dr. taysir hassan a. soliman - assiut university · dr. taysir. hassan a. soliman. lecturer,...
TRANSCRIPT

Introduction Introduction toto
Bioinformatics Bioinformatics
Dr. Dr. TaysirTaysir HassanHassan A. A. SolimanSolimanLecturer, Information Systems Dept.Lecturer, Information Systems Dept.
Faculty of Computer and Information Sciences Faculty of Computer and Information Sciences AinAin Shams University Shams University

AgendaAgenda
Definition ofDefinition of BioinformaticsBioinformaticsProgress of the Human Genome ProjectProgress of the Human Genome ProjectThe NCBI Data Model The NCBI Data Model Protein Databases Protein Databases Useful texts Useful texts
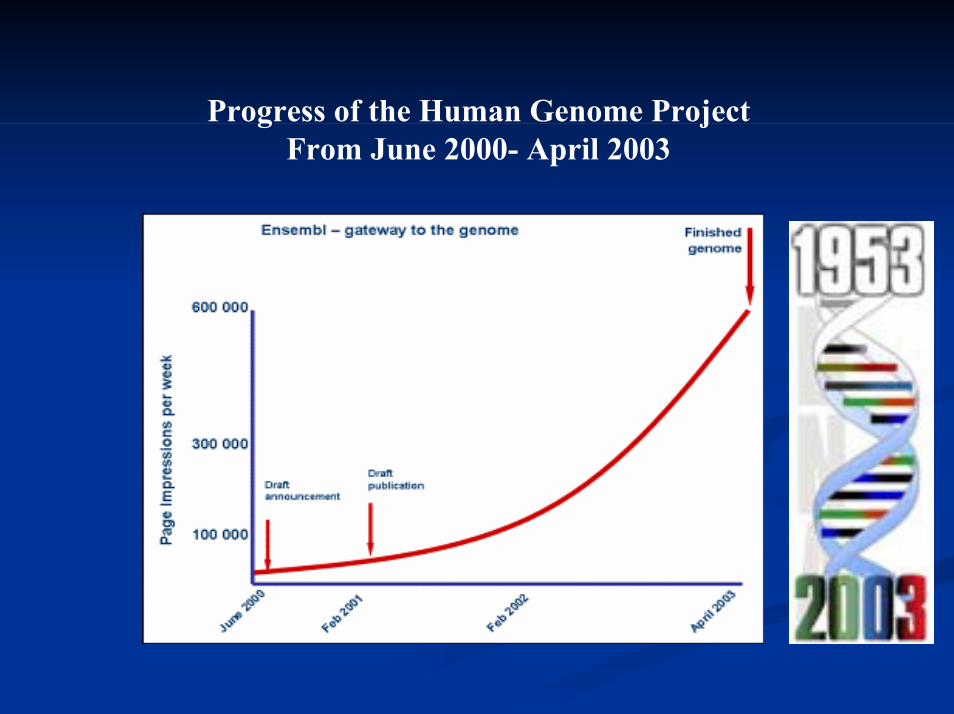
Progress of the Human Genome Project From June 2000- April 2003

Bioinformatics Bioinformatics
Roughly,Roughly, BioinformaticsBioinformatics describes use of computers to handle describes use of computers to handle biological information.biological information.In practice:In practice: BioinformaticsBioinformatics = =
““Computational Molecular BiologyComputational Molecular Biology””A tight definition (A tight definition (FredjFredj TekaiaTekaia)): :
"The mathematical, statistical and computing methods that "The mathematical, statistical and computing methods that aim to solve biological problems using DNA and amino aim to solve biological problems using DNA and amino acid sequences and related information.acid sequences and related information.““Distinction between Biomedical &Distinction between Biomedical & Bioinformatics Bioinformatics

Bioinformatics Bioinformatics As technologies improve, we are able to extract more and more As technologies improve, we are able to extract more and more information encoded in a genomeinformation encoded in a genome
biological data
proteins
genes
complexes
pathways
whole cell
community
bio-complexity
organs

