classi cazione e previsione di sistemi complessi dinamici ... · classi cazione e previsione di...
TRANSCRIPT

Classificazione e Previsione di
Sistemi Complessi Dinamici:
Simulazione Basata su Agente e
Interaction Pattern
Tesi di Laurea
Laurea Specialistica in Informatica 2009
Relatore:
Chiar.mo Prof. Federico Bergenti
Correlatori:
Chiar.mi Prof. Mirco Nanni e Prof. Mario Paolucci
Studente:
Dott. Walter Quattrociocchi
Universita degli Studi di Parma
Dipartimento di Scienze Matematiche, Fisiche e Naturali

ii

Indice
1 Ringraziamenti 1
2 Complessita e Scienza 3
2.1 Un probabile problema epistemologico . . . . . . . . 3
2.2 Emergenza . . . . . . . . . . . . . . . . . . . . . . . . 4
2.3 L’interazione come una possibile chiave di volta? . . . 6
2.4 Scienze Cognitive . . . . . . . . . . . . . . . . . . . . 10
2.5 Sistemi Complessi Adattivi . . . . . . . . . . . . . . . 12
2.6 La Modellazione Della Realta . . . . . . . . . . . . . 15
3 I Sistemi Complessi 21
3.1 Sistemi Complessi . . . . . . . . . . . . . . . . . . . . 21
3.1.1 Proprieta dei Sistemi Complessi . . . . . . . . 23
3.2 Rappresentazione dei Sistemi Complessi . . . . . . . 29
3.3 La Dinamica dei Sistemi Complessi . . . . . . . . . . 32
3.4 Dalla Dinamica del Sistema Complesso alle Sue Entita
Costituenti . . . . . . . . . . . . . . . . . . . . . . . . 35
3.5 Stato dell’Arte nell’Analisi delle Reti Sociali . . . . . 40
3.6 Identificazione di un gruppo . . . . . . . . . . . . . . 43
iii

INDICE
3.7 Riduzionismo e Aspetti Cognitivi . . . . . . . . . . . 44
4 KDD nei Sistemi Complessi 49
4.1 Data mining . . . . . . . . . . . . . . . . . . . . . . . 49
4.1.1 Il Processo di Estrazione della Conoscenza . . 51
4.2 Il Modello Crisp-DM . . . . . . . . . . . . . . . . . . 53
4.2.1 KDD descrittivo e previsivo . . . . . . . . . . 56
4.3 Il Clustering . . . . . . . . . . . . . . . . . . . . . . . 59
4.3.1 Clustering . . . . . . . . . . . . . . . . . . . . 59
4.3.2 Tassonomia degli algoritmi di clustering . . . 61
4.4 La Classificazione . . . . . . . . . . . . . . . . . . . . 63
4.5 Interazione negli Agenti . . . . . . . . . . . . . . . . 64
5 Simulazione di Sistemi Complessi con i MAS 67
5.1 Stato dell’Arte dei MAS . . . . . . . . . . . . . . . . 67
5.1.1 Origine . . . . . . . . . . . . . . . . . . . . . . 67
5.1.2 I Sistemi Basati su Agenti . . . . . . . . . . . 68
5.1.3 Le Problematiche Dei Sistemi Multi Agente . 70
5.1.4 Architetture . . . . . . . . . . . . . . . . . . . 71
5.1.5 Categorie di Agenti . . . . . . . . . . . . . . . 73
5.1.6 Tassonomia . . . . . . . . . . . . . . . . . . . 74
5.1.7 Panoramica . . . . . . . . . . . . . . . . . . . 76
5.1.8 Linguaggi Imperativi . . . . . . . . . . . . . . 91
5.1.9 Approcci Ibridi . . . . . . . . . . . . . . . . . 93
5.1.10 Framework e Piattaforme ad Agenti . . . . . . 97
5.2 Stato dell’Arte della Simulazione Basata su Agente . 100
5.3 Simulazione Sociale . . . . . . . . . . . . . . . . . . . 103
iv

INDICE
6 Interazione nella Classificazione e Previsione dei Si-
stemi Complessi 107
6.1 Introduzione . . . . . . . . . . . . . . . . . . . . . . . 107
6.2 Modellando L’Interazione . . . . . . . . . . . . . . . . 109
6.3 Origini Metodologiche . . . . . . . . . . . . . . . . . 109
6.3.1 Modellando Dinamica e Interazione . . . . . . 111
6.4 Classificazione di Oggetti Mobili . . . . . . . . . . . . 112
6.4.1 Interaction Pattern . . . . . . . . . . . . . . . 112
6.5 Applicazione I: Individuare Guidatori Pericolosi . . . 117
6.5.1 Traiettorie di Veicoli . . . . . . . . . . . . . . 118
6.6 Calcolando IPS e Attributi di Traiettorie . . . . . . . 120
6.6.1 Selezione dei segmenti di interazione . . . . . 120
6.6.2 Calcolo dei descrittori di Interazione . . . . . 121
6.7 L’algoritmo . . . . . . . . . . . . . . . . . . . . . . . 123
6.7.1 Descrizione del Dataset . . . . . . . . . . . . . 124
6.7.2 Classificazione di Traiettorie . . . . . . . . . . 128
7 Valutazioni Sociali ed Incertezza: Modellazione, Si-
mulazione e Classificazione 131
7.1 Introduzione . . . . . . . . . . . . . . . . . . . . . . . 131
7.2 La teoria della Reputazione . . . . . . . . . . . . . . 132
7.2.1 Valutazioni Sociali . . . . . . . . . . . . . . . 133
7.3 Il modello ad Agenti: RepAge . . . . . . . . . . . . . 139
7.3.1 Simulare Sistemi Complessi Modellati Su Agenti142
7.3.2 Esperimenti: Scelta di Un Partner . . . . . . . 142
7.3.3 Datamining e la Simulazione Basata su Agente 144
7.3.4 Interaction: Agents Communication in Repage 145
7.3.5 Discussione sui Risultati . . . . . . . . . . . . 149
v

INDICE
7.3.6 Valutazioni Sociali ed Incertezza . . . . . . . . 149
7.3.7 Valutazioni Sociali e False Informazioni . . . . 151
7.3.8 Simulazioni e Risultati . . . . . . . . . . . . . 155
8 Conclusioni 163
Bibliography 169
vi

Elenco delle figure
6.1 Ideal neighborhood of single point (a) and neighbo-
rhood for a time window (b) . . . . . . . . . . . . . . 122
6.2 Fixed grid neighborhood . . . . . . . . . . . . . . . . 122
6.3 Macro and micro interaction descriptors . . . . . . . 123
6.4 A Real View of the Highway . . . . . . . . . . . . . . 125
6.5 Sample of the US101 dataset . . . . . . . . . . . . . . 128
7.1 Architettura Repage . . . . . . . . . . . . . . . . . . 141
7.2 Trend of Idontknow answers in L1 and L2 . . . . . . 151
7.3 Distribution of Good Image and Good Sellers Disco-
very in L1 . . . . . . . . . . . . . . . . . . . . . . . . 152
7.4 Distribution of Good Image and Good Seller Discove-
ry in L2 . . . . . . . . . . . . . . . . . . . . . . . . . 153
7.5 Answers Given with a motivation of Bad Reputation 154
vii

ELENCO DELLE FIGURE
7.6 Global quality with increasing number of cheaters.
The curves represent quality in the stabilised regime
for L1 and L2. Until cheaters remain below the th-
reshold of 60% reputation allows for quality to rea-
ch higher values than happens in the complementary
condition. The truth circulates faster providing social
evaluations which are coherent with the reality. Co-
herence between information and reality, shared by
a larger amount of agents in L2, increases the trust
and the market is more efficient. Over the threshold
of 60%, false information floods in, hence social eva-
luations, circulating faster with reputation, are often
distorted with respect to reality. . . . . . . . . . . . . 158
7.7 Simulation Results in L1 and L2 with 0% of Cheaters
for 100 turns . . . . . . . . . . . . . . . . . . . . . . . 159
7.8 Simulation Results in L1 and L2 with 60% of Cheaters
for 100 turns. (a) Quality. The two curves represent
Quality with Image (L1) and with both Image and
Reputation (L2) when the number of cheaters inhibits
the good effect of Reputation. Reputation and Image
are on the same levels. (b) Good Sellers Discovered.
The two curves are average values of Good Sellers
found out for each simulation turn. (c) “i don’t know”
answers. The two curves are average values of “i don’t
know” answers for each simulation turn. The L2 curve
shows the ability of reputation in reducing uncertainty.160
viii

ELENCO DELLE FIGURE
7.9 Simulation Results in L1 and L2 with 100%
of Cheaters for 100 turns. (a) Quality. The two
curves represent Quality with Image (L1) and with
both Image and Reputation (L2) when there are on-
ly cheaters. Image performs better.(b) Good Sellers
discovered. The two curves shows the average values
of Good Sellers found out for each simulation turn.
In L2 more good sellers are discovered. (c) “i don’t
know” answers. The two curves are average values
of “i don’t know” answers for each simulation turn.
The L2 curve shows the ability of reputation in redu-
cing uncertainty also when the positive effects of re-
putation on the quality are neutralized and only false
information circulates. . . . . . . . . . . . . . . . . . 161
ix

ELENCO DELLE FIGURE
x

Elenco delle tabelle
6.1 Threshold values for descriptors . . . . . . . . . . . . 127
6.2 Perfomances on training set and cross-validation . . . 129
7.1 Experiments Settings . . . . . . . . . . . . . . . . . 150
xi

ELENCO DELLE TABELLE
7.2 Experiment Settings. The simulation settings which
remains the same for all the experiments. The scena-
rio is investigated for increasing number of cheaters
starting in absence of false information (0%) to arrive
with all the population composed by cheaters (100%).
Each scenario is characterized by an increasing rate
of 10% of the number of cheaters until the 60%, after
that, for a better investigation of the social evaluation
and information trustworthy phenomena the interval
of 10% is reduced to 5%, for a total of 28 simulated
scenarios. The table parameters are: the number of
buyers NB, the number of sellers NS, C the number
of cheaters, the stock for each seller S, GS the good
sellers (sellers providing the maximum quality) and
BS the bad sellers. Both the settings are simulated
with only image circulating (L1) and with both image
and reputation (L2). . . . . . . . . . . . . . . . . . . 157
xii

Capitolo 1
Ringraziamenti
L’evoluzione che genera l’uomo, un insiginificante essere che vaga
nell’universo, frutto di un caso con una probabilita di reificazione
quasi nulla, ma che dal caso e in grado di osservarsi e l’evoluzione
stessa si osserva attraverso di lui. Ad una specie di miracolo. A chi
lo ha creduto possibile, a chi non ci ha creduto.
Quattro anni di odissea, da qui ad Helsinki, passando per Halifax.
Ad un viaggio che ha avuto i suoi sacrifici. Dall’essere ridotti in uno
schema, alla continua ricerca di un qualcosa di non riduzionista, ad
una risposta che non nasconda la complessita.
A Daniela, sempre e comunque, per la pazienza, l’ansia, la gioia,
la paura, la condivisione anche negli stati di paranoia. Per la spe-
ranza. Per la vita. A Elena per l’essere guru, per la fiducia continua,
per il credere, per la serendipity e per tutto il resto. Senza di lei non
sarei qui ora. A Mirco per le ore spese a ragionare e lavorare agli
Interaction Pattern. A Mario per supportare deliri e per la grinta.
A Rosaria per la continua iniezione di fiducia, per la pazienza, per
1

Ringraziamenti
la sua apertura mentale e capacita empatica e per la pazienza nei
deliri. A Fosca per la possibilita. Ai miei e a Miriam per la costan-
za e nella continua dialettica critica/sprone. A Markus, che ora ci
dovrebbe proprio essere, ma ha preferito altrimenti.
A Maria Miceli, Rino Falcone, Federico Cecconi per la diponibi-
lita. A Michele Pinna per la gentilezza, forse ne e l’incarnazione.
A Gianfranco Rossi per il sostegno e le strategie. A Federico
Bergenti per la chiarezza. A Grazia Lotti per la materna dedizione.
A Roberto Bagnara per la determinazione.
A tutti quelli da cui ho stratto spunto sul come non essere, ma
che per motivi, non solo, di spazio non sono nominati.
Al progetto Erep. Al LABSS. All’ISTC.
Tutti hanno lasciato un’impronta indelebile, su una storia, una
delle tante. Si riflette in ogni passo, in ogni atto, cerchero di farne
tesoro e di rifletterla nella futura produzione scientifica e non solo.
Grazie.
Es muss sein.
2

Capitolo 2
Complessita e Scienza
Solo un’Intelligenza superiore che conoscesse in un dato istante
posizioni, velocita e forze agenti relative a tutti i corpi dell’universo
potrebbe, per via analitica, determinare con precisione assoluta il
comportamento passato e quello futuro della macchina del mondo
2.1 Un probabile problema epistemolo-
gico
Negli ultimi anni si va sempre piu affermando, data la sempre mag-
giore complessita dei problemi scientifici, la necessita di un paradig-
ma epistemologico che vada oltre il modello analitico classico, che da
un lato ha fornito valido supporto all’avanzamento scientifico, ci si
deve anche interrogare sulla sua capacita di rappresentare pienamen-
te le entita dei sistemi di indagine e le sue dinamiche, soprattutto
come si sono presentati in questi ultimi anni.
3

Complessita e Scienza
Dalle problematiche relative alla genomica, ai sistemi meterologi-
ci, passando per i sistemi sociali fino ad arrivare alle neuroscienze, e
sempre piu chiara la sensazione che il paradigma di indagine presen-
ta dei limiti: (i) limiti concettuali di rappresentazione poiche rimane
molto difficile modellare un sistema ed i legami che intercorrono tra
tutte le sue componenti; (ii) limiti economici, in quanto lındagine
sperimentale e cresciuta nei costi in maniera spaventosa di paripasso
con il progredire scientifico che sempre di piu si e trovato ad af-
frontare problematiche con alti livelli di incertezza, dove le relazioni
fondanti tra le componenti cambiano con il tempo e nel tempo, cam-
biando a loro volta la natura stessa del sistema rendendo di fatto
molto difficile la validazione sperimentale.
In questo lavoro non ci si pone davanti all’approccio analitico
classico in maniera antagonista, ma si cerca di proporre un comple-
tamento metodologico che provveda a raffinare e potenziare i limiti
che si vanno man mano presentando.
2.2 Emergenza
Uno dei pi importanti passi scientifici teorici fondativi a nostro avviso
risiede nel concetto di emergenza, che Fracisco Varela in una delle
sue ultime interviste ([1]) illustra in una maniera quasi elementare,
ma al contempo straordinariamente ficcante:
“[..] Come dev’essere intesa al nozione di emergenza? Ancora
una volta bisogna gettare uno sguardo sulla storia, perch si tratta di
una nozione che proviene dalla fisica, che, dall’inizio del secolo, si e
sviluppata assieme alla fisica. Proviene dall’osservazione delle transi-
4

2.2 Emergenza
zioni di fase o transizioni di stato o per dirlo piu chiaramente di come
si passa da un livello locale a un livello globale. Faccio un esempio
banale. Sono in circolazione [nell’atmosfera] innumerevoli particelle
d’aria e d’acqua e tutt’a un tratto per un fenomeno di autoorganizza-
zione - questa e la parola chiave - diventano un tornado, un oggetto
che apparentemente non esiste, non ha vera esistenza, perch esiste
soltanto nelle relazioni delle sue componenti molecolari. Nondimeno
la sua esistenza e comprovata dal fatto che distrugge tutto quello che
incontra sul suo passaggio. Dunque e un curioso oggetto. La nozione
di emergenza ha avuto molti sviluppi teorici e in biologia si trova che
i fenomeni di emergenza sono assolutamente fondamentali. Perche?
Perche ci permettono di passare da un livello piu basso a un livello
piu alto, all’emergenza di un nuovo livello ontologico. Quello che
era un ammasso di cellule improvvisamente diventa un organismo,
quello che era un insieme di individui puo diventare un gruppo socia-
le, quello che era un insieme di molecole puo diventare una cellula.
Dunque la nozione di emergenza e essenzialmente la nozione che ci
sono in natura tutta una serie di processi, retti da regole locali, con
piccole interazioni locali, che messi in condizioni appropriate, dan-
no origine a un nuovo livello a cui bisogna riconoscere una specifica
identita. Qui la parola identita e importante. Quando si parla di
una certa identita cognitiva [..]”
Ci ritroviamo in una teorizzazione che esclude a priori ogni cen-
tralizzazione e ripartizione dell’interazione che indissolubile dal con-
cetto stesso di evoluzione a sua volta dipendente strettamente dall’e-
quilibrio. L’interazione esiste in quando manifestazione fenomeno-
logica della combinazione di determinati fattori, riconducibili a loro
volta in termini di interazione.
5

Complessita e Scienza
Sempre in termini di interazione si verifica un’emergenza che por-
ta ad un cambiamento di stato del sistema stesso, ma nel sistema
stesso in quanto si ha una chiusura operazionale del sistema in se
stesso. L’emergenza e la nozione che dati alcuni processi in un uni-
verso, retti da regole locali e mossi da piccole interazioni locali, che
messi in condizioni appropriate danno origine ad un nuovo livello a
cui bisogna riconoscere una specifica identita.
Si evidenzia per tanto, la necessita evolutiva del sistema stesso
in base ad un determinato verificarsi di una o piu emergenze che
pu sfociare in uno stato di organizzazione gerarchicamente superio-
re nella struttura di incapsulamento. I fenomeni di emergenza sono
necessariamente non lineari, quindi non prevedibili poich fortemente
caotici, di conseguenza di presuppone una risposta in ambito di rea-
zione evolutiva sia ontologica sia di organizzazione della struttura
sociale del sistema. Senza una rivisitazione del concetto stesso di
evoluzione, classificazione e correlazione. L’ontogenesi - cioe la sto-
ria delle trasformazioni di un unita come risultato della storia delle
interazioni, a partire da una sua struttura iniziale - e sempre legata
al divenire di continue interazioni che, in modo dinamico, indirizza-
no, mantengono o cambiano il suo particolare sviluppo. In pratica il
sistema e definito dalla sua stessa dinamica di interazione.
2.3 L’interazione come una possibile chia-
ve di volta?
Fayerabend, in “Against Method” [2] sostiene che ci sono periodi
storici in cui il paradigma scientifico viene sovvertito e ribaltato,
6

2.3 L’interazione come una possibile chiave di volta?
perche esaurisce la sua validita nel momento in cui non e piu in
grado di spiegare in maniera ferrea i fenomeni.
Dal momento che i fenomeni si sono fatti piu complessi sia per
l’ingrandirsi dello spettro di indagine, sia per l’aumentare dell’incer-
tezza e del rumore ci si e resi conto della sempre maggiore necessita
di presentare in maniera adeguata modelli funzionali esplicativi da
utilizzare nel processo scientifico.
Definition 1 (Modello) Un modello e’ una rappresentazione della
realta’ che ridotta in alcune delle sue componenti puo’ essere spiegato
attraverso formalismi di tipo logico o matematico.
La parola chiave che fa cadere completamente la validita del pa-
radigma sta nel “ridurre”. La discussione in oggetto in questo lavo-
ro e incentrata sulla domanda - Riducendo un sistema, che per sua
natura presenta componenti complesse ed interconnesse, quanto pre-
serviamo della sua reale natura senza tralasciarne dettagli che sono
fondamentali per il sistema stesso?
A questa domanda, cercheremo di dare una risposta attraverso
una metodologia elaborata nel corso degli anni che tenta proprio
di fornire strumenti di indagine scientifica, non in conflitto con il
modello analitico tradizionale, ma di supporto e completamento.
Negli anni oltre alla complessita dei problemi e cresciuta anche
la nostra conoscenza sulla natura dei fenomeni e sulle loro proprieta.
Sono stati individuati concetti teorici fondativi come la relativita o lo
stesso concetto di emergenza. Sono state sviluppate anche molte tec-
niche di indagine: dall’impiego sempre pi massivo della simulazione,
all’annoverarsi continuo di nuove tecniche per l’analisi di grandi moli
di dati. La metodologia proposta in questo elaborato nasce proprio
7

Complessita e Scienza
dalla commistione tra un particolare tipo di simulazione, quella ba-
sata su agente, e su una recentissima tecnica di indagine dei sistemi
complessi che prende il nome di interaction pattern.
Bruce Edmonds in [3], dice che la modellazione basata su agente
permette di modellare sistemi suddividendoli in componenti auto-
nome ed interagenti, che nel loro interagire danno, dinamicamente,
vita alla completezza del sistema senza perderne le sue componenti
centrali; in questo modo diventa anche possibile studiare l’emergen-
za. Dal fronte datamining si e andata sviluppando in questi ultimi
cinque anni, una metodologia che si fonda sull’idea di classificare e
predire sistemi, non in base ai loro attributi ma in base alle loro inte-
razioni con le altre componenti: l’entita non e intesa come entita in
quanto tale, ma come somma di variazione di interazioni che variano
nel tempo [4]. Il guidatore pericoloso si riconosce per la sua mag-
giore velocita rispetto agli altri, o per il suo variare continuamente
traiettoria, piu precisamente in base al suo modo di interagire con
gli altri elementi del sistema, ambiente compreso.
Un sistema complesso e composto da entita autonome che intera-
giscono tra loro dando vita alla dinamica del sistema stesso; d’altro
canto se il sistema non avesse dinamica sarebbe statico, e di conse-
guenza facile da modellare e la necessita di nuovi strumenti per la
modellazione verrebbe a mancare. Si presenta sotto questa prospet-
tiva un doppio processo di interazione da un lato le azioni dell’indi-
viduo e le sue conseguenze, dall’altro la percezione della variazione
dell’ambiente; a legarle la sensibilit dell’ambiente alle azioni degli
agenti. Siamo difronte ad un ciclo di interazioni ricorsivo che dalla
percezione passa all’azione, e da questa alla modifica della perce-
zione. L’elaborazione delle informazioni, il trasformarle in credenze
8

2.3 L’interazione come una possibile chiave di volta?
l’agire, il variare di stato che inficiano dal singolo su tutto il sistema
e dalla somma di queste emerge il comportamento, la dinamica del
sistema stesso, che a sua volta si immerge nuovamente sugli indivi-
dui vincolandone e condizionandone le azioni e le possibili opzioni di
azione.
L’interazione secondo i nostri studi teorici la possibile chiave,
essa si propaga nel sistema, e a sua volta genera effetti e cambia-
mente attraverso l’interconnessione, ed inficia sul sistema stesso e
da origine ai fenomeni emergenti ed allo stesso tempo ne la compo-
nente atomica. Tracciare e studiare i sistemi complessi come somma
di variazioni di interazioni dei singoli individui durante il tempo e
studiarne i pattern frequenti per poi modellarli o viceversa.
Rispetto alla programmazione ad oggetti, la programmazione e
quindi i modelli computazionali ad agenti, non si fondano su una
computazione che consiste nella comunicazione tra oggetti che tra
loro cambiano il valore delle loro variabili interne; ma negli agenti
vi e un passo in piu’, un passo fondamentale: la computazione e
un’interazione tra due entita autonome dotate di un loro stato in-
terno, di percettori, di attuatori e di apparati cognitivi in grado di
trasformare le percezioni ed elaborarle e quindi poi di agire. Unendo
le peculiarita della modellazione computazionale basata su agente
ad opportune tecniche di datamining si puo forse rispondere al pro-
blema degli strumenti per l’indagine dei sistemi complessi dinamici.
La metodologia che si va a delineare in questo documento nasce pro-
prio dall’idea di unire la classificazione basata su interazione, che
passa sotto il nome di “Interaction Pattern” e di modellare e simu-
lare fenomeni particolarmente complessi e dispendiosi da indagare
altrimenti, attraverso la simulazione basata su agente, che fonda il
9

Complessita e Scienza
suo paradigma computazionale sul concetto di interazione tra entit
eterogenee ed autonome: un sistema complesso per l’appunto.
2.4 Scienze Cognitive
L’interazione ben studiata ed approfondita nelle scienze cognitive
[5] [6], ed considerata il mezzo tramite cui si istanzia la dinamica di
un sistema. Oltretutto la cognizione strettamente connessa ad uno
dei sistemi complessi piu affascinanti ovvero il cervello. Nella cogni-
zione si riflette anche il paradigma scientifico, ovvero nell’uomo che
risiede la struttura che tende al processo scientifico, che tende alla
classificazione. Affrontare i sistemi complessi attraverso la struttura
del processo cognitivo. E l’uomo che attraverso la scienza studia se
stesso e le sue origini, il frutto di un sistema complesso che l’evo-
luzione, che a sua volta ha generato un sistema complesso capace di
manipolare simboli astratti, di comunicare, di produrre.
Le scienze cognitive, secondo la definizione proposta da [7], hanno
come oggetto di studio la cognizione, cioe’ la capacita di un qualsiasi
sistema, naturale o artificiale, di comunicare a se stesso e agli altri
cio che conosce. La natura di
questa capacita e stata, in vari modi, investigata da psicologi,
filosofi, informatici,
economisti, linguisti, antropologi e biologi. Queste discipline han-
no una loro storia consolidata e metodi di studio collaudati. Le scien-
ze cognitive non sono la semplice somma di questi saperi, bens la con-
fluenza degli studi di molte discipline su alcuni problemi specifici: i
processi cognitivi.
10

2.4 Scienze Cognitive
E’ importante la terminologia utilizzata, e diverso parlare di
“scienza cognitiva” al singolare o di “scienze cognitive” al plurale.
Per “scienza cognitiva” in senso stretto si intende lo studio di un
qualsiasi sistema, naturale o artificiale, che sia in grado di filtrare e
ricevere informazioni dall’ambiente circostante (percezione e selezio-
ne delle informazioni), di rielaborarle creandone di nuove (pensiero),
di archiviarle e cancellarle (ricordo e oblio), di comunicarle ad altri
sistemi naturali o artificiali e, infine, di prendere decisioni e di agire
nel mondo adattandosi ai suoi cambiamenti (decisione e azione) e
adattando il mondo a se stesso grazie alla creazione di artefatti.
Per “scienze cognitive” si intende un campo di studio assai piu
ampio che comprende tutto cio che ha a che fare con la capacita
creativa dell’uomo e con gli artefatti da lui creati. I processi co-
gnitivi rivestono una importanza cruciale nella comprensione delle
dinamiche dei sistemi socio-economici. Proprio attraverso i processi
cognitivi gli agenti economici possono apprendere le informazioni ne-
cessarie per prendere decisioni economiche. Si puo parlare di appren-
dimento ogni qual volta un agente economico ha una comprensione
imperfetta o incompleta del mondo in cui opera, per diversi motivi:
(i) per la mancanza di parte dell’informazione rilevante per le sue
decisioni, (ii) a causa di un’imperfetta conoscenza della struttura
del mondo, (iii) Perche dispone di un repertorio di azioni limitato
rispetto a quelle virtualmente accessibili ad un decisore onniscien-
te, (iv)Perche ha una conoscenza imprecisa e parziale dei propri
obiettivi e delle proprie preferenze. L’apprendimento viene definito
come il processo dinamico di modificazione di tale conoscenza. Le
scienze cognitive studiano le varie forme di sapere tacito e esplicito
che viene generato dalle organizzazioni. Cos come l’individuo non
11

Complessita e Scienza
e consapevole dei suoi meccanismi cognitivi, le organizzazioni non
sempre posseggono un sapere codificato del loro modo di compor-
tarsi e decidere. La questione e stata studiata anche in funzione dei
suoi risvolti applicativi: essendo i saperi taciti1 molto piu difficili
da trasferire di quelli codificati, le scienze cognitive possono fornire
gli strumenti per comprendere come avviene questo difficile proces-
so. Le scienze cognitive, infine, non si occupano solo di studiare i
meccanismi cognitivi della mente, ma hanno cercato di trasferire la
nozione di adattamento, che e cruciale per comprendere l’evoluzione
naturale della specie, allo studio dei sistemi complessi. Per questo
motivo fanno parte delle scienze cognitive lo studio degli algoritmi
genetici, dei sistemi classificatori e, piu in generale, delle simulazioni
agent-based.
2.5 Sistemi Complessi Adattivi
I sistemi complessi adattivi sono stati studiati da Holland ([8]), che
li definisce: gruppi di agenti legati in un processo di co-adattamento,
in cui le mosse di adattamento di ciascuno hanno conseguenze per
l’intero gruppo di individui. Holland ([8]), mostrava che, sotto deter-
minate condizioni, modelli semplici presentano sorprendenti capacita
di auto-organizzazione. I sistemi complessi sono strettamente corre-
lati con i sistemi non lineari. La definizione di sistema non lineare
di Holland afferma che: un sistema non lineare e un sistema il cui
comportamento non e uguale alla somma delle singole parti che lo
compongono. Se, dunque, per studiare i sistemi lineari, si procede
alla loro scomposizione ed allo studio analitico di ciascuna delle sue
12

2.5 Sistemi Complessi Adattivi
parti, questo non pu‘ avvenire per lo studio dei sistemi non lineari. Il
comportamento di tali sistemi, infatti, dipende dall’interazione delle
parti, piu che dal comportamento delle parti stesse. Occorre quin-
di considerare il sistema non lineare come un tutto non uguale alla
somma delle parti e, dunque, occorre focalizzarsi sulle dinamiche di
interazione fra gli elementi che compongono il sistema. I fenome-
ni complessi non possono essere studiati con strumenti matematici
tradizionali, ma si possono analizzare osservando l’interazione degli
elementi del sistema, nel tentativo di scorgere una qualche coeren-
za. Questo tipo di coerenze, tipiche dei sistemi complessi, vengono
definite “fenomeni emergenti”.
Il termine “complesso” non e sinonimo di “complicato”, nell’ac-
cezione di difficile.
Per complessita si intende un fenomeno matematicamente defi-
nibile o un aggregato organico e strutturato di parti tra loro inte-
ragenti, che assume proprieta non derivanti dalla semplice somma
delle parti che lo compongono. Come esempio si immagini il motore
di un’automobile, composto da molti meccanismi, anche sofisticati.
Il motore viene definito “macchina banale” perche il suo funziona-
mento, per quanto difficile e complicato, e il frutto della somma tra
le parti che lo compongono, e puo essere studiato e scomponendolo
in queste parti. In contrapposizione al motore immaginiamo il formi-
caio’, un insieme di formiche che interagendo tra loro sono in grado
di mantenere, per esempio, la temperatura all’interno del formica-
io su valori costanti e con minime variazioni tra estate e inverno. Il
formicaio e un sistema complesso perche ogni singola formica non co-
nosce il meccanismo di regolazione termica dell’ambiente circostante
ma, semplicemente dall’interazione di molte formiche, si manifesta
13

Complessita e Scienza
un fenomeno “complesso”. In questo secondo caso non e possibile
studiare il formicaio studiando il comportamento delle singole formi-
che. Mentre le scienze naturali pure sono in grado di prevedere nel
dettaglio gli eventi, le scienze dei fenomeni complessi possono solo
azzardare un orientamento. Bisognerebbe comunque [9] mantenere
la consapevolezza dello scarso potere predittivo dell’econometria che,
limitando i fattori esplicativi solo a quelli misurabili, ha portato agli
insuccessi dell’interventismo macroeconomico keynesiano.
I sistemi sociali sono dunque sistemi complessi, cioe sistemi nei
quali molte cause concorrono a creare un solo effetto e, nei quali, le
relazioni fra le cause stesse sono non lineari, nel senso che l’effetto di
ogni singola causa non e indipendente da quello delle altre, per cui
non puo essere isolato.
I sistemi complessi sono generalmente composti da agenti che
interagiscono; ogni individuo interagisce solo con un ristretto numero
di altri individui e, da queste interazioni locali, emergono fenomeni
globali complessi, che non sono ipotizzabili a priori, pur conoscendo
i singoli elementi ed i legami di interazione che intercorrono fra loro.
La cosiddetta “teoria del tutto” non e quindi sufficiente a spiegare i
fenomeni complessi perce il “tutto” non e la semplice somma delle
sue parti.
Un sistema complesso viene definito da Arthur et al. (1997) [10]
come un sistema che possieda le seguenti caratteristiche:
1. La dinamica del sistema non deve avere un equilibrio globale.
2. Deve esistere interazione diffusa tra gli agenti del modello.
3. Non deve esistere un controllo centralizzato del modello.
14

