automatic extraction of document keyphrases for use in digital libraries: evaluation and...
TRANSCRIPT

Automatic Extraction of Document Keyphrases for Usein Digital Libraries: Evaluation and Applications
Steve JonesDepartment of Computer Science, University of Waikato, Private Bag 3105, Hamilton, New Zealand.E-mail: [email protected]
Gordon W. PaynterDepartment of Computer Science, University of Waikato, Private Bag 3105, Hamilton, New Zealand.E-mail: [email protected]
This article describes an evaluation of the Kea automatickeyphrase extraction algorithm. Document keyphrasesare conventionally used as concise descriptors of doc-ument content, and are increasingly used in novel ways,including document clustering, searching and browsinginterfaces, and retrieval engines. However, it is costlyand time consuming to manually assign keyphrases todocuments, motivating the development of tools thatautomatically perform this function. Previous studieshave evaluated Kea’s performance by measuring its abil-ity to identify author keywords and keyphrases, but thismethodology has a number of well-known limitations.The results presented in this article are based on eval-uations by human assessors of the quality and appropri-ateness of Kea keyphrases. The results indicate that, ingeneral, Kea produces keyphrases that are rated posi-tively by human assessors. However, typical Kea set-tings can degrade performance, particularly those relat-ing to keyphrase length and domain specificity. Wefound that for some settings, Kea’s performance is bet-ter than that of similar systems, and that Kea’s rankingof extracted keyphrases is effective. We also determinedthat author-specified keyphrases appear to exhibit aninherent ranking, and that they are rated highly andtherefore suitable for use in training and evaluation ofautomatic keyphrasing systems.
Introduction
As electronic document collections grow larger, a user’stask of finding useful information becomes more challeng-ing. World Wide Web search engines and digital librariescommonly return query result sets containing hundreds orthousands of documents. In these situations, it is clearly
infeasible for the user to examine complete documents todetermine whether or not they might be useful. Instead,document surrogates such as titles, bibliographic informa-tion, extracts containing query terms and summaries helpusers to quickly identify documents of interest.
Some types of document contain a list of key wordsspecified by the author. These keywords and key-phrases—we use the latter term to subsume the former—area particularly useful type of summary information. Theycondense documents into a few words and phrases, offeringa brief and precise description of a document’s contents.They have many further applications, including the classi-fication or clustering of documents (Jones & Mahoui, 2000;Zamir & Etzioni, 1998, 1999), search and browsing inter-faces (Gutwin, Paynter, Witten, Nevill-Manning, & Frank,1999; Jones, 1999; Jones & Paynter, 1999), retrieval en-gines (Arampatzis, Tsoris, Koster, & Van der Weide, 1998;Croft, Turtle, & Lewis, 1991; Jones & Staveley, 1999), andthesaurus construction (Kosovac, Vanier, & Froese, 2000;Paynter, Witten, & Cunningham, 2000).
Keyphrases are often chosen manually, usually by theauthor of a document but sometimes by professional index-ers. Unfortunately, not all documents contain author- orindexer-assigned keyphrases: even in collections of scien-tific papers those with keyphrases are in the minority. Ourwork with the New Zealand Digital Library (www.nzdl.org;Witten & McNab, 1997; Witten, McNab, Jones, Apperley,Bainbridge, & Cunningham, 1999a; Witten, Nevill-Man-ning, McNab, & Cunningham, 1998) illustrates this prob-lem. One collection is a mirror of the Human ComputerInteraction Bibliography (www.hcibib.org; Perlman, 1991)that contains the bibliographic details of more than 15,000documents. Less than a third of these contain author-spec-ified key words or phrases. Another collection of computerscience technical reports contains more than 40,000 docu-
Received May 21, 2001; revised December 19, 2001; accepted Decem-ber 19, 2001
© 2002 Wiley Periodicals, Inc. ● Published online 9 April 2002 in WileyInterScience (www.interscience.wiley.com). DOI: 10.1002/asi.10068
JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE AND TECHNOLOGY, 53(8):653–677, 2002

ments collected from electronic repositories around theworld. The original format of these documents is postscript,and although it is possible to extract the text of each, only1,800 contain recognizable keyphrases.
To exploit the power of keyphrases as document surro-gates in these and other collections, we must associatekeyphrases with each of the remaining documents, eithermanually or automatically. Manual keyphrase assignment istedious and time-consuming, requires expertise, and cangive inconsistent results, so automatic methods benefit boththe developers and the users of large document collections.Consequently, several automatic techniques have been pro-posed.
In this article we describe an evaluation of Kea, anautomatic keyphrase extraction algorithm developed bymembers of the New Zealand Digital Library Project (Franket al., 1999). Earlier research has measured Kea’s perfor-mance by its ability to extract keyphrases that match thosethat have been specified by document authors, and hasshown that performance to be equivalent to comparablesystems (Frank et al., 1999). Although common, this eval-uation approach assumes that author-specified keyphrasesconstitute the best possible keyphrase set. In reality, authorkeyphrase lists may not be exhaustive, or even particularlyappropriate. We are unaware of any documented evidencethat inclusion in the author’s list is a good indicator of akeyphrase’s ability to accurately reflect the topics of adocument.
This article makes a number of contributions to auto-mated keyphrase extraction. First, it augments and tests thevalidity of the previous evaluations of Kea using a differentevaluation technique—a subjective evaluation involving hu-man assessment of the quality and appropriateness of key-phrases. Second, it compares Kea’s performance as deter-mined by human assessors against the results of similarevaluations of other systems. Finally, it investigates whethercomparison against author keyphrases is a good measure ofthe results of keyphrase extraction systems.
In the following section we describe two approaches toassociating keyphrases with documents: keyphrase assign-ment, and keyphrase extraction. We provide an overview ofpreviously reported techniques for keyphrase extraction,and illustrate some of the ways in which automaticallyextracted keyphrases have been used in interactive systemsto support searching and browsing within a digital library.We then describe the Kea algorithm for keyphrase extrac-tion using a machine learning approach. We discuss issuesand techniques in evaluating keyphrases, providing a sum-mary of previous research results, before proceeding todescribe an experiment in which human assessors judgedthe quality of keyphrases extracted by Kea and gathered byother means. We present our data, which measures Kea’sperformance in a variety of ways and discuss its implica-tions. Finally, we summarize our findings and the conclu-sions that we draw from the experimental results.
Background
Keyphrases may be associated with documents by twomain methods: keyphrase assignment, and keyphrase ex-traction. Keyphrase assignment algorithms examine the textof a document and assign it keyphrases from a controlledvocabulary (Dumais, Platt, Heckerman, & Sahami, 1998).The benefits of this approach are consistency and specific-ity: similar documents are described using the same key-phrases, even if those keyphrases do not appear in thedocument text, and the vocabulary can be crafted to ensurethe required breadth and depth of topic coverage. However,this approach may ignore potentially useful keyphrases thatoccur in the text of a document if they do not appear in thevocabulary. Also, creation and maintenance of the vocabu-lary requires time and expertise, which may not always beavailable.
Keyphrase extraction techniques do not rely of the exis-tence of such a vocabulary. Instead, appropriate words andphrases are identified from within the text of a document.All words and phrases within a document are potentialkeyphrases of that document, and the extraction algorithmchooses from these candidates. A comparative drawback ofthis approach is that the keyphrases may be less consistentthan when a controlled vocabulary is used, and it is difficultto identify the “most suitable” words and phrases.
Phrase Extraction Techniques
A wide range of techniques has been applied to theproblem of phrase extraction. Turney (1999, 2000) was thefirst to treat extraction as a supervised learning problem.Phrases are classified as either positive or negative exam-ples of keyphrases based on examination of their features.Nine features are observed in the training data, including thenumber of words in a phrase, the location of the firstoccurrence of a phrase in a document, the frequency withwhich a phrase occurs within a document, whether thephrase is a proper noun and whether or not a phrase matchesa human-generated keyphrase. Turney describes two ap-proaches, the first of which uses the C4.5 decision treeinduction algorithm (Quinlan, 1993) to learn a classifier.The second, more successful, approach combines two com-ponents: Genitor, a genetic algorithm, and Extractor, a key-phrase extraction algorithm. Extractor produces a list ofkeyphrases for a document that it processes based on thesettings of 12 parameters. Genitor is used to tune the Ex-tractor parameter values to achieve optimal performance ontraining data, and is no longer needed once training iscomplete. The parameters are numeric values and represent,for example, the number of phrases desired as output, howaggressively phrases are stemmed, location of phrase oc-currence, and whether or not proper nouns are required.When the two approaches are evaluated by comparison tothe author’s keyphrases, the second, hereafter called Extrac-tor, is measurably better.
Barker and Cornacchia (2000) report a three-step key-phrase extraction algorithm. In the first step base noun
654 JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE AND TECHNOLOGY—June 2002

phrases are identified within a document. A base nounphrase is defined as a “non-recursive structure consisting ofa head noun and zero or more premodifying adjectivesand/or nouns.” The process that identifies base noun phrasesuses dictionary lookup to identify parts of speech rather thana part of speech tagger because of the availability of the rootforms of each word. In the second step the noun phrases areallocated scores according to their frequency and lengthcharacteristics. The algorithm initially discards infrequentlyoccurring phrase heads, and then scores the noun phrases ofa document that contain the remaining phrase heads. Thescore for a noun phrase is its frequency multiplied by itslength in words. In the third and final step the highestscoring phrases are postprocessed to remove single letterkeyphrases and those that are wholly contained withinlonger phrases.
Barker and Cornacchia follow a body of research thatmight be called noun-phrase extraction. Several techniqueshave been described that attempt to identify the most im-portant phrases in a document for use in document model-ling, query reformulation, and measuring document similar-ity. The basic technique is to tag the document text with apart-of-speech tagger, identify all the noun phrases, rank thenoun phrases by importance, and extract the most important.
AZ Noun Phraser, described by Tolle and Chen (2000),follows this approach. It extracts noun phrases for use inmedical document retrieval systems. It consists of a token-izer, a tagger, and a noun phrase generator. The tokenizerseparates all punctuation and other symbols from the doc-ument text without impacting upon the content. The taggerused in the system (an amended Brill tagger; Brill, 1992)assigns part of speech tags to the text. The phrase generatortransforms the tagger output into a list of noun phrases.
Anick and Vaithyanathan (1997) use noun phrases toprovide context for a user’s search activity, and to supportquery expansion and refinement in their Paraphrase SearchAssistant. The phrases are simple noun compounds—anycontiguous sequence of words that terminates in a headnoun and includes at least one other adjective and noun.These are filtered to remove “noise” phrases according to apredetermined “noise” list and a set of heuristics.
Larkey (1999) uses simple noun phrases to support queryexpansion by users in a system for searching patent records.A large text sample was extracted from historical patentrecords, segmented at delimiters like stopwords, punctua-tion, and irregular verbs, then assigned parts of speech tagsusing WordNet (an electronic lexical database; Fellbaum,1998). The remaining noun phrases were retained.
Chen (1999) proposes an extraction algorithm based onword pairs, particularly the relationships between nouns andverbs. Four attributes of a document are computed: theimportance of words, the frequency of words, the level ofcooccurrence of words, and the distance between twowords. Importance is computed by standard IDF (inversedocument frequency) measures that determine how well aword discriminates between the current document and otherdocuments. A mutual frequency value is computed to reflect
the cooccurrence of each word in a word pair. The fourattributes are used to form a model that is derived fromexemplar documents from some given corpus and can thenbe applied to new documents.
Smeaton and Kelledy (1998) automatically identify doc-ument phrases to support user-directed query reformulation.Their approach to phrase extraction is a simple one. First, allpairs of adjacent words that do not contain a stopword areidentified. Next, all three word phrases are identified wherethe words are adjacent and do not begin or end with astopword. Phrases that occur 25 or more times in a largesample of text are used for query expansion.
The InfoFinder agent (Krulwich & Burkey, 1997)“learns” user interests by extracting significant topic phrasesfrom the documents the user marks as interesting. Thephrases are used to construct Boolean queries and locatefurther documents of interest to the user. Unlike the part-of-speech-based approaches described above, documentmarkup is used to identify candidate phrases, on the as-sumption that important segments of text are often empha-sised. For example, fully capitalised single words are ex-tracted, as are short phrases that appear in a different format(perhaps italicised) from the surrounding text. Other heu-ristics search lists, section headings and diagram labels fortopic phrases.
Only the first two of the phrase extraction algorithmsabove—those suggested by Turney and Barker and Cornac-chia—are keyphrase extraction algorithms. They explicitlyattempt to model an author’s actions in choosing keywordsfor a document, and can be objectively evaluated by com-parison to the author’s choices. Although the others attemptto identify the important phrases in documents, they cannotbe evaluated in this fashion, and are in many cases designedto choose phrases quite different from traditional keywords.
Keyphrase-based user interfaces
We have been investigating how automatically extractedkeyphrases can be used to support interaction in documentretrieval systems such as digital libraries. Kea keyphraseshave enabled us to support user access to document collec-tions in the New Zealand Digital Library in a number ofways. Their most basic use is as document surrogates thataugment document metadata. Figure 1, for example, showsa page of search results arising from a query “digital li-brary” to the mirrored HCI Bibliography collection of theNZDL. The document titles shown in the left-hand columnand the document metadata in the right-hand column can beextracted from the source documents. Where author key-phrases are available they are shown below the title. Whenthey are not, Kea keyphrases are used.
We are using keyphrases in many other ways in userinterfaces. These interfaces move away from normativeterm-based query systems to support searching and brows-ing in novel ways. We will describe three such systemsdeveloped by members of the New Zealand Digital LibraryProject: KeyPhind, Kniles, and Phrasier.
JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE AND TECHNOLOGY—June 2002 655

