advanced quantitative methods: mathematics (p)revie · 2012-01-14 · courseoutline matrixalgebra...
TRANSCRIPT

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Advanced Quantitative Methods:Mathematics (p)review
Johan A. Elkink
University College Dublin
17 January 2012
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
1 Course outline
2 Matrix algebra
3 Derivatives
4 Probabilities and probability distributions
5 Expectations and variances
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Outline
1 Course outline
2 Matrix algebra
3 Derivatives
4 Probabilities and probability distributions
5 Expectations and variances
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Introduction
Topic: advanced quantitative methods in political science.
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Introduction
Topic: advanced quantitative methods in political science.
Or, alternatively: basic econometrics, as applied in political science.
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Introduction
Topic: advanced quantitative methods in political science.
Or, alternatively: basic econometrics, as applied in political science.
Or, alternatively: linear regression and some non-linear extensions.
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Readings
Peter Kennedy (2008), A guide to econometrics. 6th ed.,Malden: Blackwell.
Damodar N. Gujarati (2009), Basic econometrics. 5th ed.,Boston: McGraw-Hill.
Julian J. Faraway (2005), Linear models with R. Baco Raton:Chapman & Hill.
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Readings
Peter Kennedy (2008), A guide to econometrics. 6th ed.,Malden: Blackwell.
Damodar N. Gujarati (2009), Basic econometrics. 5th ed.,Boston: McGraw-Hill.
Julian J. Faraway (2005), Linear models with R. Baco Raton:Chapman & Hill.
Andrew Gelman & Jennifer Hill (2007), Data analysis usingregression and multilevel/hierarchical models. Cambridge:Cambridge University Press.
William H. Greene (2003), Econometric analysis. 5th ed.,Upper Saddle River: Prentice Hall.
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Topics
1 17/1 Mathematics review2 24/1 Statistical estimators3 31/1 Ordinary Least Squares4 7/2 Hypothesis testing5 14/2 Specification, multicollinearity and heteroscedasticity6 21/2 Autocorrelation7 28/2 Time-series analysis
Study break8 20/3 Maximum Likelihood9 27/3 Limited dependent variables10 3/4 Bootstrap and simulation11 10/4 Multilevel data12 17/4 Panel data
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Frequentist vs Bayesian
Frequentist statistics interprets probability as the frequency ofoccurrance in (hypothetically) many repetitions. E.g. if we throwthis dice infinitely many times, what proportion of times would itbe heads? We can here also talk of conditional probabilities:what would this frequency be if ... and some condition follows.
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Frequentist vs Bayesian
Frequentist statistics interprets probability as the frequency ofoccurrance in (hypothetically) many repetitions. E.g. if we throwthis dice infinitely many times, what proportion of times would itbe heads? We can here also talk of conditional probabilities:what would this frequency be if ... and some condition follows.
Bayesian statistics interprets probability as a belief: if I throwthis dice, what do you think is the chance of getting heads? Wecan now talk of conditional probabilities in a different way: howwould your belief change given that ... and some condition follows.
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Frequentist vs Bayesian
Frequentist statistics interprets probability as the frequency ofoccurrance in (hypothetically) many repetitions. E.g. if we throwthis dice infinitely many times, what proportion of times would itbe heads? We can here also talk of conditional probabilities:what would this frequency be if ... and some condition follows.
Bayesian statistics interprets probability as a belief: if I throwthis dice, what do you think is the chance of getting heads? Wecan now talk of conditional probabilities in a different way: howwould your belief change given that ... and some condition follows.
This course is a course in the frequentist analysis of regressionmodels.
