fpga and reconfigurable computing
DESCRIPTION
FPGA and Reconfigurable Computing. Wu, Jinyuan Fermilab ICT May, 2009. Outline. Electronic Aspect of FPGA: LED Flashing Logic Elements in a Nutshell TDC and ADC FPGA as a Computing Fabric: Moore’s Law Forever? Space Charge Computing with FPGA Cores Doublet Matching & Hash Sorter - PowerPoint PPT PresentationTRANSCRIPT

May. 2009 Wu Jinyuan, Fermilab [email protected]
1
FPGA and Reconfigurable Computing
Wu, Jinyuan
Fermilab
ICT
May, 2009

May. 2009 Wu Jinyuan, Fermilab [email protected]
2
Outline Electronic Aspect of FPGA:
LED Flashing Logic Elements in a Nutshell TDC and ADC
FPGA as a Computing Fabric: Moore’s Law Forever? Space Charge Computing with FPGA Cores Doublet Matching & Hash Sorter Triplet Matching & Tiny Triplet Finder Enclosed Loop Micro-Sequencer (ELMS)
May. 2009 Wu Jinyuan, Fermilab [email protected]
3
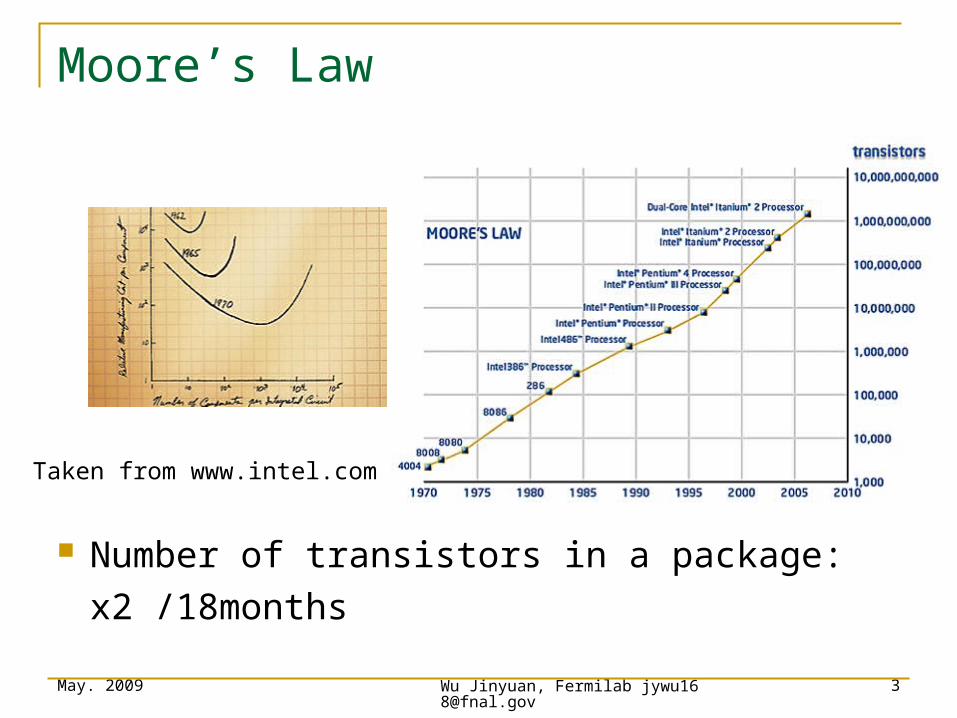
Moore’s Law
Number of transistors in a package:
x2 /18months
Taken from www.intel.com
May. 2009 Wu Jinyuan, Fermilab [email protected]
4
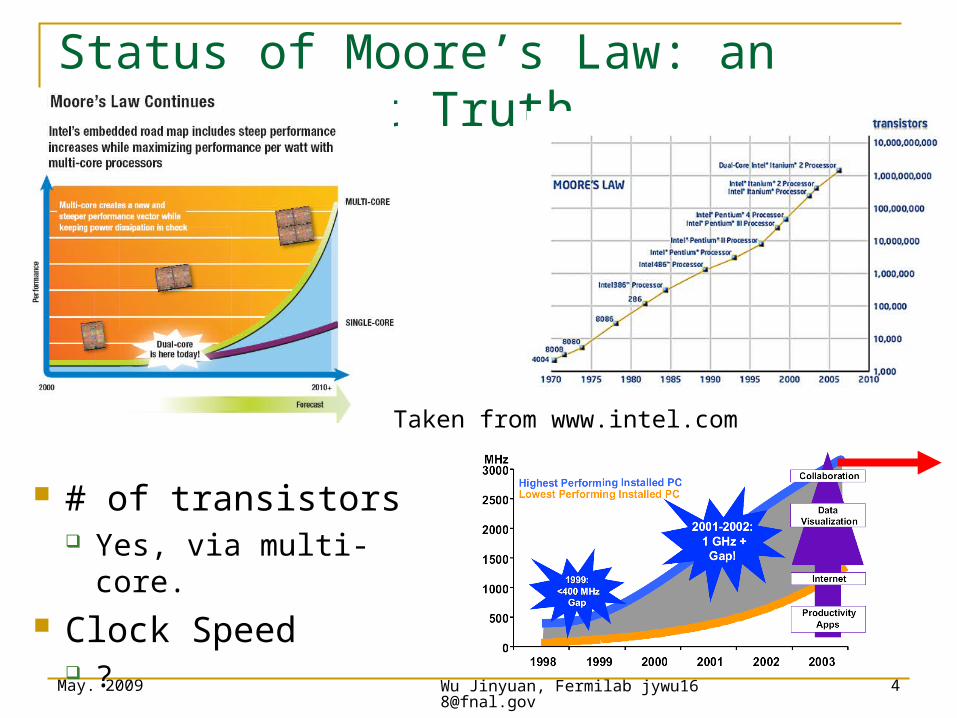
Status of Moore’s Law: an Inconvenient Truth
# of transistors Yes, via multi-core.
Clock Speed ?
Taken from www.intel.com

May. 2009 Wu Jinyuan, Fermilab [email protected]
5
The Execution & Non-Execution Cycles
In current micro-processors: Each instruction takes one clock cycle to execute. It takes many clock cycles to prepare for executing an instruction. Pipelined? Yes. But the non-execution pipeline stages consume silicon
area, power etc. To execute an instruction != to do useful calculation.
Can we do something different?
From MIT 6.823 Open Course Site

May. 2009 Wu Jinyuan, Fermilab [email protected]
6
Outline Electronic Aspect of FPGA:
LED Flashing Logic Elements in a Nutshell TDC and ADC
FPGA as a Computing Fabric: Moore’s Law Forever? Space Charge Computing with FPGA Cores Doublet Matching & Hash Sorter Triplet Matching & Tiny Triplet Finder Enclosed Loop Micro-Sequencer (ELMS)

May. 2009 Wu Jinyuan, Fermilab [email protected]
7
The Space Charge Computing
n
iij
ijijj
13
04 rr
rrF
Each electron sees sum of Coulomb forces from other N-1 electrons. The total number of calculations is about N2 and each calculation of the Coulomb force
requires a square root, a division and several multiplications. Regular sequential computers are not fast enough.
Number of
Electrons
Number of Calculations/Iteration
Computing Time/1000 Iterations
@107 Calculations/s
103 ~106 100 s
104 ~108 2.7 hours
105 ~1010 11.6 days
106 ~1012 3.2 years

May. 2009 Wu Jinyuan, Fermilab [email protected]
8
The FPGA Board
Up to 16 FPGA devices ($32 ea) can be installed onto each board. Each FPGA host one core.
May. 2009 Wu Jinyuan, Fermilab [email protected]
9
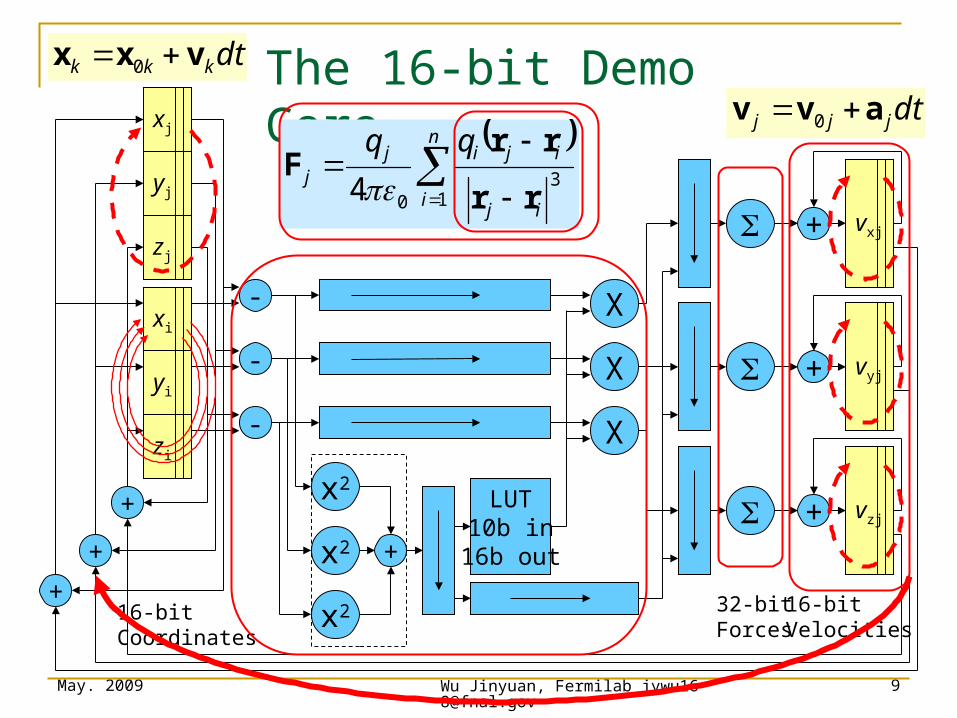
xi
- X
X
X
LUT10b in
16b out
yi
zi
16-bitCoordinates
32-bitForces
xj
yj
zj
vzj+
vyj+
vxj+
x2
x2
x2
+
-
-
+
+
+
16-bitVelocities
The 16-bit Demo Core
n
iij
ijijj
13
04 rr
rrF
dtjjj avv 0
dtkkk vxx 0
May. 2009 Wu Jinyuan, Fermilab [email protected]
10
CLK
ST
QC{1..0]
CNTC
VCCCLK INPUT
VCCST INPUT
QAA[7..0]OUTPUT
QBA[7..0]OUTPUT
up countersset 2sset
clock
cnt_en
q[1..0]
lpm_counter25
inst1
up countersclr
clock
cnt_en
q[7..0]
lpm_counter26
inst3
up countersclr
clock
cnt_en
q[7..0]
lpm_counter26
inst4
NOT
inst
OR2
inst6
CLRN
DPRN
Q
DFF
inst7CLRN
DPRN
Q
DFF
inst8
CLK
QC[0]
CLK
QC0QQ
OR2
inst9
AND2
inst10
NOT
inst12
NOT
inst13
data[7..0]eq254
eq255
lpm_decode2
inst15
data[7..0]eq254
eq255
lpm_decode2
inst16
OR2
inst11
AND2
inst14AND2
inst17
AAeqFF
BAeqFF
BAeqFF
QC[0]
CLK
CNTB
QC[0]
SCLRB
AAeqFF
QC[1]
CLK
CNTA
QC[1]
QC[0]QC0QQ
SCLRA
BAeqFF
AAeqFF
QBA[7..0]
QAA[7..0]
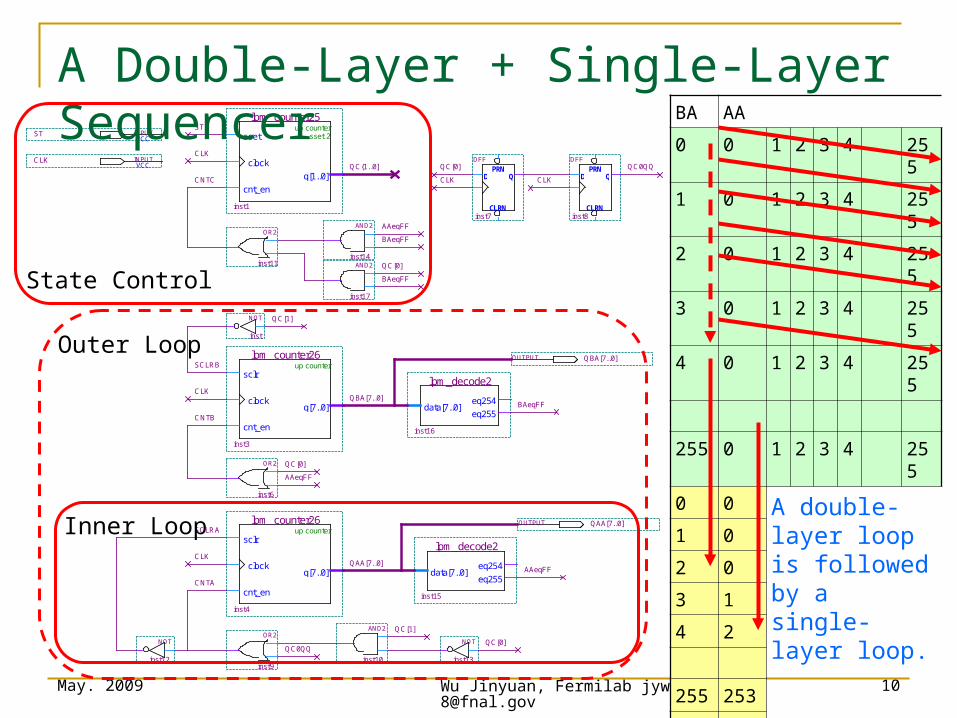
A Double-Layer + Single-Layer Sequencer BA AA
0 0 1 2 3 4 255
1 0 1 2 3 4 255
2 0 1 2 3 4 255
3 0 1 2 3 4 255
4 0 1 2 3 4 255
255 0 1 2 3 4 255
0 0 A double-layer loop is followed by a single-layer loop.
