boosting encoded dynamic features for facial expression recognition
TRANSCRIPT

Pattern Recognition Letters 30 (2009) 132–139
Contents lists available at ScienceDirect
Pattern Recognition Letters
journal homepage: www.elsevier .com/locate /patrec
Boosting encoded dynamic features for facial expression recognition
Peng Yang a,*, Qingshan Liu a,b, Dimitris N. Metaxas a
a Department of Computer Science, Rutgers, The State University of New Jersey, 110 Frelinghuysen Road, Piscataway, NJ 08854-8019, USAb National Laboratory of Pattern Recognition, Chinese Academy of Sciences, Beijing 100080, China
a r t i c l e i n f o a b s t r a c t
Article history:Available online 4 April 2008
Keywords:Pattern recognitionFacial expressionVideo understandingBoosting
0167-8655/$ - see front matter Published by Elsevierdoi:10.1016/j.patrec.2008.03.014
* Corresponding author. Fax: +1 0 7324452795.E-mail address: [email protected] (P. Yang).
It is well known that how to extract dynamic features is a key issue for video-based face analysis. In thispaper, we present a novel approach of facial expression recognition based on the encoded dynamic fea-tures. In order to capture the dynamic characteristics of facial events, we design the dynamic haar-likefeatures to represent the temporal variations of facial appearance. Inspired by the binary pattern coding,we further encode the dynamic features into the binary pattern features, which are useful to constructweak classifiers for boosting learning. Finally, the Adaboost is performed to learn a set of discriminatingencoded dynamic features for facial expression recognition. We conduct the experiments on the CMUexpression database, and the experiment result shows the power of the proposed method. We alsoextend this method to the active units (AU) recognition, and get a promising performance.
Published by Elsevier B.V.
1. Introduction
Automatic facial expression recognition has attracted muchattention in recent years due to its potential applications. Previouswork can be categorized into two classes: image-based methodsand video-based methods (Fasel and Luettin, 2003; Pantic andRothkrantz, 2000; Zeng et al., 2007). Image-based methods (Shanet al., 2005; Bartlett et al., 2003; Pantic and Rothkrantz, 2004) as-sumed that facial expressions are static and recognition is con-ducted on single image. Actually, a natural facial event evolvesover time from the onset, the apex, and the offset, so does the facialexpression. Therefore, image-based expression recognition couldnot achieve a good performance in practical systems. The video-based methods are demonstrated to be a good option, and theyaim to integrate of temporal information of facial appearance(Zhao and Pietikainen, 2007; Black and Yacoob, 1997; Yacooband Davis, 1994; Cohen et al., 2003). Although much progresshas been made by many researchers (Cohen et al., 2003; Tian,2004), achieving high accuracy is still a challenge due to the com-plicated variation of facial dynamics. How to extract and representthe dynamic features is a key issue. Normally there are two popularapproaches to extract facial features: geometric feature-basedmethods (Gu and Ji, 2004; James Lien et al., 1999; Valstar et al.,2005; Zhang et al., 1998; Tian et al., 2002) and appearance-basedmethods (Bartlett et al., 2003; Shan et al., 2005). Gabor appearancefeatures are widely used to describe local appearance (Liu and
B.V.
Wechsler, 2002; Bartlett et al., 2003; Daugman, 2003), but theircomputation expense is much higher than other local features suchas local binary pattern (LBP) (Ojala and Pietikainen, 2002) andhaar-like features (Paul and Michael, 2002).
In this paper, we propose a new approach of facial expressionrecognition. In order to capture temporal characteristic of facialexpression, we design the dynamic haar-like features to representfacial images. Compared to gabor features, haar-like features arevery simple, since they are just based on simple add or minus oper-ators (Paul and Michael, 2002). Moreover, from our experiment re-sults, we find that the haar-like features are a little better than thegabor features for describing facial expressions. The dynamic haar-like features are encoded into the binary patterns for further effec-tive analysis inspired by Ojala and Pietikainen (2002). Finally basedon the encoded dynamic features, the Adaboost is employed tolearn the combination of optimal discriminate features to con-struct the classifier. We test the proposed method on the CMU fa-cial expression database, and extensive experiments prove itseffectiveness. We also extend it for AU recognition, and get a prom-ising performance.
