department of computer science cochin...
TRANSCRIPT

Bio-inspired Networking
Department of Computer Science CUSAT
DEPARTMENT OF COMPUTER SCIENCE
COCHIN UNIVERSITY OF SCIENCE AND TECHNOLOGY
COCHIN – 682022
Certificate
This is to certify that the Seminar report entitled “Bio-inspired Networking”,
submitted by Jisha Mariam Jose , Semester II, in the partial fulfilment of the requirement for the
award of M.Tech. Degree in Computer and Information Science is a bonafide record of the Seminar
presented by her in the academic year 2011.
G Santhosh Kumar Dr. K Paulose Jacob
Seminar Guide Head of the Department

Bio-inspired Networking
Department Of Computer Science - 1 - CUSAT
ACKNOWLEDGEMENT
I express our profound gratitude to the Head of Department Dr. K Paulose Jacob for allowing me
to proceed with the seminar and also for giving me full freedom to access the lab facilities.
My heartfelt thanks to my guide Mr.G Santhosh Kumar, Lecturer, Department of Computer
Science for taking time and helping me through my seminar. He has been a constant source of
encouragement without which the seminar might not have been completed on time. I am very grateful for
his guidance.
I am also thankful to, Dr. Sumam Mary Idicula for helping me with my seminar. Her ideas and
thoughts have been of great importance.

Bio-inspired Networking
Department Of Computer Science - 2 - CUSAT
ABSTRACT
The natural world is enormous, dynamic, incredibly diverse, and highly complex. Despite the
inherent challenges of surviving in such a world, biological organisms evolve, self-organize,
self-repair, navigate, and flourish. Generally, they do so with only local knowledge and without
any centralized control.
Our computer networks are increasingly facing similar challenges as they grow larger in size,
but are yet to be able to achieve the same level of robustness and adaptability.
Many research efforts have recognized these parallels and wondered if there are some lessons
to be learned from biological systems. Here we show how biological concepts have been most
successfully applied. Also, we conclude that research efforts are most successful when they
separate biological design from biological implementation – i,e. when they extract the principles
from the former without imposing the limitations of the latter.
Keywords: Bio-inspired networking, Swarm intelligence, Artificial immune systems,
Epidemic routing, Molecular communication

Bio-inspired Networking
Department Of Computer Science - 3 - CUSAT
CONTENTS
1. INTRODUCTION………………………………………………………………………………...4
2. CLASSIFICATION……………………………………………………………………………….5
3. CHALLENGES IN NETWORKING……………………………………………………………..6
3.1 LARGE SCALE NETWORKING……………………………………………………….6
3.2 DYNAMIC NATURE……………………………………………………………………7
3.3 NEED FOR INFRASTRUCTURE-LESS AND AUTONOMOUS OPERAION……….7
3.4 HETROGENEOUS ARCHITECTURE………………………………………………….8
3.5 COMMUNICATION ON MICROLEVEL………………………………………………8
4. DESIGN OF BIO-INSPIRED SOLUTION……………………………………………………….9
5. BIOLOGICAL MODEL INSPIRING COMMUNICATIOON NETWORK DESIGNS………...9
5.1 PARALLEL STRUCTURES……………………………………………………………10
5.2 COMPLEXITY AND ROBUSTNESS………………………………………………….11
6. APPROACHES TO BIO-INSPIRED NETWORKING………………………………………....12
6.1 SWARM INTELLIGENCE……………………………………………………………...12
6.1.1 ANT INSPIRED ROUTING…………………………………………………....12
6.1.2 BEE INSPIRED ROUTING…………………………………………………….15
6.2 ARTIFICIAL IMMUNE SYSTEM……………………………………………………...18
6.3 INFORMATION EPIDEMICS………………………………………………………….19
6.3.1 EPIDEMIC ROUTING…………………………………………………………20
7. CONCLUSION…………………………………………………………………………………..21
8. REFERENCE…………………………………………………………………………………….22

Bio-inspired Networking
Department Of Computer Science - 4 - CUSAT
1. INTRODUCTION
The term bio-inspired has been introduced to demonstrate the strong relation between a
particular system or algorithm, which has been proposed to solve a specific problem, and a
biological system, which follows a similar procedure or has similar capabilities.
In the last 15 years, we have witnessed unprecedented growth of the Internet. Moreover, the
Internet continues to evolve at a rapid pace in order to utilize the latest technological advances
and meet new usage demands. It has been a great research challenge to find an effective means to
influence its future and to address a number of important issues facing the Internet today, such as
overall system security, routing scalability, effective mobility support for large numbers of
moving components and the various demands put on the network by the ever-increasing number
of new applications and devices.
Although the Internet is perhaps the world‟s newest large-scale, complex system, it is
certainly not the first nor the only one. Certainly, the most commonly known large-scale,
complex systems are biological. Biological systems have been evolving over billions of years,
adapting to an ever-changing environment. They share several fundamental properties with the
Internet, such as the absence of centralized control, increasing complexity as the system grows in
size, and the interaction of a large number of individual, self governing components. Despite
their disparate origins (one made by nature, the other made by man), it is easy to draw analogies
between these two systems. so, there is a great opportunity to find solutions in biology that can
be applied to problems in networking.As a result of millions of years of evolution, biological
systems and processes have intrinsic appealing characteristics. They are
adaptive to the varying environmental circumstances,
robust and resilient to the failures caused by internal or external factors,
able to achieve complex behaviors on the basis of a usually limited set of basic rules,
able to learn and evolve itself when new conditions are applied,
effective management of constrained resources with an apparently global intelligence
larger than the superposition of individuals,
able to self-organize in a fully distributed fashion,
collaboratively achieving efficient equilibrium,
survivable despite harsh environmental conditions due to its inherent and sufficient
redundancy.
The common rational behind this effort is to capture the governing dynamics and understand
the fundamentals of biological systems in order to devise new methodologies and tools for
designing and managing communication systems and information networks that are inherently
adaptive to dynamic environments, heterogeneous, scalable, self-organizing, and evolvable.

