS
TMS-4V/SP
データ連携支援
DATABASE
DATAREPLICATOR
UOC
HiRDB Datareplicator
VOS3[LPAR#1] VOS3[LPAR#2]
HP-UX[L2000×4]
HiRDB/Parallel Server
◇構成◇・センタホスト[#1]でオンライン業務を実施
#2ホストでデータを抽出してサーバに送信・反映・サーバに反映したデータは営業店から参照・サーバに複製データ、取引履歴を蓄積することにより
新しい業務(サービス)を実施可能
◇特長◇・既存ホストを生かしたサーバ業務連携・SQLを利用した非定型な問合せ発行により、
従来ではできなかった問い合わせが可能・SQL文と簡単なスクリプトを使用することにより、
アプリケーションを作成することなく業務を実現・レプリケーションした取引履歴等に対して、更に
簡単な加工を行い、新しい業務を実施
◇方式◇・TMS-4Vオンラインとデータ連携部分を別LPARとし
APJをディスク共用することでオンラインに負担を掛けない
・データ連携支援のUOCを使用して、取引履歴等の蓄積型データをも作成
・10秒間隔の送信でできるだけリアルデータを反映・サーバ側でSQLを並列実行することで、ピーク時
200万SQLを最小の遅延で反映・バッチにて大量更新される表は、XT-Dataextractor
にて夜間一括転送SQL
SQL
SQL
SQL
営業店端末
SQL

© Hitachi, Ltd. 2012, 2019. All rights reserved.
4-16 データ連携方法 分析用DB作成
42
考慮事項
その他
マスタサイトでの更新を履歴として使用し、データ分析業務などに適用
障害時のデータ回復が複雑になる
UOCを適用せざるを得ないケースもある
目的
項 目 内 容 設計すべき事項
回復方法をよく検討する(回復不能となる場合もあり得る)
UOCの適用に当っては作業量をよく見積もること(難しいため)
連携方向 通常、マスタサイトからレプリカサイトへの1方向
連携数 マスタとレプリカの関係はM:1
マスタとレプリカ側での表の構成は異なる。履歴として蓄積型DBを作成したり、表の集約や表の加工を行うケースもある
表構成
反映遅延 業務要件に依存 送信間隔は業務要件時間の半分程度から考慮する
HiRDB Datareplicatorの機能範囲を事前に調査すること。標準機能でできない場合にはUOCで実現するか後でAPで加工するか検討(SPM、トリガで代用可能な場合もあり)
Mは5程度におさえる
-
-

© Hitachi, Ltd. 2012, 2019. All rights reserved.
4-17 適用事例 分析用DB作成
43
PDMII E2
VOS3
XDM/DS
オンライン業務
HP-UX
HiRDB/Single Server
<時系列表>
<複製表>
HiRDB Datareplicator
SQL
本部端末(PC)
分析業務
◇構成◇・センタホスト[VOS3]で基幹業務を実行。
基幹業務での更新データをサーバに送信・サーバには複製表と時系列表を同時作成。
時系列表を入力にして、分析業務で使用するテーブルを作成
・本部端末から分析業務を実施
◇特長◇・既存ホストを生かしたサーバ業務連携・SQLを利用した非定型な問合せ発行により、
従来ではできなかった問い合わせが可能・時系列表を作成することにより、分析業務用
のデータを容易に作成して活用
◇方式◇・PDMIIを入力として、データ連動を実行・HiRDB Datareplicatorによる反映処理
実行時に複製表と時系列表の2表に反映・送信間隔を30分とし、30分間のデータを
反映完了後イベント機能使用により、分析テーブル作成ジョブを自動起動
アプリケーション
<分析表>

© Hitachi, Ltd. 2012, 2019. All rights reserved.
5. システム設計のポイント
44

© Hitachi, Ltd. 2012, 2019. All rights reserved.
5-1 システム設計のポイント ー項目ー
45
5-2 構成の設計
・表構成の考え方
・連動方向・連携数の考え方
5-3 大量データ更新の反映(性能)
・反映処理の方式(トランザクション/表)
・反映処理のCOMMIT発行間隔
・レプリケーション滞留監視機能
・反映遅延の考え方
5-4 HiRDB/Parallel Serverの注意点
・マルチFESの注意
・ PURGE TABLEの連動
・反映トランザクション同期機能の検討
5-5 リソース見積もり
・I/Oバッファ
・ファイル
・キューファイル容量
5-6 検討が必要なパラメタ/環境設定
・検討が必要なパラメタ
・反映側の環境設定

© Hitachi, Ltd. 2012, 2019. All rights reserved.
5-2-1
46
以下の場合には、HiRDB Datareplicatorは不向きです。 HiRDB Dataextractorによる連携を推奨します。・前日分データ等、抽出側と反映側の同期間隔の長いもの・特定時間帯にバッチ等により大量更新される表・採番(without rollbackオプション付き)表
HiRDB Datareplicatorに適さない表
抽出側表と反映側表の対応はできるだけシンプルにすることを推奨します。・反映側の表は、抽出側と同一形式、または、抽出側のサブセットであることが望ましい・複雑な対応を行おうとするとUOCを使用する必要がある(この場合、障害時の回復手順も複雑になる)・複雑な対応が必要な場合には、時系列表を使用してデータを蓄積し、後でユーザアプリケーションにより対応させることも考慮する
表の対応はシンプルに
抽出元と反映先の表の列データ型が異なる場合には、HiRDB Datareplicator標準機能では、反映先RDBMSのデータ型変換機能を使用してデータ変換をしようとします。反映先RDBMSでデータ変換ができない場合にはSQLエラーとなり反映できません。UOCにて対応することが必要となりますが、列データ編集UOCを作成することで簡単に対応できる場合があります。
列のデータ型が異なる場合
連動対象の表定義を変更した場合、HiRDB Datareplicatorに認識させるためプリプロセス(hdeprep)を実行する必要があります。また、格納サーバ(BES)の変更を伴う場合には、HiRDB Datareplicatorの再初期化が必要です。定義変更の手順に必ずプリプロセスを入れるようにしてください。
表定義変更時にはプリプロセスを忘れずに
反映対象表には、すべてのマッピングキー列を構成列とするユニークキーインデクスを定義します。ユニークキーインデクスを定義していないと、キー重複エラーを検知できなくなります。さらに、UPDATEとDELETEの反映性能が著しく低下します。
マッピングキーの定義
構成の設計
表構成の考え方

© Hitachi, Ltd. 2012, 2019. All rights reserved.
5-2-2
47
抽出側と反映側との接続方式は送信先数に応じて選択してください。(送信先は少ない方が良いです)・通常は常設コネクション方式(nodemst方式)を推奨・送信先が10を超える場合には、送信時コネクション方式(sendmst方式)を推奨
なお、予め今後送信先が追加されることが判っている場合には、予備として定義しておくことをお勧めします。
送信先数に応じて送信方式を選択
多段階の連動は、中間にあるサーバが障害となると回復が大変になります。2段階構成を推奨します。・3段階以上の連動(サーバA⇒サーバB⇒サーバCとAのデータを伝播する構成)は最小限にする・多段階でループする構造は絶対に構成しない
抽出側表と反映側表を双方向で連携することはデータ不整合を発生させる要因になります。・双方向で連携する場合には、別表に分ける・どうしても双方向で連携したい場合には、更新を実行する時間帯を分ける、また、ループバック抑止のパラメタを設定する
双方向の連動はやらない
抽出システム定義、または、送信環境定義で指定します。・できるだけ反映までを短くしたいのであれば、5秒または10秒間隔で送信することをお勧めします。・送信間隔に0指定をするのは、更新(送信)トランザクションが秒1件以下の場合を目安にしてください。そうでない場合、逆に送信遅延が発生することがあります。
送信間隔の設計
多段階の連動は最小限に
構成の設計
連携方向・連携数の考え方①

© Hitachi, Ltd. 2012, 2019. All rights reserved.
5-2-3
48
項番 定義ファイル名 パラメタ 内容
1
抽出システム定義
sendcontrol= nodemst|sendmst
抽出データを送信するときの処理方式を指定します。nodemst :各送信先ごとに送信プロセスを起動して、送信処理を送信先ごとに並列処理します。sendmst:送信マスタプロセスで送信プロセス数を制御します。
2 smt_sendintvl=送信マスタプロセス送信間隔
送信マスタプロセスの送信間隔を指定します。送信間隔の単位はsmt_sendintvl_scaleオペランドで指定します。このオペランドは、sendcontrolオペランドにsendmstを指定した場合に有効です。0を指定すると、トランザクション単位で更新情報を送信します。ただし、反映までの時間を短くしたい場合は、1秒からチューニングを始めてください。0を指定すると送信処理が遅くなる場合があります。sendcontrolオペランドにsendmstを指定すると、送信環境定義のsendintvlオペランドの指定値は無視されて、このオペランドの指定値に従って送信処理が実行されます。
3 送信環境定義
sendintvl=送信間隔 抽出した更新情報を反映側システムに送信するときの送信間隔を指定します。送信間隔の単位はsendintvl_scaleオペランドで指定します。0を指定すると、トランザクション単位で更新情報を送信します。ただし、反映までの時間を短くしたい場合は、1秒からチューニングを始めてください。0を指定すると送信処理が遅くなる場合があります。
構成の設計
連携方向・連携数の考え方②

© Hitachi, Ltd. 2012, 2019. All rights reserved.
5-3-1
49
抽出側DBMSで更新されたトランザクション順に反映側HiRDBのデータベースに反映します。反映処理に反映プロセスと反映SQLプロセスを一つずつ割り当てて反映する方式です。
トランザクション単位反映方式
一つまたは複数の反映対象表ごとに反映グループを作り、各グループで並行に反映します。各反映対象表の更新量が均等であれば、反映処理の性能向上が期待できます。一方で、起動プロセス数が増えてメモリの使用量が多くなるため、メモリ容量を考慮した上で選択してください。表単位反映方式には、次に示す種類があります。
◇表単位分割方式◇キーレンジ単位分割方式◇ハッシュ分割方式
表単位反映方式
大量データ更新の反映
反映処理の方式①
解説
反映処理の方式には、トランザクション単位反映方式と表単位反映方式の二つがあります。
通常はトランザクション単位反映方式を使用します。
データ量が多い場合(反映件数×SQL処理単価がマシンの能力を超えてしまう場合)には、
表単位反映方式を検討してください。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
5-3-2
50
項番 表単位反映方式の種類 内容
1 表単位分割方式 ①一つまたは複数の反映対象表ごとに反映グループを作成します。②抽出側DBMSで更新されたトランザクションを、ユーザの定義した反映グループごとに分けて、並列に反映します。
2 キーレンジ単位分割方式 ①一つの反映対象表で一つの反映グループを作成し、さらに反映グループの中でキーレンジ分割条件を指定します。②抽出側DBMSで更新されたトランザクションを、ユーザが定義したキーレンジに従って、並列に反映します。
3 ハッシュ分割方式 ①一つの反映対象表で一つの反映グループを作成します。②抽出側DBMSで更新されたトランザクションを、ハッシュ法で並列に反映します。
大量データ更新の反映
反映処理の方式②

© Hitachi, Ltd. 2012, 2019. All rights reserved.
5-3-3
51
FES反映側Datareplicator
反映情報キューファイル
load * from UPD1 to T1
load * from UPD2 to T2
load * from UPD3 to T3
load * from UPD4 to T4
group GRP1 by T1,T2
group GRP2 by T3,T4
<反映定義>
BES
T2
T1
反映プロセスT1,T2
反映SQLプロセス
GRP1
GRP2
T4
T3
表単位分割方式
FES反映側Datareplicator
反映情報キューファイル
load * from UPD1 to T1
load * from UPD2 to T2
<反映定義>
BEST1
トランザクション単位反映方式
T2
反映プロセスT3,T4
反映SQLプロセス
※1:反映SQLプロセスを管理するプロセス※2:反映情報キューファイルから入力した更新情報を基にSQL文を生成し、反映側DBにSQL文を発行
するプロセス
反映プロセス※1 T1, T2
反映SQLプロセス※2
大量データ更新の反映
反映処理の方式③

© Hitachi, Ltd. 2012, 2019. All rights reserved.
5-3-4
52
FES反映側Datareplicator
反映情報キューファイル
load * from UPD1 to T1
group GRP1 by T1
in host1/front1 having
c1<100,c1<200,other
<反映定義>
BES
反映プロセス
反映SQLプロセス(c1<100)
GRP1
キーレンジ単位分割方式
反映SQLプロセス(c1<200)
反映SQLプロセス(other)
キーレンジ~99
キーレンジ100~199
キーレンジ200~
反映側Datareplicator
反映情報キューファイル
load * from UPD1 to T1
group GRP1 by T1
hash in host1/front1
(RDAREA1),host2/front2
(other)
<反映定義>
BES
T1のRDAREA1
反映プロセス
反映SQLプロセス( RDAREA1)
GRP1
ハッシュ分割方式
反映SQLプロセス( RDAREA1以外)
T1のRDAREA2
T1
BES
T1
FES
host1/
front1
FES
host2/
front2
条件に合致する反映SQLプロセスだけがSQL文を発行
条件に合致する反映SQLプロセスだけがSQL文を発行
大量データ更新の反映
反映処理の方式④

© Hitachi, Ltd. 2012, 2019. All rights reserved.
5-3-5
53
項番 定義ファイル名 パラメタ 内容
1
反映環境定義
startmode={ trn|tbl|spd } 反映側Datareplicator起動時の反映方式を指定します。
trn :トランザクション単位反映方式で反映処理を開始します。
tbl :表単位反映方式(表単位分割方式、キーレンジ単位分割方式、ハッシュ分割方式)で反映処理を開始します。
spd :反映側Datareplicatorの起動時に反映処理を停止したまま、受信処理だけを開始します。
2 breakmode= trn|tbl 反映側Datareplicatorの起動時から停止状態にある反映処理を開始する場合の反映方式を指定します。
trn :トランザクション単位反映方式で反映処理を開始します。
tbl :表単位反映方式(表単位分割方式、キーレンジ単位分割方式、ハッシュ分割方式)で反映処理を開始します。
大量データ更新の反映
反映処理の方式を指定する定義パラメタ

© Hitachi, Ltd. 2012, 2019. All rights reserved.
5-3-6
54
項番 定義ファイル名 パラメタ 内容
1
反映環境定義
cmtintvl=反映処理コミット間隔 反映側Datareplicatorが反映側HiRDBに対してコミットを発行する間隔を、抽出側システムでのトランザクション数で指定します。
2 trncmtintvl=トランザクション単位反映方式での反映処理コミット間隔
トランザクション単位反映方式で反映処理を実行中に、反映側Datareplicatorが反映側HiRDBに対してコミットを発行する間隔を、抽出側システムでのトランザクション数で指定します。
3 tblcmtintvl=表単位反映方式での反映処理コミット間隔
表単位反映方式で反映処理を実行中に、反映側Datareplicatorが反映側HiRDBに対してCOMMIT
を発行する間隔を、抽出側システムでのトランザクション数で指定します。
大量データ更新の反映
反映処理のCOMMIT発行間隔
解説
反映側HiRDBにCOMMITを発行する間隔は、反映環境定義のcmtintvl 、 trncmtintvl 、またはtblcmtintvlオペランドに指定する抽出側システムでのトランザクション数により決まります。コミットの発行間隔の設定の考慮点を以下に示します。・COMMITを発行する間隔が小さいよりも大きい方が、より多くのトランザクションに対するSQL文を
1回で発行するため、反映側HiRDBへの負荷が減り、性能面での向上が期待できます。しかし、障害発生時、未反映のトランザクションが多くなり、回復に長い時間が掛かります。
・1コミット間隔の反映処理で出力される反映側HiRDBのログ量を考慮し、システムログファイルなど、障害回復用のファイルが満杯にならないようにしてください。
・反映処理のCOMMIT発行間隔を長くすると、反映先HiRDBサーバの排他資源などの必要リソース量が増加します。必要リソース量を考慮して、COMIIT発行間隔を調整してください。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
5-3-7
55
送信滞留時間
HiRDB
LOG
抽出側Datareplicator
抽出キューファイル
反映側Datareplicator
反映キューファイル
HiRDB
DB抽出 送信 受信 反映
抽出滞留時間
反映滞留時間
警告メッセージに応じてDisk配置の確認やチューニング等の対処を行います。
■抽出滞留時間超過 :抽出キューファイルのI/Oに時間がかかっていることが考えられます。
Diskのスペックや配置を見直してください。
■送信滞留時間超過 :反映キューファイルのI/O時間 、もしくは、抽出側、反映側の通信に時間がかかっている
ことが考えられます。 Diskのスペックや配置、もしくは通信回線を見直してください。
■反映滞留時間超過 :反映先DBMSへのSQL実行に時間がかかっていることが考えられます。
反映先DBMSのSQL実行に関するチューニングを行ってください。
更新の発生 抽出完了 送信完了 反映完了(時間)
滞留時間ごとに
しきい値を設定
できます
大量データ更新の反映
レプリケーション滞留監視機能①
解説抽出側DBの更新からレプリケーションによる反映完了までに要する時間が一定時間を
超過した場合に、警告メッセージを出力しユーザに遅延を知らせる機能です。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
5-3-8
56
項番 定義ファイル名 パラメタ 内容
1 抽出環境定義
extract_delay_limit_time
=抽出滞留時間しきい値
更新情報がシステムログファイルに格納された時刻と、抽出情報キューファイルに抽出情報が書き込まれる時刻との差(抽出滞留時間)のしきい値を指定します。
2 送信環境定義
send_delay_limit_time
=送信滞留時間しきい値
更新情報がシステムログファイルに格納された時刻と、更新データが送信されて反映側DBMSで受信が完了した時刻との差(送信滞留時間)のしきい値を指定します。
3 反映環境定義
reflect_delay_limit_time
=反映滞留時間しきい値
更新情報がシステムログファイルに格納された時刻と、反映側DBでその更新情報が反映
された時刻との差(反映滞留時間)のしきい値を指定します。
大量データ更新の反映
レプリケーション滞留監視機能②

© Hitachi, Ltd. 2012, 2019. All rights reserved.
5-3-9
57
受信機能
HiRDB
Datareplicator
DB
HiRDB
反映機能
反映キューファイル
制御機能
UOC
アプリケーション
DB
HiRDB
LOG
抽出機能
HiRDB
Datareplicator
送信機能
抽出キューファイル
制御機能
SQL① ② ③ ④ ⑤ ⑥
① アプリケーションがHiRDBにCOMMITを発行した時点が、反映遅延ゼロの位置となる② 抽出機能がログから読み込みキューに出力する時間(READとWRITEの時間)。ただし、ログ終端に追いついた場合、
一定時間スリープする(5-3-10の項番1のパラメタでチューニング可)③ 送信機能が対象トランザクションを監視し、組立てて送信する時間、送信間隔(5-3-10の項番3のパラメタで指定)に依存する。
なお、キュー終端に追い付いた場合、一定時間スリープする(5-3-10の項番2のパラメタでチューニング可)④ 更新トランザクションがネットワークを通過する時間⑤ 受信機能が更新トランザクションを受取りキューに出力する時間。(ここはタイマ監視なし)⑥ 反映機能がキューから読み込みSQLを組立ててHiRDBに発行し、COMMITする時間。(COMMIT完了までの時間が遅延時間)
反映側では抽出側トランザクションを纏めてCOMMIT発行するため、COMMIT間隔(5-3-10の項番5、6のパラメタで指定)に依存。また、キュー終端に追い付いた場合には一定時間スリープする(5-3-10の項番4のパラメタでチューニング可)
送信間隔と反映COMMIT間隔で反映遅延時間が決まる
大量データ更新の反映
反映時間の考え方

© Hitachi, Ltd. 2012, 2019. All rights reserved.
5-3-10
58
項番 定義ファイル名 パラメタ名 パラメタの説明 設定時の留意点
1 抽出環境定義 ext_wait_interval 抽出対象DBMS からの更新情報の終端を検知してから次回の抽出を再開するまでの間隔を指定
システムログファイル/
キューファイル終端検知した場合のスリープ時間。トラフィックが少ない場合小さくすることを推奨。
2抽出システム定義
送信環境定義
[smt_]queue_read_wait_interval 抽出情報キューファイルの終端を検知してから次回の読み込みを再開するまでの間隔を指定
[smt_]sendintvl
[smt_]sendintvl_scale
送信マスタプロセスの送信間隔を指定
ネットワークとデータ量から算出して、できるだけ小さい値を推奨。
3
項番 定義ファイル名 パラメタ名 パラメタの説明 設定時の留意点
4
反映システム定義
反映環境定義
ref_wait_interval 反映プロセスが、反映情報キューファイルの終端を検知してから次回の読み込みを再開するまでの間隔を指定
キューファイル終端検知した場合のスリープ時間。トラフィックが少ない場合小さくすることを推奨。
5
cmtintvl 反映側Datareplicatorが反映側HiRDBに対してCOMMITを発行する間隔を、抽出側システムでのトランザクション数で指定
高トラフィックの場合は大きめに(50以上)、低トラフィックの場合には小さめに(10
程度)。
6
commit_wait_time 反映プロセスが反映情報キューファイルの終端を検知してから、反映側HiRDBに対してCOMMITを発行するまでの間隔を指定
抽出側
反映側
大量データ更新の反映
反映時間で検討が必要な定義パラメタ

© Hitachi, Ltd. 2012, 2019. All rights reserved.
5-4-1 HiRDB/Parallel Serverの注意点
59
反映側HiRDBのマルチFES環境に対して、反映定義で指定した反映先のフロントエンドサーバと実際に
反映処理を実行するバックエンドサーバの起動するマシンが異なる場合には、 1回の反映処理ごとに
フロントエンドサーバとバックエンドサーバとの間の通信が発生して、効率的な処理が実行できません。
このため、反映定義でフロントエンドサーバを指定する場合には、表データを格納しているマシンで起動し
ているフロントエンドサーバを指定してください。
マルチFESの注意
パラレルサーバ構成で、横分割表に対してPURGE TABLEを実行する場合、各BESからPURGE TABLE
が抽出・送信されます。反映側で手動でPURGE TABLEを発行することが必要となるため、運用手順を確立しておいてください。
PURGE TABLEの連動
HiRDB/Parallel Serverで発生するトランザクションには、各バックエンドサーバで発生するトランザクション(トランザクションブランチ)と、それらをまとめるトランザクション(グローバルトランザクション)があります。通常、HiRDB Datareplicatorはトランザクションブランチ単位で連動しますが、反映トランザクション同期機能を使用すると、グローバルトランザクション単位でのデータの整合性を保証します。
反映トランザクション同期機能の適用検討

