chapter 6 feasibility study on random number...
TRANSCRIPT

156
CHAPTER 6
FEASIBILITY STUDY ON RANDOM NUMBER
GENERATORS FOR SYMMETRIC KEY
CRYPTOGRAPHY
6.1 SYMMETRIC KEY CRYPTOGRAPHY
Cryptography is the art of ensuring the secrecy and authenticity of
information through encryption that transforms the plain text into an unreadable
format called cipher text. Decryption is the reverse process that converts the
unintelligible cipher text back to plain text. Cryptography systems can be broadly
classified into symmetric key systems and asymmetric key systems. Symmetric key
or secret key system uses a single key that is shared by both the sender and receiver.
Asymmetric key or public key system uses two keys: a public key known to
everyone, and a private key that only the receiver holds.
Modern cryptography is heavily based on mathematical theory and computer
science practices. It is the foundation for computer and communications security,
with end products that are imminently practical. It brings together fields like number
theory, computational-complexity theory, and probability theory. Modern
cryptographic algorithms are designed around computational hardness assumptions
that such algorithms are hard to break in practice by any adversary. It is theoretically
possible to break such a system, but it is infeasible to do so by any known practical
means. This forms the basic idea or assumption behind such algorithms. These
schemes are therefore termed computationally secure. But theoretical advances and
faster computing technology are required to be continually adapted to maintain the

157
status “computationally secure”. There exist information-theoretically secure
schemes that provably cannot be broken even with unlimited computing power.
A cryptosystem is “information-theoretically secure” if its security is derived
purely from information theory. That is, it is secure even when the adversary has
unlimited computing power. The adversary simply does not have enough
information to break the security. An algorithm or encryption protocol that has
information-theoretic security does not depend for its effectiveness on unproven
assumptions about computational hardness, and such an algorithm is not vulnerable
to future developments in quantum computing. An example of an information-
theoretically secure cryptosystem is the one-time pad. These schemes are more
difficult to implement than the best computationally secure mechanisms due to the
need for resources like powerful algorithms, computational power, and storage
capacities.
In cryptography, One-Time Pad (OTP) is a type of encryption which has
been proven to be impossible to crack if used correctly. Each bit or character from
plaintext is encrypted by a modular addition with a bit or character from a secret key
of the same length as the plaintext, resulting in a cipher-text. If the key is truly
random, as large as or greater than the plaintext, never reused in whole or part, and
kept secret, the cipher-text will be impossible to decrypt or break without knowing
the key [183]. It has also been proven that any cipher with perfect secrecy property
must use keys with effectively the same requirements as OTP keys. However,
practical problems like, requirement for a long non-repetitive key, computation
power, storage capacities have prevented one-time pads from being widely used.
Symmetric key algorithms [43] are a class of algorithms for cryptography
that use the same cryptographic keys for both encryption of plain text and decryption
of cipher text. The requirement that both parties have access to the secret key is one
of the main drawbacks of symmetric key encryption in comparison to public key
encryption [40]. Public key cryptography allows users to communicate securely

158
using a pair of keys; one is public and the other is private. These two keys are not
independent but are mathematically related. The working principle of symmetric key
cryptography is shown in Figure 6.1.
Figure 6.1 The working principle of a symmetric key system.
The main problem with symmetric key cryptography is key management. A
person with an unauthorized access to the symmetric key not only can decrypt
messages sent with that key, but can encrypt new messages and send them as if they
came from one of the two parties who were originally using the key. This type of
attack is called “masquerade” and is classified as an active attack. The other
classification of attack is the passive attack. Passive attacks are very difficult to
detect because they do not involve any alteration of data. When messages are
exchanged, neither the sender nor the receiver is aware that a third party has read the
messages. The major drawback to secret key ciphers is in exchanging the secret key
because any exchange must retain the privacy of the key, otherwise any type of
active or passive attacks will be launched with the acquired secret key. This usually
means that the secret key must be encrypted in a different key, and the recipient must
already have the key that will be needed to decrypt the encrypted secret-key. This
can lead to a never-ending dependency on another key.

159
Symmetric key ciphers are implemented as either block ciphers or stream
ciphers [37]. A block cipher allows input in blocks of plaintext as opposed to the
input form used by a stream cipher which allows individual characters. Stream
ciphers, in contrast to the block cipher, create an arbitrarily long stream of key
material, which is combined with plaintext bit-by-bit or character-by-character,
similar to one-time pad. Symmetric-key cryptography is sometimes called secret-key
cryptography. The Advanced Encryption Standard (AES) specifies a cryptographic
algorithm that can be used to protect electronic data [147]. The AES algorithm is a
symmetric block cipher that can encrypt and decrypt information. The AES
algorithm is capable of using cryptographic keys of 128, 192, and 256 bits to encrypt
and decrypt data in blocks of 128 bits. Symmetric key systems are simpler and
faster, but their main drawback is that two parties must somehow exchange the key
in a secure way. Public key encryption avoids this problem because the public key
can be distributed in a non-secure way, and the private key is never transmitted. But
the main drawback of these public key systems is that they cannot be used in most
secured one-time pad schemes.
Cryptanalysis is the art of defeating cryptographic security systems, and
gaining access to the contents of encrypted messages without being given the
cryptographic key. Cryptanalysis is the study of methods to obtain the meaning of
encrypted information without access to the key. It is also the study of how to crack
encryption algorithms or their implementations. Any cryptographic algorithm to be
considered as secure should have high complexity and tolerance against
cryptanalysis. In one-time pads, the cipher-text provides no information about the
original message to a cryptanalyst (except the maximum possible length of the
message). This is a very strong notion of security first developed by Claude Shannon
and proved mathematically to be true for the one-time pad [183]. He proved that
properly used one-time pads are secure in this sense even against adversaries with
infinite computational power. A feasibility study is performed for attack proof
random number generator and cryptographic mechanism in the following parts of the
chapter.

160
6.2 RANDOM NUMBER GENERATORS
The need for random and pseudorandom numbers arises in many computer
and communication applications. These applications involve simulations, efficient
algorithms, and cryptography. Many cryptographic protocols also require random or
pseudorandom inputs at various points. For example, auxiliary quantities used in
generating digital signatures or generating challenges in authentication protocols
need random numbers. A Random Number Generator (RNG) is a computational or
physical device designed to generate a sequence of numbers or symbols that lack any
pattern, i.e. appear random [151]. Random number generators suitable for use in
cryptographic applications may need to meet stronger requirements than for other
applications. In particular, their outputs must be unpredictable in the absence of
knowledge of the inputs. There are two basic types of generators used to produce
random sequences: random number generators and pseudorandom number
generators. For cryptographic applications, both these generator types produce a
stream of zeros and ones that may be divided into sub-streams or blocks of random
numbers.
The first type of sequence generator is a Random Number Generator (RNG).
A RNG uses a nondeterministic source (i.e., the entropy source), along with some
processing function (i.e., the entropy distillation process) to produce randomness.
The use of a distillation process is needed to overcome any weakness in the entropy
source that results in the production of non-random numbers (e.g., the occurrence of
long strings of zeros or ones). The entropy source typically consists of some physical
quantity, such as the noise in an electrical circuit, the timing of user processes (e.g.,
key strokes or mouse movements), or the quantum effects in a semiconductor.
Various combinations of these inputs may be used. The outputs of a RNG may be
used directly as a random number or may be fed into a PseudoRandom Number
Generator (PRNG). To be used directly (i.e., without further processing), the output
of any RNG needs to satisfy strict randomness criteria as measured by statistical
tests in order to determine that the physical sources of the RNG inputs appear

161
random. For example, a physical source such as electronic noise may contain a
superposition of regular structures, such as waves or other periodic phenomena,
which may appear to be random, yet are determined to be non-random using
statistical tests [151].
For cryptographic purposes, the output of RNGs needs to be unpredictable.
However, some physical sources (e.g., date/time vectors) are quite predictable. In
addition, the production of high-quality random numbers may be time consuming,
making such production undesirable when a large quantity of random numbers is
needed. To produce large quantities of random numbers, pseudorandom number
generators may be preferable.
The second type of generator is a PseudoRandom Number Generator
(PRNG). A PRNG is a deterministic algorithm that takes as input a short random
string called a seed and stretches it to output a longer sequence of bits that is
“pseudorandom”. The generation of pseudo-random numbers is an important and
common task in computer programming. While cryptography and certain numerical
algorithms require very high degree of apparent randomness, many other operations
only need a modest amount of unpredictability. Weaker forms of randomness are
used in hash algorithms and in creating amortized searching and sorting algorithms.
A PRNG uses one or more inputs and generates multiple “pseudorandom” numbers.
Inputs to PRNGs are called seeds. In contexts in which unpredictability is needed,
the seed itself must be random and unpredictable. Hence, by default, a PRNG should
obtain its seeds from the outputs of a RNG; i.e., a PRNG requires a RNG as a
companion. The outputs of a PRNG are typically deterministic functions of the seed;
i.e., all true randomness is confined to seed generation. The deterministic nature of
the process leads to the term “pseudorandom”. Since each element of a
pseudorandom sequence is reproducible from its seed, only the seed needs to be
saved if reproduction or validation of the pseudorandom sequence is required [151].

