exchange server 2013 architecture deep dive, part 2
Post on 19-Oct-2014
2.990 views
DESCRIPTION
More info on http://techdays.be.TRANSCRIPT

Exchange Server 2013Architecture Deep Dive, Part 2Scott SchnollPrincipal Technical WriterMicrosoft Corporation

Agenda
Mailbox Server RoleAvailability Improvements

Mailbox Server Role

Mailbox Server Role
Server that hosts components that process, render and store Exchange data
Includes components previously found in separate roles
Connectivity to a mailbox is always provided by the protocol instance on the server hosting the active database copy

Database Availability Group
Collection of servers that form a unit of high availability
Boundary for replication and *over
DAG members can be in different sites
Can have a maximum of 16 Mailbox servers
MBX1
MBX2
MBX16

Mailbox Server Role Changes
Managed Store and IOPS reductions
Transport-related Changes
Larger mailbox support
Modern public folders
New search infrastructure

Managed Store and IOPS Reductions
Covered in Database and Store Changes

Transport-related Changes

Transport-related Changes
Transport on Mailbox server is comprised of three services:• Microsoft Exchange Transport - Stateful and handles SMTP
mail flow for the organization and performs content inspection
• Microsoft Exchange Mailbox Transport Delivery - Receives mail from the Transport service and deliveries to the mailbox database
• Microsoft Exchange Mailbox Transport Submission - Takes mail from the mailbox databases and submits to the Transport service

