genotype and haplotype reconstruction from low- coverage short sequencing reads ion mandoiu computer...
TRANSCRIPT

Genotype and Haplotype
Reconstruction from Low-
Coverage Short Sequencing
Reads
Ion Mandoiu
Computer Science and Engineering Department
University of Connecticut
Joint work with S. Dinakar, J. Duitama, Y. Hernández, J. Kennedy, and Y. Wu

Outline
Introduction
Single SNP Genotype Calling
Multilocus Genotyping Problem
Experimental Results
Conclusion

Illumina Genome Analyzer II35-75bp reads2-3Gb/2 day run
Roche/454 FLX Titanium400bp reads400-600Mb/10h run
ABI SOLiD 335-50bp reads5-7.5Gb/3.5-7 day run
Recent massively parallel sequencing technologies deliver orders of magnitude higher throughput compared to classic Sanger sequencing
Ultra-high throughput DNA sequencing
Helicos HeliScope25-55bp reads~2.5Gb/day

UHTS enables personal genomics
$100
$1,000
$10,000
$100,000
$1,000,000
$10,000,000
$100,000,000
days weeks months years
Sequencing Time
Co
st
Illumina@36xSOLiD@12x

Sequencing can potentially provide all genetic variations (SNPs, CNVs, genome rearrangements) at single-base resolution…
However, medical use requires determination of both alleles (genotype) at variable loci
Accurate genotype calling is limited by coverage depth due to random nature of shotgun sequencing
For the Venter and Watson genomes (both sequenced at ~7.5x average coverage), comparison with SNP genotyping chips has shown only ~75% accuracy for sequencing based calls of heterozygous SNPs [Levy et al 07, Wheeler et al 08]
Challenges for medical applications of sequencing

Allele coverage for heterozygous SNPs (Watson 454 @ 5.85x avg. coverage)
-1
0
1
2
3
4
5
6
-1 0 1 2 3 4 5 6
Reference allele coverage
Var
ian
t al
lele
co
vera
ge

Allele coverage for heterozygous SNPs (Watson 454 @ 2.93x avg. coverage)
-1
0
1
2
3
4
5
6
-1 0 1 2 3 4 5 6
Reference allele coverage
Var
ian
t al
lele
co
vera
ge

Allele coverage for heterozygous SNPs (Watson 454 @ 1.46x avg. coverage)
-1
0
1
2
3
4
5
6
-1 0 1 2 3 4 5 6
Reference allele coverage
Var
ian
t al
lele
co
vera
ge

Most prior genotype calling methods are based on allele coverage
[Levy et al 07] and [Wheeler et al 08] require that each allele be covered by at least 2 reads in order to be called
Combined with hypothesis testing based on the binomial distribution when calling hets
Binomial probability for the observed number of alleles must be at least 0.01
[Wendl&Wilson 08] generalize coverage methods to allow an arbitrary minimum allele coverage k
Prior work

MAQ [Li,Ruan&Durbin 08] Widely used read mapping program Single SNP genotype calling incorporating read
mapping confidence and quality scores Mostly tuned for de novo SNP discovery…
Prior work (contd.)

[Wendl&Wilson 08] estimate that 21x coverage will be required for sequencing of normal tissue samples based on idealized theory that “neglects any heuristic inputs”
What coverage is required?

We propose methods incorporating additional sources of information extracted from a reference panel such as Hapmap:
Allele/genotype frequencies
Linkage disequilibrium Experimental results show significantly improved
genotyping accuracy
Do heuristic inputs help?

Outline
Introduction
Single SNP Genotype Calling
Multilocus Genotyping Problem
Experimental Results
Conclusion

Known SNP positions
Biallelic SNPs 0 = major allele, 1 = minor allele
SNP genotypes: 0/2 = homozygous major/minor,
1=heterozygous
Basic assumptions

ri = set of mapped reads covering SNP locus i
For each read r in ri r(i) = the allele observed at locus i
= probability that r(i) is incorrect, where qr(i) is the phred quality score of r(i)
mr = mapping confidence of r
10/)(
)(10 irqir
Incorporating base call and read mapping uncertainty
Mapped reads with allele 0
Mapped reads with allele 1
Sequencing errors
Inferred genotypes012100120

ri = set of mapped reads covering SNP locus i
For each read r in ri r(i) = the allele observed at locus i
= probability that r(i) is incorrect, where qr(i) is the phred quality score of r(i)
mr = mapping confidence of r
10/)(
)(10 irqir
Incorporating base call and read mapping uncertainty
1)(r
0)(r
)( )()1()0|r(
irr
mm
irr
irii
i
r
ir
r
i
GP
r
2
1)1|r(
ir rm
ii GP
0)(r
1)(r
)( )()1()2|r(
irr
mm
irr
irii
i
r
ir
r
i
GP

