applying data mining to contract...
TRANSCRIPT

Applying Data Mining toContract Inference
Master Thesis
Nikolay KazminETH Zurich
February 22, 2010 - August 22, 2010
Supervised by:Yi WeiProf. Bertrand Meyer

Abstract
This master thesis report will introduce the techniques that we use to auto-matically infer contracts for a given class. The report will cover briefly thebuilding of the automatic test suite, the generation of the change profile andthen will get into great details on the implication inference. It will focus on thedecision tree and linear regression learning techniques to infer contracts. Exper-iments show that for standard data structure classes such as linked list, array,stack, query and hash table, 75% of the complete contracts can be inferred fullyautomatically.

Contents
1 Introduction 6
2 Contract Inference: an Overview 82.1 Example . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82.2 Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
3 Test Generation 113.1 History . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113.2 How AutoTest works . . . . . . . . . . . . . . . . . . . . . . . . . 123.3 AutoTest for AutoInfer . . . . . . . . . . . . . . . . . . . . . . . . 13
4 Change Profile 144.1 Monitored Entities . . . . . . . . . . . . . . . . . . . . . . . . . . 144.2 Value Sets . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
5 Change Profile Interface 185.1 ARFF Files . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 185.2 The WEKA Library . . . . . . . . . . . . . . . . . . . . . . . . . 19
5.2.1 WEKA ARFF ATTRIBUTE . . . . . . . . . . . . . . . 205.2.2 WEKA ARFF RELATION . . . . . . . . . . . . . . . . 225.2.3 WEKA ARFF RELATION PARSER . . . . . . . . . . 24
6 Contract Inference Techniques 256.1 Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 256.2 RM BUILDER . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
6.2.1 RM DECISION TREE BUILDER . . . . . . . . . . . . . 286.2.2 RM LINEAR REGRESSION BUILDER . . . . . . . . . . 28
6.3 XML Generation . . . . . . . . . . . . . . . . . . . . . . . . . . . 306.3.1 RM SEED XML GENERATOR . . . . . . . . . . . . . . 306.3.2 RM XML GENERATOR . . . . . . . . . . . . . . . . . . 31
6.4 Parsing the Decision Tree . . . . . . . . . . . . . . . . . . . . . . 326.4.1 RM DECISION TREE STACK ITEM . . . . . . . . . . . 366.4.2 Parsing helper methods . . . . . . . . . . . . . . . . . . . 366.4.3 Parsing illustrated . . . . . . . . . . . . . . . . . . . . . . 38
6.5 Parsing the Linear Regression . . . . . . . . . . . . . . . . . . . . 456.6 Decision Tree and Linear Regression Classes . . . . . . . . . . . . 45
6.6.1 Decision Trees . . . . . . . . . . . . . . . . . . . . . . . . 466.6.2 Linear Regression . . . . . . . . . . . . . . . . . . . . . . . 49
4

6.7 Support Classes . . . . . . . . . . . . . . . . . . . . . . . . . . . . 506.7.1 RM CONSTANTS . . . . . . . . . . . . . . . . . . . . . . 506.7.2 RM ENVIRONMENT . . . . . . . . . . . . . . . . . . . . 51
7 Results 537.1 Experimental Setup . . . . . . . . . . . . . . . . . . . . . . . . . 537.2 Results and Evaluation . . . . . . . . . . . . . . . . . . . . . . . . 54
7.2.1 Soundness . . . . . . . . . . . . . . . . . . . . . . . . . . . 547.2.2 Completeness . . . . . . . . . . . . . . . . . . . . . . . . . 547.2.3 Redundancy . . . . . . . . . . . . . . . . . . . . . . . . . . 55
8 Conclusions 578.1 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 578.2 Future Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 578.3 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
8.3.1 Static Techniques . . . . . . . . . . . . . . . . . . . . . . . 588.3.2 Dynamic Techniques . . . . . . . . . . . . . . . . . . . . . 58

Chapter 1
Introduction
Contracts are crucial for automated software verification, testing and fixing.However, in reality, programs usually come with very basic and far from com-plete set of contracts. This fact pushed forward the development of automatedcontract inference techniques. Current solutions utilize both static(by programanalysis) and dynamic(by leveraging program execution data, such as Daikon[9])techniques to infer contracts.
Although these inference techniques have their strengths and show some in-teresting results, the contracts that they infer are far from complete and usuallyonly reveal basic properties. Static approaches majorly work on small programsand reports sound, but very conservative contracts; most of the existing dy-namic approaches, although scale to large systems, suffer from only being ableto report simple contracts automatically, such as ”the size of a list is increasedby one”.
The present work describes how we can use data mining techniques to au-tomatically infer postconditions for commands(postconditions for short there-after). Commands are routines that do not return any value, they serve tomodify objects. By contrast, queries are pure routines or attributes which re-turn information about objects. Postcondition are important for a client tounderstand what a class does, and they naturally follow the theory of abstractdata types. In this report we focus on inferring implications whose premisesuses a single formula or conjunctions of formulae. This particular type of post-conditions are hard to infer with existing techniques. We demonstrate thatwhen simple contracts are available, which is the case for languages with de-sign by contracts support[4], our techniques can infer stronger contracts fullyautomatically.
We implemented in Eiffel a system called AutoInfer to automatically gener-ate contracts using various techniques and flexible enough to allow additionalinference strategies to be added. An overview of the whole AutoInfer systemcan be seen on Figure 1.1.
On the figure we see three ways to infer contracts; Basic Templates andQuantified expressions are interesting techniques, but the present master thesis
6

Introduction 7
Test suite
Change profile
Quantifiedexpressions
Implicationexpressions
Inferredcontracts
Changeanalysis
Predicatemining Validation
Decision tree learning
Confidencefiltering
Basictemplates
Validation
Eiffelclass
AutoTest
Figure 1.1: An overview of the AutoInfer system
is focused entirely on the Implication Expressions path. We used a learningmachine called rapidminer[28] to run the actual learning algorithms - decisiontree and linear regression. The main contribution of the master work is thecreation of the RM library which gives us an Eiffel interface to rapidminer. Thelibrary knows how to run rapidminer and knows how to transform the resultsinto a form which can be used by the rest of the system.
This thesis will try to explain each part of the process of using data miningtechniques to infer implication expressions. Chapter 2 will introduce briefly thewhole system, it will show a motivating example and explain how AutoInferworks in general. Chapter 3 covers the test generation part, it will answer ques-tions like: why do we need tests, what techniques do we use for test generation.Chapter 4 explains what is the change profile, how do we generate it and whatdata is included in it. Chapter 5 is the first chapter that will get into the codeof AutoInfer. It will show how the data from the change profile is transferredto the learning machine(rapidminer in this case). It will introduce the ARFFfile format and the library that we wrote to interact with those kinds of files- the WEKA library. Chapter 6 is the main chapter in the thesis, it describesthe meat of the innovation we did with AutoInfer- using data mining to infercontracts. This chapter will introduce the rapidminer learning machine and thelibrary that works with it - the RM library. It will then go into great implemen-tation details on how RM works. The chapter before the last, Chapter 7, willshow the results that we achieved with AutoInfer, it describes the experimentsthat we ran and how we evaluated them. Chapter 8 draws conclusions and hintsabout future work.

Chapter 2
Contract Inference: anOverview
AutoInfer is a fairly complicated system, it integrates a lot of previous workwith a whole new set of components and technologies. In this chapter we willfirst try to provide a motivating example that is going to be used for the restof the report and then provide a short glimpse into all of the main componentsthat comprise AutoInfer. We give a view of the big picture and draw the frameof AutoInfer without getting into details. All the main components that we seein this chapter will be carefully discussed later.
2.1 Example
Class LINKED_LIST is the standard Eiffel implementation of lists using dynamicallocation. Its interface includes a number of queries—attributes or pure func-tions returning components of the object state—and commands—proceduresmodifying the state of the list. For example, the query occurrences (v: ANY)
returns a nonnegative integer counting the number of times its argument v ap-pears in the list, whereas the command extend (v: ANY) augments the list byadding v to the end of the list.
Programmers also documented the intended semantics of several of the publicfeatures (queries and commands) of LINKED_LIST by writing a contract in theform of pre and postcondition clauses. Contracts, in particular, describe theeffects of a command on the object state in terms of the values returned bypublic queries before and after the execution of the command [23]. For example,developers annotated extend with the postcondition clause post_1 in extend: thenumber of occurrences of the inserted element v in the list is increased by one.
As it is often the case with contracts written by programmers [26], thepostcondition post_1 of extend is interesting but largely incomplete, as it failsto mention the effect of executing the command on other components of theobject state, described by other queries. Which facts should be included in the
8

Contract Inference: an Overview - Overview 9
Listing 2.1: Eiffel : Extend method
1 extend (v: ANY)
2 −− Add ‘v’ to end. Do not move cursor.3 ensure
4 −− Programmer’s written5 post_1: occurrences (v) = old (occurrences (v)) + 1
67 −− Automatically inferred8 post_2: count = old count + 1
9 post_3: i_th (old count + 1) = v
10 post_4: forall i . 1 ≤i ≤old count implies i_th (i) = old i_th (i)
11 post_5: old after implies index = old index + 1
12 post_6: not old after implies index = old index
postcondition to make it complete [27], that is describing (directly or indirectly)the effect on every visible component of the list?
• Element v is inserted at the end of the list.
• All the elements that were in the list before executing extend are stillthere, in the same positions.
• The internal cursor of the list does not change position.
The techniques described in the present paper, implemented in the AutoIn-fer tool, can automatically infer postconditions clauses post_2 to post_6 in List-ing 2.1, which completely formalize the effects of extend:
• post_2 asserts that exactly one element is added.
• post_3 states that v appears at position old count + 1: the position nextto the last valid position of the list before invoking extend.
• post_4 says that, for each valid position i of the old list, the element atposition i is the same before and after invoking extend.
• post_5 and post_6 formalize the position of the cursor in terms of itsinteger position index: if the cursor was after the last element of the listbefore invoking extend, it is now after the new last element, correspondingto an increment of index by one; otherwise the index is simply unchanged.
2.2 Overview
Figure 2.1 shows all the elements that take part in the contract inference andshows how they relate to each other.
1. The input is an Eiffel class, equipped with public queries, commands, andpossibly a few basic contracts.

Contract Inference: an Overview - Overview 10
Test suite
Change profile
Implicationexpressions
Inferredcontracts
Changeanalysis
Decision tree learning
Confidencefiltering
Eiffelclass
AutoTest
Figure 2.1: How AutoInfer works.
2. Using the random testing techniques implemented in the AutoTest frame-work, AutoInfer generates a test suite that exercises as many routines aspossible (Section 3).
3. AutoInfer executes the test suite and profiles the results, monitoring inparticular which arguments and values returned by queries change whenexecuting a command. This information is collected in a change profile(Section 4).
4. AutoInfer applies machine learning techniques, based on decision treelearning algorithms, to expressions in the change profile. The goal is find-ing correlations between expressions that change or stay constant. Everycorrelation with 100% confidence translates into a likely valid contract inthe form of an implication (Section 6). For example, decision tree learningbuilt post_5 and post_6 in Listing 2.1 by observing queries that changewhen executing extend.