© Hitachi, Ltd. 2012, 2019. All rights reserved.
5-4-2
60
アプリケーション HiRDB(ユニット2)
抽出側
Data
rep
licato
r
口座A
X-100万円
HiRDB
(ユニット1)
HiRDB(ユニット3)
抽出側
Data
rep
licato
r
口座B
Y+100万円
反映側HiRDB反映側Datareplicator
口座A
X-100万円口座B
Y万円
COMMIT
口座A
-100万円(UPDATE)
FES
BES1
BES2
口座B
+100万円(UPDATE)
COMMIT
口座A
-100万円(UPDATE)
COMMIT
口座B
+100万円(UPDATE)
口座A
X-100万円口座B
Y+100万円
抽出側HiRDB/Parallel Server
■通常運用の例
抽出側HiRDBのBES1のデータ操作とBES2のデータ操作が、反映側では非同期にCOMMITされる
口座Aと口座Bの整合性が取れない瞬間が存在する
HiRDB/Parallel Serverの注意点
反映トランザクション同期機能①
解説抽出側がHiRDB/Parallel Serverの場合、通常は、
バックエンドサーバ単位のトランザクションとして反映処理が実行されます。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
5-4-3
61
アプリケーション HiRDB(ユニット2)
抽出側
Data
rep
licato
r
口座A
X-100万円
HiRDB
(ユニット1)
HiRDB(ユニット3)
抽出側
Data
rep
licato
r
口座B
Y+100万円
反映側HiRDB反映側Datareplicator
COMMIT
口座A
-100万円(UPDATE)
FES
BES1
BES2
口座B
+100万円(UPDATE)
口座A
-100万円(UPDATE)
COMMIT
(同期イベント)
口座B
+100万円(UPDATE)
口座A
X-100万円口座B
Y+100万円
抽出側HiRDB/Parallel Server抽出側HiRDBのBES1のデータ操作とBES2のデータ操作が、反映側でも同期を取ってCOMMITされる
■反映トランザクション同期機能を使用した場合の例
※ 反映トランザクション同期機能を使用する場合、以下の注意事項があります。①イベントを発行するシェルスクリプトを作成する必要があります。
(マニュアルにサンプルあり)②イベント発行間隔が遅延します。③処理の遅い方に合わせて同期をとるため、反映処理が遅延することがあります。
COMMIT
同期イベント
COMMIT(無視)
COMMIT(無視)
HiRDB/Parallel Serverの注意点
反映トランザクション同期機能②
解説
バックエンドサーバ間で反映処理の同期を取りたい場合は、反映トランザクション同期機能を適用してください。反映トランザクション同期機能は、イベント機能を利用して実現します。反映側Datareplicatorから発生するトランザクションでCOMMITを発行する契機は、同期イベントだけになり、反映環境定義cmtintvlオペランド(反映処理コミット間隔)の指定は無視されます。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
5-5-1
62
機能 バッファ種別 定義ファイル名 パラメタ名 内容
抽出 システムログI/Oバッファ
抽出環境定義 logiosize システムログファイルからシステムログを抽出するときに使用する。抽出側HiRDBのpd_log_max_data_sizeに指定した値以上にする。抽出側がHiRDB/Parallel Serverの場合には、バックエンドサーバごとに見積もる。
抽出情報キューI/Oバッファ
抽出環境定義 quiosize 抽出した更新情報を抽出情報キューファイルに格納するときに使用する。「(抽出環境定義のqueuesizeオペランドの指定値-1)÷指 定値」で余りがない値にする。抽出側がHiRDB/Parallel Serveの場合には、バックエンドサーバごとに見積もる。抽出プロセスで一つ使用する。
送信 トランザクション管理情報バッファ
送信環境定義 maxtran
maxtrandata
抽出側Datareplicatorでは、maxtranオペランドで指定した同時実行最大トランザクション数と、maxtrandataオペランドで指定したトランザクション内最大更新情報数の積を、トランザクション管理情報バッファサイズの初期値とする。このため、領域追加が発生しないでメモリ不足にならないようにmaxtran
オペランドとmaxtrandataオペランドを指定する。
送信用の抽出情報キューI/Oバッファ
送信環境定義 readbufnum 送信用の抽出情報キューI/Oバッファの数(抽出した更新情報を格納したときと同じサイズで、更新情報を読み込む必要があるため、抽出用の抽出情報キューI/Oバッファと同じになる。)
更新情報編集バッファ 送信環境定義 editbufsize より多くの更新情報を1回で編集でき、読み書きの回数を少なくできるように1SQL以上の更新情報が格納できるサイズにする。大きくしすぎるとメモリ不足になることもあるので注意する。
リソースの見積もり
バッファの見積もり

© Hitachi, Ltd. 2012, 2019. All rights reserved.
5-5-2
63
機能 ファイル種別 定義ファイル名 パラメタ名 内容
抽出 抽出マスタエラー情報ファイル
抽出システム定義 errfilesz 既定値は16キロバイトです。長時間のエラー情報を残したいときに拡張する。
抽出ノードマスタエラー情報ファイル
抽出マスタトレースファイル
int_trc_filesz 1個当たりの最大格納サイズを指定する。採取する項目(抽出システム定義int_trc_lvl)の指定がある場合、余裕をもって(1MB以上を推奨)指定する。
抽出ノードマスタトレースファイル
反映 反映ステータスファイル 反映環境定義 statsfile 抽出側DBから送られてくる抽出定義情報が格納されるため、抽出定義プリプロセスファイルのサイズで見積もる。
未反映情報ファイル unreffilesz 未反映情報ファイルの上限サイズを指定する。発生する可能性のあるSQLエラーの容量が大きい場合には、ファイルの容量を拡張する。unreffile1とunreffile2の両方に対応。
反映エラー情報ファイル 反映システム定義 errfilesz 反映エラー情報ファイルの上限サイズを指定する。既定値は16キロバイトです。長時間のエラー情報を残したいときに、ファイルの容量を拡張する。
稼働トレースファイル(反映トレースファイル)
int_trc_filesz 1個当たりの最大格納サイズを指定する。採取する項目(反映システム定義int_trc_lvl)の指定がある場合、余裕をもって指定する。
リソースの見積もり
ファイルの見積もり

© Hitachi, Ltd. 2012, 2019. All rights reserved.
5-5-3
64
キューファイルの容量は以下のようにすることを推奨します。・抽出キューファイルは、データを数日間保持できる容量にする(3日分以上を推奨)
抽出キューファイルは、通信経路障害あるいは反映側マシン障害による停止時間を考慮する必要があります。反映側が回復後、追い付きできる許容時間を考慮して、許容時間分はデータを蓄積できる容量を確保することが必要です。抽出キューファイルが満杯となると、HiRDBのシステムログに未抽出データが蓄積されていきます。なお、抽出キューファイルは、3~4個空きを持たせておくようにしてください(緊急時に追加できるように)。
・反映キューファイルは、反映停止運用の時間分蓄積できる容量とする反映キューファイルは抽出キューファイル程の容量は不要です。再編成処理等により反映処理を停止させておく時間帯の分を考慮して容量を決めてください。反映キューファイルが満杯となると、抽出キューファイルに未送信データとして蓄積されます。
長時間実行されるトランザクションがある場合には、そのトランザクションと並行実行されるトランザクションのデータ量を加えた分以上のキューファイル容量が必要です。長時間実行のトランザクションに対しては、定期的にCOMMITするような作りとすることを検討してください。
キューファイルの容量
レプリケーション対象データが多い大規模システムでは、障害発生時を想定し、大容量のキューファイルを準備する必要があります。HiRDB Datareplicatorでは、1つあたりのキューファイルのサイズを最大1TBまで設定することができます。なお、抽出キューファイル数は最大16個まで、反映キューファイル数は最大8個まで設定することができます。容量とファイル数とを考慮して、それぞれの値を検討してください。
キューファイル容量の最大値
リソースの見積もり
キューファイルの容量設計について

© Hitachi, Ltd. 2012, 2019. All rights reserved.
5-5-4
65
障害が長期化した場合、キューファイルの容量不足に陥る危険性があります。キューファイルの容量不足
に陥ると、障害範囲が広がってしまいますので、十分に注意してください。
キューファイルの容量
キューファイルの使用率を確認して、空き容量が十分であるか確認してください。キューファイルの使用率は、状態表示コマンド(抽出側Datareplicatorの場合には、hdestateコマンド、反映側Datareplicatorの場合には、hdsstateコマンド)で確認できます。
障害が発生したら
リソースの見積もり
キューファイル容量不足を回避するために
© Hitachi, Ltd. 2012, 2019. All rights reserved.
5-6-1
66
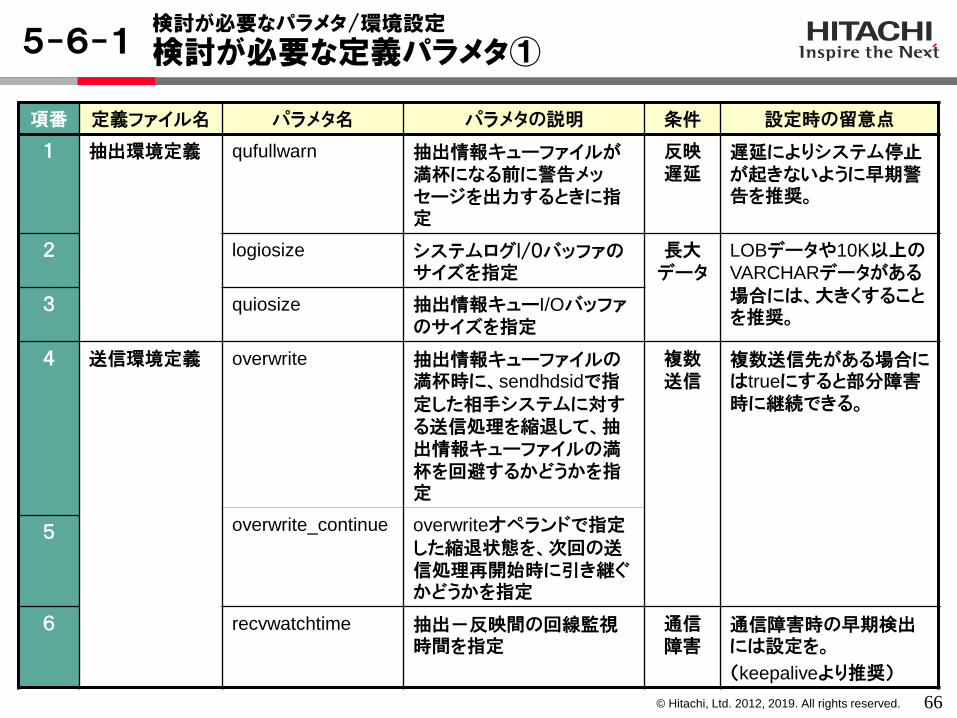
項番 定義ファイル名 パラメタ名 パラメタの説明 条件 設定時の留意点
1 抽出環境定義 qufullwarn 抽出情報キューファイルが満杯になる前に警告メッセージを出力するときに指定
反映遅延
遅延によりシステム停止が起きないように早期警告を推奨。
2 logiosize システムログI/Oバッファのサイズを指定
長大データ
LOBデータや10K以上のVARCHARデータがある場合には、大きくすることを推奨。
3 quiosize 抽出情報キューI/Oバッファのサイズを指定
4 送信環境定義 overwrite 抽出情報キューファイルの満杯時に、sendhdsidで指定した相手システムに対する送信処理を縮退して、抽出情報キューファイルの満杯を回避するかどうかを指定
複数送信
複数送信先がある場合にはtrueにすると部分障害時に継続できる。
overwrite_continue overwriteオペランドで指定した縮退状態を、次回の送信処理再開始時に引き継ぐかどうかを指定
5
6 recvwatchtime 抽出-反映間の回線監視時間を指定
通信障害
通信障害時の早期検出には設定を。
(keepaliveより推奨)
検討が必要なパラメタ/環境設定
検討が必要な定義パラメタ①

© Hitachi, Ltd. 2012, 2019. All rights reserved.
5-6-2
67
項番 定義ファイル名 パラメタ名 パラメタの説明 条件 設定時の留意点
7 抽出システム定義
反映システム定義
file_dupenv 二重化定義ファイル名を絶対パス名、または相対パス名で指定
耐障害性
キューファイル、ステータスファイルは障害発生すると継続不可となるのでニ重化を推奨。
8 反映環境定義 db_connect_retry_
number反映側DatareplicatorがターゲットDBにコネクトしようとしてエラーになった場合の、コネクトリトライ回数を指定
系切り替え
HiRDB DatareplicatorがHiRDBより先に起動しても、HiRDB起動完了まで接続リトライできる時間を設定。
9 db_connect_retry_
interval
反映側DatareplicatorがターゲットDBに対してコネクトリトライする場合のリトライ間隔を、秒単位で指定
検討が必要なパラメタ/環境設定
検討が必要な定義パラメタ②

© Hitachi, Ltd. 2012, 2019. All rights reserved.
5-6-3
68
①PDSWATCHTIME
反映側でのSQL発行タイミングは抽出側での更新データ発生タイミングに依存するため、PDSWATCHTIMEは0(ゼロ)を指定するようにしてください。
②PDSWAITTIME、PDCWAITTIME
反映側DatareplicatorはPDSWAITTIME、PDCWAITTIMEを0(ゼロ)に設定して動作します。以下の場合にはHDSCLTWAITTIME=USERを指定した上で、 PDSWAITTIME、PDCWAITTIMEを個別に設定してください。(a) 監視時間の上限値をユーザにより規定されている場合
反映同期点間隔≠1の場合には、PDSWAITTIME=0、PDCWAITTIME=ユーザ規定値を、反映同期点間隔=1の場合には、PDSWAITTIME、PDCWAITTIMEにユーザ規定値を設定してください。
(b)2相コミット方式を使用する場合PDSWAITTIME=0を設定し、 PDCWAITTIMEに反映SQLプロセス数×10以上を指定してください。
③PDDBLOG
反映側Datareplicatorでは反映処理がCOMMITまで完了したものは再実行はできません。ログレスモードで実行した場合、障害発生後に反映完了時点までDBを戻せなくなるため、ログ取得モードで実行してください。
④PDFESHOST、PDSERVICEGRP
反映先がHiRDB/Parallel Serverの場合、デフォルトで接続したいフロントエンドサーバを指定してください。表単位反映を使用する場合には、反映定義のgroup文にて、更にグループ毎の接続先を指定してください。
⑤その他(a)抽出側と反映側の文字コードが異なる場合には、文字コードに関する変数を指定することが必要な場合があ
ります。(b)インナレプリカ機能使用時で特定世代に反映する場合には、反映先レプリカ世代を指定してください。
検討が必要なパラメタ/環境設定
反映側の環境設定
解説
反映側Datareplicatorは、反映側HiRDBから見ると、クライアントアプリケーションとして動作
します。HiRDB Datareplicator起動コマンド実行シェルまたは起動コマンド投入ユーザプロファイ
ルに以下のHiRDBクライアント環境変数を設定してください。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
6. 環境構築のポイント
69

© Hitachi, Ltd. 2012, 2019. All rights reserved.
6-1 反映側DB初期構築の方法
70
HiRDB Datareplicatorによる初期構築の詳細な手順は、次の「初期構築の手順」を参照してください。
解説
HiRDB Datareplicatorの初期化のとき、抽出側DBMSと反映側DBMSを一致させておきま
す。抽出側にデータが登録されていない場合は、HiRDB Datareplicatorの初期化を実施し
た後、抽出側DBMSにデータを登録していきます。この登録内容をHiRDB Datareplicator
が反映側DBMSに反映させます。
抽出側DBMSの表にデータが登録されている場合は、HiRDB Dataextractor (あるいは
アンロード+ftp+ロード)を使用して、抽出側DBMSのデータをすべて反映側DBMSに
一括反映します。その後、反映側Datareplicatorの初期化を実施し、運用を開始します。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
6-2 HiRDB Datareplicatorによる初期構築の手順
71
事前に設計を完了させておきます。E-①、R-①
運用ディレクトリを作成します。インストールディレクトリとは異なる場所を推奨します。
E-②、R-②rawデバイスに作成する場合に、領域を割当てます。
E-③、R-③Datareplicatorの各種定義ファイルを運用ディレクトリ下に作成します。
E-④、R-④通信に必要な情報を登録します。
E-⑤、R-⑤Dataextractor(あるいはアンロード+ftp+ロード)を実行して、DBの同期を取ります。
E-⑥:pdstopコマンドを実行します。E-⑦:hdestart –iを実行します。E-⑧:pdsysでpd_rpl_init_start=Yに変更します。E-⑨:pdstartコマンドを実行します。E-⑩:hdeprepコマンドを実行します。R-⑥:hdsstart –i –fを実行します。E-⑪:hdestartを実行します。E-⑫、R-⑦
反映側でhdsstateコマンドを実行し、接続したことを確認します。
E-⑬、R-⑧抽出側でデータを更新し、反映側で反映が完了したことを確認します。
運用ディレクトリの作成 運用ディレクトリの作成
抽出側Datareplicator 反映側Datareplicator
キュー領域の作成 キュー領域の作成
定義ファイルの作成 定義ファイルの作成
Hosts、services、Inetd.confへの登録
Hosts、services、の登録
ターゲットDBの作成 ターゲットDBの作成
HiRDBの正常停止
Datareplicator初期化
HiRDBパラメタの変更
HiRDBの起動
プリプロセスの実行
Datareplicator初期開始
Datareplicatorの起動
接続の確認 接続の確認
データの更新
反映の確認
E-①
E-②
E-③
E-④
E-⑤
E-⑥
E-⑦
E-⑧
E-⑨
E-⑩
E-⑪
E-⑫
E-⑬
R-①
R-②
R-③
R-④
R-⑤
R-⑥
R-⑦
R-⑧

© Hitachi, Ltd. 2012, 2019. All rights reserved.
6-3 HiRDB Datareplicatorのソフトウェア構成
72
HiRDBHiRDB
HiRDB
FES
BES1
BES2
MGR
抽出側Datareplicator
サーバマシン サーバマシン
サーバマシン
抽出側Datareplicator
抽出側システム 反映側システム
HiRDB
FES1
MGR
HiRDB
BES1
HiRDB
BES2
サーバマシンサーバマシン
サーバマシン
反映側
Data
rep
licato
r
抽出側Datareplicator
解説
◆抽出側のHiRDB Datareplicator
HiRDB/Single Server の場合・・・ HiRDB/Single Serverがあるサーバマシン
HiRDB/Parallelの場合・・・システムマネジャ(MGR) とバックエンドサーバ(BES)がある
すべてのサーバマシン
◆反映側のHiRDB Datareplicator
HiRDB/Single Serverの場合・・・ HiRDB/Single Serverがあるサーバマシン
HiRDB/Parallelの場合・・・どこかのサーバマシンに一つあれば良い
通常はフロントエンドサーバ(FES)があるサーバマシン

© Hitachi, Ltd. 2012, 2019. All rights reserved.
抽出マスタエラー情報
抽出マスタトレース
二重化制御
2個 2個
1個
抽出ノードマスタエラー情報
2個
抽出システム定義
抽出環境定義
抽出定義 二重化定義
1個 1個 1~n個
1個 1個
初期化前にユーザが作成するファイル
送信環境定義
HiRDB
SDS
抽出側システム
サーバマシン
抽出側Datareplicator
2個
コマンドログ
抽出定義プリプロセス
1個
hdeprepコマンド実行時に作成するファイル
初期化時に作成するファイル
起動時に作成するファイル
抽出サーバステータス※1
データ連動用連絡※1
抽出情報キュー※1
1個1個
2~16個
抽出マスタステータス※1
1個
二重化定義可能
※1: UNIX(R)版は、信頼性の高いキャラクタ型スペシャルファイルにすることを奨励します。
6-4-1
73
抽出側Datareplicatorのファイルの構成
HiRDB/Single Server
解説抽出側Datareplicatorを動作するために必要なファイルの構成について、 HiRDB/Single Server
を例に示します。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
HiRDBHiRDB
HiRDB
FES
BES1
BES2
MGR
抽出側Datareplicator
サーバマシン サーバマシン
サーバマシン
抽出側Datareplicator
抽出側Datareplicator
抽出側システム
抽出マスタエラー情報
抽出マスタトレース
二重化制御
抽出定義プリプロセス
1個2個
2個 2個1個
抽出システム定義
抽出環境定義
抽出定義 二重化定義
1個 1個 1~n個
1個 1個
初期化時に作成するファイル
初期化前にユーザが作成するファイル
抽出ノードマスタトレース
抽出ノードマスタエラー情報
2個2個
初期化時に作成するファイル
抽出サーバステータス※1
データ連動用連絡※1
抽出情報キュー ※1
1個1個2~16個
抽出マスタステータス※1
1個
二重化定義可能
二重化定義可能
送信環境定義
BESのサーバ
MGRのあるサーバ
コマンドログ
hdeprepコマンド実行時に作成するファイル
起動時に作成するファイル
※1: UNIX版は、信頼性の高いキャラクタ型スペシャルファイルにすることを奨励します。
6-4-2
74
抽出側Datareplicatorのファイルの構成
HiRDB/Parallel Server
解説
抽出側Datareplicatorを動作するために必要なファイルの構成について、 HiRDB/Parallel Server
を例に示します。抽出側のファイルは、MGRのサーバに作成するファイルとBESごとに作成する
ファイルがあります。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
6-5-1
75
項番 ファイル名 用度 必要/
任意パラメタ名 定義
ファイル名
1 抽出定義プリプロセスファイル hdeprepコマンドを実行して、抽出定義ファイルを内部形式に変換したファイル
必要 ー ー
2 抽出情報キューファイル 抽出処理によってHiRDBシステムログファイルから抽出した更新情報が格納されるファイル
必要 qufilexxx、queuesize
抽出環境定義
3 抽出マスタステータスファイル 害発生時に回復に必要な抽出/送信の状態などが格納されるファイル
必要
ー ー4 抽出サーバステータスファイル 必要
5 抽出マスタエラー情報ファイル 抽出処理や送信処理がエラーになったときに、エラーの詳細情報が出力されるファイル
(起動時にファイルが無い場合には、起動時に作成します)
必要 errfilesz 抽出システム定義
6 抽出ノードマスタエラー情報ファイル
必要
7 抽出マスタトレースファイル HiRDB Datareplicatorの稼働状況を取得するファイル(抽出システム定義でint_trc_lvl=naを指定した場合は作成しません)
任意 int_trc_lvl、int_trc_filesz
抽出システム定義
8 抽出ノードマスタトレース
ファイル
任意
必要:抽出側Datareplicator を起動する上で必要なファイルパラメタの指定が無い場合、既定値またはDatareplicatorが算出してファイルを作成します。
任意:パラメタの指定やファイルの作成によって作成しないファイル
抽出側のファイル
初期起動時に作成されるファイル

