automatic assessment of vocabulary usage without negative - ets
TRANSCRIPT

ResearchReports REPORT 67
NOVEMBER 2001TEST OF ENGLISH AS A FOREIGN LANGUAGE
Automatic Assessment ofVocabulary Usage WithoutNegative Evidence
Claudia Leacock
Martin Chodorow

Automatic Assessment of Vocabulary Usage Without Negative Evidence
Claudia Leacock
Martin Chodorow
Educational Testing Service Princeton, New Jersey
RR-01-21

Educational Testing Service is an Equal Opportunity/Affirmative Action Employer.
Copyright © 2001 by Educational Testing Service. All rights reserved.
No part of this report may be reproduced or transmitted in any form or by any means,electronic or mechanical, including photocopy, recording, or any information storageand retrieval system, without permission in writing from the publisher. Violators willbe prosecuted in accordance with both U.S. and international copyright laws.
EDUCATIONAL TESTING SERVICE, ETS, the ETS logos, Graduate RecordExaminations, GRE, TOEFL, and the TOEFL logo are registered trademarks ofEducational Testing Service. The Test of English as a Foreign Language and e-ratersystem are trademarks of Educational Testing Service.
College Board is a registered trademark of the College Entrance Examination Board.
Microsoft is a registered trademark of Microsoft Corporation.
®
®®

Abstract
This report describes the implementation and evaluation of an automated statistical method for assessing an examinee's use of vocabulary words in constructed responses. The grammatical error-detection system, ALEK (Assessing Lexical Knowledge), infers negative evidence from the low frequency or absence of constructions in 30 million words of well-formed, copy-edited text from North American newspapers. ALEK detects two types of errors: those that violate basic principles of English syntax (e.g., agreement errors as in a desks) and those that show a lack of information about a specific word (e.g., treating a mass noun as a count noun in a pollution). The system evaluated word usage in essay-length responses to Test of English as a Foreign Language (TOEFL®) prompts. ALEK was developed using three words and was evaluated on an additional 20 words that appeared frequently in TOEFL essays and in a university word list. System accuracy was evaluated to investigate its potential for scoring performance-based measures of communicative competence. It performed with about 80% precision and 20% recall. False positives (correct usages that ALEK identified as errors) and misses (usage errors that were not recognized by ALEK) were analyzed, and methods for improving system performance were outlined.
Key words: ALEK, constructed response, grammatical error detection, natural language processing
i

ii
The Test of English as a Foreign LanguageTM (TOEFL®) was developed in 1963 by the NationalCouncil on the Testing of English as a Foreign Language. The Council was formed through thecooperative effort of more than 30 public and private organizations concerned with testing the Englishproficiency of nonnative speakers of the language applying for admission to institutions in the UnitedStates. In 1965, Educational Testing Service® (ETS®) and the College Board® assumedjoint responsibility for the program. In 1973, a cooperative arrangement for the operation of theprogram was entered into by ETS, the College Board, and the Graduate Record Examinations® (GRE®)Board. The membership of the College Board is composed of schools, colleges, school systems, andeducational associations; GRE Board members are associated with graduate education.
ETS administers the TOEFL program under the general direction of a policy board that was establishedby, and is affiliated with, the sponsoring organizations. Members of the TOEFL Board (previously thePolicy Council) represent the College Board, the GRE Board, and such institutions and agencies asgraduate schools of business, junior and community colleges, nonprofit educational exchangeagencies, and agencies of the United States government.
✥ ✥ ✥
A continuing program of research related to the TOEFL test is carried out under the direction of theTOEFL Committee of Examiners. Its 13 members include representatives of the TOEFL Board, anddistinguished English as a second language specialists from the academic community. The Committeemeets twice yearly to oversee the review and approval of proposals for test-related research and to setguidelines for the entire scope of the TOEFL research program. Members of the Committee ofExaminers serve three-year terms at the invitation of the Board; the chair of the committee serves onthe Board.
Because the studies are specific to the TOEFL test and the testing program, most of the actual researchis conducted by ETS staff rather than by outside researchers. Many projects require the cooperationof other institutions, however, particularly those with programs in the teaching of English as a foreignor second language and applied linguistics. Representatives of such programs who are interested inparticipating in or conducting TOEFL-related research are invited to contact the TOEFL programoffice. All TOEFL research projects must undergo appropriate ETS review to ascertain that dataconfidentiality will be protected.
Current (2001-2002) members of the TOEFL Committee of Examiners are:
Lyle Bachman University of California, Los AngelesDeena Boraie The American University of CairoMicheline Chalhoub-Deville (Chair) University of IowaJodi Crandall (Ex Officio) University of Maryland, BaltimoreCatherine Elder University of AucklandGlenn Fulcher University of SurreyWilliam Grabe Northern Arizona UniversityStan Jones Carleton UniversityKeiko Koda Carnegie Mellon UniversityRichard Luecht University of North Carolina at GreensboroTerry Santos Humboldt State UniversityMerrill Swain The University of TorontoRichard Young University of Wisconsin-Madison
To obtain more information about TOEFL programs and services, use one of the following:
Email: [email protected]
Web site: http://www.toefl.org

Acknowledgments
Special acknowledgment is due to the following individuals for their substantial contributions to the success of this project:
��Carol Taylor and William Ward for their advice regarding the study proposal
��Patricia Carey for providing us with Concordance Study TOEFL essays
��Isaac Bejar, Reynaldo Macias, and Mary Schedl for helpful comments on earlier versions of this report
��Susanne Wolff for her assistance in manually evaluating the grammaticality of sentences in this study
��Philip Oltman and Kenneth Sheppard for their continued encouragement and support
iii

Table of Contents
Page
Introduction................................................................................................................................... 1
Background ................................................................................................................................... 2
ALEK Architecture ...................................................................................................................... 3 Preprocessing ...................................................................................................................... 4 Measures Based on the General Corpus ............................................................................. 5 Measures Comparing the Word-Specific Corpus to the General Corpus ........................... 6 Testing the Validity of the "n-gram" Measure.................................................................... 7 System Development .......................................................................................................... 8
ALEK Evaluation: Experimental Design and Results .............................................................. 9 Results................................................................................................................................. 9 Analysis of Hits and Misses.............................................................................................. 11 Analysis of False Positives ............................................................................................... 13
Comparison of Results................................................................................................................ 14
Possible Applications .................................................................................................................. 15 Holistic scoring ................................................................................................................. 15 Diagnostic Feedback......................................................................................................... 17 Conclusion ........................................................................................................................ 17
References .................................................................................................................................... 18
iv

