1. 什么是聚类? -...
TRANSCRIPT


1. 什么是聚类?

聚类
聚类就是按照某个特定标准(如距离准则)把一个数据集分割
成不同的类或簇,使得同一个簇内的数据对象的相似性尽可能大,同时不在同一个簇中的数据对象的差异性也尽可能地大。即聚类后同一类的数据尽可能聚集到一起,不同数据尽量分离。
1.在无标签的数据集中寻找高相似度的集合(groups)
2.在图中寻找紧密连接的集合

聚类任务
形式化描述
假定样本集 包含 个无标记样本,每个样本
是一个 维的特征向量,聚类算法将样本集
划分成 个不相交的簇 。其中 ,且
。。
相应地,用 表示样本 的“簇标记”(即cluster label),即 。于是,聚类的结果可用包含 个元素的簇标记向量 表示。

聚类的应用
聚类算法的主要应用包括:
(1)其他数据挖掘任务的关键中间环节:用于构建数据
概要,用于分类、模式识别、假设生成和测试;用于异常
检测,检测远离群簇的点。
(2)数据摘要、数据压缩、数据降维:例如图像处理中
的矢量量化技术。创建一个包含所有簇原型的表,即每个
原型赋予一个整数值,作为它在表中的索引。每个对象用
与它所在簇相关联的原型的索引表示。
(3)协同过滤:用于推荐系统和用户细分。
(4)动态趋势检测:对流数据进行聚类,检测动态趋势
和模式。
(5)用于多媒体数据、生物数据、社交网络数据的应用。

2. 如何评估聚类效果?

性能度量
聚类性能度量,亦称为聚类“有效性指标”(validity index)
直观来讲:
我们希望“物以类聚”,即同一簇的样本尽可能彼此相似,不同簇的样本尽可能不同。换言之,聚类结果的“簇内相似度”(intra-cluster similarity)高,且“簇间相似度”(inter-cluster similarity)低,这样的聚类效果较好.
聚类性能度量:
外部指标 (external index)
将聚类结果与某个“参考模型”(reference model)进行比较。
内部指标 (internal index)
直接考察聚类结果而不用任何参考模型。

性能度量
对数据集 ,假定通过聚类得到的簇划分为
,参考模型给出的簇划分为 .相应地,令 与 分别表示与 和 对应的簇标记向量.
我们将样本两两配对考虑,定义

性能度量 - 外部指标
Jaccard系数(Jaccard Coefficient, JC)
FM指数(Fowlkes and Mallows Index, FMI)
Rand指数(Rand Index, RI)
[0,1]区间内,越大越好.

性能度量 – 内部指标
考虑聚类结果的簇划分 ,定义
簇 内样本间的平均距离
簇 内样本间的最远距离
簇 与簇 最近样本间的距离
簇 与簇 中心点间的距离

性能度量 – 内部指标
DB指数(Davies-Bouldin Index, DBI)
Dunn指数(Dunn Index, DI)
越小越好.
越大越好.

3. 典型的聚类方法有哪些?

典型的聚类方法
聚类分析算法主要可以分为:
划分法(Partitioning Methods)
层次法(Hierarchical Methods)
基于密度的方法(density-based methods)
基于网格的方法(grid-based methods)
基于模型的方法(Model-Based Methods)

基于距离的算法
划分算法和层次算法可以看做是基于距离的聚类算法。划分算法(partitioning method)是简单地将数据对象划分成不重叠的子集(簇),使得每个数据对象恰在一个子集中。给定一个有N个元组或者纪录的数据集,分裂法将构造K个分组,每一个分组就代表一个聚类,K<N。而且这K个分组满足下列条件:(1)每一个分组至少包含一个数据纪录;(2)每一个数据纪录属于且仅属于一个分组(注意:这个要求在某些模糊聚类算法中可以放宽);
对于给定的K,算法首先给出一个初始的分组方法,以后通过反复迭代的方法改变分组,使得每一次改进之后的分组方案都较前一次好,而所谓好的标准就是:同一分组中的记录越近越好,而不同分组中的纪录越远越好。

基于距离的算法
传统的划分方法可以扩展到子空间聚类,而不是搜索整个数据空间。当存在很多属性并且数据稀疏时,这是有用的。为了达到全局最优,基于划分的聚类可能需要穷举所有可能的划分,计算量极大。
实际上,大多数应用都采用了流行的启发式方法,如k-均值和k-中心算法,渐近的提高聚类质量,逼近局部最优解。这
些启发式聚类方法很适合发现中小规模的数据库中小规模的数据库中的球状簇。为了发现具有复杂形状的簇和对超大型数据集进行聚类,需要进一步扩展基于划分的方法。
使用这个基本思想的算法有:K-MEANS算法、K-MEDIANS算法、K-MEDOIDS算法、CLARANS算法。

基于距离的算法
层次算法(hierarchical method)是嵌套簇的集族,组织成一棵树。除
叶子结点外,树中每一个结点(簇)都是其子女(子簇)的并,而树根是包含所有对象的簇。这种方法对对给定的数据集进行层次似的分解,直到某种条件满足为止。
层次法对给定的数据对象集合进行层次似的分解。按层次分解的形成方式,层次法可分为凝聚和分裂两大类。
凝聚的方法,也称为自底向上的方法,一开始将每个对象作为单独的一个类,然后相继地合并相近的类,直到所有的类合并为一个(层次的最上层),或者达到一个终止条件为止。分裂的方法,也称为自顶向下的方法, 一开始将所有的对象置于一个类中。
在迭代的每一步中,类被分裂为更小的类,直到每个类只包含一个对象,或者达到一个终止条件为止。在凝聚或者分裂层次聚类方法中,通常以用户定义的希望得到的类的数目作为结束条件。在类的合并或分裂过程中,需要考察类间的距离。
层次方法中代表算法有BIRCH、CURE、ROCK、CHAMELEON算法等。
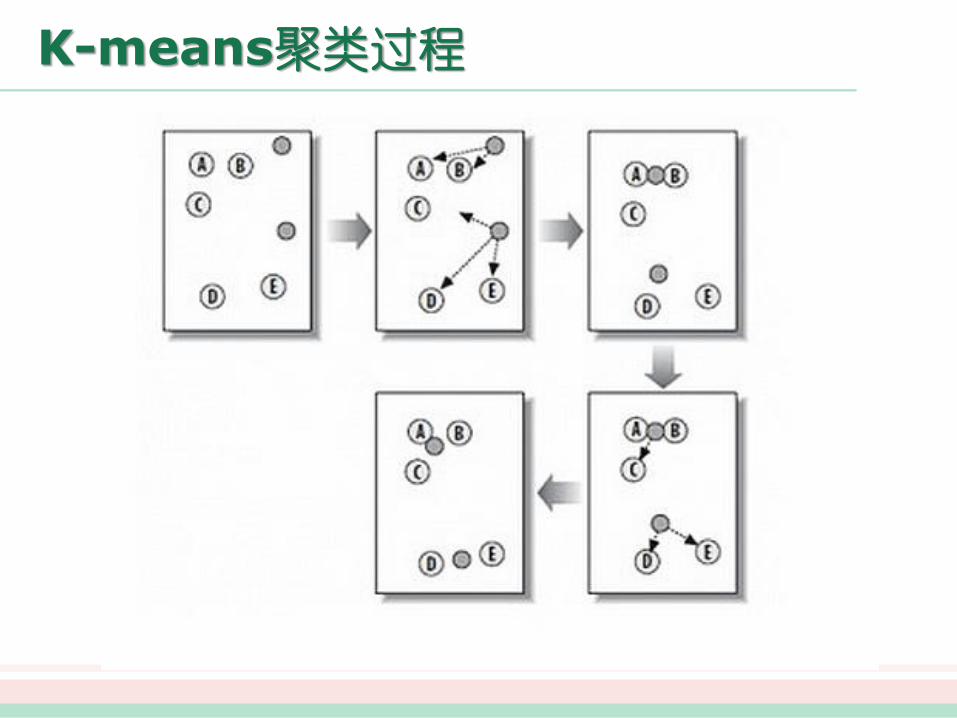
K-means聚类过程
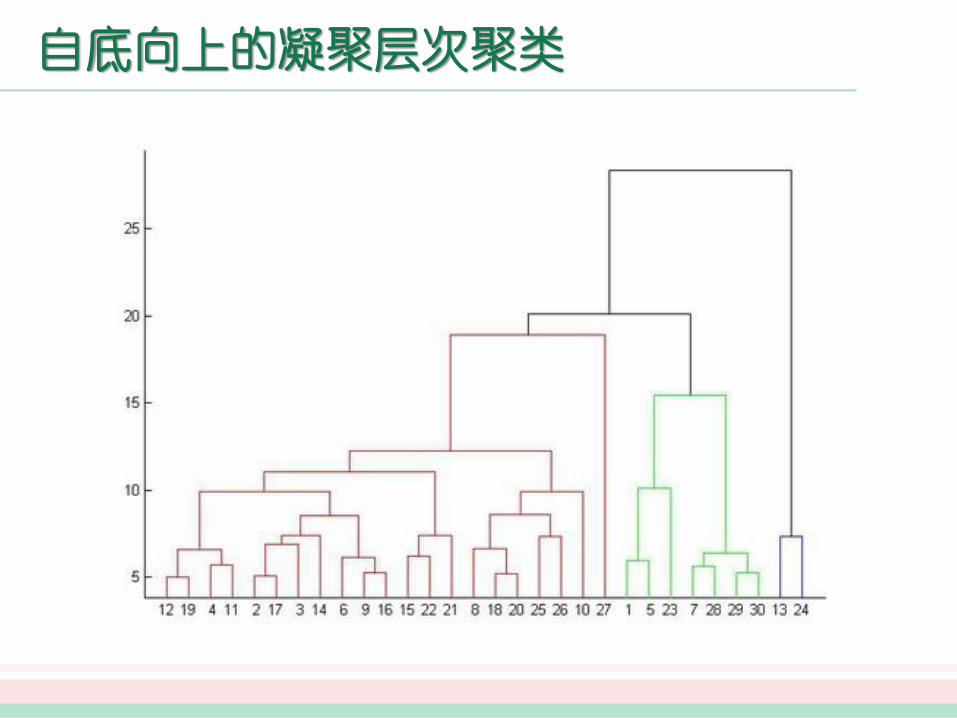
自底向上的凝聚层次聚类

