1 the texture benchmark: measuring performance of text queries on a relational dbms vuk ercegovac...
TRANSCRIPT

1
The TEXTURE Benchmark: Measuring Performance of Text Queries on a Relational DBMS
Vuk Ercegovac
David J. DeWitt
Raghu Ramakrishnan
2
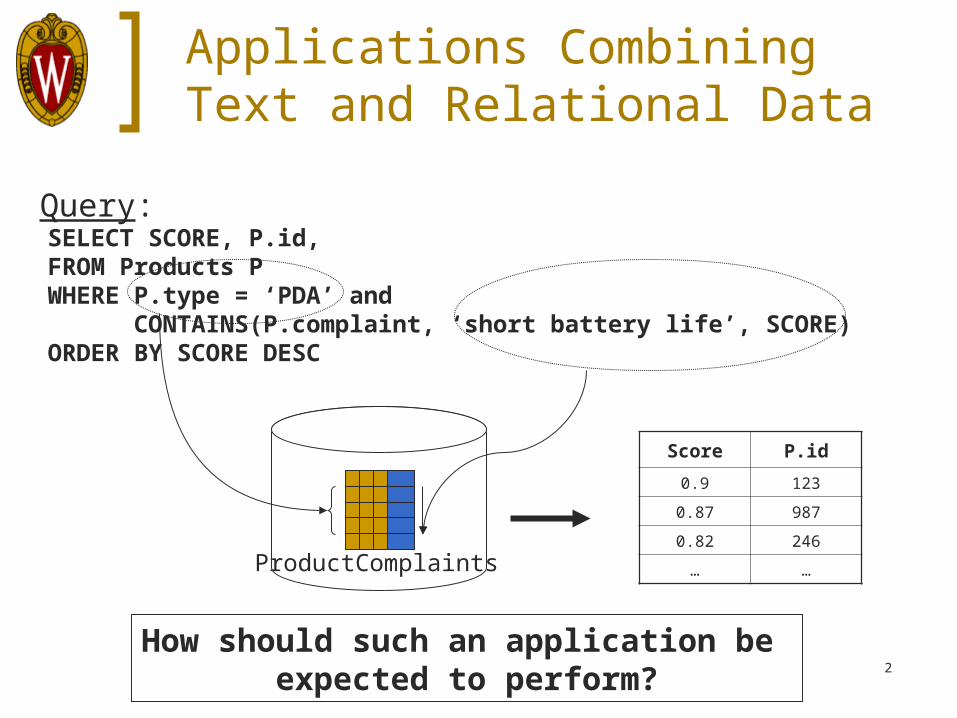
Applications Combining Text and Relational Data
Query:
How should such an application be expected to perform?
Score P.id
0.9 123
0.87 987
0.82 246
… …
SELECT SCORE, P.id,FROM Products PWHERE P.type = ‘PDA’ and CONTAINS(P.complaint, ‘short battery life’, SCORE)ORDER BY SCORE DESC
ProductComplaints

3
Possibilities for Benchmarking
Measure
WorkloadQuality
Response Time/
Throughput
Relational N/ATPC[3], AS3AP[10],
Set Query[8]
Text TREC[2], VLC2[1] FTDR[4], VLC2[1]
Relational + Text
?? TEXTURE
1. http://es.csiro.au/TRECWeb/vlc2info.html2. http://trec.nist.gov3. http://www.tpc.org4. S. DeFazio, Full-text Document Retrieval Benchmark, chapter 8. Morgan Kaufman, 2 edition, 19938. P. O’Neil. The Set Query Benchmark. The Benchmark Handbook, 199110. C. Turbyfill, C. Orji, and D. Bitton. AS3AP- a Comparative Relational Database Benchmark. IEEE Compcon, 1989.