Applying Bayes’ formula:
Where are genotype frequencies inferred from a representative panel
}2,1,0{)|r()(
)|r()()r|(
g iiii
iiiiiii gGPgGP
gGPgPgGP
)( ii gGP
Single SNP genotype calling

Outline
Introduction
Single SNP Genotype Calling
Multilocus Genotyping Problem
Experimental Results
Conclusion

Haplotype structure in human populations

Similar models proposed in [Schwartz 04, Rastas et al. 05, Kennedy et al. 07, Kimmel&Shamir 05, Scheet&Stephens 06]
HMM model of haplotype frequencies

Random variables Fi = founder haplotype at locus i Hi = observed allele at locus i
For fully specified model and given haplotype h, P(H=h|M) can be computed in O(nK2) using forward algorithm, where n=#SNPs, K=#founders
Graphical Model Representation
F1 F2 Fn…
H1 H2 Hn

F1 F2 Fn…
H1 H2 Hn
G1 G2 Gn
…R1,1 R2,1
F'1 F'2 F'n…
H'1 H'2 H'n
R1,c … R2,c …Rn,1 Rn,c1 2 n
HF-HMM for multilocus genotype inference
P(f1), P(f’1), P(fi+1|fi), P(f’i+1|f’i), P(hi|fi), P(h’i|f’i) trained using Baum-Welch algorithm on haplotypes inferred from the populations of origin for mother/father

F1 F2 Fn…
H1 H2 Hn
G1 G2 Gn
…R1,1 R2,1
F'1 F'2 F'n…
H'1 H'2 H'n
R1,c … R2,c …Rn,1 Rn,c1 2 n
HF-HMM for multilocus genotype inference
P(gi|hi,h’i) set to 1 if h+h’i=gi and to 0 otherwise
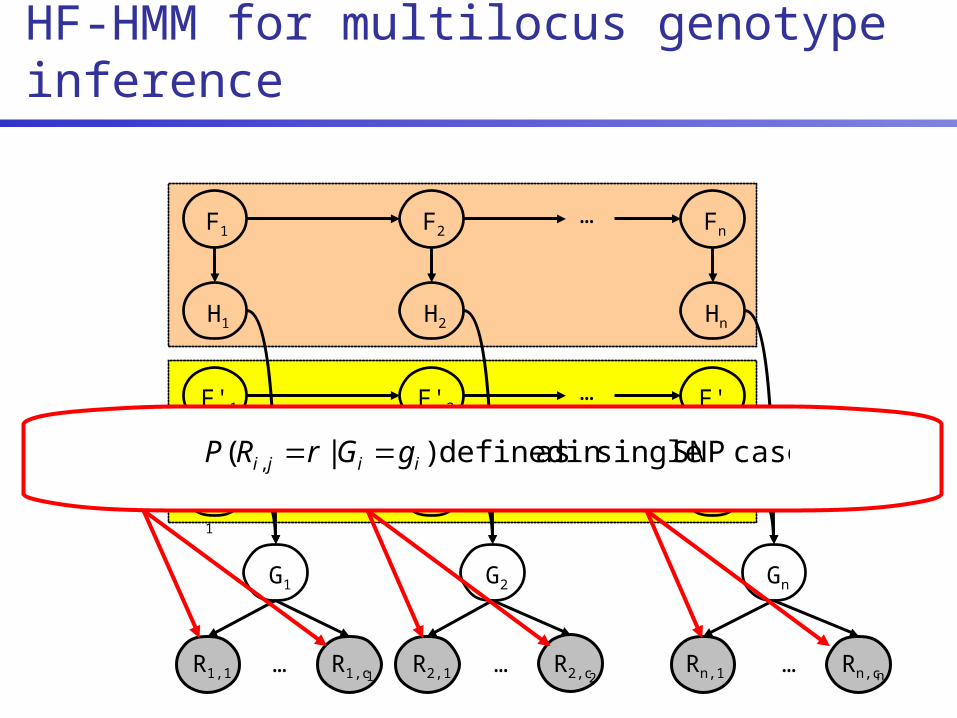
F1 F2 Fn…
H1 H2 Hn
G1 G2 Gn
…R1,1 R2,1
F'1 F'2 F'n…
H'1 H'2 H'n
R1,c … R2,c …Rn,1 Rn,c1 2 n
HF-HMM for multilocus genotype inference
case SNP singlein as defined )|( , iiji gGrRP