2.6 La Modellazione Della Realta
4. Si deve creare una gerarchia a livelli con interazioni reciproche.
5. Gli agenti devono imparare ed evolversi in funzione dell’am-
biente e delle loro interazioni.
Come risultato di tali proprieta si ottiene un ambiente caratte-
rizzato da razionalita limitata e da aspettative non razionali. Per
affrontare i “fenomeni complessi” puo essere utile la teoria dell’ “in-
dividualismo metodologico”. Non potendo avere informazioni com-
plete su stato e circostanze in cui si trovano i singoli elementi sociali,
mentali o biologici, si ipotizza che essi si muovano a livello micro
in base a certi principi: razionalita orientata allo scopo o al valore;
significativita delle connessioni tra neuroni o ricerca della soprav-
vivenza. Ipotizzando alcuni meccanismi causali tra i singoli micro
elementi , si immagina una metodologia di ricerca che conduca a
predire l’emergere a livello macro di certi tipi di “fenomeni comples-
si” nella loro forma astratta di “modelli” (patterns). Questi modelli
sono i modelli simulativi.
2.6 La Modellazione Della Realta
I fenomeni complessi sono difficilmente studiabili con gli stessi stru-
menti utilizzati per i sistemi semplici, come calcoli matematico-
statistici e sperimentazioni in laboratorio. Il motivo risiede nel gran-
dissimo numero di variabili che si dovrebbero manipolare, che risul-
terebbe non gestibile con equazioni matematiche. I sistemi complessi
hanno anche delle componenti dinamiche di imprevedibilita e caoti-
che, che gli strumenti tradizionali hanno difficolta ad affrontare. Le
15

Complessita e Scienza
simulazioni, e in particolare le simulazioni condotte mediante mo-
delli ad agen- ti adattivi, rappresentano il principale strumento per
lo studio di fenomeni complessi tipici delle scienze sociali. Con il
termine simulazione sociale si definisce dunque l’utilizzo di modelli
di teorie esplicite cerati ed eseguiti con l’ausilio del computer. Lo
scopo e ricreare e studiare aspetti essenziali della socialita e delle so-
cieta naturali, siano esse umane, animali o artificiali. Per agente si
intende l’unita di popolazione osservata: una popolazione puo essere
una societa umana, una specie animale, un’azienda o, per esempio,
una catena di fornitura. La simulazione puo essere divisa in due fasi
distinte:
1. La “modellizzazione”, ossia l’ideazione e la costruzione concet-
tuale del modello da simulare.
2. La “creazione” vera e propria del programma di simulazione
con il supporto di strumenti informatici.
Le scienze tradizionali utilizzano un processo di “analisi” dei fe-
nomeni, mentre le simulazioni sono una tecnica di “sintesi” dei feno-
meni. Analizzare i fenomeni significa partire dalla realta, dividerla
nei suoi componenti e poi ricostruire i fenomeni reali mettendo in-
sieme queste componenti mediante la teoria e il ragionamento. Le
simulazioni seguono invece la via della “sintesi” della realta, dove
sintesi vuol dire partire dalle componenti per studiare cosa emerge
quando queste componenti vengono messe insieme e fatte interagire.
I modelli cos creati partono dalla descrizione dei singoli componenti
semplici, che vengono fatti interagire nel computer, producendo il
sistema complesso oggetto della teoria. Le simulazioni non servono
16

2.6 La Modellazione Della Realta
soltanto a scoprire quali predizioni empiriche si possono derivare da
una teoria una volta che la teoria e stata formulata e realizzato il pro-
gramma per eseguirla nel computer. Le simulazioni servono anche
per elaborare le teorie, per esplorarne e valutarne le caratteristiche
e le implicazioni mentre le si sta ancora costruendo. Piu specifica-
mente con le simulazioni diventa possibile sviluppare e valorizzare
un metodo di ricerca che viene usato in modo implicito e spesso
inconsapevole in tutte le scienze: il metodo degli esperimenti men-
tali. La simulazione viene definita da [11] un “esperimento mentale
assistito dal computer”. Il computer viene utilizzato per assistere
il ricercatore nella costruzione degli esperimenti mentali, ma questo
non significa che lo scienziato non continui ad elaborare teorie con
metodi tradizionali, per confrontarle con i risultati degli esperimenti
al computer. Il ricercatore che utilizza le simulazioni finisce per ela-
borare la teoria insieme alla simulazione, con un continuo processo
di prove ed errori, che si sviluppa in parte nella mente del ricercatore
e in parte nella simulazione. I principali vantaggi delle simulazioni
al computer rispetto a tecniche sperimentali tradizionali sono:
• La possibilita di inserire gradualmente le diverse parti della
teoria nel programma. Questo significa poter modificare i dati
gia presenti, verificarne la coerenza interna ed esterna in ogni
momento e osservare i risultati generati dal computer. Questo
vantaggio oggi puo essere sfruttato appieno proprio grazie a
strumenti informatici come la programmazione orientata agli
oggetti e software per la simulazione agent-based come Swarm2
.
• La grande flessibilita offerta dalle simulazioni allo sperimen-
17

Complessita e Scienza
tatore. Negli esperimenti di laboratorio tradizionali bisognava
studiare con attenzione tutte le variabili ambientali prima di
eseguire ogni esperimento, perche risultava lungo, difficile e
costoso ricreare lo stesso esperimento in condizioni leggermen-
te differenti. Oggi, grazie alle simulazioni di mondi artificiali,
tempo e causalita sono determinati dallo sperimentatore, le
caratteristiche ambientali possono essere modificate, la rileva-
zione dei dati piu precisa e l’esperimento puo essere ripetuto
a piacere. In sintesi possono essere modificati i parametri del
modello che si studia in modo semplice e veloce.
• La possibilita di modificare comodamente i parametri di osser-
vazione. L’osservatore influenza sempre il fenomeno osservato.
Questo principio e molto rilevante nelle scienze sociali (si pensi
all’influenza dell’intervistatore sull’intervistato in un sondag-
gio). Rimane comunque importante nell’osservazione di qual-
siasi fenomeno, anche solo perche la percezione della realta e
sempre filtrata attraverso la soggettivita dell’osservatore. La
possibilita di modificare tutti i parametri dell’osservatore con-
sente di isolare e studiare in modo migliore il fenomeno. La
velocita di scorrimento del tempo e particolarmente rilevan-
te perche contribuisce a ridurre la durata della ricerca che,
se svolta nella realta, potrebbe richiedere la ripetizione perio-
dica delle osservazioni, impegnando tempi considerevolmente
lunghi. Casi particolari, ma spesso rilevanti, si manifestano
difficilmente in ambiti reali, o sono difficilmente osservabili.
La ripetizione della rilevazione e le variazioni delle condizioni
possono facilitarne l’osservazione nel tentativo di individuare
18

2.6 La Modellazione Della Realta
fenomeni emergenti.
• La possibilita di tenere sotto osservazione il modello. Le sonde
consentono di tenere sotto controllo tutte le variabili di ogni
agente della simulazione, anche senza dover preventivamente
decidere quali saranno rilevanti. L’utilizzo degli agenti virtuali
consente di rilevare i dati facilmente, evitando errori e senza
determinare a priori quali grandezze osservare.
L’indagine su ambiti virtuali risulta, quindi, molto vantaggiosa ri-
spetto allo studi tradizionale in laboratorio, pe l’analisi dei fenomeni
definiti “complessi”.
19

Complessita e Scienza
20

Capitolo 3
I Sistemi Complessi
La simplicite est la complexite resolue
(Constantin Brancusi)
3.1 Sistemi Complessi
Per sistema si intende in una prima definizione molto generica un’in-
sieme di entita collegata da qualche relazione e che il sistema vari
nel tempo.
Come gia introdotto nel capitolo precedente, il campo di indagine
di questo lavoro e sui sistemi complessi, non da intendersi come siste-
mi troppo difficili da capire, ma come sistemi riconducibili per pro-
prieta ad un determinato insieme, che prende il nome di “complesso”
per la sua impossibilita di essere previsto e modellato.
Piu precisamente, con la parola chiave “sistemi complessi” si in-
dica una branca ben specifica della scienza dei sistemi che studia
le proprieta comuni di sistemi considerati complessi che si manife-
21

I Sistemi Complessi
stano in natura, nella societa e nella scienza, e che stanno sempre
diventando piu preponderanti. Non che questi non siano mai esistiti,
ma bens tanti dei problemi affrontati finora stanno rivelando che i
sistemi in indagine sempre piu spesso, quando si allarga l’angolo di
osservazione, ricadono nella definizione di sistema complesso.
Entrando nel dettaglio, un sistema complesso e un sistema per
cui e difficile, se non addirittura impossibile, restringere la sua de-
scrizione in un numero di parametri o variabili caratterizzanti senza
il rischio di perderne l’essenza globale e le conseguenti ed annesse
proprieta funzionali.
I sistemi complessi, sono una materia di studio che nasce al con-
fine tra diverse discipline scientiche come i sistemi non lineari, il
chaos, i sistemi autorganizzanti, societa, societa artificiali, questa
prossimita ontologico scientifica fa si che i sistemi complessi e quindi
ne ereditano sia le teorie fondative sia gli strumenti e le tecniche
di indagine dando vita ad una commistione emergente molto ben
fornita, ma a nostro avviso ancora incompleta.
In concomitanza con il sempre maggior numero di sistemi di in-
dagine scientifica riconducibili per proprieta e natura ai sistemi com-
plessi, negli ultimi decenni lo studio di questa materia sta rifiorendo
e riprendendo forte vitalita, soprattutto nelle aree scientifiche che si
servono per la modellazione dell’approccio classico dei modelli ma-
tematici, che spesso diventa sempre piu complesso e difficilmente
fruibile e che, lato assolutamente non banale, produce modelli non
scalabili e che sono rappresentati in maniera riduzionista, e non in
grado di cogliere a pieno le caratteristiche principali di un sistema
complesso.
Per riduzionista si intende quella pratica comune alle scienza che
22

3.1 Sistemi Complessi
tende ad eliminare dettagli ritenuti non rilevanti per la dinamica o
per l’essenza del modello in indagine. Il punto e che spesso, questo
lasciar fuori dettagli comporta la perdita di elementi fondamentali
per le dinamiche sistemiche, sia da un punto di vista ontologico sia da
un punto di vista prettamente funzionale. Se un sistema caotico e un
sistema molto sensibile alle condizioni iniziali, come si fa a scegliere,
per via del loro gran numero, quali parametri includere e quali no,
visto che non siamo ingrado di distinguere quelli significativi? Come
si puo eludere il grande livello di ignoranza rispetto alla materia
di indagine e arrogarsi la responsabilita di tagliare via dal modello
parti non ritenute significativamente rilevanti? Molto spesso si parla
di sistemi complessi, non tanto come materia, ma come approccio
di indagine, non a caso sempre di piu si incontra il termine sistema
complesso per indicare un approccio di ricerca comune a diverse
discipline come le neuroscienze, le scienze sociali, la metereologia,
la chimica, la psicologia, la vita artificiale, il calcolo evolutivo, la
biologia molecolare.
3.1.1 Proprieta dei Sistemi Complessi
I fondatori seicenteschi della scienza moderna, invece, furono ispi-
rati dalla fede nella possibilita di scoprire la struttura reale della
natura. La visione meccanicistica che divenne il fondamento del-
l’intera scienza del Seicento, facendo coincidere la natura con una
perfettissima macchina, presuppone un ordine senza eccezioni, una
realta strutturata secondo rapporti determinati che trovano la loro
espressione nella matematica. Per pensatori come Galileo, Keplero,
Cartesio, Leibniz, la scienza puo e deve impiegare la matematica per
23

I Sistemi Complessi
portare alla luce l’ordine del mondo in quanto la realta soggiacen-
te ai fenomeni e matematica. Per essi il principio di causalita, il
postulato deterministico, non esprime altro che la convinzione del-
l’identita tra matematica e natura: a quest’ultima deve inerire la
stessa infallibilita che si esprime nelle regole della matematica; sen-
za questa infallibilita la natura non sarebbe penetrabile dal pensiero
matematico.
Nell’opera di Newton viene lasciata cadere ogni giustificazione
metafisica del matematismo: la matematica ritorna strumento, men-
tre il determinismo della natura assume la veste di un puro postu-
lato circa una natura semplice e sempre conforme a se stessa senza
il quale lo scienziato non potrebbe operare. La diffusione della fisica
newtoniana sul continente genero due sostanziali mutamenti nella
visione del determinismo fisico: da un lato si assistette a una critica
al determinismo su basi empiristiche, dall’altro lato a un suo conso-
lidamento a partire da una prospettiva razionalistica. Nel newtonia-
nesimo olandese ebbe inizio quell’opera di demolizione delle pretese
newtoniane di produrre una scienza empirica ma al contempo certa,
che sul terreno filosofico verra condotta all’estremo da Hume.
I sistemi compelssi, sono sistemi che sono caratterizzati da al-
cune proprieta ben definite che oltre ad essere utili ad individuarli,
chiarisce significativamente la loro natura ed importanza. Prima di
tutto, ricadono nell’insieme dei sistemi complessi tutti quei sistemi
che sono composti da entita indipendenti connesse tra loro da una
qualunque relazione non additiva.
Nel dettaglio siamo in grado di individuare come sistemi com-
plessi, quei sistemi che presentano principalmente quattro proprieta
caratterizzanti:
24

3.1 Sistemi Complessi
• Non determinismo, ovvero l’impossibilita di descrivere il si-
stema con funzioni deterministiche, il comportamento di un si-
stema complesso e per lo piu stocastico, ma condizionato dallo
stato della totalita delle componenti. Per Bolztmann [12], il
substrato atomico e molecolare dei fenomeni pare essere real-
mente soggetto al disordine, al caos, e le ipotesi teoriche di
natura probabilistica tendono ad approssimare lo stato natu-
rale, offrendo l’immagine di una Natura non completamente
determinata. Nel corso della sua attivita Boltzmann non riusc
a essere sempre chiaro circa la portata gnoseologica da attri-
buire all’ipotesi del disordine molecolare, e anche i prosecutori
della sua opera intesero le ipotesi probabilistiche come asserti
che si potevano applicare a sistemi molto complessi, ma re-
golati ancora da un rigoroso determinismo. Con l’inizio del
Novecento, poi, la teoria cinetica, sotto l’impulso dell’opera di
Gibbs si trasformo in meccanica statistica, cioe in una teoria
completamente svincolata da ipotesi sul reale comportamento
delle molecole. Ma il problema del determinismo s’impose con
forza all’attenzione dei fisici solo con la formulazione di una
teoria che quel determinismo metteva in discussione in forme
precise, la meccanica quantistica.
• Non decomponibilita, ovvero l’impossibilita di essere de-
composto e ridotto in parti piu piccoli per via della struttura
caotica dell’aggregazione delle sue componenti
• Distribuzione, ovvero la dinamica del sistema non e centra-
lizzata, ma somma di elementi che interagiscono, distribuendo
ad ogni entita e ad ogni interazione nel micro livello una parte
25

I Sistemi Complessi
che costituisce la dinamica nel macro livello; e distribuita l’in-
formazione che circola, ogni cambiamento di stato e verificato
dalla dinamica dei singoli componenti.
• Emergenza , ovvero dall’interazione delle componenti nel mi-
cro livello puo emergere un determinato fenomeno Un compor-
tamento emergente o proprieta emergente puo comparire quan-
do un numero di entita semplici (agenti) operano in un ambien-
te, dando origine a comportamenti piu complessi in quanto col-
lettivita. La proprieta stessa non e predicibile e non ha prece-
denti, e rappresenta un nuovo livello di evoluzione del sistema.
I comportamenti complessi non sono proprieta delle singole en-
tita e non possono essere facilmente riconosciuti o dedotti dal
comportamento di entita del livello piu basso. La forma e il
comportamento di uno stormo di uccelli o di un branco di pe-
sci sono buoni esempi.Una delle ragioni per cui si verifica un
comportamento emergente e che il numero di interazioni tra le
componenti di un sistema aumenta combinatoriamente con il
numero delle componenti, consentendo il potenziale emergere
di nuovi e piu impercettibili tipi di comportamento. D’altro
canto, non e di per s sufficiente un gran numero di interazio-
ni per determinare un comportamento emergente, perch molte
interazioni potrebbero essere irrilevanti, oppure annullarsi a
vicenda. In alcuni casi, un gran numero di interazioni puo in
effetti contrastare l’emergenza di comportamenti interessanti,
creando un forte rumore di fondo che puo zittire ogni segnale
di emergenza; il comportamento emergente potrebbe in questo
caso aver bisogno di essere temporaneamente isolato dalle altre
26

3.1 Sistemi Complessi
interazioni mentre raggiunge una massa critica tale da autoso-
stenersi. Si nota quindi che non e solo il numero di connessioni
tra le componenti a incoraggiare l’emergenza, ma anche l’orga-
nizzazione di queste connessioni. Un’organizzazione gerarchica
e un esempio che puo generare un comportamento emergente
(una burocrazia puo avere un comportamento diverso da quel-
lo degli individui umani al suo interno); ma forse in maniera
piu interessante, un comportamento emergente puo nascere da
strutture organizzative piu decentralizzate, come ad esempio
un mercato. In alcuni casi, il sistema deve raggiungere una
certa soglia di combinazione di diversita, organizzazione e con-
nettivita prima che si presenti il comportamento emergente.
Apparentemente i sistemi con proprieta emergenti o strutture
emergenti sembrano superare il principio entropico e sconfig-
gere la seconda legge della termodinamica, in quanto creano
e aumentano l’ordine nonostante la mancanza di un control-
lo centrale. Questo e possibile perch i sistemi aperti possono
estrarre informazione e ordine dall’ambiente. Secondo una pro-
spettiva emergente l’intelligenza emerge dalle connessioni tra
i neuroni, senza la necessita di ipotizzare un’anima per spie-
gare come il cervello possa essere intelligente, mentre i singoli
neuroni di cui esso e costituito non lo sono. Il comportamento
emergente e importante anche nei giochi e nella loro struttura.
Ad esempio il gioco del poker, in particolare nella sua forma
priva di un sistema rigido di puntate, e essenzialmente guidato
dall’emergenza. Cio significa che giocare ad un tavolo piuttosto
che ad un altro puo essere radicalmente differente, nonostante
le regole di base siano le stesse. Le variazioni che si sviluppano
27

I Sistemi Complessi
sono esempi di metagioco emergente, il catalizzatore principale
dell’evoluzione di nuovi giochi.
• Autoorganizzazione la capacita delle componenti di auto
organizzarsi all’interno del sistema; Un CAS puo essere de-
scritto come un instabile aggregato di agenti e connessioni,
auto-organizzati per garantirsi l’adattamento. Secondo Hol-
land [13], un CAS e un sistema che emerge nel tempo in forma
coerente, e si adatta ed organizza senza una qualche entita
singolare atta a gestirlo o controllarlo deliberatamente. L’a-
dattamento e raggiunto mediante la costante ridefinizione del
rapporto tra il sistema e il suo ambiente (co-evoluzione).
Non stiamo parlando di cose appartenenti al mero mondo teorico,
ma di sistemi che osserviamo e vediamo tutti i giorni le macchine nel
traffico, il funzionamento di un’azienda, ma pensandoci bene, il siste-
ma complesso piu affascinante e quello dell’essere umano, della sua
mente. Chi legge questo documento e la somma di un’interazione di
cellule che interagiscono attraverso molecole, micro sistemi indipen-
denti, ma se scissi, non sarebbero l’essere umano. Dennet definisce
la coscenza come un fenomeno emergente in un sistema complesso
che e quello della mente [14].
In un sistema complesso e anche presente la gerarchia tra le com-
ponenti, in quanto esistono livelli e gradi di interazione, che per
convenzione vengono divisi in al massimo tre livelli che denotano il
livello di osservazione: micro livello, meso livello e macro livello. Ma
non e affatto escluso dalla teoria che come due entita interagiscono a
creare un sistema complesso, che due sistemi complessi tra loro non
interagiscono dando origine ad un terzo e cosi via.
28

3.2 Rappresentazione dei Sistemi Complessi
3.2 Rappresentazione dei Sistemi Com-
plessi
Come si potra facilmente intuire la natura dei stessa dei sistemi
complessi, ne rende molto difficile una rappresentazione matematica
rigorosa ed esaustiva. Nella maggior parte dei sistemi complessi le
caratteristiche e proprieta fondamentali della dinamica sono descrit-
te non dai singoli punti ma dalle relazioni tra essi, che variando nel
tempo rendono il sistema dinamico. Prendiamo per esempio inter-
net. In questo caso i nodi sono le pagine WEB ed i collegamenti sono
i link ad altre pagine. Per comprendere quali sono i siti piu impor-
tanti e necessario dunque cercare i siti che hanno piu collegamenti.
Per trovare un modello che descriva la struttura di queste reti sa-
rebbe necessario tenere conto delle motivazioni che spingono un sito
a collegarsi ad un altro (un modello microscopico). Tuttavia risulta
al momento proibitivo sviluppare un modello in grado di descrivere
tale situazione. Allora cio che si cerca e un modello semplificato del-
la struttura delle reti (un modello macroscopico) che, partendo da
semplici assunti, sia in grado di descrivere questo fenomeno cos com-
plesso. La teoria delle reti ha una tradizione che risale al 1700 con
i primi studi di Eulero , il quale pone i fondamenti della descrizione
matematica delle reti: la teoria dei grafi. Uno dei primi modelli di
reti proposto risale agli anni ’60 ed e la rete aleatoria o democratica
descritta da Erdos e Renyi. Questo tipo di rete descrive una sistema
costituito da un numero fissato di nodi che hanno un valore medio di
collegamenti, o grado, ben preciso. In questi tipi di reti i vari nodi
sono indistinguibili gli uni dagli altri, in quanto hanno praticamente
29

I Sistemi Complessi
tutti lo stesso grado, da qui il termine reti democratiche.Le reti de-
mocratiche hanno il pregio di essere semplici nella costruzione, ma
non sono adatte a descrivere le reti reali. Verso la fine degli anni
’90 e stato proposto un modello estremamente semplice ma effica-
ce che permette di descrivere alcune delle caratteristiche principali
delle reti che ritroviamo in natura, nelle scienze sociali e in biologia.
Questo modello si basa su due assunti principali: la rete e in conti-
nua crescita ed inoltre chi apre un nuovo sito preferisce collegarlo a
siti che hanno gia un alto numero di connessioni. Reti con questa
struttura si dicono scale-free. Contando il numero di nodi che nella
rete hanno lo stesso numero di connessioni si ottiene una legge di
potenza: infatti esistono molti nodi che hanno poche connessioni, e
pochi nodi che hanno molte connessioni. Questa particolare legge
rimane inalterata aumentando il numero di nodi della rete, cioe ri-
sulta indipendente dalla grandezza o scala della rete; da qui il nome
scale-free. Indincando con N il numero di nodi con K connessioni
abbiamo definita la seguente relazione
N ∼= 1Ky
Il coefficiente che compare nella formula e diverso in tipi di reti
differenti, ma risulta quasi sempre compreso tra 1 e 3. La rete dei
router del traffico nel WorldWideWeb Accanto al grado di connetti-
vita delle reti un’altra caratteristica fondamentale e il diametro della
rete che misura il numero di collegamenti necessario per connettere
due nodi qualsiasi. I primi studi quantitativi sulle reti sociali che
misurano questa proprieta risalgono agli anni ’60. In questo conte-
sto i nodi rappresentano le persone ed il collegamento la conoscenza
dei due individui. Milgram [15] negli USA escogito un esperimento
30

3.2 Rappresentazione dei Sistemi Complessi
che permettesse di rivelare la rete di conoscenze navigando tra i vari
nodi: invio ad un certo numero di persone che vivevano sulla costa
orientale delle lettere chiedendo di spedirle a loro volta a dei cono-
scenti in modo che queste lettere arrivassero a Chicago attraverso
una catena di amici di amici. I modelli che abbiamo descritto, oltre
a riprodurre gli effetti di scale-free e small world hanno permesso
di evidenziare una proprieta che non era stata precedentemente os-
servata, ovvero la solidita delle reti. In una rete di tipo scale-free
possono avvenire dei guasti che disattivano un nodo e di conseguenza
i suoi collegamenti. Scegliendo in modo casuale il nodo da disattiva-
re, vi e una buona probabilita che tale nodo non sia rilevante, poich
sono pochissimi i nodi, con un grado di connettivita talmente alto
da garantire la solidita della rete. Viceversa ad un attacco mira-
to la rete porge il suo tallone d’Achille: conoscendo i suoi nodi piu
importanti, un pirata informatico riesce ad oscurare l’intera rete at-
taccando pochi punti ma ben collegati. L’effetto small world e stato
studiato per la prima volta nelle reti sociali mentre lo studio della
rete WorldWideWeb ha evidenziato la natura scale-free. Queste due
caratteristiche si ritrovano con sorprendente regolarita in reti nate in
contesti differenti che spaziano dalle scienze sociali al metabolismo
cellulare, toccando anche il mondo del cinema e delle collaborazio-
ni scientifiche. Utilizzando cos un modello estremamente semplice
e possibile descrivere e classificare i vari tipi di reti non in funzione
del loro particolare campo di applicazione, ma grazie a concetti uni-
versali come per esempio il coefficiente della legge di potenza o la
distanza media tra due nodi qualsiasi.
31

I Sistemi Complessi
3.3 La Dinamica dei Sistemi Complessi
E’ notevole che ci siano voluti piu di 40 anni perch la scienza si inter-
rogasse sul perch certi sistemi complessi (tra cui alcune reti e Inter-
net) non seguissero affatto comportamenti casuali. Tuttavia dobbia-
mo comprendere che e solo grazie all’evolvere di Internet come rete,
e dei suoi nuovi scenari possibili, che per i fisici fu possibile ottene-
re sperimentalmente dati che prima erano accessibili solo attraverso
modelli teorici. Dal 1959, da quando due matematici ungheresi, l’i-
nimitabile Paul Erdos e il suo collaboratore Alfred Renyi, iniziarono
a studiare il comportamento delle reti in comunicazione e nelle scien-
ze biologiche, molta acqua e passata sotto i ponti. Essi suggerirono,
con convincenti calcoli, che i sistemi complessi si comportavano in
32

3.3 La Dinamica dei Sistemi Complessi
maniera del tutto aleatoria, casuale [16].
Solo quarant’anni dopo, nel 1999, il fisico Albert-Lszl Barabsi e
i suoi collaboratori Reka Albert e Hawoong Jeon si accorsero che
non tutte le reti si comportavano come sistemi casuali: ma che anzi,
erano molti gli esempi di reti che presentavano un comportamento
altamente organizzato: due di queste era proprio Internet e il World
Wide Web [17]. Teniamo presente che gli strumenti che prima di tali
studi venivano utilizzati per spiegare il comportamento di Internet si
basavano su idee mutuate dall’analisi sul comportamento di sistemi
privi di organizzazione. Gli attuali protocolli sono stati sviluppati
negli anni Settanta, quando la rete era piccola, sfruttando le tecno-
logie disponibili allora. L’importanza di conoscere la topologia della
rete e dei suoi attributi e legata dunque alla necessita di abbatte-
re le limitazioni intrinseche al modello: senza tali conoscenze non
si possono ad esempio progettare nuovi strumenti e nuovi servizi.
Da cui l’importanza di introdurre nuovi modelli che spieghino con
maggiore raffinatezza le caratteristiche di questi sistemi. I sistemi
complessi come internet non possono essere spiegati come una sem-
plice connessione tra hub, cos come un organismo vivente non puo
venire descritto solo come una riduzione alle sue particelle elemen-
tari reti invarianza di scala (le cellule) e alle leggi fondamentali della
chimica. Un ecosistema digitale, cos come un ecosistema biologico
o sociale, e sufficientemente reale al pari delle sue parti costituenti:
del che ci accorgiamo con disagio quando, ad esempio, l’ecosistema
viene perturbato da inquinamenti o virus, oppure quando si presenta
con tanti problemi irrisolti. Ecco cos che si rendeva necessario uno
studio piu olistico, che tenesse conto dell’estrema complessita delle
relazioni tra le parti. Nell’esperimento che consisteva nella map-
33

I Sistemi Complessi
patura di una piccola porzione del World Wide Web il gruppo di
Barabasi si accorse che l’80 percento delle pagine possedevano non
piu di quattro link entranti, ma una piccola minoranza (meno dello
0,01 percento di tutti i nodi) ne avevano piu di mille, e pochissimi an-
che milioni. Conteggiando quante pagine web avevano esattamente
k link dimostro che la distribuzione invece di diminuire con velocita
esponenziale, diminuiva con una legge di potenza: la probabilita che
un nodo sia connesso a k altri nodi era proporzionale a 1/kn. Il
valore della potenza n per i link entranti risultava essere 2, 2, valore
sperimentalmente e intrinsecamente legato alla struttura del WWW.
In termini algebrici era come dire che ogni volta che il numero di col-
legamenti in entrata diminuiva di un fattore 10, il numero di pagine
che avevano quel numero di collegamenti aumentava, mediamente,
di un fattore 10 elevato alla potenza di 2, 2. Un numero che e circa
uguale a 158. Per dirla in altre parole, significa che le pagine con un
numero di collegamenti dieci volte maggiore erano 158 volte meno
probabili. Significa che il sistema si sta autoorganizzando. Questi
fenomeni si ritrovano di solito nei sistemi in transizione di fase, e
accadono quando un sistema si trova ad esempio sull’orlo di un ba-
ratro, in bilico tra l’ordine e il caos. Si riconoscono ad esempio nei
frattali, quando una parte arbitrariamente piccola riproduce il tut-
to. Emergono anche nella spiegazione del modo in cui si diffondono
le epidemie, nelle statistiche dei fenomeni naturali (terremoti, tsu-
nami), tutti casi in cui il valore medio di una curva gaussiana non
puo spiegare adeguatamente la distribuzione generale. In una prima,
forte approssimazione, il Web e un esempio di come questo curioso
andamento spieghi l’accrescere dei nodi di grandi hub, che diventano
sempre piu connessi a discapito della maggior parte dei nodi meno
34

3.4 Dalla Dinamica del Sistema Complesso alle Sue EntitaCostituenti
connessi. Infatti nel Web esistono molte pagine che hanno pochi link
in entrata, e poche pagine che hanno invece un elevato numero di
collegamenti.
Nel modello a invarianza di scala l’eta dei nodi e il fattore piu
importante e con l’ingresso di nuove pagine gli hub piu popolari han-
no maggiori probabilita di essere linkati, accrescendo ulteriormente
la loro connettivita, un fenomeno che comunemente e conosciuto
con il nome di collegamento preferenziale (preferential attachment).
Ma questo modello non e sufficiente a spiegare perch alcuni nodi o
website, entrati piu recentemente in competizione, riescano in breve
tempo a diventare piu popolari di altri.
3.4 Dalla Dinamica del Sistema Com-
plesso alle Sue Entita Costituenti
Negli ultimi tempi, la comunita scientifica sta proponendo diverse
analisi e approcci per sfruttare le reti sociali nel problema di profi-
lare l’utente, al fine di proporre risultati sempre piu pertinenti agli
interessi dell’individuo. L’analisi della rete sociale dell’utente offre
una grande potenza per predire molte informazioni. La topologia
di reti complesse e stato ultimamente argomento di studi intensivi.
E’ stato riconosciuto che tale tipologia gioca un importante ruolo
in molti sistemi e processi. Recentemente, e stato osservato che le
reti sociali esibiscono una struttura della comunita molto chiara. In
un’organizzazione emerge facilmente lo schema formale della struttu-
ra della comunita, ed e altres possibile osservare il legame informale
che sorge tra gli individui basato su relazioni personali, politiche, cul-
35

I Sistemi Complessi
turali e cos via. La profonda comprensione della struttura informale
che soggiace allo schema formale.
Le comunita virtuali evolvono intorno ad una determinata area
d’attivita (ad es. i ricercatori del Semantic Web) oppure si costrui-
scono attorno ad uno stesso topic di interesse (ad es. i primi piatti
tipici dell’Abruzzo). La longevita e persistenza di tali comunita nel
tempo risiede nello scambio di informazioni tra i membri della co-
munita. Comunicazioni tipiche includono transazioni commerciali,
informazioni documentali, scambi di conoscenza, risposte alle richie-
ste, avvisi, suggerimenti, aiuti, riferimenti e cos via. Esempi ben
conosciuti sono sistemi quali e-Bay, Firefly, Wikipedia, Expert’s Ex-
change. Al fine di suggerire all’utente informazioni maggiormente
aderenti ai suoi interessi, e sicuramente utile studiare la rete socia-
le dell’individuo, analizzare la rete di amicizie, capire la profondita
delle relazioni con gli altri utenti. Ad esempio, derivare i campi di
interesse delle conoscenze piu strette puo aumentare la precisione dei
risultati forniti all’utente che, probabilmente, avra sviluppato inte-
ressi simili ai propri amici e colleghi. Altres, puo esser determinante
individuare quei nodi che hanno un elevato grado di interconnessione
con gli altri membri della comunita: tali nodi centrali (spesso indi-
cati con il termine di hubs) possono rappresentare un grave punto
di dispersione quando si tratta di analizzare le immediate conoscen-
ze dell’individuo. Altro punto di sicuro interesse, e l’individuazione
delle sottocomunita che si creano all’interno della rete sociale: ad
esempio, si puo pensare di delineare quale sia l’insieme degli amici di
un membro dentro l’intera rete sociale, piuttosto che quella dei colle-
ghi di lavoro, oppure dei compagni di studio. Per tali motivi, sembra
opportuno restringere il campo delle reti sociali a quelle etichettate
36