Chapter 3
Test Generation
3.1 History
AutoTest was conceived back in 2003[3], and performs fully automatic unit test-ing of Eiffel classes containing contracts. According to the Design by Contractsoftware development methodology[23], contracts (routine pre- and postcondi-tions and class invariants) express elements of the specification of the software.If they are executable, they can be monitored at runtime and any contract vio-lation signals a fault in the executed program. This enables AutoTest to use thecontracts present in the code as an automated oracle[17]. AutoTest is writtenin Eiffel for testing Eiffel classes, but it can be ported to any other languagewith design-by-contract support.
The current version of AutoTest employs a directed random strategy for in-put generation, but the tool has a pluggable architecture so that other strategiesfor input creation can easily be added. In particular, a command line optionselects the desired input generation method out of the available ones. Using thecurrently selected strategy, AutoTest automatically generates inputs, runs theroutine under test with these inputs, and monitors contracts. If it detects anycontract violation (except for the case in which a generated test does not fulfillthe precondition of the routine under test), it reports a fault. The detectedproblem may lie either in the implementation or in the contract, requiring fur-ther analysis, but this is not significant at this point: regardless of the locationof the fault, a contract violation signals a mistake in the developer’s thinking,so a testing tool should report it as a fault[17].
The motivation behind AutoTest is that random testing has several ad-vantages: ease of implementation in an automatic testing tool, no overhead forchoosing inputs out of the set of all inputs, lack of bias. The approach was a sub-ject to careful evaluation[16] and was found to produce satisfying results. Sincethen AutoTest was improved by a method called Adaptive Random Testing[17]and remains an open question subject to further improvement. This is veryimportant for AutoInfer, because as you will see later, the inferred contracts areonly as good as the generated test suite, so the better the test suite the better
11

Test Generation - How AutoTest works 12
Generate and selectinputs
Run test cases withselected inputs TC1: 10101011
TC2: 10110011TC3:10000110
Interpred resultspass/fail
TC1: PASSTC2: PASSTC3: FAIL
Figure 3.1: Test Generation process.
the contracts.
3.2 How AutoTest works
AutoTest was developed as a push-button testing framework. All informationthat it requires is a set of classes to be tested. It takes care to automateeverything else[24]:
• Tests are generated by randomly creating instances of the classes and thencalling their routines with various arguments.
• Success or failure are determined by using the classes’ constracts as oracles.
Figure 1 shows the general algorithm that AutoTest follows when testing aclass[24].
• Create instances of the class under test
• Select several from these objects for testing.
• Select the required arguments for the features to be called. Selected ar-guments must satisfy the preconditions of the feature under test, else thetest is irrelevant.
• Run the tests.
• Use the oracles to determine if the test passed or failed.
The unit of testing is a routine call of the form target.routine(arguments).How thorough the testing is depends mainly on the number of different objectsthat we run the tests on, both on the target and on the argument level. Toobtain a test input, AutoTest maintains an object pool. Whenever it needs anobject of a type T, it decides whether to create a new instance of T or drawfrom the pool. Creation is necessary if the pool does not contain an instanceof T; but even if it does, AutoTest will, with a preset frequency(which can beadjusted by an argument), create an object and add it to the pool[24]. Aneffective strategy needs both possibilities:

Test Generation - AutoTest for AutoInfer 13
• New objects diversify the pool.
• Creating a new object every time would restrict tests to youthful ob-ject structures. For example, a newly created list object represents a listwith zero elements or one element; realistic testing needs lists with manyelements, obtained by creating a list then repeatedly calling insertion pro-cedures.
When creating new objects we must be sure that upon creation they satisfytheir class invariants. That’s why AutoTest depends on the normal construc-tors provided by every class. They guarantee an object state that satisfies theinvariant. The algorithm for creating new objects goes like this:
• Choose one particular constructor.
• Choose the proper arguments for this constructor, such that are typecompliant and satisfy the preconditions.
• Create the object and make a call to the routine under test.
Every object created that way is added to the pool.
3.3 AutoTest for AutoInfer
AntoInfer develops dynamic techniques for contract inference. Dynamic tech-niques observe the state at predefined program points, such as the entry andexit point of a routine; properties which are invariant over several program runscharacterizes likely valid contracts. Now it is clear why the inferred contractsare only as good as the test suite; in other words, sound and interesting con-tracts require a set of test cases which execute program paths extensively andwith varied values.
For the purposes of AutoInfer we adapted the AutoTest random testingframework to build test suites completely automatically. AutoTest works onEiffel classes equipped with contracts. It generates a pool of random objects bycalling constructors and commands with random arguments. Then, AutoTestgenerates a test case for a routine r of class C by selecting from the pool a targetobject of class C and a collection of objects that conform to r’s arguments. Theprecondition of r serves as a filter on the objects in the pool to select a validinput; the postcondition of r constitutes instead an oracle to determine if thetest case executed correctly or exposed a bug.
Currently AutoInfer focuses on inferring expressive postcondition clauses ofcommands (namely, state-modifying procedures). The focus on postconditionsis justified by the empirical observation that preconditions are usually muchsimpler than postconditions, and in fact programmers often write complete pre-conditions [26]. This is a fortunate situation for the automated generation oftest cases in AutoInfer: we modified AutoTest to discard failing test cases andwe increased its capability of exercising commands with the precondition satis-faction technique developed in recent work [31]. The test suites built with thismethod proved to be appropriate for dynamic contract inference techniques.

Chapter 4
Change Profile
AutoInfer runs the test suite generated by AutoTest, and collects informationabout the behavior of the commands that is visible to clients of the current classC.
Observable objects. AutoTest maintains a pool of objects during thegeneration of test cases; AutoInfer re-runs the test cases in the same environmentand keeps track of the observable objects. An object is observable at some timet if the pool contains a reference o to the object at time t, either because therandom generation process created o or because some invoked public routinereturned o (which has been stored away). Ot denotes the set of references toobjects that are observable at time t. For a reference r ∈ Ot, [[r]]t denotes theobject attached to r at time t.
Note that not all objects in the system at some time t are observable. Forexample, each element in a LINKED_LIST is an instance of class LINKABLE, contain-ing a reference to the stored value and a pointer to the next element in the list;while the stored value is accessible and hence observable, the whole LINKABLE
object is an internal representation which is not created nor modified directlyand hence not observable.
4.1 Monitored Entities
Whenever a test case exercises a routine, AutoInfer keeps track of the value ofa number of entities right before and after executing the routine’s body.
Symbolic expressions. Let c be a command with formal arguments a1, . . . , am.Ac denotes the set of symbolic expressions {Current, a1, . . . , am} correspondingto the current object and formal arguments.
Consider an execution k of c, begun at time t and terminated at time t′;notice that Ot = Ot′ because any new object created internally by the commandis not observable.
• For a ∈ Ac, bacck ∈ Ot is the actual reference denoted by a during the
14

Change Profile - Monitored Entities 15
execution k of c.
• For every public query q of class C, Eq[Ac] is the set of (statically) type-safe expression calls a0.q(a1, . . . , an) where each ai ranges over Ac and nis q’s number of arguments.
AutoInfer records the set V kq [Ac] consisting of the triples of values 〈e, v, v′〉 for
all e = a0.q(a1, . . . , an) ∈ Eq[Ac], where v is the value returned by evaluatinge on the objects [[ba0cck]]t, . . . , [[bancck]]t before the call k to c, and v′ is thecorresponding value after the call (i.e., at t′).
Reachable objects. For every execution k of a command c, AutoInferalso evaluates expression calls on observable objects that are reachable from c’starget and arguments.
• Rck ⊆ Ot is the set of all references to observable objects reachable from
the actuals {bacck | a ∈ Ac}.
• For every public query q of class C, Eq[Rck] is the set of (statically) type-
safe calls r0.q(r1, . . . , rn) where each ri ranges over Rck and n is q’s number
of arguments. Notice that, unlike Eq[Ac], the members of Eq[Rck] are not
symbolic programming language expressions, but represent actual calls interms of references to observable objects in the object pool.
AutoInfer records the set Vq[Rck] consisting of the triples of values 〈ε, v, v′〉
for all ε = r0.q(r1, . . . , rn) ∈ Eq[Rck], where v is the value returned by evaluating
ε on the objects [[r0]]t, . . . , [[rn]]t before the call k to c, and v′ is the correspondingvalue after the call (i.e., at t′).
Examples. Consider an invocation k of command extend (v: ANY) of classLINKED_LIST on the list of Figure 4.1. l, v, and o denote references to the targetlist, the actual argument, and an object stored in the list. Then:
• Aextend is {Current, v}; Ekhas[A
extend] is{Current.has (v), Current.has (Current)};
• V khas[A
extend] is {〈Current.has (v), False, True〉,〈Current.has (Current), False, False}
• Rextendk is {l, v, o};
Ehas[Rextendk ] is {l.has (v), l.has (l), l.has (o)};
• Vhas[Rextendk ] is {〈l.has (v), False, True〉, 〈l.has (l), False, False〉, 〈l
.has (o), True, True〉}.
Queries with preconditions. For queries q with preconditions, AutoIn-fer extends the sets Eq[Rc
k] and Vq[Rck] with calls to q using “special” values
suggested by the precondition. In particular, an algorithm derived from previ-ous work [32] can symbolically solve arithmetic constraints in preconditions forextremal values, and add the corresponding arguments to the set of reachableobjects. E+
q [Rck] denotes the extension of Eq[Rc
k] with the expressions suggestedby constraint solving; V +
q [Rck] is defined accordingly.

Change Profile - Value Sets 16
lo v
Figure 4.1: An instance of linked list.
As an example, query i_th (i: INTEGER) of classLINKED_LIST has a single integer argument, constrained by the precondition1 ≤ i ≤ count. The linear constraint suggests the two extremal values 1 andcount as valid arguments; correspondingly, E+
i th[Rextendk ] extends Ei th[Rextend
k ]with the two expressions l.i_th (1) and l.i_th (l.count).
4.2 Value Sets
Value sets summarize the effects of a command c on the values of a public queryq.
Queries. The value set Qcq of command c on query q is the set{
〈v, v′〉 | 〈ε, v, v′〉 ∈⋃k
V +q [Rc
k]
}of all values q evaluates to in any execution of c.
A query q is variant with a command c iff: (1) it evaluates to different valuesfor some executions of c, that is |Qc
q| > 1; and (2) the set⋃
k E+q [Rc
k] containsat least two invocations to q with different arguments.
Expressions. The value set Ece of command c on expression e = a0.q(a1, . . . , an) ∈Eq[Ac] is the set {
〈v, v′〉 | 〈e, v, v′〉 ∈⋃k
V kq [Ac]
}of all values e evaluates to in any execution of c. An expression e is variant witha command c iff Ece contains at least a pair 〈v, v′〉 such that v′ 6= v. The notionof variant expression guides the selection of potential consequents in contractsinvolving implications (Section 6).
Based on the value set, the pre, post, and change sets collect the values thatan expression e takes as a result of executing a command c.
• The pre set ←−χ ce of c on e is the set {v | 〈v, v′〉 ∈ Ece} of all values e evaluates
to before executions of c.
• The post set −→χ ce of c on e is the set {v′ | 〈v, v′〉 ∈ Ece} of all values e
evaluates to after executions of c.
• The change set χce of c on e, defined only for calls to queries returning
numeric values, is the set {v′ − v | 〈v, v′〉 ∈ Ece} of all differences betweenthe values e evaluates to after and before executions of c.

Change Profile - Value Sets 17
A few examples for command extend of class LINKED_LIST illustrate the notionof change set.
• Query call Current.is_empty determines if the current list is empty or not.extend may execute on empty or non-empty lists; anyway, the list will benon-empty after the execution of the command. Hence, for a non-trivialtest suite, the pre set of extend on Current.is_empty is {True, False} andthe post set is {False}.
• Query call Current.count returns the number of elements stored in thecurrent list. extend always increases count by one, so the change set ofextend on Current.count is {1}. On the contrary, the post set collects allpositive integers from 1 to the maximum length of a list generated in thetest suite.

