feasibility studies of hpc cloud - nchcevent.nchc.org.tw/2011/southeast_asia/upload/content...– a...
TRANSCRIPT

Feasibility Studies of HPC Cloud
SEAIP2011@Taichung, Nov.29 2011
Yoshio Tanaka
Information Technology Research Institute, National Institute of Advanced Industrial Science and Technology (AIST),
Japan

HPC Cloud HPC Cloud utilizes cloud resources in High Performance Computing (HPC) applications
2
Physical Cluster
Virtualized Clusters
Users require resources according to needs
Provider allocates users a dedicated virtual cluster on demand

Advanced HPC Infrastructure
GEO Science Bio Informatics Nano Tech.
Gateway
Federation of HPC resources

Is HPC Cloud Promising? • Supposed Pros:
– User side: easy to deployment – Provider side: high resource utilization
• Supposed Cons: – Performance degradation?
4
Are these supposed Pros & Cons correct ?
• Is it easy to deploy applications? • Are resources highly utilized? • How is the performance degradation? • What are the other issues need to be solved?

Challenges – Resource Mgmt. - • How should we hide heterogeneity of
supercomputers? – A lot of works have to be done in traditional Grid.
• Deployment & test on each system.
– Need to enable easy deployments of applications. • Build Once, Run Everywhere
• Meta-scheduler and monitoring – A lot of papers, but no practical meta-scheduler. – Monitoring with appropriate security is also a
challenging issue. – Need to enable appropriate scheduling based on SLA
and monitoring.

Challenges – Network and Security -
• Is best-effort basis Internet fine? – Network should be one of Cloud resources. – E.g. performance-assured optical path.
• Virtualization of interconnection – IB, Myrinet, 10/100G – How should we reduce overhead?
• What is appropriate security for HPC Cloud? – Should we continue to use GSI? – ID management and ID federation are the keys.
• OpenID Connect / OAuth 2.0

Challenges – Storage -
• Location-transparent storage – Could be used for sharing VM images and storing
input and output data. – S3-like Cloud storage? – Shared / Global file system? – Dropbox? – Any possibility to use fast file transfer services (e.g.
Globus Online)?

Contents of the rest of my talk
• Performance evaluation of HPC Cloud – Performance tuning – Evaluation
• Inter-cloud QoS-guaranteed Virtual Infrastructure
8

0
20
40
60
80
100
0 100 200 300 400 500
InfiniBandGigabit Ethernet10 Gigabit Ethernet
LINPACK Efficiency
※Efficiency=(Maximum LINPACK performance:Rmax)/(Theoretical peak performance:Rpeak)
InfiniBand: 79%
Gigabit Ethernet: 54%
10 Gigabit Ethernet: 74%
TOP500 rank
Effi
cien
cy (
%)
TOP500 June 2011
#451 Amazon EC2 cluster compute instances
Virtualization causes the performance degradation!
GPGPU machines

Current HPC Cloud
Its performance is not good and
unstable.
“True” HPC Cloud The performance is
closing to that of bare metals.
Toward a practical HPC Cloud
Use PCI passthrough
Set NUMA affinity
Reduce VMM noise (not completed)
11
VM1
NIC
VMM
Physical driver
Guest OS
To reduce the overhead of interrupt virtualization To disable unnecessary services on the host OS (i.e., ksmd).
VM (QEMU process)
Linux kernel
KVM
Physical CPU
VCPU threads
Guest OS Threads
CPU socket

IO virtualization
12
IO emulation VM1
NIC
VMM
Guest driver
Physical driver
Guest OS VM2
vSwitch
…
PCI passthrough VM1
NIC
VMM
Physical driver
Guest OS VM2
…
SR-IOV VM1
NIC
VMM
Physical driver
Guest OS VM2
…
Switch (VEB)
IO emulation PCI passthrough SR-IOV VM sharing ✔ ✖ ✔
Performance ✖ ✔ ✔

NUMA affinity
14
P3
VM (QEMU process)
P0
Linux kernel
KVM
Physical CPU P1 P2
VCPU threads
Process scheduler
Guest OS
Threads
CPU socket
V3 V0 V1 V2
bind threads to vSocket
pin vCPU to CPU (Vn = Pn)
numactl
taskset
Bare Metal KVM Linux
P0 Physical CPU P1 P2 P3
Process scheduler
Threads
numactl
memory
memory
CPU socket

Evaluation
15
Compute node(Dell PowerEdge M610)
CPU Intel quad-core Xeon E5540/2.53GHz x2
Chipset Intel 5520
Memory 48 GB DDR3
InfiniBand Mellanox ConnectX (MT26428)
15
Blade switch
InfiniBand Mellanox M3601Q (QDR 16 ports)
Evaluation of HPC applications on 16 nodes cluster (part of AIST Green Cloud Cluster)
Host machine environment OS Debian 6.0.1
Linux kernel 2.6.32-5-amd64
KVM 0.12.50
Compiler gcc/gfortran 4.4.5
MPI Open MPI 1.4.2
VM environment VCPU 8 Memory 45 GB