Transport-related Changes
Transport has the following responsibilities• Receives all inbound mail to the organization• Submits all outbound mail from the organization• Handles all internal message processing such as transport
rules, content filtering, and antivirus• Performs mail flow routing• Queue messages• Supports SMTP extensibility
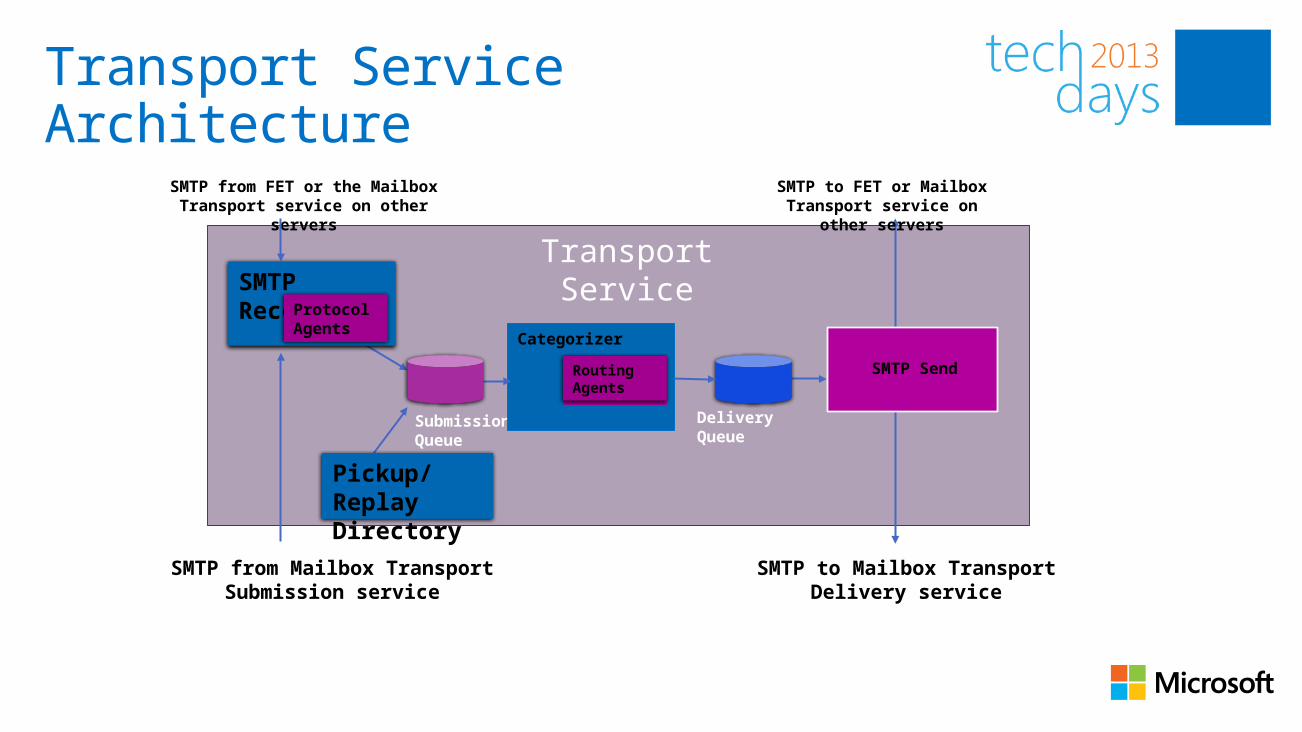
Transport Service Architecture
Transport Service
SMTP to Mailbox Transport Delivery service
SMTP from FET or the Mailbox Transport service on
other servers
SMTP to FET or Mailbox Transport service on other
servers
Submission Queue
Delivery Queue
Pickup/Replay Directory
Categorizer
Routing Agents
SMTP ReceiveProtocol
Agents
SMTP Send
SMTP from Mailbox Transport Submission
service
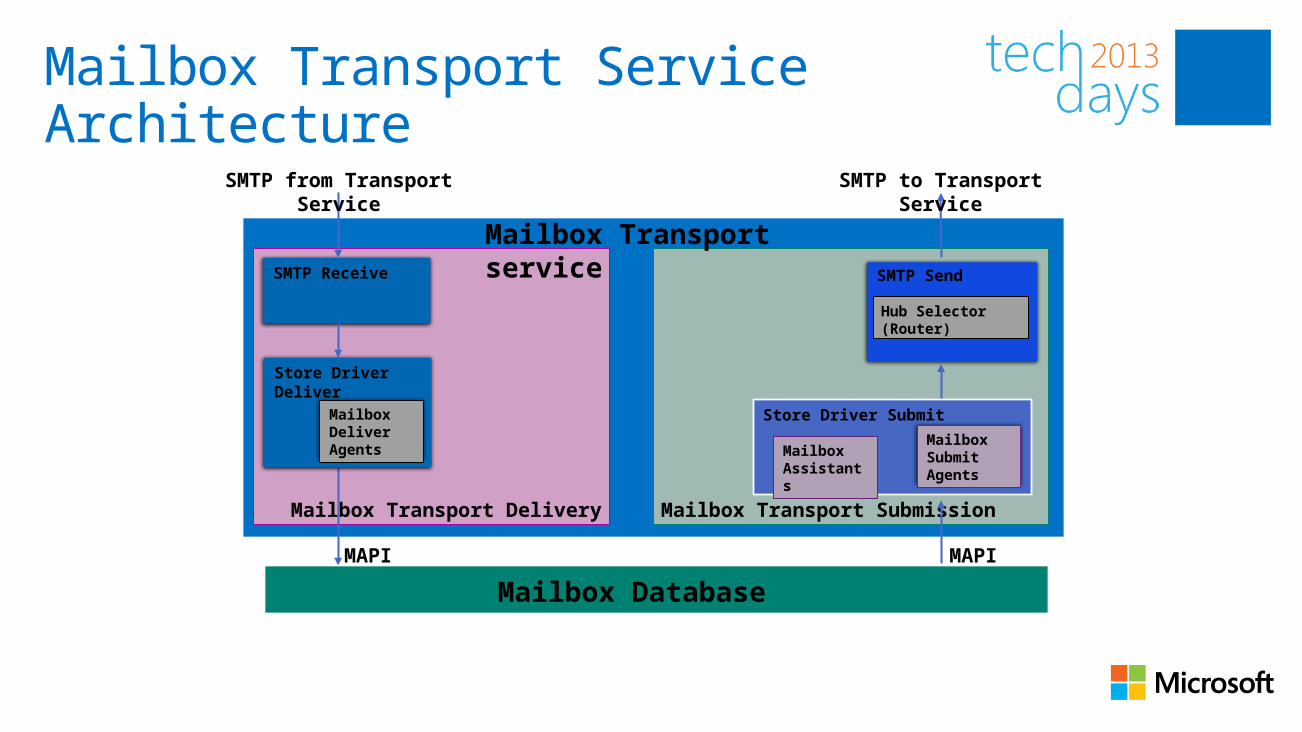
Mailbox Transport Service Architecture
Mailbox Transport SubmissionMailbox Transport Delivery
Mailbox Transport service SMTP SendSMTP Receive
Hub Selector (Router)
Store Driver Submit
Mailbox Assistants
Mailbox Submit Agents
MAPI MAPI
Mailbox Database
SMTP to Transport Service
SMTP from Transport Service
Store Driver Deliver
Mailbox Deliver Agents

Mailbox Transport
Two separate services to handle mail submissions (from the store) and mail delivery (from the Transport service)Mailbox Assistant and Store Driver combinedLeverages SMTP (encrypted) for communication with the Transport component and TCP465 for inbound trafficLeverages local RPC for delivery to storeIs stateless and does not have a persistent storage mechanism

Mailbox Transport
When receiving a message, the Mailbox Transport component can either deliver the message or not deliver the messageIf non-delivery is chosen, then the Mailbox Transport component must provide a response back to Transport• Retry delivery• Generate an NDR• Reroute the message

Larger Mailbox Support

Larger Mailbox Support
Large Mailbox Size is 100 GB+Aggregate Mailbox = Primary Mailbox + Archive Mailbox + Recoverable Items
1-2 years of mail (minimum)Increase IW productivityEliminate or reduce PST filesEliminate or reduce third-party archive solutions
OST size control with Outlook 2013
Time Items Mailbox Size
1 Day 150 11 MB
1 Month 3300 242 MB
1 Year 39000 2.8 GB
2 Years 78000 5.6 GB
4 Years 156000 11.2 GB