Bio-inspired Networking
Department Of Computer Science - 5 - CUSAT
2. CLASSIFICATION
Biologically inspired research, grouped by topic, and classified in two ways:
– by the biological field that inspired each topic, and
– by the area of networking in which the topic lies.
They are shown by figure 1 and figure 2 respectively.
Fig 1
Fig 2

Bio-inspired Networking
Department Of Computer Science - 6 - CUSAT
3. CHALLENGES IN NETWORKING
The evolution in communication and networking technologies brings many potential
advantages to our daily lives. At the same time, the complexity of the existing and envisioned
networked information systems has already gone far beyond what conventional networking
paradigms can do in order to deploy, manage, and keep them functioning correctly and in an
expected manner. Self organization techniques are demanded to overcome current technical
limitations. In fact, there exist many common significant challenges that need to be addressed for
practical realization of these existing and next generation networking architectures, such as
increased complexity with large scale networks, their dynamic nature, resource constraints,
heterogeneous architectures, absence or impracticality of centralized control and infrastructure,
need for survivability. Clearly, at the same time there exists similar problems and their naturally
evolved biological solution approaches for these networking paradigms. The main challenge is
neither the inspiration nor the application, but is understanding the biological system and its
behavior, the modeling of the system, and the conceptual derivation of technical solutions.
The main common challenges of the existing and the next generation networks are
3.1. LARGE SCALE NETWORKING
One of the main challenges is related to the sheer size exhibited by the networking systems,
which connect huge numbers of users and devices. For example, Wireless Sensor Networks
(WSNs) are composed of a large number, e.g., in numbers ranging between few hundreds to
several hundred thousands, of low-end sensor nodes.
The direct consequence of such large scales is the huge amount of traffic load to be incurred
over the network. This could easily exceed the network capacity, and hence, hamper the
communication reliability due to packet losses by both collisions in the local wireless channel as
well as congestion along the path from the event field towards the sink.
As the network scale expands, the number of possible paths, and hence, the search space for
the optimal route also drastically enlarges. The maintenance of routing tables and the amount of
traffic for table updates also increases.
Hence, networking mechanisms must be scalable and adaptive to variations in the network
size. Fortunately, there exist many biological systems that inspire the design of effective
communication solutions for large scale networks. For example, Ant Colony Optimization
(ACO) techniques that are based on optimizing global behavior in solving complex tasks through
individual local means provide efficient routing mechanisms for large-scale mobile ad hoc
networks. In addition, information dissemination over large scales can be handled with the help
of epidemic spreading, which is the main transmission mechanism of viruses over the large and
scale-free organism populations.

Bio-inspired Networking
Department Of Computer Science - 7 - CUSAT
3.2. DYNAMIC NATURE
Unlike the early communication systems composed of a transmitter/receiver pair and
communication channel, which are all static, the existing and the envisioned networking
architectures are highly dynamic in terms of node behaviors, traffic and bandwidth demand
patterns, channel and network conditions.
The channel conditions and link qualities are highly dynamic due to mobility of the nodes,
and environmental variations as a result of this movement. This dynamic nature can be seen in
the target tracking applications of sensor networks, where the amount of traffic created by the
sensor nodes may drastically increase at the time of detection and may decay with time. Also in
case of cognitive radio, whose objective itself is to leverage the dynamic usage of spectrum
resources in order to maximize the overall spectrum utilization.
The biological systems and processes are known to be capable of adapting themselves to
varying circumstances towards the survival. For example, Artificial Immune System (AIS),
inspired by the principles and processes of the mammalian immune system, efficiently detects
variations in the dynamic environment or deviations from the expected system patterns.
3.3. NEED FOR INFRASTRUCTURE-LESS AND AUTONOMOUS OPERATION
Some networks are by definition free from infrastructure such as wireless adhoc networks,
Wireless Sensor Networks (WSNs). These networking environments mandate for distributed
communication and networking algorithms, can function effectively without any help from a
centralized unit. But communication networks are subject to failure either by device
malfunction, e.g., nodes in a certain area may run out of battery in sensor networks, or misuse of
their capacity, e.g., overloading the network may cause heavy congestion blocking the
connections. It is clear that networks must be capable of re-organizing and healing themselves to
be able to resume their operation. Hence, the existing and next generation information networks
must have the capabilities of self-organization, self-evolution and survivability.
Inherent features of many biological systems stand as promising solutions for these
challenges.
Ant colonies, inspire the design of communication techniques for infrastructure-less
networking environments.
Autonomous behavior of artificial immune systems inspire the design of effective
algorithms for unattended and autonomous communication in sensor networks