This paper is organized as following, we give an overview of ourproposed method in Section 2, and design the dynamic haar-likefeatures in Section 3. How to create the code book and encodethe dynamic features is addressed in Section 4. The boosting learn-ing is introduced in Section 5. Experiments are reported in Section6, followed by the conclusions in Section 7.
2. Overview of the proposed approach
Since facial expression variations are dynamic in temporal do-main, it is a trend to use the variations of temporal information

Fig. 1. The structure of the proposed framework.
Fig. 2. The flowchart of dynamic features extraction.
Fig. 4. Example of one dynamic feature unit ui;j in an image sequence.
P. Yang et al. / Pattern Recognition Letters 30 (2009) 132–139 133
for facial expression recognition (Zhao and Pietikainen, 2007). Inthis paper, we propose a novel framework for facial expression rec-ognition based on the encoded dynamic features. Fig. 1 illustratesthe structure of our framework, which has three main compo-nents: dynamic feature extraction, coding dynamic features, andAdaboosting learning. For the component of the dynamic featureextraction, we design the dynamic haar-like features to capturethe temporal variations of facial expressions. Inspired by the binarypattern coding (Ojala and Pietikainen, 2002), we analyze the distri-bution of each dynamic feature, and we create a code book for it.Based on the code books, the dynamic features are further mappedinto the binary pattern features. Finally the Adaboost is used tolearn a set of discriminating coded features for facial expressionrecognition.
3. Dynamic feature representation
The haar-like features achieved a great performance in facedetection (Paul and Michael, 2002). Due to their much lower com-putation cost compared to the gabor features, we exploit the haar-like features to represent face images, and extend them to repre-sent the dynamic characteristic of facial expression. Fig. 3 showsthe example of extracting the haar-like features in a face image.The dynamic haar-like features are built by two steps: (1) thou-sands of haar-like features are extracted in each frame and (2)the same haar-like features in the consecutive frames are com-bined as the dynamic features. Fig. 2 shows the flowchart of the dy-namic haar-like features, and the details are described in thefollowing.
Fig. 3. Example of haar-like features superimposed onto a face image.
For simplicity, we denote one image sequence I ¼ fI1; I2; . . . ; Ingwith n frames. We define Hi ¼ fhi;1;hi;2; . . . ;hi;mg, as the haar-likefeature set in the image Ii, where m is the number of the haar-likefeature. Corresponding to each haar-like feature hi;j, we build a dy-namic haar-like feature ui;j in the temporal window as ui;j ¼fhi;j;hiþ1;j; . . . ;hiþl;jg. Fig. 4 gives an illustration. We call each ui;j asa dynamic feature, we can see that the size of dynamic feature is
Fig. 5. Example of coding one dynamic feature unit ui;j .

Fig. 6. The procedure of the expression recognition.
Fig. 7. Examples of six basic expressions (anger, disgust, fear, happiness, sadness and surprise).
Table 1The area under the ROC curves (based on haar-like feature and gabor feature)
Expression Haar-like feature Gabor feature
Static Encoded dynamic Static Encoded dynamic
Angry 0.883 0.982 0.790 0.970Disgust 0.933 0.987 0.931 0.980Fear 0.858 0.830 0.835 0.600Happiness 0.982 0.983 0.960 0.960Sadness 0.895 0.945 0.891 0.957Surprise 0.996 0.996 0.985 1.000
Table 2The area under the ROC curves with different window size based on haar-like feature
Expression Encoded dynamic haar-like feature + AdaBoost
Windowsize 3
Windowsize 4
Windowsize 5
Windowsize 6
Windowsize 7
Angry 0.982 0.964 0.977 0.918 0.945Disgust 0.987 0.983 0.966 0.963 0.967Fear 0.83 0.873 0.838 0.844 0.84Happiness 0.983 0.977 0.99 0.979 0.978Sadness 0.946 0.967 0.96 0.954 0.954Surprise 0.996 0.998 0.99 0.998 1.00
Table 3The area under the ROC curves with different window size based on gabor feature
Expression Encoded dynamic gabor feature + AdaBoost
Windowsize 3
Windowsize 4
Windowsize 5
Windowsize 6
Windowsize 7
Angry 0.97 0.986 0.976 0.953 0.991Disgust 0.98 0.941 0.910 0.890 0.954Fear 0.6 0.610 0.609 0.690 0.770Happiness 0.96 0.946 0.989 0.940 0.925Sadness 0.957 0.983 0.929 0.954 0.975Surprise 1.00 1.00 0.990 0.999 0.997
Fig. 8. Different facial motion speed of different subjects.