List of Tables
Page
Table 1. Percent of n-grams with Mutual Information Less than -3.60, by Score Point .............8
Table 2. Precision and Recall of Development Words ................................................................9
Table 3. Precision and Recall for 20 Evaluation Words ............................................................10
Table 4. Relation of ALEK's Hits, Misses, and False Positives ................................................11
Table 5. Analysis of 200 Hits and 200 Misses Based on a Random Sample of Each ...............12
Table 6. Distribution of Types of False Positives......................................................................13
Table 7. Proportion of Sentences, by Score Point, Classified as Containing an Error by ALEK and by a Human Judge .....................................................................................16
v

Introduction
A good indicator of whether a person knows the meaning of a word is the ability to use it appropriately in a sentence (Miller & Gildea, 1987). Correct usage requires knowledge of how a word is spelled, its part of speech, appropriate inflection (e.g., tense, subject-verb agreement), argument structure (e.g., whether a verb is transitive), selectional preferences (e.g., the object of drink is a liquid), and collocational relations (e.g. in conclusion as opposed to at conclusion). Qian and Harley (1998) include all of these facets of word knowledge in their working definition for depth of vocabulary knowledge.
Multiple-choice items, such as those found in the Test of English as a Foreign Language (TOEFL) Reading Comprehension and Structure and Written Expression sections, typically do not test more than one or two of these facets of lexical (word) knowledge. A very different test of vocabulary that simultaneously probes many different aspects of knowledge would involve tracking how examinees actually use vocabulary words. For example, in TOEFL essays and in the proposed TOEFL 2000 cross-modal reading-writing tasks (Cumming, Kantor, Powers, Santos, & Taylor, 2000; Enright et al., 2000), the test taker is free to use any words when composing a response to a reading prompt. In this study, we propose a method to evaluate word usage in such constructed responses.
As with any manual evaluation of constructed responses, scoring vocabulary usage is time-consuming and therefore costly. The practical implications of automated or partially-automated scoring are obvious — not only in terms of money saved, but also in terms of the automatic generation of diagnostic feedback. The purpose of this study was to investigate the feasibility of assessing vocabulary usage automatically. We developed, implemented and evaluated a novel corpus-based statistical system — ALEK (Assessing Lexical Knowledge) — to automatically identify inappropriate usage of specific words in computer-based TOEFL essays by looking at the local contextual cues that surround a target word.
Once built, statistical systems can score responses efficiently, but their development typically requires hundreds of manually scored examples for training. Therefore, a major objective of the current study was to bypass the laborious and costly process of collecting errors (negative evidence) for each word that we evaluated. Instead, we trained ALEK on a general corpus of copy-edited English text taken from the San Jose Mercury News and on example usages of the target word taken from North American newspapers. ALEK identified inappropriate usage based on the divergence between the word's local contextual cues and models of context it has derived from the corpora of well-formed sentences.
A requirement that we have imposed on ALEK is that all steps in the process — except for choosing the target words and evaluating the results — be automated. In this study, we chose the target words empirically, based on their frequency in the TOEFL CBT essay pool that was available at the time (July 1999) and their inclusion in a college word list (Nation, 1990). Once a target word is chosen, preprocessing, building a model of the word's usage, and identifying usage errors in essays are performed without manual intervention. As discussed later in the Results section, it takes about three hours for one person to evaluate a word model.
1

Background
Approaches to detecting errors by nonnative writers typically produce grammars that look for specific expected error types (Schneider & McCoy, 1998; Park, Palmer, & Washburn, 1997). Under this approach, essays written by students who speak English as a second language (ESL) are collected and examined for errors. Parsers are then adapted to identify those error types that were found in the essay collection.
We take a different approach, initially viewing error detection as an extension of the word sense disambiguation (WSD) problem. WSD is the process of identifying the intended sense when a polysemous word — a word that has more than one sense — is used. For example, consider the intended sense of the noun line in "People waited in a long line at the bank" as opposed to "The XYZ Corporation announced a new line of products today." People discriminate among the senses of a polysemous word so quickly and effortlessly that we are unaware of the process. Computationally, however, word sense disambiguation is a very hard problem. For the last decade, it has been a major focus of research in computational linguistics.
WSD research has consistently found that much of the information about a word can be obtained from a very limited context. Kaplan (1955) ran the first experiment to determine how much context people need to identify the intended sense of a word, and discovered that people typically recognize the intended sense of a polysemous word by looking at a narrow window of �2 surrounding words. In 1985, Choueka and Lusignan replicated Kaplan's results.
Statistically-based computer programs can also identify word sense based on a small window of context. In 1998, the University of Brighton sponsored the SENSEVAL workshop to evaluate and compare the efficacy of systems for automatic word sense identification (Kilgarriff & Palmer, 2000). We entered a system called ETS-Princeton, created through a joint project of Educational Testing Service (ETS) and Princeton University, that was developed by Chodorow, Leacock, and Miller (2000). In all, participants entered 18 systems, each of which was trained and tested on materials for 35 words. ETS-Princeton was among the four most accurate systems, all of which had performance results ranging from 79% to 81% correct.
Corpus-based WSD systems identify the intended sense of a polysemous word by (1) collecting a set of example sentences for each of the word's various senses, and (2) automatically extracting salient contextual cues from these sets to (3) build a statistical model for each sense. They identify the intended sense of the word in a novel sentence by extracting its contextual cues and selecting the most similar word sense model (e.g., Yarowsky, 1993; Leacock, Chodorow, & Miller, 1998). Step one is a long, tedious and error-prone process, and is called "the knowledge acquisition bottleneck." Steps two and three, on the other hand, can be completed within seconds.
Golding (1995) showed how methods used for WSD (decision lists and Bayesian classifiers) could be adapted to detect errors resulting from common spelling confusions among sets of homophones, such as there, their, and they’re. He extracted contexts from correct usages of each confusable word in a training corpus, and then identified a new occurrence as an error when it matched the wrong context.
2

