continuous unsupervised training of deep architectures
TRANSCRIPT

Continuous Unsupervised Training
of Deep Architectures
Biometric System Laboratory
DISI - University of Bologna http://biolab.csr.unibo.it
6th July 2017 – IIT Genova
Davide Maltoni
Vincenzo Lomonaco

1Biometric System Laboratory
Outline
Deep architectures
Supervised, Semi supervised and Unsupervised learning
Continuous Incremental learning & Forgetting
Temporal Coherence for Semi Supervised Learning
Core50: Dataset & Benchmark

2Biometric System Laboratory
Deep architectures Hierarchical architectures with many layers
Neural Networks (with more than 3 levels)
Convolutional Neural Networks (CNN)
Hierarchical Temporal Memory (HTM)
Multi-stage Hubel-Wiesel Architectures (Ranzato 2007)
Alternating layers of feature detectors (Hubel and Wiesel’s simple cells)
and local pooling/subsampling of features (Hubel and Wiesel’s complex
cells).
We focused on CNN and HTM
Increasing the number of alternating feature extraction (discrimination)
and feature pooling (generalization) layers seems to be the key to tackle
invariance
Deep architectures (1)

3Biometric System Laboratory
State-of-the-art achievements in many fields:
vision (object classification, detection, segmentation)
speech recognition
natural language processing
Mainly supervised training (backpropagation like) with huge and
fixed datasets:
ImageNet - ILSVRC (1.2M labeled images - 1,000 classes)
YouTube-8M (7M videos – 4,716 classes)
Microsoft Coco (2M instances, 300,000 images – 80 classes)
GPU parallelism to speed-up training (months days)
Deep architectures (2)

4Biometric System Laboratory
Learning features
Learning Features by Watching Objects Move (Pathak et al, 2017)
Unsupervised motion-based segmentation as pseudo ground truth
Sparse Autoencoder objective function designed to optimize the input
reconstruction (promote sparsity and feature grouping)
Learning low level feature detectors (V1 like) is quite simple (Olshausen & Field,
1996), but learning high level feature detectors requires huge amount of data (Le
2012, Google)
Unsupervised learning
reconstruction pooling

5Biometric System Laboratory
Semi-supervised
Typically a small set of labeled data + large set of unlabeled data. Knowledge
of pattern absolute density can help to optimize the decision boundary
Self-training
a system is first trained with a small amount of labeled data and then used to
classify the unlabeled data. The most confident unlabeled points are
(iteratively) added to the training set.
but unfortunately:
patterns whose label can be correctly guessed do not bring much value to
improve the current representation
really useful patterns (in term of diversity) are not added because of the low self-
confidence
Semi-supervised training
(Xiaojin Zhu, 2007)

6Biometric System Laboratory
Adapt an already trained architecture to solve a new problem (in
the same domain)
Very popular today (avoid time consuming retraining from scratch)
Replace (at least) the last layer (top classifier)
Reuse of features
– Keep them fixed and train only top layers
– Tune them together with top layers
Is not incremental
– Relevant accuracy degradation on the original task
Transfer learning

7Biometric System Laboratory
Why it is important:
Many real-world scenarios are not fixed a priori
Training data often available as subsequent batches or from streaming sources
Main Strategies:
store the past data and retrain the system from scratch (often unrealistic)
data comes in sequential batches, used once and then lost (more feasible)
Problems:
– Catastrophic forgetting (McCloskey & Cohen 1989)
– Stability-plasticity dilemma (Mermillod et al. 2013)
Continuous - Incremental learning

8Biometric System Laboratory
Solutions:
– Incremental Classifiers – Camoriano et. al. 2016, Lomonaco & Maltoni 2016*
Keep feature extraction fixed and train an incremental classifier (e.g. RLS, SVM)
– Early stopping each batch produces only slight changes in the parameters
– Self-refreshinggenerative models to create pseudo-patterns
– Elastic Weight Consolidation (EWC) – Kirkpatrick et al. 2016
move only non-critical weights
– Learning without Forgetting (LwF) – Li & Hoiem 2016
promote output stability (of the old network on new patterns)
Interesting approaches, but tested only on simple (two or few task) problems.
Continuous - Incremental learning (2)
* Lomonaco and Maltoni, Comparing Incremental Learning Strategies for Convolutional Neural Networks, Workshop on
Artificial Neural Networks in Pattern Recognition, 2016.