Modern Public Folders

Modern Public Folders
Public folders based on the mailbox architecture
Single-master model Hierarchy is stored in a PF mailbox (one writeable) Content can be broken up and placed in multiple mailboxes The hierarchy folder points to the target content mailbox
Because it’s a mailbox, it’s in a mailbox database…thus, High availability achieved through continuous replication No separate replication mechanism
Similar administrative features to current PFs No end-user changes
MBX2013
CAS2013
MBX2013
MBX2013
Public logon
Private logon
Public logon
Content Mailbox
Hierarchy Mailbox
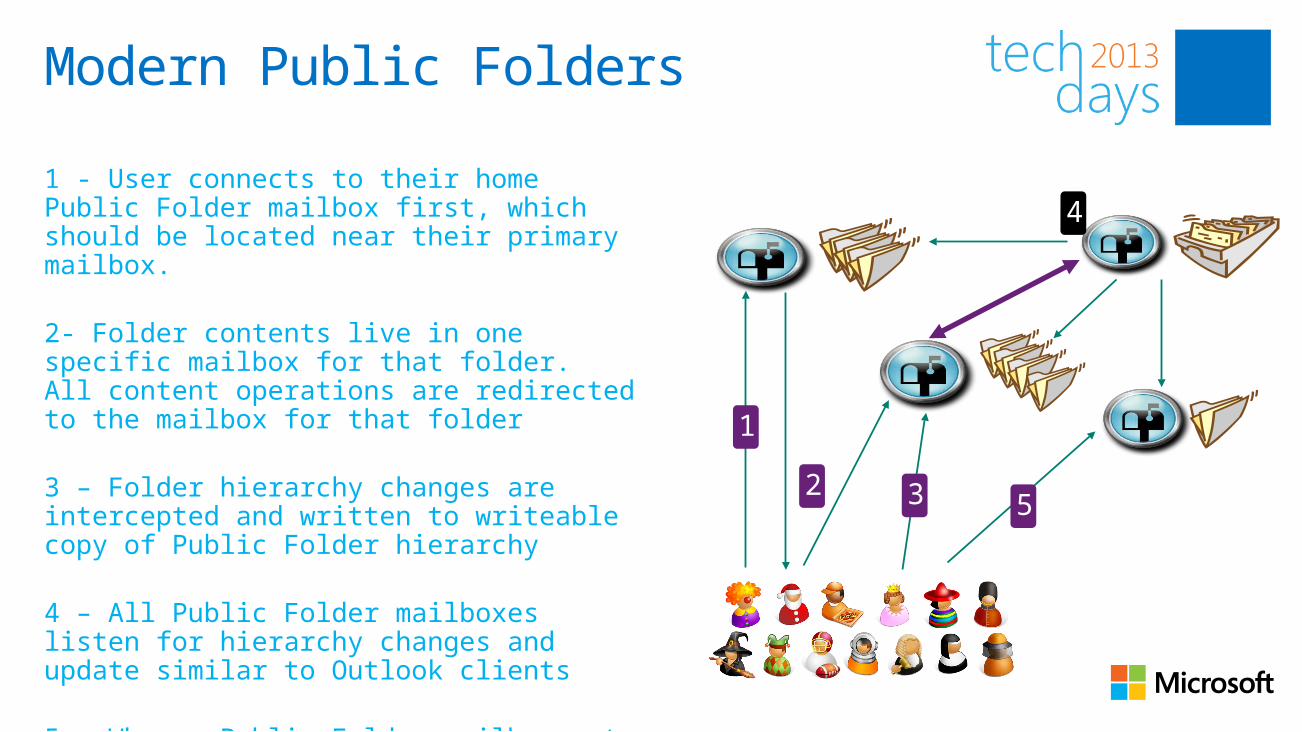
Modern Public Folders
1 - User connects to their home Public Folder mailbox first, which should be located near their primary mailbox.
2- Folder contents live in one specific mailbox for that folder. All content operations are redirected to the mailbox for that folder
3 – Folder hierarchy changes are intercepted and written to writeable copy of Public Folder hierarchy
4 – All Public Folder mailboxes listen for hierarchy changes and update similar to Outlook clients
5 - When a Public Folder mailbox gets full, move some folders to a new mailbox
1
2 3 5
4

