fpga-based high-performance computing - hpc …. elraba kau… · fpga-based high-performance...
TRANSCRIPT

Spatial Computing
FPGA-Based High-performance Computing
Dr. Muhammad Elrabaa
Design, Automation, and Computer Architecture Group
Computer Engineering Department, KFUPM

Outline
Introduction & Motivation
FPGAs’ Architectures and Design Flows
Spatial versus Temporal Computing
Recent use of FPGAs in High Throughput
applications
Current FPGA Research at KFUPM
Conclusions
M. Elrabaa, HPC Conference, KAUST 2017 2

New applications have catapulted HPC from the narrow scientific applications domain tothe main stream, the cloud; packet processing, machine learning, searches, analytics,business logic …etc.
Massively parallel, streamed computations have gone main stream
Introduction: FPGAs in HPC! Really?
M. Elrabaa, HPC Conference, KAUST 2017 3
AI revenue growth projection. Source: Tractica
27 different industry
segments and 191 use
cases for AI so far
Projected revenues by
2025: US$ 36.8B
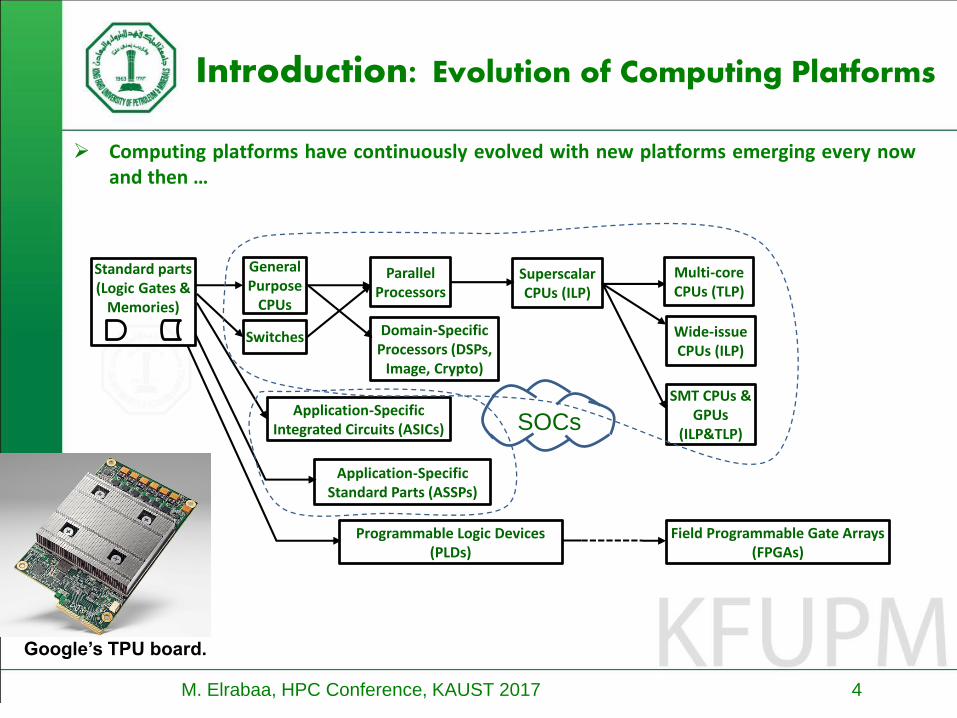
Computing platforms have continuously evolved with new platforms emerging every nowand then …
Introduction: Evolution of Computing Platforms
M. Elrabaa, HPC Conference, KAUST 2017 4
Standard parts (Logic Gates &
Memories)
General Purpose
CPUs
Switches
Parallel Processors
Domain-Specific Processors (DSPs,
Image, Crypto)
Application-Specific Integrated Circuits (ASICs)
Application-Specific Standard Parts (ASSPs)
Superscalar CPUs (ILP)
Multi-core CPUs (TLP)
Wide-issue CPUs (ILP)
SMT CPUs & GPUs
(ILP&TLP)
Programmable Logic Devices (PLDs)
SOCs
Field Programmable Gate Arrays (FPGAs)
Google’s TPU board.

