elisa - web.math.ku.dkweb.math.ku.dk/~richard/download/courses/biochem_2006/elisa.pdf · elisa...
TRANSCRIPT

ELISA
ELISA (enzyme-linked immunosorbent assay) forsøg bruges til atdetektere og kvantificere stoffer såsom proteiner, peptider, antistoffer o.lig.
Teknikken er ganske snedig, og muliggør at man inddirekte kan måle småkoncentrationer af stofferne.
Den direkte måling er et optisk signal relateret til koncentrationen.Kvalitativt gælder at
større koncentration ⇒ større signal
Vi skal se, hvordan vi kan kvantificere denne sammenhæng lidt nøjere.
– p. 1/16

DNase data
0 2 4 6 8 10 120.
00.
51.
01.
52.
0
Run 1
koncentration
optis
k si
gnal
0 2 4 6 8 10 12
0.0
0.5
1.0
1.5
2.0
Run 2
koncentration
optis
k si
gnal
– p. 2/16
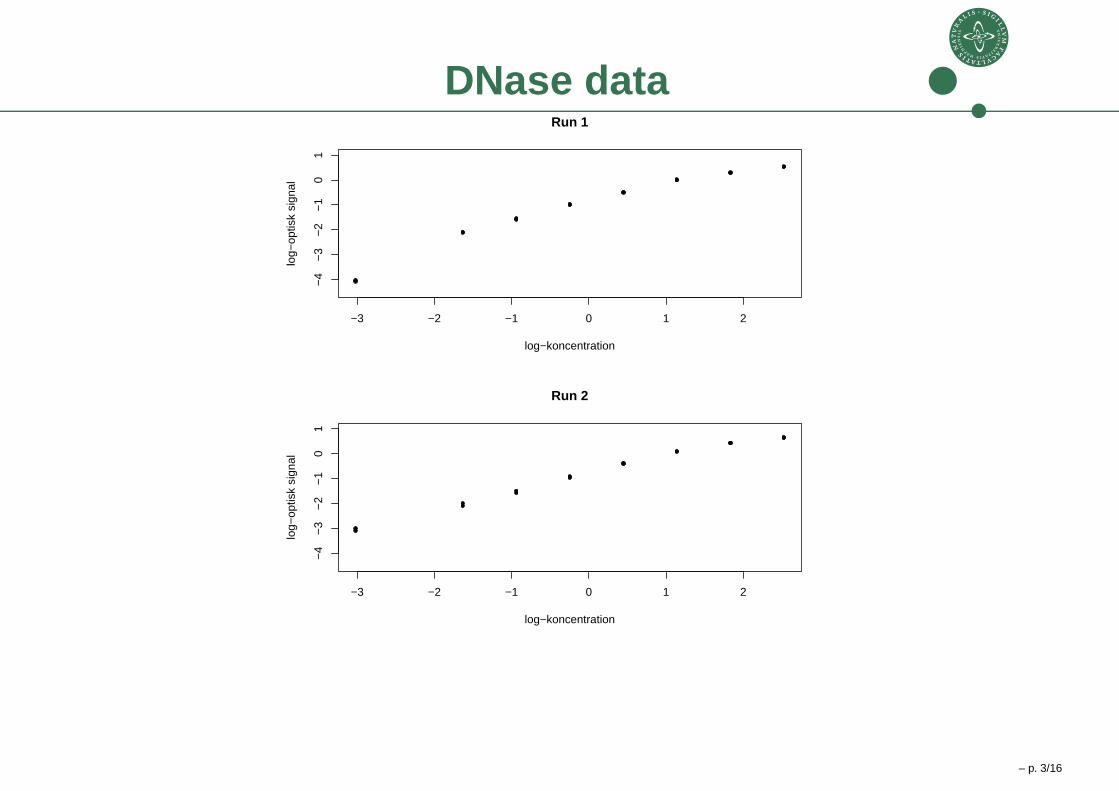
DNase data
−3 −2 −1 0 1 2−
4−
3−
2−
10
1
Run 1
log−koncentration
log−
optis
k si
gnal
−3 −2 −1 0 1 2
−4
−3
−2
−1
01
Run 2
log−koncentration
log−
optis
k si
gnal
– p. 3/16

DNase dataRun 1 Run 2
Conc. Density Conc. Density
0.05 0.02 0.05 0.04
0.05 0.02 0.05 0.05
0.20 0.12 0.20 0.14
0.20 0.12 0.20 0.12
0.39 0.21 0.39 0.23
0.39 0.21 0.39 0.21
0.78 0.38 0.78 0.40
0.78 0.37 0.78 0.38
1.56 0.61 1.56 0.67
1.56 0.61 1.56 0.68
3.12 1.02 3.12 1.12
3.12 1.00 3.12 1.08
6.25 1.33 6.25 1.55
6.25 1.36 6.25 1.53
12.5 1.73 12.5 1.93
12.5 1.71 12.5 1.91 – p. 4/16