Table 4The area under the ROC curves on different T
Expression Encoded dynamic haar feature + AdaBoost (window size is 3)
T = 2.4 T = 1.9 T = 1.65 T = 1.5 T = 1.2 T = 1.0 T = 0.6 T = 0.3
Angry 0.913 0.991 0.982 0.978 0.977 0.969 0.953 0.73Disgust 0.978 0.983 0.987 0.993 0.996 0.995 0.834 0.82Fear 0.799 0.78 0.83 0.81 0.84 0.83 0.943 0.92Happiness 0.965 0.975 0.983 0.974 0.978 0.965 0.903 0.75Sadness 0.92 0.955 0.9456 0.942 0.933 0.938 0.897 0.75Surprise 0.995 0.995 0.996 0.998 0.997 0.998 1.00 0.99
134 P. Yang et al. / Pattern Recognition Letters 30 (2009) 132–139

0 0.2 0.4 0.6 0.8 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
false positive rate
true
pos
itive
rat
e
ROC curve for expression Angry
Coded Dynamice FeatureStatic Feature
0 0.2 0.4 0.6 0.8 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
false positive rate
true
pos
itive
rat
e
ROC curve for expression Disguss
Coded Dynamice FeatureStatic Feature
0 0.2 0.4 0.6 0.8 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
false positive rate
true
pos
itive
rat
e
ROC curve for expression Fear
Coded Dynamice FeatureStatic Feature
0 0.2 0.4 0.6 0.8 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
false positive rate
true
pos
itive
rat
e
ROC curve for expression Happy
Coded Dynamice FeatureStatic Feature
0 0.2 0.4 0.6 0.8 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
false positive rate
true
pos
itive
rat
e
ROC curve for expression Sadness
Coded Dynamice FeatureStatic Feature
0 0.2 0.4 0.6 0.8 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
false positive rate
true
pos
itive
rat
e
ROC curve for expression Surprise
Coded Dynamice FeatureStatic Feature
Fig. 9. ROC curves of expression based on coded dynamic features and static features.
P. Yang et al. / Pattern Recognition Letters 30 (2009) 132–139 135
decided by the temporal window size. The temporal variation of fa-cial expressions can be effectively described by all the ui;js.
4. Coding the dynamic features
As mentioned above, a dynamic feature unit is composed of aset of the haar-like features in the same position along the tempo-
ral window. Thus, each dynamic unit is a feature vector. In this pa-per, we further code the dynamic feature unit into a binary patterninspired by Daugman (2003) and Ojala and Pietikainen (2002). Thiscoding scheme has two advantages: (1) it is easier to constructweak learners for Adaboost learning with a scalar feature than witha feature vector and (2) the proposed binary coding is based on thestatistical distribution, so the encoded features are robust to noise.

136 P. Yang et al. / Pattern Recognition Letters 30 (2009) 132–139
We create one code book for each facial expression as follows:first, we analyze the distribution of each feature h�;j under eachexpression, and then the mean l and the variance r can be esti-mated from this distribution. The gaussian distribution Njðl; rÞ isadopted to model the distribution of the feature unit h�;j. Second,we obtain the code book ðN1ðl1; r1Þ;N2ðl2; r2Þ; . . . ;Nmðlm; rmÞÞ foreach expression. Based on the code book, we can map the eachhaar-like feature hi;j to f1;0g pattern by the formula:
Ci;j ¼0 : if khi;j�ljk
rj> T
1 : if khi;j�ljkrj
< T
8<: ð1Þ
where T is the threshold, we will give a detail analysis on the influ-ence of different T values in Section 6, and we find our method is notsensitive to T. Based on the formula (1), we get the binary patternEi;j. Fig. 5 gives the procedure of creating the coded feature Ei;j withlength L, and we can convert binary vector Ei;j to a scalar.