Chapter 5
Change Profile Interface
In the previous two sections we saw briefly how AutoTest works and after thathad on overview of what information is collected in the change profile. In thissection we will describe how the data collected in the change profile is passeddown the chain. We will describe in details the format of the files where westore the change profile data and the library classes that we created to interactwith those files.
5.1 ARFF Files
An ARFF (Attribute-Relation File Format) file is an ASCII text file that de-scribes a list of instances sharing a set of attributes. ARFF files were developedby the Machine Learning Project at the Department of Computer Science ofThe University of Waikato for use with the Weka machine learning software[2].We picked the ARFF format, because it is supported by the two most famouseopen source learning machines - Rapid Miner[28] and WEKA[33] and also suitsour needs perfectly.
The ARFF files have two distinctive parts - the header part and the datapart. The header contains the name of the relation and a set of attributes.Listing 5.1 shows a typical header of an ARFF file used by AutoInfer. As wecan see from the value of the @RELATION tag, this is the ARFF file for thecommand forth in the class LINKED_LIST. The list of attributes is right afterthe header. Every line starts with the @ATTRIBUTE tag, then the name ofthe attribute follows and we have the type of the attribute in the end. Theattributes in our case are query calls or whole expressions that we observe andcollect information about during the execution of the test suite. We made someinternal conventions in the names of the attributes, namely:
• If the attribute name starts with “pre::”, then this expression is measuredbefore the execution of the forth command.
• If the attribute name starts with “post::”, then this expression is measuredafter the execution of the forth command.
18

Change Profile Interface - The WEKA Library 19
Listing 5.1: Eiffel : ARFF File Header Section
@RELATION LINKED_LIST.forth
@ATTRIBUTE "pre::{0}.count" NUMERIC
@ATTRIBUTE "pre::{0}.after" {True, False, NA}
@ATTRIBUTE "pre::{0}.before" {True, False, NA}
@ATTRIBUTE "pre::{0}.is_empty" {True, False, NA}
@ATTRIBUTE "pre::{0}.extendible" {True, False, NA}
@ATTRIBUTE "pre::{0}.has ({0})" {True, False, NA}
@ATTRIBUTE "post::{0}.count" NUMERIC
@ATTRIBUTE "post::{0}.after" {True, False, NA}
@ATTRIBUTE "post::{0}.before" {True, False, NA}
@ATTRIBUTE "post::{0}.is_empty" {True, False, NA}
@ATTRIBUTE "post::{0}.has ({0})" {True, False, NA}
@ATTRIBUTE "to::{0}.index" NUMERIC
• If the attribute name starts with “to::”, then this signifies the absolutechange after the execution of the forth command.
• If the attribute name starts with “by::”, then this signifies the relativechange after the execution of the forth command.
• The values in the curly brackets are zero-based operand indices with 0being the target objects and 1,2... the arguments.
The type of the attribute is the last part of the attribute definition. Thetype can be: NUMERIC, STRING, DATE and nominal. On Listing 5.1 we cansee many cases of nominal attributes, lets take the ”pre::{0}.after” for example,it is a nominal attribute and the possible values it can take are “True, False andNA”.
The data section of the ARFF starts with the data declaration tag - @DATAand what follows are the actual instance lines. Each instance is represented on aseparate line and the attribute values for each instance are delimited by commas.Attribute values must appear in the same order as they were declared in theheader section; meaning that the the data corresponding to the nth attribute,must be in the nth place on the data instance line. Listing 5.2 shows an excerptof the data section from an arff file that we use in AutoInfer.
5.2 The WEKA Library
When we decided to use the ARFF file format for our purposes we had todevelop a library to actually interact with those kinds of files. We developedthe WEKA library exactly for that purpose and this section will cover the mainclasses of the WEKA library in details. Figure 5.1 shows a diagram of all theclasses in the WEKA library.

Change Profile Interface - The WEKA Library 20
Listing 5.2: Eiffel : ARFF File Data Section
@DATA
1,False,2,False,True,False,True,True,False...
2,False,2,False,False,False,True,True,True...
3,False,5,False,False,False,True,True,False...
4,False,1,False,False,False,True,True,False...
5,True,2,False,False,False,True,True,True...
6,False,2,False,True,False,True,True,True...
7,False,0,False,True,True,True,True,False...
8,False,2,False,True,False,True,True,False...
9,True,2,False,True,False,True,True,True...
10,False,1,False,True,False,True,True,True...
11,False,3,False,True,False,True,True,True...
12,True,1,False,False,False,True,True,True...
.
.
.
Figure 5.1: WEKA Library Class Diagram
5.2.1 WEKA ARFF ATTRIBUTE
This is an deferred class providing Eiffel representation to the attributes thatwe saw in the header section of the ARFF files. It has four subclasses each rep-resenting an attribute with a different type. We don’t have a subclass for thedate type since we are not currently interested in them, but we have a supportfor attributes with one additional type: the Boolean, which in the ARFF filesis represented as a nominal type with only two possible values: True and False.The four subclasses of WEKA_ARFF_ATTRIBUTE are WEKA_ARFF_NOMINAL_ATTRIBUTE,WEKA_ARFF_BOOLEAN_ATTRIBUTE, WEKA_ARFF_NUMERIC_ATTRIBUTE andWEKA_ARFF_STRING_ATTRIBUTE. The most important features of the interface ofWEKA_ARFF_ATTRIBUTE can be seen on the listing 5.3.
Every attribute object will keep the name of the attribute and as guaranteedby the class invariant this name will not be empty. Every object has the func-tionality to report exactly what type of an attribute it is(is_numeric, is_boolean,

Change Profile Interface - The WEKA Library 21
Listing 5.3: Eiffel : WEKA ARFF ATTRIBUTE Interface
1 deferred class interface
2 WEKA_ARFF_ATTRIBUTE
3 feature −− Access4 as_nominal (a_values: DS_HASH_SET [STRING_8]):
WEKA_ARFF_NOMINAL_ATTRIBUTE
5 −− Norminal attribute from Current under the set of values ‘ a values ’67 name: STRING_8
8 −− name of current attribute9
10 signature: STRING_8
11 −− String representing the signature of Current attribute .1213 value (a_value: STRING_8): STRING_8
14 −− Value from ‘a value’, possibly processed to fit the type of current1516 feature −− Status report17 is_boolean: BOOLEAN
18 −− Is current attribute of boolean type?1920 is_date: BOOLEAN
21 −− Is current attribute of date type?2223 is_nominal: BOOLEAN
24 −− Is current attribute of norminal type?2526 is_numeric: BOOLEAN
27 −− Is current attribute of numeric type?2829 is_string: BOOLEAN
30 −− Is current attribute of string type?3132 is_valid_value (a_value: STRING_8): BOOLEAN
33 −− Is ‘a value ’ a valid value for current attribute?3435 invariant
36 not_name_is_empty: not name.is_empty
3738 end

Change Profile Interface - The WEKA Library 22
is_nominal, is_string). And the last important feature that we implementedwas the signature; which gives the attribute objects the functionality to presentthemselves as a string ready to be placed in an ARFF file.
5.2.2 WEKA ARFF RELATION
The WEKA_ARFF_RELATION is the exact Eiffel equivalent of an ARFF file. Theinterface of the class with its most important features can be seen in listing 5.4.
WEKA_ARFF_RELATION inherits from ARRAYED_LIST [ARRAYED_LIST [STRING]], thisis where we store all the values for our attributes, in an ARFF context this willbe the place where we store the @DATA instances. The class also has a fieldcalled attributes, it is of type ARRAYED_LIST [WEKA_ARFF_ATTRIBUTE] and it holdsall the attributes of the relation; it is from where we will generate the @AT-TRIBUTE part of the ARFF file. To finish with the data storage, we have topresent three other fields:
• name is where we keep the name of the relation, this is the string right nextto the @RELATION in an ARFF file.
• comment is the comment that comes exactly after the @RELATION lineand before any of the @ATTRIBUTEs.
• trailing_comment is the comment that comes in the very end of the file,after the last @DATA line has passed.
Besides storing a whole ARFF file, the WEKA_ARFF_RELATION class has manymore useful features. Here is a motivation and explanation for some of them:
• out is an extremely useful feature, it gives us a valid ARFF string rep-resentation of the current WEKA_ARFF_RELATION object. This way we caneasily print the relation into a file and feed it to the learning machine thatwe are using. This is actually one of the methods by which the changeprofile part of the system interacts with the part that is doing the learning.
• nominalized_cloned_object provides a WEKA_ARFF_RELATION with only nom-inal attributes. This is useful because some learning algorithms can onlywork with nominal attributes so if we want to use them we need such suchnominal representation.
• projection is very useful when we want to cut out some attributes fromour relation. During the change profile generation we collect a lot of dataabout many expressions and queries, not all of that data is relevant so thisfeature helps us filter it out.
• is_instance_valid helps us when we add another data instance to ourrelation. It will check if the data is valid according to the particularattributes that the relation holds.

Change Profile Interface - The WEKA Library 23
Listing 5.4: Eiffel : WEKA ARFF RELATION Interface
class
WEKA_ARFF_RELATION
inherit
ARRAYED_LIST [ARRAYED_LIST [STRING]]
feature −− Accessname: STRING
−− Name of current file
attributes: ARRAYED_LIST [WEKA_ARFF_ATTRIBUTE]
−− List of attributes mentioned in current relation−− The order of attributes in this list determines the order of values .
comment: STRING
−− Comments to be located after the relation name, before attributedeclaration
trailing_comment: STRING
−− Comments that appear at the end of the file
out, as_string: STRING
−− Current weka relation as string
values_of_attribute (a_attribute: WEKA_ARFF_ATTRIBUTE): LINKED_LIST [
STRING]
−− List of values of ‘ a attribute ’ across all instances .−− The order of values are preserved.
projection (a_attribute_selection_function: FUNCTION [ANY, TUPLE [
WEKA_ARFF_ATTRIBUTE], BOOLEAN]): like Current
−− Projection of Current by selecting only attributes that satisfies ‘a attribute selection function ’
−− The order of the attributes in the resulting relation is the same as inthe original relation .
nominalized_cloned_object: like Current
−− Cloned version of Current, with all numeric values normalized
attribute_by_name (a_name: STRING): WEKA_ARFF_ATTRIBUTE
−− Attribute in ‘ attributes ’ with ‘a name’
feature −− Hash table generatorsitem_as_hash_table: HASH_TABLE [STRING, STRING]
−− Returns a hash table where the keys are the attribute names and thevalues comes from the current item
feature −− Status reportis_instance_valid (a_instance: like item): BOOLEAN
−− Does ‘a instance’ contain valid values for ‘ attribute ’?end

Change Profile Interface - The WEKA Library 24
Listing 5.5: Eiffel : WEKA ARFF RELATION PARSER Interface
1 class interface
2 WEKA_ARFF_RELATION_PARSER
3 create
4 make (a_file_path: STRING_8)
56 feature −− Access7 had_errors: BOOLEAN
8 −− Were errors encountered during parsing.9
10 last_relation: WEKA_ARFF_RELATION
11 −− The last relation parsed by the ‘ parse relation ’ command.1213 parse_relation
14 −− Parses the arff file to generate a WEKA ARFF RELATION1516 set_file_path (a_file_path: STRING_8)
17 −− ‘a file path ’ is the absolute file path to the arff file18 end
5.2.3 WEKA ARFF RELATION PARSER
The WEKA_ARFF_RELATION is the Eiffel representation of an ARFF file and its out
feature provides the functionality to present a WEKA_ARFF_RELATION as a ARFFfile. WEKA_ARFF_RELATION_PARSER provides the functionality to parse an ARFF fileand create a WEKA_ARFF_RELATION from it. The interface ofWEKA_ARFF_RELATION_PARSER is on listing 5.5 . Since it only has one purpose: toparse ARFF files into WEKA_ARFF_RELATION objects, the interface is quite simple.First we set set the absolute file path to the ARFF file that we want to parse,we can do that with the constructor or the dedicated setter feature. Then wecall the parse_relation command and after we check for errors in had_errors wecan get the newly parsed WEKA_ARFF_RELATION from the last_relation feature.
In the end we have to mention the WEKA_ARFF_ATTRIBUTE_FACTORY class. It isquite important for the parsing, it has the responsibility to create the correctWEKA_ARFF_ATTRIBUTE objects when the ARFF file is being parsed.