4
Contributions of TEXTURE
Design micro-benchmark to compare response time using a mixed relational + text query workload
Develop TextGen to synthetically grow a text collection given a real text collection
Evaluate TEXTURE on 3 commercial systems

5
Why a Micro-benchmark Design?
A fine level of control for experiments is needed to differentiate effects due to: How text data is stored How documents are assigned a score Optimizer decisions

6
Why use Synthetic Text?
Allows for systematic scale-up User’s current data set may be too small
Users may be more willing to share synthetic data
Measurements on synthetic data shown empirically by us to be close to same measurements on real data

7
A Note on Quality
Measuring quality is important! Easy to quickly return poor results
We assume that the three commercial systems strive for high quality results Some participated at TREC Large overlap between result sets

8
Outline
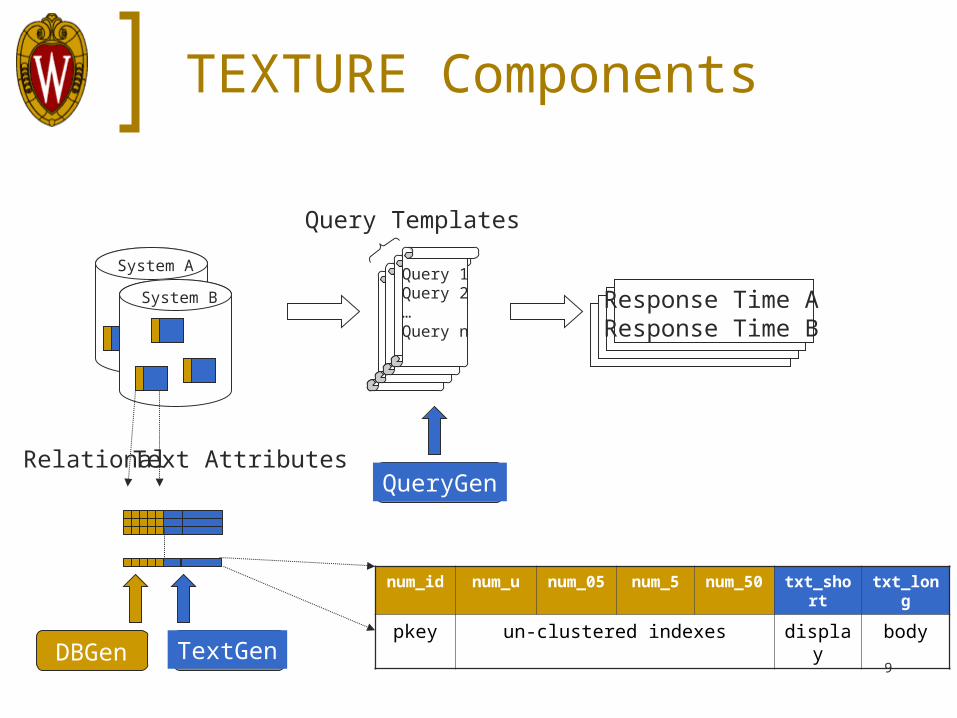
TEXTURE Components Evaluation Synthetic Text Generation
9
System A
TEXTURE Components
Relational Text Attributes
DBGen TextGen
System B Response Time AResponse Time B
num_id num_u num_05 num_5 num_50 txt_short txt_long
pkey un-clustered indexes display body
QueryGen
Query 1Query 2…Query n
Query Templates

10
Overview of Data
Schema based on Wisconsin Benchmark [5] Used to control relational predicate selectivity
Relational attributes populated by DBGen [6] Text attributes populated by TextGen (new)
Input: D: document collection, m: scale-up factor
Output: D’: document collection with |D| x m documents Goal: Same response times for workloads on D’ and
corresponding real collection
5. D. DeWitt. The Wisconsin Benchmark: Past, Present, and Future. The Benchmark Handbook, 1991.6. J. Gray, P. Sundaresan, S. Englert, K. Baclawski, and P. J. Weinberger. Quickly Generating Billion-record Synthetic Databases. ACM SIGMOD, 1994

11
Overview of Queries
Query workloads derived from query templates with following parameters
Text expressions: Vary number of keywords, keyword selectivity, and
type of expression (i.e., phrase, Boolean, etc.) Keywords chosen from text collection
Relational expression: Vary predicate selectivity, join condition selectivity
Sort order: Choose between relational attribute or score
Retrieve ALL or TOP-K results

12
Example Queries
SELECT SCORE, num_id, txt_shortFROM RWHERE NUM_5 = 3 and CONTAINS(R.txt_long, ‘foo bar’, SCORE)ORDER BY SCORE DESC
SELECT S.SCORE, S.num_id, S.txt_shortFROM R, SWHERE R.num_id = S.num_id and S.NUM_05 = 2 and CONTAINS(S.txt_long, ‘foo bar’, S.SCORE)ORDER BY S.SCORE DESC
Example of a single relation, mixed relational and text query that sorts according to a relevance score.
Example of a join query, sorting according to a relevance score on S.txt_long.

