building a beow ulf cluster for mcnp performance; a … · building a beow ulf cluster for mcnp...
TRANSCRIPT

BUILDING A BEOWULF CLUSTER
FOR MCNP PERFORMANCE; A LOW COST SOLUTION
BY:
Nathan Carstens
SUBMITTED TO:
Dr . Mike Dr iscoll MIT Department of Nuclear Engineer ing
DATE:
October 7, 2002

TABLE OF CONTENTS
ABSTRACT 1 GENERAL BEOWULF BACKGROUND 2 Introduction 2 Audience 2 Goals 2 Beowulf Defined 2 Cluster Design 3 Use 3 How it Works 3 Operating System 3 USERS GUIDE 5 How To Login 5 Working With Nodes 5 MCNP 5 PVM 6 Job Scheduling 7 MCODE & Or igen 7 Questions 7 BUILDING A BEOWULF 8 Introduction 8 BIOS, BIOS, BIOS! 11 Video Card 12 DHCP 13 TFTP 13 NFS 14 DNS 14 Logging Into Nodes 15 Telnet 15 RSH 15 SSH 15 Resetting Nodes 16 PVM 16 MCNP 16 Cost 17

PERFORMANCE IMPROVEMENT 19 Introduction 19 Bandwidth 19 Switch 19 PCI Bus 19 CPU 20 Results 20 MCNP PERFORMANCE RESULTS 21 Introduction 21 Example Output 21 Tests 25 Problem Complexity 25 Number Of Par ticles 25 Number Of Nodes 25 Results 25 Fraction of Maximum Run Time - HTR 26 Deviation from L inear ity - HTR 27 Fraction of Maximum Run Time - Eskom 28 Deviation from L inear ity - Eskom 29 Deviation from L inear ity - HTR & Eskom 30 Optimizing MCNP4C 31 CONCLUSION 32 REFERENCES 33 Appendix A: /etc/dhpcd.conf 34 Appendix B: (node) linux-2.4.18/.config 37 Appendix C: /etc/expor ts 46 Appendix D: (node) /etc/fstab 47 Appendix E: (node) /etc/init.d/rcS 48

Appendix F: /etc/hosts 51 Appendix G: (node) /etc/init.d/hostname.sh 52 Appendix H: Password Update Scr ipt 53 Appendix I : (node) /sbin/resetd.c 54 Appendix J: /sbin/resetc.c 56 Appendix K: Echelon Cost Analysis 58 Appendix L : /usr /bin/stasks 60

LIST OF GRAPHS Graph 1: Nodes On Rack 8 Graph 2: Frontal View of Nodes 9 Graph 4: 24 Port Switch 10 Graph 4: Server 11 Graph 5: Communication Versus Processing Time 22 Graph 6: Ineffective Problem 23 Graph 7: Effective Problem 24 Graph 8: Fraction of Maximum Run Time - HTR 26 Graph 9: Deviation from L inear ity - HTR 27 Graph 10: Fraction of Maximum Run Time - Eskom 28 Graph 11: Deviation from L inear ity - Eskom 29 Graph 12: Deviation from L inear ity - HTR & Eskom 30

1
ABSTRACT
This document examines the MIT Nuclear Engineering Department’s 30 node diskless
Beowulf Cluster. Beginning with a general introduction, it will offer a users manual, a series of
tips on how to build a similar cluster, and a method for optimally using MCNP on this cluster.
The paper will focus upon the complex software setup required but will also touch upon
hardware optimization and cost. It is intended for a general audience who are somewhat familiar
with Unix and MCNP.

2
INTRODUCTION This paper is an introduction to the MIT Nuclear Engineering Department's Beowulf Cluster. Building a Beowulf Cluster is a complex learning process that greatly depends upon your hardware and software requirements. This paper will provide a basic understanding of the cluster's setup and capabilities. It will focus upon a general understanding of Beowulf Clusters, offer a user's manual, give tips for building a similar Beowulf, and finally present Monte Carlo Neutral Particle Version 4C (MCNP4C) performance results for this design. Audience Users of Echelon will find it useful to concentrate on the User’s Manual. Greater understanding of the cluster and MCNP performance will be gained from the other sections of the document but is not needed for basic use. Those looking to build a Beowulf Cluster will find the Building A Beowulf section critical. In addition to illustrating the basic steps necessary to prepare the software, the section offers numerous tips that may save the builder months of unnecessary effort. A careful scrutiny of the appendices will be necessary as the builder sets up the various sections of the cluster. The builder may wish to begin with Appendix K; Echelon Cost Analysis if budget considerations will be driving the project. Scripts may be used and modified as desired. The MCNP Performance Results section will be of interest to the user looking to understand why MCNP run time depends so greatly on the input file. This section will also be of interest to those building a Beowulf Cluster for MCNP k-code performance. The builder will gain an understanding of important hardware choices and expected performance results in future clusters. Goals The goal of the Beowulf Cluster, Echelon, was to decrease the real time required to run the MCNP code at a low cost. While many solutions exist to speed up an MCNP run, the requirement of low cost strongly suggests the use of a Beowulf Cluster. Beowulf Defined Beowulf Clusters may be defined as a dedicated group of interconnected computers using mainly off the shelf hardware for the purpose of computation. Beowulf Clusters were invented at NASA during the early 1990's to fill the need for cheap computation. In the past this need was met by custom designed supercomputers. Unfortunately, supercomputers are exceedingly expensive and therefore available to only a small group of users. The term Beowulf was chosen because like the hero in the ancient English legend, Beowulf would slay the monster Grendel (expensive supercomputers). For many applications Beowulf has lived up to its name and largely replaced the supercomputers of old for a fraction of the cost.

3
Cluster Design Echelon is a 30-node Beowulf disk-less Cluster. It has one server, which controls the other computers, called nodes. Each node has a motherboard, a processor, and RAM hooked to the server via Ethernet. Nodes do not have hard drives, monitors, keyboards etc. The server is a standard computer with two hard drives using RAID 1 software. The server also has five Ethernet cards. One card links the whole cluster to the Internet (nodes are not directly connected to the Internet). The second and third cards are linked to a 24 port 100 MB/s N-way switch linked to the first 15 nodes. The fourth and fifth Ethernet cards are linked to a 24 port 100 MB/s N-way switch linked to the final 15 nodes. One may wonder if a disk-less Cluster is worth the more exotic software setup than simply using a hard disk on each node. While there are many applications that benefit from or require a local hard disk, the Beowulf designer shouldn’ t choose a node with disks simply because it is easier to setup. Any timesavings in initial setup will be lost in the long-term to the greater maintenance requirements of a cluster with local disks. A cluster made with individual disks on each node adds a significant capital cost and will require constant maintenance. Keeping software, files, and the kernel of a complex file system perfectly synchronized is much easier on one hard drive than 30. Use Echelon is designed to decrease the real time required for certain computationally intensive tasks. The nodes, switches, and Ethernet cards operate at 100 MB/s over Ethernet. This setup is more than adequate for computationally intensive tasks that don't need to communicate often. Monte Carlo codes are ideal for this type of system since they don't need to communicate during computation. Correspondingly the user will experience poor performance in codes that continuously communicate due to the high latency of the Ethernet and switches used in this system. Navier-Stokes equations and Fast Fourier Transforms are only two examples of codes that may actually run slower than if they were run on single processor. How I t Works When a node boots, its BIOS uses a code called Etherboot, which requests an IP from the server via DHCP. DHCP checks the MAC address (a number unique to every Ethernet card) and if it matches the list in its database it assigns the node an IP. Now Etherboot requests a kernel and a very basic file system via TFTP. The server's inet.d daemon will receive this request and start TFTP to export the kernel and a wrapper containing information for the kernel to boot and request NFS. Now the node boots the kernel and using the wrapper requests pieces of a file system via NFS from the server. NFS on the server checks these requests and, if they are allowed, exports the file system to the node. This continues until the node has loaded a complete Linux operating system.

4
Operating System This system uses Woody Debian Linux. Linux was chosen, as it is a free operating system that has a proven history of excellence with Beowulf Clusters and MCNP. Debian was selected, as it is a completely free version of Linux that provides updates and software via the Internet. Finally, Woody was selected, as it is a stable version that nevertheless receives frequent updates to the latest software available.

5
USER'S GUIDE How To Login Echelon only allows ssh connections. Telnet, rsh, ftp, and other common connection programs are not allowed to connect for security reasons. There are secure programs for every operating system that will allow you to connect to Echelon. For Unix simply get a copy of ssh. If your distribution does not provide it search the web and download a copy. Windows users can either download PUTTY or get a copy of Cygwin. PUTTY is a secure terminal system for Windows that may be downloaded at http://www.chiark.greenend.org.uk/~sgtatham/putty/download.html. Cygwin is a Unix like environment that runs inside Windows and provides all the major Unix utilities, including ssh. Cygwin is large download and may be found at "http://cygwin.com". Once ssh is working simply type "ssh [email protected]" with the appropriate user-name. You will be prompted for your password and then you will connect to the server. If DNS doesn't work you may use the static IP address 18.54.0.188. Working With Nodes Once you are logged into Echelon you may transfer to a node only with ssh. The nodes are numbered from 1-30 with the prefix of e. For example to log into the 5th node you would type "ssh e5". You do not need to supply a user-name and you will not be asked for a password on this internal network. Please take care if you are new to the Unix environment that you know where you are. It is quite easy to run MCNP on the server when you intended it for a node. The reader should note that except for the /home directory no files modified on a node affect files on the server. The directories that each node must write in (tmp, var, and etc) are mounted as RAM disks on each node. The rest of the file system (usr, root, bin ...) is exported from the server read only. The directory /home is exported read and write so be careful. The command rm -rf $HOME will destroy all of your files whether you are on a node or the server. MCNP While almost embarrassingly parallel, MCNP still requires a decent input file to achieve good performance on a cluster. MCNP files may be run with a command line like "mcnp i=... tasks -nx1", where n is the appropriate number of tasks. Previous users will recognize the only change is the addition of the tasks command. Please note that unless PVM is running MCNP will not function in parallel. See the PVM documentation below for more information. MCNP requires massive amounts of processing power but only very modest amounts of memory. While Monte Carlo algorithms are embarrassingly parallel, the MCNP applications required by this department largely center on criticality calculations which require the

6
computation of an eigenvalue (the keff) approximately 200 times. The eigenvalue computation requires communication from each node to the server. This communication prevents MCNP from being perfectly parallel and can make problem design very important. There is a communications startup overhead that is somewhat proportional to the number of tasks run. Running 60 tasks requires much more time for startup compared to running 6 tasks. Except for special circumstances running one task per node is optimal. The requirements of the problem should determine the number of nodes used. Problems that use small numbers of neutrons (less than 1000) would be well served by running on one or perhaps two nodes. An MCNP run using 15 neutrons per generation will run significantly slower on 30 nodes than one processor. Please don't run MCNP calculations on the server; ssh to a node and run it there. Rough experimentation reveals that even at 2000 neutrons per generation the communication time is frequently the barrier to performance, not calculation. Due to the complexity of optimally running MCNP k-code calculations in parallel, a script was created to determine the appropriate number of nodes for a problem. It was determined that the three most important factors are the number of number of nodes used, the number of particles in the problem, and the complexity of the problem. Using methods fully described in the MCNP Performance section a script, stasks, was created. The script requires two inputs; the number of particles and the complexity of the problem. The number of particles is self-explanatory but must be kept between 1,000 and 20,000. This script is a rough approximation and user judgment should be used to extrapolate beyond its tested data. The complexity is an integer between 1 and 10 where 1 is exceedingly simple and 10 is terribly complex. For example a plutonium sphere would receive a value of 1 where a full core pebble bed reactor with thousands of fuel balls would be a 10. While adding nodes usually decreases the real time used, it may waste a lot of processing time in communication. The script will choose an appropriate number of nodes such that the time spent communicating is less than half the total time. The whole command would look like "stasks 5000 4" for a problem with 5000 particles and a complexity factor of 4. PVM PVM provides the libraries that make it transparent for other codes to use clusters of computers as one machine. PVM maintains connections with the nodes (called hosts by PVM) by making a file in the /tmp directory under the users uid. This requires that each user start PVM and add hosts before MCNP can be run in parallel. Without PVM running, MCNP will give error messages and run the problem solely on the machine it is executed from. PVM should be started when you login and closed when you logout. PVM may be started by typing "spvm.auto" and stopped by typing "spvm.stop". Spvm.auto starts pvm on all the nodes that aren’ t currently running mcnp while spvm.stop gracefully stops pvm for that user. Users may check what nodes are currently running themselves by running “smcnp.check.” PVM startup will normally take about 10 seconds after which MCNP will begin.