Chapter 6
Contract InferenceTechniques
6.1 Overview
In this section we will provide an overview on the actual contract inferrenceprocess. We are using an open source learning machine called rapidminer to dothe actual data mining. Although it has an API we are using it as a blackboxby just providing an xml and an arff files to it and then parse the resulting file.All these elements: the generation of the xml, running the rapidminer, parsingthe models, generating the decision trees and linear regressions are handled bythe RM library which will be described in details in this chapter.
A diagram of the important classes in the RM library can be seen on Fig-ure 6.1.
A quick explanation for the most important classes is the following:
• RM_CONSTANTS is the class where we keep all the constants that we need forthe RM library. Classes that use RM_CONSTANTS extensively inherit from itfor convenience.
• RM_BUILDER is the main class in the RM library, users of the library mustcreate instances of child classes of RM_BUILDER in order to use the libraryfeatures.
• RM_XML_GENERATOR and RM_SEED_XML_GENERATOR are the classes responsiblefor generating the xml file which will be fed to rapidminer. They are usedinternally by the RM_BUILDERs.
• RM_DECISION_TREE_PARSER is used internally to parse the file with the deci-sion tree model generated by rapidminer.
• RM_LINEAR_REGRESSION_PARSER is used internally to parse the file with thelinear regression generated by rapidminer.
25

Contract Inference Techniques - RM BUILDER 26
Figure 6.1: An instance of linked list.
• RM_DECISION TREE is the RM class that represents a decision tree. It is theend result of the RM_DECISION_TREE_BUILDER’s build method.
• RM_LINEAR_REGRESSION is the RM class that represents a linear regression.It is the end result of the RM_LINEAR_REGRESSION_BUILDER’s build method.
6.2 RM BUILDER
RM_BUILDER and its two descendants are the three most important classes in theRM library. RM_BUILDER is a deferred(abstract) class that defines the interfaceof the library to a huge extend. Its most important feature is the build com-mand. It implements the template method pattern[12] and defines the generalalgorithm that all builders follow. The source code of the build feature can beseen on Listing 6.1.
Each one of the commands that build calls can be overridden by the childclasses to fit their particular needs but for most of them RM_BUILDER alreadyprovides a default implementation. The only two that must be overridden, theyare defined as deferred, are parse_model and parse_performance, because the

Contract Inference Techniques - RM BUILDER 27
Listing 6.1: Eiffel : build’s source code
1 build
2 −− Builds the classification with the help of rapidminer. Implements thetemplate method pattern.
3 do
4 prepare_xml_file
56 run_rapidminer
78 parse_model
910 parse_performance
1112 clean_files
13 end
model files and the performance files that can be generated by rapidminer varygreatly from model to model so a default implementation is inpractical. A quickdescription of all the commands called by build is:
• prepare_xml_file creates the xml file which will be fed to rapidminer.
• run_rapidminer takes the xml file generated in the previous feature andruns rapidminer externally with it.
• The result of rapidminer is a model file which is then parsed by parse_model
and turned into RM class.
• parse_performance parses the performance file generated by rapidminer.Note that this file is only generated if validation is turned on.
• clean_files deletes all the temporary files created by RM_BUILDER.
When we want to support a new algorithm in the RM library and the currentconcrete builders (RM_DECISION_TREE_BUILDER and RM_LINEAR_REGRESSION_BUILDER
) cannot handle it, we need to create another builder class that inherits fromRM_BUILDER and provides implementation for the parse_model and parse_performance
features. It should also provide an interface for fetching the result, sinceRM_BUILDER does not know what the result will be. For exampleRM_DECISION_TREE_BUILDER has a feature last_tree which returns a result of typeRM_DECISION_TREE allowing the users to get the resulting tree from the builder.
Another purpose of RM_BUILDER is to act as a data-holder for the commonattributes of all the builders. Here is a list of all the variables that are storedin RM_BUILDER and are accessible to its children:
• algorithm_name is the name of the algorithm that will be used by rapid-miner. All algorithms are defined in the RM_CONSTANTS class.

Contract Inference Techniques - RM BUILDER 28
• validation_code is the validation that will be used by rapidminer. Allvalidation types are defined in the RM_CONSTANTS class.
• arff_file_path is the absolute path to the arff file. We have the function-ality to create a builder with a WEKA_ARFF_RELATION instead of an ARFFfile. The object will then be written into a file behind the scenes andarff_file_path will be filled with a predefined value.
• selected_attributes is a list of selected attributes to which rapidminerwill perform the required algorithms.
• label_name is the target attribute, it must be a part of the selected_attributes
.
• algorithm_parameters is a non-mandatory field holding any specific pa-rameters that we might have for the algorithm. It has a setter methodset_algorithm_parameters(a_parameters: HASH_TABLE [STRING, STRING])
where the key is the parameter’s name and value is the value.
• validation_parameters is a non-mandatory field holding any specific pa-rameters that we might have for the validation. It has a setter methodset_validation_parameters(a_parameters: HASH_TABLE [STRING, STRING])
where the key is the parameter’s name and value is the value.
To fill all those variables RM_BUILDER provides two features: init andinit_with_relation. Their interface can be seen on Listing 6.2.
6.2.1 RM DECISION TREE BUILDER
RM_DECISION_TREE_BIULDER is a concrete class inheriting from RM_BUILDER. Itspurpose is to run rapidminer with all the decision tree algorithms which arecurrently supported: decision tree, decision stump, chaid and id3.
It has two constructors which can be seen on Listing 6.3. Note that theconstructors don’t allow to set the algorithm and validation, these two variableshave default values decision tree and no validation and can be changed throughsetter features.
Unique feature of RM_DECISION_TREE_BIULDER is the last_tree query whichreturns a RM_DECISION_TREE object, which is the tree generated by the previousexecution of the build feature.
6.2.2 RM LINEAR REGRESSION BUILDER
RM_LINEAR_REGRESSION_BUILDER is a concrete class inheriting from RM_BUILDER.Its purpose is to run rapidminer with the one linear regression algorithm whichis currently supported: linear regression.
It has two constructors which are the same as in RM_DECISION_TREE_BIULDER
and can be seen on Listing 6.3. Note that the constructors don’t allow to

Contract Inference Techniques - RM BUILDER 29
Listing 6.2: Eiffel : RM BUILDER init interface
1 init (a_algorithm_name: STRING; a_validation_code: INTEGER;
a_arff_file_path: STRING; a_selected_attributes: LIST [STRING];
a_label_name: STRING)
2 −− ‘a algorithm name’ is the algorithm name representing the type ofalgorithm to be performed by rapid miner.
3 −− ‘a validation code’ is the validation which will be performed by rapidminer.
4 −− ‘ a arff file path ’ is the absolute file path to the arff file , whichwill provide the data for rapid miner.
5 −− ‘ a selected attributes ’ is the attributes to be selected by RapidMiner6 −− ‘a label name’ is the target attribute name.7 −− Initialize some attributes .8 require
9 selected_attributes_not_empty: not a_selected_attributes.is_empty
10 a_label_attribute_valid: a_selected_attributes.has (a_label_name)
11 valid_algorithm: is_valid_algorithm_name (a_algorithm_name)
1213 init_with_relation (a_algorithm_name: STRING; a_relation:
WEKA_ARFF_RELATION; a_selected_attributes: DS_HASH_SET [
WEKA_ARFF_ATTRIBUTE]; a_label_attribute: WEKA_ARFF_ATTRIBUTE)
14 −− Initialize current with ARFF relation ‘a relation ’.15 −− ‘a algorithm name’ is the algorithm name representing the type of
algorithm to be performed by rapid miner.16 −− ‘a validation code’ is the validation which will be performed by rapid
miner.17 −− ‘ a selected attributes ’ is a subset of attributes in ‘ a relation ’,
which will be used for the tree learning .18 −− ‘ a label attribute ’ is the goal attribute whose values are to be
classified by the learnt tree .19 −− Use default decision tree algorithm, and default validation criterion .20 require
21 a_selection_attributes_valid: a_selected_attributes.is_subset (
a_relation.attribute_set)
22 a_label_attribute_valid: a_selected_attributes.has (
a_label_attribute)
23 valid_algorithm: is_valid_algorithm_name (a_algorithm_name)

Contract Inference Techniques - XML Generation 30
Listing 6.3: Eiffel : RM BUILDER children’s constructors
1 make(a_arff_file_path: STRING; a_selected_attributes: LIST [STRING];
a_label_name: STRING)
2 −− creates a decision tree builder with default decision tree algorithmand
3 −− ’no validation’4 require
5 selected_attributes_not_empty: not a_selected_attributes.is_empty
6 a_label_attribute_valid: a_selected_attributes.has (a_label_name)
78 make_with_relation (a_relation: WEKA_ARFF_RELATION;
a_selected_attributes: DS_HASH_SET [WEKA_ARFF_ATTRIBUTE];
a_label_attribute: WEKA_ARFF_ATTRIBUTE)
9 −− Initialize current with ARFF relation ‘a relation ’.10 −− ‘ a selected attributes ’ is a subset of attributes in ‘ a relation ’,
which will be used for the tree learning .11 −− ‘ a label attribute ’ is the goal attribute whose values are to be
classified by the learnt tree .12 −− Use default decision tree algorithm, and default validation criterion .13 require
14 a_selection_attributes_valid: a_selected_attributes.is_subset (
a_relation.attribute_set)
15 a_label_attribute_valid: a_selected_attributes.has (
a_label_attribute)
set the algorithm and validation, these two variables have default values lin-ear regression and no validation and can be changed through setter features.
Unique feature of RM_LINEAR_REGRESSION_BUILDER is the last_regression querywhich returns a RM_LINEAR_REGRESSION object, it is the linear regression gener-ated by the previous execution of the build feature.
6.3 XML Generation
The XML generation is a fundamental part of the RM library, because it isthe only way we can interface with rapidminer and tell it what to do. Wehave two classes that deal with xml generation, those are RM_XML_GENERATOR
and RM_SEED_XML_GENERATOR. They are described in details in the following twosubsections.
6.3.1 RM SEED XML GENERATOR
By analysis of the XML files generated for rapidminer itself, we noticed thatthey change very slightly from algorithm to algorithm(only the name of thealgorithm changes in fact), but change much more drastically when we havevalidation or no validation. We decided to encapsulate all those similarities anddifferences in a class called RM_SEED_XML_GENERATOR, which would generate the

Contract Inference Techniques - XML Generation 31
Listing 6.4: Eiffel : RM SEED XML GENERATOR interface
1 make (a_algorithm_name: STRING; a_validation_code: INTEGER)
2 −− ‘a algorithm name’ is the algorithm name representing the type ofalgorithm to be performed by rapid miner.
3 −− ‘a validation code’ is the validation which will be performed by rapidminer.L
4 do
5 algorithm_name := a_algorithm_name
6 validation_code := a_validation_code
7 end
89 xml: STRING
10 −− seed xml for rapidminer with the appropriate placeholders for validationand algorithms
1112 generate_xml
13 −− generates the seed xml depending on the algorithm type and the validationtype.
14 −− It puts the required placeholders .
skeleton of our XML file and will put placeholders on the places where additionalinformation is required.
The class has a very simple interface(Listing 6.4). It has a constructor takingthe algorithm name and the validation code; it has a command generate_xml
which tells the class to generate the xml skeleton depending on the algorithmand validation and it has a query xml which will return the resulting xml. As wehave mentioned above the xml will have placeholders, defined in RM_CONSTANTS
, which will signify places where additional information must be inserted(theactual insertion is handled by the RM_XML_GENERATOR class).
As we have already hinted before, the XML skeleton does not differ for thedifferent algorithms, but it differs greatly depending on whether there is valida-tion or not. Because of that in the RM_SEED_XML_GENERATOR class we have hard-coded the xml in two private methods: no_validation_xml and x_validation_xml
. So what the generate_xml feature does is just to call one of these two methodsdepending on the validation type and then return its result.
One important fact about RM_SEED_XML_GENERATOR is that only theRM_XML_GENERATOR knows about it, no other class uses it in any way. This allowsus to abstract away the particularities of the xml required by rapidminer andgives us the flexibility to support other learning machines.
6.3.2 RM XML GENERATOR
RM_XML_GENERATOR is the “official” XML generating class, it is used by RM_BUILDER
in the prepare_xml_file feature. However its interface is not more complex thatthe one of RM_SEED_XML_GENERATOR, the only difference is in the constructor whichtakes a few more arguments, since RM_XML_GENERATOR is supposed to produce the