GIVEN:
• Shotgun read sets r=(r1, r2, … , rn)
• Trained HMM models representing LD in populations of origin for mother/father
• Quality scores & read mapping confidence values
FIND:
• Multilocus genotype g*=(g*1,g*2,…,g*n) with maximum posterior probability, i.e., g*=argmaxg P(g | r)
Multilocus genotyping problem

Theorem: maxgP(g | r) cannot be approximated within unless ZPP=NP
Computational complexity
)( 1 nO
Idea: reduction from the clique problem

Posterior decoding algorithm
1. For each i = 1..n, compute
2. Return *)*,...,(* 1 nggg
)r,(maxarg)r|(maxarg* igigi gPgPgii

)()|r()r,( '' ''1 ,1 ,, i
i
ff
K
f
i
ff
i
ff
K
fiii ggPgPiii iiiii
fi …
hi
gi
…r1,1
ri,1
f’i …
h’i
r1,c …ri,c …Rn,1 Rn,c
1i n
…
…
Forward-backward computation

)()|r()r,( '' ''1 ,1 ,, i
i
ff
K
f
i
ff
i
ff
K
fiii ggPgPiii iiiii
fi …
hi
gi
…r1,1
ri,1
f’i …
h’i
r1,c …ri,c …Rn,1 Rn,c
1i n
…
…
Forward-backward computation

)()|r()r,( '' ''1 ,1 ,, i
i
ff
K
f
i
ff
i
ff
K
fiii ggPgPiii iiiii
fi …
hi
gi
…r1,1
ri,1
f’i …
h’i
r1,c …ri,c …Rn,1 Rn,c
1i n
…
…
Forward-backward computation

)()|r()r,( '' ''1 ,1 ,, i
i
ff
K
f
i
ff
i
ff
K
fiii ggPgPiii iiiii
fi …
hi
gi
…r1,1
ri,1
f’i …
h’i
r1,c …ri,c …Rn,1 Rn,c
1i n
…
…
Forward-backward computation
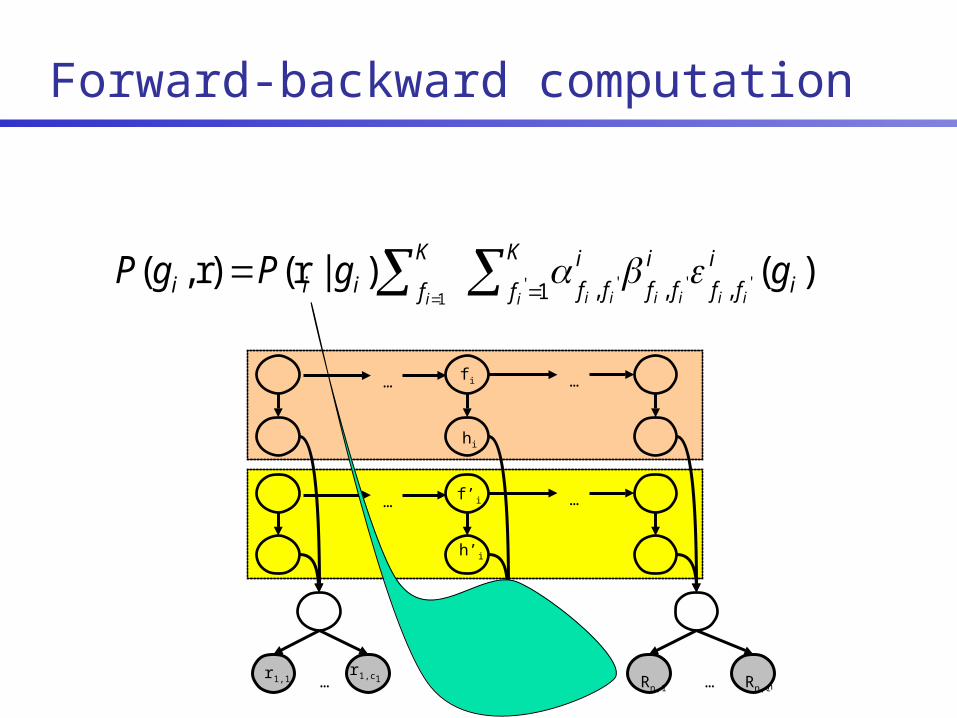
)()|r()r,( '' ''1 ,1 ,, i
i
ff
K
f
i
ff
i
ff
K
fiii ggPgPiii iiiii
fi …
hi
gi
…r1,1
ri,1
f’i …
h’i
r1,c …ri,c …Rn,1 Rn,c
1i n
…
…
Forward-backward computation