MPI Point-to-Point communication performance
16
(higher is better)
PCI passthrough improves MPI communication throughput close to that of bare metal machines.
Bare Metal: non-virtualized cluster
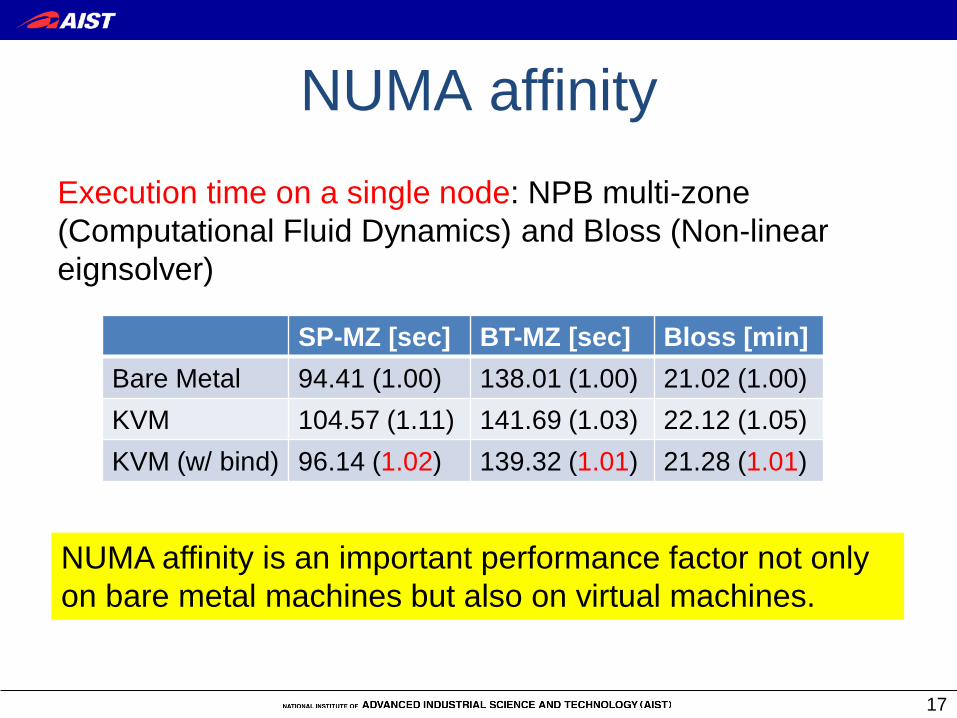
NUMA affinity Execution time on a single node: NPB multi-zone (Computational Fluid Dynamics) and Bloss (Non-linear eignsolver)
17
SP-MZ [sec] BT-MZ [sec] Bloss [min] Bare Metal 94.41 (1.00) 138.01 (1.00) 21.02 (1.00) KVM 104.57 (1.11) 141.69 (1.03) 22.12 (1.05) KVM (w/ bind) 96.14 (1.02) 139.32 (1.01) 21.28 (1.01)
NUMA affinity is an important performance factor not only on bare metal machines but also on virtual machines.

NPB BT-MZ: Parallel efficiency
18
0
20
40
60
80
100
0
50
100
150
200
250
300
1 2 4 8 16
Para
llel e
ffici
ency
[%]
Perf
orm
ance
[G
op/s
tota
l]
Number of nodes
Bare Metal
KVM
Amazon EC2
Bare Metal (PE)
KVM (PE)
Amazon EC2 (PE)
(higher is better)
Degradation of PE: KVM: 2%, EC2: 14%

Bloss: Parallel efficiency
19
Degradation of PE: KVM: 8%, EC2: 22%
Bloss: non-linear internal eigensolver – Hierarchical parallel program by MPI and OpenMP
Overhead of communication and virtualization

Insights gained through the experiments
HPC Cloud is promising! • The performance of coarse-grained parallel
applications is comparable to bare metal machines
• Open issues – VMM noise reduction – VMM-bypass device-aware VM scheduling – Live migration with VMM-bypass devices
20

Resource managements for federating Cloud
- Inter-cloud QoS-guaranteed Virtual Infrastructure -

Data Intensive Computing and Cloud • HPC may require access to huge data (data intensive
applications) – Cloud data centers own a large amount of computers and
storages, and provide a fragment of them as a "Virtual Infrastructure",
• Difficult to achieve performance of data intensive applications on a Cloud: – Peta-scale data may not be stored in a single cloud – Network has been considered as an "as is" resource
• Bandwidth between resources, such as computers and storage, is not guaranteed
Isolated and QoS-guaranteed Virtual Infrastructure (VI) constructed over Intercloud is required