KeyPhind
KeyPhind provides a mixture of searching and browsingmechanisms to help users identify documents of interest(Gutwin, Paynter, Witten, Nevill-Manning, & Frank, 1999).Figure 2 shows the KeyPhind interface. The user has typedan initial search term query into the search box at the top,and a list of keyphrases containing query is displayed to theleft. The user has selected one of these phrases, dynamicquery, and a list of the documents with which that phrasehas been associated has appeared in the lower panel. Bydouble-clicking on a keyphrase a user simulates entry ofthat phrase into the search box, extending their originalsearch string, and narrowing their search.
To the right of Figure 2, a second list of phrases hasappeared. These are the keyphrases that cooccur with dy-namic query; that is, the phrases that have been associatedwith the same documents. By selecting one of these the userfurther narrows the list of documents that are displayed.
Kniles
Kniles uses keyphrases to automatically construct brows-able hypertexts from plain text documents (Jones & Payn-ter, 1999). Link anchors are inserted into the text wherevera phrase occurs that is a keyphrase in another document ordocuments, as is shown in the left-most pane of Figure 3.
Keyphrases assigned to the current document (by Kea or theauthor) are displayed in a bold font, while those that onlypertain to other documents are in the regular weight font.
A second frame in the interface (to the right of Fig. 3)provides a summary of the keyphrase anchors that havebeen inserted into the document. The upper portion lists thekeyphrases that have been assigned to the current documentby Kea or the author, the lower portion shows a list ofrelated topics; that is, the keyphrases of other documentsthat occur within the current document. When the userselects a phrase (from either pane) a new Web page isgenerated that lists the documents for which the phrase is akeyphrase. Selecting a document from the list loads it, withhyperlinks inserted, into the web browser.
Phrasier
Kniles is a simplified, Web-based version of Phrasier, aprogram that supports authors and readers who work withina digital library (Jones, 1999; Jones & Paynter, 1999; Jones& Staveley, 1999). In Phrasier, browsing and queryingactivities are seamlessly integrated with document author-ing and reading tasks.
Figure 4 shows the Phrasier interface. The user hasloaded a plain text document into the top-most pane, andkeyphrases have been used to dynamically insert hypertext
FIG. 1. Search results from a collection of the NZDL. Author or Kea keyphrases are included as a component of document summaries.
656 JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE AND TECHNOLOGY—June 2002

link anchors into the text. Keyphrases are displayed moreprominently than the rest of the text, and frequently occur-ring keyphrases more prominently than rarely occurringkeyphrases.
Phrasier supports multidestination links, and two levelsof gloss (preview information about the link destination)allow users to evaluate a link before following it. In Figure4, the user has clicked on the highlighted phrase digitallibraries and is examining the gloss of the third of fiverelated documents.
Keyphrases that appear in the text are listed to the left ofthe bottom panel. One or more keyphrases can be selectedto produce a ranked list of documents that relate to thecombination of topics (bottom right). The list is produced bya retrieval engine that uses a keyphrase-based similaritymeasure. Any of the documents in this list can be loadedinto the main viewing pane. In fact, the main window is atext editor, and the user can create a document by typing itdirectly into Phrasier. As the user enters text, keyphrases areidentified in real time, highlighted, and turned into linkanchors with associated destination documents, providingimmediate access to related material.
Other Systems
A number of other systems exploit phrases to enhanceuser interaction. The Journal of Artificial Intelligence Re-search (http://extractor.iit.nrc.ca/jair/keyphrases/) can be ac-cessed through an interface that is based around keyphrasesproduced by Extractor (Turney, 2000). Larkey (1999) de-scribes a system for searching a database of patent infor-mation. Within the system phrases are used to suggest queryexpansions to users based on the search terms that havebeen specified. Similarly, Pedersen Cutting, and Tukey(1991) use phrases to support query reformulation in theirSnippet Search system. Krulwich and Burkey (1997) exploitheuristically extracted phrases to inform InfoFinder, an “in-telligent” agent that learns user interests during access toon-line documents.
Kea
Kea is a keyphrase extraction algorithm developed bymembers of the New Zealand Digital Library Project. Keatreats keyphrase extraction as a machine learning problem
FIG. 2. The KeyPhind user interface. A query term is entered, resulting in the display of keyphrases containing the term. Keyphrases that cooccur withthe selected phrases are shown to the right, and related documents at the bototm.
JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE AND TECHNOLOGY—June 2002 657

(Frank et al., 1999; Witten & Frank, 2000). The algorithm issubstantially simpler, and therefore less computationallyintensive, than many of the phrase extraction techniquesdescribed earlier.
Kea’s operation is illustrated by Figure 5. It uses a modelto identify the phrases in a document that are most likely tobe good keyphrases. The model must be learned from a setof training documents with exemplar keyphrases. The ex-emplar keyphrases are usually supplied by authors, althoughit is also acceptable to manually provide exemplar key-phrases. Once a model for identifying keyphrases is learnedfrom the training documents it can be used to extract key-phrases from other documents.
Training Kea
To learn a model, Kea translates the training documentsinto textual form and extracts a set of candidate phrases. Foreach document in turn, every sequence of one to four wordsis identified, case-folded, and stemmed using the iteratedLovins stemmer (Lovins, 1968). Stems that are equivalent
are merged into a single canonical form. Many phrases arediscarded at this stage, including those that begin or endwith a stopword, those which consist only of a proper noun,those that do not match predefined phrase length con-straints, and those that occur only once within a document.
Three attributes of each remaining phrase are calculated:whether or not it is an exemplar keyphrase of the document,the distance into a document that it first occurs, and its TF �IDF value. The distance value is real and in the range 0 to1, indicating the proportion of the document occurring be-fore a phrase’s first appearance. TF � IDF is a standardinformation retrieval metric that estimates how specific aphrase is to a document. TF (term frequency) is a measureof how frequently a phrase occurs in a particular document,and DF (document frequency) is a measure of how manyother documents contain the phrase. The TF � IDF value isdetermined by multiplying TF by the inverse of DF.
The candidate phrases from each document are com-bined and used to construct a Naı̈ve Bayes classifier (Do-mingos & Pazzani, 1997) that predicts whether or not agiven phrase is a keyphrase based on its distance and TF �
FIG. 3. The Kniles user interface. Automatically extracted keyphrases are identified as link anchors within viewed documents. To the right, phrase listsprovide links to lists of documents on related topics.
658 JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE AND TECHNOLOGY—June 2002

IDF attributes. Each Kea model consists of this classifierand two supporting files containing lists of stopwords andphrase frequencies.
A range of options allows control over the model build-ing process, and consequently, the characteristics of thekeyphrases that will eventually be extracted. These includemaximum and minimum acceptable phrase length (in
words), and an extension to the model that has an additionalnumerical attribute for the number of times that phraseoccurs as an author-specified keyphrase in a corpora ofrelated documents. The effect of these parameters on thequality of Kea’s output is explored later in this article.
A number of prebuilt models are available for Kea.These include aliweb, which was trained on a representative
FIG. 4. The Phrasier user interface. Users type or view documents in the upper window, where keyphrases are variably highlighted and act as link anchors.Each anchor contains link previews. Items in a phrase list can be selected to form a query to retrieve related documents.
JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE AND TECHNOLOGY—June 2002 659

sample of Web pages identified by Turney, and cstr, whichwas trained on a collection of computer science technicalreports.
Extracting Keyphrases
Once a model for identifying keyphrases is learned fromthe training documents, it can be used to extract keyphrasesfrom other documents. Each document is converted to plaintext form and all its candidate phrases are extracted. Manyare immediately discarded, using the same criteria as de-scribed for the training process. The distance and TF � IDFattributes are computed for the remaining phrases. TheNaı̈ve Bayes model uses these attributes to calculate theprobability that each candidate phrase is a keyphrase. Themost probable candidates are output in ranked order; theseare the keyphrases that Kea associates with the document.
The number of phrases extracted from each documentcan be controlled, and is typically around 10 (depending onthe intended application), even though the number identifiedby the author may vary. The length of the phrases, ex-pressed as the minimum and maximum number of words itcontains, can also be controlled. Table 1 shows sample Keaoutput for this document (which has no keyphrases of itsown) using the aliweb model. The left-most column showsthe keyphrases as they appear with the document text. The
middle column shows the stemmed and case-folded form ofthe keyphrase. The right-most column shows the scoreallocated by Kea to each phrase. This score is a measure ofhow suitable a phrase is as a keyphrase of the document andallows keyphrases to be ranked (see (Frank et al., 1999) fora full explanation).
FIG. 5. The Kea keyphrase extraction process. In the optional training stage (top) a keyphrase model is built. In the extraction stage (bottom) a modelis applied to identify keyphrases within documents (right).
TABLE 1. Kea output for a draft of this article (aliweb model, two- tothree-word phrases).
Unstemmedkeyphrase Stemmed keyphrase Keyphrase score
Digital Libraries digit libr 0.15095707184225382keyphrase extraction keyphr extract 0.15095707184225382author keyphrases author keyphr 0.05354113508124128et al et al 0.05354113508124128extraction algorithm extract algorithm 0.022510514132182073keyphrase extraction
algorithmkeyphr extract
algorithm0.022510514132182073
computer science computer sc 0.022510514132182073automatic keyphrase
extractionautom keyphr extract 0.022510514132182073
assigned keyphrases assign keyphr 0.022510514132182073document content docum cont 0.022510514132182073searching and
browsingsearch and brow 0.022510514132182073
Document clustering docum cluster 0.022510514132182073
660 JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE AND TECHNOLOGY—June 2002