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Homeworks
50 % Bi-weekly homeworksdue before class the following week
50 % Replication paperdue April 29, 2011, 5 pm
No exam
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Homeworks
50 % Bi-weekly homeworksdue before class the following week
50 % Replication paperdue April 29, 2011, 5 pm
No exam
Working with others is a good idea
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Grade conversions
Homeworks UCD TCD Homeworks UCD TCD
95-100% A+ A+ 45-49% E+ D91-94% A A 37-44% E D87-90% A- A 33-36% E- D83-86% B+ B+ 0-32% F F79-82% B B75-78% B- B70-74% C+ C+66-69% C C62-65% C- C58-61% D+ C54-57% D C50-53% D- C
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Replication paper
Find replicable paper now and check whether appropriate
Contact authors asap if you need their data
See Gary King, “Publication, publication”
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Syllabus and website
Website: http://www.joselkink.net/teaching
Syllabus downloadable there
Slides and notes on website
Data for exercises on website
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Outline
1 Course outline
2 Matrix algebra
3 Derivatives
4 Probabilities and probability distributions
5 Expectations and variances
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Vectors: examples
v =
3415
w =[
3.23 1.30 7.89 1.00]
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Vectors: examples
v =
3415
w =[
3.23 1.30 7.89 1.00]
β =
β0β1β2β3β4
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Vectors: examples
v =
3415
w =[
3.23 1.30 7.89 1.00]
β =
β0β1β2β3β4
v and β are column vectors, while w is a row vector. When notspecified, assume a column vector.
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Vectors: transpose
v =
3415
v′ =[
3 4 1 5]
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Vectors: summation
v =
35913
N∑
i
vi = 3 + 5 + 9 + 1 + 3
= 21
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Vectors: addition
2316
+
6392
=
86108
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Vectors: multiplication with scalar
v =
2316
3v =
69318
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Vectors: inner product
v =
5313
w =
7681
v′w = 5 · 7 + 3 · 6 + 1 · 8 + 3 · 1 = 64
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Vectors: outer product
v =
5313
w =
7681
vw′ =
35 30 40 521 18 24 37 6 8 121 18 24 3
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Matrices: examples
M =
3 4 51 2 10 9 8
I =
1 0 0 00 1 0 00 0 1 00 0 0 1
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Matrices: examples
M =
3 4 51 2 10 9 8
I =
1 0 0 00 1 0 00 0 1 00 0 0 1
The latter is called an identity matrix and is a special type ofdiagonal matrix.
Both are square matrices.
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Matrices: transpose
X =
1 3 29 8 89 8 5
X′ =
1 9 93 8 82 8 5
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Matrices: transpose
X =
1 3 29 8 89 8 5
X′ =
1 9 93 8 82 8 5
(A′)′ = A
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Matrices: indexing
X4×3 =
x11 x12 x13x21 x22 x23x31 x32 x33x41 x42 x43
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Matrices: indexing
X4×3 =
x11 x12 x13x21 x22 x23x31 x32 x33x41 x42 x43
Always rows first, columns second.
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Matrices: indexing
X4×3 =
x11 x12 x13x21 x22 x23x31 x32 x33x41 x42 x43
Always rows first, columns second.
So Xn×k is a matrix with n rows and k columns. yn×1 is a columnvector with n elements.