1 0
2 0
3 1
4 2
255 253
0 254
0 255
0 0
Inner Loop
Outer Loop
State Control
May. 2009 Wu Jinyuan, Fermilab [email protected]
11
LUT10b in
16b out
x2
x2
x2
+
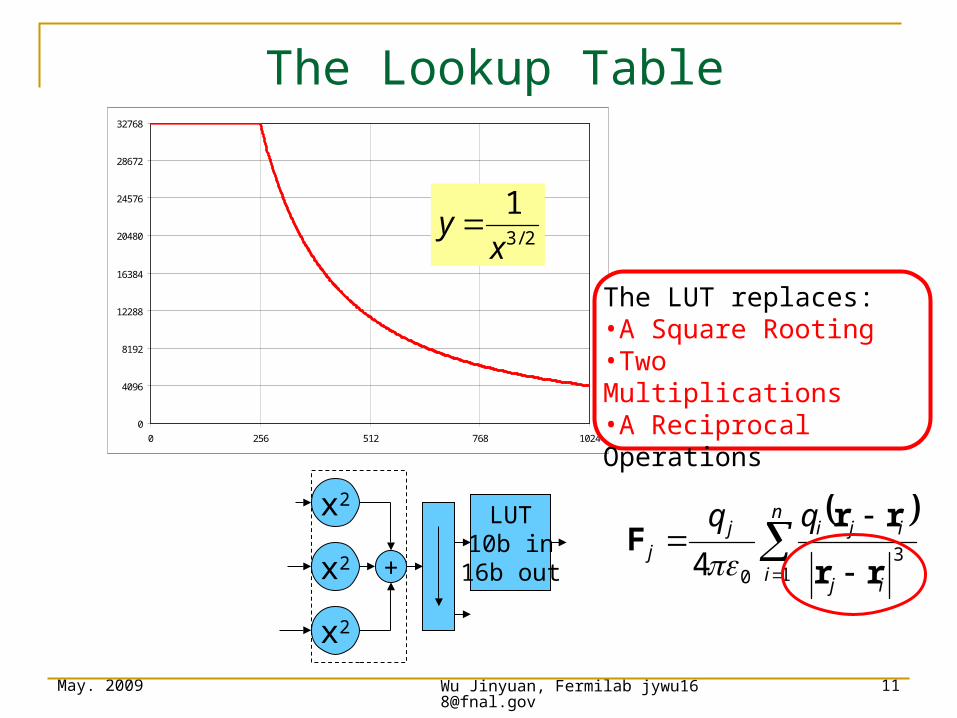
The Lookup Table
n
iij
ijijj
13
04 rr
rrF
0
4096
8192
12288
16384
20480
24576
28672
32768
0 256 512 768 1024
2/3
1
xy
The LUT replaces:•A Square Rooting•Two Multiplications•A ReciprocalOperations
May. 2009 Wu Jinyuan, Fermilab [email protected]
12
xi
- X
X
X
LUT10b in
16b out
yi
zi
16-bitCoordinates
32-bitForces
x2
x2
x2
+
-
-
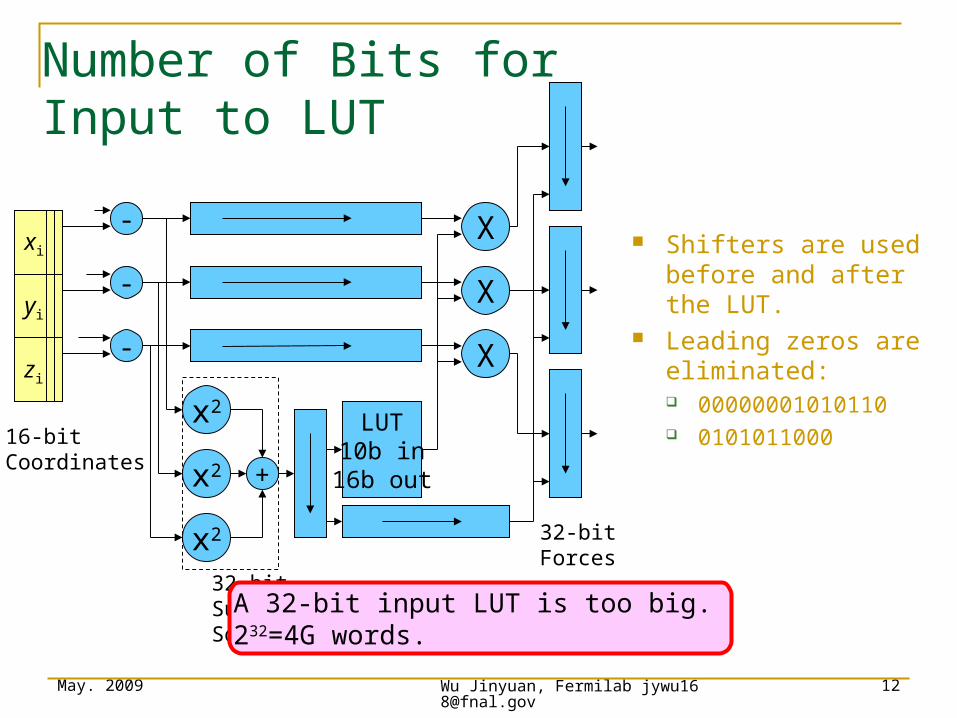
Number of Bits for Input to LUT
32-bitSum ofSquares
A 32-bit input LUT is too big. 232=4G words.
Shifters are used before and after the LUT.
Leading zeros are eliminated: 00000001010110 0101011000
May. 2009 Wu Jinyuan, Fermilab [email protected]
13
x1 x2(x1-x2)
(x1-x2)^2Sum of 3 Squares
LUT
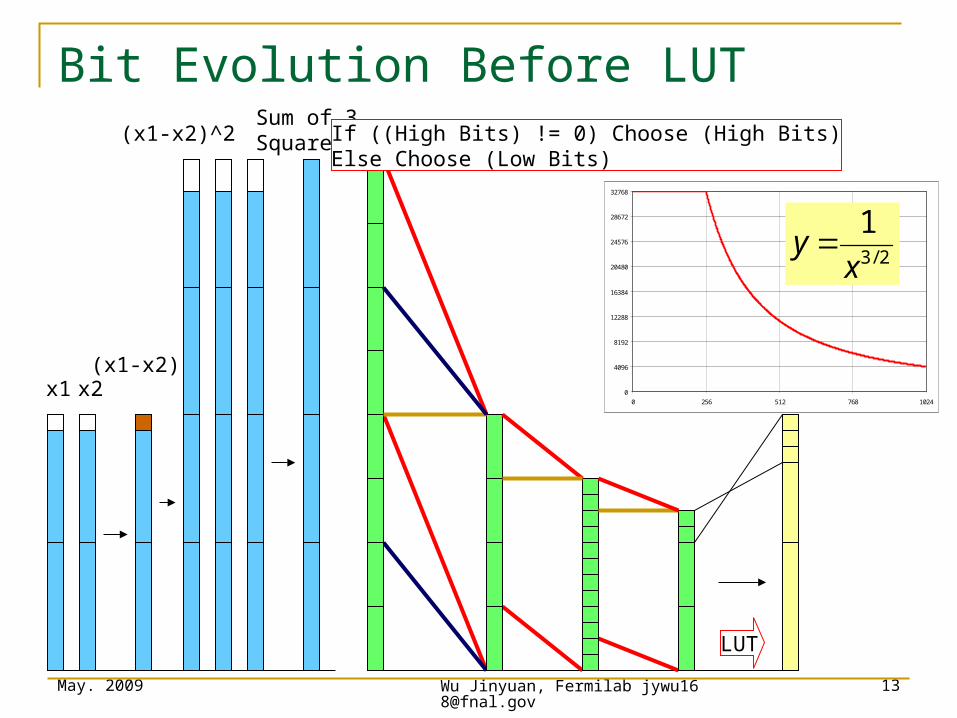
Bit Evolution Before LUT
0
4096
8192
12288
16384
20480
24576
28672
32768
0 256 512 768 1024
2/3
1
xy
If ((High Bits) != 0) Choose (High Bits)Else Choose (Low Bits)
May. 2009 Wu Jinyuan, Fermilab [email protected]
14
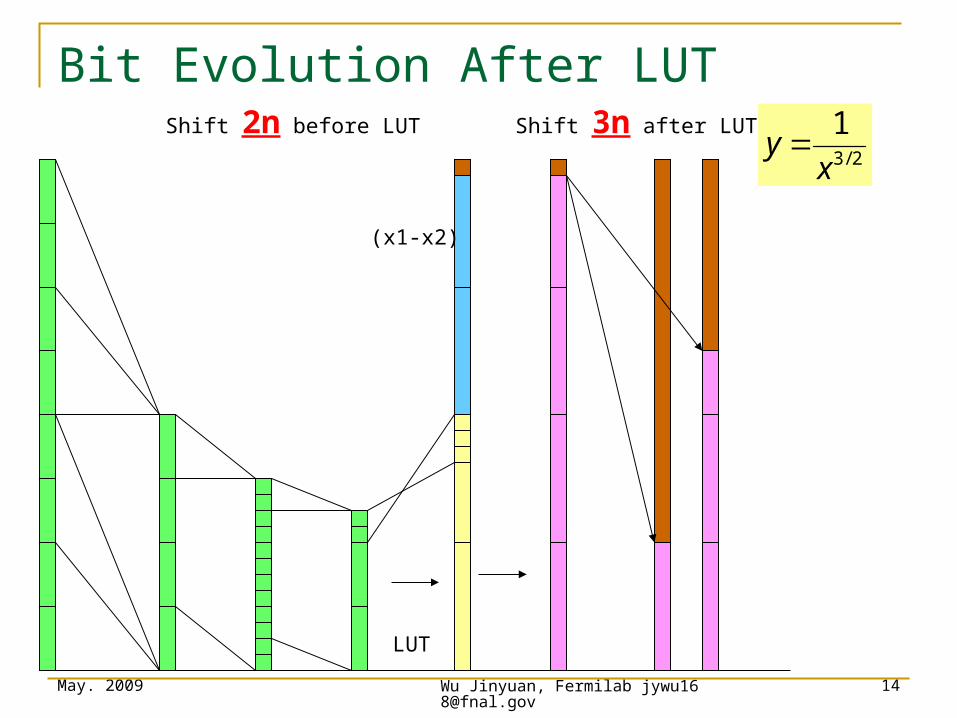
(x1-x2)
LUT
Bit Evolution After LUTShift 2n before LUT Shift 3n after LUT
2/3
1
xy
May. 2009 Wu Jinyuan, Fermilab [email protected]
15
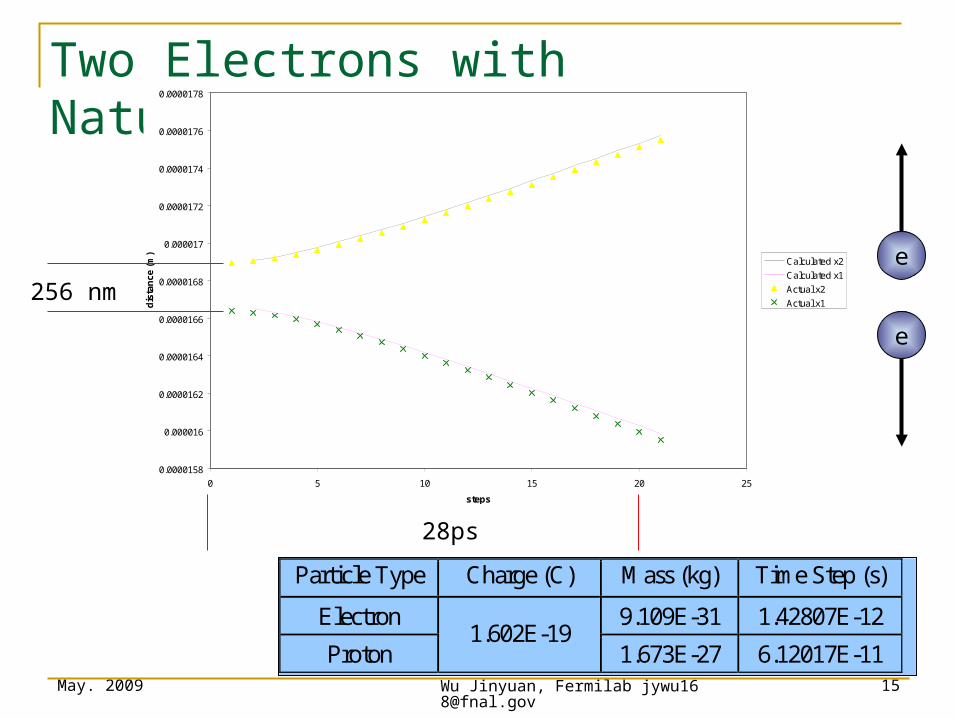
Two Electrons with Natural Scales
0.0000158
0.000016
0.0000162
0.0000164
0.0000166
0.0000168
0.000017
0.0000172
0.0000174
0.0000176
0.0000178
0 5 10 15 20 25
steps
dis