9Biometric System Laboratory
Natural learning
Continuous / Lifelong (and possibly online)
Partially supervised (or with reinforcement), but mostly unsupervised
Multimodal / Multitask
human-like learning involves an initial small amount of direct instruction (e.g.
parental labeling of objects during childhood) combined with large amounts of
subsequence unsupervised experience (e.g. self-interaction with objects)
Ultimate interest

10Biometric System Laboratory
HTM
Hierarchical Temporal Memory (HTM) is a biologically-inspired
computational framework proposed by Hawkins and George
Dileep George, Jeff Hawkins, “A Hierarchical Bayesian Model of Invariant Pattern
Recognition in the Visual Cortex”, IJCNN 2005.
Dileep George, Jeff Hawkins, “Towards a Mathematical Theory of Cortical Micro-
circuits”, PLoS Comput. Biol. 5(10), 2009.
A silicon-valley company (Numenta) created to develop/market HTM technology.
HTM review and implementation details in:
Davide Maltoni, “Pattern recognition by Hierarchical Temporal Memory”, Tech.
Report, DEIS – University of Bologna, April 2011:
http://cogprints.org/9187/1/HTM_TR_v1.0.pdf
HTM Supervised Refinement (HSR) is a backpropagation-like approach
to tune HTM after initial Pre-training:
Rehn, E. M. and Maltoni, D. “Incremental learning by message passing in hierarchical
temporal memory”. Neural Computation, 26(8):1763–1809, 2014.

11Biometric System Laboratory
HTM generations
We work on the “first generation” of HTM.
In 2011 Numenta focused on a different model (called CLA: Cortical
Learning Algorithms) :
better suited for dynamic patterns and their temporal relations (compete with
Recurrent NN, LSTM).
Practical applications of CLA are tools for anomaly detection on data streams (e.g.
stock market data, network intrusion detection, etc.).
CLA is not efficient enough to work with high-dimensional patterns such as images.
12Biometric System Laboratory
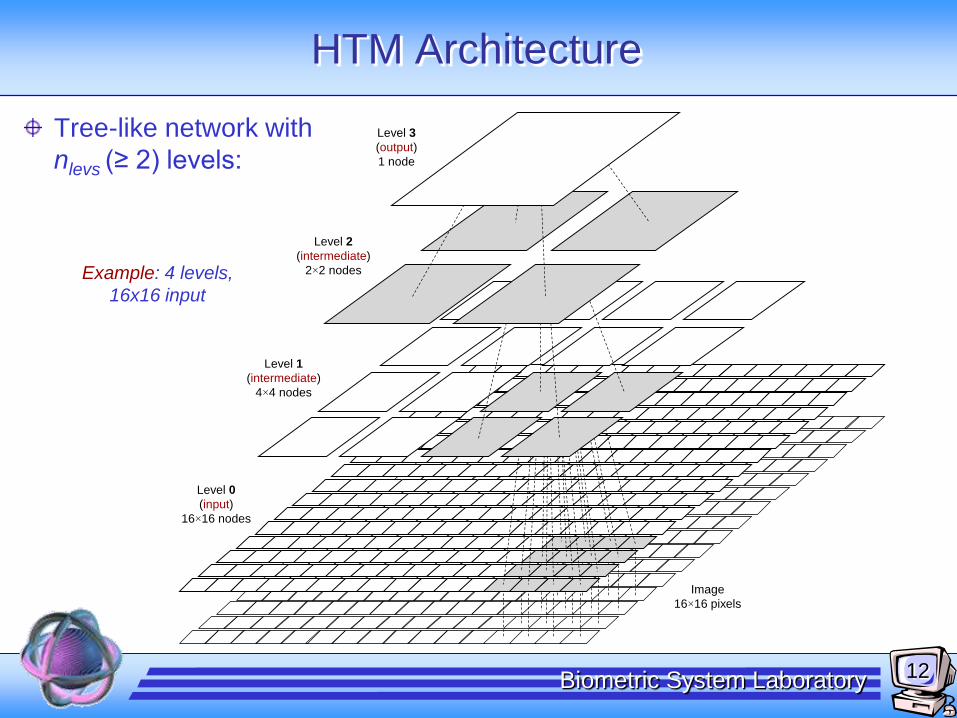
HTM Architecture
Tree-like network with
nlevs (≥ 2) levels:
Level 3
(output)
1 node
Level 2
(intermediate)
2×2 nodes
Level 1
(intermediate)
4×4 nodes
Level 0
(input)
16×16 nodes
Image
16×16 pixels
Example: 4 levels,
16x16 input

13Biometric System Laboratory
Node structure
Input nodes (level 0) are simple interfaces between pixels and level 1 nodes.
Intermediate nodes are the real computation engine of HTM: they store
coincidences and temporal groups.
A single output node works as a pattern classifiers (e.g., a NN classifiers).
𝛌2− … 𝛌1
− 𝛌𝑚−
Coincidences C
Temporal groups G Matrix
𝐜2 … 𝐜1 𝐜𝑛𝑐
𝐠2 … 𝐠1 𝐠𝑛𝑔 𝐏𝐂𝐆
𝛌− = 𝛌1−,𝛌2
−…𝛌𝑚−
𝐲
𝛌+
𝛌2− … 𝛌1
− 𝛌𝑚−
Coincidences C
Prior class prob. Matrix
𝐜2 … 𝐜1 𝐜𝑛𝑐
[𝑃(𝑤1),𝑃(𝑤2)… 𝑃(𝑤𝑛𝑤 )] 𝐏𝐂𝐖
𝛌− = 𝛌1−,𝛌2
−…𝛌𝑚−
𝐲
[𝑃(𝑤1|𝑒),𝑃(𝑤2|𝑒)… 𝑃(𝑤𝑛𝑤|𝑒)]
Intermediate
nodeOutput
node