Domain-Specific Extraction
The model is a replaceable component of the extractionprocess. Most Kea users bypass the training stage and applya model that was created previously for a different docu-ment collection and distributed with Kea. Existing modelsare convenient, but previous work shows that models builtfor specific collections are more likely to account for theidiosyncrasies of that collection’s keyphrases, and that amodel can be tailored to a collection by the inclusion of thekeyphrase frequency attribute described above (Frank et al.,1999).
Keyphrase Evaluation Techniques
There are two basic methods for evaluating automati-cally generated keyphrases. The first adopts the standardInformation Retrieval metrics of precision and recall toreflect how well generated phrases match a set of “relevant”phrases. The second gathers subjective assessments fromhuman readers.
The first approach requires a set of “relevant” phrasesagainst which extracted phrases can be compared. The key-words provided by document authors are usually used.Evaluation is very simple because the outcomes are welldefined and easy to measure: to what extent does the ex-tracted phrase set match the author phrase set? Performanceis measured using precision (the proportion of the extractedphrases that match author phrases) and recall (the propor-tion of the author phrases that appear in the extracted set).
Barker and Cornacchia (2000) describe four limitationsof this type of evaluation. First, the keyphrases provided byauthors may not appear in the text of the document to whichthey belong, in either their full or stemmed forms, andtherefore, such keyphrases can never be identified by anapproach based solely on phrase extraction. Second, authorsmay select keyphrases for purposes other than summariza-tion of a document’s topics. Third, extraction systems mayselect far more keyphrases for a document that have beenprovided by the authors. Finally, relatively few documentsof limited type have author keyphrases (or those assignedmanually by other means) associated with them.
The second approach, human phrase assessment, hasbeen used in several previous studies (Barker & Cornacchia,2000; Chen, 1999; Tolle & Chen, 2000; Turney, 2000).They follow essentially the same methodology: subjects areprovided with a document and a phrase list, and asked toassess in some way the relevance of the individual phrases(or sets of phrases) to the given document.
Human evaluation suffers some disadvantages: it can betime-consuming and expensive; assessors may not makeconsistent judgements, either individually or as a group; andthe experimental methodology must be appropriately de-signed and administered. However, the evaluation can movecloser to ecological validity—matching the nature of deci-sions that users will make in the course of their interactionswith systems exploiting keyphrases.
In some cases, precision and recall measures can also beapplied to subjective evaluations. Tolle and Chen (2000)use amended precision/recall measures, which they termsubject precision (SP) and subject recall (SR). These mea-sures avoid the requirement for a priori correct and consis-tent judgements of “relevant” items. SP is defined to be theproportion of extracted phrases selected as relevant by asubject. SR is defined to be the proportion of all the phrasesselected as relevant by a subject that were extracted by thealgorithm under consideration.
Prior to this study, Kea has been evaluated against authorkeyphrases under a variety of settings and circumstances(Frank et al., 1999), but there has not been a direct humanevaluation of the keyphrases generated by Kea.
Evaluating Kea’s Keyphrases
We have adopted a range of evaluation approaches,including precision/recall of author keyphrases, humanevaluation, and subject precision/recall measures. The eval-uation had three aims. First, we wished to evaluate thekeyphrases produced by Kea with a variety of models andsettings. Second, we wished to compare a subjective eval-uation of Kea to the results of evaluations based on theauthor keyphrases. Finally, we wished to determine if theauthor’s keyphrases are a good standard against which tomeasure performance—do readers think the author key-words are good keyphrases?
Method
The basic methodology of the evaluation was simple:each of 28 subjects was given a technical document and alist of approximately 60 candidate keyphrases. The sub-jects’ task was to read the document, and then to rate thesuitability of each of the candidates as a keyphrase of thedocument.
The subjects were allocated two documents each, andallowed as much time as they needed to complete each task.The first task was waiting for them when they arrived. Whenthey completed it they were allowed a short break (if theydesired), and the materials for the second task were thensupplied and the process repeated. All of the subjects exceptfor two (discussed below) completed both documents within2 hours. The mean time taken for the first document was 43minutes (SD � 17 minutes), and for the second was 28minutes (SD � 7 minutes).
Instructions
The subjects were instructed to first read the paper fully.They were then told to reveal the phrase list and asked:“How well does each of the following phrases representwhat the document is either wholly or partly about?” Thelist of phrases was presented in the following form:
JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE AND TECHNOLOGY—June 2002 661

hypertextNot at all Perfectly
0 1 2 3 4 5 6 7 8 9 10co-citation analysisNot at all Perfectly
0 1 2 3 4 5 6 7 8 9 10
Subjects indicated their rating by drawing a circle aroundthe appropriate value. Subjects could refer back to the paperand reread it as often as required.
Experimental Texts
A set of six English language papers from the Proceed-ings of the ACM Conference on Human Factors 1997(“Proceedings of CHI’97: Human Factors in ComputingSystems,” 1997) were used as test documents. They weresuitable for our purposes because they contain author-spec-ified keywords and phrases, and provide a good fit with thebackground and experience of our subjects. The list ofselected papers is shown in Table 2.
Each paper was eight pages long. The plain text wasextracted from each original electronic version of the paper,and then processed by Kea to extract keyphrases. BeforeKea was applied to each paper, the author’s keyphraseswere removed so that they would not influence extractionand assessment, and so that the papers would better repre-sent the bulk of technical reports that do not have authorkeyphrases.
Subjects
Subjects were recruited from a final year course onHuman Computer Interaction (HCI) being taken as part ofan undergraduate degree programme in Computer Science.28 subjects were recruited, of which 23 were male and fivefemale. All had completed at least 3 years of undergraduateeducation in computer science or a related discipline and
were nearing completion of a 15-week course on HCI. Thefirst language of 15 of the subjects was English. The young-est subject was 21, the oldest 38, and the mean age was 25.
Allocation
Two documents were allocated to each of the subjects.Papers were allocated randomly to the subjects, thoughpresentation order, number of viewings of each paper, andsubjects’ first language were controlled, resulting in thedistribution in Table 3. Two of the subjects, whose firstlanguage was not English, read only one document duringthe experimental session, and the numbers marked with anasterisk reflect this variation from the planned allotment.
Generating the Phrase Lists
Each phrase list contained phrases from a variety ofsources: Kea keyphrases extracted from the paper, author
TABLE 2. The documents used in the study and their author-specified keyphrases as they appear in the articles. All appear in the Proceedings of CHI’97:Human Factors in Computing Systems, ACM Press, 1997.
Paper ID Reference
1 Borchers, J.O. WorldBeat: Designing a baton-based interface for an interactive music exhibit. pp. 131–138.interface design, interactive exhibit, baton, music, education
2 Kandogan, E., & Shneiderman, B. Elastic windows: Evaluation of multi-window operations. pp. 250–257.Window Management, Multi-window operations, Personal Role Management, Tiled Layout, User Interfaces, Information Access and
Organization3 Wilcox, L.D., Schilit, B.N., & Sawhney, N. Dynomite: A dynamically organized ink and audio notebook. pp. 186–193.
Electronic notebook, note-taking, audio interfaces, hand writing, keyword indexing, ink properties, retrieval, paper-like interfaces, PDA,pen computing
4 Myers, B.A. Scripting graphical applications by demonstration. pp. 534–541.Scripting, Macros, Programming by Demonstration (PBD), Command Objects, Toolkits, User Interface Development Environments,
Amulet5 Tauscher, L., & Greenberg, S. Revisitation patterns in World Wide Web navigation. pp. 399–406.
History mechanisms, WWW, Web, hypertext, navigation6 Pitkow, J., & Pirolli, P. Life, death and lawfulness on the electronic frontier. pp. 383–390.
Clustering, categorization, cocitation analysis, World Wide Web, hypertext, survival analysis, usage models
TABLE 3. Allotment of subjects to papers, including viewing order andlanguage characteristics of subjects.
Paper
1 2 3 4 5 6
All subjects Viewed 1st 5 5 4 7 5 2Viewed 2nd 4 5 5 4 5 3Total 9 10 9 11 10 5
English firstlanguage Viewed 1st 3 2 2 3 3 2
Viewed 2nd 2 3 3 2 2 3English
NOT firstlanguage Viewed 1st 2 3 2 4 2
Viewed 2nd 2 2* 2* 2 2
Numbers marked * were initially assigned an extra assessment that didnot take place.
662 JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE AND TECHNOLOGY—June 2002

keyphrases specified in the paper, and unrelated controlphrases. The presentation order of the phrases within eachlist was randomised for each subject.
Three Kea models were used to extract keyphrases. Thefirst, aliweb, was trained on a set of typical Web pagesfound by Turney (1999, 2000). The second, cstr, is derivedfrom a collection of computer science technical reports asdescribed by Frank et al. (1999). The third, cstr-kf, wastrained on the same documents as cstr, but uses a furtherattribute that reflects how frequently a phrase occurs as aspecified keyphrase in a set of training documents. Experi-ments using information retrieval measures show that, av-eraged over hundreds of computer science documents, thecstr model extracts better phrases than the aliweb model,and that the cstr-kf model extracts better phrases than either(Frank et al., 1999).
For each model, two Kea settings were varied: the max-imum and minimum phrase length. Four phrase sets wereproduced with each model, corresponding to phrases of oneto three words, one to four words, two to three words, andtwo to four words. The first two variations reflect the waythat Kea is typically used to approximate author keyphrases,and 15 phrases were extracted. The latter two reflect Kea’suse in a number of digital library user interfaces that wedescribe earlier in this article—KeyPhind, Kniles, andPhrasier—all of which ignore keyphrases that consist of asingle word.
Six unrelated phrases were introduced into each phraselist to enable coarse measurement of how carefully thesubjects considered the task. This set consists of the namesof food products.
In total there were 14 phrase sets for each paper: fourphrase length variations for each of three Kea models, theauthor keyphrases, and the food set. The 14 sets describingeach document were merged into a single master list foreach document. Exact duplicates were removed, but phrasesthat differed even slightly (in their capitalization or suffixes)were included in the master list once in each form in whichthey appeared.
For every paper, there is overlap between the Kea phraselists, and between the Kea lists and the author keyphrases.The number of phrases from each source and the totalnumber of phrases in the list for each paper are shown inTable 4. In only one paper—paper 5—was the full set ofauthor keyphrases extracted by Kea. Table 5 shows some ofthe phrase sets extracted from the paper. Phrases in bold arethose that Kea extracted that are equivalent to author key-phrases (after case-folding and stemming). The shaded areasindicate the keyphrases that would be extracted using thedefault settings for each model. No single model found allfive author phrases in the first fifteen extracted phrases.
Table 6 shows the frequency with which each phraselength occurred for the Kea and author phrases. The Keafrequencies include the phrases identified by Kea that werealso author-specified keyphrases. More than half of thephrases (183 of 347, or 53%) consisted of a single word.Just over a third of phrases (123 of 347, or 35%) consisted
of two words. Thirty-nine phrases (11%) consisted of threewords, and only two of the phrases consisted of four words.Almost a half (48%) of all phrase were single-word phrasesprovided by Kea. Both of the four-word phrases were pro-vided by authors. Of the Kea phrases alone, 54% consistedof one word, 35% two words, and 12% three words.
Results
Before we draw any conclusions about the relative meritsof the extraction methods, we first demonstrate that there isagreement between the subjects. Unless a significant levelof agreement can be established, we cannot determine thatone phrase is judged better than another for any reason otherthan chance, nor make any authoritative conclusions aboutthe relative utility of the extraction methods. Following this,we consider standard information retrieval measures of pre-cision and recall with respect to Kea’s in identifying authorkeyphrases for each paper. We then present the results ofsubject precision and recall measures. Finally, in this sec-tion we consider the scores that the subjects assigned to thekeyphrases, and use the scores to compare the range ofkeyphrase sets under consideration.
Intersubject Areement
We measured the level of intersubject agreement usingtwo statistical techniques: the Kappa Statistic K and theKendall Coefficient of Concordance W (Siegel & Castellan,1988). These measures show significant agreement betweenthe subjects, and we reject the hypothesis that the effects weobserve occur merely by chance.
Using Kappa, the level of agreement is represented by K,a real number that ranges from zero to 1. A value of zeroreflects a level of agreement between the subjects that couldhave been expected to occur by chance. A value of 1 reflectscomplete agreement between the subjects. The Kappa sta-tistic assumes that the observations are assignments to un-ordered categories—in our study the scores given by theassessors act as unordered categories to which each phrasemay be assigned. Although it is widely used, Kappa is notan optimal measure of interassessor agreement for our pur-poses, as will be discussed below. We have included it to
TABLE 4. Profile of keyphrases associated with each document.
Paper
Number of keyphrases
Author Merged Kea Food Combined list
1 5 49 6 582 6 47 6 583 10 51 6 664 8 54 6 685 5 51 6 576 7 55 6 67Total 41 307 36 374
Exact duplicates are merged when lists are combined.
JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE AND TECHNOLOGY—June 2002 663