Contract Inference Techniques - Parsing the Decision Tree 32
final xml file and must have more information for that purpose.
The most interesting method in the RM_XML_GENERATOR class is the generate_xml
, it’s source can be seen on Listing 6.5
As we can see, it again implements the template method pattern[12], butin contrast to the RM_BUILDER’s build method it does not have any gabs to befilled. All the methods are working and can be used immediately, we don’t needto subclass RM_XML_GENERATOR in order to use it. We decided to use the templatemethod for flexibility, if another approach to xml was required to be able tohandle it with a simple subclass. Lets explain in details what all the methodcalls in the generate_xml are supposed to do:
1. First we create the RM_SEED_XML_GENERATOR and save the xml skeleton fromit.
2. Then we put the absolute file path of the ARFF file in the xml.
3. After that we write which are the selected attributes in the xml.
4. We put the label name in.
5. We put the algorithm name in the xml.
6. If there is some validation we put the validation name and the validationparameters.
7. In the end we write the algorithm parameter(if any) in the xml file.
8. After the generate_xml is finished we should have no placeholders in thexml string left, which is specified in the postconditions.
In the current implementation of RM_XML_GENERATOR we use a private methodcalled replace_placeholder (a_placehodler_name: STRING; a_replacement: STRING
). It replaces a placeholder name with the a replacement, we will not get intodetails about this method, because the implementation is trivial.
After the generate_xml method is finished we can take the final xml stringfrom the xml query and handle it however necessary. In the current implemen-tation it is handled in the RM_BUILDER’s prepare_xml_file which basically takesthe xml string and writes it into a predefined file. The source of this methodcan be seen on Listing 6.6
6.4 Parsing the Decision Tree
When we run the decision tree algorithms in rapidminer, it generates a modelfile that needs to be parsed in order to create the inferred tree as an Eiffel ob-ject. Currently all decision tree algorithms that we support generate the sametype of output, but in order to be flexible enough we created an abstract classto encapsulate the interface of the decision tree parsers from their concrete im-plementation. This abstract class is called RM_DECISION_TREE_PARSER_INTERFACE.Its interface is quite simple and can be seen on Listing 6.7.

Contract Inference Techniques - Parsing the Decision Tree 33
Listing 6.5: Eiffel : generate xml source
generate_xml
−− Generates the xml for rapidminer according to the arguments provided inthe creation feature . Use ‘xml’ to get the result .
local
rm_seed_generator: RM_SEED_XML_GENERATOR
do
create rm_seed_generator.make (algorithm_name, validation_code)
rm_seed_generator.generate_xml
xml := rm_seed_generator.xml
put_file_path
put_selected_attributes
put_label_name
put_algorithm_name
if validation_code 6={RM_CONSTANTS}.no_validation then
put_validation_name
put_validation_parameters
end
put_algorithm_parameters
ensure
no_placeholder: not xml.has_substring (placeholder_algorithm_name)
no_placeholder: not xml.has_substring (
placeholder_algorithm_parameters)
no_placeholder: not xml.has_substring (placeholder_data_file)
no_placeholder: not xml.has_substring (placeholder_label_name)
no_placeholder: not xml.has_substring (
placeholder_selected_attributes)
no_placeholder: not xml.has_substring (placeholder_validation_name)
no_placeholder: not xml.has_substring (
placeholder_validation_parameters)
end

Contract Inference Techniques - Parsing the Decision Tree 34
Listing 6.6: Eiffel : prepare xml file source
1 prepare_xml_file
2 −− Writes the xml from the xml generator into the xml file locationprovided from the environment.
3 −− This xml file should contain all the information required by rapidminerto run correctly .
4 local
5 l_file: PLAIN_TEXT_FILE
6 l_rm_xml_generator: RM_XML_GENERATOR
7 do
8 l_rm_xml_generator := create_xml_generator
9 l_rm_xml_generator.generate_xml
1011 create l_file.make_open_write (rm_environment.
rapid_miner_xml_file_path)
12 l_file.put_string (l_rm_xml_generator.xml)
13 l_file.close
14 end
Listing 6.7: Eiffel : RM DECISION TREE PARSER INTERFACE features
1 feature −− Access2 tree_root: RM_DECISION_TREE_NODE
3 −− Will hold the root of the tree after the model file is parsed45 feature −− Interface6 parse_model
7 −− Parses the model file generated by rapidminer. The path to the file issaved in ‘ model file path ’.
8 deferred
9 end
Contract Inference Techniques - Parsing the Decision Tree 35
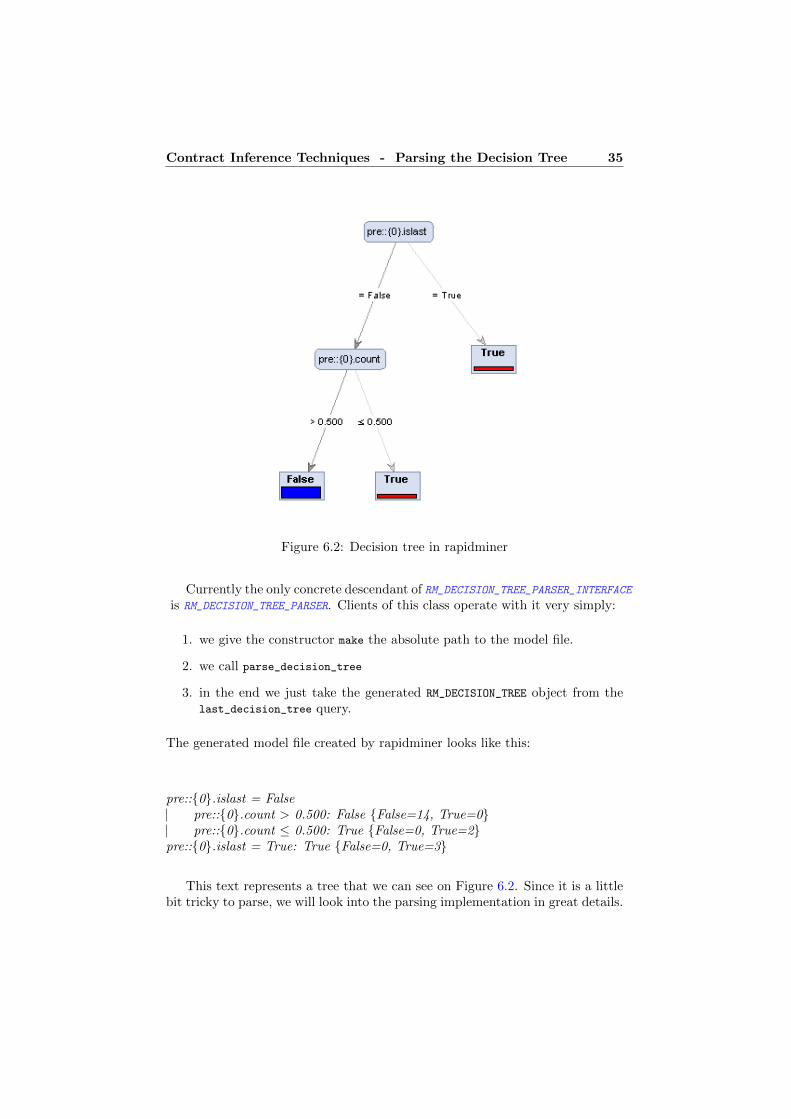
Figure 6.2: Decision tree in rapidminer
Currently the only concrete descendant of RM_DECISION_TREE_PARSER_INTERFACEis RM_DECISION_TREE_PARSER. Clients of this class operate with it very simply:
1. we give the constructor make the absolute path to the model file.
2. we call parse_decision_tree
3. in the end we just take the generated RM_DECISION_TREE object from thelast_decision_tree query.
The generated model file created by rapidminer looks like this:
pre::{0}.islast = Falsepre::{0}.count > 0.500: False {False=14, True=0}pre::{0}.count ≤ 0.500: True {False=0, True=2}
pre::{0}.islast = True: True {False=0, True=3}
This text represents a tree that we can see on Figure 6.2. Since it is a littlebit tricky to parse, we will look into the parsing implementation in great details.

Contract Inference Techniques - Parsing the Decision Tree 36
6.4.1 RM DECISION TREE STACK ITEM
We use a stack to parse the decision tree, and the elements of the stack are oftype RM_DECISION_TREE_STACK_ITEM. It is a simple class serving entirely a dataholding purpose. It has three pieces of information that it holds:
• node holds a reference to a RM_DECISION_TREE_NODE
• condition holds the condition for going down the next edge of node
• depth holds the depth of in the tree under construction. This can bedetermined by the number of — before the actual name of the node in themodel file.
6.4.2 Parsing helper methods
Since parsing the tree is not trivial, there are many ways to do it, we needed alot of helper features. In this section we will briefly describe each of them, beforewe move to the next section and show how is the parsing actually accomplished.Their signatures can be seen on Listing 6.8
A brief explanation for all of these features follows below:
• as we have mentioned before we use a stack to parse the tree. When theinformation to be added to the stack is parsed we call handle_add_to_stack.We will illustrate better in the next section how exactly areRM_DECISION_TREE_STACK_ITEM objects added to the stack.
• node_depth will just count the number of vertical lines in the beginning ofthe argument that we give it and return this number.
• clean_line will give us the same string that we feed as an argument butwithout any trailing vertical lines or spaces. We call it after we haverecorded the depth.
• has_leaf will tell us if the current line in the model file has a leaf nodeon it or not. “pre::{0}.count > 0.500: False {False=14, True=0}” is anexample of a line with a leaf node.
• cleared_leaf_details will remove all traces of leaves from a given lineand will return the result. This is done so we can parse lines with leavesand lines without leaves in the same fashion. For example if we give“pre::{0}.count > 0.500: False {False=14, True=0}” as an argument,the result will be “pre::{0}.count > 0.500”.
• node_name will give us the name of the node from a line from the modelfile. For example given an argument like “pre::{0}.count > 0.500”, it willreturn “pre::{0}.count”. The argument that we give must be cleared fromleaf details.

Contract Inference Techniques - Parsing the Decision Tree 37
Listing 6.8: Eiffel : Decision tree parsing helpers
1 create_new_node (a_line: STRING)
2 −− Parses the line, creates the nodes and edges that it contains and savesthem into ‘ stack ‘.
34 handle_add_to_stack (a_name: STRING; a_depth: INTEGER; a_condition:
STRING)
5 −− adds another item in the stack making sure that the new element is added6 −− only when the top element of the stack has smaller depth. If depth is
equal7 −− just the condition is changed89 cleared_leaf_details (a_line:STRING): STRING
10 −− will delete everything after the : before the leaf value including it1112 leaf_name (a_line: STRING): STRING
13 −− extracts the leaf name from a string.1415 clean_line (a_line: STRING): STRING
16 −− removes the trailing ’|’ from the beginning of the line1718 node_depth (a_line: STRING): INTEGER
19 −− tells us how many levels deep is the node on this line2021 node_name (a_line: STRING): STRING
22 −− Extracts the node name from a rapidminer model file line2324 condition (a_line: STRING): STRING
25 −− Extracts the condition from tha rapidminder model file line2627 operator_index (a_line: STRING): INTEGER
28 −− Returns the index of the operator in this line2930 has_leaf (a_line: STRING): BOOLEAN
31 −− Tells if a line from the model file produced by RM has a leaf node in it .

Contract Inference Techniques - Parsing the Decision Tree 38
• condition is very similar to node_name, however it will return the rightside of the equation. Given “pre::{0}.count > 0.500” as an argument,condition will return “> 0.500”. The argument that we give must becleared from leaf details.
6.4.3 Parsing illustrated
In this section we will show how a tree is being parsed. We will use the examplemodel file from the previous section which we will write here again for conve-nience.
pre::{0}.islast = Falsepre::{0}.count > 0.500: False {False=14, True=0}pre::{0}.count ≤ 0.500: True {False=0, True=2}
pre::{0}.islast = True: True {False=0, True=3}

Contract Inference Techniques - Parsing the Decision Tree 39
Depth Condition Node
0 = False
pre::{0}.islast
Figure 6.3: Stack after parsing the first line of rapidminer model file
First line is: “pre::0.islast = False”Its depth is 0It has no leafThe node name is “pre::0.islast”The condition is “= False”Figure 6.3 shows the stack after the line is parsed.