Bioinformatics Bioinformatics
1. What is Bioinformatics?
Bioinformatics is the application of computational techniques to
Analyze
Info.
Large Macromolecules
Biological Databases
Organize Understand
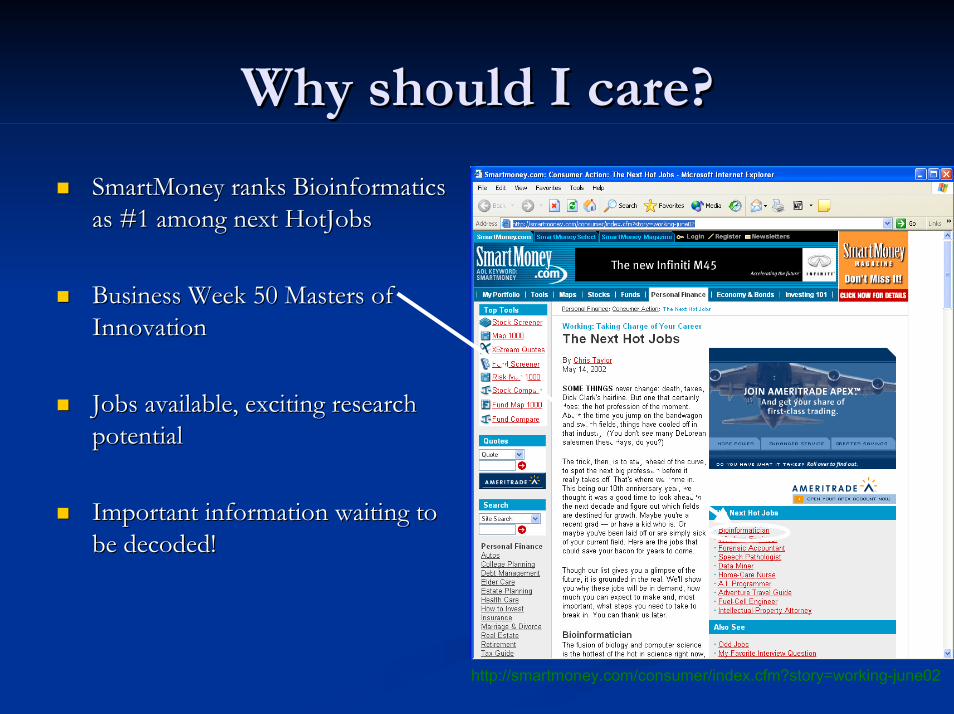
Why should I care?Why should I care?
SmartMoneySmartMoney ranksranks BioinformaticsBioinformaticsas #1 among next as #1 among next HotJobsHotJobs
Business Week 50 Masters of Business Week 50 Masters of InnovationInnovation
Jobs available, exciting research Jobs available, exciting research potentialpotential
Important information waiting to Important information waiting to be decoded!be decoded!
http://smartmoney.com/consumer/index.cfm?story=working-june02

Why isWhy is bioinformaticsbioinformatics important?important?
Supply/demand: few people Supply/demand: few people adequately trained in both adequately trained in both biology and computer biology and computer sciencescience
Genome sequencing, Genome sequencing, microarraysmicroarrays, etc lead to large , etc lead to large amounts of data to be amounts of data to be analyzedanalyzed
Leads to important Leads to important discoveries discoveries
Saves time and moneySaves time and money

What skills are needed?What skills are needed?
WellWell--grounded in one of the following areas:grounded in one of the following areas:Computer scienceComputer scienceMolecular biologyMolecular biologyStatisticsStatistics
Working knowledge and appreciation in the Working knowledge and appreciation in the others!others!

