efficiency of algorithms csci 107 lecture 6-7. topics –data cleanup algorithms copy-over,...
TRANSCRIPT

Efficiency of Algorithms
Csci 107
Lecture 6-7

• Topics
– Data cleanup algorithms• Copy-over, shuffle-left, converging pointers
– Efficiency of data cleanup algorithms– Order of magnitude (1), (n), (n2)
– Binary search

(Time) Efficiency of an algorithm worst case efficiency
is the maximum number of steps that an algorithm can take for any collection of data values.
Best case efficiency
is the minimum number of steps that an algorithm can take any collection of data values.
Average case efficiency
- the efficiency averaged on all possible inputs
- must assume a distribution of the input
- we normally assume uniform distribution (all keys are equally
probable)
If the input has size n, efficiency will be a function of n

Order of Magnitude
• Worst-case of sequential search: – 3n+5 comparisons– Are these constants accurate? Can we ignore them?
• Simplification: – ignore the constants, look only at the order of magnitude– n, 0.5n, 2n, 4n, 3n+5, 2n+100, 0.1n+3 ….are all linear– we say that their order of magnitude is n
• 3n+5 is order of magnitude n: 3n+5 = (n)• 2n +100 is order of magnitude n: 2n+100=(n)• 0.1n+3 is order of magnitude n: 0.1n+3=(n)• ….

Data Cleanup Algorithms
What are they?
A systematic strategy for removing errors from data.
Why are they important?
Errors occur in all real computing situations.
How are they related to the search algorithm?
To remove errors from a series of values, each value must be examined to determine if it is an error.
E.g., suppose we have a list d of data values, from which we want to remove all the zeroes (they mark errors), and pack the good values to the left. Legit is the number of good values remaining when we are done.
d1 d2 d3 d4 d5 d6 d7 d8
5 3 4 0 6 2 4 0Legit

Data Cleanup: Copy-Over algorithm
Idea: Scan the list from left to right and copy non-zero values to a new list
Copy-Over Algorithm (Fig 3.2)Variables: n, A1, …, An, newposition, left, B1,…,Bn• Get values for n and the list of n values A1, A2, …, An• Set left to 1• Set newposition to 1• While left <= n do
• If Aleft is non-zero • Copy A left into B newposition
(Copy it into position newposition in new list• Increase left by 1• Increase newposition by 1
• Else increase left by 1 • Stop

Efficiency of Copy-Over
• Best case: – all values are zero: no copying, no extra space
• Worst-case: – No zero value: n elements copied, n extra space– Time: (n) – Extra space: n

Data Cleanup: The Shuffle-Left Algorithm
• Idea: – go over the list from left to right. Every time we see a
zero, shift all subsequent elements one position to the left.
– Keep track of nb of legitimate (non-zero) entries
• How does this work?
• How many loops do we need?