FPGAs started as a way to test new circuits before they are implemented as ASICs(lower-power and higher-performance) if volumes were sufficient,
They have come a long way since! In the last 20 years, moving steadily up the foodchain from glue logic to co-processors, to being utilized in a variety of high-performance, mission-critical applications from data centers to supercomputers.
GPUs are good in executing streamed parallel threads in lock-step (or close to lock-step) – not good with running multiple sequential applications in parallel – CPUs arebetter – FPGAs, are much better!
FPGAs are being embedded into devices alongside a cluster of CPUs, utilizing thesame bus structure for pre- or post-processing, as a way of reducing the mainprocessor cluster’s load.
Embedded FPGAs are being used for network acceleration, performing packetprocessing, deep packet inspection, encryption/compression or other types ofpackage processing before the switch or CPU structure has to decide what to do withthat information.
In the wireless segment, embedded FPGAs are being used as a digital front end,performing linearization, pre-distortion, and other tasks between the power amp andthe radio card, or in the communication link
These new trends reflects statements made by several hi-tech executives that FPGAswill constitute 20% of data centers by 2020 …
Introduction: FPGAs in HPC
M. Elrabaa, HPC Conference, KAUST 2017 5

FPGAs @ Data Centers: Packet Processing
M. Elrabaa, HPC Conference, KAUST 2017 6
TCP Stack: 1,000s of simultaneous connections
Packet classification & Forwarding

FPGAs are reprogrammable (or rather re-configurable) silicon chips.
With pre-built configurable logic blocks, I/Os, memories, and routing resources, it can be configured to implement any custom hardware functionality.
The figures below show simplified view of current FPGA architectures.
Not shown: ‘Hard Macros’ (DSPs, Encryption/Decryption, CPUs), and internal configuration ports
FPGAs’ Architectures
M. Elrabaa, HPC Conference, KAUST 2017 7
Blo
ck R
AM
s
Blo
ck R
AM
s
Configurable Logic
Blocks
Configurable
I/O Blocks
Block RAMs
PSM PSM
CLB
PSM PSM
CLB CLB
CLBCLB CLB
CLBCLB CLB
Programmable Switch
Matrix
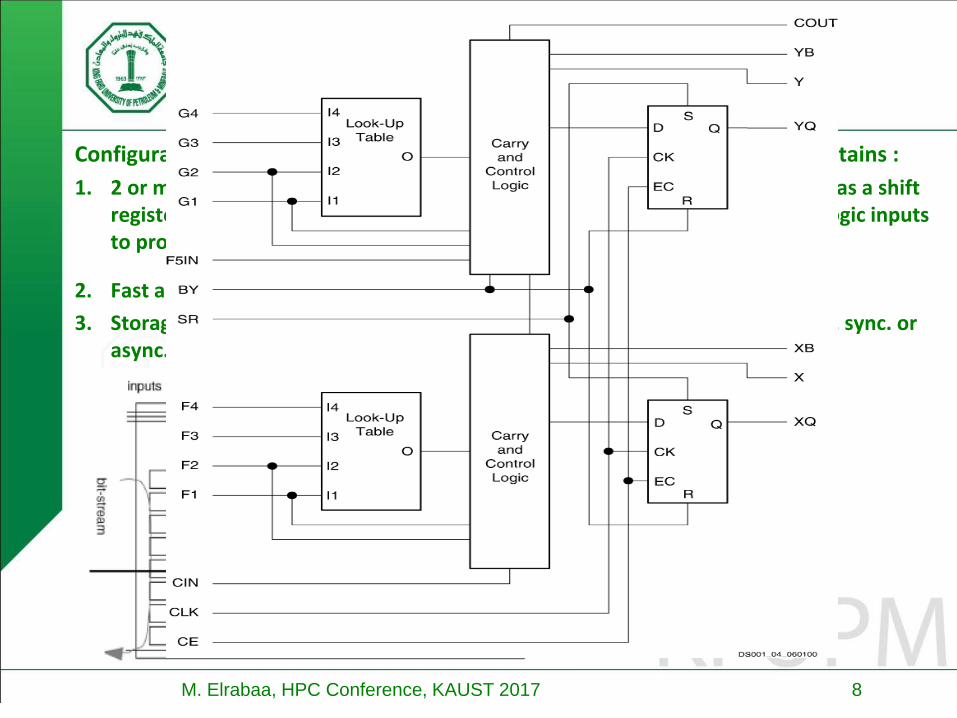
Configurable logic is usually clustered into slices (or logic elements). Each contains :
1. 2 or more n-input Look-Up-Tables or LUTs – an SRAM with 2n cells connected as a shift register (for configuration purposes), cells’ O/Ps are multiplexed by the LUT logic inputs to produce the output -- Can implement any n-input logic function
2. Fast arithmetic logic: Carry & Control, Multiplier logic, Multiplexer logic
3. Storage element: Latch or flip-flop with Set and reset, True or inverted inputs, sync. or async. control
FPGAs’ Architectures, Contd.
M. Elrabaa, HPC Conference, KAUST 2017 8
Configuration
bit-stream

