利用weka进行大数据分析和挖掘 -...
TRANSCRIPT

2014/12/18 1
利用Weka进行大数据分析和挖掘
交流QQ群:117667692

• WEKA简介
• 数据集
• 数据准备
• 数据预处理
• 分类
• 聚类
• 关联规则
• 选择属性
• 数据可视化
• 知识流界面

2014/12/18 3
1、WEKA简介
• WEKA的全名是怀卡托智能分析环境• Waikato Environment for Knowledge Analysis
• Weka也是新西兰的一种鸟名
• 是新西兰怀卡托大学WEKA小组用Java开发的机器学习/数据挖掘开源软件。其源代码获取
• http://www.cs.waikato.ac.nz/ml/weka/
• http://prdownloads.sourceforge.net/weka/weka-3-6-6jre.exe
• 2005年8月,在第11届ACM SIGKDD国际会议上,怀卡托大学的WEKA小组荣获了数据挖掘和知识探索领域的最高服务奖,WEKA系统得到了广泛的认可,被誉为数据挖掘和机器学习历史上的里程碑,是现今最完备的数据挖掘工具之一。WEKA的每月下载次数已超过万次。

Weka学习配套教材:《数据挖掘:实用机器学习技术》第2版
http://huangbo929.blog.edu.cn/home.php?mod=space&uid=294073&do=blog&view=me&classid=2931&page=7

开源的数据(BigData)分析及挖掘软件:
1 weka http://www.cs.waikato.ac.nz/ml/weka/
2 Yale http://rapid-i.com/
3 KNIME http://www.knime.org/index.html
4 R (统计软件) http://www.r-project.org/
5 Rattle(R基础上的GUI) http://rattle.togaware.com/
6 AlphaMiner(哈工大基于weka内核开发)
http://bi.hitsz.edu.cn/AlphaMiner/index.htm
7 在Excel中实现了决策树、神经网络等算法。
http://www.geocities.com/adotsaha/
8 Apache Lucene:http://lucene.apache.org/

2014/12/18 6
WEKA软件
• 主要特点
• 它是集数据预处理、学习算法(分类、回归、聚类、关联分析)和评估方法等为一体的综合性数据挖掘工具。
• 具有交互式可视化界面。• 提供算法学习比较环境• 通过其接口,可实现自己的数据挖掘算法
WEKA的界面

2014/12/18 7
探索环境
命令行环境知识流环境
算法试验环境

2014/12/18 8
Explorer环境

2014/12/18 9
把“Explorer”界面分成8个区域
• 区域1的几个选项卡是用来切换不同的挖掘任务面板。
• Preprocess(数据预处理):选择和修改要处理的数据。
• Classify(分类):训练和测试分类或回归模型。
• Cluster(聚类):从数据中聚类。
• Associate(关联分析):从数据中学习关联规则。
• Select Attributes(选择属性):选择数据中最相关的属性。
• Visualize(可视化):查看数据的二维散布图。
• 区域2是一些常用按钮。包括打开、编辑、保存数据及数据转换等功能。
例如,我们可以把文件“bank-data.csv”另存为“bank-data.arff”。
• 区域3中可以选择(Choose)某个筛选器(Filter),以实现筛选数据或
者对数据进行某种变换。数据预处理主要就利用它来实现。

2014/12/18 10
• 区域4展示了数据集的关系名、属性数和实例数等基本情况。
• 区域5中列出了数据集的所有属性。
• 勾选一些属性并“Remove”就可以删除它们,删除后还可以利用区域2的“Undo”按钮找回。
• 区域5上方的一排按钮是用来实现快速勾选的。
• 区域6中显示在区域5中选中的当前某个属性的摘要。
• 摘要包括属性名(Name)、属性类型(Type)、缺失值(Missing)数及比例、不同值(Distinct )数、唯一值(Unique)数及比例
• 对于数值属性和标称属性,摘要的方式是不一样的。图中显示的是对数值属性“income”的摘要。
• 数值属性显示最小值(Minimum)、最大值(Maximum)、均值(Mean)和标准差(StdDev)
• 标称属性显示每个不同值的计数

2014/12/18 11
• 区域7是区域5中选中属性的直方图。
• 若数据集的最后一个属性(这是分类或回归任务的默认目标
变量)是类标变量(例如“pep” ),直方图中的每个长方
形就会按照该变量的比例分成不同颜色的段。
• 要想换个分段的依据,在区域7上方的下拉框中选个不同的
分类属性就可以了。
• 下拉框里选上“No Class”或者一个数值属性会变成黑白的直
方图。

2014/12/18 12
• 区域8窗口的底部区域,包括状态栏、log按钮和Weka鸟。
• 状态栏(Status)显示一些信息让你知道正在做什么。例如,如
果 Explorer 正忙于装载一个文件,状态栏就会有通知。
• 在状态栏中的任意位置右击鼠标将会出现一个小菜单。这个菜
单给了你两个选项:
• Memory Information--显示WEKA可用的内存量。
• Run garbage collector--强制运行Java垃圾回收器,搜索不再
需要的内存空间并将之释放,从而可为新任务分配更多的内
存。
• Log按钮可以查看以weka操作日志。
• 右边的weka鸟在动的话,说明WEKA正在执行挖掘任务。

2014/12/18 13
KnowledgeFlow环境

2014/12/18 14
2、WEKA数据集
• WEKA所处理的数据集是一个.arff文件的二维表

2014/12/18 15
• 表格里的一个横行称作一个实例(Instance),相当于统计学中的一个样本,或者数据库中的一条记录。
• 竖行称作一个属性(Attribute),相当于统计学中的一个变量,或者数据库中的一个字段。
• 这样一个表格,或者叫数据集,在WEKA看来,呈现了属性之间的一种关系(Relation)。
• 上图中一共有14个实例,5个属性,关系名称为“weather”。
• WEKA存储数据的格式是ARFF(Attribute-Relation File Format)文件,这是一种ASCII文本文件。
• 上图所示的二维表格存储在如下的ARFF文件中。这也就是WEKA自带的“weather.arff”文件,在WEKA安装目录的“data”子目录下可以找到。

@relation weather
@attribute outlook {sunny, overcast, rainy}
@attribute temperature real@attribute humidity real@attribute windy {TRUE, FALSE}@attribute play {yes, no}
@data
sunny,85,85,FALSE,nosunny,80,90,TRUE,noovercast,83,86,FALSE,yesrainy,70,96,FALSE,yesrainy,68,80,FALSE,yesrainy,65,70,TRUE,noovercast,64,65,TRUE,yessunny,72,95,FALSE,nosunny,69,70,FALSE,yesrainy,75,80,FALSE,yessunny,75,70,TRUE,yesovercast,72,90,TRUE,yesovercast,81,75,FALSE,yesrainy,71,91,TRUE,no

2014/12/18 17
WEKA数据文件
• WEKA存储数据的格式是ARFF(Attribute-Relation File Format)文件
• 这是一种ASCII文本文件
• 文件的扩展名为.arff
• 可以用写字板打开、编辑 ARFF文件
• 文件中以“%”开始的行是注释,WEKA将忽略这些行。
• 除去注释后,整个ARFF文件可以分为两个部分:
• 第一部分给出了头信息(Head information),包括了对关系的声明和对属性的声明。
• 第二部分给出了数据信息(Data information),即数据集中给出的数据。从“@data”标记开始,后面的就是数据信息了。


2014/12/18 19
关系声明
• 关系名称在ARFF文件的第一个有效行来定义,格式为:
@relation <关系名>
• <关系名>是一个字符串。如果这个字符串包含空格,它必须加上引号(指英文标点的单引号或双引号)。

2014/12/18 20
属性声明
• 属性声明用一列以“@attribute”开头的语句表示。
• 数据集中的每一个属性都有对应的“@attribute”语句,来定义它的属性名称和数据类型(datatype):
@attribute <属性名> <数据类型>
• 其中<属性名>必须以字母开头的字符串。和关系名称一样,如果这个字符串包含空格,它必须加上引号。
• 属性声明语句的顺序很重要,它表明了该项属性在数据部分的位置。
• 例如,“humidity”是第三个被声明的属性,这说明数据部分那些被逗号分开的列中,第2列(从第0列开始)数据 85 90 86 96 ... 是相应的“humidity”值。
• 其次,最后一个声明的属性被称作class属性,在分类或回归任务中,它是默认的目标变量。

2014/12/18 21
数据类型
• WEKA支持四种数据类型
• numeric 数值型
• <nominal-specification> 标称(nominal)型
• string 字符串型
• date [<date-format>] 日期和时间型
• 还可以使用两个类型“integer”和“real”,但是WEKA把它们都当作“numeric”看待。
• 注意:“integer”,“real”,“numeric”,“date”,“string”这些关键字是区分大小写的,而“relation”、“attribute ”和“data”则不区分。

2014/12/18 22
• 数值型属性• 数值型属性可以是整数或者实数,但WEKA把它们都当作实数看待。例如:
@attribute temperature real
• 字符串属性• 字符串属性可以包含任意的文本。例如:
@attribute LCC string

2014/12/18 23
• 标称属性• 标称属性由<nominal-specification>列出一系列可能的类别名称并放在花括号中:{<nominal-name1>, <nominal-name2>, <nominal-name3>, ...} 。
• 数据集中该属性的值只能是其中一种类别。
• 例如属性声明:
@attribute outlook {sunny, overcast, rainy}
说明“outlook”属性有三种类别:“sunny”,“ overcast”和“rainy”。而数据集中每个实例对应的“outlook”值必是这三者之一。
• 如果类别名称带有空格,仍需要将之放入引号中。

2014/12/18 24
• 日期和时间属性
• 日期和时间属性统一用“date”类型表示,它的格式是:
@attribute <属性名> date [<date-format>]
• 其中<date-format>是一个字符串,来规定该怎样解析和显示日期或时间的格式,默认的字符串是ISO-8601所给的日期时间组合格式:
“yyyy-MM-dd HH:mm:ss”
• 数据信息部分表达日期的字符串必须符合声明中规定的格式要求,例如:@ATTRIBUTE timestamp DATE "yyyy-MM-dd HH:mm:ss" @DATA "2011-05-03 12:59:55"

2014/12/18 25
数据信息
• 数据信息中“@data”标记独占一行,剩下的是各个实例的
数据。
• 每个实例占一行,实例的各属性值用逗号“,”隔开。
• 如果某个属性的值是缺失值(missing value),用问号“?”
表示,且这个问号不能省略。
• 例如:
@data
sunny,85,85,FALSE,no
?,78,90,?,yes

2014/12/18 26
稀疏数据
• 有的时候数据集中含有大量的0值,这个时候用稀疏格式的数据存储更加省空间。
• 稀疏格式是针对数据信息中某个对象的表示而言,不需要修改ARFF文件的其它部分。例如数据:
• @data 0, X, 0, Y, "class A" 0, 0, W, 0, "class B"
• 用稀疏格式表达的话就是@data
{1 X, 3 Y, 4 "class A"} {2 W, 4 "class B"}
• 注意:ARFF数据集最左端的属性列为第0列,因此,1 X表示X为第1列属性值。

2014/12/18 27
3、数据准备
• 数据获取
• 直接使用ARFF文件数据。
• 从CSV,C4.5,binary等多种格式文件中导入。
• 通过JDBC从SQL数据库中读取数据。
• 从URL(Uniform Resource Locator)获取网络资源的数据。
• 数据格式转换
• ARFF格式是WEKA支持得最好的文件格式。
• 使用WEKA作数据挖掘,面临的第一个问题往往是数据不是ARFF
格式的。
• WEKA还提供了对CSV文件的支持,而这种格式是被很多其他软件
(比如Excel)所支持。
• 可以利用WEKA将CSV文件格式转化成ARFF文件格式。

2014/12/18 28
数据资源
• WEKA自带的数据集C:\Program Files\Weka-3-6\data
• 网络数据资源
http://archive.ics.uci.edu/ml/datasets.html

2014/12/18 29
.XLS .CSV .ARFF
• Excel的XLS文件可以让多个二维表格放到不同的工作表(Sheet)中,只能把每个工作表存成不同的CSV文件。
• 打开一个XLS文件并切换到需要转换的工作表,另存为CSV类型,点“确定”、“是”忽略提示即可完成操作。
• 在WEKA中打开一个CSV类型文件,再另存为ARFF类型文件即可。

2014/12/18 30
打开Excel的Iris.xls文件
2014/12/18 31

2014/12/18 32
将iris.xls另存为iris.csv文件

2014/12/18 33
2014/12/18 34
2014/12/18 35
在weka的Explorer中打开Iris.csv文件

2014/12/18 36

2014/12/18 37
将iris. csv另存为iris. arff 文件
2014/12/18 38

2014/12/18 39
4、数据预处理 preprocess
• 在WEKA中数据预处理工具称作筛选器(filters)
• 可以定义筛选器来以各种方式对数据进行变换。
• Filter 一栏用于对各种筛选器进行必要的设置。
• Choose 按钮:点击这个按钮就可选择 WEKA 中的某个筛选器。
• 选定一个筛选器后,它的名字和选项会显示在 Choose 按钮旁边的文本框中。

2014/12/18 40
载入数据
• Explorer的预处理( preprocess )页区域2的前4个按钮用
来把数据载入WEKA:
• Open file.... 打开一个对话框,允许你浏览本地文件系
统上的数据文件。
• Open URL.... 请求一个存有数据的URL地址。
• Open DB.... 从数据库中读取数据。
• Generate.... 从一些数据生成器(DataGenerators)中
生成人造数据。

2014/12/18 41
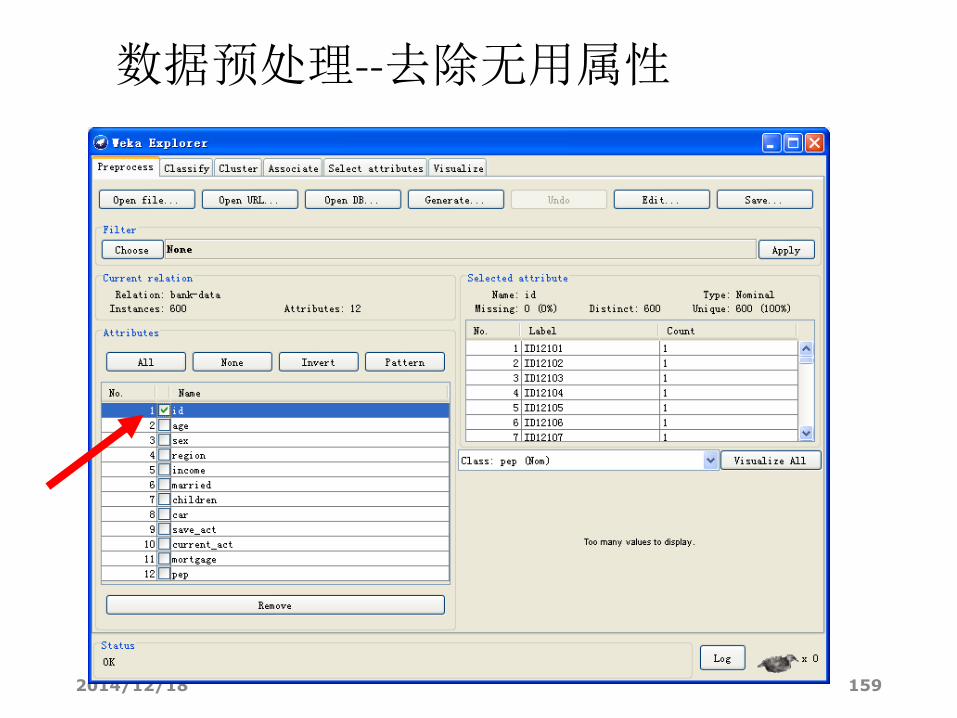
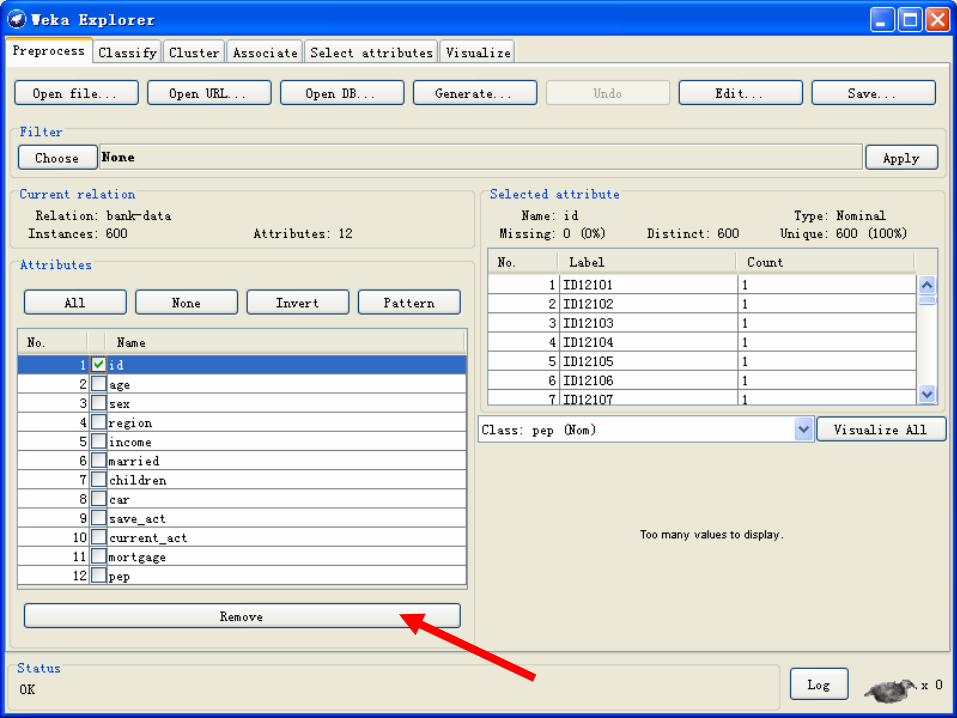
去除无用属性
• 通常对于数据挖掘任务来说,像ID这样的信息是无用的,
可以将之删除。
• 在区域5勾选属性“id”,并点击“Remove”。
• 将新的数据集保存,并重新打开。

2014/12/18 42
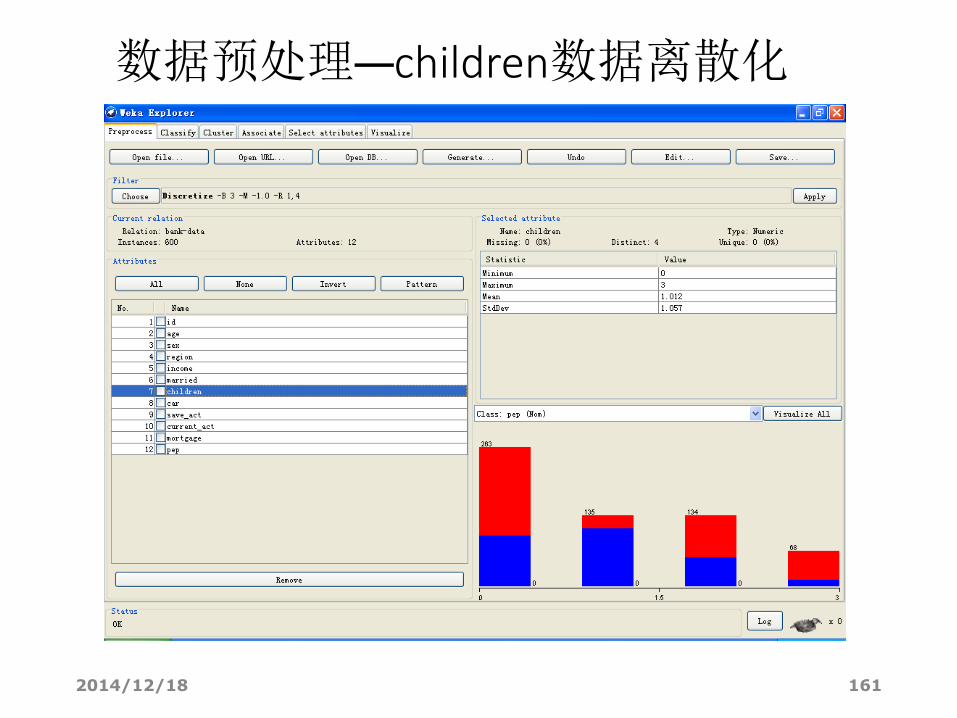
数据离散化
• 有些算法(如关联分析),只能处理标称型属性,这时候就需要对数值型的属性进行离散化。
• 对取值有限的数值型属性可通过修改.arff文件中该属性数据类型实现离散化。
• 例如,在某数据集中的 “children”属性只有4个数值型取值:0,1,2,3。
• 我们直接修改ARFF文件,把@attribute children numeric
改为@attribute children {0,1,2,3}
就可以了。
• 在“Explorer”中重新打开“bank-data.arff”,看看选中“children”属性后,区域6那里显示的“Type” 变成“Nominal”了。

2014/12/18 43
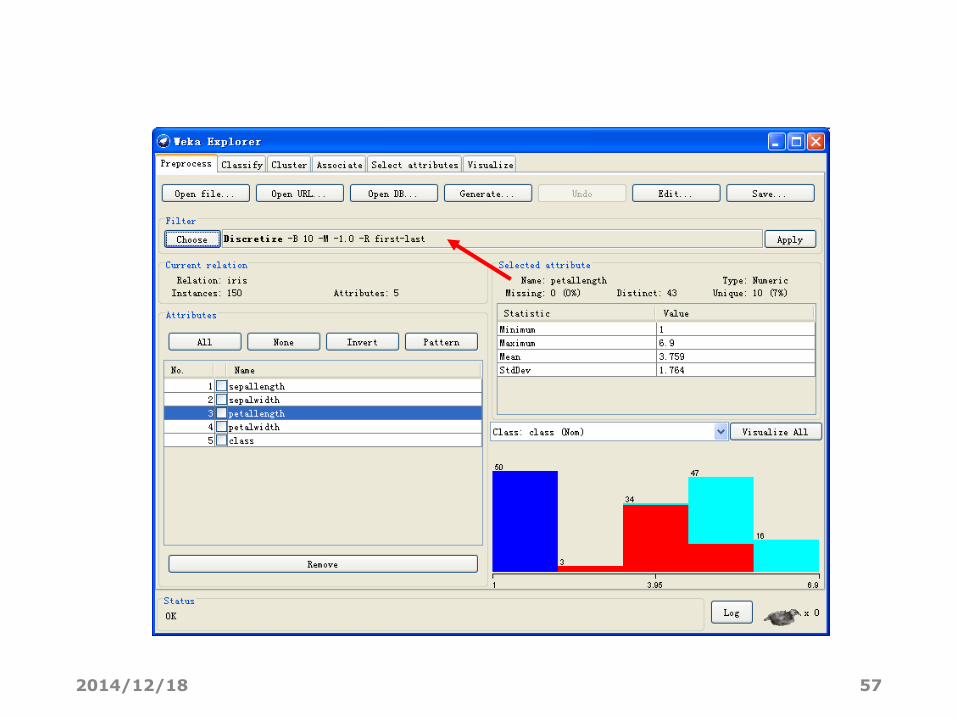
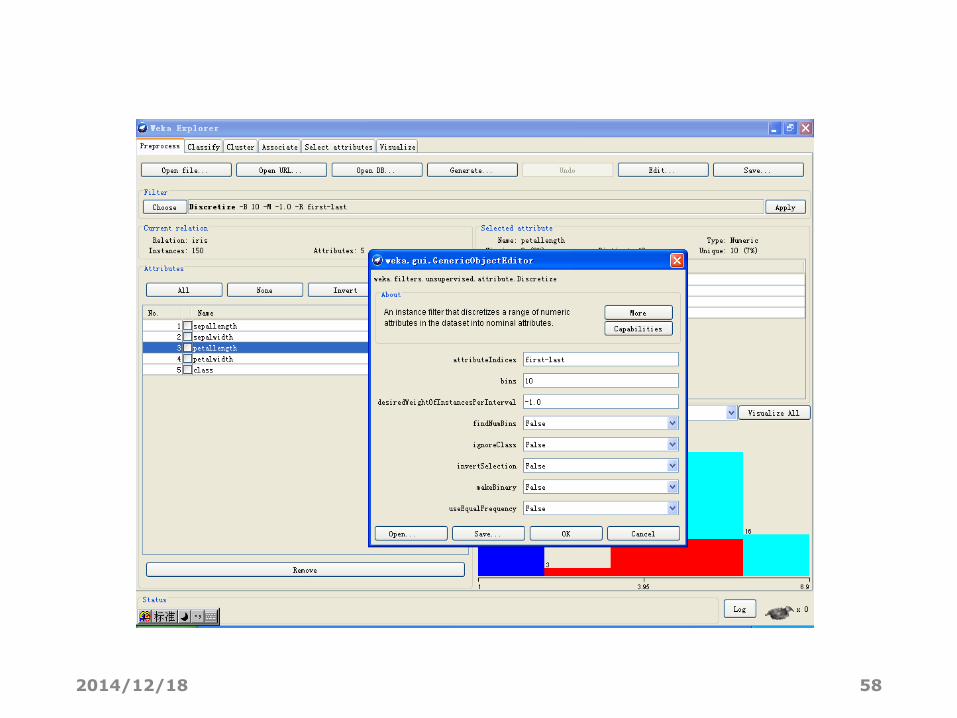
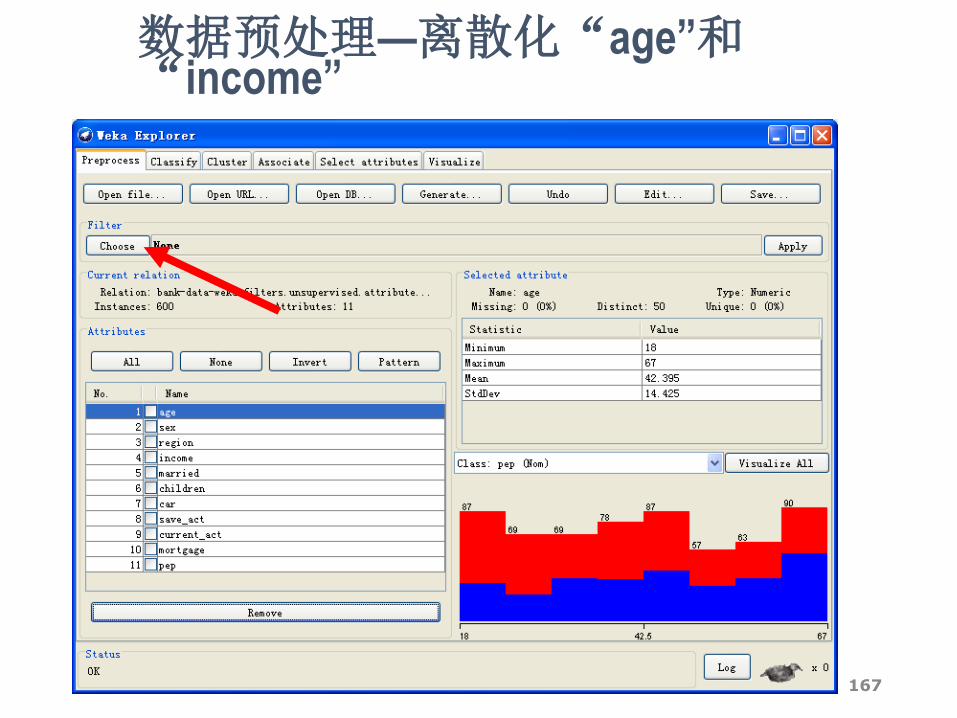
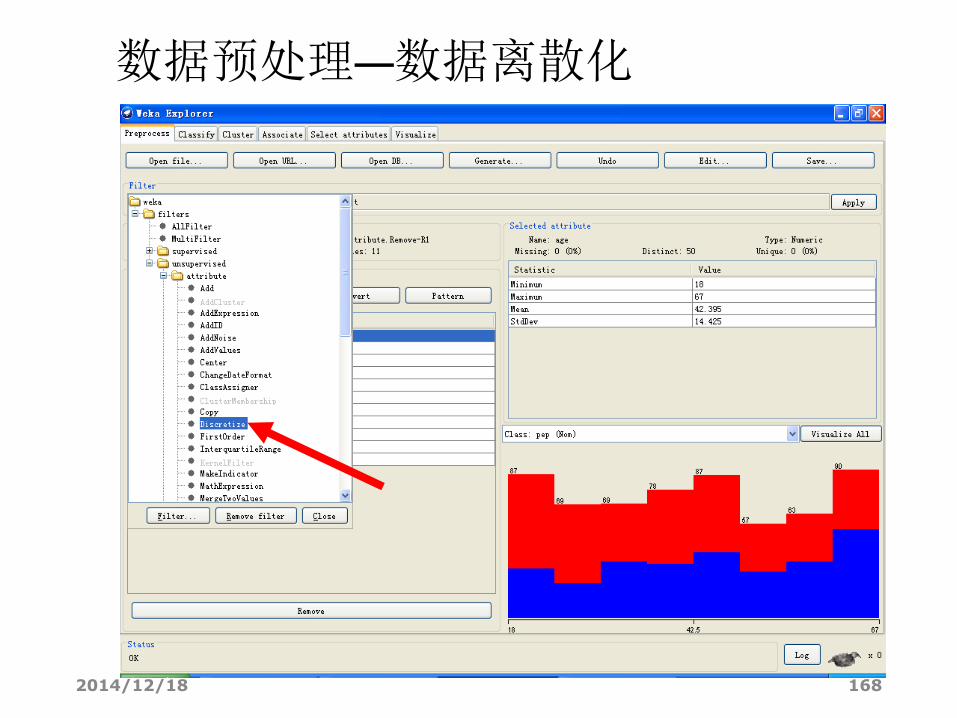
• 对取值较多的数值型属性,离散化可借助WEKA中名为“Discretize”的Filter来完成。
• 在区域2中点“Choose”,出现一棵“Filter树”,逐级找到“weka.filters.unsupervised.attribute.Discretize”,点击。
• 现在“Choose”旁边的文本框应该显示“Discretize -B 10 -M -0.1 -R first-last”。
• 点击这个文本框会弹出新窗口以修改离散化的参数。
2014/12/18 44
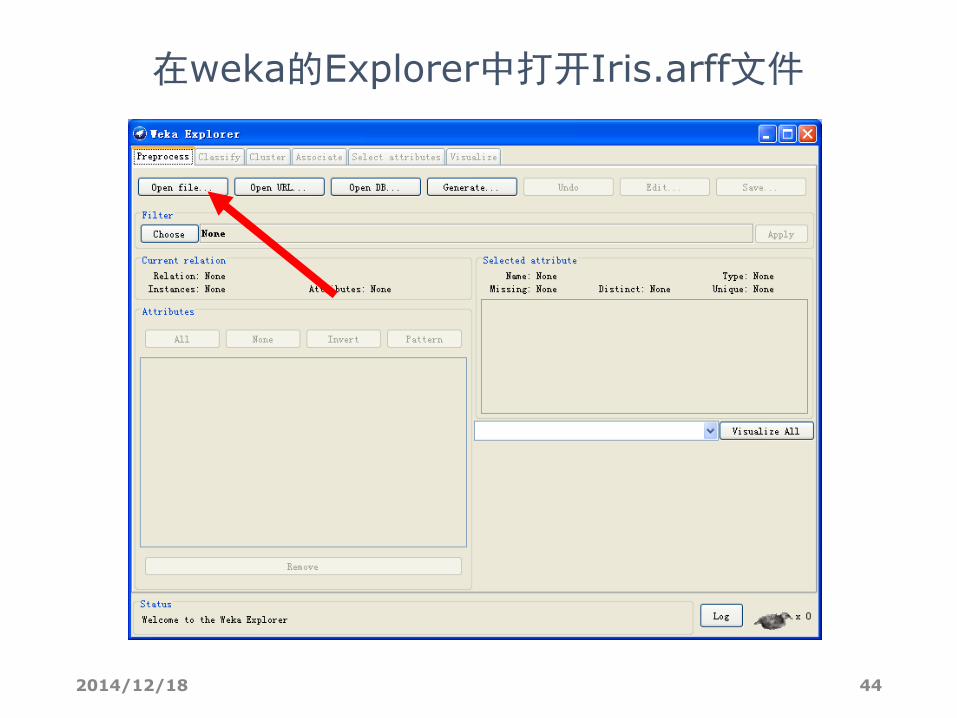
在weka的Explorer中打开Iris.arff文件

