comparing supervised machine learning algorithms using weka & orange abhishek iyer
Post on 19-Dec-2015
229 views
TRANSCRIPT

Comparing Supervised Machine Learning
algorithms using WEKA & Orange
Abhishek Iyer

What is Machine Learning?
In 1959, Arthur Samuel defines machine learning as the field of study that gives computers the ability to learn without being explicitly programmed
A computer is said to learn by experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.
Why use machine learning ?

Applications of Machine Learning Today Bioinformatics
Cheminformatics
Data Mining
Character Recognition
Spam Detection
Pattern Recognition
Speech Recognition
Smart ADS
Game Playing and so on…….

Types of Machine Learning Algorithms
Supervised Machine Learning
Unsupervised Machine Learning
Semi Supervised Learning
Reinforced Learning
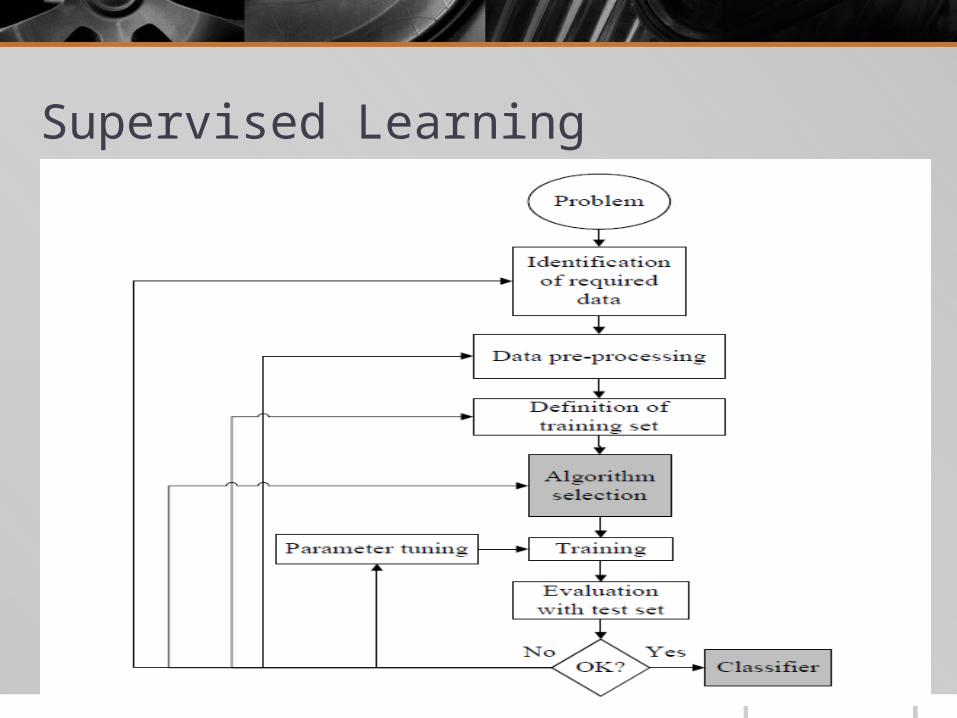
Supervised Learning

Sad state of affairs – Too many options Linear/ Polynomial Regression
Logistic Regression
K-nearest neighbor
Neural Nets
Decision Trees
SVM’s
Naïve Bayes
Inductive Logic Programming
………….

Purpose of research paper
The primary focus of this research paper will be on comparing supervised
learning algorithms.
Comparisons will be made between Decision trees, Artificial Neural
Networks, Support Vector Machines (SVM),Naïve Bayes, Logistic Regression
and k-nearest neighbor to decide which algorithm is the most efficient.
Research will also give us insight into the different domains where a certain
algorithm performs better than the others.
Will use WEKA ,Orange, TunedIT.org to compare the algorithms.