In other words,In other words,BioinformaticsBioinformatics integratesintegrates
Biology is a data rich science

From chromosomes to sequence data
Large scale DNA sequencing
CGCCAGCTGGACGGGCACACCATGAGGCTGCTGACCCTCCTGGGCCTTCTGTGTGGCTCGGTGGCCACCCCCTTAGGCCCGAAGTGGCCTGAACCTGTGTTCGGGCGCCTGGCATCCCCCGGCTTTCCAGGGGAGTATGCCAATGACCAGGAGCGGCGCTGGACCCTGACTGCACCCCCCGGCTACCGCCTGCGCCTCTACTTCACCCACTTCGACCTGGAGCTCTCCCACCTCTGCGAGTACGACTTCGTCAAG

Eukaryotic GenomesEukaryotic Genomes
Yeast Yeast : : //genome//genome--www.www.stanfordstanford..eduedu//SaccharomycesSaccharomyces
FlyFly : : //flybase.bio.indiana.edu:7081//flybase.bio.indiana.edu:7081
WormWorm : : //www.//www.sangersanger.ac..ac.ukuk/Projects/C_/Projects/C_eleganselegans
MouseMouse : : //www.//www.ensemblensembl.org/.org/MusMus__musculusmusculus
Puffer FishPuffer Fish : : //www.//www.ensemblensembl.org/.org/FuguFugu__rubripesrubripes
MosquitoMosquito : : //www.//www.ensemblensembl.org/Anopheles_.org/Anopheles_gambiaegambiae

So, what Computer Scientists doSo, what Computer Scientists doforfor BioinformaticsBioinformatics? ?
Computer scientists are responsible for Computer scientists are responsible for INTEGRATING INTEGRATING and and ANALYZINGANALYZING all literature from both patents and all literature from both patents and publications in publications in PubMEDPubMED (MEDLINE) in NCBI(MEDLINE) in NCBI
12 million records

What else?What else?
Computer scientists are responsible for developing tools for Computer scientists are responsible for developing tools for performing various operations, such as BLAST at NCBI performing various operations, such as BLAST at NCBI
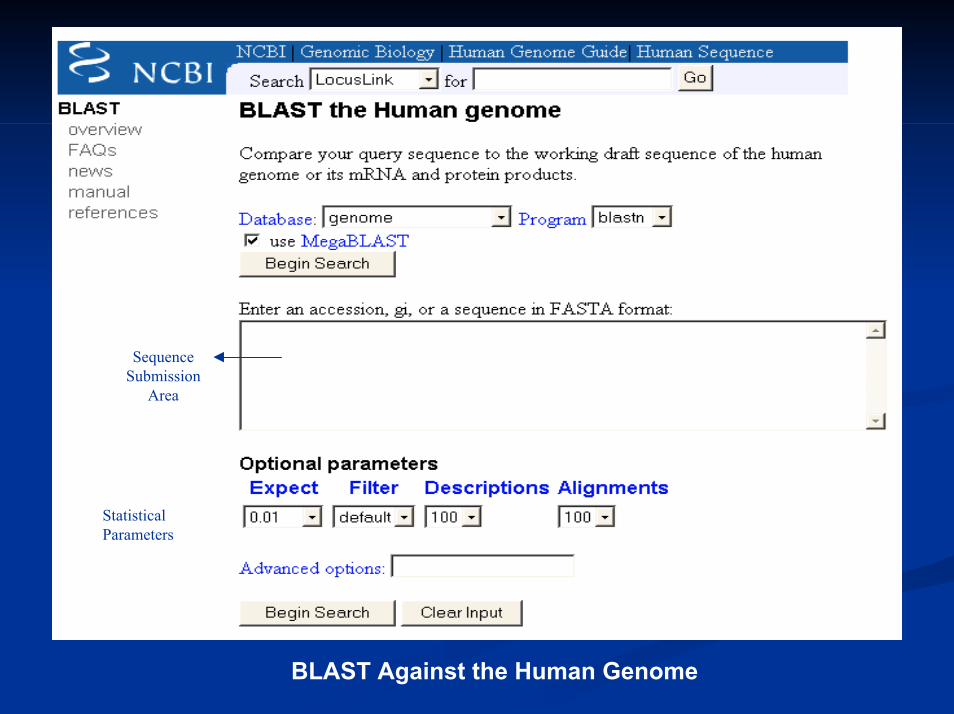
Sequence Submission
Area
Statistical Parameters
BLAST Against the Human Genome