However, most grammatical errors are not the result of simple word confusions. This complicates the task of building a model of incorrect usage. One approach we considered was to proceed without such a model: Represent appropriate word usage (across senses) in a single model and compare a novel example to that model. The most appealing part of this formulation was that we could bypass the knowledge acquisition bottleneck. All occurrences of the word in a collection of edited text could be automatically assigned to a single training set representing appropriate usage. Inappropriate usage would be signaled by contextual cues that do not occur in training.
Unfortunately, this approach was not effective for error detection. An example of a word usage error is often very similar to the model of appropriate usage. An incorrect usage can contain two or three salient contextual elements as well as a single anomalous element. The problem of error detection does not entail finding similarities to appropriate usage; rather, it requires identifying one element among the contextual cues that simply does not fit. Therefore, we have extensively modified the ETS-Princeton WSD architecture so that it detects a single anomalous element.
ALEK Architecture
What kinds of anomalous elements does ALEK identify? As noted earlier, writers sometimes produce errors that violate basic principles of English syntax (e.g., agreement, as in a desks), while other mistakes show a lack of information about a specific word (e.g., treating a mass noun as a count noun, as in a pollution). In order to detect these two types of problems, ALEK uses a 30-million-word general corpus of English from the San Jose Mercury News and, for each target word, a word-specific corpus of 10,000 example sentences from North American newspaper text.1
ALEK infers negative evidence from contextual cues that do not co-occur with the target word in either the word-specific corpus or the general English corpus. It uses two kinds of contextual cues in a narrow window of two positions surrounding the target word: function words (closed-class categories, such as determiners, pronouns, and prepositions) and part-of-speech tags (Brill, 1994) that identify the syntactic category of each word (e.g., plural noun or third person pronoun). Using the general corpus, ALEK computes a mutual information measure to determine which sequences of part-of-speech tags and function words are unusually rare and are, therefore, likely to be ungrammatical in English (e.g., singular determiner preceding a plural noun, as in a benefits). Using the word-specific corpus, ALEK looks for sequences that are common in the general corpus, but unusual in the word-specific corpus (e.g., the singular determiner a preceding a singular noun is common in English, but rare when the noun is pollution). These divergences between the word-specific and general corpora reflect syntactic properties that are peculiar to the target word — for example, whether it is a mass noun (like knowledge) or a count noun (like benefit).
1 The word-specific corpora are extracted from the Linguistic Data Consortium North American News Text Corpus, North American News Text Supplement, and Tipster CD-ROMs (www.ldc.upenn.edu).
3

In the remainder of this section, we further describe ALEK's operation and architecture. We begin with by detailing the preprocessing of the input, which is required to enrich the data and standardize its form. Next, we examine statistical measures based on mutual information; these are used to flag low probability sequences as possible errors. Then we evaluate the validity of scoring based on low probability sequences. Finally, we discuss how the system was developed using a small sample of words.
Preprocessing
For the present study, preprocessing was identical for the general corpus, the word-specific corpora, and the TOEFL essays that were evaluated for word usage errors. The goal of preprocessing is to make explicit the elements that carry grammatical information in a sentence. For each word, these elements are: part of speech, inflection, and whether the word is a function word. Below, we step through the process using an example sentence from the word-specific corpus for job.
Step 1. Extract sentences from machine-readable corpora. When evaluating a usage in a TOEFL essay, an additional program is used to detect sentence boundaries.
Friends counseled Mitchard to get a full-time job, but she concentrated instead on her writing.
Step 2. Assign a part-of-speech tag to each word using an automatic part-of-speech tagger. In the example below, parts of speech are marked using Brill's (1994) tags. For example, plural nouns are marked with NNS, proper names with NNP, adjectives with JJ, adverbs with RB, past tense verbs with VBD, and so on. For some closed-class categories, these tags are supplemented with an "enriched" tag set that was adapted from Francis and Kučera (1982). For example, where appropriate, AT (singular determiner) replaces DT, the more general label that is used for all determiners in the Brill tag set.
Friends/NNS counseled/VBD Mitchard/NNP to/TO get/VB a/AT full-time/JJ job/NN ,/, but/CC she/PPS concentrated/VBD instead/RB on/IN her/PRP$ writing/VBG ./.
Step 3. Strip out inflection morphology to reduce each word to a base form (e.g., reduce counseled to counsel). This enables ALEK to generalize across inflectional variants. Inflectional and syntactic information is retained in the part-of-speech tag.
friend/NNS counsel/VBD Mitchard/NNP to/TO get/VB a/AT full-time/JJ job/NN ,/, but/CC she/PPS concentrate/VBD instead/RB on/IN her/PRP$ write/VBG ./.
For the purposes of the present study, in selecting sentences for the word-specific corpora, we minimized the mismatch between the domain of North American newspapers and the TOEFL essays. For example, in the newspaper domain, concentrate is usually used as a
4

noun, as in orange juice concentrate or chemical concentrates. In the TOEFL essays, however, concentrate is rarely used as a noun. Thus, sentence selection for the word-specific corpora was constrained to reflect the distribution of part-of-speech tags for the target word in a random sample of TOEFL essays. Consequently, concentrate is used as a noun in only 9% of its word-specific corpus, matching its proportion of noun use in the TOEFL essay pool.
After the sentences have been preprocessed, statistics on sequences of grammatical elements are collected. ALEK collects bigrams, sequences of two adjacent elements, and trigrams, sequences of three adjacent elements, from them. It counts sequences of adjacent part-of-speech tags and function words. For example, the sequence a/AT full-time/JJ job/NN contributes one occurrence each to the bigrams AT + JJ, JJ + NN, a + JJ, and to the part-of-speech tag trigram AT + JJ + NN. Each individual tag and function word also contributes to its own single element (unigram) count. These frequencies form the basis of the error detection measures. Now ALEK can locate sequences that are unexpected, based on mutual information and chi-square, measures that assess the degree of association between elements.
Measures Based on the General Corpus
The system computes mutual information comparing the number of observed occurrences of bigrams in the general corpus to the number that is expected based on the assumption of independence, as shown below:
��
���
��
� )()()(log2 BPAP
ABPMI
Here, P(AB) is the probability of the occurrence of the AB bigram, estimated from its
frequency in the general corpus, and P(A) and P(B) are the unigram probabilities of the first and second elements of the bigram, also estimated from the general corpus. For example, suppose that singular determiners (AT) have a relative frequency of .1 and plural nouns (NNS) have a relative frequency of .2. The mutual information value is the log of the actual relative frequency of the sequence AT + NNS in the corpus divided by .02 (i.e., .1 � .2), the expected relative frequency. Sequences such as a/AT desk/NNS (a desks) are ungrammatical, so the relative frequency of the tag bigram (AT + NNS) in the general corpus will be much less than expected on the assumption of independence. As a result, the value of MI will be negative, since it will be the log of a ratio less than 1.
Trigram sequences are also used, but in this case, the mutual information computation compares the co-occurrence of ABC to a model in which A and C are assumed to be conditionally independent given B (see Lin, 1998), as shown below:
���
����
�
���
)|()|()()(log2 BCPBAPBP
ABCPMI
5