Bio-inspired Networking
Department Of Computer Science - 8 - CUSAT
3.4. HETROGENEOUS ARCHITECTURE
Next generation communication systems are envisioned to be composed of a vast class of
communicating devices differing in their communication/storage/ processing capabilities,
ranging from simple sensors to mobile vehicles equipped with broadband wireless access
devices. For example, Internet of things is defined as a vision of network of objects which
extends the Internet capabilities into our daily lives transforming our immediate environment
into a large-scale wireless networks of uniquely identifiable objects, Cognitive radio networks,
Wireless mesh networks and WiMAX, Sensor Network and Vehicular AdHoc
Network(VANET). Such heterogeneity and asymmetry in terms of capabilities, communication
devices and techniques need to be understood, modeled and effectively managed.
Different levels of heterogeneity are also observed in biological systems. For example, in
many biological organisms, despite external disturbances, a stable internal state is maintained
through collaborative effort of heterogeneous set of subsystems and mechanisms, e.g., nervous
system, endocrine system, immune system. On the other hand, insect colonies are composed of
individuals with different capabilities and abilities to respond to a certain environmental stimuli.
Despite this inherent heterogeneity, colonies can globally optimize the task allocation and
selection processes via their collective intelligence.
3.5. COMMUNICATION ON MICRO LEVEL
With the advances in micro- and nano-technologies, electro-mechanical devices have
beendownscaled to micro and nano levels. „„Nanonetworks” could be defined as a network
composed of nano-scale machines, i.e., nano-machines, cooperatively communicating with each
other and sharing information in order to fulfill a common objective. The dimensions of nano-
machines render conventional communication technologies such as electromagnetic wave,
acoustic, inapplicable at these scales due to antenna size and channel limitations.
The main idea of nano-machines and nano-scale communications and networks have also
been motivated and inspired by the biological systems and processes. Hence, it is conceivable
that the solutions for the challenges in communication and networking at micro and nano-scales
could also be developed through inspiration from the existing biological structures and
communication mechanisms. In fact, many biological entities in organisms have similar
structures with nano-machines. For example, every living cell has the capability of sensing the
environment, receiving external signals, performing certain tasks at nano-scales. The inspiration
from cellular signaling networks, and hence, molecular communication, provide important
research directions and promising design approaches for communication and networking
solutions at micro- and nano-scales.

Bio-inspired Networking
Department Of Computer Science - 9 - CUSAT
4. DESIGN OF BIO-INSPIRED SOLUTION
Many methods and techniques are really bio-inspired as they follow principles that have been
studied in nature and that promise positive effects if applied to technical systems. Three steps can
be identified that are always necessary for developing bio-inspired methods:
Identification of analogies – which structures and methods seem to be similar,
Understanding – detailed modeling of realistic biological behavior,
Engineering – model simplification and tuning for technical applications.
Fig. 3. Necessary steps to adapt biological mechanisms to technical solutions.
5. BIOLOGICAL MODELS INSPIRING COMMUNICATION NETWORK
DESIGNERS
Inspiration to develop scalable and self organizing computer networks are inspired from the
biological mechanisms and behavior of the general organization of biological systems, i.e. the
structure of bodies down to organs and cells. Many models are similar on the micro and macro
level – basically exploiting similar communication and coordination mechanisms. This can be
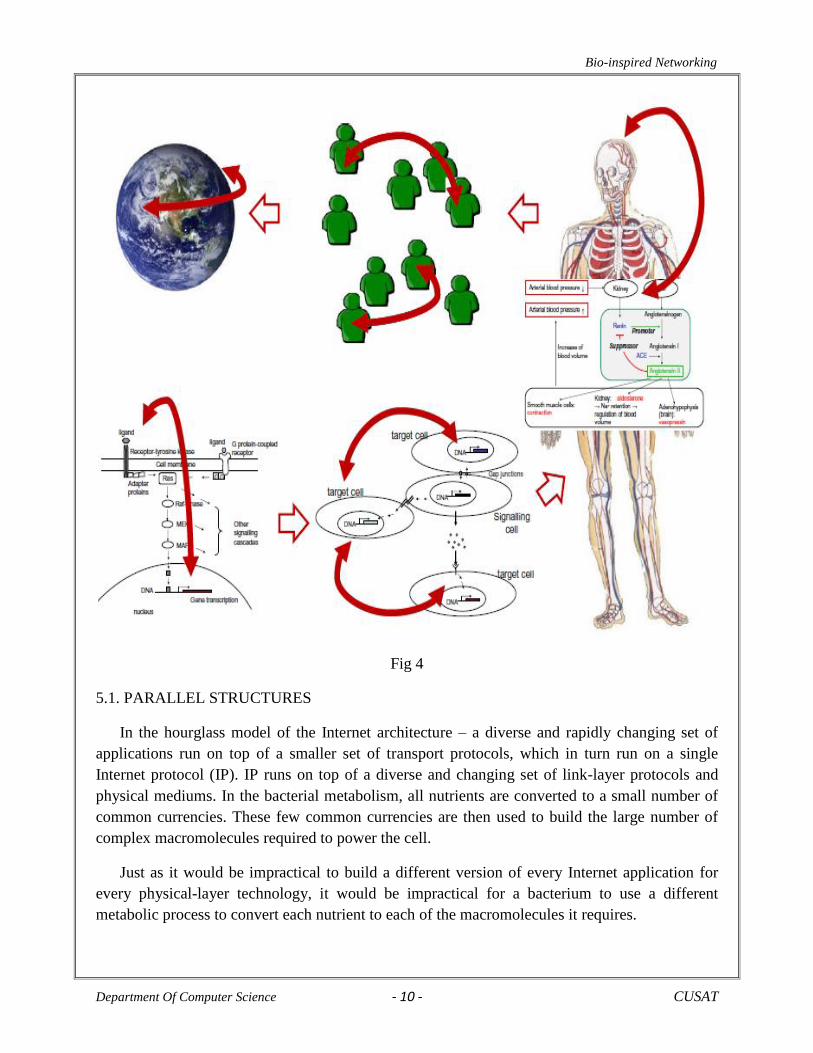
explained by figure 4; i,e. studying techniques on the micro level, i.e. on a cellular basis or the
signaling pathways between cells, have similar mechanisms when compared to studies of the
macro level, i.e. the coordination among people in a group or even around the globe.
Bio-inspired Networking
Department Of Computer Science - 10 - CUSAT
Fig 4
5.1. PARALLEL STRUCTURES
In the hourglass model of the Internet architecture – a diverse and rapidly changing set of
applications run on top of a smaller set of transport protocols, which in turn run on a single
Internet protocol (IP). IP runs on top of a diverse and changing set of link-layer protocols and
physical mediums. In the bacterial metabolism, all nutrients are converted to a small number of
common currencies. These few common currencies are then used to build the large number of
complex macromolecules required to power the cell.
Just as it would be impractical to build a different version of every Internet application for
every physical-layer technology, it would be impractical for a bacterium to use a different
metabolic process to convert each nutrient to each of the macromolecules it requires.