13
Outline
TEXTURE Components Evaluation Synthetic Text Generation

14
Overview of Experiments
How is response time affected as the database grows in size?
How is response time affected by sort order and top-k optimizations?
How do the results change when input collection to TextGen differs?

15
Data and Query Workloads
TextGen input is TREC AP Vol.1[1] and VLC2 [2] Output: relations w/ {1, 2.5, 5, 7.5, 10} x 84,678 tuples Corresponds to ~250 MB to 2.5 GB of text data
Text-only queries: Low (< 0.03%) vs. high selectivity (< 3%) Phrases, OR, AND
Mixed, single relation queries: Low (<0.01%) vs. high selectivity (5%) Pair with all text-only queries
Mixed, multi relation queries: 2, 3 relations, vary text attribute used, vary selectivity
Each query workload consists of 100 queries
1. http://es.csiro.au/TRECWeb/vlc2info.html2. http://trec.nist.gov

16
Methodology for Evaluation
Setup database and query workloads Run workload per system multiple times
to obtain warm numbers Discard first run, report average of
remaining Repeat for all systems (A, B, C) Platform: Microsoft Windows 2003
Server, dual processor 1.8 GHz AMD, 2 GB of memory, 8 120 GB IDE drives
17
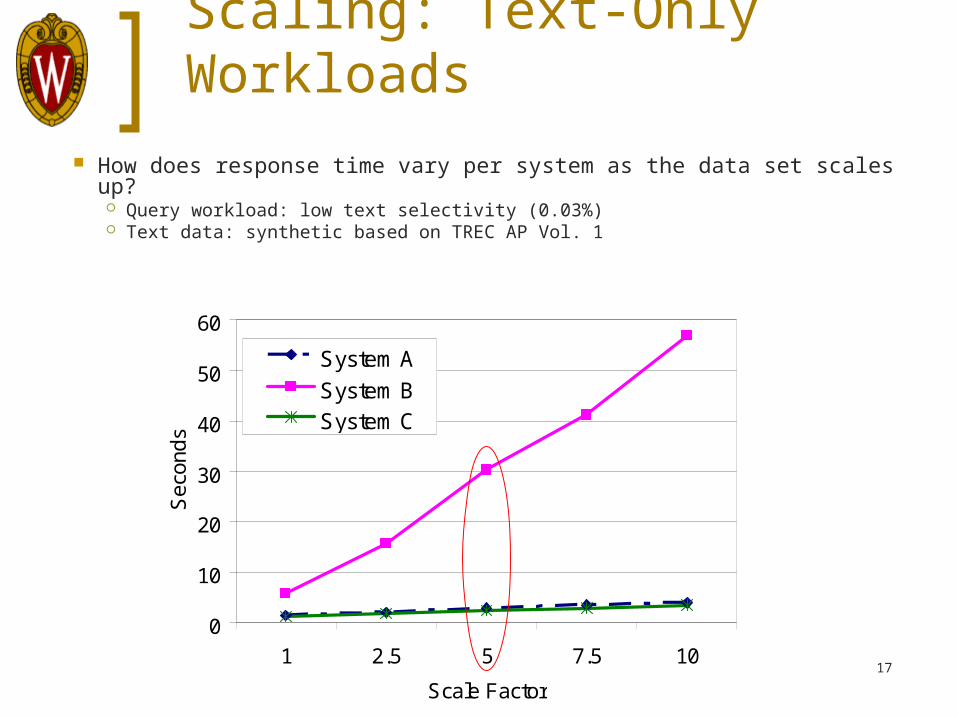
Scaling: Text-Only Workloads
How does response time vary per system as the data set scales up? Query workload: low text selectivity (0.03%) Text data: synthetic based on TREC AP Vol. 1
0
10
20
30
40
50
60
1 2.5 5 7.5 10
Scale Factor
Sec
onds
System A
System BSystem C

