from the archives: future of supercomputing at altparty 2009
TRANSCRIPT

CSC – Tieteen tietotekniikan keskus Oy
CSC – IT Center for Science Ltd.
The Future of Supercomputing
Olli-Pekka Lehto
Systems Specialist

CSC – IT Center for Science
• Center for Scientific Computing
– Offices located in Keilaniemi, Espoo
– All shares owned by the ministry of education
– Founded in 1970 as a technical support unit for the Univac 1108
• Provides a variety of services to the Finnish researchcommunity
– High Performance Computing (HPC) resources
– Consulting services for scientific computing
– Scientific software development (Chipster, Elmer etc.)
– IT infrastructure services
– ISP services (FUNET)

CSC in numbers
• ~180 employees
• 3000 researchers use the
computing capacity
actively
– Around 500 projects at any
given time
• ~320 000 FUNET end-
users in 85 organizations
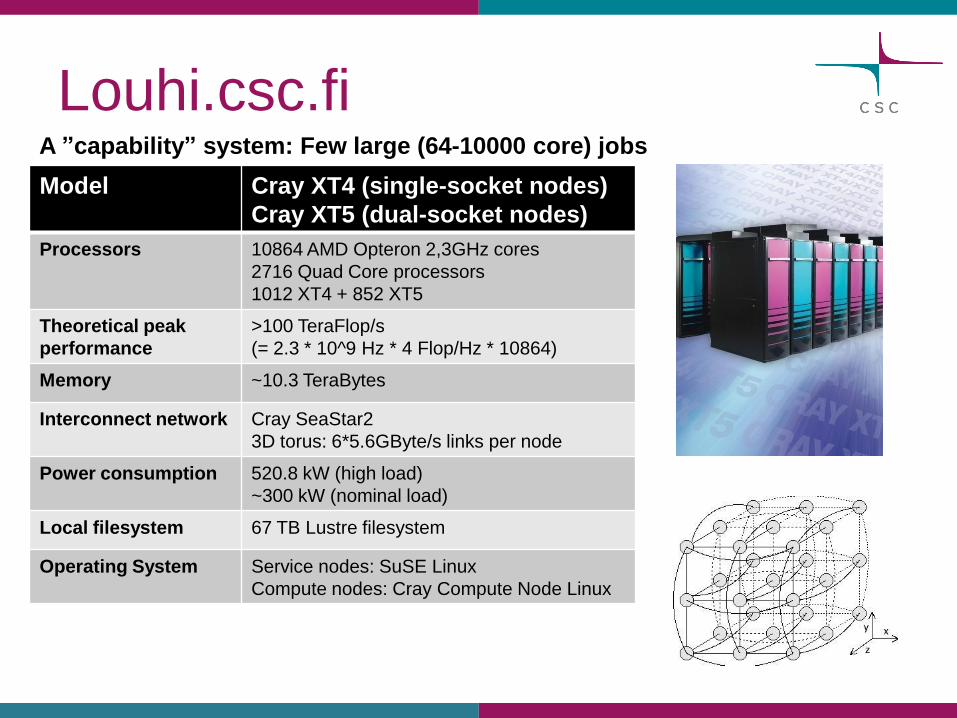
Louhi.csc.fi
Model Cray XT4 (single-socket nodes)
Cray XT5 (dual-socket nodes)
Processors 10864 AMD Opteron 2,3GHz cores
2716 Quad Core processors
1012 XT4 + 852 XT5
Theoretical peak
performance
>100 TeraFlop/s
(= 2.3 * 10^9 Hz * 4 Flop/Hz * 10864)
Memory ~10.3 TeraBytes
Interconnect network Cray SeaStar2
3D torus: 6*5.6GByte/s links per node
Power consumption 520.8 kW (high load)
~300 kW (nominal load)
Local filesystem 67 TB Lustre filesystem
Operating System Service nodes: SuSE Linux
Compute nodes: Cray Compute Node Linux
A ”capability” system: Few large (64-10000 core) jobs

Murska.csc.fi
Model HP Proliant Blade cluster
Processors 2176 AMD Opteron 2,6GHz cores
1088 Dual Core processors
544 Blade servers
Theoretical peak
performance
~11.3 TeraFlop/s
(= 2.6 * 10^9 Hz * 4 Flop/Hz * 2176)
Memory ~5 TB
Interconnect network Voltaire 4x DDR InfiniBand
(16Gbit/s fat-tree network)
Power consumption ~75 kW (high load)
Local filesystem 98 TB Lustre filesystem
Operating System HP XC Cluster Suite (RHEL based Linux)
A ”capacity” system: Many small (1-128 core) jobs

Why use supercomputers?
• Constraints
– Results are needed in a reasonable time
• Impatient users
• Time-critical problems (e.g. weather forecasting)
– Large problem sizes
• The problem does not fit into the memory of a single system
• Many problem types require all the processing power close to each other
– Distributed computing (BOINC etc.) workwell only on certain problem types