Issues for Virtual Infrastructure (VI) over Inter-cloud
• A unified interface and scheduling system to request network and other resources – R&E networks have begun delivering dynamic network
service, which can guarantee network bandwidth – Dynamic circuit services have not been utilized effectively
• A mechanism to set up an isolated application execution environment, automatically – Exchange VI hosts' IP addresses, assigned dynamically – Set up ssh keys, VLAN and file systems of VMs
• Difficult to provide each user with monitoring results of the VI – Monitoring of not physical resources (c.f. Ganglia), but VI

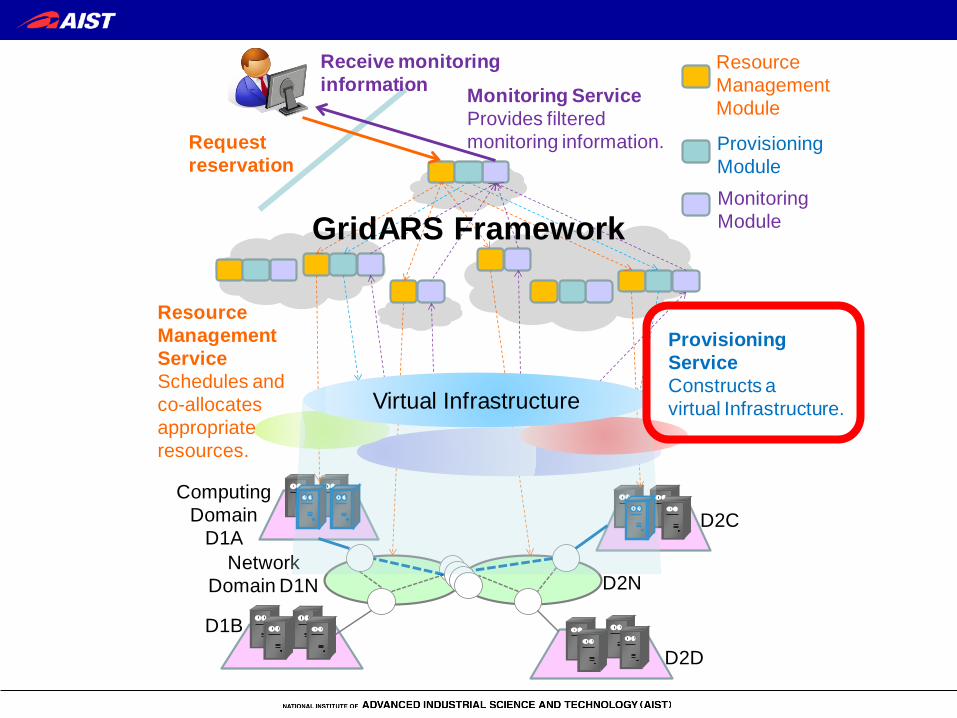
ComputingDomain
D1A
D1B
NetworkDomain D1N D2N
D2C
D2D
Provisioning ServiceConstructs avirtual Infrastructure.
Monitoring ServiceProvides filtered monitoring information.Request
reservation
Receive monitoring information
Monitoring Module
Provisioning Module
Resource Management Module
Resource ManagementServiceSchedules and co-allocates appropriateresources.
Virtual Infrastructure
GridARS Framework
GridARS Resource Management Framework

Resource Management Service
• Integrates not only computers and storage, but also dynamic circuit network, based on advance reservation
• Applies web services-based unified interfaces – GNS-WSI
• Defined by G-lambda, a joint project of KDDI R&D labs, NTT, NICT and AIST
• Supports various resources
– NSI (Network Service Interface) • Defined by Open Grid Forum NSI working group • Open interface standard to make dynamic circuit services
interoperable among different domains

Resource Management Service
• Consists of Global Resource Coordinators (GRC) and Resource Managers (RM)
• GRC can schedule appropriate resources using 0-1 integer programming model
• GRC negotiates with the related RMs and co-allocates the resources
GRC
NRM
CRM SRM
CRM NRM
SRM CRM
GRC GRC
Domain 1 Domain 3
User
GRS
Domain 0
CRM Domain 2
Scheduling
Allocated
ComputingDomain
D1A
D1B
NetworkDomain D1N D2N
D2C
D2D
Provisioning ServiceConstructs avirtual Infrastructure.
Monitoring ServiceProvides filtered monitoring information.Request
reservation
Receive monitoring information
Monitoring Module
Provisioning Module
Resource Management Module
Resource ManagementServiceSchedules and co-allocates appropriateresources.
Virtual Infrastructure
GridARS Framework