Historically, FPGAs have always been coupled to a host CPU with various degrees of coupling – converged to two forms
1. As an attached processing unit (like GPUs) on the PCIe bus – under direct and explicit control of the host – FPGA accelerators
2. As a network attached processing unit – providing network services – FPGA custom-computing-machines
FPGA Coupling to a Host
M. Elrabaa, HPC Conference, KAUST 2017 9

M. Elrabaa, HPC Conference, KAUST 2017 10
· Schematic· RTL HDL (Verilog, VHDL)
START
· High-Level Description (C/C++, BlueSpec)
High-Level Synthesis (HLS)
Logic Synthesis
Device Library
Verification
MAP
OK?
NO
Yes
Verification
OK?
Yes
NO
RTL
Generic Netlist
Place & Route
Device-Specific Netlist
Timing Verification
OK?
Yes
NO
Generate Configuration
Configure Device
END
FPGA Design Flow

Spatial Versus Temporal Computing
M. Elrabaa, HPC Conference, KAUST 2017 11
Temporal: Break down computations into
time-sequenced steps Re-use of computing resources
that were designed to handle ‘any’ type of computations – equally inefficiently!
Spatial: Break down computations into space
connected operators Operators can be replicated as much as
needed – efficient implementation for a specific computation – Area, Power, & speed can be optimized simultaneously
Fine-grain parallelism can be fully exploited in addition to coarse-grain parallelism