7
PVM may be started manually by typing "PVM $HOME/.beowulf/hosts" at the command line. The hosts file simply lists the hostname of each node to be added. This will start PVM with every node available. After a moment PVM will start up a shell where you may execute commands. Type, "help" for more information or simply type "quit" to exit PVM leaving it running. Users interested in watching PVM at work (at about a 10% performance loss) may experiment with the command "xpvm $HOME/.beowulf/hosts". Job Scheduling Currently, there is no job scheduling software installed on Echelon. It is planned that PBS will be added in the near future but for now it is first come first served. MCODE and ORIGEN MCODE and Origen questions should be addressed to Zhiwen Xu at [email protected]. Questions Please e-mail all questions and comments to [email protected]

8
BUILDING A BEOWULF Introduction It will be assumed that the user has setup up a computer running Debian Linux and has connected that computer to the nodes via Ethernet cards and switches. Several pictures of Echelon are included below:
Graph 1: Nodes on Racks

9
Graph 2: Frontal view of Nodes

10
Graph 3: 24 Port Switch

11
Graph 4: Server
Now one must prepare this computer to act as a server for the nodes. The first step in this process is determining how a node's BIOS will communicate with the server. BIOS, BIOS, BIOS! The major mistake made in the construction of Echelon was not carefully scrutinizing the BIOS before purchase. While most current BIOS contain Intel's PXE code, the motherboards purchased only contained Novell RPL for network booting. By the time this problem was circumvented it required about two months of work and the purchase of additional hardware. Future users may find it difficult to determine detailed information on their BIOS capabilities before purchase but it will be well worth their time in the long run. Unfortunately, the BIOS code included, RPL, is quite similar to several other products called RPL produced by different companies all of which are not compatible. Unfortunately, Novell basically provides no support for its RPL code. Novell RPL is a very old code that was used on Windows machines for some network functions. While Novell does have an RPL server for old versions of Windows it neither offers support for

12
Linux nor documentation on its standards so that support could be created. There is very little information on the Internet even mentioning Novell's RPL let alone documenting it. This BIOS complication was compounded into a serious problem by the vendor of the BIOS. The BIOS was Originally created by AMIBIOS a well-known corporation, which offers good support and documentation. Unfortunately, the nodes were purchased from a Taiwanese manufacturer, which modifies the BIOS code they Originally purchase. These modifications make AMIBIOS unwilling and perhaps unable to provide support for these modified BIOS. The Taiwanese company sells only to major distribution centers and provides absolutely no user support. The distribution centers have basically no knowledge of the BIOS they are selling and similarly offer no user support. The user is left with no one to consult and must try to graph out this code without help. Once again, there is almost no applicable information on the Internet. After a significant investment in web research one may discover MARS_NWE. This is an old and rare German Linux program that claims to communicate with Novell RPL. This code is not well documented but one user was encountered in the Czech Republic who claimed to have made this program work with Novell RPL. Despite having copies of his configuration files this code was never made to work with RPL. Eventually, a Computer Engineering student, Blaise Gassend, donated time to help find a way to communicate with Novell RPL. Despite numerous attempts he was unable to find a way to make this work. It is not known if this problem was a failure of MARS_NWE or an incomplete implementation of Novell RPL in the BIOS. After several weeks of work an AMIBIOS program was stumbled upon that allows a user to add or delete modules from an AMIBIOS BIOS. This program is not directly offered from AMIBIOS and it is suspected that the company may not wish this code to be available let alone distributed. Once this code became available it was rather straight forward, albeit time consuming, to remove the Novell RPL code and insert Etherboot by flashing the BIOS on each node. Etherboot was chosen, as it is a well-documented and easy to use Linux code that would allow a node to boot a Linux kernel quickly. Video Card Now that a code was found to communicate with the server a second major problem with the BIOS arose. The installed BIOS expected and required the presence of a video card to boot properly even to the point of loading modules. While many motherboards include basic video cards, at the time of this cluster’s purchase motherboards did not offer a cheap video card and DDR RAM DIMMS. The choice was made to use DDR RAM for its greater speed in the hope that the video card issue could be resolved. Once again AMIBIOS wouldn't support the BIOS and the manufacturer who modified it doesn't offer support. While numerous approaches were investigated no easy method was found to circumvent the problem. Eventually, Blaise was able to translate the BIOS into Assembly and edit out the video card call on BIOS startup. Unfortunately, Assembly is a difficult language and the BIOS had a large amount of code so it wasn't possible to fully inspect the code to assure all

13
the necessary changes were made. This method initially worked well but decayed for some time. After all the nodes were flashed to the new BIOS and booted there were three that still required a video card. Eventually 13 nodes required a video card to boot. It is not understood why some nodes require a video card and some do not nor why it can change over time. It is believed that the situation has reached a steady state value. Once video cards were purchased for these thirteen nodes they performed correctly and allowed the Etherboot module to load. Currently all nodes with or without a video card work perfectly. Finally, the nodes were prepared to the point were future builders should begin. Upon boot up the Etherboot module is loaded and attempts to communicate with the server. DHCP Etherboot (and most comparable codes) begin communicating with the server via DCHP calls. This requires the user to setup the server's DHCP server before anything else can proceed. In Debian it is quite simple to install DHCP using dselect. Make sure you have a recent DCHP version (already assured if your using the testing version of Debian), as still common previous versions do not support many major features. Once DHCP is installed it must be congraphd for your setup. The user must chose whether he will dynamically or statically assign IP addresses for its nodes. It is recommended that for dedicated clusters and in cases where one expects the same computers to be served repeatedly, that static IP addresses be used, as it is inherently simpler and dynamic assignment isn't really necessary. A copy of the /etc/dhcpd.conf file is located in the Appendix A. If you use more than one subnet be sure to edit the /etc/default/dhcp file. This file controls what interfaces are allowed to access DHCP. The user can easily spend hours of frustration if the proper interfaces are not added in this file. Don't forget to include "options routers" in each subnet declaration. Without this declaration nodes will not know which router they should talk to and DHCP will default to the first gateway listed. This will result in the nodes not on the first subnet being unable to communicate with the server as they are using the first subnet's gateway. TFTP Once a node has determined its IP from the server it will request a kernel from TFTP. TFTP setup is relatively simple and well documented on the internet. It is recommended that the user create a directory in the root file system that will hold all the nodes files. Don't forget to modify the node's kernel to optimize it for the node's needs. A copy of the .config file for this cluster's nodes has been included in Appendix B. Once the kernel has been created it must be modified by the mknbi program. This program basically wraps the kernel in a tiny bit of extra data that tells the node where to get its root file system. It is recommended that

14
the user create a script to automate the kernel creation and modification process. The TFTP root file system contains only the very basic parts of the Linux file system. The node will need most of the /etc, /bin, and the /sbin directory. It is recommended that empty directories be included for the rest of the file system as it may be remounted with NFS later. NFS Now that the node has downloaded the kernel, booted the kernel, requested and mounted a basic file system, it will go through a normal Linux startup. The user may now choose how he wants to create the node's file system. While there are numerous ways to handle this task one of the easiest is using NFS to mount as much of the file system as possible read only and mounting the rest as RAM disks. The advantages of this method are that it is impossible for the node to damage the servers file system, only one node file system is required for all the nodes, and the nodes file system is completely clean at every reboot. The disadvantage is that logs are not saved for the nodes and the RAM disks take up some of the nodes’ RAM. The builder will also have to create several scripts that allow a node to differentiate itself from other nodes. Once a node is properly setup the logs are not needed, MCNP has very low memory requirements leaving plenty of memory to spare, and the tricky script will be included as Appendix G. NFS setup is quite simple and well documented for the Debian system. NFS has all its main options declared in /etc/exports. This file details what directories may be exported via NFS and what its permissions will be once exported. A copy of this file is included in the Appendix C. Once NFS is available the node must request it. Perhaps the easiest way is to request the file system by modifying the node's /etc/fstab file. A copy of this file is included in Appendix D. The more difficult part centers around how to mount the RAM disks. In this case this was handled by editing the /etc/init.d/rcS file. A copy of this file is included as Appendix E and should be perused to fully understand the process. Note that one cannot mount directories like /usr inside this file. When rcS is run most of the node's daemons haven't been started and /usr will try to use daemons not present on the system and hang until the request times out. It is recommended that except for /etc, /tmp, and /var that the nodes use the exact same file system as the server. This will mean the /bin and /sbin directories exported with TFTP will be discarded when those directories are remounted. This approach has the advantage of keeping the administrator from having to create and administer a second file system, a non-trivial consideration. DNS DNS may be setup up so the server knows how to differentiate one node from another. An easy, secure, and probably adequate alternative is simply to list all the nodes in the /etc/hosts file. A copy of this file is included in the Appendix F. A node must also differentiate itself from the other nodes on the network. Creating a script that assigns the hostname based upon the IP given by the server can do this. An example script is

15
included in Appendix G. Logging Into Nodes Now that you have a fully functioning system you must decide on the method of controlling the nodes. Telnet, RSH, and SSH all provide somewhat similar capabilities but only SSH offers good security and encryption and was used exclusively on this cluster for reasons discussed below. Telnet Telnet transmits passwords and data in clear text that is easy to sniff. This makes telnet an unacceptable security risk for use on the Internet. It also makes telnet an unacceptable risk even in a network protected by a gateway if multiple users are present. RSH Rsh was the default connection method in the past. Many programs (such as PVM) require rsh for making connections to other nodes. Unfortunately, rsh has two fundamental security flaws that have a history of being exploited. The easiest way to setup rsh is with a hosts.equiv file. This file globally sets what users and hosts may login without a password. Unfortunately, it allows authorized users to login as a different authorized user! This makes the users home directories writeable by other users. This problem may be avoided by creating individual .rhosts files in each users directory instead of the global hosts.equiv but it does not circumvent the second fundamental flaw. Rsh transmits passwords and data in clear text. While “ r” programs are not as easy to sniff as telnet these packets are still transmitted in clear text. Additionally, whenever a user is not known to the system and rsh asks for a password this packet is transmitted in an easily sniffable form. SSH Ssh encrypts both data and passwords and does not permit users to masquerade as other users. Unfortunately, this security requires a performance cost. When logging in it may take Ssh over four times as long to log in as rsh. However, a properly designed program will only login once during the whole calculation. Ssh takes about 10 seconds to log onto 30 nodes and therefore this time may be neglected. Ssh also has a performance cost when transmitting data since the CPU must encrypt all the data before it is sent. Fortunately, MCNP uses pvm communication routines when it calculates eigenvalues with k-code runs and thus is not an issue for this cluster. The administrator should properly test a new configuration to determine if ssh encryption is a performance limiter. PVM requires rsh to communicate with the nodes. Not installing rsh and making a symbolic link from rsh to ssh can circumvent this feature.