162
Ironically, pseudorandom numbers often appear to be more random than
random numbers obtained from physical sources. If a pseudorandom sequence is
properly constructed, each value in the sequence is produced from the previous value
via transformations that appear to introduce additional randomness. A series of such
transformations can eliminate statistical auto-correlations between the input and the
output. Thus, the outputs of a PRNG may have better statistical properties and be
produced faster than a RNG [151].
6.3 QUATERNION JULIA FRACTALS
Keys are generated by numerous ways in cryptography [149], [150]. Most of
the symmetric key generations are based on the pseudorandom number theory [151].
Fractals are also used in the key generation for cryptography [184]. In general,
symmetric key algorithms use a unique key to be shared between the communicating
hosts for data transfer. The methods used to share a unique key through a
communication channel by the hosts are always insecure even though they are
encrypted [185]. This makes the symmetric key algorithms more vulnerable during
attacks. A possible way to protect from such attacks is by avoiding the secret key
exchange through communication channels and negotiating the selection of common
key by the communicating hosts through a secure and suitable technique. This
research proposes a model to generate a real-time based key by using quaternion
Julia fractal images.
Quaternion Julia fractal image is considered for its complex image structure
and chaotic behaviour. Small variations in the Julia parameters will result in a drastic
change of image structure due to the chaotic nature of the mathematical function.
The number of iterations, complex number and control value are the determining
parameters of dynamically varying quaternion Julia image structure. The considered
parameters are initialised in the proposed model of symmetric key generation during
the establishment of communication between hosts. The model generates variable

163
length, dynamic, one time usable key from quaternion Julia image to encrypt or
decrypt data without involving exchange of key. The time stamp used during the
initialization process makes the quaternion Julia image different in real-time. The
instantaneous symmetric key is generated by the hosts simultaneously without third
party intervention, and the exchange of key between hosts is barred to protect from
attacks against the key during key exchange. In the multi-party data transfer
scenario, the communicating hosts should exchange individual time stamps for each
other party and can work simultaneously in data transfer through different ports.
6.3.1 Fractals
Almost all studies of fractals, coming out from iterations of rational functions
in the complex domain, are based upon the fundamental description by Gaston
Maurice Julia [186] and upon some very important articles by Pierre Fatou [187].
Both authors opened the door to a path leading to a deeper knowledge of the
behaviour of iterated rational functions in the complex domain. A fractal is a
mathematical set that has a fractal dimension that usually exceeds its topological
dimension and may fall between the integers [188]. Fractals are typically self-similar
patterns, where self-similar means they are “the same from near as from far”. The
definition of fractal goes beyond self-similarity in itself to exclude trivial self-
similarity and includes the idea of a detailed pattern repeating itself. As
mathematical equations, fractals are usually nowhere differentiable, which means
that they cannot be measured in traditional ways [186]-[188].
The term “fractal” was first used by the mathematician Benoît Mandelbrot in
1975. Mandelbrot based it on the Latin frāctus meaning “broken” or “fractured”, and
used it to extend the concept of theoretical fractional dimensions to geometric
patterns in nature. Mandelbrot solidified hundreds of years of thought and
mathematical development in coining the word “fractal” and illustrated his
mathematical definition with striking computer-constructed visualizations. One often

164
cited description that Mandelbrot published to describe geometric fractals is “a rough
or fragmented geometric shape that can be split into parts, each of which is (at least
approximately) a reduced-size copy of the whole” [188]. The general consensus is
that theoretical fractals are infinitely self-similar, iterated, and detailed mathematical
constructs having fractal dimensions. Fractal patterns with various degrees of self-
similarity have been rendered or studied in images, structures and sounds and found
in nature, technology, and art [189]. Some common techniques [186]-[190] for
generating fractals are listed as follows:
(i) Iterated function systems: These systems use fixed geometric
replacement rules which may be stochastic or deterministic. Some
examples are Koch snowflake, Cantor set, Sierpinski carpet, Sierpinski
gasket, Peano curve, Harter-Heighway dragon curve, T-Square, Menger
sponge [190].
(ii) Strange attractors: These methods use iterations of a map or solutions of
a system of initial-value differential equations that exhibit chaos.
(iii) L-systems: These systems use string rewriting which may resemble
branching patterns, such as in plants, biological cells (e.g., neurons and
immune system cells).
(iv) Escape-time fractals: These fractal generation methods use a formula or
recurrence relation at each point in a space (such as the complex plane);
usually quasi-self-similar; also known as “orbit” fractals; e.g., the
Mandelbrot set, Julia set, Burning Ship fractal, Nova fractal and Lyapunov
fractal. The 2D vector fields that are generated by one or two iterations of
escape-time formulae also give rise to a fractal form when points (or pixel
data) are passed through this field repeatedly.
(v) Random fractals: These fractal generation methods use stochastic rules.
Some examples are Lévy flight, percolation clusters, self-avoiding walks,
fractal landscapes, trajectories of Brownian motion, and the Brownian tree
(dendritic fractals generated by modeling diffusion-limited aggregation or
reaction-limited aggregation clusters).

165
6.3.2 Hamiltonian Quaternion
In mathematics, a Hamiltonian system is a system of differential equations
which can be written in the form of Hamilton's equations. Hamiltonian systems are
usually formulated in terms of Hamiltonian vector fields on a symplectic manifold or
Poisson manifold. Hamiltonian systems are a special case of dynamical systems. The
quaternions are a number system that extends the complex numbers. They were first
described by Irish mathematician Sir William Rowan Hamilton in 1843 and applied
to mechanics in three-dimensional space [191]. A feature of quaternions is that the
product of two quaternions is non-commutative. Hamilton defined a quaternion as
the quotient of two directed lines in a three-dimensional space or equivalently as the
quotient of two vectors. Quaternions can also be represented as the sum of a scalar
and a vector. Quaternions find use in both theoretical and applied mathematics, in
particular for calculations involving three-dimensional rotations such as in three-
dimensional computer graphics and computer vision. They can be used alongside
other methods, such as Euler angles and rotation matrices, or as an alternative to
them depending on the application [192].
In modern mathematical language, quaternions form four-dimensional
associative normed division algebra over the real numbers, and thus also form a
domain. In fact, quaternions were the first non-commutative division algebra to be
discovered. The algebra of quaternions is often denoted by H (for Hamilton), or by
. As a set, the quaternions H are equal to R4, a four-dimensional vector space over
the real numbers. H has three operations: addition, scalar multiplication, and
quaternion multiplication. The sum of two elements of H is defined to be their sum
as elements of R4. Similarly, the product of an element of H by a real number is
defined to be the same as the product in R4. In order to define the product of two
elements in H requires a choice of basis for R4 [191].
The elements of this basis are customarily denoted as 1, i, j, and k. Every
element of H can be uniquely written as a linear combination of these basis

166
elements, that is, as a1 + bi + cj + dk, where a, b, c, and d are real numbers. The
basis element ‘1’ will be the identity element of H, meaning that multiplication by 1
does nothing, and for this reason, elements of H are usually written as a + bi + cj +
dk, suppressing the basis element ‘1’. Given this basis, associative quaternion
multiplication is defined by first defining the products of basis elements and then
defining all other products using the distributive law. Using the basis 1, i, j, k of H
makes it possible to write H as a set of quadruples:
, , , , , , .a b c d a b c d Η R (6.1)
Then the basis elements are:
1 1,0,0,0 ,0,1,0,0 ,0,0,1,0 ,0,0,0,1 .
ijk
(6.2)
A number of the form a + 0i + 0j + 0k, where ‘a’ is a real number, is
called real, and a number of the form 0 + bi + cj + dk, where b, c, and d are real
numbers, and at least one of b, c, or d is nonzero, is called pure imaginary. If
a + bi + cj + dk is any quaternion, then ‘a’ is called its scalar part and bi + cj + dk is
called its vector part. The scalar part of a quaternion is always real, and the vector
part is always pure imaginary. Even though every quaternion is a vector in a four-
dimensional vector space, it is common to define a vector to mean a pure imaginary
quaternion. With this convention, a vector is the same as an element of vector
space R3. Hamilton called pure imaginary quaternions as right quaternions and real
numbers (considered as quaternions with zero vector part) as scalar quaternions. If a
quaternion is divided up into a scalar part and a vector part as
3, , , , .q r v q r v
(6.3)

167
Then, the formulas for addition and multiplication are:
1 1 2 2 1 2 1 2, , , ,r v r v r r v v
(6.4)
and 1 1 2 2 1 2 1 2 1 2 2 1 1 2, , . , .r v r v r r v v r v r v v v
(6.5)
where “·” is the dot product and “×” is the cross product.
Quaternions can be represented as pairs of complex numbers. From this
perspective, quaternions are the result of applying the Cayley–Dickson
construction to complex numbers. This is a generalization of the construction of the
complex numbers as pairs of real numbers. Let C2 be a two-dimensional vector space
over complex numbers. Choose a basis consisting of two elements 1 and j. A vector
in C2 can be written in terms of the basis elements 1 and j as
1 .a bi c di j (6.6)
If we define j2 = −1 and ij = −ji, then we can multiply two vectors using the
distributive law. When ‘k’ is used in place of the product ‘ij’, it leads to the same
rules for multiplication as the usual quaternions. Therefore the above vector of
complex numbers corresponds to the quaternion a + bi + cj + dk. If we write the
elements of C2 as ordered pairs and quaternions as quadruples, then the
correspondence is
, , , , .a bi c di a b c d (6.7)
Julia sets are produced by a procedure of repeated iterations [186], [192]. The
polynomial used in the process of iteration is quadratic, cubic, quartic or any higher