Example FASTA sequenceExample FASTA sequence
>JC2395>JC2395
NVSDVNLNKNVSDVNLNK------YIWRTAEKMKYIWRTAEKMK------ICDAKKFARQHKIPESKIDEIEHNSPQDAAEICDAKKFARQHKIPESKIDEIEHNSPQDAAE--------
--------------------------------------------------QKIQLLQCWYQSHGKTQKIQLLQCWYQSHGKT——GACQALIQGLRKANRCDIGACQALIQGLRKANRCDI
AEEIQAMAEEIQAM
>KPEL_DROME>KPEL_DROME
MAIRLLPLPVRAQLCAHLDALMAIRLLPLPVRAQLCAHLDAL----------DVWQQLATAVKLYPDQVEQISSQKQRGRSDVWQQLATAVKLYPDQVEQISSQKQRGRS----------
--------------------------------------------------ASNEFLNIWGGQYNASNEFLNIWGGQYN--------HTVQTLFALFKKLKLHNHTVQTLFALFKKLKLHN
AMRLIKDYAMRLIKDY
>FASA_MOUSE>FASA_MOUSE
NASNLSLSKNASNLSLSK------YIPRIAEDMTYIPRIAEDMT------IQEAKKFARENNIKEGKIDEIMHDSIQDTAEIQEAKKFARENNIKEGKIDEIMHDSIQDTAE--------
--------------------------------------------------QKVQLLLCWYQSHGKSQKVQLLLCWYQSHGKS----DAYQDLIKGLKKAECRRDAYQDLIKGLKKAECRR
TLDKFQDMTLDKFQDM

GenBankGenBank FilesFiles

OneOne--line descriptionsline descriptions

Resources Available through the Resources Available through the OnlineOnline MendelianMendelian Inheritance in Inheritance in
Man (OMIM) Web SiteMan (OMIM) Web Site

Resources Available through the Resources Available through the Cancer Genome Anatomy Project Cancer Genome Anatomy Project
(CGAP) Web Site(CGAP) Web Site

Resources Available through the Resources Available through the Cancer Genome Anatomy Project Cancer Genome Anatomy Project
(CGAP) Web Site(CGAP) Web Site

Some Online Animal Genome Some Online Animal Genome Sources (Part 1)Sources (Part 1)

Some Online Animal Genome Some Online Animal Genome Sources (Part 2)Sources (Part 2)
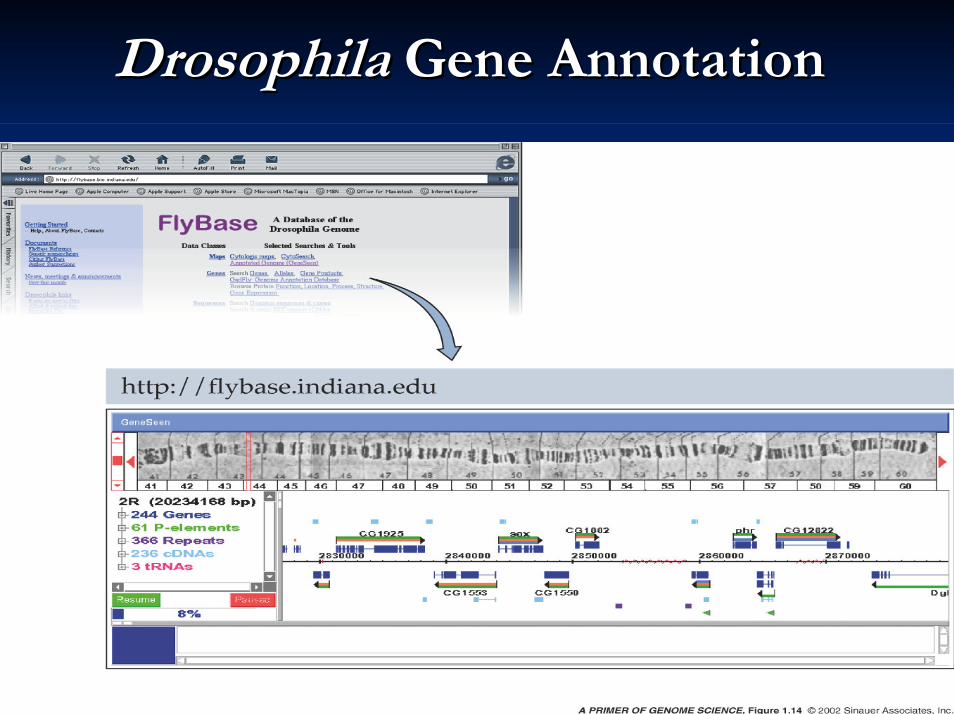
DrosophilaDrosophila Gene AnnotationGene Annotation