allow comparisons between the intersubject agreement ob-served in our subjects and in other studies (Barker & Cor-nacchia, 2000; Chen, 1999). Kappa is defined as
K �P�A� � P�E�
1 � P�E�
where P(A) is the proportion of times that k raters agree, andP(E) is the proportion of times that we would expect the kraters to agree by chance.
Table 7 illustrates the agreement between the subjectsusing the Kappa score. Three different levels of granularityare considered. First, the categories are the scores markedby the user on the 11-point scale. Second, we translatesubjects’ 11-point responses to three categories, simulatingresponses of bad, so-so, and good. The three categories areformed from the ranges 0–3, 4–6, and 7–10. Third, the11-point responses are translated into two categories, effec-
tively a bad/good judgement. The two points are formed bythe ranges 0–5 and 6–10. Two statistics are shown for eachpaper: the Kappa score K, and the z-score, a test of thesignificance of K. The number of phrases being rated foreach paper is sufficiently large to allow us to use an ap-proximation of the variance of K and consequently calculatez (Siegel & Castellan, 1988).
As expected, the level of agreement increases as thenumber of categories decreases from 11 to 3 to 2. Althoughthe values of K are small, they are all significant (p� 0.001). There is no discernible trend regarding agreementwithin the English-first-language and non-English-first-lan-guage groups.
A drawback of the Kappa statistic is that it considersagreement on unordered categories. Consider, for example,two subjects, one of whom always rates a phrase exactly onepoint higher than the other subject. Although they agreeabout which phrases are the best, and which are worst, and
TABLE 5. Selected keyphrases associated with paper 5.
Author keywords
Keywords extracted by Kea (length 1–3)
Foodaliweb model cstr model cstr-kf model
History mechanisms revisit revisit navigation onionWWW URL web browsers garlicweb history navigation World Wide Web milkhypertext user URL browsing ham and eggs
navigation history mechanisms history patterns pumpkin pienavigation history mechanisms web browsers vegetable souppages pages predictpatterns web pages WWWweb browsers empiricalweb pages user hypertextstack Tauscher accessedvisited World Wide Web methodsrecency visited listpredict browsing recurrencefrequency stack actions
Keyphrases shown in bold are the author keyphrases identified by Kea. The shaded area indicates the keyphrases thatwould be extracted using the default settings of each Kea model. Author keyphrases are shown in the order in which theyoccur in the paper. Kea keyphrases are in ranked order, with the best shown first.
TABLE 6. Frequency of author and Kea keyphrases of length 1–4.
Paper
Frequency of phrases of length
1 2 3 4
Kea Author Kea Author Kea Author Kea Author
1 24 3 22 2 3 0 0 02 23 0 20 4 4 1 0 13 31 4 17 6 3 0 0 04 29 4 17 1 8 1 0 15 25 4 19 1 7 0 0 06 33 3 11 3 11 1 0 0
For all documents 165 18 106 17 36 3 0 2
Kea totals include phrases that are also author keyphrases.
664 JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE AND TECHNOLOGY—June 2002
on the ordering of the phrases, their agreement is zero whenmeasured by Kappa. In part, we wished to make compara-tive assessments of each of the keyphrase sources that weconsidered in our study—to determine whether one sourcewas better or worse than another—not to make absolutejudgements based on phrase scores. Consequently, we con-sidered the level of agreement between the subjects’ relativerankings of the phrases.
The Kendall Coefficient of Concordance (W) is a mea-sure of agreement between rankings. As with K, it has avalue between 0 (agreement as expected by chance) and 1(complete agreement). Our data contains a large number ofties (phrases with the same score), and W has been com-puted with an appropriate correction (Siegel & Castellan,1988). Table 8 shows the result using the full 11-point scale.In each case, W is nonzero, indicating that there is intersub-ject agreement. The �2 score and degrees of freedom (df)can be used to determine the level of significance of the Wvalue. The level of agreement is significant (p � 0.001) forall papers.
The Kendall Coefficient demonstrates that there are sig-nificant (and usually strong) levels of agreement betweenthe subjects when they assess the keyphrases. We concludethat subjects agree sufficiently to justify further investiga-tion into the relative quality of the different keyphraseextraction methods.
Precision and Recall
Previous evaluations of Kea have focussed on two infor-mation retrieval measures: precision and recall. The preci-sion of a set of phrases is the proportion of the set that areauthor keyphrases. In Table 5, for example, three of the 15phrases extracted using the aliweb model are equivalent toauthor-specified keyphrases of the documents,1 so the pre-cision is 3/15, or 20%. Recall is the proportion of the totalnumber of author keyphrases that are identified by thealgorithm. In this example, there are five author keyphrases
and three are identified by the aliweb model; thus the recallis 3/5 � 60%. If we combine the three models in Table5—aliweb, cstr, and cstr-kf—then all five author keyphrasesappear in the phrase set, so the recall is 100%. There are 28unique phrases in the merged set, so the precision is 5/28� 18%.
Table 9 shows the precision and recall when each of themodels is used to extract a maximum of 6, 9, 12, and 15phrases. The first two columns identify the model, the thirdshows the actual number of author keyphrases identified byKea, the fourth shows the precision (based on the 41 author-assigned keyphrases for the six documents as in Table 4,Author column), and the fifth the recall. For example, whenthe aliweb model is used to produce six phrases of one tothree words for each of the documents, seven of the 41author keyphrases were extracted. This gives recall of 7/41or 0.17. As 36 keyphrases were produced for the six docu-ments, the precision is 7/36 or 0.19.
A common trade-off in information retrieval is illustratedin Table 9: as the number of extracted phrases increases,recall increases but precision decreases. The highest preci-sion that was achieved was 0.28, when the cstr model wasused to produce a maximum of six keyphrases of one tothree words. Approximately one out of every four Keakeyphrases was an author keyphrase. The lowest level ofprecision, 0.06, occurred when the aliweb model was usedto extract 12 phrases of two or three words: approximatelyonly one in 20 was an author keyphrase. The largest numberof author keyphrases was identified by the cstr model, whena maximum of 15 phrases of lengths 1–3 or 1–4 wereproduced for each document. Thirteen author keyphraseswere found, giving recall of 0.32. The lowest recall, of 0.05,was the cstr-kf model producing six keyphrases of two tofour words.
When we compare each model for phrases of length 1–3(or 1–4) we observe that cstr produces the best precisionand recall results, followed by aliweb, and then cstr-kf.When the minimum phrase length is two words, we observethat cstr still has the best performance, but that cstr-kfbecomes better than aliweb as more keyphrases are ex-tracted. Precision and recall are usually smaller for phrasesof length 2–4 than for those of length 1–4. This is because18 of the author phrases consist of only one word, andcannot be extracted with a minimum phrase length of twowords.
1 Following Turney we consider two phrases as equivalent if theircase-folded and stemmed versions are the same.
TABLE 8. Intersubject agreement (for all subjects) measured with theKendall Coefficient of Concordance using the full 11-point scale.
Paper W X2 df
1 0.63 321.03 582 0.70 400.67 583 0.63 368.90 664 0.32 236.11 685 0.38 215.65 576 0.72 237.81 67
TABLE 7. Interassessor agreement measured by Kappa at three levels ofgranularity: the full 11-point scale, a three-point scale, and a two-pointscale.
Paper
Number of points in scale
11 3 2
K z K z K z
1 0.13 14.99 0.26 16.06 0.32 14.142 0.14 15.74 0.32 18.14 0.39 18.373 0.15 17.44 0.28 15.22 0.29 10.584 0.08 12.48 0.14 9.85 0.16 8.865 0.13 15.29 0.22 13.11 0.27 11.926 0.16 5.88 0.29 6.50 0.37 6.69
JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE AND TECHNOLOGY—June 2002 665
Human Assessments
Across all documents the mean score assigned by sub-jects to a keyphrase from the combined Kea and authorkeyphrase sets (excluding food phrases) was 5.60. This isslightly above the midpoint of the scale used to score thephrases. Table 10 shows the mean scores allocated tophrases for each paper and each phrase length. We see thatfor all of the papers the mean phrase score was higher thanthe midpoint of 5.
For each of the phrase lengths the author phrases received,on average, higher scores than Kea phrases of the same length.The mean score for a single-word author phrase was 6.14,compared to 4.33 for a single-word Kea phrase. The corre-sponding scores for two-word phrases were 7.12 and 5.59, andfor three-word phrases they were 5.40 and 4.96. On average,only two-word Kea phrases were rated positively—that is, theyscored more than 5. In all but two cases (author-keyphrases forpapers 4 and 6) subjects preferred two-word keyphrases oversingle-word keyphrases, whether they were supplied by au-thors or by Kea. The relationship between two-word andthree-word phrases is slightly less evident.
Figure 6 shows the scores for Kea sets containing key-phrases of one to three words. Figure 7 shows the scores forKea sets in which the length of keyphrases is two to threewords. In both graphs the author and food sets are included,along with an artificial set, labeled best. A best set ofkeyphrases was created for each paper by calculating themean score for each phrase, across all subjects, and thenselecting the 15 phrases with the highest mean scores. Thebest phrases sets were combined to provide the best line inFigures 6 and 7.
The results for phrases of lengths 1–4 and 2–4 are notshown because they are very similar to their counterparts oflengths 1–3 and 2–3m respectively, due to only two of thekeyphrases containing four words. These were author key-phrases for papers 2 and 4. Similarly, removing the re-sponses of the subjects whose first language is not Englishdoes not have a significant effect.
The phrases that are unrelated food products are rated verylowly. Only nine of the 324 scores assigned to food phrases(2.8%) were nonzero, and no food phrase was assigned anonzero score by a subject whose first language is English.
TABLE 9. Combined precision and recall measured against author keyphrases for each Kea model.
ModelKeyphrase
length
Number of author phrasesidentified by Kea (of 41) Precision Recall
Number of Kea phrases extracted per paper
6 9 12 15 6 9 12 15 6 9 12 15
aliweb 1–3 7 8 9 10 0.19 0.15 0.13 0.11 0.17 0.20 0.22 0.241–4 7 8 9 10 0.19 0.15 0.13 0.11 0.17 0.20 0.22 0.24
cstr 1–3 10 10 10 13 0.28 0.19 0.14 0.14 0.24 0.24 0.24 0.321–4 8 9 12 13 0.22 0.17 0.17 0.14 0.20 0.22 0.29 0.32
cstr-kf 1–3 5 6 8 8 0.14 0.11 0.11 0.09 0.12 0.15 0.20 0.201–4 5 7 7 8 0.14 0.13 0.10 0.09 0.12 0.17 0.17 0.20
aliweb 2–3 4 4 4 0.11 0.07 0.06 0.10 0.10 0.102–4 4 4 4 0.11 0.07 0.06 0.10 0.10 0.10
cstr 2–3 6 6 8 0.17 0.11 0.11 0.15 0.15 0.202–4 4 4 6 0.11 0.07 0.08 0.10 0.10 0.15
cstr-kf 2–3 3 5 7 0.08 0.09 0.10 0.07 0.12 0.172–4 2 4 7 0.06 0.07 0.10 0.05 0.10 0.17
food 0 0.00 0.00
TABLE 10. The mean scores of a Kea or author phrase of one to four words for each paper.
Paper
Mean score for each phrase length
Mean
1 2 3 4
Kea Author Kea Author Kea Author Kea Author
1 4.53 5.00 5.79 7.67 5.67 5.732 3.79 5.92 7.68 7.43 2.30 6.50 5.603 4.32 6.11 5.25 6.13 3.44 5.054 5.06 5.87 6.28 5.64 6.27 5.91 4.82 5.695 4.82 5.93 6.21 9.30 3.77 6.016 3.48 7.80 4.09 6.29 3.20 8.00 5.48
Mean for alldocuments 4.33 6.14 5.59 7.12 4.96 5.40 5.66 5.60
666 JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE AND TECHNOLOGY—June 2002
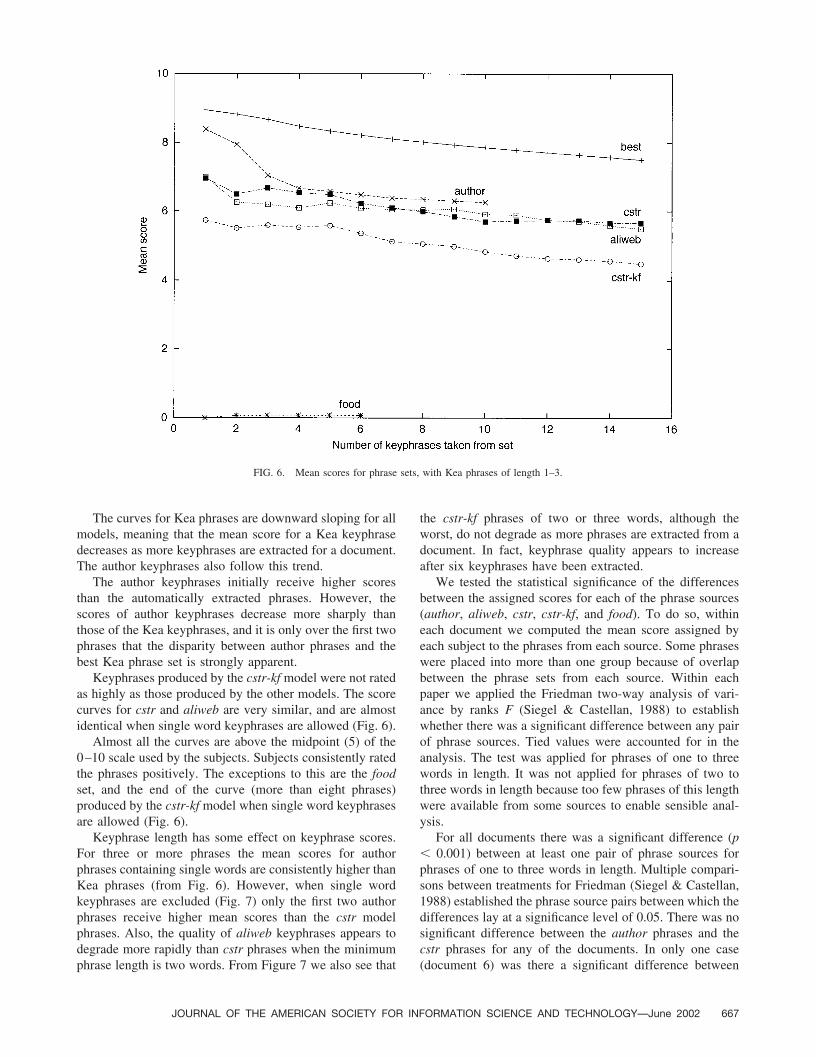
The curves for Kea phrases are downward sloping for allmodels, meaning that the mean score for a Kea keyphrasedecreases as more keyphrases are extracted for a document.The author keyphrases also follow this trend.
The author keyphrases initially receive higher scoresthan the automatically extracted phrases. However, thescores of author keyphrases decrease more sharply thanthose of the Kea keyphrases, and it is only over the first twophrases that the disparity between author phrases and thebest Kea phrase set is strongly apparent.
Keyphrases produced by the cstr-kf model were not ratedas highly as those produced by the other models. The scorecurves for cstr and aliweb are very similar, and are almostidentical when single word keyphrases are allowed (Fig. 6).
Almost all the curves are above the midpoint (5) of the0–10 scale used by the subjects. Subjects consistently ratedthe phrases positively. The exceptions to this are the foodset, and the end of the curve (more than eight phrases)produced by the cstr-kf model when single word keyphrasesare allowed (Fig. 6).
Keyphrase length has some effect on keyphrase scores.For three or more phrases the mean scores for authorphrases containing single words are consistently higher thanKea phrases (from Fig. 6). However, when single wordkeyphrases are excluded (Fig. 7) only the first two authorphrases receive higher mean scores than the cstr modelphrases. Also, the quality of aliweb keyphrases appears todegrade more rapidly than cstr phrases when the minimumphrase length is two words. From Figure 7 we also see that
the cstr-kf phrases of two or three words, although theworst, do not degrade as more phrases are extracted from adocument. In fact, keyphrase quality appears to increaseafter six keyphrases have been extracted.
We tested the statistical significance of the differencesbetween the assigned scores for each of the phrase sources(author, aliweb, cstr, cstr-kf, and food). To do so, withineach document we computed the mean score assigned byeach subject to the phrases from each source. Some phraseswere placed into more than one group because of overlapbetween the phrase sets from each source. Within eachpaper we applied the Friedman two-way analysis of vari-ance by ranks F (Siegel & Castellan, 1988) to establishwhether there was a significant difference between any pairof phrase sources. Tied values were accounted for in theanalysis. The test was applied for phrases of one to threewords in length. It was not applied for phrases of two tothree words in length because too few phrases of this lengthwere available from some sources to enable sensible anal-ysis.
For all documents there was a significant difference (p� 0.001) between at least one pair of phrase sources forphrases of one to three words in length. Multiple compari-sons between treatments for Friedman (Siegel & Castellan,1988) established the phrase source pairs between which thedifferences lay at a significance level of 0.05. There was nosignificant difference between the author phrases and thecstr phrases for any of the documents. In only one case(document 6) was there a significant difference between
FIG. 6. Mean scores for phrase sets, with Kea phrases of length 1–3.
JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE AND TECHNOLOGY—June 2002 667

