eurocogsci2011
DESCRIPTION
Eurocogsci2011TRANSCRIPT

Unsupervised Grounding of Spatial RelationsMichal Vavrecka ([email protected])
Department of Electrical Engineering, Czech Technical UniversityPrague, Czech Republic
Igor Farkas ([email protected])Department of Applied Informatics, Comenius University
Bratislava, Slovak Republic
Abstract
We present a connectionist model for grounding color, shapeand spatial relations of two objects in 2D space. The modelconstitutes a two-layer architecture that integrates informationfrom visual and auditory inputs. The images are presented asthe visual inputs to an artificial retina and five-word sentencesdescribing them (e.g. “Red box above green circle”) serve asauditory inputs with phonological encoding. The visual sceneis represented by the Self-Organizing Map and the auditorydescription is processed by a recursive SOM (RecSOM) thatlearns to topographically represent sequences. Both primaryrepresentations are integrated in a multimodal module (imple-mented by SOM or Neural Gas algorithms) in the second layer.We tested this two-layer architecture with several modifica-tions (a single SOM representing both color shape and spa-tial relations vs. separate SOMs for spatial relations and forshape and color, imitating what and where pathways) and sev-eral conditions (scenes with varying complexity up to 3 col-ors, 5 object shapes and 4 spatial relations). In the scenes withhigher complexity we reached better results with NG algorithmin the multimodal layer compared to SOM, which was proba-bly due to flexible neighborhood relations in NG algorithm,hence relaxing topographic organization. The results confirmtheoretical assumptions about different nature of visual and au-ditory coding. Our model efficiently integrates the two sourcesof information while reflecting their specific features.Keywords: spatial terms; unsupervised symbol grounding;self-organization; multimodal representation
IntroductionIn applied artificial intelligence, the continuing and challeng-ing problem is the design of an adaptive system that inter-acts with the environment and is able to understand its in-ternal representations. These representations should captureattributes of the environment, store them as concepts, andconnect these to the symbolic level. This idea is related tothe perceptual theory of cognition where the representation iscreated from the perceptual inputs (sensory modalities). Asthe next step we should integrate representations from dif-ferent modalities to the multimodal level. Barsalou (1999)introduced this principle as the Perceptual Symbol System.The integration of modalities is also described in the area ofneuroscience. For instance, Damasio (1989) postulates con-vergence zones, which integrate the information from sensorymaps and represent them. The convergence zones create hi-erarchical levels of associations from the specific modalities.There are similar ideas in cognitive psychology. Dual cod-ing theory (Paivio, 1986) describes two independent but con-nected representational systems, which create internal repre-sentations of the external environment. These are the ver-bal and image codes. In the mentioned theories we should
identify some ideas, which are fruitful for the following dis-cussion about the perceptually formed conceptual level andthe way how to ground symbols to these concepts. The-ories about integration of modalities should help us under-stand the symbol grounding process. The basic task for sym-bol grounding is to find the function and the internal mech-anism to create representations that are intrinsic to the sys-tem and do not need to be interpreted by an external ob-server (Ziemke, 1999). Our approach presents the radicalversion of the symbol grounding architecture based on thetheory of embodied cognition (Varela et al., 1991) arguingthat the co-occurrence of inputs from the environment is asufficient source of information to create an intrinsic repre-sentational system (Vavrecka, 2009). These representationspreserve constant attributes of the environment. To the con-trary of the classical grounding architecture (Harnad, 1990)we propose an alternative solution of this problem. Thereis a different way of symbolic input processing by a separateauditory subsystem and further integration of auditory and vi-sual information in a multimodal layer. Multimodal layer in-corporates the process of identification (in terms of Harnad’stheory). Our approach is similar to the “grounding transfer”(Riga et al., 2004) based on self-organizing maps (SOM; Ko-honen 2001) and the supervised multi-layer perceptron, butour system works in a fully unsupervised manner that impliesa different way of creating the symbolic (lexical) level. Ourmodel goes beyond the lexical level, because it can processsentences. We test our model in the area of spatial orienta-tion similar to Regier (1996) who created a neural networkmodel consisting of several modules to ground spatial terms,but trained in supervised manner. Our main goal is to extendthe research in this area by application of unsupervised learn-ing algorithms where the target signal only functions as anadditional input rather than being the source for error-basedlearning.