14Biometric System Laboratory
Coincidences
Each coincidence is a sort of feature extractor that spans a portion of the image
corresponding to the node receptive field (i.e., small at low levels and large at high
levels). Coincidences are used to perform a spatial analysis of input patterns and to
find out spatial similarities.
Example of level 1 coincidences

15Biometric System Laboratory
Temporal groups
A temporal group is a subset of coincidences, that could be spatially quite different
each from the other, but that are likely to be originated from simple variations of the
same pattern.
HTM exploits temporal smoothness to create temporal groups: patterns presented
to the network very close in time, are likely to be variants of the same pattern that is
smoothly moving throughout the network field of view.
Example of level 1 groups
𝐠1
𝐠2
𝐠3
𝐠4
𝐠5
𝐠6
𝐠7
𝐠8
𝐠9
𝐠10
𝐠11
𝐠12
𝐠13
𝐠14

16Biometric System Laboratory
HTM vs CNN
Key points:
Bayesian probabilistic formulation: Bayesian Network + Bayesian Belief propagation
equations. Parameters values constrained by probability laws.
Top down and bottom-up information flow: feedback messages from higher levels
carry contextual information to bias the behavior of lower levels. By fusing bottom up
and top down messages each HTM node reaches an internal state (called node belief
and corresponding to Bayes posterior) which is an optimal probabilistic explanation of
the external stimuli.
Pooling is a key component in HTM (some CNN work well even without pooling
layers).
Unsupervised Pre-training is very effective in HTM.
Compares favorably on small-scale problems, difficult to scale-up. Designing large
HTM is not easy (architectural choices, pre-training, code optimization, numerical
problems).
16x16 32x32 64x64 128x128 …

17Biometric System Laboratory
From supervised to Semi-Supervised Tuning
Exploiting time (again) as supervisor.
Biological plausibility: … hypothesis under which invariance is learned
from temporal continuity of object features during natural visual
experience without external supervision (Li & DiCarlo 2008)
SST idea: pass back the current output vector as desired vector (i.e.,
label) for the next pattern
D. Maltoni and V. Lomonaco, Semi-supervised Tuning from Temporal Coherence,
International Conference on Pattern Recognition, 2016.
ArXiv 1511.03163

18Biometric System Laboratory
SST (1)
Temporal coherent patterns: 𝒗 𝑡 , 𝑡 = 1…𝑚
A classifier 𝑵 maps an input pattern to an output vector: 𝒗 𝑡 → 𝑵 𝒗 𝑡
Loss function to be minimized (e.g. backprop): 1
2𝑵 𝒗 𝑡 − 𝒅(𝒗 𝑡 )
2
1. Supervised Tuning (SupT):
𝒅 𝒗 𝑡 = 𝚫𝑤 = 0,… , 1, …0 w is the pattern class
2. Supervised Tuning with Regularization (SupTR):
𝒅 𝒗 𝑡 = 𝜆 ∙ 𝚫𝑤 + 1 − 𝜆 ∙ 𝑵 𝒗 𝑡−1
position w

19Biometric System Laboratory
SST (2)
3. Semi Supervised Tuning – Basic (SST-B):
𝒅 𝒗 𝑡 = 𝑵 𝒗 𝑡−1
4. Semi Supervised Tuning – Advanced (SST-A):
𝒇 𝒗 𝑡 =
𝑵 𝒗 𝑡−1 𝑡 = 2
𝒇 𝒗 𝑡−1 +𝑵 𝒗 𝑡−1
2𝑡 > 2
𝒅 𝒗 𝑡 = 𝒇 𝒗 𝑡 𝑖𝑓 max
𝑖𝒇𝑖 𝒗
𝑡 > 𝑠𝑐
𝑵 𝒗 𝑡 𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒

20Biometric System Laboratory
SST Experiments
We generated temporal coherent sequences from NORB and COIL100
datasets by randomly walking the variation space (pose, lighting).
1 sequence for initial (supervised training) + 9 sequences for
incremental tuning
Test set contains frames with a given mindist from all training patterns

21Biometric System Laboratory
SST Experiments (2)
HTM on NORB CNN on NORB

22Biometric System Laboratory
SST Experiments (3)
making the problem harder by
reducing initial accuracy …Comparison with
self-training
Self-training