)()( '11
1
, ' fPfPii ff
K
fi
i
ffii
K
fii
i
ff
i
ff
i
ii
i
iiiigffPffP
11
1
,
'1
'
11
1
,,
1
'11'
1
'11
' )()|()|(
Runtime Direct recurrences for computing forward
probabilities:
Runtime reduced to O(nK3) by reusing common terms:
where
)()|( 11
1
,
'1
'1
,,'1
'11
'11
'1
i
K
f
i
ffiii
ff
i
ffgffP
i
iiiiii
K
f
i
ffiii
ffi
iiiiffP
1,1,
'1
'1
' )|(
}1,0{,
''
,'
' )|()|()|()(ii
iihh
iiiiiiiiii
ffhhGrPfhPfhPg

Outline
Introduction
Single SNP Genotype Calling
Multilocus Genotyping Problem
Experimental Results
Conclusion

>gi|88943037|ref|NT_113796.1|Hs1_111515 Homo sapiens chromosome 1 genomic contig, reference assemblyGAATTCTGTGAAAGCCTGTAGCTATAAAAAAATGTTGAGCCATAAATACCATCAGAAATAACAAAGGGAGCTTTGAAGTATTCTGAGACTTGTAGGAAGGTGAAGTAAATATCTAATATAATTGTAACAAGTAGTGCTTGGATTGTATGTTTTTGATTATTTTTTGTTAGGCTGTGATGGGCTCAAGTAATTGAAATTCCTGATGCAAGTAATACAGATGGATTCAGGAGAGGTACTTCCAGGGGGTCAAGGGGAGAAATACCTGTTGGGGGTCAATGCCCTCCTAATTCTGGAGTAGGGGCTAGGCTAGAATGGTAGAATGCTCAAAAGAATCCAGCGAAGAGGAATATTTCTGAGATAATAAATAGGACTGTCCCATATTGGAGGCCTTTTTGAACAGTTGTTGTATGGTGACCCTGAAATGTACTTTCTCAGATACAGAACACCCTTGGTCAATTGAATACAGATCAATCACTTTAAGTAAGCTAAGTCCTTACTAAATTGATGAGACTTAAACCCATGAAAACTTAACAGCTAAACTCCCTAGTCAACTGGTTTGAATCTACTTCTCCAGCAGCTGGGGGAAAAAAGGTGAGAGAAGCAGGATTGAAGCTGCTTCTTTGAATTTAC
>gi|88943037|ref|NT_113796.1|Hs1_111515 Homo sapiens chromosome 1 genomic contig, reference assemblyGAATTCTGTGAAAGCCTGTAGCTATAAAAAAATGTTGAGCCATAAATACCATCAGAAATAACAAAGGGAGCTTTGAAGTATTCTGAGACTTGTAGGAAGGTGAAGTAAATATCTAATATAATTGTAACAAGTAGTGCTTGGATTGTATGTTTTTGATTATTTTTTGTTAGGCTGTGATGGGCTCAAGTAATTGAAATTCCTGATGCAAGTAATACAGATGGATTCAGGAGAGGTACTTCCAGGGGGTCAAGGGGAGAAATACCTGTTGGGGGTCAATGCCCTCCTAATTCTGGAGTAGGGGCTAGGCTAGAATGGTAGAATGCTCAAAAGAATCCAGCGAAGAGGAATATTTCTGAGATAATAAATAGGACTGTCCCATATTGGAGGCCTTTTTGAACAGTTGTTGTATGGTGACCCTGAAATGTACTTTCTCAGATACAGAACACCCTTGGTCAATTGAATACAGATCAATCACTTTAAGTAAGCTAAGTCCTTACTAAATTGATGAGACTTAAACCCATGAAAACTTAACAGCTAAACTCCCTAGTCAACTGGTTTGAATCTACTTCTCCAGCAGCTGGGGGAAAAAAGGTGAGAGAAGCAGGATTGAAGCTGCTTCTTTGAATTTAC
>gnl|ti|1779718824 name:EI1W3PE02ILQXT28 28 28 28 26 28 28 40 34 14 44 36 23 13 2 27 42 35 21 727 42 35 21 6 28 43 36 22 10 27 42 35 20 6 28 43 36 22 928 43 36 22 9 28 44 36 24 14 4 28 28 28 27 28 26 26 35 2640 34 18 3 28 28 28 27 33 24 26 28 28 28 40 33 14 28 36 2726 26 37 29 28 28 28 28 27 28 28 28 37 28 27 27 28 36 28 3728 28 28 27 28 28 28 24 28 28 27 28 28 37 29 36 27 27 28 2728 33 23 28 33 23 28 36 27 33 23 28 35 25 28 28 36 27 36 2728 28 28 24 28 37 29 28 19 28 26 37 29 26 39 33 13 37 28 2828 21 24 28 27 41 34 15 28 36 27 26 28 24 35 27 28 40 34 15
>gnl|ti|1779718824 name:EI1W3PE02ILQXT28 28 28 28 26 28 28 40 34 14 44 36 23 13 2 27 42 35 21 727 42 35 21 6 28 43 36 22 10 27 42 35 20 6 28 43 36 22 928 43 36 22 9 28 44 36 24 14 4 28 28 28 27 28 26 26 35 2640 34 18 3 28 28 28 27 33 24 26 28 28 28 40 33 14 28 36 2726 26 37 29 28 28 28 28 27 28 28 28 37 28 27 27 28 36 28 3728 28 28 27 28 28 28 24 28 28 27 28 28 37 29 36 27 27 28 2728 33 23 28 33 23 28 36 27 33 23 28 35 25 28 28 36 27 36 2728 28 28 24 28 37 29 28 19 28 26 37 29 26 39 33 13 37 28 2828 21 24 28 27 41 34 15 28 36 27 26 28 24 35 27 28 40 34 15