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Matrices: addition
4 2 1 36 5 3 2112 4 21
3 0
+
7 8 2 0−3 −2 3 11
24 2 1 1
=
11 10 3 33 3 6 31
2512 6 31
3 1
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Matrices: addition
4 2 1 36 5 3 2112 4 21
3 0
+
7 8 2 0−3 −2 3 11
24 2 1 1
=
11 10 3 33 3 6 31
2512 6 31
3 1
(A+ B)′ = A′ + B′
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Matrices: multiplication with scalar
X =
4 2 1 36 5 3 2112 4 21
3 0
4X =
16 8 4 1224 20 12 86 16 71
3 0
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Matrices: multiplication
A =
[
6 41 3
]
B =
[
3 2 34 2 1
]
AB =
[
6 · 3 + 4 · 4 6 · 2 + 4 · 2 6 · 3 + 4 · 11 · 3 + 3 · 4 1 · 2 + 3 · 2 1 · 3 + 3 · 1
]
=
[
34 20 2215 8 6
]
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Matrices: multiplication
A =
[
6 41 3
]
B =
[
3 2 34 2 1
]
AB =
[
6 · 3 + 4 · 4 6 · 2 + 4 · 2 6 · 3 + 4 · 11 · 3 + 3 · 4 1 · 2 + 3 · 2 1 · 3 + 3 · 1
]
=
[
34 20 2215 8 6
]
(ABC)′ = C′B′A′
(AB)C = A(BC)
A(B+ C) = AB+ AC
(A+ B)C = AC+ BC
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Special matrices
Symmetric matrix A′ = A
Idempotent matrix A2 = A
Positive-definite matrix x′Ax > 0 ∀ x 6= 0Positive-semidefinite matrix x′Ax ≥ 0 ∀ x 6= 0
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Matrix rank
The rank of a matrix is the maximum number of independentcolumns or rows in the matrix. Columns of a matrix X areindependent if for any v 6= 0, Xv 6= 0
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Matrix rank
The rank of a matrix is the maximum number of independentcolumns or rows in the matrix. Columns of a matrix X areindependent if for any v 6= 0, Xv 6= 0
r(A) = r(A′) = r(A′A) = r(AA′)
r(AB) = min(r(A), r(B))
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Matrix rank: example 1
A =
3 5 12 2 11 4 2
For matrix A, the three columns are independent and r(A) = 3.There is no v 6= 0 such that Av = 0 (of course, if v = 0,Av = A0 = 0).
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Matrix rank: example 2
B =
3 5 92 2 61 4 3
For matrix B the first and the last column vectors are linearcombinations of each other: b•1 =
13b•3. At most two columns
(b•1 and b•2 or b•2 and b•3) are independent, so r(B) = 2. Wecould construct a matrix v such that Bv = 0, namelyv =
[
1 0 −13
]′
(or any v =[
α 0 −13α
]′
).
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Matrix rank: example 3
C =
3 5 1112
2 2 71 4 5
r(C) = 2. In this case, one cannot express one of the columnvectors as a linear combination of another column vector, but onecan express any of the column vectors as a linear combination ofthe two other column vectors. For example, c•3 = 3c•1 +
12c•2 and
thus when v =[
3 12 −1
]
′
, Cv = 0.
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Matrix inverse
The inverse of a matrix is the matrix one would have to multiplywith to get the identity matrix, i.e.:
A−1A = AA−1 = I
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Matrix inverse
The inverse of a matrix is the matrix one would have to multiplywith to get the identity matrix, i.e.:
A−1A = AA−1 = I
(A−1)′ = (A′)−1
(AB)−1 = B−1A−1
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Matrices: trace
The trace of a matrix is the sum of the diagonal elements.
A =
4 3 1 82 8 5 56 7 3 41 2 0 1
tr(A) = sum(diag(A)) = 4 + 8 + 3 + 1 = 16
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Outline
1 Course outline
2 Matrix algebra
3 Derivatives
4 Probabilities and probability distributions
5 Expectations and variances
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Derivatives of straight lines
0 1 2 3 4 5
01
23
45
A straight line
x
y
slope
y =1
2x + 2
dy
dx=
1
2
Johan A. Elkink math (p)review
Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
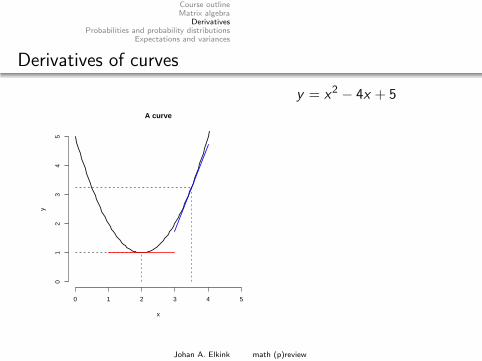
Derivatives of curves
0 1 2 3 4 5
01
23
45
A curve
x
y
y = x2 − 4x + 5
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Derivatives of curves
0 1 2 3 4 5
01
23
45
A curve
x
y
y = x2 − 4x + 5
d(axb)
dx= baxb−1
d(a+ b)
dx=
da
dx+
db
dx
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Derivatives of curves
0 1 2 3 4 5
01
23
45
A curve
x
y
y = x2 − 4x + 5
d(axb)
dx= baxb−1
d(a+ b)
dx=
da
dx+
db
dx
dy
dx= 2x − 4
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Finding location of peaks and valleys
A maximum or minimum value of a curve can be found by settingthe derivative equal to zero.