Provisioning Service
• Constructs VI over the allocated resources • Provides two functionalities:
– Environment management • Share the IP addresses, assigned by job schedulers (JS) dynamically,
among the hosts • Constructs VI using OS container
– Configure network interface of the hosts » VLAN, IP address, routing
– Set up ssh keys, authorized_hosts, known_hosts – Set up file system of each hosts
– Execution management • Launch jobs, terminate jobs etc. • Confirm network connectivity before launching a job

ComputingDomain
D1A
D1B
NetworkDomain D1N D2N
D2C
D2D
Provisioning ServiceConstructs avirtual Infrastructure.
Monitoring ServiceProvides filtered monitoring information.Request
reservation
Receive monitoring information
Monitoring Module
Provisioning Module
Resource Management Module
Resource ManagementServiceSchedules and co-allocates appropriateresources.
Virtual Infrastructure
GridARS Framework

Monitoring Service: DMS
GRC DMS/A
NRM
CRM SRM
CRM NRM
SRM CRM
GRC GRC DMS/A DMS/A
Domain 1 Domain 3
User
GRS
Domain 0
CRM Domain 2
DMC/C DMC/C
DMC/C DMC/C
DMC/C
DMC/A
ID
• In cooperation with RMS, configures monitoring instance on the related RMs
• Each monitoring instance collects its VI resource status
• Collected information is managed and filtered by each domain admin
• The monitoring results are visualized by RRDtool
Aggregator
Collector

Monitoring of the virtual infrastructure GridARS VI monitoring General monitoring system
Another user status
Network status
Computer status
Monitoring data are managed and filtered by each domain
Reservation Status
All monitoring data are gathered and provided
Ganglia

Summary: GridARS key features • Resource Management Service
– Unified resource management system of network and other resources
– A reference implementation of NSI and GNS-WSI – Dynamic resource scheduling
• Provisioning Service – Automatic construction of virtual infrastructure
• Monitoring Service – Interoperates with Resource Management Service – Provide the requester with monitoring information of the
VI resources, filtered by each domain admin
• Available at http://www.g-lambda.net/gridars

US
Asia
NSI Interoperation Demo at SC11
GridARS Resource Management Service is used in the AIST domain of the NSI international network demo
Europe
AMS-{80..83}
UVA-{80..83}
Pionier.etsPoznanAutoBAHNLoc: 52.412, 16.916
NetherLight.etsAmsterdam
DRACLoc: 52.357, 4.953
StarLight.etsChicago
OpenNSA/ArgiaLoc: 41.898, -87.618
GEANT.etsParisAutoBAHNLoc: : 48.7572, 2.3758
1780-1783
NorthernLight.etsCopenhagenOpenNSALoc: 55.637, 12.641
AIST.etsTsukubaG-LAMBDA-ALoc: 36.060, 140.133
GN3-{80..83}
AMS-{80..83}
POZ-{80..83}
POZ-{80..83}
CPH-{80..83}
CHI-{80..83}TOK-{80..83} AMS-{80..83}
KRLight.etsDaejeonDynamicKLLoc: 36.366, 127.359
CHI-{80..83}
US LHCnet
KDDI-Labs.etsFujiminoG-LAMBDA-KLoc: 35.879, 139.517
AMS-{80..83}
ACE
KRLight +GLORIAD
JGN-X
NORDUnet + SURFnet
Pionier
GEANT
FUJ-{80..83}
TOK-{80..83}
JGNX.etsTokyoG-LAMBDA-KLoc: 35.688, 139.764
TOK-{80..83}
TSU-{80..83}
1780-1783
CzechLight.etsPragueDRACLoc: : 50.088,14.421
AMS2-{80..83}
1780-17831780-1783
ESnet.etsChicagoOSCARSLoc: : 41.947908,-87.655789
ESN-{80..83}
CHI-{80..83}
UvALight.etsUniversity of AmsterdamDRACLoc: :52.352778, 4.955278
UVA2-{80..83}
A A
A
A A
A
CESNET

Summary • Cloud is a promising approach for HPC
– High productivity, easy deployments, high utilization – Overhead of virtualization is going to be negligible.
• There are still challenging issues – Resource managements – Network – Security – Storage
• Enjoy talks – Matuoka-san: GEO Grid TF – Shimojo-sensei: Next generation network – Phil: VM interoperability (enabling build once, run everywhere)

Acknowledgements
• HPC Cloud – Ryousei Takano, Tsutomu Ikegami, Akihiko Ota
• QoS guaranteed virtual infrastructure – Atsuko Takefusa, Tomohiro Kudoh, Hidemoto Nakada
• These works are partially supported by MEXT, JST, and NEDO.