csa3212: user-adaptive systems
DESCRIPTION
Dr. Christopher Staff Department of Intelligent Computer Systems University of Malta. CSA3212: User-Adaptive Systems. Topic 3: Information & Knowledge Representation. Aims and Objectives. - PowerPoint PPT PresentationTRANSCRIPT

University of Malta1 of 219
[email protected]: Topic 3© 2004- Chris Staff
Dr. Christopher StaffDepartment of Intelligent Computer Systems
University of Malta
Topic 3: Information & Knowledge Representation
CSA3212: User-Adaptive Systems

2 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Aims and Objectives
Adaptive Hypertext Systems need Hypertext, User Modelling, and Domain Modelling, and a mechanism for comparing the user model and the domain model General purpose AHSs tend to use IR
techniques to represent the domain ITSs frequently use deeper “semantic”
representations, eg, conceptual graphs

3 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Aims and Objectives
We informally introduce IR and hypertext, to compare their objectives, assumptions, similarities and differences
We’ll also talk about UM, and its relationship with IR and hypertext

4 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Aims and Objectives
Once we know what an UAS user’s interests are, we can find relevant information in the document collection Guide user along path Show relevant document to user Make recommendation to user Select next item in curriculum to teach

5 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Aims and Objectives
We’ll be looking at Objectives and Assumptions of Information
Retrieval, Hypertext, and User Modelling Data, Information, and Knowledge Information Retrieval (several models) Approaches to dealing with general knowledge Surface-based approaches to some types of
problem

University of Malta6 of 219
[email protected]: Topic 3© 2004- Chris Staff
Part I: Objectives and Assumptions of IR, HT, and UM

7 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Objectives of IR To represent documents in a collection To facilitate document retrieval from the
collection User query represents information need Matching algorithm compares user query to
document representations Matching documents presented as “relevant” Results may be ranked in order of relevance

8 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Spectrum of Indexing Methods

9 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Objectives of Hypertext A (not so new) reading system Represents an information space (typically
as a graph) Related information can be “linked” Users navigate through hyperspace by
traversing links Enables users to choose which path to
follow

10 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Assumptions of IR
The user can describe the information need The information need can be (sufficiently)
described using keywords/terms A document matching the query will be
suitable for the particular user (expert v novice)
A single document contains the information

11 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Assumptions of Hypertext
The user can find a relevant document by following links
Links will connect related information Related information is linked!

12 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
IR/Hypertext Similarities
Users can seek information IR: Query matching Hypertext (HT): Browsing
Collections of documents IR: Similar documents will have similar
representations (keywords)? HT: Similar documents will be linked?
NB: Doesn’t imply all linked docs are similar!

13 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
IR/Hypertext Differences User interaction:
HT: Follow link - most systems don’t directly support search
IR: Submit query - Most systems don’t directly support linking
Relevant info: IR: relevant info stored in single document HT: can be spread over multiple, linked
documents

14 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
IR/Hypertext Differences
Organisation: HT: graph (or network), in which related
documents are linked (at best) IR: (at best) clusters of similar documents, (at
worst) no organisation.

15 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
User Modelling Represent interesting “features of the user”
[Brusilovsky96] Used in many different domains Reference:
Kobsa, A. (1993). User Modeling: Recent Work, Prospects and Hazards, in M. Schneider-Hufschmidt, T. Kühme and U. Malinowski, eds. (1993): Adaptive User Interfaces: Principles and Practice. North-Holland, Amsterdam, 1993. (http://fit.gmd.de/~kobsa/papers/1993-aui-kobsa.pdf)
http://www.ics.uci.edu/~kobsa/

16 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
User Modelling
Many different ways of representing interests, goals, beliefs, preferences
However the user is modelled, the information that he/she can be given is only as good as the representation of the domain!

17 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Conclusion
Information Retrieval, Hypertext, and User Modelling underpin most general-purpose User Adaptive Systems
We’ve taken a look at the objectives, assumptions, similarities, and differences between IR and HT

University of Malta18 of 219
[email protected]: Topic 3© 2004- Chris Staff
Part II: Data, Information, Knowledge

19 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Background
We’ve briefly mentioned some of the user information that we might want to represent
We also need to be able to represent information about the domain so that we can reason about what the user’s interests are, etc.

20 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Background
In 1945, Vannevar Bush writes “As We May Think” Gives rise to seeking “intelligent” solutions to
information retrieval, etc. In 1949, Warren Weaver writes that if
Chinese is English + codification, then machine translation should be possible Leads to surface-based/statistical techniques

21 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Background
Even today, about 60 years later, there is significant effort in both directions
For years, intelligent solutions were hampered by the lack of fast enough hardware, software Doesn’t seem to be an issue any longer, and the
Semantic Web may be testimony to that But there are sceptics

22 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Background Take IR as an example
At the dumb end we have “reasonable” generic systems, but at other end, systems are domain specific, more expensive, but do they give “better” results?

23 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Background
If we assume that a user’s interests are known to an adaptive system…
… the adaptive system needs to know something about the domain to know how to adapt it sensibly
We will return to this later, but here we give an informal introduction

24 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Data, Information, and Knowledge
Data simple/complex structures Arbitrary sequences
“Chris”, 280963, “b47y3”
Information Data in Context
“Author’s name: Chris” “Boeing left wing Part no: b47y3”

25 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Data, Information, and Knowledge
Knowledge Knowing when to use information
“When ordering a replacement part, specify the part number and quantity required”

26 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Surface-based to Deep SemanticRepresentations Surface-based models tend to use data/information Deep semantic models tend to use knowledge Information retrieval systems (Extended/Boolean,
Statistical) “know” about term features within documents
Additionally, statistical models “know” the distribution of terms throughout the collection
Using NL statistics about the distribution of terms in language may give further information (not about terminology, though)

27 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Surface-based to Deep Semantic
“Dumb” IR systems can find documents containing “John”, “loves”, “Mary”, but cannot answer the question “Does John love Mary?” “John loves Mary” will miss “Mary is adored
by John”, “John cares deeply for Mary”, etc. Sometimes complex reasoning is also needed

