compiler principle and technology prof. dongming lu apr. 29th, 2015
TRANSCRIPT

Compiler Principle and Technology
Prof. Dongming LU
Apr. 29th, 2015

8. Code Generation PART TWO

ContentsPart One8.1 Intermediate Code and Data Structure for code Generation8.2 Basic Code Generation Techniques8.3 Code Generation of Data Structure Reference
Part Two
8.4 Code Generation of Control Statements and Logical Expression
8.5 Code Generation of Procedure and Function calls
Other Parts8.6 Code Generation on Commercial Compilers: Two Case Studies8.7 TM: A Simple Target Machine8.8 A Code Generator for the TINY Language8.9 A Survey of Code Optimization Techniques8.10 Simple Optimizations for TINY Code Generator

8.4 Code Generation of Control Statements and Logical Expressions

Describing code generation for various forms of control statements.
The structured if-statement and while-statement
Intermediate code generation for control statements involves the generation of labels
Addresses in the target code to which jumps
If labels are to be eliminated in the generation of target code, Jumps to code locations that are not yet known must be back-
patched, or retroactively rewritten.

8.4.1 Code Generation for If – and While – Statements

Two forms of the if- and while-statements: if-stmt → i f ( e x p ) stmt | i f ( exp ) stmt e l s e stmt while-stmt → w h i l e ( e x p ) s t m t
To translate the structured control features into an “unstructured” equivalent involving jumps
To be directly implemented.
Compilers arrange to generate code for such statements in a standard order that allows the efficient use of a subset of the possible jumps that target architecture might permit.

The typical code arrangement for an if-statement is shown as follows:

The typical code arrangement for a while-statement

Three-Address Code for Control Statement
For the statement:
if ( E ) S1 e l s e S2
The following code pattern is generated:
<code to evaluate E to t1>
if_false t1 goto L1
<code for S1>
goto L2
label L1
<code for S 2>
label L2

Three-Address Code for Control Statement
Similarly, a while-statement of the formwhile ( E ) S
The following three-address code pattern to be generated:label L1<code to evaluate E to t1>if_false t1 goto L2<code for S>goto L1label L2

P-Code for Control Statement
For the statementif ( E ) S1 else S 2
The following P-code pattern is generated:<code to evaluate E>fjp L1<code for S 1>ujp L2lab L1<code for S 2>lab L2

P-Code for Control Statement
And for the statementwhile ( E ) S
The following P-code pattern is generated:lab L1<code to evaluate E>fjp L2<code for S>ujp L1lab L2

8.4.2 Generation of Labels and Back-patching

One feature of code generation for control statements that can cause
problems during target code generation is the fact that, in some cases,
jumps to a label must be generated prior to the definition of the label
itself
A standard method for generating such forward jumps is either to
leave a gap in the code where the jump is to occur or to generate a
dummy jump instruction to a fake location
When the actual jump location becomes known, this location is used to
fix up, or back-patch, the missing code

During the back-patching process a further problem may arise in that many
architectures have two varieties of jumps, a short jump or branch ( within
128 bytes if code) and a long jump that requires more code space
In that case, a code generator may need to insert nop instructions when
shortening jumps, or make several passes to condense the code

8.4.3 Code Generation of Logical Expressions

The standard way to do this is to represent the Boolean value false as 0 and true as 1.
Then standard bitwise and and or operators can be used to compute the value of a Boolean expression on most architectures
A further use of jumps is necessary if the logical operations are short circuit. For instance, it is common to write in C:
if ((p!=NULL) && ( p->val==0) ) ... Where evaluation of p->val when p is null could cause a memory
fault
Short-circuit Boolean operators are similar to if-statements, except that they return values, and often they are defined using if-expressions as
a and b :: if a then b else false and a or b :: if a then true else b

To generate code that ensures that the second sub-expression will be evaluated only when necessary
Use jumps in exactly the same way as in the code for if-statements
For instance, short-circuit P-code for the C expression ( x ! = 0 ) & & ( y = = x ) is:
lod xldc 0n e qfjp L1lod ylod xe q uujp L2lab L1lod FALSElab L2