2014/12/18 45
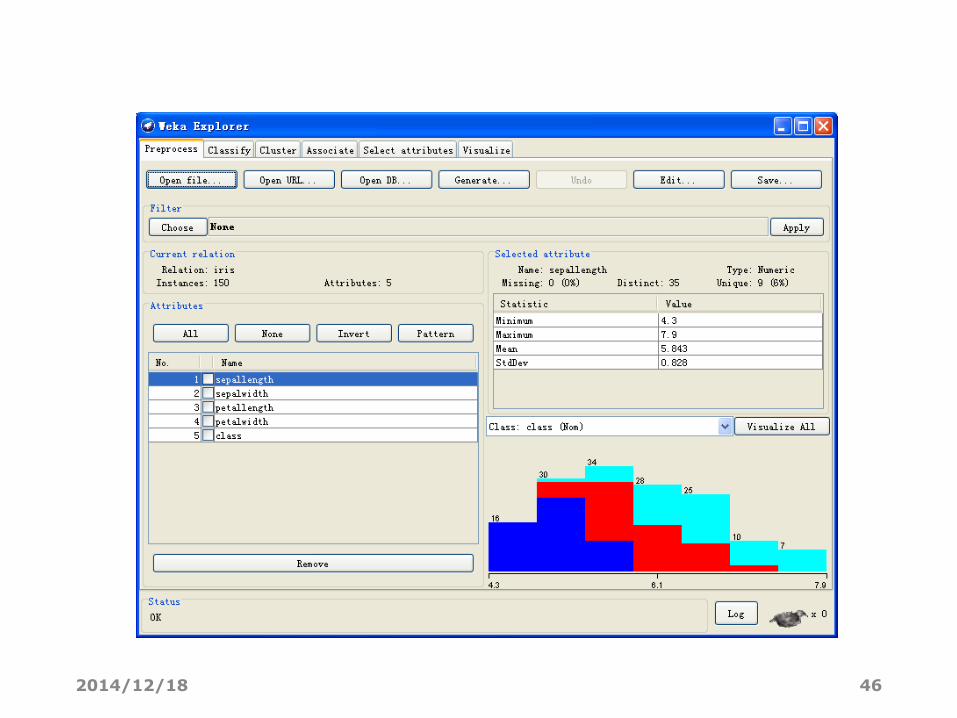
2014/12/18 46
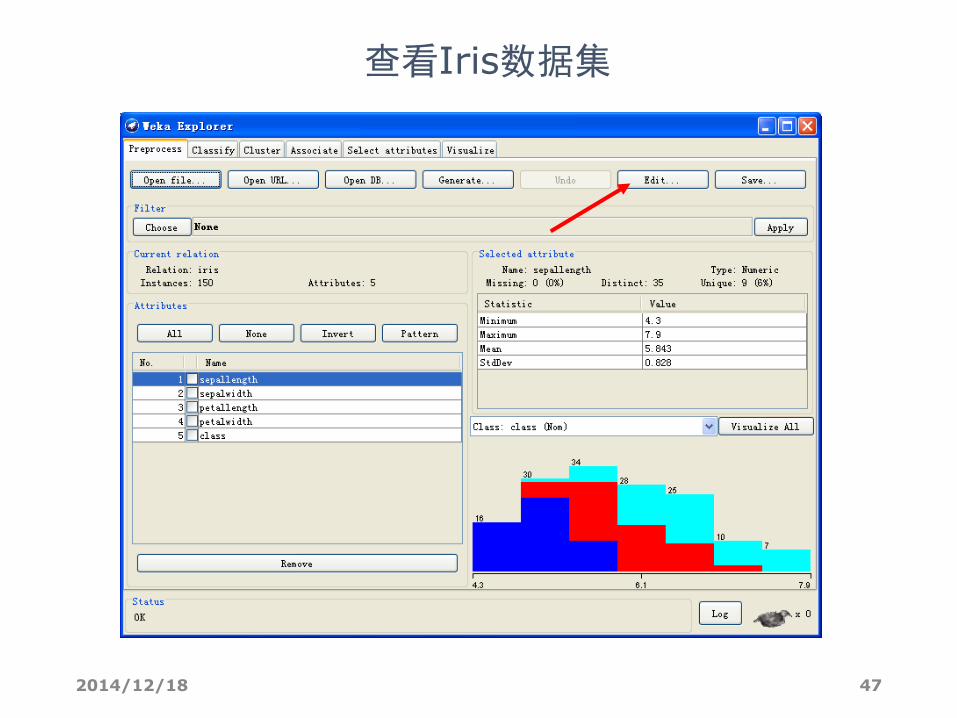
2014/12/18 47
查看Iris数据集
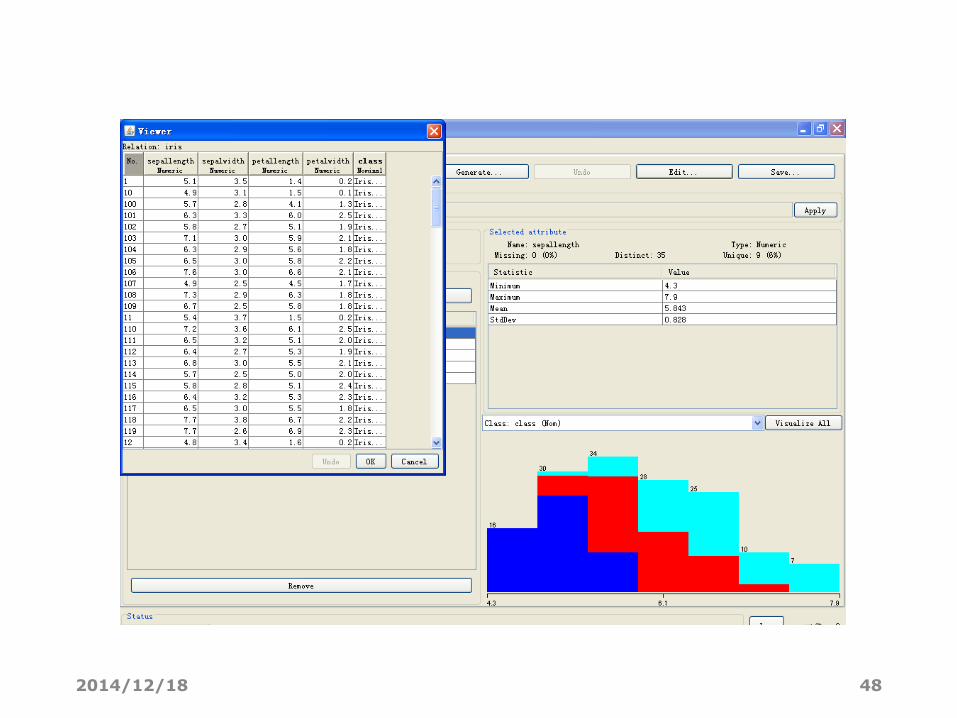
2014/12/18 48
2014/12/18 49
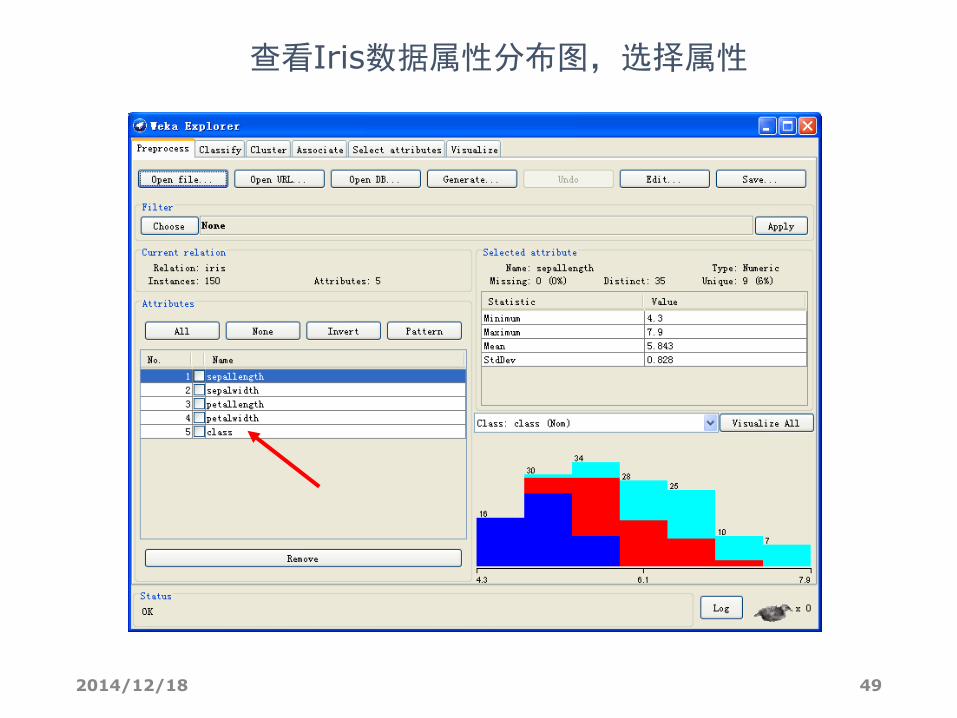
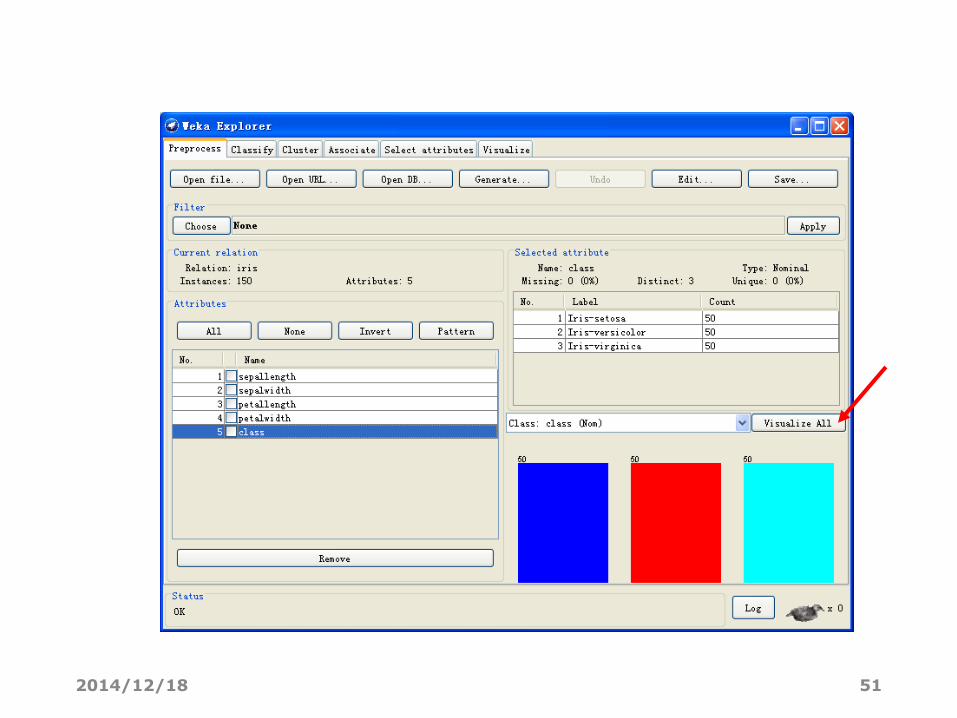
查看Iris数据属性分布图,选择属性

2014/12/18 50
2014/12/18 51
2014/12/18 52
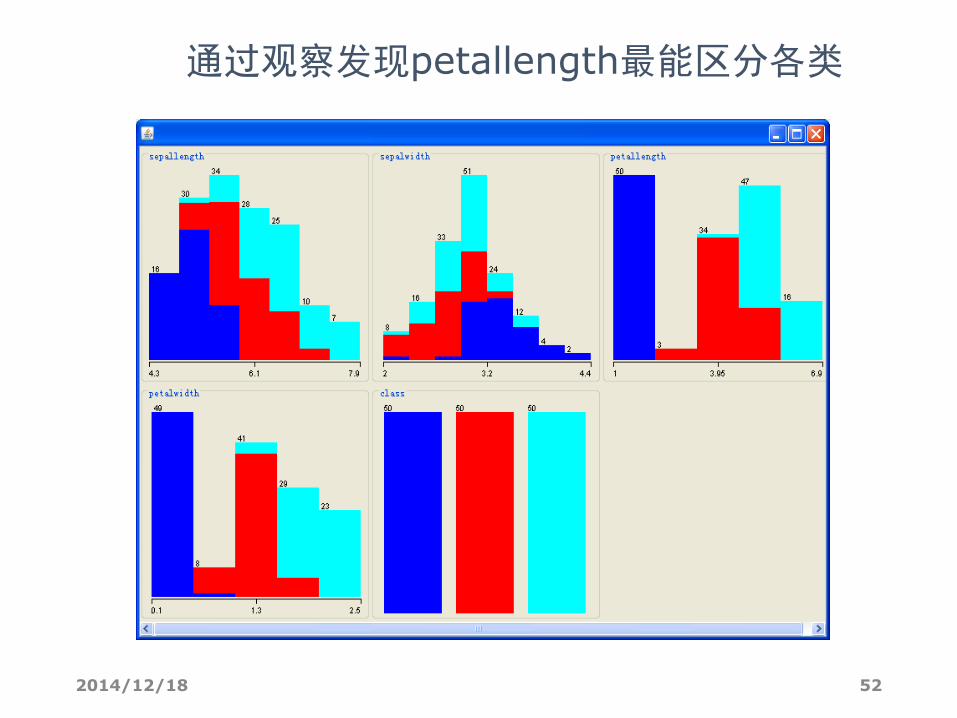
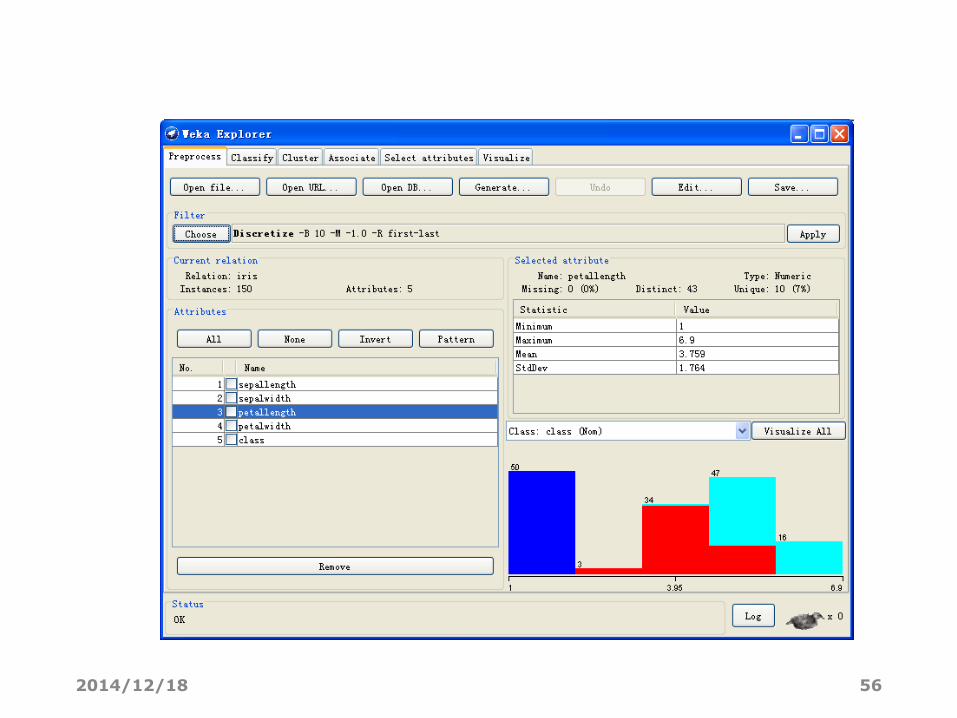
通过观察发现petallength最能区分各类

2014/12/18 53
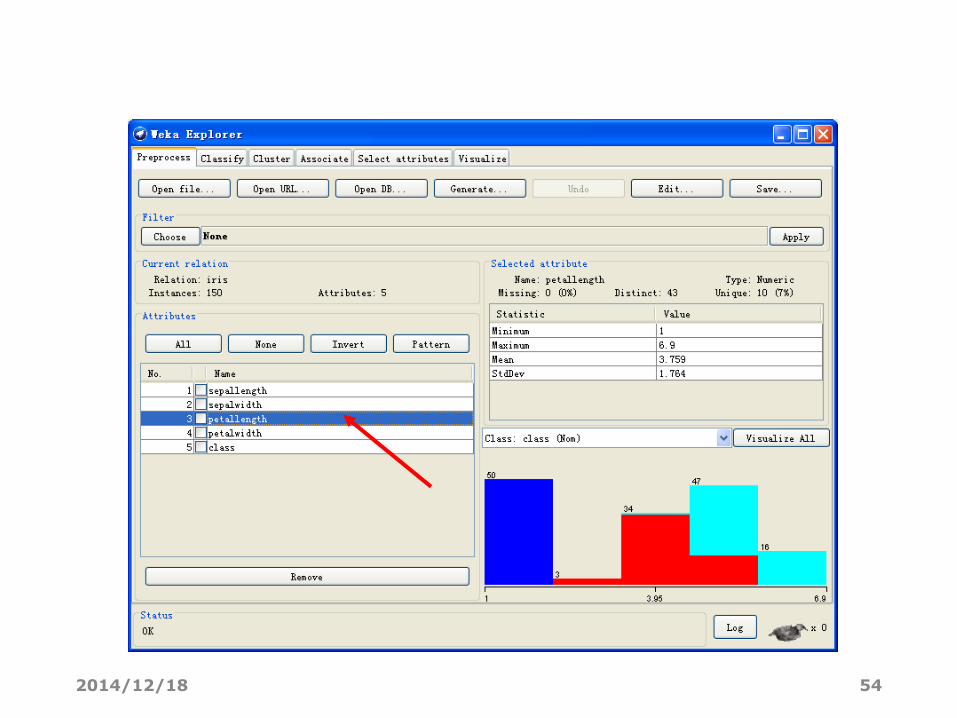
将属性petallength离散化
2014/12/18 54

2014/12/18 55
2014/12/18 56
2014/12/18 57
2014/12/18 58

2014/12/18 59
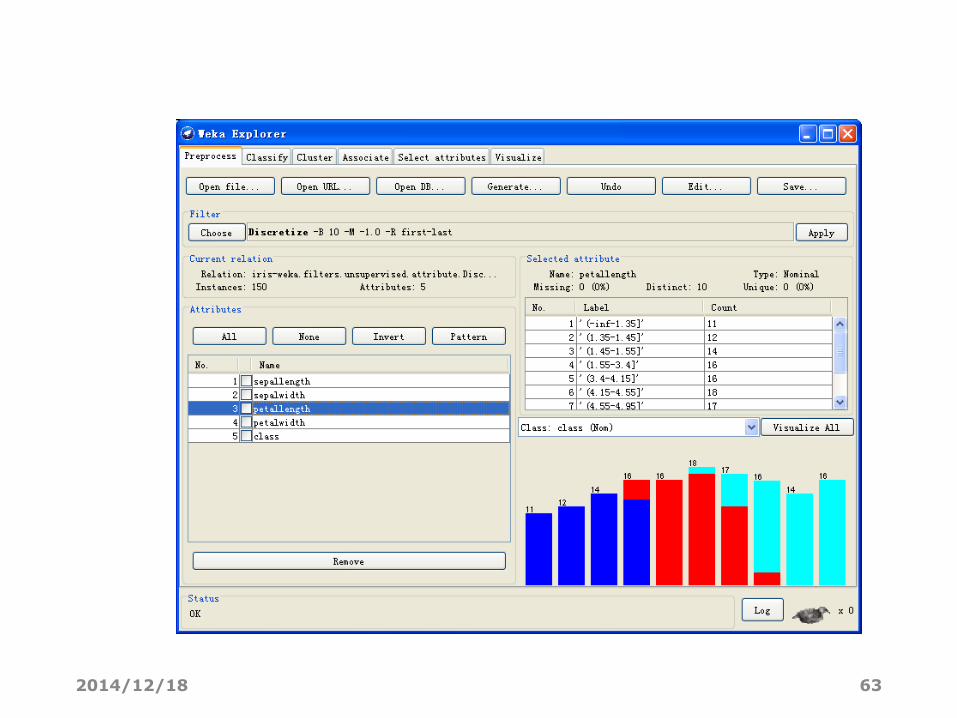
离散化成10段数据
等频离散化
离散化成10段数据

2014/12/18 60

2014/12/18 61

2014/12/18 62
2014/12/18 63

2014/12/18 64
查看离散化后的Iris数据集

2014/12/18 65

2014/12/18 66
5、分类 Classify
• WEKA把分类(Classification)和回归(Regression)都放在“Classify”选项卡
中。
• 在这两个数据挖掘任务中,都有一个目标属性(类别属性,输出变
量)。
• 我们希望根据一个WEKA实例的一组特征属性(输入变量),对目标
属性进行分类预测。
• 为了实现这一目的,我们需要有一个训练数据集,这个数据集中每个
实例的输入和输出都是已知的。观察训练集中的实例,可以建立起预
测的分类/回归模型。
• 有了这个模型,就可以对新的未知实例进行分类预测。
• 衡量模型的好坏主要在于预测的准确程度。

2014/12/18 67
WEKA中的典型分类算法
• Bayes: 贝叶斯分类器
• BayesNet: 贝叶斯信念网络
• NaïveBayes: 朴素贝叶斯网络
• Functions: 人工神经网络和支持向量机
• MultilayerPerceptron: 多层前馈人工神经网络
• SMO: 支持向量机(采用顺序最优化学习方法)
• Lazy: 基于实例的分类器
• IB1: 1-最近邻分类器
• IBk: k-最近邻分类器

2014/12/18 68
选择分类算法
• Meta: 组合方法
• AdaBoostM1: AdaBoost M1方法
• Bagging: 袋装方法
• Rules: 基于规则的分类器
• JRip: 直接方法-Ripper算法
• Part: 间接方法-从J48产生的决策树抽取规则
• Trees: 决策树分类器
• Id3: ID3决策树学习算法(不支持连续属性)
• J48: C4.5决策树学习算法(第8版本)
• REPTree: 使用降低错误剪枝的决策树学习算法
• RandomTree: 基于决策树的组合方法
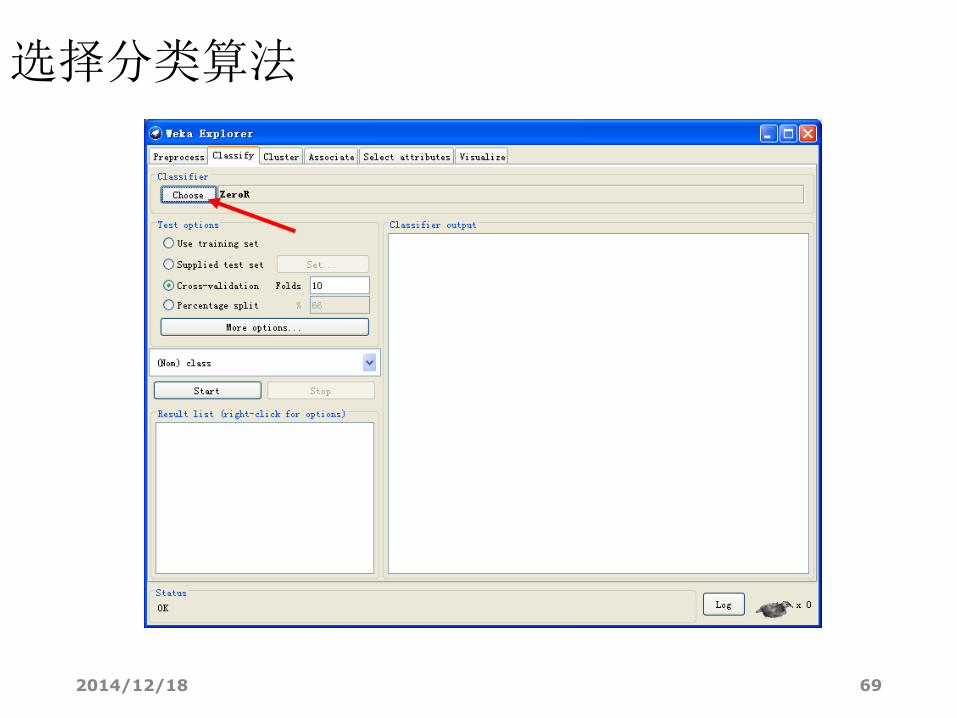
2014/12/18 69
选择分类算法

2014/12/18 70

2014/12/18 71
选择模型评估方法
• 四种方法
• Using training set 使用训练集评估
• Supplied test set 使用测试集评估
• Cross-validation 交叉验证
• 设置折数Folds
• Percentage split 保持方法。使用一定比例的训练实例作评估
• 设置训练实例的百分比