Search Foundation

Search Foundation
Significant improvements in query and indexing performance
Significant reduction in number of times an item is indexed
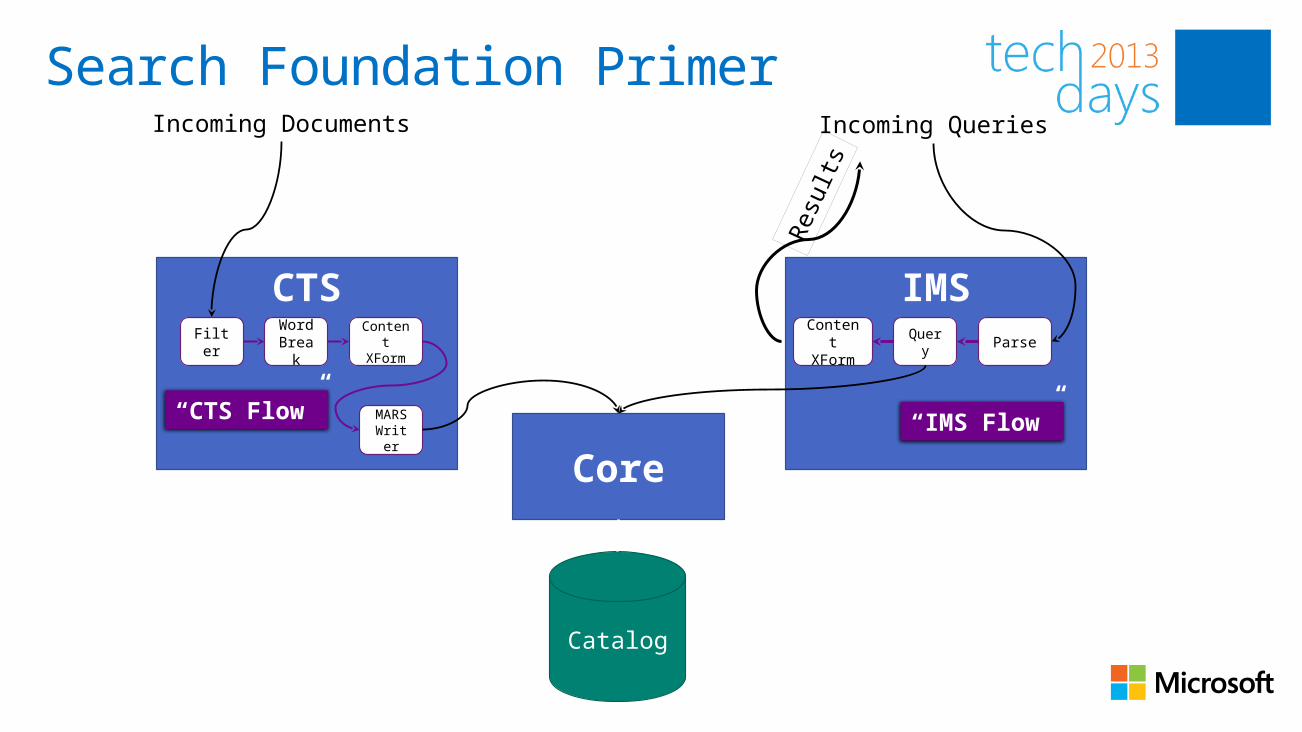
Search Foundation Primer
Core
Catalog
CTS
Incoming Documents
FilterWord Brea
k
Content
XForm
MARS Write
r
Incoming Queries
“CTS Flow”
IMSConten
t XForm
Query Parse
“IMS Flow”
Res
ults
Mailbox
DB Idx
Passive
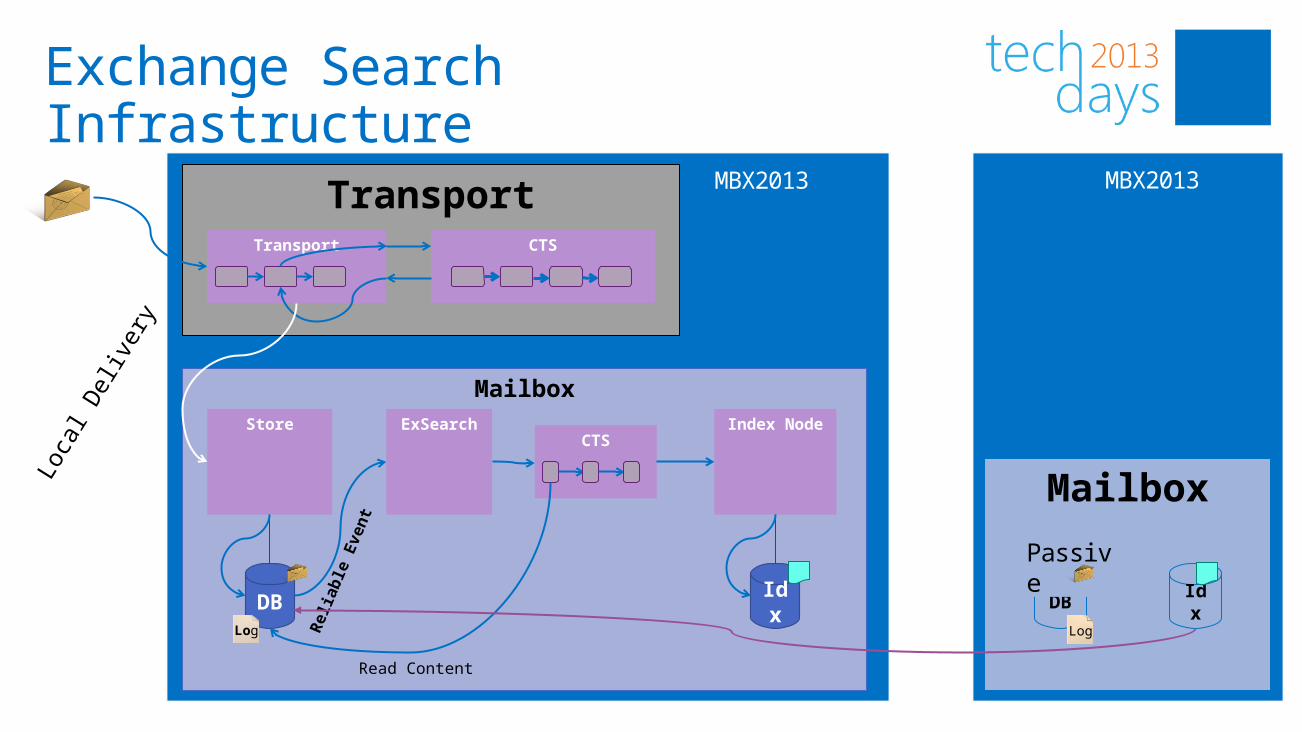
Exchange Search Infrastructure
TransportTransport CTS
MailboxStore
DB
Index Node
Idx
ExSearch
Loca
l Del
iver
y
Reliable
Event
CTS
Read Content
MBX2013
LogLog
MBX2013