3.4 Dalla Dinamica del Sistema Complesso alle Sue EntitaCostituenti
come scale-free, ed assumono particolare interesse nella profilazione
utente i metodi di clustering applicati alle social networks.
Lo user profiling e l’analisi e l’utilizzo dei dati che compongono
il profilo utente. Il calcolo della pertinenza di una risorsa in rela-
zione ad una query sottomessa da un determinato utente permette,
da sola, di compiere le prime banali operazioni di profilazione. Se,
ad esempio, un utente manifesta la propria preferenza per una ri-
sorsa proposta non ai primi posti nell’elenco dei risultati, e giusto,
che a successive interrogazioni simili, il motore di ricerca risponda
assegnando a tale risorsa maggior valore, quindi proponendola in
posizioni di maggior visibilita. Si fa presente che questa operazione,
quasi scontata, non e contemplata nel comportamento di nessuno
dei maggiori motori di ricerca, i quali, a query identiche, continuano
a rispondere con identici risultati, ignorando palesemente qualsia-
si preferenza manifestata dall’utente. L’implementazione di questa
funzionalita permetterebbe di pervenire ad un risultato ancora piu
interessante: in base ai dati presenti nel profilo, stimando rappor-
ti di vicinanza tra utenti diversi, e possibile proporre per query, e
quindi per bisogni simili, risposte e soluzioni identiche a quelle che
utenti vicini hanno gia segnalato come valide . Rappresentando i
dati del profilo utente sotto forma di matrice e possibile calcolare la
similitudine che questa ha con i profili di utenti diversi e successi-
vamente inserire i vari utenti all’interno di cluster di utenti simili,
offrendo ad ognuno di questi risposte, soluzioni e risorse scelte dagli
utenti appartenenti al medesimo gruppo. I vantaggi che si possono
trarre dall’uso di tecnologie legate allo user profiling hanno inevi-
tabili ricadute sull’utilizzo a fini didattici dei motori di ricerca. La
clusterizzazione degli utenti presuppone che i comportamenti ricor-
37

I Sistemi Complessi
renti tendano ad essere interpretati dal sistema come comportamenti
standard e in quanto tali come comportamenti da promuovere verso
tutti i componenti di uno stesso cluster. Non esiste un modo pre-
determinato di creare meccanismi di profilazione d’utenza, esistono
pero delle tecnologie che possono essere messe in campo. Alcune di
queste emergono come punti fermi, o per lo meno punti di riferimen-
to, nella realizzazione di un’architettura di profilazione: i cookie, i
classificatori, le directory, ecc. Occorre prendere in considerazione
queste tecnologie con particolare riferimento all’impiego in un siste-
ma di profilazione. Il protocollo HTTP non conserva informazioni di
stato, quindi e impossibile differenziare tra visite diverse ad un sito
web senza un metodo per marcare il visitatore. I cookie nascono per
ovviare a questa carenza del protocollo HTTP e sono utilizzati per
gestire delle variabili di stato nelle connessioni web. L’idea e quella
di memorizzare delle informazioni nel browser del visitatore tali, per
esempio, da permettere la creazione di siti individuali e personaliz-
zabili. Riflettendo con attenzione sul meccanismo dei cookie, salta
agli occhi il fatto che si tratta di un meccanismo che nasconde alcuni
pericoli. Per ovviare a questi inconvenienti occorre porre delle limi-
tazioni, che il browser attuera rigorosamente. Due sono le principali
limitazioni introdotte: la prima riguarda il dominio, la seconda la
numerosita. I cookie sono stati progettati per rispondere a esigenze
non legate ad interessi di parte specifici. Cio nonostante l’utilizzo in-
discriminato che alcune compagnie deliberatamente fanno dei cookie,
rappresenta un serio pericolo per la privacy degli utenti. La difesa
della privacy minacciata rischia pero anche di mettere in crisi i siste-
mi di profilazione. Classificare e un’attivita fondamentale svolta da
tutti gli esseri viventi. Appena avuta un’esperienza, subito si cerca
38

3.4 Dalla Dinamica del Sistema Complesso alle Sue EntitaCostituenti
di classificarla in una particolare categoria. Gli strumenti informatici
adatti ad effettuare un’operazione analoga si chiamano classificatori,
studiati a partire dagli anni ’50, con lo scopo di estrarre in maniera
automatica delle regole generali per dedurre la classe di apparte-
nenza di ogni oggetto da una serie di esempi (training set), avendo
fatto l’assunzione che - se il numero di esempi fosse stato sufficien-
temente grande e ben distribuito sulle classi esistenti - quelle stesse
regole si potessero, con buona probabilita, applicare a oggetti nuo-
vi. In questa maniera i calcolatori avrebbero imparato a classificare
tutti gli oggetti appartenenti ad un certo dominio della conoscenza.
Algoritmi che tramite meccanismi di inferenza induttiva tentano di
realizzare sistemi in grado di imparare, ossia di passare da esempi
concreti a modelli generali attraverso l’estrazione di regole da un
insieme di dati. Gli algoritmi producono una struttura dati, utiliz-
zando la quale, e possibile classificare un oggetto. Un primo esempio
puo essere l’albero di decisione (o per estensione il grafo), in cui ad
ogni nodo viene effettuato un test sugli attributi dell’oggetto, che
permette di discriminare tra due insiemi di appartenenza. Percor-
rendo tutto l’albero dalla radice alla foglia che questo permette di
individuare, si deduce la classe di appartenenza indicata nella foglia
stessa. Un secondo tipo di struttura dati finalizzata alla classificazio-
ne di oggetti, e la lista di decisione. Questa lista contiene una serie
di regole ordinate o non ordinate. Se sono ordinate, la validazione
di una regola comporta la determinazione della classe di apparte-
nenza. Viceversa, se non sono ordinate, piu regole possono essere
validate determinando classi diverse, quella corretta viene scelta per
maggioranza. Utilizzare una directory per contenere dei dati e una
modalita di organizzare l’informazione tale che la renda facilmente
39

I Sistemi Complessi
reperibile. In una infrastruttura informatica, la directory e un data-
base specializzato per l’amministrazione di informazioni su oggetti
che si devono gestire - ad esempio i dati anagrafici dei dipendenti o
le credenziali di sicurezza. A differenza di un database tradizionale
pero, una directory si distingue perch ottimizzata per le operazioni di
lettura e per transazioni semplici che coinvolgono dati di dimensioni
ridotte, inoltre si presenta come un unica entita indipendentemente
dal luogo in cui risiedono i dati. Queste caratteristiche rendono le
directory particolarmente adatte ad immagazzinare le caratteristiche
semi-statiche degli utenti.
3.5 Stato dell’Arte nell’Analisi delle Re-
ti Sociali
Studiando la struttura del Web, attraverso l’utilizzo di un Web craw-
ler, il fisico Albert Barabasi scopr, con non poca sorpresa, che questa
non presentava una connettivita casuale. Noto, invece, la presenza
di alcuni nodi con un numero di archi insolitamente elevato, che ven-
nero denominati hub o connettori. Studi successivi mostrarono che
gli hub non erano un fenomeno isolato, ma rappresentavano una ca-
ratteristica importante di sistemi complessi anche molto diversi tra
loro, dall’economia alla cellula vivente. L’ammissione dell’esistenza
dei connettori ha portato al definitivo abbandono di ogni pro-spettiva
casualista nelle reti suscitando, al contempo, la necessita di un nuovo
modello che tenesse conto dell’esistenza di questo particolare tipo di
nodi. Le reti ad invarianza di scala o, in inglese, scale-free networks
sono la classe di reti che presentano una distribuzione di grado di tipo
40

3.5 Stato dell’Arte nell’Analisi delle Reti Sociali
power law (legge di potenza) e che quindi meglio si prestano per stu-
diare la presenza degli hub e i loro effetti. Il modello maggiormente
utilizzato per la generazione di modelli atti a studiare reti ad inva-
rianza di scala e quello proposto dalla coppia di scienziati Barabasi
ed Albert, nel 1999, denominato i ricchi sono sempre piu ricchi. In
questo tipo di modello, ogni nuovo nodo crea un collegamento verso
un altro nodo della rete non con una probabilita uniforme, come ac-
cadeva invece per i grafi randomici di Erdos e Rnyi, ma in maniera
proporzionale al grado entrante corrente dei nodi. Secondo questo
sistema un nodo con molti archi entranti continuera ad attrarre
altri archi rispetto ad una pagina normale e questo e in linea an-
che con il principio dell’ 80/20 formulato da Pareto. Nello specifico
Barabasi ed Albert, per formulare il loro modello, partirono dalla
constatazione che le reti, nel tempo, tendono a modificare la loro
dimensione aumentando il numero di nodi e per fare questo i nuovi
nodi, utilizzano un collegamento preferenziale, sfruttano cioe nodi
altamente connessi, gli hub, piuttosto che nodi con un minore nu-
mero di archi. La probabilita che un nuovo nodo generi un arco per
collegarsi ad un vertice di grado k e pari a: La sommatoria posta al
denominatore e pari al grado medio della rete che e circa 2m, poich
ci sono m archi per ogni vertice aggiunto, e ogni arco, essendo non
orientato, contribuisce due volte al grado dei vertici della rete. Il
numero medio di vertici di grado k che acquistano un arco quando
un vertici con m archi viene collegato alla rete e pari a m x kpk/2m
= kpk ed e indipendente da m. Il numero npk di vertici con gra-
do k in questo modo viene decrementato da questo stesso insieme,
poich i vertici che ottengono un nuovo arco diventano di grado k+1.
Anche il numero di vertici di grado k aumenta a causa dell’influenza
41

I Sistemi Complessi
dei vertici precedentemente di grado k-1 che ora hanno acquisito un
nuovo arco. Unica eccezione sono i vertici di grado m che hanno
esattamente influenza 1. Se definiamo da pkn il valore di pk quan-
do il grafo ha n vertici, allora il cambiamento della rete in npk per
ogni vertice aggiunto e: Per le loro proprieta, il modello delle reti
scale-free sembra aderire bene alla realta delle reti sociali. Di fatto,
nelle reti sociali online e possibile spesso individuare quei membri
(nodi) che detengono un numero maggiore di connessioni rispetto
agli altri. Ad esempio, nella rete di amicizie di Facebook e facile
notare persone che hanno una lista di amici notevole, oppure in reti
piu professionali, come Linkedin, vi sono individui che rappresenta-
no un importante sbocco lavorativo, dal momento che tali membri
hanno un numero di contatti molto elevato. In entrambi i casi, tali
nodi rappresentano gli hub sopra accennati. Determinare tali nodi
puo esser di vitale importanza da diversi punti di vista, ad esempio,
decidendo di escludere i membri con elevatissimi connessioni, perch
probabili divoratori di contatti non realmente conosciuti, che minano
la veridicita della rete sociale (vedi in Facebook quelle persone con
piu di 1000 contatti). Un taglio di questo tipo permette di ridurre
drasticamente la complessita computazionale di determinati calcoli.
Ad esempio, nella profilazione di un utente e interessante esplorare
la rete di amicizie sino ad un dato livello di profondita, compito che
puo rivelarsi molto dispendioso qualora si passi sopra un hub; come
detto, le reti scale-free seguono una power law nel momento in cui un
nuovo nodo intende aggiungersi alla rete (in effetti, tendera a legarsi
a quei membri che hanno giu un elevato grado di archi uscenti).
42

3.6 Identificazione di un gruppo
3.6 Identificazione di un gruppo
Il metodo tradizionale per identificare una comunita all’interno di
una social networks e l’approccio del clustering gerarchico. L’idea
di questa tecnica e prendere un set di N nodi da clusterizzare e una
matrice di similarita (o delle distanze) di grandezza N × N ; il pro-
cesso base e: all’inizio, inserire un nodo per ogni cluster, in modo
tale che se inizialmente si hanno N nodi adesso si avranno N cluster,
e lasciare la distanza tra cluster uguale a quella tra i nodi. Successi-
vamente cercare la distanza piu vicina tra due cluster ed unire i due
cluster in uno solo ed eliminare l’altro cluster in modo tale di avere
meno cluster. Ripetere sino a che tutti i nodi sono clusterizzati. Gi-
vran and Newman, recentemente hanno proposto un algoritmo (GN)
per identificare le differenti comunita all’interno di una rete sociale.
Questo nuovo algoritmo da un risultato buono anche nelle reti in cui
il metodo del clustering gerarchico fallisce. Questo algoritmo lavora
nel modo seguente: il betweennes di un arco e definito come un nu-
mero minimo di connessioni tra coppie di nodi che attraversano un
arco. L’algoritmo GN e basato sull’idea che gli archi aventi il piu
alto grado di betweenness, collegano di fatto le comunita altamente
clusterizzate. Pertanto il taglio di tali archi permette di separare le
comunita. In tal modo, l’algoritmo procede con l’identificazione e
la rimozione dell’arco con il betweenness piu alto nella rete. Questo
processo e ripetuto fino a che la rete padre produce due reti figlie
separate. L’algoritmo puo procedere in modo iterativo sulle reti fi-
glie finch non si ottengano delle reti composte esclusivamente da un
solo nodo. Al fine di descrivere l’intero processo di scissione, vie-
ne generato un albero binario, nel quale le biforcazioni raffigurano
43

I Sistemi Complessi
le comunita e i livelli rappresentano le persone. Di conseguenza, le
informazioni della comunita nella rete originale possono esser dedot-
te dalla topologia dell’albero binario corrispondente. Quando l’arco
BE e rimosso, la rete si divide in due gruppi: un gruppo contiene
i nodi A e D, ed l’altro gruppo contiene i nodi E e I. Dopo questa
prima scissione, vi sono due comunita completamente separate: una
molto omogenea, e l’altra molto centralizzata. Sebbene le due comu-
nita abbiano caratteristiche differenti, l’algoritmo separera i nodi uno
a uno, dando luogo a due differenti sottoalberi nell’albero binario.
In realta, quando le comunita rimaste non mostrano piu particolari
strutture interne, sono divise in un modo molto irregolare che porta
un aumento della profondita dei sottoalberi. In conclusione, il diffi-
cile compito di individuare le comunita a partire dalla rete originale,
puo esser sostituito dal compito piu lieve di identificare le comunita
a partire dal relativo albero binario. Quando si lavora con reti che
hanno una struttura centralizzata, e possibile trovare i nodi centra-
li come foglie dei sottoalberi; in tal modo, si ha a disposizione un
metodo per individuare i leader di ogni comunita.
3.7 Riduzionismo e Aspetti Cognitivi
Il riduzionismo e qualcosa da evitare quando si cerca di astrarre
modelli con meccanismi molto sensibili e determinati da un eleva-
to numero di fattori e dalle loro interconnesioni, come nel caso di
tracciare un modello in grado di mappare il comportamento di un
individuo in relazione a qualche contesto al fine di evincerne feature e
caratteristiche utili sia all’identificazione sia per l’attribuzione del’in-
44

3.7 Riduzionismo e Aspetti Cognitivi
vididuo ad un qualche gruppo. E’ necessario includere componenti
e parametri che descrivano in maniera sufficientemente realistica le
entita del sistema, in particolare, ci vogliamo concentrare sulla rile-
vanza, nell’analisi delle reti sociali, degli aspetti cognitivi annessi ad
una scelta, come il trust e la reputazione. La quantita di contenuti
nel web e enorme, ma ogni singolo individuo cerchera quella che piu
soddisfa il suo fabbisogno informativo, ma non e detto che questo
sia raggiunto, sia per limiti di tempo, sia a volte anche per pigri-
zia. Spesso per risparmiare tempo nel task di formazione e revisione
delle credenze ed in particolare delle valutazioni, l’individuo, di per
se, limitato ricorre alla comunicazione per aumentare il suo livello di
conoscenza, prima di fare una scelta. In questa ultima sezione voglia-
mo sottolineare aspetti non direttamente tracciabili dell’utente che
a nostro avviso coinvolgono elementi molto significativi nella classi-
ficazione e profilazione di un individuo, ovvero considerare anche i
meccanismi che sono dietro la decisione e le varie azioni ed interazio-
ni: la socialita, la fiducia, la reputazione, le dinamiche di selezione e
di decision making, e la riduzione dell’incertezza. Nella panoramica
del web 2,0 che a quanto pare sottende ad un passaggio dell’internet
dell’ipertesto ad un internet di comunicazione elettronica, tante pro-
blematiche connesse al decision making, all’incertezza che emergono
quando l’utente e li a fruire dei servizi che la rete mette a disposzio-
ne, coinvolgeranno tematiche sociali e psicosociali che da un punto
di vista cognitivo coopteranno per una profilazione utente, non solo
concepita attraverso il suo comportamento web, ma dara significato
anche a tutti quegli elementi cognitivi, proprio delle mente umana
che guidano l’essere nelle sue scelte, nelle sue interazioni. In parti-
colare e ampliamente studiato e discusso il ruolo della reputazione
45

I Sistemi Complessi
e della fiducia nelle comunita elettroniche e da come sia possibilie
analizzare le dinamiche di opinione e di apprendimento in relazione
al contesto e al capitale culturale. In particolare, nel caso di inter-
net il capitale culturale, ovvero il dominio informativo relativo alla
rete sociale a cui si appartiente coincide potenzialmente con la tota-
lita del web, quindi la formazione e la revisione delle credenze, delle
valutazioni su un determinato target sono affette da informazioni
acquisite, da informazioni riportate, esperienze altrui, ma anche da
cio che si dice in giro, il gossip. E questo sara influenzato, sempre
secondo una visione da sistemi complessi, in cui tutto e strettamen-
te connesso e correlato, dalla fiducia, dall’informazione circolante,
dalle abitudini delle persone che l’utente conosce e imita ( secondo
il meccanismo dell’imitazione, che per molti e alla base di ogni tipo
di apprendimento) che e la prima risposta all’incertezza: imitare il
comportamente di chi vedo. La fiducia e un concetto importante
che interseca numerose discipline scientifiche. Ogni situazione che
implichi uno scambio nonsimultaneo tra organismi viventi presen-
ta un problema di fiducia. Il modello mostra come la probabilit‘
che fiducia e cooperazione emergano in tale sistema sia elevata solo
quando gli agenti hanno la possibilita di costruirsi una reputazio-
ne di cooperatori affidabili e quando l’informazione riguardo il loro
comportamento passato e sufficientemente diffusa nel sistema stes-
so. Tanto la reciprocita diretta quanto quella indiretta svolgono un
ruolo rilevante nel favorire la cooperazione, il peso della seconda e
per‘ maggiore in larga parte delle condizioni esaminate. In generale
i nostri risultati sono consistenti con quelle teorie che sostengono l’e-
sistenza di una stretta relazione tra fiducia, reputazione e reciprocita
La fiducia e un concetto importante (benche elusivo) che si situa al-
46

3.7 Riduzionismo e Aspetti Cognitivi
l’incrocio tra numerose discipline quali sociologia, economia, scienze
politiche e che mantiene un suo significato anche nelle scienze natu-
rali. Ogni situazione in cui avviene uno scambio nonsimultaneo tra
organismi viventi implica un problema di fiducia. Esempi interes-
santi di scambi non-simultanei sono stati studiati in biologia. Uno
dei pi‘ noti e la condivisione di cibo tra i pipistrelli vampiri sudame-
ricani. Nelle colonie di pipistrelli avviene spesso che i soggetti che si
sono nutriti a sufficienza condividano il loro surplus (rigurgitandone
una parte) con i compagni meno fortunati che, a loro volta, restitui-
ranno l’aiuto ricevuto alla prima occasione [18]. La condivisione del
cibo e comune anche tra scimpanze e altri e primati, incluso l’uo-
mo, come emerge dalla documentazione antropologica sui cacciatori
raccoglitori.
Nelle mondo contemporaneo, in molti casi gli esseri umani utiliz-
zano strumenti istituzionali per incentivare a comportamenti corretti
i soggetti che scambiano in modo nonsimultaneo oggetti o servizi do-
tati di valore. Tanto la costruzione quanto il funzionamento di tali
istituzioni impongono, per‘ , costi (di transazione o altro) tali da
rendere difficile il loro impiego in tutti i casi. I soggetti devono al-
lora ripiegare nuovamente sulla fiducia se vogliono impegnarsi nello
scambio. Ci‘ avviene tanto all’interno di contesti informali (prestiti
tra amici, aiuto tra vicini, ecc.) quanto formali. In questo secondo
ambito rientrano i contratti tra aziende della cosiddetta knowledge
economy, che rappresentano altrettanti scambi nonsimultanei dove
fiducia e reputazione rappresentano fondamentali strumenti di rego-
lazione. Paul Adler [19] afferma che nel caso di aziende che non
necessitino solo di beni e servizi standardizzati, ma anche di input
di innovazione e conoscenza il controllo gerarchico e il mercato non
47

I Sistemi Complessi
sono in grado di assicurare performance altrettanto elevate quanto
le comunita’ basate sulla fiducia.
Nel nostro caso sono molto rilevanti le dinamiche che sono dietro
alle transazioni sui siti di aste web (ad es. eBay) dove i compratori
devono pagare in anticipo i loro acquisti mentre i venditori spedi-
scono i beni ceduti solo dopo aver ricevuto il pagamento rappresen-
tano un esempio altrettanto interessante di scambio nonsimultaneo.
Poiche e difficile determinare l’identita reale dei contraenti, la possi-
bilita di utilizzare strumenti giuridici per far rispettare i “contratti”
e molto bassa. L’unico elemento che favorisce i compratori e quin-
di il desiderio dei venditori di mantenere la loro reputazione (nota
al momento dell’acquisto) a un livello sufficientemente elevato da
garantirsi future profittevoli transazioni [20].
48

Capitolo 4
KDD nei Sistemi Complessi
4.1 Data mining
Il data mining e una materia che si e andata affermando negli ul-
timi 10 anni ed ha per oggetto l’estrazione di un sapere o di una
conoscenza a partire da grandi quantita di dati (attraverso metodi
automatici o semi-automatici).
I motivi principali che hanno contribuito all’affermarsi del data
mining ed al suo sviluppo sono principalmente da riconducibili :
• alle grandi moli di dati in formato digitale,
• l’immagazzinamento dei dati ormai a costi molto molto esegui,
• i nuovi metodi e tecniche di analisi (apprendimento automati-
co, riconoscimento di pattern).
Le tecniche di data mining sono fondate su specifici algoritmi. I
pattern identificati possono essere, a loro volta, il punto di partenza
49

KDD nei Sistemi Complessi
per ipotizzare e quindi verificare nuove relazioni di tipo causale fra fe-
nomeni; in generale, possono servire in senso statistico per formulare
previsioni su nuovi insiemi di dati.
Un concetto correlato al data mining e quello di apprendimento
automatico (Machine learning); infatti, l’identificazione di pattern
pu paragonarsi all’apprendimento, da parte del sistema di data mi-
ning, di una relazione causale precedentemente ignota, cosa che trova
applicazione in ambiti come quello degli algoritmi euristici e della in-
telligenza artificiale. Tuttavia, occorre notare che il processo di data
mining e sempre sottoposto al rischio di rivelare relazioni causali che
poi si rivelano inesistenti.
Tra le tecniche maggiormente utilizzate in questo ambito vi sono:
• Clustering;
• Reti neurali;
• Alberi di decisione;
• Analisi delle associazioni .
Un’altra tecnica molto diffusa per il data mining e l’apprendi-
mento mediante classificazione. Questo schema di apprendimento
parte da un insieme ben definito di esempi di classificazione per ca-
si noti, dai quali ci si aspetta di dedurre un modo per classificare
esempi non noti. Tale approccio viene anche detto con supervisione
(supervised), nel senso che lo schema di apprendimento opera sotto
la supervisione fornita implicitamente dagli esempi di classificazio-
ne per i casi noti; tali esempi, per questo motivo, vengono anche
50

4.1 Data mining
detti training examples, ovvero esempi per l’addestramento. La co-
noscenza acquisita per apprendimento mediante classificazione pu
essere rappresentata con un albero di decisione.
L’estrazione dei dati vera e propria giunge quindi al termine di un
processo che comporta numerose fasi: si individuano le fonti di dati;
si crea un unico set di dati aggregati; si effettua una pre-elaborazione
(data cleaning, analisi esplorative, selezione, ecc.); si estraggono i da-
ti con l’algoritmo scelto; si interpretano e valutano i pattern; l’ultimo
passaggio va dai pattern alla nuova conoscenza cos acquisita.
4.1.1 Il Processo di Estrazione della Conoscenza
Gli stadi che caratterizzano un processo KDD sono stati identificati
nel 1996 da Usama Fayyad, Piatetsky-Shapiro e Smyth. Nell’elenca-
re e descrivere queste fasi tali studiosi pongono particolare attenzione
allo stadio del DM, cioe a tutti quegli algoritmi per l’esplorazione
e lo studio dei dati. Il DM e ritenuta la fase piu importante del-
l’intero processo KDD e questa sua enorme importanza, peraltro
riconosciuta, rende sempre piu difficile, soprattutto in termini pra-
tici, distinguere il processo KDD dal DM. Da parte nostra, anche se
alcuni ricercatori usano i termini
DM e KDD come sinonimi, cercheremo costantemente di sepa-
rare i due aspetti e di considerare il DM la fase piu significativa del
processo KDD, ma non perfettamente coincidente con esso. Iniziamo
con una descrizione delle cinque fasi del processo KDD che ricalca
sostanzialmente il modello ideato dagli studiosi citati sopra. Il pro-
cesso KDD prevede come dati in input dati grezzi e fornisce come
output informazioni utili ottenute attraverso le fasi di:
51

KDD nei Sistemi Complessi
Selezione: i dati grezzi vengono segmentati e selezionati secondo
alcuni criteri al fine di pervenire ad un sottoinsieme di dati, che rap-
presentano il nostro target data o dati obiettivo. Risulta abbastanza
chiaro come un database possa contenere diverse informazioni, che
per il problema sotto studio possono risultare inutili; per fare un
esempio, se l’obiettivo e lo studio delle associazioni tra i prodotti di
una catena di supermercati, non ha senso conservare i dati relativi
alla professione dei clienti; e invece assolutamente errato non consi-
derare tale variabile, che potrebbe invece fornire utili informazioni
relative al comportamento di determinate fasce di clienti, nel caso in
cui si voglia effettuare un’analisi discriminante.
Preelaborazione: spesso, pur avendo a disposizione il target da-
ta non e conveniente ne, d’altra parte, necessario analizzarne l’intero
contenuto; puo essere piu adeguato prima campionare le tabelle e in
seguito esplorare tale campione effettuando in tal modo un’analisi su
base campionaria. Fanno inoltre parte del seguente stadio del KDD
la fase di pulizia dei dati (data cleaning) che prevede l’eliminazione
dei possibili errori e la decisione dei meccanismi di comportamento
in caso di dati mancanti.
Trasformazioni: effettuata la fase precedente, i dati, per essere
utilizzabili, devono essere trasformati. Si possono convertire tipi di
dati in altri o definire nuovi dati ottenuti attraverso l’uso di operazio-
ni matematiche e logiche sulle variabili. Inoltre, soprattutto quando
i dati provengono da fonti diverse, e necessario effettuare una loro
riconfigurazione al fine di garantirne la consistenza.
Data Mining: ai dati trasformati vengono applicate una serie
di tecniche in modo da poterne ricavare dell’informazione non banale
o scontata, bensi’ interessante e utile. I tipi di dati che si hanno a
52

4.2 Il Modello Crisp-DM
disposizione e gli obiettivi che si vogliono raggiungere possono dare
un’indicazione circa il tipo di metodo/algoritmo da scegliere per la
ricerca di informazioni dai dati. Un fatto e certo: l’intero processo
KDD e un processo interattivo tra l’utente, il software utilizzato e gli
obiettivi, che devono essere costantemente inquadrati, ed iterativo
nel senso che la fase di DM pu prevedere un’ulteriore trasformazione
dei dati originali o un’ulteriore pulizia dei dati, ritornando di fatto
alle fasi precedenti.
Interpretazioni e Valutazioni: il DM crea dei pattern, ovvero
dei modelli,che possono costituire un valido supporto alle decisioni.
Non basta per interpretare i risultati attraverso dei grafici che visua-
lizzano l’output del DM,ma occorre valutare questi modelli e cioe
capire in che misura questi possono essere utili. E dunque possibile,
alla luce di risultati non perfettamente soddisfacenti, rivedere una o
piu fasi dell’intero processo KDD.
4.2 Il Modello Crisp-DM
Esiste un progetto finanziato dalla Commissione europea il cui obiet-
tivo e quello di definire un approccio standard ai progetti di DM,
chiamato CRISP-DM (CRoss Industry Standard Process for Data
Mining). Il CRISP-DM affronta la necessita di tutti gli utenti coin-
volti nella diffusione di tecnologie di DM per la soluzione di problemi
aziendali. Scopo del progetto ‘ definire e convalidare e uno schema
d’approccio indipendente dalla tipologia di business.
53

KDD nei Sistemi Complessi
La figura riassume lo schema CRISP-DM, oltre che chiarire l’es-
senza del DM e il suo utilizzo da parte delle imprese per incrementare
il loro business. Come possiamo vedere dalla figura il ciclo di vita di
un progetto di DM consiste di sei fasi la cui sequenza non e rigida. E
quasi sempre richiesto un ritorno indietro ed un proseguimento tra
le differenti fasi. Questo dipende dalla qualita del risultato di ogni
a fase, che costituisce la base di partenza della fase successiva. Le
54

4.2 Il Modello Crisp-DM
frecce indicano le piu importanti e frequenti dipendenze tra le fasi.
L’ellisse fuori lo schema rappresenta la natura ciclica di un processo
di DM il quale continua anche dopo che una soluzione e stata indivi-
duata e sperimentata. Spesso quanto imparato durante un processo
di DM porta a nuove informazioni in processi di DM consecutivi.
Descriviamo ora con maggiore dettaglio le fasi della figura:
Business Understanding: opportuno che in un progetto di
DM si conosca il settore di affari in cui si opera. In questo sen-
so il DM non deve, sostituire il compito dei manager tradizionali,
ma solo porsi come strumento aggiuntivo di supporto alle decisioni.
Avendo chiare le idee sul settore di affari in cui si opera, si procede
alla conversione di questa conoscenza di settore nella definizione di
un problema di DM e quindi alla stesura preliminare di un piano
prefissato per raggiungere gli obiettivi stabiliti.
Data Understanding: individuati gli obiettivi del progetto di
DM, quello di cui disponiamo per il raggiungimento di tali obietti-
vi ‘ rappresentato dai dati. Quindi la fase successiva prevede una
iniziale raccolta dei dati e una serie di operazioni sui dati stessi che
permettono di acquisire maggiore familiarita con essi, di identificare
problemi nella qualit‘ dei dati stessi, nonche scoprire le prime in-
formazioni che a volte si possono ricavare dal semplice calcolo delle
statistiche di base ( medie, indici di variabilita, ecc. . . ). E’ chiaro
inoltre come le prime due fasi siano collegate dato che rappresentano
l’individuazione dei fini e dei mezzi di un progetto di DM.
Data preparation: tale fase copre tutte le attivita che poi por-
tano alla costruzione dell’insieme di dati finale a partire dai dati
grezzi e dunque dell’insieme di dati cui applicare le tecniche di DM.
Essa comprende tra l’altro la selezione di tabelle, di records e di at-
55

KDD nei Sistemi Complessi
tributi come anche, se necessaria, la trasformazione e la pulitura dei
dati.
Modelling: in questa fase vengono selezionate e applicate varie
tecniche che permettono di ricavare dei modelli. Determinate tec-
niche, per poter essere applicate, necessitano di specifiche richieste
rispetto alla forma dei dati, per cui e spesso opportuno tornare in-
dietro alla fase di preparazione dei dati per e modificare il dataset
iniziale e adattarlo alla tecnica specifica che si vuole utilizzare.
Evaluation: prima di procedere all’impiego del modello o dei
modelli costruiti, e molto importante valutare il modello e i pas-
si eseguiti per costruirlo, accertarsi che attraverso tale modello si
possono veramente raggiungere obiettivi di business, capire se qual-
cosa di importante non e stato sufficientemente considerato nella
costruzione del modello.
Deployment: e la fase finale che prevede l’utilizzo del modello o
dei modelli creati e valutati che possono permettere il raggiungimen-
to dei fini desiderati. Le fasi di DM su descritte sembrano ricalcare
nella sostanza le fasi del piu generale processo di estrazione di cono-
scenza dai database (KDD). In realta questo progetto di DM ingloba
al suo interno le fasi del processo KDD e dimostra quanto gia affer-
mato in precedenza riguardo al sempre piu diffuso accostamento del
DM al processo KDD.
4.2.1 KDD descrittivo e previsivo
Gli approcci al DM possono essere di due tipi: di tipo top-down
e di tipo bottom-up. Nel primo caso si tratta di utilizzare la sta-
tistica come guida per l’esplorazione dei dati, cercando di trovare
56