>gnl|ti|1779718824 name:EI1W3PE02ILQXTTCAGTGAGGGTTTTTGTTTTGTTTTGTTTTGTTTTGTTTTGTTTTGTTTTTGAGACAGAATTTTGCTCTTGTCGCCCAGGCTGGTGTGCAGTGGTGCAACCTCAGCTCACTGCAACCTCTGCCTCCAGGTTCAAGCAATTCTCTGCCTCAGCCTCCCAAGTAGCTGGGATTACAGGCGGGCGCCACCACGCCCAGCTAATTTTGTATTGTTAGTAAAGATGGGGTTTCACTACGTTGGCTGAGCTGTTCTCGAACTCCTGACCTCAAATGAC>gnl|ti|1779718825 name:EI1W3PE02GTXK0TCAGAATACCTGTTGCCCATTTTTATATGTTCCTTGGAGAAATGTCAATTCAGAGCTTTTGCTCAGCTTTTAATATGTTTATTTGTTTTGCTGCTGTTGAGTTGTACAATGTTGGGGAAAACAGTCGCACAACACCCGGCAGGTACTTTGAGTCTGGGGGAGACAAAGGAGTTAGAAAGAGAGAGAATAAGCACTTAAAAGGCGGGTCCAGGGGGCCCGAGCATCGGAGGGTTGCTCATGGCCCACAGTTGTCAGGCTCCACCTAATTAAATGGTTTACA
>gnl|ti|1779718824 name:EI1W3PE02ILQXTTCAGTGAGGGTTTTTGTTTTGTTTTGTTTTGTTTTGTTTTGTTTTGTTTTTGAGACAGAATTTTGCTCTTGTCGCCCAGGCTGGTGTGCAGTGGTGCAACCTCAGCTCACTGCAACCTCTGCCTCCAGGTTCAAGCAATTCTCTGCCTCAGCCTCCCAAGTAGCTGGGATTACAGGCGGGCGCCACCACGCCCAGCTAATTTTGTATTGTTAGTAAAGATGGGGTTTCACTACGTTGGCTGAGCTGTTCTCGAACTCCTGACCTCAAATGAC>gnl|ti|1779718825 name:EI1W3PE02GTXK0TCAGAATACCTGTTGCCCATTTTTATATGTTCCTTGGAGAAATGTCAATTCAGAGCTTTTGCTCAGCTTTTAATATGTTTATTTGTTTTGCTGCTGTTGAGTTGTACAATGTTGGGGAAAACAGTCGCACAACACCCGGCAGGTACTTTGAGTCTGGGGGAGACAAAGGAGTTAGAAAGAGAGAGAATAAGCACTTAAAAGGCGGGTCCAGGGGGCCCGAGCATCGGAGGGTTGCTCATGGCCCACAGTTGTCAGGCTCCACCTAATTAAATGGTTTACA
Mapped reads & confidence values
Hapmap haplotypes
90 20934216 F 0 02110001?0100210010011002122201210211?122122021200018 F 15 1621100012010021001001100?100201?10111110111?021200015 M 0 0211200100120012010011200101101010111110111102120007 M 0 02110001001000200122110001111011100111?1212102220008 F 0 0011202100120022012211200101101210211122111?012000012 F 9 10211000100100020012211000101101110011121212102200009 M 0 0011?001?012002201221120010?1012102111221111012000011 M 7 821100210010002001221100012110111001112121210222000
90 20934216 F 0 02110001?0100210010011002122201210211?122122021200018 F 15 1621100012010021001001100?100201?10111110111?021200015 M 0 0211200100120012010011200101101010111110111102120007 M 0 02110001001000200122110001111011100111?1212102220008 F 0 0011202100120022012211200101101210211122111?012000012 F 9 10211000100100020012211000101101110011121212102200009 M 0 0011?001?012002201221120010?1012102111221111012000011 M 7 821100210010002001221100012110111001112121210222000
90 20934216 F 0 02110001?0100210010011002122201210211?122122021200018 F 15 1621100012010021001001100?100201?10111110111?021200015 M 0 0211200100120012010011200101101010111110111102120007 M 0 02110001001000200122110001111011100111?1212102220008 F 0 0011202100120022012211200101101210211122111?012000012 F 9 10211000100100020012211000101101110011121212102200009 M 0 0011?001?012002201221120010?1012102111221111012000011 M 7 821100210010002001221100012110111001112121210222000