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Finding location of peaks and valleys
A maximum or minimum value of a curve can be found by settingthe derivative equal to zero.
y = x2 − 4x + 5
dy
dx= 2x − 4 = 0
2x = 4
x =4
2= 2
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Finding location of peaks and valleys
A maximum or minimum value of a curve can be found by settingthe derivative equal to zero.
y = x2 − 4x + 5
dy
dx= 2x − 4 = 0
2x = 4
x =4
2= 2
So at x = 2 we will find a (local) maximum or minimum value -the plot shows that in this case it is a minimum.
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Derivatives in regression
This concept of finding the minimum or maximum is crucial forregression analysis.
With ordinary least squares (OLS), we estimate theβ-coefficients by finding the minimum of the sum of squarederrors.
With maximum likelihood (ML), we estimate theβ-coefficients by finding the maximum point of the(log)likelihood function.
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Derivatives of matrices
The derivative of a matrix consists of the matrix containing thederivatives of each element of the original matrix.
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Derivatives of matrices
The derivative of a matrix consists of the matrix containing thederivatives of each element of the original matrix.
M =
x2 2x 32x + 4 3x3 2x
3 2 4x
dM
dx=
2x 2 02 9x2 20 0 4
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Derivatives of matrices
d(v′x)
dx= v
d(x′Ax)
dx= (A+ A′)x
d(Bx)
dx= B
d2(x′Ax)
dxdx′= A+ A′
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Outline
1 Course outline
2 Matrix algebra
3 Derivatives
4 Probabilities and probability distributions
5 Expectations and variances
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Probabilities: definition
Frequentist definition:
P(x) = limn→∞
f (x)
n,
where P is the probability, n the number of trials and f thefrequency of event x occurring.
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Probabilities: properties
For event E in sample space S :
0 ≤ P(E ) ≤ 1
P(S) = 1
P(¬E ) = 1− P(E )
P(E1 ∪ E2) = P(E1) + P(E2) if E1 and E2 are mutually exclusive
A sample space is the set of all possible outcomes, while an eventis a specific subset of the sample space.
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Conditional probability
P(E1|E2) denotes the probability of event E1 happening, given thatevent E2 occurred.
If P(E1|E2) = P(E1) then E1 and E2 are independent events.
Johan A. Elkink math (p)review
Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
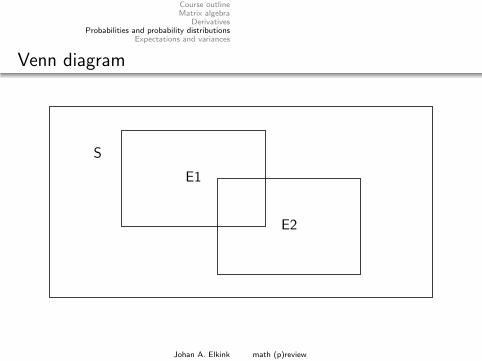
Venn diagram
E1
E2
S
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Venn diagram
E1
E2
S
P(E1)
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Venn diagram
E1
E2
E1
S
P(E1 ∪ E2)
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Venn diagram
E1
E2
S
P(E1 ∩ E2)
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Conditional probability
E1
E2
S
P(E1|E2) =P(E1∩E2)P(E2)
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Bayes’ theorem
P(E1|E2) =P(E1 ∩ E2)
P(E2)
P(E2|E1) =P(E1 ∩ E2)
P(E1)
therefore:
P(E1 ∩ E2) = P(E1|E2) · P(E2)
P(E1 ∩ E2) = P(E2|E1) · P(E1)
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Bayes’ theorem
P(E1|E2) =P(E1 ∩ E2)
P(E2)
=P(E2|E1) · P(E1)
P(E2)
=P(E2|E1) · P(E1)
P(E2|E1) · P(E1) + P(E2|¬E1) · P(¬E1)
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Bayes’ theorem
P(E1|E2) =P(E1 ∩ E2)
P(E2)
=P(E2|E1) · P(E1)
P(E2)
=P(E2|E1) · P(E1)
P(E2|E1) · P(E1) + P(E2|¬E1) · P(¬E1)
Note that while Bayesian inference is based on Bayes’ theorem, thetheorem itself holds regardless of your definition of probability.