2014/12/18 72
选择模型评估方法

2014/12/18 73
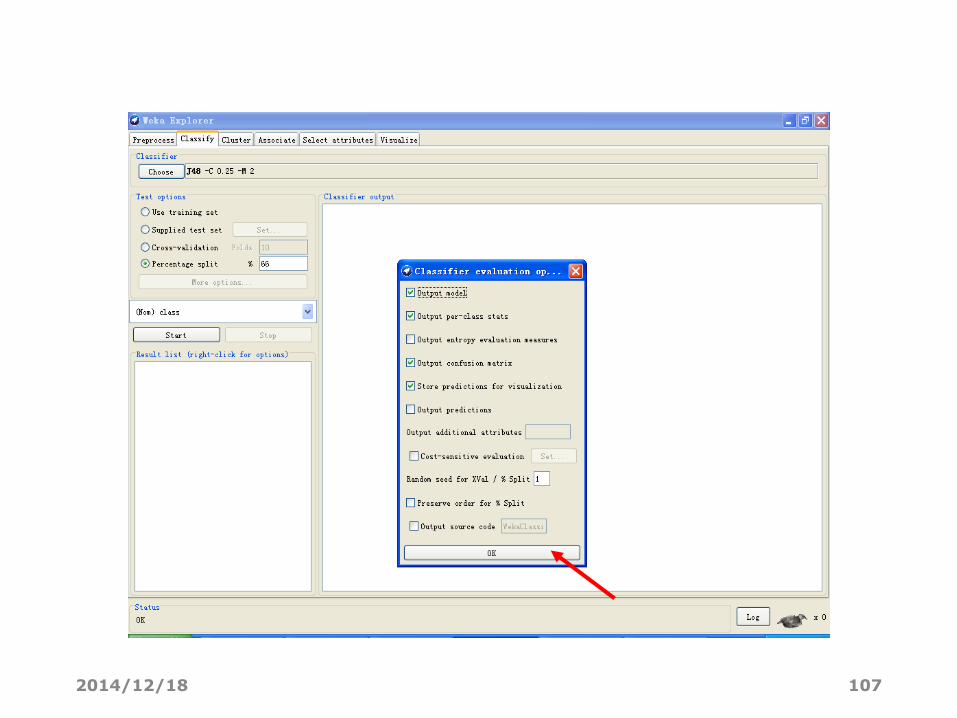
• Output model. 输出基于整个训练集的分类模型,从而模型可以被查看,可视化等。该选项默认选中。
• Output per-class stats. 输出每个class的准确度/反馈率(precision/recall)和正确/错误(true/false)的统计量。该选项默认选中。
• Output evaluation measures. 输出熵估计度量。该选项默认没有选中。
• Output confusion matrix. 输出分类器预测结果的混淆矩阵。该选项默认选中。
• Store predictions for visualization. 记录分类器的预测结果使得它们能被可视化表示。
• Output predictions. 输出测试数据的预测结果。注意在交叉验证时,实例的编号不代表它在数据集中的位置。
• Cost-sensitive evaluation. 误差将根据一个价值矩阵来估计。Set… 按钮用来指定价值矩阵。
• Random seed for xval / % Split. 指定一个随即种子,当出于评价的目的需要分割数据时,它用来随机化数据。
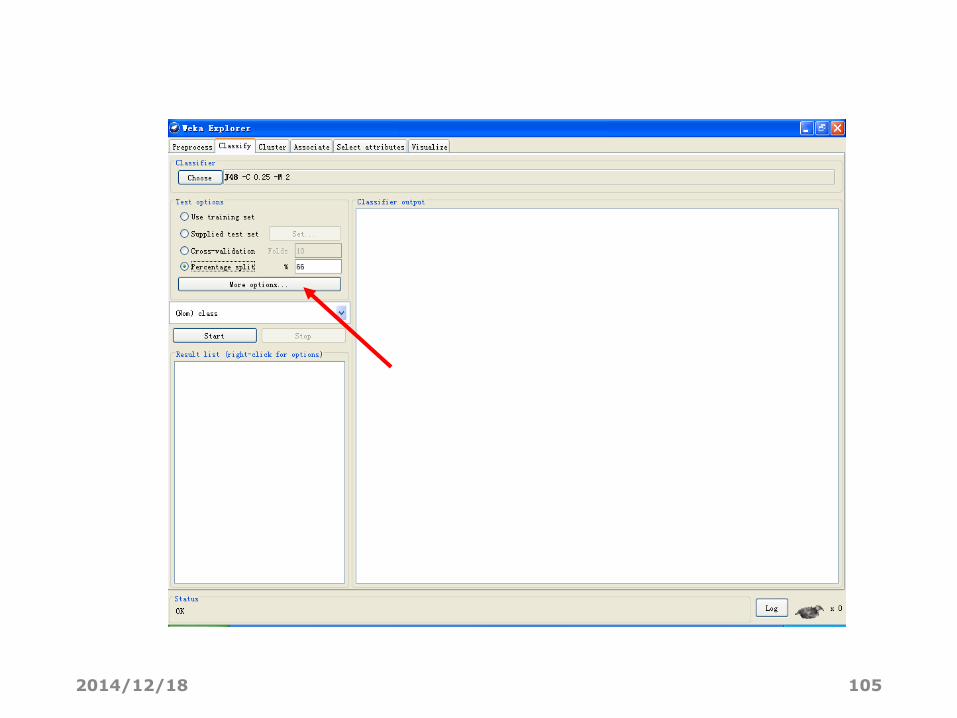
点击More options 按钮可以设置更多的测试选项:

2014/12/18 74
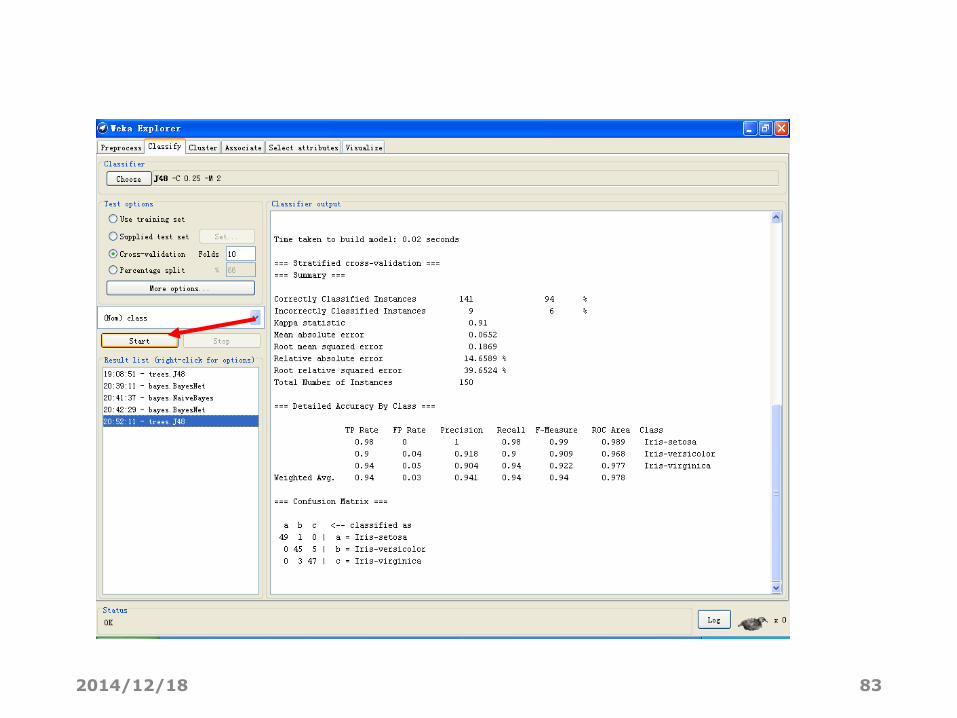
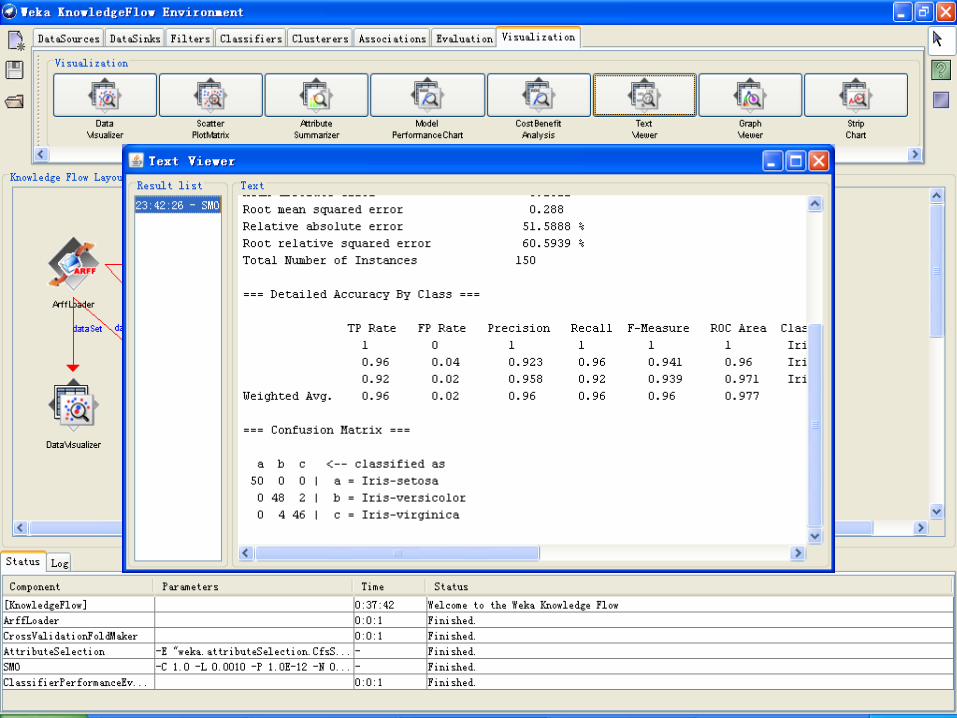
文字结果分析
• 单击start按钮,Classifier output窗口显示的文字结果信息:
• Run information 运行信息
• Classifier model (full training set) 使用全部训练数据构
造的分类模型
• Summary 针对训练/检验集的预测效果汇总。
• Detailed Accuracy By Class 对每个类的预测准确度的详细
描述。
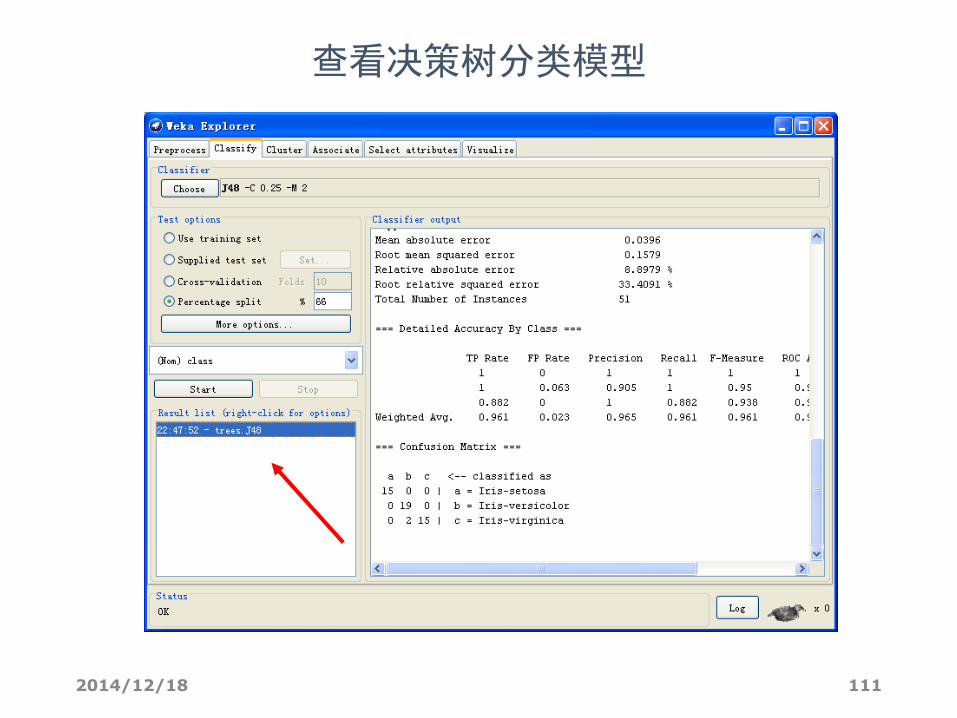
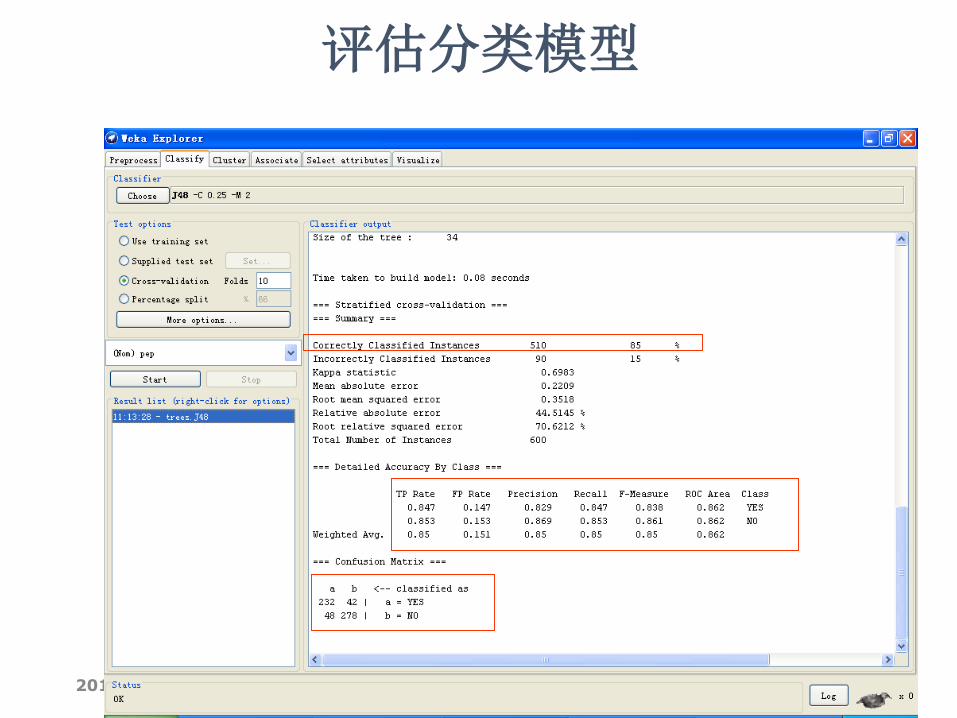
• Confusion Matrix 混淆矩阵,其中矩阵的行是实际的类,矩
阵的列是预测得到的类,矩阵元素就是相应测试样本的个数。

2014/12/18 75
文字结果

2014/12/18 76
主要指标
• Correctly Classified Instances 正确分类率
• Incorrectly Classified Instances 错误分类率
• Kappa statistic Kappa 统计数据
• Mean absolute error 平均绝对误差
• Root mean squared error 根均方差
• Relative absolute error 相对绝对误差
• Root relative squared error 相对平方根误差
• TP Rate(bad/good) 正确肯定率
• FP Rate(bad/good) 错误肯定率
• Precision(bad/good) 精确率
• Recall(bad/good) 反馈率
• F-Measure(bad/good) F测量
• Time taken to build model 建模花费的时间

2014/12/18 77
输出图形结果
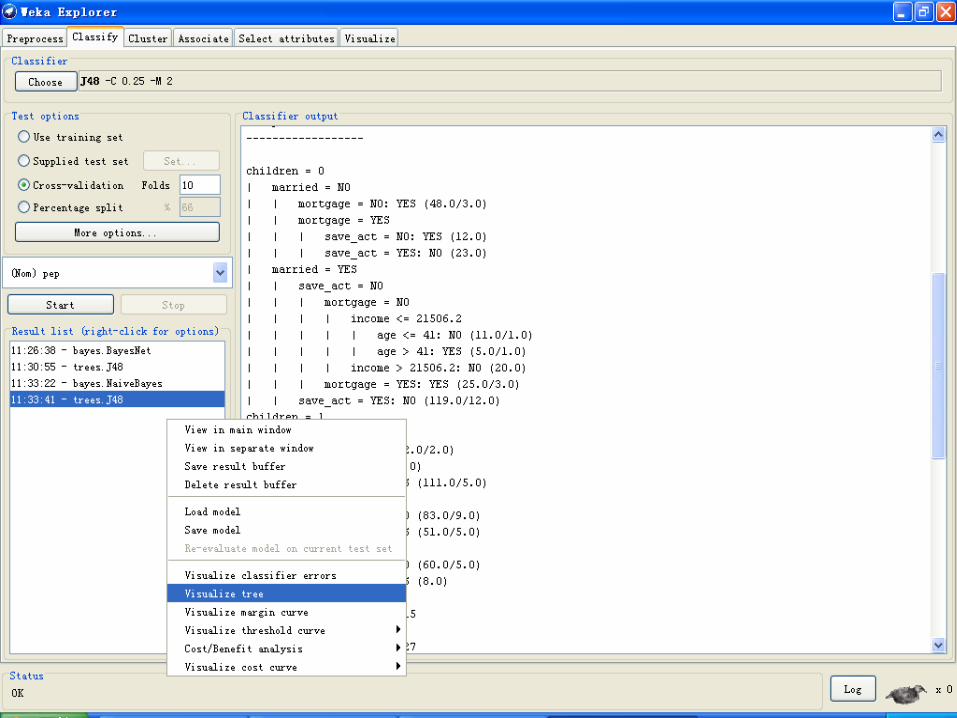
鼠标右键

2014/12/18 78
• View in main window(查看主窗口)。在主窗口中查看输出结果。
• View in separate window(查看不同的窗口)。打开一个独立的新窗口
来查看结果。
• Save result buffer(保存结果的缓冲区)。弹出对话框来保存输出结
果的文本文件。
• Load model(下载模式)。从二进制文件中载入一个预训练模式对象。
• Save model (保存模式)。将一个模式对象保存到二进制文件中,也就
是保存在JAVA 的串行对象格式中。
• Re-evaluate model on current test set(对当前测试集进行重新评
估)。通过已建立的模式,并利用Supplied test set(提供的测试集)
选项下的Set..按钮来测试指定的数据集。

2014/12/18 79
• Visualize classifier errors(可视化分类器错误)。弹出一个可视化窗
口来显示分类器的结果图。其中,正确分类的实例用叉表示,然而不正
确分类的实例则是以小正方形来表示的。
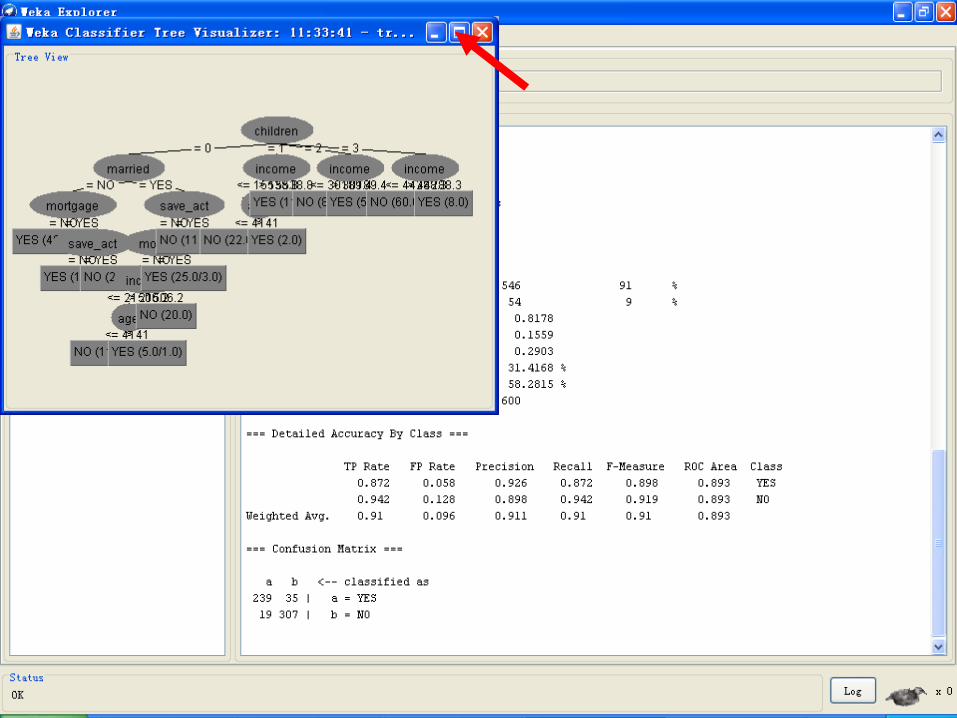
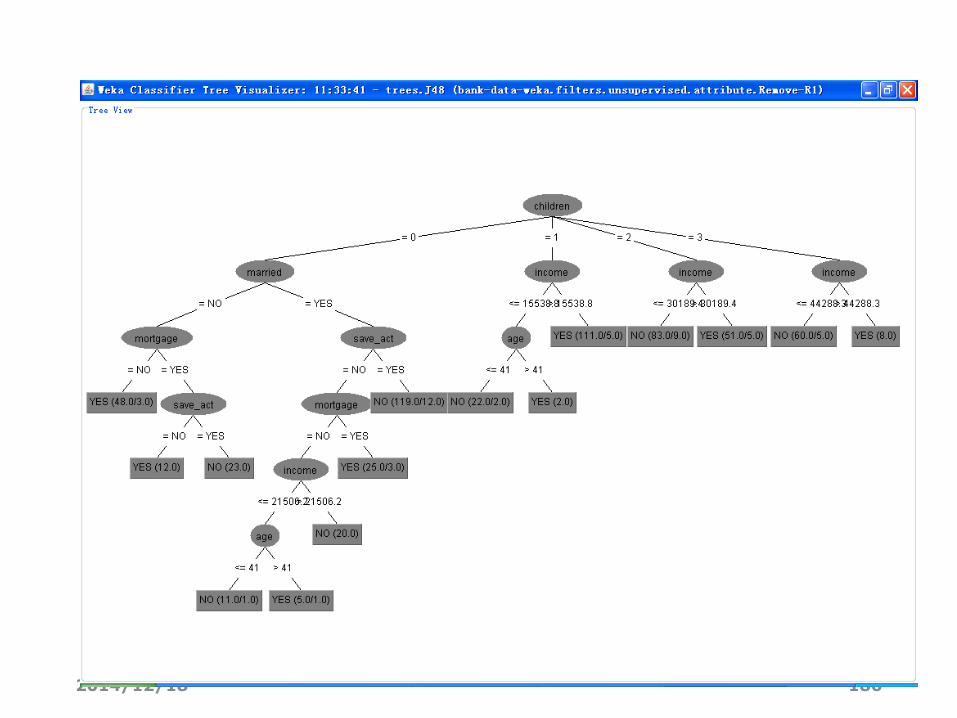
• Visualize tree(树的可视化)。如果可能的话,则弹出一个图形化的界
面来描述分类器模型的结构(这只有一部分分类器才有的)。右键单击空
白区域弹出一个菜单,在面板中拖动鼠标并单击,就可以看见每个节点
对应的训练实例。
• Visualize margin curve(边际曲线的可视化)。产生一个散点图来描述
预测边际的情况。边际被定义为预测为真实值的概率和预测为真实值之
外的其它某类的最高概率之差。例如加速算法通过增加训练数据集的边
际来更好地完成测试数据集的任务。

2014/12/18 80
• Visualize threshold curve(阈曲线的可视化)。产生一个散点
图来描述预测中的权衡问题,其中权衡是通过改变类之间阈值来
获取的。例如,缺省阈值为0.5,一个实例预测为positive的概
率必须要大于0.5,因为0.5时实例正好预测为positive。而且图
表可以用来对精确率/反馈率权衡进行可视化,如ROC 曲线分析
(正确的正比率和错误的正比率)和其它的曲线。
• Visualize cost curve(成本曲线的可视化)。产生一个散点图,
来确切描述期望成本,正如Drummond 和Holte 所描述的一样。

2014/12/18 81
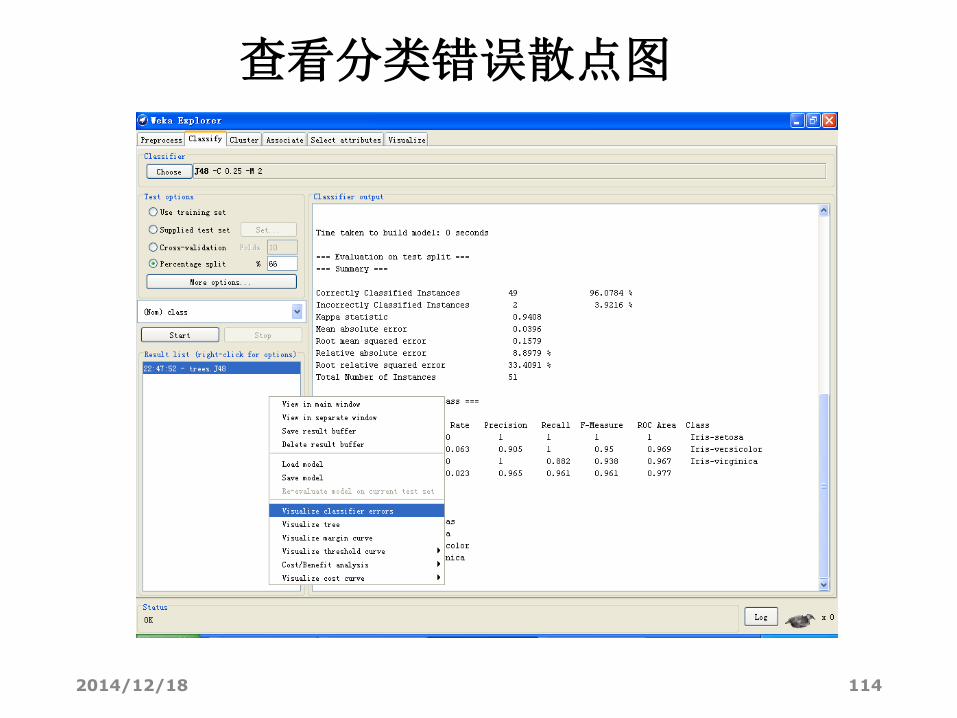
• Visualize classifier errors. 可视化分类错误
• 实际类与预测类的散布图。其中正确分类的结果用叉表示,分错的结果用方框表示。
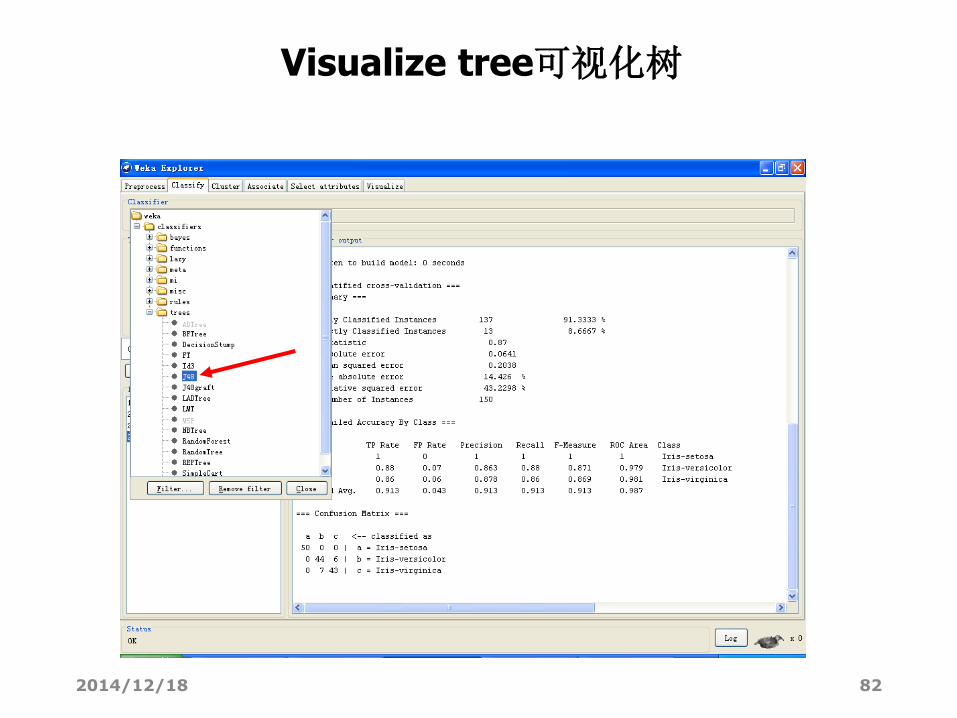
2014/12/18 82
Visualize tree可视化树
2014/12/18 83
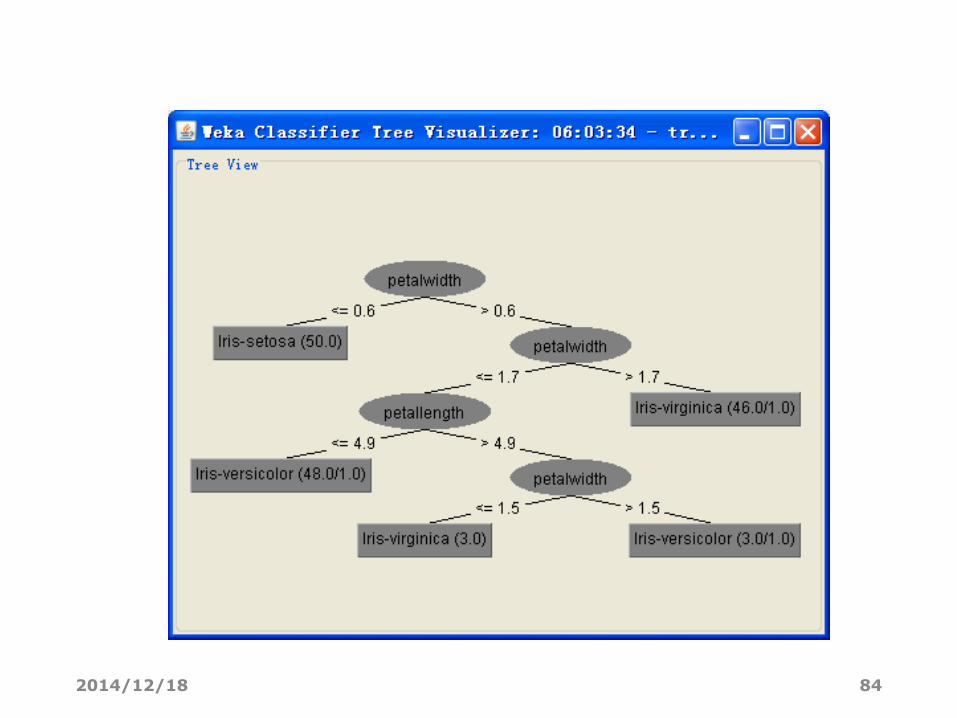
2014/12/18 84