Who uses HPC?
MILITARY
SCIENTIFIC
COMMERCIAL
Weapons modelling
Signals intelligence
Radar image processing
Nuclear physics
Mathematics
Quantum chemistry Fusion energy
Nanotechnology
Climate change
Weather forecasting
Electronic Design Automation (EDA)
Genomics
Tactical simulation
Aerodynamics
Crash simulations
Movie SFXFeature-length movies
Search engines
Oil reservoir discovery
Stock market prediction
Banking & Insurance databases
1960s 1970s 1980s 1990s 2000s
Strategic simulation ”Wargames”
2010s
Materials science
Drug design
Organ modelling

State of HPC 2009
• Move towards commodity components
– Clusters built from off-the-shelf servers
– Linux
– Open source tools (compilers, debuggers, clustering mgmt, applications)
– Standard x86 processors
• Price-performance efficient components
– Low-latency, high-bandwitdh interconnects
• Standard PCI cards
• InfiniBand, 10Gig Ethernet, Myrinet
– Parallel Filesystems
• Striped RAID (0) with fileservers
• Lustre, GPFS, PVFS2 etc.

Modern HPC systemsCommodity clusters
• A large number of regularservers connected together
– Usually a standard Linux OS
– Possible to even mix and matchcomponents from differentvendors
• May include some specialcomponents
– High-performance interconnectnetwork
– Parallel filesystems
• Low-end and midrangesystems
• Vendors: IBM, HP, Sun etc.
Proprietary supercomputers
• Designed from the groundup for HPC
– Custom interconnectnetwork
– Customized OS & software
– Vendor-specific components
• High-end supercomputersand special applications
• Examples: Cray XT-series, IBM BlueGene

The Three Walls
There are three ”walls” which CPU design is hitting now:
• Memory wall
– Processor clock rates have grown faster than memory clockrates
• Power wall
– Processors consume an increasing amount of power
– The increase is non-linear
• +13% performance = +73% power consumption
• Microarchitecture wall
– Adding more complexity to the CPUs is not helping that much
• Pipelining, branch prediction etc.

A Typical HPC System
• Built from commodity servers
– 1U or Blade form factor
– 1-10 management nodes
– 1-10 login nodes
• Program development, compilation
– 10s of storage nodes
• Hosting parallel filesystem
– 100s of compute nodes
• 2-4 CPU sockets per node (4-24 cores), AMD Opteron or Intel Xeon
• Linux OS
• Connected with InfiniBand or Gigabit Ethernet
• Programs in C/C++ or Fortran and are parallelized using MPI (Message Passing Interface) API

The Exaflop system
• Target: 2015-2018
– 10^18 (million trillion) floating-point operations per second
– Current system 0.00165 Exaflops
• Expectations with current technology evolution
– Power draw 100-300 MW
• 15-40% of a nuclear reactor (Olkiluoto I)!
• $1M/MW/year!
• Need to bring it down to 30-50 MW
– 500 000 - 5 000 000 processor cores
– Memory 30-100 PB
– Storage 1 Exabyte

Programming Languages
• Current trend (C/C++/Fortran + MPI)
– Difficult to program portable and efficient code
– MPI is not fault tolerant by default (1 task dies and the whole system crashes)
• PGAS languages to the rescue?
– Partitioned Global Address Space
– Looks like global shared memory
• But possible to define task-local regions
• Compiler generates communication code
– Current standards
• UPC - Unified Parallel C
• CAF - Co-Array Fortran
– Languages under development
• Titanium, Fortress, X10, Chapel

What to do with an exaflop?
• Long term climate-change modelling
• High resolution weather forecasts
– Prediction by city block
– Extreme weather
• Large protein folding
– Alzheimer, cancer, Parkinson’s etc.
• Simulation of a human brain
• Very realistic virtual environments
• Design of nanostructures
– Carbon nanotubes, nanobots
• Beat a human pro player in a 19x19 Go

Accelerators: GPGPU
• General Purpose Computing on Graphics Processing Units
• Nvidia Tesla/Fermi, ATI FireStream, IBM Cell, Intel Larrabee
• Advantages
– High volume production rates, low price
– High memory bandwidth on GPU (>100GB/s vs. 10-30GB/s of RAM)
– High flop rate, for certain applications
• Disadvantages
– Low performance in precise (64-bit) computation
– Getting data to the GPU memory is a bottleneck (8GB/s PCI Express)
– Vendors have different programming languages
• Now: Nvidia CUDA, ATI Stream, Intel Ct, Cell etc.
• Future: OpenCL on everything (hopefully!)
– Does not work for all types of applications
• Branching, random memory access, huge datasets etc.

