big data nebraska
TRANSCRIPT

RIDING THE DATA TIDAL WAVE IN MICROBIOLOGY
Future of Big Data, Lincoln, NE 11/6/2014
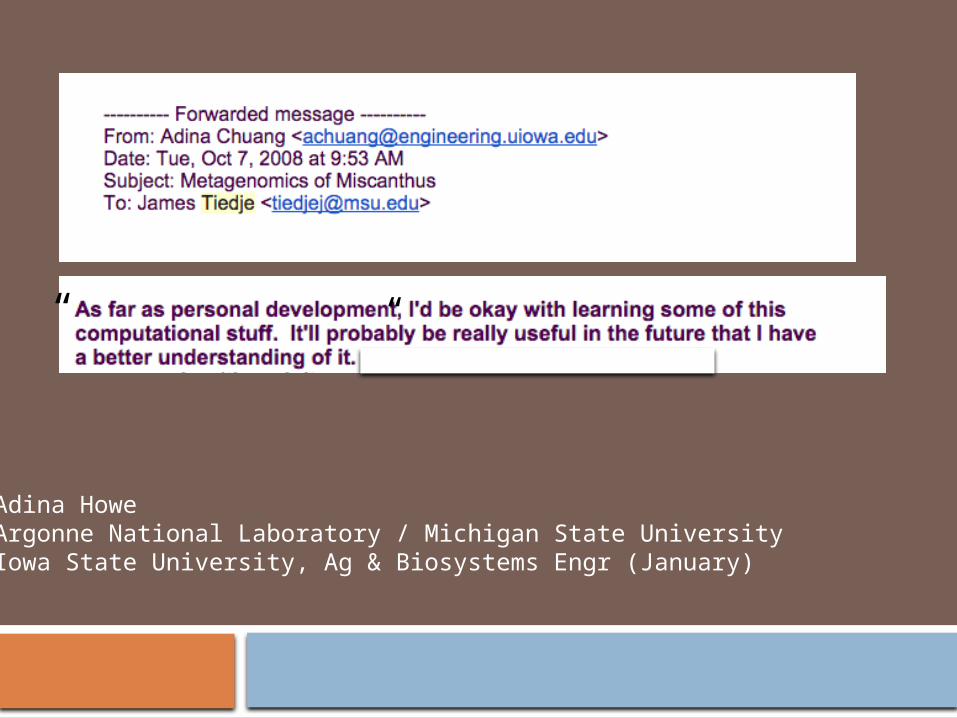
Adina Howegermslab.org (Genomics and Environmental Research in Microbial Systems)
Argonne National Laboratory / Michigan State UniversityIowa State University, Ag & Biosystems Engr (January)
Slides available at www.slideshare.com/adinachuanghowe

Microbes are critical
Climate Change
Energy Supply
USGCRP 2009
www.alutiiq.com
http://guardianlv.com/
Human & Animal Health
An understanding of microbial ecology
Global Food Security

Understanding community dynamics
Who is there? What are they doing? How are they doing it?

Understanding community dynamics
Who is there? What are they doing? How are they doing it?
Kim Lewis, 2010