Availability Improvements

Availability Improvements
Managed Availability
Transport Availability Improvements

Managed Availability
All core Exchange functionality for a given mailbox is served by the Mailbox server where that mailbox’s database is currently activeMailbox access fails over when a database fails over Protocols shift to the server hosting the active database copy
Managed AvailabilityInternal monitoring and high availability are tied together and can be used to detect and recover from problems as they occur and are discoveredBest copy selection now includes health of services when selecting best copy (best copy and server selection)

Managed Availability

Exchange Monitoring History
Exchange historically has relied on external applications like System Center Operations Manager for monitoring
SCOM uses rules to collect data and performs actions after the data is collected
Type of Monitoring Exchange 2010
Service not running Health manifest event rule
Performance counterHealth manifest counter rule
Exchange events Health manifest event rule
Non-Exchange events Health manifest event rule
Scripts, cmdlets Health manifest script rule
Test cmdlets Test Cmdlets

Service Health Landscape
Component based monitoring does not tell the story
Exchange Online service experience resulted in the need to change our approach to monitoring
Scale drives automation
Exchange Server 2013 reflects these learnings

Learnings
External monitoring solution required significant development investment for the serviceInvestments did not accrue to on-premises Exchange 2010 product
High availability components separate from the monitoring and recovery infrastructure affect end-to-end service availability goals Scalability issues with 1000s of servers and databasesMonitoring solution had separate failure modesDatabase health is not a true indicator of end-to-end serviceExisting monitoring solution was focused on system and components, not on end user experience

Exchange 2013 Monitoring
Cloud Trained
Bringing the learnings from the service to the enterprise
User focused
Monitoring based on the end user’s experience
Recovery oriented
Protect experience through recovery oriented computing

Cloud Trained
5+ Years of Directly Operating the ServiceSince 2007, the Exchange Team has been operating a cloud version of Exchange
Knowledge Is Put Back Into the ProductEngineers are on-call for service related issuesDrives accountability for awareness and motivates team toward auto-recovery
Scale, Auto-Deployment, Optics, High Availability are key tenetsDecentralized complex processingRollouts don’t require extra configuration

User Focused
If you can’t measure it, you cannot manage it
Customer Touch Point FrameworkAvailability - Can I access the service?Latency - How is my experience?Errors - Am I able to accomplish what I want?

