edinburgh mt lecture2: probability and language models
TRANSCRIPT

•Homework 1 posted, due January 28
•Recommended work plan:
•Complete “Getting Started” by TOMORROW
•Complete “Baseline” by next Friday
•Complete “The Challenge” by January 28

def translate(French): # do something return English
T : ⌃⇤f ! ⌃⇤
e
Write a function

Learn Write a functiondef learn(parallel_data): # do something return parameters
def translate(French, parameters): # do something return English
T : ⌃⇤f ⇥⇥ ! ⌃⇤
e
L : (⌃⇤f ⇥ ⌃⇤
e)⇤ ! ⇥
T (f, ✓) = arg max
e2⌃⇤e
p✓(e|f)Using probability:

Why probability?
•Formalizes...
•the concept of models
•the concept of data
•the concept of learning
•the concept of inference (prediction)
•Derive logical conclusions in the face of ambiguity.

Basic Concepts•Sample space S: set of all possible outcomes.
•Event space E: any subset of the sample space.
•Random variable: function from S to a set of disjoint events in S.
•Probability measure P: a function from events to positive real numbers satisfying these axioms:
1.
2.
3.
8E 2 F, P (E) � 0
P (S) = 1
8E1, ..., Ek
k\
i=1
Ei = ; ) P (E1 [ ... [ Ek) =kX
i=1
P (Ei)

Experiment: roll a six-side die once.What is the sample space?

16
16
16
16
16
16
S = {1, 2, 3, 4 5, 6}r.v. X(s) = s
P(X) =
if X =

Experiment: roll a six-side die twice.What is the sample space?

136136136136136136
136136136136136136
136136136136136136
136136136136136136
136136136136136136
136136136136136136
X, Y
S = {1, 2, 3, 4 5, 6}2
r.v. X(x,y) = x, Y(x,y) = y

136136136136136136
136136136136136136
136136136136136136
136136136136136136
136136136136136136
136136136136136136
p(X = 1, Y = 1) =136
A probability over multiple events is a joint probability.

136136136136136136
136136136136136136
136136136136136136
136136136136136136
136136136136136136
136136136136136136
p(1, 1) =136
A probability over multiple events is a joint probability.

136136136136136136
136136136136136136
136136136136136136
136136136136136136
136136136136136136
136136136136136136
p(Y = 1) =X
x2X
p(X = x, Y = 1) =16By axiom 3
A probability distribution over a subset of variables is a marginal probability.

136136136136136136
136136136136136136
136136136136136136
136136136136136136
136136136136136136
136136136136136136
p(X = 1) =X
y2Y
p(X = 1, Y = y) =16
A probability distribution over a subset of variables is a marginal probability.

136136136136136136
136136136136136136
136136136136136136
136136136136136136
136136136136136136
136136136136136136
joint marginal P (Y = 1|X = 1) =
P (X = 1, Y = 1)Py2Y P (X = 1, Y = y)
=16
The probability of a r.v. when the when the values of the other r.v.’s are known is its conditional probability.

136136136136136136
136136136136136136
136136136136136136
136136136136136136
136136136136136136
136136136136136136
A variable is conditionally independent of another iff its marginal probability = its conditional probability.
In other words, if knowing X tells me nothing about Y.
P (Y = 1|X = 1) = P (Y = 1) =1
6

16
16
16
16
16
16
P(X) =
if X =
16
16
16
16
16
16
P(Y) =
if Y =
P(X,Y) = P(X)P(Y)Far fewer parameters!

20°C15°C10°C5°C0°C-5°C
20°C15°C10°C5°C0°C-5°C
000
.003.01.03
.2.25.2
.147.09.07
p(snow|-5°C) = .30
In most interesting models, variables are not conditionally independent.