Gene / Genome Sequencing
Collect samples Extract DNA Sequence DNA “Analyze” DNA to identify its content and
origin
Taxonomy (e.g., pathogenic E. Coli)Function (e.g., degrades cellulose)
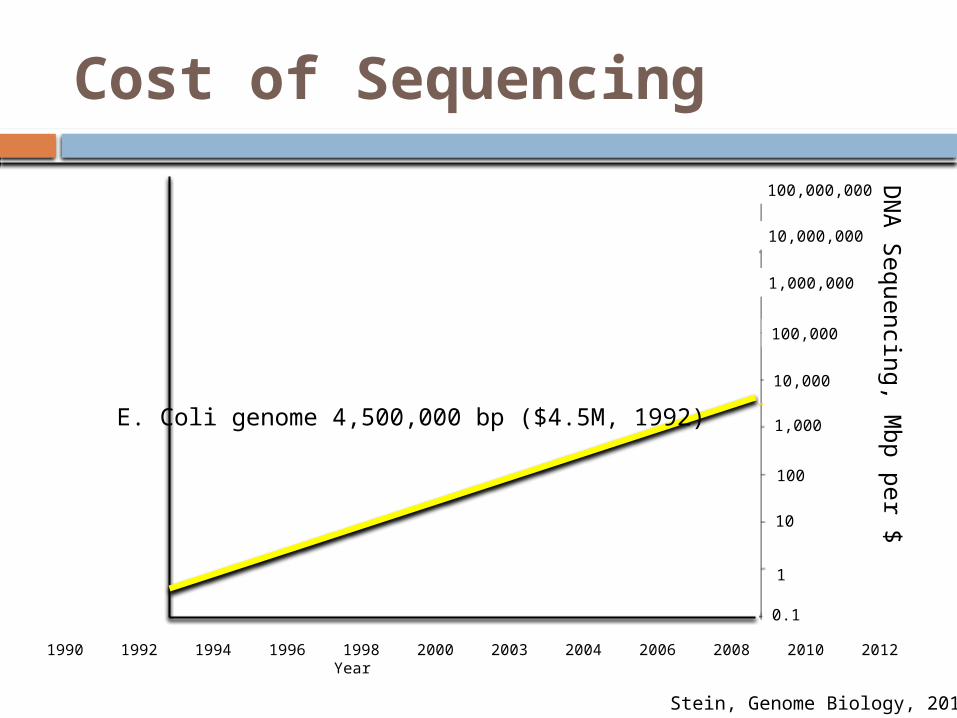
Cost of Sequencing
Stein, Genome Biology, 2010
E. Coli genome 4,500,000 bp ($4.5M, 1992)
1990 1992 1994 1996 1998 2000 2003 2004 2006 2008 2010 2012Year
0.1
1
10
100
1,000
10,000
100,000
1,000,000
DN
A S
equencin
g, M
bp p
er $
10,000,000
100,000,000
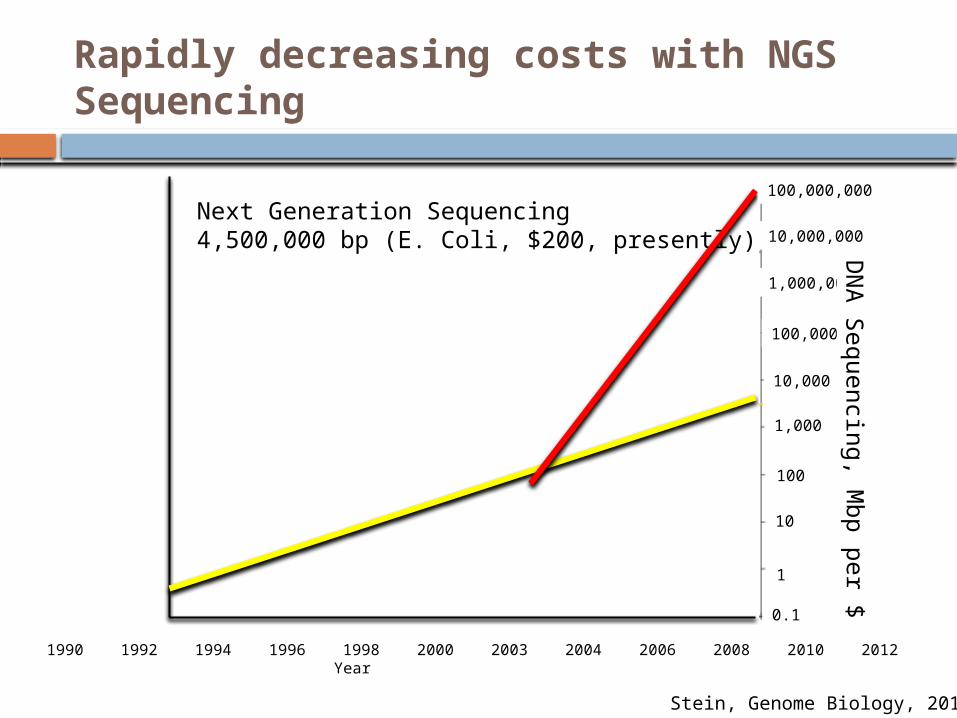
Rapidly decreasing costs with NGS Sequencing
Stein, Genome Biology, 2010
Next Generation Sequencing4,500,000 bp (E. Coli, $200, presently)
1990 1992 1994 1996 1998 2000 2003 2004 2006 2008 2010 2012Year
0.1
1
10
100
1,000
10,000
100,000
1,000,000
DN
A S
equencin
g, M
bp p
er $
10,000,000
100,000,000

Effects of low cost sequencing…
1995 First free-living bacterium sequenced for billions of dollars and years of analysis
Personal genome can be mapped in a few days and hundreds to few thousand dollars