28 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Surface-based to Deep Semantic
“Normal” hypertext (e.g., WWW) “knows” that some documents are linked
Lack of link semantics Why/for what reason have these documents
been linked? Can make assumptions
Can deduce link types (e.g., navigational, contextual, etc), but better if type was explicit

29 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Surface-based to Deep Semantic Semantic networks connect data nodes using typed
links (e.g., isa, part_of, …) Can do complex reasoning by examining
relationships between nodes If a hypertext had typed links, would it be a
semantic network? “Knowledge” and “information” are largely embedded
within unstructured text If exposed, then, potentially, a hypertext can be used to
represent and reason with information and knowledge

30 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Semantic Web
“The Semantic Web is an extension of the current web in which information is given well-defined
meaning, better enabling computers and people to work in cooperation.”
[Berners-Lee2001]
References: Tim Berners-Lee, James Hendler, Ora Lassila, The
Semantic Web, in Scientific American, May 2001 http://www.w3.org/2001/sw/

31 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Back to surface-based approaches
One of the challenges facing the Semantic Web is making the knowledge and information contained in existing Web pages explicit
Partly concerned with exposing relational data in textual documents
But also, opinions, beliefs, facts, …

32 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Background
At what point does it cease to be cost effective to attempt more intelligent solutions to the IR problem?

33 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Background Is “Information” Retrieval a misnomer?
Consider your favourite Web-based IR system... does it retrieve information?
Can you ask “Find me information about all flights between Malta and London”?
And what would you get back? Can you ask “Who was the first man on the
moon?”

34 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Background With many IR systems that we use, the
“intelligence” is firmly rooted in the user We must learn how to construct our queries so
that we get the information we seek We sift through relevant and non-relevant
documents in the results list What we can hope for is that “patterns” can
be identified to make life easier for us - e.g., recommender systems

35 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Background Surface-based techniques tend to look for and re-
use patterns as heuristics, without attempting to encode “meaning”
The Semantic Web, and other “intelligent” approaches, try to encode meaning so that it can be reasoned with and about
Cynics/sceptics/opponents believe that there is more success to be had in giving users more support, than to encode meaning into documents to support automation

36 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
However...
We will cover mostly surface-based and also some knowledge-based approaches to supporting the user in his or her task IR and IR techniques Dealing with General Knowledge

37 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Information Retrieval
We will discuss IR models... Boolean, Vector Space Model, Extended
Boolean, Phrase Matching, Probabilistic Model ... and surface-based techniques that can
improve their usability Relevance Feedback Query Reformulation

38 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Knowledge
Conceptual graphs support the encoding and matching of concepts
Conceptual graphs are more “intelligent” and can be used to overcome some problems like the Vocabulary Problem

University of Malta40 of 219
[email protected]: Topic 3© 2004- Chris Staff
Part III: Information Retrieval

41 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Aims and Objectives
Aims and objectives of IR Boolean, Extended Boolean, Vector Space,
Phrase Matching, Probabilistic models

42 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Aims and Objectives You should end up knowing the major
differences between various matching algorithms
And what each algorithm considers to be a relevant document…
Bear in mind that we will use IR in AHS to find information relevant to our user so that we can present it/lead the user to it…

43 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Aims and Objectives of IR
To facilitate the identification and retrieval of documents that contain information relevant to an information need expressed by a user
We are particularly interested in the retrieval of information from unstructured data

44 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Boolean Information Retrieval Developed in 1950’s A document is represented by a collection
of terms that occur in the document (index) The unique terms occurring in the collection
is called the vocabulary A document is represented by a bit
sequence with a 1 representing a term that is present, and 0 otherwise

45 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Boolean Information Retrieval
How is the query expressed? User thinks of terms that describe an
information need Formalises query as a boolean expression (Term27 OR Term46) NOT (Term30 AND
Term16)

46 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Boolean Information Retrieval
How does the matching algorithm work? Each term in the vocabulary has a set (or
postings list) of documents that contain the term
For each term in the query, the postings list is retrieved
Set operations (union/disjunction/intersection) All documents in the results set are returned

47 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Boolean Information Retrieval

48 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Does Boolean IR work?
Boolean IR is typically applied to a document surrogate
And is used with tremendous success in RDBMS
Most general purpose IR systems in use on the Internet are derived from BIR with some extensions…

49 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Does Boolean IR work? BIR works, and works well, when the vocabulary
is reasonably small… … when there is no ambiguity in the meaning of
terms … when the presence of a term in a document is
significant … when the absence of a term from a document
means that the document cannot be about that term

50 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Questions Arising…
Is this really information retrieval? Just because a document contains term x, does
it mean that the document is about term x? What about concepts?
What makes it possible for us to know that a fish cake is not a dessert? That “she is the apple of my eye” does not make her a piece of fruit?

51 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Questions Arising…
How can we tell that the IR system works?

52 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Precision and Recall An IR system “works” if it retrieves all
relevant documents and no non-relevant ones
What is relevance? How do we measure performance? Recall: %age of relevant docs retrieved Precision: %age of docs retrieved that are
relevant

53 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Boolean Model: Problems Blair & Maron, 1985, “An Evaluation of Retrieval
Effectiveness for a Full-Text Document-Retrieval System”
Death-knell for pure Boolean approach Evaluated IBM’s STorage And Information
Retrieval System (STAIRS) STAIRS used to index 40,000 legal documents
representing c. 350,000 pages of text
p289-blair.pdf

54 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Boolean Model: Problems
To retrieve all and only those documents that are relevant to a given request for information
Lawyers who made requests wanted at least 75% of relevant documents
Retrieval effectiveness discovered to be poor

55 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Boolean Model: Problems Lawyers would make request for information Paralegals familiar with case and trained to use
STAIRS would search for relevant documents Lawyers would rate docs “vital”, “satisfactory”,
“marginally relevant”, “irrelevant” Lawyers could modify query Iteration stops when lawyer signs that 75% of
relevant docs have been seen

56 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Boolean Model: Problems
Results: Precision on average 79.0% Recall on average only 20%!