16
Since the nodes are not directly connected to the Internet and because PVM requires that the user log into each node before codes can be run, it was decided that ssh should be setup so users do not need to enter their password when logging into a node (from the server or a node). This can be accomplished by creating a authorized_keys file in the users .ssh directory. The user will have to create a key set with the ssh_keygen utility and then copy the public file to the authorized_users file. Take care that if you are using SSH2 that you create the key with a command like "ssh_keygen -t rsa". This will change the /etc/password, password-, shadow, and shadow- files but will not update them on the separate node /etc directory on the server. This problem was avoided by linking the password and shadow files of the node and server filesystem. However, this change will not affect the nodes which have already mounted /etc as a RAM disc until the next reboot. It is recommended that the administrator create a script that automates the creation of user accounts including setting up SSH and exporting all these files at the time of the account creation. An example is included in Appendix H. Resetting Nodes Inevitably during the course of building a Beowulf the administrator will inadvertently place nodes in states where they not respond except by being reset. This often requires a trip to the office just to push one button - a task that quickly becomes tiresome. Blaise Gassend created two programs, resetc and resetd, that will allow the administrator to remotely reset the node even if most of the file system isn’ t available. Resetd is run on the nodes by /etc/init.d/rcS during boot as a daemon. It listens to a UDP port and resets the node if it receives a specific signature. That signature is supplied by the program resetc. Resetc is run on the server by command line and takes one argument, the IP address of the node to reset. The administrator should note that these functions only work if the node is booted and has access to the resetd program but is for some reason unable to handing ssh connections. This state is frequently encountered if NFS fails to mount the file system or the node encounters and error in its startup scripts. The scripts resetc and resetd are included as Appendices I and J respectively. PVM PVM setup can be difficult if the administrator is new to this program. In Debian installation is simple using dselect. It is only necessary to set the variables PVM_ROOT or PVM_ARCH in Debian during compilation. The administrator should also know that PVM is installed in /usr/lib/pvm. PVM requires that all executables be placed (or linked) in the pvm/bin/LINUX directory. MCNP further requires that the code in this directory be called mcnp.pvm. MCNP MCNP4C installation is somewhat straightforward. In Debian the user must make sure that he has the PVM development libraries installed as well as PVM for MCNP to compile in distributed memory parallel format.

17
Unfortunately, MCNP4C does not perform reliably in parallel on a distributed memory system in Linux without significant modification. This problem is difficult to solve as the MCNP4C development team works in a classified division of Los Alamos and is unavailable for support. Finally, following the events of 9/11/01 virtually all documentation was removed from the Internet. The MCNP forum is still available and may be found at http://epicws.epm.ornl.gov/ENOTE/enotmcnp4c.html. The author experienced two recurring errors that were quite difficult to diagnose and solve. These problems seem to stem from the fact that MCNP4C wasn’ t designed to run on Linux and some features haven’ t been implemented. The fist error stemmed from a lack of dynamic memory allocation in Linux. While MCNP4C would often run perfectly in parallel, after several problems have been run or when several jobs are running simultaneously MCNP4C will begin a problem then hang at the phrase "sending static commons...” On a normal run this phrase might appear for 10 seconds but in this case the code will remain permanently stuck. After this message has appeared the second error may soon occur where MCNP begins and simply dies with the message "segmentation fault". It was eventually determined that this was a memory allocation problem. The server’s memory was increased from 512MB to 1,024 MB and the problem has not reappeared. The second problem concerned long MCNP4C runs on a single processor. Long runs normally executed without fail on multiple nodes but single processor runs failed after about 3 hours. The problem was eventually traced to g77 errors concerning NFS. Apparently, g77 version 0.5.24 has an error that prevents it from accessing NFS files on very long computer runs. This error can be avoided by simply upgrading to 0.5.25 (the most recent release at the time of this writing). However, MCNP may still crash about 3 hours into a single node computation even if MCNP4C is compiled with g77 0.5.25 but this time it is due to a lack of memory. It is believed that during long run times MCNP briefly stores a large amount of data in a junk file in /tmp which is deleted a short time later. The original cluster configuration featured only 3 MB of disk space for /tmp. When the /tmp directory’s size was increased to 20MB the problem no longer occurred. Cost The total cost of Echelon was $13,251.51. At the time of purchase this was a low cost even for a Beowulf Cluster and presented a whole different paradigm than the purchase of a supercomputer. A fifteen-fold performance gain compared to one node and the possibility of running 30 jobs at the same time were achieved for a price comparable to a Unix Workstation. Of that total cost $1,633.50 was spent on the server, $364.19 was spent on each of the 30 nodes, and $692.46 was spent on other general items. No funds were spent on software, installation, or setup. A complete breakdown of the cost of the system is included as Appendix K. A cost quote from PSSC for a comparable Beowulf six months later was $31,500.00. This quote did not included shipping (perhaps $1,500.00). However, all 30 nodes in this quote did have a floppy drive, a 20 GB hard drive, and a video card. This vendor did not offer nodes without these additions. The CPU’s in the nodes were 2000+ XP’s which is faster than the 1700 XP’s

18
used, however, the cost of the 2000+ six months later was quite comparable to that of the 1700 at the time of purchase. There still would have been significant amounts of hardware and software setup but there would have been no BIOS surprises and much of the basic operating system setup would already have been complete. A 30 node array containing hard drives would provide more storage but at the cost of greater maintenance for the administrator.

19
PERFORMANCE IMPROVEMENT Introduction Performance may be greatly improved through proper testing and hardware optimization. MCNP k-code calculations feature long periods of inactivity during which nodes are busy computing followed by intense periods of communication when the burden is placed upon the network and server. It is during these periods of communication when proper testing and hardware design may improve performance. There are many factors that can limit performance. The job of the administrator is to determine the most limiting factor and alleviate it. Bandwidth The first potential bottleneck is network bandwidth. MCNP does not send much data but when numerous nodes attempt to send data at the same time the network bandwidth may limit the rate of data transfer. This can be easily be checked by running any of the numerous bandwidth monitoring tools. After some experimentation it was discovered that “sar” offered the most comprehensive data available and was used for all further tests. Some care must be taken when analyzing network traffic that the data analyzed represent the MCNP eigenvalue communication. As the eigenvalues calculation typically represents a small fraction of the total time, sar should be used over a decently long time frame and with short sampling intervals to assure that the heaviest load may be analyzed. Normally the maximum value obtained will probably be 80-90% of the listed maximum bandwidth. Switch If bandwidth is a limiting factor then the link between the switch and the server is probably the limiting factor. Where each node has its own Ethernet link to the switch the server may have only one connection. The obvious solution is to add another network card and link between the server and the switch. Before this is undertaken one should make sure the switch could transmit the extra data desired. Depending upon the quality of the switch, the fabric or backbone may only support a total transfer rate equal to one of the incoming ports. If this is the case then adding another network card will not help performance and a second (or better) switch is the appropriate step. Most quality switches will support full duplex operation meaning every port may talk at the same time at its maximum rate. In this case another network card will improve performance. PCI Bus The next potential bandwidth barrier is the PCI bus. The PCI bus maximum throughput may vary widely between motherboard chipsets. For example the latest V-Link chipset only offers

20
266 MB/s peak while the K7S5A offers 1.2 GB/s. Depending upon how many nodes your cluster is running, MCNP may transmit more data than the PCI bus can handle at once. Choose the number of Ethernet cards accordingly. CPU Finally, the CPU may limit the maximum bandwidth. When hundreds of megabytes of data arrive at the same time it takes a very fast CPU to control this process. While sar will give you a rough indication of CPU usage, a better utility is “vmstat” . Once again, care must be taken that the polling intervals are very short and enough data points are taken to determine the maximum load upon the CPU. If the CPU is found lacking a more powerful model or possibly an SMP motherboard will provide relief. CPU usage will also depend upon the type of connection being used. Ssh encrypts all the data it sends and thus requires a significant amount of processing power to receive a lot of data. If security is not an issue and a lot of data must routinely be sent with ssh, rsh is a viable alternative. Fortunately, MCNP uses pvm functions to pass data in parallel so this shouldn’ t be an issue for MCNP. Results The Echelon cluster was severely limited by bandwidth. The original configuration had two sets of 15 nodes on a network card on the server. When MCNP attempted to calculate an eigenvalue it would have all 15 nodes (if the problem was on all the nodes) communicate at virtually the same time. This communication easily maxed out the bandwidth of the server’s network card. This would leave all 15 nodes idle while they attempted to communicate which seriously decreased linearity. Doubling the number of network cards on the server ameliorated the problem. With only 7 or 8 nodes on each of the server’s network cards the cluster roughly doubled its performance when all of the nodes were used for a problem. MCNP problems that calculated an eigenvalue frequently benefited the most while problems with a large number of particles and complex geometry calculate an eigenvalue infrequently and received less of a performance boost. Further testing revealed that even during eigenvalue calculation the server’s network cards had bandwidth to spare. This new configuration is not severely limited by the bandwidth, switches, PCI bus, or CPU. Dramatic improvements would require major and expensive hardware upgrades and is unlikely to be needed for this cluster. However, the initial set of tests was well worth the effort. A $40 investment in network cards roughly doubled the performance of all thirty nodes of the $13,250 cluster.

21
MCNP PERFORMANCE Introduction MCNP4C performance is highly dependent upon the type of problem being run, the number of nodes it is run, and the hardware used. The problem has many different factors affecting its performance but the two most important factors are the number of particles and the complexity of the problem. This section will show examples of MCNP output, a series of tests focusing on the three major factors affecting performance, and finally offer a solution to optimize MCNP4C runs on Echelon. Example Output Example outputs of xpvm are included in Graphs 5 through 7 showing the relative proportion of time spent on communication versus processing in MCNP. Graph 5 illustrates the output of xpvm at the beginning of an MCNP run on two nodes. The beginning of the problem is spent setting up the run for distribution to the nodes. Once the run has began it quickly settles down to a steady state process with each node processing until it is ready to combine its results with that of other nodes to calculate an eigenvalue. Since each node has identical hardware this happens at virtually the same time without load balancing. When a node finishes processing it communicates its data to the server. Once each node has communicated with the server, the server restarts all the nodes at the same time for the next set of processing. The length of time necessary to complete an MCNP run will dictate what part of Graph 5 should be optimized. On short runs the amount of time the server takes to setup the problem with each node becomes a major factor in MCNP performance. A larger number of nodes will take longer to startup and settle to a steady state. On long runs the startup time becomes negligible and the relative amount of time a node spends processing versus communicating the eigenvalue becomes critical. The relative value depends on many factors and will be analyzed later. This problem has approximately 5% non-linearity. Graph 6 illustrates a horribly inefficient use of MCNP4C on Echelon. At 1,000 particles in a simple geometry this problem runs shorter on 1 processor than it does on 24. The graph shows that the vast majority of time is spent communicating among the various nodes while little time is spent processing. Graph 7 illustrates a reasonably efficient use of MCNP4C on Echelon. Using a complex geometry with 5,000 particles on 8 nodes MCNP spends the vast majority of its time processing and little communicating.

22
Graph 5: Communication Versus Processing Time

23
Graph 6: Ineffective Problem

24
Graph 7: Effective Problem

25
Tests A series of tests was conducted to determine how MCNP4C non-linearity relates to the number of nodes used, the number of particles in the problem, and the problem complexity. Two test problems of widely varying complexities were run with 1,000, 2,500, 5,000, 12,000 and 20,000 particles on 1, 2, 4, 8, 16, 22, and 30 nodes. Problem Complexity This parameter is hard to quantify but important. A problem’s complexity is judged on the number of cells and materials and the geometry size and intricacy. Using a scale of 1 to 10 problems may be quantified from very simple, 1, to extremely complex, 10. The first MCNP4C test problem is a model of the Eskom Pebble Bed Reactor, created by Julian Lebenhaft, using repeated structures of pebbles to fill the core. This complex problem features many different cells in numerous regions in an intricate geometry that was estimated to warrant a complexity factor of 8. The second test problem is a homogenized model of the Chinese Pebble Bed Test Reactor using only 5 cells. This simple problem received a complexity factor of 2. Number of Par ticles This parameter is both easy to quantify and optimize for a given problem. It also is the easiest parameter to modify to improve problem statistics. Three levels were chosen to test the response of MCNP to this parameter. 1,000 particles were considered the minimum number of particles that would merit consideration for use on a cluster. 5,000 were chosen, as it is the current limit that most users of the Eskom problem can afford for normal runs. Finally, 20,000 particles is an educated guess at what a cluster of 30 nodes might begin to be taxed by. Number of Nodes The number of nodes tested was simply chosen by powers of 2 where 22 was included because of the large distance between 16 and 32 and 30 was, of course, chosen as there are only 30 nodes. This gives more data points to the lower number nodes region, which is where the majority of runs are expected. Results Graphs 8 through 12 illustrate the results of the various tests. Two graphs were selected for both test problems. The first graph shows a three-dimensional plot illustrating the fraction of the maximum run time (the time necessary for 1 node to complete the problem) a given run required. The axes are the fraction of maximum time versus number of particles and the number of nodes used. The second graph illustrates how non-linear the runs in the previous graph were. Both graphs present the same information but in different forms that make it easier to understand the behavior of MCNP in parallel. Graph 13 combines graphs 9 and 11 in one graph. It illustrates the importance of problem complexity while presenting the number of particles and number of nodes versus non-linearity.