2014/12/18 85
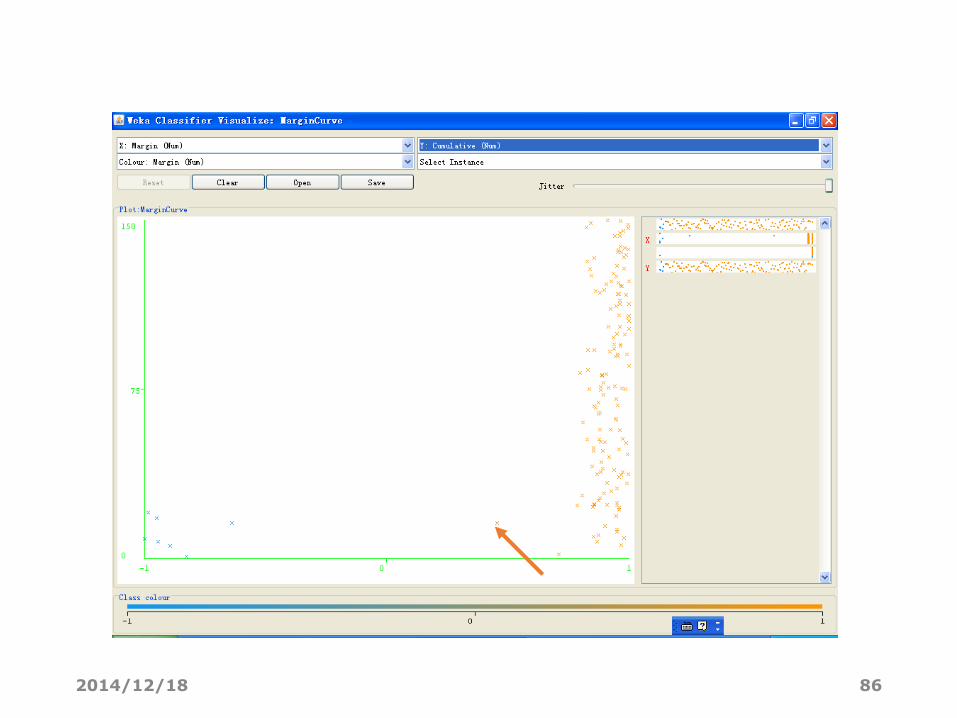
可视化边际曲线(Visualize margin curve)
• 创建一个散点图来显示预测边际值。
• 四个变量
• Margin: 预测边际值
• Instance_number: 检验实例的序号
• Current: 具有当前预测边际值的实例个数
• Cumulative: 小于或等于预测边际值的实例个数(与Instance_number一致)
2014/12/18 86

2014/12/18 87
• 单击8号检验实例,显示该点的边际值为0.5,有7个实例的边际值小于0.5。

2014/12/18 88
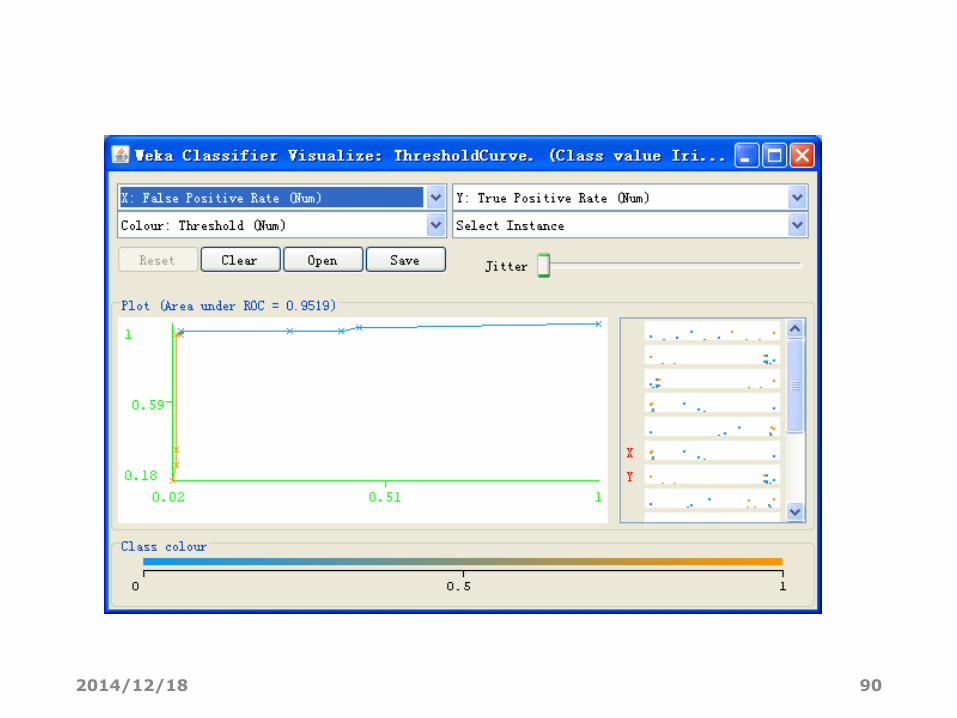
可视化阈值曲线(基于类)
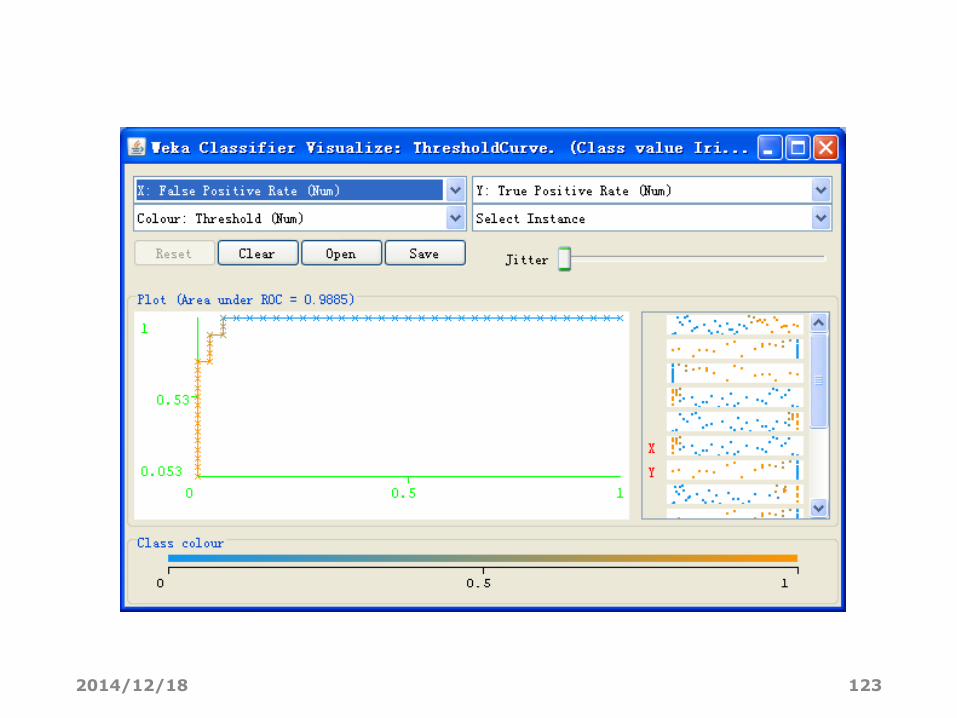
• 阈值是将检验实例归为当前类的最小概率,使用点的颜色表示阈值
• 曲线上的每个点通过改变阈值的大小生成
• 可以进行ROC分析• X轴选假正率
• Y轴选真正率

2014/12/18 89
2014/12/18 90

2014/12/18 91
ROC曲线• ROC曲线(Receiver Operating Characteeristic Curve)是显示
Classification模型真正率和假正率之间折中的一种图形化方法。
• 假设样本可分为正负两类,解读ROC图的一些概念定义:
• 真正(True Positive , TP),被模型预测为正的正样本
• 假负(False Negative , FN)被模型预测为负的正样本
• 假正(False Positive , FP)被模型预测为正的负样本
• 真负(True Negative , TN)被模型预测为负的负样本
• 真正率(True Positive Rate , TPR)或灵敏度(sensitivity)TPR = TP /(TP + FN)正样本预测结果数 / 正样本实际数
• 假正率(False Positive Rate , FPR)FPR = FP /(FP + TN)被预测为正的负样本结果数 /负样本实际数
• ( TPR=1,FPR=0 ) 是理想模型
• 一个好的分类模型应该尽可能靠近图形的左上角。

2014/12/18 92
IRIS分类示例
2014/12/18 93
在weka的Explorer中打开Iris.arff文件

2014/12/18 94
在weka的Explorer中打开Iris.arff文件

2014/12/18 95
2014/12/18 96
选择分类(Classify)数据挖掘任务

2014/12/18 97
选择分类算法

2014/12/18 98
选择决策树算法Trees->J48
2014/12/18 99
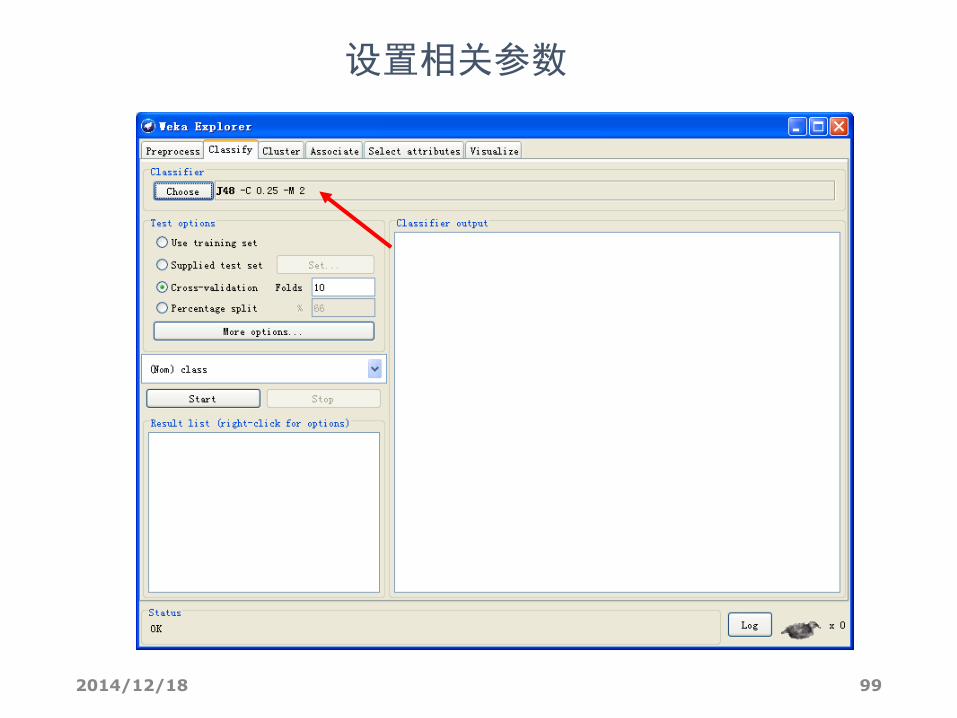
设置相关参数
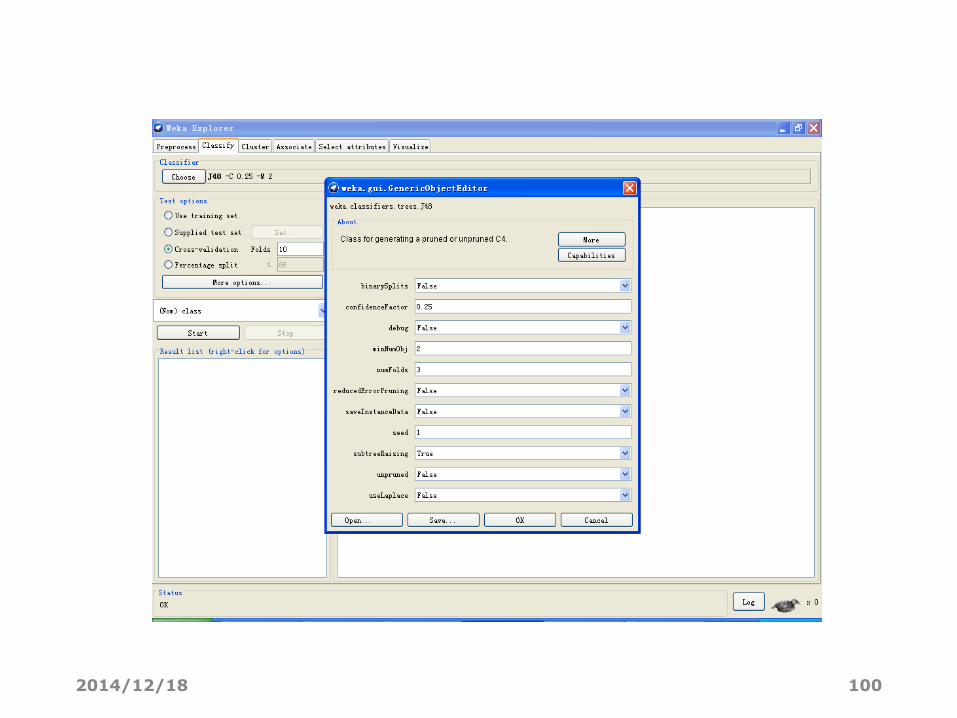
2014/12/18 100

2014/12/18 101
2014/12/18 102
选择检验方法
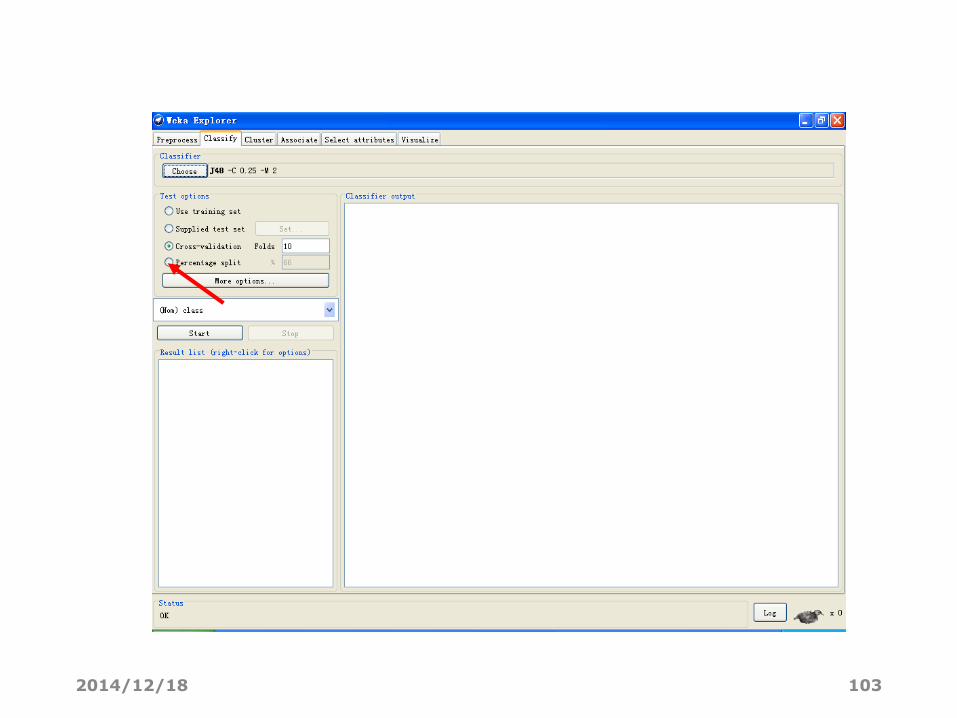
2014/12/18 103
2014/12/18 104
2014/12/18 105

2014/12/18 106
2014/12/18 107

2014/12/18 108
执行分类算法,建立决策树模型

2014/12/18 109
2012-4-9 85
查看算法执行的输出信息

2014/12/18 110
2014/12/18 111
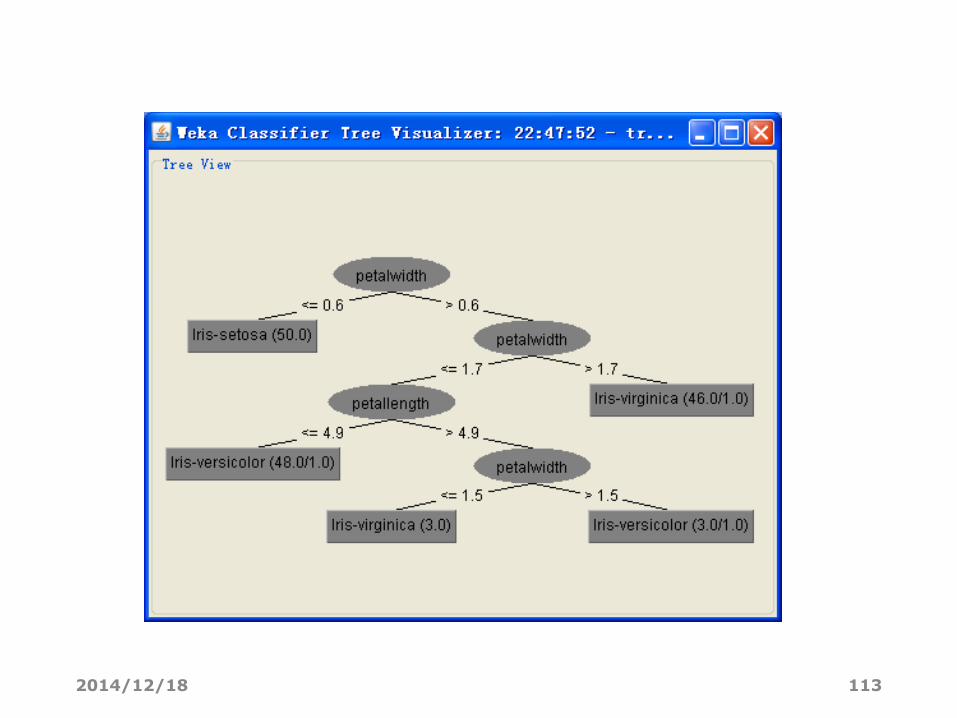
查看决策树分类模型

2014/12/18 112
2014/12/18 113
2014/12/18 114
查看分类错误散点图

2014/12/18 115
2014/12/18 116
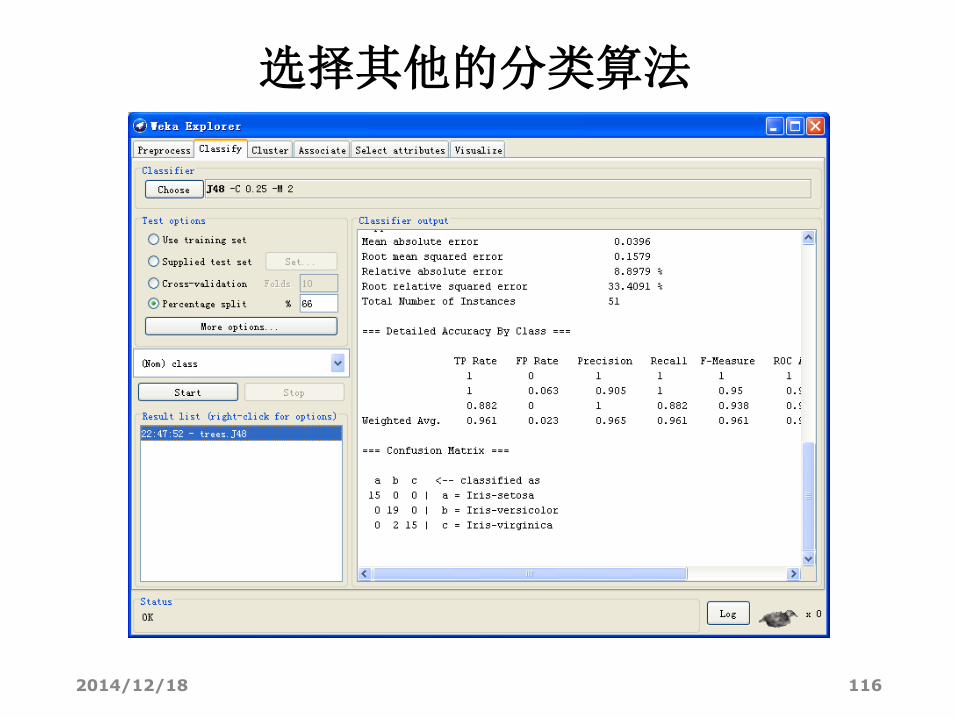
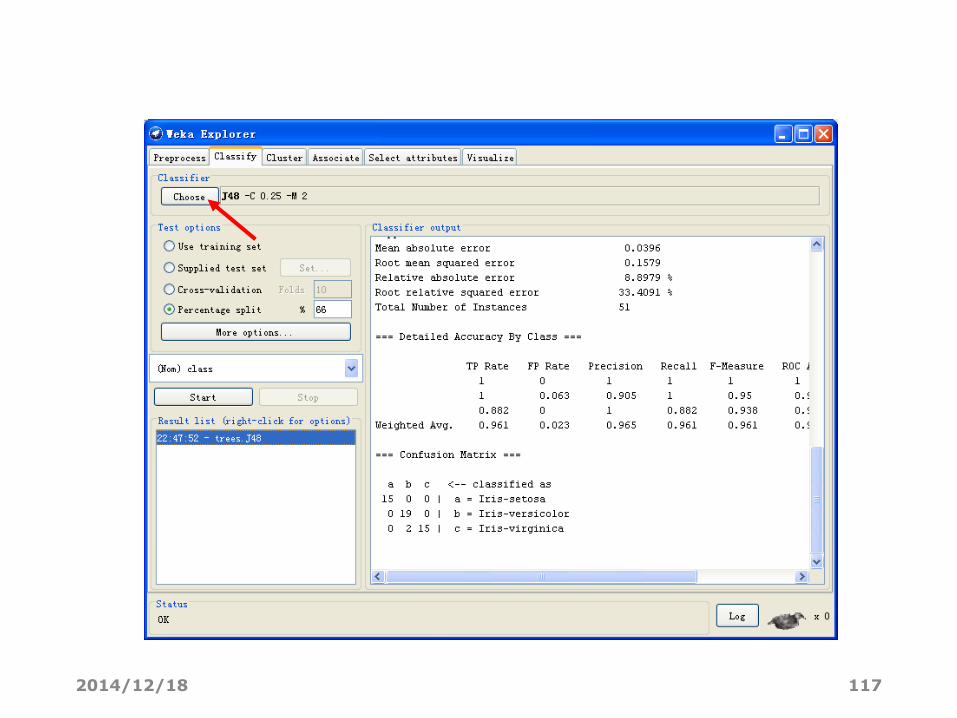
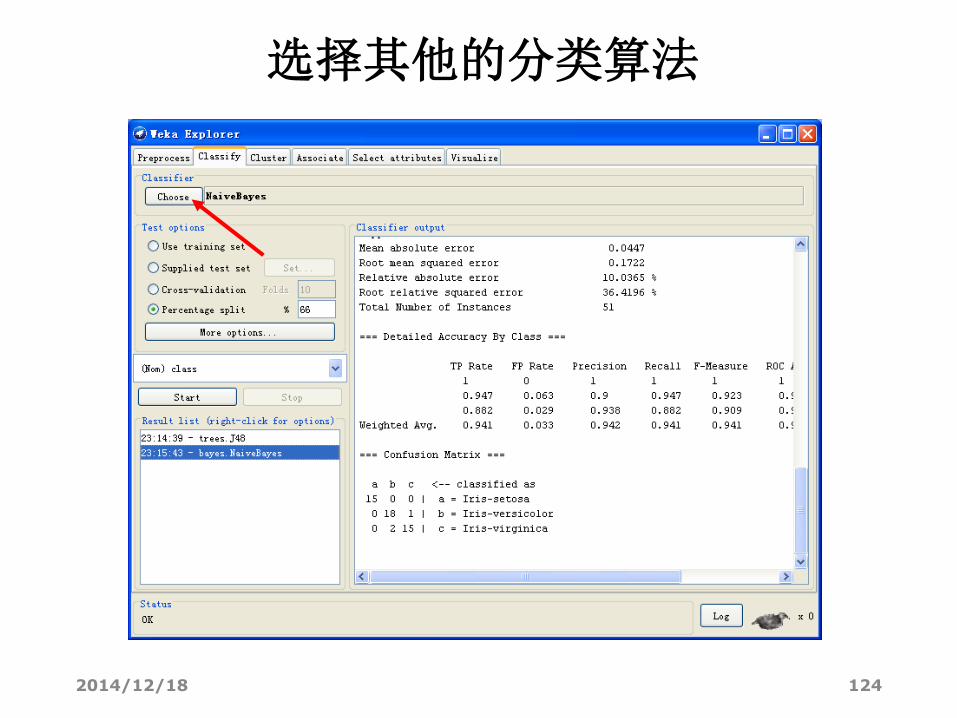
选择其他的分类算法
2014/12/18 117