High Throughput Applications:FPGA vs CPU vs GPU
FPGAs are not the fastest for FP (especially double FP), but they are the mostpower efficient!
M. Elrabaa, HPC Conference, KAUST 2017 12
Comparison of Gaxpy kernel on naive C, MKL-single thread, MKL-parallel, CUDA BLAS and FPGA
implementation in terms of (a) Execution time and (b) Average number of iterations per Joule (in “BLAS Comparison on FPGA, CPU and GPU,” U. of Pennsylvania & Microsoft Research)
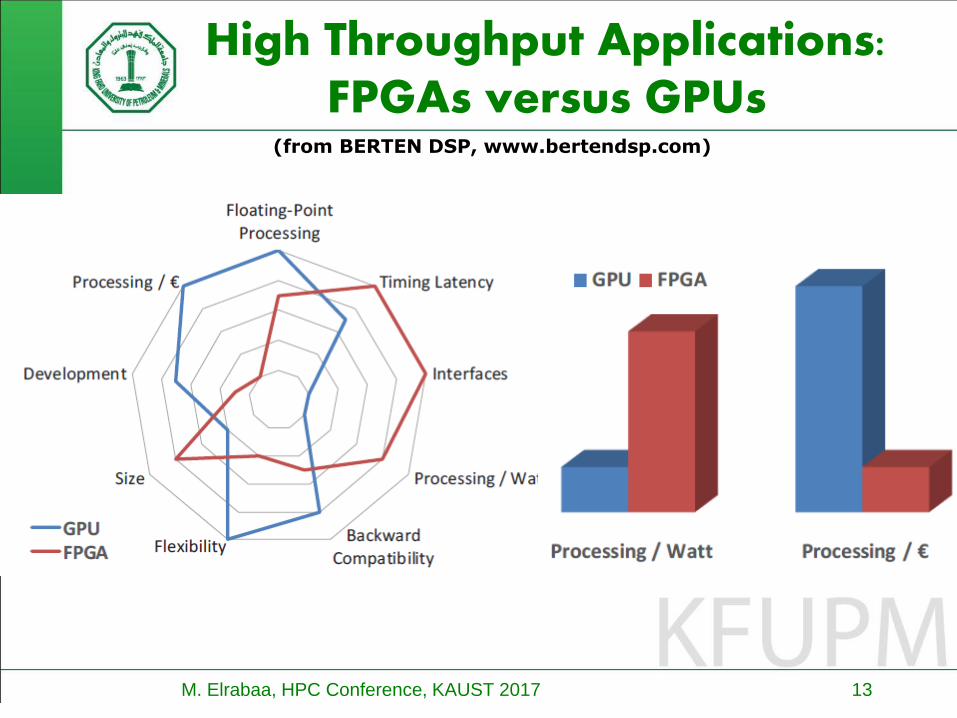
High Throughput Applications:FPGAs versus GPUs
(from BERTEN DSP, www.bertendsp.com)
M. Elrabaa, HPC Conference, KAUST 2017 13
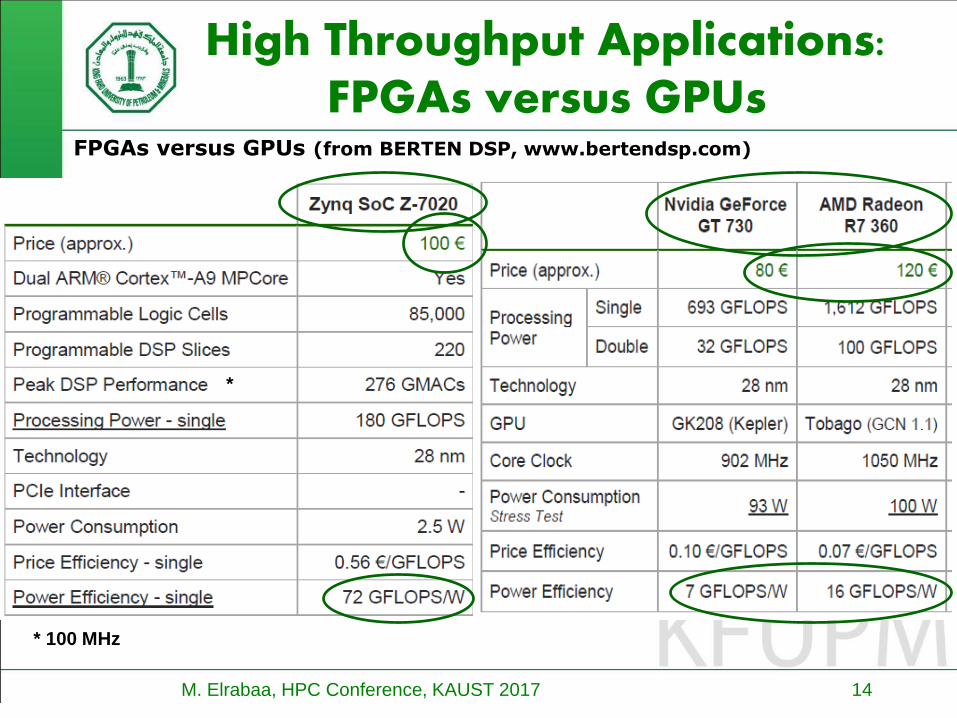
High Throughput Applications:FPGAs versus GPUs
FPGAs versus GPUs (from BERTEN DSP, www.bertendsp.com)
M. Elrabaa, HPC Conference, KAUST 2017 14
* 100 MHz
*