© Hitachi, Ltd. 2012, 2019. All rights reserved.
6-5-2
76
項番 ファイル名 用度 必要/
任意パラメタ名 定義
ファイル名
9 データ連動用連絡ファイル HiRDBでの更新情報のシステムログファイルへの格納状態や、抽出側Datareplicatorで更新情報のシステムログファイルからの読み込み状態など、抽出処理を実行するために必要なHiRDBとの連絡情報を格納、または読み込むためのファイル
必要
ー ー
10 コマンドログファイル HiRDB Datareplicatorのコマンドを実行した日付と時間の履歴を格納するファイル
必要 ー ー
11 二重化制御ファイル ファイルの二重化を制御するためのファイル
(二重化定義ファイルが無い場合は作成しません)
任意 ー ー
必要:抽出側Datareplicator を起動する上で必要なファイルパラメタの指定が無い場合、既定値またはDatareplicatorが算出してファイルを作成します。
任意:パラメタの指定やファイルの作成によって作成しないファイル
抽出側のファイル
初期起動時に作成されるファイル

© Hitachi, Ltd. 2012, 2019. All rights reserved.
6-5-3
77
項番 ファイル名 用度 必要/
任意
1 抽出システム定義ファイル 抽出側Datareplicator識別子や、送信先識別子など、抽出側Datareplicator全体の稼働環境の情報を定義
必要
2 抽出環境定義ファイル 抽出処理の稼働環境の情報を定義(抽出情報キューファイル名、抽出情報キューファイルサイズなど)
必要
3 送信環境定義ファイル 送信処理の稼働環境についての情報を定義 必要
4 抽出定義ファイル 抽出、送信処理の詳細な情報を定義(サービス名、ホスト名など) 必要
5 二重化定義ファイル 抽出側システムで使用する定義ファイル(抽出マスタステータスファイル、抽出サーバステータスファイル、抽出情報キューファイル、およびデータ連動用連絡ファイル)を二重化する場合に定義。
任意
必要:抽出側Datareplicator を起動する上で必要なファイル任意:必要に応じて作成するファイル
抽出側のファイル
ユーザが作成するファイル

© Hitachi, Ltd. 2012, 2019. All rights reserved.
6-6-1
78
抽出マスタステータスファイル
抽出マスタエラー情報ファイル
抽出ノードマスタエラー情報ファイル
抽出マスタトレースファイル
抽出ノードマスタトレースファイル
送信環境定義ファイル
抽出情報キューファイル
hdeenv
hde_prpfile 抽出定義プリプロセスファイル
mststatus
sts_サーバ名 抽出サーバステータスファイル
msterrfile1
msterrfile2
errfile1
$HDEPATH/
errfile2
msttrc.trc1
msttrc.trc2
exttrc.trc1
exttrc.trc2
hde_サーバ名 データ連動用連絡ファイル
hde_fileenv.prp 二重化制御ファイル
抽出システム定義ファイル
任意の名称 抽出環境定義ファイル
任意の名称
任意の名称 抽出定義ファイル
file_dupenvで指定した名称 二重化定義ファイル
任意の名称_サーバ名
任意の名称 コマンドログファイル
拡張子が「.mf」のファイル
ワークファイル
抽出側ディレクトリ・ファイル構成
UNIX版

© Hitachi, Ltd. 2012, 2019. All rights reserved.
6-6-2
79
抽出マスタステータスファイル
抽出マスタエラー情報ファイル
抽出ノードマスタエラー情報ファイル
抽出マスタトレースファイル
抽出ノードマスタトレースファイル
送信環境定義ファイル
抽出情報キューファイル
hde_prpfile 抽出定義プリプロセスファイル
mststatus
sts_サーバ名 抽出サーバステータスファイル
msterrfile1
msterrfile2
errfile1
errfile2
msttrc.trc1
msttrc.trc2
exttrc.trc1
exttrc.trc12
hde_サーバ名 データ連動用連絡ファイル
任意の名称 抽出環境定義ファイル
任意の名称
任意の名称 抽出定義ファイル
file_dupenvで指定した名称 二重化定義ファイル
任意の名称_サーバ名
任意の名称 コマンドログファイル
%HDEPATH%¥ hdeenv 抽出システム定義ファイル
抽出側ディレクトリ・ファイル構成
WINDOWS版

© Hitachi, Ltd. 2012, 2019. All rights reserved.
6-7 反映側Datareplicatorのファイルの構成
80
反映側システム
HiRDB
FES
MGR
HiRDB
BES1
HiRDB
BES2
サーバマシン サーバマシン
サーバマシン反映エラー情報
反映トレース
二重化制御
2個
2個1個
反映システム定義
反映環境定義
反映定義 二重化定義
1個 1個 1個 1個
初期起動時に作成するファイル
初期化前にユーザが作成するファイル
未反映情報
2個
反映ステータス※1
反映情報キュー※1
1個
2~8個
二重化定義可能
反映マスタステータス※1
1個
反映側
Da
tare
plic
ato
r
2個
コマンドログ
起動時に作成するファイル
※1: UNIX版は、信頼性の高いキャラクタ型スペシャルファイルにすることを奨励します。
解説反映側Datareplicatorを動作するために必要なファイルの構成について例を示します。反映側の
ファイルは、反映側システムごとに作成します。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
6-8-1
81
項番 ファイル名 用度 必要/
任意パラメタ名 定義
ファイル名
1 反映情報キューファイル 抽出側システムから送信される抽出定義と更新情報を格納
必要 qufilexxx、
queuesize
反映環境定義
2 反映ステータスファイル 障害発生時に回復に必要な受信/反映の状態や、抽出側システムの抽出定義の状態などを格納
必要 statsfile、
statssize
反映環境定義
3 反映マスタステータスファイル
初期開始時の実行結果が格納 必要 ー ー
4 反映エラー情報ファイル 受信処理や反映処理がエラーになったときに、エラーの詳細情報が出力(起動時にファイルが無い場合には、起動時に作成します)
必要 errfilesz 反映システム定義
5 稼働トレースファイル
(反映トレースファイル)
HiRDB Datareplicatorの動作と性能についての情報を取得(反映システム定義でint_trc_lvl=naを指定した場合は作成しません。)
任意 int_trc_lvl、int_trc_trcfilesz
反映システム定義
6 未反映情報ファイル 反映処理で発行したSQL文がエラーになったときに、そのSQL文が出力されます。(起動時にファイルが無い場合には、起動時に作成します)
必要 unreffile1、unreffile2、unreffilesz
反映環境定義
必要:反映側Datareplicator を起動する上で必要なファイル定義するパラメタが無いファイルはHiRDB Datareplicatorが算出してファイルを作成。パラメタ指定省略時は、既定値でファイルを作成。
任意: HiRDB Datareplicatorが算出してファイルを作成
反映側のファイル
初期起動時に作成されるファイル①

© Hitachi, Ltd. 2012, 2019. All rights reserved.
6-8-2
82
項番 ファイル名 用度 必要/
任意パラメタ名 定義
ファイル名
7 コマンドログファイル HiRDB Datareplicatorのコマンドを実行した日付と時間の履歴を格納
必要 ー ー
8 二重化制御ファイル ファイルの二重化を制御するためのファイル
任意 ー ー
必要:反映側Datareplicator を起動する上で必要なファイル定義するパラメタが無いファイルはHiRDB Datareplicatorが算出してファイルを作成。パラメタ指定省略時は、既定値でファイルを作成。
任意: HiRDB Datareplicatorが算出してファイルを作成
反映側のファイル
初期起動時に作成されるファイル②

© Hitachi, Ltd. 2012, 2019. All rights reserved.
6-8-3
83
項番 ファイル名 用度 必要/
任意
1 反映システム定義ファイル 反映側Datareplicator全体の稼働環境の情報を定義 必要
2 反映環境定義ファイル 反映処理の稼働環境の情報を定義(反映情報キューファイル名、反映ステータスファイル名、反映処理の方式など)
必要
3 反映定義ファイル 反映処理の詳細な情報を定義(更新情報と反映対象表との対応付け、反映先のフロントエンドサーバ、キーレンジ分割条件、ハッシュ分割条件、UOC名など)。同一形式の表に反映する場合には、反映定義を省略できます。
任意
4 二重化定義ファイル 反映側システムの二重化定義で使用する論理ファイル名と物理ファイル名の対応を定義。二重化定義で使用する場合に定義します。
任意
必要:反映側Datareplicator を起動する上で必要なファイル任意:必要に応じて作成するファイル
反映側のファイル
ユーザが作成するファイル

© Hitachi, Ltd. 2012, 2019. All rights reserved.
6-9-1
84
反映側ディレクトリ・ファイル構成
UNIX版
反映システム定義ファイル
反映マスタステータスファイル
反映エラー情報ファイル
反映トレースファイル
反映情報キューファイル
ワークファイル
未反映情報ファイル
hdsenv
hdsinittstate
errfile1
errfile2
reftrc.trc1
reftrc.trc2
hds_fileenv.prp 二重化制御ファイル
任意の名称 反映環境定義ファイル
任意の名称 反映定義ファイル
任意の名称 二重化定義ファイル
任意の名称
任意の名称 反映ステータスファイル
任意の名称
任意の名称 コマンドログファイル
拡張子が「.mf」のファイル
$HDSPATH/

© Hitachi, Ltd. 2012, 2019. All rights reserved.
6-9-2
85
反映側ディレクトリ・ファイル構成
WINDOWS版
反映システム定義ファイル
反映マスタステータスファイル
反映エラー情報ファイル
反映トレースファイル
反映情報キューファイル
ワークファイル
未反映情報ファイル
hdsenv
hdsinittstate
errfile1
errfile2
reftrc.trc1
reftrc.trc2
hds_fileenv.prp 二重化制御ファイル
任意の名称 反映環境定義ファイル
任意の名称 反映定義ファイル
任意の名称 二重化定義ファイル
任意の名称
任意の名称 反映ステータスファイル
任意の名称
任意の名称 コマンドログファイル
拡張子が「.mf」のファイル
%HDSPATH%¥

© Hitachi, Ltd. 2012, 2019. All rights reserved.
6-10 データ連動で使用するファイルの配置
86
HiRDB Datareplicatorでは、キューファイル(更新データを蓄積)、ステータスファイル(キューの書き込み/
読み込み位置管理)、連動連絡ファイル(HiRDBのシステムログ読み込み管理)を使用してデータ連動を実現します。これらは、データベース本体とは別領域に確保されるファイルであり、HiRDB Datareplicatorが管理しています。
データ連動に必要なファイル
HiRDB Datareplicatorで使用する、キューファイル、ステータスファイル、連動連絡ファイルは、いづれかひとつでも障害となるとデータ連動が継続できなくなります。このため、これらのファイルは以下のように割当てることを推奨します。・RAWファイルにする・ミラーリングする
ハードウェア(OS)によるミラー化ができるのであればそちらを推奨します。ハードウェアによるミラーを行わないのであれば、HiRDB Datareplicatorのファイル2重化機能を使用してミラーリングしてください。
また、抽出側キューファイルに障害が発生した場合、抽出側ステータスファイルの情報を利用してキューファイルを回復することができます。よって、抽出側のキューファイルとそれ以外のファイルは、異なるディスクに構築することをお勧めします。
データ連動で使用するファイルの割当て

© Hitachi, Ltd. 2012, 2019. All rights reserved.
6-11-1 抽出側Datareplicatorの定義①
87
抽出環境定義ファイル名: extenv送信環境定義ファイル名:sendenv01, sendenv02二重化定義ファイル名:dupenv
:
抽出システム定義
抽出環境定義 extenv
抽出定義 extfile
全bes共通の定義
bes固有の定義
bes固有の定義
送信環境定義 sendenv02
送信環境定義 sendenv01
extract文extract文
extract文send文
固有指定するbesの数
送信先の数
抽出する更新情報の数
0または指定する送信先の数
抽出環境定義、送信環境定義、二重化定義のファイル名を指定する
抽出側Datareplicatorの定義の対応例
extract文{{logical_file =…}} 二重化するファイルの数
二重化定義 dupenv

© Hitachi, Ltd. 2012, 2019. All rights reserved.
6-11-2 抽出側Datareplicatorの定義②
88
項番 定義名 オペランド名 内容
1 システム共通定義 pd_rpl_init_start 抽出側HiRDBのデータ連動の開始方法を指定します。
2 pd_log_rpl_no_standby_file_opr システムログファイルがスワップできなかった場合の、データ連動に対する処置を指定します。
3 ユニット制御情報定義 pd_rpl_hdepath 抽出側Datareplicatorで使うディレクトリ名を指定します。
解説
HiRDBのデータベースからデータを抽出する場合は、抽出側HiRDBの定義に
抽出側Datareplicatorを使うために必要な情報を定義します。
抽出側Datareplicatorを使うために必要なHiRDBの定義を次の表に示します。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
6-12-1 反映側Datareplicatorの定義①
89
反映環境定義ファイル名: refenv001, refenv002二重化定義ファイル名:dupenv
反映システム定義
反映定義: reffile02
反映定義: reffile01
反映環境定義 : refenv002
反映環境定義 : refenv001反映対象とする抽出側システムの数
反映環境定義、二重化定義のファイル名を指定する
反映側Datareplicatorの定義の対応例
extract文format文
extract文load文
反映するフィールドを変更する更新情報の数
反映先の数
反映定義 reffile01
extract文group文 反映グループの数
反映定義 reffile02
反映環境定義で指定したファイルの数
extract文{{logical_file =…}} 二重化するファイルの数
二重化定義 dupenv

© Hitachi, Ltd. 2012, 2019. All rights reserved.
6-12-2 反映側Datareplicatorの定義②
90
定義名 オペランド名 オペランドの内容 設定内容
システム共通定義
pd_max_access
_tables
1トランザクションで同時にアクセスできる表数と順序数生成子数の合計の最大値を指定します。
同時にアクセスできる表数と順序数生成子数とは、1トランザクション中のSQL文に記述した表と順序数生成子の延べ数。
HiRDBに同時にアクセスするテーブル数を加算します。HiRDBに同時にアクセスするテーブル数は、反映対象の表の数になります。
pd_max_users HiRDBサーバに対する最大同時接続数を指定します。HiRDB/Parallelの場合は1フロントエンドサーバに対する最大同時接続数を指定します。
HiRDBに同時に接続するデータ連動識別子の数を加算してください。HiRDBに同時に接続するデータ連動識別子の数は、反映システム定義に定義しているデータ連動識別子ごとに、次の数をすべて加算した数になります。
・トランザクション単位反映モードの場合
1個
・表単位反映モードの場合
反映定義に定義しているgroup文で指定した分割数※の合計数
※分割数の詳細を次に示します。
表単位分割方式:1個
キーレンジ単位分割方式:キーレンジ分割数
ハッシュ分割方式:ハッシュ分割数またはSQL分割数
解説
反映側HiRDBのデータベースにデータを反映する場合は、反映側HiRDB定義に
反映側Datareplicatorを使うために必要な情報を定義します。
反映側Datareplicatorを使うために必要なHiRDBの定義を次の表に示します。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
6-13-1 HiRDB Dataextractorによるデータ一括複写手順
91
E-① 、R-①抽出環境に必要な環境変数を設定します。
E-②必要な条件や設定がある場合、必要に応じて、列名記述ファイル、表式記述ファイル、ナル値情報ファイル、排他情報ファイル、反映情報ファイルを作成します。
R-②必要な条件や設定がある場合、必要に応じて、pdloadに指定するパラメタを記載したpdloadコマンドライン情報ファイル、pdload制御情報ファイルsource文情報ファイルを設定します。
E-③、R-③通信に必要な情報を登録します。
R-④反映する表、表に対するアクセス権限等の定義を行います。
E-④xtrepコマンドを入力して、データの抽出を行います。
R-⑤反映側で反映が完了したことを 確認します。
環境変数の設定 環境変数の設定
抽出側Dataextractor 反映側Dataextractor
ファイルの作成 ファイルの作成
Hostsへの登録
反映する表の定義
データの抽出
反映の確認
E-①
E-②
E-③
E-④
R-①
R-②
R-③
R-④
R-⑤
services、Inetd.confへの登録

© Hitachi, Ltd. 2012, 2019. All rights reserved.
6-13-2 HiRDB Dataextractor ソフトウェア構成
92
※1:SQLで抽出するので、FESにHiRDB Dataextractorがあると性能が良い※2:表単位反映の場合、PDLOADを使用しているため、MGRやFESをデータの転送先すると良い
解説
HiRDBからHiRDBへHiRDB Dataextractorでデータ抽出・反映する場合、HiRDB/Single Server
とHiRDB/Parallel Serverのソフトウェア構成が異なります。
◆抽出側のDataextractor
HiRDB/Single Server の場合・・・ HiRDB/Single Serverがあるサーバマシン
HiRDB/Parallelの場合・・・次のどれかのサーバのあるサーバマシン
・システムマネジャ(MGR)
・フロントエンドサーバ(FES)※1
・バックエンドサーバ(BES)
◆反映側のDataextractor
HiRDB/Single Serverの場合・・・ HiRDB/Single Serverがあるサーバマシン
HiRDB/Parallelの場合・・・次のサーバのあるサーバマシン
・システムマネジャ(MGR)
・データの転送先のサーバマシン( FESまたはBES) ※2
( RDエリア単位の格納で、直接バックエンドサーバに転送する
ときは、転送先のバックエンドサーバのあるサーバマシン
になります。 )

© Hitachi, Ltd. 2012, 2019. All rights reserved.
6-13-3 HiRDB Dataextractor ソフトウェア構成
93
HiRDB
FES MGR
抽出側Dataextractor
サーバマシン
HiRDB
BES2
サーバマシン
HiRDB
SDS
抽出側システム
サーバマシン
反映側
Data
extra
cto
r
反映側システム
抽出側システム 反映側システム
抽出側Dataextractor
サーバマシン
HiRDB
SDS
HiRDB
FES
MGR
HiRDB
BES1
HiRDB
BES2
サーバマシンサーバマシン
サーバマシン
反映側Dataextractor
HiRDB
BES1
サーバマシン

© Hitachi, Ltd. 2012, 2019. All rights reserved.
6-13-4
94
列名記述 表式記述 ナル値情報
排他情報
ユーザが作成するファイル
反映情報
エラーログ
稼動時に作成するファイルHiRDB
SDS
サーバマシン
抽出側Dataextractor SQLトレース
HiRDB Dataextractor HiRDB/Single Server
抽出側のファイルの構成
解説抽出側を動作するために必要なファイルの構成について、 HiRDB/Single Serverを例に示します。
ファイルは、インストールしたサーバマシンにファイルを作成します。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
6-13-5
95
HiRDB
FES MGR
抽出側Dataextractor
サーバマシン
HiRDB
BES2
サーバマシンHiRDB
BES1
サーバマシン
HiRDB Dataextractor HiRDB/Parallel Server
抽出側のファイルの構成
解説抽出側を動作するためのファイル構成を HiRDB/Parallel Serverを例に示します。ファイルは、
インストールしたサーバマシンにファイルを作成します。
列名記述 表式記述 ナル値情報
排他情報
ユーザが作成するファイル
反映情報
エラーログ
稼動時に作成するファイル
SQLトレース

© Hitachi, Ltd. 2012, 2019. All rights reserved.
6-13-6
96
反映側システム
HiRDB
FES
MGR
HiRDB
BES1
HiRDB
BES2
サーバマシン サーバマシン
サーバマシン
pdloadコマンドライン情報
pdloadのsource文情報
ユーザが作成するファイル
pdloadの制御情報
pdloadのナル値情報
稼動時に作成するファイル
出力
pdloadの一時エラー
エラーログ pdloadの入力データ
pdloadへのEOF通知
反映側
Data
extra
cto
r
pdloadのエラー情報
HiRDB Dataextractor
反映側のファイルの構成
解説反映側を動作するためのファイルの構成について例を示します。ファイルは、インストール
したサーバマシンごとにファイルを作成します。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
6-13-7
97
項番 ファイル名 用度 必要/
任意xtrepコマンド
1 抽出側 TCP/IPまたはOSI使用時のHiRDB
DataextractorのエラーログファイルHiRDB Dataextractorの実行結果の出力
必要 ー
2 反映側 TCP/IPまたはOSI使用時のHiRDB
DataextractorのエラーログファイルHiRDB Dataextractorの実行結果の出力
必要 ー
3 HiRDBデータベース作成ユティリティ(pdload)のエラー情報ファイル
入力データにエラーがあった場合にエラー情報が出力
必要 ー
4 HiRDBデータベース作成ユティリティ(pdload)の一時エラーファイル
一時的に作成するエラーファイル
任意 -oまたは-Oオペランド無しの場合一時的に作成
5 HiRDBデータベース作成ユティリティ(pdload)の入力データファイル
データを格納したファイル 任意 -oまたは-Oオペランド無しの場合一時的に作成
6 HiRDBデータベース作成ユティリティ(pdload)のナル値情報ファイル
入力データを比較して一致した場合、表にナル値を格納する
必要 ー
7 出力ファイル 抽出したデータの出力 任意 -oまたは-Oオペランド有りの場合作成。(環境変数XTFILESIZEでサイズの指定が可能)
9 HiRDBデータベース作成ユティリティ(pdload)へのEOF通知ファイル
一時的に作成するEOF通知ファイル
任意 -oまたは-Oオペランド無しの場合一時的に作成
10 HiRDBデータベース作成ユティリティの制御情報ファイル
pdloadの制御文 必要 ー
必要: HiRDB Dataextractor を起動する上で必要なファイル。 HiRDB Dataextractorが作成します。任意: xtrepコマンドのオペランド指定により作成するファイル
HiRDB Dataextractor
稼動時に作成されるファイル