Under this distribution, temperature and weather r.v.’s are not conditionally independent!
20°C15°C10°C5°C0°C-5°C
20°C15°C10°C5°C0°C-5°C
000
.003.01.03
.2.25.2
.147.09.07
p(snow) = .043
In most interesting models, variables are not conditionally independent.
p(snow|-5°C) = .30
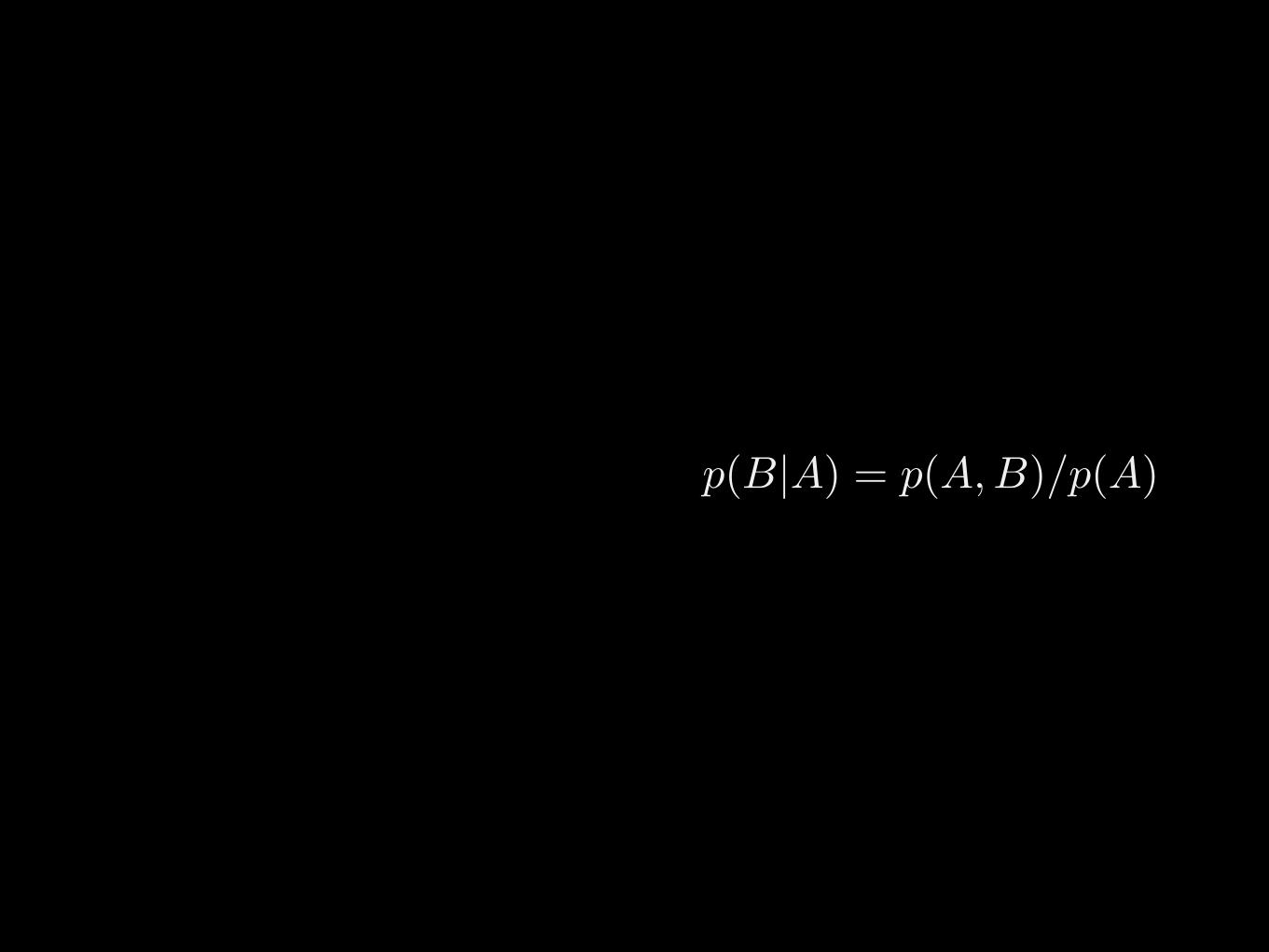
p(B|A) = p(A,B)/p(A)