As an illustration, consider the tag sequence for plural_determiner + singular_noun + singular_BE (as in, these desk is). Plural determiners precede singular nouns in noun compound constructions (these desk protectors), and singular forms of the verb BE commonly follow singular nouns (the desk is). Thus, each "half" of the trigram is part of a grammatical construction but the trigram as a whole is not grammatical. Because the frequency of the trigram in the corpus will be much less than expected on the assumption that the halves are conditionally independent, we once again have a negative value of MI, indicative of a sequence that violates a rule of English.
Measures Comparing the Word-Specific Corpus to the General Corpus
ALEK also uses mutual information to compare the distributions of tags and function words in the word-specific corpus to the distributions that are expected based on the general corpus. The measures for bigrams and trigrams are similar to those given above, except that the probability in the numerator is based on the bigrams and trigrams in the word-specific corpus that contain the target word, and the probabilities in the denominator are based on the general corpus. To return to a previous example, the phrase a pollution contains the tag bigram for singular determiner followed by singular noun (AT + NN). As noted earlier, this sequence is much less common in the word-specific corpus for pollution than would be expected from the unigram probabilities of AT and NN in the general corpus.
In addition to bigram and trigram measures, ALEK compares the target word's part-of-speech tag in the word-specific corpus and in the general corpus. Specifically, it looks at the conditional probability of the part-of-speech tag, given the major syntactic category (e.g., plural noun given noun) in both distributions, by computing the following value:
���
����
�
)|()|(log
_
_2 categorytagP
categorytagPcorpusgeneral
corpusspecific
To illustrate, about half of all noun tokens are plural in the general corpus, but in the word-specific corpus for knowledge, the plural knowledges occurs rarely, if at all.
The mutual information measures provide candidate errors, but this approach overgenerates — it finds rare, but still grammatical, sequences. To reduce this number of false positives, no candidate found by the mutual information measures is considered an error if it appears in the word-specific corpus at least two times. This increases ALEK's accuracy at the price of causing ALEK to overlook some usage errors. For example, a knowledge will not be treated as an error because it appears in the word-specific corpus as part of the longer sequence a knowledge of (as in a knowledge of mathematics).
ALEK uses another statistical technique for finding rare and possibly ungrammatical tag and function word bigrams. It computes the chi-square statistic (�2) for the difference between the bigram proportions found in the word-specific and in the general corpora, as follows:
6

��
�
�
��
�
�
�
��
corpusspecificcorpusgerneralcorpusgeneral
corpusgeneralcorpusspecific
NPPPP
___
2__2
/)1()(
�
Of course, the chi-square measure faces the same problem of overgenerating errors. Due to the large sample sizes, extreme chi-square values can be obtained, even though effect size may be minuscule. To reduce false positives, ALEK requires that effect sizes be at least in the moderate-to-small range (Cohen & Cohen, 1983).
Direct evidence from the word-specific corpus can also be used to control the overgeneration of errors. For each candidate error, ALEK compares the larger context in which the bigram appears to the contexts that have been analyzed in the word-specific corpus. From the word-specific corpus, ALEK forms templates — sequences of words and tags that represent the local context of the target word. If a test sentence contains a low probability bigram (as measured by the chi-square test), the local context of the target word is compared to all the templates of which it is a part. Exceptions to the error — that is, longer grammatical sequences that contain rare sub-sequences — are found by examining conditional probabilities.
To illustrate this, consider once again the example of a knowledge and a knowledge of. The conditional probability of of given a knowledge is high, as it accounts for most of the occurrences of a knowledge in the word-specific corpus. Based on this high conditional probability, the system will use the template for a knowledge of to keep it from being marked as an error. Other words and tags in the position following the target word have much lower conditional probability, so for example, a knowledge is will not be treated as an exception to the error.
Testing the Validity of the "n-gram" Measure
If low probability bigrams and trigrams (or n-grams) often signal grammatical errors, then we would expect TOEFL essays that received lower scores to have more of these low probability n-grams than essays that received higher scores. To test this prediction, we randomly selected 50 essays for each of the six score values (1.0 to 6.0) from the TOEFL pool. For each score value, all 50 essays were concatenated to form a super-essay. In every super-essay, for each adjacent pair or triple of tags containing a noun, verb, or adjective, n-gram mutual information values were computed based on the general corpus.
Table 1 shows, by TOEFL essay score, the percent of bigrams and of trigrams with mutual information less than -3.60, an empirically derived cutoff value for low probability. As predicted, there are significant negative correlations between score and proportion of low probability bigrams (rs = -.94, n = 6, p < .001, two-tailed) and between score and proportion of low probability trigrams (rs = -.84, n = 6, p < .05, two-tailed).
7

Table 1
Percent of n-grams with Mutual Information Less than -3.60, by Score Point
TOEFL Score
Percent of bigrams
Percent of trigrams
1.0 3.6 1.4 2.0 3.4 0.8 3.0 2.6 0.6 4.0 1.9 0.3 5.0 1.3 0.4 6.0 1.5 0.3
System Development
For the current study, ALEK was developed using three target words that were extracted from TOEFL computer-based essays (Carey, in press): concentrate, interest, and knowledge. These words were chosen because they represent different parts of speech and varying degrees of polysemy and difficulty. Each occurred in at least 300 sentences in what was then a small pool of computer-based TOEFL essays. Prior to development, each occurrence of these words was manually labeled as a correct or inappropriate usage — without taking into account grammatical errors that might have been present elsewhere in the sentence but were outside the target word's scope.
Critical values for the statistical measures were set during this development phase. The settings were based empirically on ALEK's performance so as to optimize recall while holding precision in the mid-80% range on the three development words. Candidate errors were those local context sequences that produced either:
��a mutual information value of less than -3.60 based on the general corpus
��mutual information of less than -5.00 for the word-specific/general comparison
��or a chi-square value greater than 12.82 with an effect size greater than 0.30
Precision and recall values for the three development words are shown in Table 2. Precision is the proportion of sentences that ALEK labeled as a usage error that were also labeled as errors by a human judge. Recall is the proportion of human-judged errors in the 250-sentence sample that were detected by ALEK. As previously noted, the development words were chosen for their diversity, but we were nonetheless eager to see how the system would perform using the same critical values on a new set of target words.
8

Table 2
Precision and Recall of Development Words
Target word Precision Recall
Concentrate .875 .280 Interest .840 .330 Knowledge .918 .570
ALEK Evaluation: Experimental Design and Results
ALEK was tested on 20 words that appear frequently in TOEFL essays. Candidates for this 20-word set were chosen based on two criteria: 1) They appear in a list of words that a student in a U.S. university will be expected to encounter (Nation, 1990), and 2) they were used in at least 1,000 sentences in the TOEFL CBT essay pool available in July 1999. Twenty of these candidate words were randomly selected to evaluate ALEK.
To build the usage model for each evaluation word, 10,000 sentences containing the target word were extracted from the North American News Corpus. These sentences were then preprocessed as described earlier. Next, for each of the 20 evaluation words, all of the TOEFL essay sentences were marked by ALEK as either containing an error or not containing an error. The number of test sentences for each word ranged from 1,400 to 20,000 with a mean of 8,000 sentences.
Results
To evaluate the system, for each target word we randomly extracted 125 sentences that ALEK classified as containing no error (C-set) and 125 sentences that it labeled as containing an error (E-set). These 250 sentences were then given to a linguist in a random order for blind evaluation. The linguist, who had no part in ALEK's development, marked each usage of the target word as being inappropriate or correct, and in the case of inappropriate usage, indicated how far from the target word one would have to look in order to recognize that there was an error. For example, in the case of an period, the error occurs at a distance of one word from the target word period. When the error is an omission, as in lived in Victorian period, the distance is measured from the target word to where the missing word should have appeared — in this case, two words away from the target word. When more than one error occurred, the distance of the error closest to the target word was marked.
Table 3 lists precision and recall values for the 20 test words. "Total Recall" is an estimate that extrapolates from the human judgments of the sample to the entire test set. We can illustrate this using the results for pollution. The human judge marked 91.2% of ALEK's E-set and 18.4% of its C-set as incorrect usage. To estimate ALEK's overall error rate, we first
9