Bio-inspired Networking
Department Of Computer Science - 11 - CUSAT
Similarities also exist at the individual protocol level. For example, at the transport layer, the
Transmission Control Protocol (TCP) determines the sender‟s transmission rate based on a
standard congestion control algorithm. This algorithm allows the sender‟s rate to continuously
track the optimal sending rate for the receiver, given the current state of the network. Research
has shown strong evidence that bacteria use integral feedback to govern their speed and direction
of movement when tracking the concentration of certain chemicals in their environment.
5.2. COMPLEXITY AND ROBUSTNESS
A complicated, strictly organized internal structure is necessary for any system to exhibit
robust external behavior. That is, there is an inherent trade-off between structural simplicity and
robustness. Both the human body and the Internet have a complex, strictly organized internal
structure. The human body has many different organs and physiological systems, each of which
serves a specific purpose. A kidney cannot serve as a lung nor vice versa. The Internet also
contains a number of specialized devices. At its core are high-speed routers, which single-
mindedly forward data in a highly optimized manner. At the edges of the network are a diverse
array of application-oriented devices, such as laptop computers and cellular phones. A high-
speed router would be no more helpful in reading our e-mail as a kidney would be no more
helpful in oxygenating our blood.
Also, complex systems are only optimized to be robust against expected failures or
perturbations. The system becomes quite fragile in regards to unexpected or rare failures or
perturbations. For example, humans are quite robust to the sorts of changes we have evolved to
tolerate – we live in climates from the Arctic to the Sahara desert, we can obtain energy from any
number of different food sources, and can even survive the loss of a limb. However, a small
change to an important gene or exposure to trace levels of an unusual toxin can cause massive
systemic failures. The Internet was optimized for robustness to physical failures of individual
components. However, it is fragile to even small soft failures, such as an error in the design of a
protocol (as occurred in the early days of the ARPAnet) or a single component that breaks the
rules (as with prefix hijacking).
In both biological and networked systems, far simpler designs exist, but these simpler
systems lack any resiliency to even the most common failures. Bacteria are composed of only a
single cell, rather than a complex, structured network of cells like a human, but can only tolerate
very small changes in their external environment, such as a slight change in temperature or pH.
Building a network with a star topology makes many of the most difficult design challenges in
the Internet, such as packet routing and addressing, trivially simple. However, a network with a
star topology is rendered completely useless by the failure of the single central node.