23Biometric System Laboratory
Ongoing work on SST
SST approach very effective with HTM
SST-A accuracy is sometime very close to supervised scenario.
Why does HTM work better than CNN with SST?
HTM seems to be more robust w.r.t. forgetting, Why?
In HTM we keeps coincidence fixed. Try with CNN - NiN (Network in Network) models
where we move only feature pooling weights.
Investigate other architectural differences.
New experiments on natural datasets and continuous learning
scenarios.
Core50
iCubWorld-Transf

24Biometric System Laboratory
CORe50
Dataset, Benchmark, code and additional information freely
available at: https://vlomonaco.github.io/core50

25Biometric System Laboratory
CORe50 (2)
Motivation
Temporal Coherence has already shown to be a good surrogate supervised signal
(also in complex sequence learning problems)
Still, it’s very difficult to find simple videos of objects smoothly moving in front of the
camera.
Moreover, in order to assess Continuous Learning scenarios we need the presence of
multiple (temporal coherent and unconstrained) views of the same objects taken in
different sessions (varying background, lighting, pose, occlusions, etc.)
Sometimes it is possible to generate a number of exploration sequences that turn a
native static benchmarks into continuous learning tasks, but the result is often
unnatural (Maltoni & Lomonaco 2016)

26Biometric System Laboratory
Comparison with other Datasets

27Biometric System Laboratory
50 Objects of 10 Classes

28Biometric System Laboratory
11 Sessions
One frame of the same object (#41) throughout the 11 acquisition sessions.
Three of the eleven sessions (#3, #7 and #10) have been selected for test and
the remaining 8 sessions are used for training.
29Biometric System Laboratory
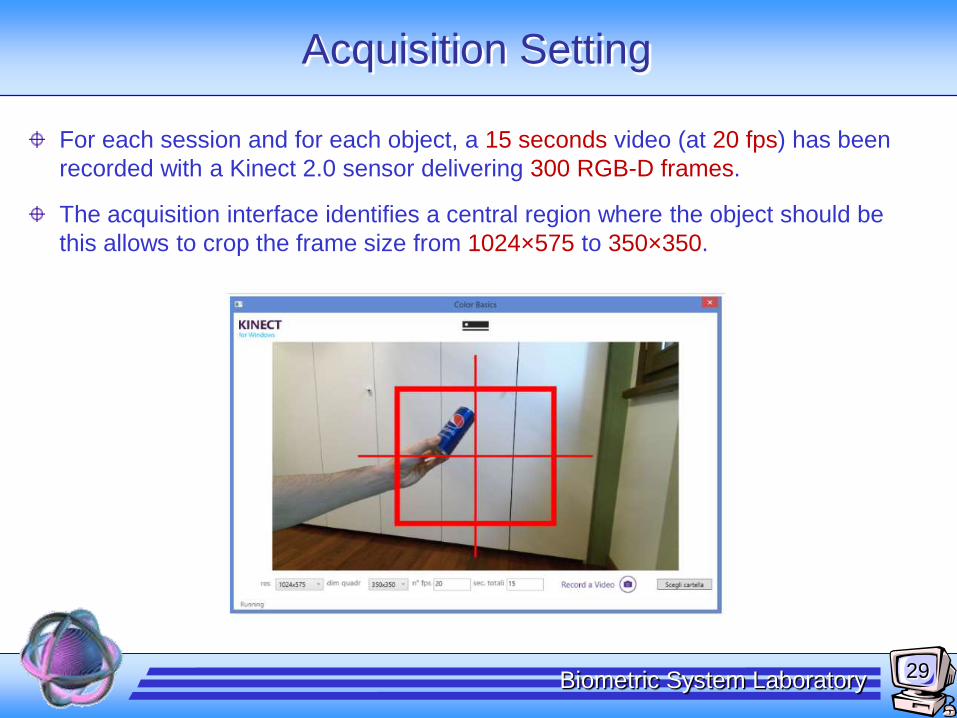
Acquisition Setting
For each session and for each object, a 15 seconds video (at 20 fps) has been
recorded with a Kinect 2.0 sensor delivering 300 RGB-D frames.
The acquisition interface identifies a central region where the object should be
this allows to crop the frame size from 1024×575 to 350×350.

30Biometric System Laboratory
Acquisition setting (2)
The 350×350 frames are then automatically cropped to 128×128 based on a
fully automated tracker.
Example of 1 second recording (at 20 fps) of object #26 in session #4 (outdoor).
Note the smooth movement, pose change and partial occlusion.

31Biometric System Laboratory
Continuous Learning Scenarios
New Instances (NI)
New training patterns of the same classes become available in subsequent
batches with new poses and conditions (illumination, background, occlusion,
etc.).
New Classes (NC)
New training patterns belonging to different classes become available in
subsequent batches.
New Instances and Classes (NIC)
New training patterns belonging both to known and new classes become
available in subsequent training batches.

32Biometric System Laboratory
Continuous Learning Strategies
Cumulative (non-continuous)
We re-train the entire model from scratch as soon as a new batch of data is
available.
Naïve
We simply continue back-propagation with early-stopping and low learning
rate.
Copy Weights with Re-init (CWR)
Simple baseline to add new classes easily disentangling the weights
effecting each class.