computed a weighted mean of these two rates, where the weights reflected the proportion of sentences that were in the E-set and C-set. The E-set contained 8.3% of the pollution sentences and the C-set had the remaining 91.7%. Using the human judgments as the gold standard, the estimated overall rate of incorrect usage is (.083 � .912) + (.917 � .184) = .245. ALEK's estimated total recall, then, is the proportion of sentences in the E-set times its precision, divided by the overall estimated error rate, or (.083 � .912) / .245 = .310.
Table 3
Precision and Recall for 20 Evaluation Words
Test word Precision Recall Total recall (estimated)
Test word Precision Recall Total recall (estimated)
affect .848 .762 .343 energy .768 .666 .104 area .752 .846 .205 function .800 .714 .168
aspect .792 .717 .217 individual .576 .742 .302 benefit .744 .709 .276 job .728 .679 .103 career .736 .671 .110 period .832 .670 .102
communicate .784 .867 .274 pollution .912 .780 .310 concentrate .848 .791 .415 positive .784 .700 .091 conclusion .944 .756 .119 role .728 .674 .098
culture .704 .656 .083 stress .768 .578 .162 economy .816 .666 .235 technology .728 .674 .093
Mean .779 .716 .190
Recall is limited in part by the fact that the system only looks at syntactic information, whereas many of the errors are semantic. For example, the phrase grow my knowledge would be marked as an error, but this kind of error would never be revealed by sequences of part-of-speech tags. Precision results vary from word to word. Conclusion and pollution have precision values in the low to middle 90s, while the precision of individual is 57%. Overall, ALEK's predictions are about 78% accurate.
In the remainder of this section, we analyze ALEK's hits (the types of errors that ALEK correctly recognizes) and misses (errors not recognized by ALEK), as well as ALEK's false positives — instances in which ALEK flags a good construction as an error. The relation among these categories is illustrated in Table 4. Two-hundred randomly sampled sentences from each category (hit, misses, and false positives) were examined for this purpose.
10