Bio-inspired Networking
Department Of Computer Science - 12 - CUSAT
6. APPROACHES TO BIO-INSPIRED NETWORKING
6.1. SWARM INTELLIGENCE
Swarm Intelligence is the property of a system whereby the collective behaviors of agents
interacting locally with their environment cause coherent functional global patterns to emerge.
Individual insects function much like simple computing devices – they execute simple
procedures based on their input, causing them to produce some output. At any given moment, an
individual insect is merely reacting to stimuli in its immediate surroundings. Largescale,
seemingly global cooperation emerges as a result of two phenomena. First, each species is
genetically pre-programmed to perform an identical set of procedures given the same set of
stimuli. Second, by performing these procedures, creatures implicitly modify their environment
(of which they are one feature), creating new stimuli for themselves and those around them. This
phenomenon of indirect communication via changes to the environment is called stigmergy.
6.1.1. ANT INSPIRED ROUTING
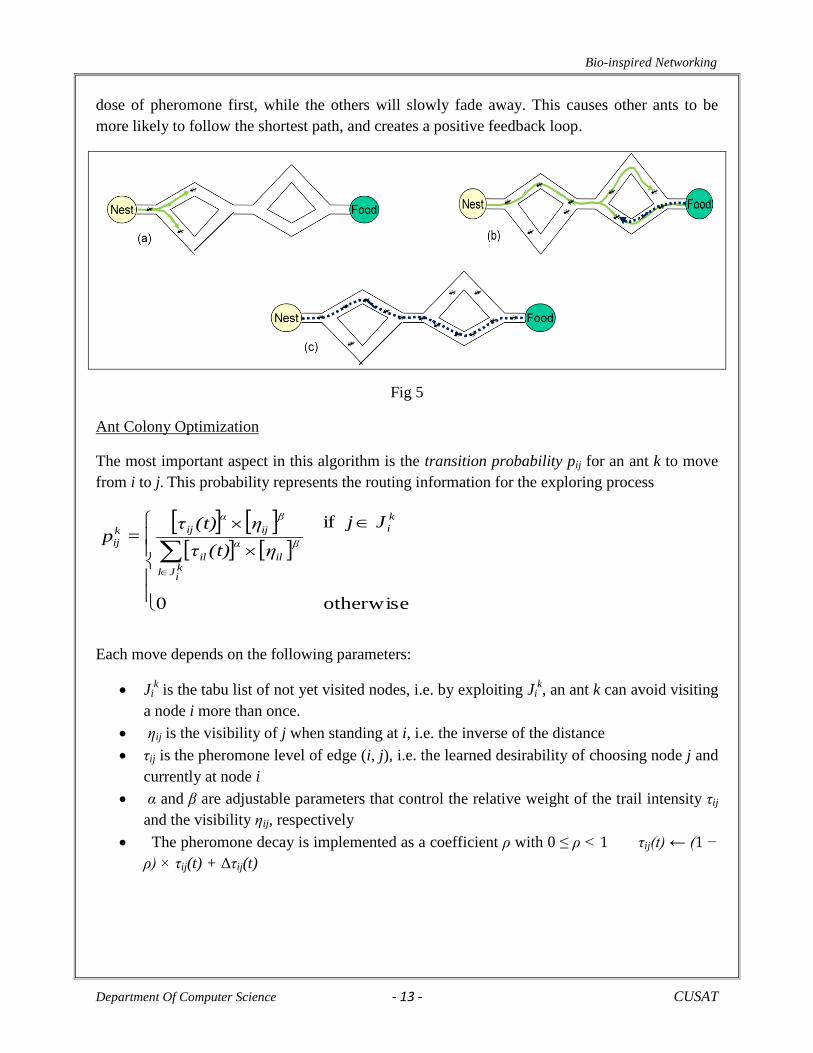
Ants have the ability to converge on the shortest path from their nest to a food source. Ants
accomplish this feat by laying various types of pheromone trails, or scent trails, as they travel.
These pheromones serve as stimuli for other ants in their colony – ants probabilistically follow
the paths with the most pheromone. When no pheromones are present, ants will follow random
paths. When an ant finds a food source, it will return to the nest the same way it came. On its
return journey, the ant continues to leave its pheromone trail behind, thereby increasing the
amount of pheromone on the successful path. The shortest successful path will receive this extra
Bio-inspired Networking
Department Of Computer Science - 13 - CUSAT
dose of pheromone first, while the others will slowly fade away. This causes other ants to be
more likely to follow the shortest path, and creates a positive feedback loop.
Fig 5
Ant Colony Optimization
The most important aspect in this algorithm is the transition probability pij for an ant k to move
from i to j. This probability represents the routing information for the exploring process
Each move depends on the following parameters:
Jik is the tabu list of not yet visited nodes, i.e. by exploiting Ji
k, an ant k can avoid visiting
a node i more than once.
ηij is the visibility of j when standing at i, i.e. the inverse of the distance
τij is the pheromone level of edge (i, j), i.e. the learned desirability of choosing node j and
currently at node i
α and β are adjustable parameters that control the relative weight of the trail intensity τij
and the visibility ηij, respectively
The pheromone decay is implemented as a coefficient ρ with 0 ≤ ρ < 1 τij(t) ← (1 −
ρ) × τij(t) + Δτij(t)
otherwise0
if k
i
ki
Jl
β
il
α
il
β
ij
α
ijk
ij
Jj
η(t)τ
η(t)τ=p

Bio-inspired Networking
Department Of Computer Science - 14 - CUSAT
After completing a tour, each ant k lays a quantity of pheromone Δτij(t) on each edge (i,j)
according to the following rule, where T k
(t) is the tour done by ant k at iteration t; L k
(t) is its
length, and Q is a parameter.
Ant-Based Control (ABC) Algorithm
It is designed for routing in circuit-switched telephone networks.ABC models destinations as
food sources, and routing tables are called pheromone tables. At any node x, each entry (d, x ->
y) in the pheromone table is the probability that an ant leaving node x will use link x -> y to
reach destination d. Thus, each node needs to store a pheromone level for each possible
destination on each of its links, so a node with m neighbors will have a pheromone table of size
(n-1) x m. This is essentially the same storage requirement as in distance vector protocols.
In order to update the pheromone tables, ants are sent at regular intervals from each node in
the network. Ants update the pheromone table at each node they visit, but they update the entry
for the source node of the ant, not the destination. To be precise, when an ant originated by node
s traverses some link p -> q, it updates the pheromone table entry (s, q -> p) at node q. Thus,
ABC assumes a symmetric cost on all links.
To ensure calls are set up on less congested paths, ants traveling on congested paths get
delayed, and ants that have been in the network longer lay less pheromone. Calls are always set
up on the links with the highest probabilities. One drawback specific to ABC is its winner-takes-
all call setup scheme, which means that if the best route to s is congested, no call can be placed
to s until the ants can change the probability distribution. ACO-based algorithms for packet-
switched networks tend to exploit the multiple paths provided in the pheromone table for load
balancing.
AntNet Algorithm
AntNet provides a proactive routing approach that periodically launch mobile agents towards
randomly selected destination nodes. Forward ants randomly follow the pheromone tables from a
source to a destination. AntNet introduces the concept of forward ants and backward ants.
Forward ants follow the pheromone tables from a source to a destination. Forward ants record
their path, as well as the actual time that they arrive at each node to measure network congestion.
When a forward ant reaches its destination, it becomes a backward ant, and returns to the source
on the reverse path of the forward ant, updating pheromone tables along the way. Pheromone
levels are increased by an amount based on the time it took the forward ant to traverse each link.
This forward-and-backward-ant scheme allows Ant-Net to support asymmetric link costs. Unlike

