decoupled dynamic filter networks
TRANSCRIPT

Decoupled Dynamic Filter Networks
Jingkai Zhou12∗ Varun Jampani3 Zhixiong Pi24 Qiong Liu1† Ming-Hsuan Yang235
1South China University of Technology 2University of California at Merced 3Google Research4Huazhong University of Science and Technology 5Yonsei University
AbstractConvolution is one of the basic building blocks of CNN
architectures. Despite its common use, standard convo-lution has two main shortcomings: Content-agnostic andComputation-heavy. Dynamic filters are content-adaptive,while further increasing the computational overhead.Depth-wise convolution is a lightweight variant, but it usu-ally leads to a drop in CNN performance or requires alarger number of channels. In this work, we propose theDecoupled Dynamic Filter (DDF) that can simultaneouslytackle both of these shortcomings. Inspired by recent ad-vances in attention, DDF decouples a depth-wise dynamicfilter into spatial and channel dynamic filters. This decom-position considerably reduces the number of parametersand limits computational costs to the same level as depth-wise convolution. Meanwhile, we observe a significantboost in performance when replacing standard convolutionwith DDF in classification networks. ResNet50 / 101 getimproved by 1.9% and 1.3% on the top-1 accuracy, whiletheir computational costs are reduced by nearly half. Ex-periments on the detection and joint upsampling networksalso demonstrate the superior performance of the DDF up-sampling variant (DDF-Up) in comparison with standardconvolution and specialized content-adaptive layers. Theproject page with code is available1.
1. IntroductionConvolution is a fundamental building block of convolu-
tional neural networks (CNNs) that have seen tremendoussuccess in several computer vision tasks, such as imageclassification, semantic segmentation, pose estimation, toname a few. Thanks to its simple formulation and opti-mized implementations, convolution has become a de factostandard to propagate and integrate features across imagepixels. In this work, we aim to alleviate two of its mainshortcomings: Content-agnostic and Computation-heavy.Content-agnostic. Spatial-invariance is one of the promi-nent properties of a standard convolution. That is, convolu-∗Work carried out during the visit of J. Zhou and Z. Pi at UC Merced†Corresponding author1https://thefoxofsky.github.io/project_pages/ddf
Figure 1. Comparison between convolution, the dynamic filter,and DDF. Top: Convolution shares a static filter among pixelsand samples. Medium: The dynamic filter generates one completefilter for each pixel via a separate branch. Bottom: DDF decouplesthe dynamic filter into spatial and channel ones.
tion filters are shared across all the pixels in an image. Con-sider the sample road scene shown in Figure 1 (top). Theconvolution filters are shared across different regions suchas buildings, cars, roads, etc. Given the varied nature ofcontents in a scene, a spatially shared filter may not be op-timal to capture features across different image regions [52,42]. In addition, once a CNN is trained, the same convolu-tion filters are used across different images (for instance im-ages taken in daylight and at night). In short, standard con-volution filters are content-agnostic and are shared acrossimages and pixels, leading to sub-optimal feature learning.Several existing works [23, 48, 42, 57, 49, 45, 22, 11] pro-pose different types of content-adaptive (dynamic) filters forCNNs. However, these dynamic filters are either compute-intensive [57, 23], memory-intensive [42, 22], or special-ized processing units [11, 48, 49, 45]. As a result, mostof the existing dynamic filters can not completely replace

standard convolution in CNNs and are usually used as afew layers of a CNN [49, 45, 42, 22], or in tiny architec-ture [57, 23], or in specific scenarios, like upsampling [48].
Computation-heavy. Despite the existence of highly-optimized implementations, the computation complexity ofstandard convolution still increases considerably with theenlarge in the filter size or channel number. This poses asignificant problem as convolution layers in modern CNNshave a large number of channels in the orders of hundredsor even thousands. Grouped or depth-wise convolutionsare commonly used to reduce the computation complexity.However, these alternatives usually result in CNN perfor-mance drops when directly used as a drop-in replacementto standard convolution. To retain similar performance withdepth-wise or grouped convolutions, we need to consider-ably increase the number of feature channels, leading tomore memory consumption and access times.
In this work, we propose the Decoupled Dynamic Fil-ter (DDF) that simultaneously addresses both the above-mentioned shortcomings of the standard convolution layer.The full dynamic filter [57, 23, 49, 45] uses a separate net-work branch to predict a complete convolution filter at eachpixel. See Figure 1 (middle) for an illustration. We observethat this dynamic filtering is equivalent to applying atten-tion on unfolded input features, as illustrated in Figure 3.Inspired by the recent advances in attention mechanismsthat apply spatial and channel-wise attention [36, 50], wepropose a new variant of the dynamic filter where we de-couple spatial and channel filters. In particular, we adoptseparate attention-style branches that individually predictspatial and channel dynamic filters, which are then com-bined to form a filter at each pixel. See Figure 1 (bottom)for an illustration of DDF. We observe that this decouplingof the dynamic filter is efficient yet effective, making DDFto have similar computational costs as depth-wise convo-lution while achieving better performance against existingdynamic filters. This lightweight nature enables DDF to bedirectly inserted as a replacement of the standard convolu-tion layer. Unlike several existing dynamic filtering layers,we can replace all k × k (k > 1) convolutions in a CNNwith DDF. We also propose a variant of DDF, called DDF-Up, that can be used as a specialized upsampling or joint-upsampling layer.
We empirically validate the performance of DDF bydrop-in replacing convolution layers in several classifica-tion networks with DDF. Experiments indicate that apply-ing DDF consistently boosts the performance while reduc-ing computational costs. In addition, we also demonstratethe superior upsampling performance of DDF-Up in objectdetection and joint upsampling networks. In summary, DDFand DDF-Up have the following favorable properties:
• Content-adaptive. DDF provides spatially-varying fil-tering that makes filters adaptive to image contents.
• Fast runtime. DDF has similar computational costs asdepth-wise convolution, so its inference speed is fasterthan both standard convolution and dynamic filters.
• Smaller memory footprint. DDF significantly reducesmemory consumption of dynamic filters, making it pos-sible to replace all standard convolution layers with DDF.
• Consistent performance improvements. Replacing astandard convolution with DDF / DDF-Up results in con-sistent improvements and achieves the state-of-the-artperformance across various networks and tasks.