author phrases and aliweb phrases. The author phrases weresignificantly better than cstr-kf phrases in two cases—fordocuments 2 and 5. There were two instances of differencesbetween Kea phrases sets. For documents 1 and 3 the cstrphrases were significantly better than the cstr-kf phrases.For all documents, the author phrases were significantlybetter than the food phrases. The aliweb and cstr phraseswere significantly better than the food phrases for four andfive of the documents respectively. There was no significantdifference between the cstr-kf phrases and the food phrasesfor any of the documents.
Subject Precision and Recall
The precision and recall-based evaluations describedabove require a set of “relevant” phrases to have beenidentified against which an extraction system can be as-sessed. In this case, in line with other studies, we havechosen author keyphrases as the set of relevant phrases.However, this approach suffers from a number of problemsas we outlined earlier in this article. Therefore, we have alsocalculated subject precision (SP) and subject recall (SR),which require no predetermined relevant phrases; instead,relevance is recognized as a subjective factor that is deter-mined by the people who took part in the experiment. Wehave considered keyphrases that received scores of greaterthan 5 on the zero to 10 scale to be deemed relevant.Following Tolle and Chen (2000), SP and SR for a partic-ular subject are defined as follows:
SP �
Number of phrases extracted by the modelwhich are selected as relevant by the subject
Total number of phrases extracted by the model
SR �
Number of phrases extracted by the modelwhich are selected as relevant by the subject
Total number of phrasesselected as relevant by the subject
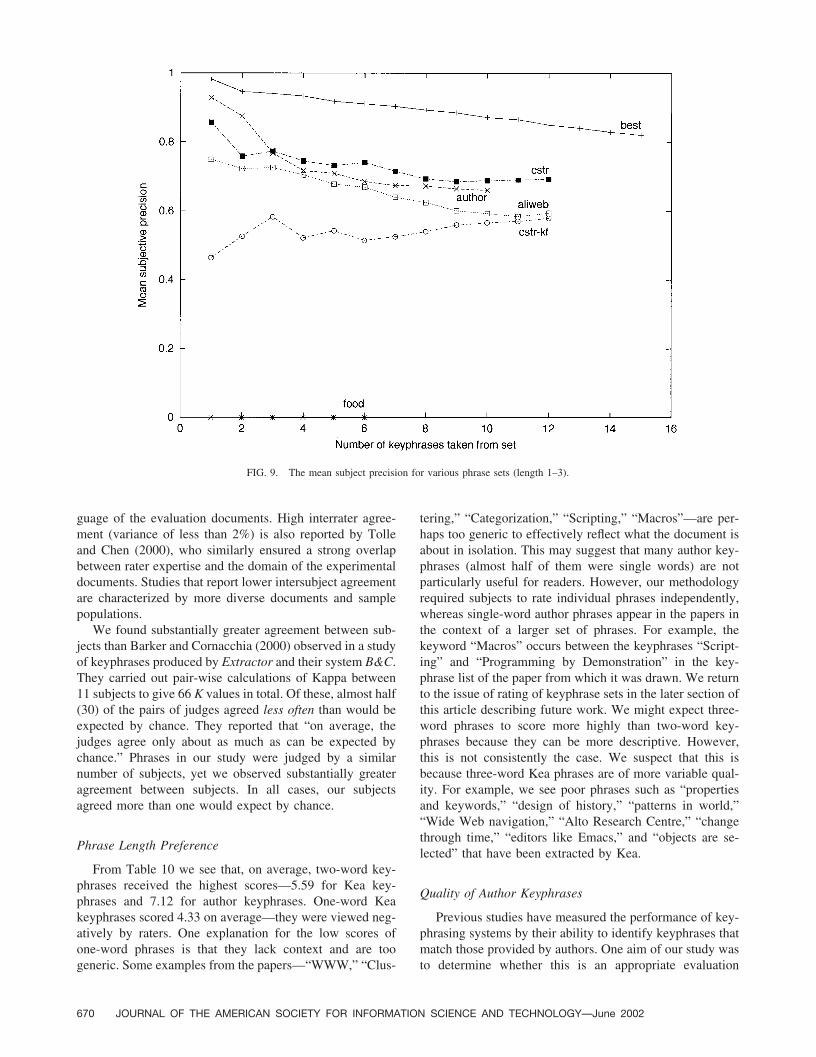
Figure 8 shows the mean subject precision (across allsubjects and documents) for keyphrases of one to threewords in length, and Figure 9 shows the same measure forkeyphrases of two or three words in length. Subject preci-sion reflects the same characteristics and relationships be-tween the keyphrase sets as revealed by the mean keyphrasescores of Figures 6 and 7. SP scores decline as morekeyphrases are extracted by each model (with the exceptionof cstr-kf for keyphrases of at least two words). The bestKea model is cstr, with aliweb almost achieving the sameperformance when single-word keyphrases are allowed.Again, the better performance of cstr is emphasized whensingle word keyphrases are excluded. Author keyphrases arebest over the first three or four keyphrases used for eachdocument. The cstr-kf model is again shown to be substan-tially worse than the others.
Subject precision scores for both aliweb and cstr showthat at least 60% of keyphrases extracted by those models
FIG. 7. Mean scores for phrase sets, with Kea phrases of length 2–3.
668 JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE AND TECHNOLOGY—June 2002
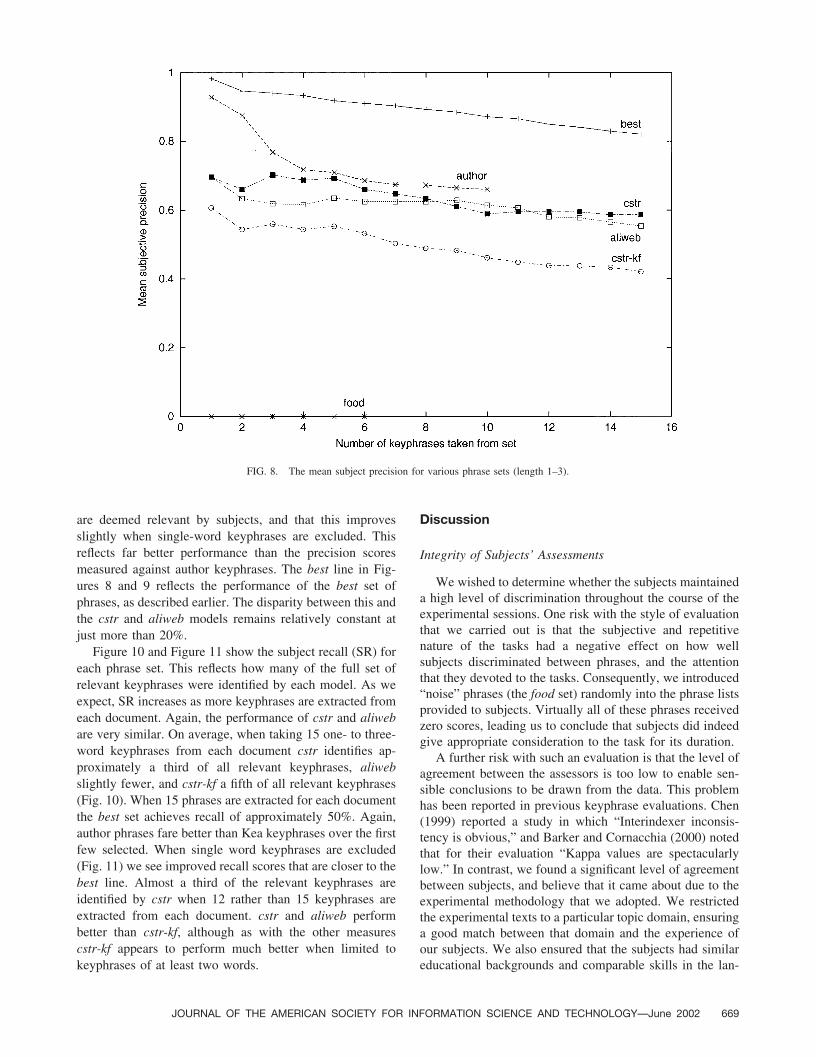
are deemed relevant by subjects, and that this improvesslightly when single-word keyphrases are excluded. Thisreflects far better performance than the precision scoresmeasured against author keyphrases. The best line in Fig-ures 8 and 9 reflects the performance of the best set ofphrases, as described earlier. The disparity between this andthe cstr and aliweb models remains relatively constant atjust more than 20%.
Figure 10 and Figure 11 show the subject recall (SR) foreach phrase set. This reflects how many of the full set ofrelevant keyphrases were identified by each model. As weexpect, SR increases as more keyphrases are extracted fromeach document. Again, the performance of cstr and aliwebare very similar. On average, when taking 15 one- to three-word keyphrases from each document cstr identifies ap-proximately a third of all relevant keyphrases, aliwebslightly fewer, and cstr-kf a fifth of all relevant keyphrases(Fig. 10). When 15 phrases are extracted for each documentthe best set achieves recall of approximately 50%. Again,author phrases fare better than Kea keyphrases over the firstfew selected. When single word keyphrases are excluded(Fig. 11) we see improved recall scores that are closer to thebest line. Almost a third of the relevant keyphrases areidentified by cstr when 12 rather than 15 keyphrases areextracted from each document. cstr and aliweb performbetter than cstr-kf, although as with the other measurescstr-kf appears to perform much better when limited tokeyphrases of at least two words.
Discussion
Integrity of Subjects’ Assessments
We wished to determine whether the subjects maintaineda high level of discrimination throughout the course of theexperimental sessions. One risk with the style of evaluationthat we carried out is that the subjective and repetitivenature of the tasks had a negative effect on how wellsubjects discriminated between phrases, and the attentionthat they devoted to the tasks. Consequently, we introduced“noise” phrases (the food set) randomly into the phrase listsprovided to subjects. Virtually all of these phrases receivedzero scores, leading us to conclude that subjects did indeedgive appropriate consideration to the task for its duration.
A further risk with such an evaluation is that the level ofagreement between the assessors is too low to enable sen-sible conclusions to be drawn from the data. This problemhas been reported in previous keyphrase evaluations. Chen(1999) reported a study in which “Interindexer inconsis-tency is obvious,” and Barker and Cornacchia (2000) notedthat for their evaluation “Kappa values are spectacularlylow.” In contrast, we found a significant level of agreementbetween subjects, and believe that it came about due to theexperimental methodology that we adopted. We restrictedthe experimental texts to a particular topic domain, ensuringa good match between that domain and the experience ofour subjects. We also ensured that the subjects had similareducational backgrounds and comparable skills in the lan-
FIG. 8. The mean subject precision for various phrase sets (length 1–3).
JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE AND TECHNOLOGY—June 2002 669
guage of the evaluation documents. High interrater agree-ment (variance of less than 2%) is also reported by Tolleand Chen (2000), who similarly ensured a strong overlapbetween rater expertise and the domain of the experimentaldocuments. Studies that report lower intersubject agreementare characterized by more diverse documents and samplepopulations.
We found substantially greater agreement between sub-jects than Barker and Cornacchia (2000) observed in a studyof keyphrases produced by Extractor and their system B&C.They carried out pair-wise calculations of Kappa between11 subjects to give 66 K values in total. Of these, almost half(30) of the pairs of judges agreed less often than would beexpected by chance. They reported that “on average, thejudges agree only about as much as can be expected bychance.” Phrases in our study were judged by a similarnumber of subjects, yet we observed substantially greateragreement between subjects. In all cases, our subjectsagreed more than one would expect by chance.
Phrase Length Preference
From Table 10 we see that, on average, two-word key-phrases received the highest scores—5.59 for Kea key-phrases and 7.12 for author keyphrases. One-word Keakeyphrases scored 4.33 on average—they were viewed neg-atively by raters. One explanation for the low scores ofone-word phrases is that they lack context and are toogeneric. Some examples from the papers—“WWW,” “Clus-
tering,” “Categorization,” “Scripting,” “Macros”—are per-haps too generic to effectively reflect what the document isabout in isolation. This may suggest that many author key-phrases (almost half of them were single words) are notparticularly useful for readers. However, our methodologyrequired subjects to rate individual phrases independently,whereas single-word author phrases appear in the papers inthe context of a larger set of phrases. For example, thekeyword “Macros” occurs between the keyphrases “Script-ing” and “Programming by Demonstration” in the key-phrase list of the paper from which it was drawn. We returnto the issue of rating of keyphrase sets in the later section ofthis article describing future work. We might expect three-word phrases to score more highly than two-word key-phrases because they can be more descriptive. However,this is not consistently the case. We suspect that this isbecause three-word Kea phrases are of more variable qual-ity. For example, we see poor phrases such as “propertiesand keywords,” “design of history,” “patterns in world,”“Wide Web navigation,” “Alto Research Centre,” “changethrough time,” “editors like Emacs,” and “objects are se-lected” that have been extracted by Kea.
Quality of Author Keyphrases
Previous studies have measured the performance of key-phrasing systems by their ability to identify keyphrases thatmatch those provided by authors. One aim of our study wasto determine whether this is an appropriate evaluation
FIG. 9. The mean subject precision for various phrase sets (length 1–3).
670 JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE AND TECHNOLOGY—June 2002

