12d.1 two example parallel programs using mpi unc-wilmington, c. ferner, 2007 mar 209, 2007
Post on 21-Dec-2015
213 views
TRANSCRIPT

12d.1
Two Example Parallel Programs using MPI
UNC-Wilmington, C. Ferner, 2007 Mar 209, 2007

12d.2
Matrix Multiplication• Matrices are multiplied together using the
dot product of each row of the first matrix with each column of the second matrix
* =
A B C

12d.3
Matrix Multiplication
• For each value at row i and column j, the result is the dot product of the ith row from A and the jth column from B:
1
0,,, *
N
kjkkiji BAC

12d.4
Matrix Multiplication• For each row i from [0..N-1] and each
column j from [0..N-1] the value for position [i][j] of the resulting matrix is computed:
for (i = 0; i < N; i++) for (j = 0; j < N; j++) { C[i][j] = 0; for (k = 0; k < N; j++) C[i][j] += A[i][k] * B[k][j]; }

12d.5
Matrix Multiplication• This can be implemented
on multiple processors where each processor is responsible for computing a different set of rows in the final matrix
• As long as each processor has the parts of the A and B matrix, they can do this without communication
C

12d.6
Matrix Multiplication• If there are N rows and P processors,
then each processor is responsible for N/P rows.
• Each processor is responsible for the rows from my_rank * N/P up to (but excluding) (my_rank + 1) * N/P
my_rank = 0
my_rank = 1
my_rank = 2
0 * N/P
1 * N/P
2 * N/P
3 * N/P
{{{

12d.7
Matrix Multiplication• This is coded as:
for (i = 0 + my_rank * N/P; i < 0 + (my_rank + 1) * N/P; i++) for (j = 0; j < N; j++) { C[i][j] = 0; for (k = 0; k < N; j++) C[i][j] += A[i][k] * B[k][j]; }

12d.8
Matrix Multiplication• One Problem: What if N/P is not an
integer? • The last processor has fewer than N/P
rows for which it is responsible.• The code on the previous slide will cause
the last processors (or last couple of processors) to compute beyond the last row of the matrix

12d.9
Matrix Multiplication• This is dealt with as follows:
blksz = (int) ceil((float) N / P);
for (i = 0 + my_rank * blksz; i < min(N, 0 + (my_rank + 1) * blksz); i++) for (j = 0; j < N; j++) { C[i][j] = 0; for (k = 0; k < N; j++) C[i][j] += A[i][k] * B[k][j]; }

12d.10
Matrix Multiplication• For example suppose N=13 and P=4.
Then:
blksz = ceiling(13/4) = 4
Processor 0 : i = [0*4..1*4) = [0..4)Processor 1 : i = [1*4..2*4) = [4..8)Processor 2 : i = [2*4..3*4) = [8..12)Processor 3 : i = [3*4..min(13,4*4))=[12..13)

12d.11
Matrix Multiplication• The assignment deals with the parallel
execution of matrix multiplication

12d.12
Numerical Integration
• Suppose we have a non-negative, continuous function f and we want to compute the integral of f from a to b:
a b
y
x
xf
dxxfb
a

12d.13
Numerical Integration
• We can approximate the integral by dividing the area into trapezoids and summing the area of the trapezoids
a b
y
x
xf

12d.14
Numerical Integration
• If we use equal width partitions, then each partition is h=(a+b)/n
a b
y
x
xf
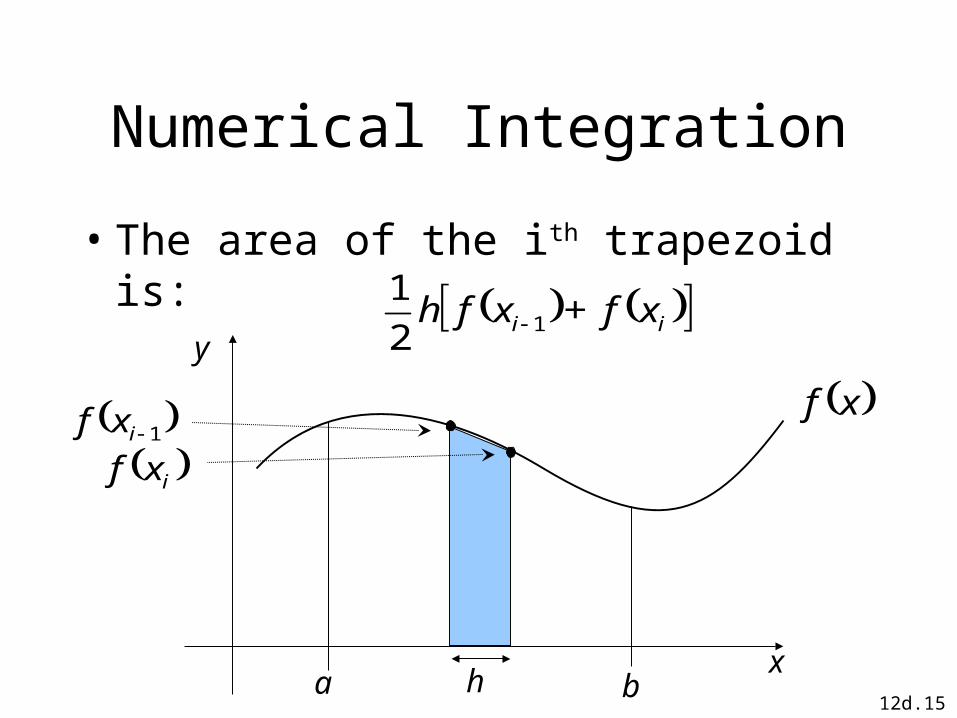
12d.15
Numerical Integration
• The area of the ith trapezoid is:
a b
y
x
xf
h
1ixf
ixf
ii xf+xfh 12
1