2. Related Work
Lightweight convolutions. Given the prominence of con-volutions in CNN architectures, several lightweight vari-ants have been proposed for different purposes. Dilatedconvolutions [4, 56] increase the receptive field of the fil-ter without increasing parameters or computation complex-ity of the standard convolution. Several lightweight mobilenetworks [17, 39, 16] use depth-wise convolutions insteadof standard ones, which separately convolve each channel.Similarly, grouped convolutions [26] group input channelsand convolve each group separately resulting in parameterand computation reduction. However, directly replacing astandard convolution with depth-wise or grouped convo-lutions usually leads to performance drops. One needs towiden the model to achieve competitive performance withthese lightweight variants of convolution. In contrast, theproposed DDF layer can be directly used as a lightweightdrop-in replacement to standard convolution layer.
Dynamic filters. For the dynamic filters, the filter neigh-borhoods and/or filter values are dynamically modified orpredicted based on the input features. Some recent ap-proaches dynamically adjust the filter neighborhoods byadaptive dilation factors [58], estimating the neighborhoodsampling grid [8], or adapting the receptive fields [43]. An-other kind of dynamic filters, more closely related to ourwork, adjusts or predicts filter values based on input features[55, 59, 5, 23, 48, 42, 57, 49, 45, 22]. In particular, semi-dynamic filters, such as WeightNet [34], CondConv [55],DyNet [59], and DynamicConv [5], predict coefficientsto combine several expert filters. The combined filter isstill applied in a convolutional manner (spatially shared).CARAFE [48] proposes a dynamic layer for upsampling,where an additional network branch is used to predict a 2Dfilter at each pixel. However, these channel-wise shared 2Dfilters cannot encode channel-specific information. Severalfull dynamic filters [23, 57, 49, 45] use separate networkbranches to predict a complete filter at each pixel. As illus-trated in Figure 2 (middle) and briefly explained in the In-troduction, these dynamic filters can only replace a few con-volution layers or can only be used in small networks due tocomputational reasons. Specifically, adaptive convolutional

(a) Decoupled Dynamic Filter Operation (DDF Op). (b) Decoupled Dynamic Filter Module (DDF Module).
Figure 2. Illustration of the DDF operation and the DDF module. The orange color denotes spatial dynamic filters / branch, and thegreen color denotes channel dynamic filters / branch. The filter application means applying the convolution operation at a single position.‘GAP’ means the global average pooling and ‘FC’ denotes the fully connected layer.
kernels [57] are only used in small networks. SOLOv2 [49]and CondInst [45] employ dynamic filters in the last fewlayers of the segmentation model. PAC [42] uses a fixedGaussian kernel on adapting features to modify the standardconvolution filter at each pixel, which is also impractical forlarge architectures due to high memory consumption. Theproposed DDF is lightweight even compared with the stan-dard convolution layer and thus can be used across all thelayers even in large networks.Attention mechanisms. Inspired by the role of attentionin human visual perception [21, 38, 7, 50], several ap-proaches [54, 47, 46, 18, 36, 50] propose to use atten-tion layers that dynamically enhance/suppress feature val-ues with predicted attention maps. SMemVQA [54] gen-erates question-guided spatial attention to capture the cor-respondence between individual words in the question andimage regions. The residual attention network [47] adoptsencoder-decoder branches to model spatial attention and re-fine features. VSGNet [46] leverages the spatial configu-ration of human-object pairs to model attention. Besidesspatial attention, SENet [18] introduces the squeeze-and-excitation structure to encode channel-wise attention and re-weights the feature channels. Subsequent methods combinespatial and channel-wise attention. BAM [36] uses spatialand channel-wise attention in parallel, whereas CBAM [50]sequentially applies spatial and channel-wise attention. Inthis work, we draw connections between dynamic filters andattention layers. Inspired by spatial and channel-wise at-tention, we propose DDF that uses decoupled spatial andchannel dynamic filters.
3. PreliminariesStandard convolution. Given an input feature representa-tion F ∈ Rc×n with c channels and n pixels (n = h × w,h and w are the width and height of the feature map); thestandard convolution operation at ith pixel can be written as
a linear combination of input features around ith pixel:F ′(.,i) =
∑j∈Ω(i)
W [pi − pj ]F(.,j) + b, (1)
where F(.,j) ∈ Rc denotes the feature vector at jth pixel;F ′ ∈ Rc′×n denotes output feature map with F ′(.,i) ∈ Rc′
denoting ith pixel output feature vector. Ω(i) denotesthe k × k convolution window around ith pixel. W ∈Rc′×c×k×k is a k × k convolution filter, W [pi − pj ] ∈Rc′×c is the filter at position offset between i and jth pix-els: [pi − pj ] ∈ (− (k−1)
2 ,− (k−1)2 ), (− (k−1)
2 ,− (k−1)2 +
1), ..., ( (k−1)2 , (k−1)
2 ) where pi denotes 2D pixel coordi-nates. b ∈ Rc′ denotes the bias vector. In standard convo-lution, the same filterW is shared across all pixels and filterweights are agnostic to input features.Dynamic filters. In contrast to standard convolution, dy-namic filters leverage separate network branches to gener-ate the filter at each pixel. The spatially-invariant filterW inEq. 1 becomes the spatially-varying filter Di ∈ Rc′×c×k×k
in this case. The dynamic filters enable learning content-adaptive and flexible feature embeddings. However, pre-dicting such a large number (nc′ck2) of pixel-wise filtervalues requires heavy side-networks, resulting in both com-pute and memory intensive network architectures. Thus,dynamic filters are usually only employed in either tiny net-works [23, 57] or can only replace a few standard convolu-tion layers [49, 45, 42, 22] in a CNN.
4. Decoupled Dynamic FilterThe goal of this work is to design a filtering operation
that is content-adaptive while being lighter-weight than astandard convolution. Realizing both the properties with asingle filter is quite challenging. We accomplish this withour Decoupled Dynamic Filter (DDF), where the key tech-nique is to decouple dynamic filters into spatial and channelones. More formally, the DDF operation can be written as:

Figure 3. Connection between dynamic filters and attention.The dynamic filter is similar to applying attention on the unfoldedfeature.