26
12
4
8
16
22
301,0002,500
5,00012,000
20,000
0.000
0.100
0.200
0.300
0.400
0.500
0.600
0.700
0.800
0.900
1.000
Fra
ctio
n o
f M
axim
um
Tim
e
Number of Nodes
Number of Particles
HTR - Simple Core - Fraction Of 1 Node Run Time
0.900-1.000
0.800-0.900
0.700-0.800
0.600-0.700
0.500-0.600
0.400-0.500
0.300-0.400
0.200-0.300
0.100-0.200
0.000-0.100
Graph 8: Fraction of Maximum Run Time - HTR
This graph illustrates two significant phenomena. The most prominent feature is the significant decrease in run time as the number of nodes increases. This gain rapidly bottoms out as the number of nodes increases. Relatively little time is gained after 8 nodes are used. The second major feature is the importance of running a large number of particles. The 1,000 particle line features virtually no time decrease when it is run on more than 4 nodes. In contrast the 20,000 particle line steadily improves its time (albeit slightly at the larger number of nodes) all the way to 30 nodes.

27
HTR - Simple Core - Deviation From Linearity
y = 31.49x - 69.052R2 = 0.9933
y = 15.028x - 37.524R2 = 0.984 y = 12.517x - 30.826
R2 = 0.9836
y = 12.133x - 32.801R2 = 0.9641
y = 10.553x - 27.417R2 = 0.9779
-200.000
0.000
200.000
400.000
600.000
800.000
1000.000
0 5 10 15 20 25 30 35
Number of Tasks
% D
evia
tio
n F
rom
Lin
ear
1,000
2,500
5,000
12,000
20,000
Linear (1,000)
Linear (2,500)
Linear (5,000)
Linear (12,000)
Linear (20,000)
Graph 9: Deviation from Linearity - HTR
This graph illustrates more clearly what the first graph suggested. It may be seen that for 1,000 particles the problem rapidly becomes non-linear. For the larger number of particles there is a steady reduction in non-linearity as the number of particles is increased. Each line has a trendline, its equation, and its r^2 value plotted as well. It may also be observed that the deviation from linearity is very nearly linear with the number of nodes. The only way to improve that linearity is by increasing the number of particles and as will be shown later the problem complexity.

28
12
4
8
16
22
301,000
2,5005,000
12,00020,000
0.000
0.100
0.200
0.300
0.400
0.500
0.600
0.700
0.800
0.900
1.000
Fra
ctio
n o
f M
axim
um
Tim
e
Number of Nodes
Number of Particles
Eskom - Complex Core - Fraction Of 1 Node Run Time
0.900-1.000
0.800-0.900
0.700-0.800
0.600-0.700
0.500-0.600
0.400-0.500
0.300-0.400
0.200-0.300
0.100-0.200
0.000-0.100
Graph 10: Fraction of Maximum Run Time – Eskom
This graph is quite similar to the Fraction of Maximum Run Time – HTR. The major distinguishing feature is that there is significant improvement in run time for greater numbers of nodes. Where the HTR graph bottomed out around 4-8 nodes the 5,000-20,000 lines show significant improvement all the way to 30 nodes. This suggests that a complex problem will run more efficiently on a large number of nodes. The 1,000 particle line, once again, actually increases in run time at large numbers of nodes.

29
Eskom - Complex Core - Deviation From Linearity
y = 24.102x - 67.271
R2 = 0.9695
y = 12.328x - 41.348
R2 = 0.9106
y = 6.187x - 16.7
R2 = 0.9764y = 3.7938x - 8.4525
R2 = 0.9817
y = 3.1637x - 6.5851
R2 = 0.9926
-100.000
0.000
100.000
200.000
300.000
400.000
500.000
600.000
700.000
800.000
0 5 10 15 20 25 30 35
Number of Tasks
% D
evia
tio
n f
rom
Lin
eari
ty
1,000
2,500
5,000
12,000
20,000
Linear (1,000)
Linear (2,500)
Linear (5,000)
Linear (12,000)
Linear (20,000)
Graph 11: Deviation From Linearity - Eskom
This graph shows the same trends as the Deviation From Linearity – HTR graph. However, in this case the difference between between the number of particles run is larger than in the HTR case. The relative importance of using a large number of particles is even more pronounced for this complex problem. The absolute non-linearity heavily favours the more complex case. fThe 12,000 and 20,000 particle case never actually surpass 100% non-linearity where the 1,000 particle case crosses somewhere near 8 nodes.

30
12
48
1622
30
HT
R 1
,000
Esk
om 1
,000
HT
R 2
,500
Esk
om 2
,500
HT
R 5
,000
Esk
om 5
,000
HT
R 1
2,00
0
Esk
om 1
2,00
0
HT
R 2
0,00
0
Esk
om 2
0,00
0
0.000
100.000
200.000
300.000
400.000
500.000
600.000
700.000
800.000
900.000
1000.000
% D
evaition
from
Lin
ear
Number of Nodes
Number of Particles + Problem Complexity
HTR-Eskom Devaition
900.000-1000.000
800.000-900.000
700.000-800.000
600.000-700.000
500.000-600.000
400.000-500.000
300.000-400.000
200.000-300.000
100.000-200.000
0.000-100.000
Graph 12: Deviation from Linearity – HTR & Eskom
This graph combines Graphs 9 & 11 into a three dimensional graph with two functions on the y axis. Our original assumptions are born out in this graph. Deviation is a maximum at high numbers of nodes, small number of particles, and simple geometries. An unexpected result is the large difference between the HTR and Eskom lines at large numbers of particles. For the 30 node line between 1,000-5,000 particles the HTR and Eskom lines are a smoothly sloping function. The 12,000 and 20,000 lines at 30 nodes shows a sharp deviation between the Eskom and HTR results. This effect may stem from the geometry complexity compounding with the number of particles. A second somewhat surprising result is how quickly these runs deviate from linearity. To stay below 100% non-linearity the user must use very small numbers of nodes (4-8) for the simple geometry. For the Eskom case one may use all 30 nodes for 20,000 particles but are confined to 8 nodes for the 1,000 particle case. This suggests that only very difficult problems should use all 30 nodes. Except in cases of complex geometries and at least 12,000 particles the user probably shouldn’ t be running on all 30

31
nodes. Optimizing MCNP4C The reader by now may have a good feeling for the complexity of optimizing MCNP4C runs. To solve this problem a script was created that will tell the user the optimum number of nodes to run for a given number of particles, problem complexity, and a desired non-linearity. Users will typically have a set problem complexity and a desired number of particles to achieve good statistics. This leaves the third major factor, the number of nodes, as the only parameter to modify to make sure that Echelon is being used effectively. It will be assumed in the subsequent process that all three major factors are separable. It is expected that this assumption will be precise enough for its use in estimating the optimal number of nodes. Using the two graphs showing non-linearity (9 & 11) and the equations for the fitted lines a series of 10 linear equations can be extracted. These equations yield non-linearity for a given number of nodes but depend on the number of particles and the problem complexity. Using the coefficients and constants in the above 10 equations one may create a new set of equations that depend on the number of particles and calculate the coefficients and constants for the original equations. Testing different curve shape showed the number of particles varies as a power function. Trendlines were fit to the power functions in order to obtain new equations to separate the problem complexity. The problem complexity was determined to be a linear function and trendlines were fit to these equations. The coefficients for these final equations were calculated and coded into a Perl script that determines the number of nodes to give at most 100% non-linearity. The script must be given two inputs; the number of particles and the problem complexity. Using the pre-determined coefficients and the given problem complexity the script calculates the coefficients for the number of particles equation. Using the number of particles and the new coefficients the script then calculates the coefficients for the final equations dealing with non-linearity. By inverting this equation and making sure the non-linearity is less than 100% one arrives at the desired number of nodes. The script, stasks, is included in Appendix L.

32
CONCLUSION
The creation of Echelon has been an educational and difficult process that required far longer than originally intended. Future designers should carefully research hardware before purchase and not be surprised that MCNP k-code performance is highly dependent on problem design. Future advances in this cluster remain to be made but the vast majority of the work is finished. While Beowulf Clusters require a significant investment in time and effort from the builder and administrator, they offer a significant advancement over current capabilities for a fraction of the cost of comparable alternatives. The builder of a Beowulf Cluster will have to contend with many problems specific to his cluster design. However, making judicious choices about the BIOS before purchase may save months. Perhaps the most important consideration would be to choose a BIOS that can easily communicate with the server. The second major concern should be making sure that the BIOS does not require a video card to boot or choosing to purchase a motherboard with a built in video card. These two problems turned the building of Echelon into a very difficult and long-term process. Once the cluster was finished it was surprising to learn that MCNP k-code performance is highly dependent upon problem design. In particular, the number of particles, problem complexity, and the number of nodes it is run on will determine how close to linear the calculation will be. A series of tests were run to determine the optimum number of nodes for a given problem complexity and number of particles. These tests were used to create a script that makes it easy for the user to get a desired performance from the cluster. Future advancements to the cluster will include job-scheduling software as more users are added to the cluster. Job scheduling software will allow users to optimally use the cluster’s resources without interfering with each other and allow the administrator to set job priority. Beowulf Clusters are a highly adaptable low cost solution for computationally intensive tasks that don’ t require frequent communication. Future improvements will be made but to date an approximately a fifteen-fold serial speedup and a thirty-fold parallel speedup in MCNP k-code calculations was achieved. This achievement cost just over $13,250 suggesting that a Beowulf Cluster is a cost effective solution for rapid MCNP k-code calculations.

33
REFERENCES
NOTE: These references will provide general information about individual pieces of software and specific setups. The reader will have to adapt this general information to his specific case.
Beowulf Cluster Computing with Linux, Thomas Sterling, The MIT Press, Cambridge, 2002.
Boot + Root + Raid + Lilo : Software Raid HOWTO http://www.linuxhq.com/ldp/howto/Boot+Root+Raid+LILO.html
Diskless Nodes HOW-To document for Linux
http://www.tldp.org/HOWTO/Diskless-HOWTO.html
Linux NFS-HOWTO http://nfs.sourceforge.net/nfs-howto/
Network Boot and Exotic Root HOWTO
http://www.tldp.org/HOWTO/Network-boot-HOWTO/
Novell Boot ROM Developer's Guide for DOS Workstations http://www.zigamorph.net/ibm8227/rpl.pdf
Project Special Brew: Super Computing on a Budget
http://www.ecs.soton.ac.uk/~srg/publications/pdf/SpecialBrew.pdf
PVM Version 3.4: Parallel Virtual Machine System http://www.netlib.org/pvm3/pvm3.4.4.tgz
Root NFS - Another Approach
http://www.tldp.org/HOWTO/Diskless-root-NFS-other-HOWTO.html
Root over nfs clients & server Howto http://www.tldp.org/HOWTO/Diskless-root-NFS-HOWTO.html
The Software-RAID HOWTO
http://www.tldp.org/HOWTO/Software-RAID-HOWTO.html