8.4.4 A Sample code Generation Procedure for If- and While- Statements

Exhibiting a code generation procedure for control statements using the following simplified grammar:
stmt → if-stmt | while-stmt | b r e a k | o t h e rif-stmt → i f ( exp ) stmt | i f ( e x p ) stmt e l s e s t m t
while-stmt → w h i l e ( e x p ) s t m t
exp → t r u e | f a l s e

The following C declaration can be used to implement an abstract syntax tree for this grammar:
typedef enum { ExpKind, IfKind,WhileKind, BreakKind, OtherKind }
NodeKind;
typedef struct streenode { NodeKind kind;
struct streenode * child[3] ;int val; /* used with ExpKind */
} STreeNode;
typedef STreeNode * SyntaxTree;

In this syntax tree structure, a node can have as many as three children, and expression nodes are constants with value true or false.
For example, the statement if (true) while (true) if (false) break else other has the syntax tree

Using the given typedef’s and the corresponding syntax tree structure, a code generation procedure that generates P-code is given as follows:
Void genCode(SyntaxTree t, char* lable)
{ char codestr[CODESIZES];
char *lab1, *lab2;
if (t!=NULL) switch (t->kind)
{case ExpKind:
if (t->val==0) emitCode(“ldc false”);
else emitcode(“ldc true”);
break;

case IfKind:genCode(t->child[0], label);lab1 = genLable();sprintf(codestr,”%s %s”, “fjp”,lab1);emitcode(codestr);gencode(t->child[1],label);if (t->child[2]!=NULL){ lab2=genlable(); sprintf(codestr,”%s %s”,”ujp”,lab2); emitcode(codestr);} sprintf(codestr,”%s %s”,”lab”,lab1); emitcode(codestr); if (t->child[2]!=NULL) { gencode(t->child[2],lable);
sprintf(codestr,”%s %s”,”lab”,lab2); emitcode(codestr);}
break;

case WhileKind;lab1=genlab();sprintf(codestr,”%s %s”, “lab”,lab1);emitcode(codestr);gencode(t->child[0],label);lab2=genlabel();sprintf(codestr,”%s %s”, “fjp”,lab2);emitcode(codestr);gencode(t->child[1],lab2);sprintf(codestr,”%s %s”, “ujp”,lab1);emitcode(codestr);sprintf(codestr,”%s %s”, “lab”,lab2);emitcode(codestr);break;

case BreakKind:sprintf(codestr,”%s %s”, “ujp”,label);emitcode(codestr);break;
case OtherKind:emitcode(“other”);break;
Default:emitcode(“other”);break;
}}

For the statement,if (true) while (true) if (false) break else other
The above procedure generates the code sequenceldc truefjp L1lab L2ldc truefjp L3ldc falsefjp L4ujp L3ujp L5lab L4Otherlab L5ujp L2lab L3Lab L1

8.5 Code Generation of Procedure and Function Calls

8.5.1 Intermediate Code for Procedures and Functions

The requirements for intermediate code representations of
function calls may be described in general terms as follows
First, there are actually two mechanisms that need descriptions:
function/procedure definition
and function/procedure call
A definition creates a function name, parameters, and code, but
the function does not execute at that point
A call creates values for the parameters and performs a jump
to the code of the function, which then executes and returns

Intermediate code for a definition must include An instruction marking the beginning, or entry point, of the code for the
function, And an instruction marking the ending, or return point, of the function
Entry instruction<Code for the function body>Return instruction
Similarly, a function call must have an instruction indicating the beginning of the computation of the arguments and an actual
call instruction that indicates the point where the arguments have been constructed
and the actual jump to the code of the function can take placeBegin-argument-computation instruction<Code to compute the arguments >Call instruction

Three-Address Code for Procedures and Functions
In three-address code, the entry instruction needs to give a name to the procedure entry point, similar to the label instruction; thus, it is a one-address instruction, which we will call simply entry. Similarly, we will call the return instruction return
For example, consider the C function definition.int f ( int x, int y ){ return x + y + 1; }
Translated into the following three-address code:entry ft1 = x + yt2 = t1 + 1return t2