Data Sets Data Sets should enclose all possible fields of implementation and
not favor any algorithm
Primary source for getting the data sets -> UCI repository
Approximately 55-60 different data sets used during the entire
experiment
Used the cross validation option with 10 folds. This option
partitions the data sets into 10 sub samples.
Scalability

Method Followed
Select a data set
Select an algorithm
Generate confusion matrix and precision values for the algorithm – data set
pair using WEKA , Orange and tunedit.org
Repeat the procedure for each algorithm under consideration
Repeat the procedure for all the data sets
Compare my results with research material available
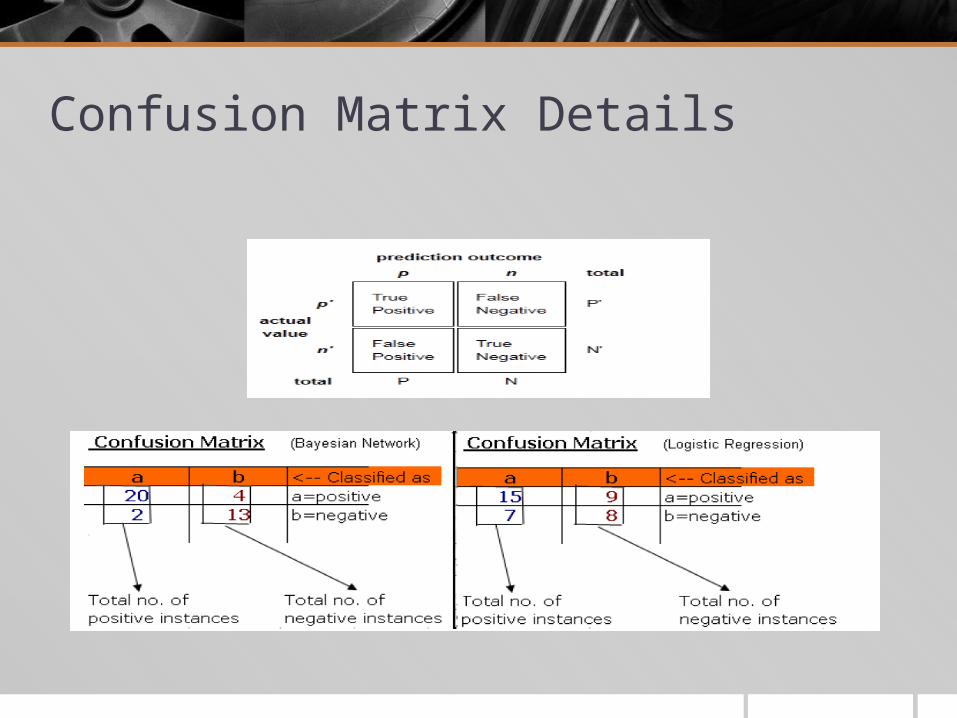
Confusion Matrix Details
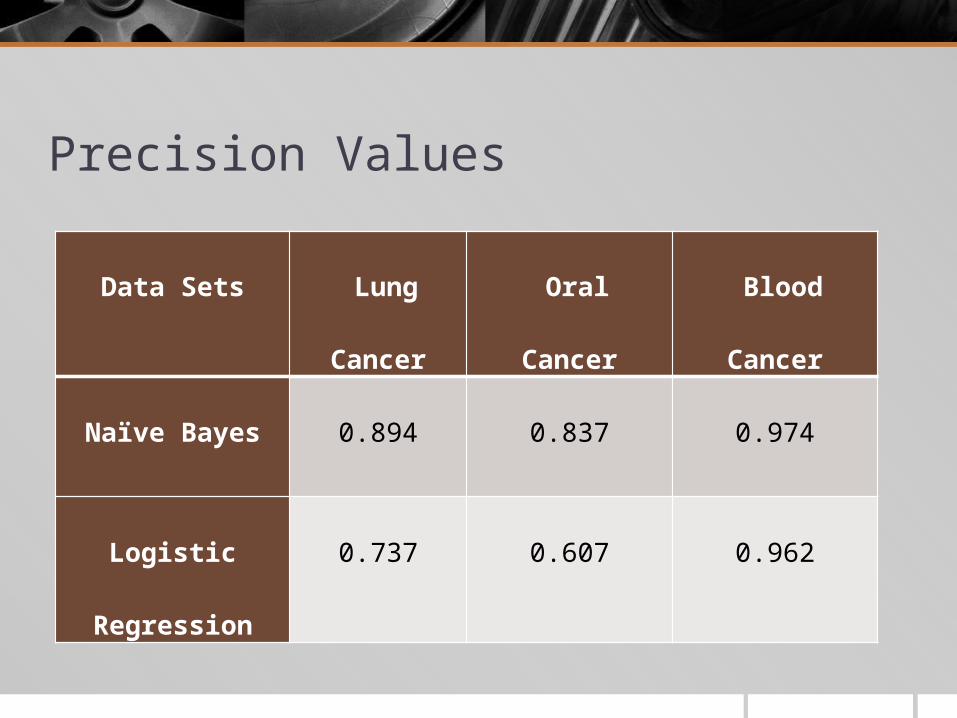
Precision Values
Data Sets Lung Cancer Oral Cancer Blood Cancer
Naïve Bayes 0.894 0.837 0.974
Logistic Regression 0.737 0.607 0.962
Demo
Boosting
Lift
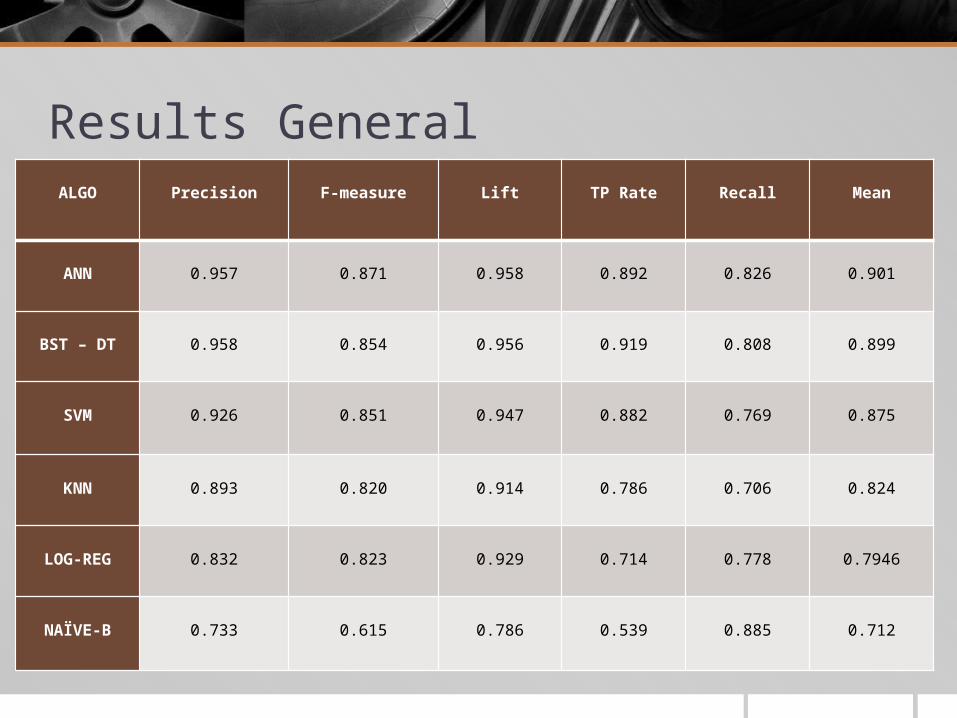
Results GeneralALGO Precision F-measure Lift TP Rate Recall Mean
ANN 0.957 0.871 0.958 0.892 0.826 0.901
BST – DT 0.958 0.854 0.956 0.919 0.808 0.899
SVM 0.926 0.851 0.947 0.882 0.769 0.875
KNN 0.893 0.820 0.914 0.786 0.706 0.824
LOG-REG 0.832 0.823 0.929 0.714 0.778 0.7946