© Hitachi, Ltd. 2012, 2019. All rights reserved.
6-13-8
98
項番 ファイル名 用度 指定方法
1 抽出側 列名記述ファイル 抽出条件を指定します。 xtrepコマンド-sオプションでファイルを指定します。
2 表式記述ファイル 抽出条件を指定します。 xtrepコマンド-wオプションでファイルを指定します。
3 ナル値情報ファイル ナル値の既定値を設定します。 xtrepコマンド-vオプションでファイルを指定します。
4 排他情報ファイル データ抽出時の排他情報を設定します。 xtrepコマンド-gオプションでファイルを指定します。
5 反映情報ファイル データ型を変換する列情報とデータ型を設定します。
xtrepコマンド-Lオプションでファイルを指定します。
6 SQLトレースファイル SQLトレース情報を取得します。 環境変数PDSQLTRACEでサイズを指定します。
7 反映側 pdloadコマンドライン情報ファイル
HiRDBのデータベース作成ユティリティ(pdload)のコマンドラインパラメタを設定します。
環境変数XTLPRMxxxxにファイルを指定します。
8 pdloadのsource文情報ファイル
HiRDBのデータベース作成ユティリティ(pdload)のパラメタである制御情報ファイル中に記述するsource文を設定します。
環境変数XTPDSRxxxxにファイルを指定します。
ユーザが作成するファイルは、必要に応じてxtrepコマンドや環境変数に任意に指定します。
HiRDB Dataextractor
ユーザが作成するファイル

© Hitachi, Ltd. 2012, 2019. All rights reserved.
6-13-9
99
エラーログファイル
表式記述ファイル
表名情報ファイル
ナル値情報ファイル
排他情報ファイル
/opt/HIRDBXT/spool/ xter
任意の名称
任意の名称
列名記述ファイル
HiRDB Dataextractor 抽出側ディレクトリ・ファイル構成
UNIX版
任意の名称
任意の名称
任意の名称

© Hitachi, Ltd. 2012, 2019. All rights reserved.
6-13-10
100
HiRDB Dataextractor
抽出側ディレクトリ・ファイル構成 WINDOWS版
エラーログファイル
表式記述ファイル
表名情報ファイル
ナル値情報ファイル
排他情報ファイル
xter
任意の名称
任意の名称
列名記述ファイル
任意の名称
任意の名称
任意の名称
インストールディレクトリ¥spool¥

© Hitachi, Ltd. 2012, 2019. All rights reserved.
6-13-11
101
pdloadコマンドライン情報ファイル
pdload制御情報ファイルsource文情報ファイル
エラーログファイル
HiRDBデータベース作成ユティリティの一時エラーファイル
HiRDBデータベース作成ユティリティの入力データファイル
HiRDBデータベース作成ユティリティの制御情報ファイル
HiRDBデータベース作成ユティリティのナル値情報ファイル
出力ファイル
HiRDBデータベース作成ユティリティへのEOF通知ファイル
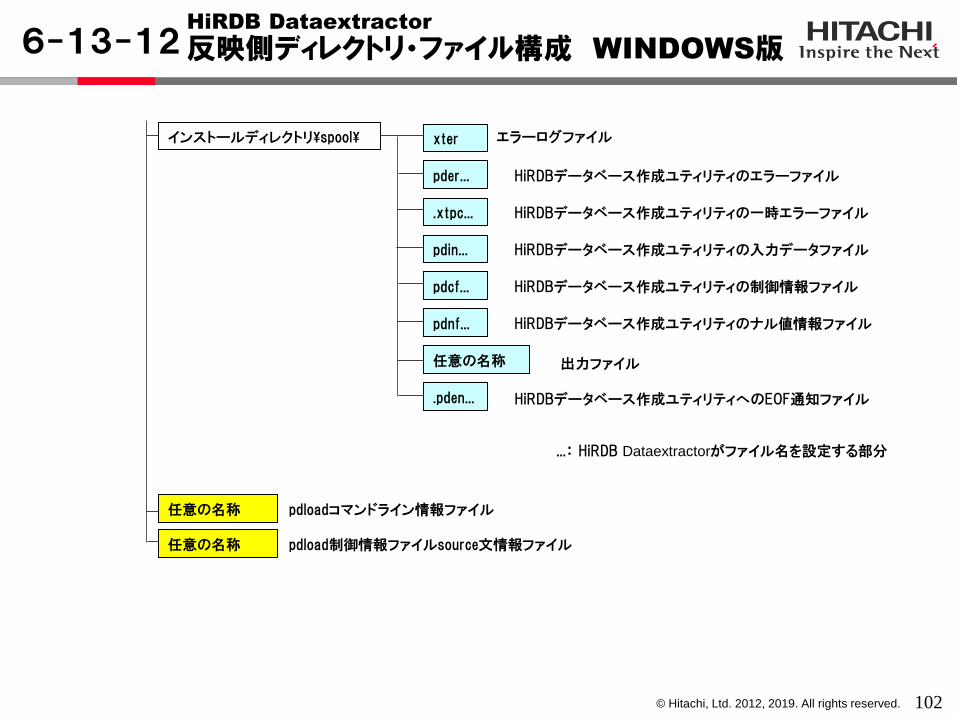
...: HiRDB Dataextractorがファイル名を設定する部分
/opt/HIRDBXT/spool/ xter
pder...
.xtpc...
pdin...
pdcf...
pdnf...
任意の名称
.pden...
任意の名称
任意の名称
HiRDBデータベース作成ユティリティのエラーファイル
HiRDB Dataextractor
反映側ディレクトリ・ファイル構成 UNIX版
© Hitachi, Ltd. 2012, 2019. All rights reserved.
6-13-12
102
...: HiRDB Dataextractorがファイル名を設定する部分
インストールディレクトリ¥spool¥
HiRDB Dataextractor
反映側ディレクトリ・ファイル構成 WINDOWS版
pdloadコマンドライン情報ファイル
pdload制御情報ファイルsource文情報ファイル
任意の名称
任意の名称
エラーログファイル
HiRDBデータベース作成ユティリティの一時エラーファイル
HiRDBデータベース作成ユティリティの入力データファイル
HiRDBデータベース作成ユティリティの制御情報ファイル
HiRDBデータベース作成ユティリティのナル値情報ファイル
出力ファイル
HiRDBデータベース作成ユティリティへのEOF通知ファイル
HiRDBデータベース作成ユティリティのエラーファイル
.pden...
任意の名称
pdnf...
pdcf...
pdin...
.xtpc...
pder...
xter

© Hitachi, Ltd. 2012, 2019. All rights reserved.
6-14 データ連動の運用に関する構築
103
データ連動に使用するファイルを二重化することで、ファイル障害時の信頼性向上を図りたい場合に
適用します。
ファイルの二重化の適用
HiRDB/Parallel Serverで、グローバルトランザクション単位でのデータの整合性を保証したい場合に適用します。
反映トランザクション同期機能の適用
系切り替え構成にする場合、HAモニタのサーバ定義や共用ボリュームの設定を行います。
系切り替え構成
© Hitachi, Ltd. 2012, 2019. All rights reserved.
6-15 ファイルの二重化
104
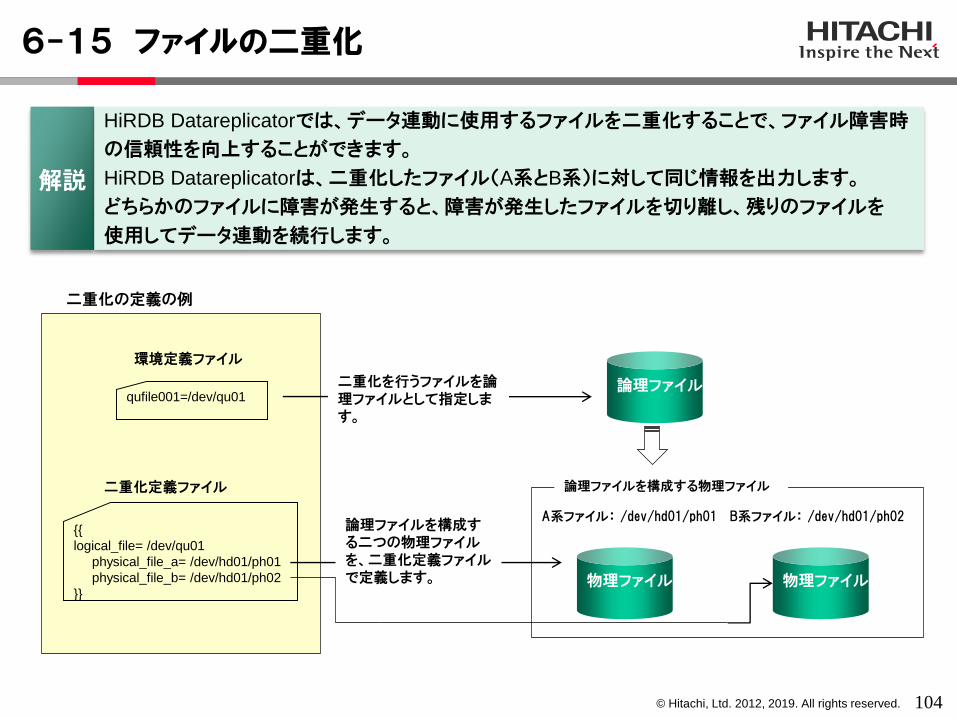
qufile001=/dev/qu01
環境定義ファイル
{{
logical_file= /dev/qu01
physical_file_a= /dev/hd01/ph01
physical_file_b= /dev/hd01/ph02
}}
二重化定義ファイル
物理ファイル
A系ファイル: /dev/hd01/ph01
物理ファイル
B系ファイル: /dev/hd01/ph02
論理ファイル
二重化の定義の例
二重化を行うファイルを論理ファイルとして指定します。
論理ファイルを構成する二つの物理ファイルを、二重化定義ファイルで定義します。
論理ファイルを構成する物理ファイル
解説
HiRDB Datareplicatorでは、データ連動に使用するファイルを二重化することで、ファイル障害時
の信頼性を向上することができます。
HiRDB Datareplicatorは、二重化したファイル(A系とB系)に対して同じ情報を出力します。
どちらかのファイルに障害が発生すると、障害が発生したファイルを切り離し、残りのファイルを
使用してデータ連動を続行します。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
6-16-1 反映トランザクション同期機能①
105
Datareplicatorの起動
抽出側Datareplicator 反映側Datareplicator
Datareplicatorの起動
業務開始
トランザクションAで更新
業務終了
Datareplicatorの終了Datareplicatorの終了
E-①
E-②
E-③
E- ⑧
E-⑩
R-①
R-⑦
トランザクションBで更新E-④
同期イベント発行E-⑤
COMMIT発行R-④
トランザクションCで更新E-⑥
UAPの実行
トランザクションAの更新R-②
トランザクションBの更新R-③
同期イベント発行E-⑦
COMMIT発行R-⑥
トランザクションCの更新R-⑤
送信プロセスを停止E- ⑨
解説
反映トランザクション同期機能は、イベント機能を利用して実現します。
反映側Datareplicatorから発生するトランザクションでCOMMITを発行する契機は、同期イベント
だけになり、反映環境定義cmtintvlオペランド(反映処理コミット間隔)の指定は無視されます。
抽出側HiRDBのpdsysにpd_rpl_init_start=Yを定義しており、Datareplicator連携機能は使用中です。R-①:hdsstart を実行します。E-①:hdestartを実行します。E-②:抽出側で業務を開始します。E-③、R-②:トランザクションAでBES1のデータを更新E-④、R-③:トランザクションBでBES2のデータを更新E-⑤
トランザクションAとトランザクションBの更新を同期するポイントでhdeevent –n 同期イベントコードを発行します。UAPに同期したいポイントでhdeevent を発行します。
R-④:同期イベントにより、トランザクションAとトランザクションBのCOMMITを発行します。
E-⑥、R-⑤:トランザクションCでBES2のデータを更新します。E-⑦:hdeevent –n 同期イベントコードを発行します。R-⑥
同期イベントにより、トランザクションCのCOMMITを発行します。
E-⑧:抽出側のDB業務を終了します。E-⑨:hdeevent –n 0を発行します。E-⑩:hdestopを発行します。R-⑦:hdsstopを発行します。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
6-16-2 反映トランザクション同期機能②
106
PP 定義名 オペランド名 内容
HiRDB システム共通定義
pd_rpl_reflect_mode = uap トランザクションブランチ情報(HiRDB
Datareplicatorがこの機能を実現するために必要な情報)を、システムログファイルへ出力するためのオペランドです。
HiRDB
Datareplicator反映システム定義
syncgroup001 同期反映グループを構成するためのオペランドです。
送信環境定義 reflect_mode = uap トランザクションブランチ情報を、反映側Datareplicatorへ送信するためのオペランドです。
eventsync 同期イベント(同期反映グループがCOMMITを発行する契機となるイベント)の番号を指定します。
解説 反映トランザクション同期機能を使用する際に指定しておく必要があるオペランドを次に示します。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
6-17-1 系切り替え構成の構築①
107
① HiRDB DatareplicatorはHiRDBと同じ系で動作させる必要があります。(クラスタソフトウェアの設定が必要)② HiRDBとHiRDB Datareplicatorとの連動系切り替えにおいて、クラスタソフトウェアがそれぞれの切り替え順序性を設定
できない場合は、以下の設定が必要となります。・データ連動連絡ファイルは、HiRDBの切り替えに連動して切り替わる共用ボリューム内に格納する。・系切り替え先では、HiRDB Datareplicator起動シェル中にHiRDBの起動待ちを行う(起動目安時間スリープするなど)処理を入れる。
・HiRDB Datareplicator用にHiRDBとは異なるエイリアスIP(引き継ぎ要)を割り当てる。
系切り替え構成構築の留意事項
server name HiRDB
alias HIRDB
::
disk VOL1
group GRP1
server name REPLI
alias REPLI
::
lan_updown use
disk VOL2
group GRP1
<HAモニタのサーバ定義>現用系
HiRDB
Datareplicator
予備系
HiRDB
Datareplicator
・DBファイル
・データ連動用連絡ファイル
・ステータスファイル
・システムログファイル
・キューファイル
・ステータスファイル
共用ボリューム VOL1
共用ボリューム VOL2
エイリアスIPアドレス hostA(192.71.101.10)[HiRDB用]
hostX(192.71.101.20)[HiRDB Datareplicator用]
hostB
(192.71.101.51)hostC
(192.71.101.52)
HiRDBの切り替えに連動して切り替わる共用ボリューム内にデータ連動用連絡ファイルを
配置。
・HiRDBとHiRDB Datareplicatorを連動系切り替えするために、groupオペランドで同一のグループ名を指定。・HiRDB Datareplicatorの系切り替え時にエイリアスIPの切り替えを行うために、lanupdownオペランドにuseを指定。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
6-17-2 系切り替え構成の構築②
108
resource alias RES
::
disk VOL1
lan_updown use
group GRP1
server name HiRDB
alias HIRDB
::
parent RES
group GRP1
server name REPLI
alias REPLI
::
parent HIRDB
group GRP1
① HiRDBとHiRDB Datareplicatorとの連動系切り替えにおいて、クラスタソフトウェアがそれぞれの切り替え順序性を設定できる場合(HAモニタの場合はリソースサーバ機能を使用)は、系切り替え環境の構築を簡略化することができます。
・HiRDBとHiRDB Datareplicatorのファイルは同一の共用ボリューム内に格納することができます。・系切り替え先で実行されるHiRDB Datareplicator起動シェル中に、HiRDBの起動待ちを入れる必要はありません。・HiRDB用に割り当てたエイリアスIP(引き継ぎ要)をHiRDB Datareplicator用と共用することができます。
系切り替え構成構築の簡略化
<HAモニタのサーバ定義>
現用系
HiRDB
Datareplicator
予備系
HiRDB
Datareplicator
・DBファイル
・データ連動用連絡ファイル
・ステータスファイル
・システムログファイル
・キューファイル
・ステータスファイル
共用ボリューム VOL1
エイリアスIPアドレス hostA(192.71.101.10)[HiRDB、HiRDB Datareplicator用]
hostB
(192.71.101.51)hostC
(192.71.101.52)
・ リソースの切り替えのみを制御するリソースサーバを定義。・ HiRDBおよびHiRDB Datareplicatorの定義にリソースサーバを親サーバとするparentオプションを指定。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
6-17-3 系切り替え構成の注意点
109
系切り替えで1台のサーバマシン上で、一つの抽出対象HiRDBに属するノードマスタプロセスが、複数稼働する状態になり、エラー情報ファイルと稼働トレースファイルが重複して使われることがあります。抽出システム定義のerrfile_uniqueオペランドにtrueを設定して、エラー情報ファイルと稼働トレースファイルが重複して使われるのを避けるようにします。
抽出側がHiRDB/Parallel Serverで相互系切り替えの形態のときの注意
抽出側Datareplicatorでは、抽出マスタプロセスから抽出ノードマスタプロセスへの通信用にIPアドレスを引き継ぐホスト名を割り 当てる必要があります。抽出対象HiRDBのシステム共通定義のpdstartコマンド、またはpdunitコマンドの-xで指定したホスト名と、抽出ノードマスタプロセスを起動するホスト名との対応付けを定義に指定します。
<例>
pdsys(システム共通定義) pdunit -x H1 -c H2 -u unit1
hdeenv(抽出システム定義) nodedef(H1)
set node_host = H3
H1、H2: それぞれ違うIPアドレスを割り当てるホスト名H3:系間で引き継がれるIPアドレスに対応付けられたホスト名
HiRDBで高速系切り替え機能を使う場合のHiRDB Datareplicatorの定義
影響分散スタンバイレス型系切り替え機能を使う場合、バックエンドサーバ単位の系切り替え、系切り替え発生後に抽出マスタプロセスと抽出ノードマスタプロセス間の回線再接続を行うように次の抽出システム定義のオペランドを設定する必要があります。
・nodecontrolオペランドにserver を設定・node_connection_acceptオペランドにtrueを設定・connection_accept_hostnameオペランドに抽出ノードマスタプロセス接続要求受け付けホスト名を設定・connection_accept_serviceオペランドに抽出ノードマスタプロセス接続要求受け付けサービス名を設定・connection_accept_waittime=抽出ノードマスタプロセス接続要求待ち時間・connection_retry_time=抽出ノードマスタプロセス再接続処理時間
抽出側がHiRDB/Parallel Serverで影響分散スタンバイレス型系切り替えの形態のときの注意

© Hitachi, Ltd. 2012, 2019. All rights reserved.
7. 運用のポイント
110

© Hitachi, Ltd. 2012, 2019. All rights reserved.
7-1-1
111
初期作成時、障害発生時にのみ使用し、通常の運用では使用してはならないコマンドがあります。・pdrplstart/pdrplstopコマンドは通常運用で使用してはならない・pdlogchgコマンドの –Rオプションは通常運用で使用してはならない
使用してはならないコマンド
アプリケーションはログ取得モードで実行する必要があります。また、再編成等のユティリティは更新前ログ取得モードまたはログレスで実行する必要があります。
ログレスで使用すべきもの
インナレプリカ機能使用時は、連動対象データはカレント世代を更新する運用としてください。
イベント表は、連動対象表のないRDエリアに作成することを推奨します。障害時運用でRDエリア参照許可閉塞実行時にイベントコマンドが使用できなくなることを回避するためです。
データベース作成、再編成(リロード)を更新後ログ取得モード(-la)で実行すると反映側にデータ送信します。このため、更新前ログ取得モード(-lp)またはログレスモード(-ln)で実行してください。データベース定義、構成変更、ディクショナリ搬出入、リバランスを実行する場合には、プリプロセス(hdeprep)を忘れないようにしてください。ただし、RDエリア格納BESを変更する場合には、抽出側Datareplicatorの初期化を行ってください。
ユティリティ実行時の注意事項
イベント表の定義時の推奨事項
インナレプリカ機能について
注意が必要な運用操作
HiRDBの運用①

© Hitachi, Ltd. 2012, 2019. All rights reserved.
7-1-2
112
データ連動の実行中にデータ連動対象DBに対して、次のSQL文を発行しないでください。・ALTER TABLE
・DROP TABLE
・複数のBESにわたる分割表に対するPURGE TABLE
UAP実行時の注意事項
HiRDB Datareplicatorによるメッセージは、syslog(Windowsの場合はイベントログ)およびエラー情報ファイルに出力されます。エラーを早期に検知するためには、JP1等のメッセージを監視できるプログラムを使用してください。また、反映側Datareplicatorでは、情報メッセージ(KFRBxxxxx-I)が大量に出力される可能性があります(同期点間隔を短くしている場合)。syslogへのメッセージ出力量を減らすためには、syslog_message_suppressパラメタに抑止したいメッセージ番号を指定してください。
メッセージを監視
注意が必要な運用操作
HiRDBの運用②
© Hitachi, Ltd. 2012, 2019. All rights reserved.
7-1-3
113
HiRDB Datareplicatorのパラメタには、初期化を必要とするものがあります。HiRDB Datareplicatorのパラメタを変更する際には、あらかじめ初期化が必要なものか、再起動で有効となるものかを確認してください。初期化を必要とするものについては、パラメタ変更前のHiRDB Datareplicator停止時に、反映まですべて完了していることを確認するようにしてください。
HiRDB Datareplicatorのパラメタ変更
HiRDBの環境変更(RDエリアの変更、表定義の変更)は、HiRDB Datareplicatorにも影響があります。初期化、プリプロセスを漏らした場合、HiRDB Datareplicator起動後にエラーとなる、もしくは反映側でSQLエラーとなります。HiRDBの環境変更を行う場合には、HiRDB Datareplicatorの手順も組み込むようにしてください。なお、環境変更の内容によりHiRDB
Datareplicatorの必要手順も変わってきますが、運用ミスを防止するためには、HiRDB Datareplicatorの手順をできるだけ統一化しておくことをお薦めします。
HiRDBの環境変更
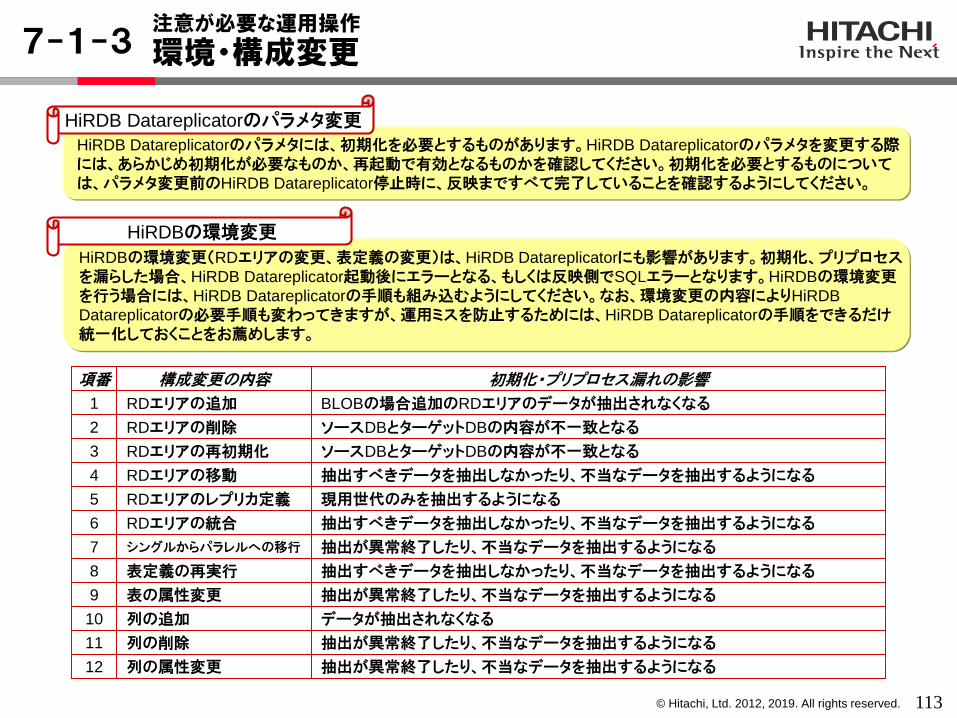
RDエリアの追加
RDエリアの削除
RDエリアの再初期化
シングルからパラレルへの移行
RDエリアの移動
RDエリアのレプリカ定義
RDエリアの統合
表定義の再実行
列の追加
列の削除
列の属性変更
BLOBの場合追加のRDエリアのデータが抽出されなくなる
ソースDBとターゲットDBの内容が不一致となる
ソースDBとターゲットDBの内容が不一致となる
抽出が異常終了したり、不当なデータを抽出するようになる
抽出すべきデータを抽出しなかったり、不当なデータを抽出するようになる
現用世代のみを抽出するようになる
抽出すべきデータを抽出しなかったり、不当なデータを抽出するようになる
抽出すべきデータを抽出しなかったり、不当なデータを抽出するようになる
データが抽出されなくなる
抽出が異常終了したり、不当なデータを抽出するようになる
抽出が異常終了したり、不当なデータを抽出するようになる
表の属性変更 抽出が異常終了したり、不当なデータを抽出するようになる
構成変更の内容 初期化・プリプロセス漏れの影響
1
2
3
4
5
6
7
8
9
10
11
12
項番
注意が必要な運用操作
環境・構成変更