Three-Address Code for Procedures and Functions
For example, suppose the function f has been defined in C as in the previous example.
Then, the call f ( 2+3, 4)
Translates to the three-address code begin_args t1 = 2 + 3 arg t1 arg 4 call f

P-code for Procedures and functions
The entry instruction in P-code is ent, and the return instruction is ret
int f ( int x, int y ){ return x + y + 1; }
The definition of the C function f translates into the P-codeent flod xlod ya d ildc 1a d ir e t

P-code for Procedures and functions
Our example of a call in C (the call f (2+3, 4) to the function f described
previously) now translates into the following P-code:
m s t
ldc 2
ldc 3
a d i
ldc 4
cup f

8.5.2 A Code Generation Procedure for Function Definition and Call

The grammar we will use is the following:program → decl-list exp
decl-list → decl-list decl | εdecl → f n id ( param-list ) = e x p
param-list → p a ram - list, id | idexp → exp + exp | call | num | idcall → id ( arg-list )
arg-list → a rg-list, exp | exp
An example of a program as defined by this grammar is
fn f(x)=2+xfn g(x,y)=f(x)+yg ( 3 , 4 )

We do so using the following C declarations:
typedef enum{PrgK, FnK, ParamK, PlusK, CallK, ConstK, IdK} NodeKind ;
typedef struct streenode{ NodeKind kind; struct streenode *lchild,*rchild, * s i b l i n g ; char * name; /* used with FnK,ParamK,Callk,IdK */ int val; /* used with ConstK */} StreeNode;
typedef StreeNode * SyntaxTree;

Abstract syntax tree for the sample program :fn f(x)=2+xfn g(x,y)=f(x)+yg ( 3 , 4 )

Given this syntax tree structure, a code generation procedure that produces P-code is given in the following:
Void genCode( syntaxtree t){ char codestr[CODESIZE];
SyntaxTree p;If (t!=NULL)Switch (t->kind){ case PrgK:
p = t->lchild;while (p!=NULL){ gencode(p);
p = p->slibing;}gencode(t->rchild);break;

case FnK:sprintf(codestr,”%s %s”,”ent”,t->name);emitcode(codestr);gencode(t->rchild);emitcode(“ret”);break;
case ConstK:sprintf(codestr,”%s %d”,”ldc”,t->val);emitcode(codestr);break;
case PlusK:gencode(t->lchild);gencode(t->rchild);emitcode(“adi”);break;
case IdK:sprintf(codestr,”%s %s”,”lod”,t->name);emitcode(codestr);break;

case CallK:emitCode(“mst”);p = t->rchild;while (p!=NULL){genCode(p); p = p->sibling;}sprintf(codestr,”%s %s”,”cup”,t->name);emitcode(codestr);break;default:emitcode(“Error”);break;
}}
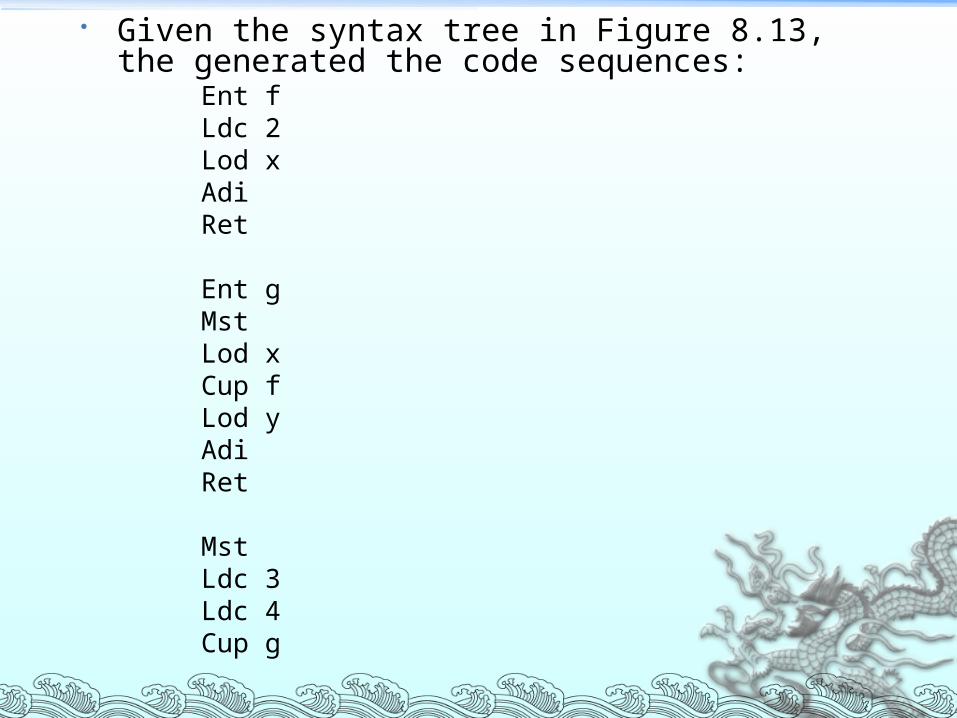
Given the syntax tree in Figure 8.13, the generated the code sequences:
Ent fLdc 2Lod xAdiRet
Ent gMstLod xCup fLod yAdiRet
MstLdc 3Ldc 4Cup g