Recovery Oriented
Key principle: Stuff breaks, but the experience does not
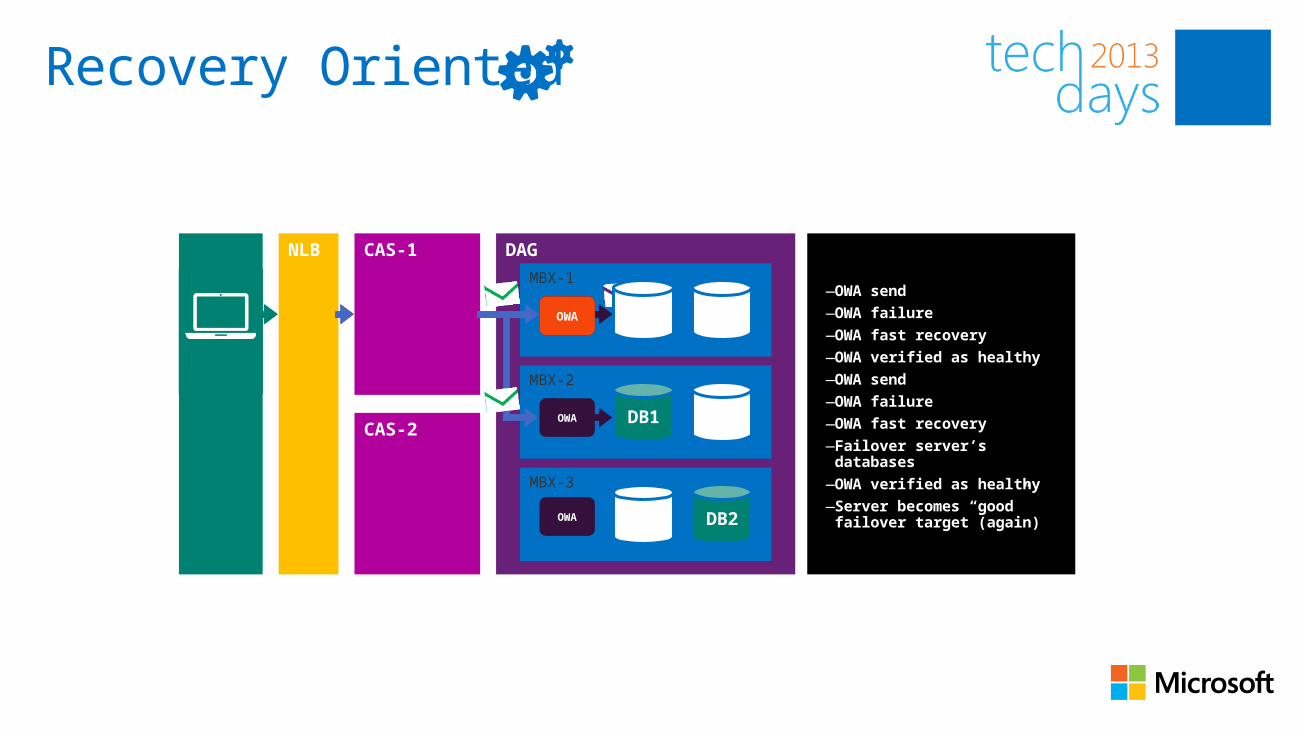
—OWA send—OWA failure—OWA fast recovery—OWA verified as healthy —OWA send—OWA failure—OWA fast recovery—Failover server’s databases—OWA verified as healthy —Server becomes “good” failover target (again)
NLB CAS-1
CAS-2
DAG
MBX-1
DB1
DB2
MBX-2
OWADB1
DB2
MBX-3
OWADB1
DB2
OWAOWAOWA
OWADB1
DB1
Recovery Oriented

Managed Availability Framework
Exchange Server
PROBE
CHECK
NOTIFY
MONITOR
“state of the world”
ESCALATE
“take human driven action”
RECOVER
“restore service or prevent
failure”
Managed Availability
SCOMManaged Availability
Probe Engine
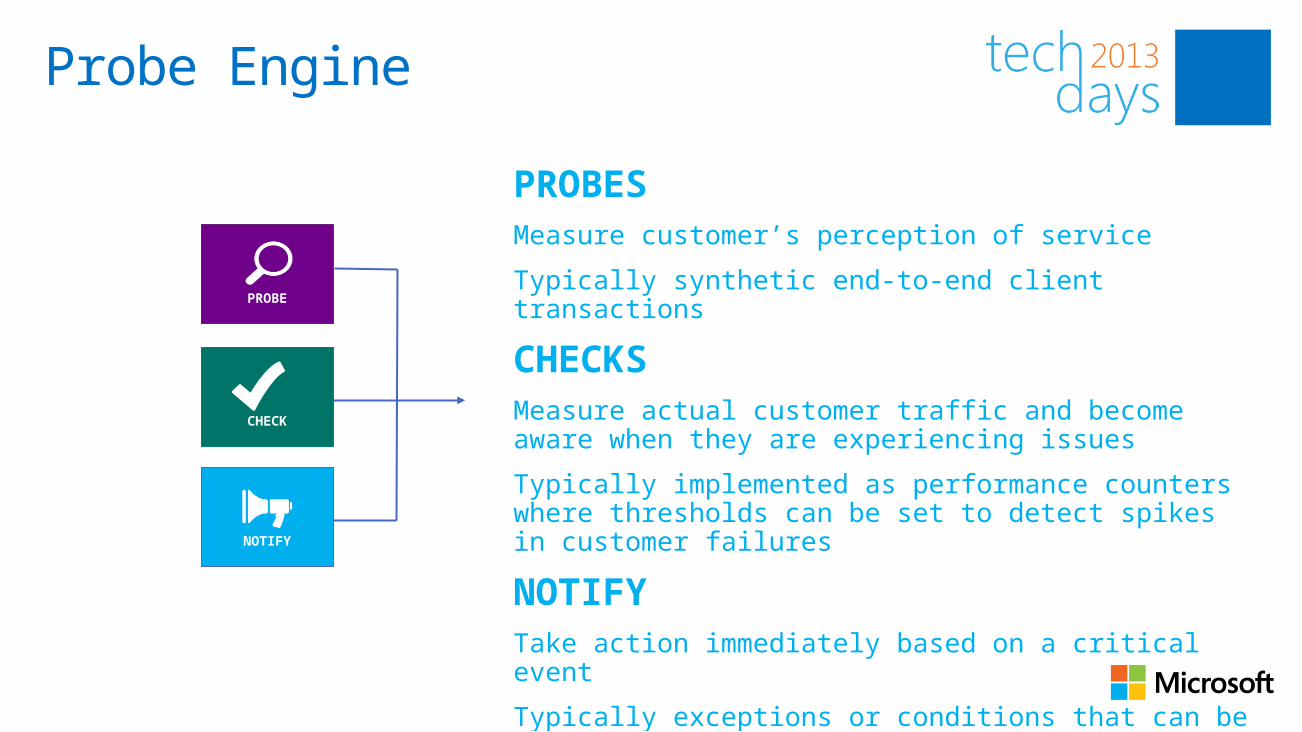
PROBESMeasure customer’s perception of service
Typically synthetic end-to-end client transactions
CHECKSMeasure actual customer traffic and become aware when they are experiencing issues
Typically implemented as performance counters where thresholds can be set to detect spikes in customer failures
NOTIFYTake action immediately based on a critical event
Typically exceptions or conditions that can be detected without a large sample set
PROBE
CHECK
NOTIFY