The experimental continuum
Single Isolate Pure Culture
EnrichmentMixed Cultures
Natural systems
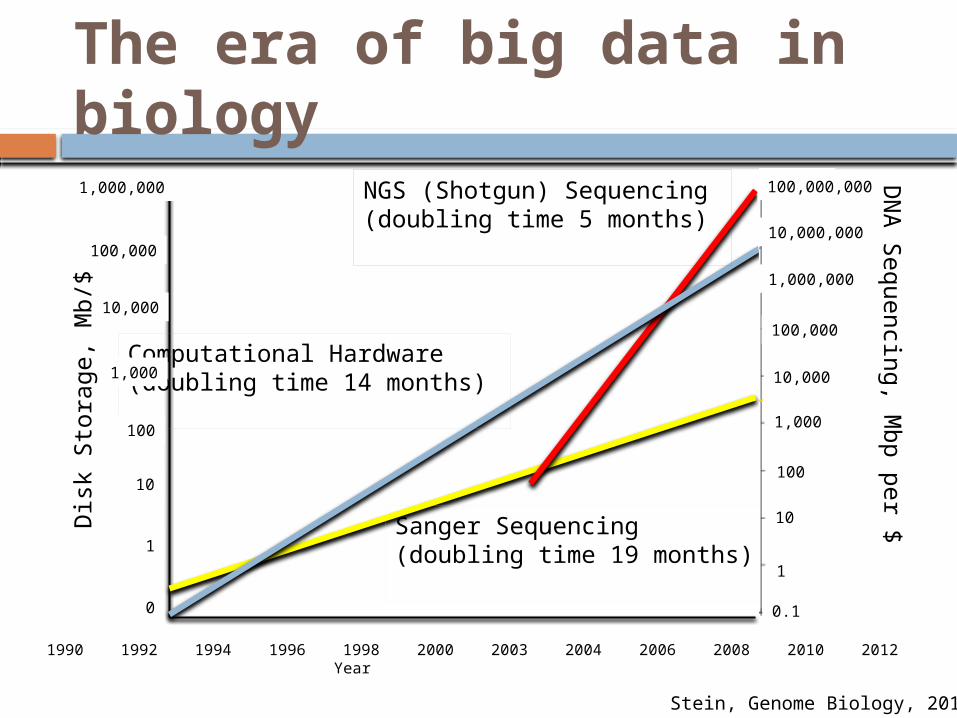
The era of big data in biology
Stein, Genome Biology, 2010
Computational Hardware(doubling time 14 months)
Sanger Sequencing(doubling time 19 months)
NGS (Shotgun) Sequencing(doubling time 5 months)
1990 1992 1994 1996 1998 2000 2003 2004 2006 2008 2010 2012Year
0
1
10
100
1,000
10,000
100,000
1,000,000
Dis
k Sto
rage,
Mb/$
0.1
1
10
100
1,000
10,000
100,000
1,000,000
DN
A S
equencin
g, M
bp p
er $
10,000,000
100,000,000
0.1
1
10
100
1,000
10,000
100,000
1,000,000
10,000,000
100,000,000

Postdoc experience with data
2003-2008 Cumulative sequencing in PhD = 2000 bp2008-2009 Postdoc Year 1 = 50 Gbp2009-2010 Postdoc Year 2 = 450 Gbp2014 = 50 Tbp2015 = 500 Tbp budgeted

THE DIRT ON SOIL
Biodiversity in the dark, Wall et al., Nature Geoscience, 2010 Jeremy Burgress
MAGNIFICENT BIODIVERSITY

THE DIRT ON SOIL
SPATIAL HETEROGENEITY
http://www.fao.org/ www.cnr.uidaho.edu

THE DIRT ON SOIL
DYNAMIC
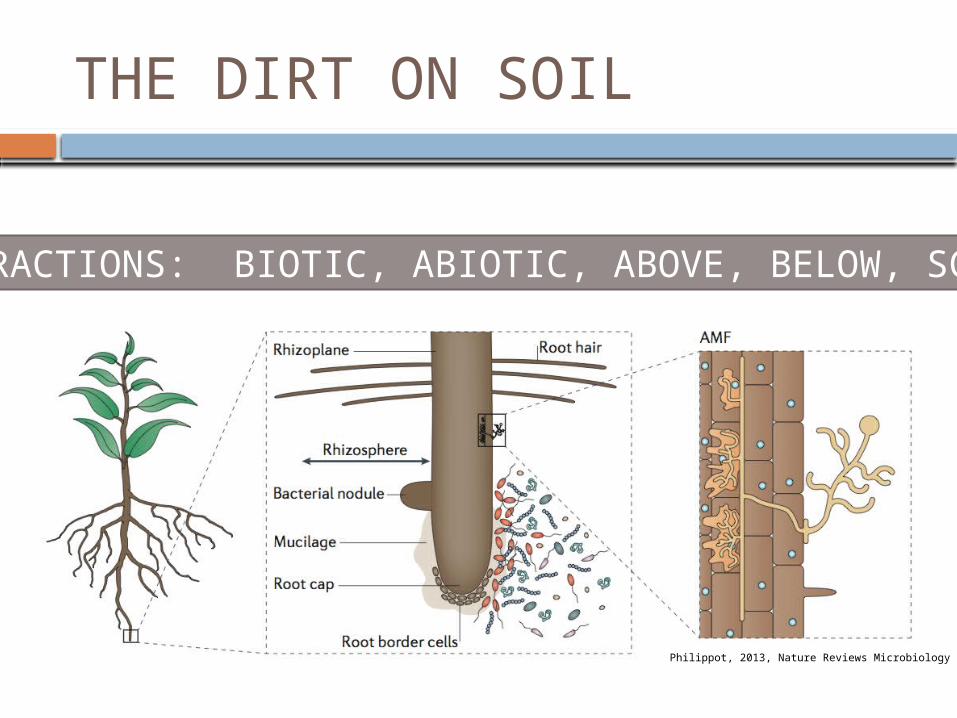
THE DIRT ON SOIL
INTERACTIONS: BIOTIC, ABIOTIC, ABOVE, BELOW, SCALES
Philippot, 2013, Nature Reviews Microbiology