8.9 A Survey of Code Optimizations Techniques

8.9.1 Principal Sources of Code Optimizations

(1) Register Allocation Good use of registers is the most important feature of efficient
code.(2) Unnecessary Operations The second major source of code improvement is to avoid
generating code for operations that are redundant or unnecessary.
(3) Costly Operations A code generator should not only look for unnecessary operations,
but should take advantage of opportunities to reduce the cost of operations that are necessary,
but may be implemented in cheaper ways than the source code or a simple implementation might indicate.

(4) Prediction Program Behavior To perform some of the previously described optimizations, a
compiler must collect information about the uses of variables, values and procedures in programs: whether expressions are reused, whether or when variables change their values or remain constant, and whether procedures are called or not.
A different approach is taken by some compilers in that statistical behavior about a program is gathered from actual executions and the used to predict which paths are most likely to be taken, which procedures are most likely to be called often, and which sections of code are likely to be executed the most frequently.

8.9.2 Classification of Optimizations

Two useful classifications are the time during the compilation process when an optimization can be applied and the area of the program over which the optimization applies:
The time of application during compilation. Optimizations can be performed at practically every stage of compilation.
For example, constant folding…. Some optimizations can be delayed until after target code has
been generated - the target code is examined and rewritten to reflect the optimization.
For example, jump optimization….

The majority of optimizations are performed either during intermediate code
generation, just after intermediate code generation, or during target code
generation.
To the extent that an optimization does not depend on the characteristics of
the target machine (called source-level optimizations)
They can be performed earlier than those that do depend on the target
architecture (target-level optimizations).
Sometimes both optimizations do.

Consider the effect that one optimization may have on another. For instance, propagate constants before performing unreachable
code elimination. Occasionally, a phase problem may arise in that each of two optimizations may uncover further opportunities for the other.
For example, consider the codex = 1;. . .y = 0;. . .if (y) x = 0;. . .if (x) y = 1;

A first pass at constant propagation might result in the codex = 1;. . .y = 0;. . .if (0) x = 0;. . .if (x) y = 1;
Now, the body of the first if is unreachable code; eliminating it yields:
x = 1;. . .y = 0;. . .if (x) y = 1;

The second classification scheme for optimizations that we consider is by the area of the program over which the optimization applies
The categories for this classification are called local, global and inter-procedural optimizations
( 1 ) Local optimizations: applied to straight-line segments of code, or basic blocks.
( 2 ) Global optimizations: applied to an individual procedure.
( 3 ) Inter-procedural optimizations: beyond the boundaries of procedures to the entire program.


8.9.3 Data Structures and Implementation Techniques for Optimizations

Some optimizations can be made by transformations on the syntax
tree itself
Including constant folding and unreachable code elimination.
However the syntax tree is an unwieldy or unsuitable structure for
collecting information and performing optimizations
An optimizer that performs global optimizations will construct from
the intermediate code of each procedure
A graphical representation of the code called a flow graph.
The nodes of a flow graph are the basic blocks, and the edges are formed
from the conditional and unconditional jumps.
Each basic block node contains the sequence of intermediate code
instructions of the block.