57 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Boolean Model: Problems
Why? Mismatch between terminology used by
lawyers/paralegals and authors of documents Spelling mistakes in documents Use of slang and indirect reference

58 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Boolean Model: Problems The Vocabulary Problem
Furnas, et al, 1987, “The Vocabulary Problem in Human-System Communication”
“Armchair” naming of objects / concepts very inaccurate. Only c. 20% chance of two randomly selected people using the same name to refer to the same object/concept!
Implications for information retrieval Have you noticed this problem in Web-based IR
systems? Why doesn’t it seem to be a problem?
p964-furnas.pdf

59 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Boolean Model: Problems
A document satisfies a query by containing the terms as specified in the query
Document representation is independent of other documents in the collection
No way of indicating which terms are more significant than others in the query

60 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Boolean Model: Problems
Can we rank the results of a boolean query? All we are doing is checking the presence and
absence of terms On what grounds would we rank? This is also important if we are trying to
identify what, on a page of text, is likely to be of interest to the user

61 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Extended Boolean Retrieval Model Developed to address ranking problem in BIR,
using Vector Space Model-like approach (later!), while retaining Boolean query structures
E-BIR not as strict as BIR (fuzzy matches supported, as in VSM)
Term features can include frequency, location, … Reference:
G. Salton, E. Fox, and U. Wu. (1983). Extended Boolean information retrieval. Communications of the ACM, 26(12):1022-1036.

62 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Extended Boolean Retrieval Model
Matching is still based on presence or absence of terms, but now results can be ranked
Terms in docs and query are weighted according to term features
With structured documents (e.g., HTML), term features can also include structural information (title, heading, style, …)

63 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Extended Boolean Retrieval Model
With location information possible to find terms NEAR each other “computer NEAR science” not the same as
“computer AND science” ADJ (adjacent) refines the proximity measure

64 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Questions Arising…
Ranked results are an improvement NEAR is also useful to improve the quality
of results … as is ADJ Are we any closer to information retrieval?

65 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Phrase Matching Concepts may be evidenced in text as
complex/compound identifiers New York, Computer Science, information retrieval,
database management systems, … Brings us closer to information retrieval, but still
only identifies documents that contain phrases Reference:
W. Bruce Croft, Howard R. Turtle, and David D. Lewis, (1991), The use of phrases and structured queries in information retrieval, ACM SIGIR, 32-45.

66 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Phrase Matching
Extended/Boolean can express phrases using AND together with proximity operator
When is a sequence of words a phrase? Croft et. al. use a probabilistic inference net
model…

67 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Conclusion The Boolean and Extended Boolean Models give
us a simple mechanism for representing documents
If we can represent a user’s interest by the presence or absence of terms, then the user model could be used as a query to locate interesting document
Phrase matching allows us to recognise complex nouns: useful only if phrase is pervasive

68 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Vector-Space Model
For a given term, which documents are most likely to be about the term?
How does the co-occurrence of terms affect the relevance of the document?
References: G. Salton and C. Buckley. (1988). Term-weighting approaches in automatic text
retrieval. Information Processing & Management, 24(5):513--523. p18-wong (Generalised Vector Space Model).pdf - look at refs [1],[2],[3] for original
work

70 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Vector Space Model of IR
Documents (query) represented by vector of term weights
Term weight describes relative importance of term to document (query)
Measure similarity of document to query The more similar the document to the
query, the more relevant it is

71 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Vector Space Model of IR
VSM gives improved results over Boolean Can rank documents Can control output (limit the no. of documents
returned) But… not as easy to construct query
Query does not contain any structure Can’t express synonymy, etc.

72 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Vector-Space Model A document is considered to be relevant to
a query if it is similar enough A similarity measure calculates the
Euclidean Distance between a query and a document representation plotted into vector space
Relevant documents can be ranked in descending order of similarity

73 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Vector-Space Model Boolean model used simply presence or
absence of a term in a document Extended Boolean model used other term
features, including term frequency to rank relevant documents
VSM also uses distribution of term in collection: document frequency Size of collection / DF (=inverse DF)


75 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Vector-Space Model
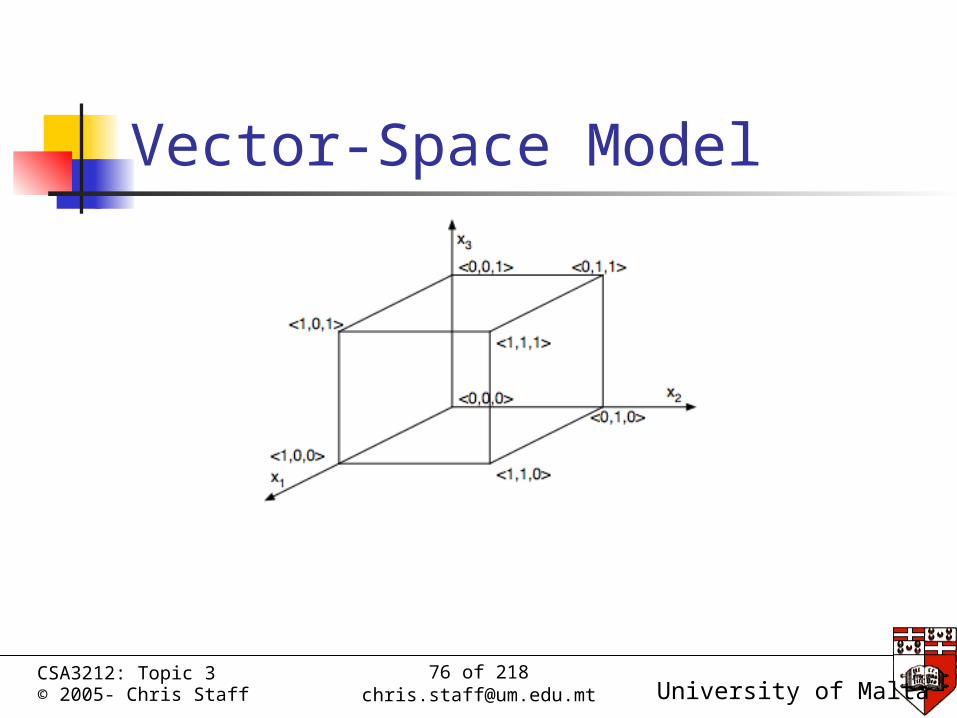
Documents are represented as m-dimensional vectors or “bags of words”
m is the size of the vocabulary wk = 1, indicates term is present in
document wk = 0, indicates term is absent dj = <1,0,0,1,...,0,0>