tan
ce (
m)
Calculated x2
Calculated x1
Actual x2
Actual x1256 nm
28ps
Particle Type Charge (C) Mass (kg) Time Step (s)
Electron 9.109E-31 1.42807E-12
Proton 1.602E-19
1.673E-27 6.12017E-11
e
e
May. 2009 Wu Jinyuan, Fermilab [email protected]
16
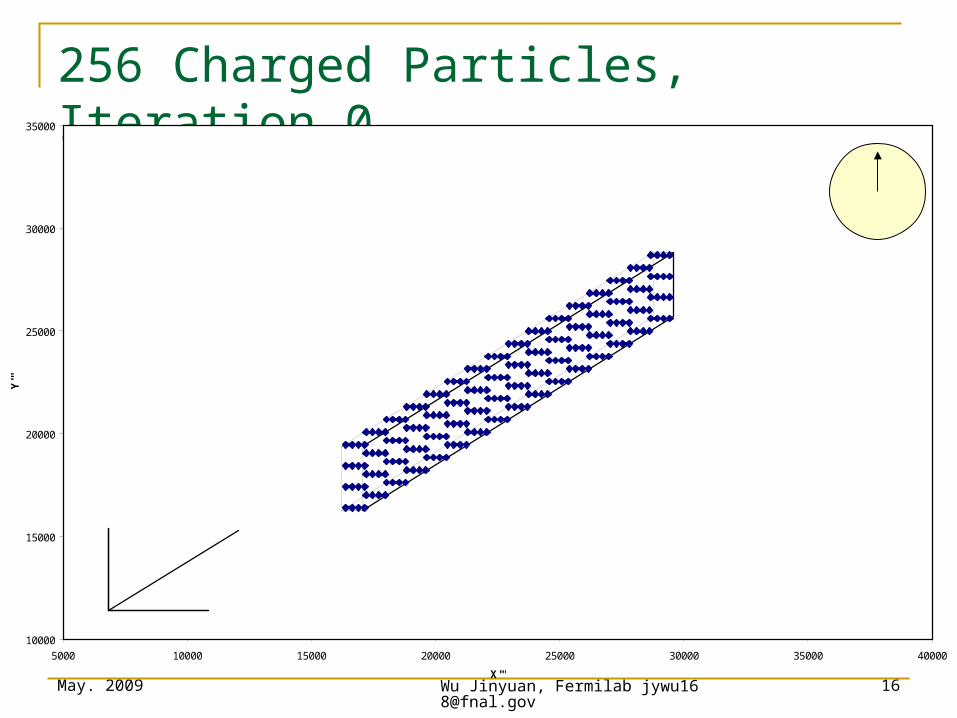
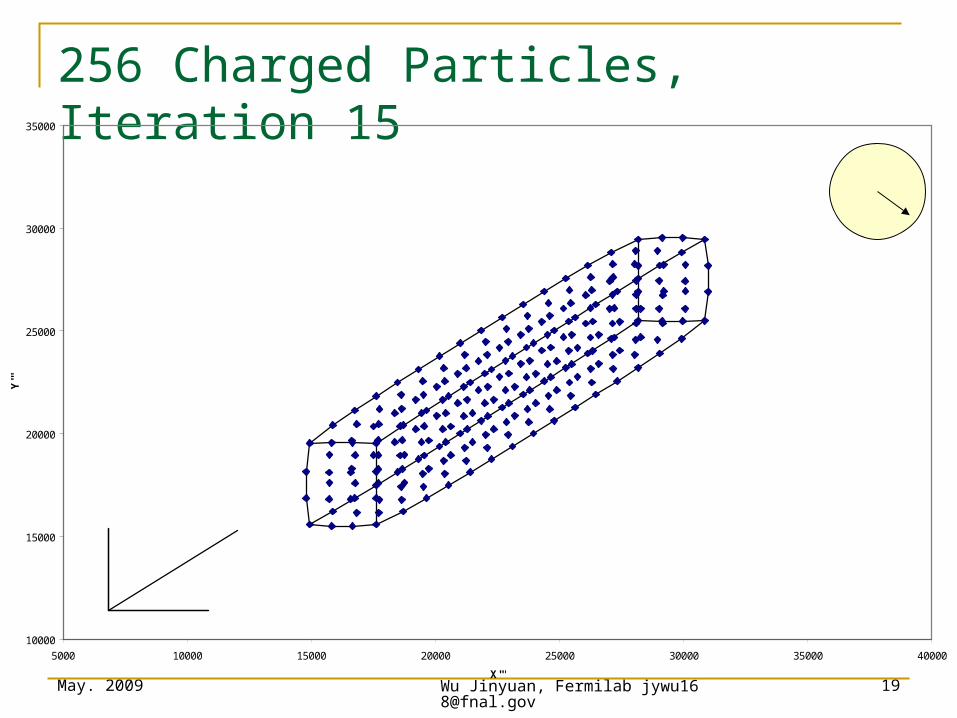
256 Charged Particles, Iteration 0
10000
15000
20000
25000
30000
35000
5000 10000 15000 20000 25000 30000 35000 40000
X'''
Y'''
May. 2009 Wu Jinyuan, Fermilab [email protected]
17
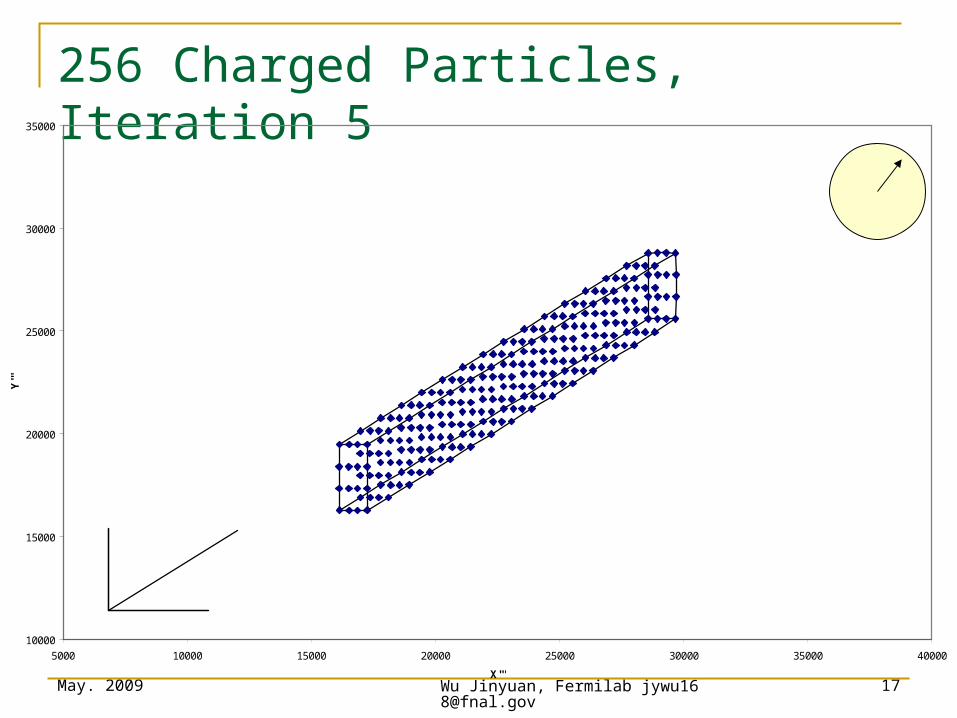
256 Charged Particles, Iteration 5
10000
15000
20000
25000
30000
35000
5000 10000 15000 20000 25000 30000 35000 40000
X'''
Y'''
May. 2009 Wu Jinyuan, Fermilab [email protected]
18
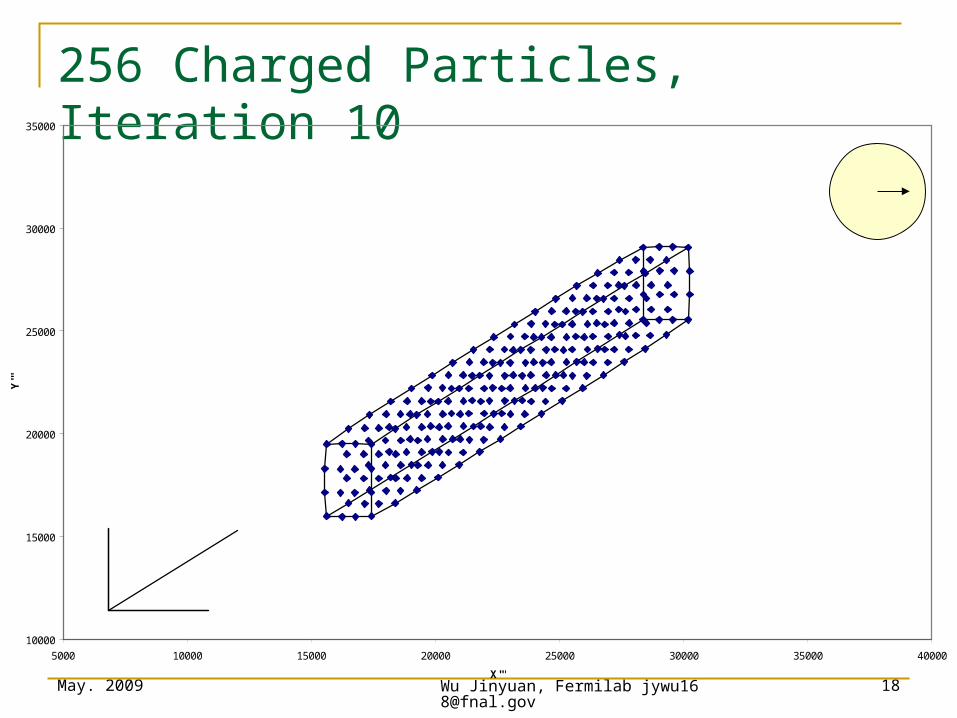
256 Charged Particles, Iteration 10
10000
15000
20000
25000
30000
35000
5000 10000 15000 20000 25000 30000 35000 40000
X'''
Y'''
May. 2009 Wu Jinyuan, Fermilab [email protected]
19
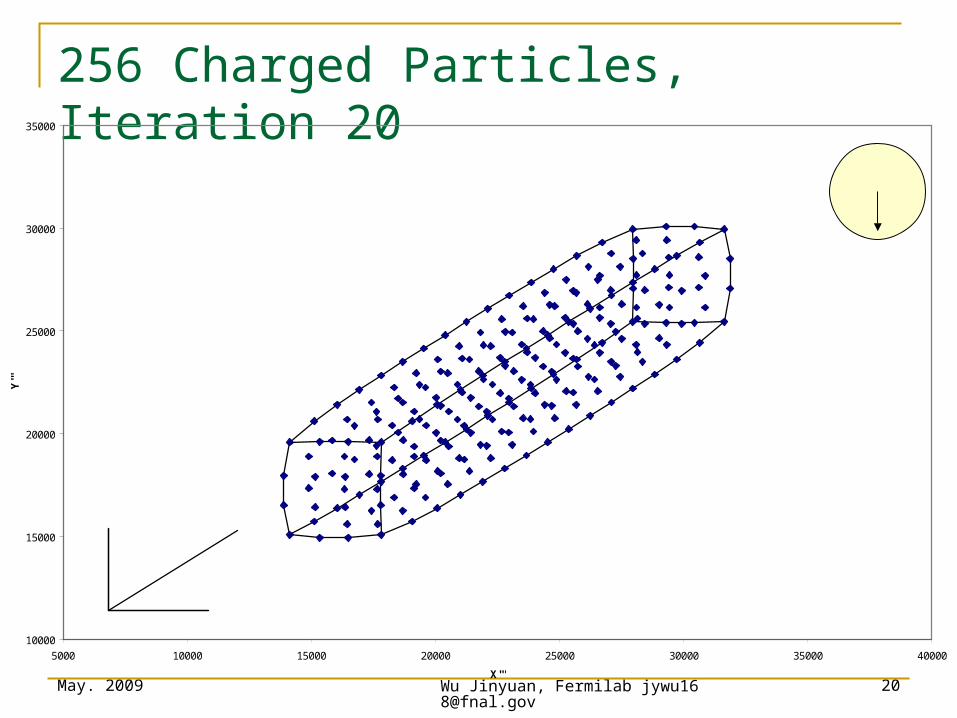
256 Charged Particles, Iteration 15
10000
15000
20000
25000
30000
35000
5000 10000 15000 20000 25000 30000 35000 40000
X'''
Y'''
May. 2009 Wu Jinyuan, Fermilab [email protected]
20
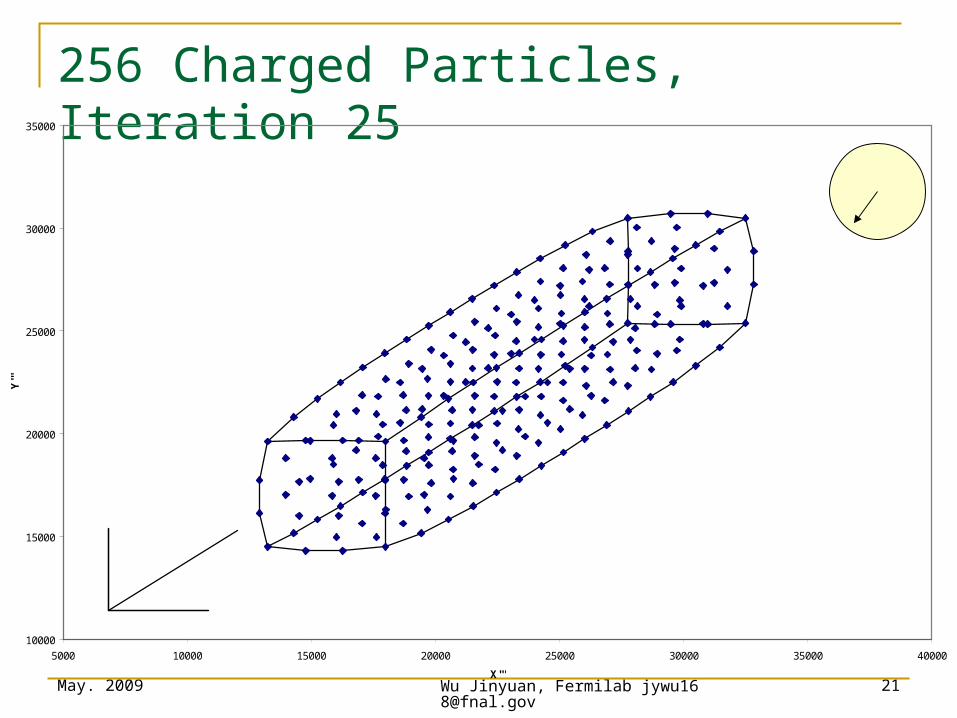
256 Charged Particles, Iteration 20
10000
15000
20000
25000
30000
35000
5000 10000 15000 20000 25000 30000 35000 40000
X'''
Y'''
May. 2009 Wu Jinyuan, Fermilab [email protected]
21
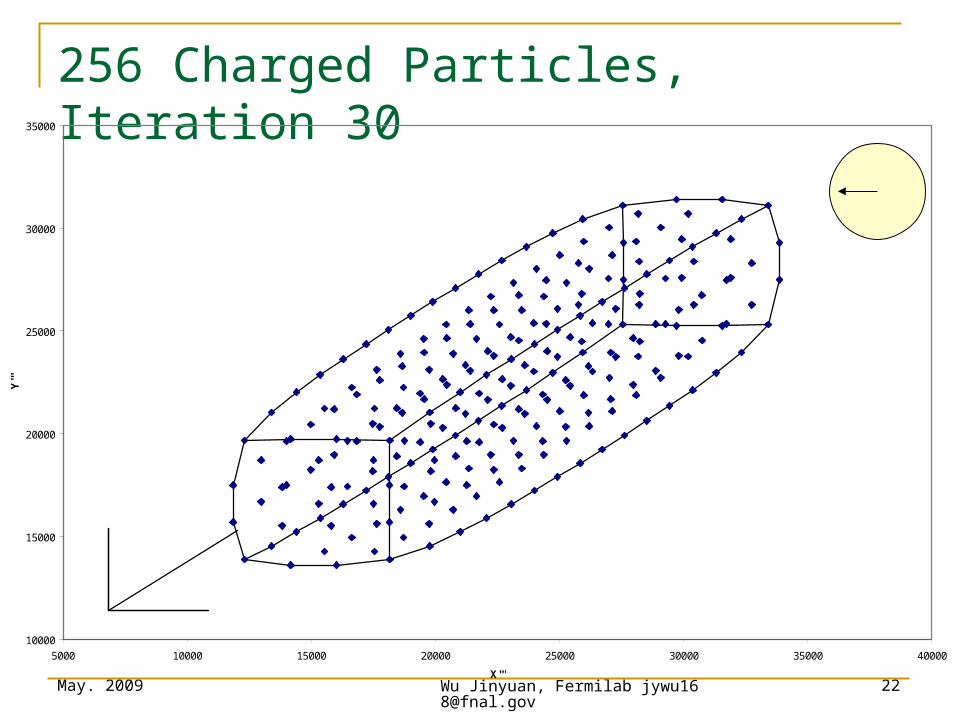
256 Charged Particles, Iteration 25
10000
15000
20000
25000
30000