2014/12/18 118QuickTime?and a TIFF (LZW) decom pressor are needed to se e this p icture.
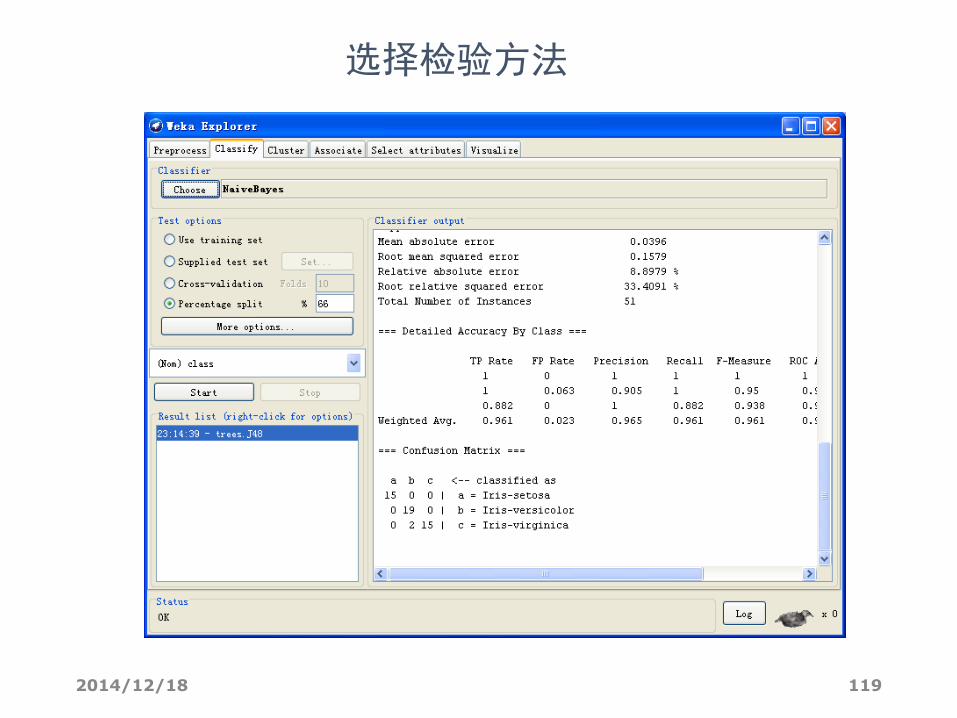
选择贝叶斯分类算法bayes->Naive bayes
2014/12/18 119
选择检验方法
2014/12/18 120QuickTime?and a TIFF (LZW) decom pressor are needed to se e this p icture.
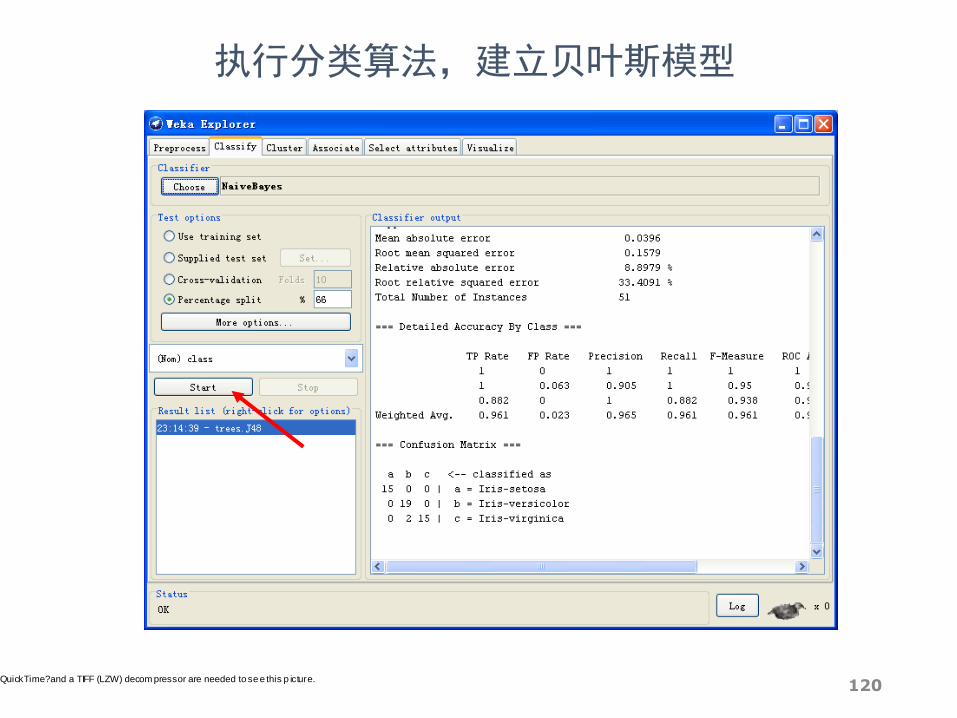
执行分类算法,建立贝叶斯模型
2014/12/18 121
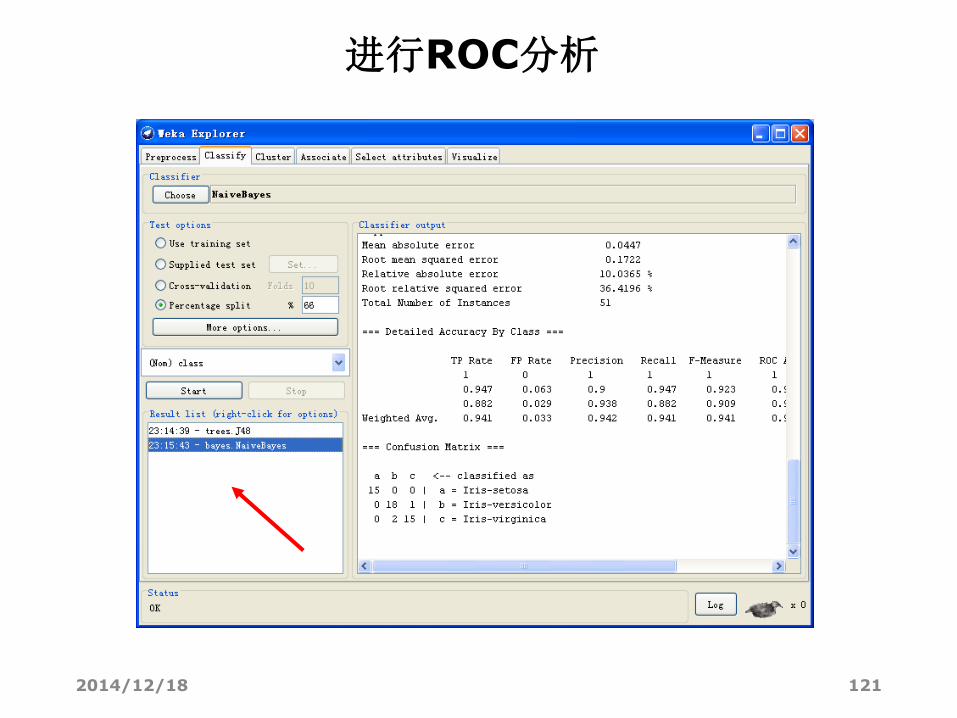
进行ROC分析

2014/12/18 122
2014/12/18 123
2014/12/18 124
选择其他的分类算法
2014/12/18 125
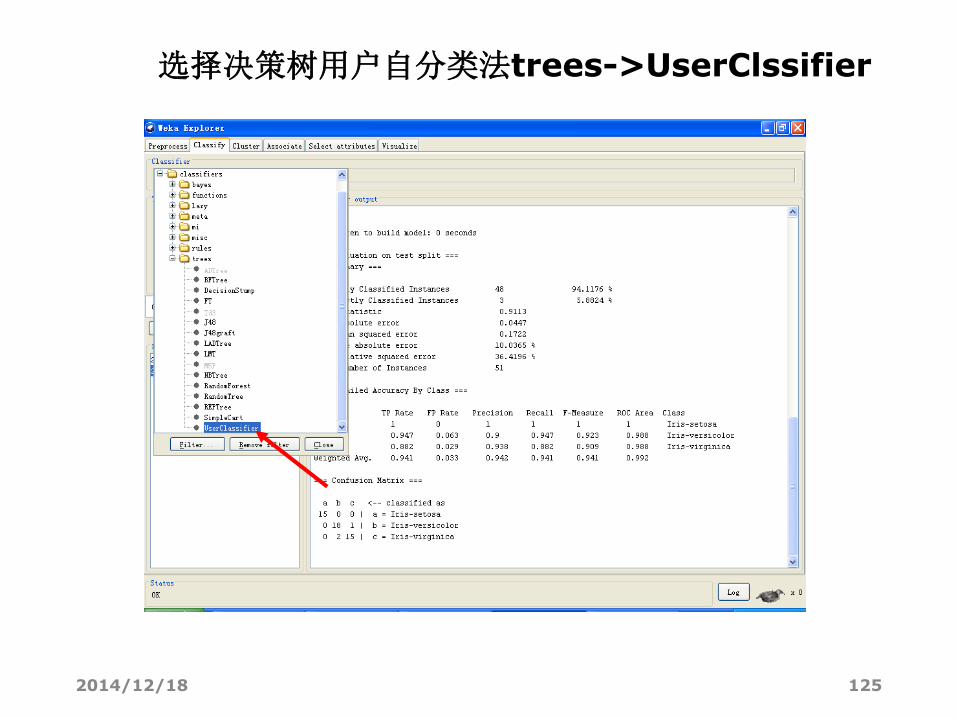
选择决策树用户自分类法trees->UserClssifier

2014/12/18 126
选择检验方法

2014/12/18 127
执行算法

2014/12/18 128
2014/12/18 129
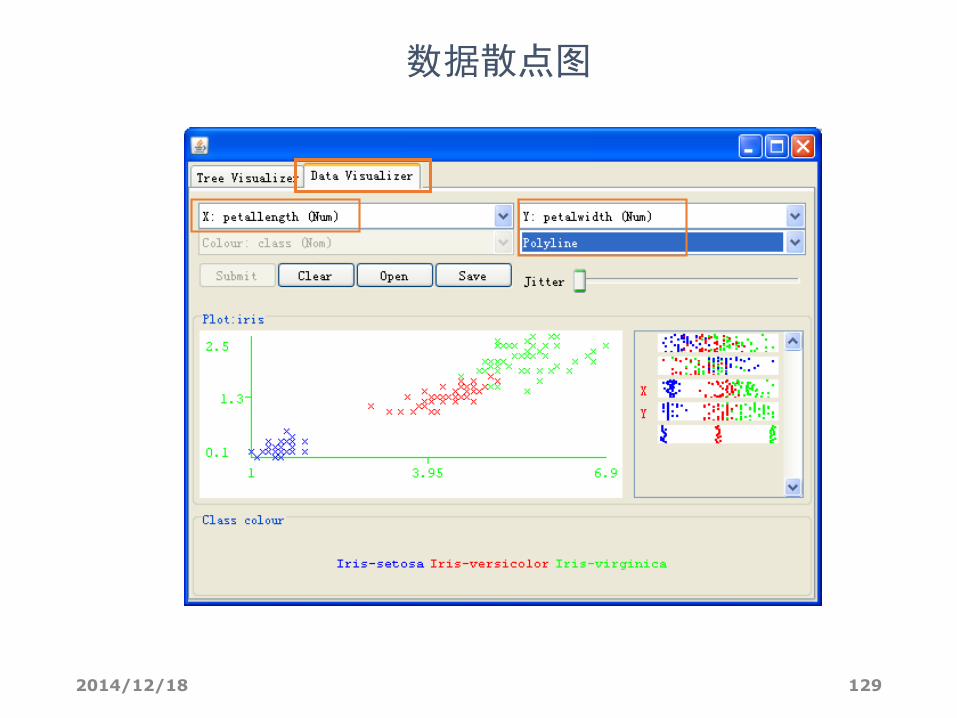
数据散点图

2014/12/18 130
但击鼠标,确定分类边界

2014/12/18 131
查看相应的分类树
2014/12/18 132
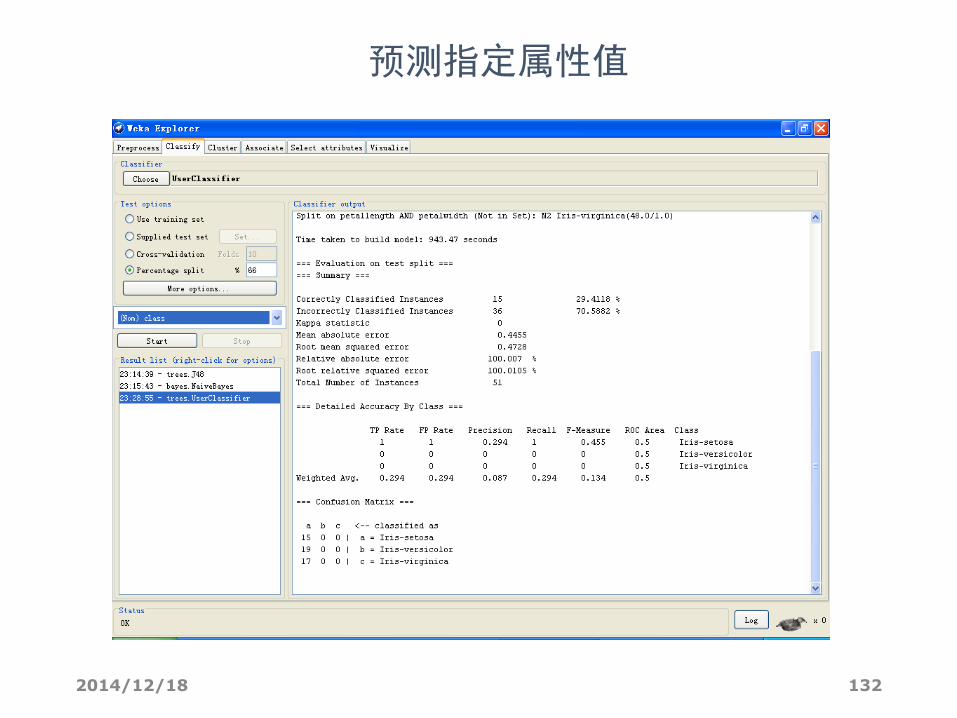
预测指定属性值
2014/12/18 133
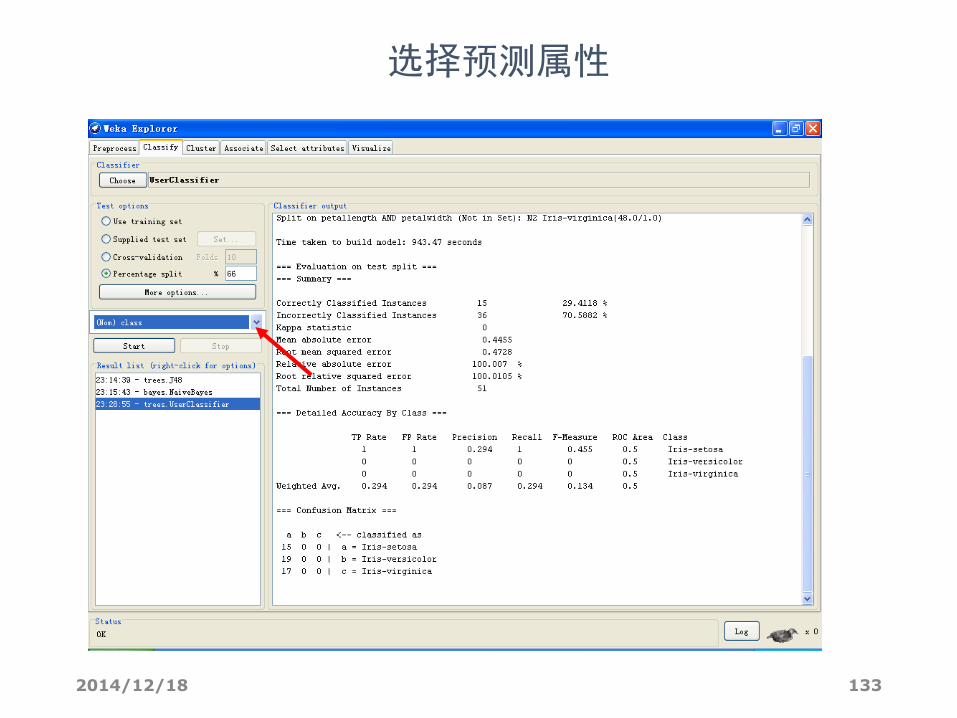
选择预测属性
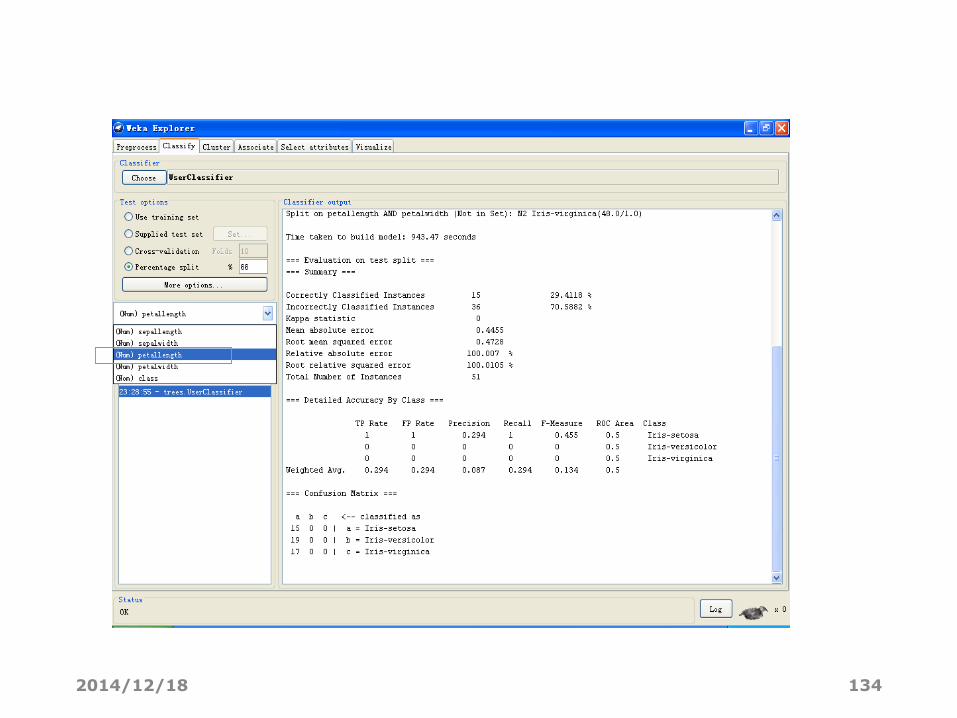
2014/12/18 134
2014/12/18 135
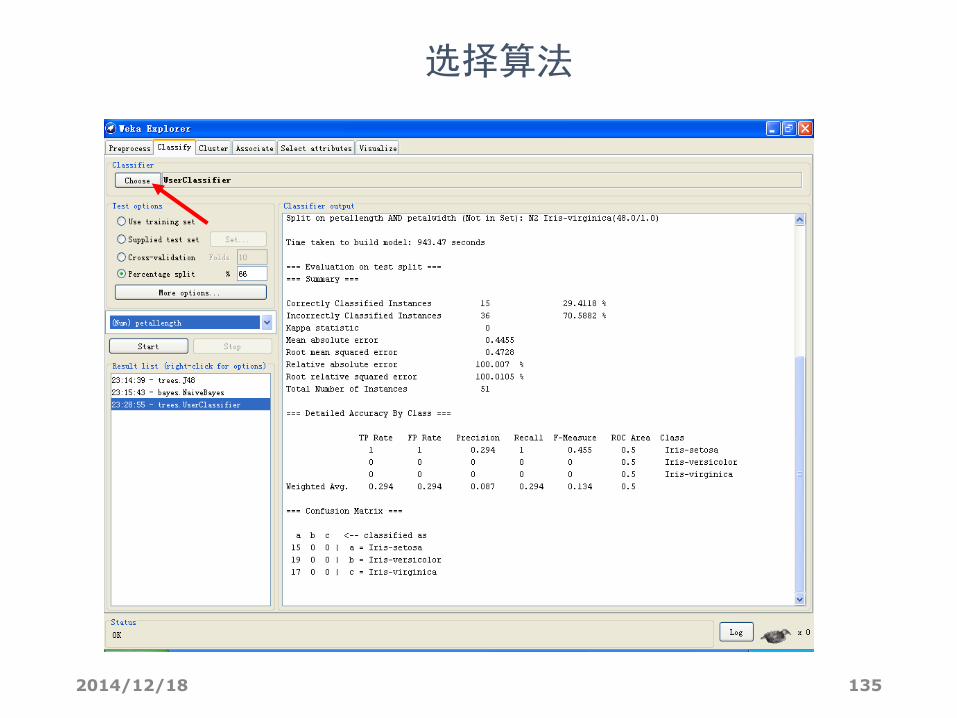
选择算法

2014/12/18 136
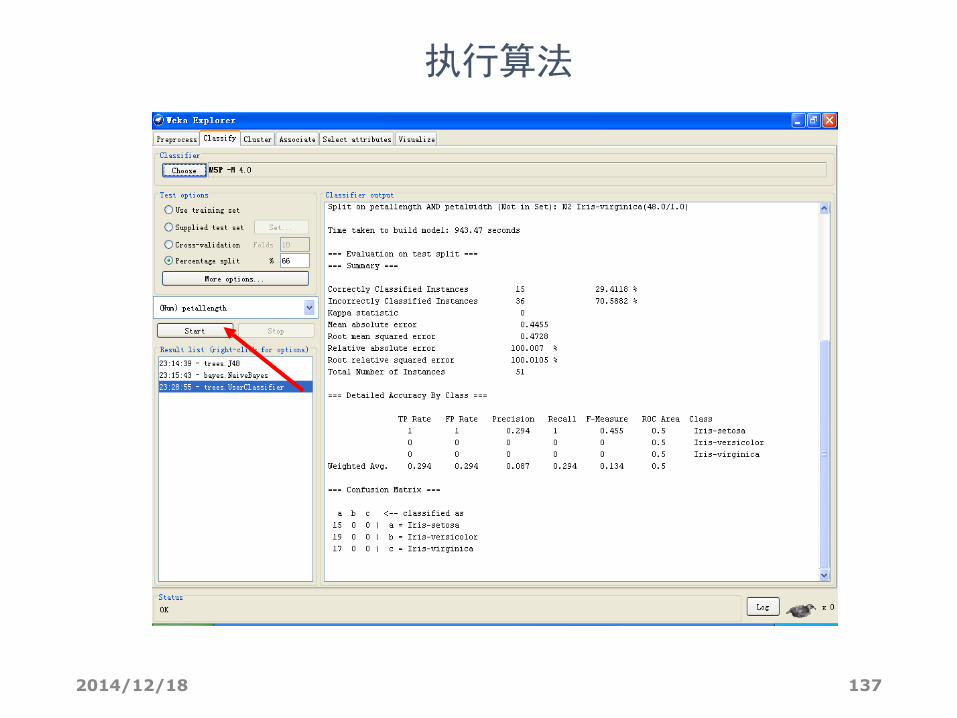
2014/12/18 137
执行算法

2014/12/18 138
观察输出信息

2014/12/18 139

2014/12/18 140
查看分类错误散点图
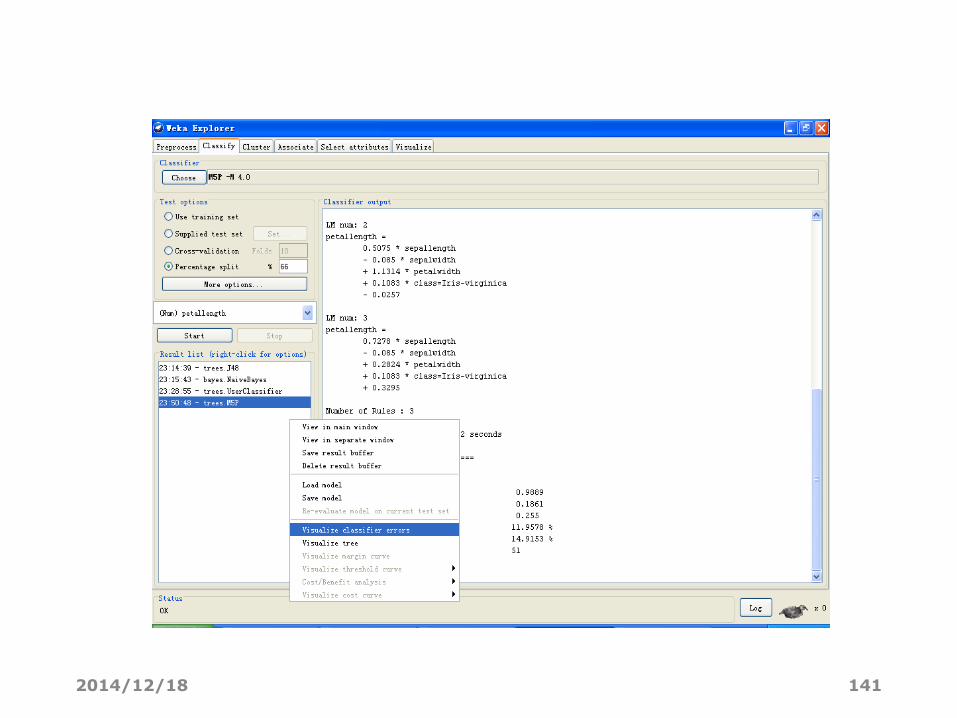
2014/12/18 141
2014/12/18 142
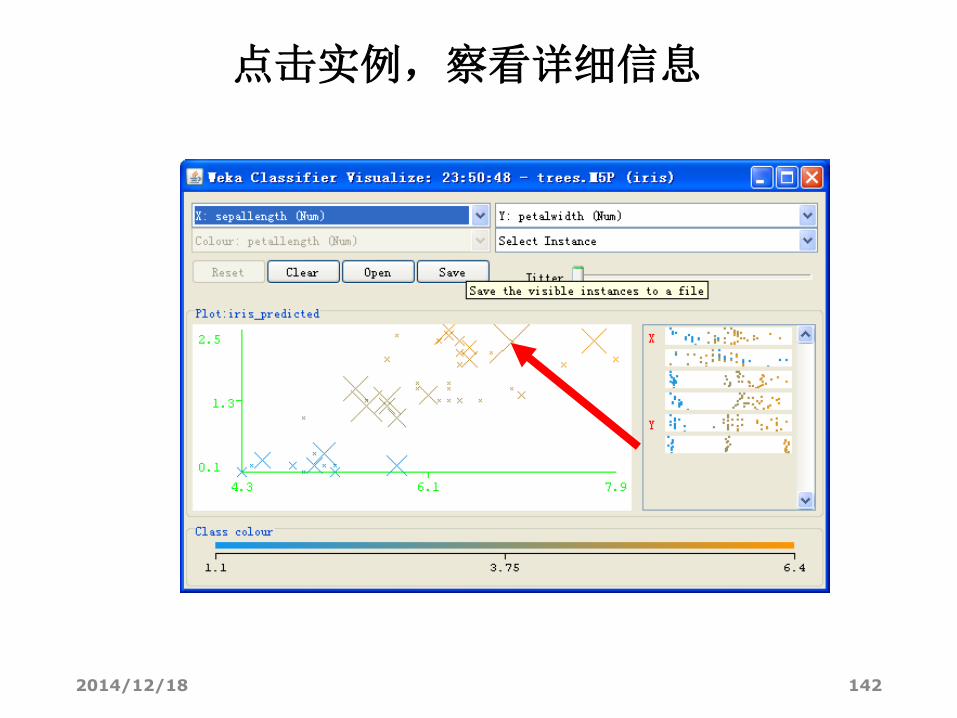
点击实例,察看详细信息