Annotation of Genes on the Annotation of Genes on the SaccharomycesSaccharomyces Genome DatabaseGenome Database

Other Computer Scientists JobsOther Computer Scientists Jobs
Prediction of: Prediction of: EvolutionEvolutionProtein foldingProtein foldingProtein functionProtein function
Computer Computer scienctistsscienctists build mathematical build mathematical models of these processes models of these processes --to infer relationships between components of to infer relationships between components of complex biological systemscomplex biological systems

Protein Databases Protein Databases
BINDINTERACTQuery secondary
databases over the Internet
Computational sequence analysis

Proteins: Prediction of biochemical function
•Relationships between
DNA or amino acidsequence 3D structure protein functions
•Use of this knowledge for prediction of function, molecular modelling, and design (e.g., new therapies)
CGCCAGCTGGACGGGCACACCATGAGGCTGCTGACCCTCCTGGGCCTTCTG…
TDQAAFDTNIVTLTRFVMEQGRKARGTGEMTQLLNSLCTAVKAISTAVRKAGIAHLYGIAGSTNVTGDQVKKLDVLSNDLVINVLKSSFATCVLVTEEDKNAIIVEPEKRGKYVVCFDPLDGSSNIDCLVSIGTIFGIYRKNSTDEPSEKDALQPGRNLVAA
GYALYGSATML

Case Study Case Study Protein DatabasesProtein Databases
Associating Gene Ontology Associating Gene Ontology Molecular Function Molecular Function
Interpro
Signature Databases
PRINTS

Gene Ontology Gene Ontology
AiCR2BRCA1
AssociatedWith OneOr
More
Acid phosohataseAconitate hydratase Basal protein localization
G-Protein coupled receptor
Has one or more
A Gene Product
GO:0003673Is located at
Is involved
in
MolecularFunction
(GO:0003674)
UsedIn
OneOr
More
CellularComponent
(GO:0005575)
BiologicalProcess
(GO:0008150)
Actin filamentMembrane
fraction

INTERPRO
Quick GO PRINTS
BLOCKS: BL00237Database Links
Integral to membrane (GO:0016021)Component
Rhodopsin-like receptor activity (GO:0005164)Function
G-Protein coupled receptor protein signaling pathway (GO:0007186)
Process
IPR000025; Melatonin ReceptorIPR000174; Interleukin-8 Receptor
Children
FamilyType
PF00001: 7tm_1PR00237: GPCRRHODOPSNPS00237: G_Protein_Recep_F1_1PS50262: G_Protein_Recep_F1_2
Signatures
Rhodopsin-like GPCR SuperfamilyName
Matches: 6914 proteinsIPR000276Access. Number
SignaturesOf
ProteinFamilies
Parts of the Children Tree
of GPCRSuperfamily
Gene Ontology Products