35000
5000 10000 15000 20000 25000 30000 35000 40000
X'''
Y'''
May. 2009 Wu Jinyuan, Fermilab [email protected]
22
256 Charged Particles, Iteration 30
10000
15000
20000
25000
30000
35000
5000 10000 15000 20000 25000 30000 35000 40000
X'''
Y'''
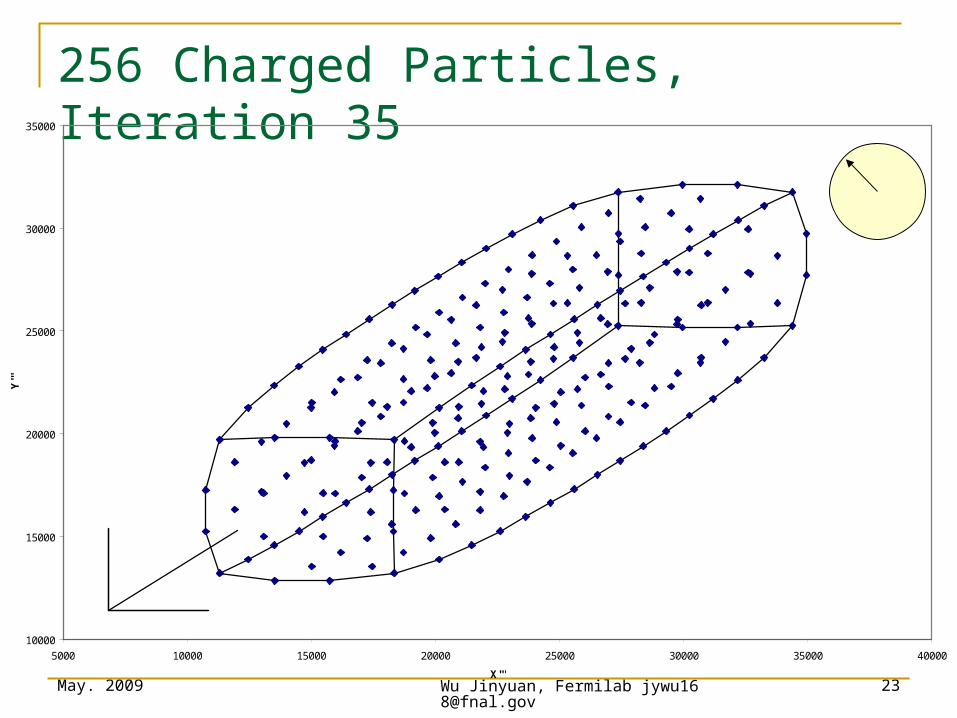
May. 2009 Wu Jinyuan, Fermilab [email protected]
23
256 Charged Particles, Iteration 35
10000
15000
20000
25000
30000
35000
5000 10000 15000 20000 25000 30000 35000 40000
X'''
Y'''
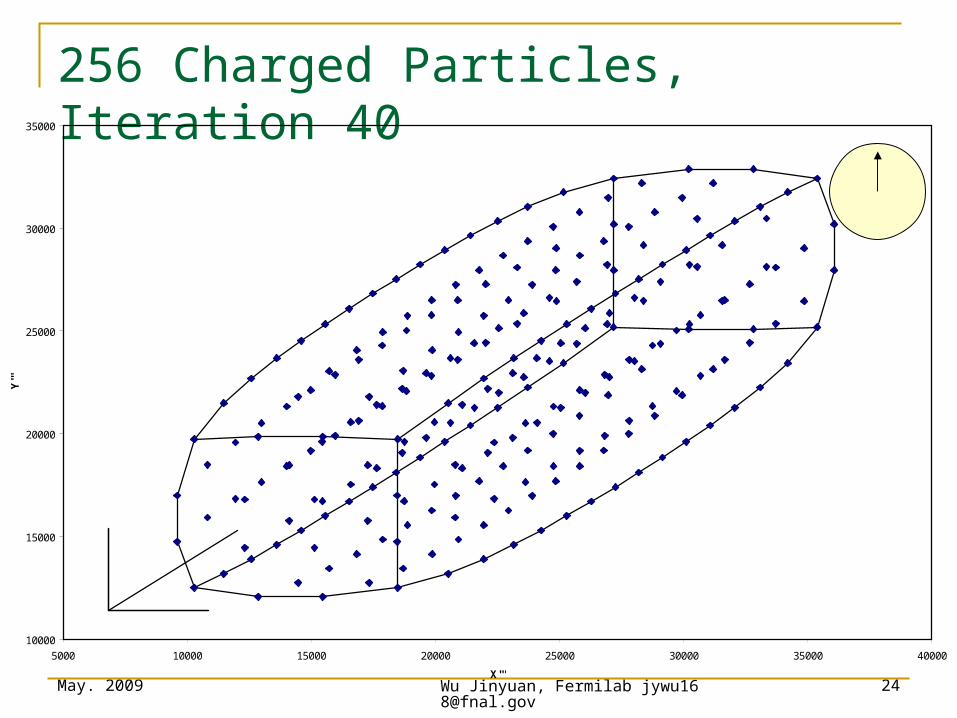
May. 2009 Wu Jinyuan, Fermilab [email protected]
24
256 Charged Particles, Iteration 40
10000
15000
20000
25000
30000
35000
5000 10000 15000 20000 25000 30000 35000 40000
X'''
Y'''
May. 2009 Wu Jinyuan, Fermilab [email protected]
25
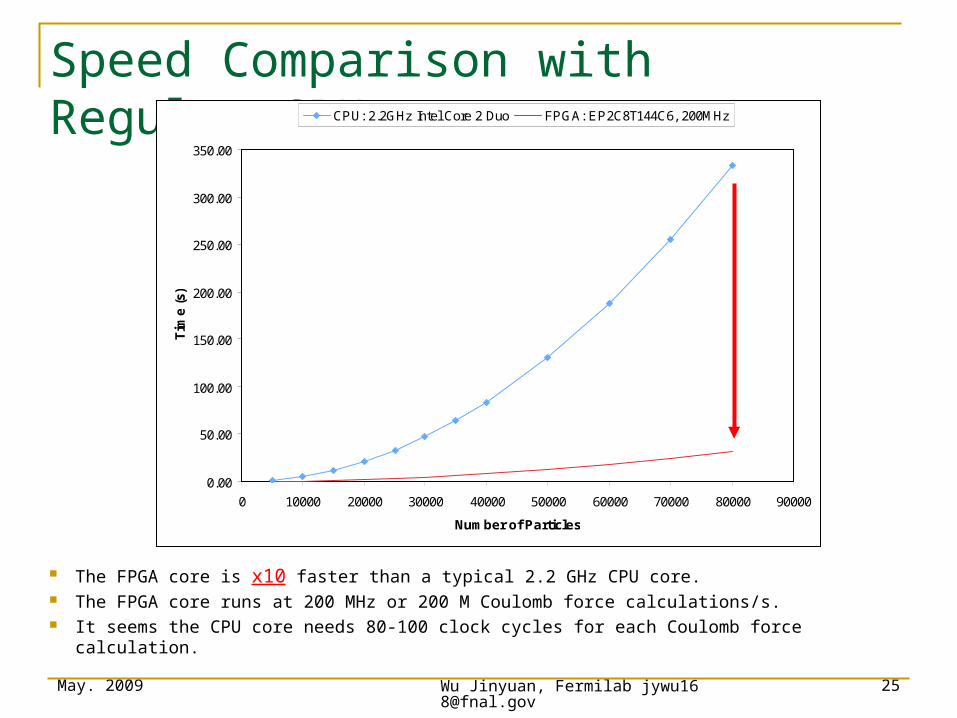
Speed Comparison with Regular CPU
The FPGA core is x10 faster than a typical 2.2 GHz CPU core. The FPGA core runs at 200 MHz or 200 M Coulomb force calculations/s. It seems the CPU core needs 80-100 clock cycles for each Coulomb force calculation.
0.00
50.00
100.00
150.00
200.00
250.00
300.00
350.00
0 10000 20000 30000 40000 50000 60000 70000 80000 90000
Number of Particles
Tim
e (s
)
CPU: 2.2GHz Intel Core 2 Duo FPGA: EP2C8T144C6, 200MHz
May. 2009 Wu Jinyuan, Fermilab [email protected]
26
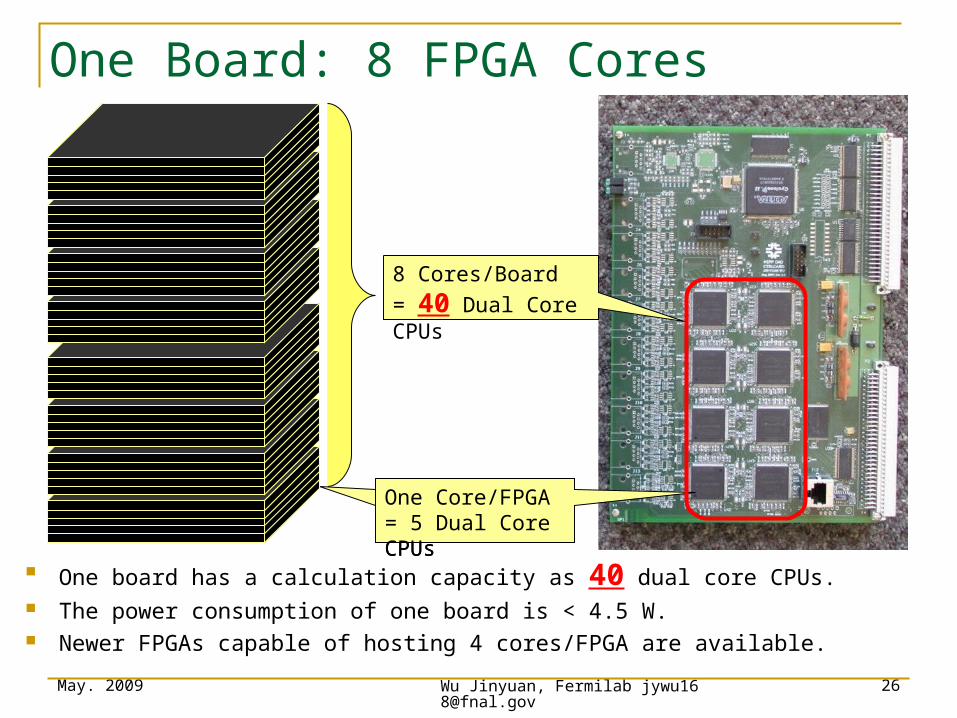
One Board: 8 FPGA Cores
One board has a calculation capacity as 40 dual core CPUs. The power consumption of one board is < 4.5 W. Newer FPGAs capable of hosting 4 cores/FPGA are available.