F ′(r,i) =∑
j∈Ω(i)
Dspi [pi − pj ]D
chr [pi − pj ]F(r,j), (2)
where F ′(r,i) ∈ R denotes the output feature value at theith pixel and rth channel, F(r,j) ∈ R denotes the input fea-ture value at the jth pixel and rth channel. Dsp ∈ Rn×k×k
is the spatial dynamic filter with Dspi ∈ Rk×k denoting the
filter at ith pixel. Dch ∈ Rc×k×k is the channel dynamicfilter with Dch
r ∈ Rk×k denoting the filter at rth channel.Figure 2(a) shows the illustration of DDF operation. Wepredict both channel and spatial dynamic filters from the in-put feature, using which we perform the above DDF opera-tion (Eq. 2) to compute the output feature map. Comparinggeneral dynamic filters (See Section 3) with DDF clearlyindicates that DDF reduces the nc′ck2 sized dynamic filterinto much smaller nk2 spatial and ck2 channel dynamic fil-ters. In addition, we implement DDF operation in CUDAalleviating any need to save intermediate multiplied filtersduring network training and inference.
DDF module. Based on DDF operation, we carefully de-sign a DDF module that can act as a basic building block inCNNs. For that, we want the filter prediction branches to belightweight as well in addition to the DDF operation itself.We notice the connection between dynamic filters and at-tention mechanisms, using which we design attention-stylebranches to predict spatial and channel filters. Figure 3 il-lustrates the connection between dynamic filters and atten-tion. Applying dynamic filters on a feature map is equiva-lent to applying attention on unfolded features. That is, weunfold the F ∈ c×n feature map into Fu ∈ c×n×k2 fea-ture map where neighboring feature values are unfolded asseparate channels. Applying dynamic filters on the originalfeature map F is the same as re-weighting the unfolded fea-ture map Fu using the generated filter tensor as attention.
Following the recent advances in attention literature [36,50] that propose to use lightweight branches to predict spa-tial and channel-wise attention, we design two attention-style branches that can generate spatial and channel dy-namic filters for DDF. Figure 2(b) illustrates the structureof spatial and channel filter branches in the DDF module.The spatial filter branch only contains one 1 × 1 convolu-tion layer. The channel filter branch first applies the globalaverage pooling to aggregate input features, then generates
channel dynamic filters via a squeeze-and-excitation struc-ture [18], where the squeeze ratio is denoted as σ ∈ R+.
As generated filter values can be extremely large or smallfor some input features, directly using them for convolutionwill make the training unstable. So, we propose to do filternormalization (FN):
Dspi = αsp D
spi − µ(Dsp
i )
δ(Dspi )
+ βsp
Dchr = αch
r
Dchr − µ(Dch
r )
δ(Dchr )
+ βchr ,
(3)
where Dshi , Dch
r ∈ Rk×k are the generated spatial andchannel filters before normalization, µ(·) and δ(·) cal-culate the mean and standard deviation of the filter,αsp, αch
r , βsp, βch
r are the running standard deviation andmean values which are similar to those coefficients in thebatch normalization (BN) [20]. FN can limit generated fil-ter values into a reasonable range, thereby avoiding the gra-dient vanishing/exploding during training.
4.1. Computational Complexity.
Table 1 shows the parameter, space and time complexitycomparisons between standard convolution (Conv), Depth-wise convolution (DwConv), full dynamic filters (DyFil-ter) [23, 57, 49, 45], and our DDF filter. For analysis, we usethe same notation as before - n : Number of pixels; c: Chan-nel number; k : Filter size (spatial extent); σ : Squeeze ratioin DDF channel filter branch. For simplicity, we assumethat both input and output features have c channels. Wealso assume that DyFilter adopts a lightweight filter predic-tion branch with a single 1× 1 convolution layer.Number of parameters. The prediction branch of DyFiltertakes c channel features as input and produces c2k2 channeloutput, where each pixel output corresponds to a completefilter at that pixel. Thus, the DyFilter prediction branch hasc3k2 parameters, which is quite high even for small valuesof c. For DDF, the spatial filter branch predicts filter ten-sors with k2 channels and thus contain ck2 parameters. Thechannel filter branch has σc2 parameters for the squeezelayer, and σc2k2 parameters for the excitation layer. In to-tal, DDF prediction branches contain ck2 + σc2(1 + k2)parameters, which is far fewer than those for DyFilter. De-pending on the values of σ, k, and c (usually set to 0.2, 3,and 256), the number of parameters for the DDF modulecan be even lower than a standard convolution layer.Time complexity. The spatial filter generation of DDFneeds 2nck2 floating-point operations (FLOPs), and thechannel filter generation takes 2σc2(1 + k2) FLOPs. Thefilter combination and application needs 3nck2 FLOPs. Intotal, DDF needs 5nck2 + 2σc2(1 + k2) FLOPs with timecomplexity of O(nck2 + c2k2). The term c2k2 can be ig-nored since n >> c, k. Thus, the time complexity of DDF

Table 1. Comparison of the parameter number and computa-tional costs. ‘Params’ means the number of parameters, ‘Time’represents the time complexity, ‘Space’ denotes the space com-plexity of generated filters.
Filter Conv DwConv DyFilter DDF
Params c2k2 ck2 c3k2 ck2 + σc2(1 + k2)Time O(nc2k2) O(nck2) O(nc3k2) O(nck2 + c2k2)Space – – O(nc2k2) O((n+ c)k2)
Table 2. Comparison of the inference latency and the max allo-cated memory. The size of the input feature is set to 2 × 256 ×200× 300, which is the common size of the P1 layer in FPN [30].The guidance feature size of PAC is the same as the input one.
Filter Conv DwConv PAC DDF
Memory 356.3M 236.0M 3406.4M 245.7MLatency 7.5 ms 1.0 ms 46.4 ms 3.0 ms
approximately equals toO(nck2), which is similar to that ofdepth-wise convolution and better than a standard convolu-tion with time complexity of O(nc2k2). The time complex-ity of DyFilter is O(nc3k2), with 2nc3k2 FLOPs for filtergeneration and 2nc2k2 FLOPs for filter application. Thusthe time complexity of DyFilter is almost c2 times higherthan that of DDF, which is quite significant. Table 2 com-pares the inference time between four kinds of filters, wherewe adopt PAC [42] as the representative of dynamic filters.Refer to the supplementary for more latency comparisonson different input sizes.Space/Memory complexity. Table 1 also compares thespace complexity of generated filters. Standard and depth-wise convolutions do not generate content-adaptive filters.DyFilter generates a complete filter at each pixel with aspace complexity of O(nc2k2). DDF has a much smallerspace complexity of O((n + c)k2), since it only needs tostore 2d spatial filters with nk2 (shared by channels) andchannel filters with ck2. See Table 2 for the comparison ofthe max allocated memory between four kinds of filters.
