3d images search benchmark by:michael gustus anat paskin supervisor:george leifman
Post on 20-Dec-2015
223 views
TRANSCRIPT

3D Images Search Benchmark
By: Michael GustusAnat Paskin
Supervisor: George Leifman

Introduction

Introduction
There are numerous algorithms There are numerous algorithms for determining similarity for determining similarity between 3-D objects.between 3-D objects.
Those output a Numeric distance Those output a Numeric distance between two objects as an index between two objects as an index of similarity.of similarity.

Introduction
We have:We have:– Database partitioned into classes of objects Database partitioned into classes of objects
(such as plains, cars, trees etc.).(such as plains, cars, trees etc.).
We receive:We receive:– Algorithms for assessing similarity between Algorithms for assessing similarity between
any two objects.any two objects.
The system should evaluate how The system should evaluate how suitable the algorithm is to be used for suitable the algorithm is to be used for the task of classifying objects the task of classifying objects according to those classes. according to those classes.
Problem Definition

Algorithm Designers’ Difficulties

Introduction
CHAIRS CLASS exampleCHAIRS CLASS example

Difficulties
The “CHAIRS CLASS”.The “CHAIRS CLASS”.
• Does computer knows that these Does computer knows that these images are chairs? images are chairs?
• Can he tell us that they look alike? Can he tell us that they look alike? • How good can computer pick out the How good can computer pick out the
others, if we will give him one of them?others, if we will give him one of them?
These are the tasks that we will These are the tasks that we will measure for different algorithmsmeasure for different algorithmsand give them an evaluation. and give them an evaluation.

Difficulties
PLANTS CLASS examplePLANTS CLASS example

Difficulties
Finding similar 3D object in a large Finding similar 3D object in a large database of 3D objects:database of 3D objects:
• 3D objects are described only by their 3D objects are described only by their surfaces.surfaces.
• No information at all about what the object No information at all about what the object represents. Is the object an airplane, a represents. Is the object an airplane, a person or a ship???person or a ship???
• Objects have different spatial orientation: Objects have different spatial orientation: objects might be flipped, rotated, objects might be flipped, rotated, translated and even scaled up or down. translated and even scaled up or down. There is no information or indication of that There is no information or indication of that in the objects representation.in the objects representation.

Benchmarking Difficulties

Difficulties
• The system should evaluate how The system should evaluate how suitable the algorithm is to be used for suitable the algorithm is to be used for the task of classifying objects the task of classifying objects according to those classes.according to those classes.
• This concept is rather hard to define This concept is rather hard to define precisely, since there are several precisely, since there are several quality factors to consider such as quality factors to consider such as accuracy, speed, adjustment to user’s accuracy, speed, adjustment to user’s needs etc. It’s hard to systematically needs etc. It’s hard to systematically determine their relative importance, determine their relative importance, and give each a quantative measure.and give each a quantative measure.

Difficulties
For example:For example:• Some requirements from a Some requirements from a
"good" similarity algorithm would "good" similarity algorithm would be invariance under (rigid be invariance under (rigid transformations) scaling, rotation transformations) scaling, rotation and translation, low sensitivity to and translation, low sensitivity to small perturbations, sampling small perturbations, sampling resolution, etc. (robustness).resolution, etc. (robustness).

Difficulties
• Some times objects from the same class look very different (or vise versa, such as pens and rockets). This inserts noise in to the classification process.

Goals

Goals
• Our main goal is to find an “objective” Our main goal is to find an “objective” method of evaluation that will rank method of evaluation that will rank search algorithms by their “search search algorithms by their “search ability”. ability”.
• The secondary goal is to find a The secondary goal is to find a test/tests that "successfully" capture test/tests that "successfully" capture the term of "search ability".the term of "search ability".

Goals
So, what's the innovation ?So, what's the innovation ?
• In this project we will examine several In this project we will examine several different benchmarking methods on a fairly different benchmarking methods on a fairly large database (about 1600 samples and a few large database (about 1600 samples and a few dozens of classes).dozens of classes).
• We will run the benchmarks on the "Sphere We will run the benchmarks on the "Sphere Algorithm" (only for an example) on a Algorithm" (only for an example) on a database not specifically designed for any database not specifically designed for any algorithm.algorithm.
• So the system should be fairly objective in So the system should be fairly objective in benchmarking 3D comparison algorithms.benchmarking 3D comparison algorithms.