34
APPENDIX A; /etc/dhcpd.conf
default-lease-time 600; max-lease-time 7200; option domain-name "echelon"; option domain-name-servers r0.echelon.edu,r1.echelon.edu,r2.echelon.edu,r3.echelon.edu; use-host-decl-names on; filename "/node/kernel/vmlinuz"; subnet 18.54.0.0 netmask 255.255.255.0 { } subnet 192.168.0.0 netmask 255.255.255.0 { option broadcast-address 192.168.0.255; option routers r0.echelon.edu; host e1 { hardware ethernet 00:07:95:B2:F3:19; fixed-address 192.168.0.1; } host e2 { hardware ethernet 00:07:95:AA:2A:AA; fixed-address 192.168.0.2; } host e3 { hardware ethernet 00:07:95:B2:F0:4D; fixed-address 192.168.0.3; } host e4 { hardware ethernet 00:07:95:C1:8E:4D; fixed-address 192.168.0.4; } host e5{ hardware ethernet 00:07:95:C1:BA:95; fixed-address 192.168.0.5; } host e6 { hardware ethernet 00:07:95:B2:EC:F7; fixed-address 192.168.0.6; } host e7 { hardware ethernet 00:07:95:BF:7D:70; fixed-address 192.168.0.7; } host e8 { hardware ethernet 00:07:95:B2:F2:31; fixed-address 192.168.0.8; } } subnet 192.168.1.0 netmask 255.255.255.0 { option broadcast-address 192.168.1.255; option routers r1.echelon.edu;

35
host e9 { hardware ethernet 00:07:95:C1:00:BF; fixed-address 192.168.1.9; } host e10 { hardware ethernet 00:07:95:C1:8C:50; fixed-address 192.168.1.10; } host e11 { hardware ethernet 00:07:95:B2:EC:F5; fixed-address 192.168.1.11; } host e12 { hardware ethernet 00:07:95:B2:F4:F2; fixed-address 192.168.1.12; } host e13 { hardware ethernet 00:07:95:B1:25:E3; fixed-address 192.168.1.13; } host e14 { hardware ethernet 00:07:95:B2:ED:9A; fixed-address 192.168.1.14; } host e15 { hardware ethernet 00:07:95:B2:ED:95; fixed-address 192.168.1.15; } } subnet 192.168.2.0 netmask 255.255.255.0 { option broadcast-address 192.168.2.255; option routers r2.echelon.edu; host e16 { hardware ethernet 00:07:95:AA:29:81; fixed-address 192.168.2.16; } host e17 { hardware ethernet 00:07:95:B2:ED:9F; fixed-address 192.168.2.17; } host e18 { hardware ethernet 00:07:95:A7:1A:9A; fixed-address 192.168.2.18; } host e19 { hardware ethernet 00:07:95:B2:F2:30; fixed-address 192.168.2.19; } host e20 { hardware ethernet 00:07:95:C1:F3:3B; fixed-address 192.168.2.20; } host e21 { hardware ethernet 00:07:95:C0:93:F1;

36
fixed-address 192.168.2.21; } host e22 { hardware ethernet 00:07:95:B1:25:E5; fixed-address 192.168.2.22; } host e23 { hardware ethernet 00:07:95:A7:1E:2A; fixed-address 192.168.2.23; } } subnet 192.168.3.0 netmask 255.255.255.0 { option broadcast-address 192.168.3.255; option routers r3.echelon.edu; host e24 { hardware ethernet 00:07:95:C2:28:6F; fixed-address 192.168.3.24; } host e25{ hardware ethernet 00:07:95:C1:8D:37; fixed-address 192.168.3.25; } host e26 { hardware ethernet 00:07:95:AA:2A:AB; fixed-address 192.168.3.26; } host e27 { hardware ethernet 00:07:95:AA:28:52; fixed-address 192.168.3.27; } host e28 { hardware ethernet 00:07:95:AA:28:5F; fixed-address 192.168.3.28; } host e29 { hardware ethernet 00:07:95:C1:BB:F6; fixed-address 192.168.3.29; } host e30 { hardware ethernet 00:07:95:B2:F0:4E; fixed-address 192.168.3.30; } }

37
APPENDIX B
(node) linux-2.4.18/.config # # Aut omat i cal l y gener at ed by make menuconf i g: don' t edi t # CONFI G_X86=y CONFI G_I SA=y # CONFI G_SBUS i s not set CONFI G_UI D16=y # # Code mat ur i t y l evel opt i ons # CONFI G_EXPERI MENTAL=y # # Loadabl e modul e suppor t # # CONFI G_MODULES i s not set # # Pr ocessor t ype and f eat ur es # # CONFI G_M386 i s not set # CONFI G_M486 i s not set # CONFI G_M586 i s not set # CONFI G_M586TSC i s not set # CONFI G_M586MMX i s not set # CONFI G_M686 i s not set CONFI G_MPENTI UMI I I =y # CONFI G_MPENTI UM4 i s not set # CONFI G_MK6 i s not set # CONFI G_MK7 i s not set # CONFI G_MELAN i s not set # CONFI G_MCRUSOE i s not set # CONFI G_MWI NCHI PC6 i s not set # CONFI G_MWI NCHI P2 i s not set # CONFI G_MWI NCHI P3D i s not set # CONFI G_MCYRI XI I I i s not set CONFI G_X86_WP_WORKS_OK=y CONFI G_X86_I NVLPG=y CONFI G_X86_CMPXCHG=y CONFI G_X86_XADD=y CONFI G_X86_BSWAP=y CONFI G_X86_POPAD_OK=y # CONFI G_RWSEM_GENERI C_SPI NLOCK i s not set CONFI G_RWSEM_XCHGADD_ALGORI THM=y CONFI G_X86_L1_CACHE_SHI FT=5 CONFI G_X86_TSC=y CONFI G_X86_GOOD_API C=y CONFI G_X86_PGE=y CONFI G_X86_USE_PPRO_CHECKSUM=y # CONFI G_TOSHI BA i s not set # CONFI G_I 8K i s not set # CONFI G_MI CROCODE i s not set # CONFI G_X86_MSR i s not set # CONFI G_X86_CPUI D i s not set CONFI G_NOHI GHMEM=y # CONFI G_HI GHMEM4G i s not set # CONFI G_HI GHMEM64G i s not set # CONFI G_MATH_EMULATI ON i s not set # CONFI G_MTRR i s not set # CONFI G_SMP i s not set # CONFI G_X86_UP_API C i s not set # CONFI G_X86_UP_I OAPI C i s not set #

38
# Gener al set up # CONFI G_NET=y CONFI G_PCI =y # CONFI G_PCI _GOBI OS i s not set # CONFI G_PCI _GODI RECT i s not set CONFI G_PCI _GOANY=y CONFI G_PCI _BI OS=y CONFI G_PCI _DI RECT=y CONFI G_PCI _NAMES=y # CONFI G_EI SA i s not set # CONFI G_MCA i s not set # CONFI G_HOTPLUG i s not set # CONFI G_PCMCI A i s not set # CONFI G_HOTPLUG_PCI i s not set CONFI G_SYSVI PC=y CONFI G_BSD_PROCESS_ACCT=y CONFI G_SYSCTL=y CONFI G_KCORE_ELF=y # CONFI G_KCORE_AOUT i s not set CONFI G_BI NFMT_AOUT=y CONFI G_BI NFMT_ELF=y CONFI G_BI NFMT_MI SC=y # CONFI G_PM i s not set # CONFI G_ACPI i s not set # CONFI G_APM i s not set # # Memor y Technol ogy Devi ces ( MTD) # # CONFI G_MTD i s not set # # Par al l el por t suppor t # # CONFI G_PARPORT i s not set # # Pl ug and Pl ay conf i gur at i on # # CONFI G_PNP i s not set # CONFI G_I SAPNP i s not set # # Bl ock devi ces # # CONFI G_BLK_DEV_FD i s not set # CONFI G_BLK_DEV_XD i s not set # CONFI G_PARI DE i s not set # CONFI G_BLK_CPQ_DA i s not set # CONFI G_BLK_CPQ_CI SS_DA i s not set # CONFI G_BLK_DEV_DAC960 i s not set CONFI G_BLK_DEV_LOOP=y # CONFI G_BLK_DEV_NBD i s not set CONFI G_BLK_DEV_RAM=y CONFI G_BLK_DEV_RAM_SI ZE=4096 CONFI G_BLK_DEV_I NI TRD=y # # Mul t i - devi ce suppor t ( RAI D and LVM) # # CONFI G_MD i s not set # CONFI G_BLK_DEV_MD i s not set # CONFI G_MD_LI NEAR i s not set # CONFI G_MD_RAI D0 i s not set # CONFI G_MD_RAI D1 i s not set # CONFI G_MD_RAI D5 i s not set # CONFI G_MD_MULTI PATH i s not set # CONFI G_BLK_DEV_LVM i s not set #

39
# Net wor ki ng opt i ons # CONFI G_PACKET=y # CONFI G_PACKET_MMAP i s not set # CONFI G_NETLI NK_DEV i s not set # CONFI G_NETFI LTER i s not set CONFI G_FI LTER=y CONFI G_UNI X=y CONFI G_I NET=y CONFI G_I P_MULTI CAST=y # CONFI G_I P_ADVANCED_ROUTER i s not set CONFI G_I P_PNP=y CONFI G_I P_PNP_DHCP=y CONFI G_I P_PNP_BOOTP=y # CONFI G_I P_PNP_RARP i s not set # CONFI G_NET_I PI P i s not set # CONFI G_NET_I PGRE i s not set # CONFI G_I P_MROUTE i s not set # CONFI G_ARPD i s not set # CONFI G_I NET_ECN i s not set # CONFI G_SYN_COOKI ES i s not set # CONFI G_I PV6 i s not set # CONFI G_KHTTPD i s not set # CONFI G_ATM i s not set # CONFI G_VLAN_8021Q i s not set # CONFI G_I PX i s not set # CONFI G_ATALK i s not set # CONFI G_DECNET i s not set # CONFI G_BRI DGE i s not set # CONFI G_X25 i s not set # CONFI G_LAPB i s not set # CONFI G_LLC i s not set # CONFI G_NET_DI VERT i s not set # CONFI G_ECONET i s not set # CONFI G_WAN_ROUTER i s not set # CONFI G_NET_FASTROUTE i s not set # CONFI G_NET_HW_FLOWCONTROL i s not set # # QoS and/ or f ai r queuei ng # # CONFI G_NET_SCHED i s not set # # Tel ephony Suppor t # # CONFI G_PHONE i s not set # CONFI G_PHONE_I XJ i s not set # CONFI G_PHONE_I XJ_PCMCI A i s not set # # ATA/ I DE/ MFM/ RLL suppor t # # CONFI G_I DE i s not set # CONFI G_BLK_DEV_I DE_MODES i s not set # CONFI G_BLK_DEV_HD i s not set # # SCSI suppor t # # CONFI G_SCSI i s not set # # Fusi on MPT devi ce suppor t # # CONFI G_FUSI ON i s not set # CONFI G_FUSI ON_BOOT i s not set # CONFI G_FUSI ON_I SENSE i s not set # CONFI G_FUSI ON_CTL i s not set # CONFI G_FUSI ON_LAN i s not set

40
# # I EEE 1394 ( Fi r eWi r e) suppor t ( EXPERI MENTAL) # # CONFI G_I EEE1394 i s not set # # I 2O devi ce suppor t # # CONFI G_I 2O i s not set # CONFI G_I 2O_PCI i s not set # CONFI G_I 2O_BLOCK i s not set # CONFI G_I 2O_LAN i s not set # CONFI G_I 2O_SCSI i s not set # CONFI G_I 2O_PROC i s not set # # Net wor k devi ce suppor t # CONFI G_NETDEVI CES=y # # ARCnet devi ces # # CONFI G_ARCNET i s not set CONFI G_DUMMY=y # CONFI G_BONDI NG i s not set # CONFI G_EQUALI ZER i s not set # CONFI G_TUN i s not set # CONFI G_ETHERTAP i s not set # # Et her net ( 10 or 100Mbi t ) # CONFI G_NET_ETHERNET=y # CONFI G_SUNLANCE i s not set # CONFI G_HAPPYMEAL i s not set # CONFI G_SUNBMAC i s not set # CONFI G_SUNQE i s not set # CONFI G_SUNGEM i s not set # CONFI G_NET_VENDOR_3COM i s not set # CONFI G_LANCE i s not set # CONFI G_NET_VENDOR_SMC i s not set # CONFI G_NET_VENDOR_RACAL i s not set # CONFI G_AT1700 i s not set # CONFI G_DEPCA i s not set # CONFI G_HP100 i s not set # CONFI G_NET_I SA i s not set CONFI G_NET_PCI =y # CONFI G_PCNET32 i s not set # CONFI G_ADAPTEC_STARFI RE i s not set # CONFI G_AC3200 i s not set # CONFI G_APRI COT i s not set # CONFI G_CS89x0 i s not set # CONFI G_TULI P i s not set # CONFI G_DE4X5 i s not set # CONFI G_DGRS i s not set # CONFI G_DM9102 i s not set # CONFI G_EEPRO100 i s not set # CONFI G_LNE390 i s not set # CONFI G_FEALNX i s not set # CONFI G_NATSEMI i s not set # CONFI G_NE2K_PCI i s not set # CONFI G_NE3210 i s not set # CONFI G_ES3210 i s not set # CONFI G_8139CP i s not set # CONFI G_8139TOO i s not set # CONFI G_8139TOO_PI O i s not set # CONFI G_8139TOO_TUNE_TWI STER i s not set # CONFI G_8139TOO_8129 i s not set # CONFI G_8139_NEW_RX_RESET i s not set CONFI G_SI S900=y