In summary, DDF has a time complexity that is simi-lar to depth-wise convolution, which is considerably betterthan a standard convolution or dynamic filter. Remarkably,despite generating content-adaptive filters, the number ofparameters in a DDF module is still smaller than that of astandard convolution layer. The space complexity of DDFcan be hundreds or even thousands of times smaller than fulldynamic filters, when c or n are in the orders of hundredswhich is quite common in practice.
5. DDF Networks for Image ClassificationImage classification is considered as a fundamental task
in computer vision. To demonstrate the use of DDFs asbasic building blocks in a CNN, we experiment with thewidely used ResNet [15] architecture for image classifi-cation. ResNets stack multiple basic/bottleneck blocks in
Figure 4. Structure of the DDF bottleneck block. We replace the3× 3 convolution layer with DDF and keep the original hyperpa-rameters, especially using the same number of channels.
which 3 × 3 convolution layers are adopted for spatial em-bedding. We substitute these 3 × 3 convolution layers inall stacked blocks with DDF. We refer to such a modifiedResNet with DDF as ‘DDF-ResNet’. Figure 4 illustratesthe use of DDF in a ResNet bottleneck block, we refer to itas DDF bottleneck block.
We evaluate DDF-ResNets on the ImageNet dataset [10]with the Top-1 and Top-5 accuracy. DDF-ResNets aretrained using the same training protocol as [27]. In partic-ular, we train models for 120 epochs by the SGD optimizerwith the momentum of 0.9 and the weight decay of 1e-4.The learning rate is set to 0.1 with batch size 256 and de-cays to 1e-5 following the cosine schedule. The input imageis resized and center-cropped to 224× 224.Ablation study. We comprehensively analyze the effectof different components in a DDF module. We chooseResNet50 [15] as our base network architecture and exper-iment with different modifications to DDF. Table 3 showsthe results of ablation experiments. First, we analyze theeffect of spatial and channel dynamic filters in DDF withclassification accuracy. Table 3(a) shows there is a signif-icant drop in performance when we replace convolutionswith only spatial dynamic filters. This is expected as spatialdynamic filters are shared by all channels, thus cannot en-code channel-specific information. By replacing the convo-lution with the channel dynamic filters, the top-1 accuracyis improved by 1.6%. Using the full DDF module, with bothspatial and channel dynamic filters, improves the top-1 ac-curacy by 1.9%. These results show the importance of boththe spatial and channel dynamic filters in DDF.
Table 3(b) compares different normalization schemes ina DDF module. Replacing the proposed filter normalizationwith a standard batch normalization [20] or a sigmoid ac-tivation leads to considerable drops in accuracy. Sigmoidactivation individually processes each filter value and maynot capture the correlation between them, while batch nor-malization considers all the filters in a batch, which mayweaken the filter dynamics across samples.
We also evaluate DDF under different squeeze ratios σ,which is used to control the feature channel compressionin the channel filter branch. As shown in table 3(c), usinghigher squeeze ratios will significantly increase the numberof parameters, while only bringing marginal performanceimprovements. Hence, we set the squeeze ratio to 0.2 by
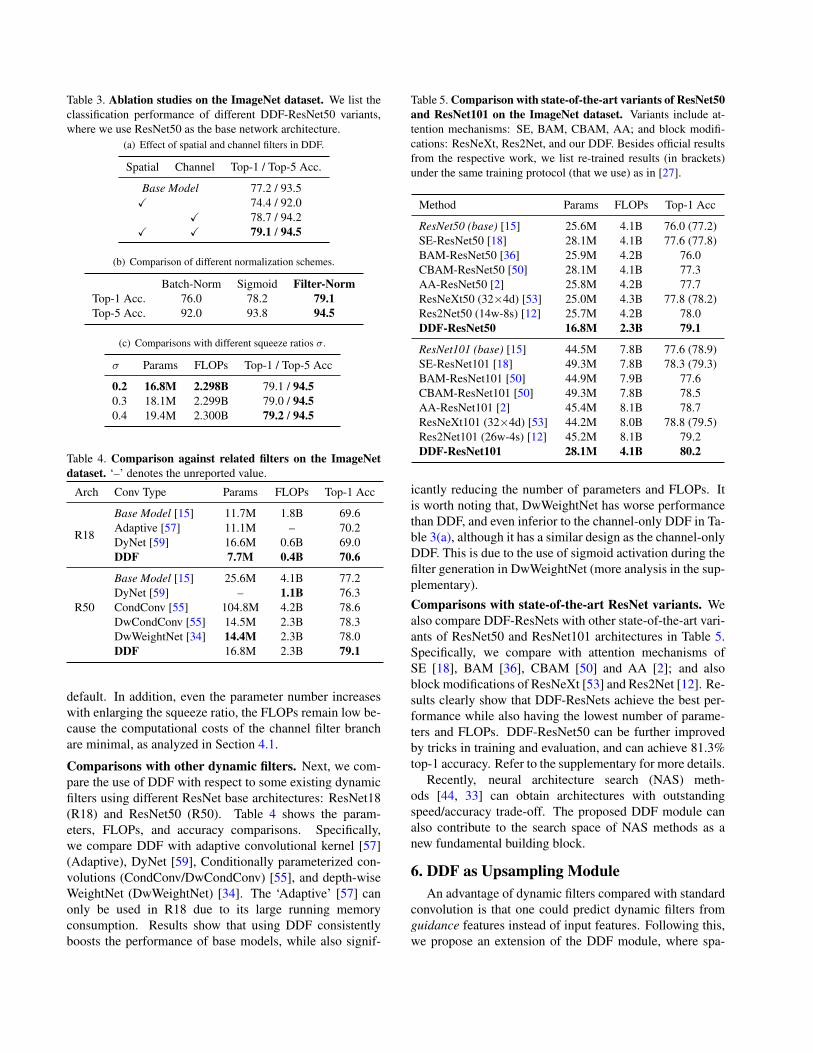
Table 3. Ablation studies on the ImageNet dataset. We list theclassification performance of different DDF-ResNet50 variants,where we use ResNet50 as the base network architecture.