One Core/FPGA= 5 Dual Core CPUsOne Core/FPGA= 5 Dual Core CPUs
8 Cores/Board
= 40 Dual Core CPUs

May. 2009 Wu Jinyuan, Fermilab [email protected]
27
Outline Electronic Aspect of FPGA:
LED Flashing Logic Elements in a Nutshell TDC and ADC
FPGA as a Computing Fabric: Moore’s Law Forever? Space Charge Computing with FPGA Cores Doublet Matching & Hash Sorter Triplet Matching & Tiny Triplet Finder Enclosed Loop Micro-Sequencer (ELMS)
May. 2009 Wu Jinyuan, Fermilab [email protected]
28
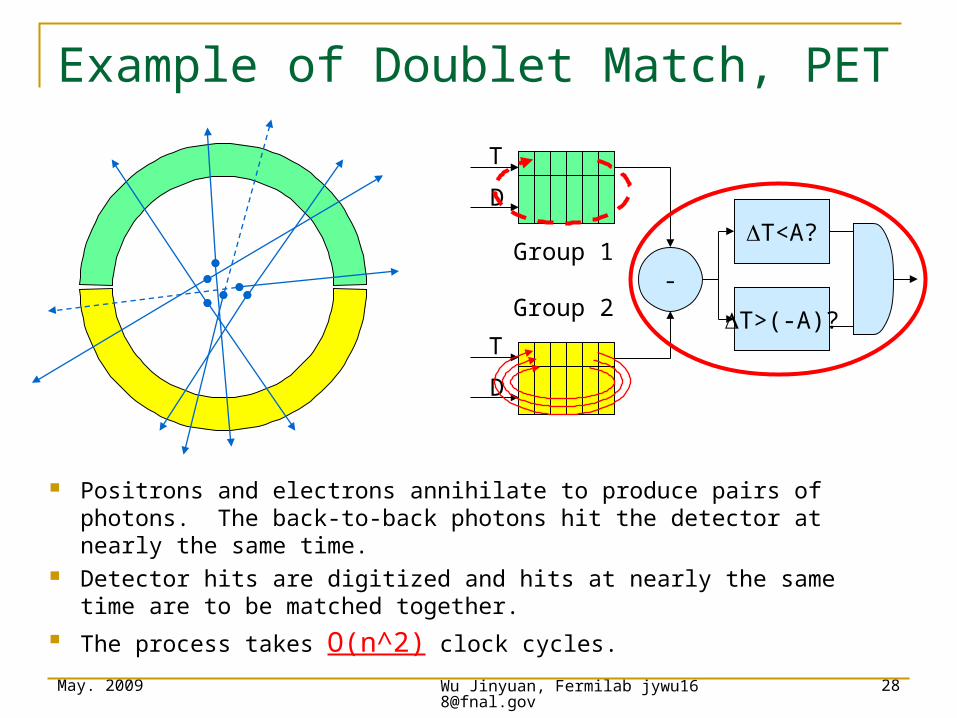
Example of Doublet Match, PET
Positrons and electrons annihilate to produce pairs of photons. The back-to-back photons hit the detector at nearly the same time.
Detector hits are digitized and hits at nearly the same time are to be matched together.
The process takes O(n^2) clock cycles.
T
D
T
D
Group 1
Group 2-
T<A?
T>(-A)?
May. 2009 Wu Jinyuan, Fermilab [email protected]
29
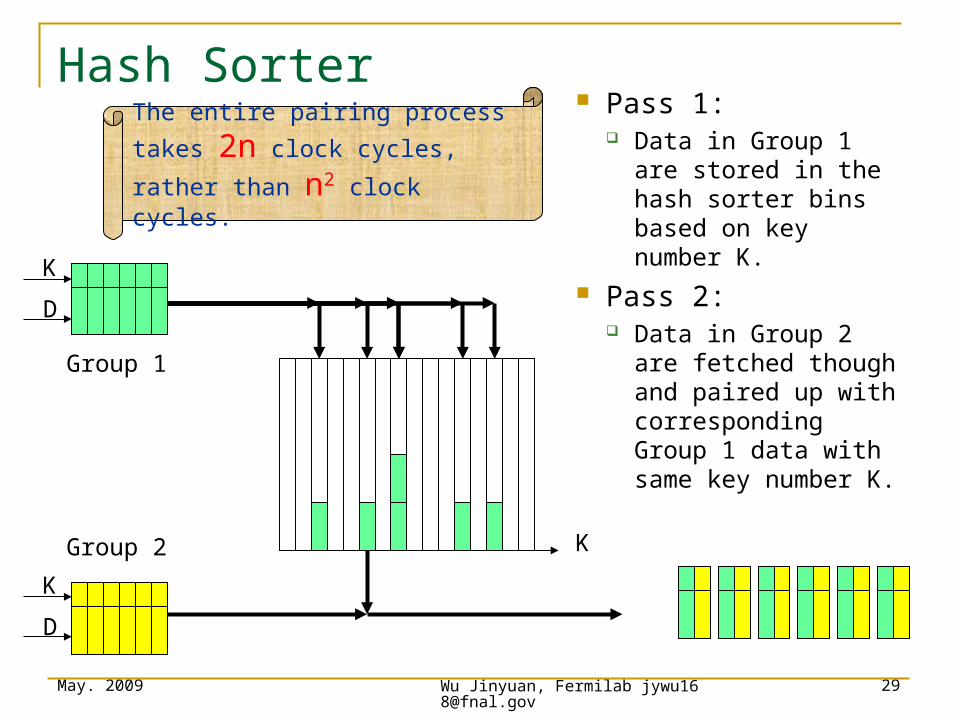
Hash Sorter
K
K
D
K
D
Pass 1: Data in Group 1 are
stored in the hash sorter bins based on key number K.
Pass 2: Data in Group 2 are
fetched though and paired up with corresponding Group 1 data with same key number K.
Group 1
Group 2
The entire pairing process
takes 2n clock cycles, rather
than n2 clock cycles.
May. 2009 Wu Jinyuan, Fermilab [email protected]
30
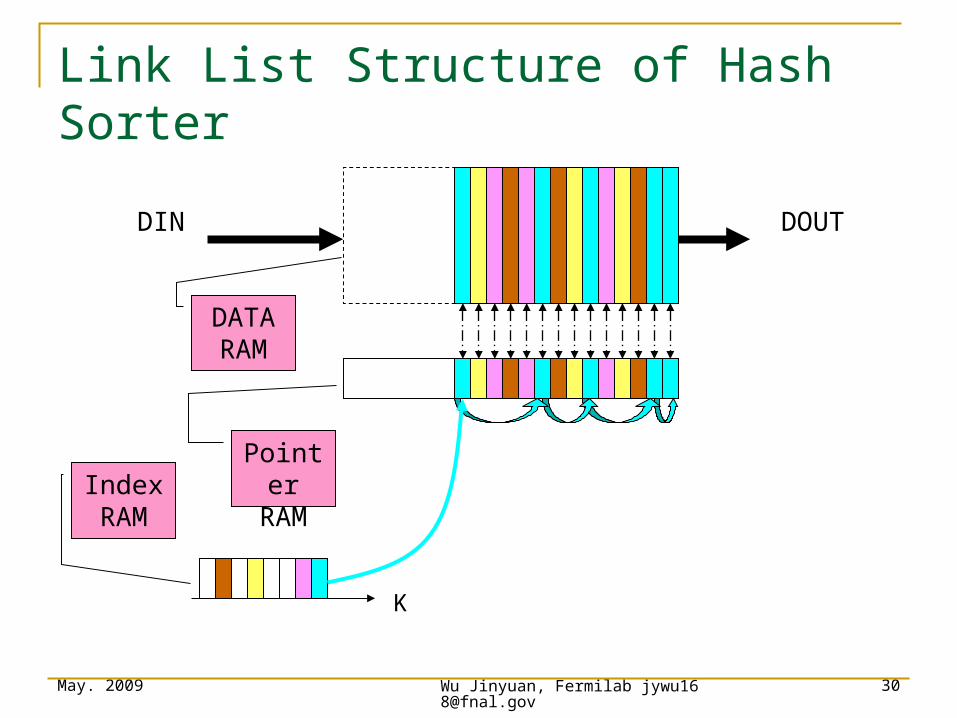
DIN DOUT
Index RAM
Pointer RAM
DATA RAM
K
Link List Structure of Hash Sorter
May. 2009 Wu Jinyuan, Fermilab [email protected]
31
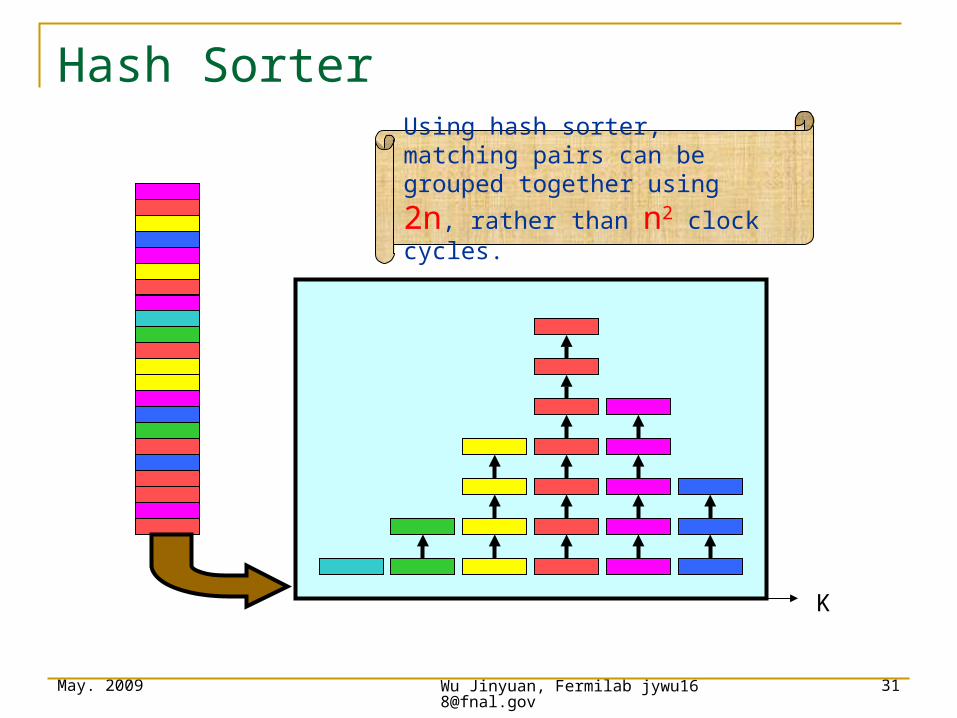
Hash Sorter
K
Using hash sorter, matching pairs can be grouped together
using 2n, rather than n2 clock cycles.

May. 2009 Wu Jinyuan, Fermilab [email protected]
32
Outline Electronic Aspect of FPGA:
LED Flashing Logic Elements in a Nutshell TDC and ADC
FPGA as a Computing Fabric: Moore’s Law Forever? Space Charge Computing with FPGA Cores Doublet Matching & Hash Sorter Triplet Matching & Tiny Triplet Finder Enclosed Loop Micro-Sequencer (ELMS)
May. 2009 Wu Jinyuan, Fermilab [email protected]
33
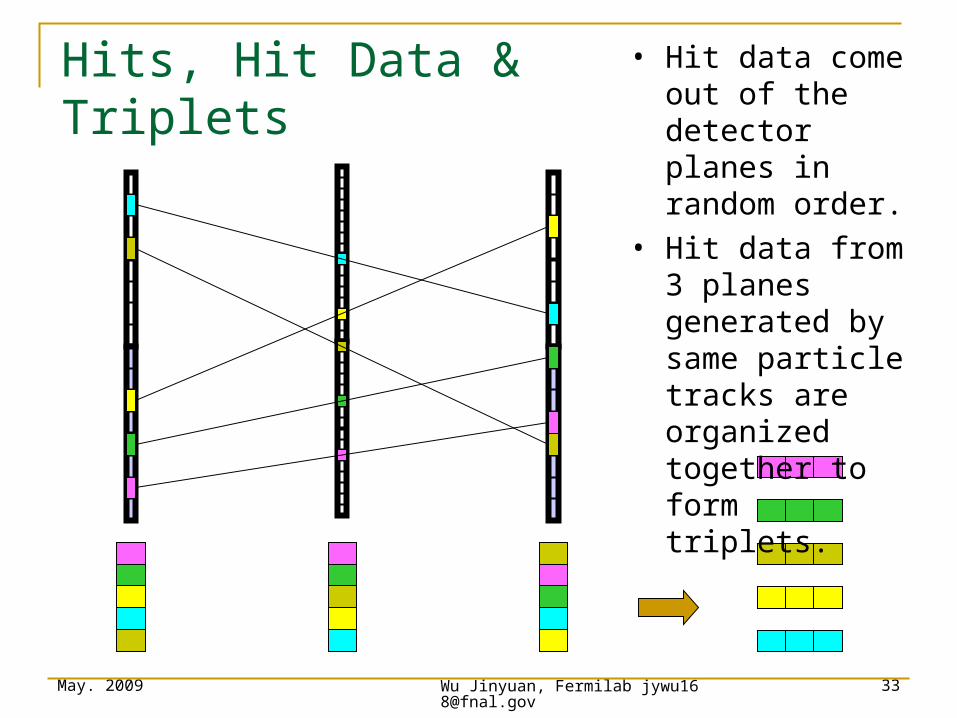
Hits, Hit Data & Triplets
• Hit data come out of the detector planes in random order.
• Hit data from 3 planes generated by same particle tracks are organized together to form triplets.
May. 2009 Wu Jinyuan, Fermilab [email protected]
34
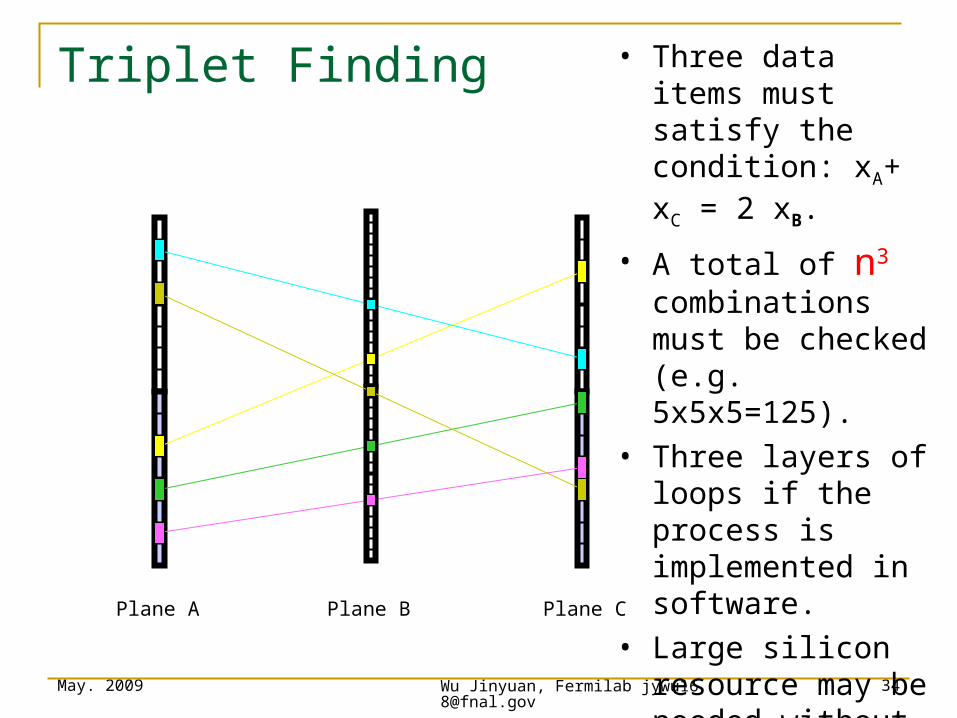
• Three data items must satisfy the condition: xA+ xC = 2 xB.