NAÏVE-B 0.733 0.615 0.786 0.539 0.885 0.712
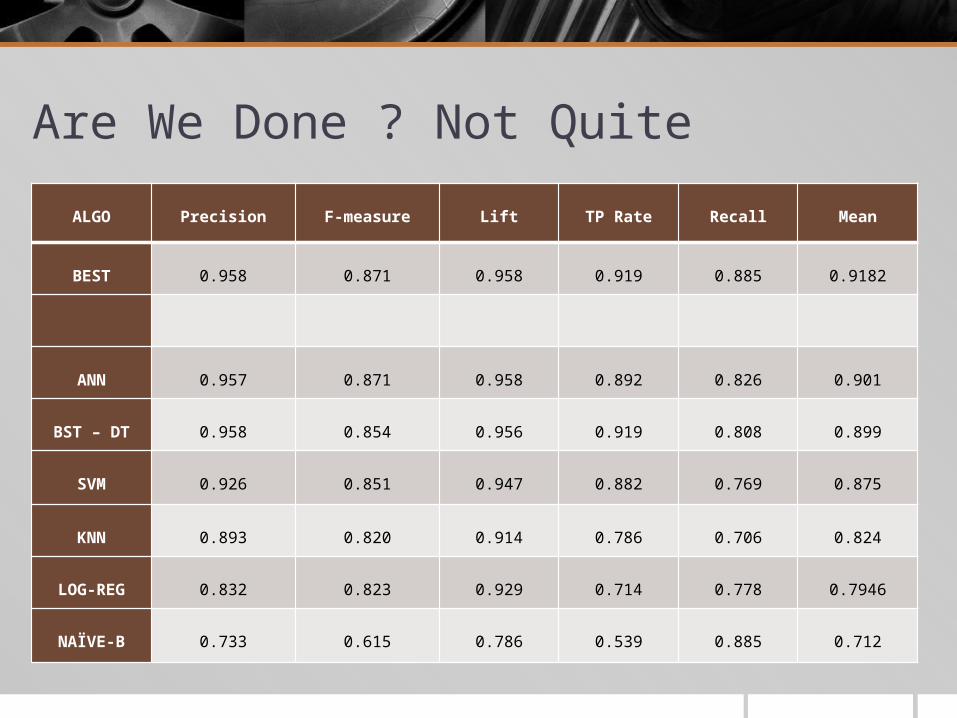
Are We Done ? Not QuiteALGO Precision F-measure Lift TP Rate Recall Mean
BEST 0.958 0.871 0.958 0.919 0.885 0.9182
ANN 0.957 0.871 0.958 0.892 0.826 0.901
BST – DT 0.958 0.854 0.956 0.919 0.808 0.899
SVM 0.926 0.851 0.947 0.882 0.769 0.875
KNN 0.893 0.820 0.914 0.786 0.706 0.824
LOG-REG 0.832 0.823 0.929 0.714 0.778 0.7946
NAÏVE-B 0.733 0.615 0.786 0.539 0.885 0.712
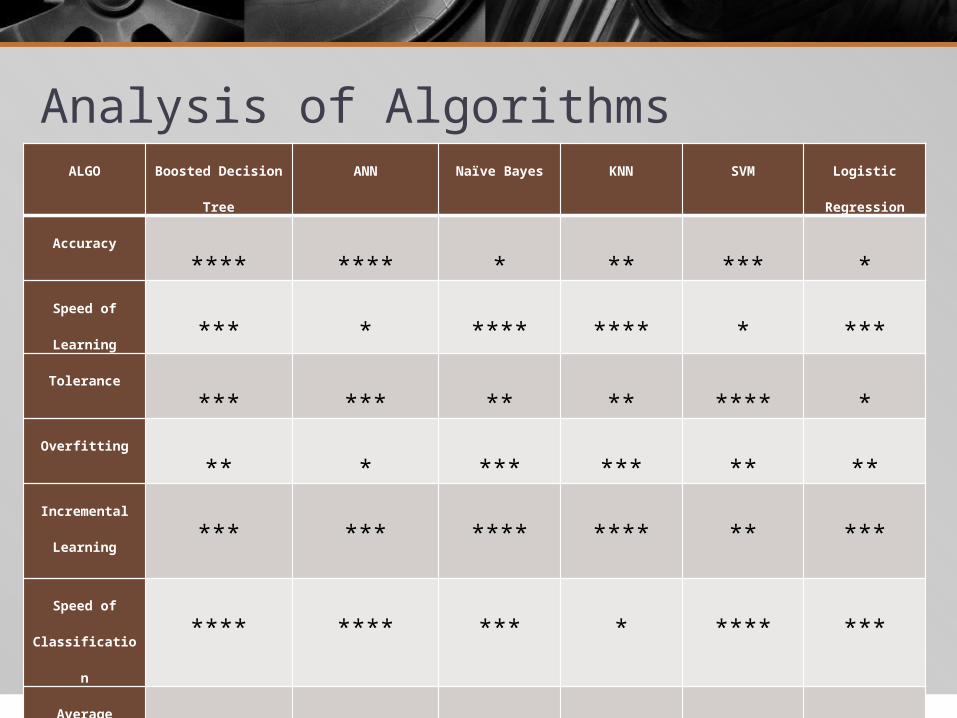
Analysis of AlgorithmsALGO Boosted Decision Tree ANN Naïve Bayes KNN SVM Logistic Regression