method. The results that we observed show that assessorsconsistently rated author keyphrases positively, indicatingthat author keyphrases are indeed a useful “gold-standard”against which to judge automatically extracted keyphrases.
We also noted that author phrase lists exhibit an inherentranking. When author phrases were ordered as they ap-peared in the experimental documents we found that themean scores were higher for those listed first than for thoselisted second and so on. Figures 6 and 7 show that the scorecurves for author phrases slope downwards as more authorphrases are considered. It appears that authors arrange theirkeyphrases with the most appropriate ones earlier in akeyphrase list, and the tendency is for the first two key-phrases to be noticeably better than later ones.
This phenomenon has implications for evaluation againstauthor keyphrases. Such measures have, to date, consideredauthor phrase lists as unordered sets, and computed preci-sion and recall values based on matches against phrasesanywhere in the set. It may be appropriate to take orderingof author phrases into account, considering not only howmany author phrases are identified but also the rank of thosephrases. This is not an issue for keyphrasing systems thatproduce unordered keyphrase suggestions, but is clearly hasimplications for systems such as Kea that produce rankedkeyphrase lists.
Kea’s Precision and Recall
Initially, the basic precision and recall scores shown inTable 9 seem to be poor. At best, precision is 28%; when six
phrases of one to three words were extracted using the cstrmodel, 10 of the 36 phrases were author phrases. The bestrecall is 32%; 13 of the 41 author phrases were extracted when15 phrases of one to four words were extracted using the cstrmodel. However, these results are similar to precision andrecall measures reported elsewhere. For example, Witten,Paynter, Frank, Gutwin, and Nevill-Manning (1999b) reportprecision of around 10.7% when assigning 15 keyphrase tocomputer science technical reports, and Turney (2000) reportsa mean precision of 12.8% (SD 8.9) over five different corporawhen extracting 15 phrases.
An important point to note is that keyphrase extractionsystems cannot extract author keyphrases unless they occurin the text of the document. In fact, of the 41 authorkeyphrases, seven did not occur within the text of theirrespective documents, and three occurred only once.2 Con-sequently, it is impossible for all author keyphrases to beidentified by an extraction algorithm: the maximum possiblerecall is 84%, and Kea, which ignores phrases that occuronly once, cannot possibly perform better than 76%.
The precision and recall scores for models producingkeyphrases of at least two words are consistently the worst.This is to be expected, given that almost half of the authorkeyphrases consist of only single words, and when authorphrases of only two words or more are considered, recall isalmost doubled and comes into line with the recall values
2 The author keyword lists were removed from each document beforeextraction, as described earlier.
FIG. 10. The mean subject recall for various phrase sets (length 1–3).
JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE AND TECHNOLOGY—June 2002 671
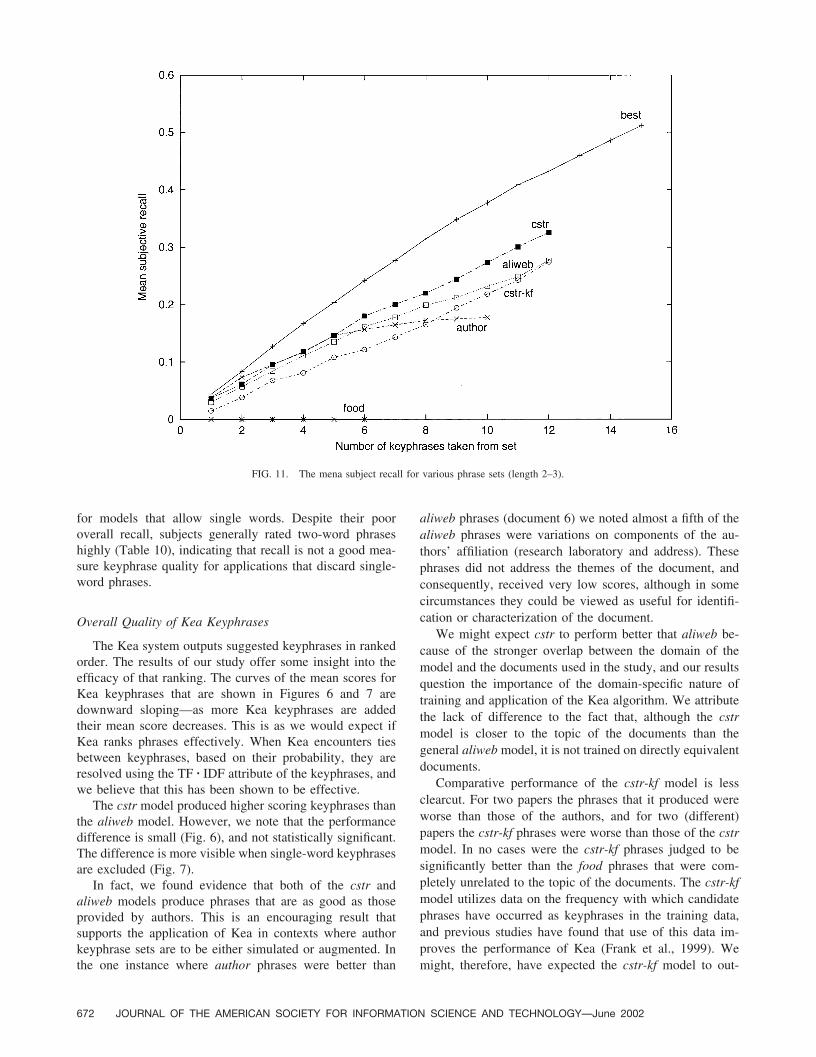
for models that allow single words. Despite their pooroverall recall, subjects generally rated two-word phraseshighly (Table 10), indicating that recall is not a good mea-sure keyphrase quality for applications that discard single-word phrases.
Overall Quality of Kea Keyphrases
The Kea system outputs suggested keyphrases in rankedorder. The results of our study offer some insight into theefficacy of that ranking. The curves of the mean scores forKea keyphrases that are shown in Figures 6 and 7 aredownward sloping—as more Kea keyphrases are addedtheir mean score decreases. This is as we would expect ifKea ranks phrases effectively. When Kea encounters tiesbetween keyphrases, based on their probability, they areresolved using the TF � IDF attribute of the keyphrases, andwe believe that this has been shown to be effective.
The cstr model produced higher scoring keyphrases thanthe aliweb model. However, we note that the performancedifference is small (Fig. 6), and not statistically significant.The difference is more visible when single-word keyphrasesare excluded (Fig. 7).
In fact, we found evidence that both of the cstr andaliweb models produce phrases that are as good as thoseprovided by authors. This is an encouraging result thatsupports the application of Kea in contexts where authorkeyphrase sets are to be either simulated or augmented. Inthe one instance where author phrases were better than
aliweb phrases (document 6) we noted almost a fifth of thealiweb phrases were variations on components of the au-thors’ affiliation (research laboratory and address). Thesephrases did not address the themes of the document, andconsequently, received very low scores, although in somecircumstances they could be viewed as useful for identifi-cation or characterization of the document.
We might expect cstr to perform better that aliweb be-cause of the stronger overlap between the domain of themodel and the documents used in the study, and our resultsquestion the importance of the domain-specific nature oftraining and application of the Kea algorithm. We attributethe lack of difference to the fact that, although the cstrmodel is closer to the topic of the documents than thegeneral aliweb model, it is not trained on directly equivalentdocuments.
Comparative performance of the cstr-kf model is lessclearcut. For two papers the phrases that it produced wereworse than those of the authors, and for two (different)papers the cstr-kf phrases were worse than those of the cstrmodel. In no cases were the cstr-kf phrases judged to besignificantly better than the food phrases that were com-pletely unrelated to the topic of the documents. The cstr-kfmodel utilizes data on the frequency with which candidatephrases have occurred as keyphrases in the training data,and previous studies have found that use of this data im-proves the performance of Kea (Frank et al., 1999). Wemight, therefore, have expected the cstr-kf model to out-
FIG. 11. The mena subject recall for various phrase sets (length 2–3).
672 JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE AND TECHNOLOGY—June 2002