基于密度的方法
绝大多数划分方法基于对象之间的距离进行聚类,这样的方法只能发现球状的类,而在发现任意形状的类上有困难。因此,出现了基于密度的聚类方法,其主要思想是:只要邻近区域的密度(对象或数据点的数目)超过某个阈值,就继续聚类。也就是说,对给定类中的每个数据点,在一个给定范围的区域内必须至少包含某个数目的点。这样的方法可以过滤“噪声”数据,发现任意形状的类。但算法计算复杂度高,一般为O(n^2),对于密度分布不均的数据集,往往得不到满意的聚类结果。
其代表算法有DBSCAN、OPTICS和DENCLUE等。
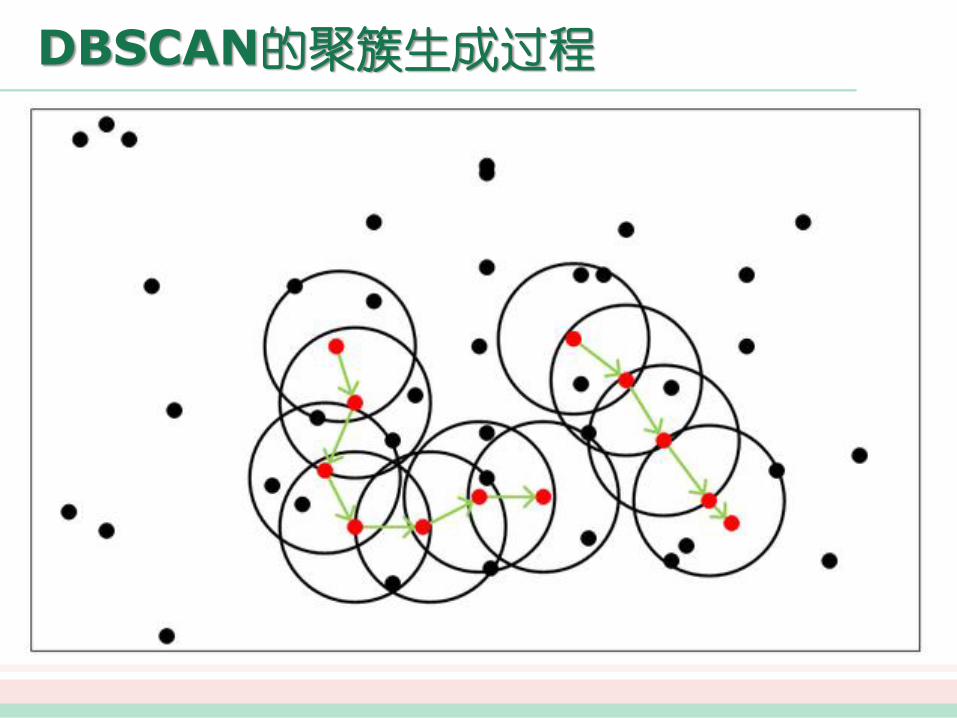
DBSCAN的聚簇生成过程

基于网格的方法
基于网格的方法把对象空间量化为有限数目的单元,形成一个网格结构。所有的聚类操作都在这个网格结构(即量化空间)上进行。这种方法的主要优点是它的处理 速度很快,其处理速
度独立于数据对象的数目,只与量化空间中每一维的单元数目有关。但这种算法效率的提高是以聚类结果的精确性为代价的。
代表算法有STING、CLIQUE、WAVE-CLUSTER等。
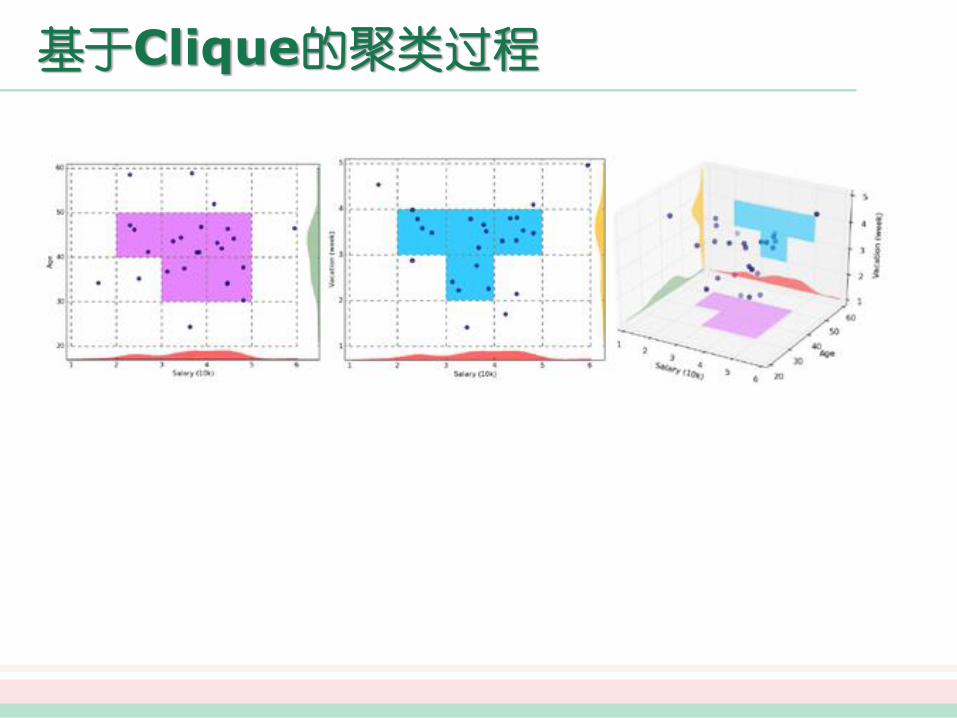
基于Clique的聚类过程