Shuffle-Left Algorithm (Fig 3.1)
Variables: n, A1,…,An, legit, left, right1 Get values for n and the list of n values A1, A2, …, An2 Set legit to n3 Set left to 14 Set right to 25 Repeat steps 6-14 until left > legit
6 if Aleftt ≠ 0
7 Increase left by 1 8 Increase right by 1
9 else10 Reduce legit by 111 Repeat 12-13 until right > n
12 Copy Aight into Aright-1
13 Increase right by 114 Set right to left + 1
15 Stop
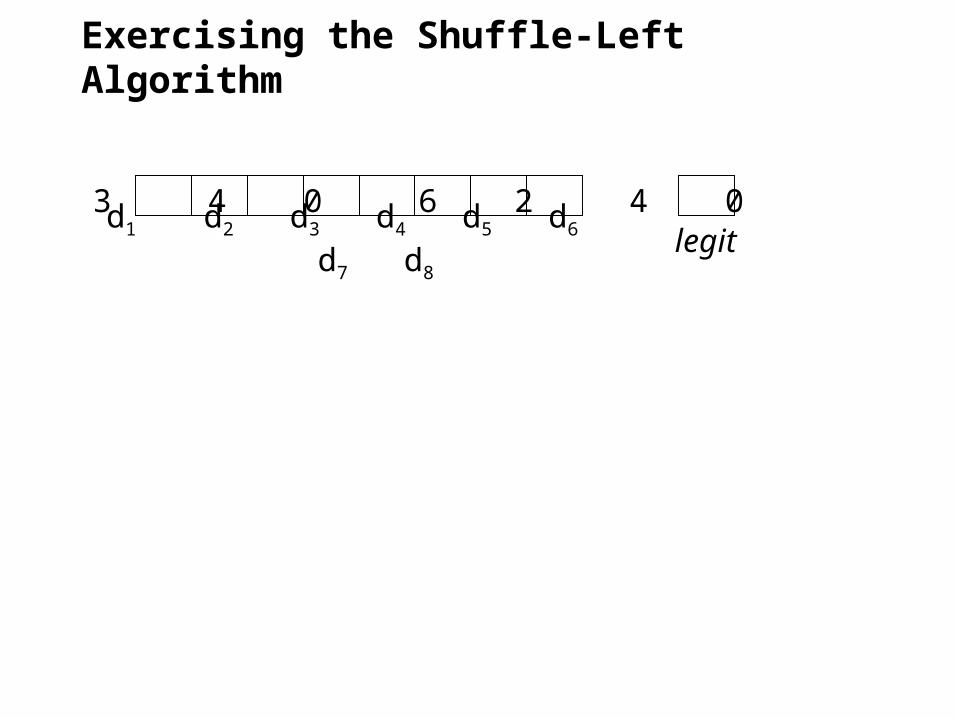
Exercising the Shuffle-Left Algorithm
d1 d2 d3 d4 d5 d6 d7 d8
5 3 4 0 6 2 4 0legit

Efficiency of Shuffle-Left• Space:
– no extra space (except few variables)
• Time– Best-case
• No zero value:• no copying ==> order of n = (n)
– Worst case• All zero values:
– every element thus requires copying n-1 values one to the left
• n x (n-1) = n2 - n = order of n2 = (n2) (why?)
– Average case• Half of the values are zero• n/2 x (n-1) = (n2 - n)/2 = order of n2 = (n2)

Data Cleanup: The Converging-Pointers Algorithm
• Idea:– One finger moving left to right, one moving
right to left– Move left finger over non-zero values;– If encounter a zero value then
• Copy element at right finger into this position
• Shift right finger to the left

Converging Pointers Algorithm (Fig 3.3)
Variables: n, A1,…, An, legit, left, right1 Get values for n and the list of n values A1, A2,
…,An2 Set legit to n3 Set left to 14 Set right to n5 Repeat steps 6-10 until left ≥ right
6 If the value of Aleft≠0 then increase left by 1
7 Else8 Reduce legit by 19 Copy the value of Aright to Aleft
10 Reduce right by 1
11 if Aleft=0 then reduce legit by 1.12 Stop
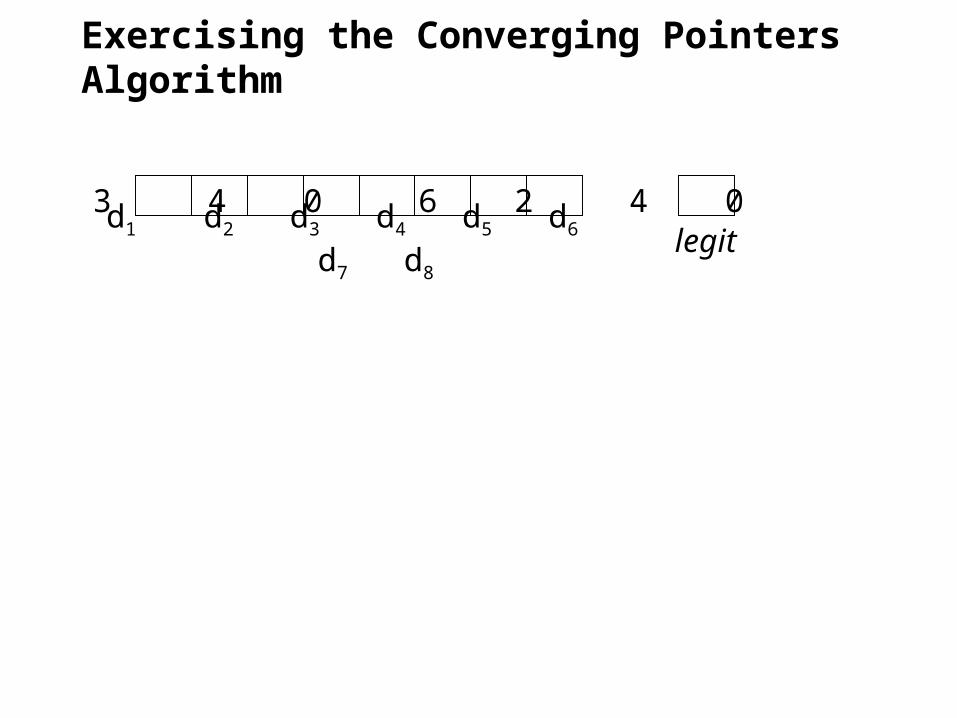
Exercising the Converging Pointers Algorithm
d1 d2 d3 d4 d5 d6 d7 d8
5 3 4 0 6 2 4 0legit

