hadoop at lookout
TRANSCRIPT

HADOOP AT LOOKOUTYash Ranadive
@yashranadive
December 9, 2014

AGENDAWhat we do @LookoutAnalytics ArchitectureEvent Ingestion PipelinesStormQuestions

BIOData Engineer at Lookout, started 2013Previously at Demandbase, Project Perf. Corp.6 years of Data EngineeringFrom Mumbai, Indiaetl.svbtle.com

WHAT WE DO@LOOKOUT

MAKE SMARTPHONES AND TABLETS SECURE& TRUSTWORTHY FOR INDIVIDUALS AND
ORGANIZATIONS


ANALYTICSINFRASTRUCTURE

WHO WE SERVEProduct ManagersSoftware DevelopersMarketingSecurity Research

DATA ANALYTICS TEAM7 Analysts/Scientists
Questions they answer
How many users located their phone yesterday?How many users were billed for AT&T?

DATA ANALYTICS TEAM3 Data Engineers
Build and maintain pipelines for Analytics and ad-hoc querying


REPORTINGTableau
Dashboards - Retentions, Activations, etc.Email reports
Custom email reports (Ruby)

ADHOC QUERYINGHive CLI - Command-line interface to HiveHue - Toad style GUI for ad hoc queries on HiveR Studio - Statistical analysisShiny - Reporting/Querying tool based on RSparkle Pony(Homegrown Ruby app) - MySQL Querying forstakeholdersHadoop File System Browser

EVENT INGESTIONPIPELINES

EVENT INGESTIONEvent data comes via:
text(JSON)binary(Protobufs)binlogs

PIPELINES

STORM

STORMApache Storm is a distributed realtime computation system. It
can be used with any programming language.

TOPOLOGY DESIGN

NIMBUS AND SUPERVISORA storm cluster has
One Nimbus node which is the masterA set of Supervisor nodes which are the workers
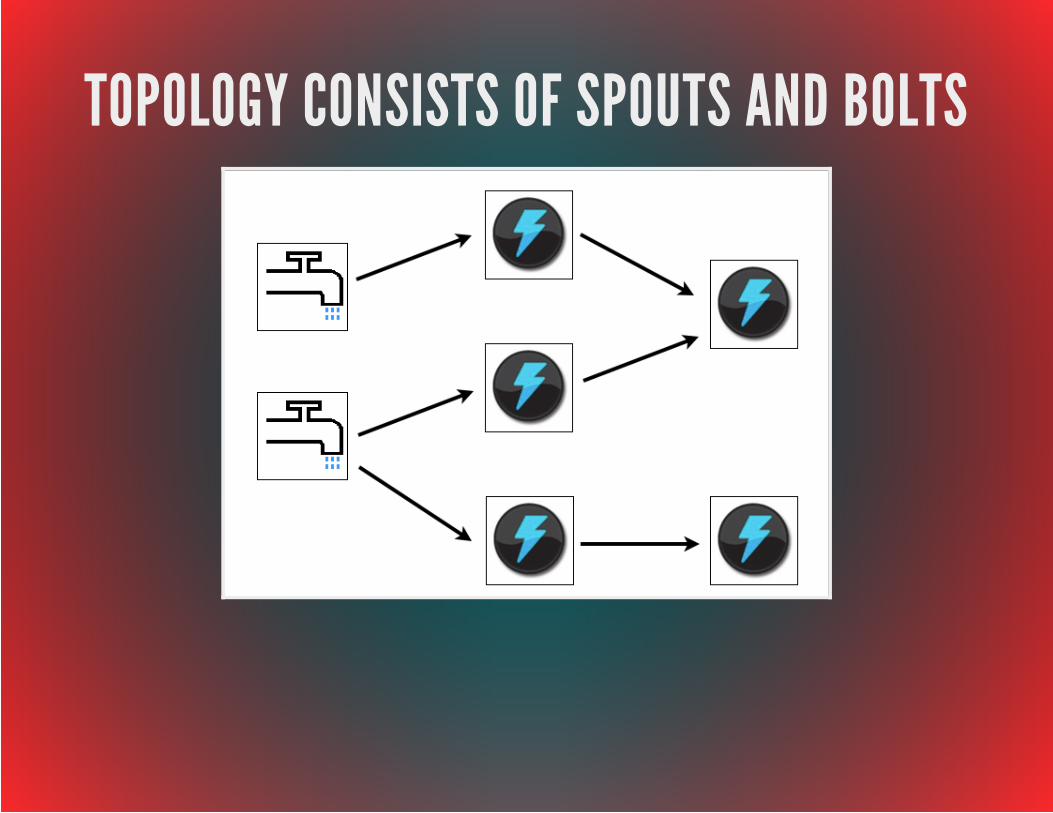
TOPOLOGY CONSISTS OF SPOUTS AND BOLTS

A SAMPLE TOPOLOGY

LANDING DATA IN HADOOPTopologies write data to a landing directory in Hadoop using
Directories are rotated depending on latency requirements ofdownstream reportsDirectories are moved to location of the table in Hive
HDFS Bolt

STORM PARALLELISM

TOPOLOGY DEPLOYMENT

DEPLOYMENTStorm topologies are jars that can be submitted to Storm Nimbus
storm jar path/to/allmycode.jar org.MyTopologyClass arg1 arg2

DEPLOYMENTConfiguration is stored in shell scripts that launch topologiesstorm jar /topolgoies/data-storm-0.0.3-SNAPSHOT.jar com.lookout.data.topology.KafkaToHdfsTopology-topologyname kafka-hdfs \-nimbushost dw-storm2 \-topologymaxtaskparallelism 1 \-D hdfs.sync.tuple.count=500 \-D hdfs.file.rotation.seconds=3600 \-D hdfs.landing.directory=/user/hive/warehouse/staging.db/locate_events \-D hdfs.destination.directory=/user/hive/warehouse/realdb.db/locate_events \-D hdfs.filesystem.url=hdfs://hadoop-cluster-01:8020/ \-D kafka.zookeeper.hosts=zk1:2181,zk2:2181,zk3:2181 \-D kafka.topic=locate_event \-D statsd.host=statsdhost

CONFIGURATIONMANAGEMENT ?

METRICS MONITORING

METRICS MONITORINGUse Storm's Metrics API (counters)Success/Failure metrics are sent to StatsD for aggregationVisualized using graphite

GRAPHITE

SLIDES

SLIDESJavascript Slides - reveal.jshttp://lab.hakim.se/reveal-js/#/

z
QUESTIONS