© Hitachi, Ltd. 2012, 2019. All rights reserved.
7-1-4
114
項番 ユティリティ名 注意
1 データベース定義ユティリティ pddef データ連動の実行中に、データ連動対象DBに対して、ALTER TABLE、DROP TABLE文を発行しないでください。
2 データベース作成ユティリティ pdload ・既存の表の場合データ連動の実行中に、作成モードで実行しないでください(-dオプションは指定できません)。追加モードで、ログ取得モードを指定して実行してください(-lオプションにaを指定)。
・新規の表の場合データ連動の実行中に連動対象の表を新規に追加するときは、ログ取得モードで実行してください(-lオプションにaを指定)。
3 データベース構成変更ユティリティ pdmod データ連動の実行中は、抽出対象表が格納してあるRDエリアを再初期化しないでください。
4 データベース再編成ユティリティ pdrorg データ連動の実行中は、ログレスモードまたは更新前ログ取得モードで実行してください(-lオプションにnまたはpを指定)。
5 データベース回復ユティリティ pdrstr データベースのバックアップとバックアップ取得以降のログを基にして回復してください。
6 リバランスユティリティ pdrbal データ連動対象表に対してリバランスユティリティを実行する場合、表定義の変更(RDエリアの追加)をする必要があります。
注意が必要な運用操作
ユティリティ実行時の注意
解説 抽出-反映間で不整合を引き起こすため、注意するユティリティ操作を以下に示します。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
7-2-1 イベント機能
115
DB再編成
【例1】15:00までの抽出側更新データが反映されたことを確認しておきたい
【例2】20:00までの抽出側更新データが反映されたら、反映側で再編成を実行したい
オンライン処理
オンライン更新反映
抽出側
反映側
オンライン処理
8:00 15:00 20:00
オンライン更新反映
バッチ処理
DB再編成バッチ更新反映
イベント投入 イベント投入
イベント直前までCOMMIT完了後、メッセージ出力
イベント直前までCOMMIT完了後、メッセージ出力して反映処理停止
【例1】 【例2】
送受信のみ実行
反映側でメッセージを拾ってDB再編成等のアクションを実行可能
反映側では、イベントコードを定義しておくことにより、反映処理停止・再起動ができます
解説
ある時点のデータまで反映側に送信・反映が完了したことを知りたい場合、あるいは、抽出側の
ある区切りまでを反映側に送信・反映が完了したことを契機に何らかのアクションを実行させたい
場合には、イベント機能を使用することで運用が容易になります。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
7-2-2 イベントの種類
116
項番 イベントの種類 反映処理の動作 イベントコード
オペランド名 定義の
種類
1 送信データ件数
リセットイベント
抽出側Datareplicatorの送信データ件数(hdestateコマンド実行結果のSend data Transmission countに表示される件数)をリセットするイベントです。
ー eventcntreset 送信環境定義
2 同期イベント バックエンドサーバ間での反映トランザクションの同期を取って、COMMITするイベントです。このイベントは、反映トランザクション同期機能を使用する場合にだけ有効です。
ー eventsync
3 トランザクション単位反映イベント
トランザクション単位での反映処理を要求するイベントです。 1 eventtrn 反映環境定義
4 表単位反映イベント 表単位での反映処理を要求するイベントです。 2 eventtbl
5 トランザクション単位反映再起動イベント
停止状態にある反映処理を、トランザクション単位での 反映処理方式で再起動するイベントです。
3 eventretrn
6 表単位反映再起動
イベント
停止状態にある反映処理を、表単位での反映処理 方式で再起動するイベントです。
4 eventretbl
7 停止イベント 反映処理の停止を要求するイベントです。 5 eventspd
8 反映処理数リセット
イベント
実行した反映処理の件数(hdsstateコマンド実行結果のreflection countに表示する件数)をリセットするイベントです。
ー eventcntreset
9 接続単位終了
イベント
抽出側システムからの更新情報の転送が終了したときに、抽出側システムから送信されるイベントです(このイベントコードは反映環境定義では指定できません)。
-1
(固定)
指定できません
解説イベントには以下の種類があります。抽出側システムで発行したイベントに従って、反映処理の動作を切り替えることができます。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
8. HiRDB Datareplicatorの運用例
117

© Hitachi, Ltd. 2012, 2019. All rights reserved.
8-1-1 初期化が必要な構成変更①
118
項番 定義名 変更内容 内容
1 抽出側システムの構成変更
抽出側HiRDBのサーバ
構成変更
抽出側HiRDBのシステム共通定義に指定するpdstart
コマンドやpdunitコマンドの定義内容を変更する場合
2 抽出側HiRDBのシステム
ログの変更
・システムログファイル数を変更する場合
・システムログファイルを初期化する場合
・HiRDBのpdlogchg –Rでシステムログの状態を強制的に変更する場合
3 連動対象表の定義変更 ・連動対象表を追加(CREATE TABLE)する場合
・連動対象表を削除(DROP TABLE)する場合
・連動対象表を変更(ALTER TABLE)する場合
4 抽出側Datareplicatorの
定義変更
・正常開始をして定義内容が有効になるオペランド以外を変更する場合
・二重化定義ファイルの定義内容を変更する場合
解説
システムの構成変更をする場合に、HiRDB Datareplicatorの初期化が必要です。初期化を
しないと、HiRDB Datareplicator内で保持している更新情報や構成情報と実体が一致しなく
なり、ユーザが意図する反映ができなくなるおそれがあります。
HiRDB Datareplicatorの初期化が必要な構成変更を次の表に示します。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
8-1-2 初期化が必要な構成変更②
119
項番 定義名 変更内容 内容
5 反映側システムの構成変更
連動対象表の定義変更 ・連動対象表を追加(CREATE TABLE)する場合
・連動対象表を削除(DROP TABLE)する場合
・連動対象表を変更(ALTER TABLE)する場合
6 反映側Datareplicatorの
定義変更
・正常開始をして定義内容が有効になるオペランド以外を変更する場合
・二重化定義ファイルの定義内容を変更する場合
7 反映側HiRDBのサーバ
構成変更
反映側HiRDBのシステム共通定義に指定するpdstart
オペランドやpdunitオペランドの定義内容を変更する場合

© Hitachi, Ltd. 2012, 2019. All rights reserved.
8-2-1
120
1.抽出DBに対する更新業務を停止
2.すべての更新情報が反映DBに反映されているか確認
3.抽出側Datareplicatorおよび反映側Datareplicatorを停止
5.抽出側Datareplicatorおよび反映側Datareplicatorを初期化
6.抽出側Datareplicatorおよび反映側Datareplicatorを起動
4.システムの構成を変更
■手順の流れ
初期化が必要な構成変更
抽出側システムの構成変更①
解説 抽出側システムの構成を変更する場合の初期化手順について次に説明します。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
8-2-2
121
1
2
E-①抽出側DBに対する更新業務を停止します。
E-②hdestateコマンドを実行し、抽出側
Datareplicatorのすべてのプロセスが稼働していることを確認します。停止しているプロセスがあれば、再起動します。
R-①hdsstateコマンドを実行し、反映側Datareplicatorのすべてのプロセスが稼働していることを確認します。停止しているプロセスがあれば、再起動します。
E-③pdlogsync -d sysを実行(BESが複数ある場合は、抽出対象表が存在するすべてのBESについてコマンドを実行)して、すべてのシステムログの内容をシステムログファイルに出力します。
E-④pdls -d rpl -jを実行して、すべての更新情報が抽出されたか確認します。
E-⑤hdestateコマンドを実行して、すべての更新情報が送信されたか確認します。
R-②hdsstateコマンドを実行して、すべての更新情報が反映されたか確認します。
DBに対する更新業務停止
Datareplicatorのすべてのプロセスが稼働している
ことを確認
抽出側Datareplicator 反映側Datareplicator
Datareplicatorのすべてのプロセスが稼働している
ことを確認
すべての更新情報が反映されたか確認
すべてのシステムログの内容をシステムログ
ファイルに出力
すべての更新情報が抽出されたか確認
E-①
E-②
E-③
E-④
E-⑤
R-①
R-②
すべての更新情報が送信されたか確認
手順の流れに対応する番号
初期化が必要な構成変更
抽出側システムの構成変更②

© Hitachi, Ltd. 2012, 2019. All rights reserved.
8-2-3
122
3
4
E-⑥hdestopコマンドを実行し、抽出側Datareplicator
を停止します。E-⑦
hdestateコマンドを実行し、抽出側Datareplicatorが停止していることを確認します。
R-③hdsstopコマンドを実行し、反映側Datareplicator
を停止します。R-④
hdsstateコマンドを実行し、反映側Datareplicatorが停止していることを確認します。
E-⑧システムの構成を変更します。
抽出側Datareplicator 反映側Datareplicator
Datareplicatorの停止
Datareplicatorの停止を確認
E-⑥
E-⑦
R-③ Datareplicatorの停止
Datareplicatorの停止を確認
R-④
システムの構成を変更E-⑧
初期化が必要な構成変更
抽出側システムの構成変更③

© Hitachi, Ltd. 2012, 2019. All rights reserved.
8-2-4
123
5
6
E-⑨pdrplstop -fを実行し、HiRDBとのデータ連携を中止します。
E-⑩hdestart -iを実行して(応答メッセージにYを入力します)、抽出側Datareplicatorを初期化します。
E-⑪hdeprep -f 抽出定義ファイルを実行して、抽出定義プリプロセスファイルを作成します。
E-⑫pdrplstartコマンドを実行し、HiRDBとのデータ連携を開始します。
R-⑤hdsstart -i -qを実行して、反映側Datareplicator
を初期化します。R-⑥
hdsstartコマンドを実行し、反映側Datareplicator
を起動します。E-⑬
hdestartコマンドを実行し、抽出側Datareplicator
を起動します。
抽出側Datareplicator 反映側Datareplicator
Datareplicatorの初期化
R-⑤ Datareplicatorを初期化
Datareplicatorの起動R-⑥
Datareplicatorの起動E-⑬
抽出定義プリプロセスファイルを作成E-⑪
E-⑩
HiRDBとのデータ連携を中止
E-⑨
HiRDBとのデータ連携を開始E-⑫
初期化が必要な構成変更
抽出側システムの構成変更④

© Hitachi, Ltd. 2012, 2019. All rights reserved.
8-3-1
124
1.抽出側Datareplicatorを停止
2.反映側Datareplicator中の更新情報がすべて反映されているか確認
3.反映側Datareplicatorを停止
5.反映側Datareplicatorを初期化
6.抽出側Datareplicatorおよび反映側Datareplicatorを起動
4.システムの構成を変更
■手順の流れ
初期化が必要な構成変更
反映側システムの構成変更①
解説 反映側システムの構成を変更する場合の初期化手順について次に説明します。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
8-3-2
125
1
2
5
3
4
E-①hdestopコマンドを実行し、抽出側Datareplicatorを停止します。
E-②hdestateコマンドを実行し、抽出側Datareplicatorの停止を確認します。
R-①hdsstateコマンドを実行し、反映側Datareplicatorのすべてのプロセスが稼働していることを確認します。停止しているプロセスがあれば、再起動します。
R-②hdsstateコマンドを実行して、すべての更新情報が反映されたか確認します。
R-③hdsstopコマンドを実行し、反映側Datareplicator
を停止します。R-④
hdsstateコマンドを実行し、反映側Datareplicatorが停止していることを確認します。
R-⑤システムの構成を変更します。
R-⑥hdsstart -i -qを実行して、反映側Datareplicator
を初期化します。
Datareplicatorの停止
Datareplicatorのすべてのプロセスが稼働している
ことを確認
抽出側Datareplicator 反映側Datareplicator
すべての更新情報が反映されたか確認
E-①
R-①
R-②
Datareplicatorの停止を確認
E-②
Datareplicatorの停止
Datareplicatorの停止を確認
R-③
R-④
システムの構成を変更R-⑤
Datareplicatorを初期化R-⑥
手順の流れに対応する番号
初期化が必要な構成変更
反映側システムの構成変更②

© Hitachi, Ltd. 2012, 2019. All rights reserved.
8-3-3
126
6
R-⑦hdsstartコマンドを実行し、抽出側Datareplicator
を起動します。E-③
hdestartコマンドを実行し、反映側Datareplicator
を起動します。
Datareplicatorを起動
抽出側Datareplicator 反映側Datareplicator
E-③
Datareplicatorを起動R-⑦
初期化が必要な構成変更
反映側システムの構成変更③

© Hitachi, Ltd. 2012, 2019. All rights reserved.
8-4-1
127
1.抽出DBに対する更新業務を停止
3.すべての更新情報が反映DBに反映されているか確認
4.抽出側Datareplicatorおよび反映側Datareplicatorを停止
6.抽出側Datareplicatorおよび反映側Datareplicatorを初期化
7.抽出側Datareplicatorおよび反映側Datareplicatorを起動
5.システムの構成を変更
2.同期イベントを実行
8.同期イベントを実行
■手順の流れ
反映トランザクション同期機能を使用している場合の
構成変更①
解説反映トランザクション同期機能を使用している場合の構成変更手順について次に説明
します。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
8-4-2
128
2
3
E-①:抽出側DBに対する更新業務を停止します。E-②
hdeevent -n イベントコードコマンドを実行し、同期を取って反映を終了させるために、同期イベントを実行します。
E-③hdestateコマンドを実行し、抽出側
Datareplicatorのすべてのプロセスが稼働していることを確認します。停止しているプロセスがあれば、再起動します。
R-①hdsstateコマンドを実行し、反映側Datareplicatorのすべてのプロセスが稼働していることを確認します。停止しているプロセスがあれば、再起動します。
E-④pdlogsync -d sys を実行(抽出対象表が存在するすべてのBESについてコマンドを実行)して、すべてのシステムログの内容をシステムログファイルに出力します。
E-⑤pdls -d rpl -jを実行して、すべての更新情報が抽出されたか確認します。
E-⑥hdestateコマンドを実行して、すべての更新情報が送信されたか確認します。
R-②hdsstateコマンドを実行して、すべての更新情報が反映されたか確認します。
DBに対する更新業務停止
Datareplicatorのすべてのプロセスが稼働している
ことを確認
抽出側Datareplicator 反映側Datareplicator
Datareplicatorのすべてのプロセスが稼働している
ことを確認
すべての更新情報が反映されたか確認
すべてのシステムログの内容をシステムログ
ファイルに出力
すべての更新情報が抽出されたか確認
E-①
E-③
E-④
E-⑤
E-⑥
R-①
R-②
すべての更新情報が送信されたか確認
同期を取って反映を終了させるために、同期イベント
を実行
E-②
1
手順の流れに対応する番号
反映トランザクション同期機能を使用している場合の
構成変更②

© Hitachi, Ltd. 2012, 2019. All rights reserved.
8-4-3
129
4
5
E-⑦hdestopコマンドを実行し、抽出側Datareplicator
を停止します。E-⑧
hdestateコマンドを実行し、抽出側Datareplicatorが停止していることを確認します。
R-③hdsstopコマンドを実行し、反映側Datareplicator
を停止します。R-④
hdsstateコマンドを実行し、反映側Datareplicatorが停止していることを確認します。
E-⑨システムの構成を変更します。
抽出側Datareplicator 反映側Datareplicator
Datareplicatorの停止
Datareplicatorの停止を確認
E-⑦
E-⑧
R-③ Datareplicatorの停止
Datareplicatorの停止を確認
R-④
システムの構成を変更E-⑨
反映トランザクション同期機能を使用している場合の
構成変更③

© Hitachi, Ltd. 2012, 2019. All rights reserved.
8-4-4
130
7
6
8
E- ⑩pdrplstop -fを実行し、HiRDBとのデータ連携を中止します。
E- ⑪hdestart -iを実行して(応答メッセージにYを入力します)、抽出側Datareplicatorを初期化します。
E- ⑫hdeprep -f 抽出定義ファイルを実行して、抽出定義プリプロセスファイルを作成します。
E- ⑬pdrplstartコマンドを実行し、HiRDBとのデータ連携を開始します。
R-⑤hdsstart -i -qを実行して、反映側Datareplicatorを初期化します。
R-⑥hdsstartコマンドを実行し、反映側Datareplicator
を起動します。E-⑭
hdestartコマンドを実行し、抽出側Datareplicator
を起動します。E-⑮
反映側Datareplicatorの同期反映グループの全プロセスを稼働状態にするために、hdeevent –n
イベントコードを実行して、同期イベントを実行します。
抽出側Datareplicator 反映側Datareplicator
Datareplicatorの初期化
R-⑤ Datareplicatorを初期化
Datareplicatorの起動R-⑥
Datareplicatorの起動E-⑭
抽出定義プリプロセスファイルを作成E-⑫
E- ⑪
HiRDBとのデータ連携を中止
E-⑩
HiRDBとのデータ連携を開始E- ⑬
同期イベントを実行E-⑮
反映トランザクション同期機能を使用している場合の
構成変更④