Reference genome sequence
>gi|88943037|ref|NT_113796.1|Hs1_111515 Homo sapiens chromosome 1 genomic contig, reference assemblyGAATTCTGTGAAAGCCTGTAGCTATAAAAAAATGTTGAGCCATAAATACCATCAGAAATAACAAAGGGAGCTTTGAAGTATTCTGAGACTTGTAGGAAGGTGAAGTAAATATCTAATATAATTGTAACAAGTAGTGCTTGGATTGTATGTTTTTGATTATTTTTTGTTAGGCTGTGATGGGCTCAAGTAATTGAAATTCCTGATGCAAGTAATACAGATGGATTCAGGAGAGGTACTTCCAGGGGGTCAAGGGGAGAAATACCTGTTGGGGGTCAATGCCCTCCTAATTCTGGAGTAGGGGCTAGGCTAGAATGGTAGAATGCTCAAAAGAATCCAGCGAAGAGGAATATTTCTGAGATAATAAATAGGACTGTCCCATATTGGAGGCCTTTTTGAACAGTTGTTGTATGGTGACCCTGAAATGTACTTTCTCAGATACAGAACACCCTTGGTCAATTGAATACAGATCAATCACTTTAAGTAAGCTAAGTCCTTACTAAATTGATGAGACTTAAACCCATGAAAACTTAACAGCTAAACTCCCTAGTCAACTGGTTTGAATCTACTTCTCCAGCAGCTGGGGGAAAAAAGGTGAGAGAAGCAGGATTGAAGCTGCTTCTTTGAATTTAC
…
…
…
… …
…
…
>gnl|ti|1779718824 name:EI1W3PE02ILQXTTCAGTGAGGGTTTTTGTTTTGTTTTGTTTTGTTTTGTTTTGTTTTGTTTTTGAGACAGAATTTTGCTCTTGTCGCCCAGGCTGGTGTGCAGTGGTGCAACCTCAGCTCACTGCAACCTCTGCCTCCAGGTTCAAGCAATTCTCTGCCTCAGCCTCCCAAGTAGCTGGGATTACAGGCGGGCGCCACCACGCCCAGCTAATTTTGTATTGTTAGTAAAGATGGGGTTTCACTACGTTGGCTGAGCTGTTCTCGAACTCCTGACCTCAAATGAC>gnl|ti|1779718825 name:EI1W3PE02GTXK0TCAGAATACCTGTTGCCCATTTTTATATGTTCCTTGGAGAAATGTCAATTCAGAGCTTTTGCTCAGCTTTTAATATGTTTATTTGTTTTGCTGCTGTTGAGTTGTACAATGTTGGGGAAAACAGTCGCACAACACCCGGCAGGTACTTTGAGTCTGGGGGAGACAAAGGAGTTAGAAAGAGAGAGAATAAGCACTTAAAAGGCGGGTCCAGGGGGCCCGAGCATCGGAGGGTTGCTCATGGCCCACAGTTGTCAGGCTCCACCTAATTAAATGGTTTACA
>gnl|ti|1779718824 name:EI1W3PE02ILQXT28 28 28 28 26 28 28 40 34 14 44 36 23 13 2 27 42 35 21 727 42 35 21 6 28 43 36 22 10 27 42 35 20 6 28 43 36 22 928 43 36 22 9 28 44 36 24 14 4 28 28 28 27 28 26 26 35 2640 34 18 3 28 28 28 27 33 24 26 28 28 28 40 33 14 28 36 2726 26 37 29 28 28 28 28 27 28 28 28 37 28 27 27 28 36 28 3728 28 28 27 28 28 28 24 28 28 27 28 28 37 29 36 27 27 28 2728 33 23 28 33 23 28 36 27 33 23 28 35 25 28 28 36 27 36 2728 28 28 24 28 37 29 28 19 28 26 37 29 26 39 33 13 37 28 2828 21 24 28 27 41 34 15 28 36 27 26 28 24 35 27 28 40 34 15
Read sequences
Quality scores
SNP genotype calls
rs12095710 T T 9.988139e-01rs12127179 C T 9.986735e-01rs11800791 G G 9.977713e-01rs11578310 G G 9.980062e-01rs1287622 G G 8.644588e-01 rs11804808 C C 9.977779e-01rs17471528 A G 5.236099e-01rs11804835 C C 9.977759e-01rs11804836 C C 9.977925e-01rs1287623 G G 9.646510e-01 rs13374307 G G 9.989084e-01rs12122008 G G 5.121655e-01rs17431341 A C 5.290652e-01rs881635 G G 9.978737e-01 rs9700130 A A 9.989940e-01 rs11121600 A A 6.160199e-01rs12121542 A A 5.555713e-01rs11121605 T T 8.387705e-01rs12563779 G G 9.982776e-01rs11121607 C G 5.639239e-01rs11121608 G T 5.452936e-01rs12029742 G G 9.973527e-01rs562118 C C 9.738776e-01 rs12133533 A C 9.956655e-01rs11121648 G G 9.077355e-01rs9662691 C C 9.988648e-01 rs11805141 C C 9.928786e-01rs1287635 C C 6.113270e-01
Pipeline for LD-Based Genotype Calling