18
Mixed Text/Relational Workloads
Workload
SystemLow
A 2.8
B 30
C 2.6
High
71
140
28
Drill down on scale factor 5 (~450K tuples) Query workload Low: text selectivity (0.03%) Query workload High: text selectivity (3%)
Do the systems take advantage of relational predicate for mixed workload queries? Query workload Mix: High text, low relational selectivity (0.01%)
Seconds per system and workload (synthetic TREC)
Mix
69 (97%)
97 (69%)
21 (75%)
19
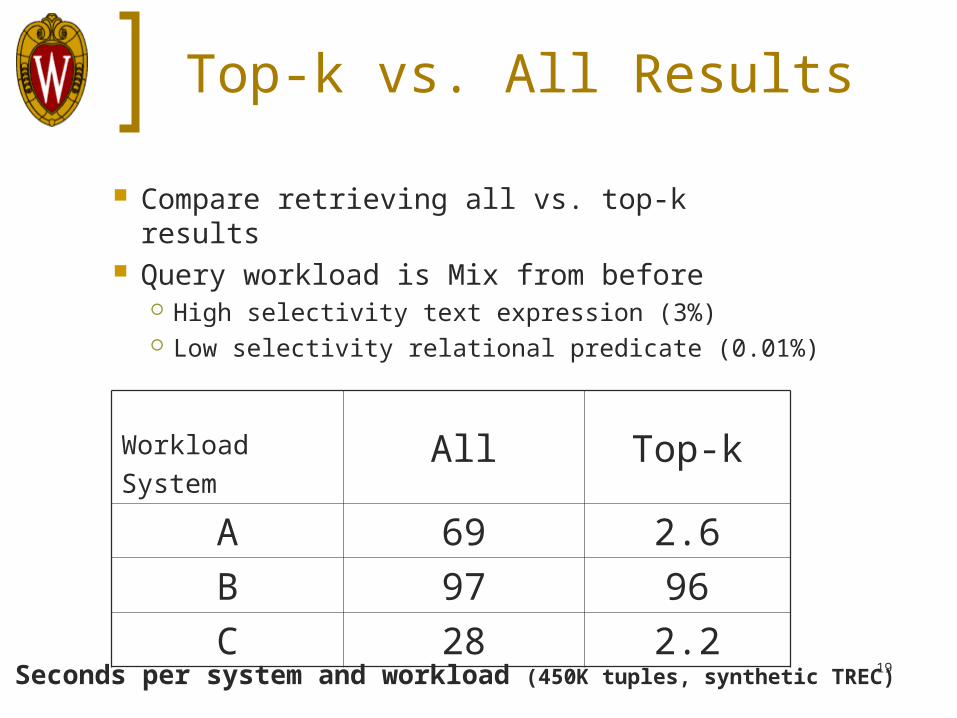
Top-k vs. All Results
Compare retrieving all vs. top-k results Query workload is Mix from before
High selectivity text expression (3%) Low selectivity relational predicate (0.01%)
Workload
SystemAll Top-k
A 69 2.6
B 97 96
C 28 2.2
Seconds per system and workload (450K tuples, synthetic TREC)
20
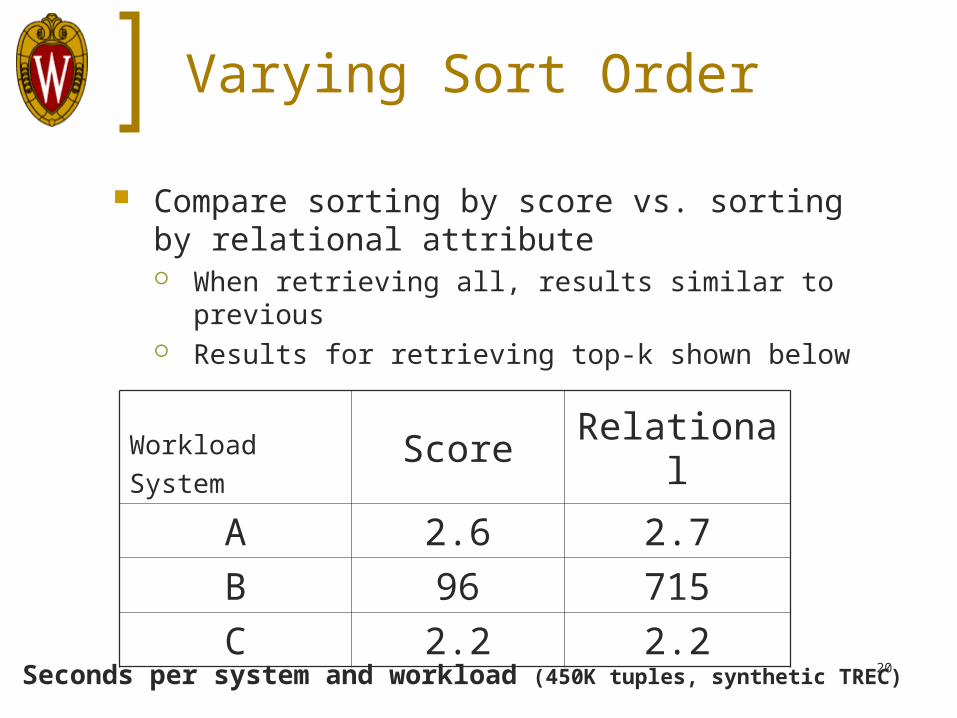
Varying Sort Order
Compare sorting by score vs. sorting by relational attribute When retrieving all, results similar to previous Results for retrieving top-k shown below
Workload
SystemScore Relational
A 2.6 2.7
B 96 715
C 2.2 2.2
Seconds per system and workload (450K tuples, synthetic TREC)