Bio-inspired Networking
Department Of Computer Science - 15 - CUSAT
ABC, AntNet uses stochastic forwarding for data packets as well. This results in load balancing
over multiple paths, which is one of the primary goals of AntNet.
There are two drawbacks specific to the AntNet algorithm. It can require long delays to
propagating routing information, since routing tables are only updated by backward ants. All
nodes in the network will need to have synchronized clocks for the timing information to be
accurate. They are not guaranteed to be loop-free. ACO-based routing algorithms generate quite
a lot of control traffic, even when the network is stable. Both ABC and AntNet do not deal well
with link failures i,e. before failures can be avoided by making ants first stochastically decrease
the probabilities on broken links. This problem can only be avoided if nodes are able to detect
link failures and explicitly notify the routing system.
Algorithms For Manets
AntHocNet is modified version of AntNet. It sets up paths when they are needed at the start
of a session. AntHocNet bears a strong resemblance to the ad-hoc on demand distance vector
(AODV) protocol, except with the addition of active probing of paths that have active data
connections (via proactive forward ants), and stochastic routing of data packets over multiple
paths with a distribution based on the pheromone tables. It uses hello packets to detect link
failures. Unlike the original AntNet scheme, AntHocNet actually has a significant advantage in
failure handling, since it can take advantage of the availability of multiple, active paths.
Another example is HOPNET, an algorithm based on ants hopping between so called zones.
In HOPNET, each node has a zone, which consists of all nodes within a specified number of
hops from the node. Within a node‟s zone, HOPNET is a proactive protocol – AntNet-style
forward ants are used to actively probe and maintain each path. When routing between zones,
HOPNET is a reactive protocol – nodes use AntNetstyle forward ants to find paths on demand.
In other words, it consists of local proactive route discovery within a node‟s neighborhood and
reactive communication between the neighborhoods.
6.1.2. BEE INSPIRED ROUTING
A honey bee colony has many features that are desirable in networks like efficient allocation of
foraging force to multiple food sources, foragers evaluate the quality of food sources visited and
then recruit optimum number of foragers for their food source by dancing on a dance floor inside
the hive, they have no central control, they make decision without global knowledge of the
environment. They perform two type of dances. They are “Round Dance” - When food source is
< 50 meters from hive and “Waggle Dance” - When food source is > 50 meters away.

Bio-inspired Networking
Department Of Computer Science - 16 - CUSAT
Consider each node in the network as a hive. There are four types of agents: packers, scouts,
foragers, and swarms.
Packers: Packers mimic the task of a food-storer bee. They always reside inside the node,
receive and store the data packets from the transport layer. Their major job is to find a forager for
their data packet and they die once they hand over it to the foragers.
Scouts : Scouts discover new routes from their launching node to their destination node. A scout
is transmitted using the broadcasting principle to all the neighbors of a node with an expanding
time to live timer (TTL), which controls the number of times a scout could be re-broadcasted.
Each scout is uniquely identified with a key based on its id and source node. Once a scout
reaches at the destination then it starts the backward journey on the same route that it followed to
the destination. A destination node sends back all of the received scouts to ensure discovery of
multiple paths. Once a scout returns to its source node then it recruits the foragers for its route by
using the metaphor of dance (as scout bees do in Nature). A dance is abstracted as the number of
clones that could be made of a scout (equivalent of recruiting forager bees in Nature).
Foragers: They receive the data packets from packers and then transport them to their
destination. Each forager has a special type: delay or lifetime. The delay foragers collect the
delay information from the network while the lifetime foragers collect the remaining battery
capacity of the nodes that they visit. The first ones try to route packets along a path that has a
minimum delay while the second ones try to route packets in such a manner that the life time of
the network is increased. A forager gets the complete route, in the form of a sequence of nodes
leading to a destination, from a scout or another forager. A forager follows point-to-point mode
of transmission till the destination and collects the information about the network state
depending upon its type. Once a forager reaches at the destination then it remains there until it
could be piggybacked on the network traffic from the destination node to its source node. This
optimization reduces the overhead of control packets and hence saves energy as well. The
foragers also use the metaphor of dance once they return to their source node in a similar way as
scouts do.
Swarms: An unreliable transport protocol, like UDP, sends no explicit acknowledgments for the
received data packets. Such a protocol may not be able to provide an implicit return path to a
waiting forager and therefore it could never return to its source node. Consequently, its source
node might run out of the foragers and unable to continue the communication. We can solve this
problem with the help of swarms. Once the difference between the incoming foragers from a
certain node i and the outgoing foragers to the same node i reaches above a threshold value at a
node j then the node j launches a swarm of foragers to the node i. We put one forager in the
header of the swarm while the others are put in the payload part of the swarm. Once the swarm
arrives at the node i then the foragers are extracted from the payload part and they are stored like
they would have arrived at the node in a normal fashion.