33Biometric System Laboratory
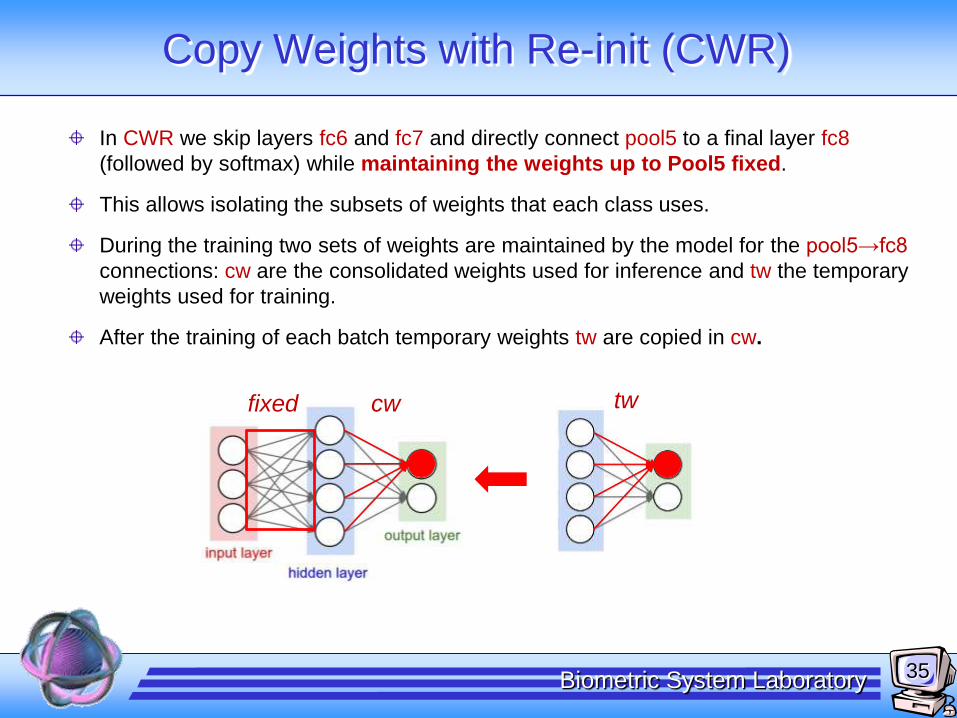
Copy Weights with Re-init (CWR)
In CWR we skip layers fc6 and fc7 and directly connect pool5 to a final layer fc8
(followed by softmax) while maintaining the weights up to Pool5 fixed.
This allows isolating the subsets of weights that each class uses.
During the training two sets of weights are maintained by the model for the pool5→fc8
connections: cw are the consolidated weights used for inference and tw the temporary
weights used for training.
After the training of each batch temporary weights tw are copied in cw.
twcwfixed

34Biometric System Laboratory
Copy Weights with Re-init (CWR)
In CWR we skip layers fc6 and fc7 and directly connect pool5 to a final layer fc8
(followed by softmax) while maintaining the weights up to Pool5 fixed.
This allows isolating the subsets of weights that each class uses.
During the training two sets of weights are maintained by the model for the pool5→fc8
connections: cw are the consolidated weights used for inference and tw the temporary
weights used for training.
After the training of each batch temporary weights tw are copied in cw.
twcwfixed
35Biometric System Laboratory
Copy Weights with Re-init (CWR)
In CWR we skip layers fc6 and fc7 and directly connect pool5 to a final layer fc8
(followed by softmax) while maintaining the weights up to Pool5 fixed.
This allows isolating the subsets of weights that each class uses.
During the training two sets of weights are maintained by the model for the pool5→fc8
connections: cw are the consolidated weights used for inference and tw the temporary
weights used for training.
After the training of each batch temporary weights tw are copied in cw.
twcwfixed