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Probability distribution
1 2 3 4 5 6
Probability distribution of a dice
E
P(E
)
0.0
0.2
0.4
0.6
0.8
1.0
A probability distribution of adiscrete variable presents theprobabilities for each possibleoutcome.
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Probability distribution
1 2 3 4 5 6
Probability distribution of a dice
E
P(E
)
0.0
0.2
0.4
0.6
0.8
1.0
A probability distribution of adiscrete variable presents theprobabilities for each possibleoutcome.
Because P(S) = 1, the bars addup to 1.
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Probability distribution
0 500000 1000000 1500000 2000000 2500000
0e+
002e
−07
4e−
076e
−07
8e−
07
Probability density of a vote
FF vote
dens
ity o
f P
A probability distribution of acontinuous variable presents theprobability density for eachpossible outcome. The surfaceunder the plot represents theprobability of the outcome beingwithin a particular range.
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Probability distribution
0 500000 1000000 1500000 2000000 2500000
0e+
002e
−07
4e−
076e
−07
8e−
07
Probability density of a vote
FF vote
dens
ity o
f P
A probability distribution of acontinuous variable presents theprobability density for eachpossible outcome. The surfaceunder the plot represents theprobability of the outcome beingwithin a particular range.
Because P(S) = 1, the surfaceunder the entire plot is 1.
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Outline
1 Course outline
2 Matrix algebra
3 Derivatives
4 Probabilities and probability distributions
5 Expectations and variances
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Expected value
The expected value of a random variable x is:
E (x) =N∑
i
P(xi ) · xi ,
whereby N is the total number of possible outcomes in S .
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Expected value
The expected value of a random variable x is:
E (x) =N∑
i
P(xi ) · xi ,
whereby N is the total number of possible outcomes in S .
The expected value is the mean (µ) of a random variable (not tobe confused with the mean of a particular set of observations).
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Moments
moments are E (x)n, n = 1, 2, ...
So µx is the first moment of x
central moments are E (x − E (x))n, n = 1, 2, ...
absolute moments are E (|x |)n, n = 1, 2, ...
absolute central moments are E (|x − E (x)|)n, n = 1, 2, ...
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Variance
The second central moment is called the variance, so:
var(x) = E (x − E (x))2 = E (x − µx)2
=
N∑
i
P(xi ) · (xi − E (x))2
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Variance
The second central moment is called the variance, so:
var(x) = E (x − E (x))2 = E (x − µx)2
=
N∑
i
P(xi ) · (xi − E (x))2
The standard deviation is the square root of the variance:
sd(x) =√
var(x) =√
E (x − E (x))2
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Covariance
The covariance of two random variables x and y is defined as:
cov(x , y) = E [(x − E (x))(y − E (y))]
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Covariance
The covariance of two random variables x and y is defined as:
cov(x , y) = E [(x − E (x))(y − E (y))]
If x and y are independent of each other, cov(x , y) = 0.
Johan A. Elkink math (p)review

Course outlineMatrix algebra
DerivativesProbabilities and probability distributions
Expectations and variances
Variance of a sum
var(x + y) = var(x) + var(y) + 2cov(x , y)
var(x − y) = var(x) + var(y)− 2cov(x , y)
Johan A. Elkink math (p)review