Bio-inspired Networking
Department Of Computer Science - 17 - CUSAT
Architecture Of BeeAdHoc
Each node in MANET has a hive, which consists of three parts:
Fig 6
Packing Floor: The packing floor is an interface to higher level transport layer like TCP or UDP.
Once a data packet arrives from the transport layer, a packer is created in the packing floor which
stores the data packet. After that the packer tries to locate a suitable forager for the data packet
from dance floor. If it finds one then it hand overs the data packet to the forager and dies.
Otherwise, it waits for a time (may be a returning forager is on its way toward the current hive)
and if no forager arrives within this time, then it launches a scout which is responsible for
discovering new routes to the destination of the data packet.
Entrance: The entrance is an interface to lower level MAC layer. The entrance handles all
incoming/outgoing packets. A scout received at the entrance is broadcasted further if its time to
live (TTL) timer has not expired or if it has not arrived at the destination. The information about
the id of the scout and its source node is stored in a table. If another replica of an already
received scout arrives at an entrance of a hive then the new replica is killed here. If a forager
with a same destination as that of the scout already exists in the dance floor then the route to the
destination is given to the scout by appending the route in the forager to its current route. If the
current node is the destination of a forager then it is forwarded to the packing floor else it is
directly forwarded to the MAC interface of the next hop node.
Dancing Floor: The dance floor is the heart of the hive because it takes important routing
decisions. Once a forager returns after its journey it recruits new foragers by dancing according
to the quality of path that it traversed. The dance floor also sends a matching forager to the
packing floor in response to a request from a packer. The foragers whose life time has expired
are not considered in the matching function. If multiple foragers match the criteria then a forager
is stochastically chosen among them. This helps in distributing the packets over multiple paths
that serves two purposes: avoid congestion under high loads and battery of different nodes are
depleted at an equal rate. A clone of the selected forager is sent to the packing floor and the
original forager is stored in the dance floor after reducing its dance number. If the dance number

Bio-inspired Networking
Department Of Computer Science - 18 - CUSAT
is zero then the original forager is sent to the packing floor and its entry is deleted from the dance
floor.
6.2. ARTIFICIAL IMMUNE SYSTEM
Just as globalization has facilitated the spread of human disease, the interconnection of an
increasing population of personal computers has enabled the spread of computer viruses on a
global scale. This is a perfect example of a problem that was new to computer networks, but for
which biology already had a solution: the immune system. The vertebrate immune system has
multiple levels of defense. The first layer of defense prevents pathogens (infectious agents) from
entering the body in the first place. This level includes the skin, and bodily secretions, such as
saliva, which have antibiotic properties. If a pathogen manages to breach these barriers and enter
the body, it is next met by the innate immune system. The innate immune system tells the
difference between the self and the foreign. Some of these defenders, called antigen presenting
cells (APCs), keep samples of the antigens they consume, and present them to the adaptive
immune system.
Similarly, in networking ; firewalls prevent intrusions from getting into one‟s network in the
first place. Secondly, if an attacker gets in, any suspicious activity is detected and flagged.
Thirdly, a subsystem is triggered to examine the suspicious activity more closely, taking swift
action to oppose known attacks.
Artificial immune systems for computers were originally conceived as a defense mechanism
for individual hosts against computer viruses. According to Jeffrey Kephrat; an analog of the
innate immune response can detect an intrusion on the host via two methods: integrity checking
of its programs and data, and an activity monitor that reacts to suspicious activity. A number of
so-called decoy programs are created that instead of destroying computer viruses, attract
infections. This allows the equivalent of the adaptive response to take over, examining the virus,
as well as how it infects. The goal is to find a byte sequence to serve as a signature that can be
used to recognize the virus, but is unlikely to match normal programs. This is done by comparing
a number of candidate signatures to a corpus of uninfected programs to determine which
signature is least likely to result in false positives. This signature is then added to the database of
known viruses. Known viruses can then be detected and removed using standard anti-virus
techniques.
Research efforts is based on an algorithm that latched onto a particular process called
negative selection, which plays a small part in allowing the vertebrate immune system to attack
never- before-seen foreign invaders without attacking the body‟s own cells. In its artificial
version, system generates a fixed-size repertoire of random strings, deleting any strings that
occur in the data that the system is told to protect. When asked to verify data, the integrity
checker looks for substrings that match the strings in the repertoire. Since all „„self” strings were
removed from the repertoire, any match implies a verification failure.

Bio-inspired Networking
Department Of Computer Science - 19 - CUSAT
Based On Danger Theory
The danger theory proposes that the immune system does not, in fact, distinguish between the
self and the foreign, but rather between the safe and the dangerous. Thus, the immune system
may attack self cells that appear dangerous, and may not attack foreign cells that appear safe. It
suggests the existence of a danger signal emitted by cells, which is a prerequisite to activation of
the adaptive immune response. The theory further suggests that these signals are implicit, such as
the presence of the detritus from an antigen-destroyed cell. The usefulness of the danger signal
concept in AIS is that suspicious activities, such as a spike in network traffic, can be used to
influence the artificial immune response.
AIS for spam filtering
In this scheme, each mail server runs an instance of the AIS, which generates signatures from
e- mail messages using a novel technique. These signatures undergo negative selection, where
signatures appearing in non-spam messages are removed. Different instances of the AIS, running
on different servers, can exchange the signatures of high-volume spam messages that they have
detected. The receiver treats these signatures as danger signals – it uses them to trigger more
intensive/active filtering, rather than simply assuming messages with these signatures are spam.
This allows an instance of the AIS to collaborate with other instances, even when they are
untrusted.
6.3. INFORMATION EPIDEMICS
Two of the most common models, the susceptible-infective-susceptible (SIS) and
susceptible- infective-removed (SIR) models are used extensively by network researchers to
model the spread of information in computer networks.
SIS model: In this model, nodes are divided into two groups: the susceptible group S and the
infective group I. A node from the susceptible group S can acquire the infection from a node in
the infective group I with some probability. Once a node becomes infective, it can recover from
the disease, but it does not acquire any immunity, meaning it moves back to the susceptible
group S. The recovery time is a random number that follows a certain probability distribution
based on the characteristics of the disease. When a node moves from the infective group I to the
susceptible group S, it can once again contract the disease from any of the remaining nodes in the
infective group I. Thus, nodes can repeatedly move from one group to the other, and, under the
right conditions, the disease may never die out.
SIR model: In this model, a node cannot transition back and forth between the susceptible group
S and the infective group I. Once a node contracts the disease, it can recover from it, again after a
random period of time. When a node recovers, it moves to the removed group R and cannot