5H1A_HUMAN: 5-HYDROXYTRYPTAMINE 1A RECEPTOR (5-HT-1A) (SEROTONIN RECEPTOR) (5- HT1A) (G-21) - HOMO SAPIENS (HUMAN).
5H1A_MOUSE: 5-HYDROXYTRYPTAMINE 1A RECEPTOR (5-HT-1A) (SEROTONIN RECEPTOR) (5- HT1A) - MUS MUSCULUS (MOUSE).
Sequence Titles
5H1A_HUMAN, 5H1A_MOUSE, 5H1A_RAT.True Positives
G protein-coupled receptors (GPCRs) constitute a vast protein family that encompasses a wide range of functions.
Documentation
1. ATTWOOD, T.K. AND FINDLAY, J.B.C. Fingerprinting G protein-coupled receptors.
PROTEIN ENG. 7(2) 195-203 (1994).
Literature References
Interpro: IPR000276, BLOCKS: BL00237, Pfam: PF00001Database References
Rhodopsin-like superfamily signature (GPCR)Title
12-JUL-1992Creation Date
7No. of Motifs
PR00237Accession
GPCRRHODOPSN [View relations][View alignment][View Structure]Identifier
No. of Motifs Included in the Fingerprint
LiteratureReferences
WhereDiscussion
About MotifsAppears
Part of IDs of Protein
Matches for Fingerprints
Part of the Search Result of IPR000276 Fingerprint

- Opsin- Chemokine Receptor- G-Protein, Gamma Subunit
InterproMappings
- Signal Transduction During Conjugation with Cellular Fusion
- Signal Transduction During Conjugation without Cellular Fusion
Child Terms
Gene Ontology (GO:0003673)(P) Biological Process (GO:0008150)
(I) Cellular Process(I) Cell Communication
(I) Signal Transduction
Tree
G-protein coupled receptor protein signaling pathway
Name
GO:0007186Term ID
- Opsin- Histamine H4 Receptor- Peropsin
InterproMappings
- Nucleotide Receptor Activity- Viral Receptor Activity- Amine Receptor Activity
Child Terms
Gene Ontology (GO:0003673)(P) Molecular Function (GO:0008150)
(I) Signal Transducer Activity(I) Receptor Activity (I) Transmembrane Receptor
Activity (I) G-Protein Coupled Receptor
Activity(I) Rhodopsin-like Receptor
Activity
Tree
Rhodopsin-like receptor activityName
GO:0001584Term ID
Part of Quick GO Reference for Biological Process of IPR000276 (GO:0007186)
Part of Quick GO Reference for Molecular Function of IPR000276 (GO:0001584)

-Orexin Receptor-Gastrin Receptor-Galanin Receptor
Interpro Mappings
- Integral to Nuclear Inner Membrane- Integral to Plasma Membrane- Integral to Golgi Membrane
Child Terms
Gene Ontology (GO:0003673)(P) Cellular Component (GO:0005575)
(I) Cell (P) Membrane
(I) Integral to Membrane
Tree
Integral to MembraneName
GO:0016021Term ID
Part of Quick GO Reference for Cellular Component of IPR000276 (GO:0005575)

3. Dump your flat files into a 3. Dump your flat files into a database database
Java Parser
Program
INTERPROXML FLAT
FILES
PRINTSXML FLAT
FILESDBLoader
Quick GOXML FLATFILES
Local Database (BioDB)