Ei;j ¼ fCi;j;Ciþ1;j; . . . ;CiþL�2;j; CiþL�1;jg ð2Þ
5. Boosting the coded dynamic features
As we know, we can extract thousands of haar-like featuresfrom one image, so we can obtain thousands of the dynamic codedfeatures. A set of discriminating features should be selected to con-struct the final expression classifier. In this paper, we use the Ada-boost learning to achieve this goal, and the weak learner is built oneach coded feature as in (Paul and Michael, 2002). For each expres-sion, we set the image sequences of this expression as the positiveexamples, and the image sequences of the other expressions as thenegative samples. Therefore, one classifier for each expression canbe built based on the corresponding coded features. The learningprocedure is in Algorithm 1. The testing procedure is displayed inFig. 6. We take six expression categories into account: happiness,sadness, surprise, disgust, fear, and anger. Six Adaboost learnersare trained to discriminate each expression from the others.
Algorithm 1 (Learning procedure).
1. Given training image sequences ðxi; yiÞ; . . . ; ðxn; ynÞ; yi 2 f1;0gfor specified expression and the other expressions, respectively.
2. Initialize weight DtðiÞ ¼ 1=N.3. Get the dynamic features on each image sequence.4. Code the dynamic features based on the corresponding code
book, and get Ei;j. Build one weak classifier on each codedfeature.
5. Use the Adaboost to get the strong classifier HðxiÞ for expressionrecognition.
6. Experiment
Our experiments are conducted on the Cohn–Kanade facialexpression database (James Lien et al., 1999), which is widely used
Table 5The area under the ROC curves (expression)
Expression Static feature + AdaBoost Coded dynamic feature + AdaBoost
Angry 0.856 0.973Disgust 0.898 0.941Fear 0.841 0.916Happiness 0.951 0.9913Sadness 0.917 0.978Surprise 0.974 0.998
to evaluate facial expression recognition algorithms. It consists of100 university students aged from 18 to 30 years. 65% subjectsare female, 15% are African–American, and 3% are Asian or Latino.Subjects are instructed to perform a series of 23 facial displays, sixof which are prototypic emotions mentioned above. We select 96subjects and 300 image sequences from the database, and eachsubject has six basic expression sequences. The six basic expres-sion samples are shown in Fig. 7.
We randomly select 60 subjects as the training set, and the restsubjects as the testing set. We use two strategies to organize thedata set: one is to manually fix the eyes’ location and crop theimages to exclude the effect of misalignment on the recognition re-sult and another one is to automatically detect face (Paul and Mi-chael, 2002) and do alignment to simulate the practicalapplication. The images are cropped and normalized to 64 � 64for both strategies. In Section 6.1, we use the manually croppeddata set to investigate the characteristics of the proposed method.In Section 6.2, we use the automatically cropped data set to verifythe performance of our method in the practical system. In (Shanet al., 2005; Whitehill and Omlin, 2006), they gave some recogni-tion ratio on each expression or AU, however, the false alarmwas ignored. To evaluate the performance completely, the ROCcurve is used in our experiment to evaluate the performance.
6.1. Analysis on the characteristics of the proposed method
In order to analyze the performance of our method without theinfluence of face misalignment (Shan et al., 2004), we take themanually cropped data set in this section, and compare the dy-namic haar-like features with the dynamic gabor feature. In ourmethod, there are only two parameters: T and L. T is threshold informula (1) and L is the size of the window in Eq. (2). We use thelast frame of each sequence to evaluate the performance of the sta-tic image-based method.