I. Technical side of microbial big data in biologyII. Future of big data in soil microbial
communitiesIII. Bottlenecks for microbiologists

Tackling Soil Biodiversity
Source: Chuck Haney
C. Titus Brown, James Tiedje, Qingpeng Zhang, Jason Pell (MSU)Janet Jansson, Susannah Tringe (JGI)

Lesson #1: Accessing information in data
http://siliconangle.com/files/2010/09/image_thumb69.png

de novo assembly
Compresses dataset size significantly Improved data quality (longer sequences, gene order)Reference not necessary (novelty)
Raw sequencing data (“reads”)Computational algorithmsInformative genes / genomes

Metagenome assembly…a scaling problem.

Shotgun sequencing and de novo assembly
It was the Gest of times, it was the wor
, it was the worst of timZs, it was the
isdom, it was the age of foolisXness
, it was the worVt of times, it was the
mes, it was Ahe age of wisdom, it was th
It was the best of times, it Gas the wor
mes, it was the age of witdom, it was th
isdom, it was tIe age of foolishness
It was the best of times, it was the worst of times, it was the age of wisdom, it was the age of foolishness

Practical Challenges – Intensive computing
Howe et al, 2014, PNAS
Months of “computer crunching” on a super computer

Practical Challenges – Intensive computing
Howe et al, 2014, PNAS
Months of “computer crunching” on a super computer
Assembly of 300 Gbp (70,000 genomes worth) can be done with any assembly program in less than 14 GB RAM and less than 24 hours.
50 Gbp = 10,000 genomes

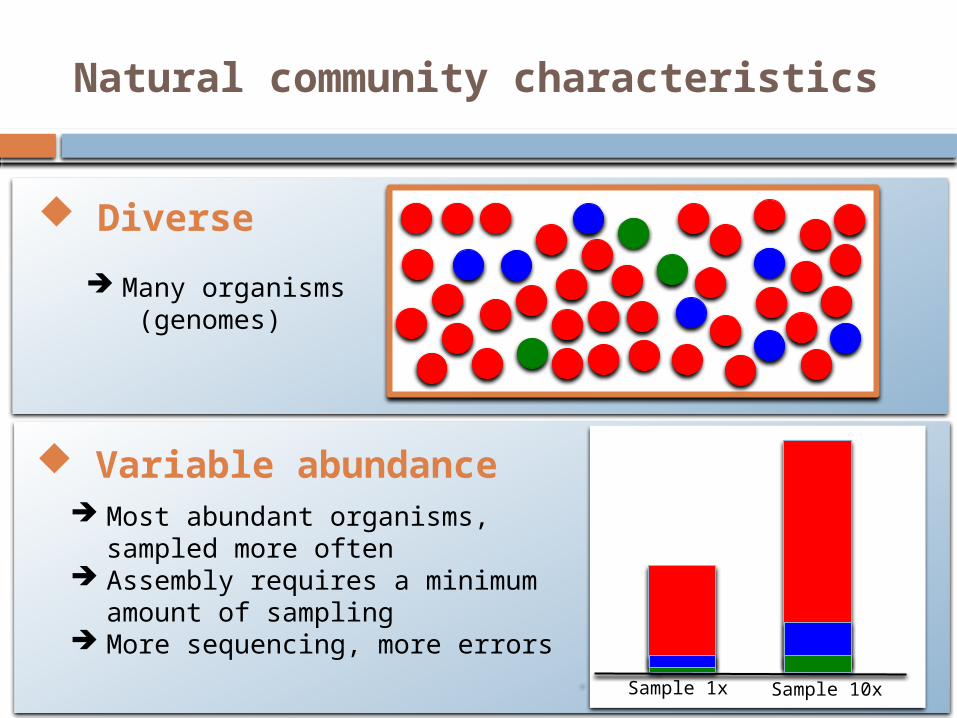
Natural community characteristics
Diverse
Many organisms (genomes)