Efficiency of Converging Pointers Algorithm
• Space– No extra space used (except few variables)
• Time– Best-case
• No zero value• No copying => order of n = (n)
– Worst-case• All values zero: • One copy at each step => n-1 copies • order of n = (n)
– Average-case• Half of the values are zero: • n/2 copies• order of n = (n)

Data Cleanup Algorithms
• Copy-Over– worst-case: time (n), extra space n– best case: time (n), no extra space
• Shuffle-left– worst-case: time (n2), no extra space– Best-case: time (n), no extra space
• Converging pointers– worst-case: time (n), no extra space– Best-case: time (n), no extra space

Order of magnitude (n2)
• Any algorithm that does cn2 work for any constant c
– 2n2 is order of magnitude n2 : 2n2=(n2)
– .5n2 is order of magnitude n2 : .5n2=(n2)
– 100n2 is order of magnitude n2: 100n2=(n2)

Another example
• Problem: Suppose we have n cities and the distances between cities are stored in a table, where entry [i,j] stores the distance from city i to city j
– How many distances in total?– An algorithm to write out these distances
• For each row 1 through n do – For each column 1 through n do
» Print out the distance in this row and column
– Analysis?

Comparison of (n) and (n2) (n): n, 2n+5, 0.01n, 100n, 3n+10,.. (n2): n2, 10n2, 0.01n2,n2+3n, n2+10,…• We do not distinguish between constants..
– Then…why do we distinguish between n and n2 ??– Compare the shapes: n2 grows much faster than n
• Anything that is order of magnitude n2 will eventually be larger than anything that is of order n, no matter what the constant factors are
• Fundamentally n2 is more time consuming than n (n2) is larger (less efficient) than (n)
• 0.1n2 is larger than 10n (for large enough n)• 0.0001n2 is larger than 1000n (for large enough n)

The Tortoise and the HareDoes algorithm efficiency matter??
– …just buy a faster machine!
Example: • Pentium Pro
– 1GHz (109 instr per second), $2000• Cray computer
– 10000 GHz(1013 instr per second), $30million
• Run a (n) algorithm on a Pentium• Run a (n2) algorithm on a Cray• For what values of n is the Pentium faster?
– For n > 10000 the Pentium leaves the Cray in the dust..

Searching• Problem: find a target in a list of values
• Sequential search– Best-case : (1) comparison
• target is found immediately
– Worst-case: (n) comparisons• Target is not found
– Average-case: (n) comparisons• Target is found in the middle
• Can we do better? – No…unless we have the input list in sorted order

Searching a sorted list
• Problem: find a target in a sorted list– How can we exploit that the list is sorted, and come up
with an algorithm faster than sequential search in the worst case?
– How do we search in a phone book?
– Can we come up with an algorithm? • Check the middle value
• If smaller than target, go right
• Otherwise go left

Binary search
• Get values for list, A1, A2, ….An, n , target• Set start =1, set end = n• Set found = NO• Repeat until ??
– Set m = middle value between start and end– If target = m then
• Print target found at position m• Set found = YES
– Else if target < Am then end = m-1Else start = m+1
• If found = NO then print “Not found”• End

Efficiency of binary search
• What is the best case?• What is the worst case?
– Initially the size of the list in n
– After the first iteration through the repeat loop, if not found, then either start = m or end = m ==> size of the list on which we search is n/2
– Every time in the repeat loop the size of the list is halved: n, n/2, n/4,….
– How many times can a number be halved before it reaches 1?