• A total of n3 combinations must be checked (e.g. 5x5x5=125).
• Three layers of loops if the process is implemented in software.
• Large silicon resource may be needed without careful
planning: O(N2)
Triplet Finding
Plane A Plane B Plane C
May. 2009 Wu Jinyuan, Fermilab [email protected]
35
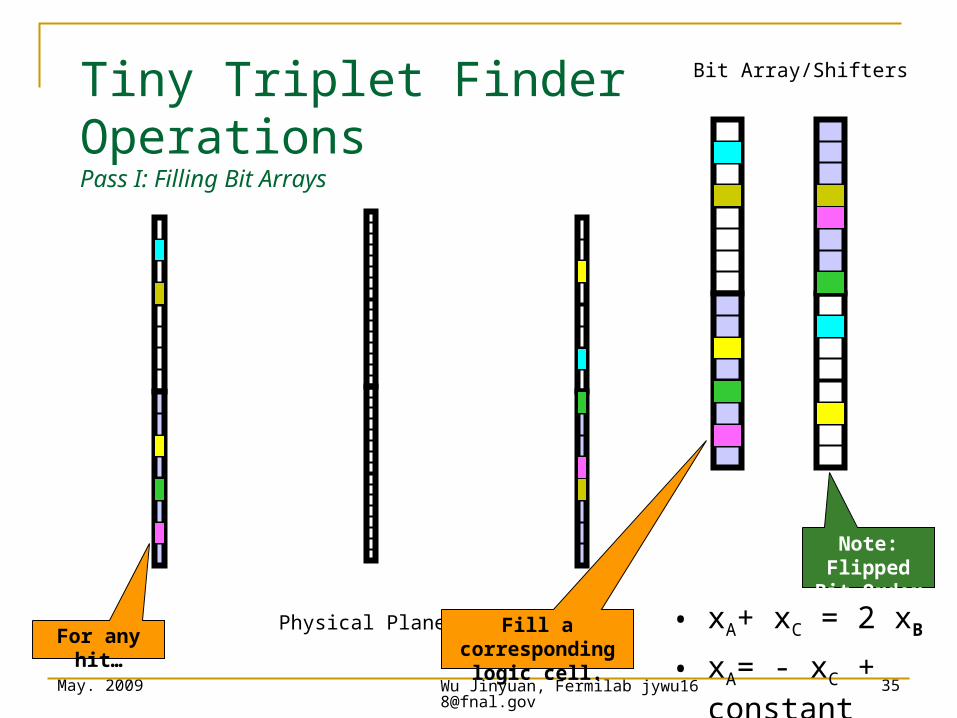
Tiny Triplet Finder OperationsPass I: Filling Bit Arrays
Note: Flipped Bit Order
Physical Planes
Bit Array/Shifters
For any hit… Fill a corresponding logic cell.
• xA+ xC = 2 xB
• xA= - xC + constant
May. 2009 Wu Jinyuan, Fermilab [email protected]
36
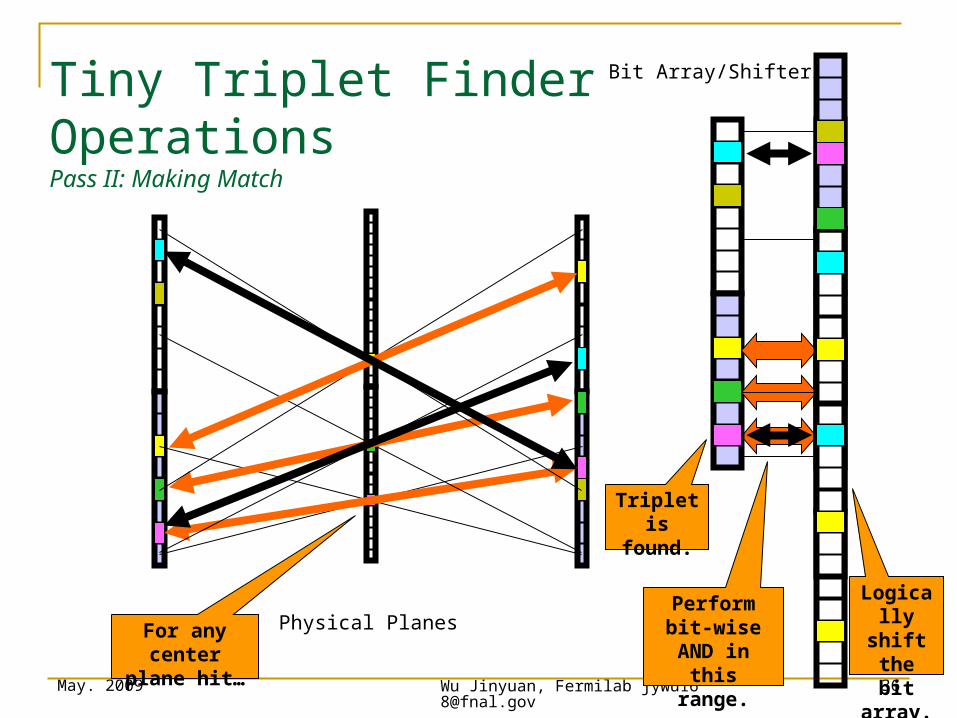
Tiny Triplet Finder Operations Pass II: Making Match
For any center plane hit…
Logically shift the
bit array.
Perform bit-wise AND in this range.
Triplet is found.
Physical Planes
Bit Array/Shifters
May. 2009 Wu Jinyuan, Fermilab [email protected]
37
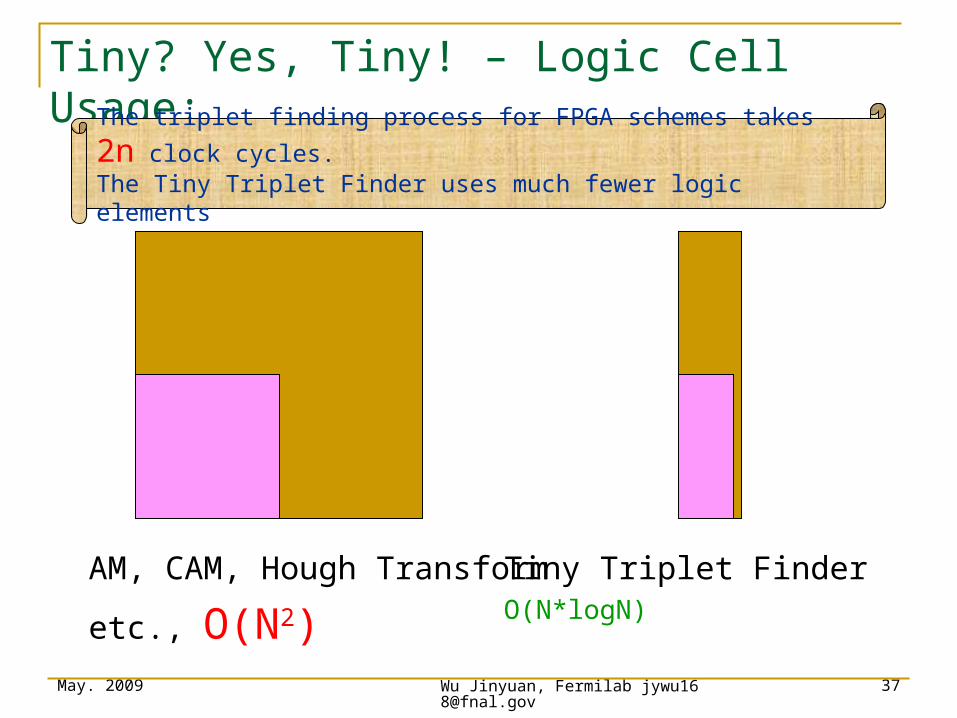
Tiny? Yes, Tiny! – Logic Cell Usage:
AM, CAM, Hough Transform
etc., O(N2)
Tiny Triplet FinderO(N*logN)
The triplet finding process for FPGA schemes takes 2n clock cycles. The Tiny Triplet Finder uses much fewer logic elements
May. 2009 Wu Jinyuan, Fermilab [email protected]
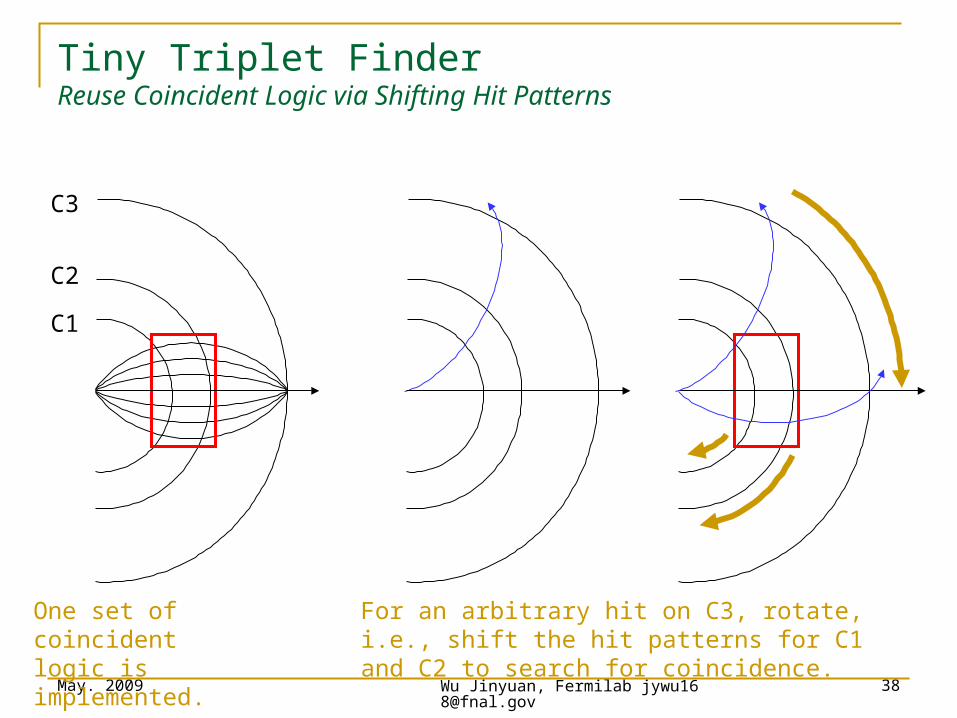
38
Tiny Triplet FinderReuse Coincident Logic via Shifting Hit Patterns
C1
C2
C3
One set of coincident logic is implemented.
For an arbitrary hit on C3, rotate, i.e., shift the hit patterns for C1 and C2 to search for coincidence.
May. 2009 Wu Jinyuan, Fermilab [email protected]
39
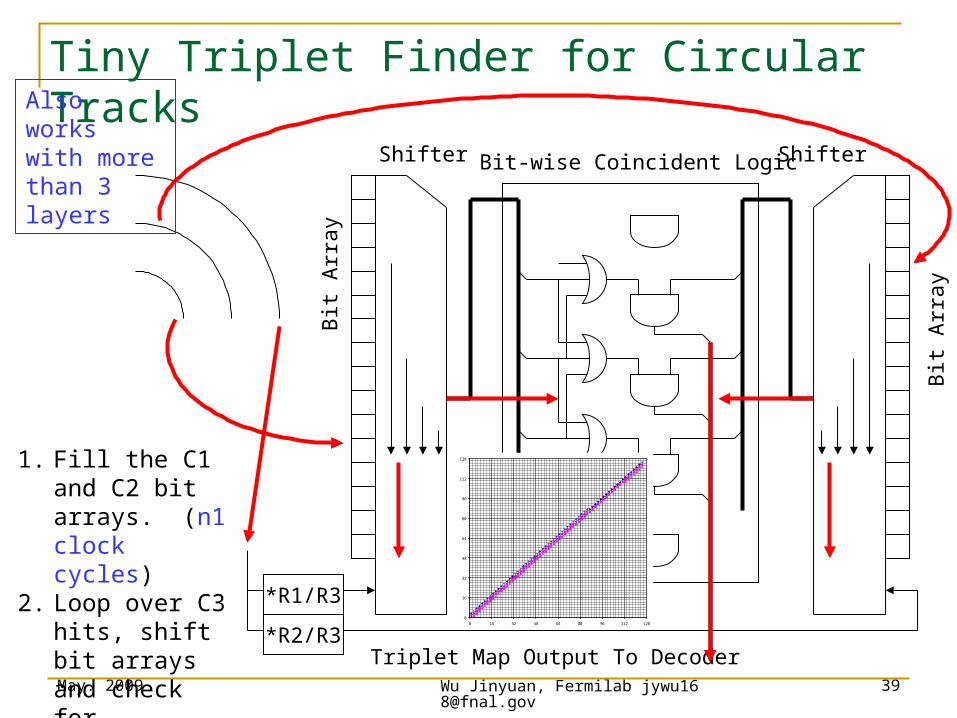
Tiny Triplet Finder for Circular Tracks
*R1/R3
*R2/R3Triplet Map Output To Decoder
Bit
Arr
ay
Shifter
Bit
Arr
ay
ShifterBit-wise Coincident Logic
0
16
32
48
64
80
96
112
128
0 16 32 48 64 80 96 112 128
1. Fill the C1 and C2 bit arrays. (n1 clock cycles)
2. Loop over C3 hits, shift bit arrays and check for coincidence. (n3 clock cycles)
Also works with more than 3 layers
May. 2009 Wu Jinyuan, Fermilab [email protected]
40
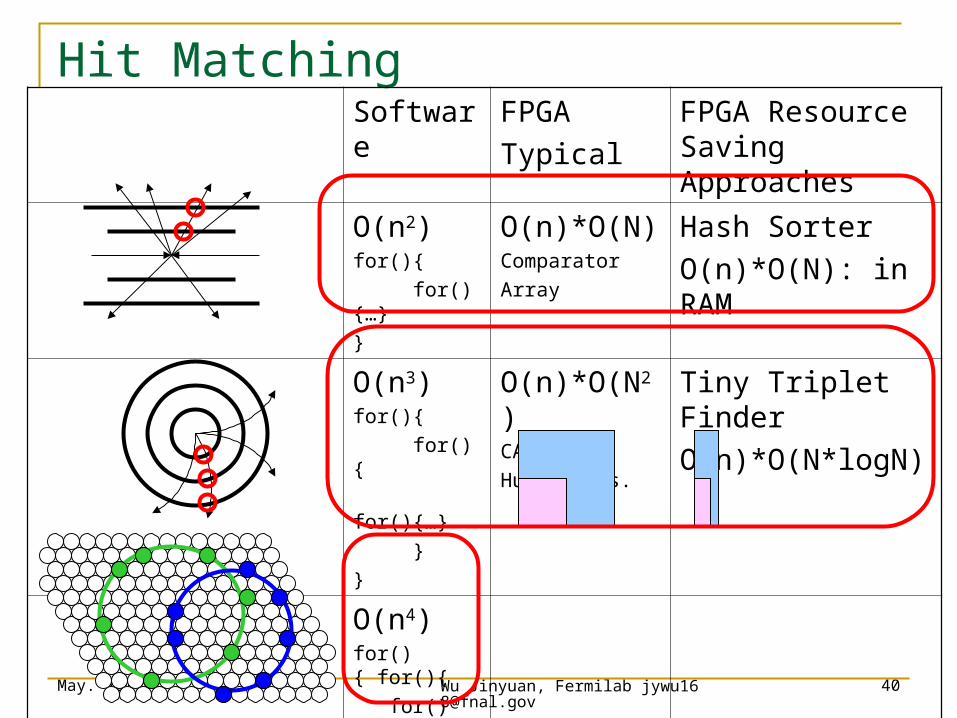
Hit MatchingSoftware FPGA
Typical
FPGA Resource Saving Approaches
O(n2)for(){
for(){…}
}
O(n)*O(N)Comparator
Array
Hash Sorter
O(n)*O(N): in RAM
O(n3)for(){
for(){
for(){…}
}
}
O(n)*O(N2)CAM,
Hugh Trans.