2014/12/18 143
该实例petallength的实际值为5.1,预测值为5.89

2014/12/18 144
训练BANK-DATA分类模型示例
• bank-data数据各属性的含义如下:id: a unique identification number age: age of customer in years (numeric) sex: MALE / FEMALE region: inner_city/rural/suburban/town income: income of customer (numeric) married: is the customer married (YES/NO) children: number of children (numeric) car: does the customer own a car (YES/NO) save_act: does the customer have a saving account (YES/NO) current_act:does the customer have a current account (YES/NO) mortgage: does the customer have a mortgage (YES/NO) pep (目标变量) : did the customer buy a PEP (Personal Equity Plan,个人参股计划) after the last mailing (YES/NO)
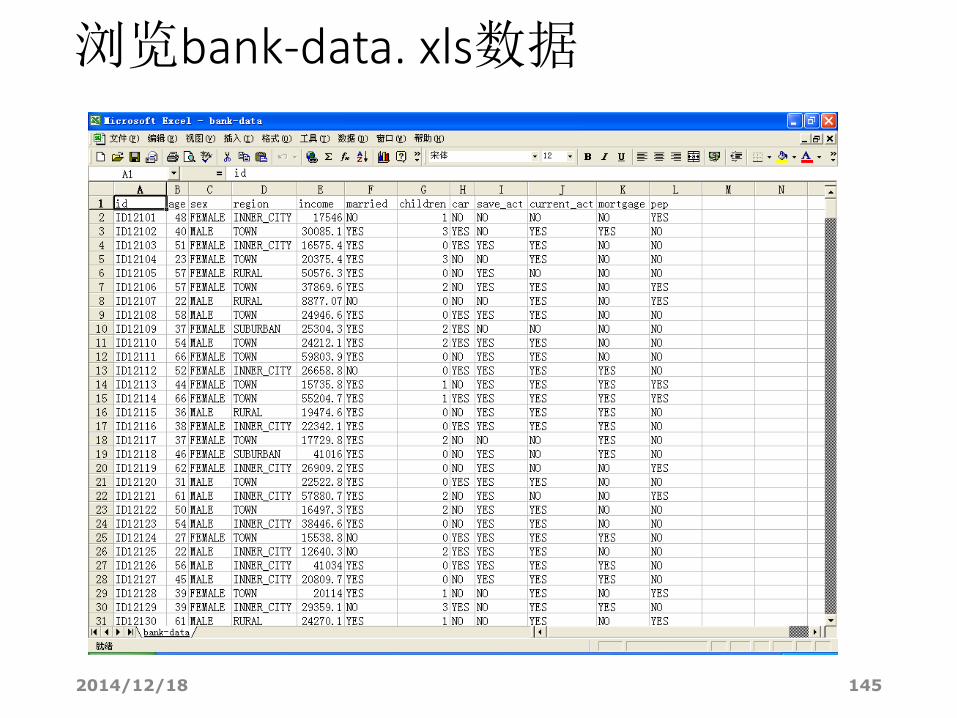
2014/12/18 145
浏览bank-data. xls数据
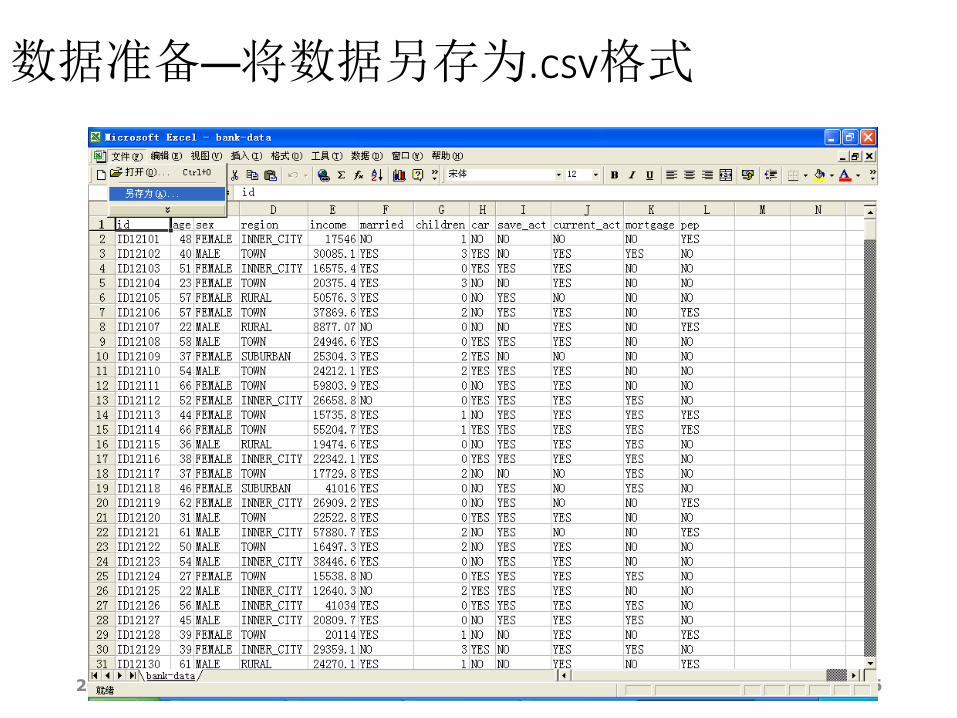
2014/12/18 146
数据准备—将数据另存为.csv格式
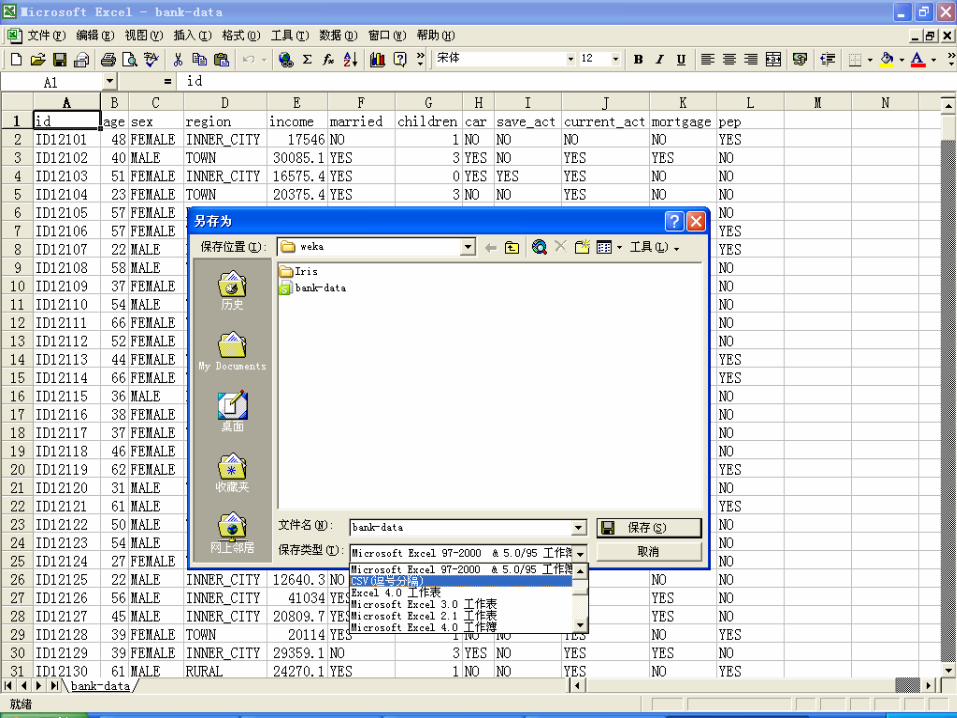
2014/12/18 147

2014/12/18 148
数据准备—在WEKA中打开bank-data. csv

2014/12/18 149
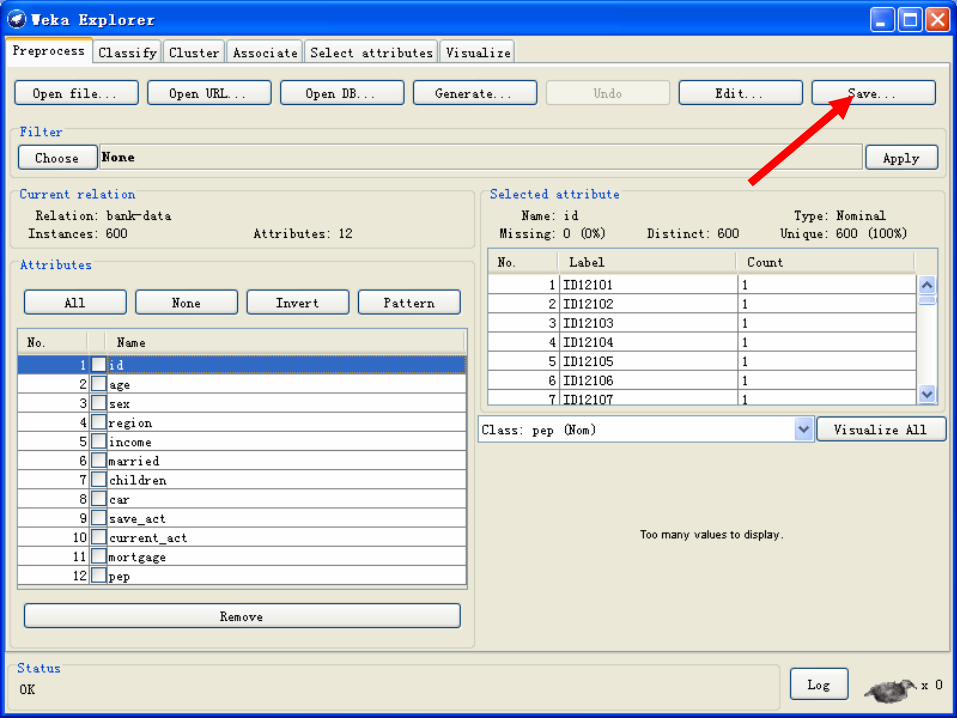
2014/12/18 150

2014/12/18 151

2014/12/18 152
数据准备—在WEKA中浏览数据

2014/12/18 153
2014/12/18 154
数据准备—将数据另存为.arff格式
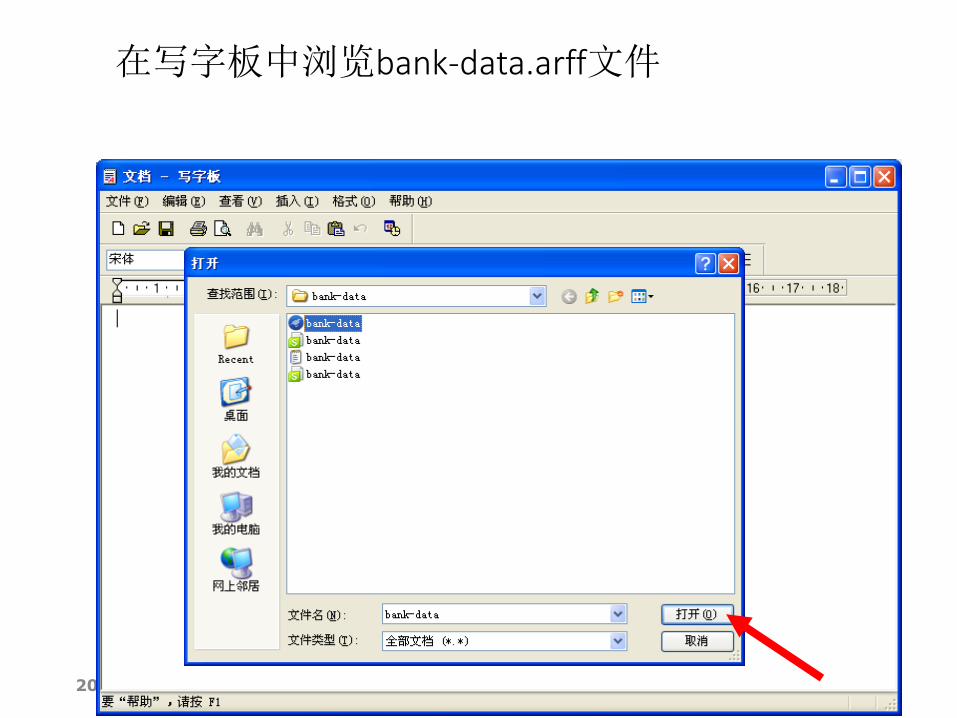
2014/12/18 155
在写字板中浏览bank-data.arff文件

2014/12/18 156

2014/12/18 157
数据预处理• 去除无用属性
通常对于数据挖掘任务来说,ID这样的信息是无用的,我们将之删除。勾选属性“id”,并点击“Remove”。将新的数据集保存为“bank-data.arff”,重新打开。
• 离散化
在这个数据集中有3个变量是数值型的,分别是“age”,“income”和“children”。其中“children”只有4个取值:0,1,2,3。这时我们直接修改ARFF文件,把@attribute children numeric 改为@attribute children {0,1,2,3} 就可以了。在“Explorer”中重新打开“bank-data.arff”,看看选中“children”属性后,显示的“Type” 变成“Nominal”了。

2014/12/18 158
数据预处理
“age”和“income”的离散化可借助WEKA中名为“Discretize”的Filter来完成。
• 点“Choose”,出现一棵“Filter树”,逐级找到“weka.filters.unsupervised.attribute.Discretize”,点击。
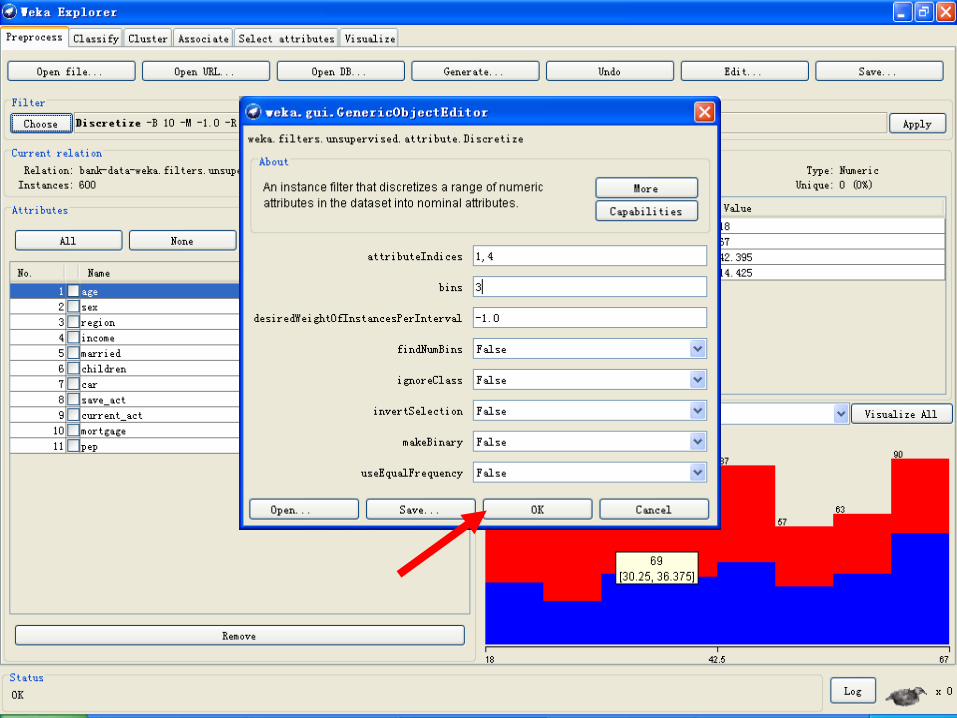
• 现在“Choose”旁边的文本框应该显示“Discretize -B 10 -M -0.1 -R first-last”。点击这个文本框会弹出新窗口以修改离散化的参数。我们不打算对所有的属性离散化,只是针对对第1个和第4个属性(见属性名左边的数字),故把attributeIndices右边改成“1,4”。计划把这两个属性都分成3段,于是把“bins”改成“3”。其它框里不用更改。
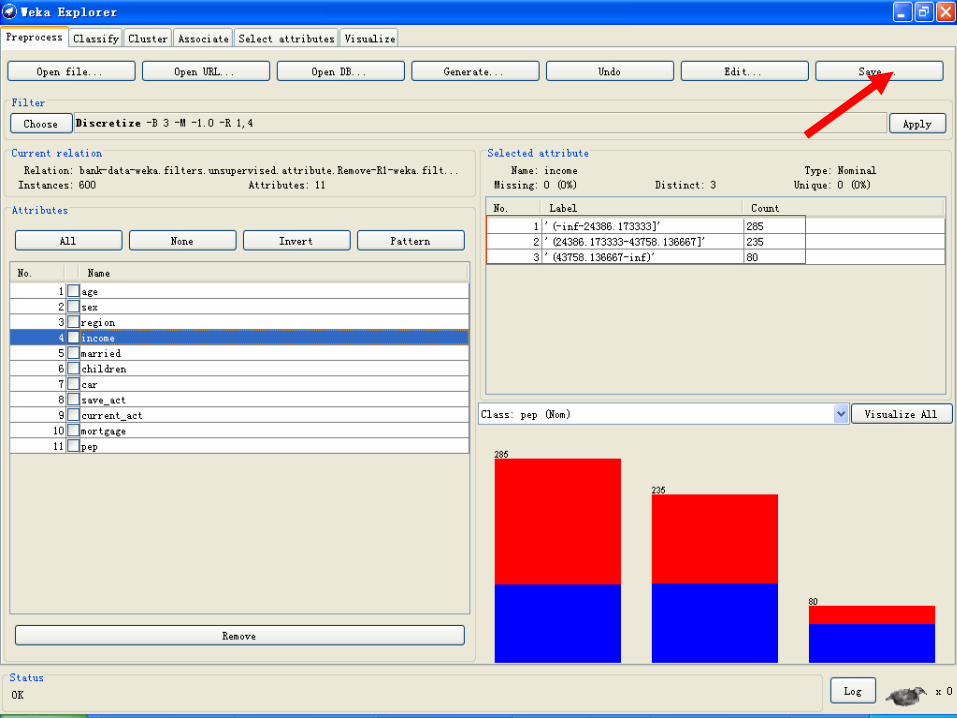
• 点“OK”回到“Explorer”,可以看到“age”和“income”已经被离散化成分类型的属性。若想放弃离散化可以点“Undo”。
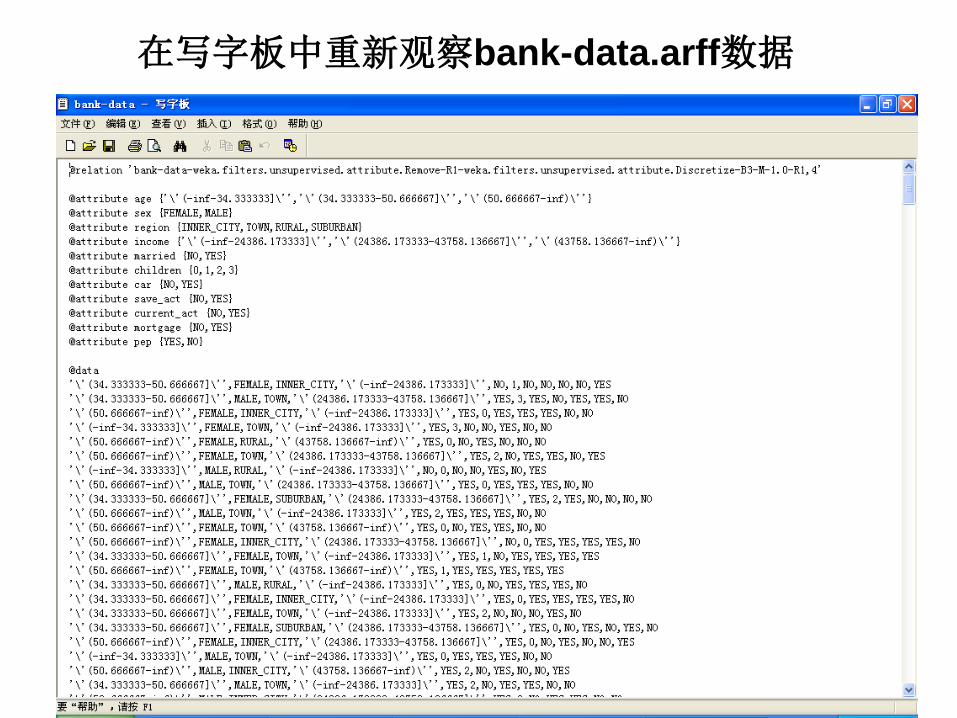
经过上述操作得到的数据集我们保存为bank-data-final.arff。
2014/12/18 159
数据预处理--去除无用属性
2014/12/18 160
2014/12/18 161
数据预处理—children数据离散化

2014/12/18 162
数据预处理—children数据离散化
• 用写字板打开bank-data.arff文件

2014/12/18 163

2014/12/18 164
在WEKA中重新打开bank-data.arff文件。

2014/12/18 165

2014/12/18 166
• 观察 children属性。
2014/12/18 167
数据预处理—离散化“age”和“income”
2014/12/18 168
数据预处理—数据离散化

2014/12/18 169

2014/12/18 170
2014/12/18 171

2014/12/18 172

2014/12/18 173
2014/12/18 174
2014/12/18 175
在写字板中重新观察bank-data.arff数据
2014/12/18 176
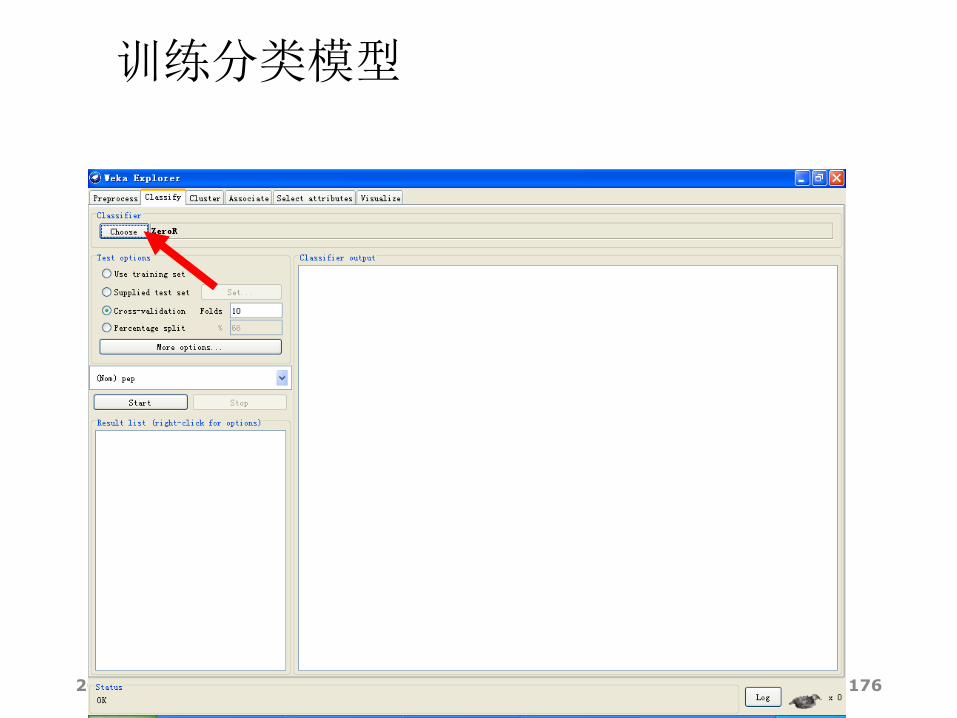
训练分类模型

2014/12/18 177

2014/12/18 178
2014/12/18 179
评估分类模型
2014/12/18 180
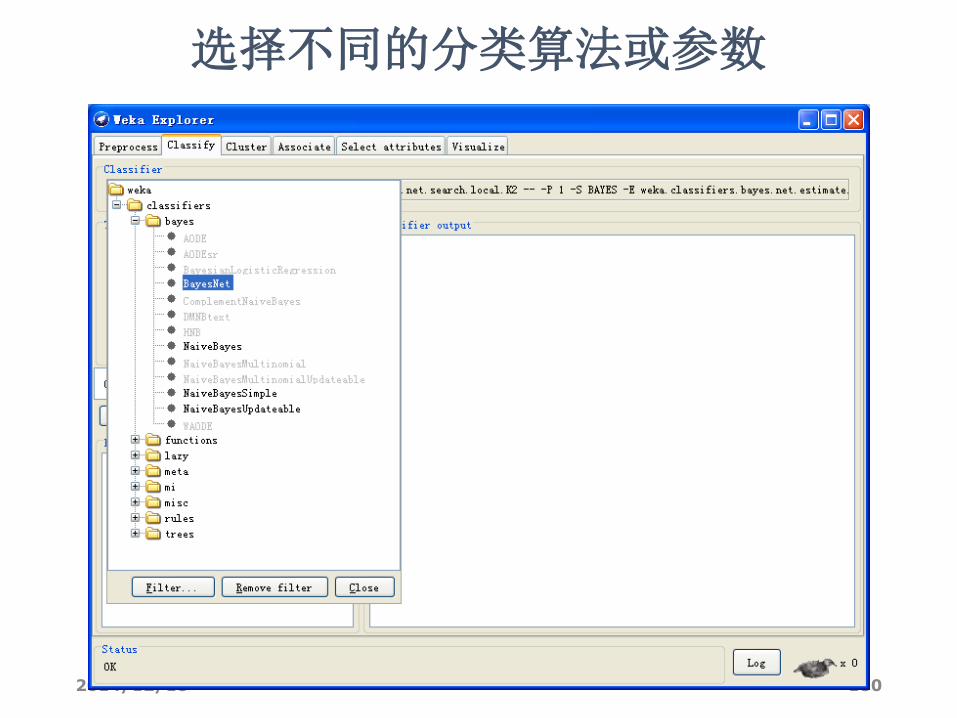
选择不同的分类算法或参数
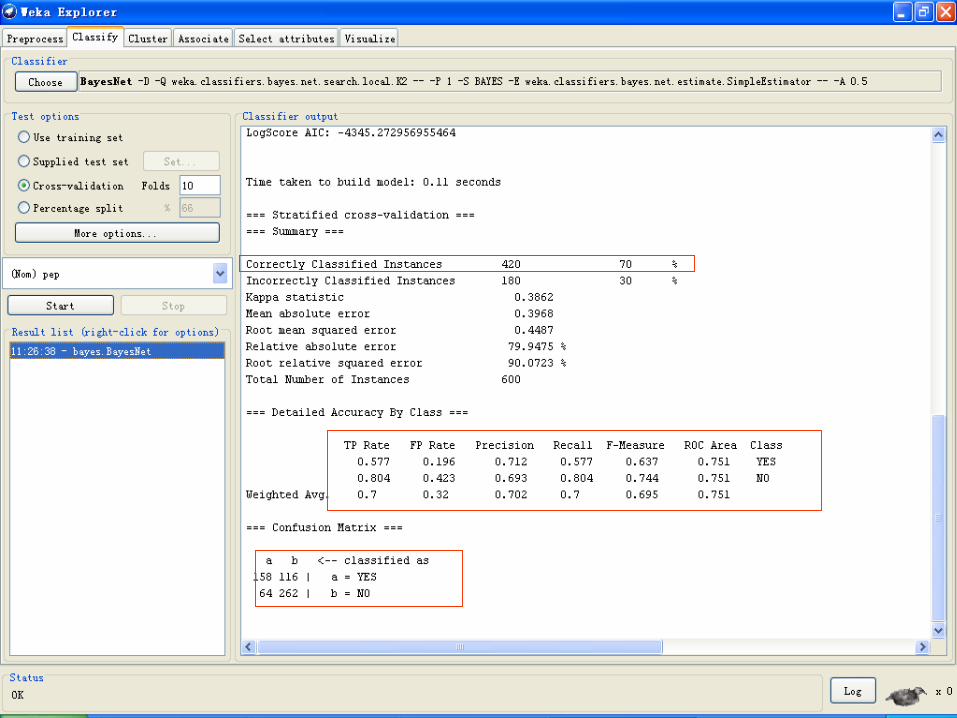
2014/12/18 181

2014/12/18 182
选择模型
2014/12/18 183
2014/12/18 184
2014/12/18 185
2014/12/18 186

2014/12/18 187
6、聚类 cluster
• 聚类分析是把对象分配给各个簇,使同簇中的对象相似,而不同簇间的对象相异。
• WEKA在“Explorer”界面的“Cluster”提供聚类分析工具
选择聚类算法

2014/12/18 188
WEKA中的聚类算法

2014/12/18 189
• 主要算法包括:
• SimpleKMeans — 支持分类属性的K均值算法
• DBScan — 支持分类属性的基于密度的算法
• EM — 基于混合模型的聚类算法
• FathestFirst — K中心点算法
• OPTICS — 基于密度的另一个算法
• Cobweb — 概念聚类算法
• sIB — 基于信息论的聚类算法,不支持分类属性
• XMeans — 能自动确定簇个数的扩展K均值算法,不支持分类属性
2014/12/18 190
参数设置
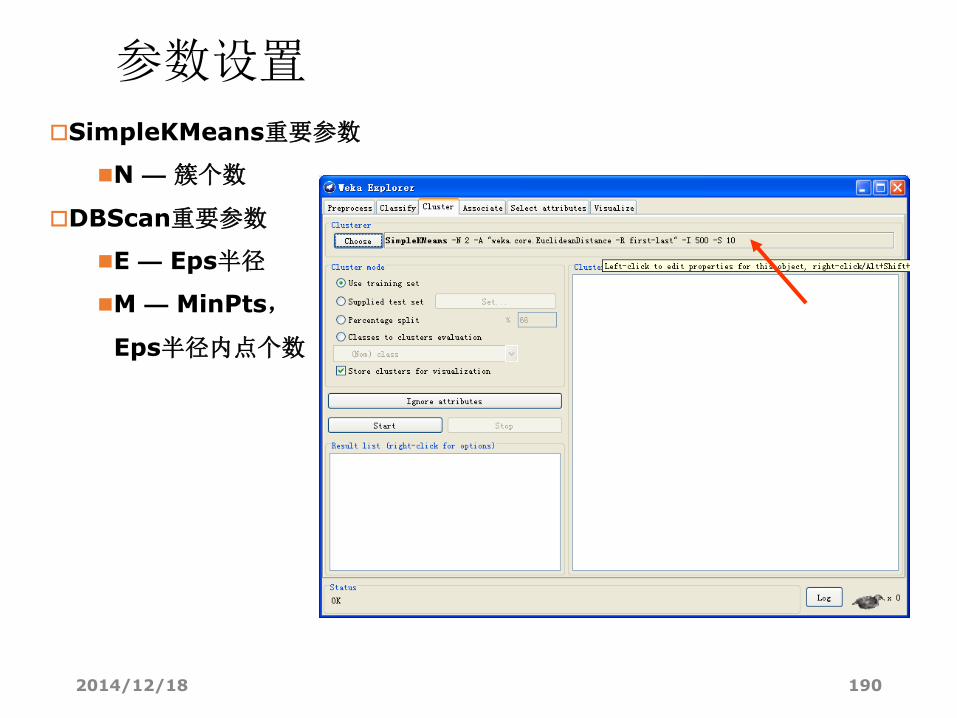
SimpleKMeans重要参数
N — 簇个数
DBScan重要参数
E — Eps半径
M — MinPts,
Eps半径内点个数
2014/12/18 191
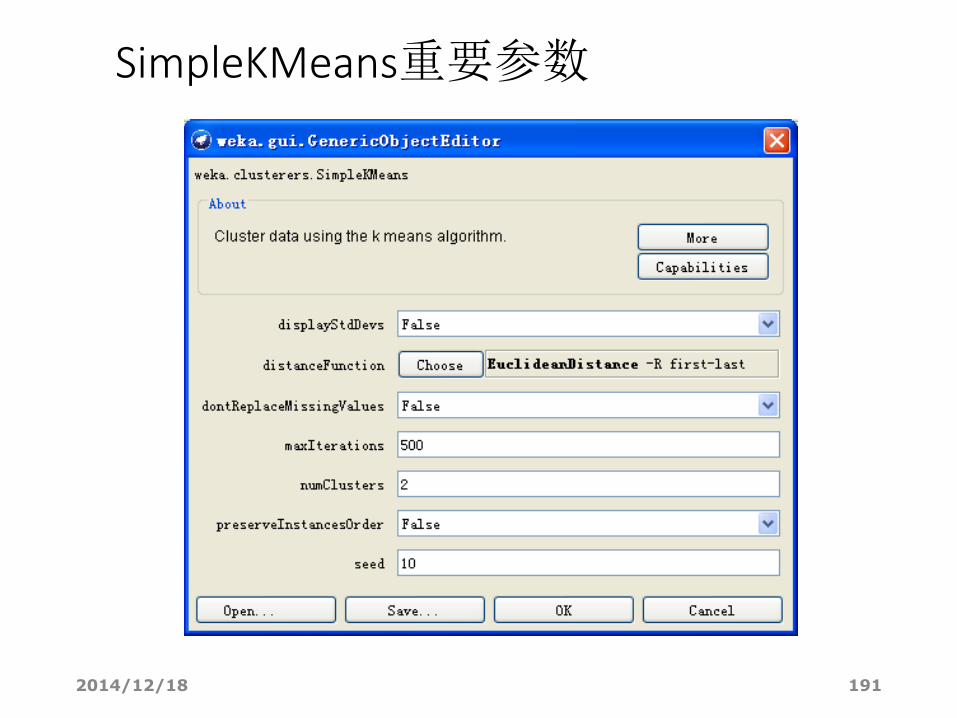
SimpleKMeans重要参数