36Biometric System Laboratory
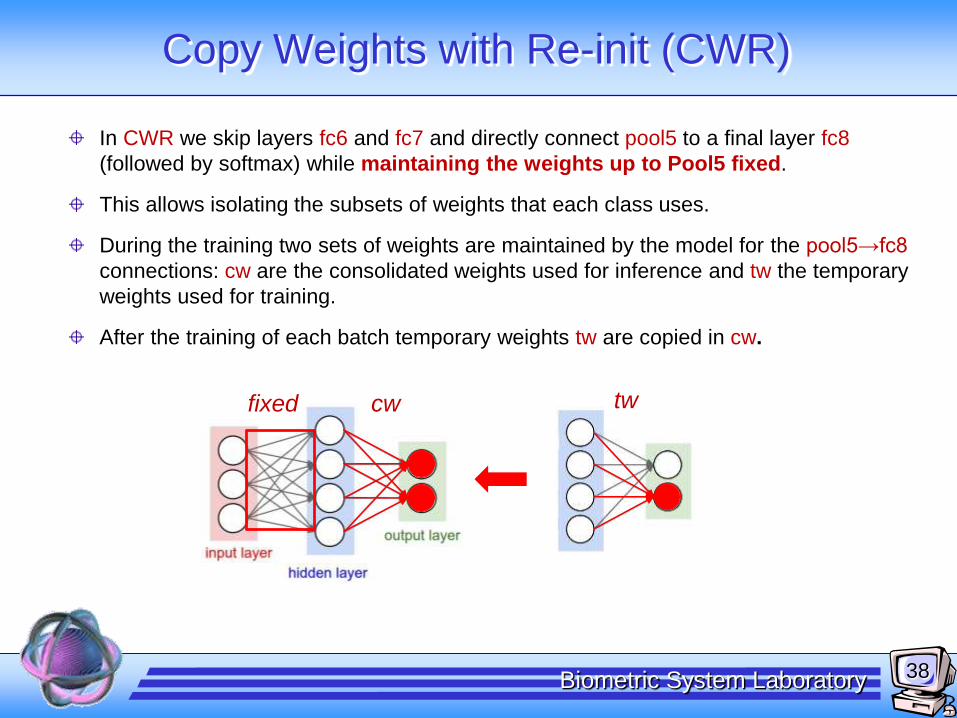
Copy Weights with Re-init (CWR)
In CWR we skip layers fc6 and fc7 and directly connect pool5 to a final layer fc8
(followed by softmax) while maintaining the weights up to Pool5 fixed.
This allows isolating the subsets of weights that each class uses.
During the training two sets of weights are maintained by the model for the pool5→fc8
connections: cw are the consolidated weights used for inference and tw the temporary
weights used for training.
After the training of each batch temporary weights tw are copied in cw.
twcwfixed