Tiny Triplet Finder
O(n)*O(N*logN)
O(n4)for(){ for(){
for(){ for()
{…}
}}}

May. 2009 Wu Jinyuan, Fermilab [email protected]
41
Outline Electronic Aspect of FPGA:
LED Flashing Logic Elements in a Nutshell TDC and ADC
FPGA as a Computing Fabric: Moore’s Law Forever? Space Charge Computing with FPGA Cores Doublet Matching & Hash Sorter Triplet Matching & Tiny Triplet Finder Enclosed Loop Micro-Sequencer (ELMS)
May. 2009 Wu Jinyuan, Fermilab [email protected]
42
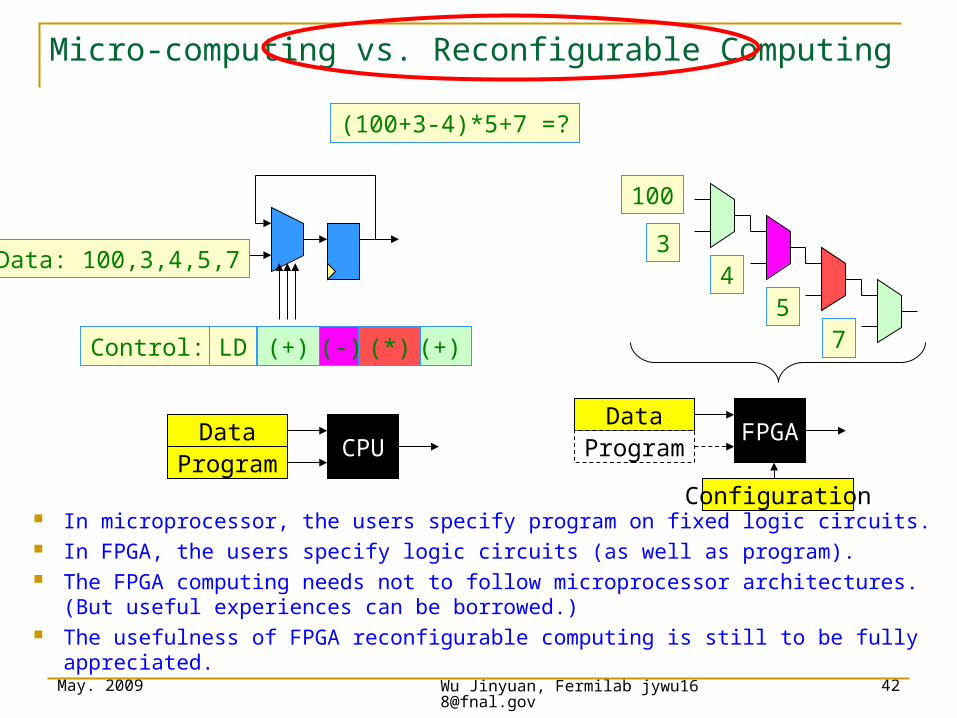
Micro-computing vs. Reconfigurable Computing
In microprocessor, the users specify program on fixed logic circuits. In FPGA, the users specify logic circuits (as well as program). The FPGA computing needs not to follow microprocessor architectures. (But useful
experiences can be borrowed.) The usefulness of FPGA reconfigurable computing is still to be fully appreciated.
(100+3-4)*5+7 =?
100
34
57Control:
Data: 100,3,4,5,7
LD (-) (+)(*)(+)
CPUFPGAData
ProgramConfiguration
DataProgram
May. 2009 Wu Jinyuan, Fermilab [email protected]
43
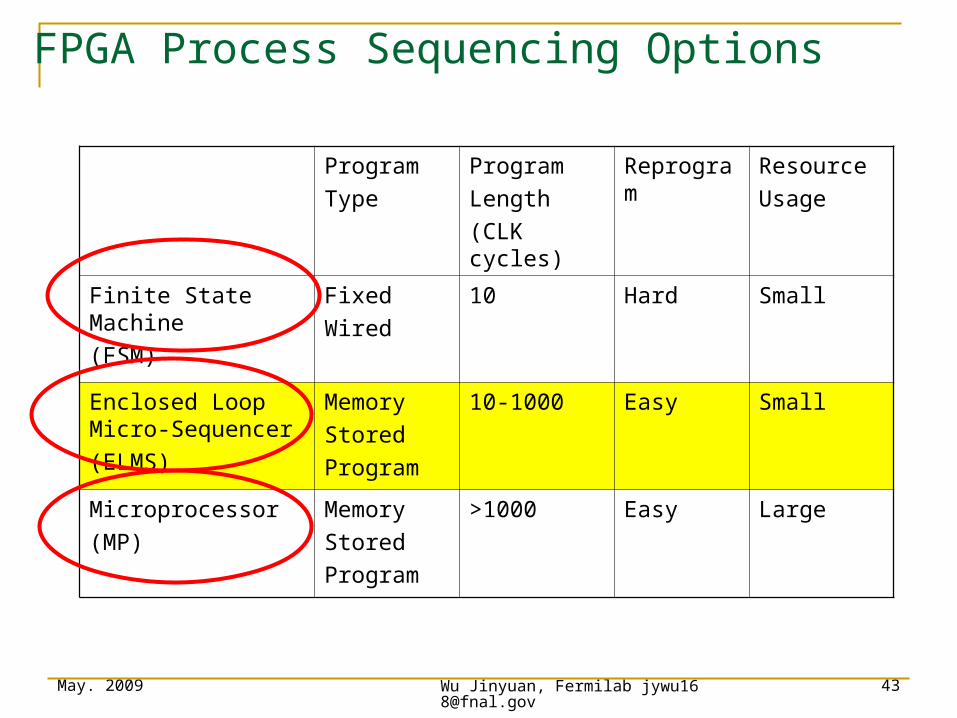
FPGA Process Sequencing Options
Program
Type
Program
Length
(CLK cycles)
Reprogram Resource
Usage
Finite State Machine
(FSM)
Fixed
Wired
10 Hard Small
Enclosed Loop Micro-Sequencer
(ELMS)
Memory
Stored
Program
10-1000 Easy Small
Microprocessor
(MP)
Memory
Stored
Program
>1000 Easy Large
May. 2009 Wu Jinyuan, Fermilab [email protected]
44
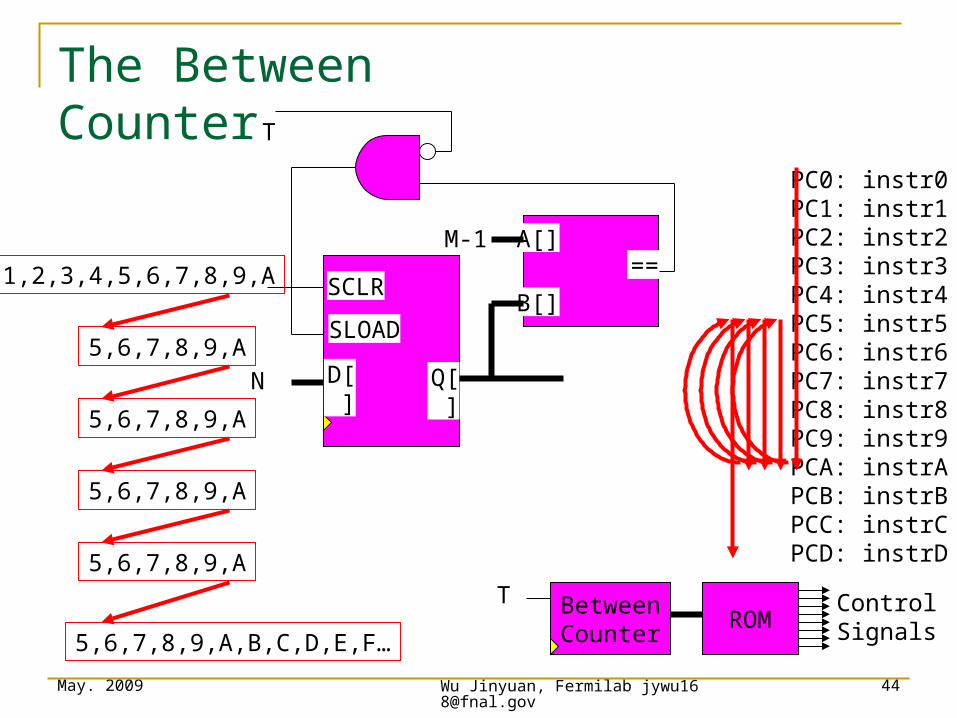
The Between Counter
0,1,2,3,4,5,6,7,8,9,A
5,6,7,8,9,ASLOAD
D[]
SCLR
N Q[]
M-1==
A[]
B[]
T
5,6,7,8,9,A
5,6,7,8,9,A
5,6,7,8,9,A
5,6,7,8,9,A,B,C,D,E,F…
PC0: instr0PC1: instr1PC2: instr2PC3: instr3PC4: instr4PC5: instr5PC6: instr6PC7: instr7PC8: instr8PC9: instr9PCA: instrAPCB: instrBPCC: instrCPCD: instrD
TROM
BetweenCounter
ControlSignals
May. 2009 Wu Jinyuan, Fermilab [email protected]
45
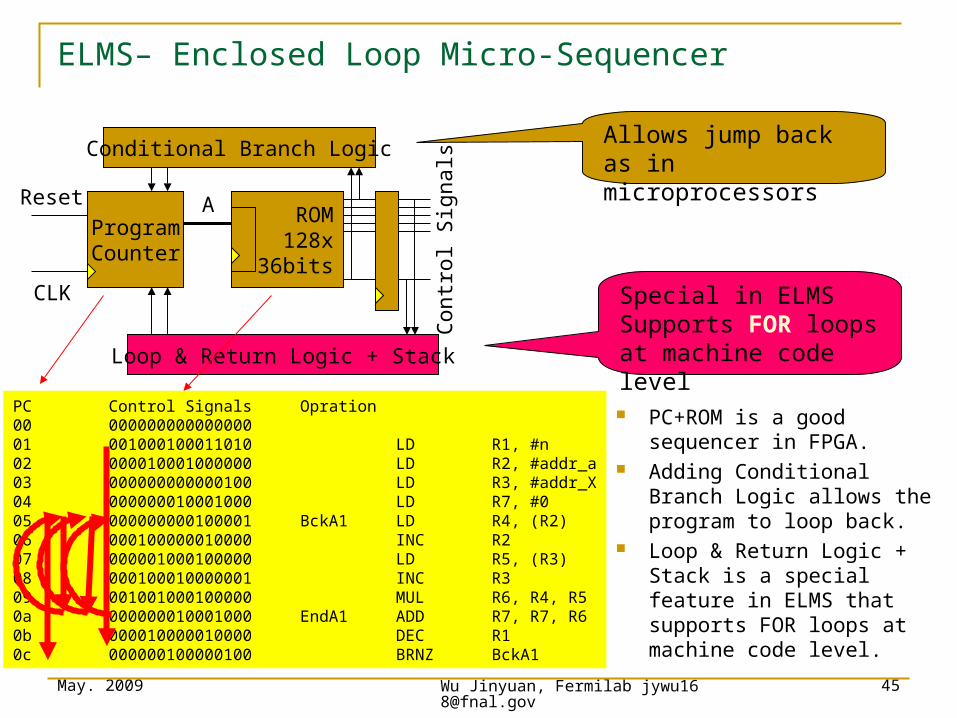
ELMS– Enclosed Loop Micro-Sequencer
Loop & Return Logic + Stack
Conditional Branch Logic
ProgramCounter
ROM128x
36bits
AReset
CLK Con
trol
Sig
nals
PC Control Signals Opration00 000000000000000 01 001000100011010 LD R1, #n02 000010001000000 LD R2, #addr_a03 000000000000100 LD R3, #addr_X04 000000010001000 LD R7, #005 000000000100001 BckA1 LD R4, (R2)06 000100000010000 INC R207 000001000100000 LD R5, (R3)08 000100010000001 INC R309 001001000100000 MUL R6, R4, R50a 000000010001000 EndA1 ADD R7, R7, R60b 000010000010000 DEC R10c 000000100000100 BRNZ BckA1
Special in ELMSSupports FOR loops at machine code level
PC+ROM is a good sequencer in FPGA.