perform the cstr model. However, the results of our studycontradict these earlier findings.
There are two reasons why our observations of cstr-kfphrase quality diverge from previous results. First, the useof keyphrase frequency data increases the domain specificnature of the extraction model, based on the notion thatcommon author keyphrases form a pseudo-controlled vo-cabulary for a topic domain, and are more likely to beselected by authors working in that domain (Frank et al.,1999). The cstr-kf model was trained on a broad collectionof Computer Science documents dealing with a range oftopics, and favors common author keyphrases from thetraining corpus. The experimental documents focussed onthe narrower topic of Computer–Human Interaction, whichmay not have been adequately represented in the trainingdocuments. Given that the cstr model did not have suchpoor performance, we believe that our study strengthens theargument that adding author keyphrase frequency informa-tion increases the domain-specific nature of a Kea model. Afurther possible reason is the quality of the input texts. Totrain the cstr-kf model, source documents were convertedfrom Postscript to plain text format automatically, and theresulting texts contained mistakes and poor formatting andwere of inconsistent length. For our study we convertedsource Portable Document Format (PDF) documents to textwith manual intervention, resulting in substantially cleanertexts that were also of a consistent length.
Subject Precision and Recall
The levels of subject precision achieved by Kea (theproportion of extracted keyphrases that are deemed rele-vant) shown in Figures 8 and 9 emphasize that subjectsconsider the majority of keyphrases that Kea produces asrelevant to the corresponding document. Precision de-creases as we select more Kea phrases for each documentbecause Kea outputs the phrases in order of decreasingsuitability, and the more keyphrases that are produced, theworse their quality. This confirms that view that Kea’sranking of keyphrases by the score that it assigns to them iseffective. This holds for phrases of one to three words andtwo or three words in length.
A larger proportion of Kea phrases are deemed relevantwhen single word phrases are excluded (Fig. 9). The obser-vations that we have made earlier regarding the effect of ourmethodology on assessment of single word phrases holdagain here.
Kea compares poorly to author keyphrases for the firstfew taken for each document, but after that point it producesalmost the same proportion of relevant phrases. However,this may be as much due to the quality of the authorkeyphrases as those produced by Kea. The best lines inFigures 8 and 9 reflect the precision achieved by the best setof phrases (described earlier). For example, from Figure 8,we see that when we take the best seven phrases for eachdocument (from whatever source), 90% of them are deemedrelevant on average. Clearly Kea has some way to go to
attain this level of performance. However, the disparity islikely less than reflected in the graphs, given that the best setwill include some author keyphrases that Kea could notpossibly extract.
Interestingly, precision of the cstr-kf model increases asmore keyphrases of two or three words are extracted, al-though it is still worse than the other models (Fig. 9).
Overall, for keyphrase sets of the size normally associ-ated with scientific papers (up to 15 or so) Kea users canexpect the majority of the keyphrases to be relevant to thepaper.
Some applications of keyphrases may require more ex-haustive lists of relevant keyphrases, when recall is empha-sized over precision. Figures 10 and 11 show subject recallcurves for each of the phrase sets. As more keyphrases areextracted for each paper, the proportion of all of the relevantkeyphrases (from all phrase sets) for that paper identified byeach model increases. We should note here that overallsubject recall (and indeed precision) are not provided, be-cause Kea is not intended to provide an exhaustive list of allcandidate keyphrases of a paper. In fact, user settings areapplied to control the number of keyphrases extracted byKea and in our study we have extracted 15 keyphrases foreach paper.
In Kea’s best subject recall performance, approximatelya third of all relevant keyphrases (from all phrase sets) areidentified by the cstr model at 15 keyphrases of a length ofone to three words, and at 12 keyphrases of a length of twoto three words. Although this appears less than the 37–51%for AZ Noun Phraser, and 72% for NPtool reported by Tolleand Chen (2000) we believe it to be comparable because ofthe rather more exhaustive keyphrase lists that they pro-duced. In fact, we expect subject recall to increase beyondthis level as more keyphrases are extracted for each docu-ment.
Related Human Evaluations
Table 11 presents the results of our study alongside thosereported from three similar subjective studies. Althougheach study applies different measures of keyphrase qualitywe have made comparisons with the available data wherepossible.
An evaluation of the Extractor system was carried out onthe World Wide Web using 205 self-selecting human asses-sors (Turney, 2000). For the study, subjects submitted doc-uments of their own choosing, for which the system thenprovided a list of seven keyphrases. Subjects were asked torate each of the suggested keyphrases as “Good” or “Bad,”and indicated their responses via a Web page form. Incontrast to our study, neither the human assessor profiles northe documents were controlled, although this method is atest of Extractor’s performance over a wide range of docu-ments. Turney reports that 62% of all phrases were judgedto be “Good,” and a further 20% were not judged to be“Bad” (received no rating).
JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE AND TECHNOLOGY—June 2002 673

To enable comparison we have taken the first sevenphrases produced by each Kea model and consideredthose receiving scores greater than five (the midpoint ofthe scoring scale) to be “Good.” For the phrase setsproduced by the cstr and aliweb models, between 71%and 80% of the phrases were “Good.” The figure forcstr-kf phrases was 60%, and 79% for author phrases.These figures appear to be better than those reported forExtractor, although in Turney’s study Extractor dealtwith (we presume) more variation of documents and topicfocus.
In a study by Barker and Cornacchia, Extractor wascompared to the B&C keyphrasing system (Barker & Cor-nacchia, 2000). Nine documents were chosen from Turney’scorpus, and four by the experimenters, giving 13 in total.Twelve subjects rated keyphrases suggested by each systemfor each document, providing judgements of “bad,” “so-so,”or “good.” These ratings were then mapped to a numeric 0(bad), 1 (so-so), 2 (good) scale. Mean scores were producedfor each system. For Extractor the mean phrase score was0.56 (SD � 0.11) and for B&C it was 0.47 (SD � 0.1),indicating that subjects had negative perceptions of thephrases produced by both systems. In comparison, Keacompares favorably, with phrases receiving, on average,positive judgements.
Tolle and Chen (2000) randomly selected 10 abstractsfrom a database of medical cancer-related literature. Nine-teen subjects, all with medical expertise, chose “relevant”phrases from a list of phrases associated with each abstract.Each phrase list contained the phrases produced by a num-ber of keyphrasing tools (Chopper, NPtool, AZ NounPhraser) for the abstract, with duplicates removed. Approx-imately 140 phrases were produced for each abstract. Sub-ject precision and subject recall values were produced for
each tool. Precision for Chopper3 was low at 6.95%. NPtool(Voutilainen, 1993), a noun phrase detector, produced pre-cision of 34.32%, and the best precision of 40% resultedfrom a version of AZ Noun Phraser. Recall ranged from12.90% (Chopper), through 37 to 51% for AZ NounPhraser, to 72% for NPtool. Although Kea’s precision ap-pears to be better than any of these tools it should be notedthat Tolle and Chen report values for the exhaustive set ofkeyphrases produced by each tool. This will degrade overallprecision, whereas for Kea we have limited the number ofkeyphrases for each paper to 15. However, we note that Keais almost attaining the recall of some AZ Noun Phrasersettings over just more than a tenth of the number ofkeyphrases extracted by AZ Noun Phraser.
Chen’s study (1999) required assessors to choose appro-priate “subjects” to represent a document—effectively akeyphrase assignment task—in the Chinese language. De-scription of the captured data is limited, but it is clear thatfor individual subjects, intersection with the automaticallyextracted set ranged from 1 to 13 keyphrases, with a meanof 5.25 (SD � 4.18). Just over half (42 of 80) of theautomatically extracted keyphrases were also selected byeight subjects across 10 documents. This appears slightlyworse than the 62% achieved by Turney, and worse than theresults achieved by Kea, although direct comparison isdifficult as the experimental texts are very different.
Limitations
We were concerned about the potential effects of asses-sor subjectivity in a study of the style that we carried out.
3 Tolle and Chen provide an overview of Chopper, which to ourknowledge has not been documented in the literature.
TABLE 11. Summary of subjective evaluations using a good, indifferent, and bad scale.
Study Documents/subjectsPhrase extraction
method
Subjective evaluation
Good(2)
Indifferent(1)
Bad(0)
Meanscore
Barker & Cornaccia, 2000 13 mixed technical documents B&C 0.5612 subjects Extractor 0.47
Turney, 2000 267 assessor-selected webpages
205 self-selecting assessors Extractor 62.0% 19.9% 18.1% 1.44Paynter & Jones, 2001 6 human–computer interaction
technical reports 28 subjectsAuthor 67.8% 10.7% 21.5% 1.46
Kea aliweb 1–3 62.2% 9.0% 28.8% 1.33Kea cstr 1–3 64.6% 7.9% 27.5% 1.37Kea cstr-kf 1–3 50.1% 8.2% 41.6% 1.08food 0.0% 0.6% 99.4% 0.01
Tolle & Chen, 2000 10 medical abstract Chopper 6.95%NPTool 34.32%
19 subjects AZ Noun 35.05Phraser �40.00%
674 JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE AND TECHNOLOGY—June 2002