4.2 Il Modello Crisp-DM
conferme a fatti che l’utente ipotizza o gia conosce, per migliorare la
comprensione di fenomeni parzialmente conosciuti. In quest’ambito
vengono utilizzate le statistiche di base, che permettono di ottenere
descrizioni brevi e concise del dataset, di evidenziare interessanti e
generali proprieta dei dati; e anche possibile l’utilizzo di tecniche
statistiche tradizionali come, ad esempio, la regressione. Tuttavia,
un approccio di tipo top-down limita i compiti del DM ad un DM di
tipo descrittivo . La sola descrizione dei dati non pu fornire quelle
informazioni di supporto alle decisioni, cui si fa costantemente rife-
rimento quando si parla di potenzilita del DM. Di conseguenza, un
approccio al DM di tipo bottom-up, nel quale l’utente si mette a sca-
vare nei dati alla ricerca di informazioni che apriori ignora, risulta di
gran lunga piu interessante. Questo secondo approccio conduce ad
un DM di tipo previsivo in cui si costruisce uno o pi‘ set di modelli,
si effettuano delle inferenze sui set di dati disponibili e si tenta di
prevedere il comportamento di nuovi dataset. E proprio nel DM di
tipo previsivo che IBM ha identificato due tipi, o modi, di operare,
che possono essere usati per estrarre informazioni di interesse per
l’utente: i Verification models e i Discovery models. I verification
models utilizzano delle ipotesi formulate dall’utente e verificano tali
ipotesi sulla base dei dati disponibili. In questi tipi di modelli riveste
un ruolo cruciale l’utente, al quale e affidato il compito di formulare
delle ipotesi sui possibili comportamenti delle variabili in questione.
Tuttavia risultano di gran lunga piu interessanti i discovery models,
che costituiscono la parte piu rilevante delle tecniche di DM. In que-
sti tipi di modelli all’utente non e affidato nessun tipo di compito
specifico, e il sistema che scopre automaticamente importanti infor-
mazioni nascoste nei dati: si cerca di individuare pattern frequenti,
57

KDD nei Sistemi Complessi
regole di associazione, valori ricorrenti. Potremmo addirittura affer-
mare che il DM e costituito dai soli discovery models, dal momento
che un’importante differenza tra i metodi tradizionali di analisi dei
dati e i nuovi metodi (di cui il DM e parte integrante) e che i pri-
mi sono guidati dalle assunzioni fatte, nel senso che viene formulata
un’ipotesi che viene saggiata attraverso i dati, mentre i secondi sono
guidati dalla scoperta, nel senso che i modelli sono automaticamen-
te estratti dai dati. L’utilizzo di queste nuove tecniche richie- de
ovviamente enormi sforzi di ricerca e in questo le maggiori perfor-
mance degli odierni calcolatori giocano un ruolo chiave. Un utilizzo
delle tecniche tradizionali di analisi dei dati si ha nelle procedure
OLAP (On Line Analytical Processing). Come affermato nella no-
ta 3 dell’introduzione, si tratta di tecniche alternative al DM che
a differenza di questo hanno alla base un’analisi essenzialmente de-
duttiva. Difatti, in tali procedure l’utilizzatore interroga il database
ponendo una serie di queries che vanno a validare o meno un’ipotesi
precedentemente formulata. Tuttavia, quando il numero delle va-
riabili cresce, l’utilizzo delle metodologie OLAP diventa sempre piu
difficoltoso, perche diventa difficile, e anche dispendioso in termini
di tempo, formulare delle buone ipotesi da saggiare. Risulta quindi
piu utile ricorrere alle tecniche di DM che liberano l’utente da com-
piti specifici, dal momento che in tale ambito non si utilizzano piu
strumenti di Query e OLAP, ma tecniche derivate dalla statistica e
dall’intelligenza artificiale.
58

4.3 Il Clustering
4.3 Il Clustering
4.3.1 Clustering
La parola inglese cluster e difficilmente traducibile, letteralmente si-
gnifica grappolo, ma anche ammasso, sciame, agglomerato, parole
che visivamente richiamano alla mente una o piu entita costituite da
elementi piu piccoli, omogenei tra loro ma allo stesso tempo distinti
da altri elementi esterni al cluster stesso. Una definizione di cluster e
peraltro difficile da trovare anche in letteratura, normalmente si par-
la di coesione interna ed isolamento esterno [21], oppure di elevato
grado di associazione naturale tra gli elementi di un cluster e di rela-
tiva distinzione tra cluster differenti [22], in modo piu generale si pu
definire cluster una parte dei dati (un sottoinsieme della popolazione
in analisi) che consiste di elementi molto simili rispetto alla rimanen-
te parte dei dati [23]. La generalita delle definizioni di cui sopra e de-
terminata principalmente dalla assoluta impossibilita di formalizzare
matematicamente il concetto di cluster in maniera univoca, del re-
sto empiricamente si possono osservare molti tipi differenti di cluster:
sferici, ellissoidali, lineari. Le tecniche che permettono di ottenere
i cluster dai dati osservati sono molteplici ed utilizzano procedure
differenti, comunemente vengono denominati algoritmi di clustering
per sottolineare il carattere automatico di tale procedura. E’ possi-
bile far risalire la nascita di tale disciplina all’inizio di questo secolo,
quando si cominci ad avvertire la necessita di sostituire l’occhio ed
il cervello umano nell’attivita classificatoria con strumenti maggior-
mente precisi, in grado di gestire enormi quantita di informazioni e
non limitati a spazi tridimensionali. Solamente con lo sviluppo e la
59

KDD nei Sistemi Complessi
diffusione dei moderni computer le procedure di clustering comincia-
rono ad essere impiegate con successo in numerose discipline: nelle
scienze naturali, nell’ambito della tassonomia numerica [24], allo sco-
po di rendere piu veloce e precisa l’opera di classificazione delle specie
viventi; nelle scienze sociali per individuare gruppi socio-economici
e segmenti di mercato; nel campo dell’intelligenza artificiale ed in
particolare nella pattern recognition, per l’analisi, il confronto ed il
riconoscimento dei dati. Seguendo questo percorso, pur in assenza
di un rigoroso fondamento teorico, ha avuto origine la disciplina oggi
nota come cluster analysis. Generalmente gli algoritmi di clustering
cercano di separare un insieme di dati nei suoi cluster costituen-
ti, evidenziando i gruppi naturali, ossia la struttura classificatoria
relativa ai dati stessi, si suppone che i dati analizzati possiedano
una propria classificazione e compito degli algoritmi di clustering e
proprio trovare la struttura classificatoria che meglio si adatta alle
osservazioni. Mentre nella classificazione la struttura dei dati e nota,
quindi si suppone che per classificare un insieme di dati non ordinati
ci si riferisca comunque ad una struttura classificatoria conosciuta,
nella cluster analysis poco o nulla e noto circa la struttura dei dati,
tutto ci che e disponibile e una collezione di osservazioni le cui rela-
tive classi si appartenenza sono ignote. Questa, che e la principale
differenza tra clustering e classificazione, ci permette di definire la
cluster analysis come strumento classificatorio empirico basato sulle
osservazioni, le eventuali informazioni note a priori possono essere
utilizzate per verificare la bonta dello schema classificatorio ottenu-
to. E’ quindi errato definire gli algoritmi di clustering metodi di
classificazione automatica visto che la struttura classificatoria vie-
ne individuata contestualmente all’assegnazione di ogni elemento al
60

4.3 Il Clustering
suo gruppo di appartenenza. Il compito degli algoritmi di cluste-
ring e quindi duplice, da un lato trovare la struttura classificatoria
intrinseca dei dati, i cosiddetti gruppi naturali, dall’altro assegnare
ogni elemento alla rispettiva classe di appartenenza, per fare questo
generalmente gli algoritmi cercano di classificare le osservazioni in
gruppi tali che il grado di associazione naturale sia alto tra i membri
dello stesso gruppo e basso tra i membri di gruppi differenti. Si pu
quindi affermare che l’essenza della cluster analysis pu anche essere
vista come l’assegnazione di appropriati significati ai termini gruppi
naturali ed associazione naturale.
4.3.2 Tassonomia degli algoritmi di clustering
Data la varieta dei metodi e degli algoritmi di clustering disponi-
bili e opportuno presentarne una classificazione [24], che permetta
di comprendere quali siano le principali caratteristiche delle diverse
procedure.
Quella presentata non e l’unica classificazione degli algoritmi di
clustering, vedi [25]. Inoltre e opportuno precisare che sono stati
esclusi dalla presente trattazione i metodi di clustering che utilizzano
la teoria dei grafi.
1. Metodi gerarchici e non gerarchici: costituisce la distinzio-
ne principale, si riferisce sia al metodo usato per ottenere i cluster
che alla struttura del risultato dell’algoritmo stesso. I metodi gerar-
chici producono delle tipiche strutture ad albero, di tipo ricorsivo
o annidato; i cluster dei livelli piu alti sono aggregazioni di cluster
dei livelli piu bassi dell’albero. I metodi non gerarchici vengono an-
che definiti partitivi poich dividono l’insieme dei dati in partizioni,
61

KDD nei Sistemi Complessi
le quali sono costituite solamente dai singoli elementi oggetto della
classificazione, l’insieme dei dati da classificare viene quindi diviso
in piu sottoinsiemi o cluster senza ulteriori suddivisioni all’interno
di ogni cluster. 2. Metodi agglomerativi e divisivi: si riferisce al
metodo con il quale operano gli algoritmi gerarchici ed anche alla
direzione seguita per costruire lo schema classificatorio (albero ge-
rarchico). I metodi agglomerativi procedono dal basso verso l’alto
unendo i singoli elementi mentre i metodi divisivi procedono dall’al-
to verso il basso scindendo i cluster in altri piu piccoli. 3. Metodi
con sovrapposizione e senza sovrapposizione (dei cluster): riguarda
i cluster prodotti con i metodi non gerarchici o partitivi e si riferisce
ai cluster ottenuti per mezzo dell’algoritmo. I cluster si definiscono
non sovrapposti quando ogni elemento appartiene ad uno e ad un
solo cluster; i cluster sovrapposti vengono anche denominati fuzzy
cluster poich ogni elemento pu appartenere a piu cluster differenti
per mezzo di un grado di appartenenza definito come segue:
L’elemento xi appartiene al cluster Ci con un grado di apparte-
nenza compreso nell’intervallo [0,1] . Questa estensione della cluster
analysis classica deriva dalla considerazione che nella realta molti
fenomeni non si presentano con contorni ben definiti, ed un elemen-
to pu appartenere contemporaneamente a piu cluster differenti. Ad
esempio nel caso si vogliano classificare diverse specie di frutta, gli
ibridi si troveranno in una posizione intermedia tra i cluster dei frut-
ti dal cui incrocio sono stati generati, ed inserirli forzatamente in
uno solo dei due cluster rappresenta una errata interpretazione della
realta [25].
62

4.4 La Classificazione
4.4 La Classificazione
Obiettivo della classificazione consiste nell’ analizzare i dati in imput
e sviluppare un’accurata descrizione o un modello per ogni classe,
usando le caratteristiche (espresse nell’esempio attraverso gli attri-
buti A1 , A2 , . . . , Ap ) presenti nei dati. Gli algoritmi di clas-
sificazione portano all’identificazione di schemi o insiemi di caratte-
ristiche che definiscono la classe cui appartiene un dato record. In
genere, partendo dall’utilizzo di insiemi esistenti e gia classificati, si
cerca di definire alcune regolarita che caratterizzano le varie classi.
Le descrizioni delle classi vengono usate per classificare records, di
cui non si conosce la classe di appartenenza, o per sviluppare una
migliore conoscenza di ogni classe nel dataset. Non a caso, alcu-
ne delle applicazioni di maggiore interesse di questa tecnica di DM
includono la ricerca, da parte delle banche, di categorie di clienti
ai quali concedere un prestito (in tal caso ogni record e etichettato
come buon creditore o cattivo creditore e gli attributi sono i dati
dei clienti relativi all’eta, al reddito, ecc . . . ) o applicazioni di
target marketing, con cui un’impresa pu individuare, sulla base delle
caratteristiche dei clienti presenti nel database, un proprio target di
mercato allo scopo di rafforzare la propria posizione
in un determinato settore (in tal caso etichettando ogni record
del database come cliente fedele e cliente non fedele). Esiste una so-
stanziale differenza, che e opportuno chiarire, tra le tecniche di clas-
sificazione e le tecniche di raggruppamento o clustering (che avremo
modo di considerare piu avanti nella tesi). Tramite la classificazio-
ne l’utente comunica al tool di DM la caratteristica chiave, di cui
i membri del gruppo devono essere dotati, e il tool non si occupa
63

KDD nei Sistemi Complessi
di nessun altro attributo che i membri del gruppo possono avere in
comune. Ad esempio, si pu dire al tool di DM di creare dei gruppi
di clienti sulla base dei diversi livelli di entrate che apportano al-
l’azienda. Utilizzando queste in- formazioni, l’azienda pu investire
tempo e denaro per corteggiare potenziali clienti con caratteristiche
simili. In altre parole, nella classificazione esiste un attributo madre,
il cui numero di modalita rappresentera il numero dei gruppi che si
verranno a formare (questo attributo madre e proprio la classe di
appartenenza). Due records appartenenti al medesimo gruppo in un
processo di classificazione possono in realta essere fortemente diversi
fra loro. Tale diversita e legata al fatto che il tool di DM ignora gli
attributi al di fuori della classe di appartenenza. Nel raggruppamen-
to non esiste un numero di gruppi prefissato. In tal caso il tool di
DM crea dei gruppi sulla base di tutti gli attributi presenti nel data-
base, in modo che ogni gruppo sia caratterizzato da elementi simili
in termini degli attributi descritti nel database e che due elementi
appartenenti a gruppi diversi siano sufficientemente distanti tra di
loro.
4.5 Interazione negli Agenti
In questa sezione analizzeremo brevemente il paradigma di modella-
zione che consente ad agenti simili di comunicare tra loro. L’aggiunta
della comunicazione incrementa di molto il livello di possibilita im-
plementative di un MAS, in particolare la programmazione ad agen-
ti e basata fortemente sul concetto di interazione e questa avviene
tramite comunicazione.
64

4.5 Interazione negli Agenti
La peculiarita di una computazione basata su interazione ha un
potenziale di rappresentazione dei fenomeni complessi che finora e
stata sottovalutata. Nei lavori [?] oppure in [26] i meccanismi di
emergenza che sono effetto della propagazione dell’interazione ven-
gono trattati come punto cardine per la rappresentazione dei sistemi
complessi.
L’aggiunta di alcune tecniche di data mining atte ad tracciare le
varie comunicazioni (interazione tra agenti) ha portato ottimi risulta-
ti sia per ci che riguarda la classificazione dei singoli comportamenti
a fini di ottimizzazione, sia a scopi predittivi.
65

KDD nei Sistemi Complessi
66

Capitolo 5
Simulazione di Sistemi
Complessi con i MAS
5.1 Stato dell’Arte dei MAS
5.1.1 Origine
L’intelligenza artificiale distribuita si e sviluppata come branca del-
l’intelligenza artificiale negli ultimi venti anni. Fondamentalmente la
tecnologia sviluppata da tale approccio epistemologico si occupa di
sistemi eterogenei composti da entita indipendenti che interagiscono
tra loro e con l’ambiente all’interno di un dominio. Tradizionalmen-
te fanno riferimento a questa tecnologia altre due sotto discipline:
Distribuited Problem Solving (DPS) che si occupa dell’elaborazione
dell’informazione in sistemi a molte componenti che lavorano separa-
tamente per di raggiungere uno scopo comune; Multiagent Systems
(MAS) che invece si occupa dell’organizzazione dei comportamenti
67

Simulazione di Sistemi Complessi con i MAS
degli agenti, in particolare per i loro aspetti sociali/interattivi dal
punto di vista computazionale.
In particolare, I MAS intendono fornire sia i principi paradigma-
tici per la costruzione di sistemi complessi sia i meccanismi per la
coordinazione e la cooperazione tra agenti indipendenti. Non c’e an-
cora una definizione chiara per i MAS, in [27] un agente e considerato
come un entita provvista di scopi e di una base di conoscenza che
percepisce l’ambiente tramite sensori ed interagisce con l’ambiente
stesso tramite attuatori. Altri autori, come Pattie Maes del MIT,
pongono l’accento sul fatto che gli ambienti i cui gli agenti si muo-
vono sono complessi e dinamici, e che gli agenti agiscono in modo
autonomo; in effetti, tutte le moderne teorie degli agenti prevedono
una loro capacita di risposta autonoma ai cambiamenti ambientali.
Altri autori, ad es. Barbara Hayes-Roth (Hayes, 1995), ritengono
che essenziale per gli agenti sia la capacita di ragionamento logico,
ma questo esclude molte altre tipologie di agenti intelligenti.
Il modo in cui l’agente agisce e chiamato comportamento o beha-
vior. Per uno studio comparativo delle tecnologie afferenti a questo
campo ci dobbiamo principalmente concentrare su due domande:
Che tipi di vantaggi offre rispetto alle alternative? In quali
contesti e particolarmente utile?
5.1.2 I Sistemi Basati su Agenti
I sistemi ad agenti torno utili quando si ha a che fare con persone
o organizzazioni interagenti con diversi ed (eventualmente in con-
flitto) finalita. Oppure se un’organizzazione vuole modellare le sue
dinamiche interne. Oppure se si vuole rappresentare un’azienda che
68

5.1 Stato dell’Arte dei MAS
interagisce con le altre e questa ha bisogno di essere descritta con
un sistema che rifletta le sue capacita e proprieta. Considerando la
proprieta degli agenti che consentono di modellare un sistema com-
plesso in componenti interagenti, ma allo stesso tempo indipendenti,
e abbastanza intuitivo immaginare che i MAS non devono necessaria-
mente essere utilizzati in sistemi distribuiti, ma possono presentare
enormi vantaggi anche in altri contesti. Avere molti agenti pu in-
crementare notevolmente la velocita di un sistema perch forniscono
un naturale uso del calcolo parallelo. Ad esempio, in un dominio
che e facilmente decomponibile in componenti che svolgono compiti
differenti, possono essere facilmente implementati con il paradigma
dei MAS superando le limitazioni imposte dai tempi computazionali.
Mentre il parallelismo pu essere raggiunto assegnando compiti dif-
ferenti ad agenti con differenti comportamenti, la robustezza e una
peculiarita che emerge dalla ridondanza di agenti. Se ad esempio, la
responsabilita e controllo sono sufficientemente suddivise nella popo-
lazione di agenti, il sistema presentera naturalmente una maggiore
tolleranza agli errori. I MAS sono anche modulari per definizione ed
e facile aggiungere un altro agente con differente capacita all’interno
di un sistema gia esistente portando enormi vantaggi in termini di
scalabilita e manutenibilita.
Dalla prospettiva di un programmatore la modularita dei sistemi
ad agenti permette una piu facile implementazione, manutenzione
e codifica delle specifiche. Piuttosto che allocare tutte le specifiche
computazionali all’interno di un unico programma monolitico, il pro-
grammatore pu identificare sotto task ed assegnarne il controllo ad
agenti differenti.
69

Simulazione di Sistemi Complessi con i MAS
5.1.3 Le Problematiche Dei Sistemi Multi Agen-
te
Si possono rilevare cinque principali problematiche nei confronti del-
la creazione di sistemi multi agente. In primo luogo, la problematica
dell’azione: come pu un insieme di agenti agire simultaneamente in
un ambiente frammentato, e come interagisce tale ambiente in rispo-
sta agli agenti? Le questioni qui sottintese sono, tra le altre, quella
della rappresentazione dell’ambiente per mezzo degli agenti, della
collaborazione tra gli agenti, e della pianificazione dell’attivita di
una molteplicita d’agenti. Inoltre, e da considerare la problematica
dell’agente e della sua relazione col mondo esterno, la quale e rappre-
sentata dal modello cognitivo di cui dispone l’agente. Ogni singolo
individuo in una societa costituita da molteplici agenti deve essere
in grado di mettere in opera le azioni piu rispondenti ai suoi obietti-
vi. Tale attitudine alla decisione e legata ad uno stato mentale che
riflette le percezioni, le rappresentazioni, le convinzioni ed un certo
numero di parametri psichici (desideri, tendenze...) dell’agente. La
problematica in questione copre anche la nozione dei vincoli dell’a-
gente nei confronti di un agente terzo. I sistemi ad agenti multipli
necessitano altres dello studio della natura delle interazioni, come
fonte di opportunita, da una parte, e di vincoli dall’altra.
70

5.1 Stato dell’Arte dei MAS
La problematica dell’interazione si interessa alle modalita di in-
terazione (quale linguaggio? quale supporto?), all’analisi ed alla
concezione delle forme d’interazione tra agenti. Le nozioni di col-
laborazione e di cooperazione (considerata come collaborazione +
coordinamento delle azioni + risoluzione dei conflitti) sono in questo
campo questioni fondamentali. Se si applicano le mere conoscenze
dei sistemi a singolo agente a quelli multi agente si avranno degli
agenti egoisti (self-interested) che non coopereranno in alcun modo,
dunque l’obiettivo del sistema sara raggiunto in minima parte.
Di seguito pu richiamarsi la problematica dell’adattamento, in
termini di adattamento individuale o apprendimento da una parte, e
adattamento collettivo o evoluzione dall’altra.Ovvero la propagazio-
ne di un comportamento basato su interazione che dal locale emerge
nel globale. Infine, rimane da discutere la questione della realizzazio-
ne effettiva e dell’implementazione dei sistemi multi agente, tramite
la strutturazione dei linguaggi di programmazione in piu tipologie,
che vanno da un linguaggio di tipo L5, o linguaggio di formalizza-
zione e specifica, ad un linguaggio di tipo L1, che e quello dell’im-
plementazione effettiva. Tra le due classi, si trovano i linguaggi per
la comunicazione tra agenti, la descrizione delle leggi dell’ambiente
e la rappresentazione delle conoscenze.
5.1.4 Architetture
Con riferimento alle cinque problematiche precedenti, e possibile de-
lineare gli elementi dell’architettura d’un sistema ad agenti multipli
come segue. Gli agenti devono essere dotati di svariati sistemi di
decisione e pianificazione. La ricerca operativa, o teoria delle deci-
71

Simulazione di Sistemi Complessi con i MAS
sioni, e una disciplina completamente dedita allo studio di questo
soggetto. Nella categoria delle interazioni con l’ambiente, un altro
problema ricorrente dei sistemi ad agenti e quello del path finding
(insieme al suo algoritmo piu conosciuto, l’algoritmo A*). Gli agen-
ti necessitano inoltre d’un modello cognitivo: anche qui esistono
diversi modelli, tra cui uno dei piu classici e il modello BDI [28]
(Beliefs-Desires-Intentions, cioe Convinzioni-Desideri-Intenzioni).
Esso considera da una parte l’insieme delle credenze (Beliefs) del-
l’agente sull’ambiente in cui si trova ad operare, che sono il risultato
delle sue conoscenze e delle sue percezioni, e dall’altra parte un insie-
me di obiettivi (Desires). Intersecando questi due insiemi, si ottiene
un nuovo insieme di intenzioni (Intentions), che in seguito possono
tradursi direttamente in azioni.
Ancora, gli agenti devono altres essere forniti di un sistema di
comunicazione. Molti linguaggi specializzati hanno visto la luce
a questo scopo: il Knowledge Query and Manipulation Language
(KQML), e piu recentemente lo standard FIPA-ACL (ACL sta per
Agent Communication Language) creato dalla Foundation for Intel-
ligent Physical Agents FIPA (http://www.fipa.org/). Entrambi gli
standard sono fondati sulla teoria degli atti linguistici, elaborata da
John Searle [29]. La problematica dell’adattamento rappresenta un
argomento spinoso, oggetto attualmente di numerose ricerche. Si po-
trebbe tuttavia citare l’esempio di alcuni virus, non solo informatici
ma anche biologici, capaci di adattarsi al loro ambiente per effetto di
mutazioni. Infine, l’implementazione effettiva di un sistema multia-
gente, se non fa parte, propriamente parlando, dell’architettura del
sistema, merita di essere evocata attraverso l’esempio fornito dai nu-
merosi linguaggi di programmazione sviluppati a scopo di ricerca nel
72

5.1 Stato dell’Arte dei MAS
settore dell’intelligenza artificiale, si pensi in particolare ai linguaggi
LISP e PROLOG.
5.1.5 Categorie di Agenti
possibile introdurre una classificazione degli agenti secondo due cri-
teri: agenti cognitivi o reattivi da una parte, comportamento teleo-
nomico (comportamenti diretti e finalizzati ad uno scopo) o riflesso
dall’altra. La distinzione tra cognitivo e reattivo attiene essenzial-
mente alla rappresentazione del mondo di cui dispone l’agente. Se il
singolo agente e dotato d’una rappresentazione simbolica del mon-
do a partire dalla quale e in grado di formulare ragionamenti, si
parlera di agente cognitivo, mentre se non dispone che d’una rap-
presentazione sub-simbolica, vale a dire limitata alle percezioni, o
anche una sua elaborazione che non faccia uso di sistemi simboli-
ci, si parlera di agente reattivo. Tale distinzione corrisponde a due
scuole di pensiero relative ai sistemi multiagente: la prima sostiene
un approccio basato su insiemi di agenti intelligenti collaborativi, da
una prospettiva piu sociologica; la seconda studia la possibilita del-
l’emergenza d’un comportamento intelligente di un insieme d’agenti
non intelligenti (come quello delle formiche simulato dalle cosiddette
ant colony). La seconda distinzione tra comportamento teleonomico
o riflesso divide i comportamenti intenzionali (perseguire scopi espli-
citi) dai comportamenti legati a delle percezioni. Le tendenze degli
agenti possono essere anche espresse esplicitamente all’interno degli
agenti o al contrario provenire dall’ambiente. possibile costruire una
tabella che raggruppi i differenti tipi d’agente:
73

Simulazione di Sistemi Complessi con i MAS
Agenti Cognitivi Agenti Reattivi
Comportamento Teleonomico Agenti Intenzionali Agenti Impulsivi
Comportamento Riflesso Agenti Modulari Agenti Tropici
Gli agenti cognitivi sono il piu delle volte intenzionali, cioe han-
no scopi prefissati che tentano di realizzare. Si possono pure trovare
talvolta degli agenti detti modulari i quali, anche se possiedono una
rappresentazione del loro universo, non hanno tuttavia degli scopi
precisi. Tali agenti potrebbero servire ad esempio a rispondere alle
interrogazioni avanzate da altri agenti su detto universo. Gli agen-
ti reattivi possono a loro volta essere suddivisi in agenti impulsivi
e tropici. Un agente impulsivo avra una missione ben determinata
(per esempio, assicurarsi che un serbatoio resti sempre sufficiente-
mente pieno) e si comportera di conseguenza qualora percepisca che
l’ambiente non risponde piu allo scopo che gli e stato affidato (il li-
vello del serbatoio e troppo basso). L’agente tropico, dal canto suo,
reagisce solo allo stato locale dell’ambiente (c’e del fuoco, io fuggo).
La fonte della motivazione e nel primo caso interna (agenti impulsivi
che hanno una missione), nel secondo caso e legata esclusivamente
all’ambiente.
5.1.6 Tassonomia
Nel corso degli anni, dal campo dell’Intelligenza Artificiale Distri-
buita sono stati redatte e presentate diverse tassonomie finalizzate
alla descrizione funzionale e concettuale delle varie caratteristiche e
le relative metriche caratterizzanti un sistema multi agente. In par-
74

5.1 Stato dell’Arte dei MAS
ticolare troviamo molto esaustiva quella che Decker [30] propone che
si basa su principalmente su 4 dimensioni quali:
• Granularita dell’Agente (grossa vs fine)
• Eterogeneita delle Conoscenza degli Agenti (rindondanza vs
specializzazione)
• Metodi per distribuire il controllo (cooperazione, competizione,
gerarchie)
• Metodologie di Comunicazione
Piu recentemente Paranuak nel 1996 ha elaborato invece, una
tassonomia per i MAS che guarda il campo da un punto di vista
maggiormente applicativo. In questo modello le caratteristiche piu
importanti risiedono nel caratteristiche di seguito riportate:
• Funzionalita del Sistema
• Architettura dell’Agente (grado di eterogeneita, reattivo o de-
liberativo)
• Architettura del Sistema (comunicazione, protocolli, parteci-
pazione umana)
Un buon contributo di questa suddivisione logica e che le caratte-
ristiche preservano relazioni di gerarchia tra agente e sistema. La tas-
sonomia qui presentata e organizzata lungo il grado di eterogeneita
ed il grado di comunicazione.
75

Simulazione di Sistemi Complessi con i MAS
5.1.7 Panoramica
In questo sezione i sistemi ad agenti vengono distinti in 4 classi prin-
cipali, le quali tendono ad accomunare i sistemi in base al capacita
o meno di comunicare ed in base al loro grado di eterogeneita. In
particolare nella tabella seguente sono illustrate le principali carat-
teristiche proprie di ogni tipologia di sistema e l’ordine di presen-
tazione sottintende un incremento del grado di complessita sia in
termini di implementazione che di potenza rappresentativa partendo
dal piu semplice al piu completo e complesso. Tali classi saranno
poi trattate specificatamente nei paragrafi successivi. Nel dettaglio
nelle prossime sezioni saranno presentanti :
1. Sistemi omogenei non comunicanti
2. Sistemi eterogenei non comunicanti
3. Sistemi omogenei comunicanti
4. Sistemi eterogenei comunicanti
76

5.1 Stato dell’Arte dei MAS
Sistemi omogenei non comunicanti
In questo contesto tutti gli agenti presentano la stessa struttura in-
terna sia gli scopi, la base di conoscenza e il set di possibili azioni.
Sono inserite nella loro implementazioni anche procedure per la se-
lezione del tipo di azione da scegliere per raggiungere l’obiettivo. Le
sole differenze rimarcabili tra gli agenti sono identificabili nella loro
struttura di sensori e le singole azioni che loro scelgono per via del
fatto che sono posizionati differentemente nell’ambiente. I sistemi
ad agenti afferenti a questa classe posseggono caratteristiche capa-
cita mutuamente distribuite tra i singoli agenti e le stesse procedure
decisionali, le informazioni circa gli stati interni degli altri invece so-
no limitate quindi non sono in grado di prevedere il comportamento
degli altri.
77

Simulazione di Sistemi Complessi con i MAS
Nel design dei sistemi basati su agenti e importante determinare
il grado di complessita delle abilita di ragionamento dell’agente. I
semplici agenti Reattivi semplicemente usano comportamenti presta-
biliti, una sorta di riflesso ad una percezione che non passa per uno
stato interno. Dall’altro lato troviamo invece gli agenti Deliberativi
che reagiscono come riflesso di un ragionamento ( una mutazione
dello stato interno) Ci sono anche tecniche prevedono un mix di
reattivita e deliberazione nel design degli agenti, un esempio molto
importante nella letteratura scientifica e il sistema OASIS che deci-
de quando essere reattivo o quando invece, eseguire dei piani. Altro
esempio di deliberazione reattiva viene da [31], come dice lo stesso
nome la tecnica e una commistione di comportamenti deliberativi e
reattivi: un agente ragiona su quale comportamento eseguire sotto il
vincolo che deve essere scelto in un intervallo di 60Hz. La Reactive
Deliberation e stata implementata la prima volta in una piattaforma
di robot calciatori [32], non fu esplicitamente pensata per i MAS ma
essendo pensata per controlli in tempo reale in ambienti dinamici e
stata naturalmente estesa agli scenario dei sistemi ad agenti.
78

5.1 Stato dell’Arte dei MAS
Un’altra importante questione da tenere in considerazione nella
costruzione di MAS e relativa alla modalita di acquisizione dell’in-
formazione da parte dell’agente, ovvero se dare all’agente una pro-
spettiva globale piuttosto che locale del mondo in cui esso agisce.
Quando la comunicazione non e possibile, gli agenti non possono in-
teragire con gli altri direttamente, ma essendo situati in un ambiente
comune, per effetto delle social action [5] possono comunque influen-
zarsi in differenti modi. Possono essere percepiti dagli altri agenti,
oppure cambiare lo stato interno di un agente come ad esempio nello
spostarlo.
Sistemi eterogenei non comunicanti
In questa sezione, rispetto alla precedente, vedremo cosa succede
quando i sistemi contengono agenti differenti tra loro. Aggiungere
eterogeneita in dominio multi agente aggiunge un grosso potenzia-
le alla complessita rappresentativa. L’eterogeneita si pu presentare
sotto diverse forme dall’avere scopi diversi all’avere diversi domini o
79

