deep continuous networks
TRANSCRIPT

ICML 2021
Deep Continuous NetworksNergis Tömen, Silvia L. Pintea, Jan van Gemert
Computer Vision Lab, TU Delft

Kar et al., Nature Neuroscience, 2019 [9] Ecker et al., ICLR, 2019 [6] Lindsey et al., ICLR, 2019 [11]
Motivation
1 Deep Continuous Networks Motivation

Conventional feed-forward CNNs
• Spatially discrete: use discretized, typically 3 × 3 kernels
• cannot learn the receptive field size during training
• Temporally discrete: use discrete, sequential layers
• cannot model the continuous evolution of neuronal activations
Motivation
2 Deep Continuous Networks Motivation

Conventional feed-forward CNNs
• Spatially discrete: use discretized, typically 3 × 3 kernels
• cannot learn the receptive field size during training
• Temporally discrete: use discrete, sequential layers
• cannot model the continuous evolution of neuronal activations
Motivation
2 Deep Continuous Networks Motivation

We present Deep Continuous Networks (DCNs):
• spatially continuous filter descriptions
• can learn the kernel size and receptive field size during training
• depthwise continuous evolution of feature maps
• can model temporal dynamics of neuronal activations in response to images
Deep Continuous Networks
3 Deep Continuous Networks Motivation

We present Deep Continuous Networks (DCNs):
• spatially continuous filter descriptions
• can learn the kernel size and receptive field size during training
• depthwise continuous evolution of feature maps
• can model temporal dynamics of neuronal activations in response to images
Deep Continuous Networks
3 Deep Continuous Networks Motivation

• Spatially continuous filters: weighted sum of basis functions
• Gaussian N-jet basis [7, 10, 8] with trainable scale (f) parameter
FαFα
Spatially Continuous Filters
4 Deep Continuous Networks DCN model
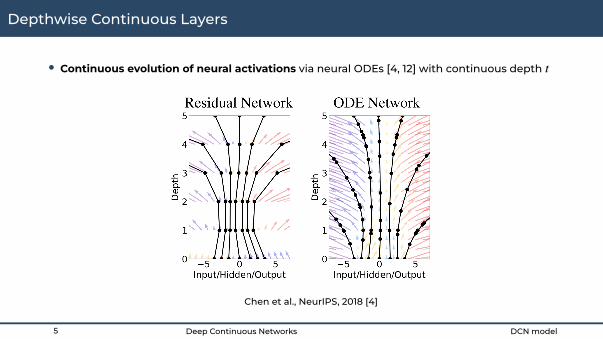
• Continuous evolution of neural activations via neural ODEs [4, 12] with continuous depth C
Chen et al., NeurIPS, 2018 [4]
Depthwise Continuous Layers
5 Deep Continuous Networks DCN model

• DCN Architecture: Cascade of continuous ODE Blocks
• ODE Block:
• Convolutional filters: Gaussian N-jet
• Feature maps: Computed by an ODE solver
• Baseline models
• ODE-Net (spatially discrete)
• ResNet-blocks (spatially and depthwise discrete)
Input Image (32x32x3)
kxk conv, 32
ODE Block 1, 32
Downsampling block 1, 64
ODE Block 2, 64
ODE Block 3, 128
fc, 10
Global Average Pooling
Downsampling block 2, 128
...
ODE Block 3, 128
Upscaling block 1, 64
ODE Block 4, 64
ODE Block 5, 32
1x1 conv, 3
Upscaling block 2, 32
Enco
der (
Cla
ssifi
catio
n)
Dec
oder
(Rec
onst
ruct
ion)
Deep Continuous Networks
6 Deep Continuous Networks DCN model