77 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Vector-Space Model
The query is then plotted into m-dimensional space and the nearest neighbours are the most relevant
However, the results set is usually presented as a list ranked by similarity to the query

78 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Vector-Space Model
Cosine Similarity Measure (from IR vector space model.pdf)
E. Garcia’s Cosine Similarity and Term Weight Tutorial

79 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Example
Q = <1,0,0,1,0,1> D = <1,0,1,0,1,1>

80 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Vector-Space Model Steps in calculating term weights
Remove stop words (using stop word list) Stem remaining words (using e.g., Porter
Stemmer) Count term frequency (TF) Count number of documents containing term
(DF) Invert it (log(N/DF)), where N is total number
of documents in collection

81 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Vector-Space Model
Calculating term weights Term weights may be binary, integers, or reals Binary values are thresholded, rather than
simply indicating presence or absence Integers or reals will be measure of relative
significance of term in document Usually, term weight is TFxIDF

82 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Vector-Space Model Normalising weights for vector length
Documents with longer vectors have a better chance of being retrieved than short ones (simply because there are a larger number of terms that they will match in a query)
Prefer shorter doc when two docs have same similarity IR should treat all relevant documents as important for
retrieval purposes Solution: , where w is weight of term i

83 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Vector-Space Model Why does VSM work?
Term discrimination Assumes that terms with high TF and low DF
are good discriminators of relevant documents Because documents are ranked, documents do
not need to contain precisely the terms expressed in the query
We cannot say anything (in VSM) about terms that occur in relevant and non-relevant documents - though we can in probabilistic IR

84 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Vector-Space Model
Vector-Space Model is also used by Recommender Systems to index user profiles and product, or item, features
Apart from ranking documents, results lists can be controlled (to list top n relevant documents), and query can be automatically reformulated based on relevance feedback (soon!)

85 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Vector-Space Model Disadvantage that terms in same document in
different collections can have different IDF, which effects term weight
Modern approaches use statistical language models to use the likelihood of occurrence in the language, rather than in the document collection
Reference: Djoerd Hiemstra and Franciska de Jong, (2001), Statistical
Language Models and Information Retrieval: natural language processing really meets retrieval.

86 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Relevance Feedback Relevance Feedback (RF) is an important
tool, much underutilised in “popular” search engines
Users not always able to describe need fully But can always recognise a relevant document!
After initial query, mark documents in the results set as relevant or non-relevant
Let the IR system re-compute the query!

87 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Vector-Space Model Relevance feedback can help UAS
determine unspecified significant terms that also indicate user interests

88 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Relevance Feedback
When a user is shown a list of retrieved documents, user can give relevance judgements
System can take original query and relevance judgements and re-compute the query
Rocchio method of relevance feedback...

89 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Relevance Feedback
Basic Assumptions Similar docs are near each other in vector space Starting from some initial query, the query can
be reformulated to reflect subjective relevance judgements given by the user
By reformulating the query we can move the query closer to more relevant docs and further away from non-relevant docs

90 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Relevance Feedback
In VSM, reformulating query means re-weighting terms in query
Not failsafe: may move query towards non-relevant docs!

91 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Relevance Feedback
The Ideal Query If we know the answer set rel, then the ideal
query is:

92 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Relevance Feedback In reality, a typical interaction will be:
User formulates query and submits it IR system retrieves set of documents User selects R’ and N’
where 0 <= <= 1 (and vector magnitude usually dropped...)

93 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Relevance Feedback What are the values of and ?
is typically given a value of 0.75, but this can vary. Also, after a number of iterations, the original weights of terms can be highly reduced
If and have equal weight, then relevant and non-relevant docs make equal contribution to reformulated query
If = 1, = 0, then only relevant docs are used in reformulated query
Usually, use = 0.75, = 0.25

94 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Relevance Feedback Example
Q: (5, 0, 3, 0, 1)R: (2, 1, 2, 0, 0) N: (1, 0, 0, 0, 2) = 0.75, = 0.50, = 0.25Q’ = 0.75Q + 0.5R – 0.25N
= 0.75(5, 0, 3, 0, 1)+0.5(2, 1, 2, 0, 0)–0.25(1,0, 0, 0, 2)
= (4.5, 0.5, 3.25, 0, 0.25)

95 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Relevance Feedback How many docs to use in R’ and N’?
Use all docs selected by user Use all rel docs and highest ranking nonrel docs Usually, user selects only relevant docs...
Should entire document vector be used? Really want to identify the significant terms...
Use terms with high-frequency/weight Use terms in doc adjacent to terms from query Use only common terms in R’ (and N’)

96 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Automatic Relevance Feedback
Users tend not to select non-relevant documents, and rarely choose more than one relevant document (http://www.dlib.org/dlib/november95/11croft.html) This makes it difficult to use relevance
feedback Current research uses automatic relevance
feedback techniques...