© Hitachi, Ltd. 2012, 2019. All rights reserved.
8-5-1 HiRDB Datareplicatorの通常運用の手順①
131
1.反映側システムの起動
2.抽出側システムの起動
3.データ連動処理の実行
4.抽出側システムの終了
5.反映側システムの終了
■手順の流れ
解説 HiRDB Datareplicatorの通常運用手順について次に説明します。
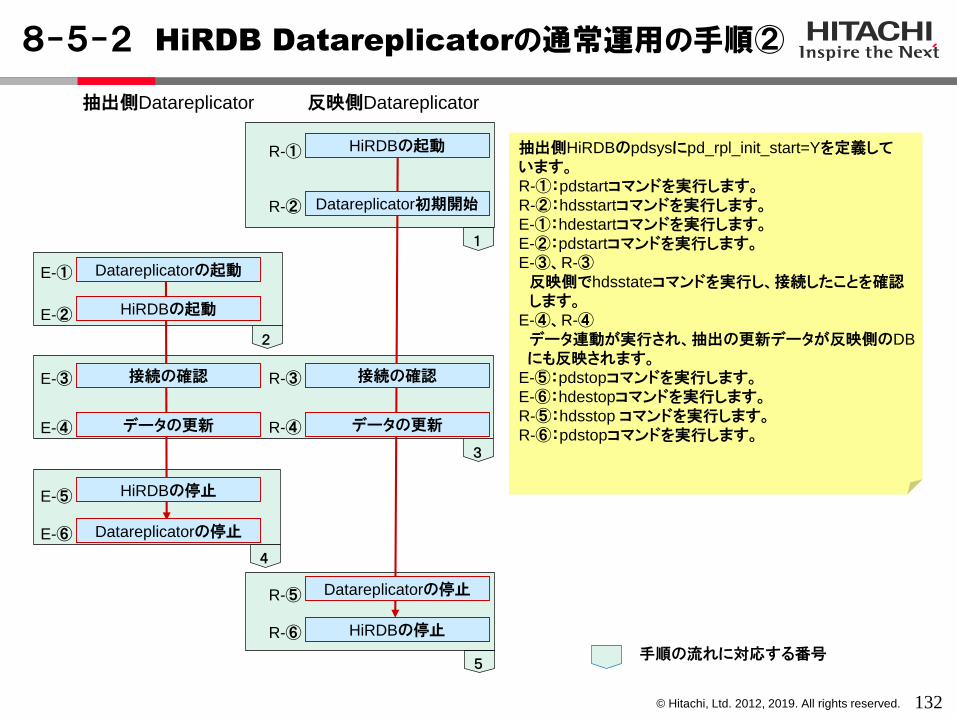
© Hitachi, Ltd. 2012, 2019. All rights reserved.
8-5-2 HiRDB Datareplicatorの通常運用の手順②
132
1
2
3
4
5
抽出側Datareplicator 反映側Datareplicator
HiRDBの起動
Datareplicator初期開始
Datareplicatorの起動
接続の確認 接続の確認
データの更新
E-②
E-①
E-③
E-④
R-②
R-③
HiRDBの起動R-①
HiRDBの停止E-⑤
Datareplicatorの停止E-⑥
Datareplicatorの停止R-⑤
HiRDBの停止R-⑥
データの更新R-④
手順の流れに対応する番号
抽出側HiRDBのpdsysにpd_rpl_init_start=Yを定義しています。R-①:pdstartコマンドを実行します。R-②:hdsstartコマンドを実行します。E-①:hdestartコマンドを実行します。E-②:pdstartコマンドを実行します。E-③、R-③
反映側でhdsstateコマンドを実行し、接続したことを確認します。
E-④、R-④データ連動が実行され、抽出の更新データが反映側のDB
にも反映されます。E-⑤:pdstopコマンドを実行します。E-⑥:hdestopコマンドを実行します。R-⑤:hdsstop コマンドを実行します。R-⑥:pdstopコマンドを実行します。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
8-6-1 抽出処理の開始方式①
133
項番 抽出処理の開始方式 開始方法
1 同時開始 hdestartコマンドを実行します。抽出側Datareplicatorが起動して、抽出側HiRDBのシステムログファイルからの更新情報の抽出、および反映側システムへの更新情報の送信を開始します。
2 送信遅延開始
1.抽出側システムでhdestart -eを実行して、抽
出側Datareplicatorを起動します。
抽出処理だけが開始されます。
2.抽出側システムでhdestart -s※1を実行して
送信処理が開始されます。
3 抽出遅延開始
1.抽出側システムでhdestart -s※1を実行しま
す。送信処理だけが開始されます。
2.抽出側システムでhdestart -eを実行します。
抽出処理が開始されます。
hdestart
抽出中送信中
1. hdestart -e
抽出中送信停止中
2. hdestart -s
抽出中送信中
1. hdestart -s 2. hdestart -e
※1送信先識別子を指定して、特定の送信先への送信処理だけを開始することもできます。
抽出停止中送信中
抽出中送信中
解説抽出処理の開始方式には、同時開始、送信遅延開始、および抽出遅延開始があります。
使用目的にあった、開始方式で運用します。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
8-6-2 抽出処理の開始方式②
134
項番 抽出処理の開始方式
使用目的 動作 注意事項
1 同時開始 システムログファイルの更新情報を抽出した順に逐次、反映側システムに送信する場合に有効です。
同時開始とすると、システムログファイルの更新情報を抽出した順に逐次、送信します。
ー
2 送信遅延
開始
反映側システムが起動されていないときや、反映側システムの負荷が高い時間を避けて運用するときに有効です。
抽出側Datareplicatorの起動時には抽出だけを開始し、hdestart -sコマンドによって送信の開始が要求された時点で送信を開始します。
抽出情報キューファイルに格納されている更新情報は送信されないで、抽出した更新情報が格納されていくため、抽出情報キューファイルの容量を十分に確保する必要があります。
3 抽出遅延
開始
抽出側HiRDBのオンライン中の負荷を考慮して運用するときに有効です。
抽出側Datareplicatorの起動時には送信だけを開始し、hdestart -eによって抽出の開始が要求された時点で、抽出を開始します。
抽出遅延開始をすると、抽出側HiRDBのシステムログファイルから更新情報を抽出しないため、システムログファイルが抽出完了になりません(スワップ先になりません)。
抽出側HiRDBで大量のトランザクションを処理することが予想される場合には、システムログファイルの容量を十分確保する必要があります。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
8-7-1 抽出処理の停止方式①
135
項番 抽出処理の停止方式 停止方法
1 抽出側HiRDBの正常終了による停止
(正常終了)
抽出システム定義の syncterm
オペランドにtrueを設定します。
2 コマンドによる停止
(強制終了)
hdestopコマンドを実行ます。
抽出中送信中
HiRDB
HiRDB Datareplicator
正常終了動作中
抽出中送信中
HiRDB
HiRDB Datareplicator
正常終了動作中
hdestop
●はHiRDB Datareplicatorを終了
解説抽出処理の停止方式は、抽出処理と送信処理の両方を同時停止して、
抽出側Datareplicatorを終了します。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
8-7-2 抽出処理の停止方式②
136
項番 抽出処理の停止方式 使用目的 動作
1 抽出側HiRDBの正常終了による停止(正常終了)
コマンドを実行しないで、抽出側HiRDBの正常終了に連動して、自動的に抽出側Datareplicatorを終了する場合に使います。
抽出側HiRDBの正常終了に連動して、自動的に抽出側Datareplicatorを終了します。
2 コマンドによる停止(強制終了)
緊急に抽出側Datareplicator
を終了する場合に使います。hdestopコマンドを実行した時点で実行中の、抽出と送信が完了した時点で、抽出側Datareplicatorを終了します。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
8-8-1 反映処理の開始方式①
137
項番 反映処理の開始方式 開始方法
1 同時開始 1.反映側Datareplicatorの起動前に、反映環
境定義の以下オペランドを設定しておきます。
・startmodeオペランドにtrn(トランザクション
単位反映方式)、またはtbl(表単位反映方式)。
2.hdsstartコマンドを実行します。
2 遅延開始
時間指定開始方式
1.反映側Datareplicatorの起動前に、反映環
境定義の以下オペランドを設定しておきます。
・startmodeオペランドにspdを指定します(反
映処理停止したまま受信処理開始)。
・breaktimeオペランドに反映処理を開始する
時間を指定します(反映側Datareplicatorの
起動時から停止状態にある反映処理を開始
する時間を反映側Datareplicatorの起動時
を起点とした相対時間で指定します)。
2.hdsstartコマンドを実行します。
hdsstart
受信中反映中
受信中反映停止中
受信中反映中
hdsstart
開始するまでの時間(相対時間)
解説
反映処理の開始方式には、同時開始と遅延開始があります。遅延開始には、時間指定開始
方式、コマンド開始方式、イベント開始方式があります。使用目的にあった開始方式で運用
します。
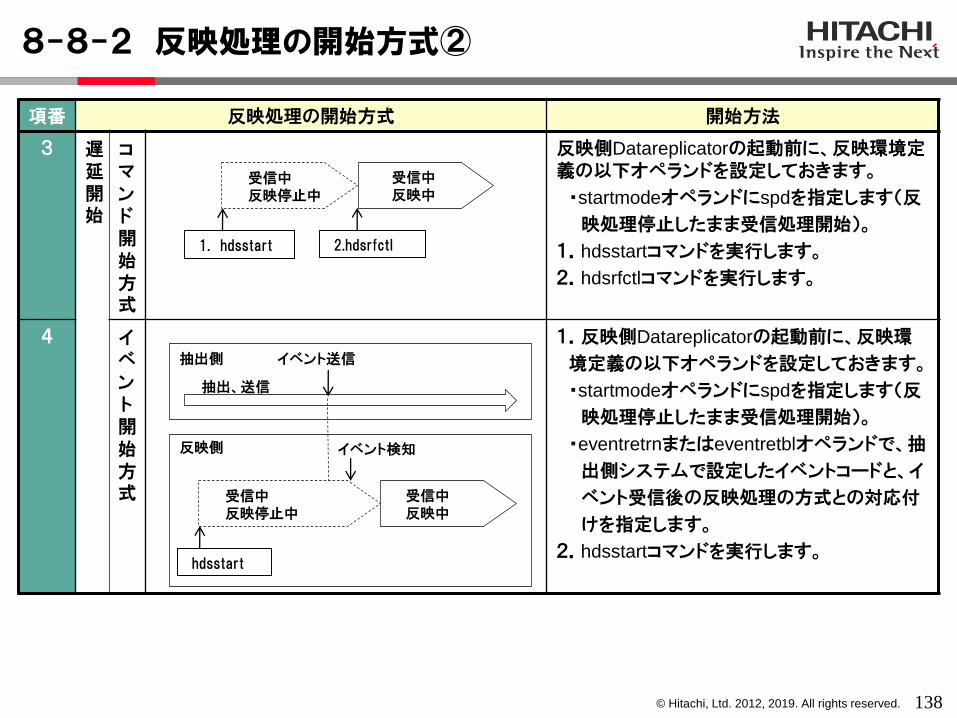
© Hitachi, Ltd. 2012, 2019. All rights reserved.
8-8-2 反映処理の開始方式②
138
項番 反映処理の開始方式 開始方法
3 遅延開始
コマンド開始方式
反映側Datareplicatorの起動前に、反映環境定義の以下オペランドを設定しておきます。
・startmodeオペランドにspdを指定します(反
映処理停止したまま受信処理開始)。
1.hdsstartコマンドを実行します。
2.hdsrfctlコマンドを実行します。
4 イベント開始方式
1.反映側Datareplicatorの起動前に、反映環
境定義の以下オペランドを設定しておきます。
・startmodeオペランドにspdを指定します(反
映処理停止したまま受信処理開始)。
・eventretrnまたはeventretblオペランドで、抽
出側システムで設定したイベントコードと、イ
ベント受信後の反映処理の方式との対応付
けを指定します。
2.hdsstartコマンドを実行します。
受信中反映停止中
受信中反映中
2.hdsrfctl
受信中反映停止中
受信中反映中
抽出側 イベント送信
抽出、送信
イベント検知
1. hdsstart
hdsstart
反映側

© Hitachi, Ltd. 2012, 2019. All rights reserved.
8-8-3 反映処理の開始方式③
139
項番 反映処理の
開始方式
使用目的 動作
1 同時開始 更新情報を受信した順に逐次、反映する場合に有効です。
反映側Datareplicatorを起動すると同時に反映処理を開始します。同時開始とすると、更新情報を受信した順に逐次反映できます。
2 遅延開始
時間指定開始方式
反映側Datareplicatorの起動後に、定期的なデータベースのメンテナンスなどの作業をする場合に有効です。
反映側Datareplicatorの起動時には、受信処理だけを開始し、任意のタイミングで反映処理を開始(遅延開始)します。
3 コマンド開始方式
日々の運用で、反映を開始する時間が異なる場合に使います。
hdsrfctlコマンドを実行してから反映処理を開始します。
4 イベント開始方式
抽出側システムの運用によって反映処理を制御する場合に使います。
抽出側システムから送信されたイベントを検知した時点で、反映処理を開始します。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
8-9-1 反映処理の停止方式①
140
項番 終了モード 同時停止の停止方式 停止方法
1 正常終了 hdsstopコマンドを実行します。
2 イベント終了 1.hdsstop -t eventを実行します。
2.抽出側Datareplicatorでhdeevent
コマンドを実行します。
hdsstop
受信中反映中
①同時停止の停止方法
受信停止中反映中
抽出側2. hdeevent
抽出、送信
イベント検知1.hdsstop
受信中反映中
受信停止中反映中
反映側
解説
反映処理の停止方式には、同時停止と単独停止があります。同時停止は、受信処理と反映処理
の両方を停止し、反映側Datareplicatorを終了します。単独停止は、受信処理を停止しないで、
反映処理だけを単独で停止します。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
8-9-2 反映処理の停止方式②
141
項番 終了モード 同時停止の停止方式 停止方法
3 即時終了 hdsstop -t immediateを実行します。
4 強制終了 hdsstop -t forceを実行します。
hdsstop
受信中反映中
受信停止中反映中
hdsstop
受信中反映中

© Hitachi, Ltd. 2012, 2019. All rights reserved.
8-9-3 反映処理の停止方式③
142
項番 停止方式 単独停止の停止 停止方法
1 コマンド停止方式
1.hdsrfctlコマンドを実行します。
2.抽出側Datareplicatorでhdeeventコマンドを実行します。
2 イベント停止方式
1.HiRDB Datareplicatorの起動前に、反映環境定義の以下オペランドを設定しておきます。
・eventspdオペランドで、抽出側システムで
設定したイベントコードとの対応付けをし
ます。
2.抽出側Datareplicatorで反映処理の
hdeeventコマンドを実行します。
②単独停止の停止方法
抽出側 2. hdeevent
抽出、送信
イベント検知1. hdsrfctl
受信中反映中
受信中反映停止
抽出側 hdeevent
抽出、送信
イベント検知
受信中反映中
受信中反映停止
反映側
反映側

© Hitachi, Ltd. 2012, 2019. All rights reserved.
8-9-4 反映処理の停止方式④
143
項番 反映処理の停止方式
使用目的 動作
1 同時停止
正常終了 抽出側システムまたは反映側システムを正常終了する場合に使います。
hdsstopコマンドの実行時に稼働中の、抽出側システムの稼働単位までの反映処理が完了した時点で、反映処理を停止し、反映側Datareplicatorは終了します。
2 イベント終了 反映側システムを計画的に終了する場合に使います。
・hdsstop -t eventを実行した後、抽出側システムから送信された何らかのイベントを検知した時点で、反映処理を停止し、反映側Datareplicatorは終了します。
・イベントを検知する前に、抽出側システムの稼働単位まで反映が完了した場合には、イベントを待たないで反映処理を停止します。
3 即時終了 反映側システムを一時的に停止する場合、または受信処理だけ実行中に反映処理を起動しないで停止する場合に実行します。
hdsstop -t immediateを実行した後、現在反映処理中の更新情報の反映が終了した時点で、反映処理を停止し、反映側Datareplicatorは終了します。
4 強制終了 反映側システムを緊急に停止する場合に使います。
・hdsstop -t forceを実行した時点で直ちに、反映処理を停止し、反映側Datareplicatorは終了します。
・同期点処理を実行中の場合には、同期点処理が完了してから反映処理を停止します。
・強制終了モードの場合、反映側DBと抽出側DBに不整合が生じることがあります。ただし、次回の反映側Datareplicatorの起動時に、反映側DBを自動的に回復します。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
8-9-5 反映処理の停止方式⑤
144
項番 反映処理の
停止方式
使用目的 動作
5 単独停止
コマンド停止方式
反映側システムから反映処理の停止を要求する場合に使います。
hdsrfctlコマンドを実行した後、抽出側システムから送信された何らかのイベントを検知した時点で、反映処理を停止します。
6 イベント停止方式
抽出側システムから反映処理の停止を要求する場合に使います。
抽出側システムから送信された反映処理停止イベントを検知した時点で、反映処理を停止します。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
8-10 反映処理方式の変更
145
抽出側
抽出、送信
1. hdsrfctl -m spd
受信中反映中
受信中反映停止
受信中反映中
2. hdsrfctl -m trnまたはhdsrfctl -m tbl
3. hdeevent –n イベントコード
反映側
イベント検知
1. hdsrfctl -m spdを実行します。2. hdsrfctl -m trn (トランザクション単位反映方式)またはhdsrfctl -m tbl (表単位反映方式)
を実行します。3. hdeeventコマンドで、反映環境定義のeventtrnオペランドまたはeventtblオペランド
に対応するイベントを発生を実行します。
解説反映側Datareplicatorでは、稼働中に反映処理方式(トランザクション単位反映方式または
表単位反映方式)を変更できます。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
8-11 データ連動の継続実行時の運用手順
146
抽出側HiRDBのpdsysにpd_rpl_init_start=Yを定義しています。E-① :pdstartコマンドを実行します。E-② : hdestartコマンドを実行します。E-③ :DB業務E-④ :pdstopコマンドを実行します。E-⑤ :hdestopコマンドを実行します。E-⑥ :pdstartコマンドを実行します。E-⑦ : hdestartコマンドを実行します。
前回のシステムログの抽出状態を引き継いで、
HiRDB Datareplicator連携を実行します。
抽出側Datareplicator
HiRDBの正常停止
HiRDBの起動
Datareplicatorの起動
DB業務
Datareplicatorの停止
HiRDBの起動
Datareplicatorの起動
E-①
E-②
E-③
E-④
E-⑤
E-⑥
E-⑦
解説
HiRDBのシステム共通定義にpd_rpl_init_start=Yを指定している場合は、抽出側HiRDBの開始
または再開始に関係なく、前回の抽出側HiRDBでのデータ連動情報のシステムログへの出力状態
と、抽出側Datareplicatorのシステムログの抽出状態を引き継いで、HiRDB Datareplicator連携
を実行します。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
8-12-1 抽出対象DBの再作成時の運用手順①
147
2.HiRDB Datareplicator連携を中止
3.抽出側Datareplicatorおよび反映側Datareplicatorを停止
4.抽出対象DBを再作成
6.抽出DBを基に反映DBを作成
7.抽出側HiRDBの正常停止
5.データ連動対象DBの更新を抑止12 .反映側Datareplicatorの初期開始
13.抽出側Datareplicatorの起動
10.抽出側HiRDBの起動
11.プリプロセスの実行
14.データ連動対象DBの更新抑止解除
15.抽出側HiRDBの業務を再開
9.抽出側Datareplicatorの初期化
■手順の流れ8.抽出側Datareplicatorおよび反映側Datareplicatorの各種定義
ファイルを変更
1.抽出側HiRDBの業務停止
解説 抽出対象DBの再作成時の運用手順について次に説明します。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
8-12-2 抽出対象DBの再作成時の運用手順②
148
2
4
5
7
8
E-①抽出側でHiRDBの業務を停止します。
E-②pdrplstopコマンドでHiRDB Datareplicator連携を中止します。
E-③ 、R- ①抽出側Datareplicatorをhdestopコマンドで終了して、反映側Datareplicatorをhdsstopコマンドで終了します。
E-④:抽出対象DBを再作成します。E-⑤データ連動対象DBのRDエリアをpdholdコマンドで閉塞して、データ連動対象DBの更新を抑止します。
E-⑥ 、R-②抽出DBを基に反映DBを作成します。Dataextractor(あるいはアンロード+ftp+ロード)を実行して、DBの同期を取ります。
E-⑦:pdstopコマンドを実行します。E-⑧ 、R-③
HiRDB Datareplicatorの各種定義ファイルで変更が必要なものは変更します。
HiRDB Datareplicator
連携を中止
抽出側Datareplicator 反映側Datareplicator
Datareplicatorを終了
Datareplicatorを終了
抽出対象DBを再作成
データ連動対象DBの更新を抑止
ターゲットDBの作成 ターゲットDBの作成
HiRDBの正常停止
E-②
E-③
E-④
E-⑤
E-⑥
E-⑦
R-①
R-②
定義ファイルの変更 定義ファイルの変更E-⑧ R-③
3
6
手順の流れに対応する番号
1
HiRDBの業務停止E-①

© Hitachi, Ltd. 2012, 2019. All rights reserved.
8-12-3 抽出対象DBの再作成時の運用手順③
149
E-⑨:hdestart –iを実行します。E-⑩ pdstartコマンドを実行します(pdsysにpd_rpl_init_start
=Yを定義しています)。E-⑪:hdeprepコマンドを実行します。R-④:hdsstart –i –fを実行します。E-⑫:hdestartコマンドを実行します。E-⑬ 、R-⑤反映側でhdsstateコマンドを実行し、接続したことを確認します。
E-⑭抽出側のデータ連動対象DBの閉塞をpdrelsコマンドで解除します。
E-⑮、R-⑥抽出側でHiRDBの業務を再開し、反映側にデータを反映します。
抽出側Datareplicator 反映側Datareplicator
HiRDBの起動
プリプロセスの実行
Datareplicator初期開始
Datareplicatorの起動
接続の確認
接続の確認
HiRDBの業務を再開 データ反映
E-⑩
E-⑪
E-⑫
E-⑬
E-⑮
R-④
R-⑤
R-⑥
更新抑止を解除E-⑭
10
11
12
13」
14
15
9
Datareplicator初期化E-⑨

© Hitachi, Ltd. 2012, 2019. All rights reserved.
8-13-1 抽出側HiRDBのシステム再構築時の運用手順①
150
1.抽出側HiRDBの正常停止
2.抽出側Datareplicatorおよび反映側Datareplicatorを停止
3.抽出側HiRDBシステム再構築
6.抽出DBを基に反映DBを作成
5.抽出側DB作成
7.抽出側Datareplicatorおよび反映側Datareplicatorの各種定義
ファイルを作成
11.抽出側Datareplicatorおよび反映側Datareplicatorを起動
4.抽出側HiRDBの起動 10.プリプロセスの実行
12.抽出側HiRDBの業務を再開
9.HiRDB Datareplicator連携を開始
8.抽出側Datareplicatorの初期化
■手順の流れ
解説 抽出側HiRDBのシステム再構築時の運用手順について次に説明します。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
8-13-2 抽出側HiRDBのシステム再構築時の運用手順②
151
5
抽出側Datareplicator 反映側Datareplicator
Datareplicatorを終了
Datareplicatorを終了
HiRDBシステム再構築
ターゲットDBの作成 ターゲットDBの作成
HiRDBの正常停止E-①
E-②
E-③
E-④
E-⑤
E-⑥
R-①
R-②
定義ファイルの変更
定義ファイルの変更
E-⑦
R-③
HiRDBの起動
DB再作成
1
2
4
6
7
手順の流れに対応する番号
抽出側HiRDBのpdsysにpd_rpl_init_start=Yを定義しています。E-①:pdstopコマンドを実行します。E-②、R- ①
抽出側Datareplicatorをhdestopコマンドで終了して、反映側Datareplicatorをhdsstopコマンドで終了します。
E-③:抽出側HiRDBのシステムを再構築します。E-④ pdsysにpd_rpl_init_start=Nを定義してpdstartを実行
します。E-⑤:抽出側HiRDBを再作成します。E-⑥、R-②
抽出DBを基に反映DBを作成します。Dataextractor(あるいはアンロード+ftp+ロード)を実行して、DBの同期を取ります。
E-⑦ 、R-③HiRDB Datareplicatorの各種定義ファイルで変更が必要なものは変更します。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
8-13-3 抽出側HiRDBのシステム再構築時の運用手順③
152
E-⑧:hdestart –iを実行します。E-⑨:pdstopコマンドを実行します。E-⑩ pdsysにpd_rpl_init_start=Yを定義してpdstartを実行
します。E-⑪ :hdeprepコマンドを実行します。R-④:hdsstart –i –fを実行します。E-⑫ :hdestartコマンドを実行します。E-⑬ 、R-⑤
反映側でhdsstateコマンドを実行し、接続したことを確認します。
E-⑭ 、R-⑥抽出側でデータを更新し、反映側で反映が完了したことを確認します。
抽出側Datareplicator 反映側Datareplicator
Datareplicator初期化
HiRDBの正常停止
プリプロセスの実行
Datareplicator初期開始
Datareplicatorの起動
接続の確認 接続の確認
データの更新
反映の確認
E-⑧
E-⑨
E-⑪
E-⑫
E-⑬
R-④
R-⑤
R-⑥
E-⑭
8
9
11
12
13
HiRDBの起動E-⑩
10