基于模型的方法
基于模型的聚类算法为每簇假定了一个模型,寻找数据对给定模型的最佳拟合。一个基于模型的算法可能通过构建反应数据点空间分布的密度函数来定位聚类。它也基于标准的统计数字自动决定聚类的数目,过滤噪声数据或孤立点,从而产生健壮的聚类方法。基于模型的聚类试图优化给定的数据和某些数据模型之间的适应性。 这样的方法经常是基于这样的假设:数据是根据潜在的概率分布生成的。
基于模型的方法主要有两类:统计学方法和网络神经方法。其中,统计学方法有COBWEB算法、GMM(Gaussian Mixture Model),神经网络算法有SOM(Self Organized Maps)算法。。
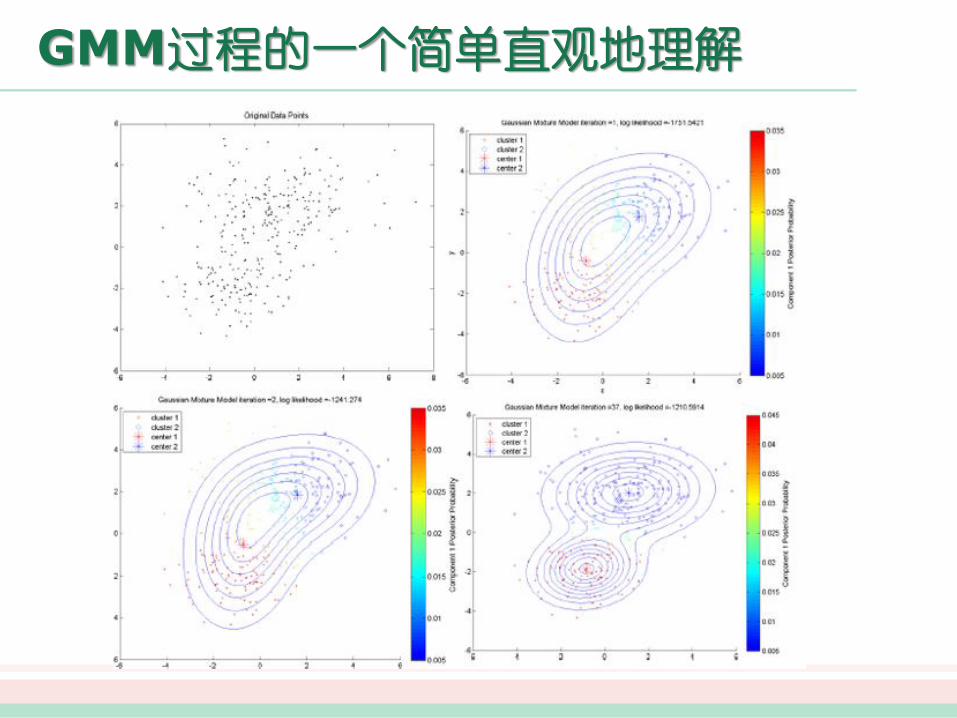
GMM过程的一个简单直观地理解

4. 对聚类分析的要求是什么?

对聚类分析的要求
聚类质量处理不同类型属性的能力:许多算法被设计用来聚类数值类型的数据。但是,应用可能要求聚类其他类型的数据,如二元类型(binary),分类/标称类型(categorical/nominal),序数型(ordinal)数据,或者这些数据类型的混合。
发现任意形态的群簇:许多聚类算法基于欧几里得或者曼哈顿距离度量来决定聚类。基于这样的距离度量的算法趋向于发现具有相近尺度和密度的球状簇。但是,一个簇可能是任意形状的。提出能发现任意形状簇的算法是很重要的。
处理噪声的能力:绝大多数现实中的数据库都包含了孤立点,缺失,或者错误的数据。一些聚类算法对于这样的数据敏感,可能导致低质量的聚类结果。

对聚类分析的要求
可伸缩性许多聚类算法在小于200个数据对象的小数据集合上工作得
很好;但是,一个大规模数据库可能包含几百万个对象,在这样的大数据集合样本上进行聚类可能会导致有偏的结果。我们需要具有高度可伸缩性的聚类算法
可伸缩性的聚类算法要求算法对所有数据进行聚类,能够处理好高维数据,可以对流数据进行聚类,算法对数据输入顺序不敏感。
可解释性和可用性用户希望聚类结果是可解释的,可理解的,和可用的。也就是说,聚类可能需要和特定的语义解释和应用相联系。

5. 聚类分析中的相似性度量有哪些?

相似性度量

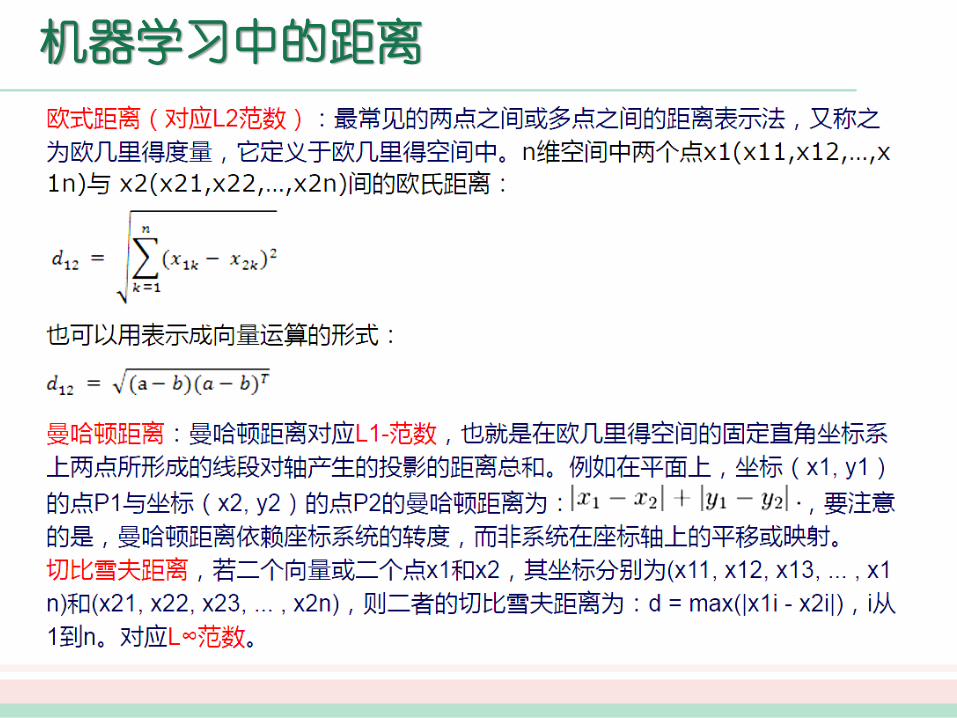
常见的距离算法
欧几里得距离(Euclidean Distance)以及欧式距离
的标准化(Standardized Euclidean distance)
马哈拉诺比斯距离(Mahalanobis Distance)
曼哈顿距离(Manhattan Distance)
切比雪夫距离(Chebyshev Distance)
明可夫斯基距离(Minkowski Distance)
汉明距离(Hamming distance)

明可夫斯基距离(Minkowski Distance)
关系:明氏距离是欧氏距离的推广,是对多个距离度量公式的概括性的表述。p=1退化为曼哈顿距离;p=2退化为欧氏距
离;切比雪夫距离是明氏距离取极限的形式。这里明可夫斯基距离就是p-norm范数的一般化定义。
下图给出了一个Lp球(||X||p=1)的形状随着P的减少的可视化图:

机器学习中的范数
机器学习中的距离

机器学习中的距离

常见的相似度(系数)算法
余弦相似度(Cosine Similarity)以及调整余弦相似度
(Adjusted Cosine Similarity)
皮尔森相关系数(Pearson Correlation Coefficient)
Jaccard相似系数(Jaccard Coefficient)
Tanimoto系数(广义Jaccard相似系数)
对数似然相似度/对数似然相似率
互信息/信息增益,相对熵/KL散度
信息检索--词频-逆文档频率(TF-IDF)

6. 什么是维数灾难?

低维嵌入
维数灾难 (curse of dimensionality)
1NN性能分析的一个重要假设:任意测试样本 附近的任意小的距离范围内总能找到一个训练样本,即训练样本的采样密度足够大,或称为“密采样”。然而,这个假设在现实任务中通常很难满足:
若属性维数为1,当 =0.001,仅考虑单个属性,则仅需1000个样本点平均分布在归一化后的属性取值范围内,即可使得任意测试样本在其附近0.001距离范围内总能找到一个训练样本,此时最近邻分类器的错误率不超过贝叶斯最优分类器的错误率的两倍。若属性维数为20,若样本满足密采样条件,则至少需要 个样本。
现实应用中属性维数经常成千上万,要满足密采样条件所需的样本数目是无法达到的天文数字。许多学习方法都涉及距离计算,而高维空间会给距离计算带来很大的麻烦,例如当维数很高时甚至连计算内积都不再容易。
在高维情形下出现的数据样本稀疏、距离计算困难等问题,是所有机器学习方法共同面临的严重障碍,被称为“维数灾难”。