Goals
As to the second goal, we have As to the second goal, we have some benchmarking algorithms some benchmarking algorithms such as:such as:– well known : “First/Second tier”, well known : “First/Second tier”,
“Nearest Neighbor” etc.“Nearest Neighbor” etc.– based on innovative ideas, such as: based on innovative ideas, such as:
“Decay test“.“Decay test“.– and two tests of our own: one of and two tests of our own: one of
them, “Best First" tries to capture a them, “Best First" tries to capture a slightly different concept of slightly different concept of "classification ability” rather"classification ability” ratherthan "search ability".than "search ability".

Implementation

Implementation
Server side:• The Benchmarking program runs on a The Benchmarking program runs on a
server. It "receives an algorithm", tests server. It "receives an algorithm", tests it using the method described later, it using the method described later, and records the results for later and records the results for later download by clients.download by clients.
Client side:• The User should implement his The User should implement his
algorithm as a Dynamically Linked algorithm as a Dynamically Linked Library (.dll) in which he provides us Library (.dll) in which he provides us interface functions.interface functions.
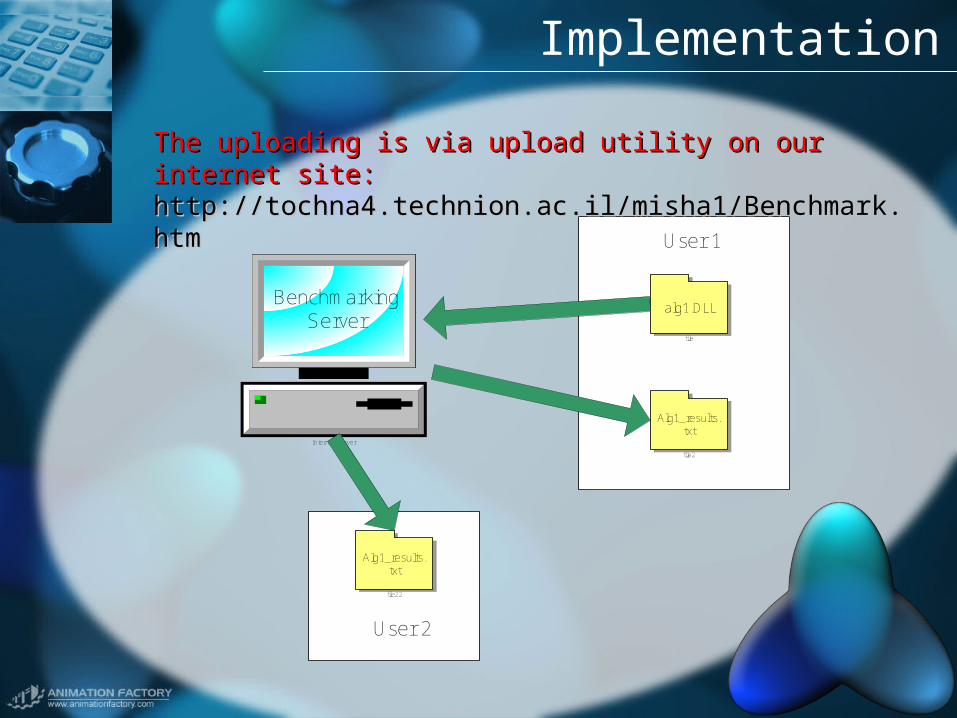
Implementation
Internet Server
BenchmarkingServer
User 1
file
alg1.DLL
file2
Alg1_results.txt
User 2
file22
Alg1_results.txt
The uploading is via upload utility on our internet site: The uploading is via upload utility on our internet site: http://tochna4.technion.ac.il/misha1/Benchmark.htmhttp://tochna4.technion.ac.il/misha1/Benchmark.htm

Implementation
The advantage of using a DLL:The advantage of using a DLL:1.1. Is mostly because it’s the most Is mostly because it’s the most
suitable way to implement an suitable way to implement an ADT (very generic).ADT (very generic).
2.2. It provides full copyrights It provides full copyrights protection to the algorithm protection to the algorithm author.author.
3.3. It is supported by every MS It is supported by every MS Windows platform. Windows platform.
4.4. There is no need to recompile, There is no need to recompile, the linkage is done in runtime.the linkage is done in runtime.

Our Method of testing

Our Method of testing
We've collected a database of We've collected a database of ~1600 images, divided into a few ~1600 images, divided into a few dozens of classes. All the tests dozens of classes. All the tests we've designed rely on the we've designed rely on the method method search(i)search(i), which calls the , which calls the algorithm on image algorithm on image ii , for each , for each image image jj in the database, and in the database, and orders the results by increasing orders the results by increasing "estimated distance" the "estimated distance" the algorithm produced. algorithm produced.