© Hitachi, Ltd. 2012, 2019. All rights reserved.
8-14 抽出側HiRDBシステム定義の変更時の運用手順
153
抽出側Datareplicator 反映側Datareplicator
Datareplicatorを終了
HiRDBシステム定義変更
HiRDBの正常停止
Datareplicatorの起動
接続の確認 接続の確認
E-①
E-②
E-③
E-④
E-⑤
E-⑥ R-①
HiRDBの起動
抽出側HiRDBのpdsysにpd_rpl_init_start=Yを定義しています。E-①:pdstopコマンドを実行します。E-②
抽出側Datareplicatorをhdestopコマンドで終了します。E-③:抽出側HiRDBのシステム定義を変更します。E-④:pdstartをHiRDBの起動します。E-⑤:hdestartコマンドを実行します。E-⑥、R-①
反映側でhdsstateコマンドを実行し、接続したことを確認します。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
8-15-1 送信先の追加の運用の手順①
154
1.新規に追加する反映側に運用ディレクトリ、キュー領域、定義ファイルの作成、hosts、servicesの登録を行う
6.抽出側Datareplicatorの定義を変更
7.抽出DBを基に新規に追加する反映側にDBを作成
3.抽出、送信処理完了の確認
4.抽出側Datareplicator停止
2.データ連動対象DBの更新を抑止
5.すべての反映側は、すべて送信されたデータが反映していることを確認
9.反映側Datareplicatorの初期開始
11.抽出側Datareplicatorの起動
10.プリプロセスの実行
12.データ連動対象DBの更新抑止解除
13.抽出側HiRDBの業務を再開
8.抽出側Datareplicatorの初期化
■手順の流れ
解説送信先の追加の運用で、抽出システム定義に対してsendidオペランドおよびsenddef
オペランドを新たに追加した場合の手順について説明します。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
8-15-2 送信先の追加の運用の手順②
155
10
9
8
5
3
4
2
抽出側Datareplicator 既存の反映側Datareplicator
全反映側は、送信されたデータがすべて反映され
ている
抽出、送信処理完了の確認
E-①
E-②
E-③
E-④
E-⑤
R-①
R-②
データ連動対象DBの更新を抑止
Datareplicator停止
抽出側の定義を変更
Datareplicator停止
運用ディレクトリの作成
新規の反映側Datareplicator
キュー領域の作成
定義ファイルの作成
hosts、servicesの登録
ターゲットDBの作成
Datareplicator初期開始
NR-①
NR-②
NR-③
NR-④
NR-⑤
NR-⑥
ターゲットDBの作成
Datareplicator初期開始R-③
E-⑥ Datareplicator初期化
プリプロセスの実行E-⑦
1
6
7
11
Datareplicatorの起動E-⑧ 手順の流れに対応する番号

© Hitachi, Ltd. 2012, 2019. All rights reserved.
8-15-3 送信先の追加の運用の手順③
156
13
12
抽出側Datareplicator 既存の反映側Datareplicator 新規の反映側Datareplicator
接続の確認
反映の確認
NR-⑦
NR-⑧
接続の確認
データの更新
E-⑨
E-⑩
接続の確認R-④
反映の確認R-⑤

© Hitachi, Ltd. 2012, 2019. All rights reserved.
8-15-4 送信先の追加の運用の手順④
157
NR-④通信に必要な情報を登録します。
E-⑤、NR-⑤抽出DBを基に反映DBを作成します。 Dataextractor(あるいはアンロード+ftp+ロード)を実行して、DBの同期を取ります。
E-⑥:hdestart –iを実行します。R-③、NR-⑥:hdsstart –i –fを実行します。E-⑦:hdeprepコマンドを実行します。E-⑧:hdestartコマンドを実行します。E-⑨、R-④、NR-⑦
反映側でhdsstateコマンドを実行し、接続したことを確認します。
E-⑩、R-⑤ 、NR-⑧抽出側でデータを更新し、反映側で反映が完了したことを確認します。
抽出側HiRDBのpdsysにpd_rpl_init_start=Yを定義しています。E-①
データ連動対象DBのRDエリアをpdholdコマンドで閉塞して、データ連動対象DBの更新を抑止します。
E-②抽出側HiRDBのシステムログをすべて抽出し、反映側へ送信されていることを確認します(抽出情報キューファイル中の更新情報もすべて送信していることを確認してください)。pdls -d rpl -jコマンド、hdestateコマンド、抽出側Datareplicatorの出力するメッセージ で確認します。
E-③:Datareplicatorをhdestopコマンドで停止します。R-①
全送信先の反映側Datareplicatorについて、抽出側から送信されたデータがすべて反映されていることを確認します。反映情報キューファイルの更新情報がすべて反映されていることを、hdsstateコマンドで確認できます。
R-②:Datareplicatorをhdsstopコマンドで停止します。E-④
抽出側Datareplicatorの定義を変更します。NR-①
運用ディレクトリを作成します。インストールディレクトリとは異なる場所を推奨します。
NR-②rawデバイスに作成する場合に、領域を割当てます。
NR-③反映側Datareplicatorの各種定義ファイルを運用ディレクトリ下に作成します。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
1.新規に追加する反映側に運用ディレクトリ、キュー領域、定義ファイルの作成、hosts、servicesの登録
5.抽出側Datareplicatorの定義を変更
6.抽出側Datareplicatorの送信先の部分初期化
3.抽出、送信処理完了の確認
4.抽出側Datareplicator停止
7.プリプロセスの実行
11.データ連動対象DBの更新抑止解除
12.抽出側HiRDBの業務を再開
8.抽出DBを基に新規に追加する反映側にDBを作成
9 .追加する反映側Datareplicatorの初期開始
2.データ連動対象DBの更新を抑止
10.抽出側Datareplicatorの起動
■手順の流れ
8-16-1 欠番の送信先を追加する運用の手順①
158
解説送信先の追加の運用で、抽出システム定義に対して欠番のsendidオペランドおよび
senddefオペランドを送信先として追加する場合の手順について説明します。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
8-16-2 欠番の送信先を追加する運用の手順②
159
9
8
7
6
5
4
3
2
抽出側Datareplicator
抽出、送信処理完了の確認
E-①
E-②
E-③
E-④
データ連動対象DBの更新を抑止
Datareplicator停止
抽出側の定義を変更
運用ディレクトリの作成
新規の反映側Datareplicator
キュー領域の作成
定義ファイルの作成
Hosts、servicesの登録
ターゲットDBの作成
Datareplicator初期開始
NR-①
NR-②
NR-③
NR-④
NR-⑤
NR-⑥
ターゲットDBの作成
プリプロセスの実行E-⑥
送信先の部分初期化E-⑤
E-⑦
1
手順の流れに対応する番号

© Hitachi, Ltd. 2012, 2019. All rights reserved.
8-16-3 欠番の送信先を追加する運用の手順③
160
12
11
抽出側Datareplicator 新規の反映側Datareplicator
接続の確認
反映の確認
NR-⑦
NR-⑧
Datareplicatorの起動
接続の確認
データの更新
E-⑩
E-⑧
E-⑨
E-⑪
データ連動対象DBの更新を抑止解除
10

© Hitachi, Ltd. 2012, 2019. All rights reserved.
8-16-4 欠番の送信先を追加する運用の手順④
161
NR-⑥:hdsstart –i –fを実行します。E-⑧:hdestartコマンドを実行します。E-⑨、NR-⑦
反映側でhdsstateコマンドを実行し、接続したことを確認します。
E-⑩データ連動対象DBのRDエリアをpdrelsコマンドでRDエリアの閉塞状態を解除します。
E-⑪、NR-⑧抽出側でデータを更新し、反映側で反映が完了したことを確認します。
E-①データ連動対象DBのRDエリアをpdholdコマンドで閉塞して、データ連動対象DBの更新を抑止します。
E-②抽出側HiRDBのシステムログをすべて抽出し、反映側へ送信されていることを確認します(抽出情報キューファイル中の更新情報もすべて送信していることを確認してください)。pdls -d rpl -jコマンド、hdestateコマンド、抽出側Datareplicatorの出力するメッセージ で確認します。
E-③:HiRDB Datareplicatorをhdestopコマンドで停止します。E-④:抽出側Datareplicatorの定義を変更します。E-⑤
hdestart –i –S 送信先識別子番号コマンドを実行します。定義変更を行った送信先に対する部分初期化をします。
E-⑥:hdeprepコマンドを実行します。NR-①
運用ディレクトリを作成します。インストールディレクトリとは異なる場所を推奨します。
NR-②rawデバイスに作成する場合に、領域を割当てます。
NR-③反映側Datareplicatorの各種定義ファイルを運用ディレクトリ下に作成します。
NR-④通信に必要な情報を登録します。
E-⑦、NR-⑤抽出DBを基に反映DBを作成します。 Dataextractor(あるいはアンロード+ftp+ロード)を実行して、DBの同期を取ります。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
8-17 送信先の削除の運用の手順
162
抽出側Datareplicator
抽出、送信処理完了の確認
E-①
E-②
E-③
E-④
データ連動対象DBの更新を抑止
Datareplicator停止
抽出側の定義を変更
プリプロセスの実行
Datareplicatorの起動
HiRDBの業務を再開
E-⑧
E-⑥
E-⑦
E-⑨
送信先の部分初期化E-⑤
データ連動対象DBの更新を抑止解除
E-①データ連動対象DBのRDエリアをpdholdコマンドで閉塞して、データ連動対象DBの更新を抑止します。
E-②抽出側HiRDBのシステムログをすべて抽出し、反映側へ送信されていることを確認します(抽出情報キューファイル中の更新情報もすべて送信していることを確認してください)。pdls -d rpl -j、hdestateコマンド、抽出側Datareplicatorの出力するメッセージ で確認します。
E-③:HiRDB Datareplicatorをhdestopコマンドで停止します。E-④:抽出側Datareplicatorの定義を変更します。E-⑤
hdestart –i –S 送信先識別子番号を実行します。定義変更を行った送信先に対する部分初期化をします。
E-⑥:hdeprepコマンドを実行します。E-⑦:hdestartコマンドを実行します。E-⑧
データ連動対象DBのRDエリアをpdrelsコマンドでRDエリアの閉塞状態を解除します。
E-⑨抽出側HiRDBの業務を再開します。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
9. 障害時の対処方法
163

© Hitachi, Ltd. 2012, 2019. All rights reserved.
9-1
164
受信機能 反映機能
反映キューファイル
制御機能
アプリケーション
DB
HiRDB
LOG
抽出機能
HiRDB Datareplicator
送信機能
抽出キューファイル
制御機能
SQL
ステータスファイル
ステータスファイル
障害ケース 対処方法 注意事項
抽出側
HiRDB
サーバ
①アプリケーション異常終了 アプリケーション再実行 -
②DBファイルディスク障害 抽出側DBをバックアップとシステムログ情報を
用いて最新の同期点まで回復し、業務および抽出
処理を再開
抽出側HiRDBサーバの
回復処理中は、抽出側
Datareplicatorを停止して
ください。③システムログファイル
ディスク障害(全系障害)
■抽出側DBとシステムログファイルを回復し、
業務および抽出処理を再開
■反映側DBを再作成する
④上記以外 障害要因を取り除いて、業務および抽出処理を再開
HiRDB Datareplicator HiRDB
② ③
④
①
DB
障害ケースと対処方法
抽出側HiRDBサーバ障害の場合

© Hitachi, Ltd. 2012, 2019. All rights reserved.
9-2
165
障害ケース 対処方法 注意事項
抽出側
Datareplicator
⑤キューファイルのみ
ディスク障害
下記のいづれかの方法で回復する
■抽出情報キューファイル回復機能を
使用して回復
■データ連動回復機能を使用して回復
■反映側DBを再作成する
障害が長期化すると、未抽出のシステム
ログファイルは上書きできないため、
システムログファイルの容量不足となり、
HiRDBサーバがユニットダウンに陥る
危険性があります。
pdloglsコマンドで、HiRDBシステムログ
ファイルの使用状況を確認してください。⑥キューファイル、
ステータスファイル
などのディスク障害
下記のいづれかの方法で回復する
■データ連動回復機能を使用して回復
■反映側DBを再作成する
⑦上記以外 障害要因を取り除いて、抽出処理を再開
受信機能 反映機能
反映キューファイル
制御機能
アプリケーション
DB
HiRDB
LOG
抽出機能
HiRDB Datareplicator
送信機能
抽出キューファイル
制御機能
SQL
ステータスファイル
ステータスファイル
HiRDB Datareplicator HiRDB
⑤ ⑥
⑦
DB
障害ケースと対処方法
抽出側Datareplicator障害の場合

© Hitachi, Ltd. 2012, 2019. All rights reserved.
9-3
166
障害ケース 対処方法 注意事項
抽出-反映間通信 ⑧通信障害 障害要因を取り除き、反映処理を再開 障害が長期化すると、抽出キュー
ファイルの容量不足に陥る危険性
があります。反映側
Datareplicator
⑨キューファイル、
ステータスファイル
などのディスク障害
下記のいづれかの方法で回復する
■データ連動回復機能を使用して回復(*1)
■反映側DBを再作成する
⑩上記以外 障害要因を取り除いて、反映処理を再開
受信機能 反映機能
反映キューファイル
制御機能
アプリケーション
DB
HiRDB
LOG
抽出機能
HiRDB Datareplicator
送信機能
抽出キューファイル
制御機能
SQL
ステータスファイル
ステータスファイル
HiRDB Datareplicator HiRDB
⑨
⑩
⑧
(*1):反映側Datareplicator運用ディレクトリ下のエラー情報ファイルも同時に障害が発生した場合は、適用できません。
DB
障害ケースと対処方法
反映側Datareplicator障害の場合

© Hitachi, Ltd. 2012, 2019. All rights reserved.
9-4
167
障害ケース 対処方法 注意事項
反映側
HiRDB
サーバ
⑪DBファイルディスク障害 反映側DBのバックアップとシステムログ情報を
用いて、最新の同期点まで回復し、反映処理を再開
障害が長期化すると、反映
キューファイルの容量不足に
陥る危険性があります。⑫上記以外 障害要因を取り除いて、反映処理を再開
受信機能 反映機能
反映キューファイル
制御機能
アプリケーション
DB
HiRDB
LOG
抽出機能
HiRDB Datareplicator
送信機能
抽出キューファイル
制御機能
SQL
ステータスファイル
ステータスファイル
DB
HiRDB Datareplicator HiRDB
⑪
⑫
障害ケースと対処方法
反映側HiRDBサーバ障害の場合

© Hitachi, Ltd. 2012, 2019. All rights reserved.
9-5
168
受信機能 反映機能
反映キューファイル
制御機能
DB
HiRDB
抽出機能
HiRDB Datareplicator
送信機能
抽出キューファイル
制御機能
ステータスファイル
ステータスファイル
DB
HiRDB Datareplicator HiRDB
一括複写
回復方法概要
反映側DB再作成
反映側DB再作成の概要
初期構築手順と同様に、HiRDB Dataextractorなどを用いて、抽出側DBのデータを一括複写することで、反映側DBを回復します。
特長
■抽出側DBと反映側DBの間で不整合が発生した
場合に、対応できます。
■DB容量が大きい環境では、反映側DBの復旧に
時間を要します。
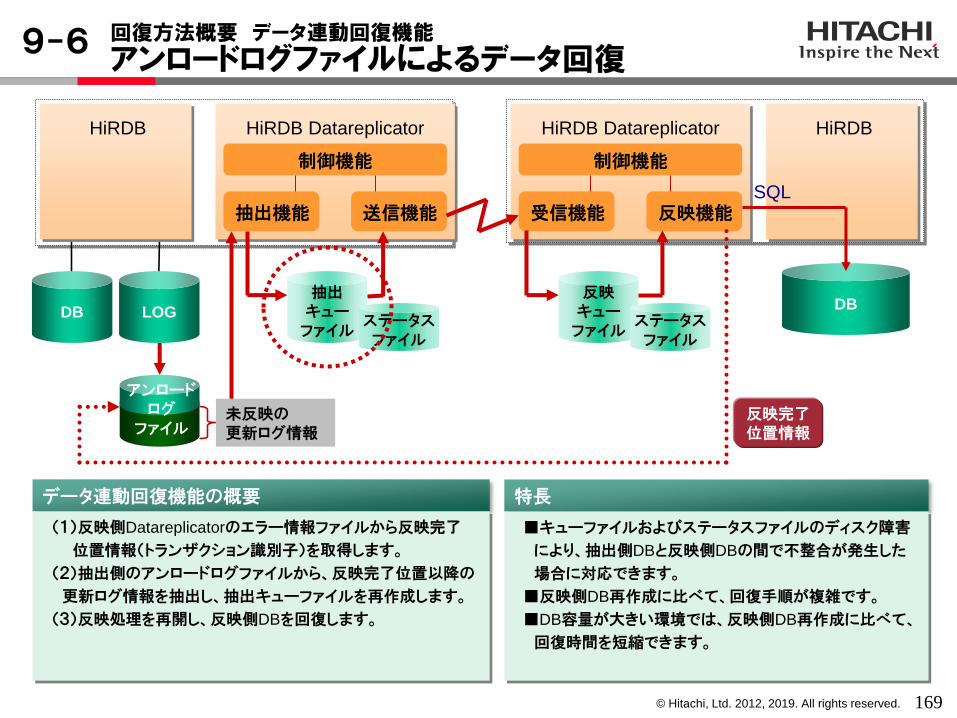
© Hitachi, Ltd. 2012, 2019. All rights reserved.
9-6
169
受信機能 反映機能
反映キューファイル
制御機能
DB
HiRDB
抽出機能
HiRDB Datareplicator
送信機能
抽出キューファイル
制御機能
ステータスファイル
ステータスファイル
HiRDB Datareplicator HiRDB
LOG
反映完了位置情報
SQL
アンロードログ
ファイル未反映の更新ログ情報
DB
回復方法概要 データ連動回復機能
アンロードログファイルによるデータ回復
データ連動回復機能の概要
(1)反映側Datareplicatorのエラー情報ファイルから反映完了
位置情報(トランザクション識別子)を取得します。
(2)抽出側のアンロードログファイルから、反映完了位置以降の
更新ログ情報を抽出し、抽出キューファイルを再作成します。
(3)反映処理を再開し、反映側DBを回復します。
特長
■キューファイルおよびステータスファイルのディスク障害
により、抽出側DBと反映側DBの間で不整合が発生した
場合に対応できます。
■反映側DB再作成に比べて、回復手順が複雑です。
■DB容量が大きい環境では、反映側DB再作成に比べて、
回復時間を短縮できます。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
9-7
170
受信機能 反映機能
反映キューファイル
制御機能
DB
HiRDB
抽出機能
HiRDB Datareplicator
送信機能
抽出キューファイル
制御機能
ステータスファイル
ステータスファイル
HiRDB Datareplicator HiRDB
更新情報入力開始位置
SQL
DB
回復情報ファイル
回復情報ファイル
LOG 未反映の更新ログ情報
回復方法概要 データ連動回復機能
システムログファイルによるデータ回復
データ連動回復機能の概要
(1)反映側Datareplicatorの回復情報ファイルを抽出側へ転送
します。
(2)回復情報ファイルを基にシステムログファイルの更新情報
入力開始位置を取得します。
(3)システムログファイルから、入力開始位置以降の更新ログ
情報を抽出し、抽出キューファイルを再作成します。
(4)反映処理を再開し、反映側DBを回復します。
特長
■キューファイルおよびステータスファイルのディスク障害
により、抽出側DBと反映側DBの間で不整合が発生した
場合に対応できます。
■反映側DB再作成に比べて、回復手順が簡単ですが、抽
出情報キューファイル回復より複雑です。
■DB容量が大きい環境では、反映側DB再作成に比べて、
回復時間を短縮できます。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
9-8
171
受信機能 反映機能
反映キューファイル
制御機能
DB
HiRDB
抽出機能
HiRDB Datareplicator
送信機能
制御機能
ステータスファイル
HiRDB Datareplicator HiRDB
送信完了位置情報
SQL
抽出キューファイル
ステータスファイル
LOG 未送信の更新ログ情報
DB
回復方法概要
抽出情報キューファイル回復機能
データ連動回復機能の概要
(1)抽出側ステータスファイルの情報を基に、システムログファイルから、反映側に未送信の更新ログ情報を抽出し、抽出キューファイルを再作成します。
(2)反映処理を再開し、反映側DBを回復します。
特長
■抽出側キューファイルのディスク障害により、抽出側DBと反映側DBの間で不整合が発生した場合に対応できます。
■反映側DB再作成に比べて、回復手順が簡単です。
■DB容量が大きい環境では、反映側DB再作成に比べて、回復時間を短縮できます。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
9-9 回復方法の比較
172
回復可能な
障害ケース
回復方法 回復
運用
難易度
反映側DB
回復時間
抽出側更新業務
停止時間
抽出側DBと反映側DBの間で不整合が発生した場合の
すべてのケースを回復可能
反映側DB再作成 中 DB容量に依存する
⇒回復に長時間を
要する場合あり
回復作業開始から
反映側DB回復完了まで
キューファイルおよびステータスファイルのディスク障害により抽出側DBと反映側DBの間で不整合が発生した場合
データ連動回復機能
アンロードログファイルによるデータ回復
高 DB容量に依存しない
⇒短時間で回復可能
回復作業開始から
反映側DB回復完了まで
システムログファイルによるデータ回復
中 DB容量に依存しない
⇒短時間で回復可能
回復作業開始から
反映側DB回復完了まで
抽出側キューファイルのディスク障害により抽出側DBと反映側DBの間で不整合が発生した場合
抽出情報キューファイル回復機能
低 DB容量に依存しない
⇒最も短時間で回復可能
(データ連動回復機能より
も短時間で回復可能)
なし
解説各回復方法の特長について、以下にまとめます。各方法の特長をよく理解して、システム
および障害ケースに適した回復方法を選択してください。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
9-10-1
173
2.現状の把握
3.任意のタイミングで、抽出側HiRDBの全抽出側対象に参照許可閉塞を実行
4.反映側のキューまたはデータセット中の更新データをすべて反映
6.全BESの全反映先について、抽出トランザクション情報(回復開始位置)を取得
5.抽出処理と反映処理を停止
10.データ連動回復機能を使った回復処理
9.HiRDB本体のデータ連動を停止
11.抽出と反映の初期化
12.HiRDB本体のデータ連動を再開始
13.参照許可閉塞を解除
8.回復のためアンロードログファイルを取得
1.障害発生 7.障害要因の排除
■手順の流れ
アンロードログファイルによる
データ回復手順①
解説 アンロードログファイルによるデータ回復手順について次に説明します。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
9-10-2
174
4
3
2
抽出側Datareplicatorの運用ディレクトリ($HDEPATH)下に環境変数(TOOL_OUTPUT_DIR=データ連動回復機能の実行結果格納ディレクトリ)を定義したファイルhde_toolenvを作成しておきます。環境変数を省略する場合は、空のファイルhde_toolenvを作成しておきます。
E-①:障害要因を特定します。E-②:pdhold –r RDエリア、 RDエリア –iを実行します。R- ①
hdsstateコマンドを実行して、すべての更新情報が反映されたか確認します。
E-③ 、R-②hdestopを実行して、抽出側Datareplicatorを停止します。
hdsstopを実行して、反映側Datareplicatorを停止します。
抽出側Datareplicator 反映側Datareplicator
障害要因を特定E-①
E-③
R-②
障害発生
Datareplicatorを停止
Datareplicatorを停止
E-②全抽出対象に参照許可
閉塞
キューまたはデータセット中の更新データをすべて反映
R-①
1
5
手順の流れに対応する番号
アンロードログファイルによる
データ回復手順②