21
Varying the Input Collection
What is the effect of different input text collections on response time? Query workload: low text selectivity (0.03%)
All results retrieved
Text Data: synthetic TREC and VLC2
Collection
SystemSynthetic
TREC
Synthetic
VLC2
A 2.9 1.2
B 30 3.6
C 2.5 1.6Seconds per system and collection (450K tuples)

22
Outline
Benchmark Components Evaluation Synthetic Text Generation

23
Synthetic Text Generation
TextGen: Input: document collection D, scale-up factor m Output: document collection D’ with |D| x m
documents Problem: Given documents D, how do we
add documents to obtain D’ ? Goal: Same response times for workloads on D’
and corresponding real collection C, |C|=|D’| Approach: Extract “features” from D and
draw |D’| samples according to features

24
Document Collection Features
Features considered W(w,c) : word distribution G(n, v) : vocabulary growth U,L : number of unique, total words per
document C(w1, w2, …, wn, c) : co-occurrence of
word groups Each feature is estimated by a model
Ex. Zipf[11] or empirical distribution for W Ex. Heaps Law for G[7]
7. H. S. Heaps, Information Retrieval, Computational and Theoretical Aspects. Academic Press, 1978.11. G. Zipf. Human Behavior and the Principle of Least Effort: An Introduction to Human Ecology. Hafner Publications, 1949.

25
Process to Generate D’
Pre-process: estimate features Depends on model used for feature
Generate |D’| documents Generate each document by sampling W
according to U and L Grow vocabulary according to G
Post-process: Swap words between documents in order to satisfy co-occurrence of word groups C

26
Feature-Model Combinations
Considered 3 instances of TextGen, each a combination of features/models
Feature
TextGenW
(Word distr.)
G(Vocab)
L(Length)
U(Unique)
C(co-occur.)
Synthetic1 Zipf
Heaps Average
N/A
Synthetic2Empirical Average
N/A
Synthetic3 Empirical

27
Which TextGen is a Good Generator?
Goal: response time measured on synthetic (S) and real (D) should be similar across systems
Does the use of randomized words in D’ affect response time accuracy?
How does the choice of features and models effect response time accuracy as the data set scales?

28
Use of Random Words
Words are strings composed of a random permutation of letters
Random words are useful for: Vocabulary growth Sharing text collections
Do randomized words affect measured response times? What is the affect on stemming, compression, and
other text processing components?

29
Effect of Randomized Words
Experiment: create two TEXTURE databases and compare across systems Database AP based on TREC AP Vol. 1 Database R-AP: randomize each word in AP Query workload: low & high selectivity keywords
Result: response times differ on average by < 1%, not exceeding 4.4%
Conclusion: using random words is reasonable for measuring response time