Accuracy**** **** * ** *** *
Speed of Learning*** * **** **** * ***
Tolerance*** *** ** ** **** *
Overfitting** * *** *** ** **
Incremental
Learning *** *** **** **** ** ***
Speed of
Classification **** **** *** * **** ***
Average 3.2 2.7 2.8 2.7 2.3 2.1
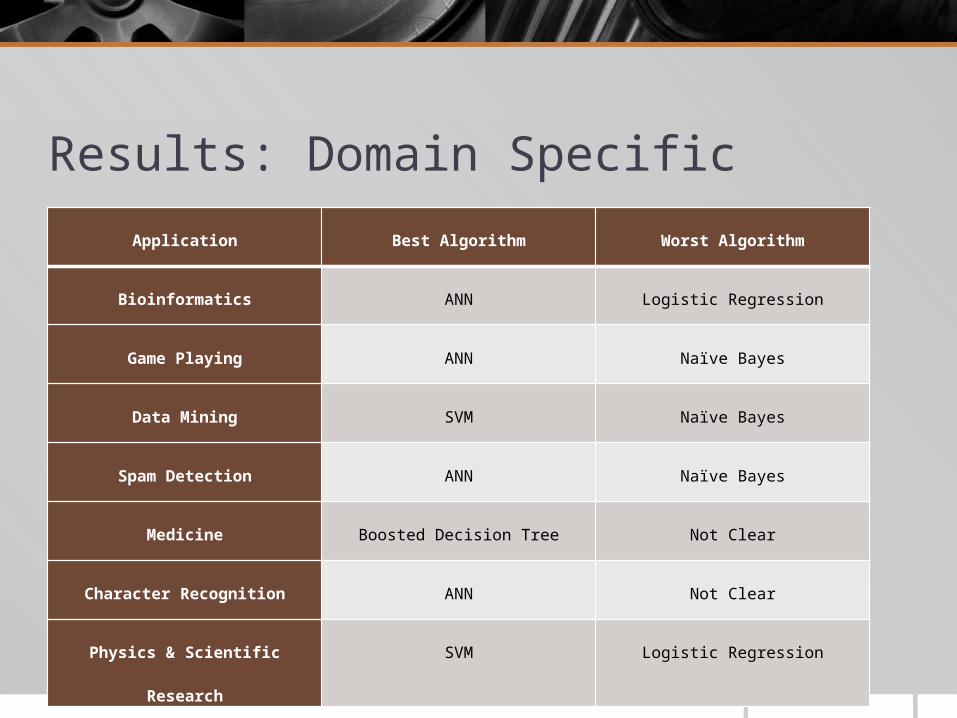
Results: Domain SpecificApplication Best Algorithm Worst Algorithm
Bioinformatics ANN Logistic Regression
Game Playing ANN Naïve Bayes
Data Mining SVM Naïve Bayes
Spam Detection ANN Naïve Bayes
Medicine Boosted Decision Tree Not Clear
Character Recognition ANN Not Clear
Physics & Scientific Research SVM Logistic Regression