Natural community characteristics
Diverse
Many organisms (genomes)
Variable abundance Most abundant organisms, sampled
more often Assembly requires a minimum amount
of sampling More sequencing, more errors
Sample 1x
Natural community characteristics
Diverse
Many organisms (genomes)
Variable abundance Most abundant organisms, sampled
more often Assembly requires a minimum amount
of sampling More sequencing, more errors
Sample 1x Sample 10x

Natural community characteristics
Diverse
Many organisms (genomes)
Variable abundance Most abundant organisms, sampled
more often Assembly requires a minimum amount
of sampling More sequencing, more errors
Sample 1x Sample 10x
Overkill

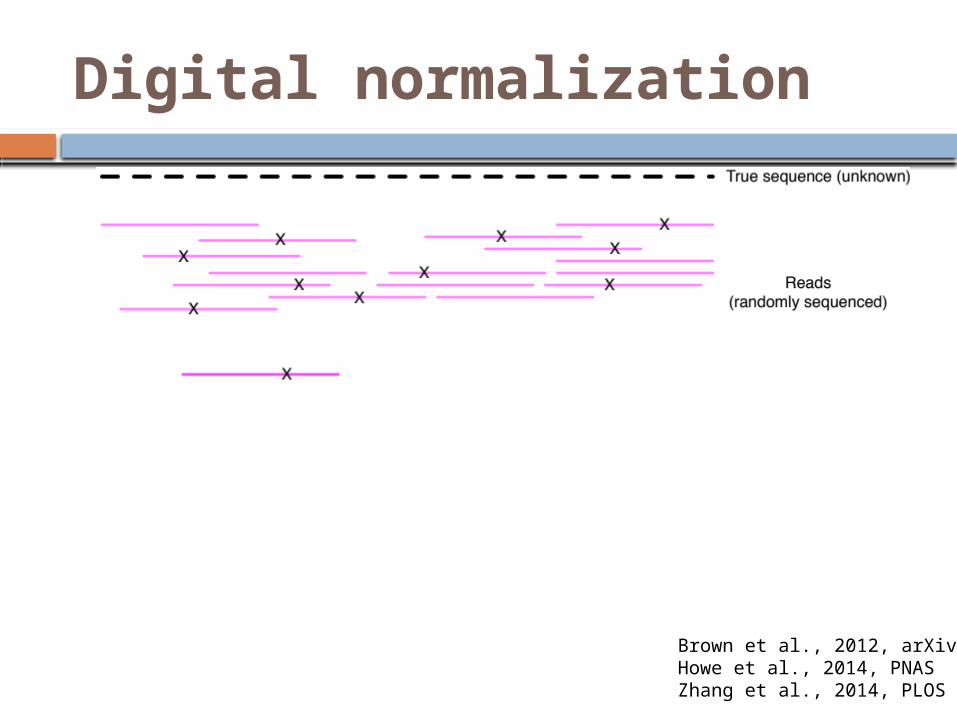
Digital normalization
Brown et al., 2012, arXivHowe et al., 2014, PNASZhang et al., 2014, PLOS One