30
Effect of Features and Models
Experiment: compare response times over same sized synthetic (S) and real (D) collections Sample s documents of D Use TextGen to produce S at several scale factors
|S| = 10, 25, 50, 75, and 100% of |D|
Compare response time across systems Must repeat for each type of text-only query
workload Used as framework for picking features/models
31
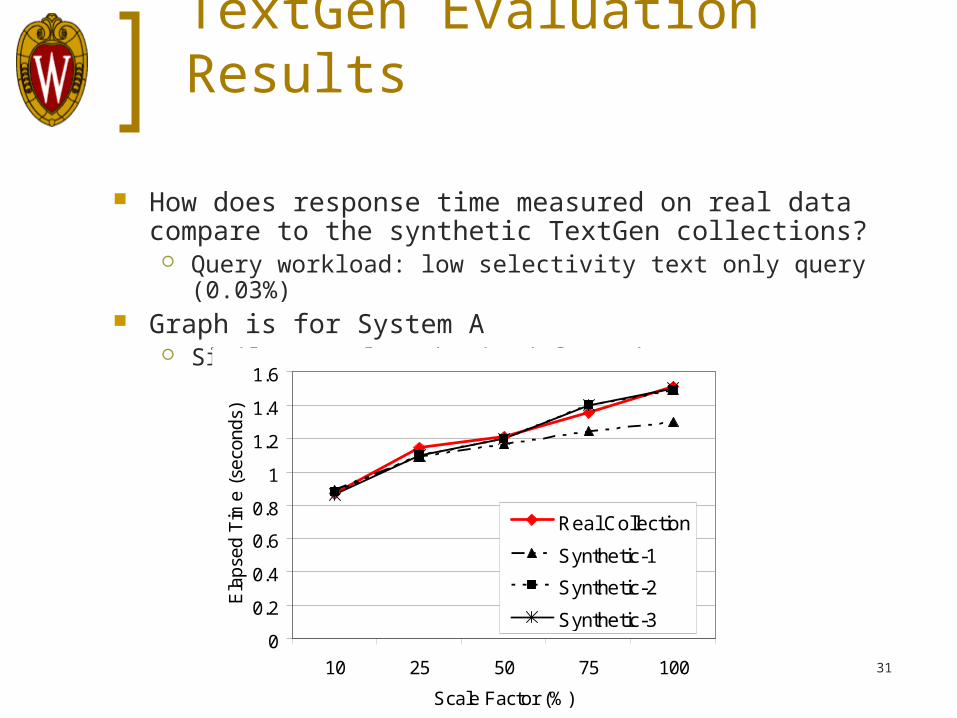
TextGen Evaluation Results
How does response time measured on real data compare to the synthetic TextGen collections?
Query workload: low selectivity text only query (0.03%) Graph is for System A
Similar results obtained for other systems
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
10 25 50 75 100
Scale Factor (%)
Ela
psed
Tim
e (s
econ
ds)
Real Collection
Synthetic-1
Synthetic-2
Synthetic-3

32
Future Work
How should quality measurements be incorporated?
Extend the workload to include updates
Allow correlations between attributes when generating database

33
Conclusion
We propose TEXTURE to fill the gap seen by applications that use mixed relational and text queries
We can scale-up a text collection through synthetic text generation in such a way that response time is accurately reflected
Results of evaluation illustrate significant differences between current commercial relational systems

34
References
1. http://es.csiro.au/TRECWeb/vlc2info.html2. http://trec.nist.gov3. http://www.tpc.org4. S. DeFazio, Full-text Document Retrieval Benchmark, chapter 8. Morgan
Kaufman, 2 edition, 19935. D. DeWitt. The Wisconsin Benchmark: Past, Present, and Future. The
Benchmark Handbook, 1991.6. J. Gray, P. Sundaresan, S. Englert, K. Baclawski, and P. J. Weinberger.
Quickly Generating Billion-record Synthetic Databases. ACM SIGMOD, 19947. H. S. Heaps, Information Retrieval, Computational and Theoretical Aspects.
Academic Press, 1978.8. P. O’Neil. The Set Query Benchmark. The Benchmark Handbook, 19919. K. A. Shoens, A. Tomasic, H. Garcia-Molina. Synthetic Workload Performance
Analysis of Incremental Updates. In Research and Development in Information Retrieval, 1994.
10. C. Turbyfill, C. Orji, and D. Bitton. AS3AP- a Comparative Relational Database Benchmark. IEEE Compcon, 1989.
11. G. Zipf. Human Behavior and the Principle of Least Effort: An Introduction to Human Ecology. Hafner Publications, 1949.

35
Questions?