(a) Effect of spatial and channel filters in DDF.
Spatial Channel Top-1 / Top-5 Acc.
Base Model 77.2 / 93.5X 74.4 / 92.0
X 78.7 / 94.2X X 79.1 / 94.5
(b) Comparison of different normalization schemes.
Batch-Norm Sigmoid Filter-NormTop-1 Acc. 76.0 78.2 79.1Top-5 Acc. 92.0 93.8 94.5
(c) Comparisons with different squeeze ratios σ.
σ Params FLOPs Top-1 / Top-5 Acc
0.2 16.8M 2.298B 79.1 / 94.50.3 18.1M 2.299B 79.0 / 94.50.4 19.4M 2.300B 79.2 / 94.5
Table 4. Comparison against related filters on the ImageNetdataset. ‘–’ denotes the unreported value.
Arch Conv Type Params FLOPs Top-1 Acc
R18
Base Model [15] 11.7M 1.8B 69.6Adaptive [57] 11.1M – 70.2DyNet [59] 16.6M 0.6B 69.0DDF 7.7M 0.4B 70.6
R50
Base Model [15] 25.6M 4.1B 77.2DyNet [59] – 1.1B 76.3CondConv [55] 104.8M 4.2B 78.6DwCondConv [55] 14.5M 2.3B 78.3DwWeightNet [34] 14.4M 2.3B 78.0DDF 16.8M 2.3B 79.1
default. In addition, even the parameter number increaseswith enlarging the squeeze ratio, the FLOPs remain low be-cause the computational costs of the channel filter branchare minimal, as analyzed in Section 4.1.
Comparisons with other dynamic filters. Next, we com-pare the use of DDF with respect to some existing dynamicfilters using different ResNet base architectures: ResNet18(R18) and ResNet50 (R50). Table 4 shows the param-eters, FLOPs, and accuracy comparisons. Specifically,we compare DDF with adaptive convolutional kernel [57](Adaptive), DyNet [59], Conditionally parameterized con-volutions (CondConv/DwCondConv) [55], and depth-wiseWeightNet (DwWeightNet) [34]. The ‘Adaptive’ [57] canonly be used in R18 due to its large running memoryconsumption. Results show that using DDF consistentlyboosts the performance of base models, while also signif-
Table 5. Comparison with state-of-the-art variants of ResNet50and ResNet101 on the ImageNet dataset. Variants include at-tention mechanisms: SE, BAM, CBAM, AA; and block modifi-cations: ResNeXt, Res2Net, and our DDF. Besides official resultsfrom the respective work, we list re-trained results (in brackets)under the same training protocol (that we use) as in [27].
Method Params FLOPs Top-1 Acc
ResNet50 (base) [15] 25.6M 4.1B 76.0 (77.2)SE-ResNet50 [18] 28.1M 4.1B 77.6 (77.8)BAM-ResNet50 [36] 25.9M 4.2B 76.0CBAM-ResNet50 [50] 28.1M 4.1B 77.3AA-ResNet50 [2] 25.8M 4.2B 77.7ResNeXt50 (32×4d) [53] 25.0M 4.3B 77.8 (78.2)Res2Net50 (14w-8s) [12] 25.7M 4.2B 78.0DDF-ResNet50 16.8M 2.3B 79.1
ResNet101 (base) [15] 44.5M 7.8B 77.6 (78.9)SE-ResNet101 [18] 49.3M 7.8B 78.3 (79.3)BAM-ResNet101 [50] 44.9M 7.9B 77.6CBAM-ResNet101 [50] 49.3M 7.8B 78.5AA-ResNet101 [2] 45.4M 8.1B 78.7ResNeXt101 (32×4d) [53] 44.2M 8.0B 78.8 (79.5)Res2Net101 (26w-4s) [12] 45.2M 8.1B 79.2DDF-ResNet101 28.1M 4.1B 80.2
icantly reducing the number of parameters and FLOPs. Itis worth noting that, DwWeightNet has worse performancethan DDF, and even inferior to the channel-only DDF in Ta-ble 3(a), although it has a similar design as the channel-onlyDDF. This is due to the use of sigmoid activation during thefilter generation in DwWeightNet (more analysis in the sup-plementary).Comparisons with state-of-the-art ResNet variants. Wealso compare DDF-ResNets with other state-of-the-art vari-ants of ResNet50 and ResNet101 architectures in Table 5.Specifically, we compare with attention mechanisms ofSE [18], BAM [36], CBAM [50] and AA [2]; and alsoblock modifications of ResNeXt [53] and Res2Net [12]. Re-sults clearly show that DDF-ResNets achieve the best per-formance while also having the lowest number of parame-ters and FLOPs. DDF-ResNet50 can be further improvedby tricks in training and evaluation, and can achieve 81.3%top-1 accuracy. Refer to the supplementary for more details.
Recently, neural architecture search (NAS) meth-ods [44, 33] can obtain architectures with outstandingspeed/accuracy trade-off. The proposed DDF module canalso contribute to the search space of NAS methods as anew fundamental building block.
6. DDF as Upsampling ModuleAn advantage of dynamic filters compared with standard
convolution is that one could predict dynamic filters fromguidance features instead of input features. Following this,we propose an extension of the DDF module, where spa-

Figure 5. Structure of the DDF-Up module. When the upsam-pling scale factor is set to 2, the DDF-Up module contains 4branches. For typical upsampling, the guidance feature is pre-dicted from input features via a depth-wise convolution layer.
(a) FPN with DDF-Up.
(b) Joint upsampling with DDF-Up.
Figure 6. Applications of the DDF-Up module. DDF-Up can beseamlessly embedded into the top-down upsampling path in theFPN [30] network for object detection and the decoder part of ajoint upsampling architecture.
tial dynamic filters are predicted using separate guidancefeatures instead of input features. Such joint filtering withinput and guidance features is useful for several tasks suchas joint image upsampling [42, 28, 29], cross-modal imageenhancement [51, 9, 6], texture removal [32] to name a few.Figure 5 illustrates the DDF Upsampling (DDF-Up) mod-ule, where the number of DDF operations used is set to x2
for the upsampling factor x (e.g., 4 DDF operations whenthe upsampling factor is 2). We stack and pixel-shuffle [40]the resulting features from the DDF operations to form out-put features. For typical upsampling (without guidance), weuse the same structure with a slight modification. We com-pute guidance features from input ones using a depth-wiseconvolution layer. DDF-Up can be seamlessly integratedinto several existing CNNs, where typical/joint upsamplingoperators are needed. Here we present two applications in
Table 6. Comparison of different upsampling modules inFPN [30] on the COCO minival split. We show FLOPs (forupsampling modules) and mAp scores on small (mApS), medium(mApM ), large (mApL), and all-scale (mAp) objects.