168
order degree [191]. The parameters required to produce Julia set are Z, C, n and m.
The Julia function is given as
( ) .nf Z Z C (6.8)
Here, Z is a complex number consisting of two components, which are independent
of each other called real and imaginary parts as in Equation (6.9), C is a constant, ‘n’
is the degree of polynomial and ‘m’ denotes the number of iterations, and is given as
.Z a ib (6.9)
When the value for C is a hyper complex number, there exist four
components called Hamiltonian Quaternion [191]. Quaternion Julia set also known
as 4D Julia set as they allow four dimensional image structures. Quaternion consists
of a real part and three imaginary parts which are denoted as 1, i, j, k, respectively,
as
.C jc kd (6.10)
A quaternion q∈ H is a wider numerical extension of a complex value and
consists of four components, a, b, c, d ∈ R. The quaternion ‘q’ is given as
,q a ib jc kd (6.11)
where 2 2 2 1.i = j = k = (6.12)
Quaternion multiplication is non-commutative, and hence quaternion is not
an abelian group. Quaternion Julia set of the quadratic iteration for fixed hyper
complex C value is given as
21 .n nZ Z C (6.13)

169
6.3.3 Visual Cryptography
Visual cryptography is a cryptographic technique which allows visual
information (pictures, text, etc.) to be encrypted in such a way that decryption
becomes a mechanical operation that does not require a computer. In 1994, Moni
Naor and Adi Shamir developed a best-known technique for visual cryptography
[193]. They demonstrated a visual secret sharing scheme, where an image was
broken up into (n) shares so that only someone with all ‘n’ shares could decrypt the
image, while any (n-1) shares revealed no information about the original image.
Each share was printed on a separate transparency, and decryption was performed by
overlaying the shares. When all ‘n’ shares were overlaid, the original image would
appear. Using a similar idea, transparencies can be used to implement a one-time pad
encryption, where a transparency is a shared random pad, and another transparency
acts as the cipher-text. When each pixel in the original image is split randomly into
two shares, the shares are correlated together and reveal the original image. While
each individual share is considered alone (i.e., when the other share is unknown), it
is indistinguishable from a random pattern. Given only a share, a second share can
be crafted to reveal any possible image; therefore, individual shares reveal no
information about the original image.
6.3.3.1 (2, N) Visual Cryptography Scheme
Sharing a secret with an arbitrary ‘N’ number of people such that at least two
of them are required to decode the secret is one form of visual secret sharing scheme
presented by Moni Naor and Adi Shamir [193]. In this scheme, a secret image which
is encoded into N shares is printed on transparencies. The shares appear random and
contain no decipherable information about the underlying secret image; however, if
any two of the shares are stacked on top of each other, the secret image becomes
decipherable by human eye. Every pixel from the secret image is encoded into
multiple subpixels in each share image using a matrix to determine the color of the

170
pixels. In the (2, N) case, a white pixel in the secret image is encoded using a matrix
from the following set:
{all permutations of the columns of}:
1 0 01 0 0
.
1 0 0
0C
(6.14)
While a black pixel in the secret image is encoded using a matrix from the following
set
{all permutations of the columns of} :
1 0 00 1 0
.
0 0 1
1C
(6.15)
For instance in the (2, 2) sharing case (the secret is split into 2 shares and
both shares are required to decode the secret), complimentary matrices is used to
share a black pixel and identical matrices to share a white pixel. Stacking the shares,
all subpixels associated with the black pixel remain black, while 50% of the
subpixels associated with the white pixel remain white.
In the Visual Cryptography Scheme (VCS) developed by Naor and Shamir, k
out of n VCS (which is also called (k, n) scheme), a binary image (picture or text) is
transformed into n sheets of transparencies of random images. The original image
becomes visible when any k sheets of the n transparencies are put together, but any
combination of less than k sheets cannot reveal the original binary image. In this
scheme, a pixel of the original image is reproduced by m subpixels on the sheets.
The pixel is considered “ON” (transparent) if the number of transparent subpixels is
more than a constant threshold, and “OFF”, if the transparent subpixels is less than a
constant lower threshold, when the sheets are stacked together. The contrast α is the

171
difference between the ON and OFF threshold number of transparent pixels. The
basic scheme is referred to as the k-out-of-n VCS, which is denoted as (k, n) VCS.
Given an original binary image, T, it is encrypted in n images such that
1 2 3
,kh h h hT S S S S (6.16)
where is a Boolean operation, , hi ∈ 1, 2,…, k is an image which appears as
white noise, k ≤ n, and n is the number of noisy images. It is difficult to decipher the
secret image using individual . Encryption is undertaken in such a way that ‘k’ or
more out of the ‘n’ generated images are necessary to reconstruct the original image
(T).
Figure 6.2 Illustration of a (2, 2) scheme with 4 sub-pixel construction [194].
In the case of (2, 2) VCS, each pixel, P, in the original image is encrypted
into two subpixels called shares. Figure 6.2 denotes the shares of a white pixel and a

172
black pixel. Note that the choice of shares for a white and black pixel is randomly
determined (there are two choices available for each pixel). Neither share provides
any clue about the original pixel since different pixels in the secret image will be
encrypted using independent random choices. When two shares are superimposed,
the value of the original pixel, P, can be determined. If P is a black pixel, we get two
black subpixels; if it is a white pixel, we get a black sub-pixel and a white sub-pixel.
Therefore, the reconstructed image will be twice the width of the original secret
image and there will be a 50% loss in contrast. However, the original image will
become visible [194].
6.3.3.2 Cryptanalysis on (2, N) Visual Cryptography Scheme
A method that allows colluding parties to cheat an honest party in visual
cryptography is proposed for cryptanalysis on (2, N) visual cryptography scheme
[195]. For instance, colluding participants may examine their shares to determine
when they both have black pixels and use that information to determine that another
participant will also have a black pixel in that location. Knowing where black pixels
exist in another party's share allows them to create a new share that will combine
with the predicted share to form a new secret message. In this way, a set of colluding
parties have enough shares to access the secret code that can cheat other honest
parties. In order to avoid such attacks, multiple encryption may be used in visual
cryptography with strong cryptographic mechanism.
6.3.4 Multiple Encryption
Multiple encryption is the process of encrypting an already encrypted
message one or more times, either using the same or a different algorithm. The terms
cascade encryption, cascade ciphering, multiple encryption, multiple ciphering, and
superencipherment, are used with the same meaning. Superencryption refers to

173
outer-level encryption of a multiple encryption. In the multiple encryption schemes,
the keys used should not be identical [149]. In the case of picking any two ciphers, if
the key used is the same for both, the second cipher could possibly undo the first
cipher, partly or entirely. This is true of ciphers where the decryption process is
exactly the same as the encryption process (symmetric cryptography); the second
cipher would completely undo the first. If an attacker attempts to recover the key
through cryptanalysis of the first encryption layer, the attacker could possibly
decrypt all the remaining layers, assuming the same key is used for all layers. In
order to prevent that risk, one can use keys that are statistically independent for each
layer (e.g. independent RNGs).
The first layer of encryption is important in multiple encryption schemes.
With the exception of one-time pad, no cipher has been theoretically proven to be
unbreakable. Furthermore, some recurring properties may be found in cipher-texts
generated by the first cipher. Since those cipher-texts are plaintexts used by the
second cipher, the second cipher may be rendered vulnerable to attacks based on
known plaintext properties [150]. This is the case when the first layer always adds
the same string, S, of characters at the beginning (or end) of all cipher-texts
(commonly known as a magic number). When found in a file, the string S allows an
operating system to know that a specific program has to be launched in order to
decrypt the file. This string should be removed before adding a second layer.
In order to prevent this kind of attack, the method provided by Bruce
Schneier is suggested [149]. First, generate a random pad of the same size of
plaintext, then XOR the plaintext with the pad, resulting in a first cipher-text.
Encrypt the pad and the first cipher-text with a different cipher and a different key,
resulting in two more cipher-texts. Concatenate the last two cipher-texts in order to
build the final cipher-text. A cryptanalyst must break both ciphers to get any
information. This will however, have the drawback of making the cipher-text twice
as long as the original plaintext.