curse of dimensionality-维数灾难
sampling采样
如果数据是低维的,所需的采样点相对就比较少;如果数据是高维的,所需的采样点就会指数级增加,而实现中面对高维问题时往往无法获得如此多的样本点(即使获得了也无法处理这么庞大数据量),样本少不具有代表性自然不能获得正确的结果。
combinatorics组合数学由于每个维度上候选集合是固定的,维度增加后所有组合的总数就会指数级增加。
machine learning机器学习
在机器学习中要求有相当数量的训练数据含有一些样本组合。给定固定数量的训练样本,其预测能力随着维度的增加而减小,这就是所谓的Hughes影响或Hughes现象。
data mining数据挖掘
在组织和搜索数据时有赖于检测对象区域,这些区域中的对象通过相似度属性而形成分组。然而在高维空间中,所有的数据都很稀疏,从很多角度看都不相似,因而平常使用的数据组织策略变得极其低效。
curse of dimensionality-维数灾难
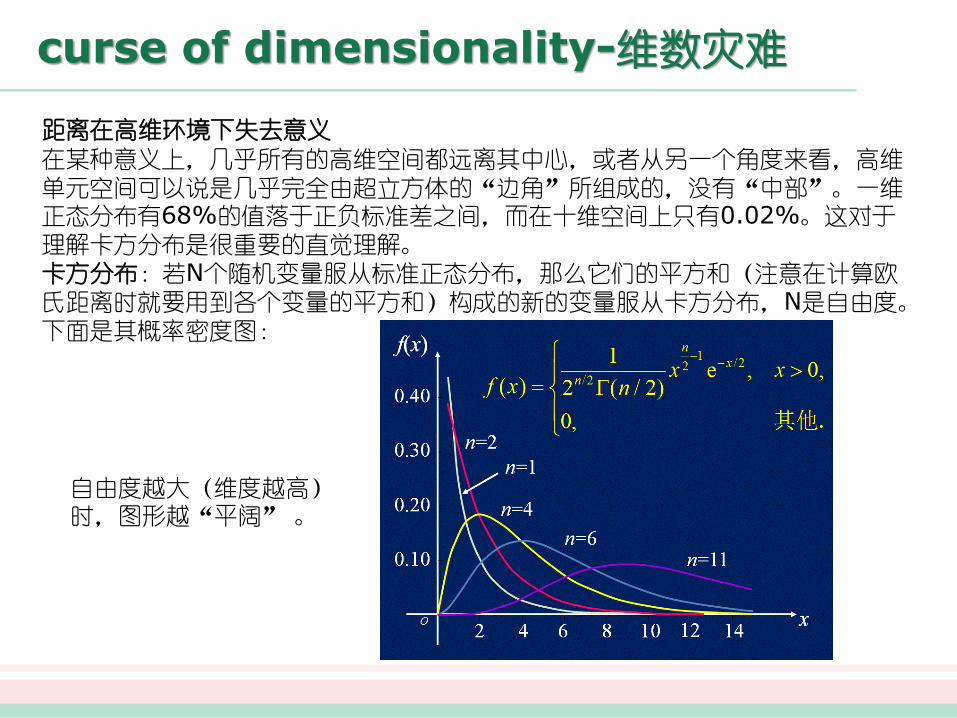
距离在高维环境下失去意义
在某种意义上,几乎所有的高维空间都远离其中心,或者从另一个角度来看,高维单元空间可以说是几乎完全由超立方体的“边角”所组成的,没有“中部”。一维正态分布有68%的值落于正负标准差之间,而在十维空间上只有0.02%。这对于理解卡方分布是很重要的直觉理解。卡方分布:若N个随机变量服从标准正态分布,那么它们的平方和(注意在计算欧氏距离时就要用到各个变量的平方和)构成的新的变量服从卡方分布,N是自由度。
下面是其概率密度图:
自由度越大(维度越高)时,图形越“平阔” 。
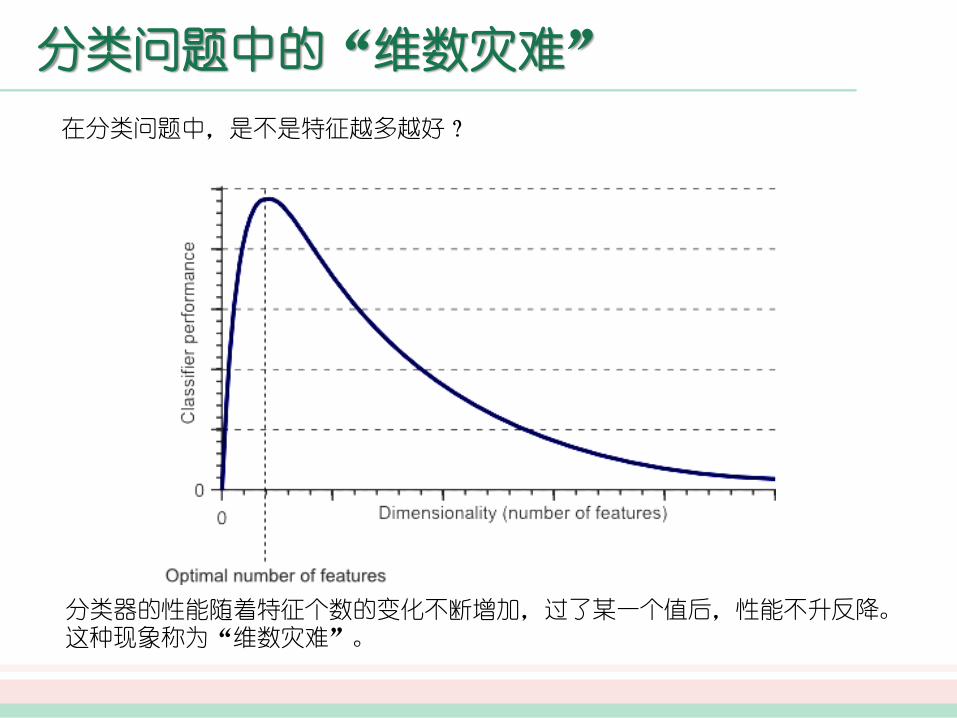
分类问题中的“维数灾难”
分类器的性能随着特征个数的变化不断增加,过了某一个值后,性能不升反降。这种现象称为“维数灾难”。
在分类问题中,是不是特征越多越好?
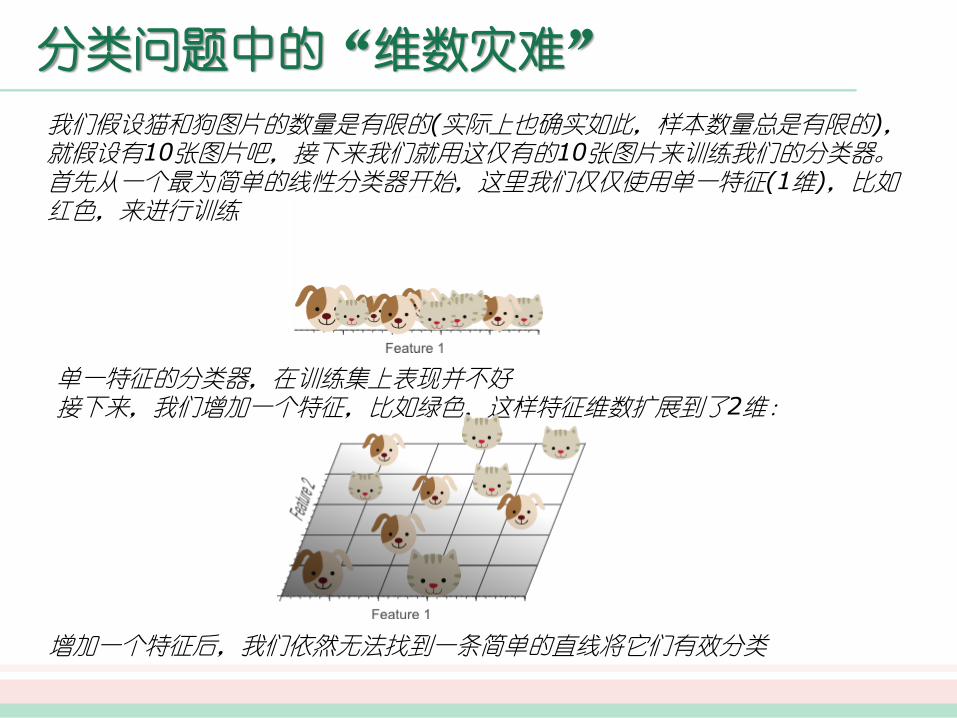
分类问题中的“维数灾难”
我们假设猫和狗图片的数量是有限的(实际上也确实如此,样本数量总是有限的),就假设有10张图片吧,接下来我们就用这仅有的10张图片来训练我们的分类器。首先从一个最为简单的线性分类器开始,这里我们仅仅使用单一特征(1维),比如红色,来进行训练
单一特征的分类器,在训练集上表现并不好接下来,我们增加一个特征,比如绿色,这样特征维数扩展到了2维:
增加一个特征后,我们依然无法找到一条简单的直线将它们有效分类
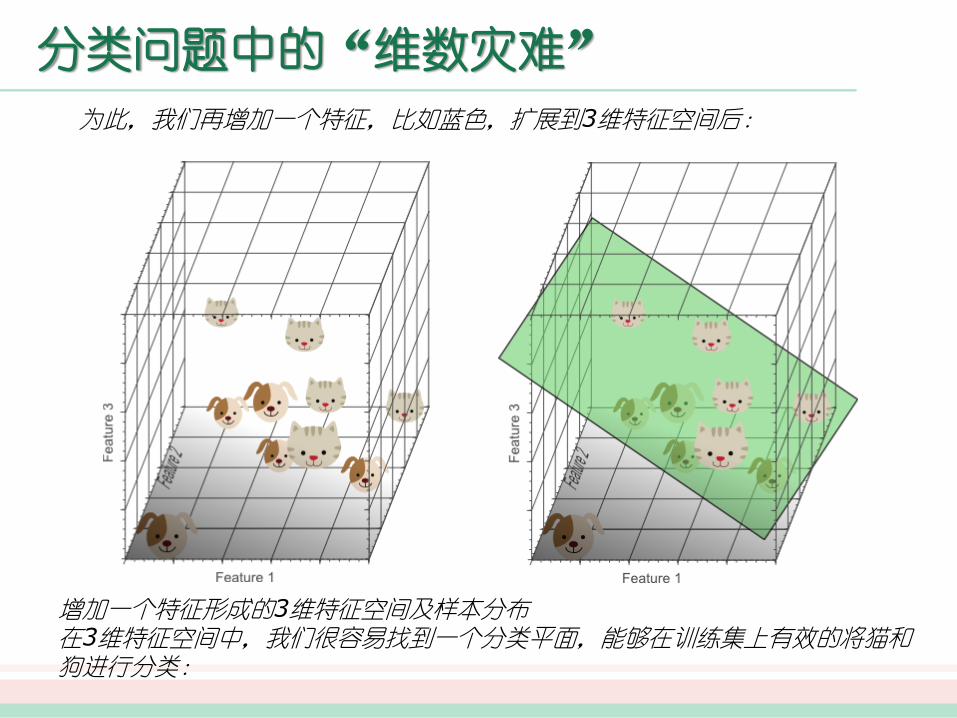
分类问题中的“维数灾难”
为此,我们再增加一个特征,比如蓝色,扩展到3维特征空间后:
增加一个特征形成的3维特征空间及样本分布在3维特征空间中,我们很容易找到一个分类平面,能够在训练集上有效的将猫和狗进行分类:
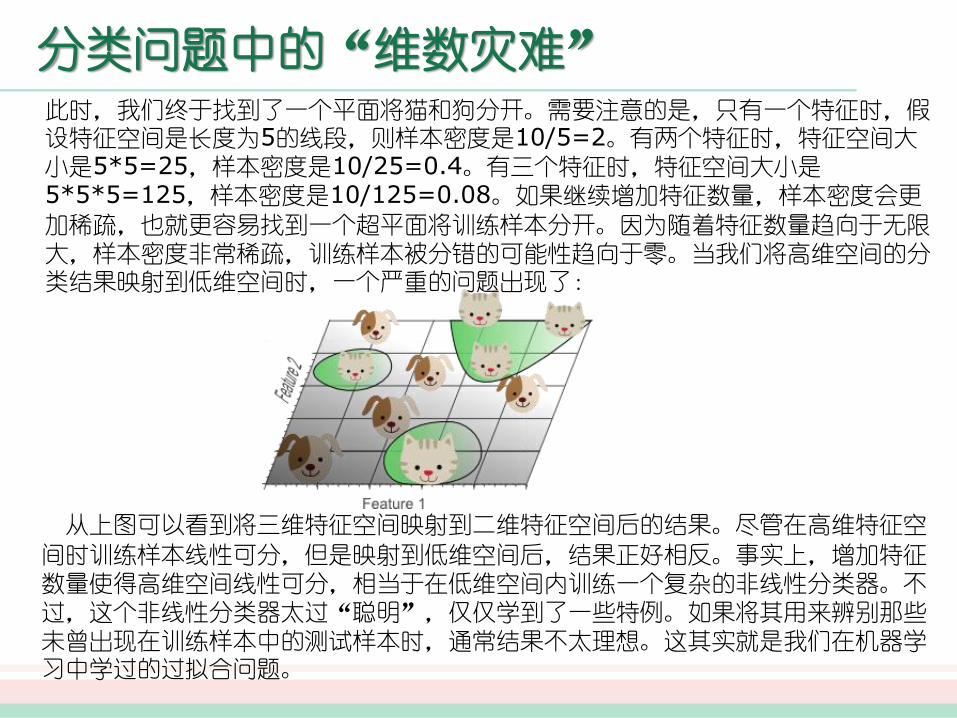
分类问题中的“维数灾难”此时,我们终于找到了一个平面将猫和狗分开。需要注意的是,只有一个特征时,假设特征空间是长度为5的线段,则样本密度是10/5=2。有两个特征时,特征空间大小是5*5=25,样本密度是10/25=0.4。有三个特征时,特征空间大小是5*5*5=125,样本密度是10/125=0.08。如果继续增加特征数量,样本密度会更
加稀疏,也就更容易找到一个超平面将训练样本分开。因为随着特征数量趋向于无限大,样本密度非常稀疏,训练样本被分错的可能性趋向于零。当我们将高维空间的分类结果映射到低维空间时,一个严重的问题出现了:
从上图可以看到将三维特征空间映射到二维特征空间后的结果。尽管在高维特征空
间时训练样本线性可分,但是映射到低维空间后,结果正好相反。事实上,增加特征数量使得高维空间线性可分,相当于在低维空间内训练一个复杂的非线性分类器。不
过,这个非线性分类器太过“聪明”,仅仅学到了一些特例。如果将其用来辨别那些未曾出现在训练样本中的测试样本时,通常结果不太理想。这其实就是我们在机器学习中学过的过拟合问题。
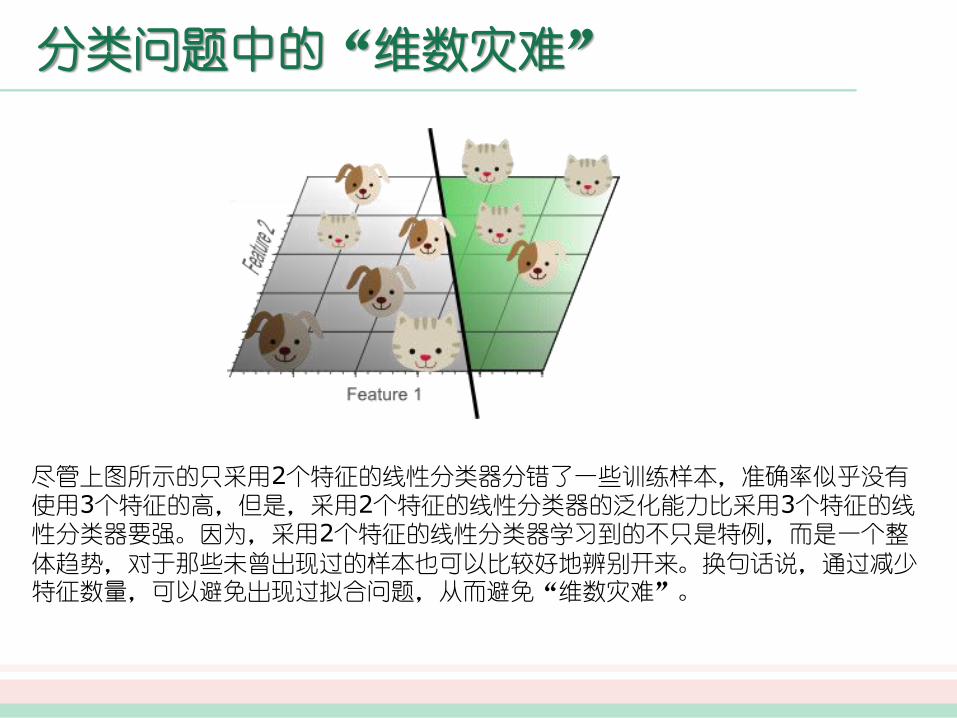
分类问题中的“维数灾难”
尽管上图所示的只采用2个特征的线性分类器分错了一些训练样本,准确率似乎没有使用3个特征的高,但是,采用2个特征的线性分类器的泛化能力比采用3个特征的线性分类器要强。因为,采用2个特征的线性分类器学习到的不只是特例,而是一个整
体趋势,对于那些未曾出现过的样本也可以比较好地辨别开来。换句话说,通过减少特征数量,可以避免出现过拟合问题,从而避免“维数灾难”。
分类问题中的“维数灾难”
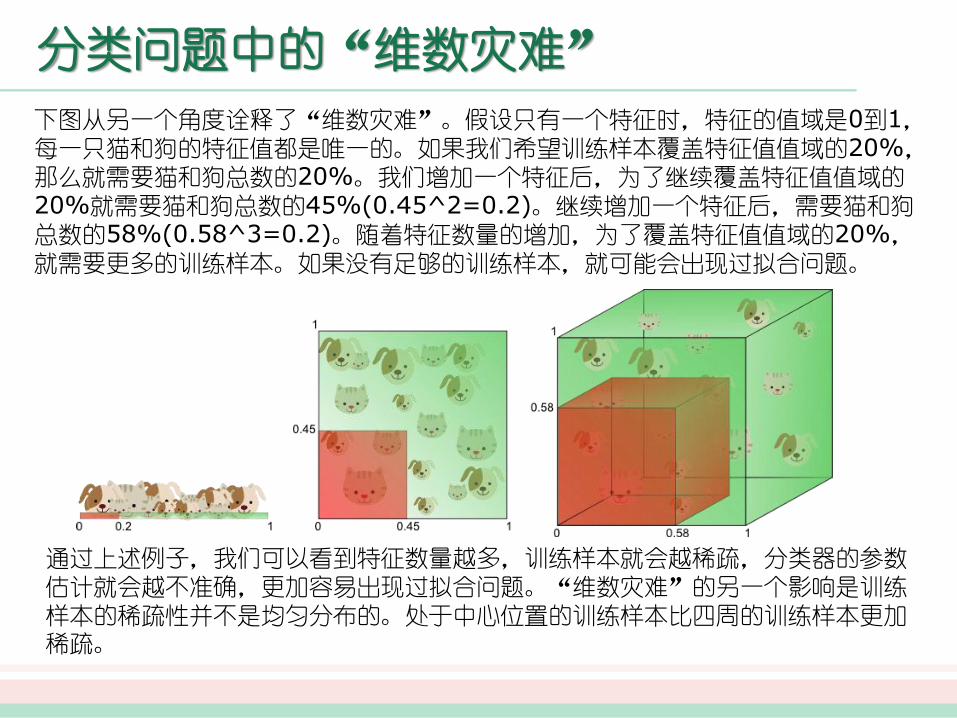
下图从另一个角度诠释了“维数灾难”。假设只有一个特征时,特征的值域是0到1,每一只猫和狗的特征值都是唯一的。如果我们希望训练样本覆盖特征值值域的20%,那么就需要猫和狗总数的20%。我们增加一个特征后,为了继续覆盖特征值值域的
20%就需要猫和狗总数的45%(0.45^2=0.2)。继续增加一个特征后,需要猫和狗总数的58%(0.58^3=0.2)。随着特征数量的增加,为了覆盖特征值值域的20%,就需要更多的训练样本。如果没有足够的训练样本,就可能会出现过拟合问题。
通过上述例子,我们可以看到特征数量越多,训练样本就会越稀疏,分类器的参数估计就会越不准确,更加容易出现过拟合问题。“维数灾难”的另一个影响是训练样本的稀疏性并不是均匀分布的。处于中心位置的训练样本比四周的训练样本更加稀疏。
分类问题中的“维数灾难”
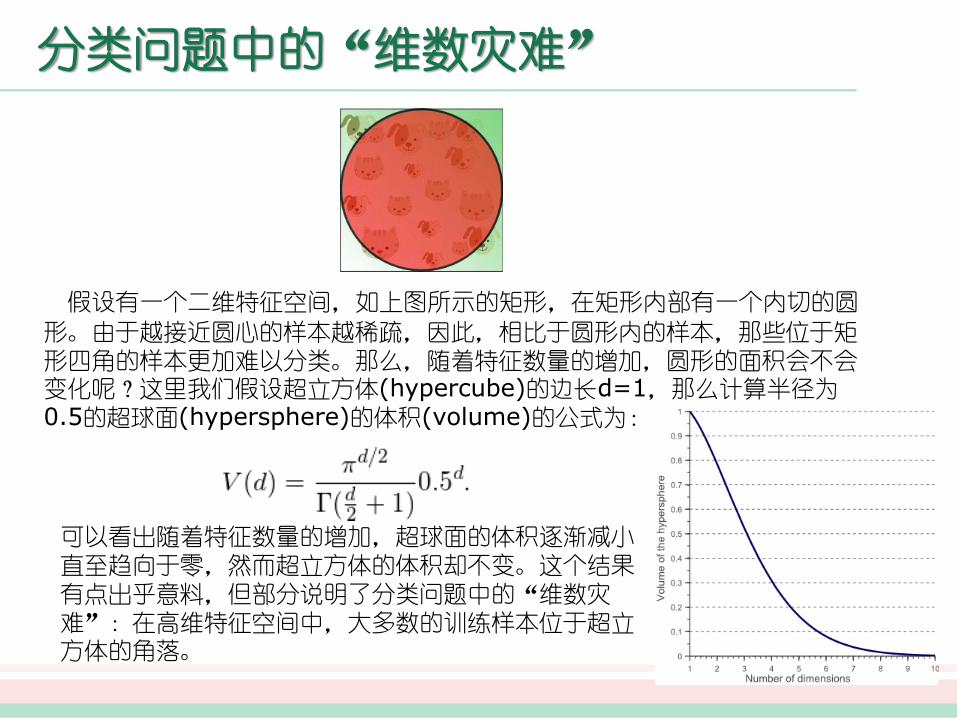