Simulazione di Sistemi Complessi con i MAS
modelli oppure azioni. Una prima sotto dimensione di questa qualita
dei sistemi e la benevolenza o la competitivita. Se hanno scopi di-
versi allora possono aiutarsi nel raggiungimento degli scopi reciproci
oppure inibirsi e attivamente crearsi difficolta a vicenda. Il grado di
eterogeneita all’interno di un MAS pu essere misurato sfruttando la
teoria dell’informazione attraverso l’uso dell’entropia sociale di [33].
Come nel caso dei sistemi omogenei, in questo scenario, gli agenti
sono situati in posti diversi dell’ambiente e quindi quello che perce-
piscono e diverso e quindi ci saranno anche azioni differenti, mentre
altri elementi di differenza sono rintracciabili in un diverso set di
azioni, in una diversa base di conoscenza.
La diversita pu anche essere riscontrata nelle diverse tipologie
di apprendimento che spaziano da un set statico di istruzioni, alla
capacita di comportamento adattivo che e qualcosa di assimilabile
all’esperienza.
Nel caso degli agenti omogenei e facile, ai fini della previsione
del comportamento di un altro agente, riprodurre il suo stato in-
terno, mentre nel caso dei sistemi eterogenei e molto piu comples-
80

5.1 Stato dell’Arte dei MAS
so. Senza comunicazione gli agenti sono forzati a comprendere il
comportamene degli altri attraverso l’osservazione.
Le azioni oltretutto possono essere interdipendenti in considera-
zione del fatto che le risorse necessarie potrebbero essere limitate.
Un classico esempio di dominio e il problema del traffico in cui molti
agenti diversi devono mandare informazioni attraverso la stessa re-
te e il load balancing in cui molti processi di computer o di utenti
hanno un limitato tempo computazionale da sfruttare insieme agli
altri. In particolare il load balancing adattivo e stato studiato come
un problema di MAS permettendo a diversi agenti quale processore
utilizzare in un dato momento, questo load balancing pu avvenire
senza nessuna struttura centralizzata e senza comunicazione.
Lo scenario trattato in questa sezione non ammette comunica-
zione, ci sono una enorme quantita di lavori indirizzati allo studio
81

Simulazione di Sistemi Complessi con i MAS
di come agenti eterogenei possono raggiungere accordi in mancanza
di comunicazione. In questo caso si parla di accordo tacito o im-
plicito. Una forma di comunicazione non esplicita e il meccanismo
di coordinamento delle formiche, ottenuto rilasciando feromone sul
terreno: pur non comunicando mai direttamente con le altre formi-
che, applicare semplici regole su quanto percepito (in base al tipo di
feromone, si seguira la traccia per cercare il cibo, o per tornare alla
tana o per evitare un luogo pericoloso) si riescono ad organizzare
comportamenti sociali complessi e particolarmente ottimizzati.
Quando gli agenti hanno scopi simili o eventualmente i loro scopi
sono dipendenti tra loro, gli agenti possono essere organizzati in un
team. Ogni agente ha un ruolo nel team, che all’interno di un sistema
con previsto atteggiamento benevolente pu permettere di assegnare
a differenti agenti differenti ruoli addirittura interscambiabili.
Sistemi omogenei comunicanti
In questa sezione analizzeremo brevemente il paradigma di modella-
zione che consente ad agenti simili di comunicare tra loro. L’aggiunta
della comunicazione incrementa di molto il livello di possibilita im-
plementative di un MAS, in particolare la programmazione ad agen-
ti e basata fortemente sul concetto di interazione e questa avviene
tramite comunicazione.
La peculiarita di una computazione basata su interazione ha un
potenziale di rappresentazione dei fenomeni complessi che finora e
stata sottovalutata. Nei lavori di [4] oppure in [?] i meccanismi di
emergenza che sono effetto della propagazione dell’interazione ven-
gono trattati come punto cardine per la rappresentazione dei sistemi
82

5.1 Stato dell’Arte dei MAS
complessi. Con l’aggiunta metodologica atta a completare il processo
di rappresentazione e validazione di alcune tecniche di data mining,
che sono finalizzate a tracciare le varie comunicazioni/interazioni (in-
terazione tra agenti) ha portato ottimi risultati sia per ci che riguarda
la classificazione dei singoli comportamenti a fini di ottimizzazione,
sia a scopi predittivi sulle dinamiche globali del sistema o delle sue
sotto componenti (micro, meso e macro livello).
Il cambio di paradigma sta proprio nel fatto che gli agenti non
vengono piu considerati qualcosa di diverso dall’ambiente, ma come
parte costitutiva. Le interazioni tra agenti determinano l’ambien-
te e cose emerge al suo interno, e questa dinamica a sua volta si
reimmerge negli agenti perch l’ambiente cambia per loro opera.
Con la comunicazione, gli agenti, oltre che a coordinarsi per una
piu proficua esecuzione di plan, sono anche in grado di usare intelli-
genza simbolica, condividere significati ed accrescere il loro livello di
conoscenza, tanto che a questo punto il fatto di essere agenti sociali
permette di definire il capitale culturale di una popolazione di agen-
ti. Lo scenario dei sistemi multi agente omogenei con la possibilita
di comunicare l’un l’altro e presentato nella figura seguente.
83

Simulazione di Sistemi Complessi con i MAS
La comunicazione pu essere broadcast, narrower oppure postata
su una blackboard condivisa da tutti.
La comunicazione pu avvenire direttamente tipo nel caso di una
riposta ad una domanda in cui l’agente richiedente R, chiede all’a-
gente informatore I un elemento necessario per la risoluzione di un
piano. L’agente I puo’ attingere alla sua base di conoscenza chiede-
re ad un agente specializzato il tipo di informazione richiesta da R
rispondere con una informazione reputazionale (acquisita ma non ve-
rificata).Ovviamente la comunicazione implica diverse specifiche di
implementazione di cui tener conto durante la fase di progettazione.
Una caratteristica molto importante degli ambienti comunicanti
passa sotto il nome di Distributed Sensing che e la capacita di elabo-
rare input proveniente da fonti diverse come nel lavoro di Matsuyama
[34] che presenta la ricostruzione visuale di una scena per l’estrazione
di semantica da piu telecamere. Un elemento molto forte da tenere
in considerazione e la semantica condivisa dell’informazione che e
strettamente connessa a come viene rappresentato ed interpretato il
contenuto di una comunicazione.
E’ possibile scambiare informazioni su cosa e stato percepito per
84

5.1 Stato dell’Arte dei MAS
una maggiore consistenza del dato oppure e possibile per gli agenti
comunciare i propri stati mentali.
Sistemi eterogenei comunicanti
Cosa succede quando agenti implementati con diverse caratteristiche
sono in grado di comunicare? Quali reali potenzialita e in grado di
sviluppare un tale approccio software? Quali sono gli accorgimenti
da tener presente durante la fase di progettazione? Quale e in questo
contesto cosi eterogeneo il ruolo della cooperazione nella formazione
di strategie? Come si riflette la cooperazione sull’apprendimento del
singolo agente?
85

Simulazione di Sistemi Complessi con i MAS
86

5.1 Stato dell’Arte dei MAS
Linguaggi Dichiarativi
I linguaggi dichiarativi, provenendo direttamente dal background
scientifico della logica ne ereditano un forte orientamento verso il
formalismo, Come nel caso specifico di FLUX, Minerva, Dali, e Re-
sPect., altri linguaggio dichiarativi sono derivati da altri formali-
smi come CLAIM che era inizialmente concepito come uno stru-
mento che dovesse dare supporto al calcolo computazionale. I piu
consueti linguaggi imperativi sono facilmente integrabili con quelli
dichiarativi.
CLAIM
CLAIM (Computational Language for Autonomous, Intelligent and
Mobile Agents )
CLAIM e un linguaggio dichiarativo di alto livello orientato agli
agenti ed e’ una componente di un framework di sviluppo chiamato
Himalaya (Hierarchical Intelligent Mobile Agents for building Large-
scale and Adaptive sYstems based on Ambients). In s il linguaggio
e un mix che offre da un lato i vantaggi che derivano dall’essere
orientato agli agenti che permette una rappresentazione formale di
aspetti cognitivi e del ragionamento, dall’altro lato tutti i vantaggi
provenienti dai linguaggi concorrenti basati sull’algebra. CLAIM e
un linguaggio che trova origine nel ambient calculus e gli agenti so-
no organizzati gerarchicamente al fine di permettere lo sviluppo di
MAS mobili: un’insieme di gerarchie di agenti connessi tra loro da
essere poi istanziati in una rete di computer. Nello specifico, ogni
agente contiene elementi cognitivi (capacita, attitudini, scopi, basi
di conoscenza), processi e sotto agenti ed e nello stesso tempo dotato
87

Simulazione di Sistemi Complessi con i MAS
di mobilita tra una gerarchia e l’altra. Un agente pu anche acquisire
durante la computazione componenti sia di intelligenza che potenza
computazionale dai suoi sotto agenti, una sorta di ereditarieta. La
mobilita e l’ereditarieta, come definiti in Himalaya, permettono lo
sviluppo di sistemi adattivi e riconfigurabili, non a caso le primitive
degli agenti sviluppati con CLAIM sono gli aspetti cognitivi, l’inte-
razione, la mobilita e la riconfigurazione. La semantica operazione
di CLAIM e derivata direttamente dalla struttura operazione di Plo-
tkin che consiste in una relazione di transizione da uno stato iniziale
ad uno stato successivo risultante da un’esecuzione di un’operazione
atomica.
Come Mobile MAS all’interno di Himalaya, e sviluppato su una
serie di computer connessi, il linguaggio CLAIM e supportato da una
piattaforma distribuita chiamata SyMPA che ha tutti gli strumenti
necessari per la gestione degli agenti: comunicazione, mobilita, si-
curezza, fault-tolerance e load balancing. SyMPA e sviluppato in
Java ed e compatibile con le specifiche di MASIF [37] standard dell’
OMG (Object Management Group). Himalaya e stato impiegato per
lo sviluppo di diverse applicazioni che ne mostrano chiaramente la
robustezza, la potenza della semantica e la forza della piattaforma:
applicazioni per la ricerca di informazione nel web, molte applica-
zioni di commercio elettronico, applicazioni per la condivisione di
risorse.
FLUX
FLUX e un linguaggio di programmazione di alto livello pensato per
lo sviluppo di agenti cognitivi. E’ un’applicazione del Fluent Calcu-
88

5.1 Stato dell’Arte dei MAS
lus, un formalismo per la rappresentazione delle azioni che fornisce
una soluzione base al classico frame problem usando il concetto as-
siomatico di aggiornamento di stato, incorporando allo stesso tempo
una grande varieta di aspetti nel reasoning sulle azioni come la ra-
mificazione ( effetti indiretti di un’ azione), qualificazioni ( fallimenti
inaspettati delle azioni), azioni non deterministiche, azioni concor-
renti. Un programma in FLUX e il risultato di una programmazione
logica tripartita: il kernel che fornisce all’agente la capacita cognitiva
per ragionare riguardo i suoi piani e le sue azioni e per la percezione
dei dati dai sensori, una teoria sottostante che provedde alla rappre-
sentazione interna del mondo, e una strategia specifica orientata al
task da compiere. La piena potenza della programmazione logica pu
essere utilizzata per la pianificazione di strategie.
MINERVA
Sulla scia di FLUX, Minerva e un sistema ad agenti progettato per
fornire un ambiente comune per gli agenti basato sulla forza della
Programmazione Logica per permettere la combinazione di mecca-
nismi non monotoni per la rappresentazione della conoscenza e del
ragionamento.
Minerva usa MDLP e KABUL per istanziare agenti e i loro ri-
spettivi comportamenti. Un agente Minverva consiste di diversi sotto
agenti specializzati, possibilmente concorrenti, che svolgono di versi
task, ed il loro comportamento e specificato in KABUL, mentre la
lettura e manipolazione della conoscenza condivisa e implementata
con MDLP.
89

Simulazione di Sistemi Complessi con i MAS
MDLP (Multi-Dimensional Dynamic Logic Programming)
il meccanismo per la rappresentazione della conoscenza di base di un
agente in Minerva, dove la conoscenza e rappresentata come un insie-
me di regole logiche organizzate in digrafi aciclici. In questi digrafi,
i vertici sono insiemi di programmi logici e gli archi rappresentano
le relazioni tra i programmi.
KABUL
KABUL (Knowledge And Behavior Update Language) e la recente
evoluzione di EVOLP, ed e un linguaggio sempre in stile di program-
mazione logica che permette la specifica e l’aggiornamento della base
di conoscenza stessa. Un programma in Kabul e un set di istruzioni
nella forma condizione-azione che pu essere considerata come una
codifica del comportamento dell’agente. L’effetto epistemico di una
azione pu essere sia un aggiornamento della base di conoscenza del-
lagente, rappresentata da un programma MDLP, oppure un auto
aggiornamento al programma KABUL, cosi da cambiare il compor-
tamento dell’agente durante il tempo. Le condizioni che determinano
l’azione scaturiscono dall’ osservazione dell’esterno, dallo stato epi-
stemico dell’agente e anche dall’esecuzione concorrente delle azioni.
Questa struttura di dipendenze dell’azione permette combinazione
di agenti con comportamenti reattivi e proattivi nel senso che non
necessariamente c’e bisogno di stimoli esterni per avviare un’azione o
un comportamento dell’agente perche possono essere anche scatenate
da elementi di razionalita forniti dalla sottostante rappresentazione
della conoscenza in MDLP.
90

5.1 Stato dell’Arte dei MAS
DALI
DALI e un linguaggio di Active Logic Programming progettato per
la specifica di esecuzioni di agenti logici. Usa le Clausole di Horn e
la sua semantica e basata sull’ultimo modello di Herbrand.. Fornisce
nel suo insieme costrutti atti a rappresentare la reattivita e la proat-
tivita attraverso regole. Un agente DALI e un programma logico che
contiene regole reattive, eventi e azioni orientate all’interazione con
l’ambiente esterno Il comportamento attivo o proattivo di DALI e
scatenato da diversi tipi di eventi : esterni, interni, eventi presenti e
passati.
ReSpecT
ReSpecT e sempre un linguaggio logico con una semantica formale
che consente la definizione di reazioni espresse in termini di regole.
Una regola in ReSpecT e una testa che specifica una comunicazio-
ne di evento che provoca la reazione e un corpo che specifica quale
azione e eseguita quando e scatenata la reazione. Quando un’azio-
ne fallisce, la reazione automaticamente fallisce e tutti i suoi effetti
sono annullati. Il comportamento coordinato pu essere aggiornato a
runtime cambiano la definizione delle reazioni.
5.1.8 Linguaggi Imperativi
L’uso degli approcci puramente imperativi nella programmazione
orientata ad agenti e meno comune principalmente per il fatto che la
maggior parte delle astrazioni connesse alla progettazione dei MAS
sono di natura tipicamente dichiarativa. Nonostante ci si trova nel
91

Simulazione di Sistemi Complessi con i MAS
panorama tecnologico applicazioni che impiegano linguaggi imperati-
vi, non esplicitamente orientati agli agenti, per lo sviluppo si sistemi
multi agente.
JACK
JACK e stato implementato e rilasciato da una compagnia priva-
ta chiamata Agent Oriented Software, tale piattaforma si basa sul
linguaggio di tipo BDI (Believes Desires Intentions) chiamato JAL.
JAL non e un linguaggio logico ma piuttosto un’estensione Java con-
tenente un insieme di costrutti sintattici (come le variabili logiche)
che permettono ai programmatori di creare piani, credenze tutto in
modalita grafica grazie al fatto che JAL presenta una sofisticata in-
terfaccia grafica con una serie di tools appositamente progettati per
una programmazione visuale. In JAL i piani possono essere com-
posti da metodi di ragionamento e raggruppati in capacita che una
volta sottese alla stessa classe funzionale creano una specifica abi-
lita dell’agente, tale approccio permette una forte modularita insita
nel linguaggio. Un’altra peculiarita di JAL risiede nella possibilita
di gestire squadre o organizzazioni di agenti che rappresenta sia un
avanzamento dal punto di vista della pura progettazione ingegneri-
stica sia perch permette di sviluppare sistemi auto organizzanti, i
quali stanno diventando sempre piu numerosi. JAL non possiede
tuttavia una semantica formale, ma nonostante questa sostanziale
mancanza, e stato utilizzato in una vastita di applicazioni industria-
li sia nella ricerca, ha una licenza di prova gratuita che pu essere
ottenuta sul sito della societa produttrice.
92

5.1 Stato dell’Arte dei MAS
5.1.9 Approcci Ibridi
Nelle sezioni precedenti abbiamo visto i principali approcci formali
usati dai linguaggi per lo sviluppo di sistemi software basati su agen-
te. Entrambi gli approcci forniscono diverse peculiarita e allo stesso
tempo sono sprovvisti di specifiche di cui e provvisto invece l’altro
approccio. Tale situazione ha chiaramente aperto la strada a tenta-
tivi di fusione che permettessero di sfruttare entrambi gli approcci in
un paradigma complementare. Questo tentativo di fusione tecnolo-
gica sotteso alla ricerca di una complementarieta tra gli approcci ha
dato vita a sistemi di sviluppo e linguaggi che passano sotto il nome
di approcci ibridi. I linguaggi di programmazione afferenti a questa
classe sono tendenzialmente linguaggi dichiarativi che incorporano
specifici costrutti che permettono l’uso di linguaggi imperativi. In
questa sezione procederemo a descrivere una selezione significativa
di questi linguaggi: 3APL, Jason, IMPACT, Go!, e AF-APL.
3APL
3APL (An Abstract Agent Programming Language triple-a-p-l) e
un linguaggio di programmazione per l’implementazione di agenti
cognitivi che possiedano credenze, scopi e piani per realizzarli insie-
me ad attitudini mentali che possano generare, rivedere i loro piani
per raggiungere i propri scopi. Le azioni sono la componente atomi-
ca di 3APL che permette l’interazione tra un agente e l’altro e tra
l’agente e l’ambiente. Il linguaggio in questione e stato ideato ad
Utrecht da Hindriks e dalla sua prima ideazione e sottoposto a con-
tinui sviluppi ed ampliamenti. Una delle features piu importanti del
linguaggio risiede nei costrutti di programmazione che permettono
93

Simulazione di Sistemi Complessi con i MAS
l’implementazione di attitudini mentali di un agente come il processo
deliberativo. In particolare e consentito la specifica diretta delle Cre-
denze, dei Piani, degli Scopi, delle Azioni e regole di ragionamento
e comunicazione. I costrutti orientati alla deliberazione permettono
di implementare piani e azioni attraverso le quali la base di cono-
scenza di un agente pu essere aggiornata e attraverso cui l’ambiente
condiviso pu essere modificato. 3APL e progettato tenendo conto
di una serie di principi ereditati dall’ingegneria del software come
la separazione dei concetti, la modularita, l’astrazione ed il riuso.
Supporta anche nativamente Prolog e Java. E’ stato utilizzato sia
in una serie di applicazioni prototipali come le aste in inghilterra,
per il blocks problem, sia in sistemi di alto livello per il controllo dei
robot come nel SONY AIBO.
JASON
JASON e un interprete per una versione estesa di AgentSpeak, un
linguaggio di programmazione logico orientato allo sviluppo degli
agenti pensato da Rao. Il linguaggio e influenzato dai lavori sul
paradigma architetturale BDI. La semantica implementata in Jason
permette una serie di features quali: comunicazione basata speech-
act, annotazioni di label sui piani, totalmente modificabile in Java,
funzioni di trust.
IMPACT
IMPACT e un sistema implementato da Subrahmanian, con lo scopo
principale di fornire un framework per costruire agenti con la massi-
ma eterogeneita di conoscenza, in modo da trasformare il codice lega-
94

5.1 Stato dell’Arte dei MAS
cy in agenti che possono comunicare ed agire. IMPACT fornisce in-
fatti, la nozione di un agente come di un programma di un linguaggio
concepito a chiamata di funzione. Una chiamata di funzione pu esse-
re vista come un incapsulamento che rappresenta logicamente le con-
dizioni e le domande prodotte dal codice. Queste vengono utilizzate
come clausole e determinano i limiti sulle azioni che possono essere
intraprese dagli agenti. Le azioni in IMPACT usano nozioni deonti-
che come obbligatorieta, permesso, divieto. Tali agenti e la loro se-
mantica e basata sulla nozione di insieme di stato razionale che sono
generalizzazioni di modelli stabili nella programmazione logica. La
piattaforma IMPACT fornisce un insieme di peculiarita orientate allo
sviluppo di agenti su rete, un servizio di rintracciamento molto simi-
le alle pagine gialle, includendo anche ragionamento probabilistico
temporale. URL: http://www.cs.umd.edu/projects/impact/
GO!
GO! e un linguaggio di programmazione multi paradigmatico con da
un lato, un insieme di funzioni dichiarative e definizioni di relazione,
e dall’altro un set di funzioni imperative comprensive di definizioni
di azioni e un ricco meccanismo di strutturazione. Basandosi sulla
programmazione simbolica del linguaggio April GO! Implementa la
rappresentazione della conoscenza in un formalismo logico, possiede
una robusta gestione del multithread, e fortemente tipizzato e di alto
livello (in termini di programmazione funzionale). Ereditando da
April la gestione dei thread che implementano meccanismi di azione,
reazione ai messaggi ricevuti e regole annesse. Un demone addetto
alla comunicazione abilita thread differenti a comunicare in maniera
95

Simulazione di Sistemi Complessi con i MAS
trasparente sopra una rete. Ogni agente, generalmente contiene un
insieme di thread ognuno dei quali pu comunicare con i thread degli
altri agenti.
AF-APL
Agent Factory Agent Programming Language (AF- APL) e il lin-
guaggio di programmazione che riesiede nel cuore di Agent Fac-
torty. AF-APL e stato originariamente basato su Agent-Oriented-
Programming, successivamente esteso con i concetti BDI. La sintassi
e la semantica sono derivate da un modello logico che vede un agen-
te come una sequenza di azioni. Il modello, nello specifico, definisce
lo stato mentale come composto di due parti primarie (attidudini
mentali) : credenze e commitments. L’insieme delle credenze e ca-
ratterizzato da una serie di dichiarazioni relative all’ambiente. Gli
agenti sono situati, nel senso che il programmatore dichiara esplici-
tamente, per ogni agente, un insieme di sensori (perceptors) collegati
ad una serie di effettori (actuators). I percettori sono istanze di classi
Java che definiscono come i dati percepiti dai sensori debbano essere
convertiti in credenze che poi possano essere aggiunte al set di cre-
denze dell’agente. Un attuatore e ugualmente un’istanza di classe
Java che ha due principali responsabilita - Definire l’identificativo
dell’azione che dovrebbe essere usata quando ci si riferisce all’azione
che e realizzata dall’attuatore - Contenere codice per implementare
l’azione
96

5.1 Stato dell’Arte dei MAS
5.1.10 Framework e Piattaforme ad Agenti
Molti dei linguaggio riportati in questo documento sono sviluppati
su di piattaforme che ne implementano la semantica, ma possiamo
trovare anche piattaforme che non sono appositamente pensate per
un particolare tipo di linguaggio, ma piuttosto si concentrano sulla
comunicazione e il coordinamento tra agenti. In questa sezione e
presentata una selezione di framework che descrive TuCSoN, JADE
e DESIRE come esempi illustrativi.
TuCSoN
TuCSoN che sta per Tuple Center Spread Over Network, e un fra-
mework per lo sviluppo della coordinazione nei MAS, basata su di
una infrastruttura generica che fornisce tools per la comunicazio-
ne e la coordinazione. Il modello e basato sul tuple centres come
un’astrazione programmabile a run-time per la sincronizzazione dei
comportamenti degli agenti. La gestione di queste features e delegata
a ReSpecT, un linguaggio di programmazione logica. Le Tuple Cen-
teres sono esempi di artefatti di coordinazione (entita di prim’ordine
che popolano l’ambiente cooperativo degli agenti, condiviso e usato
collettivamente. Questa astrazione e usata anche nella metodologia
SODA.
La tecnologia dietro TuCSoN e disponibile presso il sito del pro-
getto (tucson.sourceforge.net). E’ completamente sviluppato in Java
ed e composto da: una piattaforma run-time; un’insieme di libre-
rie per permettere l’accesso degli agenti ai servizi e per l’accesso ai
meccanismi di coordinamento. Il core della piattaforma risiede in
tuProlog, un motore a regole basato su prolog completamente inte-
97

Simulazione di Sistemi Complessi con i MAS
grato in un ambiente java. TuCSoN e molto utilizzato negli ambienti
di ricerca in particolare per la costruzione di modelli per il workflow
management, logistica e e-learning; allo stesso tempo usata come uno
dei punti di riferimento per costruire progetti accademici agent-based
usato alla facolta di ingegneria di Cesena e Bologna.
JADE
JADE (Java Agent Devolpment Framework) (Poggi e Bergenti) e
un framework Java per lo sviluppo distribuito di applicazione multi
agente. E’ un middleware ad agenti che fornisce una serie di servizi di
facile accesso e molti tool grafici per il debug ed il testing. Uno dei
principali obiettivi ella piattaforma e supportare l’interoperabilita
aderendo strettamente agli standard FIPA riguardo alle architetture
di comunicazione. Inoltre Jade e molto flessibile e pu essere adattata
per funzionare su hardware con risorse limitate come PDA e smart
phone. JADE e stato diffusamente impiegato negli ultimi anni sia
per progetti di ricerca sia per applicazioni industriali, uno dei casi
industriali piu importanti che ben rappresenta la potenza di questa
piattaforma e il sistema di supporto alle decisioni per il trapianto di
organi per la Whitestein, che ne mostra chiaramente la robustezza e
l’efficienza. La piattaforma e rilasciata con licenza GPL e distribuito
dai Tilab (Telecom Italia LABoratories), dal 2003 e stata istituita
la JADE Board come ente referente e responsabile per la gestione
del progetto che attualmente consiste di 5 membri: TILAB, Moto-
rola, Whitestein Technologies, Profactor e France Telecom. URL:
http://jade.tilab.com/
98

5.1 Stato dell’Arte dei MAS
JADEX
JADEX e un framework software per la creazione di agenti orientati
allo scopo che implementando il modello BDI. E’ stato sviluppato
come un layer razionale che governa una piattaforma middleware ad
agenti (tra cui JADE, di cui inizialmente era l’estensione BDI), e
supporta lo sviluppo ad agenti con tecnologie standard internazio-
nali come Java ed XML. Il motore di ragionamento di Jadex sorpassa
alcuni limiti dell’approccio BDI fornendo concetti come i goal espli-
citi e il meccanismo di delibera degli obiettive, rendendo molto piu
semplice il trasferimento dalla progettazione (KAOS o TROPOS)
alla fase di implementazione. JADEX e fortemente usato nelle si-
mulazioni in particolare quelle sociali (Repage Quattrociocchi 2007),
nello scheduling e nel mobile computing.
DESIRE
DESIRE (Design and Specification of Interacting REasoning com-
ponents) e una composizione di metodi di sviluppo per sistemi multi
agente basato sulla nozione di architettura componibile formulata da
Treur. In questo approccio il design di un agente e basato sui seguen-
ti aspetti: composizione dei processi, composizione della conoscen-
za e relazioni tra conoscenza e processi. La computazione secondo
questo approccio e costituita dall’interazione tra i componenti che
rappresentano i sotto processi di tutto il processo di ragionamento
dell’agente. Il processo di ragionamento e strutturato in base al nu-
mero di componenti che interagiscono tra loro. I componenti possono
o non possono essere composti da componenti, dove in particolare i
99

Simulazione di Sistemi Complessi con i MAS
componenti che non possono essere a loro volta decomposti vengono
detti primitivi.
La funzionalita globale di questo sistema e basata su queste pri-
mitive con l’aggiunta della composizione di relazione che coordina
la loro interazione. Ad esempio la specifica della relazione di com-
posizione pu coinvolgere la possibilita di scambio informativo tra i
componenti e la struttura di controllo che li attiva. DESIRE e stato
usato per applicazioni di load balancing per la fornitura di corrente
elettrica e per la diagnostica.
Tutti i sistemi qui descritti sono orientati allo sviluppo, ma ulti-
mamente ci si sta focalizzando sempre di piu per ridurre il gap tra
progettazione e sviluppo attraverso l’uso di metodologie di imple-
mentazione e rappresentazione dei vari meccanismi del MAS. Alcuni
esempi di questa tendenza sono reperibili in IGENIAS e nel suo Kit
di sviluppo oppure in MaSE e nel suo AgentTool.
5.2 Stato dell’Arte della Simulazione Ba-
sata su Agente
La Simulazione Basata su Agente (meglio nota nella denominazione
inglese Agent-Based Simulation: ABSS) consiste nel costruire mo-
delli di societa di agenti artificiali (di scala variabile e di variabile
complessita), nel trasferire questi modelli su programmi che girano
sul calcolatore, nell’ osservare “i comportamenti” di queste societa e
possibilmente nel tradurre queste osservazioni in valori, ossia in dati
quantitativi elaborati statisticamente.
Il settore si definisce in base ad uno specifico approccio teorico-
100

5.2 Stato dell’Arte della Simulazione Basata su Agente
epistemologico, metodologico, tecnico, che produce conoscenze tra-
sferibili in una varieta di ambiti applicativi.
Sul piano epistemologico, l’approccio in questione e caratterizza-
to dall’assunzione che i dati artificiali permettono di costruire teorie
utili per affrontare problemi della realta. Ci non equivale ad estra-
polare direttamente dai dati del mondo virtuale a quello reale. La si-
mulazione produce teorie testate artificialmente di fenomeni rilevanti
per la conoscenza e la trasformazione della realta.
L’approccio teorico nasce dall’integrazione di diversi grandi indi-
rizzi come la teoria dinamica dei sistemi, la teoria della razionalita
e gli Automi Cellulari, e piu recentemente la teoria degli agenti. E’
fortemente caratterizzato in senso formale e computazionale e mi-
ra ad esplorare come interagiscono diversi livelli della realta (per
esempio, quello degli individui e quello dei gruppi, delle coalizioni,
delle organizzazioni ecc.). A differenza della teoria della decisione
razionale, si basa sull’assunzione di agenti:
• eterogenei: diversi l’uno dall’altro
• complessi: con strutture interne (conoscenze e meccanismi di
regolazione) piu o meno complesse
• adattivi: capaci di apprendimento sulla base di eventi esterni
(fisici e sociali)
• flessibili: capaci di rispondere in modo diversificato al variare
di condizioni esterne, capaci di desistere da comportamenti
inutili e (auto)distruttivi
• versatili: dotati di strategia e regole concorrenti che potenzino
l’efficienza e il carattere multiuso degli agenti.
101

Simulazione di Sistemi Complessi con i MAS
A questo occorrerebbe aggiungere anche caratteri di sensibilita,
credibilita, interattivita, e infine l’emotivita e la personalita, che at-
tualmente costituiscono settori specifici d’espansione delle metodo-
logie emulative (riproduzione realistica degli agenti reali) nel campo
dell’animazione e degli attori sintetici.
Sul piano metodologico, ABSS e un approccio computazionale
che mira a:
• provare in modo rapido ed efficiente le proprieta e la perfor-
mance di un sistema artificiale (come accade invece nell’Intel-
ligenza Artificiale);
• visualizzare in laboratorio (sul computer) gli effetti sul mondo
(artificiale) del sistema costruito (gli agenti e le loro azioni
sull’ambiente sociale e fisico). La visualizzazione include la
manipolazione di caratteristiche del sistema (del modello di
sistema), e la registrazione degli effetti conseguenti. Si tratta
quindi di una metodologia esplorativo-sperimentale.
Sotto il profilo tecnico, la simulazione si serve di un computer
(o piu) sul quale gira un programma adatto per la simulazione (da
C++ a Java) nonch dotato di una buona interfaccia grafica per la
visualizzazione dei risultati, e di un programma per l’elaborazione
di statistiche sui dati. Vi sono piattaforme simulative concorren-
ziali (Swarm, SDML, MIMOSE, PART-Net, ed altri). I vantaggi
rispettivi di queste piattaforme sono analizzati in molti lavori.
Sotto il profilo applicativo, occorre partire da una constatazione
elementare. La simulazione consente l’esplorazione e la manipolazio-
ne di modelli di praticamente infiniti fenomeni sociali e ambientali.
102