97 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Automatic Relevance Feedback
Two main approaches To improve precision To improve recall

98 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Automatic Relevance Feedback
Reasons for low precision Documents contain query terms, but documents
are not “about” the “concept” or “topic” the user is interested in
E.g., user wants documents in which a cat chases a dog but the query <cat, chase, dog> also retrieves docs in which dogs chase cats
Term ambiguity

99 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Automatic Relevance Feedback Improving precision
Want to promote relevant documents in the results list
Assume that top-n (typically 20) documents are relevant, and assume docs ranked 500-1000 are non-relevant
Choose co-occurring discriminatory terms Re-rank docs ranked 21-499 using (modified)
Rocchio methodp206-mitra.pdf

100 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Automatic Relevance Feedback
Improving precision Does improve precision by 6%-13% at p-21 to
p-100 But remember that precision is to do with the
ratio of relevant to non-relevant documents retrieved
There may be many relevant documents that were never retrieved (i.e., low recall)

101 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Automatic Relevance Feedback Reasons for low recall
“Concept” or “topic” that user is interested in can be described using terms additional to those expressed by user in query
E.g., think of all the different ways in which you can express “car”, including manufacturers names (e.g., Ford, Vauxhall, etc.)
There is only a small probability that user and author use the same term to describe the same concept

102 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Automatic Relevance Feedback
Reasons for low recall “Imprudent” query term “expansion” improves
recall, simply because more documents are retrieved, but hurts precision!

103 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Automatic Relevance Feedback
Improving recall Manually or automatically generated thesaurus
used to expand query terms before query is submitted
We’re currently working on other techniques to pick synonyms that are likely to be relevant
Semantic Web attempts to encode semantic meaning into documents
p61-voorhees.pdf, qiu94improving.pdf, MandalaSigir99EvComboWordNet.pdf

108 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Overview of Web search engine design – not covering…

126 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Probabilistic IR VSM assumes that a document that contains
some term x is about that term PIR compares the probability of seeing term
x in a relevant document as opposed to a non-relevant document
Binary Independence Retrieval Model proposed by Robertson & Sparck Jones, 1976
robertson97simple.pdf, SparckJones98.pdf

127 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
BIR BIR Fundamentals:
Given a user query there is a set of documents which contains exactly the relevant documents and no other:
the “ideal” answer set Given the ideal answer set, a query can be
constructed that retrieves exactly this set Assumes that relevant documents are “clustered”,
and that terms used adequately discriminate against non-relevant documents

128 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
BIR We do not know what are, in general, the
properties of the ideal answer set All we know is that documents have terms
which “capture” semantic meaning When user submits a query, “guess” what
might be the ideal answer set Allow user to interact, to describe the
probabilistic description of the ideal answer set (by marking docs as relevant/non-relevant)

129 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
BIR
Probabilistic Principle: Assumption Given a user query q and a document dj in the
collection: Estimate the probability that the user will find dj
relevant to q Rank documents in order of their probability of
relevance to the query (Probability Ranking Principle)

130 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
BIR
Model assumes that probability of relevance depends on q and doc representations only
Assumes that there is an ideal answer set! Assumes that terms are distributed
differently in relevant and non-relevant documents

131 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
BIR
Whether or not a document x is retrieved depends on: Pr(rel|x): the probability that x is relevant Pr(nonrel|x): ... that x isn’t relevant

132 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
BIR Document Ranking Function: document x will be
retrieved if
where a2 is the cost of not retrieving a relevant document, and a1 is the cost of retrieving a non-relevant document
If we knew Pr(rel|x) (or Pr(nonrel|x)), solution would be trivial, but...

133 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
BIR
Pr x ∣ rel
Use Bayes’ Theorem to rewrite Pr(rel|x):
Pr(x): probability of observing x P(rel): a priori probability of relevance (ie, probability
of observing a set of relevant documents) : the likelihood that x is in the given
set of relevant docs

134 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
BIR
Can do the same for

135 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
BIR The document ranking function can be rewritten
as:
and simplified as:
Pr(x | rel) and Pr(x | nonrel) are still unknown, so we will replace them in terms of keywords in the document!
€
logg(x) = log Pr(x|rel )Pr(x|nonrel ) + log Pr(rel )
Pr(nonrel )

136 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
BIR We assume that terms occur independently in
relevant and non-relevant docs...
: probability that term xi is present in a document randomly selected from the ideal answer set
: probability that term xi is present in a document randomly selected from outside the ideal answer set

137 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
BIR Considering document ,
where di is the weight of term i,
where is the probability that a relevant document contains term xi (similarly for )

138 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
BIR
When di = 0 we want the contribution of term i to g(x) to be 0:
=

139 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
BIR
The term relevance weight of term xi is:
Weight of term i in document j is:

140 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
BIR
Estimation of term occurrence probability Given a query, a document collection can be
partitioned into a relevant and non-relevant set The importance of a term j is its discriminatory
power in distinguishing between relevant and non-relevant documents

141 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
BIRWith complete information about the relevant & non-relevant document sets we can estimate pj and qj:
Approximation:

142 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
BIR
Term Occurrence Probability Without Relevance Information What do we do because we don’t know rj? : since most docs are non-
relevant pj = 0.5 (arbitrary) : does this remind you
of anything?
q j = df j / N

143 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
BIR Reminder... Ranking Function
where,
pi = Pr(xi=di|rel)
qi = Pr(xi=di|nonrel)and di is the weight of term i

144 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Relevance Feedback in BIR
Want to add more terms to the query so the query will resemble documents marked as relevant (note difference from VSM)
How do we select which terms to add to the query?

145 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Relevance Feedback in BIR Rank terms in marked documents and add
the first m terms where:
N: no. of docs in the collection
ni: document frequency of term iR: no. of relevant docs selected
ri: no. of docs in R containing term i Compares frequency of occurrence of term
in R with document frequency

University of Malta146 of 219
[email protected]: Topic 3© 2004- Chris Staff
Part IV: Dealing with General Knowledge

147 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Dealing with General Knowledge
Why did “Mary hit the piggy bank with a hammer”?

148 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Dealing with General Knowledge
Do computer systems need general knowledge?
How do computer systems represent general knowledge?

149 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Dealing with General Knowledge
Do we need general knowledge? How do we represent general knowledge?