FPGA vs CPUBing Search acceleration, Microsoft Research
medium-scale deployment of FPGAs on a bed of 1,632 servers – 1 FPGA/Server (PCIe), FPGAs form a 6X8 2-D Torus/RACK using two 10 GBS SAS:
Improved the ranking throughput of each server by 95% for a fixed latency distribution
Or, while maintaining equivalent throughput, reduced the tail latency by 29%.
M. Elrabaa, HPC Conference, KAUST 2017 15

FPGA Research @ KFUPM:FPGA virtualization platform
Virtualization is key for using FPGAs as cloud service
Most sought-after approach is using Overlays: virtual, coarse-grained,programmable architectures that can be mapped to any FPGA physicalarchitecture (vendor/tool independent) – Fixed Functional Units (withsome selectable operations) + programmable interconnects – The wholefabric cycle through a compute kernel cycle-by-cycle
Meant for app developers who want to accelerate their apps with FPGAs,but lack the HW design expertise
Coarse-grained Overlay Architecture
Spatially-configured Overlay Tile Architectures

FPGA Research @ KFUPM:FPGA virtualization platform
Different approach -- a layered architecture with partial reconfiguration suitable to virtualize any design – similar to a web-service – specially suited for Clouds/datacenters –HW components
can be from 3rd party (e.g. AWS market place)
FPGA
wrapper
User Design
StaticLogic
wrapper
User Design
wrapper
User Design
Network Controller
Ethernet/Infiniband
wrapper
ICAPReconfigurable
Regions
Read channelsWrite channels
Clock Management
User Design
Wrapper
Static Logic
Network Controller
Routing Arbiter
Separate clock
domains
Handshaking-based
communication
Components
Network controller
Static region
Reconfiguration management
Wrapper + User Design

Network Controller
Network Controller
Phy_rx
Phy_tx
Buffer_rx
Buffer_t
x
Data
Session
Data Session
sniffer
TriggersMAC Addresses
table
Current
IP
Compare
Done
& CRC
OK
ARP Reply
ICMP Reply
DHCP discovery
DHCP Request
arbiter
Data
Data Link Layer Network Layer
IP Addresses
table
Current
MAC
Address
Data
Address
Address
Data
Data
Address
Dest. IP
Dest.
MAC
GMII TX
READ data channel
Read address channel
Write address channel
Write data channel
GMII RX

Network Controller, Contd.
Address Resolution Protocol (ARP): associates an IP address to the MAC address of the virtual FPGA
ICMP protocol: replys to ping requests to virtual FPGAs
DHCP: Negotiates a dynamic IP addresses for virtual FPGAs
TCP: Instantiates and terminates TCP sessions between virtual FPGA and remote devices
Successfully implemented on Xilinx FPGAs – various low-to-high end devices – supporting heterogeneous cloud deployment
Tested with 1000Mbps Ethernet Virtex6 and Spartan 6 – Atlys
Tested with 100Mbps Ethernet on Spartan 3s, Spartan 6 –Nexys3

Auto-generation of Wrappers
Buff
er
in
Buffe
r out
Input
mux
jpeg_topJPEG_bitstream
eof_data_partial_ready
end_of_file_bitstream_count
data_ready
data_in
enable
rst
end_of_file_signal
32
5
24
25
39
2
FSM
BUFGCE
Bit
unpackin
g
Bit p
ackin
g
28
64
64
Based on XML description of a user’s circuit:
Input / output names and their sizes
Define groups for input / output
Define data out ready signals
A developed SW tool translates the XML description into RTL Verilog HDL

commcontrol
main state
control
Enc/Dec
SHA3
FPGA
ICAP
modexp
Masking circuitry
PUF
Reconfigurable
logic array
FPGAs for Secure Data Processing in Public Clouds
FPGAs can be used as flexible, scalable, independent, isolated, and secure compute resources within a public cloud – natural sandboxing!
Substantially smaller attack surface – No operating systems, drivers or compilers need to be involved in FPGA configuration secure
under more robust attack models and stronger security guarantees.
FPGA i
Encrypted
dataClient Cloud Provider (CP)