Examples of Tables Examples of Tables
Example of Attributes of INTERPRO_GO Table

Part of the Motif Table
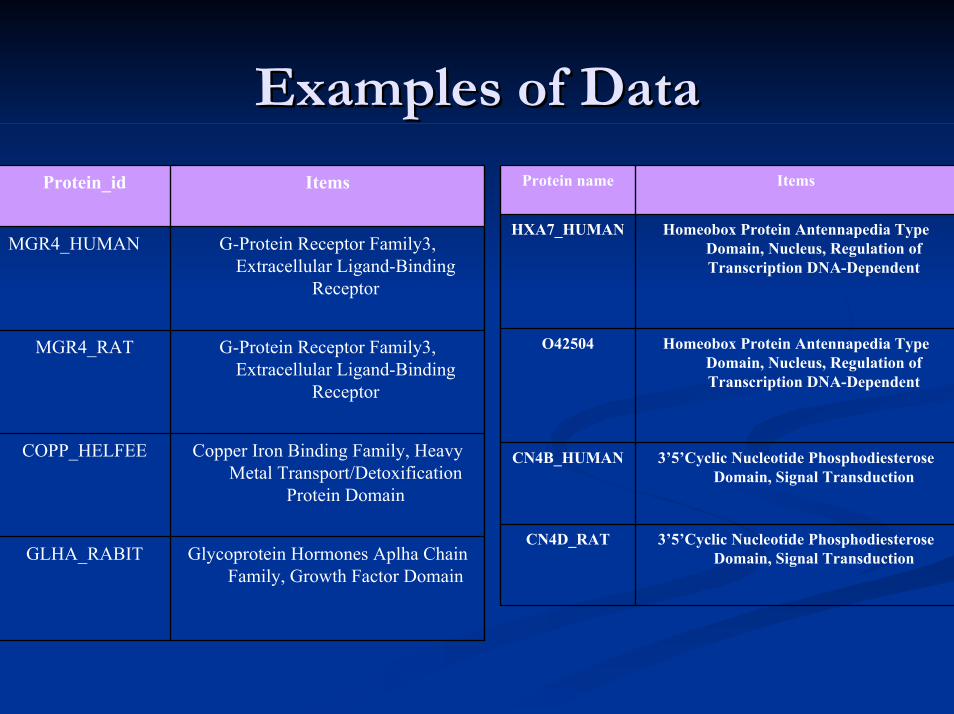
Examples of DataExamples of Data
Glycoprotein Hormones Aplha Chain Family, Growth Factor Domain
GLHA_RABIT
Copper Iron Binding Family, Heavy Metal Transport/Detoxification
Protein Domain
COPP_HELFEE
G-Protein Receptor Family3, Extracellular Ligand-Binding
Receptor
MGR4_RAT
G-Protein Receptor Family3, Extracellular Ligand-Binding
Receptor
MGR4_HUMAN
ItemsProtein_id
3’5’Cyclic Nucleotide PhosphodiesteroseDomain, Signal Transduction
CN4D_RAT
3’5’Cyclic Nucleotide PhosphodiesteroseDomain, Signal Transduction
CN4B_HUMAN
Homeobox Protein Antennapedia Type Domain, Nucleus, Regulation of Transcription DNA-Dependent
O42504
Homeobox Protein Antennapedia Type Domain, Nucleus, Regulation of Transcription DNA-Dependent
HXA7_HUMAN
Items Protein name

Examples of Generated Rules Examples of Generated Rules
100%15A protein, which belongs to Family: Mevalonate kinase it most likely contains Domain: GHMP kinases putative ATP-binding domain
R300
100%32A protein, which belongs to Family: G-protein coupled receptors family 3 (Metabotropic glutamate receptor-like) it most likely also contains Domain: Receptor Family ligand binding region
R200
100%32A protein, which belongs to Family: Xeroderma pigmentosum group G/yeast RAD Superfamily it most likely also contains Domain: 5`3`-Exonuclease N- and I- domains
R100
CSDescriptionRid
100%15If a protein is associated with Cellular component: extracellular it most likely contains Domain: Complement C3a, C4a and C5a anaphylatoxin
R600
100%97If a protein is associated with Biological process: potassium transport it most likely contains Domain: Potassium channel
R500
100%24If a protein is associated with Biological Process: defense response it most likely contains Domain: Selectin (CD62E/L/P antigens)
R400
CSDescriptionRid

How about Hardware: How about Hardware: The IBM Blue Gene SupercomputerThe IBM Blue Gene Supercomputer
•Will take on problem of protein folding.
•Protein folding is governed by basic rules of how atoms attract and repel each other, but size of proteins (thousands of atoms) makes it a very difficult problem.
•Will be able to fold a protein of up to 300 amino acids, but this will take a whole year of supercomputing time!
•One quadrillion calculations per second, ~1,000 times faster than Deep Blue that beat world chess champion Garry Kasparov in 1997.
•New architecture of more than one million CPUs. 32 CPUs per chip, bundled with computer memory.

Useful TextbooksUseful Textbooks

Other Useful TextbooksOther Useful Textbooks

Other reference booksOther reference books