Monitors
MONITORSQuery the data collected by the probes and determine if an action needs to occur based on a rule set
Depending on the rule, a monitor can escalate or initiate a responder
Monitors can be Healthy, Degraded, Unhealthy, Repairing, Disabled, or Unavailable
Defines the time from failure that a responder is executed
MONITOR“state of the world”
ESCALATE“take human driven
action”

Responders
RESPONDERA “plug-in” that executes a response to an alert generated by a monitor
Built-in sequencing mechanism to control recovery actions
Several Types of RespondersRestart Responder – Terminates and restarts serviceReset AppPool Responder – Cycles IIS application poolFailover Responder – Takes a MBX server out of serviceBugcheck Responder – Initiates a bugcheck of the serverOffline Responder- Takes a protocol on a server out of serviceOnline Responder – Places a machine back into serviceEscalate Responder – Escalates an issueSpecialized Component Responders
ESCALATE“take human driven
action”
RECOVER“restore service or
prevent failure”

Reporting
Reporting is structured into four health groups:Customer Touch Points – components which effect the real time, customer facing interactions (OWA, OLK, Mobile, UM, etc.)Service Components – components without direct real time, customer interactions (MRS, OABGen)Server Components – physical resources of the physical server (disk space, memory, network)Dependency Availability – server’s ability to call out to dependencies (AD, DNS, etc.)
Health groups are exposed in SCOM

Health Sets
A health set is a group of monitors, probes and responders that determine whether a component within the system is healthy
The health of the set will be evaluated by a “worst of” evaluation of the monitors in the health set
For example, OWA has these types of health sets…