FPGAs for Secure Data Processing: Framework
Static
logicFPGA i
FV
Client
Request FPGA
Encrypted data
Encrypted result
FPGA vendor & trusted authority
Cloud provider
Static
logic
FVProxy
Client
IOT devices
CP
FPGAs for IoTs Data Security
FPGAs for users’ Data Security

Simulating Many-Core architectures on FPGAs
Utilizing FPGAs’ fine-grain parallelism to simulate all events in parallel usingactual circuits/memories/queues/NoC and abstracted core model – Up to2200 MIPS simulation speed for simulating a 16-core target machine
Control Panel
BSV Template
Verilog Template
Software FrontendUser
Xilinx ISE
Timing Model on the FPGA
Intel Pin Tool
CET Tool
Hardware Backend
Verilog
Bit
Stream
CET Code/Data
Simulation Results
Benchmark
Configuration
Control
Results
CET Code/Data
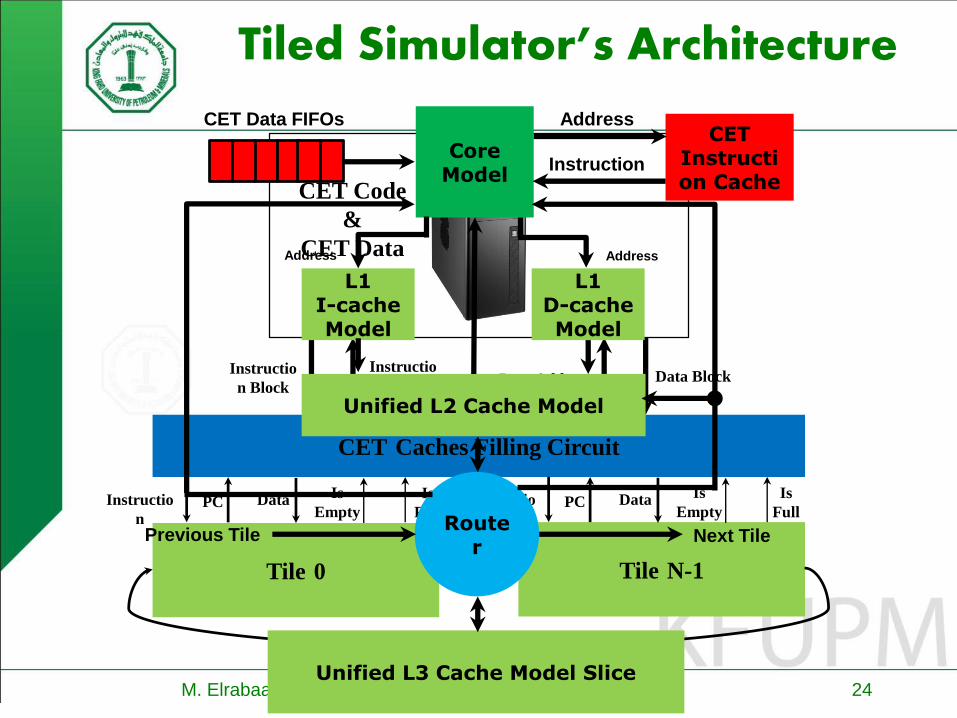
M. Elrabaa, HPC Conference, KAUST 2017 24
Tiled Simulator’s Architecture
CET Code
&
CET Data
CET Caches Filling Circuit
Tile 0 Tile N-1
Is
Full
Is
EmptyDataPCInstructio
n
Is
Full
Is
EmptyDataPCInstructio
n
Instructio
n Block
Instructio
n Address Data Address Data Block
Core Model
L1 D-cache Model
L1 I-cache Model
Unified L2 Cache Model
Unified L3 Cache Model Slice
Router
CET Instruction Cache
Address
Instruction
CET Data FIFOs
Previous Tile Next Tile
AddressAddress
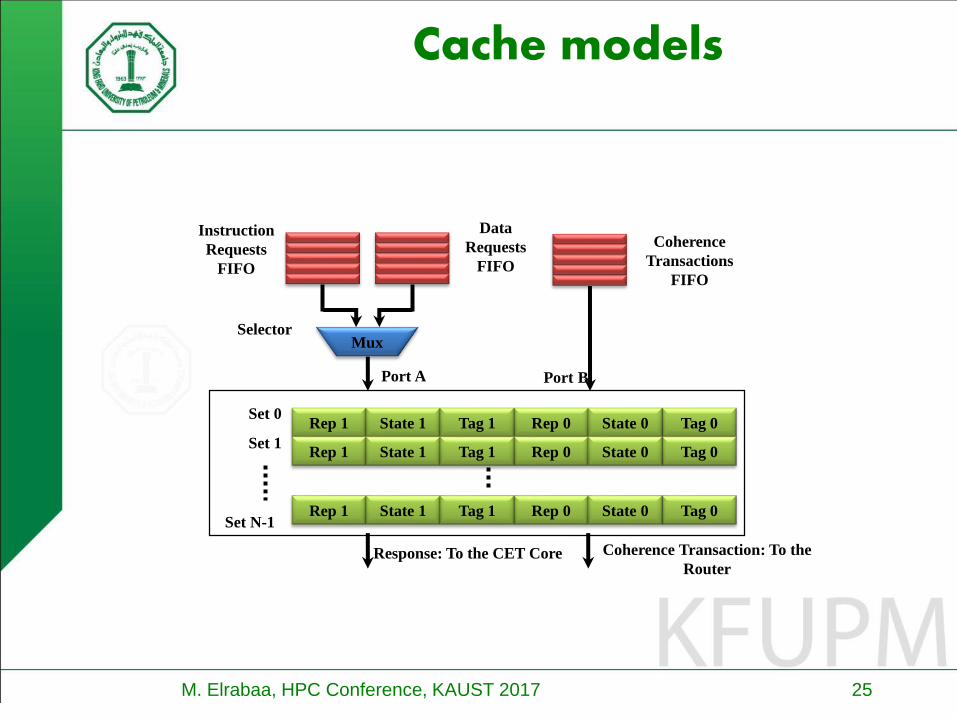
M. Elrabaa, HPC Conference, KAUST 2017 25