6.1.1. Evaluation on the dynamic haar-like and the dynamic gaborfeatures
In this experiment, we fix the window size L ¼ 3
Ei;j ¼ fCi;j; Ciþ1;j;Ciþ2;jg ð3Þ
to evaluate the performance of the haar-like and gabor features,respectively. The influence of different L will be discussed in Sec-tion 6.1.2. We set T ¼ 1:65 for all the expression, because the stan-dard normal gaussian distribution x � Nð0;1Þ, Prðkxk 6 1:65Þ ¼95%. In the practical system, for each expression different optimalthresholds T should be used to get the best performance, the de-tails about the influence of T on the recognition performance aretalked about in Section 6.1.3. The area under the ROC curves ofdifferent features is shown in Table 1. We can see that the en-coded dynamic features outperform the static features, and the dy-
Fig. 10. Example of the AUs.
0 0.2 0.4 0.6 0.8 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
false positive rate
true
pos
itive
rat
e
ROC curve for AU 1
Static featureCoded dynamic feature
0 0.2 0.4 0.6 0.8 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
false positive rate
true
pos
itive
rat
e
ROC curve for AU 2
Static featureCoded dynamic feature
0 0.2 0.4 0.6 0.8 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
false positive rate
true
pos
itive
rat
e
ROC curve for AU 4
Static featureCoded dynamic feature
0 0.2 0.4 0.6 0.8 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
false positive rate
true
pos
itive
rat
e
ROC curve for AU 5
Static featureCoded dynamic feature
0 0.2 0.4 0.6 0.8 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
false positive rate
true
pos
itive
rat
e
ROC curve for AU 10
Static featureCoded dynamic feature
0 0.2 0.4 0.6 0.8 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
false positive rate
true
pos
itive
rat
e
ROC curve for AU 12
Static featureCoded dynamic feature
0 0.2 0.4 0.6 0.8 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
false positive rate
true
pos
itive
rat
e
ROC curve for AU 14
Static featureCoded dynamic feature
0 0.2 0.4 0.6 0.8 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
false positive rate
true
pos
itive
rat
e
ROC curve for AU 20
Static featureCoded dynamic feature
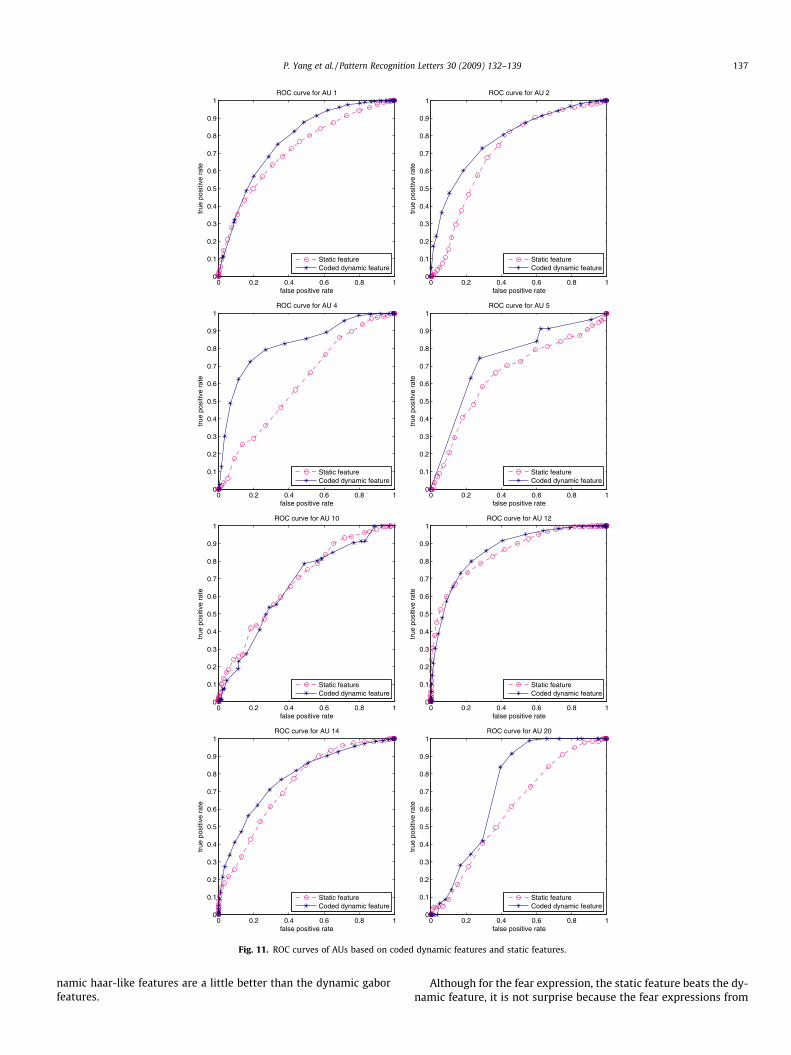
Fig. 11. ROC curves of AUs based on coded dynamic features and static features.