The ModelsWe focus on learning spatial locations of two objects in 2Dspace and their linguistic description. The conceptual level isrepresented by the visual subsystem and the symbolic levelis represented by the auditory system. We tested two ver-sions of the visual subsystem, keeping in mind the distinctionbetween what and where pathways (Ungerleider & Mishkin,1982). The former learns to represent object features (shapeand color), the latter focuses on object position. To appreciate

the importance of individual representations in the modules,we tested two models for this task. Model I contains a sin-gle SOM that learns to capture both what and where informa-tion. Model II is an extended version of Model I with separateSOMs for processing what information (color and shape) andwhere information. Figure 1 provides the sketch of Model II.
Figure 1: Visualization of information processing in Model II.There is a separate layer (unimodal what system) for representingshape and color, as opposed to Model I (where the two parts aremerged).
Training dataTHe input scenes consist of the trajector and the base objectin different spatial configurations. The position of the base isfixed in the center of the scene and the trajector is located inone of the spatial quadrants relative to the base. These are lin-guistically referred to as up, down, left, and right but percep-tually, the trajector position is fuzzy. We trained the modelsusing scenes with increasing complexity, starting with simpleinputs with 2 colors, 2 object types and 4 spatial relations,up to more complex inputs consisting of 3 colors (red, green,blue), 5 object types (box, ball, table, cup, bed) and 4 spatialrelations (above, bellow, left, right). Training data size var-ied from 6400 to 42000 examples (50-100 examples of eachspatial configuration) depending on the complexity of the en-vironment.
Visual layerThe sensory input of the visual subsystem is formed by anartificial retina (28×28 neurons) that projects to the primaryvisual layer. Visual layer consists of the SOM(s) that learn thenonlinear mapping of input vectors to output units in the to-pography preserving manner (i.e. similar inputs are mappedto neighboring units in the map). The SOM was expectedto differentiate various positions of two objects, as well asobject types and their color in Model I. Model II consistsof a separate SOM for spatial locations (resembling wheresystem) and for color and shape of objects (resembling whatsystem). The what system stands for simplified attentionalmechanisms and foveal input. There are two visual fields
(4x4 neurons) that project visual information about the tra-jector and the base in fixed position to the unimodal whatsystem SOM. The color of each pixel was encoded by the ac-tivity level, that is xxxxxxxxxxxx. Both maps were trainedfor 100 epochs with decreasing parameter values (unit neigh-borhood radius, learning rate).
Auditory layerAuditory inputs (English sentences) were encoded as phono-logical patterns representing word forms using PatPho, ageneric phonological pattern generator that fits every word(up to trisyllables) onto a template according to its vowel-consonant structure (Li & McWhinney, 2002). It uses theconcept of syllabic template: a word representation is formedby combinations of syllables in a metrical grid, and the slotsin each grid are made up by bundles of features that corre-spond to consonants and vowels. In our case, each sentenceconsists of five 54-dimensional vectors with component val-ues in the interval (0,1). These vectors are sequentially fed(one word a time) to the RecSOM (Voegtlin, 2002), a recur-rent SOM architecture, that uses a detailed representation ofthe context information (the whole output map activation) andhas been demonstrated to be able to learn to represent muchricher dynamical behavior (Tino et al., 2006), compared toother recurrent SOM models (Hammer et al., 2004). Rec-SOM learns to represent inputs (words) in the temporal con-text (hence capturing sequential information). RecSOM out-put, in terms of map activation, feeds to the multimodal layer,to be integrated with the visual pathway. Like SOM, Rec-SOM is trained by competitive, Hebbian-like algorithm. As aproperty of RecSOM, its units become sequence detectors af-ter training, topographically organized according to the suffix(the last words).
Since RecSOM, unlike SOM, is not common, we pro-vide its mathematical description here. Each neuron i ∈{1,2, ...,N} in RecSOM has two weight vectors associatedwith it: wi ∈Rn – linked with an n-dimensional input s(t) (inour case, the current word) feeding the network at time t andci ∈RN – linked with the context y(t−1) = [y1(t−1),y2(t−1), ...,yN(t−1)] containing map activations yi(t−1) from theprevious time step.
