adaptation techniques in automatic speech recognition tor andré myrvoll telektronikk 99(2), issue...
TRANSCRIPT

Adaptation Techniques in Automatic Speech
Recognition
Tor André MyrvollTelektronikk 99(2), Issue on Spoken
Language Technology in Telecommunications, 2003.

Goal and Objective
Make ASR robust to speaker and environmental variability.
Model adaptation: Automatically adapt a HMM using limited but representative new data to improve performance.
Train ASRs for applications w/ insufficient data.

What Do We Have/Adapt?
A HMM based ASR trained in the usual manner.
The output probability is parameterized by GMMs.
No improvement when adapting state transition probabilities and mixture weights.
Difficult to estimate robustly. Mixture means can be adapted “optimally”
and proven useful.

Adaptation Principles
Main Assumption: Original model is “good enough”, model adaptation can’t be re-training!

Offline Vs. Online
If possible offline (performance uncompromised by computational reasons).
Decode the adaptation speech data based on current model.
Use this to estimate the “speaker-dependent” model’s statistics.

Online Adaptation Using Prior Evolution. Present posterior
is the next prior.
ii
QQ KK
iiii
ii
iiii
iiiii
iiiiiii
iii
iiiiiii
WOp
WOpWKQOp
WOp
OWpWOp
WOpWOOp
WOpWOpWOOp
WOOp
WOpWOOpWOp
ˆ|
ˆ,|,ˆ|,,
ˆ|
,ˆ|,ˆ|
ˆ,ˆ,|
ˆ,ˆ,|,ˆ,|
ˆ,,
,ˆ,,ˆ,|ˆ,|
11
11
11
11
11
111
1
11
111
111
1
11
1
11
111
111
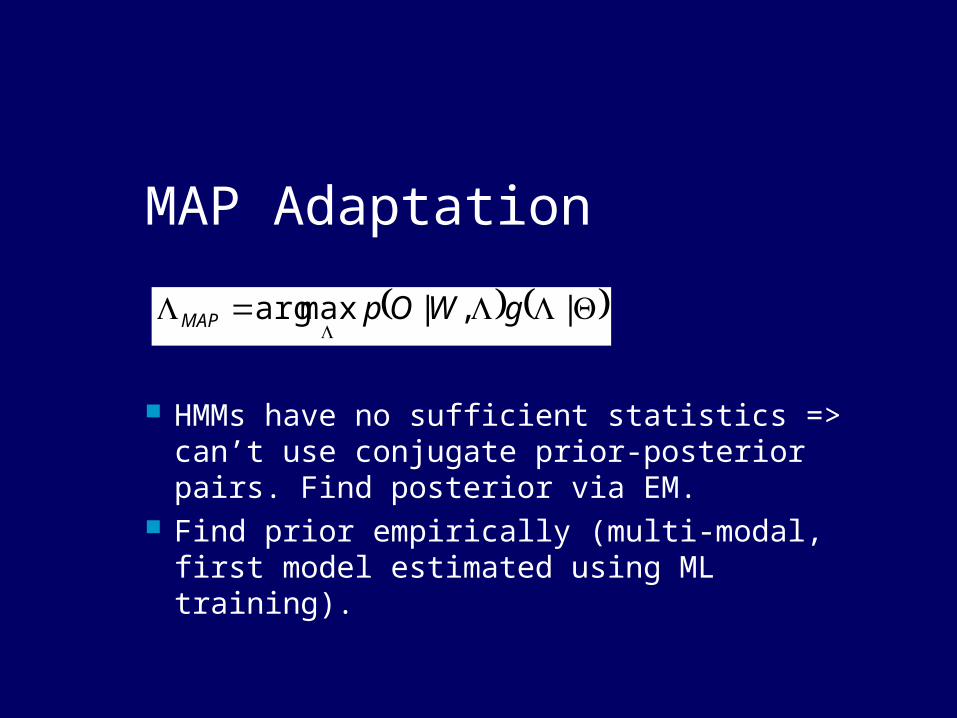
MAP Adaptation
HMMs have no sufficient statistics => can’t use conjugate prior-posterior pairs. Find posterior via EM.
Find prior empirically (multi-modal, first model estimated using ML training).
|,|maxarg gWOpMAP

EMAP
All phonemes in every context don’t occur in adaptation data; Need to store correlations between variables.
EMAP only considers correlation between mean vectors under jointly Gaussian assumption.
For large model sizes, share means across models.
TES 000~~~~

Transformation Based Model Adaptation
ML
MAP
WTOp SIML ,|maxarg
|,|maxarg gWTOp SIMAP
Estimate a transform T parameterized by .

Bias, Affine and Nonlinear Transformations ML estimation of
bias. Affine
transformation. Nonlinear
transformation ( may be a neural network).
mrm b̂
mrmmrm
mrmmrm
AA
bA
ˆ
ˆ
mm g ˆ

MLLR
mmΝxbAxxf ,~;
bA W
mm W ˆ
mmTmm BHB ˆˆ
W,,|maxargˆ WOpWW
Apply separate transformations to different parts of the model (HEAdapt in HTK).

SMAP
),(~
,0~
2/1
Ny
INy
xy
mt
mt
mtmt
tmmm
mm
)(ˆ
ˆ2/12/1
2/1
No mismatch
Mismatch
and estimated by usual ML methods on adaptation data.
Model the mismatch between the SI model (x) and the test environment.

Adaptive Training
Gender dependent model selection VTLN (in HTK using WARPFREQ)

Speaker Adaptive Training
Assumption: There exists a compact model (c), which relates to all speaker-dependent model via an affine transformation T (~MLLR). The model and the transformation are found using EM.
rCrr
R
rTC WTOpT ,|maxarg, ,
1,

Cluster Adaptive Training
Group speakers in training set into clusters. Now find the cluster closest to the test speaker.
Use Canonical Models bM
M
rmm
Cmm
.....1
m

Eigenvoices
Similar to Cluster Adaptive Training. Concatenate means from ‘R’ speaker
dependent model. Perform PCA on the resulting vector. Store K << R eigenvoice vectors.
Form a vector of means from the SI model too. Given a new speaker, the mean is a linear
combination of SI vector and eigenvoice vector.

Summary
2 major approaches: MAP (&EMAP) and MLLR.
MAP needs more data (use of a simple prior) than MLLR. MAP --> SD model.
Adaptive training is gaining popularity. For mobile applications, complexity
and memory are major concerns.