Adding Conditional Branch Logic allows the program to loop back.
Loop & Return Logic + Stack is a special feature in ELMS that supports FOR loops at machine code level.
Allows jump back as in microprocessors
May. 2009 Wu Jinyuan, Fermilab [email protected]
46
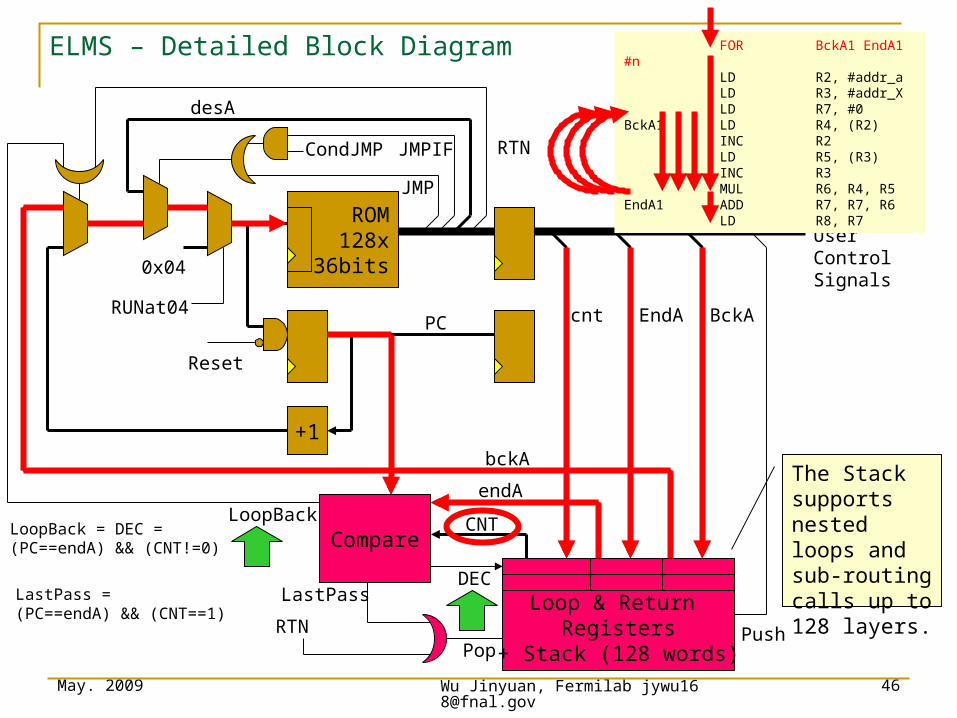
ELMS – Detailed Block Diagram
UserControlSignals
ROM128x
36bits
+1
CondJMP
PC
Reset
Loop & Return Registers
+ Stack (128 words)
Compare
RTNJMPIF
CNT
endA
bckA
PushPop
LoopBack
DEC
RTN
LastPass
LoopBack = DEC =(PC==endA) && (CNT!=0)
LastPass =(PC==endA) && (CNT==1)
desA
JMP
0x04
RUNat04 cnt EndA BckA
FOR BckA1 EndA1 #nLD R2, #addr_aLD R3, #addr_XLD R7, #0
BckA1 LD R4, (R2)INC R2LD R5, (R3)INC R3MUL R6, R4, R5
EndA1 ADD R7, R7, R6LD R8, R7
The Stack supports nested loops and sub-routing calls up to 128 layers.

May. 2009 Wu Jinyuan, Fermilab [email protected]
48
What’s Good About ELMS: FOR Loops at Machine Code Level w/ Zero-Over Head
Looping sequence is known in this example before entering the loop. Regular micro-processor treat the sequence as unknown. ELMS supports FOR loops with pre-defined iterations at machine code level. Execution time is saved and micro-complexities (branch penalty, pipeline bubble, etc.)
associated with conditional branches are avoided.
LD R1, #nLD R2, #addr_aLD R3, #addr_XLD R7, #0
BckA1 LD R4, (R2)INC R2LD R5, (R3)INC R3MUL R6, R4, R5
EndA1 ADD R7, R7, R6DEC R1BRNZ BckA1
FOR BckA1 EndA1 #nLD R2, #addr_aLD R3, #addr_XLD R7, #0
BckA1 LD R4, (R2)INC R2LD R5, (R3)INC R3MUL R6, R4, R5
EndA1 ADD R7, R7, R6
n
iii XaY
0
25%
Microprocessor The ELMS
Conditional Branch
May. 2009 Wu Jinyuan, Fermilab [email protected]
49
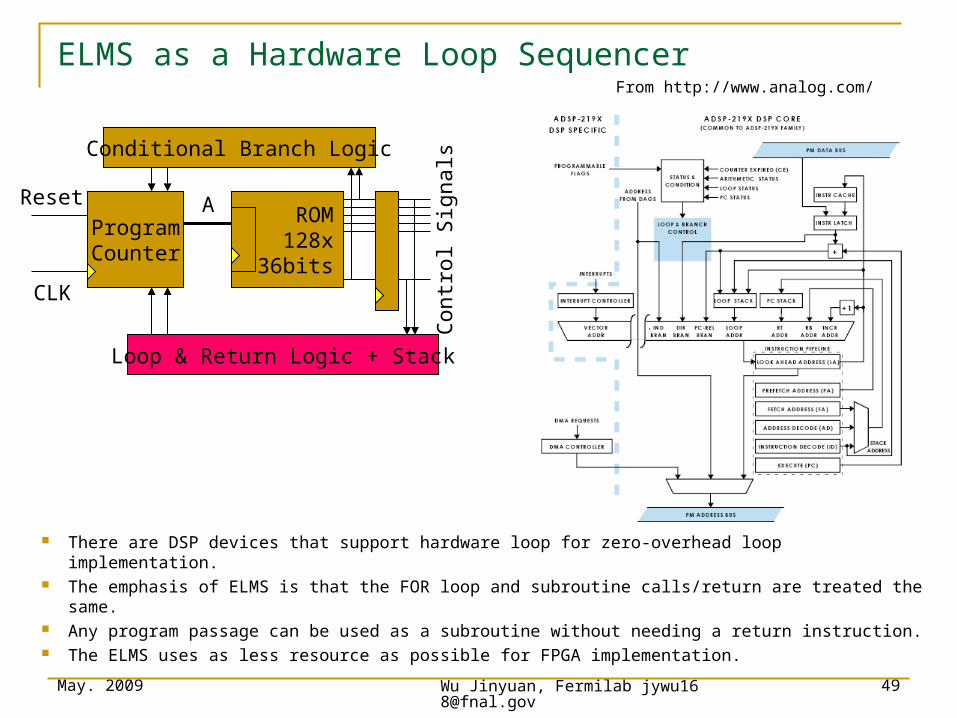
ELMS as a Hardware Loop Sequencer
Loop & Return Logic + Stack
Conditional Branch Logic
ProgramCounter
ROM128x
36bits
AReset
CLK Con
trol
Sig
nals
There are DSP devices that support hardware loop for zero-overhead loop implementation. The emphasis of ELMS is that the FOR loop and subroutine calls/return are treated the same. Any program passage can be used as a subroutine without needing a return instruction. The ELMS uses as less resource as possible for FPGA implementation.
From http://www.analog.com/
May. 2009 Wu Jinyuan, Fermilab [email protected]
50
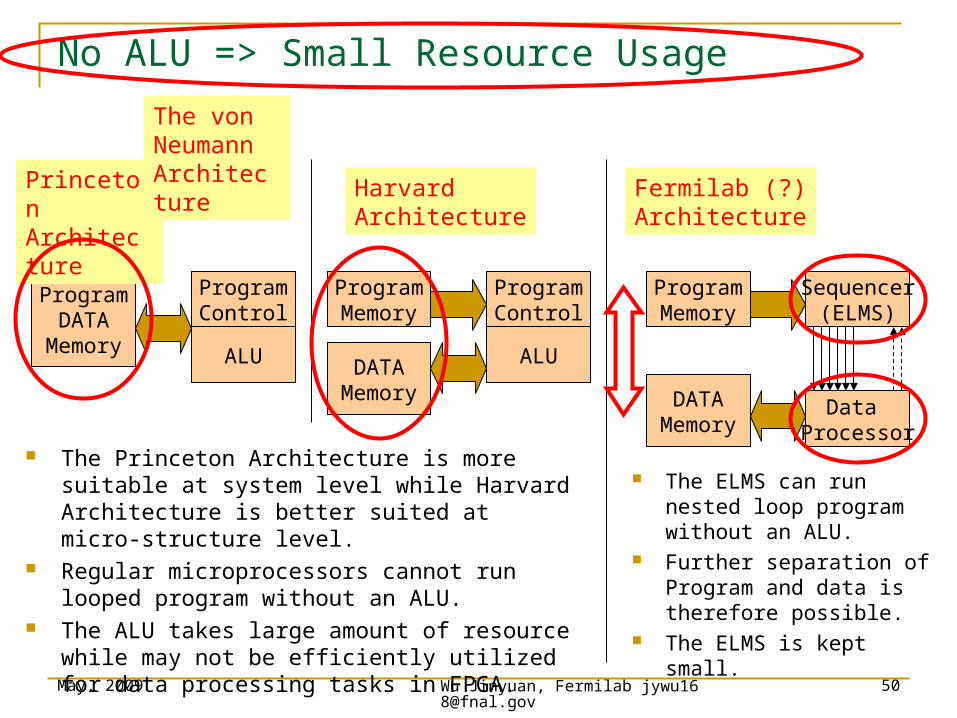
No ALU => Small Resource Usage
ProgramDATA
Memory
PrincetonArchitecture
HarvardArchitecture
Fermilab (?)Architecture
ProgramControl
ALU
ProgramMemory
ProgramControl
ALUDATAMemory
ProgramMemory
Sequencer(ELMS)
Data Processor
DATAMemory
The Princeton Architecture is more suitable at system level while Harvard Architecture is better suited at micro-structure level.
Regular microprocessors cannot run looped program without an ALU.
The ALU takes large amount of resource while may not be efficiently utilized for data processing tasks in FPGA.
The ELMS can run nested loop program without an ALU.
Further separation of Program and data is therefore possible.
The ELMS is kept small.
The von NeumannArchitecture
May. 2009 Wu Jinyuan, Fermilab [email protected]
51
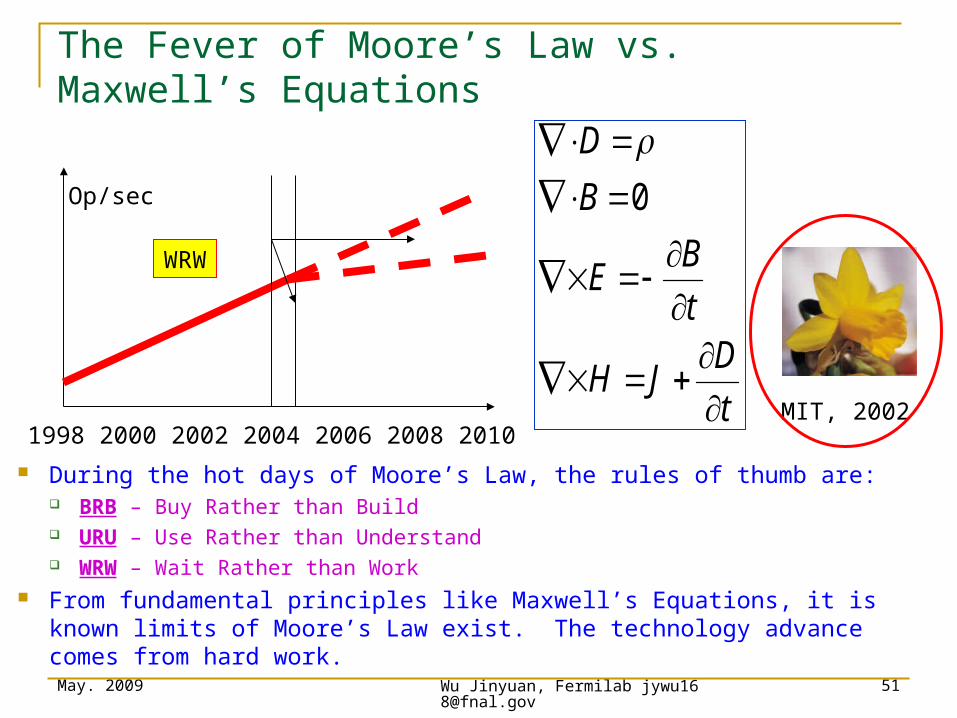
The Fever of Moore’s Law vs. Maxwell’s Equations
t
DJH
t
BE
B
D
0
1998 2000 2002 2004 2006 2008 2010
Op/sec
MIT, 2002
During the hot days of Moore’s Law, the rules of thumb are: BRB – Buy Rather than Build URU – Use Rather than Understand WRW – Wait Rather than Work
From fundamental principles like Maxwell’s Equations, it is known limits of Moore’s Law exist. The technology advance comes from hard work.
WRW

May. 2009 Wu Jinyuan, Fermilab [email protected]
52
Indirect Cost of Complexity
If something like this can do the job…
… why do these?

May. 2009 Wu Jinyuan, Fermilab [email protected]
53
The Winning Line of FPGA Computing
We commonly heard: FPGA devices contains millions gate. High parallelism can be implemented in FPGA. FPGA cost drops by half every 18 months.
We want to emphasize, especially to our young students:
1. Creativity,
2. Creativity,
3. Creativity, on Arithmetic ops, on Algorithms, on Architectures & on All Aspects.
O Freunde, nicht diese Töne!