Bio-inspired Networking
Department Of Computer Science - 20 - CUSAT
contract the disease again. In addition, nodes in the susceptible group S cannot contract the
disease from any of the nodes of the removed group R. Thus, in the SIR model, a disease will
eventually die out, assuming the population of the nodes does not increase over time.
Kephart and White applied the SIS model to directed graphs where each edge can have a
different probability of transmitting infection. Individual system is represented as a node in a
graph. Susceptible nodes become infected by an infective node if the nodes have an edge
connecting them, and the directionality of the edge is from infective node to susceptible node. Each edge is associated with rate of infection, a rate at which infection can be detected and
"cured“.
6.3.1. EPIDEMIC ROUTING
There are clear topological similarities between MANETs and human networks – the
mobility of nodes in a MANET is not only similar to, but often governed by, the movements of
their human owners. Just as humans can only transmit infection to others within a small range of
their physical location, their ad-hoc wireless devices can often only communicate with other
wireless devices within a similarly small range. As a result, a MANET may never be fully
connected at any particular instant in time. Yet, it is quite possible that a sender would wish to
reach a destination that it does not currently have a path to.
Epidemic Routing distribute application messages to hosts, called carriers, within connected
portions of ad hoc networks. In this way, messages are quickly distributed through connected
portions of the network. Epidemic Routing then relies upon carriers coming into contact with
another connected portion of the network through node mobility. At this point, the message
spreads to an additional island of nodes. Through such transitive transmission of data, messages
have a high probability of eventually reaching their destination. Figure 7 depicts Epidemic
Routing at a high level, with mobile nodes represented as dark circles and their wireless
communication range shown as a dotted circle extending from the source. In Figure 7, a source,
S, wishes to send a message to a destination, D , but no connected path is available from S to D.
S transmits its messages to its two neighbors, C1 and C2 within direct communication range. At
some later time, as shown in Figure 8, C2, comes into direct communication range with another
host, C3 ,and transmits the message to it. C3 is in direct range of D and finally sends the message
to its destination.
Fig 7 Fig 8

Bio-inspired Networking
Department Of Computer Science - 21 - CUSAT
7. CONCLUSION
The realization of the next generation networks, e.g., cognitive radio networks , sensor
networks, vehicular communication networks, terrestrial next generation Internet, InterPlaNetary
Internet ETC have many common significant barriers such as the increased complexity with
large scale networks, dynamic nature, resource constraints, heterogeneous architectures,
absence or impracticality of centralized control and infrastructure.
The next generation of bio-inspired research will be most successful if it takes a more
conceptual, systems-level approach. This means studying not just the behavior of individual
components of the system, but their interactions, and the characteristics of the system that forms
as a result.
The goal of bio-inspired research requires a new high-level approach:
Work with biologists to understand the organization and interactions of complex
biological systems, from the component level all the way up to the systems level.
Identify systems-level, organizational principles that can be applied to specific
problems in the computer networking domain.
Determine how to apply these principles to solve the problem at hand, using them to
guide the development of new architectures, algorithms, and software.
Recognizing and understanding these higher-level principles requires a strong grasp of
biology, as well as an awareness of current biological research. Thus, one of the major tenets of
this approach is a need to work more closely with biologists. Luckily, a systems-level approach
to biology, appropriately termed systems biology, has been gaining in popularity among
biologists in recent years.

Bio-inspired Networking
Department Of Computer Science - 22 - CUSAT
8. REFERENCE
[1] Dressler F and Akan O.B, “A Survey on Bio-Inspired Networking” Computer Networks
, vol.54, no.6,2010,pp. 881-900
[2] Meisel M ,Pappas V and Zhang L,”A taxonomy of biologically inspired research in
computer networking”, Computer Networks, vol.54,n0.6,2009,pp. 901-916
[3] Wedde H.F, Farooq M, Pannenbaecker T, Vogel B, Mueller C, Meth J, and Jeruschkat R.
“BeeAdHoc: an energy efficient routing algorithm for mobile ad-hoc networks inspired by
bee behavior” Proceedings of ACM GECCO, 2005,pp .153–160.
[4] Kephart J, White S, “Directed-graph epidemiological models of computer viruses”:
Proceedings of IEEE Computer Society Symposium on Research in Security and Privacy,
1991, pp. 343–359.
[5] Vahdat A, Becker D, “Epidemic routing for partially-connected adhoc networks”,
Technical Report CS-2000-06, Duke University, 2000.
http://issg.cs.duke.edu/epidemic/epidemic.pdf accessed on 25 Jan 2011