37Biometric System Laboratory
Copy Weights with Re-init (CWR)
In CWR we skip layers fc6 and fc7 and directly connect pool5 to a final layer fc8
(followed by softmax) while maintaining the weights up to Pool5 fixed.
This allows isolating the subsets of weights that each class uses.
During the training two sets of weights are maintained by the model for the pool5→fc8
connections: cw are the consolidated weights used for inference and tw the temporary
weights used for training.
After the training of each batch temporary weights tw are copied in cw.
twcwfixed
38Biometric System Laboratory
Copy Weights with Re-init (CWR)
In CWR we skip layers fc6 and fc7 and directly connect pool5 to a final layer fc8
(followed by softmax) while maintaining the weights up to Pool5 fixed.
This allows isolating the subsets of weights that each class uses.
During the training two sets of weights are maintained by the model for the pool5→fc8
connections: cw are the consolidated weights used for inference and tw the temporary
weights used for training.
After the training of each batch temporary weights tw are copied in cw.
twcwfixed
39Biometric System Laboratory
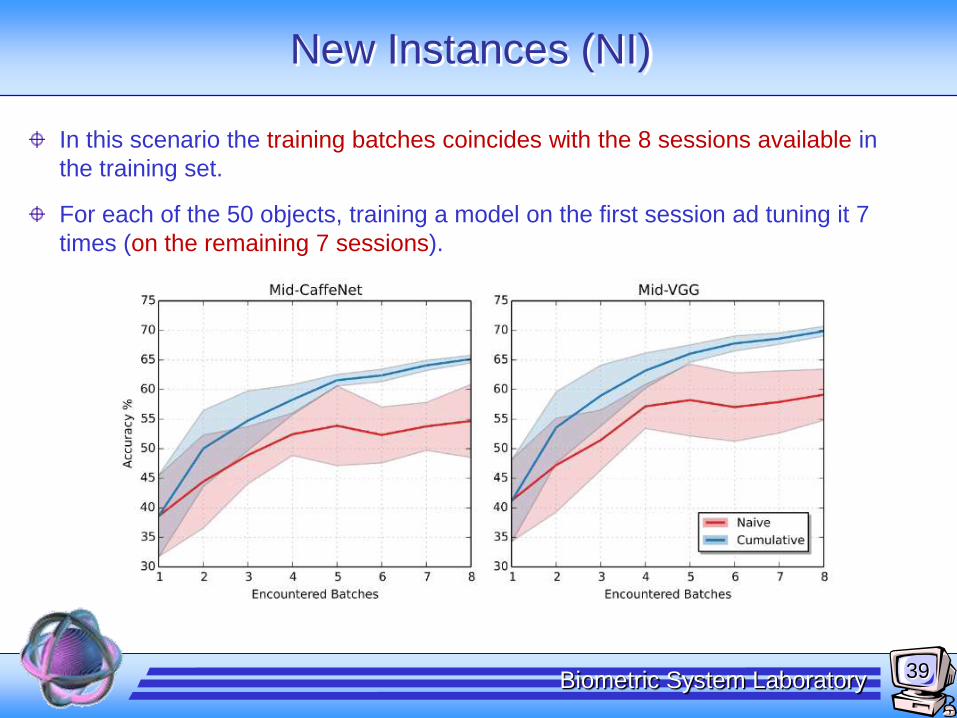
New Instances (NI)
In this scenario the training batches coincides with the 8 sessions available in
the training set.
For each of the 50 objects, training a model on the first session ad tuning it 7
times (on the remaining 7 sessions).
40Biometric System Laboratory
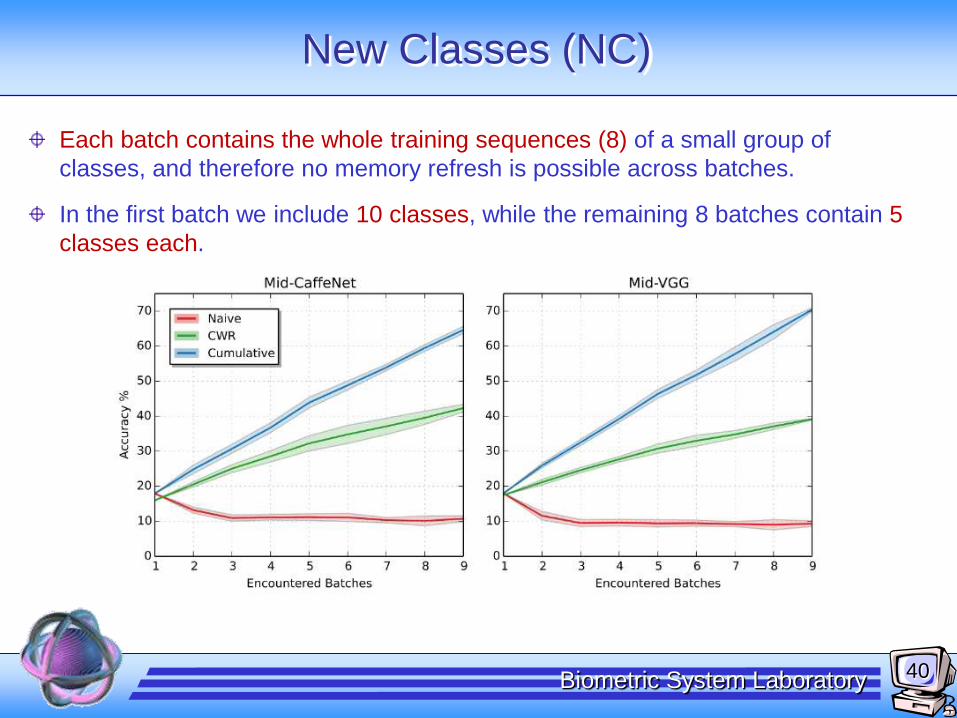
New Classes (NC)
Each batch contains the whole training sequences (8) of a small group of
classes, and therefore no memory refresh is possible across batches.
In the first batch we include 10 classes, while the remaining 8 batches contain 5
classes each.
41Biometric System Laboratory
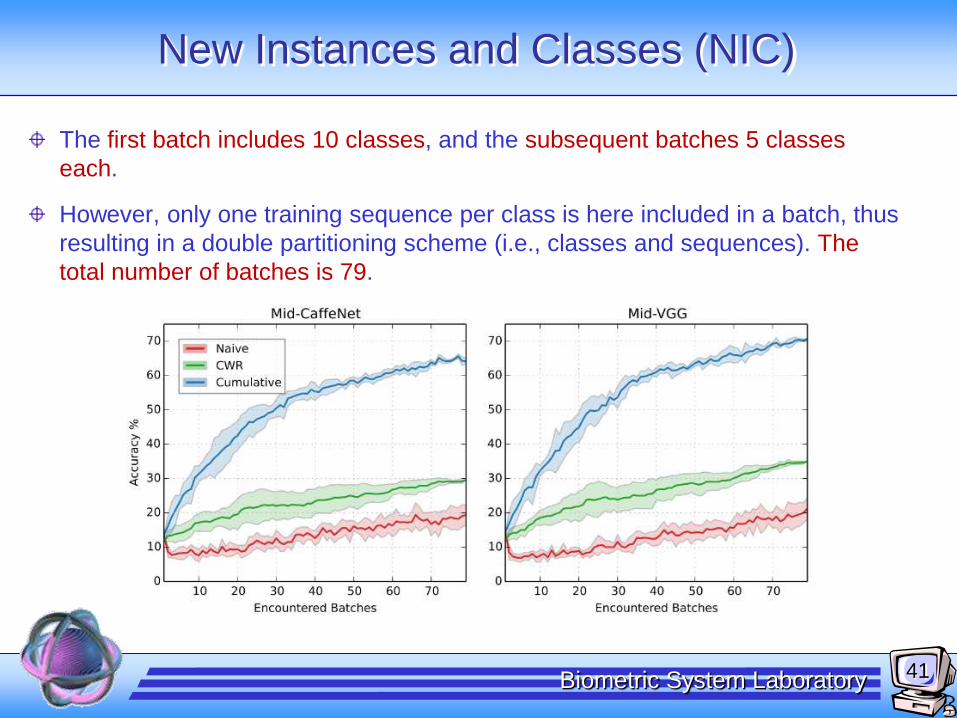
New Instances and Classes (NIC)
The first batch includes 10 classes, and the subsequent batches 5 classes
each.
However, only one training sequence per class is here included in a batch, thus
resulting in a double partitioning scheme (i.e., classes and sequences). The
total number of batches is 79.