A single pass can construct a flow graph, together with each of its
basic blocks, over the intermediate code
Each new basic block is identified as follows:
The first instruction begins a new basic block;
Each label that is the target of a jump begin a new basic block;
Each instruction that follows a jump begins a new basic block;

A standard data flow analysis problem is to compute, for each
variable, the set of so-called reaching definitions of that variable at
the beginning of each basic block.
Here a definition is an intermediate code instruction that can set the
value of the variable, such as an assignment or a read
Another data structure is frequently constructed for each block, called
the DAG of a basic block.
DAG traces the computation and reassignment of values and variables in a
basic block as follows.
Values that are used in the block that come from elsewhere are
represented as leaf nodes.

Operations on those and other values are represented by interior
nodes.
Assignment of a new value is represented by attaching the name of
target variable or temporary to the node representing the value
assigned
For example:

Repeated use of the same value also is represented in the DAG structure. For example, the C assignment x = (x+1)*(x+1) translates into the three-
address instructions:t1 = x + 1t2 = x + 1t3 = t1 * t2x = t3
DAG for this sequence of instructions is given, showing the repeated use of the expression x+1

The DAG of a basic block can be constructed by maintaining two
dictionaries.
A table containing variable names and constants, with a lookup
operation that returns the DAG node to which a variable name is
currently assigned.
A table of DAG nodes, with a lookup operation that, given an operation
and child node
Target code, or a revised version of intermediate code, can be generated
from a DAG by a traversal according to any of the possible topological sorts
of the nonleaf nodes.
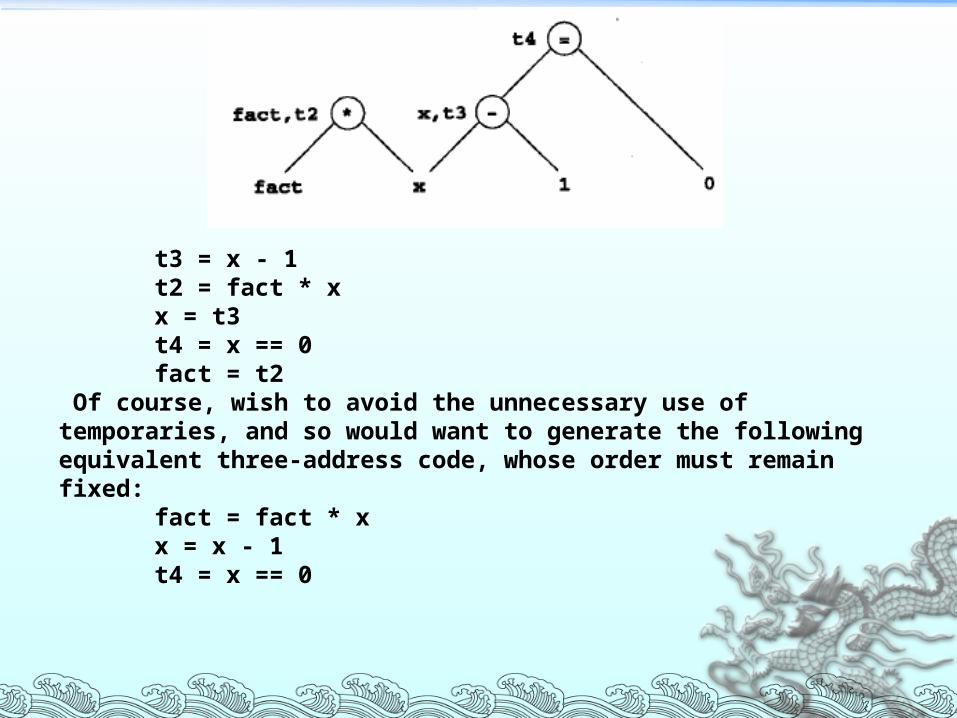
t3 = x - 1t2 = fact * xx = t3t4 = x == 0fact = t2
Of course, wish to avoid the unnecessary use of temporaries, and so would want to generate the following equivalent three-address code, whose order must remain fixed:
fact = fact * xx = x - 1t4 = x == 0