The output of a unit i at time t is computed as yi(t) =exp(−di(t)), where
di(t) = α · ‖s(t)−wi‖2 +β · ‖y(t−1)− ci‖2.
Here, ‖ · ‖ denotes the Euclidean norm, α > 0 and β > 0 aremodel parameters that respectively influence the effect of theinput and the context upon neuron’s profile. Their suitablevalues are usually found heuristically. Both weight vectorsare updated using the same form of SOM learning rule:
∆wi = γ ·hik · (s(t)−wi),
∆ci = γ ·hik · (y(t−1)− ci),
where k is an index of the best matching unit at time t,k = argmini∈{1,2,...,N} di(t), and 0 < γ < 1 is the learning rate.

Note that the best matching (‘winner’) unit can be equiva-lently defined as the unit k of the highest activation yk(t):k = argmaxi{yi(t)}. Neighborhood function hik is a Gaussian(of width σ) on the distance d(i,k) of units i and k in themap: hik = exp(−d(i,k)2/σ2). The ‘neighborhood width’, σ,linearly decreases in time to allow for forming topographicrepresentation of input sequences.
Multimodal layerThe units in the multimodal layer identify unique categories(if possible) and represent them. In agreement with the theoryof perceptual symbol systems (Barsalou, 1999), the main taskfor the multimodal layer is to process the output from the uni-modal layers and to find and learn the categories by mappingand merging different sources of information (visual and au-ditory) that refer to the same object in the external world. Wetested two versions of the multimodal layer, namely SOM andNeural Gas (NG) algorithms (Martinetz & Schulten, 1991).Both algorithms are unsupervised, based on the competitionamong units and the same cooperative learning rule, but NGuses a flexible neighborhood function, hence relaxing topo-graphic organization, as opposed to fixed (2D) neighborhoodrelations in SOM. The size of the multimodal layer was set toallow a distinct localist representation of all object combina-tions (3 colors× 5 object types, 2 objects in scene)× 4 spatialterms = 840 combinations) in the most complex data set, sothere were 29×29 = 841 neurons. Inputs for this layer are out-puts of unimodal first-layer modules (concatenated from bothmodalities) using the k-WTA (i.e. winner-takes-all) mecha-nism, where k most active units are proportionally turned on(with the activity of the best matching unit rescaled to 1), andall other units are reset to zero (in the models, we used k = 6).The motivation for this type of output representation consistsin introducing some overlaps between similar patterns to fa-cilitate generalization. On the other hand, the output rep-resentation in the multimodal layer is chosen to be localistfor better interpretation of results and the calculation of errorrate.
ResultsWe trained the system with fixed size of the multimodal layerand varying size of the unimodal maps (ranging from 10×10to 35×35 neurons) for 100 epochs and tested the models us-ing a novel set of inputs. The size of the testing set was 30%of the overall data set. All inputs were indexed for the calcu-lation of the error in the multimodal layer. We applied a vot-ing algorithm after the training set to label each neuron in thelayer based on its most frequent response. Then we measuredthe effectiveness of this system, based on the percentage ofcorrectly classified test inputs. There were low error rates inthe auditory unimodal layer in Model I and II and in whatunimodal system in Model II. This was thank to the smallervariability of the inputs because the same sentence describesthe spatial location presented to the primary auditory systemand the objects are presented to the what system without spa-tial variability. On the other hand, we observed a high error
rate in where system for the the trajector shape that varied inthe different positions of the specific area. There was alsoa difference between the what and where system effective-ness in the Model II. The where system was more accuratein the representation of spatial locations and the what systemrepresents color and shape of trajector with a smaller error,because there are specific inputs projected to the particularsubsystems. The analysis of the model behavior revealed thatthe trajector shape and the spatial term representations arethe most difficult tasks for visual unimodal systems. This iscaused by the variability and fuzziness of these inputs. Theresults for them are depicted in Figures 2 and 3.
Figure 2: Error rates in the multimodal layer for the trajector shaperepresentation. Model II based on Neural Gas performs best.
Figure 3: Error rates in the multimodal layer for the spatial termrepresentation. Model I based on Neural Gas performs best.