Contract Inference Techniques - Parsing the Decision Tree 40
Depth Condition Node
0 = False
pre::{0}.islast
False
1 > 0.500pre::{0}.count
= False
> 0.500
Figure 6.4: Stack after parsing the second line of rapidminer model file
Second line is: “ pre::{0}.count > 0.500: False {False=14, True=0}”Its depth is 1It has a leaf, the name of the leaf is “False” a node is created with that name.The node name is “pre::0.count”The condition is “> 0.500”The top element of the stack has a depth of 0 and the new element has a depthof 1 so the new element will be added on top of the stack. It will be connectedto the previous top element with an edge holding the old top’s condition. Theleaf element parsed here will be connected to the new top element with an edgeholding its current condition. The result is on Figure 6.4.

Contract Inference Techniques - Parsing the Decision Tree 41
Depth Condition Node
0 = False
pre::{0}.islast
False
1 ≤ 0.500pre::{0}.count
= False
> 0.500True
≤ 0.500
Figure 6.5: Stack after parsing the third line of rapidminer model file
Third line is: “ pre::{0}.count ≤ 0.500: True {False=0, True=2}”Its depth is 1It has a leaf, the name of the leaf is “True” a node is created with that name.The node name is “pre::{0}.count ”The condition is “≤ 0.500”The depth of the new element is the same as the depth of the current topstack element. This means that they are the same node so only the conditionis changed. The new leaf node is connected to the current top node with thecurrent condition.

Contract Inference Techniques - Parsing the Decision Tree 42
Depth Condition Node
0 = False
pre::{0}.islast
False
pre::{0}.count= False
> 0.500True
≤ 0.500
Figure 6.6: Stack after poping the top element
Fourth line is: “pre::{0}.islast = True: True {False=0, True=3}”Its depth is 0It has a leaf, the name of the leaf is “True” a node is created with that name.The node name is “pre::{0}.islast ”The condition is “= True”The depth of the current node is less than the depth of the top node. We popthe stack until we reach a node that has depth bigger or equal or we have anempty stack(Figure 6.6). Continues...

Contract Inference Techniques - Parsing the Decision Tree 43
Depth Condition Node
0 = True
pre::{0}.islast
False
pre::{0}.count
= False
> 0.500
True
≤ 0.500
True
= True
Figure 6.7: Stack after parsing the fourth line of rapidminer model file
Fourth line is: “pre::{0}.islast = True: True {False=0, True=3}”Its depth is 0It has a leaf, the name of the leaf is “True” a node is created with that name.The node name is “pre::{0}.islast”The condition is “= True”The depth of the current node is equal to the depth of the top node which meansthey represent the same node so only the condition is changed. The leaf nodeis connected to the current top node with an edge holding this condition.

Contract Inference Techniques - Parsing the Decision Tree 44
pre::{0}.islast
False
pre::{0}.count
= False
> 0.500
True
≤ 0.500True
= True
Figure 6.8: The generated tree
The file is over, we start popping the stack until we reach the last node whichwill be the root of our tree. Figure 6.8 shows the final tree.

Contract Inference Techniques - Parsing the Linear Regression 45
Listing 6.9: Eiffel : RM LINEAR REGRESSION PARSER INTERFACE fea-tures
1 feature
2 last_linear_regression: RM_LINEAR_REGRESSION
34 parse_linear_regression
5 −− Parses the linear regression from the file located at ‘ model file path ’6 deferred
7 end
6.5 Parsing the Linear Regression
After rapidminer is finished with the execution of the linear regression learning,it generates a model file holding the linear regression that it has inferred. So inorder to transfer those results in Eiffel we needed to parse this file. We noticedthat different linear regression algorithms might have different model formatsso we needed to abstract away the interface of the parsers from their implementa-tion. That’s why we created the deferred classRM_LINEAR_REGRESSION_PARSER_INTERFACE. It holds the two main features thatevery linear regression parser must support, they can be seen on Listing 6.9.
Currently there is only one descendant of theRM_LINEAR_REGRESSION_PARSER_INTERFACE class, the concreteRM_LINEAR_REGRESSION_PARSER. It works very simply:
1. we give the constructor make the absolute path to the model file.
2. we call parse_linear_regression.
3. in the end we just take the generated RM_LINEAR_REGRESSION object fromthe last_linear_regression query.
The model file for currently the only one supported linear regression algo-rithm looks like that:
1.000 ∗ pre :: {0}.count (6.1)
+1.000 (6.2)
So it is really easy to parse: for every line we just find the first * symbol andthen try to turn the left part to a number and the right part we just keep asstring. If there is no * on the line then it means that we have reached theconstant regressor and we just parse the number and keep it.
6.6 Decision Tree and Linear Regression Classes
Currently the RM library supports two major classes of algorithms: decisiontrees and linear regressions. They are represented in the library by the classes

Contract Inference Techniques - Decision Tree and LinearRegression Classes 46
Listing 6.10: Eiffel : RM DECISION TREE NODE interface
1 is_sample_accurate: BOOLEAN
2 −− Taking this node as a root of a tree , is this tree accurate according tothe samples in the leaves?
34 classification (a_instance: HASH_TABLE [STRING, STRING]): STRING
5 −− Classication of the goal attribute given the instance ‘ a instance ’.6 −− Given a hash table with all the attributes as keys and their respective
values ,7 −− it will return the value calculated by the decision tree algorithm8 −− Key of ‘a instance’ is attribute name, value is attribute value .
RM_DECISION_TREE and RM_LINEAR_REGRESSION respectively. In this chapter wewill look carefully into their interface and their internal structures.
6.6.1 Decision Trees
RM_DECISION_TREE is the class representing a decision tree in the RM library.Its instances are created by RM_DECISION_TREE_BUILDER. Internally, the tree isrepresented by objects from RM_DECISION_TREE_NODE and RM_DECISION_TREE_EDGE
which are described below.
RM DECISION TREE NODE
Each node in the decision tree keeps three pieces of information:
• name is the name of the attribute that is represented by this node, howeverif the node is a leaf(which is determined by the is_leaf query) then name
becomes the value of the target attribute.
• edges query is a list of all the edges that go out of that node, if is_leaf istrue then edges must be empty
• samples is relevant only for leaf nodes, it holds the information about howmany tests evaluated to the current value and are there any test thatevaluated to a different value. The rapidminer format for the sampleslooks like this: True : 5, False : 0, STAY FALSE : 0
RM_DECISION_TREE has two more interesting features in its interface and theirsignature can be see on Listing 6.12.
• is_sample_accurate will tells us if for a given node X all the samples in itssubtree are accurate, this means that if we call this feature for the rootof the tree we will get if the whole tree is accurate. We have seen howsamples look above, a sample is defined as accurate if only one value inthe hash table is bigger than zero.

Contract Inference Techniques - Decision Tree and LinearRegression Classes 47
Listing 6.11: Eiffel : RM DECISION TREE EDGE interface
1 is_condition_satisfied (a_value:STRING): BOOLEAN
2 −− Calculates if ‘ a value ’ satisfies the condition(operator and value) ofthat edge.
• classification takes a hash table with the names of the attributes as keysand their values as the values. As you can recall the name of a node isactually the attribute name so for the current node it will take from thehash table the value of that node and check the conditions for all the edgesgoing out. When it finds a condition that is satisfied by the current valuein the hash table it will go down the tree. In the end the result value isthe name of the first leaf node that is encountered.
RM DECISION TREE EDGE
RM_DECISION_TREE_EDGE is in generall simpler than its node counterpart, but itagain keeps three pieces of data in it:
• node is a reference to a RM_DECISION_TREE_NODE object, it is the object towhich the edge leads to.
• operator holds the value of the operator that is part of the condition forpassing this edge.
• value holds the value that stands on the right side of operator, togetherthey form the condition for passing through this edge.
The rest of the interface for the edge class consists of only one method, itssignature can be seen on Listing 6.11. The feature is_condition_satisfied takesa string value and determines if that value satisfies the condition of the currentnode or not.
RM DECISION TREE PATH NODE
This is a faily simple class, it is used by only one feature: paths which is apart of the interface of the RM_DECISION_TREE interface. It will be covered inmore details later in this chapter, but basically the paths method return a listof all the paths from the root to each leaf node. RM_DECISION_TREE_PATH_NODE
represents a single step into the path from the root to a leaf. It doesn’t do anywork, it just holds three values:
• attribute_name holds the name of the attribute for this step.
• operator_name holds the operator for that step
• value_name holds the value for that step
In the end the attribute, operator and value form an expression that will bepart of the future contracts.

Contract Inference Techniques - Decision Tree and LinearRegression Classes 48
Listing 6.12: Eiffel : RM DECISION TREE interface
1 feature −− Access23 last_classification: STRING
4 −− Last result from the classify command.56 root: RM_DECISION_TREE_NODE
7 −− The root node of the tree.89 label_name: STRING
10 −− The name of the target attribute of that tree1112 paths: LINKED_LIST [LINKED_LIST [RM_DECISION_TREE_PATH_NODE]]
13 −− List of paths from current tree14 −− Eath inner list represents a path, the first element is the root node,15 −− the last element is a leaf node.1617 feature −− Status report1819 is_accurate: BOOLEAN
20 −− Is Current tree accurate?2122 feature −− Clasification2324 classify (a_sample: HASH_TABLE [STRING, STRING])
25 −− Use current tree to classify the instance given by ‘a sample’, storeresult in ‘ last classification ’.
26 −− Key of ‘a sample’ is attribute name, value is the value of thatattribute in ‘a sample’.
RM DECISION TREE’s Interface
The public interface of the decision tree can be seen on Listing 6.12. Most ofthe features are self explanatory or easily understood from the comment, so wewill look only into the more interesting ones.
• paths is maybe the most important feature of the decision tree, becausein the end it will give us the contract candidates. This query returns alist of all the paths from the root to each leaf node. A path is just a listof RM_DECISION_TREE_PATH_NODE objects and as we have already mentionedbefore, each RM_DECISION_TREE_PATH_NODE forms an expression that will bepart of the future contract.
• is_accurate tells us if the decision tree was constructed accurately, cur-rently there are two ways to assert that. The first way is to build thetree with validation turned on, then the validation parser will check if thetree was constructed with 100% accuracy and will set it properly. Thesecond way is to have no validation by rapidminer, but count on the sam-ples of each node. As we have already discussed in the previous section,

Contract Inference Techniques - Decision Tree and LinearRegression Classes 49
Listing 6.13: Eiffel : RM LINEAR REGRESSION interface
1 feature
2 last_regression: DOUBLE
3 −− Last regression of ‘dependent variable’ calculated by ‘ regress ’45 regress (a_regressor_values: HASH_TABLE [DOUBLE, STRING])
6 −− Calculate the value of ‘dependent variable’ based on the values7 −− of regressor variables given by ‘ a regressor values ’, and store8 −− result in ‘ last regression ’.9 require
10 a_regressor_values_valid:
11 across a_regressor_values as l_regressors all
12 l_regressors.key /~ constant_regressor and then
13 regressors.has (l_regressors.key)
14 end
is_samples_accurate is part of the interface of RM_DECISION_TREE_NODE sowe just have to call it for the root node and return the result.
• classify will take a hash table with attribute names as keys and attributevalues as values and will use the decision tree to give us the value of the tar-get attribute under the conditions in the hash table. From an implemen-tation point of view it will just use the interface of RM_DECISION_TREE_NODEand call the classification feature for the root node of the tree. Theresult is then stored and can be retrieved from the last_classification
query.
6.6.2 Linear Regression
RM_LINEAR_REGRESSION is a far simpler class than RM_DECISION_TREE, it doesn’tuse any custom external classes to structure its internal state. A linear re-gression is of the form: “dependent variable = coeficient1*regressor1 + coeffi-cient2*regressor2 + ...” and as we know that then it is very easy to understandthe internal representation of RM_LINEAR_REGRESSION. It has two data holders:
• dependent_variable is a string variable holding the name of the dependentvariable
• regressors is a hash table with the string name of the regressor as keysand the value of the coefficients as values.
The interface of RM_LINEAR_REGRESSION is also very simple, its two most impor-tant features can be seen on Listing 6.13.
The regress feature takes a hash table where each key is a name of a regressorand its corresponding value is the value of the regressor. So when we call regresswe replace the regressors names in the regressors by the values that we get asarguments and calculate the final result, which can then be accessed with thelast_regression feature.