174
6.3.5 Proposed Cryptographic Model
A new way of generating real-time symmetric key used for cryptography is
shown in the proposed model. Instead of a key used in symmetric key cryptography,
the proposed model uses multiple symmetric keys during the complete session of
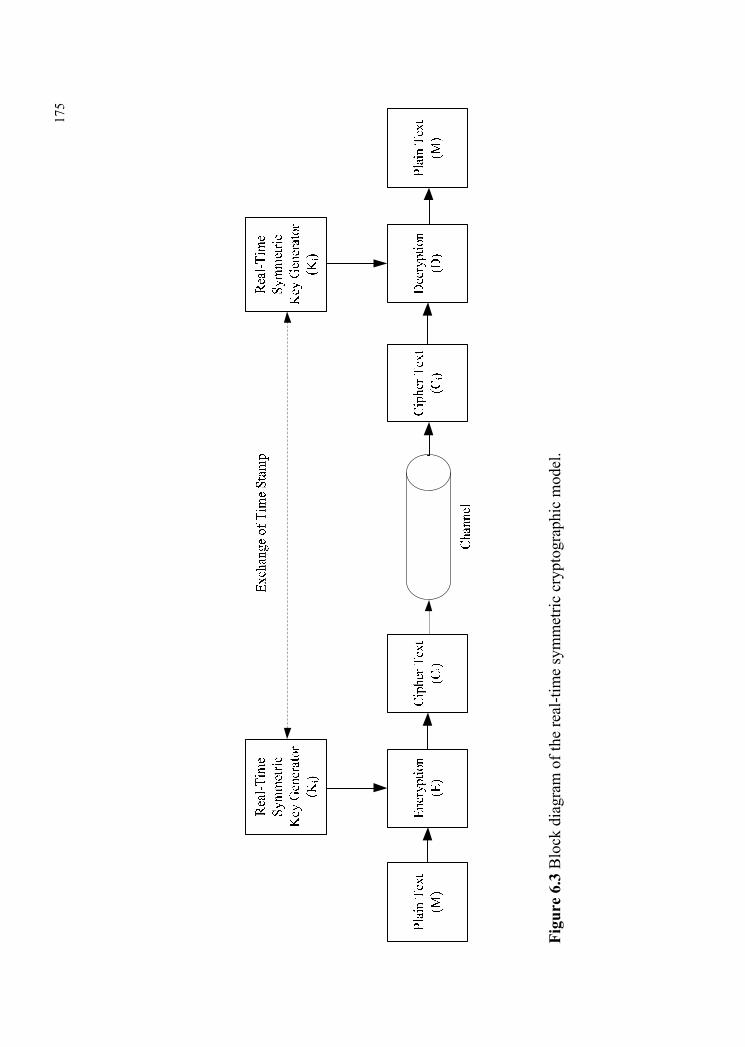
data transfer. Figure 6.3 shows the detailed structure of the model. Plain text (M) is
encrypted by the instantaneously generated real-time symmetric key (Ki) to produce
the cipher text (Ci). The cipher text is then transmitted from the transmitting host
through a communication channel. The encryption process is shown as
,iK iE (M ) = C (6.17)
where i 1, 2,⋯∞.
The received cipher text (Ci) is then decrypted with the real time symmetric
key (Ki) generated at the receiving host independently, to get back the plain text (M).
The operation of the model is divided into four phases as connection establishment
phase, key generation phase, cryptography phase, and acknowledgment phase. The
decryption process is shown as
.iK iD (C ) = M (6.18)
6.3.5.1 Connection Establishment Phase
The transmitting host should establish the connection with the receiving host
through Secure Sockets Layer (SSL) handshake. During connection establishment,
the transmitting host should send the date and time stamp which is calculated from
its database such that the new time stamp can be calculated by the receiving host to
verify authentication.
175
Fig
ure
6.3
Blo
ck d
iagr
am o
f th
e re
al-t
ime
sym
met
ric
cryp
togr
aphi
c m
odel
.

176
The sending time stamp calculated at the transmitter side through host
machine current time stamp is given as
– .
Sending time stamp New time stampHost machine current time stamp
(6.19)
The transmitting host should calculate from the new time stamp for the value
of sending time stamp. The proposed model assumes that the connection
establishment is made in real-time to avoid time differences in calculation. Once
time stamp is shared, both hosts will perform the next phase simultaneously as
shown in Figure 6.4.
6.3.5.2 Key Generation Phase
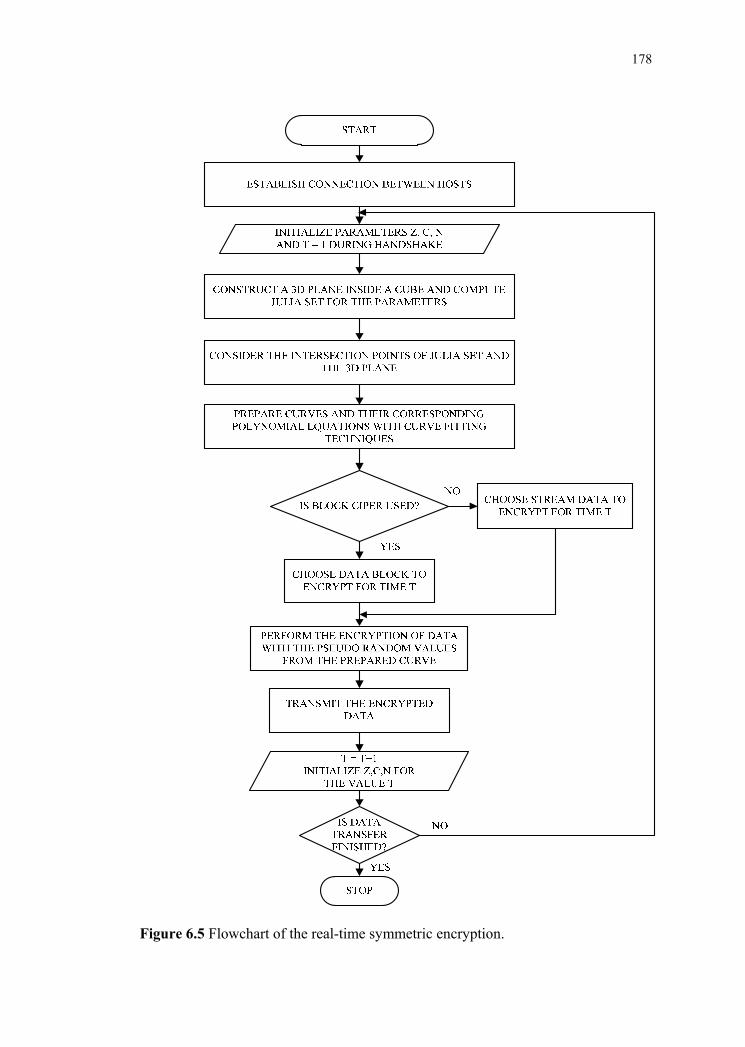
Real-time Symmetric key generator uses Quaternion Julia set to generate
different symmetric keys of variable lengths. The key generator is initialized by time
stamp as shown in the flowchart given in Figure 6.5.
When the connection establishment phase is over, the received date and time
stamp is given to the key generator where a new time stamp is produced by adding
the received time stamp and the current time stamp from the host machine for the
purpose of authentication is given by
.
New time stamp Received time stampHost machine current time stamp
(6.20)

177
Fig
ure
6.4
Seq
uenc
e di
agra
m o
f th
e pr
opos
ed s
ymm
etri
c cr
ypto
grap
hic
mod
el.
178
Figure 6.5 Flowchart of the real-time symmetric encryption.

179
The new time stamp is available in the database as an authentication of the
transmitting host. This is to avoid random time stamp attack to study the key
generation algorithm. Once a new time stamp is calculated, it is checked from the
database to initialize the Julia parameters. Attackers cannot repeat the same date and
time stamp for hosting attack at a later time as the new time stamp uses the current
time of the host machine. The initialized Julia parameters generate quaternion Julia
image. A 3D plane is considered with angle initialized during the initialization of the
Julia parameters. The intersection points of the 3D plane and the Julia image are
plotted. Real-time symmetric key of required size is obtained from the plotted image
as shown in Figure 6.6.
6.3.5.3 Encryption and Decryption of Data
The symmetric key obtained from the key generator is used for encryption
and decryption of data by the hosts, respectively. The proposed model uses two types
of encryption techniques. Firstly, encryption technique uses the XOR operation. This
is for low confidential and high speed data transfer. The encryption and decryption
schemes are given in Equations (6.21) and (6.22) respectively, as
,i iM K = C (6.21)
and .i iC K = M (6.22)
The second encryption technique is for high confidential data, where AES
symmetric encryption algorithm is used but with different keys from the real-time
symmetric key generator for each block of data to be transferred. The wide range of
keys generated from the model is used for one-time pad.
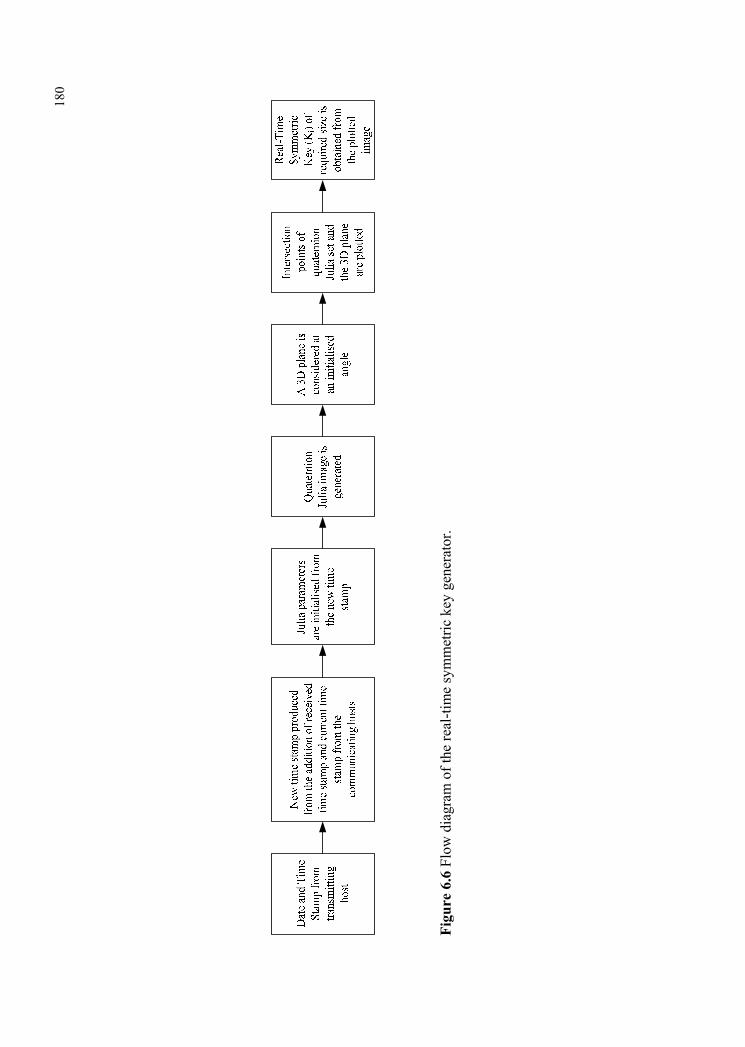
180
Fig
ure
6.6
Flo
w d
iagr
am o
f th
e re
al-t
ime
sym
met
ric
key
gene
rato
r.