Digital normalization
Brown et al., 2012, arXivHowe et al., 2014, PNASZhang et al., 2014, PLOS One
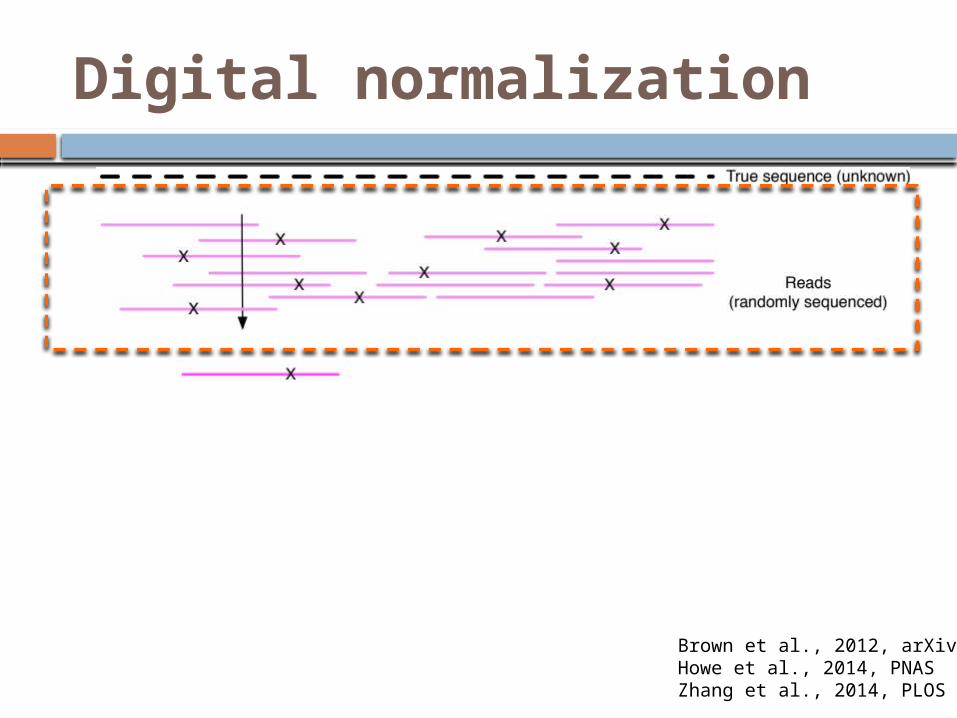
Digital normalization
Brown et al., 2012, arXivHowe et al., 2014, PNASZhang et al., 2014, PLOS One
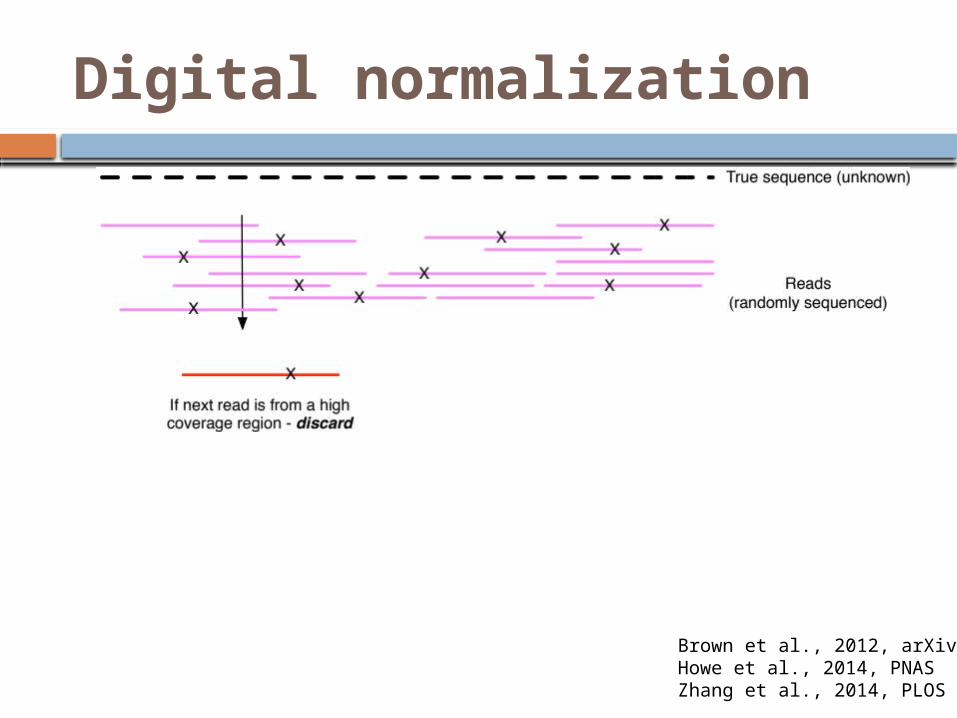
Digital normalization
Brown et al., 2012, arXivHowe et al., 2014, PNASZhang et al., 2014, PLOS One
Digital normalization
Brown et al., 2012, arXivHowe et al., 2014, PNASZhang et al., 2014, PLOS One

Digital normalization
Brown et al., 2012, arXivHowe et al., 2014, PNASZhang et al., 2014, PLOS One
Scales datasets for assembly up to 95% - same assembly outputs.
Genomes, mRNA-seq, metagenomes (soils, gut, water)

Tackling Soil Biodiversity
Source: Chuck Haney
C. Titus Brown, James Tiedje, Qingpeng Zhang, Jason Pell (MSU)Janet Jansson, Susannah Tringe (JGI)

The reality?

More like…
Source: Chuck HaneyHowe et. al, 2014, PNAS

What we learned from deeply sequencing soil
Grand Challenge effort – 10% of soil biodiversity sampled
Incredible soil biodiversity (estimate required 10 Tbp/sample)
“To boldly go where no man has gone before”: >60% Unknown
Howe et al, 2014, PNAS
Managed agriculture soils exhibit less diversity, likely from its history of cultivation.

If soil is so diverse, what are the most consistent signals we can see at the plot levels?