These refer to the model with unimodal maps having30×30 neurons and the multimodal layer consisting of29×29 neurons. We compare two Models (I and II), usingone of the two algorithms (SOM and NG) compared in caseof scenes with increasing complexity. The error rate for therepresentation of trajector color, base color and base shapewas very low in all scenarios and the results were similar forboth models and algorithms.
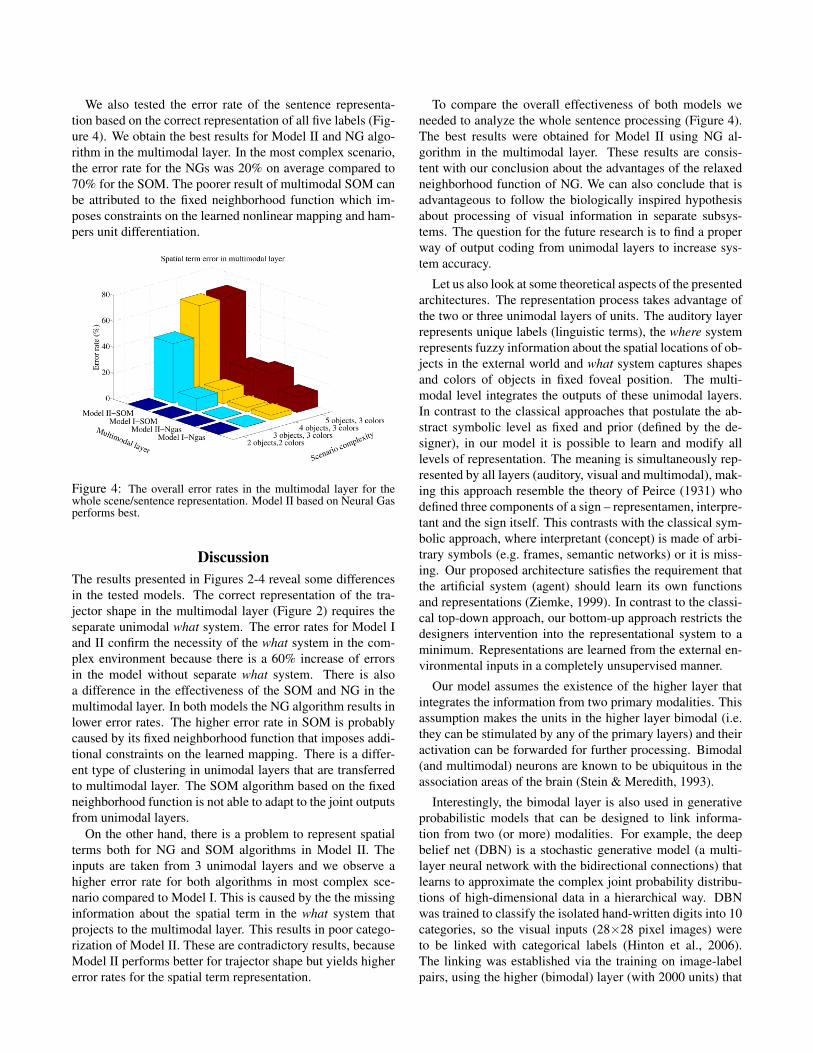
We also tested the error rate of the sentence representa-tion based on the correct representation of all five labels (Fig-ure 4). We obtain the best results for Model II and NG algo-rithm in the multimodal layer. In the most complex scenario,the error rate for the NGs was 20% on average compared to70% for the SOM. The poorer result of multimodal SOM canbe attributed to the fixed neighborhood function which im-poses constraints on the learned nonlinear mapping and ham-pers unit differentiation.
Figure 4: The overall error rates in the multimodal layer for thewhole scene/sentence representation. Model II based on Neural Gasperforms best.
DiscussionThe results presented in Figures 2-4 reveal some differencesin the tested models. The correct representation of the tra-jector shape in the multimodal layer (Figure 2) requires theseparate unimodal what system. The error rates for Model Iand II confirm the necessity of the what system in the com-plex environment because there is a 60% increase of errorsin the model without separate what system. There is alsoa difference in the effectiveness of the SOM and NG in themultimodal layer. In both models the NG algorithm results inlower error rates. The higher error rate in SOM is probablycaused by its fixed neighborhood function that imposes addi-tional constraints on the learned mapping. There is a differ-ent type of clustering in unimodal layers that are transferredto multimodal layer. The SOM algorithm based on the fixedneighborhood function is not able to adapt to the joint outputsfrom unimodal layers.