Contract Inference Techniques - Support Classes 50
Listing 6.14: Eiffel : Supported algorithms
1 feature −− Algorithm types2 algorithm_decision_tree: STRING = "decision_tree"
3 −− Name of the default decision tree algorithm.45 algorithm_linear_regression: STRING = "linear_regression"
6 −− Name of the default linear regression algorithm.78 algorithm_decision_stump: STRING = "decision_stump"
9 −− Learns only a root node of a decision tree .1011 algorithm_chaid: STRING = "chaid"
12 −− Learns a pruned decision tree based on a chi squared attribute relevancetest .
1314 algorithm_id3: STRING = "id3"
15 −− Learns an unpruned decision tree from nominal attributes only.
Listing 6.15: Eiffel : Decision tree algorithms set
1 decision_tree_algorithms: DS_HASH_SET [STRING]
2 −− Set of the names of supported decision tree algorithms3 once
4 ...
5 end
6.7 Support Classes
There are a few classes in the RM library which only serve to provide informationfor other classes. They are described in this chapter.
6.7.1 RM CONSTANTS
RM_CONSTANTS holds a lot of constants and has a lot of service features that manyof the RM classes use.
Algorithm support
It holds all of the supported algorithms, a list of those can be seen on List-ing 6.14.
RM_CONSTANTS also have features to get whole sets of algorithms. For exampleon Listing 6.15 we can see the feature that will give us a set of all the supporteddecision tree algorithms.

Contract Inference Techniques - Support Classes 51
Listing 6.16: Eiffel : Status report features
1 does_support_missing_values(a_name: STRING): BOOLEAN
2 −− Does the algorithm with name ‘a name’ support arff files with missingvalues .
34 does_support_numeric_values(a_name: STRING): BOOLEAN
5 −− Does the algorithm with name ‘a name’ support arff files with numericvalues.
67 is_valid_algorithm_name (a_name: STRING): BOOLEAN
8 −− Does ‘a name’ represent a supported rapidminer algorithm?9
1011 is_valid_validation_code (a_code: INTEGER): BOOLEAN
12 −− Does ‘a code’ represent a supported rapidminer validation?
Status report
This class can also provides us with a lot of useful information about an algo-rithm, namely if it supports missing or numeric values. This is useful, becausewhen we prepare the information for rapidminer we need to make sure thatall the requirements for the data are met. RM_CONSTANTS also provides us withthe functionality to check if a given algorithms is currently supported. Thesefeatures are very useful when we write the preconditions of the builders, wewant to make sure that they are constructed only with supported algorithmsand validations. All these features can be seen on Listing 6.16
Placeholders
As we have already mentioned before, RM_CONSTANTS holds all the placeholdersthat are used by the RM_XML_GENERATOR and RM_SEED_XML_GENERATOR.
6.7.2 RM ENVIRONMENT
RM_ENVIRONMENT is a fairly simple deferred class, it has two concrete descen-dants: RM_ENVIRONMENT_WINDOWS and RM_ENVIRONMENT_UNIX which stand for thetwo types of systems that we currently support. A particular object fromthe RM_ENVIRONMENT family must only come from the special query method inRM_CONSTANTS called rm_environment which will handle which concrete class tobe generated for the current machine. The whole interface of RM_ENVIRONMENT ison Listing 6.17. It deals only with file paths which are different among differentsystems.

Contract Inference Techniques - Support Classes 52
Listing 6.17: Eiffel : RM ENVIRONMENT interface
1 model_file_path: STRING
2 −− the location of the model file generated by rapidminer3 deferred
4 end
56 performance_file_path: STRING
7 −− the location of the performance file generated by rapidminer if validationis active
8 deferred
9 end
1011 rapid_miner_xml_file_path: STRING
12 −− the location of the xml file needed to run rapidminer. This file tellsrapidminer what to do.
13 deferred
14 end
1516 rapid_miner_arff_file_path: STRING
17 −− the location where the arff file will be created.18 deferred
19 end
2021 rapid_miner_working_directory:STRING
22 −− where will rapidminer be executed. nothing is created here.23 deferred
24 end

Chapter 7
Results
This section reports the results of experiments that applied AutoInfer to Eiffelimplementations of several common data structures.
7.1 Experimental Setup
Table 7.1: Classes used in the experiments and their elements.Class LOC #Cmd #Qry #Pre #PostARRAY 1463 15 32 69 107HASH_TABLE 2021 14 36 49 102LINKED_QUEUE 2099 6 20 78 94LINKED_STACK 2088 9 18 78 94LINKED_SET 2352 19 37 99 101LINKED_LIST 2000 26 34 70 91Total 12023 89 177 373 589
Table 7.2: Classes used in the experiments and inferred contracts statistics.Class #Inf %Snd %Cmp %V %R %AARRAY 235 94 66 80 0 74HASH_TABLE 200 94 50 74 8 22LINKED_QUEUE 61 96 100 62 2 84LINKED_STACK 115 96 100 68 0 100LINKED_SET 294 88 68 68 2 36LINKED_LIST 378 98 84 76 2 74Total 1283 94 75 72 2 56
Selection of classes. Table 7.1 lists the Eiffel classes implementing datastructures used in the experiments; all the classes are from EiffelBase, the stan-dard Eiffel data structure library. For each class, consider its size in lines ofcode (LOC), the number of commands (#Cmd), queries (#Qry), precondi-tion (#Pre) and postcondition (#Post) clauses provided by developers.
53

Results - Results and Evaluation 54
Setup and performance. All the experiments ran on a Windows 7 ma-chine with a 2.53 GHz Intel dual-core CPU and 4 GB of memory. AutoInfer wasthe only computationally-intensive process running during the experiments.
The generation of the test suite (Section 3) ran for about 30 hours for eachclass; after the automated elimination of duplicated test cases, the final test suiteconsisted of 10 to 400 non-failing runs per command of each class. Followingthe test suite generation, the construction of the change profile (Section 4) tookanother 20–40 minutes for each class; finally, the actual contract inference phaseran for an average of 5.7 minutes per command.
7.2 Results and Evaluation
Table 7.2 summarizes the results of the contract inference experiments. The sev-enth column (#Inf) reports the total number of inferred postcondition clausesof commands. We assess the quality of the inferred contracts according to theirsoundness, completeness, and redundancy. Future work (Section 8.2) will ad-dress the limitations evidenced by the experiments.
7.2.1 Soundness
Dynamic inference techniques cannot guarantee that every validated contract issound. We manually inspected the contracts inferred to determine their sound-ness. The second column of Table 7.2 (%Snd) reports the percentage of soundcontract clauses. The percentage is quite high, and in line with the results ob-tained with other state-of-the-art dynamic inference tools for expressive speci-fication inference (see Section 8.3).
Table 7.3 breaks down the total number of inferred clauses by type of as-sertion, revealing that clauses with implications (Section 6) have the highestpercentage of unsoundness. This is the result of implications being the most sen-sitive to biased or incomplete test suites. As a representative example, considercommand merge_left (other: LINKED_LIST) of class LINKED_LIST, which mergesthe list other to the left of the cursor in the current list. During the experiments,no pair of objects of class LINKED_LIST created by the test suite contained exactlythe same elements, except for a few distinct instances of empty lists. AutoInfernoticed this accidental fact and correspondingly inferred the postcondition old
is_equal (other)implies is_empty for merge_left. This postcondition is clearlyunsound, as it is a mere reflection of an insufficiently varied test suite.
7.2.2 Completeness
Completeness addresses the question: is some contract clause missing? Foreach command c, we manually prepared a detailed postcondition πc and demon-strated it complete according to a definition introduced in previous work [27],similar to the notion of relative completeness for algebraic specifications [14].

Results - Results and Evaluation 55
Informally, the postcondition of a command is complete if it describes the effectsof the command, directly or indirectly, on every public query of the class.
We then used these manually prepared complete postconditions as a yard-stick to assess the completeness of inferred contracts: whenever the set of soundpostcondition clauses inferred by AutoInfer for a command c entails the com-plete postcondition πc, we consider the inferred contracts of c as complete aswell. The third column (%Cmp) of Table 7.2 lists the percentage of commandsfor which AutoInfer inferred a complete set of postconditions. Figures above75% on average indicate that the inferred contracts are often very expressiveand of high quality.
The table also shows that it is harder to generate complete postconditionsfor commands of classes implementing sets, arrays, and hash tables. These datastructures have a more sophisticated semantics for commands than list datatypes; in a set, for example, the effect of adding an element changes accordingto whether the element is already present in the set or not. Correspondingly,AutoInfer sometimes does not generate a sufficiently varied set of objects orsimply lacks a template needed to express a certain postcondition clause.
7.2.3 Redundancy
A postcondition clause is redundant if it can be inferred by the other clauses ofthe same command. More precisely, we introduce two notions of redundancy,of different strength. A postcondition clause is:
• A repetition if it is implied by the other postcondition clauses using onlyfirst-order reasoning and arithmetic; for example, forall i. count - 1 +
i = old count + i and count >old count are both repetitions of count=old count + 1.
• A variation if it is implied by the other postcondition clauses, assumingknowledge of all complete contracts of queries mentioned. For example,post_7 in Listing 2.1 is a variation because it is implied by the combinationof post_2 with post_3: the last element corresponds to the element atposition count, which equals old count+ 1 after executing extend; thisreasoning required knowledge of the exact contract of last.
Every repetition is a variation, while the converse does not hold in gen-eral. A variation which is not a repetition is likely to be a valuable form ofredundancy, as it explicitly expresses the effect of a command on the value ofqueries not mentioned explicitly by other clauses, and makes the postconditionself-contained.
The eleventh and twelfth columns of Table 7.2 list the (largest) percentageof postcondition clauses that are variations of the others (%V) and the fractionof variations that are also repetitions (%R). The figures suggest that most ofthe redundant clauses are still useful and relevant.
As a further datum to assess informally the value of most inferred clauses,consider the last column (%A) of Table 7.2; it lists the percentage of program-mer’s written postcondition clauses that are a repetition of those automatically

Results - Results and Evaluation 56
inferred. Given that an assertion written by programmers is certainly relevant,the abundance of inferred clauses subsuming programmer’s written ones is evi-dence of mostly useful redundancies occurring.
Table 7.3: Type and soundness of inferred contracts.Type #Inf #Snd (%)Quantification 276 271 (98%)Implication 242 220 (90%)Linear relation 49 49 (100%)Equality 716 677 (94%)

Chapter 8
Conclusions
8.1 Conclusions
The importance of specifications and the lack of them in reality boosts theeffort spent in contract inference. We demonstrate that when simple contractsare available, more complex contracts can be inferred fully automatically: For xclasses implementing standard data structures such as linked list, array, stack,queue and hash table, 75% of the complete contracts can be inferred, and thefalse positive rate is low. The contracts are inferred solely based on the anslysisof class structure and the available simple contracts, which means when givensome unknown classes, as long as those classes come with a suitable set ofqueries, which they usually do, and preferably, some simple contracts, thesetechniques will work.
The tool implementing the proposed techniques is written in Eiffel. But, itis straitforward to port the same ideas to other Object-oriented languages suchas Java and C#: For most of the frame properties and implications, the pro-posed techniques can be directly applied; for sequence-based contracts, simplecontracts need to be provided, for example, using JML in Java and the contractlibrary in C# 3.0 or later.
8.2 Future Work
Soundness of inferred contracts. Some of the inferred contracts are notsound; this happens more often with assertions involving implications. We planto identify unsound contracts by trying to automatically generate test cases thatviolate them.
More forms for contracts. Inferring contracts for programs other thandata structure implementations will require new forms for candidate assertionsbeyond universal quantifications and implications. For example, we will considerexistential quantifications and expressions based on mathematical models thatoccur frequently in class abstractions, such as the bag [36]. There are still some
57