181
6.3.5.4 Acknowledgement Phase
In order to change the key, the model avoids sending time stamps every time.
Instead, the receiving host will send a positive or negative acknowledgement for
each block in the case of block cipher and per session for stream cipher. At the initial
stage, the new time stamp generated is tested with a dummy data block and once the
attempt is successful, the receiving host will send a positive acknowledgement.
When a positive acknowledgement is received, both hosts simultaneously update the
new time stamp by adding the number of iterations used in the last Julia set with the
previous new time stamp.
. New time stamp Previous new time stampNumber of iterations in the last Julia set
(6.23)
If a receiving host is unable to decrypt the dummy data block, it will send
negative acknowledgement. Once negative acknowledgement is received by the
transmitting host, it calculates a fresh time stamp to start a new session.
6.3.5.5 Numerical Results and Discussions
Quad 1.20 is a 3D fractal generator [196]. This software is used to render the
3D image structure of 4D Quaternion Julia set by making one of the dimensions a
constant [197]. Additionally 3D intersection plane is defined to slice the image. A
part of the proposed model is tested by generating various quaternion Julia images
and slicing them through 3D planes. Some of the results obtained from Quad fractal
generator are shown in Figures 6.7, 6.8, 6.9, and 6.10. A small variation in the Julia
parameter shows an entirely different Julia fractal image. These dynamically varying
images after slicing represent the instantaneous symmetric keys.

182
Figure 6.7 Quaternion Julia set associated with C = 0.727 – 0.256i + 0.4j + 0.02k
without intersection plane and number of iterations = 14.
Figure 6.8 Intersection of Quaternion Julia set associated with
C = 0.727 – 0.256i + 0.4j + 0.02k, intersection plane w = 0.542, Q-space normal
vector=0.2+0.025i+0.1j, number of iterations = 14.

183
Figure 6.9 Intersection of Quaternion Julia set associated with
C = - 0.5 + 0.6i + 0.4j + 0.5k, intersection plane w = 0.09457, Q-space normal
vector=i+j, number of iterations = 10.
Figure 6.10 Intersection of Quaternion Julia set associated with C = 0.7 + 0.5i + 0.2j
+ 0k, intersection plane w = 0.00012, Q-space normal vector=0.2+0.025i+0.1j,
number of iterations = 50.

184
The main highlight of the proposed model is that the keys are not exchanged
through the communication channel. This gives very little information for security to
be breached. The only way to get the plain text from the cipher text is by brute-force
attack [198]. As the keys change in real-time for each block of data, the process of
cryptanalysis will be time and energy consuming. The real-time symmetric key in
the proposed model undergoes three degrees of randomness along with the property
of one-time pad. This makes cryptanalysis a difficult process compared to the life
time of the message used. Due to three degrees of randomness, key prediction and
cryptanalysis is a complex task. The three degrees of randomness that exist in the
generated key are as follows:
(1) Quaternion Julia Set: Due to chaotic behavior, a minor variation in the
quaternion Julia parameters produces an entirely different image fractal. As
there are infinite combinations of these parameters, the proposed model
results with a nearly infinite number of new quaternion Julia images between
intervals of time. The generation of quaternion Julia set is an irreversible
process making it impossible to predict the parameters from the image
structure and vice versa.
(2) Slicing by 3D plane: The second degree of randomness is made by slicing
the generated quaternion Julia image structure. The proposed model
considers only the intersection points of quaternion Julia image with the 3D
plane at a random angle to overcome the problem of self-similarity in the
structure of Julia fractal images. This makes the same quaternion Julia image
with the 3D plane of different slicing angle, resulting in entirely different
points of intersection.
(3) Variable key size: The third degree of randomness is obtained by selecting
some random points from the full set of intersection points depending upon
the size of key needed. A similar way in the selection of points is employed
at encryption and decryption ends. The generated variable length keys have
high degree of anonymity for the process of encryption/decryption by stream
ciphering and block ciphering of variable block size.

185
6.3.5.6 Simulation Results and Discussions
The generated quaternion Julia images are directly used for symmetric
encryption and decryption in visual cryptography. An algorithm is proposed for
visual cryptography and following are the steps used:
(i) A Julia image is generated with the considered parameters. The parameter
considerations are negotiated between the sender and the receiver in advance
through the proposed model. A random key (Key_1) is generated in the same
size of the generated Julia image for encryption as
_ _1 _1.Julia image Key Crypt (6.24)
(ii) The data (text or image) to be transmitted securely is encrypted with a newly
generated random key (Key_2) as
_ 2 _ 2.D ata K ey C rypt (6.25)
(iii) The encrypted data files from step (i) and (ii) are further encrypted as in
(6.26).
_1 _ 2 _ 3.Crypt Crypt Crypt (6.26)
(iv) During key transfer, only Key_1, Key_2 and the final encrypted data file
(Crypt_3) are sent through the channel.
(v) In the decryption process, quaternion Julia image is generated at the receiver
end through previously negotiated parameters as in (6.24) to get Crypt_1.
(vi) The obtained encrypted data file from step (iv) is used to decrypt the finally
sent encrypted data file (Crypt_3) as
_1 _ 3 _ 2.Crypt Crypt Crypt (6.27)

186
(vii) The obtained data file from step (v) is used with key file (Key_2) to decrypt
the required data file as
_ 2 _ 2 .Key Crypt Data (6.28)
(a) (b)
Figure 6.11 (a) The text file to be transferred securely (b) Generated quaternion Julia image.
(a) (b)
Figure 6.12 A random key file (a) Key_1 (b) Key_2.

