hadoop at ayasdi
TRANSCRIPT

Hadoop at AyasdiMohit Jaggi
andHuang Xia, Zhen Li, Ajith Warrier

Overview
- HDFS for storage- YARN for integration into Hadoop data lake- Parquet as the file format- bigdf based on Spark for feature
engineering, data wrangling
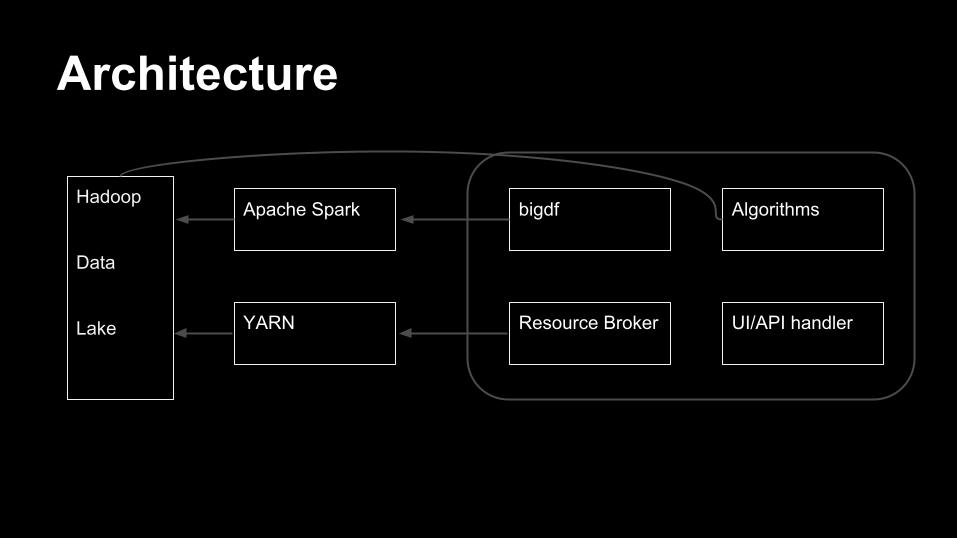
Hadoop
Data
Lake
bigdf
Resource Broker
Apache Spark
YARN
Algorithms
UI/API handler
Architecture

!! Audience Poll !!
1. How many data scientists?2. How many backend engineers?3. UI/frontend engineers?4. Using hadoop in production?5. Using Spark in production?6. Personally worked on data bigger than 100GB? 1TB? 10TB?
1PB?

HDFS

HDFS - Motivation
- installed base, large community- ecosystem to connect to most other data
sources- commodity cluster- experiments with distributed NAS didn't
show enough promise to justify the additional cost and complexity

HDFS - Usage
- used as distributed storage- jobs dispatched to least loaded node- run Spark jobs

FishFiFishing for insights...
big data

YARN - Motivation
- Ayasdi scheduler- maximize throughput for batch jobs- minimize latency for interactive “tasklets”
- wanted to deploy in existing Hadoop data lakes
- integrated inhouse scheduler with YARN- “tasklets” get a long running container- batch jobs get a container on demand

YARN - Challenges
- increased latency observable for small batch jobs
- early adopter pains- sparse documentation- not the best API design

big data store
compressed data

Parquet - Motivation
- legacy: data stored in both row and column major
- requires expensive transpose on ingestion- were designing a “tiled file format” when
discovered parquet

Parquet - Challenges
- early adopter challenges- sparse documentation- needed to access package private APIs

big data

bigdf - Motivation
- born out of experience using spark for feature engineering
- creating classes for RDDs not reusable across projects
- SQL not expressive enough

bigdf - details- open source since Sep 2014- precedes Spark DataFrame, so built on spark-core
engine- experimenting with Catalyst using Spark DataFrame
APIs, looks promising- python and scala APIs- feature engineering library [not open source :-( ]- fast CSV reader(and other features) contributed to
spark-csv

bigdf - future
- wrapper around Spark DF - to protect from API changes- to add features e.g. “sparse column set” as “round-
trip time” for pull requests into large open source projects is high

Thanks!
www.ayasdi.comhttp://engineering.ayasdi.com
https://github.com/AyasdiOpenSource/bigdfhttp://www.ayasdi.com/company/careers/