Conclusions - Related Work 58
Listing 8.1: Eiffel : Contracts we still cannot infer
1 ARRAY.keep_head (n)
2 ensure
3 n <old count implies count = n
4 n ≥ old count implies count = old count
contracts like on Listing 8.1, which come between a decision tree and linearregression and which we still cannot infer. We will also try to figure out a wayto infer these types of contracts.
Contracts of queries. Developing inference techniques for contracts ofqueries, as opposed to commands, is particularly challenging. A query’s postcon-dition describes the result returned in terms of elementary features of the class.For example, the postcondition of query occurrences (v: G) of class LINKED_LISTmust relate the nonnegative integer returned by the query to the elements equalto v stored in the list. We plan to rely on the notion of model of a class [27] todefine a base according to which the semantics of queries can be formalized.
8.3 Related Work
Various approaches have targeted the problem of automatically inferring spec-ifications of software components; a useful classification is between static anddynamic techniques.
8.3.1 Static Techniques
Static techniques analyze the source code of a program and infer specificationelements by applying analytical techniques to the formal semantics of programelements. The correct inference of all but the simplest classes of propertiesis undecidable, hence static techniques are usually sound but incomplete, andfocus on tractable specifications.
For example, the abstract interpretation framework supports the inferenceof specifications such as interval constraints [5] or affine relations among vari-ables [21]. Other static techniques can infer extended typing information [25],light-weight annotations ensuring the absence of out-of-bound and void pointerdereferencing errors [10], sequence diagrams describing the flow of informationamong objects [29], and invariants of loops [18, 11].
8.3.2 Dynamic Techniques
Dynamic techniques summarize properties that are invariant over multiple runsof a program and suggest them as likely specification elements. The dynamicapproach is very flexible in that it is applicable even if the source code is notavailable and does not require a sophisticated analytical framework. On the

Conclusions - Related Work 59
other hand, dynamic invariants come with no guarantee of soundness or com-pleteness and their quality heavily depend on the choice of runs they summarize.Regardless of these limitations, dynamic techniques work quite well in practiceand have been deployed to infer useful specifications in various forms.
To allow a closer comparison with the techniques of the present paper, therest of this section focuses on applications of dynamic techniques to inferringspecifications of components, in particular implementations of abstract datatypes and other data structures.
Finite-State Behavioral Specifications
Behavioral specifications summarize the interface behavior of a component as afinite-state automaton: transitions constrain the sequences of commands thatcan occur and abstract a finite number of runs.
Ammons et al. [1] build probabilistic finite-state automata that characterizeorder and data dependencies among successive invocations of public routines;their technique exploits machine learning algorithms. Whaley et al. [34] comple-ment dynamic techniques with static techniques to deduce common as well asillegal call sequences; a finite-state model summarizes the combined knowledgeabout the component’s behavior.
Dallmeier et al. [7] capture the relationship between commands and queriesof a class with nondeterministic finite-state automata models. Automata statesabstract concrete object states as a collection of queries; automata transitionsare associated with commands that change the object state. Xie et al. [35] buildsimilar automata with multiple state abstractions, for example summarizing theinformation about the branch coverage achieved by a certain routine. Lorenzoliet al. [22] extend the finite-state model with information about the values ofattributes associated with each transition, and describe an extension of the k-tail learning algorithm to build such extended models from a set of runs.
Finite-state specifications are easy to read and straightforward to analyzeand even execute; on the other hand, they are usually quite coarse-grained andhence imprecise, especially to characterize exactly the effects of a command ona given object state. In this respect, algebraic specifications offer a more refinedmodel for the specification of components.
Algebraic Specifications
Algebraic specifications formalize component behavior in terms of functions onobjects and primitive sorts, and equational axioms that describe the mutualrelationship among applications of such functions [14].
Henkel et al. [15] show how to infer complex algebraic specifications ofabstract data type implementations from automatically generated test cases.Ghezzi et al. [13] generalize and abstract finite-state models by means of graph-transformation systems, whose rules correspond to equations of the algebraicspecification; their technique can build more accurate models than Henkel etal.’s when applied to Java data structure implementations.

Conclusions - Related Work 60
Algebraic specifications are quite expressive and appropriate to documentabstract data type implementations. Among their limitations, however, is thedifficulty of dealing with the frame problem; on the contrary, the techniquesof the present paper can infer frame properties of routines quite effectively.Another limitation, shared by algebraic and finite-state models, is the fact thatthe specification refers to a whole class or component and does not describe theeffects of each routine in isolation. This may hinder the integration of inferredspecifications with programming languages supporting design-by-contract in theform of user-provided annotations.
Contract Specifications
Ernst et al. [9] pioneered the usage of dynamic techniques for specification in-ference with the Daikon tool. Daikon infers likely specifications in the form ofannotations such as routine pre and postconditions.
Daikon works with a pre-defined set of annotation templates which includesimple relations among program variables and conjunctions thereof. The successof the approach has spawned a number of derivative work aimed at extendingthe technique to support more complex specifications, such as implications anddisjunctive constraints [20], or to target it to specific features or programs,such as polymorphic object-oriented languages [19] or the consistency of datastructure implementations [8].
Other work combined dynamic and static techniques, such as symbolic exe-cution [6, 30], to boost the quality of the inferred specifications and to solve theproblem of generating a set of test cases that guarantee an accurate inference.
The techniques of the present paper support several of these features with anoriginal approach that leverages the availability of simple programmer-writtencontracts and is quite effective in terms of completeness and readability of theinferred specifications.

Bibliography
[1] Glenn Ammons, Rastislav Bodık, and James R. Larus. Mining specifica-tions. In POPL, pages 4–16, 2002.
[2] http://www.cs.waikato.ac.nz/ ml/weka/arff.html.
[3] Karine Arnout, Xavier Rousselot, and Bertrand Meyer. Automatic testcase generation based on design by contract. Draft Report, 2003.
[4] Patrice Chalin. Are practitioners writing contracts? In The RODIN Book,volume 4157 of LNCS, pages 100–113, 2006.
[5] Patrick Cousot and Nicolas Halbwachs. Automatic discovery of linear re-straints among variables of a program. In POPL, pages 84–96, 1978.
[6] Christoph Csallner, Nikolai Tillmann, and Yannis Smaragdakis. DySy:Dynamic symbolic execution for invariant inference. In ICSE, pages 281–290, 2008.
[7] Valentin Dallmeier, Christian Lindig, Andrzej Wasylkowski, and AndreasZeller. Mining object behavior with ADABU. In WODA, May 2006.
[8] Brian Demsky, Michael D. Ernst, Philip J. Guo, Stephen McCamant,Jeff H. Perkins, and Martin Rinard. Inference and enforcement of datastructure consistency specifications. In ISSTA, pages 233–243, 2006.
[9] Michael D. Ernst, Jake Cockrell, William G. Griswold, and David Notkin.Dynamically discovering likely program invariants to support program evo-lution. IEEE Trans. Software Eng., 27(2):99–123, 2001.
[10] Cormac Flanagan and K. Rustan M. Leino. Houdini, an annotation as-sistant for ESC/Java. In FME, volume 2021 of LNCS, pages 500–517.Springer, 2001.
[11] Carlo A. Furia and Bertrand Meyer. Inferring loop invariants using post-conditions. In Fields of Logic and Computation, volume 6300 of LNCS.Springer, 2010.
[12] Erich Gamma, Richard Helm, Ralph Johnson, and John Vlissides. DesignPatterns. Addison-Wesley, Boston, MA, 1995.
[13] Carlo Ghezzi, Andrea Mocci, and Mattia Monga. Synthesizing intensionalbehavior models by graph transformation. In ICSE, pages 430–440, 2009.
61

[14] John V. Guttag and James J. Horning. The algebraic specification of ab-stract data types. Acta Inf., 10:27–52, 1978.
[15] Johannes Henkel, Christoph Reichenbach, and Amer Diwan. Discover-ing documentation for java container classes. IEEE Trans. Software Eng.,33(8):526–543, 2007.
[16] Manuel Oriol Bertrand Meyer Ilinca Ciupa, Andreas Leitner. Experimentalassessment of random testing for object-oriented software. In Proceedings ofthe 2007 international symposium on Software testing and analysis, 2007.
[17] Manuel Oriol Bertrand Meyer Ilinca Ciupa, Andreas Leitner. Artoo: Adap-tive random testing for objectoriented software. In Proceedings of the 30thinternational conference on Software engineering, 2008.
[18] Laura Kovacs and Andrei Voronkov. Finding loop invariants for programsover arrays using a theorem prover. In FASE, volume 5503 of LNCS, pages470–485. Springer, 2009.
[19] Nadya Kuzmina and Ruben Gamboa. Extending dynamic constraint de-tection with polymorphic analysis. In WODA, pages 57–63, 2007.
[20] Nadya Kuzmina, John Paul, Ruben Gamboa, and James Caldwell. Extend-ing dynamic constraint detection with disjunctive constraints. In WODA,pages 57–63, 2008.
[21] Francesco Logozzo. Automatic inference of class invariants. In VMCAI,volume 2937 of LNCS, pages 211–222. Springer, 2004.
[22] Davide Lorenzoli, Leonardo Mariani, and Mauro Pezze. Automatic gener-ation of software behavioral models. In ICSE, pages 501–510, 2008.
[23] Bertrand Meyer. Object-Oriented Software Construction, 2nd edition.Prentice Hall Professional Technical Reference, 1997.
[24] Bertrand Meyer, Arno Fiva, Ilinca Ciupa, Andreas Leitner, Yi Wei, andEmmanuel Stapf. Programs that test themselves. Computer, 42:46–55,2009.
[25] Robert O’Callahan and Daniel Jackson. Lackwit: A program understand-ing tool based on type inference. In ICSE, pages 338–348, 1997.
[26] Nadia Polikarpova, Ilinca Ciupa, and Bertrand Meyer. A comparative studyof programmer-written and automatically inferred contracts. In ISSTA2009, Proceedings of the 2009 International Symposium on Software Testingand Analysis, pages 93–104, Chicago, IL, USA, July 21–23, 2009.
[27] Nadia Polikarpova, Carlo A. Furia, and Bertrand Meyer. Specifyingreusable components. In VSTTE, 2010.
[28] http://rapid-i.com/content/view/181/190/.
[29] Atanas Rountev and Beth Harkness Connell. Object naming analysis forreverse-engineered sequence diagrams. In ICSE, pages 254–263, 2005.
62

[30] Nikolai Tillmann, Feng Chen, and Wolfram Schulte. Discovering likelymethod specifications. In ICFEM, volume 4260 of LNCS, pages 717–736.Springer, 2006.
[31] Yi Wei, Serge Gebhardt, Manual Oriol, and Bertrand Meyer. Satisfyingtest preconditions through guided object selection. In ICST, 2010.
[32] Yi Wei, Yu Pei, Carlo A. Furia, Lucas S. Silva, Stefan Buchholz, BertrandMeyer, and Andreas Zeller. Automated debugging of programs with con-tracts. In ISSTA, pages 61–72, 2010.
[33] http://www.cs.waikato.ac.nz/ml/weka/.
[34] John Whaley, Michael C. Martin, and Monica S. Lam. Automatic extrac-tion of object-oriented component interfaces. In ISSTA, pages 218–228,2002.
[35] Tao Xie, Evan Martin, and Hai Yuan. Automatic extraction of abstract-object-state machines from unit-test executions. In ICSE, pages 835–838,2006.
[36] Kuat Yessenov, Ruzica Piskac, and Viktor Kuncak. Collections, cardinal-ities, and relations. In VMCAI, volume 5944 of LNCS, pages 380–395.Springer, 2010.
63