A similar traversal of the DAG of above Figure results in the following revised three-address code:
t1 = x + 1x = t1 * t1
Using DAG to generate target code for a basic block, we automatically get local common sub expression elimination
The DAG representation also makes it possible to eliminate redundant stores and tells us how many references to each value there are

A final method that is often used to assist register allocation as code generator proceeds
Involves the maintenance of data called register descriptors and address descriptors.
Register descriptors associate with each register a list of the variable names whose value is currently in the register.
Address descriptors associate with each variable name the locations in memory where its value is to be found.
For example, take the basic block DAG of Figure 8.19 and consider the generation of TM code according to a left-to-right traversal of the interior nodes,
Using the three registers 0, 1, and 2. Assume that there are four address descriptors: inReg(reg_no), isGlobal(global_offset), isTemp(temp_offset), and isCounst(value).
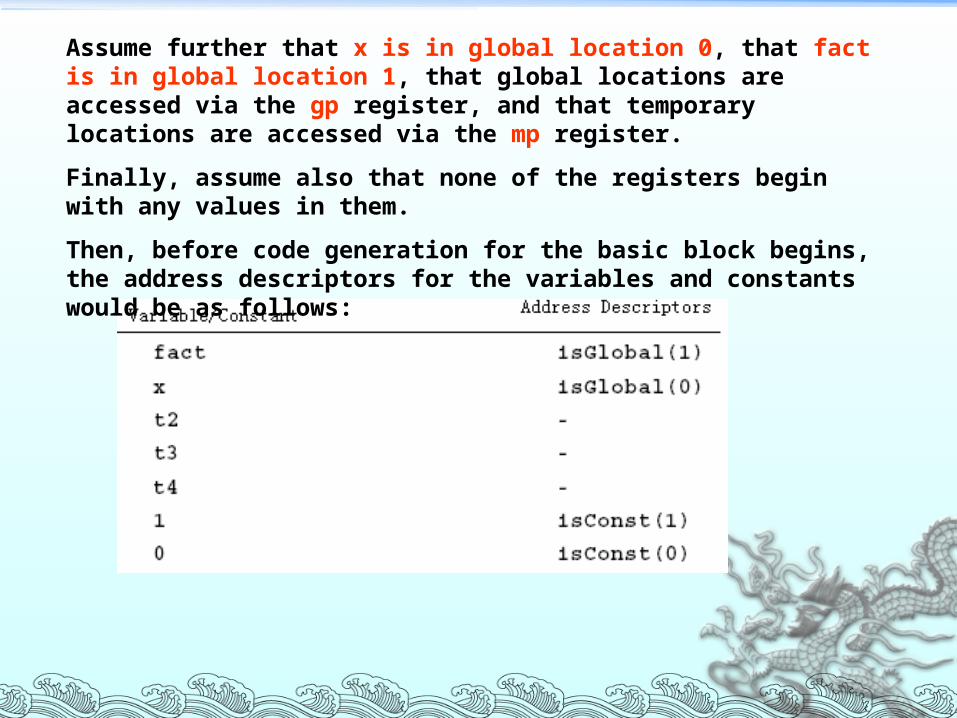
Assume further that x is in global location 0, that fact is in global location 1, that global locations are accessed via the gp register, and that temporary locations are accessed via the mp register.
Finally, assume also that none of the registers begin with any values in them.
Then, before code generation for the basic block begins, the address descriptors for the variables and constants would be as follows:

Now assume that the following code is generated:LD 0,1(gp) load fact into reg 0LD 1,0(gp) load x into reg 1MUL 0,0,1
The address descriptors would now be
Variable/Constant Address Descriptors

And the register descriptors would be
Register Variables Contained

Now, given the subsequent codeLDC 2,1(0) load constant 1 into reg 2ADD 1,1,2
The address descriptors would become:Variable/Constant Address Descriptors
And the register descriptors would become:Register Variables Contained

End of Part TwoTHANKS