12d.16
Numerical Integration
• The area for all trapezoids is: ...
2
1
2
12110 +xf+xfh+xf+xfh
nn xf+xfh+ 12
1...
nxf++xf+xf+xfh
= ...222 210
hxf++xf+xf+xf+xf= nn 1210 ...2/2/

12d.17
Numerical Integration Sequential program
double f(double x);
main (int argc, char *argv[])
{
int N, i;
double a, b, h, x, integral;
char *usage = "Usage: %s a b N \n";
double elapsed_time;
struct timeval tv1, tv2;

12d.18
Numerical Integration Sequential program
if (argc < 4) {
fprintf (stderr, usage, argv[0]);
return -1;
}
a = atof(argv[1]);
b = atof(argv[2]);
N = atoi(argv[3]);

12d.19
Numerical Integration Sequential program
gettimeofday(&tv1, NULL);
h = (b - a) / N;
integral = (f(a) + f(b))/2.0;
x = a + h;
for (i = 1; i < N; i++) {
integral += f(x);
x += h;
}
integral = integral*h;
gettimeofday(&tv2, NULL);

12d.20
Numerical Integration Sequential program
elapsed_time = (tv2.tv_sec - tv1.tv_sec) +
((tv2.tv_usec - tv1.tv_usec) / 1000000.0);
printf ("elapsed_time=\t%lf seconds\n",
elapsed_time);
printf ("With N = %d trapezoids, \n", N);
printf ("estimate of integral from %f to %f = %f\n", N, a, b, integral);
}

12d.21
Numerical Integration Sequential program
double f(double x)
{
return 6*x*x - 5*x;
}

12d.22
Numerical Integration Sequential program
$ ./integ 1 3 10000
a = 1.000000, b = 3.000000, N = 10000
elapsed_time= 0.000567 seconds
With N = 10000 trapezoids,
estimate of integral from 1.000000 to 3.000000 = 32.000000

12d.23
Numerical Integration Parallel program
• Each processor will be responsible for computing the area of a subset of trapezoids
a b
y
x
xf{
P0
{
P1
{P
2

12d.24
Numerical Integration Parallel program
double f (double x);
int main(int argc, char *argv[])
{
int N, P, mypid, blksz, i;
double a, b, h, x, integral, localA, localB,
total;
char *usage = "Usage: %s a b N \n";
double elapsed_time;
struct timeval tv1, tv2;
int abort = 0;

12d.25
Numerical Integration Parallel program
a = atof(argv[1]);
b = atof(argv[2]);
N = atoi(argv[3]);
MPI_Bcast (&a, 1, MPI_DOUBLE, 0,
MPI_COMM_WORLD);
MPI_Bcast (&b, 1, MPI_DOUBLE, 0,
MPI_COMM_WORLD);
MPI_Bcast (&N, 1, MPI_INT, 0, MPI_COMM_WORLD);
h = (b - a) / N;

12d.26
Numerical Integration Parallel program
blksz = (int) ceil ( ((float) N) / P);
localA = a + mypid * blksz * h;
localB = min(b, a + (mypid + 1) * blksz * h);
integral = (f(localA) + f(localB))/2.0;
x = localA + h;
for (i = 1; i < blksz && x <= localB; i++) {
integral += f(x);
x += h;
}
integral = integral*h;

12d.27
Numerical Integration Parallel program
MPI_Reduce (&integral, &total, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD);
if (mypid == 0) printf ("integral = %f\n", total);}
float f(float x)
{
return 6*x*x - 5*x;
}

12d.28
Numerical Integration Parallel program
$ mpicc mpiInteg.c -o mpiInteg -lm$ mpirun -nolocal -np 4 mpiInteg 1 3 10000
elapsed_time= 0.001416 secondsintegral = 32.000000