Method FLOPs mApS mApM mApL mAp
Nearest (base) 0.00B 21.2 41.0 48.1 37.4Bilinear 0.02B 22.1 41.2 48.4 37.6Deconv [35] 12.57B 21.0 41.1 48.5 37.3P.S. [40] 50.18B 21.4 41.5 48.6 37.7CARAFE [48] 2.14B 22.6 42.0 49.8 38.5DDF-Up 0.58B 22.1 42.4 49.9 38.6
object detection and joint depth upsampling tasks.
Object detection with DDF-Up. Detecting objects in animage is one of the core dense prediction tasks in com-puter vision. We adopt FasterRCNN [37] with the FeaturePyramid Network (FPN) [30] as our base detection archi-tecture and embed DDF-Up modules into FPN. FPN is aneffective U-net shaped feature fusion module, where the de-coder pathway upsamples high-level features while combin-ing low-level ones. As illustrated in Figure 6(a), we replacethe nearest-neighbor upsampling modules in FPN with ourDDF-Up modules.
We analyze the effectiveness of DDF-Up modules withexperiments on the COCO detection benchmark [31] whichcontains 115K training and 5K validation images. We reportstandard COCO [31] metrics for small (mApS), medium(mApM ), large (mApL), and all-scale (mAp) objects onthe minival split. We implement our models based on theMMDetection [3] toolbox and train them using the stan-dard training protocol therein. Specifically, we train dif-ferent models for 12 epochs using the SGD optimizer witha momentum of 0.1 and the weight decay of 1e-4. We usea batch size of 16 and set the learning rate to 0.2 which de-cays by the factor of 0.1 at 8 and 11th epochs. We resize theshorter side of the input image to 800 pixels, while keepingthe longer side no larger than 1333 pixels.
We compare DDF-Up with the generic nearest-neighbor(Nearest) and bilinear (Bilinear) interpolations, as wellas learnable Deconvolution (Deconv) [35], Pixel Shuffle(P.S.) [40], and CARAFE [48] upsampling modules. Ta-ble 6 exhibits the comparison results. FPN with DDF-Upyields a 1.2% mAp improvement over the baseline whichadopts the nearest-neighbor interpolation. DDF-Up alsobrings obvious improvements against static-filtering upsam-pler (like Deconv and P.S.), and is on par with the recent dy-namic upsampling technique CARAFE while utilizing onlyone-third of FLOPs as CARAFE.
Joint depth upsampling with DDF-Up. We analyze theuse of DDF-Up as a joint upsampling module by integrat-ing it into a joint depth upsampling network. Here, the task

Input Guidance Bilinear PAC-Net [42] DDF-Up-Net (Ours) GTFigure 7. 16× joint depth sampling results on sample images. DDF-Up-Net recovers more depth details compared with PAC-Net [42]and other techniques.
is to upsample a low-resolution depth map given a higher-resolution RGB image as guidance. This experiment al-lows to compare DDF-Up with content-adaptive filteringtechniques such as Pixel-Adaptive Convolution (PAC) [42]which is a current state-of-the-art for this task. We use asimilar network architecture to PAC-Net [42], where weemploy our DDF-Up modules instead of PAC joint upsam-pling modules. We call the resulting network ‘DDF-Up-Net’. Figure 6(b) illustrates DDF-Up-Net where we firstencode low-resolution input features from the given depthmap (X) and high-resolution guidance features (G) fromRGB images. Then, we employ DDF-Up in the decoderto joint upsample depth features with guidance features andobtain high-resolution depth output (Xup). Each DDF-Upmodule does 2× upsampling, we sequentially use k DDF-Up modules when the upsampling factor is 2k.
We conduct experiments on the NYU depth V2dataset [41] which has 1449 RGB-depth pairs. Follow-ing PAC-Net [42], we use the nearest-neighbor downsam-pling to generate low-resolution inputs from the ground-truth (GT) depth maps. We split the first 1000 samples fortraining and the rest for testing. We train DDF-Up-Net for1500 epochs using the Adam optimizer [24]. We use a batchsize of 8 and set the learning rate to 1e-4 which decays bythe factor 0.1 at 1000 and 1350th epochs. During train-ing, the input images are resized and random-cropped to256× 256.
Table 7 reports Root Mean Square Error (RMSE) scoresof different techniques for three upsampling factors, i.e.,4×, 8×, and 16×. DDF-Up-Net performs better thanstate-of-the-art techniques across all the upsampling factors.It surpasses the standard CNN techniques like DJF [28]and DJF+ [29] by a large margin. It also improves overdynamic-filtering PAC [42] while reducing computationalcosts by an order of magnitude. See Table 2 for the costcomparison between PAC and DDF-Up. We visualize sam-pled 16× upsampling results in Figure 7, where we can seethat DDF-Up-Net recovers more details compared to PAC-Net and other techniques.
Table 7. Joint depth upsampling results on the NYU Depth V2dataset. We exhibit RMSE results (in the order of 10−2, lower isbetter) of different techniques and different upsampling factors.
Method 4× 8× 16×
Bicubic 8.16 14.22 22.32MRF (32×4d) 7.84 13.98 22.20GF [14] 7.32 13.62 22.03Ham et al. [13] 5.27 12.31 19.24FBS [1] 4.29 8.94 14.59JBU [25] 4.07 8.29 13.35DMSG [19] 3.78 6.37 11.16DJF [28] 3.54 6.20 10.21DJF+ [29] 3.38 5.86 10.11PAC-Net [42] 2.39 4.59 8.09DDF-Up-Net 2.16 4.40 7.72
7. Conclusion
In this work, we propose a lightweight content-adaptivefiltering technique called DDF, where our key strategy isto predict decoupled spatial and channel dynamic filters.We show that DDF can seamlessly replace standard con-volution layers, consistently improving the performance ofResNets while also reducing model parameters and compu-tational costs. In addition, we propose an upsampling vari-ant called DDF-Up, which boosts performance as both ageneral upsampling module in detection and a joint upsam-pling module in joint depth upsampling. DDF-Up also ismore computationally efficient compared with specializedcontent-adaptive layers. Overall, DDF has rich representa-tive capabilities as a content-adaptive filter while also beingcomputationally cheaper than a standard convolution, mak-ing it highly practical to use in modern CNNs.