Datasets
Watson Sequencing data: 74.4 million 454 reads (of 106.5
million reads used in [Wheeler et al 08]) Reference panel: CEU genotypes from Hapmap r23a
phased using the ENT algorithm [Gusev et al. 08] Ground truth: duplicate Affymetrix 500k SNP
genotypes Read length distribution
0
500000
1000000
1500000
2000000
0 100 200 300 400 500 600 700 800 900 1000 1100 1200

Datasets (contd.) NA18507 (Illumina & SOLiD)
Sequencing data: 525 million Illumina reads (36bp, paired) and 764 million SOLiD reads (24 - 44bp, unpaired)
Reference panel: YRI haplotypes from Hapmap r22 excluding NA18507 haplotypes
Ground truth: Hapmap r22 genotypes

Mapping Procedure
454 reads mapped on human genome build 36.3 using the NUCMER tool of the MUMmer package [Kurtz et al 04] with default parameters
Additional filtering: at least 90% of the read length matched to the genome, no more than 10 errors (mismatches or indels)
Reads meeting above conditions at multiple genome positions (likely coming from genomic repeats) were discarded
Illumina and SOLiD reads mapped using MAQ [Li,Ruan&Durbin 08] with default parameters
For reads mapped at multiple positions MAQ returns best position (breaking ties arbitrarily) together with mapping confidence
We filtered bad alignments and discarded paired end reads that are not mapped in pairs using the “submap -p” command
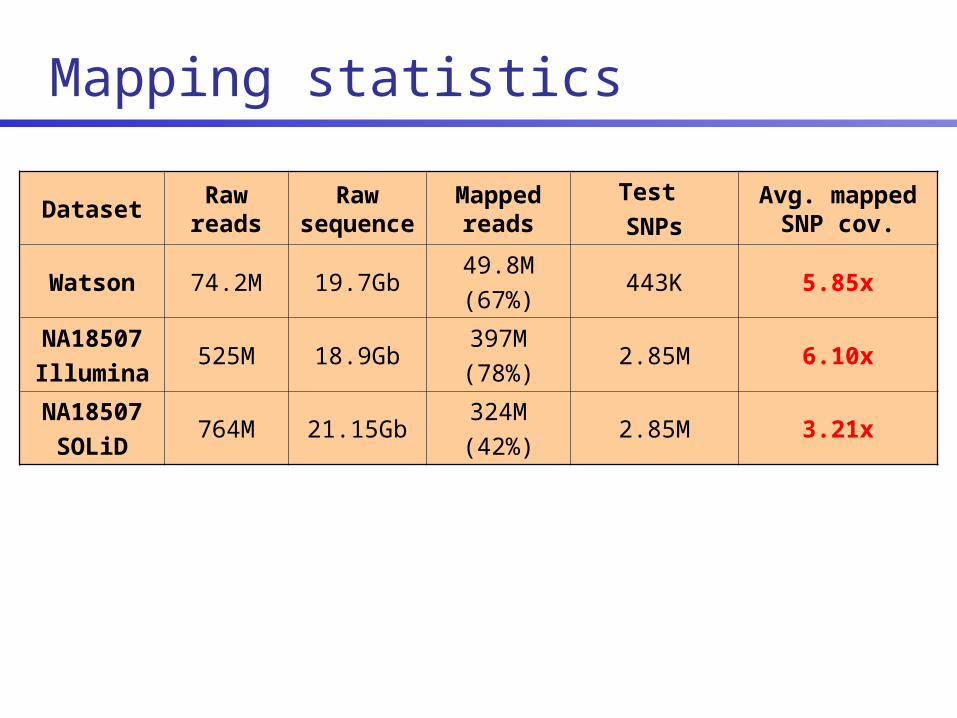
Mapping statistics
DatasetRaw
reads
Raw sequenc
e
Mapped reads
Test SNPs
Avg. mapped SNP cov.
Watson 74.2M 19.7Gb49.8M(67%)
443K 5.85x
NA18507Illumina
525M 18.9Gb397M(78%)
2.85M 6.10x
NA18507SOLiD
764M 21.15Gb324M(42%)
2.85M 3.21x