假设有一个二维特征空间,如上图所示的矩形,在矩形内部有一个内切的圆
形。由于越接近圆心的样本越稀疏,因此,相比于圆形内的样本,那些位于矩形四角的样本更加难以分类。那么,随着特征数量的增加,圆形的面积会不会变化呢?这里我们假设超立方体(hypercube)的边长d=1,那么计算半径为0.5的超球面(hypersphere)的体积(volume)的公式为:
可以看出随着特征数量的增加,超球面的体积逐渐减小直至趋向于零,然而超立方体的体积却不变。这个结果
有点出乎意料,但部分说明了分类问题中的“维数灾难”:在高维特征空间中,大多数的训练样本位于超立方体的角落。
分类问题中的“维数灾难”
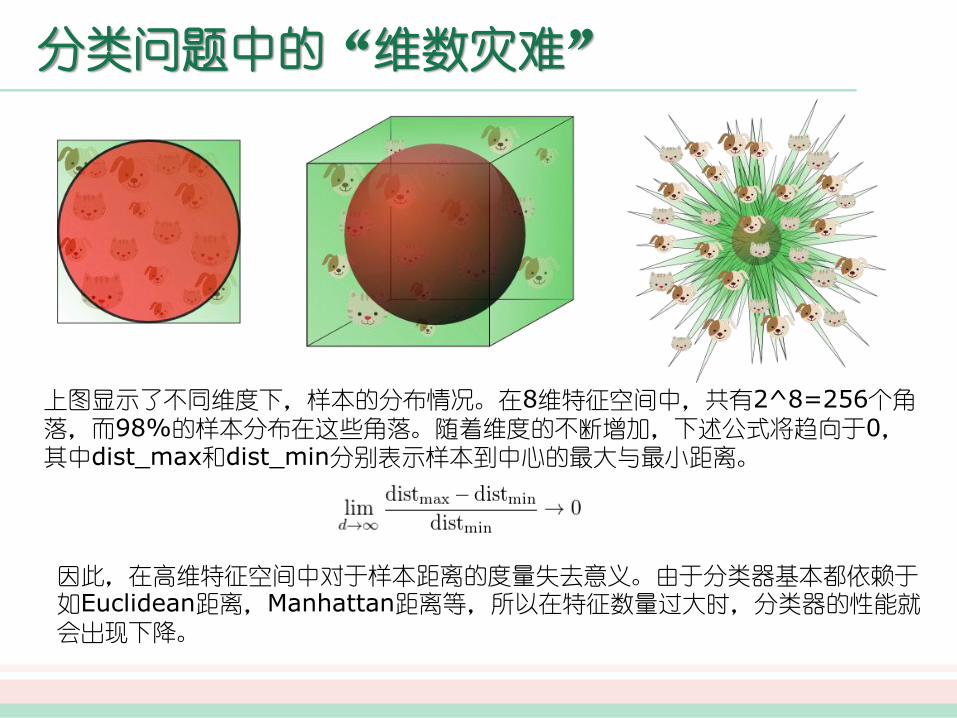
上图显示了不同维度下,样本的分布情况。在8维特征空间中,共有2^8=256个角落,而98%的样本分布在这些角落。随着维度的不断增加,下述公式将趋向于0,其中dist_max和dist_min分别表示样本到中心的最大与最小距离。
因此,在高维特征空间中对于样本距离的度量失去意义。由于分类器基本都依赖于如Euclidean距离,Manhattan距离等,所以在特征数量过大时,分类器的性能就会出现下降。
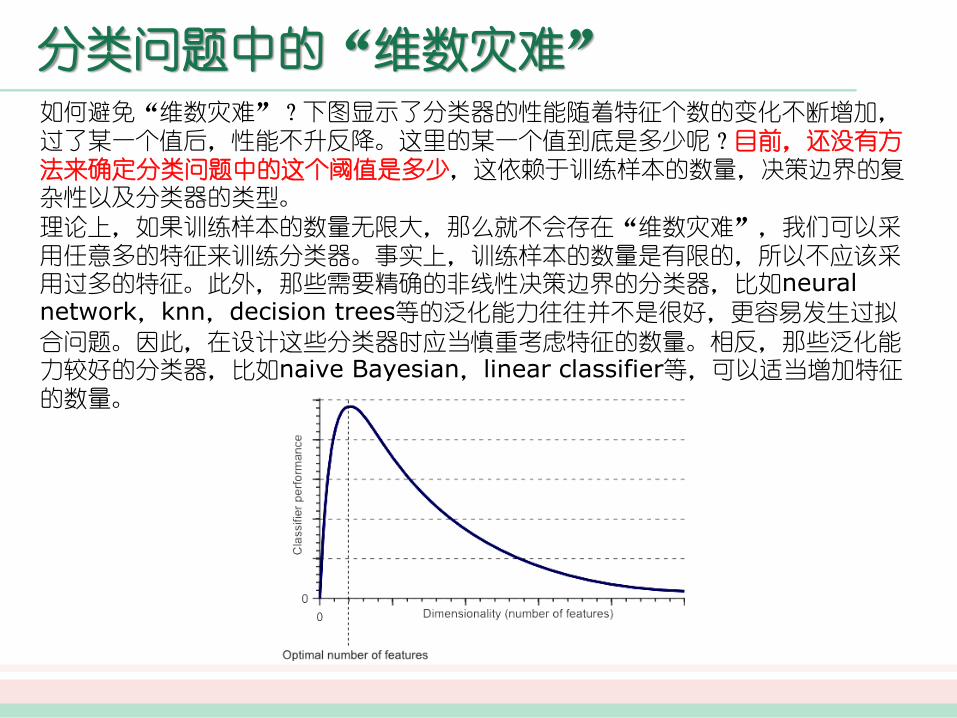
分类问题中的“维数灾难”如何避免“维数灾难”?下图显示了分类器的性能随着特征个数的变化不断增加,过了某一个值后,性能不升反降。这里的某一个值到底是多少呢?目前,还没有方法来确定分类问题中的这个阈值是多少,这依赖于训练样本的数量,决策边界的复杂性以及分类器的类型。
理论上,如果训练样本的数量无限大,那么就不会存在“维数灾难”,我们可以采用任意多的特征来训练分类器。事实上,训练样本的数量是有限的,所以不应该采用过多的特征。此外,那些需要精确的非线性决策边界的分类器,比如neural network,knn,decision trees等的泛化能力往往并不是很好,更容易发生过拟
合问题。因此,在设计这些分类器时应当慎重考虑特征的数量。相反,那些泛化能力较好的分类器,比如naive Bayesian,linear classifier等,可以适当增加特征的数量。
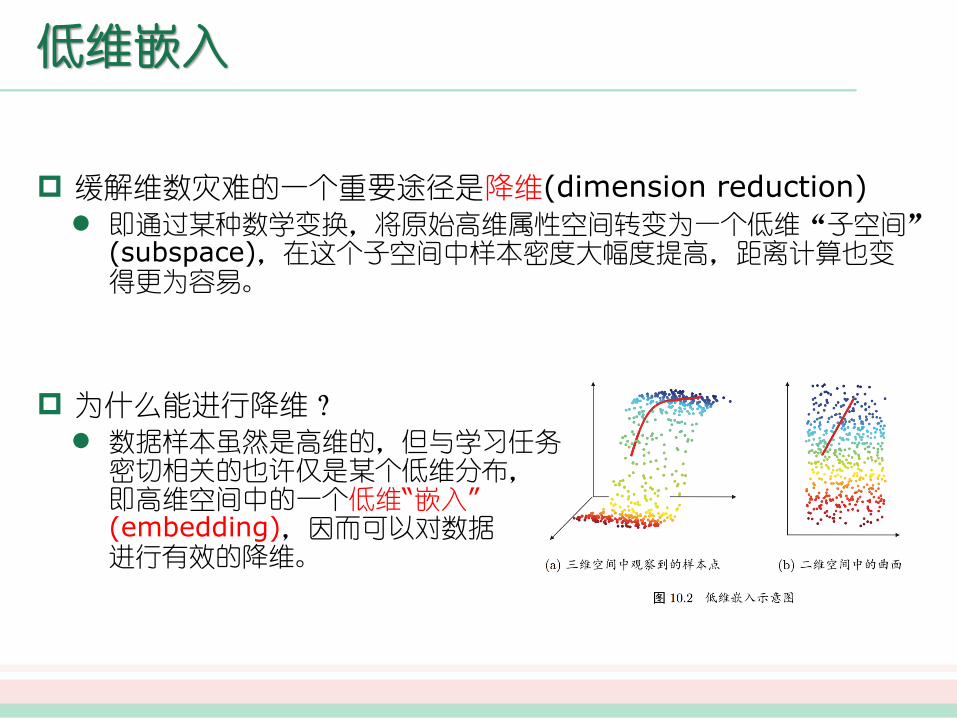
低维嵌入
缓解维数灾难的一个重要途径是降维(dimension reduction)
即通过某种数学变换,将原始高维属性空间转变为一个低维“子空间”(subspace),在这个子空间中样本密度大幅度提高,距离计算也变得更为容易。
为什么能进行降维?
数据样本虽然是高维的,但与学习任务密切相关的也许仅是某个低维分布,即高维空间中的一个低维“嵌入” (embedding),因而可以对数据进行有效的降维。