Table 4
Relation of ALEK's Hits, Misses, and False Positives
ALEK predicted "error" ALEK predicted "correct" Labeled by human as error Hit: agreement on error Miss Labeled by human as correct False positive Agreement on correct
Analysis of Hits and Misses
Nicholls (1999) identifies four error types: an unnecessary word (affect to their emotions), a missing word (opportunity of job), a word or phrase that needs replacing (every jobs), and a word used in the wrong form (pollutions). ALEK recognized all of these types of errors in many environments. During the development stage, when the uses of the target word were judged manually as being well-formed or ill-formed, we found it useful to add some additional error categories. The final taxonomy we used is shown in Table 5.
For closed-class categories (determiners, pronouns, quantifiers, and prepositions), we identified whether a word was missing, the wrong word was used (choice), and when an extra word was used. For open-class words (nouns, verbs, adjectives, and adverbs), we included the fourth category, form, indicating that the wrong form was used, including inappropriate compounding. For verbs, we included a subtype of this error, that of verb-object nonagreement and subject-verb nonagreement. Since TOEFL readers are not supposed to take punctuation into account, we marked punctuation errors only when they caused the evaluator to "garden path," or initially misinterpret the sentence. Spelling was marked either when a function word was misspelled, causing part-of-speech tagging errors, or when the writer's intent was unclear. The two categories, sentence fragment and word order are self-explanatory.
The distributions of categories for hits and misses, also shown in Table 5, were not strikingly different. However, the hits were primarily syntactic in nature while the misses were both semantic (as in open-class: choice) and syntactic (as in closed-class: missing).
11
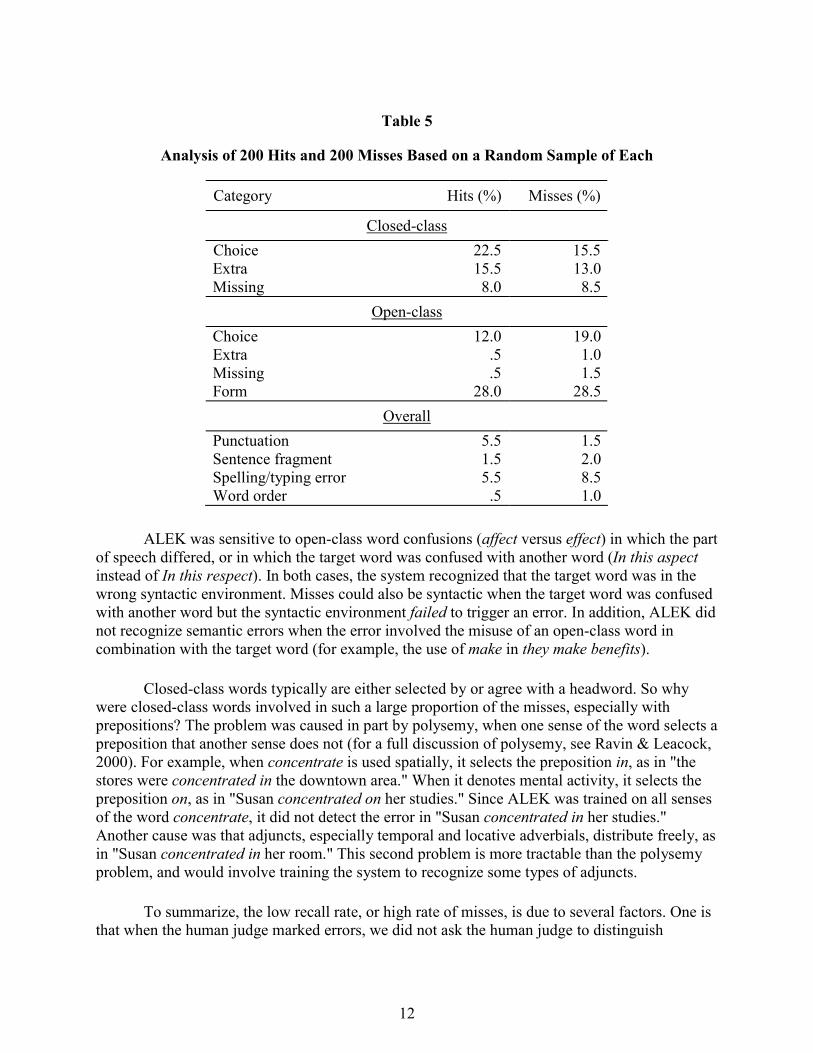
Table 5
Analysis of 200 Hits and 200 Misses Based on a Random Sample of Each
Category Hits (%) Misses (%)
Closed-class Choice 22.5 15.5 Extra 15.5 13.0 Missing 8.0 8.5
Open-class Choice 12.0 19.0 Extra .5 1.0 Missing .5 1.5 Form 28.0 28.5
Overall Punctuation 5.5 1.5 Sentence fragment 1.5 2.0 Spelling/typing error 5.5 8.5 Word order .5 1.0
ALEK was sensitive to open-class word confusions (affect versus effect) in which the part
of speech differed, or in which the target word was confused with another word (In this aspect instead of In this respect). In both cases, the system recognized that the target word was in the wrong syntactic environment. Misses could also be syntactic when the target word was confused with another word but the syntactic environment failed to trigger an error. In addition, ALEK did not recognize semantic errors when the error involved the misuse of an open-class word in combination with the target word (for example, the use of make in they make benefits).
Closed-class words typically are either selected by or agree with a headword. So why were closed-class words involved in such a large proportion of the misses, especially with prepositions? The problem was caused in part by polysemy, when one sense of the word selects a preposition that another sense does not (for a full discussion of polysemy, see Ravin & Leacock, 2000). For example, when concentrate is used spatially, it selects the preposition in, as in "the stores were concentrated in the downtown area." When it denotes mental activity, it selects the preposition on, as in "Susan concentrated on her studies." Since ALEK was trained on all senses of the word concentrate, it did not detect the error in "Susan concentrated in her studies." Another cause was that adjuncts, especially temporal and locative adverbials, distribute freely, as in "Susan concentrated in her room." This second problem is more tractable than the polysemy problem, and would involve training the system to recognize some types of adjuncts.
To summarize, the low recall rate, or high rate of misses, is due to several factors. One is that when the human judge marked errors, we did not ask the human judge to distinguish
12
between syntactic errors (which ALEK is sensitive to) and semantic errors (which ALEK does not recognize). Therefore, ALEK will never be able to find many of the misses. Other problems are more tractable.
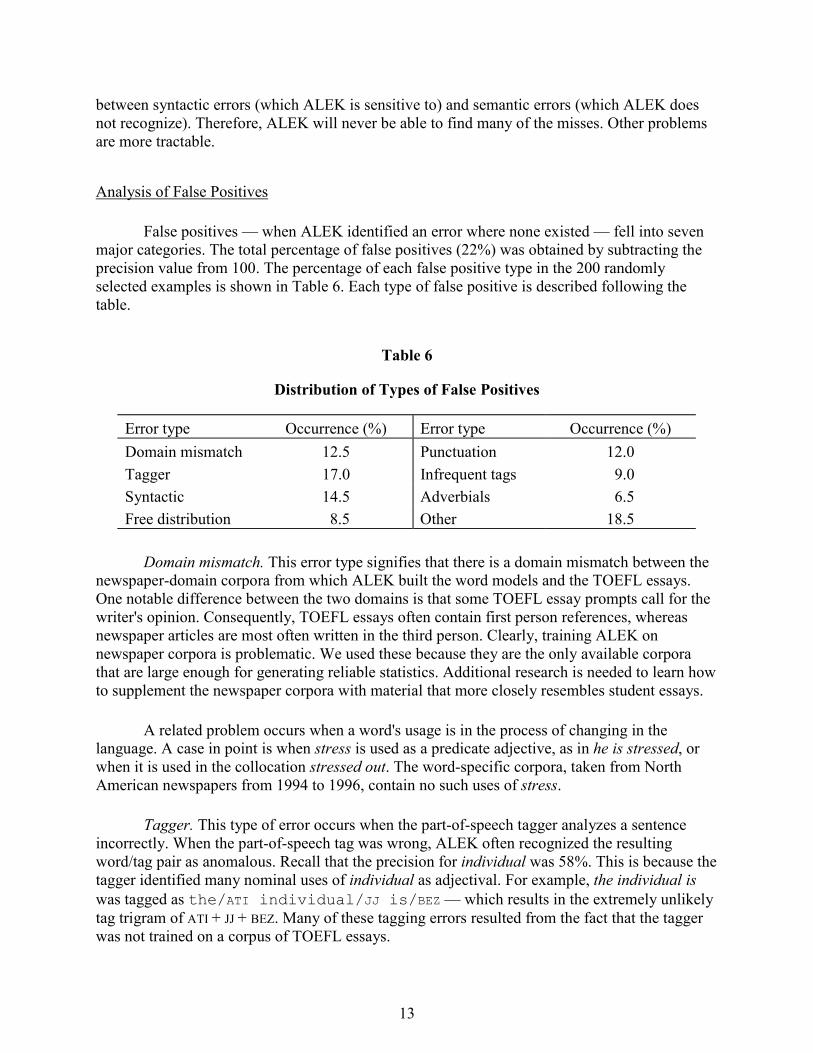
Analysis of False Positives
False positives — when ALEK identified an error where none existed — fell into seven major categories. The total percentage of false positives (22%) was obtained by subtracting the precision value from 100. The percentage of each false positive type in the 200 randomly selected examples is shown in Table 6. Each type of false positive is described following the table.
Table 6
Distribution of Types of False Positives
Error type Occurrence (%) Error type Occurrence (%) Domain mismatch 12.5 Punctuation 12.0 Tagger 17.0 Infrequent tags 9.0 Syntactic 14.5 Adverbials 6.5 Free distribution 8.5 Other 18.5
Domain mismatch. This error type signifies that there is a domain mismatch between the
newspaper-domain corpora from which ALEK built the word models and the TOEFL essays. One notable difference between the two domains is that some TOEFL essay prompts call for the writer's opinion. Consequently, TOEFL essays often contain first person references, whereas newspaper articles are most often written in the third person. Clearly, training ALEK on newspaper corpora is problematic. We used these because they are the only available corpora that are large enough for generating reliable statistics. Additional research is needed to learn how to supplement the newspaper corpora with material that more closely resembles student essays.
A related problem occurs when a word's usage is in the process of changing in the language. A case in point is when stress is used as a predicate adjective, as in he is stressed, or when it is used in the collocation stressed out. The word-specific corpora, taken from North American newspapers from 1994 to 1996, contain no such uses of stress.
Tagger. This type of error occurs when the part-of-speech tagger analyzes a sentence incorrectly. When the part-of-speech tag was wrong, ALEK often recognized the resulting word/tag pair as anomalous. Recall that the precision for individual was 58%. This is because the tagger identified many nominal uses of individual as adjectival. For example, the individual is was tagged as the/ATI individual/JJ is/BEZ — which results in the extremely unlikely tag trigram of ATI + JJ + BEZ. Many of these tagging errors resulted from the fact that the tagger was not trained on a corpus of TOEFL essays.
13