Health Sets
ProtocolHealth Set
ProxyHealth Set
CTPHealth Set
CAS
MBX
PROTOCOL
STORE
PROTOCOL PROXY
4
3
2
1
OWA
OWA.Proxy
OWA.Protocol
Viewing Health Set Data
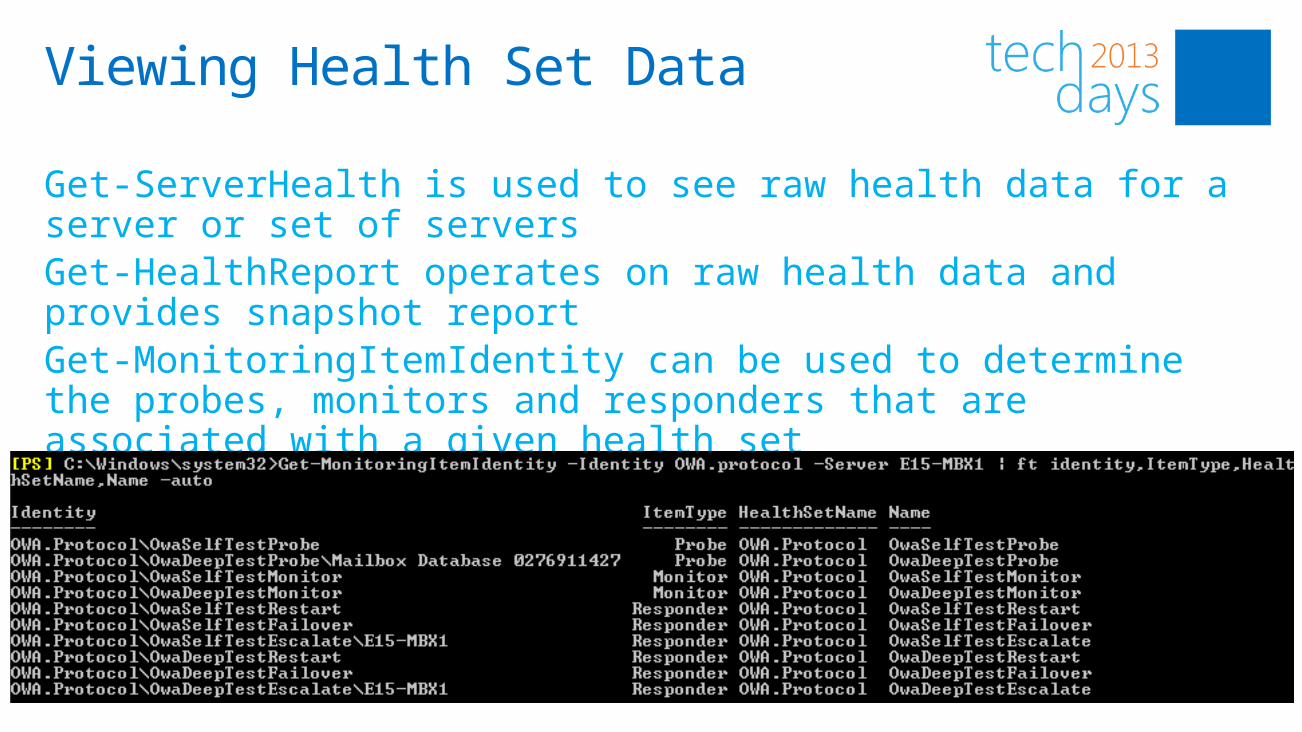
Get-ServerHealth is used to see raw health data for a server or set of serversGet-HealthReport operates on raw health data and provides snapshot reportGet-MonitoringItemIdentity can be used to determine the probes, monitors and responders that are associated with a given health set

Overrides
Admins can alter the thresholds and parameters used by the probes, monitors and respondersEnables emergency actionsEnables fine tuning of thresholds specific to the environment
Can be deployed for specific servers or for the entire environmentServer related overrides are stored in the registryGlobal overrides are stored in Active Directory
Can be set for a specified duration or to apply to a specific version of the serverAre not immediately implemented; Exchange Health Service only reads configuration every 10 minutes (and global changes depend on AD replication)Wildcards are not supported (cannot override entire health set in one activity)

Overrides
See what overrides have been setGet-ServerMonitoringOverride –Server <Server>Get-GlobalMonitoringOverride
Create an overrideAdd-ServerMonitoringOverride <HealthSet>\<Name> -Server <Server> -ItemType <Monitor,Probe,Responder> [-Duration <Time> -ApplyVersion <Version>] -PropertyName <Property> -PropertyValue <Value>
Add-GlobalMonitoringOverride <HealthSet>\<Name> -ItemType <Monitor,Probe,Responder> [-Duration <Time> -ApplyVersion <Version>] -PropertyName <Property> -PropertyValue <Value>
Remove OverrideRemove-ServerMonitoringOverrideRemove-GlobalMonitoringOverride

Transport Availability Improvements

Transport Availability ImprovementsEvery message is redundantly persisted before its receipt is acknowledged to the senderDelivered messages are kept redundant in transport, similar to active messages
Every DAG represents a transport HA boundary and owns its HA implementationIf you have a stretched DAG, you also have transport site resilienceResubmits due to transport DB loss or MDB *over are fully automatic and do not require any manual involvement

Shadow Redundancy ImprovementsSame fundamental concept as in Exchange 2010, with new implementation in Exchange 2013All mail is made redundant on a another serverShadow messages are queued until Primary server successfully delivers the mailShadow server regularly heartbeats Primary server for status on the primary copyOn Primary server failure, Shadow server self-promotes itself as the Primary and delivers mail

Shadow Redundancy ImprovementsGuaranteed RedundancyNew transport configuration – RejectOnShadowFailure ensures that no message is acknowledged and accepted unless a shadow copy was first createdMessages are made redundant on other servers within a DAG or another siteMessages are tried for a configurable amount of time before giving up and rejecting the message

Safety Net
Introduced in Office 365 to redundantly store all mail for a configured time span to protect against mailbox irrecoverable failures
SafetyNet retains data for a set period of time, regardless of whether the message has been successfully replicated to all database copies or delivered to final destination
Consolidates, improves and replaces Transport Dumpster
Processes replay requests from “primary” or “shadow” SafetyNet for lossy mailbox failovers

Summary
Exchange Server 2013 uses Building Blocks to facilitate deployments at all scales – from self-hosted, small organizations to Office 365
Exchange Server 2013 provides you with an architecture that is Flexible, Scalable, and Simpler and helps customers reduce costs