7. 典型降维算法比较?

从什么角度出发来降维
一般来说可以从两个角度来考虑做数据降维,一种是直接提取特征子集做特征抽取,一种是通过线性/非线性的方式将原来高维空间变换到一个新的空间。
后一种的角度一般有两种思路来实现,一种是基于从高维空间映射到低维空间的projection方法,其中代表算法就是PCA,而其他的LDA、Autoencoder也算是这种,主要目的就是学习或者算出一个矩阵变换W,用这个矩阵与高维数据相乘得到低
维数据。另一种是基于流形学习的方法,流形学习的目的是找到高维空间样本的低维描述,它假设在高维空间中数据会呈现一种有规律的低维流形排列,但是这种规律排列不能直接通过高维空间的欧式距离来衡量,如下图所示,某两点实际上的距离应该是下右图展开后的距离。如果能够有方法将高维空间中流形描述出来,那么在降维的过程中就能够保留这种空间关系,为了解决这个问题,流形学习假设高维空间的局部区域仍然具有欧式空间的性质,即它们的距离可以通过欧式距离算出(Isomap),或者某点坐标能够由临近的节点线性组合算出(LLE),从而可以获得高维空间的一种关
系,而这种关系能够在低维空间中保留下来,从而基于这种关系表示来进行降维,因此流形学习可以用来压缩数据、可视化、获取有效的距离矩阵等。
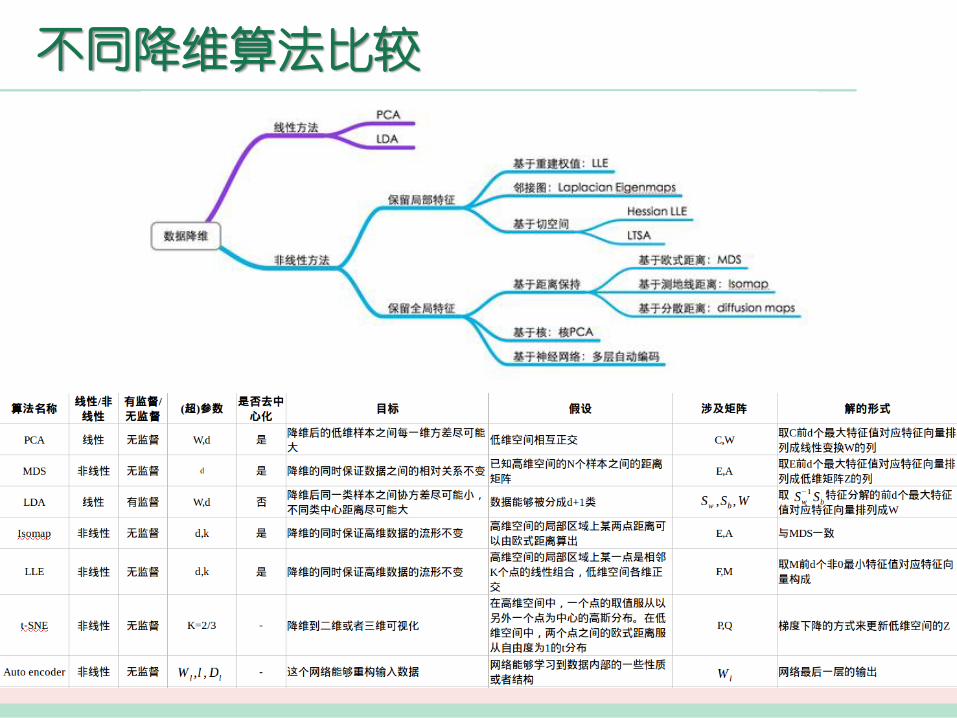
不同降维算法比较