On the other hand, there is a problem to represent spatialterms both for NG and SOM algorithms in Model II. Theinputs are taken from 3 unimodal layers and we observe ahigher error rate for both algorithms in most complex sce-nario compared to Model I. This is caused by the the missinginformation about the spatial term in the what system thatprojects to the multimodal layer. This results in poor catego-rization of Model II. These are contradictory results, becauseModel II performs better for trajector shape but yields highererror rates for the spatial term representation.
To compare the overall effectiveness of both models weneeded to analyze the whole sentence processing (Figure 4).The best results were obtained for Model II using NG al-gorithm in the multimodal layer. These results are consis-tent with our conclusion about the advantages of the relaxedneighborhood function of NG. We can also conclude that isadvantageous to follow the biologically inspired hypothesisabout processing of visual information in separate subsys-tems. The question for the future research is to find a properway of output coding from unimodal layers to increase sys-tem accuracy.
Let us also look at some theoretical aspects of the presentedarchitectures. The representation process takes advantage ofthe two or three unimodal layers of units. The auditory layerrepresents unique labels (linguistic terms), the where systemrepresents fuzzy information about the spatial locations of ob-jects in the external world and what system captures shapesand colors of objects in fixed foveal position. The multi-modal level integrates the outputs of these unimodal layers.In contrast to the classical approaches that postulate the ab-stract symbolic level as fixed and prior (defined by the de-signer), in our model it is possible to learn and modify alllevels of representation. The meaning is simultaneously rep-resented by all layers (auditory, visual and multimodal), mak-ing this approach resemble the theory of Peirce (1931) whodefined three components of a sign – representamen, interpre-tant and the sign itself. This contrasts with the classical sym-bolic approach, where interpretant (concept) is made of arbi-trary symbols (e.g. frames, semantic networks) or it is miss-ing. Our proposed architecture satisfies the requirement thatthe artificial system (agent) should learn its own functionsand representations (Ziemke, 1999). In contrast to the classi-cal top-down approach, our bottom-up approach restricts thedesigners intervention into the representational system to aminimum. Representations are learned from the external en-vironmental inputs in a completely unsupervised manner.
Our model assumes the existence of the higher layer thatintegrates the information from two primary modalities. Thisassumption makes the units in the higher layer bimodal (i.e.they can be stimulated by any of the primary layers) and theiractivation can be forwarded for further processing. Bimodal(and multimodal) neurons are known to be ubiquitous in theassociation areas of the brain (Stein & Meredith, 1993).
Interestingly, the bimodal layer is also used in generativeprobabilistic models that can be designed to link informa-tion from two (or more) modalities. For example, the deepbelief net (DBN) is a stochastic generative model (a multi-layer neural network with the bidirectional connections) thatlearns to approximate the complex joint probability distribu-tions of high-dimensional data in a hierarchical way. DBNwas trained to classify the isolated hand-written digits into 10categories, so the visual inputs (28×28 pixel images) wereto be linked with categorical labels (Hinton et al., 2006).The linking was established via the training on image-labelpairs, using the higher (bimodal) layer (with 2000 units) that

learned the joint distribution of those pairs. DBN was shownto be superior to various other (discriminatory) models in thisclassification task. From the perspective of the representa-tions formed in the multimodal units, their goal was the sameas that in our models (although our units are deterministicrather than stochastic).
Our model also shares some similarities with the DevLexmodel of early lexical acquisition (Li et al., 2004). De-vLex, originally inspired by the DISLEX model (Miikku-lainen, 1997) also consists of self-organizing maps, but theseare directly interconnected, rather than projecting their out-puts to a higher, multimodal layer. DevLex was proposedto learn the form-meaning associations (phonological wordforms and meanings) via Hebbian updating the (bidirectional)connection links, aiming to model the processes of lexicalcomprehension and production. DevLex does not contain ahigher (e.g. multimodal) layer that integrates the modalities,as other grounding models (Riga et al., 2004; Roy & Mukher-jee, 2005). Instead, the overall representation of the meaningis in DevLex taken as the joint co-activation in the two maps.At the same time, each map has a capacity to activate theother map, yielding the overall representation. However, di-rect linking of the sensory modalities is also based on neuro-scientific rationale, because the brain is known to have thesedirect connections as well (see e.g. Allman et al. 2009).