Syntactic analysis. This type of error results from using part-of-speech tags instead of supertags (Joshi & Srinivas, 1994) or a full parse, either of which would give syntactic relations between constituents. For example, ALEK false alarmed on arguments of ditransitive verbs, such as offer, and flagged as an error, you benefits, in offers you benefits.
Free distribution. Elements that distribute freely, such as adverbs and conjunctions, tend to be identified as errors when they occur in some positions.
Punctuation. The omission of punctuation in an essay, most notably periods and commas, was often marked by ALEK as an error. This is because newspaper copy editors adhere strictly to punctuation rules, and this is reflected in both the general and word-specific models. However, since a punctuation error is not indicative of the author's ability to use the test word, the omission of punctuation was considered an error by the human judge only when it caused a misanalysis of the sentence. We need to study how to generalize over punctuation when collecting bigrams and trigrams.
Infrequent tags. An undesirable result of our "enriched" tag set was that some tags did not occur frequently enough in the corpora to provide reliable statistics. For example, the statistics for the post-determiner last, as in the last time I saw Paris, was not reliable because it occurred too infrequently in the 30-million-word general corpus.
Adverbials. Temporal and locative adverbial phrases, usually headed by a preposition, can be used with most verbs as adjuncts. However, ALEK often identified these adjuncts as errors because the target word did not select the head preposition. The same holds for complex adverbials that are headed by prepositions (e.g., as well as).
These seven error types (all categories except for "other") account for 81% of ALEK's false positives. Solutions to some of these problems (e.g., generalizing over punctuation and identifying locative and temporal adverbials) will clearly be more tractable than solutions to other problems described earlier (e.g., polysemy).
Comparison of Results
Comparison of these results to those of other systems is difficult because there is no generally accepted test bank or performance baseline to use. Given this limitation, we compared ALEK's performance to a widely used grammar checker — the one incorporated in Microsoft® Word 97. To run the comparison, we created Word 97 files for all of the TOEFL sentences that contained our three development words — concentrate, interest, and knowledge — and then manually corrected any errors outside the target word's local context before checking them with Word 97.
The grammar checker's performance for concentrate showed overall precision of 0.89 and recall of 0.07. For interest, precision was 0.85 with recall of 0.11. In sentences containing knowledge, precision was 0.99 and recall was 0.30. Word 97's grammar checker correctly detected the ungrammaticality of knowledges, as well as a knowledge, while it avoided flagging
14

a knowledge of. Its precision in error detection is impressive, but the lower recall values indicate that it responds to fewer error types than ALEK. In particular, Word 97 was not sensitive to the inappropriate selection of prepositions for our three words (as in, have knowledge on history and to concentrate at science).
Research has been reported on grammar checkers specifically designed for an ESL population. These have been developed by hand, based on small training and test sets. Schneider and McCoy (1998) developed a system tailored to errors made by native users of American Sign Language in written English text. This system was tested on 79 sentences containing determiner and agreement errors, and 101 grammatical sentences. We calculate that their precision was 78% with 54% recall. Park, Palmer, and Washburn (1997) adapted a categorial grammar to recognize "classes of errors [that] dominate" in the nine essays they inspected. This system was tested on eight essays, but precision and recall figures were not reported.
From the inception of our research, we have required that ALEK not make use of negative evidence. Negative evidence, in the form of a collection of ill-formed sentences produced by ESL students, is expensive to collect and may, in part, explain why the research of Schneider and McCoy (1998) and Park, Palmer, and Washburn (1997) is limited. Another problem with training a system on negative evidence is that the sample that is collected could bias the system with respect to a particular native language. By the same token, grammars created to recognize specific error types, which are inferred from negative evidence, could yield a similar bias. ALEK's corpus-based approach uses English usage and nothing else as evidence. It simply recognizes deviations from general English and word-specific corpora.
Possible Applications
The estimated word usage error rate in the TOEFL essays for the 20 words in this study is 24%.2 Word usage errors occur so frequently in these essays that detecting them automatically could facilitate both holistic scoring and diagnostic feedback. One possible scenario is that ALEK could be used to build models for several hundred words that are used frequently in TOEFL essays. Whenever these words occur in an essay, ALEK would be able to evaluate the contexts immediately surrounding them.
However, no matter how well ALEK performs, there will be words for which precision is too low for the model to be accepted. This is why every aspect of ALEK is automated except for selection of the target words and evaluation of the model. The performance of every word usage model will need to be evaluated by a human judge, but this task is accomplished quickly. It took about three hours to evaluate ALEK's model for each word in this study.
Holistic scoring
Preliminary results indicate that ALEK's error detection is predictive of TOEFL's holistic scores. If ALEK accurately detects usage errors, then we would expect it to report more errors in 2 As noted earlier in the Results section, recall was based on error rates estimated from the manually inspected sentences when the error occurred within two positions surrounding the target word.
15

essays with lower scores than in those with higher scores. We have already seen in Table 1 that there is a negative correlation between essay score and two of ALEK's component measures — the general corpus bigrams and trigrams. However, the data in Table 1 were not based on specific vocabulary items and do not reflect overall system performance, which includes the use of its other measures as well.
Table 7 shows the proportion of sentences that were classified by ALEK as containing errors at each of six score points.3 As predicted, the correlation is negative (rs = -1.00, n = 6, p < .001, two-tailed). These data support the validity of the system as a detector of inappropriate usage, even when only a limited number of words are targeted and only the immediate context of each target word is examined. For comparison, Table 7 also shows the estimated proportions of inappropriate usage by score point based on the human judge's classification. Here, too, there is a negative correlation (rs = -.90, n = 5, p < .05, two-tailed).
Table 7
Proportion of Sentences, by Score Point, Classified as Containing an Error by ALEK and by a Human Judge
TOEFL Score
ALEK Human
1 .091 --- 2 .085 .375 3 .067 .268 4 .057 .293 5 .048 .232 6 .041 .164
In tabulating these data, we were struck by the scarcity of examples of the test words in
the essays that received the lowest scores. These writers have both the highest probability of making an error when they use a test word and the lowest probability of actually using one. Only 276 usages of the 20 test words were found in essays at score point 1, and at score point 2 there were 2,442 usages, while there were 42,556 usages at score point 6. This pattern of avoidance is undoubtedly indicative of examinees' unfamiliarity with the test words. To recognize when the writer is avoiding unfamiliar words, we need a separate measure that is related to vocabulary size — such as the content vector analysis of the e-rater™ system (Burstein & Chodorow, 1999).
3 Half-point score values were rounded up to the next full point to allow for comparison with the classifications of the human judge, who evaluated small samples of sentences. Arranging the scores in fewer categories increased the number of sentences per category, and therefore the reliability of the estimates in the human column. Score point 1 appeared infrequently in the sentences of the test set, and it did not appear at all in the samples evaluated by the judge.
16