5.3 Simulazione Sociale
Qualunque fenomeno pu essere riprodotto in un computer, almeno
in linea di principio. E’ evidente che vi sono limiti e difficolta re-
lative ai diversi fenomeni. In particolare, vi sono problemi relativi
alla verifica della robustezza dei modelli e quindi alla manipolazio-
ne (assegnazione di valori diversi alle variabili che rappresentano le
dimensioni di cambiamento) del sistema osservato. Piu e semplice
il modello e piu e attendibile, almeno piu e verificabile. Ma piu e
semplice un modello, e meno realistico o rilevante e spesso il fenome-
no visualizzato, soprattutto quando sono troppo semplici gli agenti
simulati, fino al punto di azzerare una o piu delle caratteristiche di
intelligenza, autonomia, eterogeneita elencate in precedenza. Sul-
le potenzialita applicative torneremo in seguito. Rispetto a questi
problemi e difficolta, la pratica della simulazione suggerisce alcuni
rimedi; fra gli altri, l’utilizzazione di piattaforme e modelli di agenti
versatili, che possano essere utilizzati per obiettivi diversificati; l’e-
laborazione interdisciplinare dei modelli simulativi; il confronto, ove
possibile, con dati reali (studi cross-metodologici).
5.3 Simulazione Sociale
ABSS e un settore di ricerca fortemente interdisciplinare nel quale
cooperano tutti coloro i quali sono interessati ai fenomeni comples-
si, fisici e sociali, alle proprieta di organizzazione e auto organiz-
zazione dei sistemi complessi, alla previsione, monitoraggio, pianifi-
cazione, regolazione e governance di questi sistemi, o alla semplice
esplorazione e spiegazione di questi fenomeni.
Operano nell’ambito della simulazione basata su agenti coloro
103

Simulazione di Sistemi Complessi con i MAS
che sono interessati a fare previsioni sulle tendenze di cambiamento,
a monitorare gli effetti delle innovazioni (culturali, economiche, tec-
nologiche e istituzionali), l’introduzione di nuove misure, politiche e
ordinamenti, nella realta socio-economico-istituzionale esistente.
Sono inoltre interessati alla simulazione coloro che progettano o
ottimizzano sistemi di produzione, di comunicazione, interazione e
organizzazione (reti e tecnologie informatiche). Economisti, scien-
ziati sociali, fisici e teorici della complessita, filosofi analitici, desi-
gner e scienziati di tecnologie informatiche, scienziati dell’artificiale,
scienziati cognitivi.
Un impulso decisivo all’espansione di ABSS viene da coloro che
studiano l’evoluzione dei sistemi (complessi), biologi, etologi, evolu-
zionisti, studiosi di AL, socio-biologi e studiosi di evoluzione cultu-
rale, psicologi evoluzionisti. La simulazione serve per prevedere il
futuro cos come per capire la traiettoria evolutiva di processi e feno-
meni nel passato, la formazione e la dissoluzione di sistemi. Storici,
archeologi, paleontologi sono fra gli studiosi attualmente piu inte-
ressati alla simulazione con agenti. Infine se ne occupano geografi e
climatologi, specie quelli che si riconoscono in un approccio integra-
to alle questioni ambientali, allo sviluppo sostenibile sia sul piano
ambientale che economico, sociale e culturale.
La ABSS non s’identifica con la scienza dei sistemi (dinamici)
complessi, anche se la complessita e certamente una questione im-
portante allo studio dell’approccio simulativo. D’altro canto, non si
identifica con l’approccio computazionale dei fenomeni sociali basa-
to su modelli formali dell’azione razionale (come la game theory).
Mira piuttosto all’adozione e all’elaborazione di modelli di agenti
autonomi ed eterogenei, dotati di strutture interne e di capacita di
104

5.3 Simulazione Sociale
adattamento e di apprendimento, per lo studio di fenomeni com-
plessi, nei quali l’agente, le sue strutture e i suoi processi mentali
costituiscono un livello specifico e un fattore di complessita, di cui
occorre tener conto.
In primo luogo, la simulazione mira alla visualizzazione (riprodu-
zione su computer) e alla manipolazione sperimentale delle variabili
del sistema costruito. In secondo luogo, e un approccio basato su
agenti: ci permette di esplorare e manipolare gli effetti dell’azione
di sistemi intelligenti (di per s in qualche misura complessi) sulla
realta osservabile. In terzo luogo, e di conseguenza, la simulazione
basata su agenti non si limita allo studio delle proprieta emergenti
all’auto organizzazione dei sistemi complessi, ma ha una portata co-
noscitiva e applicativa piu ampia, relativa alla gamma dei fenomeni
a cavallo fra governance (governo dei processi di trasformazione dei
sistemi complessi attraverso disegno di politiche e propagazione di
meccanismi di regolazione distribuiti) ed auto organizzazione.
Fondamentalmente, si tratta di un approccio che serve a moni-
torare l’introduzione deliberata di nuove misure, politiche e ordina-
menti, istituzioni e organizzazioni, cos come ad esplorare le tendenze
evolutive (o involutive) spontanee dei sistemi.
Inoltre, la simulazione non necessariamente applica modelli pre-
scrittivi delle azioni e dell’agente piu o meno razionale. Si basa su
modelli di agenti di variabile complessita, con caratteristiche mentali
e capacita di apprendimento ed adattamento diversificate (utili agli
obiettivi della simulazione).
L’approccio ABSS serve allo studio esplorativo-sperimentale e al-
la visualizzazione di fenomeni in societa artificiali. Dal punto di vista
conoscitivo, favorisce la modellazione dei meccanismi sottostanti ai
105

Simulazione di Sistemi Complessi con i MAS
fenomeni che si vogliono osservare. ABSS viene solitamente adottato
nello studio dei seguenti fenomeni e processi:
• evoluzione della reciprocita, dell’altruismo e della cooperazione
• emergenza di fenomeni di auto organizzazione
• evoluzione e involuzione di forme culturali e di interi gruppi
sociali
• emergenza di mercati e di istituti economici
• differenziazione sociale, formazione di coalizioni e di gerarchie
• propagazione di opinioni
• segregazione sociale, ecc.
Per quanto riguarda il trasferimento di ABSS alla societa e al-
l’impresa, questo si muove fra tre grandi poli: ambiente, societa, pro-
duzione (sviluppo tre volte sostenibile), e con due funzionalita: mo-
nitoraggio, o esplorazione di andamenti e processi, e effettiva imple-
mentazione o incorporazione delle tecniche e metodologie simulative
nella produzione di beni e servizi.
106

Capitolo 6
Interazione nella
Classificazione e Previsione
dei Sistemi Complessi
6.1 Introduzione
Dopo aver introdotto nei capitoli precedenti il panorama dei sistemi
complessi, il suo intersecare il percorso di molte discipline, e aven-
do presentato i sistemi multi-agente ed il data mining, che sono gli
elementi costituenti del framework di indagine dei sistemi comples-
si, oggetto di questo lavoro, in questa sezione verra presentata for-
malmente la metodologia e successivamente saranno discussi alcuni
esempi di applicazioni su problemi scientifici reali.
Come gia ampiamente detto nei capitoli precedenti, il meto-
do scientifico, pur presentando strumenti formalmente rigorosi per
la una corretta formulazione di una teoria scientifica, presenta dei
107

Interazione nella Classificazione e Previsione dei SistemiComplessi
limiti.
Primo problema: L’osservazione e oggettiva o soggettiva?. Uno
stesso fenomeno pu essere osservato da piu punti di vista e con dif-
ferenti preconoscenze che influenzano l’osservazione. Non dimenti-
chiamo che la scienza stessa e frutto di un processo umano, ovvero
la classificazione che il sistema complesso uomo elabora, attraverso
un processo cognitivo, del sistema complesso di cui lui stesso e en-
tita interagente: l’universo e l’intellegibile. Secondo problema: Gli
anelli di retroazione non sempre le leggi di causa-effetto seguono re-
lazioni semplici e lineari; a volte, specie in biologia, gli effetti di un
evento agiscono sulle cause che li hanno determinati, o divengono a
loro volta causa di altri fenomeni. Il primo caso applicativo reale
degli interaction pattern e avvenuto nell’ambito di un progetto eu-
ropeo GeoPKDD che e orientato all’estrazione di conoscenza dalle
traiettorie di veicoli.
Questo lavoro fa riferimento alla tentativo di classificare e predire
il comportamento di individui pericolosi nel traffico che fa riferimen-
to ad un articolo recentemente pubblicato nell’ambito di un progetto
europeo [4], in cui vi e una vera e propria trattazione della metodo-
logia di classificazione basato sul tracciamento dell’interazione. Ov-
vero, gli individui vengono catalogati come serie spazio temporali di
interazioni in relazione agli individui afferenti al loro stesso gruppo.
108

6.2 Modellando L’Interazione
6.2 Modellando L’Interazione
6.3 Origini Metodologiche
In generale si contemplano due approcci fondamentali per la clas-
sificazione, in senso statistico, su dati complessi: la classificazione
statistiche e quella strutturale. Ciascun approccio impiega differenti
tecniche per i task di descrizione e classificazione che costituiscono
l’estrazione dei pattern.
Classificazione Statistica deriva da solidi e confermati con-
cetti della teoria statistica delle decisioni strumenti per discriminare
dati provenienti da differenti fonti basati su raggruppamenti di tipo
quantitativo. La natura quantitativa della classificazione statistica,
in ogni caso, rende difficile il processo di discriminazione laddove le
caratteristiche morfologiche e strutturali del sistema sono invece se-
manticamente rilevanti. Questo limite ha portato allo sviluppo per
un approccio strutturale.
Classificazione Strutturale, chiamata anche estrazione sintat-
tica di pattern poiche affonda le sue radici nella teoria dei linguaggi
formali, si costituisce su regole strutturali per discirminare dati pro-
venienti da fonti differenti, raggruppandoli per relazioni e interco-
nessioni di tipo morfologico. Data questa caratteristica concettuale,
la classificazione strutturale si e dimostrata molto efficace nella clas-
sificazione di dati aventi un’organizzazione inerente ed idenfiticabile,
come ad esempio i dati di tipo immagine che sono organizzati per
locazione all’interno di un rendering grafico, serie storiche. L’utilita
dei sistemi di classificazione di tipo strutturale, in ogni caso, e limi-
tato dal punto di vista della descrizione e modellazione del task di
109

Interazione nella Classificazione e Previsione dei SistemiComplessi
classificazione.
La descrizione di un sistema di classificazione strutturale e diffici-
le perche non esiste una soluzione generale ed univoca per l’estrazione
di proprieta di derivazione strutturale dai dati che si rivela particolar-
mente svantaggioso dove non si conosce esattamente la distribuzione
e la topologia semantica di interazione dei dati. Al momento non
esiste ancora una metodologia stabilita nella definizione di queste
invarianti. La risposta a questo problema generalmente consiste nel
design di primitive molto semplici ed altamente generiche ma della
quali non si conosce la reale valenza dal punto di vista di estrazione
semantica.
Nessuno dei due schemi e ottimo.
Le primivite semplici sono indipendenti dal dominio, ma cattura-
no solo un porzione della totalita delle informazioni derivabili dalla
strutturae e oltretutto pospone temporalmente una profonda inter-
pretazione D’altro canto le primitive derivanti da domini applicativi
specifici devono essere sviluppate con il supporto di un esperto di do-
minio, ma la formalizzazione della conosocenza di dominio necessaria
pu essere un compito difficile e spesso non sempre soddisfacente.
Per superare la serie di limitazioni sopramensionate, un approccio
che sia dominio indipendente si rivela indispensabile. Un approccio
che sia capace di estrarre e catturare features morfologiche e sia in
grado di classificare senza appaggiarsi a qualsiasi tipo di conoscenza
di dominio. Un approccio ibrido che impieghi la classificazione sta-
tisticha per discriminare features di tipo morfologico sembra essere
una soluzione naturale.
110

6.3 Origini Metodologiche
6.3.1 Modellando Dinamica e Interazione
Un’entita pu essere considerata come una variazione temporale di
fenomeni interattivi.
Ogni insieme di oggetti che coesiste in uno spazio comune es-
senzialmente costituisce un sistema complesso dinamico dove ogni
oggetto agisce sotteso alle regole che il sistema stesso genera, inter-
ferendo con esse, interagendo con le altre entita. Questo spazio di
interazione e un fenomeno di gruppo che ha un ruolo significativo nel
determinare le caratteristiche intrinseche della dinamica di un siste-
ma e dovrebbere essere modellato in modo da tracciare l’interazione.
La semantica sottostante il comportamento delle dinamiche del siste-
ma e delle sue componenti scaturisce dal fenomeno locale dell’intera-
zione. La modellazione di informazioni strutturate come interazioni
misurati come variazioni statistiche in sotto insiemi strutturali.
La nostra metodologia si fonda sull’interazione e presenta un ap-
proccio alla modellazione che pu essere schematizzato in un processo
a due passi principali.
• trovare regioni, ovvero contesti di interazioni in cui siano ri-
levabili fenomeni interessanti nel sistema in esame, Le regioni
possono essere espresse come pattern complessi come l’insie-
me di regioni di interazioni ed interdipendenze, sequenze di
interazioni. In particolare la scelta della regioni nel nostro mo-
dello rimane anche coerente al principio dei pattern frequenti
(Cheng et al 2007) ovvero per la classificazione mediante intem
descrittive, il potere discriminante di ogni singolo item che ri-
corre raramente e basso a differenza di quelli che invece sono
da considerarsi ricorrenti. A partire da questo, si assume che
111

Interazione nella Classificazione e Previsione dei SistemiComplessi
le regioni con una ragionevole frequenza di interazioni possano
essere le piu “promottenti” per estrarre features discriminanti.
• Il processo di categorizzazione di ogni contesto trovato, per
mezzo di serie di descrittori che forniscono una sintesi quanti-
tativa degli ogetti coinvolti, le loro mutue interazioni e le loro
relazioni con l’ambiente circostante.
Ogni caraterizzazione di un interazione ad un contesto contribui-
sce a caraterizzare quegli oggetti che si muovono in lui e che sono
connessi con esso in qualche modo.
L’interazione caraterrizza e riassume lo stato del sistema in istan-
tanee spazio-temporali. Una profonda incursione nella classificazione
della dinamica del sistema, e quindi dei fenomeni generati e di ogni
entita in esso coinvolta pu essere ottenuto attraverso un’analisi com-
parativa tra regioni o a differenti istanti, o in differenti spazi. Ovvero
la comparazione delle varie istantanee di interazione pu avvenrire da
tutte le prospettive dello spazio di features definite dall’interazione.
6.4 Classificazione di Oggetti Mobili
6.4.1 Interaction Pattern
Gli oggetti possono essere rappresentati generalmente su tutto il loro
spazio di esistenza da un sottoinsieme delle loro proprieta osservabili
varianti nel tempo. Per esempio, un oggetto mobile pu essere rappre-
sentato come un intervallo temporale piu le sue coordinate spaziali
dipendenti dal tempo come velocita ed accelarazione.
112

6.4 Classificazione di Oggetti Mobili
Definition 2 (Oggetti) Ogni oggetto O e rappresentato da una
coppia, composta da un intervallo e una sequenza di funzioni che
associano ad ogni istante temporale un valore reale in <
FO = (I, 〈f 1O, . . . , f
nO〉)
∀1≤i≤n. fiO : I → R
FO e detto l’insieme degli oggetti osservabili O.
Il sottoinsieme delle proprieta che descrive un oggetto definisce
lo spazio, sia esso fisico o virtuale, in cui l’oggetto esiste, interagisce
ed evolve
Ad esempio, le coordinate spaziali degli oggetti mobili definisco-
no il vincolo posizionale in cui risiede l’oggetto, e gli oggetti vicini
saranno l’ogetto di eventuali o potenziali interazioni.
Definition 3 (Attribuiti di Locazione) Dato l’insieme osserva-
bile FO = (I, S) di oggetti O, si definiscono attributi di locazione di
O come sottoinsieme LocO di S:
LocO ⊆ S
Similmente un sottoinsieme di proprieta di un oggetto descrive le
sue attivita rilevanti in termini di interazioni, poiche il loro valore pu
essere usato per caratterizzare le possibili interazioni tra oggetti. Per
esempio una proprieta rilevante negli oggetti mobili pu essere la ve-
locita, e la differenza di velocita rispetto ad un insieme di oggetti che
condividono una qualche relazione spazio temporale e discriminante
e descrittiva dell’interazione che intercorre tra gli oggetti.
113

Interazione nella Classificazione e Previsione dei SistemiComplessi
Definition 4 (Attributi di Interazione) Dato l’insieme osserva-
bile FO = (I, S) di oggetti O, si definiscono attribuiti di interazione
di O un sottoinsieme IntO di S:
IntO ⊆ S
Gli attributi di interazione e locazione possono sovrapporsi ( in ge-
nerale, LocO ∩ IntO 6= ∅.
L’interazione tra oggetti e una relazione che implica una mutua
localita, per cui la nozione di prossimita, o in altri termini, l’iden-
tificazione delle regioni di influenza (contesti di interazione) di ogni
oggetto, pu essere definita sugli attribuiti di locazione, perche questi
descrivono la loro posizione nello spazio. Queste interazioni gene-
ralmente hanno una durata limitata a possono cambiare durante il
tempo, quindi vanno misurate all’interno di finestre temporali a tem-
po finito. Per esempio, per gli oggetti mobili un insieme di regioni
spaziali pu essere definito e questo non inficia sulla misurazione del-
l’interazione perche viene misurata separatamente per ogni regione
ad ogni istante, stante la definizione degli oggetti tra cui l’interazione
intercorre.
Definition 5 (Regioni di Interazione e Intervalli) Data una po-
polazione di oggetti tale che ogni oggetto O hanno gli stessi attributi
di locazione Loc e interazione Int, si definiscono regioni di intera-
zioni come una collezione di insieme distinti contenenti attributi di
locazione:Regions = {R ⊆ R|Loc|} s.t.∀r′,r′′∈Regions,r′ 6=r′′r
′ ∩ r′′ = ∅
114

6.4 Classificazione di Oggetti Mobili
Allo stesso modo definiamo gli intervalli temporali di interazione o in
breve intervalli di interazione come un insieme di distinti intervalli
temporali
Intervals = {[a, b] ⊆ R} s.t.∀I′,I′′∈Intervals,I′ 6=I′′I
′ ∩ I ′′ = ∅
Al fine di caratterizzare l’interazione tra oggetti vicini, si cercano
le relazioni tra gli attributi di interazione e gli oggetti di interazio-
ne. Questo pu essere fatto in diversi modi, come cercare correlazio-
ni statistiche tra oggetti nell’intorno di un determinato punto spa-
zio/temporale tra attributi di interazioni e oggetti interagenti. Que-
sto pu essere ottenuto mediante correlazione statistica o attraverso
la ricerca di pattern predefiniti.
Definition 6 ( Descrittori di Interazione) Data una popolazio-
ne di oggetti tale che ogni oggetto O abbia gli stessi attributi di lo-
cazione Loc e attributi di interazione Int, si definisce descrittore di
interazione per un oggetto O = (I, S) in una regione r e un interval-
lo temporale T , e per attributi di interazione f , come una funzione
del tipo ID(O, r, T, f):
ID(O, r, T, f) =AV G t ∈ T ∧
O′ : LocO′ (t) ∈ r
(fO(t)− fO′(t)) if t ∈ I ∩ I ′
undef otherwise
dove I ′ rappresenta la definizione di intervallo di oggetti O′.
I descrittori di interazione descrivo come ogni oggetto e corre-
lato con gli altri in ogni regione per ogni intervallo temporale, e di
115

Interazione nella Classificazione e Previsione dei SistemiComplessi
coseguenza i descrittori risultatni per ogni differente attributo di in-
terazione descrive un oggetto da diverse angolazioni. E’ qui che si
evince il punto di forza del sistema di classificazione, ovvero un entita
non e piu considerata come un corpus isolato, bens il risultato di una
totalita di interazioni che ne determinano lo status dell’oggetto come
entita di un sistema complesso basato per l’appunto su componenti
interagenti. Ovviamente ogni oggetto attraversera diversi insiemi di
possibili regioni e lo fara, per via del vincolo temporale, in maniera
ordinata. Inoltre, nelle situazioni reali, gli attribuiti di ogni ogget-
to non sono fruibili in modalita continua, ma solo discreta vincolata
dalla frequenza di osservazione dei punti. Il risultato finalee che ogni
oggetto e descritto come una collezione di serie storiche una per ogni
attributo di interazione, che descrive, come e per ogni punto di vi-
sta, l’interazione che varia nel tempo tra l’oggetto O e tutto gli altri
Ovvero, come questa interazione l’oggetto si evolve e si comporta
diversamente rispetto agli altri. Le interazioni sporadiche possono
essere cassata come fenomeni sospetti, i comportamenti riccorrent
possono essere invece visti come potenzialmente significativi per la
detection del profilo di ogni singolo oggetto.
Definition 7 (Interaction patterns) Data una popolazione di og-
getti Objs, tale che ogni oggetto O ∈ Objs ha gli stessi attributi di
locazione ed interazione Loc e Int, si definisce un interaction pat-
tern per ogni attributo di interazione f ∈ Int come ogni sequenza
di valori V = 〈v1, . . . vn〉 ∈ Rn tale che dato una soglia di supporto
discriminante σ ∈ [0, 1] e una tolleranza all’errore ε ∈ R+:
| { O ∈ Objs | match(V, ID(O, f)) } ||Objs|
≥ σ
116

6.5 Applicazione I: Individuare Guidatori Pericolosi
dove:
match(V, V ′) ⇔ ∃i1<···<in ∀1≤j≤n |V [j]− V ′[ij]| ≤ ε
Un approssimazione degli interaction pattern cosi descritti pos-
sono essere ottenuti dal processo di discretizzazione del valore di
ogni descrittore di interazione e comparando due valori se e soltan-
to se questi cadono nello stesso intervallo descritto dalle soglie di
discretizzazione.
6.5 Applicazione I: Individuare Guida-
tori Pericolosi
Gli interaction pattern sono stati utilizzati per la prima volta in un
problema di classificazione su serie spazio temporali. Per l’esattezza
le serie numeriche in esame sono traiettorie d veicoli rilevate attraver-
so telecamere su autostrade. L’obiettivo dell’esperimento era quello
di individuare gli individui pericolosi o potenzialmente pericolosi nel
loro atteggiamento di guida. L’esperimento e servito anche da test-
bed per le performance del framework degli interaction pattern. Il
lavoro e stato pubblicato come Technical Report sul progetto GEO-
PkDD coordinato dall’ISTI-CNR di Pisa nella persona della Prof.ssa
Fosca Giannotti.
117

Interazione nella Classificazione e Previsione dei SistemiComplessi
6.5.1 Traiettorie di Veicoli
Il Problema
Il problema affrontato in questo lavoro e un istanziazione del clas-
sico problema di classificazione specifico per dati da traiettorie, Si
analizza il traffico su un frammento della strada statunitense US101
Hollywood highway, e vengono impiegati per la classificazione set di
descrittori di interazione molto semplice:
• mutua distanza tra punti traiettoria
• velocita assoluta e relativa alla regione spazio-temporale
• concentrazione di macchine su ogni regione spazio-temporale
L’obiettivo della classificazione e quello di identificare guidatori
pericolosi descritto da una variabile target che sara defenita come
l’attitudine degli individui nel prossimo futuro ad avere una velocita
relativa elevata rispetto agli altri e una distanza minore rispetto alla
media del suo contesto di interazione.
Traiettorie di oggetti mobili sono comunemente rappresentati co-
me sequenze di locazioni spaziali con etichetta temporale. Quanto
c’e necessita dell’attributo qualitativo della continuita, la posizione
la posizione nell’istante successivo si ottiene mediante interpolazione,
di cui la piu usata e quella lineare. Di conseguenza, vengono defini-
te le traiettorie punto a punto e saranno usate per approssimare la
traiettoria reale seguita dall’oggetto in movimento
Definition 8 (Traiettoria) Dato un oggetto mobile o e la sua esi-
stenza in un intervallo spazio temporale Io ⊂ R, una traiettoria per
118

6.5 Applicazione I: Individuare Guidatori Pericolosi
o e una sequenza To = 〈(t1, x1, y1), . . . , (tn, xn, yn)〉, n ∈ N , tale che
∀1 ≤ i ≤ n : (ti, xi, yi) ∈ I ×R2, e ∀1 ≤ i < n : ti < ti+1. Si definice
con TT l’universo di tutte le traiettorie possibili.
Data la definizione di traiettoria ora il problema di classificazione
pu essere definito come segue:
Definition 9 (Classificazione di Traiettorie) Dato un insieme
di etichette L e un dataset D di n traiettorie etichettate, D =
〈(T1, l1), . . . , (Tn, ln)〉, dove ∀1 ≤ i ≤ n : li ∈ L and Ti ∈ TT , il pro-
blema di classificazione della traiettoria consiste nell’estrarre una
funzione C : TT → L che meglio approssima l’etichetta associata
indotta da D.
Le proprieta delle traiettorie considerate nel calcolo dei descrit-
tori di interazione si riferiscono a specifici istanti spazi temporali che
sono rappresentativi di momenti rilevanti dell’istantanea dell’evolu-
zione del sistema stesso.
(descr1 = val1, . . . , descrn = valn)
(descr1 = val1, . . .)→ (descr′1 = val′1, . . .)
Ogni pattern rappresenta il modo in cui una serie di oggetti mo-
bili ha interagiot all’interno dello stesso contesto. Ogni pattern pu
essere ustato come una feature per il task di classificazione, dato che
le modalita di interazione tenute da ogni singola traiettoria ne deter-
minao ovviamente il profilo. L’uso della frequenza come criterio di
selezione dei pattern e coerente con quanto sostiene Chang in cui si
119

Interazione nella Classificazione e Previsione dei SistemiComplessi
mostra come pattern frequenti siano piu significativi e piu utili per
gli scopi del problema di classificazione.
6.6 Calcolando IPS e Attributi di Tra-
iettorie
6.6.1 Selezione dei segmenti di interazione
Per definizione, l’interazione di un oggetto con gli altri e altamente
dinamica e variabile durante il tempo, la sua variazione implica un
cambiamento della sua valenza semantica. Quindi ogni traiettoria
va ricalcolata per ogni istante t appartenente che alla traiettoria.
Per fare questo una soluzione accurata e non riduzionista consiste
nel comparare la variazione anche con le traiettoria a cui l’oggetto
passa vicino. (i.e. tra la distanza ds) agli oggetti di riferimento
dentro una finestra spazio temporale [t − dt, t + dt],e comparare il
segmento della traiettoria che condividono la stessa finestra
Un esempio di questo processo e mostrato in Figure 6.1(a), dove
la linea rossa identifica le parti della traiettoria che intercorrono e
potenzialmente interagiscono all’interazione/azione con la traiettoria
centrale al tempo t.
Un altro approccio, meno preciso, per il calcolo dei descrittori di
interazione, che e poi quello seguito in questa fase di test, richiede
la partizione temporale degli assi in finestre della stessa ampiezza
e poi di ricalcolare il valore di ogni traiettoria ad ogni intervallo. I
segmenti degli oggetti confinanti da considerare sono individuati in
modo similare come la soluzione generale descritta prima, assumento
120

6.6 Calcolando IPS e Attributi di Traiettorie
che la regione spazio temporale che definisce il vicinato viene ridotta
ad una serie di cilindri aventi come centri ad ogni punto di riferimento
ed abbastanza alto da coprire il gap tra il punto in esame ed il suo
successivo.
Questo e mostrato in Figure 6.1(b), dove, la linea rossa identifica
le parti rilevanti degli oggetti limitrofi. Da notare che l’intervallo
temporale e fissatto a priori, mentre il vicinato spaziale segue l’og-
getto di riferimento misurando e valorizzando i descrittori in maniera
relativa.
Un approssimazione del risultato pu essere ottenuto fissando una
griglia spaziale tale che i descrittori sono calcolati per ogni segmento
di traiettoria relativa ad ogni cella dellga griglia ( una cella spaziale
in un dato intervallo temporale) prendendo anche in considerazione
tutti i segmenti di traiettoria nelle zone circostanti che cadrebbero
nelle cella Figure 6.2 mostra un esempio grafico con la stessa nota-
zione grafica precedente. Questa volta sia l’intervallo temproale che
spaziale sono fissati.
6.6.2 Calcolo dei descrittori di Interazione
In questo lavoro si considerano due famiglie principali di descrittori,
dipendenti dal processo di calcolo che richiede (vedi Figure 6.3, che
sintetizza graficamente entrambi gli approcci):
macro interaction descriptors: tutti gli altri oggetti sono aggre-
gati in un singolo valore o oggetto complesso, poi l’oggetto di
riferimento e confrontato con il risultato del dato aggregato e
ritorna un singolo valore. Ad esempio la prima aggregazione
pu ritornare la velocita media globale, mentre la comparazio-
121
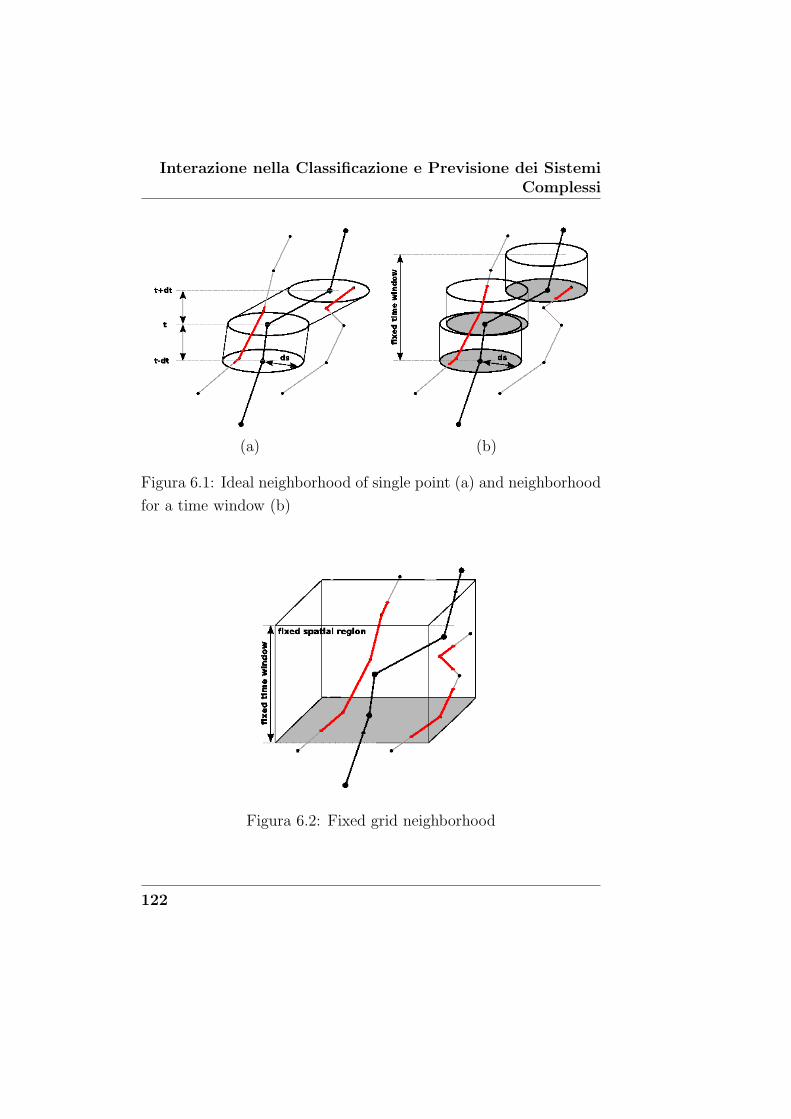
Interazione nella Classificazione e Previsione dei SistemiComplessi
(a) (b)
Figura 6.1: Ideal neighborhood of single point (a) and neighborhood
for a time window (b)
Figura 6.2: Fixed grid neighborhood
122

6.7 L’algoritmo
Figura 6.3: Macro and micro interaction descriptors
ne calcola le differenze tra la velocita media dell’oggetto in
esame rispetto ai suoi vicini (all’interno della finestra spazio
temporale.
micro interaction descriptors: l’oggetto di riferimento e compa-
rato con ogni oggetto vicino e poi i risutalti ottenuti sono
aggregati in un singolo valore.
6.7 L’algoritmo
Il metodo generale e riassunto nell’ algoritmo 1, che segue come dal
modello matematico introdotto nelle sezioni precedenti una procedu-
ra tripartita: (i) estrazione di feature,, che ritorna una descrizione
delle traiettorie in input espresso come un vettore booleano;(ii) la
selezione di feature che filtra gli insieme rilevanti e (iii) infine la
costruzione del modello di classificazione.
123