p(A, B) = p(A) · p(B|A)
Chain rule

p(A, B) = p(A) · p(B|A)
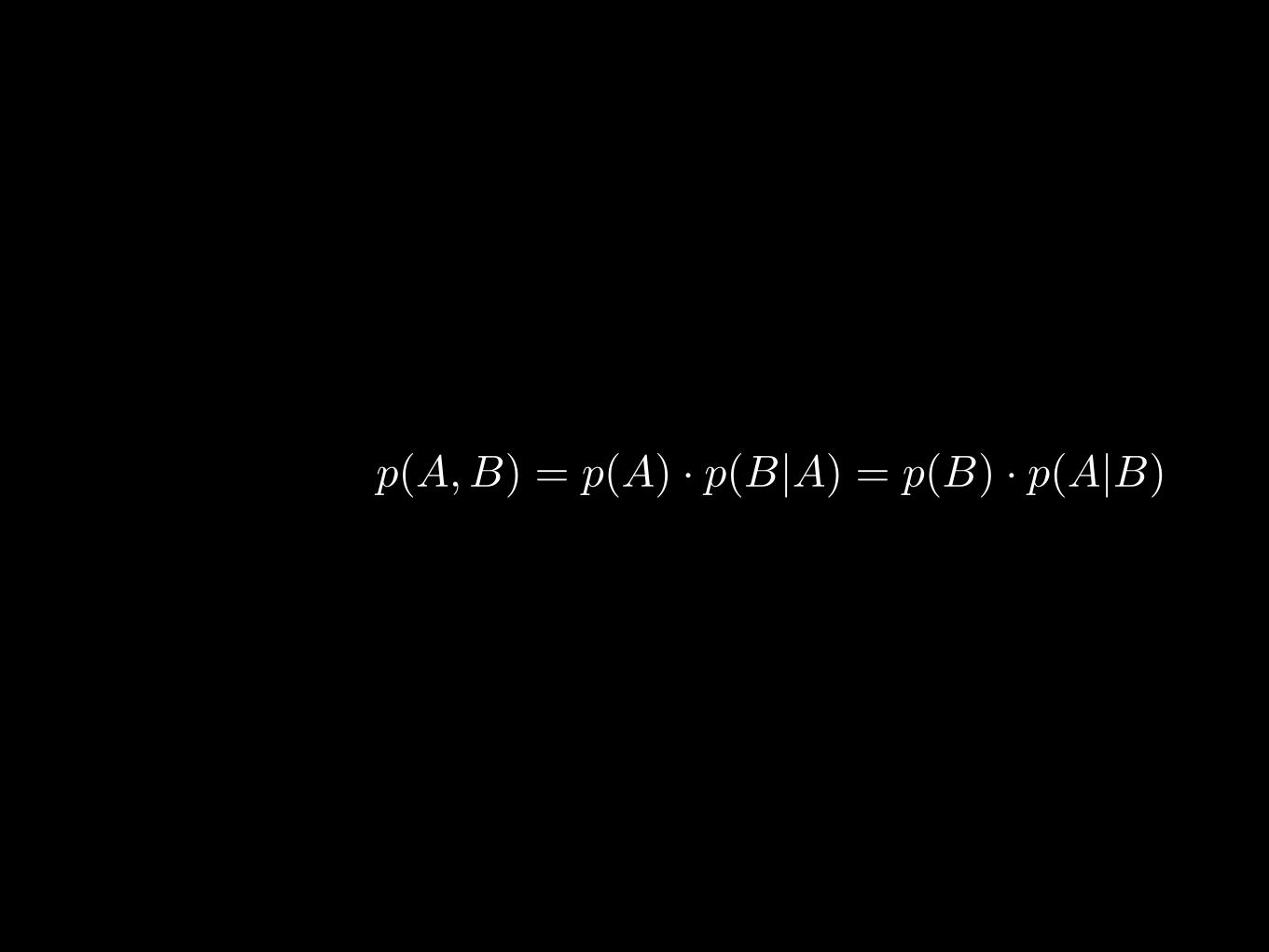
p(A, B) = p(A) · p(B|A) = p(B) · p(A|B)