8.关于度量学习

度量学习
研究动机
在机器学习中,对高维数据进行降维的主要目的是希望找到一个合适的低维空间,在此空间中进行学习能比原始空间性能更好。事实上,每个空间对应了在样本属性上定义的一个距离度量,而寻找合适的空间,实质上就是在寻找一个合适的距离度量。那么,为何不直接尝试“学习”出一个合适的距离度量呢?
度量学习(Metric Learning)度量(Metric)的定义
在数学中,一个度量(或距离函数)是一个定义集合中元素之间距离的函数。一个具有度量的集合被称为度量空间。度量学习(Metric Learning)也就是常说的相似度学习。距离测度学习
的目的即为了衡量样本之间的相近程度,而这也正是模式识别的核心问题之一。大量的机器学习方法,比如K近邻、支持向量机、径向基函数网络等分类方法以及K-means聚类方法,还有一些基于图的方法,其性能好坏都主要有样本之间的相似度量方法的选择决定。

度量学习的方法
度量学习方法可以分为通过线性变换的度量学习和度量学习的非线性模型
通过线性变换的度量学习由于线性度量学习具有简洁性和可扩展性(通过核方法可扩展为非线性度量方法),现今的研究重点放在了线性度量学习问
题上。线性的度量学习问题也称为马氏度量学习问题,可以分为监督的和非监督的学习算法。
监督的马氏度量学习可以分为以下两种基本类型:I 监督的全局度量学习:该类型的算法充分利用数据的标签信息。如• Information-theoretic metric learning(ITML)• Mahalanobis Metric Learning for Clustering([1]中的度量学习方法,有时也称为MMC)• Maximally Collapsing Metric Learning (MCML)

度量学习的方法
II 监督的局部度量学习:该类型的算法同时考虑数据的标签信息和数据点之间的几何关系。如
• Neighbourhood Components Analysis (NCA)• Large-Margin Nearest Neighbors (LMNN)• Relevant Component Analysis(RCA)• Local Linear Discriminative Analysis(Local LDA)

度量学习的方法
此外,一些很经典的非监督线性降维算法可以看作属于非监督的马氏度量学习。如•主成分分析(Pricipal Components Analysis, PCA)•多维尺度变换(Multi-dimensional Scaling, MDS)•非负矩阵分解(Non-negative Matrix Factorization,NMF)•独立成分分析(Independent components analysis, ICA)
•邻域保持嵌入(Neighborhood Preserving Embedding,NPE)•局部保留投影(Locality Preserving Projections. LPP)

度量学习的方法
度量学习的非线性模型
非线性的度量学习更加的一般化,非线性降维算法可以看作属于非线性度量学习。经典的算法有等距映射(Isometric Mapping,ISOMAP) 、局部线性嵌入(Locally Linear Embedding, LLE) ,以及拉普拉斯特征映射(Laplacian Eigenmap,LE ) 等。
另一个学习非线性映射的有效手段是通过核方法来对线性映射进行扩展。此外还有:• Non-Mahalanobis Local Distance Functions• Mahalanobis Local Distance Functions• Metric Learning with Neural Networks
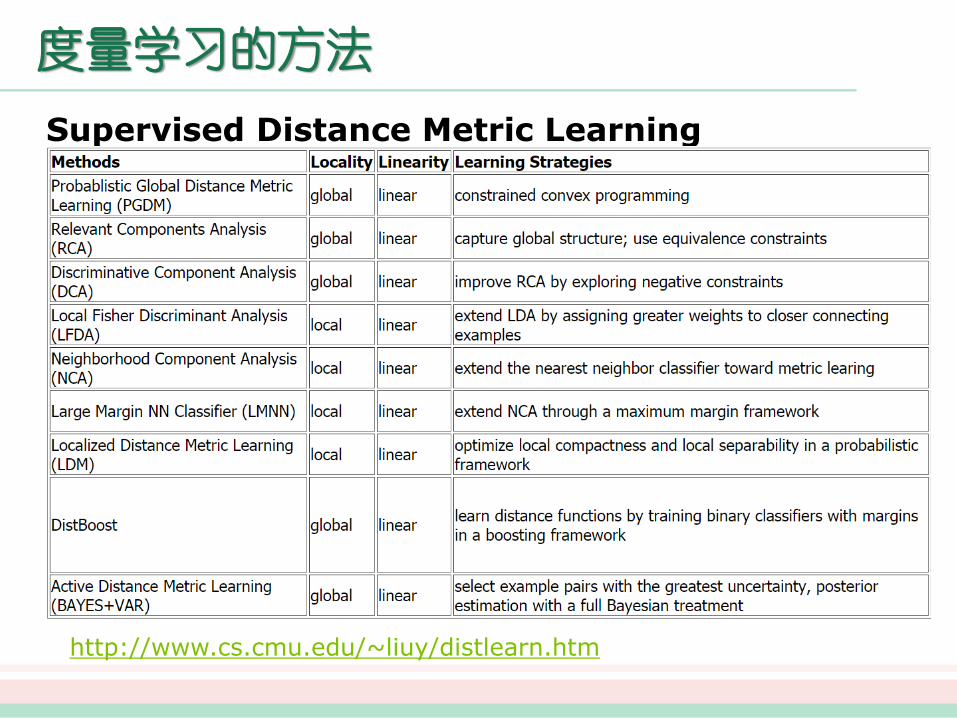
度量学习的方法
Supervised Distance Metric Learning
http://www.cs.cmu.edu/~liuy/distlearn.htm
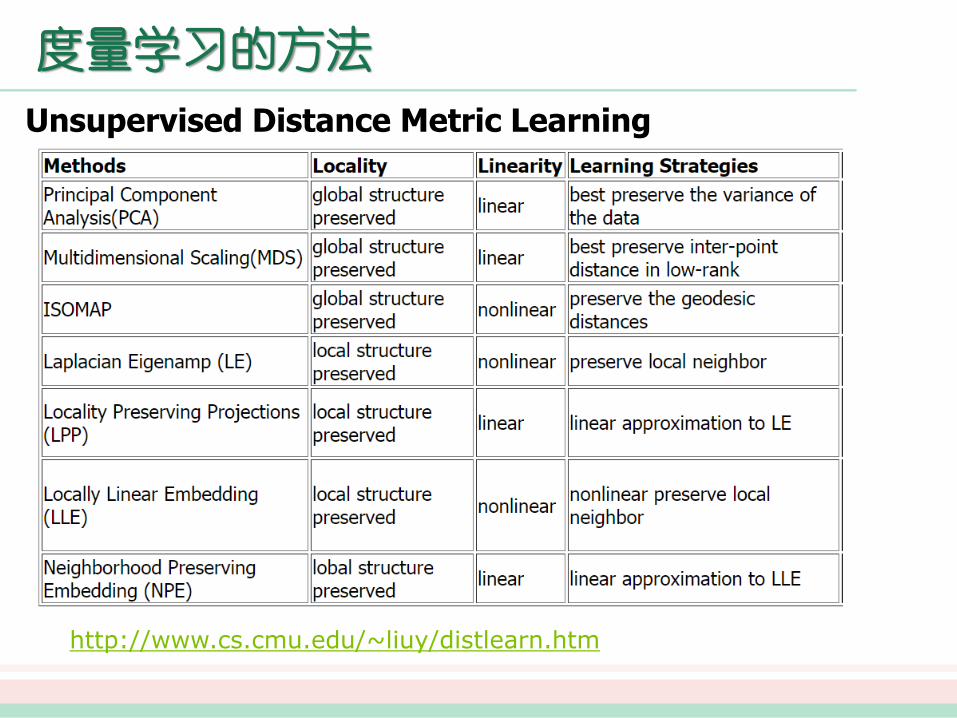
度量学习的方法
Unsupervised Distance Metric Learning
http://www.cs.cmu.edu/~liuy/distlearn.htm

本周课程:
ch11 特征选择与稀疏学习 ch12 计算学习理论
下周课程: ch13 半监督学习 ch14 概率图模型