8. AcknowledgementThis work is supported in part by the National Natural
Science Foundation of China (No.61976094). M.-H. Yangis supported in part by NSF CAREER 1149783.

References[1] Jonathan T Barron and Ben Poole. The fast bilateral solver.
In ECCV, 2016. 8[2] Irwan Bello, Barret Zoph, Ashish Vaswani, Jonathon Shlens,
and Quoc V Le. Attention augmented convolutional net-works. In ICCV, 2019. 6
[3] Kai Chen, Jiaqi Wang, Jiangmiao Pang, Yuhang Cao, YuXiong, Xiaoxiao Li, Shuyang Sun, Wansen Feng, Ziwei Liu,Jiarui Xu, Zheng Zhang, Dazhi Cheng, Chenchen Zhu, Tian-heng Cheng, Qijie Zhao, Buyu Li, Xin Lu, Rui Zhu, Yue Wu,Jifeng Dai, Jingdong Wang, Jianping Shi, Wanli Ouyang,Chen Change Loy, and Dahua Lin. MMDetection: Openmmlab detection toolbox and benchmark. arXiv preprintarXiv:1906.07155, 2019. 7
[4] Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos,Kevin Murphy, and Alan L Yuille. Deeplab: Semantic imagesegmentation with deep convolutional nets, atrous convolu-tion, and fully connected crfs. IEEE Transactions on PatternAnalysis and Machine Intelligence, 40(4):834–848, 2017. 2
[5] Yinpeng Chen, Xiyang Dai, Mengchen Liu, DongdongChen, Lu Yuan, and Zicheng Liu. Dynamic convolution: At-tention over convolution kernels. In CVPR, 2020. 2
[6] Yukyung Choi, Namil Kim, Soonmin Hwang, Kibaek Park,Jae Shin Yoon, Kyounghwan An, and In So Kweon. Kaistmulti-spectral day/night data set for autonomous and assisteddriving. IEEE Transactions on Intelligent TransportationSystems, 2018. 7
[7] Maurizio Corbetta and Gordon L Shulman. Control of goal-directed and stimulus-driven attention in the brain. NatureReviews Neuroscience, 2002. 3
[8] Jifeng Dai, Haozhi Qi, Yuwen Xiong, Yi Li, GuodongZhang, Han Hu, and Yichen Wei. Deformable convolutionalnetworks. In ICCV, 2017. 2
[9] Pingyang Dai, Rongrong Ji, Haibin Wang, Qiong Wu, andYuyu Huang. Cross-modality person re-identification withgenerative adversarial training. In IJCAI, 2018. 7
[10] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li,and Li Fei-Fei. Imagenet: A large-scale hierarchical imagedatabase. In CVPR, 2009. 5
[11] Raghudeep Gadde, Varun Jampani, Martin Kiefel, DanielKappler, and Peter V Gehler. Superpixel convolutional net-works using bilateral inceptions. In ECCV, 2016. 1
[12] Shanghua Gao, Ming-Ming Cheng, Kai Zhao, Xin-YuZhang, Ming-Hsuan Yang, and Philip HS Torr. Res2net: Anew multi-scale backbone architecture. IEEE Transactionson Pattern Analysis and Machine Intelligence, 2019. 6
[13] Bumsub Ham, Minsu Cho, and Jean Ponce. Robust imagefiltering using joint static and dynamic guidance. In CVPR,2015. 8
[14] Kaiming He, Jian Sun, and Xiaoou Tang. Guided image fil-tering. In ECCV, 2010. 8
[15] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun.Deep residual learning for image recognition. In CVPR,2016. 5, 6
[16] Andrew Howard, Mark Sandler, Grace Chu, Liang-ChiehChen, Bo Chen, Mingxing Tan, Weijun Wang, Yukun Zhu,
Ruoming Pang, Vijay Vasudevan, et al. Searching for mo-bilenetv3. In ICCV, 2019. 2
[17] Andrew G Howard, Menglong Zhu, Bo Chen, DmitryKalenichenko, Weijun Wang, Tobias Weyand, Marco An-dreetto, and Hartwig Adam. Mobilenets: Efficient convolu-tional neural networks for mobile vision applications. arXivpreprint arXiv:1704.04861, 2017. 2
[18] Jie Hu, Li Shen, and Gang Sun. Squeeze-and-excitation net-works. In CVPR, 2018. 3, 4, 6
[19] Tak-Wai Hui, Chen Change Loy, and Xiaoou Tang. Depthmap super-resolution by deep multi-scale guidance. InECCV, 2016. 8
[20] Sergey Ioffe and Christian Szegedy. Batch normalization:Accelerating deep network training by reducing internal co-variate shift. ICML, 2015. 4, 5
[21] Laurent Itti, Christof Koch, and Ernst Niebur. A modelof saliency-based visual attention for rapid scene analysis.IEEE Transactions on Pattern Analysis and Machine Intelli-gence, 1998. 3
[22] Varun Jampani, Martin Kiefel, and Peter V Gehler. Learningsparse high dimensional filters: Image filtering, dense crfsand bilateral neural networks. In CVPR, pages 4452–4461,2016. 1, 2, 3
[23] Xu Jia, Bert De Brabandere, Tinne Tuytelaars, and Luc VGool. Dynamic filter networks. In NeurIPS, 2016. 1, 2, 3, 4
[24] Diederik P Kingma and Jimmy Ba. Adam: A method forstochastic optimization. ICLR, 2015. 8
[25] Johannes Kopf, Michael F Cohen, Dani Lischinski, and MattUyttendaele. Joint bilateral upsampling. ACM Transactionson Graphics, 2007. 8
[26] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton.Imagenet classification with deep convolutional neural net-works. In NeurIPS, 2012. 2
[27] Duo Li, Anbang Yao, and Qifeng Chen. Psconv: Squeezingfeature pyramid into one compact poly-scale convolutionallayer. In ECCV, 2020. 5, 6
[28] Yijun Li, Jia-Bin Huang, Narendra Ahuja, and Ming-HsuanYang. Deep joint image filtering. In ECCV, 2016. 7, 8