p(A) · p(B|A) = p(B) · p(A|B)

p(B|A) =p(B) · p(A|B)
p(A)

p(B|A) =p(B) · p(A|B)
p(A)Bayes’ Rule

p(B|A) =p(B) · p(A|B)
p(A)Bayes’ Rule
prior likelihoodposterior
evidence

p(English|Chinese) =
p(English) × p(Chinese|English)
p(Chinese)
likelihoodprior
evidence
Bayes’ Rule

p(English|Chinese) =
p(English) × p(Chinese|English)
p(Chinese)
channel modelsignal model
normalization (ensures we’re working with valid probabilities).
Noisy Channel

p(English|Chinese) =
p(English) × p(Chinese|English)
p(Chinese)
translation modellanguage model
normalization (ensures we’re working with valid probabilities).
Machine Translation

English
p(Chinese|English)

English
p(Chinese|English)
× p(English)

English
p(Chinese|English)
× p(English)
� p(English|Chinese)

p(English|Chinese) =
p(English) × p(Chinese|English)
p(Chinese)
translation modellanguage model
evidence
Machine Translation

p(English|Chinese) ∼
p(English) × p(Chinese|English)
Machine Translation
How do we define the probability of a sentence?
How do we define the probability of a Chinese sentence, given a particular English sentence?
Questions we must answer:
What is the sample space?

n-gram Language Models
S = V*V = set of all English words
Define an infinite set of events:Xi(s) = ith word in s if len(s)≥i, ε otherwise.
Must define: p(X0...X∞)

n-gram Language Models
S = V*V = set of all English words
Define an infinite set of events:Xi(s) = ith word in s if len(s)≥i, ε otherwise.
Must define: p(X0...X∞)
= p(X0) p(X1|X0) .... p(Xk|X0...Xk-1) ....by chain rule:

n-gram Language Models
S = V*V = set of all English words
Define an infinite set of events:Xi(s) = ith word in s if len(s)≥i, ε otherwise.
Must define: p(X0...X∞)
= p(X0) p(X1|X0) .... p(Xk|X0...Xk-1) ....by chain rule:
= p(X0) p(X1|X0) .... p(Xk|Xk-1) ....assume conditional independence:

Key idea: since the language model is a joint model over all words in a sentence, make each word depend on n-1 previous
words in the sentence.
n-gram Language Models

p(However|START )
n-gram Language Models

p(However|START )
A number between 0 and 1.
n-gram Language Models

p(However|START )
A number between 0 and 1.X
x
p(x|START ) = 1
n-gram Language Models

However
p(However|START )
Language Models

However ,
p(, |However)
Language Models

However , the
p(the|, )
Language Models

However , the sky
p(sky|the)
Language Models

However , the sky remained
Language Models
p(remained|sky)

However , the sky remained clear
Language Models
p(clear|remained)

However , the sky remained clear ... wind .
Language Models
p(STOP |.)...

p(English) =
length(English)!
i=1
p(wordi|wordi−1)
Language Models

p(English) =
length(English)!
i=1
p(wordi|wordi−1)
Language Models
Note: the probability that word0=START is 1.

p(English) =
length(English)!
i=1
p(wordi|wordi−1)
Language Models
Note: the probability that word0=START is 1.
This model explains every word in the English sentence.

p(English) =
length(English)!
i=1
p(wordi|wordi−1)
Language Models
Note: the probability that word0=START is 1.
This model explains every word in the English sentence.But it makes very strong conditional independence
assumptions!