150 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Dealing with General Knowledge
As usual, has its roots in philosophy (epistemology) Early (i.e., Greek) revolved around Absolute
and Universal Ideas and Forms (Plato) Aristotle: Logic for representing and reasoning
about knowledge
http://pespmc1.vub.ac.be/EPISTEMI.html

151 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Dealing with General Knowledge
Following Renaissance, two main schools of thought
Empiricists Knowledge as product of sensory perception
Rationalists Product of rational reflection

152 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Dealing with General Knowledge
Kantian Synthesis of empiricism and reflectionism Knowledge results from the organization of
perceptual data on the basis of inborn cognitive structures, called "categories".
Categories include space, time, objects and causality.
(viz. Chomsky’s Universal Grammar)

153 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Dealing with General Knowledge Pragmatism
Knowledge consists of models that attempt to represent the environment to simplify problem-solving
Assumption: Models are “rich”. No model can ever hope to capture all relevant information, and even if such a complete model would exist, it would be too complicated to use in any practical way.

154 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Dealing with General Knowledge Pragmatism (contd.)
The model which is to be chosen depends on the problems that are to be solved (context).
But see also discussions on pragmatic vs. cognitive contexts! (Topic 3)
Basic criterion: model should produce correct (or approximate) (testable) predictions or problem-solutions, and be as simple as possible.
This is the approach mainly used in CS/AI today

155 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Dealing with General Knowledge “The first theories of knowledge stressed its absolute,
permanent character, whereas the later theories put the emphasis on its relativity or situation-dependence, its continuous development or evolution, and its active interference with the world and its subjects and objects. The whole trend moves from a static, passive view of knowledge towards a more and more adaptive and active one”.
http://pespmc1.vub.ac.be/EPISTEMI.html

156 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Dealing with General Knowledge
We’ll look at four overviews of and approaches to knowledge in computer systems McCarthy (1959, mcc.pdf) Sowa (1979, p79-1010.pdf) McCarthy (1987, p1030-mccarthy.pdf) Brézillon & Pomerol (2001, is-context-a-kind.pdf)

157 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Dealing with General Knowledge
McCarthy, J. 1959. “Programs with Common Sense”
“a program has common sense if it automatically deduces for itself a sufficiently wide class of immediate consequences of anything it is told and what it already knows”.

158 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Dealing with General Knowledge
Objective: “to make programs that learn from their experience as effectively as humans do”
To learn to improve how to learn And to do it in logic using a logical
representation

159 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Dealing with General Knowledge Minimum features required of a machine that can
evolve intelligence approaching that of humans Representation of all behaviours Interesting changes in behaviour must be expressible All aspects of behaviour must be improvable Must have notion of partial success System must be able to create/learn subroutines

160 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Dealing with General Knowledge Bar-Hillel’s biggest complaint (in my
opinion) is “A deductive argument, where you have first to
find out what are the relevant premises, is something which many humans are not always able to carry out successfully. I do not see the slightest reason to believe that at present machines should be able to perform things that humans find trouble in doing”
We’ll return to this in Closed World vs. Open World Assumption

161 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Dealing with General Knowledge Sowa, J. 1979. “Semantics of Conceptual Graphs” McCarthy used logic as representation of
“statements about the world” as well as “theorem prover” to infer/deduce new knowledge (assumptions) about the world
Sowa uses CG as “a language for representing knowledge and patterns for constructing models”

162 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Dealing with General Knowledge
Sowa proposes CGs as better alternative to semantic networks and predicate calculus SemNets have no well-defined semantics PC is “adequate for describing mathematical
theories with a closed set of axioms... But the real world is messy, incompletely explored, and full of unexpected surprises”

163 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Dealing with General Knowledge
CGs serve two purposes: They can be used as canonical representations
of meaning in Natural Language They can be used to construct abstract
structures that serve as models in the model-theoretic sense (e.g., microtheories)

164 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Dealing with General Knowledge To understand a sentence:
1. Convert utterance to CG2. Join CG to graphs that help resolve
ambiguities and incorporate background information
3. Resulting graph is nucleus for constructing models (of worlds) in which utterance is true
4. Laws of world block illegal extensions5. If model could be extended infinitely, result
would be complete standard model

165 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Dealing with General Knowledge
“Mary hit the piggy bank with a hammer”

166 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Dealing with General Knowledge
Linearizing the conceptual graph[PERSON:Mary]->(AGNT)->[HIT:c1]<-(INST) <- [HAMMER]
[HIT:c1]<-(PTNT)<-[PIGGY-BANK:i22103]

167 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Dealing with General Knowledge
Context-sensitive logical operators Allow building models of possible worlds and
checking their consistency Def: “A sequent is a collection of conceptual
graphs divided into two sets, called the conditions u1,..., un and the assertions v1,..., vm. It is written u1,..., un ->v1,..., vm.”

168 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Dealing with General Knowledge Cases of sequents:
simple assertion: no conditions, one assertion (->v) disjunction: no conditions, one or more assertions
(->v1,..., vm) simple denial: one condition, no assertions (u->) compound denial: 2 or more conditions, no assertions
(u1,..., un->) conditional assertion: u1,..., un ->v1,..., vm empty clause: -> Horn clause: anything with at most one assertion (inc. 0)

169 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Dealing with General Knowledge “no one knows how to make a general database of
commonsense knowledge that could be used by any program that needed the knowledge”
Examples: robots moving things around, what we know about families, buying and selling...
“In my opinion, getting a language [my italics] for expressing general commonsense knowledge for inclusion in a general database is the key problem of generality in AI.”
McCarthy, J. 1987. “Generality in Artificial Intelligence” (1971 Turing Award Lecture)

170 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Dealing with General Knowledge How can we write programs that can learn
to modify their own behaviour, including improving the way they learn? Friedberg (A Learning Machine, c. 1958) Newell, Simon, Shaw (General Problem Solver, c. 1957-1969) Newell, Simon (Production Machines, 1950-1972) McCarthy (Logical Representation, c. 1958) McCarthy (Formalising Context, 1987)

171 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Dealing with General Knowledge
A Learning Machine Learns by making random modifications to a
program Discard flawed programs Learnt to move a bit from one memory cell to
another In 1987, was demonstrated to be inferior to
simply re-writing the entire program

172 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Dealing with General Knowledge
General Problem Solver Represent problems of some class as problems
of transforming one expression into another using a set of allowed rules
First system to separate problem structure from the domain
McCarthy claims problem in representing commonsense knowledge as transformations

173 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Dealing with General Knowledge
Production (Expert) Systems Represent knowledge as facts and rules Facts contain no variables or quantifiers New facts are produced by inference,
observation and user input Rules are usually coded by programmer/expert Rules are usually not learnt or generated by
system (but see data mining)

174 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Dealing with General Knowledge
Logical Representation Representing information declaratively Although Prolog can represent facts in logical
representation and reason using logic, it cannot do universal generalization, and so cannot modify its own behaviour enough
So McCarthy built Lisp...