[29] Yijun Li, Jia-Bin Huang, Narendra Ahuja, and Ming-HsuanYang. Joint image filtering with deep convolutional net-works. IEEE Transactions on Pattern Analysis and MachineIntelligence, 2019. 7, 8
[30] Tsung-Yi Lin, Piotr Dollar, Ross Girshick, Kaiming He,Bharath Hariharan, and Serge Belongie. Feature pyramidnetworks for object detection. In CVPR, 2017. 5, 7
[31] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays,Pietro Perona, Deva Ramanan, Piotr Dollar, and C LawrenceZitnick. Microsoft coco: Common objects in context. InECCV, 2014. 7
[32] Feng Liu and Michael Gleicher. Texture-consistent shadowremoval. In ECCV, 2008. 7
[33] Hanxiao Liu, Karen Simonyan, and Yiming Yang. Darts:Differentiable architecture search. ICLR, 2019. 6
[34] Ningning Ma, Xiangyu Zhang, Jiawei Huang, and Jian Sun.Weightnet: Revisiting the design space of weight networks.In ECCV, 2020. 2, 6

[35] Hyeonwoo Noh, Seunghoon Hong, and Bohyung Han.Learning deconvolution network for semantic segmentation.In ICCV, 2015. 7
[36] Jongchan Park, Sanghyun Woo, Joon-Young Lee, and In SoKweon. Bam: Bottleneck attention module. BMVC, 2018.2, 3, 4, 6
[37] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun.Faster r-cnn: Towards real-time object detection with regionproposal networks. In NeurIPS, 2015. 7
[38] Ronald A. Rensink. The dynamic representation of scenes.Visual Cognition, 2000. 3
[39] Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zh-moginov, and Liang-Chieh Chen. Mobilenetv2: Invertedresiduals and linear bottlenecks. In CVPR, 2018. 2
[40] Wenzhe Shi, Jose Caballero, Ferenc Huszar, Johannes Totz,Andrew P Aitken, Rob Bishop, Daniel Rueckert, and ZehanWang. Real-time single image and video super-resolutionusing an efficient sub-pixel convolutional neural network. InCVPR, 2016. 7
[41] Nathan Silberman, Derek Hoiem, Pushmeet Kohli, and RobFergus. Indoor segmentation and support inference fromrgbd images. In ECCV, 2012. 8
[42] Hang Su, Varun Jampani, Deqing Sun, Orazio Gallo, ErikLearned-Miller, and Jan Kautz. Pixel-adaptive convolutionalneural networks. In CVPR, 2019. 1, 2, 3, 5, 7, 8
[43] Domen Tabernik, Matej Kristan, and Ales Leonardis.Spatially-adaptive filter units for compact and efficient deepneural networks. International Journal of Computer Vision,2020. 2
[44] Mingxing Tan, Bo Chen, Ruoming Pang, Vijay Vasudevan,Mark Sandler, Andrew Howard, and Quoc V Le. Mnas-net: Platform-aware neural architecture search for mobile.In CVPR, 2019. 6
[45] Zhi Tian, Chunhua Shen, and Hao Chen. Conditional convo-lutions for instance segmentation. In ECCV, 2020. 1, 2, 3,4
[46] Oytun Ulutan, ASM Iftekhar, and Bangalore S Manjunath.Vsgnet: Spatial attention network for detecting human objectinteractions using graph convolutions. In CVPR, 2020. 3
[47] Fei Wang, Mengqing Jiang, Chen Qian, Shuo Yang, ChengLi, Honggang Zhang, Xiaogang Wang, and Xiaoou Tang.Residual attention network for image classification. InCVPR, 2017. 3
[48] Jiaqi Wang, Kai Chen, Rui Xu, Ziwei Liu, Chen Change Loy,and Dahua Lin. Carafe: Content-aware reassembly of fea-tures. In ICCV, 2019. 1, 2, 7
[49] Xinlong Wang, Rufeng Zhang, Tao Kong, Lei Li, and Chun-hua Shen. Solov2: Dynamic, faster and stronger. arXivpreprint arXiv:2003.10152, 2020. 1, 2, 3, 4
[50] Sanghyun Woo, Jongchan Park, Joon-Young Lee, and InSo Kweon. Cbam: Convolutional block attention module.In ECCV, 2018. 2, 3, 4, 6
[51] Ancong Wu, Wei-Shi Zheng, Hong-Xing Yu, ShaogangGong, and Jianhuang Lai. Rgb-infrared cross-modality per-son re-identification. In ICCV, 2017. 7
[52] Jialin Wu, Dai Li, Yu Yang, Chandrajit Bajaj, and XiangyangJi. Dynamic filtering with large sampling field for convnets.In ECCV, 2018. 1
[53] Saining Xie, Ross Girshick, Piotr Dollar, Zhuowen Tu, andKaiming He. Aggregated residual transformations for deepneural networks. In CVPR, 2017. 6
[54] Huijuan Xu and Kate Saenko. Ask, attend and answer: Ex-ploring question-guided spatial attention for visual questionanswering. In ECCV, 2016. 3
[55] Brandon Yang, Gabriel Bender, Quoc V Le, and JiquanNgiam. Condconv: Conditionally parameterized convolu-tions for efficient inference. In NeurIPS, 2019. 2, 6
[56] Fisher Yu and Vladlen Koltun. Multi-scale context aggrega-tion by dilated convolutions. ICLR, 2016. 2
[57] Julio Zamora Esquivel, Adan Cruz Vargas, PauloLopez Meyer, and Omesh Tickoo. Adaptive convolu-tional kernels. In ICCV Workshops, 2019. 1, 2, 3, 4,6
[58] Rui Zhang, Sheng Tang, Yongdong Zhang, Jintao Li, andShuicheng Yan. Scale-adaptive convolutions for scene pars-ing. In ICCV, 2017. 2
[59] Yikang Zhang, Jian Zhang, Qiang Wang, and Zhao Zhong.Dynet: Dynamic convolution for accelerating convolutionalneural networks. arXiv preprint arXiv:2004.10694, 2020. 2,6