Cache models
Tag 0
Tag 0
Tag 0
Response: To the CET Core
Instruction
Requests
FIFO
Data
Requests
FIFO
Coherence
Transactions
FIFO
Port BPort A
Set 0
Set 1
Rep 0 State 0Rep 1 State 1 Tag 1
Rep 0 State 0Rep 1 State 1 Tag 1
Set N-1Rep 0 State 0
Mux
Rep 1 State 1 Tag 1
Coherence Transaction: To the
Router
Selector

M. Elrabaa, HPC Conference, KAUST 2017 26
Simulation Speeds
0
500
1000
1500
2000
2500
Sim
ula
tio
n S
pe
ed
(M
IPS)
Simulation Speed (MIPS)
1 Thread
2 Threads
4 Threads
8 Threads
16 Threads

M. Elrabaa, HPC Conference, KAUST 2017 27
With ChipScope® (Xilinx)
Real-time Simulation Monitoring
With our SW Control Panel

Conclusions
FPGAs have moved up the computing food chain to become one of the
apex computing platforms
Perfect for data-flow computations, not so perfect for double FP
Their use in Clouds/Data Centers is detrimental – packet inspection,
processing, and forwarding – 160+ papers from Microsoft research
alone on FPGA usage in clouds/datacenters in the past 6 years!
Naturally secure, but lots of work needed to make them become
mainstream for app developers
Acknowledgments:
My PhD students; Amran Al-Alghbari, Ayman Hroub, and Mohammed Al-Asli
My KFUPM colleagues in Comp. Architecture and HPC; Dr. Mayez Al-Mohammad, and
Dr. Muhammad Mudawar
KFUPM & KACST: For research grants, facilities and support.
M. Elrabaa, HPC Conference, KAUST 2017 28