• DCN Architecture: Cascade of continuous ODE Blocks
• ODE Block:
• Convolutional filters: Gaussian N-jet
• Feature maps: Computed by an ODE solver
• Baseline models
• ODE-Net (spatially discrete)
• ResNet-blocks (spatially and depthwise discrete)
Input Image (32x32x3)
kxk conv, 32
ODE Block 1, 32
Downsampling block 1, 64
ODE Block 2, 64
ODE Block 3, 128
fc, 10
Global Average Pooling
Downsampling block 2, 128
...
ODE Block 3, 128
Upscaling block 1, 64
ODE Block 4, 64
ODE Block 5, 32
1x1 conv, 3
Upscaling block 2, 32
Enco
der (
Cla
ssifi
catio
n)
Dec
oder
(Rec
onst
ruct
ion)
Deep Continuous Networks
6 Deep Continuous Networks DCN model
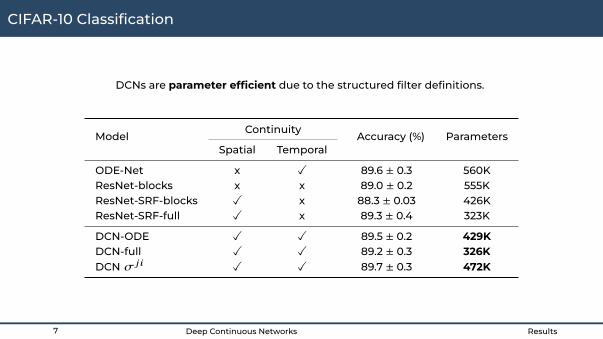
DCNs are parameter efficient due to the structured filter definitions.
ModelContinuity
Accuracy (%) ParametersSpatial Temporal
ODE-Net x X 89.6 ± 0.3 560KResNet-blocks x x 89.0 ± 0.2 555KResNet-SRF-blocks X x 88.3 ± 0.03 426KResNet-SRF-full X x 89.3 ± 0.4 323K
DCN-ODE X X 89.5 ± 0.2 429KDCN-full X X 89.2 ± 0.3 326KDCN f 98 X X 89.7 ± 0.3 472K
CIFAR-10 Classification
7 Deep Continuous Networks Results

DCNs are data efficient.
Model # images per class
2 4 8 16 32 52 64 103 128 512 1024
ResNet34† 17.5±2.5 19.5±1.4 23.3±1.6 28.3±1.4 33.2±1.2 – 41.7±1.1 – 49.1±1.3 – –
CNTK† 18.8±2.1 21.3±1.9 25.5±1.9 30.5±1.2 36.6±0.9 – 42.6±0.7 – 48.9±0.7 – –
ResNet-blocks 16.7±0.8 19.6±1.0 22.0±1.3 28.1±1.7 35.4±0.9 39.8±0.6 41.6±1.5 49.0±0.2 50.9±0.6 70.4±1.2 76.8±0.7
ODE-Net 16.8±2.8 20.5±0.8 23.1±2.5 29.8±0.8 36.4±1.0 41.7±1.2 42.3±0.2 48.6±0.5 50.7±0.7 71.7±1.5 77.4±0.5
DCN-ODE 16.4±1.6 19.8±0.7 26.5±0.9 31.2±0.6 37.7±0.6 44.5±0.8 48.0±1.3 54.2±0.8 58.2±0.7 75.5±0.8 79.7±0.3
Baseline results † from [2].
CIFAR-10 Classification: Small-data regime
8 Deep Continuous Networks Results

DCNs allow for meta-parametrization of filters as a function of depth C .
Model Parametrization Accuracy (%)
DCN-ODE f, U 89.46 ± 0.16
DCN f (C) f = 20C+1 , U 89.97 ± 0.30
DCN f (C2) f = 20C2+1C+2 , U 89.93 ± 0.28
DCN f (C) , U(C) f = 20BC+1B , U = 0UC + 1U 89.88 ± 0.25
CIFAR-10 Classification: Filter meta-parametrization
9 Deep Continuous Networks Results

f distributions after training are consistent with biological observations [13].
block
1: con
v1
block
1: con
v2
block
2: con
v1
block
2: con
v2
block
3: con
v1
block
3: con
v20.4
0.6
0.8
1.0
1.2
1.4
1.6
Lear
ned
scal
e σ
DCN-ODEDCN-fullResNet-SRF-blocksResNet-SRF-full
0 2 4Learned scale σ
0
500
1000
1500
2000
2500
3000
3500
# of
filte
rs
block 1: conv1block 1: conv2block 2: conv1block 2: conv2block 3: conv1block 3: conv2
Learning the receptive field size
10 Deep Continuous Networks Results