Case: Nvidia Fermi
• Announced last month, available in 2010
• New HPC-oriented features
– Error-correcting memory
– High double precision performance
• 512 compute cores, ~3 billion transistors
– 750 GFlops (Double Precision)
– 1.5 Tflops (Single Precision)
• 2011: Fermi-based Cray supercomputerin Oak Ridge National Laboratory
– ”10 times faster than the current state of the art”: ~20 Petaflops

Case: Intel Larrabee
• Intel’s new GPU architecture, available in 2010
• Based on Pentium x86 processor cores
– Initially tens of cores per GPU
– Pentium cores with vector units
– Compatible with x86 programs
• Cores connected with a ring bus

Accelerators: FPGA
• Field Programmable Gate Arrays
• Vendors: Clearspeed, Mitrionics, Convey, Nallatech
• Chip with programmable logic units
– Units connected with a programmable network
• Advantages
– Very low power consumption
– Arbitrary precision
– Very efficient in search algorithms
– Several in-socket implementations
• FPGA sits directly in the CPU socket
• Disadvantages
– Difficult to program
– Limited number of logic blocks

Performance
SP and DP GFlops
0
500
1000
1500
2000
2500
3000
3500
4000
4500
Nvidi
a G
efor
ce G
TX280
Nvidi
a Tes
la C
1060
Nvidi
a Tes
la S
1070
ATI Rade
on 4
870
ATI Rade
on X
2 48
70
ATI Fire
Stream
925
0
Clear
Speed
e710
Clear
Speed
CATS70
0
IBM
Power
XCel
l 8i
AMD O
pter
on B
arce
lona
GF
Lo
p/s
SP Gflop/s
DP Gflop/s
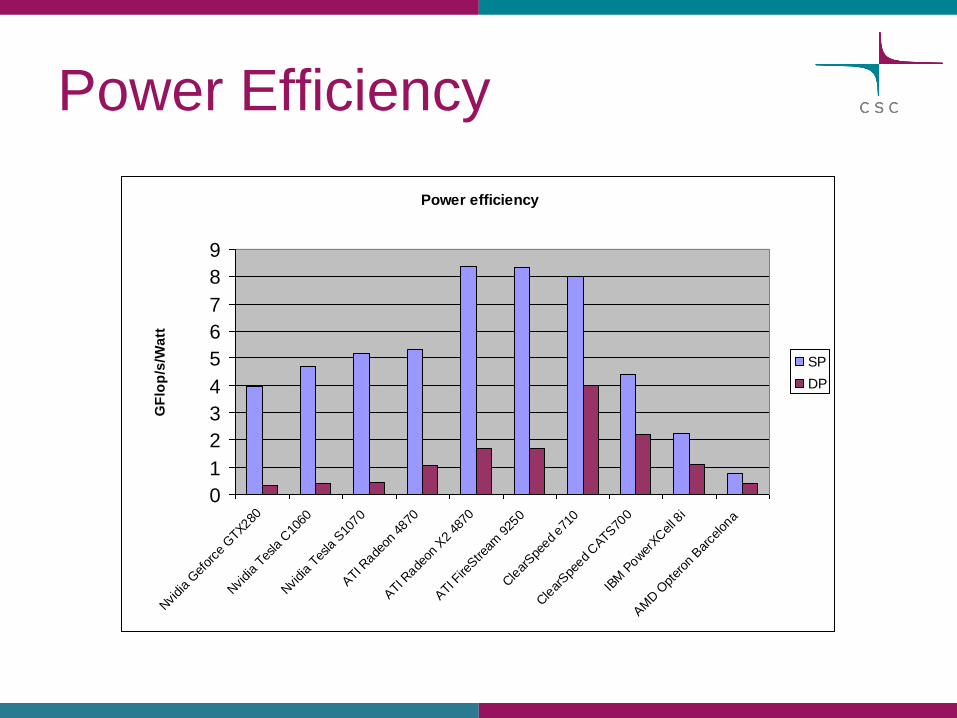
Power Efficiency
Power efficiency
0
1
2
3
4
5
6
7
8
9
Nvidia
Gef
orce
GTX280
Nvidia
Tesla
C10
60
Nvidia
Tesla
S10
70
ATI R
adeon
4870
ATI R
adeon
X2
4870
ATI F
ireStre
am 9
250
Cle
arSpe
ed e71
0
Cle
arSpe
ed CATS
700
IBM
Pow
erXC
ell 8
i
AM
D O
pter
on B
arce
lona
GF
lop
/s/W
att
SP
DP

3D Integrated Circuits
• Wafers stacked on top of each other
• Layers connected with through-silicon ”vias”
• Many benefits
– High bandwidth and low latency
– Saves space and power
– Added freedom in circuit design
– The stack may consist of different types of wafers
• Several challenges
– Heat dissipation
– Complex design and manufacturing
• HPC killer-app: Memory stacked on top of a CPU

Other Technologies To Watch
• SSD (Solid State Disk)
– Fast transactions, low power, improving reliability
– Fast checkpointing and restarting of programs
• Optics on silicon
– Lightpaths both on a chip and on the PCB
• New memory technologies
– Phase-change memory etc.
– Low-power, low-latency, high bandwidth
• Green datacenter technologies
• DNA computing
• Quantum computing

Conclusions
• Differences between clusters and proprietarysupercomputers is diminishing
• Accelerator technology is promimsing
– Simple, vendor independent programming models areneeded
• Lots of programming challenges in parallelisation
– Similar challenges in mainstream computing today
• Going to Exaflop will be very tough
– Innovation needed in both software and hardware

Questions