P. Yang et al. / Pattern Recognition Letters 30 (2009) 132–139 137
namic haar-like features are a little better than the dynamic gaborfeatures.
Although for the fear expression, the static feature beats the dy-namic feature, it is not surprise because the fear expressions from
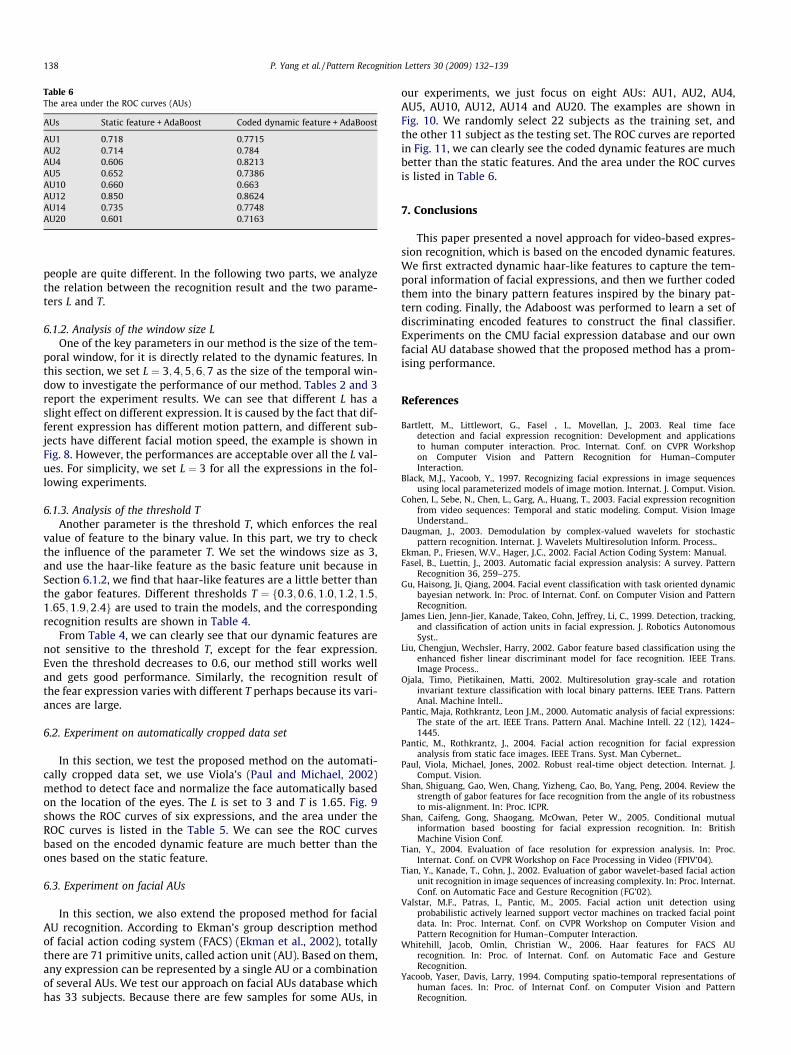
Table 6The area under the ROC curves (AUs)
AUs Static feature + AdaBoost Coded dynamic feature + AdaBoost
AU1 0.718 0.7715AU2 0.714 0.784AU4 0.606 0.8213AU5 0.652 0.7386AU10 0.660 0.663AU12 0.850 0.8624AU14 0.735 0.7748AU20 0.601 0.7163
138 P. Yang et al. / Pattern Recognition Letters 30 (2009) 132–139
people are quite different. In the following two parts, we analyzethe relation between the recognition result and the two parame-ters L and T.