41
# CONFI G_EPI C100 i s not set # CONFI G_SUNDANCE i s not set # CONFI G_TLAN i s not set # CONFI G_VI A_RHI NE i s not set # CONFI G_VI A_RHI NE_MMI O i s not set # CONFI G_WI NBOND_840 i s not set # CONFI G_NET_POCKET i s not set # # Et her net ( 1000 Mbi t ) # # CONFI G_ACENI C i s not set # CONFI G_DL2K i s not set # CONFI G_MYRI _SBUS i s not set # CONFI G_NS83820 i s not set # CONFI G_HAMACHI i s not set # CONFI G_YELLOWFI N i s not set # CONFI G_SK98LI N i s not set # CONFI G_FDDI i s not set # CONFI G_HI PPI i s not set # CONFI G_PLI P i s not set # CONFI G_PPP i s not set # CONFI G_SLI P i s not set # # Wi r el ess LAN ( non- hamr adi o) # # CONFI G_NET_RADI O i s not set # # Token Ri ng devi ces # # CONFI G_TR i s not set # CONFI G_NET_FC i s not set # CONFI G_RCPCI i s not set # CONFI G_SHAPER i s not set # # Wan i nt er f aces # # CONFI G_WAN i s not set # # Amat eur Radi o suppor t # # CONFI G_HAMRADI O i s not set # # I r DA ( i nf r ar ed) suppor t # # CONFI G_I RDA i s not set # # I SDN subsyst em # # CONFI G_I SDN i s not set # # Ol d CD- ROM dr i ver s ( not SCSI , not I DE) # # CONFI G_CD_NO_I DESCSI i s not set # # I nput cor e suppor t # # CONFI G_I NPUT i s not set # CONFI G_I NPUT_KEYBDEV i s not set # CONFI G_I NPUT_MOUSEDEV i s not set # CONFI G_I NPUT_JOYDEV i s not set # CONFI G_I NPUT_EVDEV i s not set

42
# # Char act er devi ces # CONFI G_VT=y CONFI G_VT_CONSOLE=y CONFI G_SERI AL=y CONFI G_SERI AL_CONSOLE=y # CONFI G_SERI AL_EXTENDED i s not set # CONFI G_SERI AL_NONSTANDARD i s not set CONFI G_UNI X98_PTYS=y CONFI G_UNI X98_PTY_COUNT=256 # # I 2C suppor t # # CONFI G_I 2C i s not set # # Mi ce # # CONFI G_BUSMOUSE i s not set # CONFI G_MOUSE i s not set # # Joyst i cks # # CONFI G_I NPUT_GAMEPORT i s not set # CONFI G_QI C02_TAPE i s not set # # Wat chdog Car ds # # CONFI G_WATCHDOG i s not set # CONFI G_I NTEL_RNG i s not set CONFI G_NVRAM=y CONFI G_RTC=y # CONFI G_DTLK i s not set # CONFI G_R3964 i s not set # CONFI G_APPLI COM i s not set # CONFI G_SONYPI i s not set # # Ft ape, t he f l oppy t ape devi ce dr i ver # # CONFI G_FTAPE i s not set # CONFI G_AGP i s not set # CONFI G_DRM i s not set # CONFI G_MWAVE i s not set # # Mul t i medi a devi ces # # CONFI G_VI DEO_DEV i s not set # # Fi l e syst ems # # CONFI G_QUOTA i s not set # CONFI G_AUTOFS_FS i s not set # CONFI G_AUTOFS4_FS i s not set # CONFI G_REI SERFS_FS i s not set # CONFI G_REI SERFS_CHECK i s not set # CONFI G_REI SERFS_PROC_I NFO i s not set # CONFI G_ADFS_FS i s not set # CONFI G_ADFS_FS_RW i s not set # CONFI G_AFFS_FS i s not set # CONFI G_HFS_FS i s not set # CONFI G_BFS_FS i s not set # CONFI G_EXT3_FS i s not set # CONFI G_JBD i s not set # CONFI G_JBD_DEBUG i s not set

43
# CONFI G_FAT_FS i s not set # CONFI G_MSDOS_FS i s not set # CONFI G_UMSDOS_FS i s not set # CONFI G_VFAT_FS i s not set # CONFI G_EFS_FS i s not set # CONFI G_JFFS_FS i s not set # CONFI G_JFFS2_FS i s not set # CONFI G_CRAMFS i s not set # CONFI G_TMPFS i s not set # CONFI G_RAMFS i s not set # CONFI G_I SO9660_FS i s not set # CONFI G_JOLI ET i s not set # CONFI G_ZI SOFS i s not set # CONFI G_MI NI X_FS i s not set # CONFI G_VXFS_FS i s not set # CONFI G_NTFS_FS i s not set # CONFI G_NTFS_RW i s not set # CONFI G_HPFS_FS i s not set CONFI G_PROC_FS=y CONFI G_DEVFS_FS=y # CONFI G_DEVFS_MOUNT i s not set CONFI G_DEVFS_DEBUG=y CONFI G_DEVPTS_FS=y # CONFI G_QNX4FS_FS i s not set # CONFI G_QNX4FS_RW i s not set # CONFI G_ROMFS_FS i s not set CONFI G_EXT2_FS=y # CONFI G_SYSV_FS i s not set # CONFI G_UDF_FS i s not set # CONFI G_UDF_RW i s not set # CONFI G_UFS_FS i s not set # CONFI G_UFS_FS_WRI TE i s not set # # Net wor k Fi l e Syst ems # # CONFI G_CODA_FS i s not set # CONFI G_I NTERMEZZO_FS i s not set CONFI G_NFS_FS=y CONFI G_NFS_V3=y CONFI G_ROOT_NFS=y # CONFI G_NFSD i s not set # CONFI G_NFSD_V3 i s not set CONFI G_SUNRPC=y CONFI G_LOCKD=y CONFI G_LOCKD_V4=y # CONFI G_SMB_FS i s not set # CONFI G_NCP_FS i s not set # CONFI G_NCPFS_PACKET_SI GNI NG i s not set # CONFI G_NCPFS_I OCTL_LOCKI NG i s not set # CONFI G_NCPFS_STRONG i s not set # CONFI G_NCPFS_NFS_NS i s not set # CONFI G_NCPFS_OS2_NS i s not set # CONFI G_NCPFS_SMALLDOS i s not set # CONFI G_NCPFS_NLS i s not set # CONFI G_NCPFS_EXTRAS i s not set # CONFI G_ZI SOFS_FS i s not set # CONFI G_ZLI B_FS_I NFLATE i s not set # # Par t i t i on Types # # CONFI G_PARTI TI ON_ADVANCED i s not set CONFI G_MSDOS_PARTI TI ON=y # CONFI G_SMB_NLS i s not set # CONFI G_NLS i s not set # # Consol e dr i ver s # CONFI G_VGA_CONSOLE=y

44
# CONFI G_VI DEO_SELECT i s not set # CONFI G_MDA_CONSOLE i s not set # # Fr ame- buf f er suppor t # # CONFI G_FB i s not set # # Sound # # CONFI G_SOUND i s not set # # USB suppor t # # CONFI G_USB i s not set # CONFI G_USB_UHCI i s not set # CONFI G_USB_UHCI _ALT i s not set # CONFI G_USB_OHCI i s not set # CONFI G_USB_AUDI O i s not set # CONFI G_USB_BLUETOOTH i s not set # CONFI G_USB_STORAGE i s not set # CONFI G_USB_STORAGE_DEBUG i s not set # CONFI G_USB_STORAGE_DATAFAB i s not set # CONFI G_USB_STORAGE_FREECOM i s not set # CONFI G_USB_STORAGE_I SD200 i s not set # CONFI G_USB_STORAGE_DPCM i s not set # CONFI G_USB_STORAGE_HP8200e i s not set # CONFI G_USB_STORAGE_SDDR09 i s not set # CONFI G_USB_STORAGE_JUMPSHOT i s not set # CONFI G_USB_ACM i s not set # CONFI G_USB_PRI NTER i s not set # CONFI G_USB_DC2XX i s not set # CONFI G_USB_MDC800 i s not set # CONFI G_USB_SCANNER i s not set # CONFI G_USB_MI CROTEK i s not set # CONFI G_USB_HPUSBSCSI i s not set # CONFI G_USB_PEGASUS i s not set # CONFI G_USB_KAWETH i s not set # CONFI G_USB_CATC i s not set # CONFI G_USB_CDCETHER i s not set # CONFI G_USB_USBNET i s not set # CONFI G_USB_USS720 i s not set # # USB Ser i al Conver t er suppor t # # CONFI G_USB_SERI AL i s not set # CONFI G_USB_SERI AL_GENERI C i s not set # CONFI G_USB_SERI AL_BELKI N i s not set # CONFI G_USB_SERI AL_WHI TEHEAT i s not set # CONFI G_USB_SERI AL_DI GI _ACCELEPORT i s not set # CONFI G_USB_SERI AL_EMPEG i s not set # CONFI G_USB_SERI AL_FTDI _SI O i s not set # CONFI G_USB_SERI AL_VI SOR i s not set # CONFI G_USB_SERI AL_I PAQ i s not set # CONFI G_USB_SERI AL_I R i s not set # CONFI G_USB_SERI AL_EDGEPORT i s not set # CONFI G_USB_SERI AL_KEYSPAN_PDA i s not set # CONFI G_USB_SERI AL_KEYSPAN i s not set # CONFI G_USB_SERI AL_KEYSPAN_USA28 i s not set # CONFI G_USB_SERI AL_KEYSPAN_USA28X i s not set # CONFI G_USB_SERI AL_KEYSPAN_USA28XA i s not set # CONFI G_USB_SERI AL_KEYSPAN_USA28XB i s not set # CONFI G_USB_SERI AL_KEYSPAN_USA19 i s not set # CONFI G_USB_SERI AL_KEYSPAN_USA18X i s not set # CONFI G_USB_SERI AL_KEYSPAN_USA19W i s not set # CONFI G_USB_SERI AL_KEYSPAN_USA49W i s not set # CONFI G_USB_SERI AL_MCT_U232 i s not set # CONFI G_USB_SERI AL_KLSI i s not set

45
# CONFI G_USB_SERI AL_PL2303 i s not set # CONFI G_USB_SERI AL_CYBERJACK i s not set # CONFI G_USB_SERI AL_XI RCOM i s not set # CONFI G_USB_SERI AL_OMNI NET i s not set # CONFI G_USB_RI O500 i s not set # # Bl uet oot h suppor t # # CONFI G_BLUEZ i s not set # # Ker nel hacki ng # # CONFI G_DEBUG_KERNEL i s not set