2014/12/18 192
• displayStdDevs:是否显示数值属性标准差和分类属性个数
• distanceFunction:选择比较实例的距离函数
• (默认: weka.core.EuclideanDistance)
• dontReplaceMissingValues:是否不使用均值/众数(mean/mode)替换缺失值。
• maxIterations:最大迭代次数
• numClusters:聚类的簇数
• preserveInstancesOrder:是否预先排列实例的顺序
• Seed:设定的随机种子值

2014/12/18 193
聚类模式Cluster Mode

2014/12/18 194
• 使用训练集 (Use training set) — 报告训练对象的聚类结果和
分组结果
• 使用附加的检验集 (Supplied test set) — 报告训练对象的聚类
结果和附加的检验对象的分组结果
• 百分比划分 (Percentage split) — 报告全部对象的聚类结果、
训练对象的聚类结果,以及检验对象的分组结果
• 监督评估 (Classes to clusters evaluation) — 报告训练对象的
聚类结果和分组结果、类/簇混淆矩阵和错误分组信息
2014/12/18 195
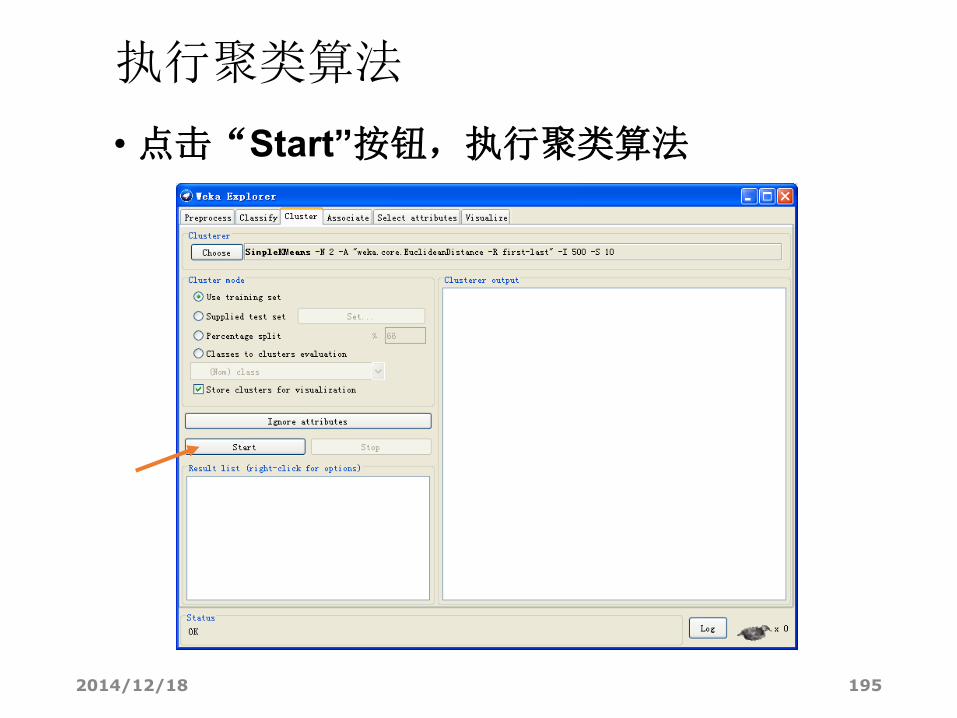
执行聚类算法
• 点击“Start”按钮,执行聚类算法
2014/12/18 196
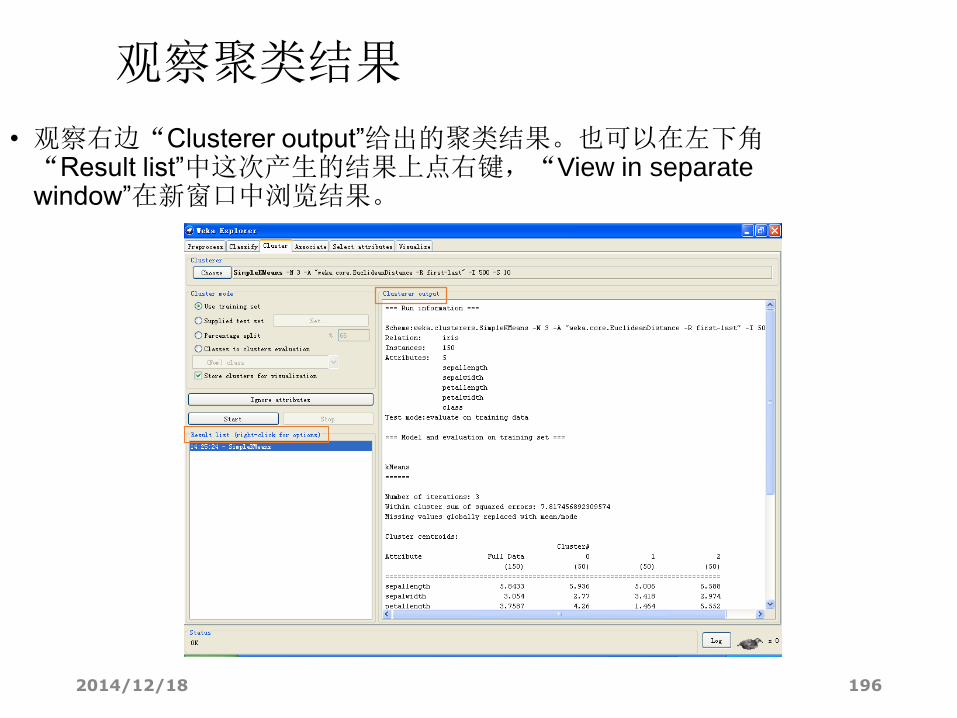
观察聚类结果
• 观察右边“Clusterer output”给出的聚类结果。也可以在左下角“Result list”中这次产生的结果上点右键,“View in separate window”在新窗口中浏览结果。

2014/12/18 197
=== Run information === %运行信息
Scheme:weka. clusterers. SimpleKMeans -N 3 -A “weka. core. EuclideanDistance -R first-last” -I 500 -S 10
% 算法的参数设置:-N 3 -A “weka. core. EuclideanDistance -R first-last” -I 500 -S 10;
% 各参数依次表示:
% -N 3 –聚类簇数为3;
% -A “weka. core. EuclideanDistance – 中心距离为欧氏距离;
% - I 500 --最多迭代次数为500;
% -S 10 --随机种子值为10。
Relation: iris %数据集名称
Instances: 150 %数据集中的实例个数

2014/12/18 198
Attributes: 5 %数据集中的属性个数及属性名称
sepallength
sepalwidth
petallength
petalwidth
Ignored: %忽略的属性
class
Test mode:Classes to clusters evaluation on training data %测试模式
=== Model and evaluation on taining set === %基于训练数据集的模型与评价
kMeans %使用kMeans算法
======
Number of iterations: 6 kMeans %迭代次数
Winthin cluster sum of squared errors: 6.998114004826762 % SSE(误差的平方和)
Missing values globally replaced with mean/mode %用均值/众数替代缺失值
2014/12/18 199
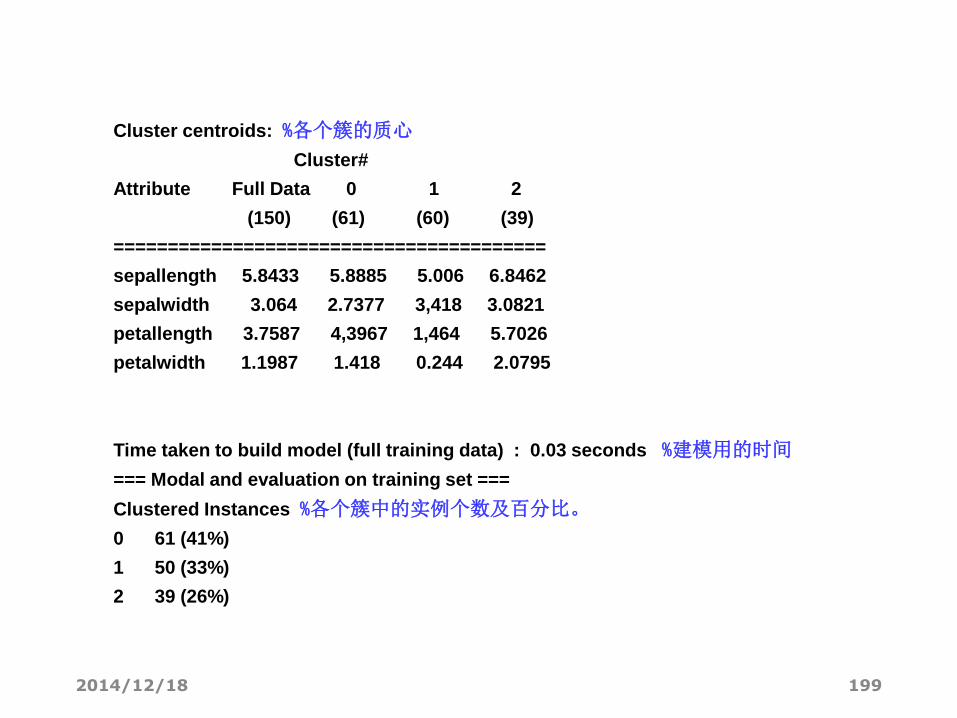
Cluster centroids: %各个簇的质心
Cluster#
Attribute Full Data 0 1 2
(150) (61) (60) (39)
========================================
sepallength 5.8433 5.8885 5.006 6.8462
sepalwidth 3.064 2.7377 3,418 3.0821
petallength 3.7587 4,3967 1,464 5.7026
petalwidth 1.1987 1.418 0.244 2.0795
Time taken to build model (full training data) : 0.03 seconds %建模用的时间
=== Modal and evaluation on training set ===
Clustered Instances %各个簇中的实例个数及百分比。
0 61 (41%)
1 50 (33%)
2 39 (26%)

2014/12/18 200
注意:采用有监督聚类(即已知建模数据集的类标号),才会出现以下执行信息。
Class attribute: class %类标号属性名称
Classes to Clusters: %类簇混淆矩阵
0 1 2 <-- assigned to cluster
0 50 0 | Iris-setosa
47 0 3 | Iris-versicolor
14 0 36 | Iris-virginisa
Cluster 0 <-- Iris-versicolor
Cluster 1 <-- Iris-setosa
Cluster 2 <-- Iris-virginica
Incorrectly clustered instances : 17.0 11.3333 % %错分实例个数及百分比

2014/12/18 201
• 文字分析
• SimpleKMeans
• 非监督模式:运行信息、KMeans结果(迭代次数、SSE、簇中心)、检验对象的分组信息
• 监督模式:运行信息、KMeans结果(迭代次数、SSE、簇中心)、类/簇混淆矩阵、错误分组的对象个数和比例
• 簇中心:对于数值属性为均值,对于分类属性为众数
• DBScan
• 非监督模式:运行信息、DBScan结果(迭代次数、各个训练对象的分组信息)、检验对象的分组信息
• 监督模式:运行信息、 DBScan结果(迭代次数、各个训练对象的分组信息)、类/簇混淆矩阵、错误分组的对象个数和比例
• 图形分析(必须将store clusters for visualization勾上)
• 可视化簇指派 (Visualize cluster assignments):2D散布图,能够可视化类/簇混淆矩阵

2014/12/18 202
SimpleKMeans聚类结果分析
• 重要的输出信息
• “ Within cluster sum of squared errors ”评价聚类好坏的标准—SSE,即误差的平方和。SSE值越小说明聚类结果越好。
• “Cluster centroids:”之后列出了各个簇中心的位置。对于数值型的属性,簇中心就是它的均值(Mean),分类型的就是它的众数(Mode)。
• “Clustered Instances”是各个簇中实例的数目及百分比。
2014/12/18 203
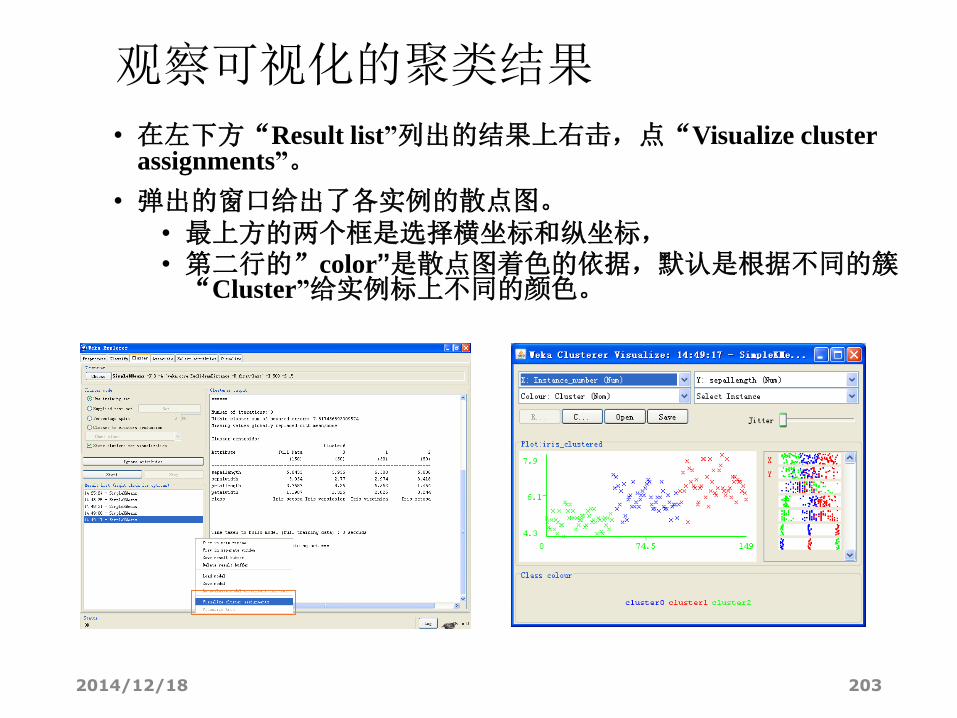
观察可视化的聚类结果
• 在左下方“Result list”列出的结果上右击,点“Visualize cluster assignments”。
• 弹出的窗口给出了各实例的散点图。• 最上方的两个框是选择横坐标和纵坐标,• 第二行的”color”是散点图着色的依据,默认是根据不同的簇“Cluster”给实例标上不同的颜色。
2014/12/18 204
示例:对IRIS数据集作聚类分析
2014/12/18 205
采用无监督聚类,删除原有的类标号

2014/12/18 206
选择聚类数据挖掘任务
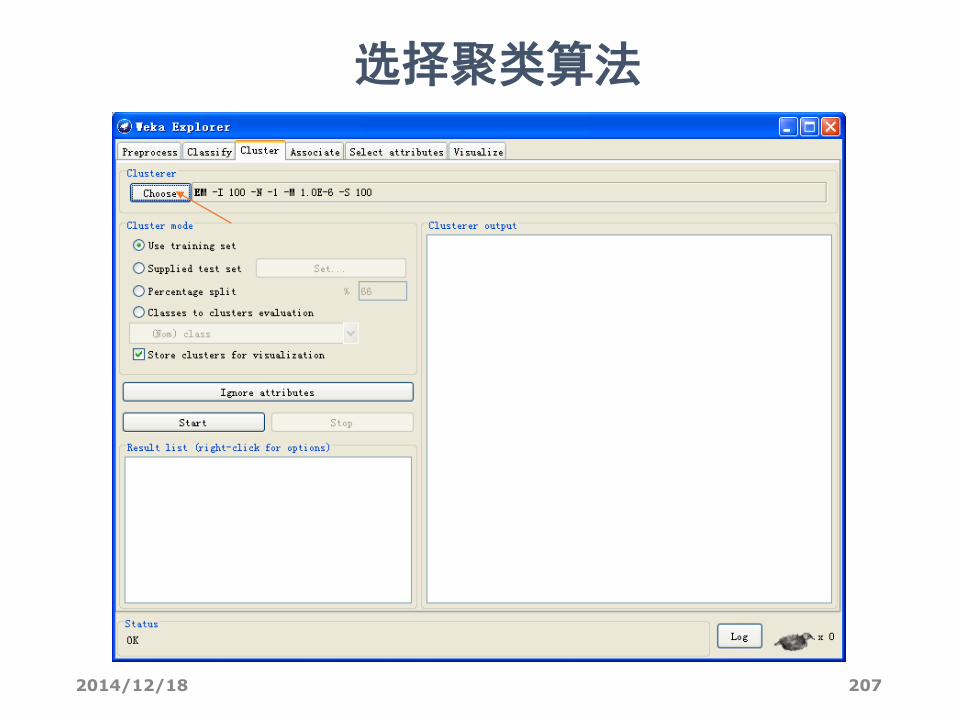
2014/12/18 207
选择聚类算法

2014/12/18 208
选中SimpleKMeans算法

2014/12/18 209
设置参数
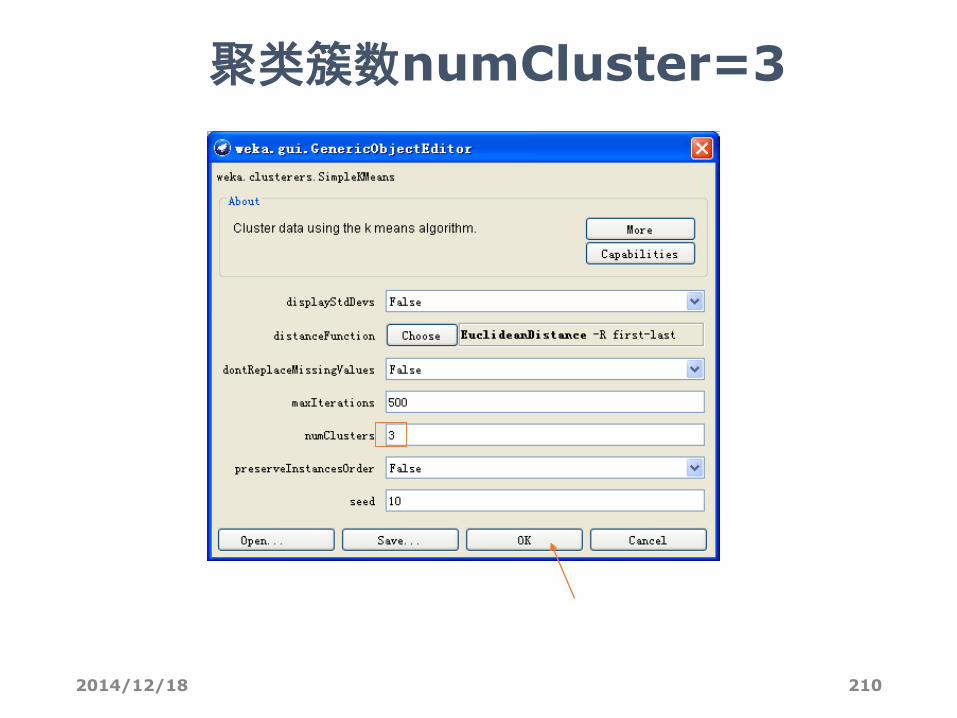
2014/12/18 210
聚类簇数numCluster=3

2014/12/18 211
执行聚类算法

2014/12/18 212
观察聚类结果
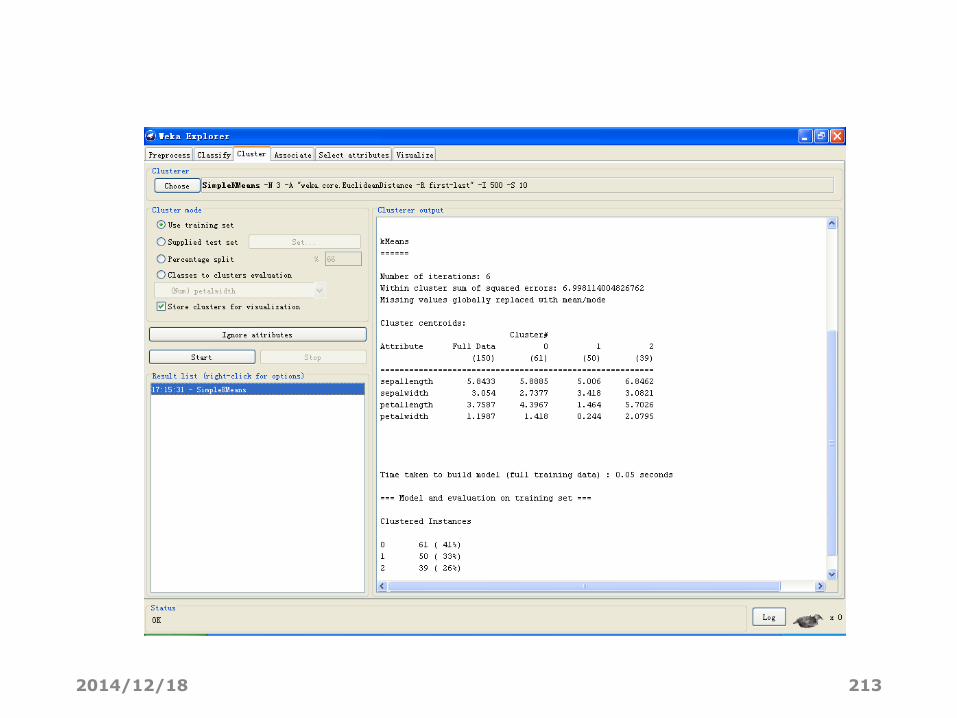
2014/12/18 213
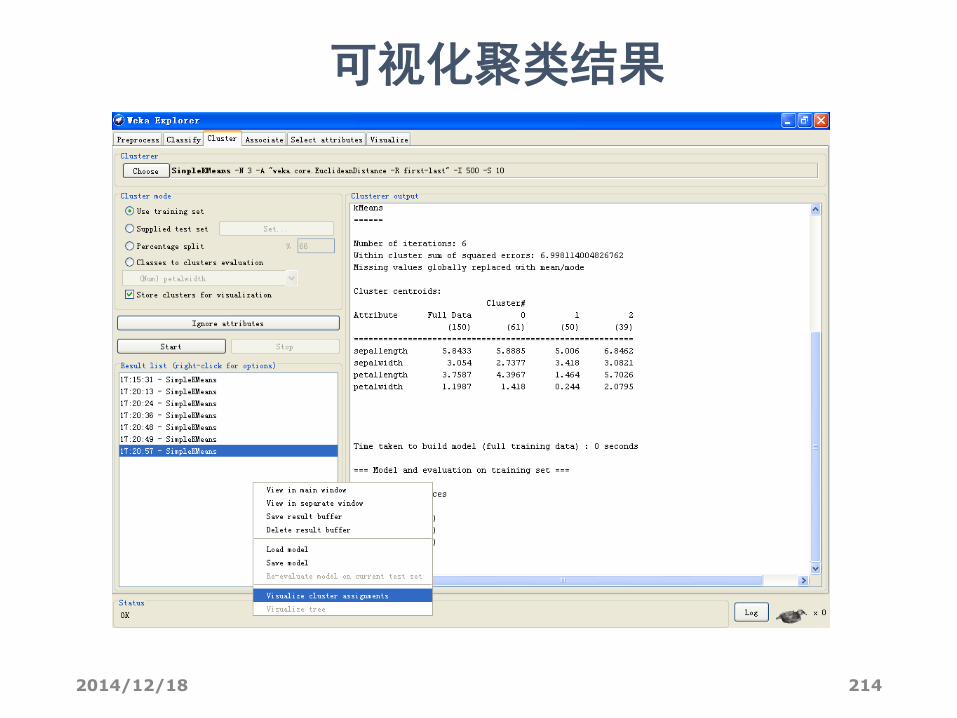
2014/12/18 214
可视化聚类结果
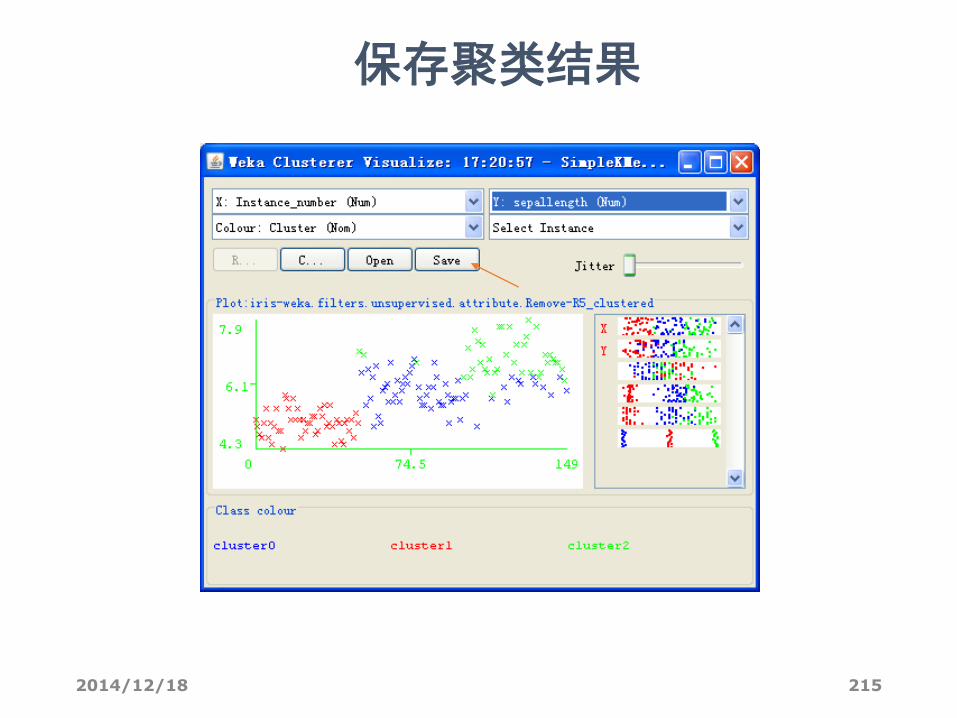
2014/12/18 215
保存聚类结果

2014/12/18 216

2014/12/18 217
在写字板中观察实例的簇

2014/12/18 218
聚类实验—银行客户分类
• 本次实验利用Weka中提供的simpleKmeans (K-
均值)算法对“bank-data”数据进行聚类分析,
其目的是发现相似客户群,以满足银行的客户
细分需求,为银行针对不同客户群体的营销策
略提供支持。

2014/12/18 219
数据的准备及预处理
• 原始数据“bank-data.xls”是excel文件格式的数据,需要转换成Weka支持的ARFF文件格式的。转换方法:
• 在excel中打开“bank-data.xls”,选择菜单文件—>另存为,在弹出的对话框中,文件名输入“bank-data”,保存类型选择“CSV(逗号分隔)”,保存,我们便可得到“bank-data.csv”文件;
• 然后,打开Weka的Exporler,点击Open file按钮,打开刚才得到的“bank-data.csv”文件;
• 点击“save”按钮,在弹出的对话框中,文件名输入“bank-data.arff”,文件类型选择“Arff data files(*.arff)”,这样得到的数据文件为“bank-data.arff”。