Is there an identifiable “soil functional core” (carbon cycling focus)?
Kirsten Hofmockel, Iowa State University
Ames, Iowa, COBS Field Site, Fertilized Prairie Whole Soil Samples
4 deeply sampled whole soil metagenomes (16S rRNA 5000 reads, Shotgun 20-50 million reads)

How much genetic sequence do you think is shared in 4 replicates?
More than 1%? 10%? 50%? What kind of genes do you expect in this
core? Minimal critical genes will be abundant &
diverse
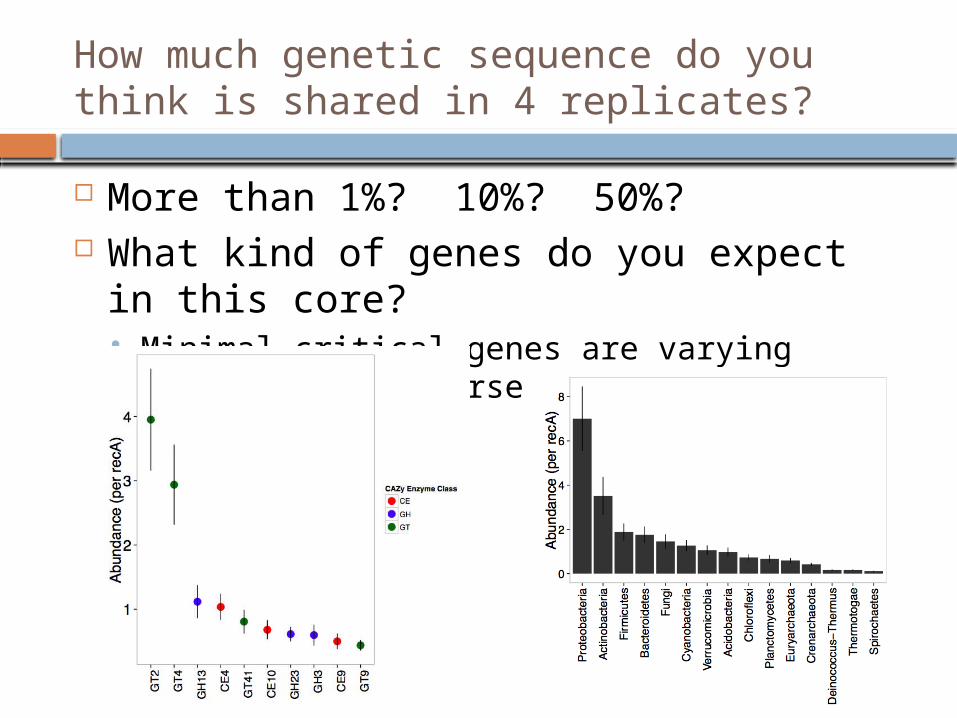
How much genetic sequence do you think is shared in 4 replicates?
More than 1%? 10%? 50%? What kind of genes do you expect in this
core? Minimal critical genes are varying abundances
& diverse

Core genes: soil-specific
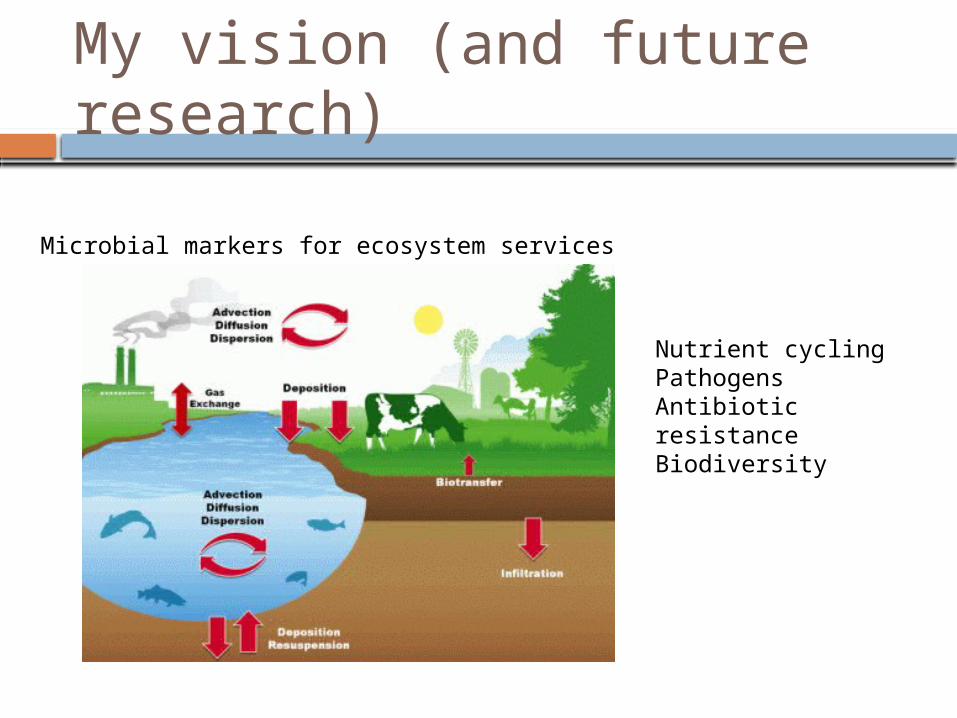
My vision (and future research)
Microbial markers for ecosystem services
Nutrient cyclingPathogensAntibiotic resistanceBiodiversity