© Hitachi, Ltd. 2012, 2019. All rights reserved.
9-10-3
175
9
8
7
抽出側Datareplicator 反映側Datareplicator
障害要因を取り除く
HiRDB Datareplicator連携停止
E-④
E-⑥
R-③抽出トランザクション情報(回復開始位置)の取得
アンロードログファイルを取得
E-⑤
6
E-⑦ Datareplicator初期化
反映エラー情報ファイルの退避R-④
プリプロセスの実行E-⑧
連動回復用バックアップファイル作成
E-⑨
10
アンロードログファイルによる
データ回復手順③
R-③hdsrefinfm -f 反映ステータスファイル名 -l 9
-p 解析結果出力ファイル名を実行して、全BESの全反映先について、抽出トランザクション情報(回復開始位置)を取得します。エラー情報ファイルの最後に出力されているKFRB03009-Iメッセージを検索して、このメッセージの「Additional Transaction Info =」に出力されている抽出トランザクション情報を取得します。
E-④:障害要因を取り除きます。E-⑤回復のためのアンロードログファイルを取得します。
E-⑥pdrplstop -f コマンドを実行して、HiRDB Datareplicator連携を中止します。(抽出側HiRDBのpdsysにpd_rpl_init_start=Yを定義しています。)
R-④:cpコマンドを実行し、反映エラー情報ファイルを退避します。
E-⑦:hdestart -i を実行し、抽出側Datareplicatorを初期化します。
E-⑧:hdeprep -f 抽出定義ファイル名を実行します。E-⑨
pdfbkup HiRDBファイルシステム領域名/HiRDBファイル名バックアップファイル名 を実行します。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
9-10-4
176
10
E-⑩logmrg バックエンドサーバ名 分割ブロック数 出力先ディレクトリ 入力元ディレクトリ {アンロードログファイル名|連動回復用バックアップファイル} 〔{アンロードログファイル名|連動回復用バックアップファイル}〕 を実行して、障害回復ツールが入力できる形式およびサイズに分割します。
E-⑪:$HDEPATH/caplogparm_BES名のファイルに、回復情報ファイルにオペランド(RCVR_STARTオペランド、RCVR_RPLSTOPオペランド)を指定します。
E-⑫:データ連動回復機能1のセットアップを行います。suを実行し、管理者に切り替えてから setup_tool1を実行します。「Setup for <hdecapture_tool1> complete.」のメッセージが出力されることを確認します。
E-⑬:hdestart -eを実行します。E-⑭:データ連動回復機能2のセットアップを行います。suを実行し、管理者に切り替えてから setup_tool2を実行します。「Setup for <hdecapture_tool2> complete.」のメッセージが出力されることを 確認します。
E-⑮:hdestart -eを実行します。E-⑯
mvコマンド を実行し、 $HDEPATH/caplogparm_BES名のファイルを別名にします。
E-⑰unsetup_toolコマンドを実行します。 suを実行し、管理者に切り 替えてから unsetup_toolを実行して、 「Unsetup for
<hdecapture_tool> complete.」のメッセージが出力されることを確認します。
R-⑤:hdsstart –iを実行します。E-⑱
hdestart –sを実行して、抽出側Datareplicatorの送信機能だけを起動します。
抽出側Datareplicator 反映側Datareplicator
データ連動回復機能1のセットアップE-⑫
回復情報ファイルにオペランドを指定
E-⑪
データ連動回復機能1の実行E-⑬
データ連動回復機能2のセットアップE-⑭
データ連動回復機能2の実行E-⑮
E-⑯ 回復情報ファイルの退避
データ連動回復機能2のアンセットアップ
E-⑰
データ連動回復機能の送信機能を起動E-⑱
反映の初期化R-⑤
アンロードファイルを分割E-⑩
アンロードログファイルによる
データ回復手順④

© Hitachi, Ltd. 2012, 2019. All rights reserved.
E-⑲hdestateを実行し、hdestateコマンドで送信のキューファイルreadオフセットがキューファイルwriteオフセットに追い付くまで監視します。
E-⑳hdestopを実行して抽出側の送信プロセスを停止します。
R-⑥hdsstopを実行して反映側の反映プロセスを停止します。
E-21:hdestart –iを実行します。また、hdeprep -f 抽出定義ファイル名を実行します。
R-⑦hdsstart -iを実行して反映側Datareplicatorを初期開始し
ます。E-22:hdestart を実行します。E-23:pdrplstartコマンドを実行します。E-24:pdrels –r RDエリア、 RDエリア を実行します。
9-10-5
177
13
12
11
抽出側Datareplicator 反映側Datareplicator
送信のキューファイルを監視
E-⑲
E-⑳ Datareplicator停止
R-⑥ Datareplicator停止
E-21 Datareplicator初期化
R-⑦ Datareplicator初期開始
E-22 Datareplicator起動
参照許可閉塞を解除E-24
データ連動機能を再開E-23
10
アンロードログファイルによる
データ回復手順⑤

© Hitachi, Ltd. 2012, 2019. All rights reserved.
9-11 反映完了位置確認方法
178
抽出側Datareplicator 反映側Datareplicator
更新トランザクション1
更新トランザクション2
更新トランザクション3
hdsrefinfm
キューファイル内データ表示コマンドを実行することでデータの内容を確認することができます。(表示はトランザクション単位となります。)
・反映完了ポイントより前のデータを表示することで、どの更新データまで反映できているのかを確認することができます。
・反映完了ポイントより後のデータを表示することで、どの更新データから反映が行われていないかを確認することができます。
表示結果
更新トランザクション1更新データ1更新データ2更新データ3
更新トランザクション2更新データ4更新データ5
更新トランザクション3更新データ6
更新トランザクション4更新データ7更新データ8
更新トランザクション5更新データ9
反映完了済み
反映未完了
反映キューファイル
反映完了ポイント
・更新データ1の内容・更新データ2の内容・更新データ3の内容
・更新データ4の内容・更新データ5の内容
・更新データ6の内容
解説障害発生時に、どの更新データまで反映されたのかを判断するために、キューファイルに
格納されている更新データの内容を表示するコマンドをサポートしました。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
9-12-1
179
1.障害発生
2.現象の把握
4.反映処理の停止
6.障害要因の排除
7. 反映の初期化
5.回復情報ファイルを転送
8.抽出の初期化
BESの数繰り返す
反映Datareplicatorの数繰り返す
9.回復処理
3.抽出処理の停止
■手順の流れ
システムログファイルによる
データ回復手順①
解説 システムログファイルによるデータ回復手順について次に説明します。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
9-12-2
180
7
5
4
3
2
E-①:障害要因を特定します。E-②
hdestopを実行して、抽出側Datareplicatorを停止します。R- ①
hdsstop -t immediateを実行して、反映側Datareplicatorを停止します。
R-②回復情報ファイルを、抽出側へバイナリモードで転送します。抽出側システムに対応する回復情報ファイルが複数ある場合、すべての回復情報ファイルを、それぞれ該当するBES
(障害の発生していないBESも含む)の$HDEPATH下に転送します。
E-③:障害要因を取り除きます。R-③
hdsstart -i –fを実行して反映側Datareplicatorを初期開始します。
抽出側Datareplicator 反映側Datareplicator
障害要因を特定
障害要因を取り除く
Datareplicator初期開始
E-①
E-②
E-③
R-①
R-②回復情報ファイルを抽出側に転送
R-③
障害発生
Datareplicatorを停止
Datareplicatorを停止
1
6
手順の流れに対応する番号
システムログファイルによる
データ回復手順②

© Hitachi, Ltd. 2012, 2019. All rights reserved.
9-12-3
181
抽出側Datareplicator 反映側Datareplicator
HiRDB Datareplicator連携中止
データ連動回復でDatareplicatorを起動
E-④
E-⑧
Datareplicator初期化E-⑤
プリプロセスの実行E-⑥
HiRDB Datareplicator
連携の開始E-⑦
8
9
システムログファイルによる
データ回復手順③
E-④pdrplstop -f コマンドを実行して、HiRDB Datareplicator連携を中止します。
E-⑤hdestart - iを実行して、抽出側Datareplicatorを初期化します。
E-⑥:hdeprep -f 抽出定義ファイル名を実行します。E-⑦:pdrplstartコマンドを実行します。
(抽出側HiRDBのpdsysにpd_rpl_init_start=Yを定義しています。)
E-⑧:hdestart - vを実行します。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
9-13-1
182
2.現状の把握
4.抽出サーバステータス
ファイルのバックアップを取得
7.抽出Datareplicatorを再開始
6.抽出情報キューファイル回復機能を使った回復処理
1.障害発生
5.障害要因の排除
3.抽出側Datareplicator停止
■手順の流れ
抽出情報キューファイル回復機能による
回復手順①
解説 抽出情報キューファイル回復機能による回復手順について次に説明します。
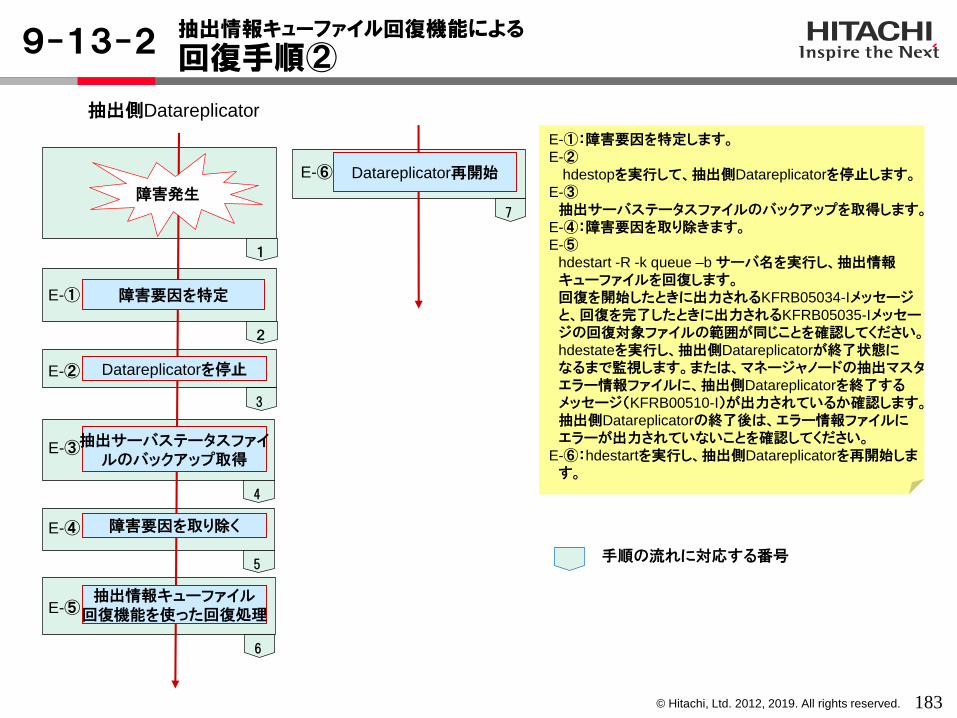
© Hitachi, Ltd. 2012, 2019. All rights reserved.
9-13-2
183
3
6
5
4
2
1
E-①:障害要因を特定します。E-②
hdestopを実行して、抽出側Datareplicatorを停止します。E-③抽出サーバステータスファイルのバックアップを取得します。
E-④:障害要因を取り除きます。E-⑤
hdestart -R -k queue –b サーバ名を実行し、抽出情報キューファイルを回復します。回復を開始したときに出力されるKFRB05034-Iメッセージと、回復を完了したときに出力されるKFRB05035-Iメッセージの回復対象ファイルの範囲が同じことを確認してください。hdestateを実行し、抽出側Datareplicatorが終了状態になるまで監視します。または、マネージャノードの抽出マスタエラー情報ファイルに、抽出側Datareplicatorを終了するメッセージ(KFRB00510-I)が出力されているか確認します。抽出側Datareplicatorの終了後は、エラー情報ファイルにエラーが出力されていないことを確認してください。
E-⑥:hdestartを実行し、抽出側Datareplicatorを再開始します。
抽出側Datareplicator
障害要因を特定
障害要因を取り除く
E-①
E-④
障害発生
E-②
抽出サーバステータスファイルのバックアップ取得
抽出情報キューファイル回復機能を使った回復処理E-⑤
Datareplicatorを停止
E-③
7
Datareplicator再開始E-⑥
手順の流れに対応する番号
抽出情報キューファイル回復機能による
回復手順②

© Hitachi, Ltd. 2012, 2019. All rights reserved.
9-14 キューファイル容量不足を回避するために
184
障害が発生したらキューファイルの使用率を確認して、空き容量が十分であるか確認してください。キューファイルの使用率は、状態表示コマンドで確認できます。
障害検知が遅れる可能性もある
抽出側DBが更新されてから、反映側DBへ反映されるまでの時間を監視して、抽出および反映処理が順調に行われていることを確認してください。上記の監視は、レプリケーション滞留監視機能で実現できます。
ポイント 説明
解説
障害が長期化した場合、キューファイルの容量不足に陥る危険性があります。
キューファイルの容量不足に陥ると、障害範囲が広がってしまいますので、
十分に注意してください。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
9-15 キューファイル使用率の表示
185
キューファイル1
<凡例>
■キューファイルの使用率の表示は、抽出側Datareplicatorの場合には、hdestateコマンド反映側Datareplicatorの場合には、hdsstateコマンドを使用します。
■キューファイルの使用率の表示し、使用率の傾向を調査してください。使用率が増加傾向にある場合は、レプリケーションの滞留が発生している可能性があります。滞留要因として、HiRDB Datareplicator、もしくはHiRDBのエラー停止や、性能問題などがある可能性があります。
キューファイル3
処理完了ポイント(抽出の場合は、送信完了ポイント反映の場合は、反映完了ポイントを示す。)
格納データの終端
キューファイル2
キューファイル4
未処理のデータを示す。
未使用、あるいは処理済みのデータを示す。
①※1 ② ③
使用率(%) =( ① + ② + ③ )
キューファイル全容量* 100
※1:処理完了ポイントがあるキューファイルには、スワップできないため、使用率を求める時には、処理完了ポイントがあるキューファイル全体を未処理として算出します。
解説状態表示コマンドでは、抽出および反映キューファイルの使用率を表示します。本情報により、
レプリケーション内で遅延している処理の特定や、キューファイル拡張時期が予測できます。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
9-16 ディザスタリカバリシステムの場合
186
反映完了位置の確認
反映側DBが、どのトランザクションまで反映が完了しているか確認し、未反映のトランザクションを洗い出してください。反映が完了しているトランザクションの確認は、更新情報内容確認コマンドで確認できます。
ポイント 説明
メインサイトマシン再起動時の未送信データの救済
メインサイトの災害程度が軽く、マシンが再起動できた場合には、抽出側Datareplicatorの起動オプションを変更することで、メインサイト側に居残っている未送信データをSQLテキスト形式で出力することが可能です。(更新SQL出力機能)未送信データを副センタ側の本番データと比較することで、反映漏れを救済することができます。
リモートサイトからメインサイトへのデータの切り戻し
HiRDB Dataextractorなどを使用して、一括反映を行います。
解説
HiRDB Datareplicatorは非同期・遅延方式のデータ連動であるため、メインサイト被災時に
トランザクションの欠損が発生する可能性があります。被災時間帯のデータをクライアント側
のログ等で後から検証できる仕掛けを持つなど、障害対応策を考慮してください。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
9-17 FAQ(1サーバマシンに複数環境を構築する場合)
187
/HiRDB_S1/HDS
inode番号 65536
/HiRDB_S2/HDS
inode番号 65536
共用メモリ
運用ディレクトリのinode番号が同じの場合、他の環境の共用メモリを参照してしまい、起動エラーとなる。
同じ
HiRDB Datareplicator ①運用ディレクトリ
/HiRDB_S1/HDS
AIX
HiRDB Datareplicator ②運用ディレクトリ
/HiRDB_S2/HDS
現象
OSがAIXである1つのサーバマシンに、複数のHiRDB Datareplicatorの環境を構築してい
る場合、あるHiRDB Datareplicatorが既に起動している状態で、2つ目以降の
HiRDB Datareplicatorを起動すると、共用メモリの不正参照により、起動に失敗する。
原因 複数のHiRDB Datareplicatorで、同一の共用メモリを使用しようとしたため。
解説
HiRDB Datareplicatorでは、運用ディレクトリのinode番号を基に、使用する共用メモリを決定しています。inode番号は、ディスクのパーティション内では、ディレクトリおよびファイルごとに一意な値が割り当てられますが、パーティションをまたがると重複した値が割り当てられることもあります。特に、AIXの場合は、重複する可能性が高いです。よって、1つのサーバマシン上に複数のHiRDB Datareplicatorの環境を構築する場合(系切り替え構成の予備系も含む)は、運用ディレクトリのinode
番号に重複がないことを、確認してください。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
9-18 FAQ(反映キューファイルの滞留)
188
反映側HiRDB反映側Datareplicator
反映キューファイル 反映
SQL 表
インデクス
◆事例①◆インデクスが多すぎて、インデクスのメンテナンス処理に時間がかかり、SQL実行時間が遅くなっていた⇒インデクスの見直しが必要
◆事例②◆表の格納先RDエリアの使用率が100%に達し、その後データを格納する空き領域を探す処理に時間がかかり、SQL実行時間が遅くなっていた⇒RDエリアを拡張、またはデータベースの再編成などのデータベースメンテナンス対策が必要
現象反映側のHiRDBサーバ、HiRDB Datareplicator共に稼働しているが、反映キューファイル
の滞留が発生する。
原因
以下の要因などにより、反映側Datareplicatorから反映側HiRDBサーバへのSQL実行に
時間を要しているため。
◆反映表へのインデクス定義数が多すぎる
◆反映表の格納先RDエリアの使用率が100%に達している など
解説
反映キューの滞留が発生した場合は、SQLトレースを取得して、
反映側DatareplicatorのSQL実行時間に問題がないか確認してください。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
9-19 FAQ(その他①)
189
A: 以下のいずれかの可能性があります。◇マッピングキーとインデクスが不一致となっている。◇反映側DBの表を更新している。
[対処方法]
抽出側DBと反映側DBの内容を一致させ、HiRDB Datareplicatorを初期化した後、運用を再開してください。
Q:反映処理がSQL実行で、キー重複エラー、もしくは該当行無しとなった。
A: 抽出・反映間の通信回線で障害が発生している可能性があります。[対処方法]
抽出側Datareplicatorのすべてのプロセスが停止した後、抽出側Datareplicatorを再起動してください。
Q:hdestopを実行したが、すぐに停止せず、最終的にエラー停止した。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
9-20 FAQ(その他②)
190
A:共用ライブラリPATH(HP-UXの場合、SHLIB_PATH)にHiRDBのLIBパス($PDDIR/lib)が指定されていない可能性があります。
[対処方法]
共用ライブラリPATHに$PDDIR/libを追加してください。(IPFマシンの場合、$PDDIR/client/libも必要となります。)
Q:反映処理が起動できないが、エラーメッセージが出力されず、対処が分からない。
A: 抽出対象表の更新が、長大トランザクションの可能性があります。[対処方法]
hdemodqコマンドで抽出情報キューファイルを追加してください。追加しても、エラーとなる場合は、抽出環境定義ファイルのqueuesizeオペランドの指定値を修正して、再度抽出側Datareplicatorを初期化してください。
Q:抽出情報キューファイル満杯が解消されない。
A: HiRDB Datareplicatorのバージョンが、08-01より前である可能性があります。[対処方法]
リモートデスクトップ(Windows Terminal Service)には、08-01以降のバージョンで対応しています。それ以前のバージョンに対して、リモートデスクトップ経由で操作した場合、正しく動作しませんのでご注意ください。
Q:リモートデスクトップ経由で操作すると、正しく動作しない。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
10. おわりに
191

© Hitachi, Ltd. 2012, 2019. All rights reserved.
10-1 おわりに
192
これからもHiRDBにご期待ください!

© Hitachi, Ltd. 2012, 2019. All rights reserved. 193
他社商品名、商標等の引用に関する表示など
■商標類・ IBM,AIXは,世界の多くの国で登録されたInternational Business Machines Corporationの商標です。・ OracleとJavaは,Oracle Corporation 及びその子会社,関連会社の米国及びその他の国における登録商標です。・ Red Hat, and Red Hat Enterprise Linux are registered trademarks of Red Hat, Inc. in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the U.S. and other countries.・ UNIXは,The Open Groupの米国ならびに他の国における登録商標です。・ Windows, およびSQL Serverは,米国Microsoft Corporationの米国およびその他の国における登録商標または商標です。
・ その他記載の会社名、製品名は、それぞれの会社の商号、商標もしくは登録商標です。
■対象となる製品記載の仕様は、HiRDB Version 9及びVersion 10です。製品の改良により予告なく記載されている仕様が変更になることがあります。

© Hitachi, Ltd. 2012, 2019. All rights reserved.
END
194
HiRDBによるデータレプリケーションの解説
株式会社 日立製作所 サービス&プラットフォームビジネスユニットサービスプラットフォーム事業本部 DB部