DNase linear regression
Vi foreslår den lineære regressionsmodel
log(signal) = α + β log(koncentration)
på de log-transformerede målinger. Dvs. X = log(koncentration) ogY = log(signal).
Run 1 Run 2
n = 16 n = 16
X = 0.018 Y = −1.027 X = 0.018 Y = −0.853∑
x2 = 47.48∑
xy = 37.40∑
x2 = 47.48∑
xy = 33.51
b1 = 37.4047.48 = 0.79 b1 = 33.51
47.48 = 0.71
a1 = −1.027 − 0.79 × 0.018 = −1.04 a1 = −0.853 − 0.71 × 0.018 = −0.87
s2Y ·X = residual SS
14 = 0.093 s2Y ·X = residual SS
14 = 0.024
– p. 5/16

DNase linear regression
−3 −2 −1 0 1 2−
4−
3−
2−
10
1
Run 1
log−koncentration
log−
optis
k si
gnal
−3 −2 −1 0 1 2
−4
−3
−2
−1
01
Run 2
log−koncentration
log−
optis
k si
gnal
– p. 6/16

DNase konfidensintervaller
Spredningen (run 1) på en ny Y -måling for en given X-værdi er
(sY
)1 =
√
0.093
[
1 +1
14+
(X − 0.018)2
47.48
]
.
−3 −2 −1 0 1 2
−4
−3
−2
−1
01
Run 1 − konfidensbånd for en ny måling
log−koncentration
log−
optis
k si
gnal
– p. 7/16

DNase invers prediktion
Angiv et konfidensinterval for koncentrationen, hvis det optiske signal er0.5 (run 1).
log(0.5) = −0.693 X = −0.693+1.040.79 = 0.439 ˆConc = exp(X) = 1.55
Med t = tα(2),14 = 2.144 er
K = 0.792 − 2.1442(0.093/47.48) = 0.61.
Et 95% konfidensinterval for X beregnes ved formel (17.31) til[−0.41, 1.32]. Et 95% konfidensinterval for koncentrationen er derfor
[exp(−0.41), exp(1.32)] = [0.66, 3.71].
– p. 8/16

DNase - modeldiskussion
Fitter modellen? Tilsyneladende ikke særligt godt for store og småkoncentrationer.
Konsekvensen er bl.a. stort variansestimat og store konfidensintervaller.
Vigtig anvendelse af regressionsanalyse i ELISA-forsøg er netop til inversprediktion ved “fornuftige koncentrationer”.
Vi prøver at se bort fra den mindste koncentration samt de to størstekoncentrationer – vel vidende at det begrænser variationsområdet forkoncentrationer, hvor modellen kan bruges.
– p. 9/16

DNase modificeret linear regression
Run 1 Run 2
n = 10 n = 10
X = −0.24 Y = −1.03 X = −0.24 Y = −0.96∑
x2 = 10.06∑
xy = 9.83∑
x2 = 10.06∑
xy = 9.77
b1 = 9.8310.06 = 0.77 b1 = 9.77
10.06 = 0.78
a1 = −1.03 + 0.77 × 0.24 = −0.84 a1 = −0.96 + 0.78 × 0.24 = −0.77
s2Y ·X = residual SS
10 = 0.0013 s2Y ·X = residual SS
10 = 0.0028
– p. 10/16
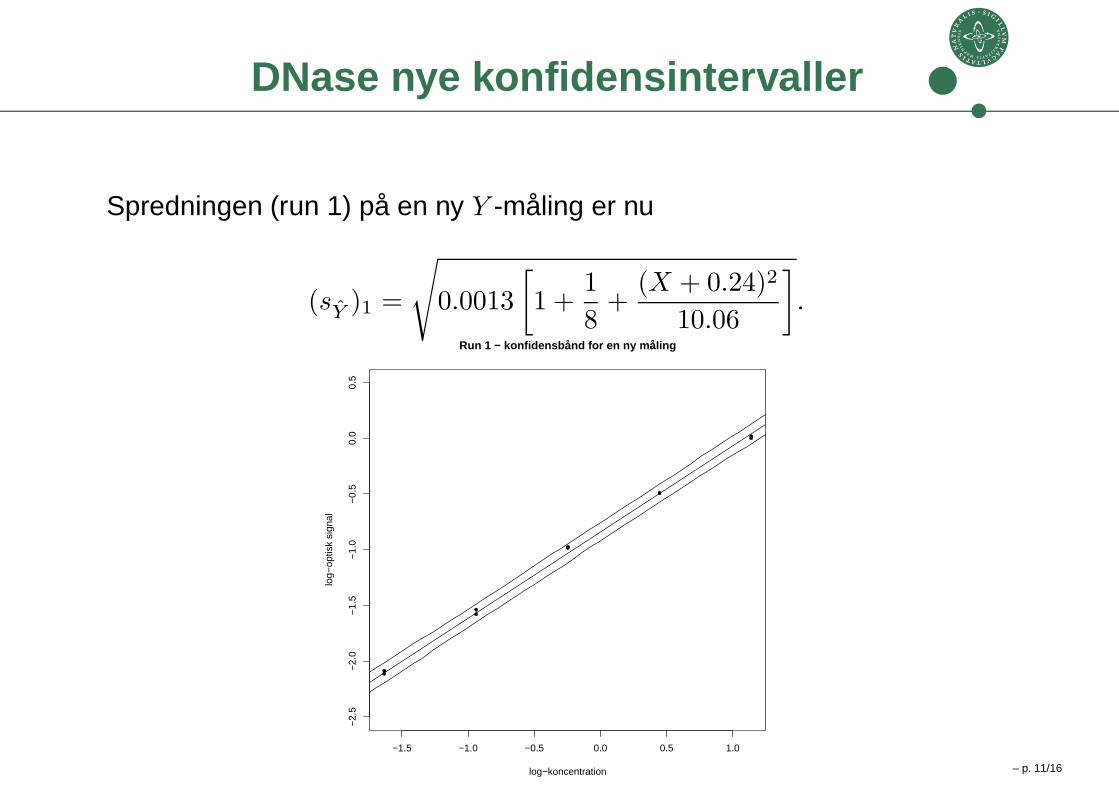
DNase nye konfidensintervaller
Spredningen (run 1) på en ny Y -måling er nu
(sY
)1 =
√
0.0013
[
1 +1
8+
(X + 0.24)2
10.06
]
.
−1.5 −1.0 −0.5 0.0 0.5 1.0
−2.
5−
2.0
−1.
5−
1.0
−0.
50.
00.
5Run 1 − konfidensbånd for en ny måling
log−koncentration
log−
optis
k si
gnal
– p. 11/16