Similar to rate-based, continuous-receptive-field population models of biological vision [3, 1, 5],
DCNs display emergent pattern completion.
input image masked image
him(0) him_masked(0)
0.2
0.4
0.6 D(t)
him(T) him_masked(T)
0 2integration time t
0.5
1.0
D(t)DCN
basel
ine
mask 4x
4
mask 6x
6
mask 8x
8
mask 10
x10
mask 12
x12
70
80
90
Valid
atio
n Ac
cura
cy [%
]
DCNResNet-blocksODE-Net
Pattern Completion
11 Deep Continuous Networks Results

• ODE-based dynamics are sensitive to con-
trast changes.
• Contrast robustness can be improved by
scaling the numerical ODE integration time
proportionately to input contrast at test time.
• Contrast-robust networks can cut down the
computational cost.
20
40
60
80
Valid
atio
n Ac
cura
cy [%
]
ODE-Net (robust)DCN (robust)DCN:3 (robust)ODE-Net (naive)DCN (naive)DCN:3 (naive)
0
50
NFE
ODE block 1
0.001 0.01 0.1 1Contrast Level c
100200300
Tota
l NFE All ODE blocks
Efficient ODE computation via contrast robustness
12 Deep Continuous Networks Results

We present spatially and depthwise-continuous DCN models:
• Data efficient
• Learn biologically plausible RF sizes
• Links to biological models from computational neuroscience
• Computational efficiency via contrast-robustness
Conclusion
13 Deep Continuous Networks Results

Thanks!
Please see the paper for more!

[1] Shunichi Amari. “Dynamics of pattern formation in lateral-inhibition type neural fields”. In: Biological Cybernetics 27.2 (1977),pp. 77–87.
[2] Sanjeev Arora et al. “Harnessing the Power of Infinitely Wide Deep Nets on Small-data Tasks”. In: International Conference onLearning Representations (ICLR). 2020.
[3] Paul C Bressloff et al. “Geometric visual hallucinations, Euclidean symmetry and the functional architecture of striate cortex”.In: Philosophical Transactions of the Royal Society of London. Series B: Biological Sciences 356.1407 (2001), pp. 299–330.
[4] Ricky T. Q. Chen et al. “Neural Ordinary Differential Equations”. In: NeurIPS (2018).[5] Stephen Coombes. “Waves, bumps, and patterns in neural field theories”. In: Biological Cybernetics 93.2 (2005), pp. 91–108.[6] Alexander S Ecker et al. “A rotation-equivariant convolutional neural network model of primary visual cortex”. In: International
Conference on Learning Representations (ICLR). 2019.[7] Luc Florack et al. “The Gaussian scale-space paradigm and the multiscale local jet”. In: IJCV 18.1 (1996), pp. 61–75.[8] Jorn-Henrik Jacobsen et al. “Structured receptive fields in CNNs”. In: CVPR. 2016, pp. 2610–2619.[9] Kohitij Kar et al. “Evidence that recurrent circuits are critical to the ventral stream’s execution of core object recognition be-
havior”. In: Nature Neuroscience 22.6 (2019), pp. 974–983.[10] Tony Lindeberg. Scale-space theory in computer vision. Vol. 256. Springer Science & Business Media, 2013.[11] Jack Lindsey et al. “A Unified Theory of Early Visual Representations from Retina to Cortex through Anatomically Constrained
Deep CNNs”. In: International Conference on Learning Representations (ICLR). 2019.[12] Lars Ruthotto and Eldad Haber. “Deep neural networks motivated by partial differential equations”. In: Journal ofMathematical
Imaging and Vision (2019), pp. 1–13.[13] Hsin-Hao Yu et al. “Spatial and temporal frequency tuning in striate cortex: functional uniformity and specializations related to
receptive field eccentricity”. In: European Journal of Neuroscience 31.6 (2010), pp. 1043–1062.
References
15 Deep Continuous Networks References