187
(a) (b)
(c)
Figure 6.13 Samples of encrypted data files (a) Crypt_1, (b) Crypt_2, and (c) Crypt_3.
(a) (b)
Figure 6.14 Samples of the decrypted files from the transmitted (a) Key_1 and (b) Key_2.
188
Figure 6.15 The text file exactly decrypted through the correct procedure.
(a) (b)
Figure 6.16 The image file through the visual cryptography (a) transmitted and (b) received by decryption.
Any efficient cryptography should satisfy the following properties and the
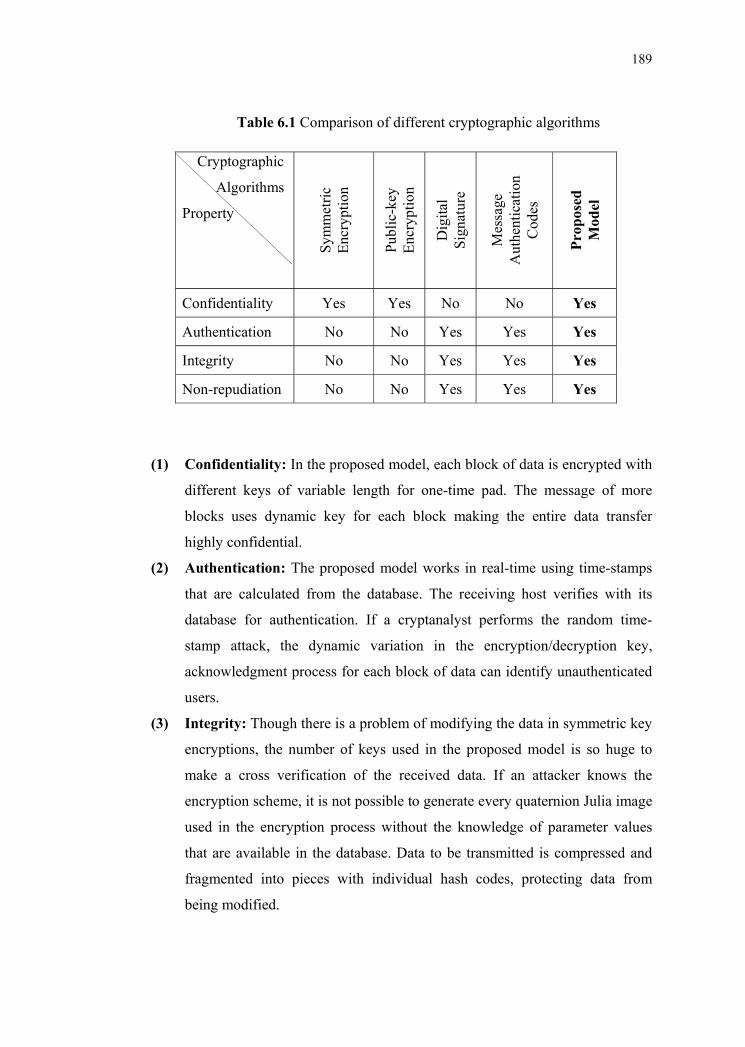
proposed model addresses them with positive remarks. Table 6.1 shows a
comparison between general cryptographic algorithms and the proposed model
[199]. The proposed model supports four main properties of efficient cryptography.
189
Table 6.1 Comparison of different cryptographic algorithms
Cryptographic
Algorithms
Property
Sym
met
ric
E
ncry
ptio
n
Pub
lic-
key
E
ncry
ptio
n
Dig
ital
Sig
natu
re
Mes
sage
A
uthe
ntic
atio
n C
odes
Pro
pos
ed
Mod
el
Confidentiality Yes Yes No No Yes
Authentication No No Yes Yes Yes
Integrity No No Yes Yes Yes
Non-repudiation No No Yes Yes Yes
(1) Confidentiality: In the proposed model, each block of data is encrypted with
different keys of variable length for one-time pad. The message of more
blocks uses dynamic key for each block making the entire data transfer
highly confidential.
(2) Authentication: The proposed model works in real-time using time-stamps
that are calculated from the database. The receiving host verifies with its
database for authentication. If a cryptanalyst performs the random time-
stamp attack, the dynamic variation in the encryption/decryption key,
acknowledgment process for each block of data can identify unauthenticated
users.
(3) Integrity: Though there is a problem of modifying the data in symmetric key
encryptions, the number of keys used in the proposed model is so huge to
make a cross verification of the received data. If an attacker knows the
encryption scheme, it is not possible to generate every quaternion Julia image
used in the encryption process without the knowledge of parameter values
that are available in the database. Data to be transmitted is compressed and
fragmented into pieces with individual hash codes, protecting data from
being modified.

190
(4) Non-repudiation: The sender cannot deny the sending of messages as the
model uses real-time cryptography along with the time stamp from the
sender. The handshake process during connection establishment verifies the
sender’s authentication through the time-stamp. As the time stamp is not
selected randomly at the transmitting host, the problem of repudiation is
solved. The initialization processes are hidden from the users and a log is
stored at a secure place for every attempt in establishing connection, serving
a powerful non-repudiation of the transmitting host.
The proposed model can be used for low confidential - high speed data
transfer and high confidential - low speed data transfer by selecting the appropriate
encryption key size and algorithm. This model supports data transfer between two
party and multi-party, starting from secret numbers like credit card numbers, to very
large data files like video on demand, can be secretly transferred. In the multi-party
data transfer scenario, communicating hosts should exchange individual time stamps
for each other party and can work simultaneously in transferring data through
different ports. The proposed model can be securely implemented as software or
dedicated customized hardware in communicating hosts without giving way for
compromising with the attackers.
6.4 ASTRONOMICAL DATA AS RANDOM NUMBERS
Astronomical objects are those objects that evolve in space with certain mass
and velocity, which are specifically comets, asteroids, planets, moons, and stars.
Data collected from the scientific study of the universe, especially the relative
motions, relative positions, and sizes of astronomical objects are astronomical data.
As the universe is ever expanding, the relative positions and other parameters of
astronomical objects continuously varies with respect to time. This variation derives
different data comparing any two astronomical objects at different times. The
random number generation method uses two different algorithms in random number

191
generation. The first algorithm has a fixed location as its reference and while the
other has varying locations as its reference. However, random numbers to be suitable
for use in cryptographic applications may need to meet stronger requirements than
other applications. In particular, their outputs must be unpredictable in the absence
of knowledge of the inputs. In order to test the randomness of the generated
sequence, common methods use statistical tests. This feasibility study uses a
standard statistical test suite, including frequency test, run test, random binary matrix
rank test, complexity test, universal test, and entropy test for testing the randomness
of numbers generated by the two algorithms employed in this study.
6.4.1 Julian Day
The standard date and time considered for astronomical calculations in
research is the Julian Day, which has both time and standard date embedded in its
system for recording days. Julian day is used in the Julian Date (JD) system of time
measurement for scientific use by the astronomical community, presenting the
interval of time in days and fractions of a day since January 1, 4713 BC Greenwich
noon. Julian date is recommended for astronomical use by the International
Astronomical Union. The Julian Day Number (JDN) is the Julian day with the
fractional part ignored. It is sometimes used in calendric calculation, in which case,
JDN 0 is used for the date equivalent to Monday January 1, 4713 BC in the Julian
calendar. The term Julian date is widely used to refer to the day-of-year (ordinal
date) although this usage is not strictly in accordance to standards set by some
international organizations.
Historical Julian dates were recorded relative to GMT or Ephemeris Time,
but the International Astronomical Union now recommends that Julian Dates be
specified in Terrestrial Time. The Julian Day Number (JDN) is the integer part of the
Julian Date (JD). The day commencing at the above-mentioned epoch is JDN 0.
Negative values can be used for dates preceding JD 0, though they predate all

192
recorded history. However, in this case, the JDN is the greatest integer not greater
than the Julian date rather than simply the integer part of the JD. A Julian date of
2456073.05486 indicates the date and Universal Time as Saturday May 26, 2012 at
13:18:59.9. The decimal parts of a Julian date:
0.1 = 2.4 hours or 144 minutes or 8640 seconds
0.01 = 0.24 hours or 14.4 minutes or 864 seconds
0.001 = 0.024 hours or 1.44 minutes or 86.4 seconds
0.0001 = 0.0024 hours or 0.144 minutes or 8.64 seconds
0.00001 = 0.00024 hours or 0.0144 minutes or 0.864 seconds.
The Julian day system was introduced by astronomers to provide a single
system of dates that could be used when working with different calendars and to
unify different historical chronologies. Julian day and Julian date are not directly
related to the Julian calendar, although it is possible to convert any date from one
calendar to the other.
6.4.2 Fixed Location
The fixed location algorithm considers any one of the astronomical objects,
especially, planet, moon or sun as a reference for its calculations. The Julian date and
time are used to locate the position of the reference object in space and any time in
the past or future. The distance calculation is the major parameter in the random
number generation algorithm. The units of distance between the reference object and
the other astronomical objects are in kilometres (km), Astronomical Unit (AU), and
light year (ly). As the units are of different scales, the common unit used is
kilometres. The Astronomical Unit and light year are converted to kilometres as
well. The distance values obtained in kilometres serve as the generated random
numbers. The values of Julian date keep changing every span of time. Along with
the Julian date, specific locations (latitude and longitude) and angles from the
horizon also provide with different objects in space for consideration.

193
6.4.3 Variable Location
In order to obtain much variation in the distance data, variable locations are
considered. In this variable location algorithm, the reference astronomical object
changes every span of time. Mathematical equations like, iteration methods are used
to compute the next jump or hop to other astronomical objects. As the reference
varies along with the Julian date, location, angle from horizon, and the visible
astronomical objects also vary. This variation derives an entirely different set of
distance values to be considered as random numbers. In the duration of a particular
data transfer process, many hops occur depending on the need for random numbers.
The units of distance between the reference object and the other astronomical objects
are converted into kilometres (km) from Astronomical Unit (AU), and light year (ly).
Apart from distance calculation from the surface of the reference object, distance
calculation from the centre of the object also increases the difference in distance
values.
6.4.4 Numerical Results and Discussions
The sky data used in the feasibility study of the proposed algorithms are
obtained from the planetarium software called “Starry Night”. Starry Night [200] is
desktop astronomy software that focuses heavily in providing attractive, realistic
imagery, although recent versions have also increasingly targeted the amateur
astronomical community with features like observation planning, telescope control,
and multiple-panel printing. The key features of the software are:
Display a realistic night sky, including stars from the USNO A2
catalogue, the Hipparcos Catalogue, the Tycho-2 Catalogue, and the
Tully catalogue of galaxies;
View the night sky from any location on Earth or any position in the solar
system, the nearby Milky Way, or the Local Group of galaxies;

194
Display any date and time for thousands of years in the past and future;
Animate time forwards or backwards at any rate;
Create observing plans;
Calculate ephemerides of solar system objects;
Display of current imagery from solar and Earth-observing satellites;
Generate a Hertzsprung-Russell diagram of the displayed stars;
Control most popular GOTO telescopes through a serial interface cable;
and
Display the sky using an all-sky photographic mosaic created from CCD
imagery.
The software and version used to obtain sky data is “Starry Night Pro Plus”
of version 6.3.9. The observing list of the astronomical objects used in the random
number generator is shown in Figure 6.17. Some of the screen shots of sky from
different locations for different Julian Days are shown in Figures 6.18 and 6.19.
Figure 6.17 The observing list of the astronomical objects used in the random number generator.