Our model is also very similar to the model of Dorffner etal. (1996). They created a connectionist system consisting oftwo primary levels (symbolic and conceptual) connected toone central layer. There is a linking layer (the counterpart ofour multimodal layer) interconnecting the two primary layersvia localist units that link both representations (i.e. one unitconnects one word-concept pair of primary representations).First, one set of links (weights to the linking layer) is trainedusing a competitive mechanism exploiting the winner-take-allapproach. Then, the winners weights towards the other layerare updated according to the outstar rule (Grossberg, 1987).Hence, the purpose is to learn form-concept mapping, me-diated by the linking layer. Regarding DevLex, the similarmapping was obtained by connecting the two SOMs directly.In both models, these mappings were aimed at simulating theword comprehension (form-to-meaning) and the word pro-duction (meaning-to-form).
The mentioned models deal with lexical level but ourmodel goes beyond words because it is able to represent sen-tences with fixed grammar via RecSOM map. It finds themapping of the particular words to the concepts in the multi-modal layer without any prior knowledge, so the system pro-poses the solution to the binding problem.
The mapping in our models is actually a clustering pro-cess. If (at least) one perceptual input source creates discreteclusters, successful learning can be achieved. In case of allfuzzy sources of information, it is difficult to create a systemthat is able (without any additional information) to provide asuccessful mapping, e.g. to learn a new meaning of spatialposition in the middle of two spatial areas (below and right)
and the auditory information, i.e. “beright.” In other words,the successful clustering presumes that at least one modal-ity provides distinct activation vectors for different classes todrive the clustering process (i.e. the classes are well separablein the corresponding input subspace).
ConclusionFrom the computational point of view, the process of identi-fication is the most difficult and time-consuming task. Themain goal is to find a mapping between the concept andthe symbol. This is an association between a nonarbitraryconcept and an arbitrary string in Harnad‘s model. We usethe principle of self-organization and a separate layer in ourmodel to integrate and store these mappings. This systemdesign allows us in principle to append other modalities intothis system and still represent discrete multimodal categories.Our current version of the model does not provide the directassociation, but it could be implemented via the multimodallayer by adding the top-down links from it to the unimodallayers.
The main advantage of our model is the hierarchical rep-resentation of the sign components. It guarantees better pro-cessing and storing of representations because the sign (mul-timodal level) should be possible to justify and modify it fromboth modalities (the sequential “symbolic” auditory level andthe parallel “conceptual” visual level). The separate multi-modal level provides a platform for the development of sub-sequent stages of this system (e.g. inference mechanisms).
In our model we have created a system that is able to rep-resent constant features of the environment and identify themwith abstract symbols. Meaning is nonarbitrarily representedat the conceptual level (interpretant) that guarantees the cor-respondence of the internal representational system with theexternal environment.
Even though our model (especially Model II with NG al-gorithm in the multimodal layer) was shown to perform wellthere are ways how to increase its accuracy. For instance, itshould be possible to simplify the task of the where systemby reducing the two objects to radially symmetric blobs ofactivation. Actually, our preliminary simulations confirmedthis hypothesis.
The next stage can be to use this representational systemin the process of thinking (mental manipulation of groundedrepresentations). We want to test our representational systemmade of two components of the sign (an arbitrary symbol anda nonarbitrary concept) in the process of inference. We intendto compare systems based on the prior symbolic level (theclassical grounding approach) with the system based on thesymbols grounded to the nonarbitrary concepts via the mul-timodal layer. The goal is to confirm the advantages of themultimodal representations in the area of symbol grounding.
AcknowledgmentsThis research was supported by the research program MSM6840770012 of the CTU in Prague, Czech Republic and by

SAIA scholarship (M.V.) and by Slovak Grant Agency forScience, no. 1/0361/08 (I.F.).