Capabilities exist already…

Is more data better?
Bottlenecks for the emerging microbiologists

Technical obstacles in the big data deluge
Access to the data Access to the resources
Democratization of both data and resource access“80% of awards and 50% of $$ are for grants < $350,000” (Ian Foster)
Data volume and velocity Previous efforts are difficult to integrate Innovation is necessary

Software DevelopersComputer Scientists
CliniciansPIs
Data generatorsMicrobiologists
Data AnalyzersStatisticiansBioinformaticians
http://ivory.idyll.org/blog/2014-the-emerging-field-of-data-intensive-biology.html
Data intensive microbiology



Social obstacles – the main challenge
Shift of costs do not mean shift of expectations
http://www.deluxebattery.com/25-hilarious-expectation-vs-reality-photos/
Dear PI,
It will take longer than the time it took you to do your experiment to analyze the data. Please do not write me for results within 24 hours of your sequences becoming available.
- Adina
Culture of sharing
http://www.heathershumaker.com/
Metagenomic Datasets

Training / Incentives
Emails between collaborators don’t contain as much “science” as I’d like:
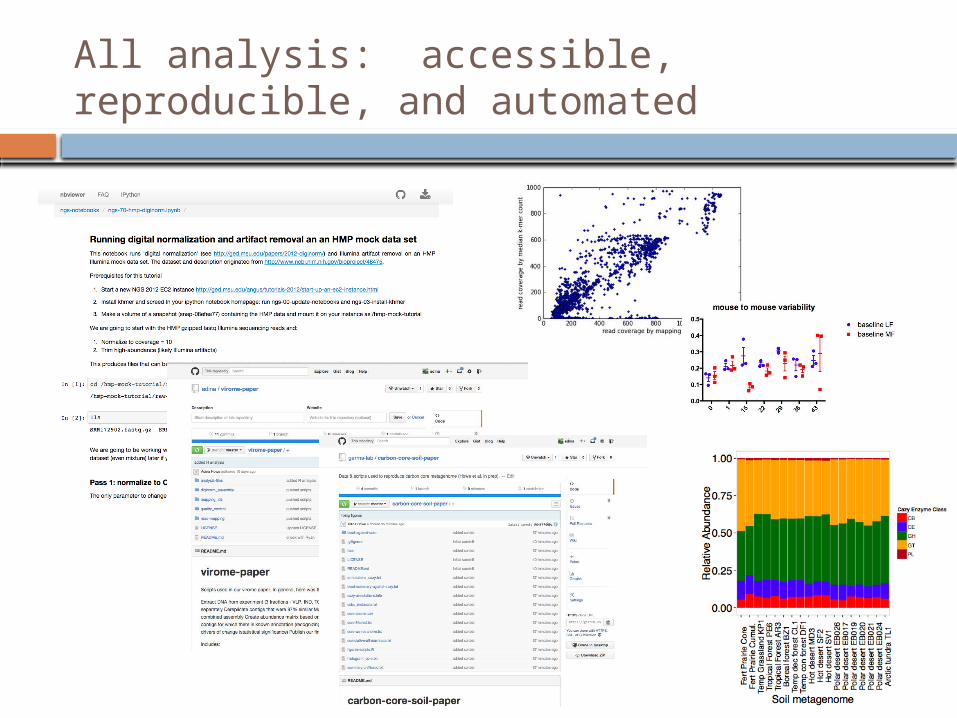
All analysis: accessible, reproducible, and automated

All analysis: accessible, reproducible, and automated
To reproduce analysis in a publication,
1. Rent Amazon EC2 computer2. Clone github repository containing data and scripts3. Open IPython notebook and execute
To run same analysis on different dataset, 4. Replace data files with your own data, execute
notebook.5. Tweak scripts as needed.

The journey in summary
RIDING THE BIG DATA TIDAL WAVE OF MODERN MICROBIOLOGY
Adina HoweArgonne National Laboratory / Michigan State UniversityIowa State University, Ag & Biosystems Engr (January)
“”
RIDING THE BIG DATA TIDAL WAVE OF MODERN MICROBIOLOGY
Adina HoweArgonne National Laboratory / Michigan State UniversityIowa State University, Ag & Biosystems Engr (January)

Acknowledgements
C. Titus Brown (MSU) James Tiedje (MSU) Daina Ringus (UC) Folker Meyer (ANL) Eugene Chang (UC) NSF Biology Postdoc Fellowship DOE Great Lakes Bioenergy Research
Center