195
(a)
(b)
Figure 6.18 The astronomical data collection through the fixed position algorithm
for Julian Day Number (a) 2455375.13597 and (b) 2293519.18722.
196
(a)
(b)
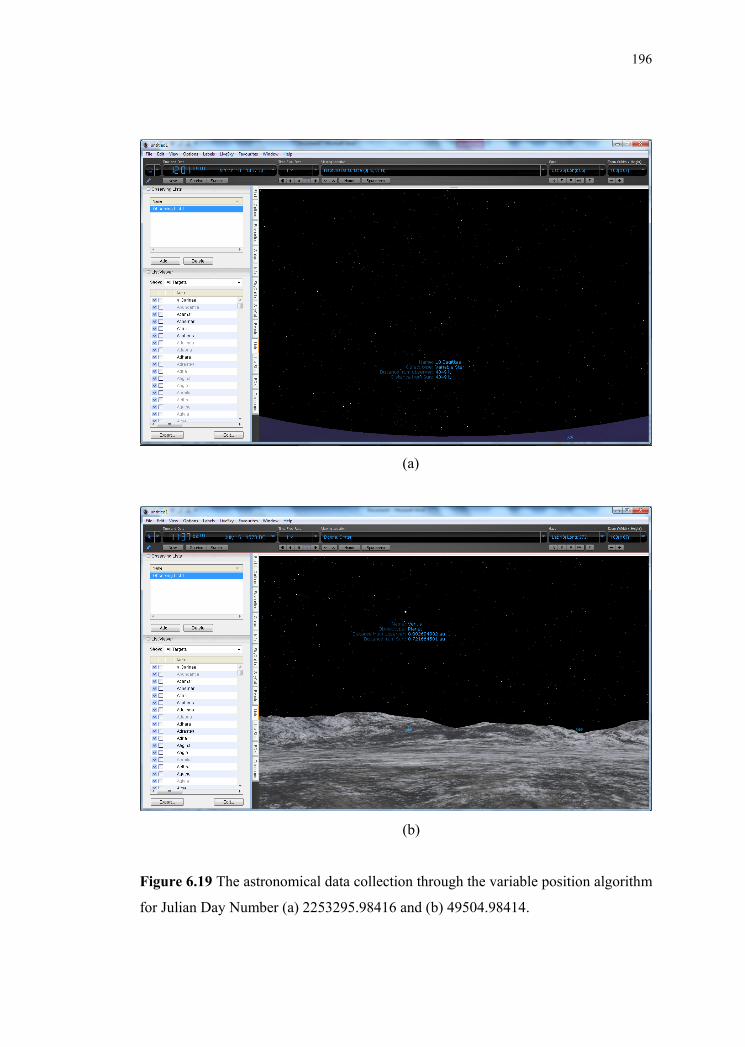
Figure 6.19 The astronomical data collection through the variable position algorithm
for Julian Day Number (a) 2253295.98416 and (b) 49504.98414.

197
6.4.5 Statistical Tests for randomness
Numerous statistical tests can be applied for a generated random number
sequence to compare and evaluate its randomness. Randomness is a probabilistic
property; that is, the properties of a random number sequence that can be
characterized and described in terms of probability. The National Institute of
Standards and Technology (NIST) Test Suite is a statistical package consisting of 15
tests developed to test the randomness of (arbitrarily long) binary sequences
produced by either hardware or software based cryptographic random or
pseudorandom number generators [151].
The NIST statistical test suite includes Frequency (Monobit) Test, Frequency
Test within a Block, Runs Test, Longest-Run-of-Ones in a Block Test, Binary
Matrix Rank Test, Discrete Fourier Transform (Spectral) Test, Non-overlapping
Template Matching Test, Overlapping Template Matching Test, Universal Statistical
Test, Linear Complexity Test, Serial Test, Approximate Entropy Test, Cumulative
Sums (Cusums) Test, Random Excursions Test, and Random Excursions Variant
Test. For each test, a relevant randomness statistic must be chosen and used to
determine the acceptance or rejection of the randomness hypothesis. Under an
assumption of randomness, such a statistic has a distribution of possible values.
A theoretical reference distribution of this statistic under the randomness
hypothesis is determined by mathematical methods. From this reference distribution,
a critical value is determined (typically, this value is “far out” in the tails of the
distribution, say out at the 99% point). During a test, a test statistic value is
computed on the data (the sequence being tested). This test statistic value is
compared to the critical value. If the test statistic value exceeds the critical value, the
hypothesis for randomness is rejected. Otherwise, the randomness hypothesis is
accepted. The random numbers generated using fixed location and variable location
algorithms for a single Julian date are shown in Figure 6.20. The generated random
numbers from both the algorithms exhibit uniform distribution.

198
(a
)
(b
)
Fig
ure
6.2
0 R
ando
m n
umbe
rs g
ener
ated
thro
ugh
(a)
fixe
d lo
cati
on a
lgor
ithm
and
(b)
var
iabl
e lo
cati
on a
lgor
ithm
.
0246810
12
14
16
18
20
3908190930877233830759260812149282982922302759022320997140339124079357051179374349078389630304406457004422838649437526325452006915466668234481283921494844933509107536523055265537066682551583604567128484584752113603231612622308275647156501669254111692592530721494791756303051787922564823226529856093501887727683926975208
1043164372129307445013994575691523717204181621349728013848062984492440451460684863998804191269818702045634330471938093549281.62624E+111.92959E+111.61778E+15
Frequency
Ran
dom Numbers Ran
ge
0246810
12
14
16
18
20
2027119415897
20725447229064559433723958037327545640652480943699397146802207150201899553764048357253159960960028067382389673673426377932610683993516989963828697673911810377133071116524619119846651413088977011375103208146502371015365829601660719152178091422019604567882349246862258978306127733149992905437385305381220732144844053513742340395597194741823711204402345088457851448447742217495077665942592392658071775990407883315566
14163480065848932218131.29667E+111.6757E+11
2.53323E+111.76E+15
Frequency
Ran
dom Numbers Ran
ge

199
The statistics obtained from 13 tests are used to calculate a P-value that
summarizes the strength of evidence against the randomness hypothesis. For these
tests, each P-value is the probability that a perfect random number generator would
have produced a sequence less random than the sequence that was tested, given the
kind of non-randomness assessed by the test. If a P-value for a test is determined to
be equal to 1, then the sequence appears to have perfect randomness. A P-value of
zero indicates that the sequence appears to be completely non-random. A
significance level (α) is chosen for the tests as 0.01. If P-value ≥ α, then the
randomness hypothesis is accepted, otherwise, the randomness hypothesis is
rejected. Table 6.2 shows the summary of P-values for each statistical test in
comparison to the proposed algorithms with linear congruential and modular
exponentiation methods. The histogram comparison chart for the P-values of
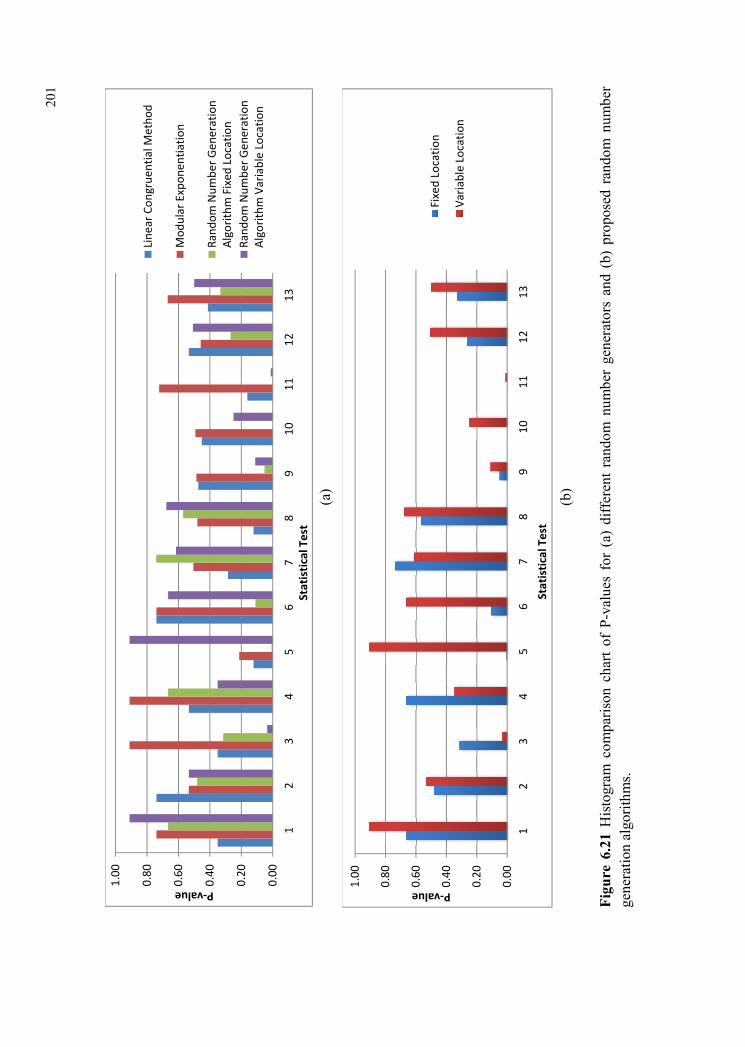
different random number generators and two algorithms are shown in Figure 6.21.
The statistical test results for this study shows that the proposed algorithms
performed well compared to the proven pseudorandom number generators,
especially in the frequency test, run test, rank test, and spectral DFT test. In some
cases like, overlapping template test and universal test, the performance of the
proposed algorithms did not meet the standards set due to the distance values,
becoming identical for one or more stars in the different clusters. This is due to lack
of precision in the calculation of distance parameters. The simple mathematical
iteration equation considered in variable locations algorithm influences the hop of
the data from their reference points. The redundancy existing in the considered
iteration equation affects the random number sequence to a great extent is shown
through the non-overlapping template and overlapping template tests in Figure
6.21(a). The consideration of complex mathematical equations on the other hand
increases the computational complexity and also the time for the algorithms to run.
In the overall analysis, both algorithms perform much better than the publicly
available random number generation techniques in some tests. Both fixed location
algorithm and variable location algorithm exhibits equal levels of randomness in
their statistical tests, respectively.