This problem is magnified with a small number of subjects,and so we maximized the number of assessments of eachkeyphrase. As a result there was a trade-off in the number ofexperimental documents that we used, which was smallerthat we would have ideally chosen with more resources,particularly more subjects. However, our methodology (28subjects and six papers) is comparable to other studies.Tolle and Chen (2000) had 19 subjects view 10 abstractsand associated phrase lists. Barker and Cornacchia (2000)had 12 judges view 13 documents, and Chen (1999) usedeight subjects and 10 texts.
Unlike Turney’s Web-based study, and Barker and Cor-nacchia’s study we used a set of experimental documentsfrom a restricted topic domain (Computer–Human Interac-tion) and of a restricted style (conference research papers).A possible limitation, therefore, is the extent to which theresults that we observed for the Kea system could be gen-eralized beyond such papers. It is important to emphasize,however, that Kea can be trained on example documentsthat are similar to the target corpus from which keyphrasesare to be extracted. We have shown here that Kea performswell when prebuilt and generic extraction models are de-ployed without building a tailored model, which we expectto be a common use of the system. We, therefore, believethat a generic model such as aliweb could perform equallywell on other corpora, and that by building a tailored modelperformance could be further improved.
One might consider the narrow profile of the subjects tobe a limitation of our study. However, we wished to mini-mize risks of variation in interassessor ratings that were dueto controllable factors. We note that Tolle and Chen (2000)used subjects with a narrow profile who were conversantwith the domain of the documents under consideration, andunlike other studies did not suffer from low levels of inter-assessor agreement. We followed that same approach in ourexperiment, matching document domain and subject exper-tise, and consequently observed significant levels of agree-ment between subjects.
The results that we have reported are based on subjects’ratings of individual keyphrases, and we have amalgamatedthem to reflect ratings of the phrase sources. However,Barker and Cornacchia’s study (2000) showed that subjects’ratings of individual keyphrases were inconsistent with rat-ings of keyphrase sets from the same source. They foundthat keyphrase sets from their B&C system were preferredmore often that sets produced by Extractor, but ratings ofindividual keyphrases reflected a preference for Extractor.Therefore, we are unable to suggest that the positive ratingsof Kea that we observed would also hold when keyphraselists were considered. We, therefore, plan to assess andcompare the performance of different phrase sources whentheir output is considered as a whole. This future study willuse the same keyphrases and documents that we have de-scribed, and employ a comparable set of human assessors,to allow a direct comparison between the two studies.
We introduced “noise” phrases (the food set) to measurethe subjects’ attention to the task. Clearly, these phrases are
significantly different to the topic domain of the documentsand provide only coarse measures. Consequently, their util-ity is limited. However, we considered this preferable to theuse of any phrases that could possibly be construed asrelevant to the topic of a paper, and chose them to be asunambiguously unrelated as possible.
A further issue of interest is the extent to which Keacovers the multiple topics that are present in many docu-ments. Some portions of these documents may not be rep-resented by any of the keyphrases extracted from the whole.Kea makes no attempt to establish the topical composition-ality of documents—it treats them as bags of candidatephrases. However, there may be cues within documents thatcan help to improve the extraction process and ensure goodtopic coverage. Initially we intend to analyze the location ofKea keyphrases within their source documents to determinehow well they represent the entirety of the text. Futureversions of Kea may attempt to exploit structural markup orautomatically detected topic boundaries.
Conclusions
The results of the study lead us to conclude that Keaextracts good keyphrases. Kea phrases were judged posi-tively on average, and are no worse, statistically, than thoseprovided by authors when the aliweb or cstr models areapplied. The performance of the aliweb model is encourag-ing given the evidence that it can be effectively applied todocuments that are dissimilar in type and domain to thoseon which it was trained. This alleviates the need for Kea’susers to build their own models, a characteristic that isparticularly useful when little or no training data is avail-able.
For the most effective settings for Kea, 80% of theextracted keyphrases received positive assessments. Thislevel of performance indicates that Kea is usefully deploy-able in a variety of application areas, for example, the kindsof system we described in this article, and other situationswhere keyphrases are required but do not exist. Kea mayalso be used effectively to augment existing author key-phrases, as Kea phrases were rated highly even when theydid not match those chosen by authors. Additionally, webelieve that the order in which Kea ranks keyphrases is veryeffective. This is important for applications where restrictednumbers of keyphrases are required—users can be confi-dent that they are getting the best of the available key-phrases. Cross-study comparison show that Kea outper-forms other keyphrasing systems based on reported perfor-mance measures, although we are cautious about attachingtoo much significance to these observations given the dif-ferences between the evaluation methodologies.
Our results contradict previous evaluations of the effectof employing collection-wide keyphrase frequencies (cstr-kf) when building Kea models. Further investigation isrequired as to why this configuration degrades performance,though likely causes are a mismatch between the domain of
JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE AND TECHNOLOGY—June 2002 675

the model and the domain of the target documents andquality of the input text during training.
Previous studies have used author keyphrases as a gold-standard, against which other keyphrases are compared, butoffered no evidence that author keyphrases are good key-phrases. Our results show that authors do provide goodquality keyphrases, at least for the style of documents in ourstudy. This vindicates the use of author keyphrases as abenchmark against which to evaluate keyphrasing systems,and as a source of training data for keyphrase extractionsystems. The study also shows that author keyphrases arelisted with the best keyphrases first. This implies that moresophisticated measures of extracted keyphrase quality thansimple precision and recall may be desirable.
We and other developers have created a number ofsystems that illustrate the variety of ways in which phrasescan be used in user interfaces for accessing on-line infor-mation. Their utility ultimately depends on the availabilityof accurate, reliable keyphrases. This article has shown thatwhen human-assigned descriptors are not provided or areinsufficient, the Kea system can supply suitable replace-ments.
Acknowledgments
Thanks to the anonymous referees for their insightful andhelpful comments.
References
Anick, P., & Vaithyanathan, S. (1997). Exploiting clustering and phrasesfor context-based information retrieval. Proceedings of SIGIR’97: The20th international conference on research and development in informa-tion retrieval (pp. 314–322). Philadelphia: ACM Press.
Arampatzis, A.T., Tsoris, T., Koster, C.H.A., & Van der Weide, T.P.(1998). Phrase-based information retrieval. Information Processing &Management, 34(6), 693–707.
Barker, K., & Cornacchia, N. (2000). Using noun phrase heads to extractdocument keyphrases. Proceedings of the thirteenth Canadian confer-ence on artificial intelligence (LNAI 1822) (pp. 40–52). Montreal,Canada.
Brill, E. (1992). A simple rule-based part-of-speech tagger. Proceedings ofANLP-92: Third conference on applied natural language processing (pp.152–155).
Chen, K.-H. (1999). Automatic identification of subjects for textual doc-uments in digital libraries. Los Alamos, NM: Los Alamos NationalLaboratory.
Croft, B., Turtle, H., & Lewis, D. (1991). The use of phrases and structuredqueries in information retrieval. Proceedings of SIGIR’91 (pp. 32–45).Philadelphia: ACM Press.
Domingos, P., & Pazzani, M. (1997). On the optimality of the simpleBayesian classifier under zero-one loss. Machine Learning, 29(2/3),103–130.
Dumais, S.T., Platt, J., Heckerman, D., & Sahami, M. (1998). Inductivelearning algorithms and representations for text categorization. Proceed-ings of the 7th international conference on information and knowledgemanagement (pp. 148–155). Philadelphia: ACM Press.
Fellbaum, C. (Ed.). (1998). WordNet: An electronic lexical database.Cambridge: MIT Press.
Frank, E., Paynter, G., Witten, I., Gutwin, C., & Nevill-Manning, C.(1999). Domain-specific keyphrase extraction. Proceedings of the six-
teenth international joint conference on aritificial intelligence (pp. 668–673). San Mateo, CA: Morgan Kaufmann.
Gutwin, C., Paynter, G.W., Witten, I.H., Nevill-Manning, C., & Frank, E.(1999). Improving browsing in digital libraries with keyphrase indexes.Journal of Decision Support Systems, 27(1–2), 81–104.
Jones, S. (1999). Design and evaluation of phrasier, an interactive systemfor linking documents using keyphrases. In M. Sasse & C. Johnson(Eds.), Proceedings of human–computer interaction. INTERACT’99(pp. 483–490). Edinburgh, UK: IOS Press.
Jones, S., & Mahoui, M. (2000). Hierarchical document clusteringusing automatically extracted keyphrases. Proceedings of the thirdinternational Asian conference on digital libraries (pp. 113–120).Seoul, Korea.
Jones, S., & Paynter, G. (1999). Topic-based browsing within a digitallibrary using keyphrases. In E. Fox & N. Rowe (Eds.), Proceedings ofdigital libraries’99: The fourth ACM conference on digital libraries (pp.114–121). Berkeley, CA: ACM Press.
Jones, S., & Staveley, M. (1999). Phrasier: A system for interactivedocument retrieval using keyphrases. In M. Hearst, F. Gey, & R. Tong(Eds.), Proceedings of SIGIR’99: The 22nd international conference onresearch and development in information retrieval (pp. 160–167).Berkeley, CA: ACM Press.
Kosovac, B., Vanier, D.J., & Froese, T.M. (2000). Use of keyphraseextraction software for creation of an AEC/FM thesaurus. ElectronicJournal of Information Technology in Construction, 5, 25–36.
Krulwich, B., & Burkey, C. (1997). The Infofinder agent—Learning userinterests through heuristic phrase extraction. IEEE Intelligent Systems &Their Applications, 12(5), 22–27.
Larkey, L.S. (1999). A patent search and classification system. Proceedingsof digital libraries’99: The fourth ACM conference on digital libraries(pp. 179–187). Berkeley, CA: ACM Press.
Lovins, J.B. (1968). Development of a stemming algorithm. MechanicalTranslation and Computational Linguistics, 11, 22–31.
Paynter, G.W., Witten, I.H., & Cunningham, S.J. (2000). Evaluating ex-tracted phrases and extending thesauri. Proceedings of the third inter-national conference on Asian digital libraries (pp. 131–138). Seoul,Korea.
Pedersen, J., Cutting, D., & Tukey, J. (1991). Snippet search: A singlephrase approach to text access. Proceedings of the 1991 joint statisticalmeetings. American Statistical Association.
Perlman, G. (1991). The HCI bibliography project. SIGCHI Bulletin, 2(3),15–20.
Proceedings of CHI’97. (1997). Human factors in computing systems.Philadelphia: ACM Press.
Quinlan, J.R. (1993). C4.5: Programs for machine learning. San Mateo,CA: Morgan Kaufmann.
Siegel, S., & Castellan, N.J. (1988). Nonparametric statistics for the be-havioral sciences (2nd ed.). New York: McGraw Hill College Div.
Smeaton, A., & Kelledy, F. (1998). User-chosen phrases in interactivequery formulation for information retrieval. Proceedings of the 20thBCS IRSG colloquium. Grenoble, France.
Tolle, K.M., & Chen, H. (2000). Comparing noun phrasing techniques foruse with medical digital library tools. Journal of the American Societyfor Information Science, 51(4), 352–370.
Turney, P.D. (1999). Learning to extract keyphrases from text (TechnicalReport ERB-1057; NRC #41622). Canadian National Research Council,Institute for Information Technology.
Turney, P.D. (2000). Learning algorithms for keyphrase extraction. Infor-mation Retrieval, 2(4), 303–336.
Voutilainen, A. (1993). NPtool, a detector of English noun phrases. Pro-ceedings of the first ACL workshop on very large corpora (WVLC-1)(pp. 42–51). Columbus, OH.
Witten, I.H., & Frank, E. (2000). Data mining. San Francisco, CA: MorganKauffman.
Witten, I.H., & McNab, R. (1997). The New Zealand digital library—Collections and experience. Electronic Library, 15(6), 495–504.
676 JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE AND TECHNOLOGY—June 2002

Witten, I.H., McNab, R.J., Jones, S., Apperley, M., Bainbridge, D., &Cunningham, S.J. (1999). Managing complexity in a distributed digitallibrary. IEEE Computer, 32(2), 74–79.
Witten, I.H., Nevill-Manning, C., McNab, R., & Cunningham, S.J. (1998).A public library based on full-text retrieval. Communications of theACM, 41(4), 71–75.
Witten, I.H., Paynter, G.W., Frank, E., Gutwin, C., & Nevill-Manning,C.G. (1999). KEA: Practical automatic keyphrase extraction. In E.A.Fox & N. Rowe (Eds.), Proceedings of digital libraries ’99: The fourth
ACM conference on digital libraries (pp. 254–255). Berkeley, CA:ACM Press.
Zamir, O., & Etzioni, O. (1998). Web document clustering: A feasibilitydemonstration. Proceedings of SIGIR’98: The 21st international confer-ence on research and development in information retrieval (pp. 46–54).Philadelphia: ACM Press.
Zamir, O., & Etzioni, O. (1999). Grouper: A dynamic clustering interfaceto Web search results. Computer Networks and ISDN Systems, 31(11–16), 1361–1374.
JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE AND TECHNOLOGY—June 2002 677