175 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Dealing with General Knowledge Logical Representation
McCarthy’s “dream” is that commonsense knowledge possessed by humans could be written as logical sentences and stored in a db
Facts about the effects of actions is essential (when we hear the squeal of tyres we expect a bang...)
Necessary to say that an action changes only features of the situation to which it refers

176 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Dealing with General Knowledge
Context We understand under-qualified utterances
because we understand them in context “The book is on the table” “Where is the book?”

177 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Dealing with General Knowledge
Context “Can you fetch me the book, please?” Up until the last utterance, the physical location
of the book was not significant, and we were able to have a short dialogue about it
Fully qualified utterances are too unwieldy to use in conversation
Occasionally gives rise to misunderstandings...

178 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Dealing with General Knowledge
Context “The book is on the table” is valid for a large
number of different contexts, in which the specific book and the specific table, and perhaps even the location of the specific table can be significant and can also change over time
Utterances are understood in context

179 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Dealing with General Knowledge
Is Context a ... collective Tacit Knowledge? How does data become knowledge?

180 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Dealing with General Knowledge
Is Context a ... collective Tacit Knowledge? Context is “the collection of relevant conditions
and surrounding influences that make a situation unique and comprehensible”

182 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Dealing with General Knowledge
Closed world vs. Open World assumption Closed World
I assume that anything I don’t know the truth of is false: I know everything that is true
Open World I assume that anything I don’t know the truth of is
unknown: Some things I don’t know may be true: I don’t know everything

183 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Dealing with General Knowledge Prolog, for instance, will return “false”
about any fact that is missing from its database, or for which it cannot derive a truth-value
A three-valued logic permits assertions to be true, false, or unknown
However, reasoning and truth-maintenance become expensive in the open world

184 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Dealing with General Knowledge
The Web is an open world so the Semantic Web needs to reason within an open world (perhaps even across ontologies)
Doesn’t mean that to solve some problems, SW cannot temporarily assume a closed-world (within an agreed ontology)
ekaw2004.pdf

University of Malta185 of 219
[email protected]: Topic 3© 2004- Chris Staff
Part V: Back to Surface-Based Approaches

186 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Surface-based approaches
Semantic representations and the ability to reason would give computational systems enormous potential
Currently, it is not known what the limitations of the Semantic Web might be
But it is certainly expensive to model knowledge (time, money, computationally)

187 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Surface-based approaches Surface-based approaches attempt to approximate
using information in the correct context (knowledge), but recognise their limitations
We’ll look at Question-Answering (Turing Test!) HyperContext WebWatcher What can we learn from analysing Query Logs?
Context Paths?

188 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Question-Answering on the Web Web has information about everything
Can we build programmes that use it? Two aspects to IR:
Coverage (find all relevant documents) Question-Answering (find the answer to specific
query). In QA we want one answer to our question How much NLP do we need to use to answer fact-
based questions? Answers that require reasoning are much harder!

189 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Question-Answering Most IR tasks assume that user can predict what
terms a relevant document will contain But sometimes what we want is the answer to a
direct question “Who was the first man on the moon?”
Do we really want a list of millions of documents that contain first, man, moon?
And do we really want to have to read them to find the answer?

190 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Question-Answering
All we want is one document, or one statement, that contains the answer
Can we take advantage of IR on the Web to do this?
Taking advantage of redundancy on the Web E.g., Mulder, Dumais, Azzopardi

191 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Mulder
Uses Web as collection of answers to factual questions “Who was the first man on the moon?” “What is the capital of Italy?” “Where is the Taj Mahal?”
kwok01scaling.pdf

192 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Mulder
Turns questions into partial phrases, and then submits a phrase query to an IR system
“Does John love Mary?” is turned into the query “John loves Mary”
Documents containing the phrase are evidence
What are the limitations?

193 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Mulder
Three parts to a QA system: Retrieval Engine
Indexes documents in a collection and retrieves them
Query Formulator Converts NL question into formal query
Answer Extractor Locates answer in text

194 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Mulder
Six parts to Mulder: Question Parsing Question Classification Query Formulation Search Engine Answer Extraction Answer Selection

195 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Dumais et al
Takes advantage of multiple, differently phrased, answer occurrences on Web
Doesn’t need to find all answer phrases Just the ones that match the query pattern
Rules for converting questions, finding answers are mostly handwritten
p291-dumais

196 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Dumais et al
Steps Rewrite question into weighted query patterns
Use POS tagger + lexicon to seek alternative word forms
Search Mine N-grams in summaries Filter and re-weight N-grams Tile N-grams to yield longer answers

197 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Azzopardi Joel Azzopardi, 2004, “Template-Based Fact
Finding on the Web” FYP report, CSAI Can find factoids about a series of queries relating
to a particular topic using majority polling (voting) to decide amongst competing answers
Series of topic sensitive query patterns stored in template

198 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Azzopardi
Template is learned by comparing a sample of documents about a topic
Commonly occurring phrases (trigrams) extracted and turned into partial query in template, together with answer “type”

199 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Azzopardi When user wants information regarding a topic,
use appropriate template together with subject (e.g., person’s name)
Subject is appended to partial queries in template - queries are submitted to Google
Top-n documents retrieved and processed to identify candidate answers
Uses voting to decide on most frequently occurring answer

200 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Surface-based approaches
So, given that we are operating in a hypertextual environment, what can we use to i) identify what is of interest to a user Assumptions
1: the user interest is represented by a description 2: description is a formal statement
ii) adapt hyperspace to the user

201 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Surface-based approaches
This addresses our immediate concerns i) identify what is of interest to a user
so that a user doesn’t have to describe it user modelling in topic 5
ii) adapt hyperspace to the user so that a user doesn’t have to find it adaptation techniques in topics 6 & 7

202 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Surface-based approaches At their most fundamental
An IR system is document representation + algorithm for matching query to documents
Assume binary weights for terms A hypertext is a collection of nodes and links
IR and Hypertext allow user interaction What else can we say about the structures, user
interaction, with a view to learning about the user?