ReferencesAllman, B., Keniston, L., & Meredith, M. (2009). Not just for
bimodal neurons anymore: The contribution of unimodalneurons to cortical multisensory processing. Brain Topog-raphy, 21, 157-167.
Barsalou, L. (1999). Perceptual symbol systems. Behavioraland brain sciences, 22(04), 577-660.
Damasio, A. (1989). Time-locked multiregional retro-activation: A systems level proposal for the neural sub-strates of recall and recognition. Cognition, 33, 25-62.
Dorffner, G., Hentze, M., & Thurner, G. (1996). A connec-tionist model of categorization and grounded word learn-ing. In Proceedings of the Groningen assembly on lan-guage acquisition (GALA’95).
Grossberg, S. (1987). Competitive learning: From interactiveactivation to adaptive resonance. Cognitive Science, 11(1),23-63.
Hammer, B., Micheli, A., Sperduti, A., & Strickert, M.(2004). Recursive self-organizing network models. NeuralNetworks, 17(8-9), 1061-1085.
Harnad, S. (1990). The symbol grounding problem. PhysicaD, 335-346.
Hinton, G., Osindero, S., & Teh, Y. (2006). A fast learningalgorithm for deep belief nets. Neural Computation, 18,1527-1554.
Kohonen, T. (2001). Self-organizing maps. Springer. (3rdedition)
Li, P., Farkas, I., & MacWhinney, B. (2004). Early lexicaldevelopment in a self-organizing neural network. NeuralNetworks, 17(8-9), 1345-1362.
Li, P., & McWhinney, B. (2002). PatPho: A phonologicalpattern generator for neural networks. Behavior ResearchMethods, Instruments and Computers.
Martinetz, T., & Schulten, K. (1991). A neural-gas networklearns topologies. In T. Kohonen, K. Mkisara, O. Simula,& J. Kangas (Eds.), Proceeedings of the international con-ference on artificial neural networks (p. 397-402). Ams-terdam: North-Holland.
Miikkulainen, R. (1997). Dyslexic and category-specificaphasic impairments in a self-organizing feature mapmodel of the lexicon. Brain and Language, 57, 334-366.
Paivio, A. (1986). Mental representation: A dual codingapproach. Oxford: Oxford University Press.
Peirce, C. (1931). Collected papers of Charles SandersPeirce (C. Hartshorne, Ed.). Harvard University Press.
Regier, T. (1996). The human semantic potential: Spatial lan-guage and constrained connectionism. Cambridge, MA:MIT Press.
Riga, T., Cangelosi, A., & Greco, A. (2004). Symbol ground-ing transfer with hybrid self-organizing/supervised neural
networks. In International joint conference on neural net-works (IJCNN’04).
Roy, D., & Mukherjee, N. (2005). Towards situated speechunderstanding: Visual context priming of language mod-els. Computer Speech and Language, 19(2), 227-248.
Stein, B., & Meredith, M. (1993). Merging of the senses.Cambridge, MA: MIT Press.
Tino, P., Farkas, I., & Mourik, J. van. (2006). Dynamics andtopographic organization in recursive self-organizing map.Neural Computation, 18, 2529–2567.
Ungerleider, L., & Mishkin, M. (1982). Two cortical vi-sual systems. In D. Ingle, M. Goodale, & R. Mansfield(Eds.), Analysis of visual behaviour (p. 549-586). Cam-bridge, MA: MIT Press.
Varela, F., Thompson, E., & Rosch, E. (1991). The embod-ied mind – cognitive science and human experience. Cam-bridge, MA: MIT Press.
Vavrecka, M. (2009). Model for the grounding of spatial rela-tions (in Czech). In M. Petru (Ed.), Struny mysli: Kognice2007 (p. 139-148). Ostrava, Czech Republic: Montanex.
Voegtlin, T. (2002). Recursive self-organizing maps. NeuralNetworks, 15(8-9), 979-992.
Ziemke, T. (1999). Rethinking grounding. In A. Riegler,M. Peschl, & A. von Stein (Eds.), Understanding repre-sentation in the cognitive sciences (p. 177-190). New York:Plenum Press.