Interazione nella Classificazione e Previsione dei SistemiComplessi
Algorithm 1 DDT-Class
Require: a dataset D of labeled trajectories, a set or regions R, a
set of descriptor types F , an integer threshold nF , and a min.
support threshold σ
Ensure: a trajectory classification model M
1: D′ = DDFeatureExtraction(D,R, F, nF , σ);
2: D′′ = FeatureSelection(D ′);
3: M = ClassificationAlgorithm(D ′′);
4: return M .
The feature extraction step is performed adopting an interac-
tion pattern-based approach, and requires a complex sequence of
operations that is succinctly provided in Algorithm 2.
6.7.1 Descrizione del Dataset
L’esperimento e stato condotto su dati relativi alla NGSIM U.S.
101, una collezione di dati liberamente scaribabile relativa a tra-
iettorie ricostruite da immagini rilasciate dalla a Federal Highway
Administration and the Next Generation Simulation program
(http://www.ngsim.fhwa.dot.gov/).
I dati descrivono il traffico di veicoli su un tratto di strada di
2100 piedi e sei corsie, di cui cinque principali ed una di suppor-
to al traffico, di Los Angeles. Nella collezione sono presenti 6101
traiettorie che corrispondono approssimativamente ad un totale di
4 milioni di punti traiettoria, ogni punto e espresso come una qua-
drupla 〈ID, t, x, y〉, piu alcune informazioni derivate come velocita,
distanza etc.
124

6.7 L’algoritmo
Figura 6.4: A Real View of the Highway
125

Interazione nella Classificazione e Previsione dei SistemiComplessi
La Figure 6.4 mostra una proeizione spaziale di un campione del
dataset di input. Il movimento e la direzione e lungo l’asse Y, in
particolare l’esistenza di molte corsie sull’asse Y e visibile.
In quello che segue si riporta la scelta fatta e i risultati ottenuti
attraverso la fase del preprocessing. In particolare si descrive come
la variabile target della classificazione e stata derivata dal momento
che non era esplicitata dall’interno del dataset.
Variabile Target Il task di classificazione era centrato sull’i-
dentificazione di veicoli che, all’interno del segmento di strada moni-
torato, mostrino eventualmente qualche comportamento pericoloso.
Questa situazione e stata formalizzata attraverso una semplice regola
che etichetta una traiettoria come pericolosa se le seguenti condizioni
si verificano in un certo istante
• il veicolo supera la soglia delle condizioni prestabilite
• la sua velocita relativa e maggiore del 50% della media nella
sua regione
A questo proposito la strada e stata divisa in due da un lato il
primo 75% per l’estrazione delle feature e per la fase di learning,
dall’altro il 25% per il test di correttezza sulla classificazione. Il
processo di attribuzione delle etichette ha classificato come pericolosi
circa il 38% di profili pericolosi e il 62% come normali.
Traduzione di Traiettorie.
Le regioni di interazione usate nell’esperimento sono definite co-
me celle spazio temporali su una griglia che divide lo spazio in 7×11
celle spaziali ed il tempo in 11 intervalli. Per l’esattezza, ogni cella
spaziale e di larga dai 12 ai 220 piedi e copre approssimativamen-
te un segmento di una singola corsia, delle 847 celle solo 539 sono
visitate da almeno un veicolo.
126

6.7 L’algoritmo
speed n. vehicles distance
low Esp < 27.5 Efr < 58.5 Edist < 34
mid 27.5 ≤ Esp < 36 58.5 ≤ Efr < 70 34 ≤ Edist < 135
high Esp ≥ 36 Efr ≥ 70 Edist ≥ 135
Tabella 6.1: Threshold values for descriptors
Per ogni regione sono calcolati rispettivamente tre descrittori:
Esp, Efr, and Edist, che descrivono rispettivamente, la velocita me-
dia, il numero di veicoli e la distanza media tra un veicolo ed il suo
successivo.
Questi valori poi, sono stati discretizzati in 3 classi: {hSp,mSp, lSp}per la velocita (high-speed, medium-speed, low-speed); {hFr,mFr, lFr},per il numero di veicoli; e {hDist,mDist, lDist} per la mutua
distanza.
Table 6.1 mostra nel dettaglio le rispettive soglie che limitano le
varie classi ottenute attraverso un binning sulla frequenza uguale.
(lDist,hSp, lFr)⇒ (hSp→ lSp)⇒⇒ (lSp→ hSp, lFr→ hFr)⇒ . . .
Estrazione di Interaction Pattern. Gli Interaction Patterns
sono stati estratti tramite SLPminer [35] con una soglia minima di
supporto σ = 10%, e selezionando solo i pattern massimali. Il risul-
tato consiste in un totale di 223 interaction pattern che includono
anche l’esempio seguente:
(lDist)⇒ (lDist→mDist)⇒⇒ (lSp→mSp)⇒ (mDist→ hDist)
L’esempio descrive un quite behavior.
127

Interazione nella Classificazione e Previsione dei SistemiComplessi
Figura 6.5: Sample of the US101 dataset
Un altro caso e il seguente:
(mFr,mSp)⇒ (mFr→ hFr)⇒⇒ (hSp→mSp)⇒ (hFr→mFr)
6.7.2 Classificazione di Traiettorie
Dopo la traduzione di ogni traiettoria in un vettore booleano di featu-
re, uno per ogni interaction pattern estratto, il passo di classicazione
e stato fatto su tre differenti schemi derivati da Weka library [36]:
Decision Trees (DT), Bayesian Networks (BN) e Vote Perceptrons
(VP).
128

6.7 L’algoritmo
Training Cross-validation
DT BN VP DT BN VP
RoI 73% 74% 74% 73% 69% 68%
IP 77% 69% 72% 75% 66% 57%
IP+RoI 84.2% 76% 75% 77% 72% 69%
Tabella 6.2: Perfomances on training set and cross-validation
Per tutti e tre i casi le performance sono state comparate rispetto
ad una semplice classificazione su regioni Table 6.2.
129

Interazione nella Classificazione e Previsione dei SistemiComplessi
Algorithm 2 DDFeatureExtraction
Require: a dataset D of labeled trajectories, regions R, descriptor
F , a threshold nF , and a min. support threshold σ
Ensure: a dataset D′ extending D with new features
1: for all r ∈ R do
2: Dr = { traj. segments of D contained in r};3: for all descriptor types f ∈ F do
4: fr = avg t1,t2∈Drf(t1, t2);
5: end for
6: end for
7: for all f ∈ F do
8: If = intervals {I1f , . . . , I
nFf } that partition {fr}r∈R into equal
frequency groups;
9: end for
10: for all f ∈ F, r ∈ R do
11: fdiscr = i, s.t. fr ∈ I i
f ; // Discretize fr
12: end for
13: T = {tR|t ∈ D ∧ tR = sequence of regions in R
visited by t};14: T ′ = {t′|tr ∈ TR ∧ t′ = tr by replacing each
region r in tf with {fdiscr }f∈F};
15: for all t′ ∈ T ′, and each set of values t′i in t′ do
16: Remove from t′i all values f ∈ t′i that appear in t′i−1;
17: end for
18: IP = set of frequent sequential patterns computed on T ′ with
σ;
19: D′ = add a column ip to D for each ip ∈ IP , and let ∀t ∈ D, ip ∈IP : t[ip] = true iff t supports IP ;
20: return D′;
130

Capitolo 7
Valutazioni Sociali ed
Incertezza: Modellazione,
Simulazione e
Classificazione
I fatti non ci sono, bensı solo interpretazioni.
Frederich Nietzsche (da Frammenti postumi, in Opere, Adelphi, Mi-
lano 1964)
7.1 Introduzione
In questo capitolo, a differenza del precedente che presenta un appli-
cazione parziale, ovvero orientata solo all’aspetto predittivo, viene
presentata un applicazione completa della metodologia per l’anali-
si, modellazione e simulazione dei sistemi complessi. L’esempio in
131

Valutazioni Sociali ed Incertezza: Modellazione,Simulazione e Classificazione
esame parte dalla modellazione di una teoria, la implementa come
sistema ad agenti e gli interaction pattern vengono utilizzati da un
lato per la classificazione degli individui, dall’altra per la validazione
della teoria. Un aspetto molto importante nell’esempio in questio-
ne e che l’uso degli interaction pattern, ha permesso di individuare
caratteristiche proprie del modello teorico che non erano state pre-
se in considerazione, ma sono emerse come proprieta intrinseche del
sistema complesso in esame. Per l’esattezza la teoria in indagine e
quella sulla teoria della reputazione [37] che introduce una distin-
zione fondamentale tra i tipi di valutazioni circolanti nel contesto
sociale: l’immagine e la reputazione.
7.2 La teoria della Reputazione
Lo studio della reputazione in ambito cognitivo e possibile a patto di
considerare le conseguenze dei processi cognitivi individuali sul meso-
livello dei fenomeni sociali, e la successiva immergenza del fenomeno
nei processi cognitivi individuali. Per meso-livello intendiamo il li-
vello dell’interazione sociale in gruppi non rigidamente strutturati.
A tale livello emergono le conseguenze sociali dei processi cognitivi
individuali all’interno del gruppo studiato. Tali conseguenze han-
no ricadute sulle proprieta e capacita degli agenti. Parliamo cos di
reputazione come di un fenomeno socio-cognitivo emergente al meso-
livello. Successivamente al suo emergere, la reputazione influenza le
conoscenze e le decisioni degli agenti, immergendosi nei loro processi
cognitivi. Si tratta dunque di un fenomeno sociale dotato di una di-
namica top-down e bottom-up. La reputazione e una caratteristica
132

7.2 La teoria della Reputazione
dei soggetti che deriva dalle azioni del gruppo in cui sono inseriti e
in particolare dalla trasmissione di valutazione sociale.
Si tratta di un fenomeno all’attenzione di economisti, psicologi,
biologi ect. Da circa 10 anni se ne registra l’utilizzo nell’ambito delle
interazioni mediate dalla rete, sia per attivita commerciali sia per ci
che concerne le dinamiche sociali nel contesto del web 2.0 sempre
maggiormente caratterizzato da applicazioni che ricadono sotto il
nome di social networking (flickr.com, digg, reddit).
7.2.1 Valutazioni Sociali
La conoscenza sociale valutativa include fenomeni distinti, in parti-
colare l’immagine e la reputazione, nonch il processo di trasmissione
della prima che contribuisce a determinare la seconda, ossia il gossip.
Passiamo rapidamente in rassegna questi tre aspetti, cominciando
dalla reputazione.
La reputazione un artefatto sociocognitivo evoluto per i vari pro-
blemi di ordine sociale incontrati dalle societa umane, in particolare
il controllo sociale e la selezione dei partner negli scambi [37]. La
reputazione interagisce con, ma va distinta dalla valutazione o im-
magine sociale [38]. Quest’ultima rappresenta il giudizio di valore
che il valutatore si formato sul conto di un certo target (individuo,
azienda, istituzione, ecc.), e pu essere basata su esperienza diretta
o indiretta del target da parte del valutatore. L’immagine coinvolge
tre personaggi o ruoli sociali: il valutatore (v), il target o oggetto
di valutazione (t) che pu essere individuale o sovraindividuale, ed in
questo secondo caso pu essere rappresentato da una azienda, un’or-
ganizzazione, un gruppo sociale, un’istituzione pubblica o privata,
133

Valutazioni Sociali ed Incertezza: Modellazione,Simulazione e Classificazione
persino una nazione o uno stato; il beneficiario (b), cioe colui che
utilizzera la valutazione per scegliere il target (per esempio, come
partner di scambio economico), oppure per starne alla larga. Nel
rendere esplicito il proprio giudizio attraverso un feedback diretto,
il valutatore si impegna sul valore di verita del giudizio espresso
e si assume una responsabilita sia nei confronti del target, specie
nel caso il giudizio sia negativo, sia nei confronti del destinatario
dell’informazione, specie se il giudizio positivo. Non cos nella repu-
tazione, che nasce dal riportare le valutazioni altrui. La reputazione
e un fenomeno misto o ibrido: e un oggetto della mente, ossia una
rappresentazione e piu esattamente una credenza su una valutazio-
ne altrui, ma e anche una proprieta oggettiva acquisita dal target,
emergente dalla circolazione di questa rappresentazione nel gruppo
sociale. La reputazione e dunque una proprieta acquisita: nessuno
nasce con una reputazione personale, ma semmai con quella che ere-
dita dai propri genitori e dal gruppo di appartenenza. Quasi sempre,
nel corso della propria esistenza, si acquisiscono una o piu reputa-
zioni a seconda dei gruppi che si frequentano e delle attivita che si
svolgono. Ognuno di noi, accanto alla reputazione complessiva che
possiede, pu trovarsi ad essere oggetto di svariate dicerie che si riferi-
scono ai diversi ruoli pubblici che ricopre, come anche a quelli privati
di moglie, madre, amante, collega, ecc. La reputazione e anche una
proprieta oggettiva. Spesso essa si incolla al target senza che costui
se ne renda nemmeno conto, n tanto meno lo voglia (spesso, infatti,
la reputazione non corrisponde ad una valutazione positiva). E’ infi-
ne una proprieta emergente, che deriva dallo scambio d’informazioni
fra membri del gruppo, i quali si aggiornano l’un l’altro sulle voci che
girano a proposito di questo o di quello. I personaggi sono questa
134

7.2 La teoria della Reputazione
volta ben quattro: come nel caso precedente ci sono il valutatore, il
target e il beneficiario, ma in piu questa volta c’e anche il vettore
dell’informazione, l’informatore. Nel riferire le voci che girano sul
conto di un target, l’informatore non un valutatore, non fornisce
giudizi personali, ne si assume alcuna responsabilita, nella misura
in cui non sarebbe pronto a giurare sul valore di verita delle voci
riferite. Si limita a riferire chiacchiere, e spesso gode nel farlo. Perch
lo fa? Vediamo l’uso delle due forme di valutazione sociale. A che
cosa possa servire l’immagine, e abbastanza ovvio: senza dubbio, il
beneficiario della valutazione, che spesso coincide con lo stesso va-
lutatore, ne trae ispirazione per le scelte sociali che si trova a fare.
Al mercato, il compratore si fa un’idea della qualita dei prodotti in
vendita osservando la mercanzia sulle bancarelle, e questo lo aiutera
a orientarsi nella scelta. In altre situazioni sociali, l’osservazione del
comportamento altrui ci consente di formarci un’opinione persona-
le su questo e su quello, che magari decidiamo di tenere per noi, e
che comunque utilizzeremo al momento di scegliere la compagnia,
il partner, l’interlocutore giusto. L’osservazione degli altri sembra
aver favorito l’evoluzione del comportamento prosociale, addirittura
l’evoluzione dell’altruismo.. ’ facile intuire perch: l’immagine forma-
ta attraverso l’osservazione diretta del target serve a decidere come
comportarsi nei suoi confronti, ad applicare un’autodifesa preventiva
nel caso si tratti di un poco di buono, oppure nel caso opposto ad
investire su di lui. Ma per ovvie ragioni l’immagine non basta. In
primo luogo, quella che ci formiamo attraverso la nostra esperien-
za del target e un’opinione spesso pagata a caro prezzo. Qualche
volta, l’esperienza pu rivelarsi fatale, e non ci da il tempo di sfrutta-
re la conoscenza che ne ricaviamo. I pipistrelli vampiri della specie
135

Valutazioni Sociali ed Incertezza: Modellazione,Simulazione e Classificazione
Desmodus Rotundus sono diventati celebri nel mondo dell’etologia
e della sociobiologia la disciplina che studia le basi biologiche del
comportamento sociale per un particolare tipo di altruismo, la con-
divisione del cibo all’interno del nido anche fra non consanguinei.
Studi recenti condotti su popolazioni artificiali (simulate al calco-
latore) di Desmodus Rotundus mostrano infatti che la popolazione
sopravvive a condizione che il cibo venga scambiato solo all’interno
del nido e che il processo di riproduzione distribuisca la popolazione
in nidi di non piu di una dozzina di individui ciascuno. In queste
condizioni, che fra l’altro corrispondono sostanzialmente a quel che
succede in natura, possiamo parlare di una sorta di immagine di co-
residente che precede e sostituisce l’esperienza diretta. L’immagine
pubblica, trasparente, pu rivelarsi controproducente, specie se il tar-
get e un buon diavolo. Si consideri il caso dell’osservazione diretta.
Gli studi di Nowak e Sigmund ne hanno documentato gli effetti po-
sitivi su un gioco asimmetrico, nel quale fra due individui scelti a
caso dalla popolazione iniziale uno, il potenziale donatore, decide di
fare o meno una donazione a favore dell’altro, anche sulla base del-
l’immagine che il potenziale destinatario si e a poco a poco costruito
nel corso della sua vita precedente e che e accessibile direttamente
agli osservatori. In queste circostanze, e praticamente giocoforza -
ed infatti gli autori lo documentano anche attraverso un modello ad
equazioni - che la popolazione converga rapidamente sulla donazione
condizionata, cioe sulla donazione elargita a favore di chi gode di una
buona immagine di donatore. Ma il risultato sarebbe profondamente
diverso se il gioco fosse simmetrico e includesse l’opzione di sfrutta-
mento: l’immagine pubblica di cooperatore si trasformerebbe nella
piu tragica delle calamita rendendo le colombe ancor piu vulnerabili
136

7.2 La teoria della Reputazione
e gettandole in pasto ai falchi senza alcuna protezione n esitazione.
Per concludere, sia che derivi dall’esperienza diretta, sia che deri-
vi dall’osservazione del comportamento altrui, l’immagine non e n
sufficiente n priva di controindicazioni. E’ qui che entra in gioco la
comunicazione, il gossip. In che modo e con quali effetti? Nei nostri
termini, il gossip e un tipo di comunicazione nel quale si riportano
le valutazioni altrui, l’immagine che gli altri hanno o dicono di ave-
re su un determinato target, senza necessariamente condividerla o
dichiarare di condividerla. Per questa ragione, il gossip e uno scam-
bio allusivo ed ambiguo di informazione sul conto di qualcuno che e
assente. In sostanza, si chiacchiera sul conto di chi non c’e, spesso
riportando voci attribuite ad altri, senza rivelarne l’identita. Perch
lo si fa? Il gossip e antico quanto l’uomo. Secondo alcuni [39], ha fa-
vorito la dimensione sociale della nostra specie, allargando le dimen-
sioni dei gruppi di cacciatori e raccoglitori e consentendo un notevole
miglioramento delle capacita produttive, destinate ad affrontare le
carestie, se non all’accumulazione vera e propria. A dispetto di alcu-
ne recenti teorie sulla socialita, che farebbero discendere la capacita
di comprendere l’azione altrui grazie all’osservazione simulata del
comportamento osservato, questa teoria poggia invece non solo sulla
cosiddetta teoria della mente ossia sulla rappresentazione della men-
te altrui nella propria, ma anche sulla capacita di manipolare nella
propria mente le credenze degli altri, di confrontarle con le proprie
a proposito dello stesso oggetto (target), di farle interagire oppure
di mantenerle distinte e di usarle indipendentemente l’una dall’altra
per azioni diverse. Nel caso del gossip, si usano le credenze altrui
senza necessariamente averle integrate con le proprie: l’informatore
pu decidere di trasmetterle come conoscenze altrui, prima e a dispet-
137

Valutazioni Sociali ed Incertezza: Modellazione,Simulazione e Classificazione
to delle proprie. Per comprendere perch lo fa, occorre fare qualche
breve incursione sugli usi del gossip, che nonostante alcune sparse
evidenze antropologiche di supporto, resta ancora a livello di specu-
lazione, piu o meno suggestiva. Il gossip rientra fra quei fenomeni
sociali che sono stati definiti di coopertizione, cioe di cooperazione
nella competizione. Piu specificamente, il gossip e un’arma insidiosa
e sottile, a beneficio dei deboli, cioe di chi non ha capacita di violenza
diretta, contro tutti coloro che minacciano la solidita e stabilita del
gruppo: gli sfruttatori, i potenti, i superiori di rango, le celebrita,
coloro che si espongono, i nuovi arrivati, gli sconosciuti, ecc. Certo,
si tratta di un comportamento aggressivo e vile, infalsificabile e dal
quale non ci si pu difendere. Ma e proprio a questa caratteristica
che il fenomeno deve le sue possibilita di espansione: il gossip funzio-
na se e fintantoch consente all’autore di nascondersi, di non rivelare
le proprie fonti, di non portare evidenze a supporto delle proprie
denunce, in una parola di colpire senza essere colpito, evitando la
rappresaglia e lo scontro aperto. Odioso quanto si vuole, in virtu
del gossip e possibile coniugare il controllo sociale con la riduzione
dell’aggressivita diretta, degli scontri aperti, delle rappresaglie, delle
faide. E’ al gossip che si deve ricondurre la costruzione del capi-
tale sociale, cioe di quelle reti di conoscenza preventiva n certa n
effettivamente condivisa nelle quali gli individui sono immersi, e che
svolgono una funzione di controllo senza disgregare completamente il
gruppo. Quest’uso del gossip e documentato in una varieta di culture
tradizionali, dove i membri sono sottoposti al controllo certamente
subdolo e crudele della vergogna, del disonore, della diffamazione,
tanto piu grave quanto piu e sfuggente e impalpabile, ed e difficile
difendersene, ma proprio per questo inesorabile.
138

7.3 Il modello ad Agenti: RepAge
7.3 Il modello ad Agenti: RepAge
Regage [38] e un implementazione della teoria della reputazione me-
diante agenti. La piattaforma utilizzata per l’implementazione e
Jadex. Regage fornisce valutazioni su potenziali partner ed e ali-
mentato da informazioni provenienti dagli altri agenti e da quelle
risultanti da esperienze dirette. Per selezionare un buon partner
gli agenti necessitano di formare e aggiornare le proprie valutazioni,
per cui devono scambiarsi informazioni, ovvero comunicare. Se gli
agenti trasmettono solo ci che ritengono affidabile, le informazioni
sarebbero destinate a fermarsi presto. Al fine di preservare la loro
autonomia gli agenti devono decidere quando poter condividere o
meno le proprie valutazioni con gli altri. Se gli agenti trasmetto-
no anche le opinioni degli altri come se fossero le proprie e allora
possibile per l’agente scegliere quale tipo di informazione rilasciare.
Quindi al fine di preservare le propria autonomia gli agenti de-
vono
• formare entrambe le valutazioni (image) e meta-valutazioni
(reputation), tenendo presente la distinzione ontologica della
rappresentazione prima di
• decidere quando integrare o non integrare l’informazione repu-
tazionale con la propria immagine di un target.
A differenza dei sistemi attuali repage permette agli agenti di
trasmettere la propria immagine rispetto ad un target, che loro con-
siderano essere veritiera, o riportare quello che loro hanno ascoltato,
sentito dire, rispetto ad un determinato target, ovvero la sua repu-
tazione che sia essa considerata vera o falsa. Nel caso della reputa-
139

Valutazioni Sociali ed Incertezza: Modellazione,Simulazione e Classificazione
zione ovviamente non c’e responsabilita rispetto al valore di verita
dell’informazione riportata ed eventualmente delle sue conseguen-
ze. Di conseguenza dagli agenti ci si aspetta una trasmissione di
informazione, fondamentalmente incerta,
Il componente principale dell’architettura di Repage (7.1) e la
memoria, che e composta da un insieme di predicati. I predicati
sono oggetti contenenti o una valutazione sociale, afferente ad uno
dei tipi accettati da Repage (immagine, reputazione, voce condivi-
sa, valutazione condivisa), o uno dei tipi usati per il calcolo delle
valutazioni (valore dell’informazione, valutazione relativa agli infor-
matori). I predicati contengono una tupla di cinque numeri stanti
a rappresentare la valutazione piu il suo valore di forza atto ad in-
dicare il suo valore di confidenza rispetto a ci che l’agente crede
vero. I predicati sono concettualmente organizzati in differenti livel-
li e connessi da una rete di dipendenze, specificando quale predicato
contribuisce al valore degli altri. Ogni predicato nella memoria di
Repage ha un insieme di antecedenti e un altro di conseguenti. Se
un antecedente viene creato, rimosso o aggiornato il predicato vie-
ne di conseguenza ricalcolato e tutta la rete di dipendenze viene
aggiornata di conseguenza
In questo contesto non si vuole procedere ad una spiegazione
dettagliata dei meccanismi architetturali sia software che logici di
repage, per questi si rimanda agli articoli [38] e [40].
140

7.3 Il modello ad Agenti: RepAge
Figura 7.1: Architettura Repage
141

Valutazioni Sociali ed Incertezza: Modellazione,Simulazione e Classificazione
7.3.1 Simulare Sistemi Complessi Modellati Su
Agenti
In questa sezione si descrive il modello di interazione implementato,
basato su comunicazione tra agenti. Agenti cognitivi dotati di una
base di conoscenza e delle regole che simulano il processo mentale
della formazione e revisione delle credenze attraverso la comunica-
zione di esperenzie dirette o di voci circolanti (gossip). Il gossip e
da considerarsi come l’elemento cardine di un processo costitutivo
della formazione di identita di gruppo. E’ il sistema di trasmissione
di informazione piu antico. Tutto ci che circola su una rete sociale,
espresso come fonte di informazione, e detto dominio informativo.
Ovvero quel capitale di informazioni, condivise, che passano sul ca-
nale delle comunicazione da agente ad agente. Un agente e in grado
di adottarla o meno. Si teorizza anche la capacita cognitiva dell’a-
gente di ricreare nella propria struttura di credenze quella acquisita
dagli altri attraverso la comunicazione al fine di ridurre l’incertazza
in un processo complesso dinamico fondato su interazioni [41].
7.3.2 Esperimenti: Scelta di Un Partner
In questa sezione presentiamo i nostri esperimenti estendendo le pro-
cedure di processo decisionale proprie di Repage e determinando le
tecniche adottate per i processi di estrazione di conoscenza. Il de-
sign delle simulazioni presenta le impostazioni piu semplici, dove
l’informazione accurata e da considerarsi un bene, nel senso che l’in-
formazione e sia opinabile che scarsa. Viene usata una metafora di
mercato di agenti con instabilita. La derivazione di regole di design
142

7.3 Il modello ad Agenti: RepAge
mirate alla semplificazione ha riguardato principalmente il mercato,
per permettere un migliore studio del processo cognitivo implemen-
tato. L’esperimento simulativo presenta uno scenario con solo due
tipi di agenti i buyer e i seller. Tutti gli agenti cognitivi implementati
agiscono in unita di tempo discreto, che chiameremo turni da ora in
avanti. In un turno, un buyer fa un atto di comunicazione, al fine
di acquisire informazioni ed un’operazione di acquisto. Inoltre, ogni
buyer risponde a tutte le richieste di informazione ricevute.
Un buyer, dato il suo ruolo di fornitore di informazioni, assumere
anche una strategia di imbroglio informazionale, mirata al proprio
vantaggio. I buyer che mentono, riportando informazioni false di
proposito prendono il nome di Cheaters (si guardi la descrizione
algoritmica delle answering action implementate).
I beni del mercato sono costituiti da un fattore di utilita che viene
interpretata come qualita con un valore compreso tra 0 e 100.
I seller sono costituiti da un valore costante di qualita ed da
un quantitativo di merce vendibile fisso. Lo stock di ogni agente
decresce ad ogni acquisto. I seller sono agenti essenzialmente di
tipo reattivo, il loro ruolo funzionale all’interno della simulazione e
limitato alla fornitura di beni di qualita variabile ai buyers. I seller
escono dalla simulazione quando il loro stock esaurisce o quando
per un certo numero di turni non vendono nulla, a questo punto
vengono sostituiti da un nuovo seller con caretteristiche simili, ma
non necessariamente identiche.
L’uscita dei seller dal mercato e un punto fondamentale per il
valore informativo della valutazione sociale, ovvero e questo che ren-
de l’informazione necessaria e lascia sempre aperto un certo livello
di incertezza sia a livello di dominio informazionale sia a livello di
143

Valutazioni Sociali ed Incertezza: Modellazione,Simulazione e Classificazione
esperienza diretta. La trasmissione di informazione affidabile per-
mette una scoperta dei buoni venditori molto piu rapida ed efficace,
perche la selezione sara mirata e guidata. In uno scenario in cui lo
stock fosse stato implementato come fisso, una volta che tutti i buyer
fossero stati identificati, i buyer non sarebbero stati motivati a cam-
biare causando il conseguente fallimento dell’esperimento. Inoltre lo
stock limitato rende i buoni venditori una risorsa scarsa, quindi per
gli agenti e strategico non diffondere in giro l’informazione.
7.3.3 Datamining e la Simulazione Basata su Agen-
te
Il nostro approccio e inteso a spiegare i fenomeni emergenti nei si-
stemi complessi usando tecniche specifiche di datamining, atte alla
classificazione delle interazioni su modelli computazionali simulati
basati su agenti. In queste simulazioni uno dei task piu richiesti e
di classificare e predire il comportamento futuro di un certo sistema,
non strutturato e per alcuni aspetti non chiaro.
Come visto nei capitoli precedenti il data mining e una giovane
ma ben consolidata disciplina che si focalizza sull’estrazione di in-
formazioni da grandi moli di dati. Le informazioni estratte possono
essere correlazioni tra eventi o comportamenti ricorrenti di entita.
Gli ultimi sviluppi del datamining hanno portato la materia a svi-
lupparsi in molti domini applicativi complessi come gli itemset (ov-
vero eventi che accadono simultaneamente), sequenze (serie storiche,
processi stocastici, traiettorie, sequenze di eventi), e grafi (relazioni
peer-to-peer, social network analysis, legami molecolari, etc).
La metodologia della simulazione basata su agente (MABS) se-
144

7.3 Il modello ad Agenti: RepAge
gue invece un primo passo orientato alla teorizzazione di fenomeni
complessi, poi il modello viene implementato per essere simulato. I
risultati alla fine sono verificati con la loro coerenza sia con il mo-
dello, e laddove possibile, con una funzione di verosimiglianza con i
dati reali.
Si potrebbe dire che la metodologia MABS sia debole dal punto di
vista della validazione, la nostra soluzione e quella di applicare massi-
vamente strumenti e tecniche di datamining mirate a classificare l’in-
terazione per sfruttare l’interazione che e comune alla simulazione,
agli interaction patter ed ai sistemi complessi.
7.3.4 Interaction: Agents Communication in Re-
page
Nei nostri esperimenti il processo decisionale e un punto cardine che
determina le performance e le dinamiche di tutto il sistema. Dal lato
dei seller, la procedura e limitata alla vendita dei prodotti, Dal punto
di vista dei buyer per ogni turno loro devono chiedere informazioni
ad una altro buyer e acquistare sulla base delle loro credenze. Tutte
vengono implementate come interazione. Le azioni interazioni dei
buyer possono essere riassunte in tre macro classe di seguito riportate
che poi verrano presentate algoritmicamente.
• Buying Action
• Asking Action
• Answering Action
145

Valutazioni Sociali ed Incertezza: Modellazione,Simulazione e Classificazione
Buying action
In questa azione/interazione la domanda che si pone l’agente e relati-
va a quale agente scegliere per acquistare. Repage fornisce informa-
zioni riguardo l’immagine e la reputazione di ogni seller. L’opzione
piu semplice potrebbe essere quella di prendere l’agente con la mi-
gliore immagine, o nel caso di L2 quello con la miglior reputazione
nel caso l’immagine non fosse disponibile. Nel modello viene im-
postata una soglia sopra la quale l’agente e considerato accettabile
per procedere all’acquisto. Inoltre, la possibilita di cercare nuovi
venditori e limitita. In generale comunque, l’immagine e sempre da
considerarsi prioritaria rispetto alla reputazione, visto che l’una e
verifica mentre l’altra no.
Algorithm 3 Buy Action pseudo code L1
1: Candidate Seller := Select randomly one good enough image’s
seller;
2: If Candidate Seller is empty or decided to risk then Candidate
Seller := select randomly one seller without image;
3: Buy from Candidate Seller;
Asking action
Come nell’azione precedente, la prima decisione e a quale agente
richiedere informazioni, e la procedura e esattamente la stessa nel
caso del processo decisionale relativo alla scelta del seller, con l’u-
nica differenza che l’immagine e la reputazione hanno come target
l’informatore, ovvero la sua attendibilita. Negli agenti e stata imple-
mentata anche la paura della ritorsione, quindi l’immagine, ovvero
146