203 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Surface-based approaches IR:
User submits query System returns relevant documents User reads/accesses some With relevance feedback, user can select examples of
relevant/non-relevant documents and IR system will modify the query
If we “remember” users we can remember terms used/documents viewed

204 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Surface-based approaches IR:
Documents may be relevant to different queries Can we learn anything from this?
Some words in query are used as context (to eliminate docs containing diff word senses)
Relevance feedback

205 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Surface-based approaches Hypertext
What’s a link really? Navigation history Automatic link “typing” Contextualisation of information
Is a document necessarily identically relevant to all parents? Is all of a document necessarily relevant to all parents?
Can we learn anything about documents which link to the same child/children?
Are assumptions made about information by authors along a path?

206 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Surface-based approaches
HyperContext If we index multiple representations of the
same document, will retrieval effectiveness improve?
Can information be added to an interpretation (from its parents) to improve relevance?
Can information be removed from an interpretation if it is non-relevant to a parent?

207 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Surface-based approaches This surface-based approach improves
retrieval by filtering out non-relevant terms from documents and by adding relevant terms to documents reducing the number of false positives increasing the chances of locating a relevant
document It does nothing to expose the “meaning” of
the data in the document

208 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Other examples WebWatcher [Armstrong95]
Adds user’s search terms to links on path to relevant document so that future users can be guided
Added terms do not need to be present anywhere in the hypertext
Reference R. Armstrong, D. Freitag, T. Joachims, and T. Mitchell. Webwatcher : A
learning apprentice for the world wide web . In 1995 AAAI Spring Symposium on Information Gathering from Heterogeneous Distributed Environments, March 1995. http://citeseer.nj.nec.com/armstrong95webwatcher.html

209 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Other examples
Analysing Query Logs Can documents be clustered according to the
terms that are used in queries? Can queries be automatically expanded to find
documents relevant to what the user intended to ask for?
Can we use the results of past similar queries?

210 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Other examples Analysing “context paths” [Mizuuchi99]
Terms “assumed” in Web pages may be explicit in the access paths to those Web pages
Users who follow links will have read the information
But the info will be missing from the destination pg
Reference Mizuuchi, Y., and Tajima, K., 1999, “Finding Context
Paths for Web Pages”, in Proc. Hypertext 99. http://citeseer.nj.nec.com/mizuuchi99finding.html

211 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Other examples Mizuuchi and Tajima use implicit link types to
determine whether a path is “significant” Link types:
Intradirectory, downward, upward, sibling, intersite Link roles:
Entrance, back, jump

212 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Conclusion Surface-based approaches to UAS
frequently couple IR or log analysis with hypertext
The IR aspect is typically term-feature based
“Meaning” is less embedded within the words/phrases that occur in a document, but with how the document is actually used

213 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Conclusion These techniques can be coupled with NL
techniques, such as Entity Name Recognition to improve term recognition E.g., President of USA in one doc is referred to
as George W. Bush in another. Query (which is about GWB) is specified as “George Bush”
Still cannot do reasoning about the content of documents

214 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Summary
We’ve discussed a few popular models of IR that are more “intelligent” that plain old Extended Boolean Information Retrieval
They still treat terms as atoms that are representative of the semantic meaning of the document

215 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Summary But word order generally insignificant (“bag of
words”) Cannot distinguish between “dog chased cat” and “cat
chased dog” unless phrase matching also used, but then cannot tell that “cat
chased dog” and “dog was chased by cat” are semantically equivalent
What about information extraction? George W. Bush = President of the United States of
America

216 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Summary
More “intelligent” approaches have been used
And more “intelligence” is being put “into” the Web
Personalisation and user-adaptivity also require high accuracy in determining which documents are relevant to a user

217 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Summary Sowa’s conceptual graphs and McCarthy’s
Generality in AI/Notes on Contextual Reasoning are seminal works that underpin much that is happening in the Semantic Web
CGs represent semantic content of utterances in interchangeable format (KIF)
McCarthy claims that it is hard to make correct inferences in the absence of contextual information

218 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
Summary Because of the expense of CGs, they are
still very much domain specific SemWeb hopes that by bringing massive
numbers of people together there will be a proliferation of “ontologies” to make it happen
Guha did his PhD “Contexts: A Formalisation and Some Applications” at Stanford, under John McCarthy. His work on Cyc underpins RDF, DAML+OIL

219 of [email protected] University of Malta
CSA3212: Topic 3© 2005- Chris Staff
For next topic “Seven Issues” References:
Reflections on NoteCards: seven issues for the next generation of hypermedia systems Frank,G. Halasz July 1988 Communications of the ACM, Volume 31, Issue 7
ACM Journal of Computer Documentation (JCD), Volume 25, Issue 3 (http://portal.acm.org/toc.cfm?id=507317&type=issue&coll=ACM&dl=ACM&CFID=14254782&CFTOKEN=22435962). Entire issue devoted to “Seven Issues”
Seven Issues, Revisited. Panel Session, Hypertext ‘02.
Read http://ted.hyperland.com/buyin.txt The Problems of Hypertext, from Nelson, T. 1987,
“Literary Machines”, Edition 87.1