42Biometric System Laboratory
Conclusions
Continuous/Lifelong Learning enables a boarder range of real-word applications
and counts a number of different advantages
Biologically grounded and memory/computational efficient
Enables adaptation and knowledge reuse/refining
Ideal fit for unsupervised streaming perception data (Visual, Audio, etc..)
Focus on all the three main scenarios NI, NC and NIC not just NC
Recent literature on Continuous/Lifelong learning focuses on simple sequences of
different tasks (maximum 3-4).
Temporal coherence is one of the key towards unsupervised continuous
learning
Sequence learning, Semi-Supervised Tuning (SST), etc…

43Biometric System Laboratory
Future Plans
Continuing out work in SST and CORe50
HTM vs CNN comparison
Further tests on CORe50 and iCubWorld-Transf
Implementing and evaluating LwF and EWC on Core50
LwF and EWC have been only tested in a NC-like scenario.
It is not trivial to apply them in the NI and NIC scenarios.

Thank you for listening!
Biometric System Laboratory
DISI - University of Bologna http://biolab.csr.unibo.it
6th July 2017 – IIT Genova
Davide Maltoni
Vincenzo Lomonaco
Continuous Unsupervised Training of Deep Architectures

45Biometric System Laboratory
CNN incremental (supervised) training (2)
incremental
Strategy day1 day2 day3
Lenet7 36,00% 37,55% 35,84%
AlexNet + RLS 58,20% 66,39% 74,10%
AlexNet + SVM 56,32% 66,19% 72,07%
FRCNN + Svm 51,63% 59,63% 70,00%
AlexNet + finetuning (last lvl) 54,01% 60,00% 65,38%
AlexNet + finetuning 70,70% 77,14% 76,85%
IcubWorld28Img_size: 128x128
Inc_batches: 3
Num_classes: 5 (x4 obj)
Time
Time
46Biometric System Laboratory
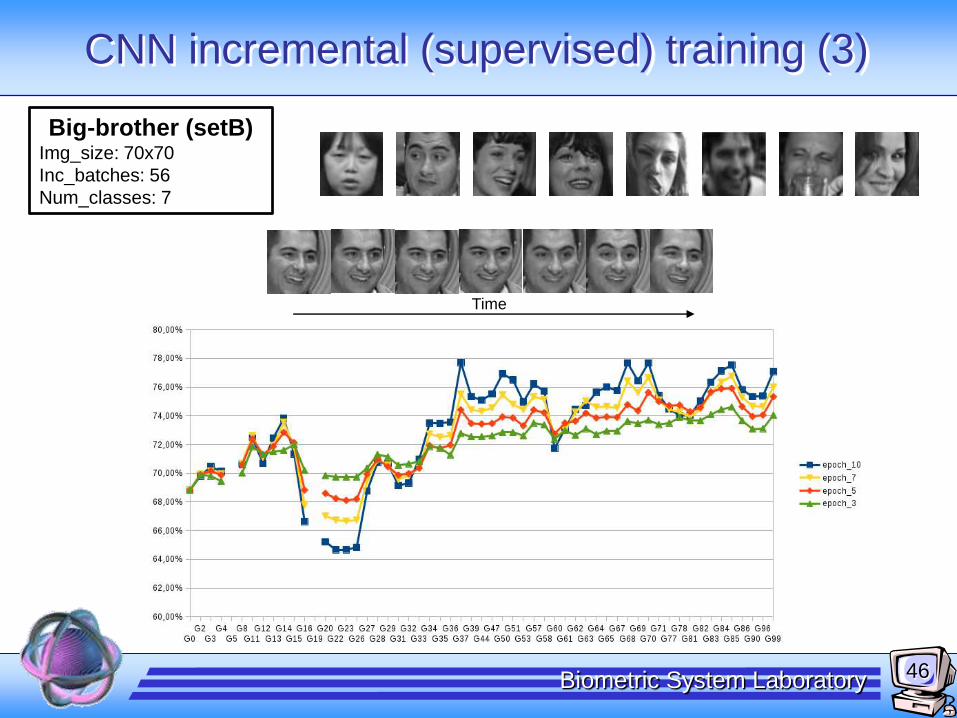
CNN incremental (supervised) training (3)
Big-brother (setB)Img_size: 70x70
Inc_batches: 56
Num_classes: 7