DNase ny invers prediktion
Angiv et konfidensinterval for koncentrationen, hvis det optiske signal er0.5 (run 1).
log(0.5) = −0.693 X = −0.693+0.840.77 = 0.19 ˆConc = exp(X) = 1.21
Med t = tα(2),14 = 2.144 er
K = 0.772 − 2.1442(0.0013/10.06) = 0.59.
Et 95% konfidensinterval for X beregnes ved formel (17.31) til[0.078, 0.30]. Et 95% konfidensinterval for koncentrationen er derfor
[exp(0.078), exp(0.30)] = [1.08, 1.36].
– p. 12/16

Test for ens varianser
Alle koncentrationer:
F =0.093
0.024= 3.88
F0.05(1),14,14 = 2.48 – vi forkaster, at varianserne er ens.Centrale koncentrationer alene:
F =0.028
0.013= 2.15
F0.05(1),8,8 = 3.44 – vi acceptere, at varianserne er ens.
– p. 13/16

Test for ens hældning
Alle koncentrationer: s2b1−b2
= 0.05847.48 + 0.058
47.48 = 0.0024
t =0.79 − 0.71√
0.0024= 1.63
t0.05(2),28 = 2.05 – vi accepterer, at hældningerne er ens. Det fælleshældningsestimat er bc = 0.75.Centrale koncentrationer alene: s2
b1−b2= 0.00041
t =0.77 − 0.78√
0.00041= −0.50
t0.05(2),16 = 2.12 – vi accepterer, at hældningerne er ens. Det fælleshældningsestimat er bc = 0.78.
– p. 14/16

Test for ens intercept
Idet X er den samme i de to grupper, simplificeres t-teststørrelsen for ensintercept til
Y1 − Y2√
(s2Y ·X)c
[
1n1
+ 1n2
]
.
Alle koncentrationer: (s2Y ·X)c = 1.88
28 = 0.067
t =0.853 − 1.03
√
0.067(1/14 + 1/14)= −1.81
t0.05(2),29 = 2.05 – vi accepterer hypotesen om ens intercept.
Centrale koncentrationer alene: s2b1−b2
= 0.03317 = 0.00196
t =0.96 − 1.03
√
0.00196(1/10 + 1/10)= −3.54
t0.05(2),17 = 2.11 – vi forkaster hypotesen om ens intercept.– p. 15/16

Konklusioner
Vi drager forskellige konklusioner afhængigt af, om vi tager alle koncentrationer med eller ej.I lyset af det bedre modelfit for de centrale koncentrationer alene samt godkendelse af testetfor ens varianser i dette tilfælde, må vi lægge mest vægt på konklusionerne i dette tilfælde.
For de centrale koncentrationer ser det ud til, at den rette linje fitter data fint, samt athældningen tilsyneladende ikke afhænger af forsøgsgangen (run). Derimod er interceptetafhængigt af forsøgsgang. Der er således en variation indenfor hver forsøgsgang, som erganske lille, men så er der ydermere en variation mellem forsøgsgangene. Det er derforvanskeligt at lave en kalibreringskurve, som kan bruges til invers prediktion for alle fremtidigeforsøg. Normalt laver man derfor i hver forsøgsgang en ny kalibreringskurve(standardkurven).
Bedre standardkurver, som kan dække et større koncentrationsområde, kan opnås med
ikke-lineær regression, men i det centrale koncentrationsområde, hvor usikkerheden på de
ikke-lineære regressionsfunktioner også er mindst, vil selv en ikke-lineær
regressionsfunktion være stort set lineær.
– p. 16/16