Finally, not all errors are equal. For example, a typographical error such as "teh job" is far less serious than an agreement error such as "these job." By comparing scores to the distribution of grammatical errors in essays, we will be able to develop better models of how human readers grade, including the weights given to different error types and to the variety of errors exhibited within a single essay.
Diagnostic Feedback
The current version of ALEK determines whether an error it recognizes is a violation of a principle of English grammar or the misuse of a specific target word. When ALEK locates an unusual n-gram in the general corpus, the writer probably violated a general rule of English — for example, using a singular determiner followed by a plural noun (this areas). As noted earlier, misuse of a target word is signaled when an n-gram is unusual in the word-specific corpus. For example, ALEK flags conclusion when it is preceded by the preposition on (as in the ill-formed On conclusion), but ALEK is not triggered when conclusion is preceded by in (as in, In conclusion). ALEK infers, from the word-specific corpus, that conclusion has a collocational relation with the preposition in, but not with on.
To provide more specific diagnostic feedback, we need to identify which low probability n-grams correspond to specific errors in the typology provided in Table 4. Another potentially productive area for research would be to build models for closed-class words — the various types of determiners and prepositions, for example. These additional word models would enable ALEK to evaluate a much larger portion of each sentence than the immediate vicinity of an open-class word, as it currently does.
Conclusion
We have demonstrated the feasibility of an automated system for detecting errors in TOEFL essays. We have also suggested how such a system either could be integrated into holistic scoring or developed independently as a way to deliver diagnostic feedback on word usage and grammar. During the course of this research, we have identified the system's strengths and how various of its components can be improved.
As noted earlier in Table 3, ALEK currently detects only about one-fifth of the errors that a human judge detects (mean total recall = .19). To improve ALEK's recall, research should focus on areas identified earlier in our analysis of ALEK's hits and misses. To improve precision, research should concentrate on areas identified earlier in our analysis of false positives generated by ALEK. Many of these improvements will be based on existing technology. Other developments, such as identifying freely distributing adjuncts, will open up new, and we believe tractable, areas for natural language processing research.
17

References
Brill, E. (1994). Some advances in rule-based part of speech tagging. Proceedings of the 12th National Conference on Artificial Intelligence, AAAI-94 (pp. 256-261). Cambridge, MA: MIT Press.
Burstein, J., & Chodorow, M. (1999). Automated essay scoring for nonnative English speakers. Paper presented at the Symposium of the Association of Computational Linguistics and the International Association of Language Learning Technologies Workshop on Computer-Mediated Language Assessment and Evaluation of Natural Language Processing, College Park, MD. Available: http://www.ets.org/research/acl99rev.pdf.
Carey, P. (in press). TOEFL CBT concordance study. Princeton, NJ: Educational Testing Service.
Chodorow, M., Leacock C., & Miller, G. A. (2000). A topical/local classifier for word sense identification. Computers and the Humanities, 34(1-2), 115-120.
Choueka, Y., & Lusignan, S. (1985). Disambiguation by short contexts. Computers and the Humanities, 19(3), 147-158.
Cohen, J., & Cohen, P. (1983). Applied multiple regression/correlation analysis for the behavioral sciences. Hillsdale, NJ: Erlbaum.
Cumming, A., Kantor, R., Powers, D., Santos, T., & Taylor, C. (2000). TOEFL 2000 writing framework: A working paper (TOEFL Monograph Series Report No. 18). Princeton, NJ: Educational Testing Service.
Enright, M., Grabe, W., Koda, K., Mosenthal, P., Mulcahy-Ernt, P., & Schedl, M. (2000). TOEFL 2000 reading framework: A working paper (TOEFL Monograph Series Report No. 17). Princeton, NJ: Educational Testing Service.
Francis, W., & Kučera, H. (1982). Frequency analysis of English usage: Lexicon and grammar. Boston: Houghton Mifflin.
Golding, A. (1995). A Bayesian hybrid for context-sensitive spelling correction. Proceedings of the 3rd Workshop on Very Large Corpora, Cambridge, MA, ACL-95, 39-53.
Joshi, A. K., & Srinivas, B. (1994). Disambiguation of super parts of speech (or supertags): Almost parsing. Proceedings of the 15th International Conference on Computational Linguistics, Kyoto, 154-160. Available: http://citeseer.nj.nec.com/srinivas94disambiguation.html.
Kaplan, A. (1955). An experimental study of ambiguity and context. Mechanical Translation, 2, 39-46.
Kilgarriff, A., & Palmer, M. (2000). Introduction to the special issue on SENSEVAL. Computers and the Humanities, 34(1-2), 1-13.
18

Leacock, C., Chodorow, M., & Miller, G. A. (1998). Using corpus statistics and WordNet's lexical relations for sense identification. Computational Linguistics, 24(1), 147-165.
Lin, D. (1998). Extracting collocations from text corpora. Paper presented at the First Workshop on Computational Terminology, Montreal, Canada. Available: http://citeseer.nj.nec.com/41721.html.
Miller, G. A., & Gildea, P. (1987). How children learn words. Scientific American, 257, 94-99.
Nation, I. S. P. (1990). Teaching and learning vocabulary. New York: Newbury House.
Nicholls, D. (1999). The Cambridge Learner Corpus - Error coding and analysis for writing dictionaries and other books for English learners. Paper presented at the Summer Workshop on Learner Corpora, Showa Woman’s University, Tokyo.
Park, J. C., Palmer, M., & Washburn, G. (1997). Checking grammatical mistakes for English-as-a-second-language (ESL) students. Proceedings of the Korean-American Scientists and Engineers Association (KSEA) 8th Northeast Regional Conference & Job Fair. New Brunswick, NJ: KSEA.
Qian, D. D., & Harley, B. (1998). The role of depth of vocabulary knowledge in adult ESL learners' comprehension of academic texts. Paper presented at the Conference of the Canadian Association for Applied Linguistics on Trends in Second Language Teaching and Learning, Ottawa, Canada.
Ravin, Y., & Leacock, C. (Eds.). (2000). Polysemy: Theoretical and computational approaches. Oxford, England: Oxford University Press.
Schneider, D. A., &. McCoy, K. F. (1998). Recognizing syntactic errors in the writing of second language learners. Proceedings of the 17th International Conference on Computational Linguistics, 36th Annual Meeting of the Association for Computational Linguistics, Montreal, 1198-1204. Available: http://citeseer.nj.nec.com/schneider98recognizing.html.
Yarowsky, D. (1993). One sense per collocation. Proceedings of the ARPA Workshop on Human Language Technology (pp. 266-271). San Francisco: Morgan Kaufman.
19

57906-005535 • Y111M.700 • Printed in U.S.A.
I.N. 987668
Test of English as a Foreign LanguageP.O. Box 6155
Princeton, NJ 08541-6155USA
�������������������������������������������������
To obtain more information about TOEFL
programs and services, use one of the following:
Phone: 609-771-7100Email: [email protected]
Web site: http://www.toefl.org