Challenges Faced Enormous data
Understanding the machine learning algorithms
Type conversion to support .arff for WEKA and .tab or .si format for Orange
Overfitting : Model described random noise instead of the underlying
relationship due to an excessively complex model with too many parameters
Inductive Bias : Assumptions used to predict outputs, given inputs that were
not encountered in the training set
Class membership probabilities: Uncertainty in classification due to low
probabilistic confidence.

The Future The key question when dealing with Machine Learning is not whether a
learning algorithm is superior to others, but under which conditions a particular method can significantly outperform others on a given application problem.
After a better understanding of the strengths and limitations of each method, the possibility of integrating two or more algorithms together to solve a problem should be investigated.
Improve the running time of the algorithms
Possibly build a super powerful algorithm that could be used in every
domain and for any data set
Questions?

References Andrew.NG, " Machine Learning CS 229 ", Machine Learning Stanford
University 2009.
Rich Caruana and Alexandru Niculescu-Mizil, " An Empirical Comparison of Supervised Learning Algorithms", Department of Computer Science, Cornell University, 2006.
Yang.T,"Computational Verb Decision Trees" , Yang's Scientific Press, 2006
Rich Caruana and Alexandru Niculescu-Mizil, "Obtaining Calibrated Probabilities from Boosting Isotonic Regression.", Department of Computer Science, Cornell University, 2006.
Aik Choon Tan and David Gilbert, “An empirical comparison of supervised machine learning techniques in bioinformatics”, Department of Computer Science, University of Glasgow, 2003
Sameera Mahajani, “Comparing Data mining techniques for cancer classification”, Department of Computer Science, CSU Chico

Annotated Bibliography 1. Aik Choon Tan and David Gilbert, “An empirical comparison of supervised machine learning
techniques in bioinformatics”, Department of Computer Science, University of Glasgow, 2003
This paper presents the theory and research involved behind the application of supervised machine learning techniques to the field of bioinformatics and classification of biological data. The paper suggests with enough practical evidence that none of the supervised machine learning algorithms perform consistently well over the data sets selected. Observations in this paper show that a combination of machine learning techniques perform much better than the individual ones and the performance is highly dependent on the type of training data. The paper also suggests some important points to consider while selecting a supervised machine learning algorithm for a data set.
2. Rich Caruna and Alexandru Niculescu-Mizil, “An Empirical Comparison of Supervised Learning Algorithms”, Department of Computer Science, Cornell University, 2006
This paper performs a very detailed empirical comparison of ten machine learning algorithms using eight performance criteria considering a variety of data sets and well documented results. The paper suggests that calibrated boosted trees are the best supervised learning algorithm followed by Random forests, SVM’s and neural networks. The paper also talks about the various new supervised learning algorithms recently introduced and how they are more efficient than the older algorithms. The paper discusses the significant variations seen according to the various problems and metrics and evaluates the situations under which these kind of performance fluctuations occur.