46
APPENDIX C /etc/expor ts
# /etc/exports: the access control list for filesystems which may be exported # to NFS clients. See exports(5). # #all subnets /node/nfsroot 192.168.0.0/255.255.0.0(ro,no_root_squash) /usr 192.168.0.0/255.255.0.0(ro,no_root_squash) /bin 192.168.0.0/255.255.0.0(ro,no_root_squash) /sbin 192.168.0.0/255.255.0.0(ro,no_root_squash) /lib 192.168.0.0/255.255.0.0(ro,no_root_squash) /root 192.168.0.0/255.255.0.0(ro,no_root_squash) /home 192.168.0.0/255.255.0.0(rw,no_root_squash)

47
APPENDIX D (node) /etc/fstab.basic
#! /bin/sh # #<file system> <mount point> <type> <options> <dump> <pass> proc /proc proc defaults 0 0 /dev/ram1 /var ext2 defaults,remount 0 0 /dev/ram2 /tmp ext2 defaults,remount 0 0 /dev/ram3 /etc ext2 defaults,remount 0 0 #subnet for this node to mount nfs shares

48
APPENDIX E (node) /etc/init.d/rcS
#! / bi n/ sh # # r cS Cal l al l S??* scr i pt s i n / et c/ r cS. d i n # numer i cal / al phabet i cal or der . # # Ver si on: @( #) / et c/ i ni t . d/ r cS 2. 76 19- Apr - 1999 mi quel s@ci st r on. nl # #st ar t r eset daemon / sbi n/ r eset d PATH=/ sbi n: / bi n: / usr / sbi n: / usr / bi n r unl evel =S pr evl evel =N umask 022 expor t PATH r unl evel pr evl evel #mount node wr i t abl e di r ect or i es as RAM di sks echo Mount i ng / t mp mke2f s - q - i 20480 / dev/ r am2 20480 mount - n / dev/ r am2 / t mp - o def aul t s, r w chmod a+r wx / t mp echo t mp ok f or pvm now echo Mount i ng / et c cp - a / et c / t mp #keep basi c et c f i l es f r om bei ng mount ed over mke2f s - q - i 5120 / dev/ r am3 5120 mount - n / dev/ r am3 / et c - o def aul t s, r w cp - a / t mp/ et c/ * / et c r m - r f / t mp/ et c echo Mount i ng / var mke2f s - q - i 5120 / dev/ r am1 5120 mount - n / dev/ r am1 / var - o def aul t s, r w cp - a / nodef s/ var / echo done wi t h RAM mount s #check f or whi ch subnet node i s supposed t o be on by det er mi ni ng I P a=$( i f conf i g et h0 | gr ep " i net addr " | sed " s/ . * i net addr : 192\ . 168\ . \ ( [ 0- 9] * \ ) . * / \ 1/ " )

49
#r est of f st ab f i l e wi t h cor r ect gat eway f or i t ' s i p b=" r $a. echel on. edu: / usr / usr nf s def aul t s, r o 0 0" c=" r $a. echel on. edu: / home / home nf s def aul t s, r w 0 0" d=" r $a. echel on. edu: / bi n / bi n nf s def aul t s, r o 0 0" e=" r $a. echel on. edu: / sbi n / sbi n nf s def aul t s, r o 0 0" f =" r $a. echel on. edu: / l i b / l i b nf s def aul t s, r o 0 0" g=" r $a. echel on. edu: / r oot / r oot nf s def aul t s, r o 0 0" #wr i t e compl et e f st ab echo cr eat i ng l ast hal f of f st ab echo $b$' \ n' $c$' \ n' $d$' \ n' $e$' \ n' $g$' \ n' $g$' \ n' > / et c/ f st ab. uni que echo cr eat i ng act ual f st ab cat / et c/ f st ab. basi c / et c/ f st ab. uni que > / et c/ f st ab echo done wi t h r cS st uf f now * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * #back t o nor mal r cS* * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * # # See i f syst em needs t o be set up. Thi s i s ONLY meant t o # be used f or t he i ni t i al set up af t er a f r esh i nst al l at i on! # i f [ - x / sbi n/ unconf i gur ed. sh ] t hen / sbi n/ unconf i gur ed. sh f i # # Sour ce def aul t s. # . / et c/ def aul t / r cS expor t VERBOSE # # Tr ap CTRL- C &c onl y i n t hi s shel l so we can i nt er r upt subpr ocesses. # t r ap " : " I NT QUI T TSTP # # Cal l al l par t s i n or der .

50
# f or i i n / et c/ r cS. d/ S??* do # I gnor e dangl i ng syml i nks f or now. [ ! - f " $i " ] && cont i nue case " $i " i n * . sh) # Sour ce shel l scr i pt f or speed. ( t r ap - I NT QUI T TSTP set st ar t . $i ) ; ; * ) # No sh ext ensi on, so f or k subpr ocess. $i st ar t ; ; esac done # # For compat i bi l i t y , r un t he f i l es i n / et c/ r c. boot t oo. # [ - d / et c/ r c. boot ] && r un- par t s / et c/ r c. boot # # Fi ni sh set up i f needed. The comment above about # / sbi n/ unconf i gur ed. sh appl i es her e as wel l ! # i f [ - x / sbi n/ set up. sh ] t hen / sbi n/ set up. sh f i

51
APPENDIX F /etc/hosts
127.0.0.1 localhost #beowulf stuff 192.168.0.128 echelon.edu echelon 192.168.0.128 r0.echelon.edu r0 192.168.1.128 r1.echelon.edu r1 192.168.2.128 r2.echelon.edu r2 192.168.3.128 r3.echelon.edu r3 192.168.0.1 e1.echelon.edu e1 192.168.0.2 e2.echelon.edu e2 192.168.0.3 e3.echelon.edu e3 192.168.0.4 e4.echelon.edu e4 192.168.0.5 e5.echelon.edu e5 192.168.0.6 e6.echelon.edu e6 192.168.0.7 e7.echelon.edu e7 192.168.0.8 e8.echelon.edu e8 192.168.1.9 e9.echelon.edu e9 192.168.1.10 e10.echelon.edu e10 192.168.1.11 e11.echelon.edu e11 192.168.1.12 e12.echelon.edu e12 192.168.1.13 e13.echelon.edu e13 192.168.1.14 e14.echelon.edu e14 192.168.1.15 e15.echelon.edu e15 192.168.2.16 e16.echelon.edu e16 192.168.2.17 e17.echelon.edu e17 192.168.2.18 e18.echelon.edu e18 192.168.2.19 e19.echelon.edu e19 192.168.2.20 e20.echelon.edu e20 192.168.2.21 e21.echelon.edu e21 192.168.2.22 e22.echelon.edu e22 192.168.2.23 e23.echelon.edu e23 192.168.3.24 e24.echelon.edu e24 192.168.3.25 e25.echelon.edu e25 192.168.3.26 e26.echelon.edu e26 192.168.3.27 e27.echelon.edu e27 192.168.3.28 e28.echelon.edu e28 192.168.3.29 e29.echelon.edu e29 192.168.3.30 e30.echelon.edu e30 # The following lines are desirable for IPv6 capable hosts # (added automatically by netbase upgrade) ::1 ip6-localhost ip6-loopback fe00::0 ip6-localnet ff00::0 ip6-mcastprefix ff02::1 ip6-allnodes ff02::2 ip6-allrouters ff02::3 ip6-allhosts

52
APPENDIX G
(node) /etc/init.d/hostname.sh
#! / bi n/ sh # host name. sh Set host name. # # Ver si on: @( #) host name. sh 1. 10 26- Feb- 2001 mi quel s@ci st r on. nl # i f [ - f / et c/ host name ] t hen i f conf i g et h0 | gr ep " i net addr " | sed " s/ . * i net addr : 192\ . 168\ . [ 0- 9] * \ . \ ( [ 0- 9] * \ ) . * / e\ 1/ " > / et c/ host name host name - - f i l e / et c/ host name f i

53
APPENDIX H Password Update Scr ipt
#!/bin/bash for ((i=1; i <= 30 ; i++)) #run through all nodes do echo updating node $i scp /etc/passwd e$i:/etc/ scp /etc/passwd- e$i:/etc/ scp /etc/shadow e$i:/etc/ scp /etc/shadow- e$i:/etc/ scp /etc/gshadow e$i:/etc/ scp /etc/gshadow- e$i:/etc/ scp /etc/group e$i:/etc/ scp /etc/group- e$i:/etc/ done echo all passwords updated

54
APPENDIX I (node) /sbin/resetd.c
#i ncl ude <sys/ socket . h> #i ncl ude <net i net / i n. h> #i ncl ude <sys/ t ypes. h> #i ncl ude <ar pa/ i net . h> #i ncl ude <st di o. h> #i ncl ude <st dl i b. h> #i ncl ude <uni st d. h> #i ncl ude <sys/ r eboot . h> #i ncl ude " r eset . h" char buf f [ 256] ; voi d daemoni ze( ) { / / Based on t he Uni x Pr ogr ammi ng FAQ swi t ch ( f or k( ) ) { case - 1: per r or ( " Fi r st f or k" ) ; exi t ( 1) ; case 0: br eak; def aul t : exi t ( 0) ; } set s i d( ) ; swi t ch ( f or k( ) ) { case - 1: per r or ( " Second f or k" ) ; exi t ( 1) ; case 0: br eak; def aul t : exi t ( 0) ; }

55
chdi r ( " / " ) ; umask( 0) ; c l ose( 0) ; c l ose( 1) ; c l ose( 2) ; } i nt mai n( ) { i nt udp_socket = socket ( PF_I NET, SOCK_DGRAM, I PPROTO_UDP) ; st r uct sockaddr _i n t o; i nt l en; i f ( udp_socket == - 1) { per r or ( " socket " ) ; exi t ( 1) ; } t o. s i n_f ami l y = AF_I NET; t o. s i n_por t = PORT; t o. s i n_addr . s_addr = i net _addr ( " 0. 0. 0. 0" ) ; i f ( bi nd( udp_socket , ( st r uct sockaddr * ) &t o, s i zeof ( t o) ) ) { per r or ( " bi nd" ) ; exi t ( 1) ; } daemoni ze( ) ; do { i f ( ( l en = r ecv( udp_socket , buf f , 256, MSG_WAI TALL) ) == st r l en( MAGI C) + 1 && st r ncmp( MAGI C, buf f , l en) == 0) { pr i nt f ( " Reboot i ng! ! %i \ n" , r eboot ( RB_AUTOBOOT) ) ; per r or ( " " ) ; } } whi l e ( 1) ; r et ur n 0; }

56
APPENDIX J /sbin/resetc.c
#include <sys/socket.h> #include <netinet/in.h> #include <sys/types.h> #include <arpa/inet.h> #include <string.h> #include <stdio.h> #include <stdlib.h> #include <netdb.h> #include "reset.h" //int prepaddr(char *hostname, int port, struct sockaddr_in *addr) //{ // struct hostent *host; // // do // host = gethostbyname(hostname); // while (host == NULL && h_errno == TRY_AGAIN); // // if (host == NULL) // { // endhostent(); // return -1; // } // // bzero(addr, sizeof(*addr)); // addr->sin_family = host->h_addrtype; // (void) memcpy(&(addr->sin_addr), host->h_addr, host->h_length); // endhostent(); // addr->sin_port = htons(port); // // return 0; //} int main(int argc, char **argv) { int udp_socket = socket(PF_INET, SOCK_DGRAM, IPPROTO_UDP); struct sockaddr_in to; if (argc != 2) { printf("Bad args : resetc machine\n"); return 1;