6.1.2. Analysis of the window size LOne of the key parameters in our method is the size of the tem-
poral window, for it is directly related to the dynamic features. Inthis section, we set L ¼ 3;4;5;6;7 as the size of the temporal win-dow to investigate the performance of our method. Tables 2 and 3report the experiment results. We can see that different L has aslight effect on different expression. It is caused by the fact that dif-ferent expression has different motion pattern, and different sub-jects have different facial motion speed, the example is shown inFig. 8. However, the performances are acceptable over all the L val-ues. For simplicity, we set L ¼ 3 for all the expressions in the fol-lowing experiments.
6.1.3. Analysis of the threshold TAnother parameter is the threshold T, which enforces the real
value of feature to the binary value. In this part, we try to checkthe influence of the parameter T. We set the windows size as 3,and use the haar-like feature as the basic feature unit because inSection 6.1.2, we find that haar-like features are a little better thanthe gabor features. Different thresholds T ¼ f0:3;0:6;1:0;1:2;1:5;1:65;1:9;2:4g are used to train the models, and the correspondingrecognition results are shown in Table 4.
From Table 4, we can clearly see that our dynamic features arenot sensitive to the threshold T, except for the fear expression.Even the threshold decreases to 0.6, our method still works welland gets good performance. Similarly, the recognition result ofthe fear expression varies with different T perhaps because its vari-ances are large.
6.2. Experiment on automatically cropped data set
In this section, we test the proposed method on the automati-cally cropped data set, we use Viola’s (Paul and Michael, 2002)method to detect face and normalize the face automatically basedon the location of the eyes. The L is set to 3 and T is 1.65. Fig. 9shows the ROC curves of six expressions, and the area under theROC curves is listed in the Table 5. We can see the ROC curvesbased on the encoded dynamic feature are much better than theones based on the static feature.
6.3. Experiment on facial AUs
In this section, we also extend the proposed method for facialAU recognition. According to Ekman’s group description methodof facial action coding system (FACS) (Ekman et al., 2002), totallythere are 71 primitive units, called action unit (AU). Based on them,any expression can be represented by a single AU or a combinationof several AUs. We test our approach on facial AUs database whichhas 33 subjects. Because there are few samples for some AUs, in
our experiments, we just focus on eight AUs: AU1, AU2, AU4,AU5, AU10, AU12, AU14 and AU20. The examples are shown inFig. 10. We randomly select 22 subjects as the training set, andthe other 11 subject as the testing set. The ROC curves are reportedin Fig. 11, we can clearly see the coded dynamic features are muchbetter than the static features. And the area under the ROC curvesis listed in Table 6.
7. Conclusions
This paper presented a novel approach for video-based expres-sion recognition, which is based on the encoded dynamic features.We first extracted dynamic haar-like features to capture the tem-poral information of facial expressions, and then we further codedthem into the binary pattern features inspired by the binary pat-tern coding. Finally, the Adaboost was performed to learn a set ofdiscriminating encoded features to construct the final classifier.Experiments on the CMU facial expression database and our ownfacial AU database showed that the proposed method has a prom-ising performance.
References
Bartlett, M., Littlewort, G., Fasel , I., Movellan, J., 2003. Real time facedetection and facial expression recognition: Development and applicationsto human computer interaction. Proc. Internat. Conf. on CVPR Workshopon Computer Vision and Pattern Recognition for Human–ComputerInteraction.
Black, M.J., Yacoob, Y., 1997. Recognizing facial expressions in image sequencesusing local parameterized models of image motion. Internat. J. Comput. Vision.