200
T
able
6.2
Com
pari
son
of P
-val
ues
for
diff
eren
t ran
dom
num
ber
gene
rato
rs u
sing
ast
rono
mic
al d
ata
S.
No.
S
tati
stic
al T
est
P-v
alu
es
Lin
ear
Con
gru
enti
al
Met
hod
Mod
ula
r E
xpon
enti
atio
n
Ran
dom
Nu
mb
er
Gen
erat
ion
Alg
orit
hm
Fix
ed
Loc
atio
n
Var
iab
le
Loc
atio
n
1 F
requ
ency
0.
3504
85
0.73
9918
0.
6659
26
0.91
1413
2 B
lock
Fre
quen
cy (
m =
128
) 0.
7399
18
0.53
4146
0.
4807
31
0.53
4146
3 C
usum
-For
war
d 0.
3504
85
0.91
1413
0.
3154
37
0.03
5174
4 C
usum
-Rev
erse
0.
5341
46
0.91
1413
0.
6659
26
0.35
0485
5 R
uns
0.12
2325
0.
2133
09
0.00
7991
0.
9114
13
6 L
ong
Run
s of
One
s 0.
7399
18
0.73
9918
0.
1100
93
0.66
5926
7 R
ank
0.28
5242
0.
5047
05
0.74
1298
0.
6157
40
8 S
pect
ral D
FT
0.
1223
25
0.47
9683
0.
5703
92
0.67
7141
9 N
on-o
verl
appi
ng T
empl
ates
(m
= 9
, B =
000
0000
01)
0.47
3499
0.
4856
66
0.05
2642
0.
1116
26
10
Ove
rlap
ping
Tem
plat
es (
m =
9)
0.45
1777
0.
4922
36
0.00
0001
0.
2500
00
11
Uni
vers
al
0.16
1696
0.
7224
45
0.00
1207
0.
0124
34
12
App
roxi
mat
e E
ntro
py (
m =
3)
0.53
4146
0.
4583
50
0.26
8227
0.
5081
52
13
Lin
ear
Com
plex
ity
(M =
500
) 0.
4127
19
0.66
8474
0.
3333
00
0.50
0000
201
(a
)
(b
) F
igu
re 6
.21
His
togr
am c
ompa
riso
n ch
art
of P
-val
ues
for
(a)
diff
eren
t ra
ndom
num
ber
gene
rato
rs a
nd (
b) p
ropo
sed
rand
om n
umbe
r ge
nera
tion
alg
orith
ms.
0.00
0.20
0.40
0.60
0.80
1.00
12
34
56
78
910
11
12
13
P‐value
Statistical Test
Linear Congruen
tial M
ethod
Modular Exponen
tiation
Random Number Generation
Algorithm Fixed
Location
Random Number Generation
Algorithm Variable Location
0.00
0.20
0.40
0.60
0.80
1.00
12
34
56
78
910
11
12
13
P‐value
Statistical Test
Fixed Location
Variable Location

202
Comparing the two algorithms, the variable locations algorithm performs
better than the fixed location algorithm in frequency test, runs test, longest runs of
ones test, overlapping template test, approximate entropy test, and linear complexity
test, as shown in Figure 6.21(b). This is obvious as the variable location algorithm
changes its reference object multiple times within a single phase of data transfer
process. The problem in scalability arises due to high powered computational
processes, and huge storage requirements in handling heavy astronomical databases
along with the mathematical iterations for hop calculations.
6.5 TECHNICAL AND OPERATIONAL FEASIBILITY
The feasibility study is an influencing factor that contributes to the analysis
of system implementation. The consideration of whether to design and implement a
particular system depends on the feasibility study on a targeted system. Technical
feasibility study is carried out to determine whether the proposed system has the
capability, in terms of software, hardware, personnel, and expertise to handle the
completion of a task. In the generation of random numbers through quaternion Julia
images for visual cryptography, the major demand is for fast and efficient algorithms
to render 3D Julia images from the computation of equations. The processor capacity
and storage spaces are also equally needed for proficient operation of the
cryptographic mechanism. As computer industry is advancing in the manufacture of
reliable processors working at high speed and high capacity storage disks, the above
mentioned problems are easily solved. Moreover, software industry currently
concentrates in 3D technology related products, which in turn helps in obtaining an
efficient 3D rendering image software. Random number generator using
astronomical data needs a reliable processor, huge storage space, and real-time
update of astronomical database. The random numbers generated using astronomical
method has proved their randomness property up to the standard in the conducted
statistical tests. The scalability, consistency, and unpredictable nature of the
generated random numbers utilizing astronomical data make them suitable for

203
cryptographical applications. Due to advances in computer manufacturing industry
and fast internet technologies, the above mentioned problems can be solved
efficiently. As the hardware and necessary software for designing and
implementation of the proposed system is already available, the system is technically
feasible.
Operational feasibility is a measure of how well a proposed system solves the
identified problems, and takes advantage of the opportunities identified in the scope
of research. The system should also satisfy the requirements identified in the
requirement analysis phase of system development. Since the software is intended at
making operations easy and faster, the intended user must have the fundamental
knowledge of the computer, and operating systems environment. The proposed
system is intended at providing a high level of abstraction to the user so that even
any person with average knowledge in the working of a computer is able to use it
efficiently. Moreover, the proposed system works as a background operation during
the user’s usage of the computer, makes user interaction to a minimum level. Since
all these requirements are easy and affordable, the random number generator system
is operationally feasible.
6.6 ECONOMIC FEASIBILITY
Economic Feasibility is concerned with the cost incurred for development
and implementation of the proposed system, the maintenance of the system, and the
benefits derived from it. The hardware and software required for the implementation
of the proposed system is already available. The hardware mentioned in the proposed
system is a personal computer or laptop with fast processor and broadband internet
connection. The software used in the proposed system, like 3D image rendering
software and astronomical database are available free of cost. The only cost involved
is that for coding, implementing and maintaining random number generator

204
software. Hence, with the consideration of the above facts, the proposed random
number generator systems are economically feasible.
6.7 SUMMARY
Real-time cryptography is on much demand for network and information
security. This proposed mathematical model has the advantage of generating
instantaneous real-time symmetric keys by the hosts simultaneously, and are not
shared in the public channel. The dynamically varying keys hold the unpredictability
nature making data transfer secure. The quaternion Julia set has a chaotic nature
which gives an entirely different image structure for small variations in the Julia
fractal parameters. The proposed model works with the complex image structure of
quaternion Julia set and the three degree of randomness in the generated key makes
it difficult to predict the sequence. The proposed model has applications from low
confidential to high confidential data transfer in two party and multi-party scenarios.
The generated Julia fractal images are also used in visual cryptography without the
need for key exchange.
The random numbers generated using astronomical data has proved their
randomness property up to the standard in the conducted statistical tests. The
scalability, consistency, and unpredictable nature of the generated uniformly
distributed random numbers utilizing astronomical data make them suitable for
cryptographical applications. Among the considered algorithms, variable locations
algorithm performs well due to the change of reference astronomical objects in every
span of time. The consistent generation of random numbers need high computational
power and huge storage capacity that can be achieved with modern day computers.
The application of the proposed method of random number generation is in
symmetric cryptography for peer-to-peer networks, grid computing, and cloud
computing. The next chapter explains about the Conclusions and future directions of
this research work.