57
} to.sin_family = AF_INET; to.sin_port = PORT; to.sin_addr.s_addr = inet_addr(argv[1]); // if (prepaddr(argv[1], PORT, &to) < 0) // { // perror("prepaddr"); // return 1; // } if (sendto(udp_socket, MAGIC, strlen(MAGIC) + 1, 0, (struct sockaddr*) &to, sizeof(to))) { perror("sendto"); return 1; } return 0;
}
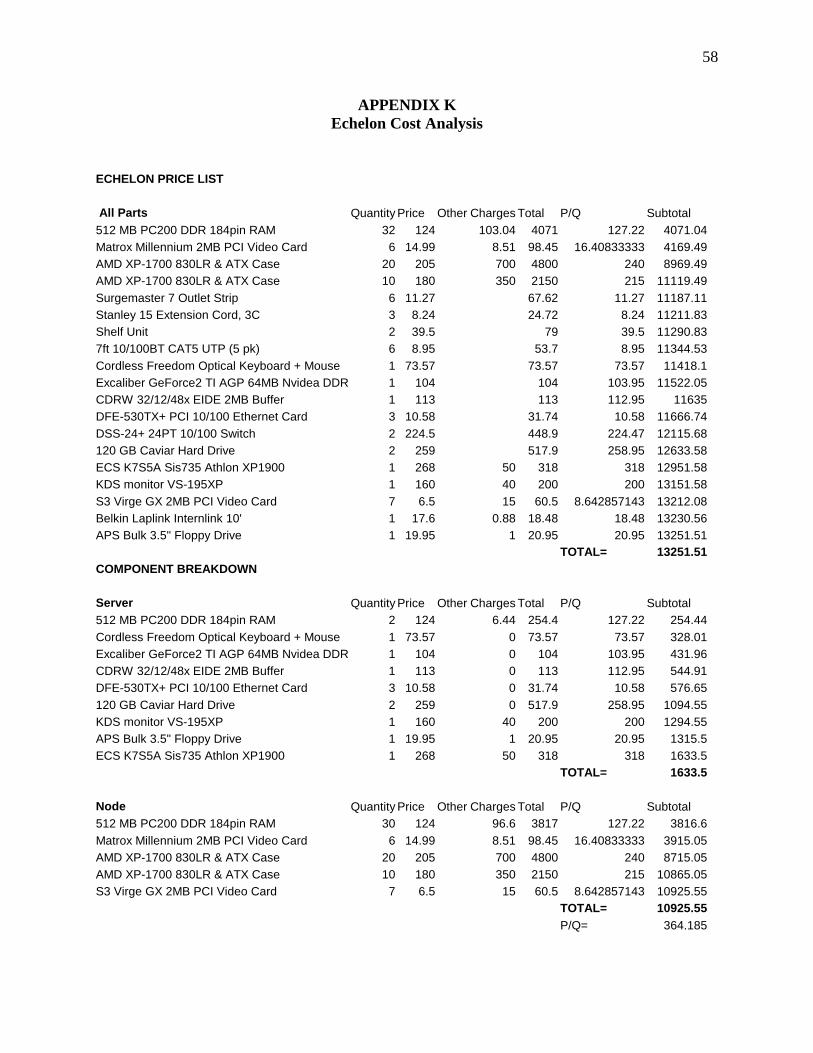
58
APPENDIX K Echelon Cost Analysis
ECHELON PRICE LIST All Parts Quantity Price Other Charges Total P/Q Subtotal 512 MB PC200 DDR 184pin RAM 32 124 103.04 4071 127.22 4071.04 Matrox Millennium 2MB PCI Video Card 6 14.99 8.51 98.45 16.40833333 4169.49 AMD XP-1700 830LR & ATX Case 20 205 700 4800 240 8969.49 AMD XP-1700 830LR & ATX Case 10 180 350 2150 215 11119.49 Surgemaster 7 Outlet Strip 6 11.27 67.62 11.27 11187.11 Stanley 15 Extension Cord, 3C 3 8.24 24.72 8.24 11211.83 Shelf Unit 2 39.5 79 39.5 11290.83 7ft 10/100BT CAT5 UTP (5 pk) 6 8.95 53.7 8.95 11344.53 Cordless Freedom Optical Keyboard + Mouse 1 73.57 73.57 73.57 11418.1 Excaliber GeForce2 TI AGP 64MB Nvidea DDR 1 104 104 103.95 11522.05 CDRW 32/12/48x EIDE 2MB Buffer 1 113 113 112.95 11635 DFE-530TX+ PCI 10/100 Ethernet Card 3 10.58 31.74 10.58 11666.74 DSS-24+ 24PT 10/100 Switch 2 224.5 448.9 224.47 12115.68 120 GB Caviar Hard Drive 2 259 517.9 258.95 12633.58 ECS K7S5A Sis735 Athlon XP1900 1 268 50 318 318 12951.58 KDS monitor VS-195XP 1 160 40 200 200 13151.58 S3 Virge GX 2MB PCI Video Card 7 6.5 15 60.5 8.642857143 13212.08 Belkin Laplink Internlink 10' 1 17.6 0.88 18.48 18.48 13230.56 APS Bulk 3.5" Floppy Drive 1 19.95 1 20.95 20.95 13251.51 TOTAL= 13251.51 COMPONENT BREAKDOWN Server Quantity Price Other Charges Total P/Q Subtotal 512 MB PC200 DDR 184pin RAM 2 124 6.44 254.4 127.22 254.44 Cordless Freedom Optical Keyboard + Mouse 1 73.57 0 73.57 73.57 328.01 Excaliber GeForce2 TI AGP 64MB Nvidea DDR 1 104 0 104 103.95 431.96 CDRW 32/12/48x EIDE 2MB Buffer 1 113 0 113 112.95 544.91 DFE-530TX+ PCI 10/100 Ethernet Card 3 10.58 0 31.74 10.58 576.65 120 GB Caviar Hard Drive 2 259 0 517.9 258.95 1094.55 KDS monitor VS-195XP 1 160 40 200 200 1294.55 APS Bulk 3.5" Floppy Drive 1 19.95 1 20.95 20.95 1315.5 ECS K7S5A Sis735 Athlon XP1900 1 268 50 318 318 1633.5 TOTAL= 1633.5 Node Quantity Price Other Charges Total P/Q Subtotal 512 MB PC200 DDR 184pin RAM 30 124 96.6 3817 127.22 3816.6 Matrox Millennium 2MB PCI Video Card 6 14.99 8.51 98.45 16.40833333 3915.05 AMD XP-1700 830LR & ATX Case 20 205 700 4800 240 8715.05 AMD XP-1700 830LR & ATX Case 10 180 350 2150 215 10865.05 S3 Virge GX 2MB PCI Video Card 7 6.5 15 60.5 8.642857143 10925.55 TOTAL= 10925.55 P/Q= 364.185
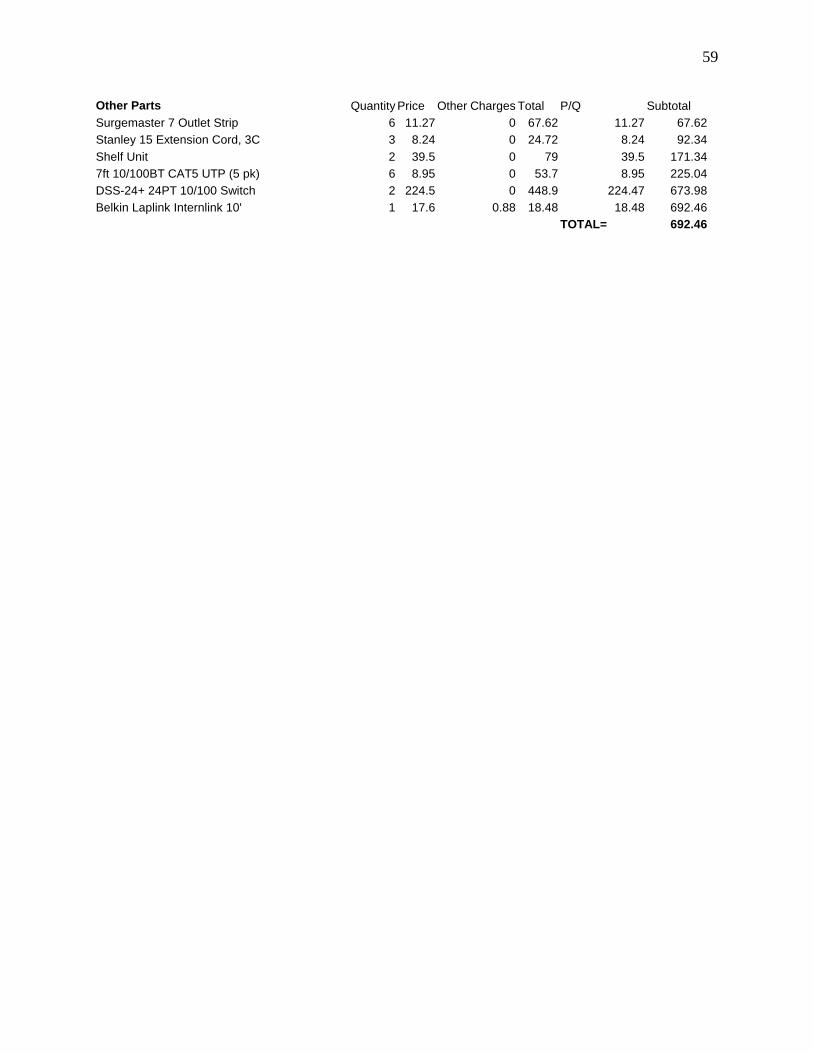
59
Other Parts Quantity Price Other Charges Total P/Q Subtotal Surgemaster 7 Outlet Strip 6 11.27 0 67.62 11.27 67.62 Stanley 15 Extension Cord, 3C 3 8.24 0 24.72 8.24 92.34 Shelf Unit 2 39.5 0 79 39.5 171.34 7ft 10/100BT CAT5 UTP (5 pk) 6 8.95 0 53.7 8.95 225.04 DSS-24+ 24PT 10/100 Switch 2 224.5 0 448.9 224.47 673.98 Belkin Laplink Internlink 10' 1 17.6 0.88 18.48 18.48 692.46 TOTAL= 692.46

60
APPENDIX L /usr /bin/stasks
#!/usr/bin/perl #tells user number of tasks to run for a given particle number, problem #complexity, and non-linearity #$1=particles #$2=complexity, 1 extremely simple - 10 extremely complex #non-linearity=100% use strict; if ($#ARGV < 1 || $#ARGV > 2) #make sure there are two or three arguments { #don't tell user about third argument unless he already knows print "Bad arguments.\n Use two arguments: particles, complexity\n"; exit 1 } my $P = $ARGV[0]; #particles my $CF = $ARGV[1]; #complexity my $NL = 100; #print "a # = $#ARGV\n"; ##set non-linearity and check its value #if ($#ARGV == 1) #if there are two arguments set non-linearity to default #{ # my $NL = 100; #non-linearity, set to 100 by default #} if ($#ARGV == 2) #there are three arguments { $NL = $ARGV[2]; #non-linearity set by user #print "NL = $NL\n"; if ($NL <= 0) #make sure non-linearity is appropriate { print "Bad arguments.\n Non-linearity must be greater than or equal to 0"; exit 1 } } #print "P=$P\n"; #print "CF=$CF\n"; #print "NL=$NL\n";

61
#number of particles greater than >= 1000 and <= 20000 if ($P < 1000 || $P > 20000) { print "The number of partcles must be greater than 1,000\n"; print "and less than 20,000 i.e. 5000\n\n"; print "if you desire something outside this range you must extrapolate yourself\n"; exit 1 } #complexity between 1 and 10 if ($CF < 1 || $CF > 10) { print "The problem complexity must be between 1 and 10\n"; print "where 1 is exceedingly simple and 10 very complex\n"; print "i.e. 5\n"; exit 1; } #coefficients to adjust a problem for complexity factor my $cc1=426.58*$CF-616.17; #print "cc1=$cc1\n"; my $cc2=-3516.5*$CF+6673.3; #print "cc2=$cc2\n"; my $ec1=-0.0622*$CF-0.2; #print "ec1=$ec1\n"; my $ec2=-0.0931*$CF-0.0803; #print "ec2=$ec2\n"; #coefficients to adjust a problem for number of particles my $c1=$cc1*$P**($ec1); #print "c1=$c1\n"; my $c2=$cc2*$P**($ec2); #print "c2=$c2\n"; #full equations for number of nodes only dependent upon non-linearity, # of #particles, and complexity factor my $n=($NL-$c2)/$c1; #make sure $N isn't greater than # of nodes if ($n > 30) { $n=30; } #output to user the number of tasks print "$n\nUse this as a rough estimate, round to the nearest node.\n";

62