Our Method of testing
All tests we've designed rely All tests we've designed rely only on this ordering, and on only on this ordering, and on the class each the class each jj actually actually belongs to, and don't utilize belongs to, and don't utilize the distances themselves. the distances themselves.
1
0
Distance toimage i
Other images

Our Method of testing
The result for each element The result for each element ii is a is a number in [0..1].number in [0..1].(0 - worst performance, 1 - best performance)(0 - worst performance, 1 - best performance)
It attempts to reflect how well the test It attempts to reflect how well the test did for the object by it's criteria. To did for the object by it's criteria. To evaluate the algorithm's overall evaluate the algorithm's overall performance it's reasonable to performance it's reasonable to average over all the elements in the average over all the elements in the database (possibly a weighted database (possibly a weighted average, by class sizes).average, by class sizes).All but one tests use this method. All but one tests use this method.

Benchmark Tests

Benchmark Tests
Partial success
Test DescriptionThe Test has a parameter 0 < Frac <= 1. For each element i in a class, let it’s class be of size Si , scan the result, and count how many element are encountered until the Frac*Si elements of i’s class are seen (denote it n). The result for i in this search is
iS
iS
n
SFrac i*
The overall Test result is an average over all i’s in the database.

Benchmark Tests
MotivationThe test tries to grasp the concept of “success density”, that is, what is the density of correct results on different scales, as described in the test. Frac indicates the scale we are interested in.

Benchmark Tests
)2___'(log
)()(
searchinpositionsj
iclassjclassR
base
ij
Gradual decay
Test DescriptionFor each i in database, scan the test results, for each
element j in the result, compute Let Ci be the size of i’s class. The result for i is:
iC
j base
resultjj
j
R
2 )(log1
(That is, normalize by the best possible result). The overall Result is the average over all ’s.

Benchmark Tests
MotivationThe value of each correct result is estimated according to it’s position in the search, the further a result is located, the less it’s worth, since users are “impatient”, and are less likely to examine results far away. It’s possible to make the base a parameter that changes in proportionproportion to “patience factor”.

Benchmark Tests
Nearest neighborTest DescriptionFor each i in database, check whether the second result is of i’s class. The final result is an average over all i’s in database. It’s also possible to average by classes (regardless of size, which is actually possible in any other test).
MotivationThe first result in any reasonable algorithm is the object itself, so it’s not a good quality indication to count it. It checks whether the second result is of the same class, used whenIt’s important that the element considered best isactually from the same class.

Benchmark Tests
First/Second Tier
First TierFor each element, test the success percentage for the first k elements, where k is the size of the element’s class. Final result is the average of all results over the elements in the database. It’s also possible to average by classes.
* also known ( in data retrieval terminology) as recall.
Second TierSame as First Tier, but works with k=2*(size of e’s class for each element we search).

Benchmark Tests
Best FirstTest description:For each class i, run First Tier on each element in the class. Find the best result among them, Best_i, then average over the classes.
Motivation:Till Now We’ve considered tests that do some kind of evaluation on each element and then averages on all element (possibly weighted by class sizes). Such measures don’t necessarily reflect how well this algorithm can be used as a classifier.That is, given some new element , that belongs to one of the classes in the database, use the database and the algorithm to determine to which class the new element belongs.

The user interface

The user interface
• The user interface is rather The user interface is rather minimalistic.minimalistic.
• Benchmarking of an Benchmarking of an algorithm requires only few algorithm requires only few basic functions to interface basic functions to interface with the system:with the system:

The user interface
this function processes the this function processes the input off file, and creates a input off file, and creates a “signature” that holds all the “signature” that holds all the information the algorithm information the algorithm needs about the object, and needs about the object, and returns it’s start address as returns it’s start address as void*void*..
void* CreateSignature(File smp.off);void* CreateSignature(File smp.off);

The user interface
gets two signatures gets two signatures previously created by it, and previously created by it, and returns the computed returns the computed “distance” between them. “distance” between them.
int CompareSignature(void* sig1, void* sig2);int CompareSignature(void* sig1, void* sig2);

The user interface
The system also supports benchmarking with feedback, if the benchmarked algorithm supports this version.In this case the search runs repeatedly, and for each iterationthe algorithm gets info of which signatures of the first few were correct (in the objects’ class),and which weren’t.
int CompareSignatureWithFeedBack(…);int CompareSignatureWithFeedBack(…);

Results

Results

Conclusions

Results
Nearest Neighbor:As expected for large enough
(10+) the results are high. For small classes the results are around 0, unless there is very high similarity in the class. Another element is likely to get a higher grade than all others in class.