Cohen, I., Sebe, N., Chen, L., Garg, A., Huang, T., 2003. Facial expression recognitionfrom video sequences: Temporal and static modeling. Comput. Vision ImageUnderstand..
Daugman, J., 2003. Demodulation by complex-valued wavelets for stochasticpattern recognition. Internat. J. Wavelets Multiresolution Inform. Process..
Ekman, P., Friesen, W.V., Hager, J.C., 2002. Facial Action Coding System: Manual.Fasel, B., Luettin, J., 2003. Automatic facial expression analysis: A survey. Pattern
Recognition 36, 259–275.Gu, Haisong, Ji, Qiang, 2004. Facial event classification with task oriented dynamic
bayesian network. In: Proc. of Internat. Conf. on Computer Vision and PatternRecognition.
James Lien, Jenn-Jier, Kanade, Takeo, Cohn, Jeffrey, Li, C., 1999. Detection, tracking,and classification of action units in facial expression. J. Robotics AutonomousSyst..
Liu, Chengjun, Wechsler, Harry, 2002. Gabor feature based classification using theenhanced fisher linear discriminant model for face recognition. IEEE Trans.Image Process..
Ojala, Timo, Pietikainen, Matti, 2002. Multiresolution gray-scale and rotationinvariant texture classification with local binary patterns. IEEE Trans. PatternAnal. Machine Intell..
Pantic, Maja, Rothkrantz, Leon J.M., 2000. Automatic analysis of facial expressions:The state of the art. IEEE Trans. Pattern Anal. Machine Intell. 22 (12), 1424–1445.
Pantic, M., Rothkrantz, J., 2004. Facial action recognition for facial expressionanalysis from static face images. IEEE Trans. Syst. Man Cybernet..
Paul, Viola, Michael, Jones, 2002. Robust real-time object detection. Internat. J.Comput. Vision.
Shan, Shiguang, Gao, Wen, Chang, Yizheng, Cao, Bo, Yang, Peng, 2004. Review thestrength of gabor features for face recognition from the angle of its robustnessto mis-alignment. In: Proc. ICPR.
Shan, Caifeng, Gong, Shaogang, McOwan, Peter W., 2005. Conditional mutualinformation based boosting for facial expression recognition. In: BritishMachine Vision Conf.
Tian, Y., 2004. Evaluation of face resolution for expression analysis. In: Proc.Internat. Conf. on CVPR Workshop on Face Processing in Video (FPIV’04).
Tian, Y., Kanade, T., Cohn, J., 2002. Evaluation of gabor wavelet-based facial actionunit recognition in image sequences of increasing complexity. In: Proc. Internat.Conf. on Automatic Face and Gesture Recognition (FG’02).
Valstar, M.F., Patras, I., Pantic, M., 2005. Facial action unit detection usingprobabilistic actively learned support vector machines on tracked facial pointdata. In: Proc. Internat. Conf. on CVPR Workshop on Computer Vision andPattern Recognition for Human–Computer Interaction.
Whitehill, Jacob, Omlin, Christian W., 2006. Haar features for FACS AUrecognition. In: Proc. of Internat. Conf. on Automatic Face and GestureRecognition.
Yacoob, Yaser, Davis, Larry, 1994. Computing spatio-temporal representations ofhuman faces. In: Proc. of Internat Conf. on Computer Vision and PatternRecognition.

P. Yang et al. / Pattern Recognition Letters 30 (2009) 132–139 139
Zeng, Zhihong, Pantic, Maja, Roisman, Glenn I., Huang, Thomas S., 2007. A survey ofaffect recognition methods: Audio, visual and spontaneous expressions. In:Internat Conf. on Multimodal Interfaces.
Zhang, Zhengyou, Lyons, M., Schuster, M., Akamatsu, S., 1998. Comparison betweengeometry-based and gabor-wavelets-based facial expression recognition using
multi-layer perceptrong. In: Proc. Internat. Conf. on Automatic Face and GestureRecognition.
Zhao, G., Pietikainen, M., 2007. Texture recognition using local binary patternswith an application to facial expressions. IEEE Trans. Pattern Anal. MachineIntell..