7.3 Il modello ad Agenti: RepAge
Algorithm 4 Buy Action pseudo code L2
1: Candidate Seller := Select randomly one good enough image’s
seller;
2: If Candidate Seller is empty then Candidate Seller := select
randomly one good enough seller reputation;
3: If Candidate Seller is empty or decided to risk then Candidate
Seller := select randomly one seller without image;
4: Buy from Candidate Seller;
l’esperienza diretta che implica responsabilita, viene trasmessa solo
se c’e un certo grado di confidenza sulla valutazione (per maggiori
dettagli si guardi [40]).
Algorithm 5 Asking action pseudo code L1
1: Candidate Informer := Select randomly one good enough
informer image;
2: If Candidate Informer is empty or decided to risk then Candi-
date Informer := select randomly one buyer without image as
informer;
3: Ask to Candidate Informer;
Una volta scelto l’informatore a cui chidere, va scelto il tipo di
domanda. Ovvero, nel modello si contemplano solo due possibili
domande:
• Q1: Chiedere informazioni riguardo un buyer come informato-
re ovvero quanto e onesto il buyer X come informatore
• Q2: Chiedere un po’ di buoni e cattivi seller
147

Valutazioni Sociali ed Incertezza: Modellazione,Simulazione e Classificazione
Da notare che Q2 non si riferisce ad uno specifico individuo,
ma a tutto il dominio informativo che pu avere l’agente richiedente.
Questo e stato necessario per consentire l’interazione con un numero
elevato di seller, quando la probabilita di scegliere un seller di cui
l’agente ha informazioni e molto bassa.
Answering action
Sia l’agente S l’agente che fa la domanda e R l’agente interroga-
to. Gli agenti possono mentire, sia perche sono cheater sia perche
si stanno vendicando. Quando un buyer e un cheater l’informazione
viene cambiata nel suo valore opposto. Mentre la vendetta e som-
ministrata mandato informazioni non precise dal punto di vista del
mittente, per esempio rispondendo “I don’t Know” anche quando
l’informazione richiesta e effettivamente disponibile nella mente del-
l’agente quando R ha una cattiva immagine di S come informatore.
In L1 ovvero quando circola solo immagine il cheating avviene man-
dando “Idontknow” anche quando R ha l’informazione. Questo evita
possibile vendette su informazioni incerte perche il loro rilascio non
comporta nessun impegno di responsabilita. Se e ammessa la repu-
tazione, ovvero in L2, invece e fatta convertendo tutta l’immagine
posseduta in reputazione, sempre per evitare possibili ritorsioni.
Algorithm 6 Answering Q1 Decision Procedure R in L1
1: ImgX := Get image of agent X as informant;
2: if ImgX exists and strength(ImgX)≥ thStrength then send ImgX
to agent S, END else send Idontknow to agent S, END;
3: if ImgX does not exist then send Idontknow to agent S;
148

7.3 Il modello ad Agenti: RepAge
Algorithm 7 Answering Q1 Decision Procedure R in L2
1: ImgX := Get image of agent X as informant;
2: if ImgX exists and strength(ImgX)≥ thStrength then send ImgX
to agent S, END;
3: else convert ImgX to RepX and send RepX to S, END
4: if ImgX does not exist then RepX := Get reputation of agent X
as informant;
5: if RepX exists then send RepX to S, END;
6: if RepX does not exist then send Idontknow to agent S;
Algorithm 8 Answering Q2 Decision Procedure R in L1
1: IG := Get good enough images of sellers; IB := Get bad enough
images of sellers;
2: if IG is not empty then CandImage := Pick one randomly from
IG1;
3: else if IB is not empty then CandImage := Pick one randomly
from IB;
4: if CandImage is not empty and strength(CandImage) ≥thStrength then sent CandImage to S, END;
5: if CandImage is not empty and strength(CandImage) <
thStrength then send Idontknow to S, END;
6: if CandImage is empty then send Idontknow to agent S;
7.3.5 Discussione sui Risultati
7.3.6 Valutazioni Sociali ed Incertezza
La reputazione riduce l’incertezza 7.2. Il risultato e relativo ad un
esperimento simulativo
149

Valutazioni Sociali ed Incertezza: Modellazione,Simulazione e Classificazione
Tabella 7.1: Experiments Settings
Experiment Code Level Settings Percentage of Cheaters
A L1 0%
B L1 10%
C L1 20%
D L1 30%
A1 L2 0%
B1 L2 10%
C1 L2 20%
D1 L2 30%
Lo scenario di questo esperimento simulativo consiste in un mer-
cato fisso dove il numero di buyer e seller e fissato rispettivamente
a 100 e 15. Gli agenti che agiscono come cattivi informatori, ovvero
cheater informazionali sono fissati al 20%. Per ogni scenario le simu-
lazioni sono eseguite sia in modalita L1, ovvero con solo immagine
circolante, che in L2, con sia immagine che reputazione.
La figura mostra che il L1 e L2 nonostante ci sia la stessa quantita
di informazione circolante c’e un forte calo della curva delle risposten
incerte quelle del tipo Idontknow
La nostra teoria della reputazione suggerisce che i fenomeni di
riduzione dell’incertezza sono effetti emergenti non solo per la mag-
gior quantita di informazione circolante, ma anche un effetto quali-
tativo dovuto a differenti fonti di informazioni disponibili. Ovvero,
fonti eterogenee di informazione rendono il sistema decisionale piu
tollerante all’incertezza, permettendo di conseguenza prestazione del
mercato molto superiori, sia per la piu efficace scoperta dei mentitori,
150

7.3 Il modello ad Agenti: RepAge
Figura 7.2: Trend of Idontknow answers in L1 and L2
sia per la piu efficace scoperta di buoni venditori.
7.3.7 Valutazioni Sociali e False Informazioni
Un altro aspetto molto importante che e stato oggetto di studio at-
traverso la piattaforma Repage e stato la relazione tra la credibilita
dell’informazione e la formazione delle opinioni. Che cosa succede
quando il dominio informativo e poco credibile a il livello di fiducia
e basso? Possono le false informazioni indurre in uno stato di im-
mobilizzazione e polarizzazione delle opinioni? Qual’e il ruolo del-
l’incertezza e delle valutazione sociali nelle profezie autoavveranti?
Nel mondo reale ogni decisione necessita di strategie atte a ridurre
l’incertezza rispetto allo stato di natura, ovvero lo stato dei fatti
percepito da cui deriva la determinazione del costo di una scelta. In
accordo con quanto sostiene Shannon [42], c’e incertezza quando un
151

Valutazioni Sociali ed Incertezza: Modellazione,Simulazione e Classificazione
Figura 7.3: Distribution of Good Image and Good Sellers Discovery
in L1
152

7.3 Il modello ad Agenti: RepAge
Figura 7.4: Distribution of Good Image and Good Seller Discovery
in L2
153

Valutazioni Sociali ed Incertezza: Modellazione,Simulazione e Classificazione
Figura 7.5: Answers Given with a motivation of Bad Reputation
154

7.3 Il modello ad Agenti: RepAge
agente non riesce a distinguere rispetto a tutto lo spettro di alterna-
tive con uguale probabilita di reificazione. In particolare il processo
decisionale impone agli agenti la necessita di avere strumenti cogni-
tivi atti a ridurre l’incertezza, che nel caso in esame passa per il
gossip.
Questa fase del lavoro quindi cercava di studiare la relazione che
intercorre tra affidabilita dell’informazione e il processo cognitivo di
formazione e revisione delle credenze rispetto ad un processo deci-
sionale, quale quello della scelta di un partner. Gli esperimenti sono
stati studiati proprio al fine di stressare l’importanza della qualita
dell’informazione.
Si suppone infatti, che piu il mercato sia influenzato da false in-
formazioni circolanti, piu gli agenti saranno costretti a ridurre l’in-
certezza per cercare di selezionare il miglior partner. Dato che la
reputazione ha dimostrato di ridurre l’incertezza nei nostri lavori
precedenti, ci aspettiamo che in questo caso la reputazione amplifi-
chi l’effetto della falsa informazione portando il mercato al collasso
per scarsita di informazioni veritiere. Nel dettaglio si e cercato di
capire come un canale di trasmissione dell’informazione veloce co-
me la reputazione possa inficiare sul livello di trust e quindi sulle
performance del mercato.
7.3.8 Simulazioni e Risultati
Ogni scenario simulativo e descritto da sei parametri : il numero
di buyers (NB), il numero di sellers (NS), il numero di cheaters
(C), lo stock per ogni seller (S), i buoni venditori che sono seller che
forniscono la qualita massima (GS) e i bad sellers (BS).
155

Valutazioni Sociali ed Incertezza: Modellazione,Simulazione e Classificazione
Ogni scenario e visto sia con immagine circolante (L1), sia con
immagine e reputazione (L2).
L’esperimento esplora 28 scenari differnti con un gran numero di
cattivi venditori rispetto ai buoni che invece sono fissati ad un nume-
ro molto basso. Lo scenario e esplorato per un numero incrementale
della percentuale di cheater. Per ogni scenario ci sono 50 buyer, e
25 seller, in modo che l’offerta sia anche scarsa. I cheater variano
in percentuale da 0 a 100 a passo 10. Tutti gli scenari quindi sono
simulati in L1 e L2 per 10 volte per avere poi possibilita di mediare
il risultato rispetto alla stocasticita indotta.
Guardando alla Figure 7.8(a), dove viene mostrata il trend del-
la quality, si pu notare che le curve sia in L1 che L2 convergono per
tutti i turni simulativi. Figure 7.8(b) mostra che sono scoperti piu
good seller in L1 che in L2, indicando che c’e un maggiore consumo di
risorse e quindi maggiore richiesta. Figure 7.8(c) mostra che la re-
putazione ha migliori performance anche ad alti livelli di cheating in-
formazionale, per l’esattezza fino al 60% del totale dell’informazione
circolante.
Quando l’informazione non e attendibile, essendo il mercato po-
polato solo da cheater, i differenti impatti delle valutazione circolanti
sulla qualita sono visibili in Figure 7.9(a), dove la curva di L2 e a
valori di qualita piu bassi rispetto ad L1.
La scoperta dei buoni venditori, mostrata in Figure 7.9(b)
presenta valori piu alti in L2 che in L1.
Il trend dell’incertezza in Figure 7.9(c) mostra che in ogni caso
la reputazione riduce sempre bene l’incertezza anche quando circola
solo falsa informazione.
La reputazione, secondo il nostro modello, fa collassare il mercato
156

7.3 Il modello ad Agenti: RepAge
NS NB L S GS BS
25 50 L1 30 15% 50%
25 50 L2 30 15% 50%
Tabella 7.2: Experiment Settings. The simulation settings which re-
mains the same for all the experiments. The scenario is investigated
for increasing number of cheaters starting in absence of false infor-
mation (0%) to arrive with all the population composed by cheaters
(100%). Each scenario is characterized by an increasing rate of 10%
of the number of cheaters until the 60%, after that, for a better
investigation of the social evaluation and information trustworthy
phenomena the interval of 10% is reduced to 5%, for a total of 28 si-
mulated scenarios. The table parameters are: the number of buyers
NB, the number of sellers NS, C the number of cheaters, the stock
for each seller S, GS the good sellers (sellers providing the maximum
quality) and BS the bad sellers. Both the settings are simulated wi-
th only image circulating (L1) and with both image and reputation
(L2).
157

Valutazioni Sociali ed Incertezza: Modellazione,Simulazione e Classificazione
Figura 7.6: Global quality with increasing number of cheaters. The
curves represent quality in the stabilised regime for L1 and L2. Until
cheaters remain below the threshold of 60% reputation allows for
quality to reach higher values than happens in the complementary
condition. The truth circulates faster providing social evaluations
which are coherent with the reality. Coherence between information
and reality, shared by a larger amount of agents in L2, increases
the trust and the market is more efficient. Over the threshold of
60%, false information floods in, hence social evaluations, circulating
faster with reputation, are often distorted with respect to reality.
158

7.3 Il modello ad Agenti: RepAge
(a) Quality of Contracts (b) Good Sellers Discovery
(c) Uncertain Answers
Figura 7.7: Simulation Results in L1 and L2 with 0% of Cheaters
for 100 turns
159

Valutazioni Sociali ed Incertezza: Modellazione,Simulazione e Classificazione
(a) Quality of Contracts (b) Good Sellers Discovery
(c) Uncertain Answers
Figura 7.8: Simulation Results in L1 and L2 with 60% of Cheaters for
100 turns. (a) Quality. The two curves represent Quality with Image
(L1) and with both Image and Reputation (L2) when the number
of cheaters inhibits the good effect of Reputation. Reputation and
Image are on the same levels. (b) Good Sellers Discovered. The
two curves are average values of Good Sellers found out for each
simulation turn. (c) “i don’t know” answers. The two curves are
average values of “i don’t know” answers for each simulation turn.
The L2 curve shows the ability of reputation in reducing uncertainty.
160
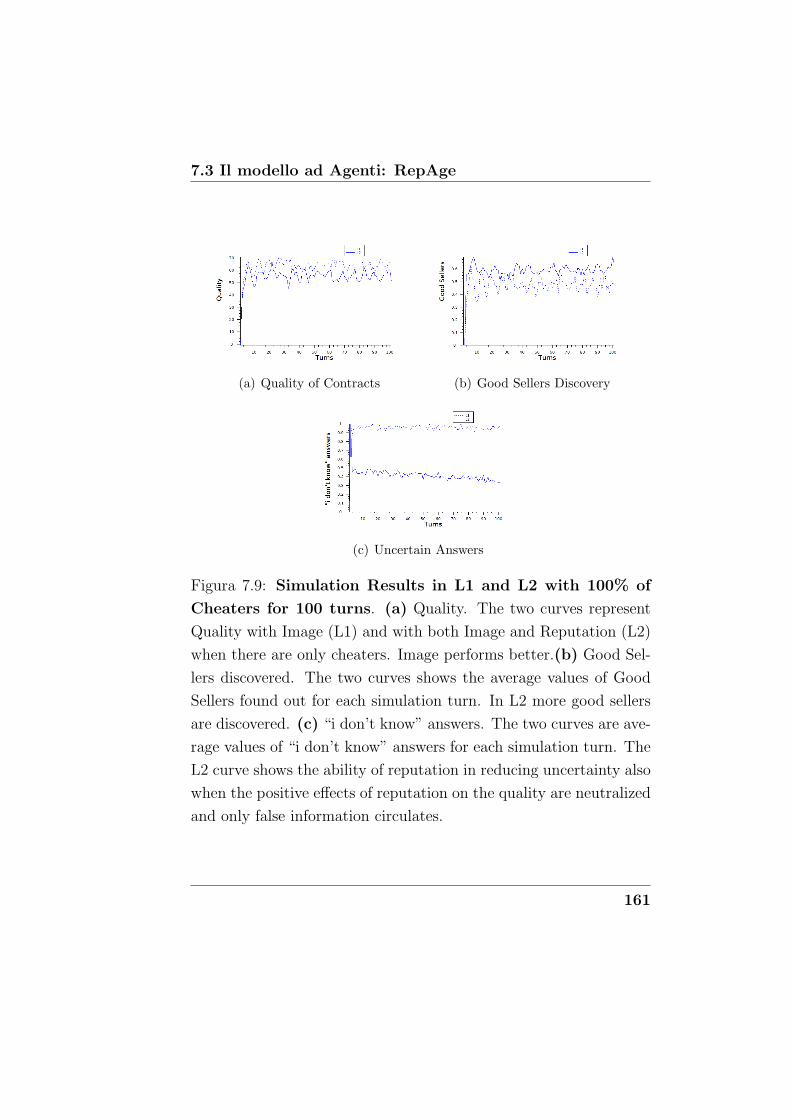
7.3 Il modello ad Agenti: RepAge
(a) Quality of Contracts (b) Good Sellers Discovery
(c) Uncertain Answers
Figura 7.9: Simulation Results in L1 and L2 with 100% of
Cheaters for 100 turns. (a) Quality. The two curves represent
Quality with Image (L1) and with both Image and Reputation (L2)
when there are only cheaters. Image performs better.(b) Good Sel-
lers discovered. The two curves shows the average values of Good
Sellers found out for each simulation turn. In L2 more good sellers
are discovered. (c) “i don’t know” answers. The two curves are ave-
rage values of “i don’t know” answers for each simulation turn. The
L2 curve shows the ability of reputation in reducing uncertainty also
when the positive effects of reputation on the quality are neutralized
and only false information circulates.
161

Valutazioni Sociali ed Incertezza: Modellazione,Simulazione e Classificazione
se il livello di alta informazione e superiore al 60%.
162

Capitolo 8
Conclusioni
Nel complesso del lavoro si e introdotta una metodologia in corso di
raffinamento orientata alla analisi dei sistemi complessi che si basa
su sistemi basati su agenti e tecniche di data mining orientate alla
classificazione delle interazioni tra entita.
Entrambe le componenti del metodo sono state sviluppate in col-
laborazione con altri ricercatori la cui attivita risulta essere di rilievo
sia nell’ambito della simulazione basata su agente, sia per la classifi-
cazione. Piu precisamente per la simulazione il lavoro stato portanto
avanti per il lato simulativo durante i 3 anni di collaborazione con
il LABSS (laboratorio di simulazione sociale basata su agente), ca-
pitanato splendidamente da Rosaria Conte, del Istituto di Scienze e
Tecnologie della Cognizione del CNR. Mentre la parte relativa alle
tecniche di data mining per la classificazione e stata sviluppata con
il KddLab del ISTI anch’esso afferente al CNR.
Tutti i passi e le concettualizzazioni metodologiche sono state svi-
luppate in un percorso scientifico, giudicato positivo in diverse sedi
163

Conclusioni
internazionali, sono stati pubblicati sia su rivista che a conferenze
internazionali articoli che utilizzano questa metodologia nel processo
di indagine.
I lavori pubblicati relativi a questa dissertazione sono in totale
11 tra pubblicazioni su rivista, che conferenze internazionali.
La necessita di un paradigma pi attento alle strutture dei sistemi
complessi viene individuata principalmente dal consistente interessa-
mento della scienza rispetto a problematiche relative alla concettua-
lizzazione di dinamiche molto complicate e non riassumibili in sche-
mi o modelli di semplice rappresentazione e quindi non facilmente
fruibili.
Questo fatto viene palesato, reso evidente e condiviso da diversi
contesti a partire dalle problematiche relative alla genomica, alla pro-
teomica, ai sistemi meterologici, ai processi cognitivi, passando per i
sistemi sociali fino ad arrivare alle neuroscienze sia dalla prospettiva
dell’individuo che sociale. E sempre piu chiara la sensazione che il
paradigma di indagine, di analisi, di verifica e di fruizione presenta
dei limiti: (i) limiti concettuali di rappresentazione poiche rimane
molto difficile modellare un sistema ed i legami che intercorrono tra
tutte le sue componenti; (ii) limiti economici, in quanto lındagine
sperimentale e cresciuta nei costi in maniera spaventosa di paripasso
con il progredire scientifico che sempre di piu si e trovato ad af-
frontare problematiche con alti livelli di incertezza, dove le relazioni
fondanti tra le componenti cambiano con il tempo e nel tempo, cam-
biando a loro volta la natura stessa del sistema rendendo di fatto
molto difficile sia la validazione sperimentale sia la classificazione
dei fenomeni.
Problematiche afferenti a questa classe definita “Sistemi Com-
164

plessi” richiedono una teorizzazione che esclude a priori ogni centra-
lizzazione, ripartizione e riduzione dell’interazione che e indissolu-
bile dal concetto stesso di evoluzione che e a sua volta dipendente
strettamente dall’equilibrio generato dalle componenti e dalla loro
interazione mutevole.
L’interazione esiste in quando manifestazione fenomenologica del-
la combinazione di determinati fattori, riconducibili a loro volta in
termini di interazione.
Sempre in termini di interazione si verifica un’emergenza che por-
ta ad un cambiamento di stato del sistema stesso, ma nel sistema
stesso in quanto si ha una chiusura operazionale del sistema in se
stesso. L’emergenza e la nozione che dati alcuni processi in un uni-
verso, retti da regole locali e mossi da piccole interazioni locali, che
messi in condizioni appropriate danno origine ad un nuovo livello a
cui bisogna riconoscere una specifica identita.
Si evidenzia per tanto, la necessita evolutiva del sistema stesso
in base ad un determinato verificarsi di una o piu emergenze che
pu sfociare in uno stato di organizzazione gerarchicamente superio-
re nella struttura di incapsulamento. I fenomeni di emergenza sono
necessariamente non lineari, quindi non prevedibili poich fortemente
caotici, di conseguenza di presuppone una risposta in ambito di rea-
zione evolutiva sia ontologica sia di organizzazione della struttura
sociale del sistema. Senza una rivisitazione del concetto stesso di
evoluzione, classificazione e correlazione. L’ontogenesi - cioe la sto-
ria delle trasformazioni di un unita come risultato della storia delle
interazioni, a partire da una sua struttura iniziale - e sempre legata
al divenire di continue interazioni che, in modo dinamico, indirizza-
no, mantengono o cambiano il suo particolare sviluppo. In pratica il
165

Conclusioni
sistema e definito dalla sua stessa dinamica di interazione.
I sistemi complessi, sono una materia di studio che nasce al con-
fine tra diverse discipline scientiche come i sistemi non lineari, il
chaos, i sistemi autorganizzanti, societa, societa artificiali, questa
prossimita ontologico scientifica fa si che i sistemi complessi e quindi
ne ereditano sia le teorie fondative sia gli strumenti e le tecniche
di indagine dando vita ad una commistione emergente molto ben
fornita, ma a nostro avviso ancora incompleta.
In concomitanza con il sempre maggior numero di sistemi di in-
dagine scientifica riconducibili per proprieta e natura ai sistemi com-
plessi, negli ultimi decenni lo studio di questa materia sta rifiorendo
e riprendendo forte vitalita, soprattutto nelle aree scientifiche che si
servono per la modellazione dell’approccio classico dei modelli ma-
tematici, che spesso diventa sempre piu complesso e difficilmente
fruibile e che, lato assolutamente non banale, produce modelli non
scalabili e che sono rappresentati in maniera riduzionista, e non in
grado di cogliere a pieno le caratteristiche principali di un sistema
complesso.
Per riduzionista si intende quella pratica comune alle scienza che
tende ad eliminare dettagli ritenuti non rilevanti per la dinamica o
per l’essenza del modello in indagine. Il punto e che spesso, questo
lasciar fuori dettagli comporta la perdita di elementi fondamentali
per le dinamiche sistemiche, sia da un punto di vista ontologico sia da
un punto di vista prettamente funzionale. Se un sistema caotico e un
sistema molto sensibile alle condizioni iniziali, come si fa a scegliere,
per via del loro gran numero, quali parametri includere e quali no,
visto che non siamo ingrado di distinguere quelli significativi? Come
si puo eludere il grande livello di ignoranza rispetto alla materia
166

di indagine e arrogarsi la responsabilita di tagliare via dal modello
parti non ritenute significativamente rilevanti? Molto spesso si parla
di sistemi complessi, non tanto come materia, ma come approccio
di indagine, non a caso sempre di piu si incontra il termine sistema
complesso per indicare un approccio di ricerca comune a diverse
discipline come le neuroscienze, le scienze sociali, la metereologia,
la chimica, la psicologia, la vita artificiale, il calcolo evolutivo, la
biologia molecolare.
Dopo aver introdotto nei capitoli precedenti il panorama dei si-
stemi complessi, il suo intersecare il percorso di molte discipline,
e avendo presentato i sistemi multi-agente ed il data mining, che
sono gli elementi costituenti del framework di indagine dei siste-
mi complessi, e stata introdotta un’esemplificazione relativa sia alla
modellazione dei fenomeni sia alla loro possibile interpretazione.
Il metodo proposto si basa essenzialmente sul concetto di inte-
razione. Con una modellazione computazionale basata sui sistemi
ad agente, mentre per la parte di analisi e validazione empirica agli
Interaction Pattern.
Sono stati introdotti due casi di studio, il primo orientato alla
classificazione stretta di entita a partire dalle loro interazioni, il se-
condo invece propone un sistema di analisi mirato alla costruzione
di un modello simulativo basato su agenti per l’analisi dei processi
cognitivi pro-sociali.
Ovvero in questo lavoro fa riferimento alla tentativo di classifica-
re e predire il comportamento di individui pericolosi nel traffico che
fa riferimento ad un articolo recentemente pubblicato nell’ambito di
un progetto europeo [4], in cui vi e una vera e propria trattazione
della metodologia di classificazione basato sul tracciamento dell’inte-
167

Conclusioni
razione. Ovvero, gli individui vengono catalogati come serie spazio
temporali di interazioni in relazione agli individui afferenti al loro
stesso gruppo.
Nel secondo esempio a differenza del precedente che presenta un
applicazione parziale, ovvero orientata solo all’aspetto predittivo,
viene presentata un applicazione completa della metodologia per l’a-
nalisi, modellazione e simulazione dei sistemi complessi. L’esempio
in esame parte dalla modellazione di una teoria, la implementa come
sistema ad agenti e gli interaction pattern vengono utilizzati da un
lato per la classificazione degli individui, dall’altra per la validazione
della teoria. Un aspetto molto importante nell’esempio in questio-
ne e che l’uso degli interaction pattern, ha permesso di individuare
caratteristiche proprie del modello teorico che non erano state pre-
se in considerazione, ma sono emerse come proprieta intrinseche del
sistema complesso in esame. Per l’esattezza la teoria in indagine e
quella sulla teoria della reputazione [37] che introduce una distin-
zione fondamentale tra i tipi di valutazioni circolanti nel contesto
sociale: l’immagine e la reputazione.
168

Bibliografia
[1] Benvenuto Sergio. Consciousness in the neurosciences. a conver-
sation with francisco varela. Journal of European Psychoana-
lysis - www.psychomedia.it/number14/varela.htm, 14:109–122,
2002.
[2] Paul K. Feyerabend. Against method: Outline of an anarchistic
theory of knowledge. Humanities Press.
[3] B. Edmonds. Against: a priori theory, For: descriptively
adequate computational modelling, pages 175–179. Routledge,
2003.
[4] Mirco Nanni and Walter Quattrociocchi. Representation,
synthesis and classification of trajectories from dynamicity
descriptors. In Technical report GeoPKDD Project, 2007.
[5] Cristiano Castelfranchi. The theory of social functions. chal-
lenges for multi-agent-based social simlation and multi-agent
learning. Cognitive Systems, 2001.
169

BIBLIOGRAFIA
[6] Rosaria Conte and Jaime Sichman. Dependence within and
between groups. Computational and Mathematical Organization
Theory, 2002.
[7] L. Marengo, G. Dosi, P. Legrenzi, and C. Pasquali. The
structure of problem-solving knowledge and the structure of
organizations. Ind Corp Change, 9(4):757–788, December 2000.
[8] John H. Holland. Adaptation in Natural and Artificial Systems:
An Introductory Analysis with Applications to Biology, Control
and Artificial Intelligence. MIT Press, Cambridge, MA, USA,
1992.
[9] Friedrich Hayek. Economics and knowledge. Economica, 4:33–
54, 1937.
[10] Kirk A. Abbott, Benjamin A. Allan, and Arthur W. Wester-
berg. Global Preordering for Newton Equations Using Model
Hierarchy. AIChE Journal, 1997. In press.
[11] Cangelosi A., Nolfi S., and Parisi D. On Growth, Form, and
Computers, chapter Artificial life models of neural development,
pages 339–354. London UK, Academic Press, 2003.
[12] S.W. Mahfoud. Boltzmann selection. In T. Back, editor, Pro-
ceedings of the 7th International Conference on Genetic Al-
gorithms, pages C2.5:1–4. Morgan Kaufmann, San Francisco,
1997.
170

BIBLIOGRAFIA
[13] John H. Holland. Adaptation in natural and artificial systems:
An introductory analysis with applications to biology, control,
and artificial intelligence. University of Michigan Press.
[14] Daniel C. Dennett. Consciousness Explained. Gardners Books,
June 2004.
[15] Jeffrey Travers and Stanley Milgram. An experimental study of
the small world problem. Sociometry, 32(4):425–443, 1969.
[16] Fan R. K. Chung, Paul Erdos, and Ronald L. Graham. Erdos
on Graphs: His Legacy of Unsolved Problems. AK Peters, Ltd.,
1 edition, January 1998.
[17] Albert-Laszlo Barabasi. Linked: How Everything Is Connected
to Everything Else and What It Means for Business, Science,
and Everyday Life. Plume Books, April 2003.
[18] Gerald S. Wilkinson. Reciprocal food sharing in the vampire
bat. Nature, 308(5955):181–184, March 1984.
[19] Paul S. Adler. Market, hierarchy, and trust: The knowledge
economy and the future of capitalism. Organization Science,
12(2):215–234, March 2001.
[20] Paul Resnick and Richard Zeckhauser. Trust Among Stran-
gers in Internet Transactions: Empirical Analysis of eBay’s
Reputation System. Elsevier Science, November 2002.
[21] Brian S. Everitt and Torsten Hothorn. A Handbook of Statistical
Analyses Using R. Chapman & Hall/CRC, 1 edition, February
2006.
171

BIBLIOGRAFIA
[22] B. . G. Rosen, C. Anderberg, and R. Ohlsson. Parameter cor-
relation study of cylinder liner roughness for production and
quality control. Proceedings of the I MECH E Part B Journal
of Engineering Manufacture, 222(11):1475–1487.
[23] Boris Mirkin. Clustering for Data Mining: A Data Recovery
Approach (Computer Science and Data Analysis). Chapman &
Hall/CRC, April 2005.
[24] P. H. SNEATH and R. R. SOKAL. Numerical taxonomy.
Nature, 193:855–860, March 1962.
[25] James C. Bezdek. Cluster validity with fuzzy sets. Cybernetics
and Systems, 3(3):58–73, 1973.
[26] Walter Quattrociocchi, Daniela Latorre, Mirco Nanni, and Ele-
na Lodi. Dealing with interaction for complex systems mo-
delling and prediction. INTERNATIONAL JOURNAL OF
ARTIFICIAL LIFE RESEARCH (IJALR), 1:00, 08.
[27] Stuart Russell and Peter Norvig. Artificial Intelligence: A
Modern Approach. Prentice Hall, second edition, December
2002.
[28] Anand S. Rao and Michael P. Georgeff. Decision procedures for
bdi logics. J Logic Computation, 8(3):293–343, June 1998.
[29] John R. Searle. Expression and Meaning: Studies in the Theory
of Speech Acts. Cambridge University Press, October 1979.
172

BIBLIOGRAFIA
[30] M. Luck, M. D’inverno, M. Fisher, and Fomas’97 Contribu-
tors. Foundations of multi-agent systems: Techniques, tools and
theory. Knowledge Engineering Review, 13(3):297–302, 1998.
[31] R. A. Barman, S. J. Kingdon, A. K. Mackworth, D. K. Pai,
M. K. Sahota, H. Wilkinson, and Y. Zhang. Dynamite: A
testbed for multiple mobile robots. In in ‘Proceedings, IJCAI-
93 Workshop on Dynamically Interacting Robots, pages 38–44,
1993.
[32] A. Balluchi, A. Balestrino, and A. Bicchi. Efficient parallel al-
gorithm for optimal block decomposition of transfer function
matrices for decentralized control of large-scale systems. In
Decision and Control, 1993., Proceedings of the 32nd IEEE
Conference on, pages 3750–3755 vol.4, 1993.
[33] T. Balch and M. Hybinette. Social potentials for scalable multi-
robot formations. volume 1, pages 73–80 vol.1, 2000.
[34] Kiminori Matsuyama. Growing through cycles. Econometrica,
67(2):335–347, 1999.
[35] Masakazu Seno and George Karypis. Slpminer: An algorithm
for finding frequent sequential patterns using length-decreasing
support constraint. In In Proceedings of the 2nd IEEE Inter-
national Conference on Data Mining (ICDM, pages 418–425,
2002.
[36] Weka Machine Learning Project. Weka. URL
http://www.cs.waikato.ac.nz/˜ml/weka.
173

BIBLIOGRAFIA
[37] Rosaria Conte and Mario Paolucci. Reputation in Artificial
Societies: Social Beliefs for Social Order. Springer, October
2002.
[38] Jordi Sabater-Mir, Mario Paolucci, and Rosaria Conte. Repage:
REPutation and imAGE among limited autonomous partners.
JASSS - Journal of Artificial Societies and Social Simulation,
9(2), 2006.
[39] R. Dunbar. The social brain hypothesis. Evolutionary
Anthropology, 6:178–190, 1998.
[40] Isaac Pinyol, Mario Paolucci, Jordi Sabater-Mir, and Rosaria
Conte. Beyond accuracy. reputation for partner selection with
lies and retaliation. In Eighth International Workshop on Multi-
Agent-Based Simulation, pages 134–146, 2007.
[41] M. Sunnafrank. Predicted outcome value during initial in-
teractions: A reformation of uncertainty reduction theory.
volume 13, pages 191–210, 1986.
[42] CE Shannon and W Weaver. The Mathematical Theory of
Communication. University of Illinois Press, Urbana, Illinois,
1949.
174

BIBLIOGRAFIA
175