Concordance vs. avg. coverage(Watson 454 reads)
0
10
20
30
40
50
60
70
80
90
100
0 1 2 3 4 5 6
Avg. Coverage
% C
on
cord
an
ce
Binomial (Homo)
HMM-Posterior (Homo)
Binomial (Het)
HMM-Posterior (Het)

Tradeoff with call rate (5.85x Watson 454 reads, homo SNPs)
97
97.5
98
98.5
99
99.5
100
0 10 20 30 40 50
% uncalled
% c
on
cord
ance
1SNP-Posterior Binomial0.01 HMM-Posterior

Tradeoff with call rate (5.85x Watson 454 reads, het SNPs)
80
82
84
86
88
90
92
94
96
98
100
0 5 10 15 20 25 30 35 40 45 50
% uncalled
% c
on
co
rda
nc
e
1SNP-Posterior Binomial0.01 HMM-Posterior

Concordance vs. avg. coverage for NA18507 (Illumina & SOLiD reads)
0
10
20
30
40
50
60
70
80
90
100
0 1 2 3 4 5 6
Avg. Coverage
% C
on
cord
an
ce
Binomial (Homo) Illumina
HMM-Posterior (Homo) Illumina
Binomial (Het) Illumina
HMM-Posterior (Het) Illumina
Binomial (Homo) SOLiD
HMM-Posterior (Homo) SOLiD
Binomial (Het) SOLiD
HMM-Posterior (Het) SOLiD

Effect of local recombination rate (NA18507 Illumina)
91%
92%
93%
94%
95%
96%
97%
98%
99%
100%
-4.5 -4 -3.5 -3 -2.5 -2 -1.5 -1 -0.5 0 0.5 1 1.5
log(cM/Mb)
% C
on
cord
ance
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
% H
apm
ap S
NP
s
Concordance (homo) Concordance (het)
% of homo % of het

Effect of SNP coverage (NA18507 Illumina)
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
SNP coverage
% C
on
cord
ance
0%
2%
4%
6%
8%
10%
12%
14%
16%
18%
20%
% H
apm
ap S
NP
s
Concordance (homo) Concordance (het)% of homo % of het

Posterior decoding algorithm has scalable running time and yields significant improvements in genotyping calling accuracy
Improvement depends on the coverage depth (higher at lower coverage), e.g., accuracy achieved by previously proposed binomial test at 5-6x average coverage is achieved by HMM-based posterior decoding algorithm using less than 1/4 of the reads
Open source code available at http://dna.engr.uconn.edu/software/GeneSeq/
LD-based genotype calling increasingly attractive as reference panels improve (denser, more samples, more populations)
Allows sequencing larger populations for the same cost
Conclusions

Haplotype reconstruction Promising preliminary results using Viterbi-like algorithm
based on HF-HMM
Extension to population sequencing data Removes need for reference panels!
Integrated read mapping, SNP identification, and haplotype reconstruction
EM algorithm that iteratively refines two full haplotype sequences and read mapping probabilities
Integrates read data with LD info available for known SNPs Takes advantage of reads overlapping multiple SNP loci Allows reconstruction of complete sequences for CNVs
Reconstruction of complex haplotype spectra mRNA isoforms, quasispecies
Ongoing work

Acknowledgments
Work supported in part by NSF awards IIS-0546457 and DBI-0543365 to IM and IIS-0803440 to YW. SD and YH performed this research as part of the Summer REU program “Bio-Grid Initiatives for Interdisciplinary Research and Education" funded by NSF award CCF-0755373.