2014/12/18 220
• K均值算法只能处理数值型的属性,遇到分类型的属性时要把它变为若干个取值0和1的属性。
• WEKA将自动实施这个分类型到数值型的变换,而且WEKA会自动对数值型的数据作标准化。
• 因此,对于ARFF格式的原始数据“bank-data.arff”,我们所做的预处理只是删去属性“id”,修改属性“children”为分类型。修改过程如下:
• 打开“bank-data.arff”,将@attribute children numeric改成如下:

2014/12/18 221
使用WEKA聚类
• 用“Explorer”打开包含600条实例“bank-data.arff”,并切换到“Cluster”。
• 点击“Choose”按钮,选择“SimpleKMeans” 。
• 点击旁边的文本框,修改参数• “numClusters”为6,说明我们希望把这600条实例聚成6类,即K=6。
• 下面的“seed”参数是要设置一个随机种子,依此产生一个随机数,用来得到K均值算法中第一次给出的K个簇中心的位置。我们暂时让它就为10。
• 选中“Cluster Mode”的“Use training set”
• 点击“Start”按钮
• 观察右边“Clusterer output”给出的聚类结果。

2014/12/18 222
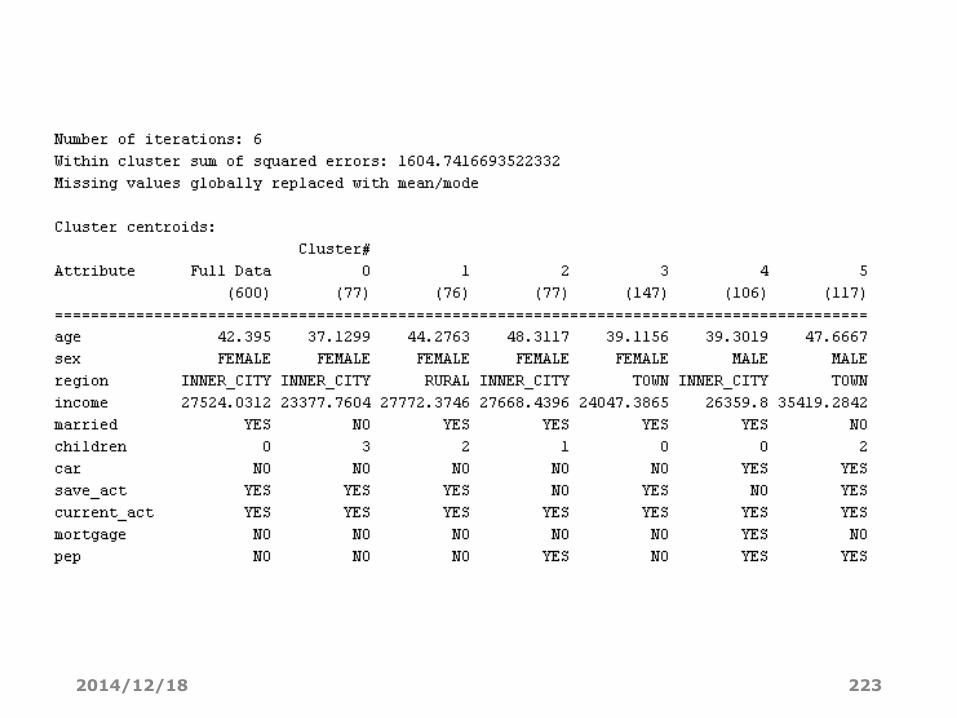
2014/12/18 223

2014/12/18 224

2014/12/18 225
结果分析
• 当前Within cluster sum of squared errors: 1604.7416693522332,调整“seed”参数,观察Within cluster sum of squared errors(SSE)变化。采纳SSE最小的一个结果。
• “Cluster centroids:”之后列出了各个簇中心的位置。对于数值型的属性,簇中心就是它的均值(Mean),如cluster0的数值型变量age的均值37.1299;分类型的就是它的众数(Mode),如cluster0的分类型变量children的众数为3,也就是说这个属性上取值为众数值3(有3个孩子)的实例最多。
• 为了观察可视化的聚类结果,在左下方“Result list”列出的结果上右击,点“Visualize cluster assignments”。弹出的窗口给出了各实例的散点图。最上方的两个框是选择横坐标和纵坐标,第二行的”color”是散点图着色的依据,默认是根据不同的簇“Cluster”给实例标上不同的颜色。例如,横坐标选择Instance_number,纵坐标选择income。
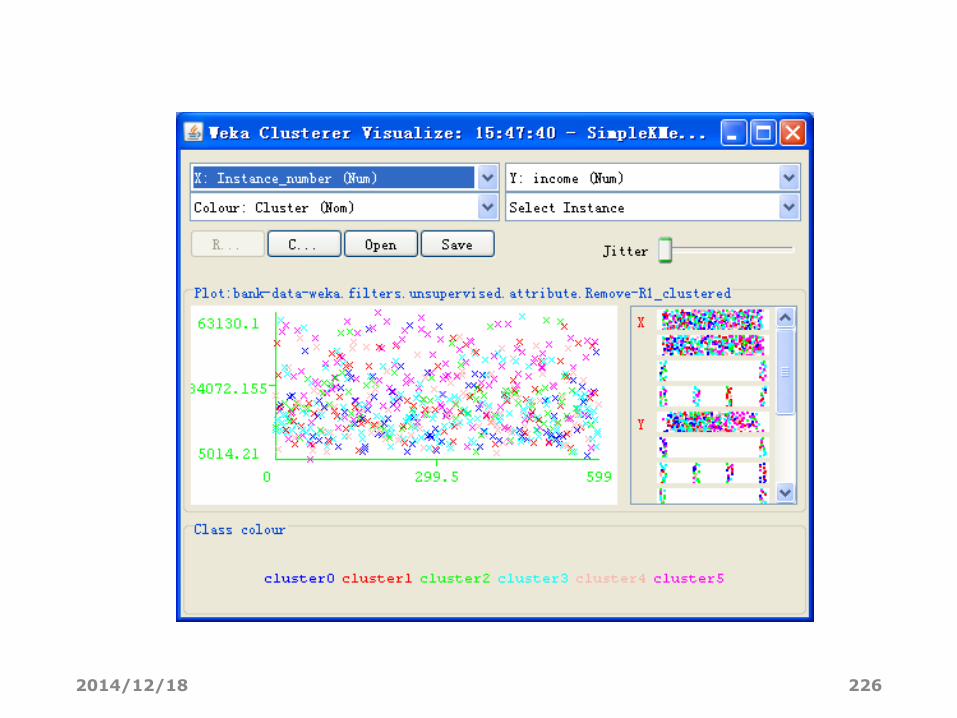
2014/12/18 226

2014/12/18 227
• 点击“Save”,把聚类结果保存成bank_Cluster.arff文件。可以在写字板中打开观察聚类结果文件。在这个新的ARFF文件中,“instance_number”属性表示某实例的编号,“Cluster”属性表示聚类算法给出的该实例所在的簇。

2014/12/18 228
7、关联规则associations
• WEKA关联规则学习能够发现属性组之间的依赖关系:
• 例如,milk, butter bread, eggs (置信度 0.9 and 支持数 2000)
• 对于关联规则L->R
• 支持度(support)—— 同时观察到前件和后件的概率
support = Pr(L,R)
• 置信度(confidence)—— 出现前件时同时出现后件的概率
confidence = Pr(L,R)/Pr(L)

2014/12/18 229
关联规则挖掘的主要算法
• WEKA数据挖掘平台上的关联规则挖掘的主要算法有:
• Apriori--能够得出满足最小支持度和最小支持度的所有关联规则。
• PredictiveApriori--将置信度和支持度合并为预测精度而成为单一度测量法,找出经过预测精度排序的关联规则。
• Terius--根据确认度来寻找规则,它与Apriori一样寻找其结论中含有多重条件的规则,但不同的是这些条件相互间是‘或’,而不是‘与’的关系。
• 这三个算法均不支持数值型数据。
• 事实上,绝大部分的关联规则算法均不支持数值型。所以必须将数据进行处理,将数据按区段进行划分,进行离散化分箱处理。

2014/12/18 230

2014/12/18 231
算法属性设置

2014/12/18 232
• car:如果设为真,则会挖掘类关联规则而不是全局关联规则。
• classindex: 类属性索引。如果设置为-1,最后的属性被当做类属性。
• delta: 以此数值为迭代递减单位。不断减小支持度直至达到最小支持度或产生了满足数量要求的规则。
• lowerBoundMinSupport: 最小支持度下界。
• metricType: 度量类型,设置对规则进行排序的度量依据。可以是:置信度(类关联规则只能用置信度挖掘),提升度(lift),平衡度(leverage),确信度(conviction)。
• minMtric :度量的最小值。
• numRules: 要发现的规则数。
• outputItemSets:如果设置为真,会在结果中输出项集。
• removeAllMissingCols: 移除全部为缺失值的列。
• significanceLevel :重要程度。重要性测试(仅用于置信度)。
• upperBoundMinSupport: 最小支持度上界。 从这个值开始迭代减小最小支持度。
• verbose: 如果设置为真,则算法会以冗余模式运行。

2014/12/18 233
度量类型metricType
• Weka中设置了几个类似置信度(confidence)的度量来衡量规则的关联程度,它们分别是:
• Lift,提升度:置信度与后件支持度的比率
lift = Pr(L,R) / (Pr(L)Pr(R))
Lift=1时表示L和R独立。这个数越大(>1),越表明L和B存在于一个购物篮中不是偶然现象,有较强的关联度。
• Leverage,平衡度:在前件和后件统计独立的假设下,被前件和后件同时涵盖的超出期望值的那部分实例的比例。
leverage = Pr(L,R) - Pr(L)Pr(R)
Leverage=0时L和R独立,Leverage越大L和R的关系越密切。
• Conviction,可信度:也用来衡量前件和后件的独立性。conviction = Pr(L)Pr(!R) / Pr(L,!R) (!R表示R没有发生)
从它和lift的关系(对R取反,代入Lift公式后求倒数)可以看出,这个值越大, L和R越关联。

2014/12/18 234
关联规则挖掘算法运行信息
• === Run information === %运行信息
• Scheme: weka.associations.Apriori -I -N 10 -T 0 -C 0.9 -D 0.05 -U 1.0 -M 0.1 -S -1.0 -c -1% 算法的参数设置:-I -N 10 -T 0 -C 0.9 -D 0.05 -U 1.0 -M 0.5 -S -1.0 -c -1 ;% 各参数依次表示:% I - 输出项集,若设为false则该值缺省;% N 10 - 规则数为10;% T 0 – 度量单位选为置信度,(T1-提升度,T2杠杆率,T3确信度);% C 0.9 – 度量的最小值为0.9;% D 0.05 - 递减迭代值为0.05;% U 1.0 - 最小支持度上界为1.0;% M 0.5 - 最小支持度下届设为0.5;% S -1.0 - 重要程度为-1.0;% c -1 - 类索引为-1输出项集设为真% (由于car, removeAllMissingCols, verbose都保持为默认值False,因此在结果的参数设置为缺省,若设为True,则会在结果的参数设置信息中分别表示为A, R,V)

2014/12/18 235
• Relation: mushroom %数据集名称Instances: 8124 %数据项个数Attributes: 23 %属性项个数/属性项
cap-shapecap-surfacecap-colorbruises?odorgill-attachmentgill-spacinggill-sizegill-colorstalk-shapestalk-rootstalk-surface-above-ringstalk-surface-below-ringstalk-color-above-ringstalk-color-below-ringveil-typeveil-colorring-numberring-typespore-print-colorpopulationhabitatclass

2014/12/18 236
• === Associator model (full training set) ===
• Apriori=======
• Minimum support: 0.95 (7718 instances)
%最小支持度0.95,即最少需要7718个实例Minimum metric <confidence>: 0.9
%最小度量<置信度>: 0.9Number of cycles performed: 1 %进行了1轮搜索
Generated sets of large itemsets: %生成的频繁项集Size of set of large itemsets L(1): 3 %频繁1项集:3个Large Itemsets L(1): %频繁1项集(outputItemSets设为True, 因此下面会具体列出)gill-attachment=f 7914veil-type=p 8124veil-color=w 7924

2014/12/18 237
• Size of set of large itemsets L(2): 3
Large Itemsets L(2): %频繁2项集gill-attachment=f veil-type=p 7914gill-attachment=f veil-color=w 7906veil-type=p veil-color=w 7924
Size of set of large itemsets L(3): 1 Large Itemsets L(3): %频繁3项集gill-attachment=f veil-type=p veil-color=w 7906

2014/12/18 238
• Best rules found: %最佳规则
1. veil-color=w 7924 ==> veil-type=p 7924 conf:(1)2. gill-attachment=f 7914 ==> veil-type=p 7914 conf:(1)3. gill-attachment=f veil-color=w 7906 ==> veil-type=p 7906 conf:(1)4. gill-attachment=f 7914 ==> veil-color=w 7906 conf:(1)5. gill-attachment=f veil-type=p 7914 ==> veil-color=w 7906 conf:(1)6. gill-attachment=f 7914 ==> veil-type=p veil-color=w 7906 conf:(1)7. veil-color=w 7924 ==> gill-attachment=f 7906 conf:(1)8. veil-type=p veil-color=w 7924 ==> gill-attachment=f 7906 conf:(1)9. veil-color=w 7924 ==> gill-attachment=f veil-type=p 7906 conf:(1)10. veil-type=p 8124 ==> veil-color=w 7924 conf:(0.98)

2014/12/18 239
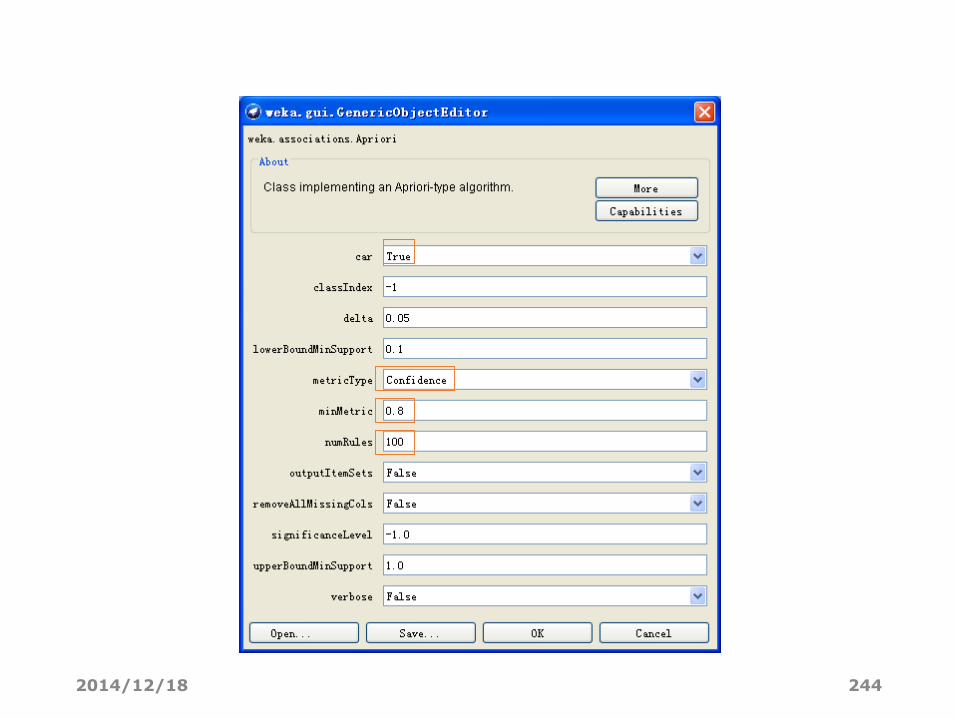
数据挖掘任务• 挖掘支持度在10%到100%之间,并且置信度超过0.8且置信度排在前100位的分类关联规则
• 数据集为“weather.nominal.arff”
• “car”设为True
• “metricType”设为confidence
• “minMetric”设为0.8
• “numRules”设为100

2014/12/18 240
在WEKA中打开“weather.nominal.arff”数据集
2014/12/18 241
选择关联分析

2014/12/18 242
选择Apriori算法

2014/12/18 243
设定参数
2014/12/18 244

2014/12/18 245
执行算法
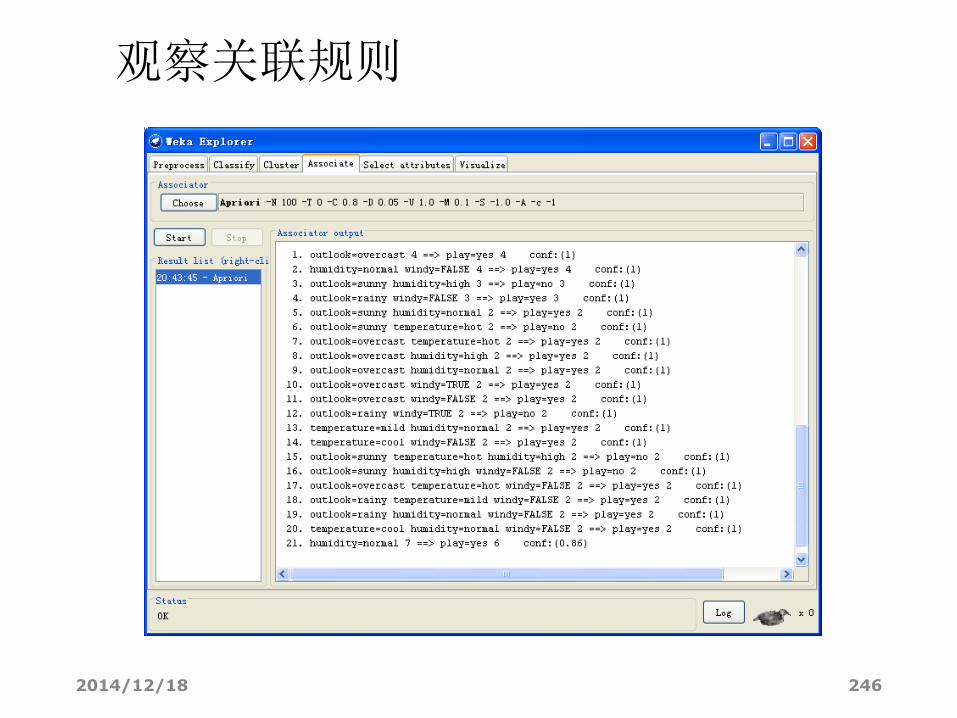
2014/12/18 246
观察关联规则

2014/12/18 247
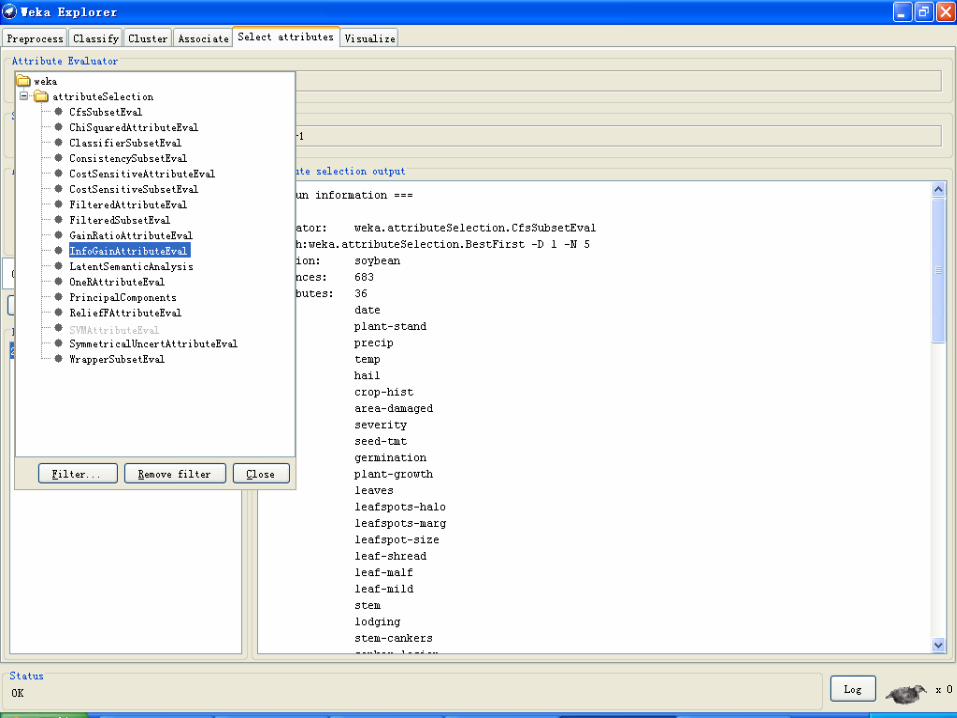
8、属性选择 Select Attributes
• 属性选择是搜索数据集中全部属性的所有可能组合,找出预测效果最好的那一组属性。
• 为实现这一目标,必须设定属性评估器(evaluator)和搜索策略。
• 评估器决定了怎样给一组属性安排一个表示它们好坏的值。
• 搜索策略决定了要怎样进行搜索。
• 选项
• Attribute Selection Mode 一栏有两个选项。
• Use full training set. 使用训练数据的全体决定一组属性的好坏。
• Cross-validation. 一组属性的好坏通过一个交叉验证过程来决定。Fold 和 Seed 分别给出了交叉验证的折数和打乱数据时的随机种子。
• 和 Classify 部分一样,有一个下拉框来指定class属性。

2014/12/18 248
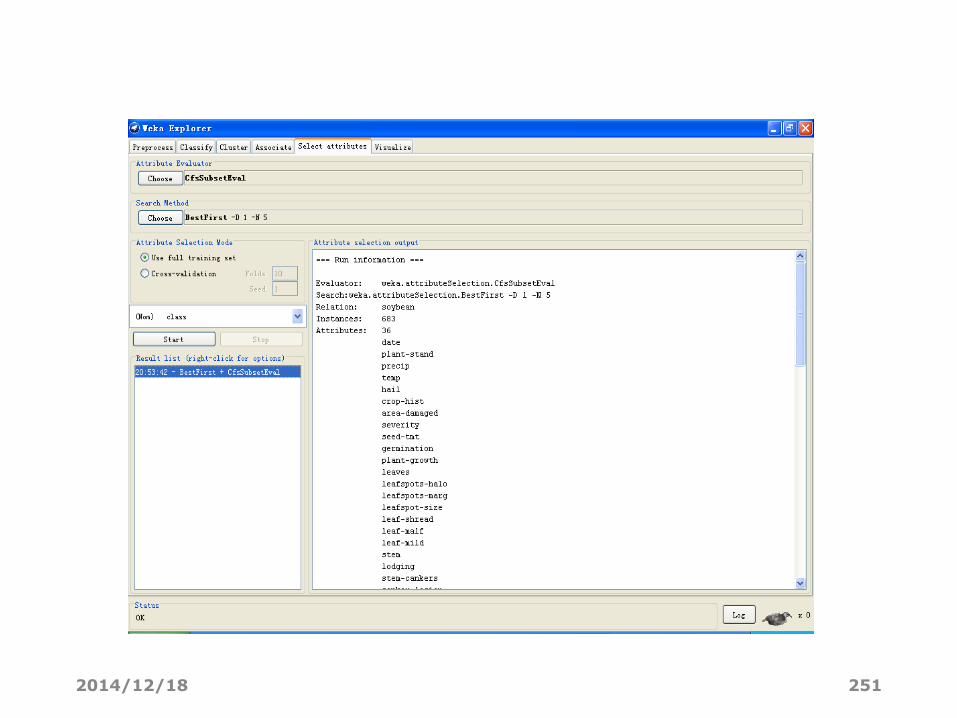
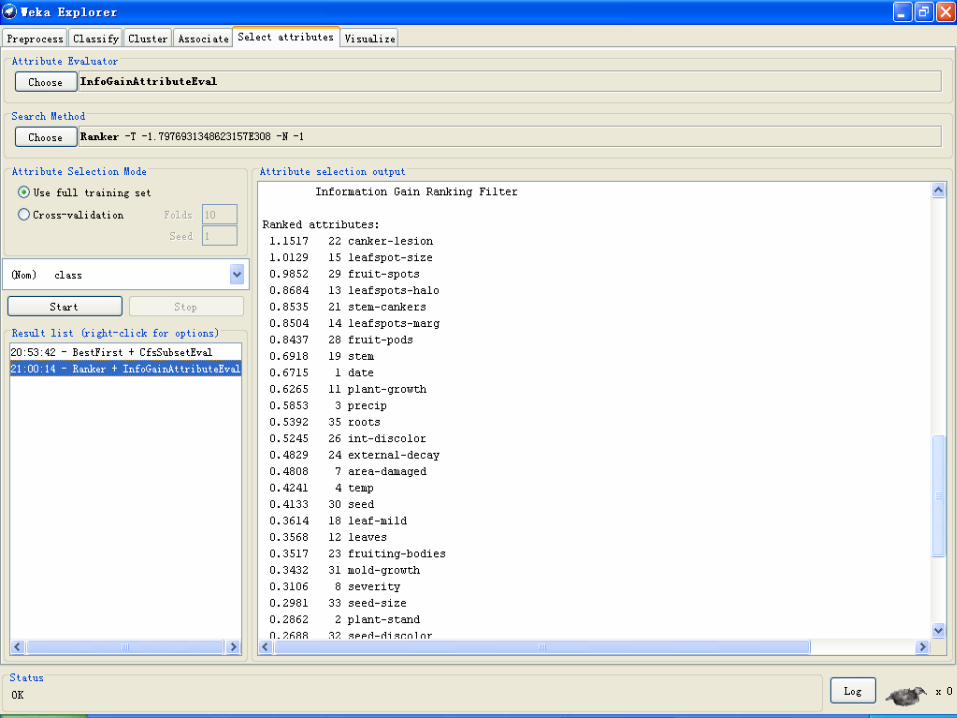
• 执行选择
• 点击Start按钮开始执行属性选择过程。它完成后,结果会输出到
结果区域中,同时结果列表中会增加一个条目。
• 在结果列表上右击,会给出若干选项。其中前面三个(View in
main window,View in separate window 和 Save result buffe)和
分类面板中是一样的。
• 还可以可视化精简过的数据集(Visualize reduced data)
• 能可视化变换过的数据集(Visualize transformed data)
• 精简过/变换过的数据能够通过 Save reduced data... 或 Save
transformed data... 选项来保存。
2014/12/18 249

2014/12/18 250
2014/12/18 251

2014/12/18 252
2014/12/18 253

2014/12/18 254
2014/12/18 255

2014/12/18 256
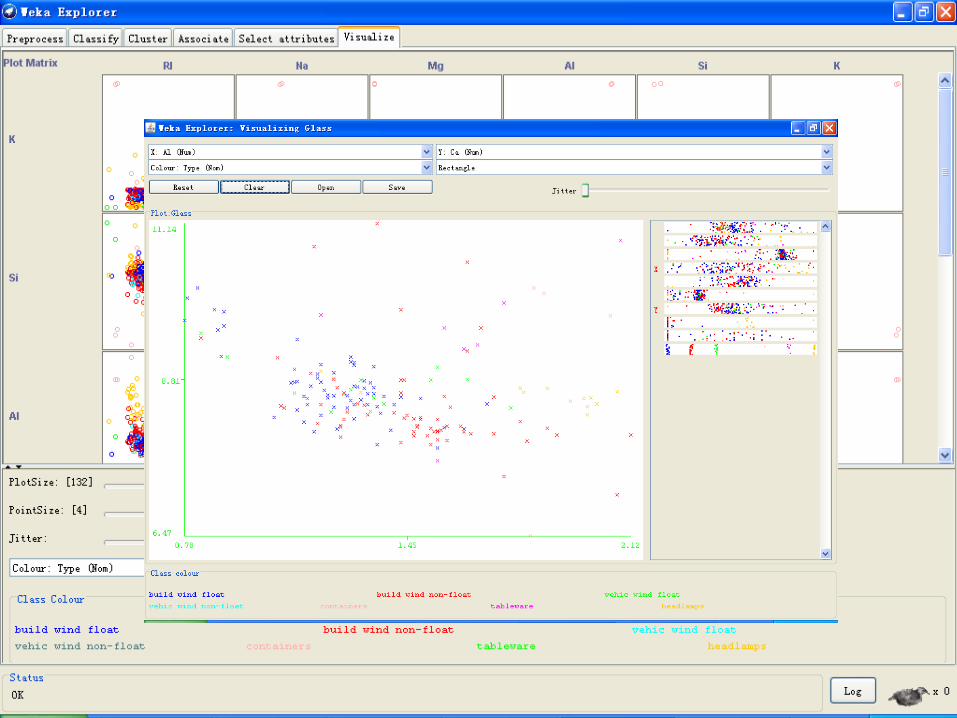
9、数据可视化 Visualize
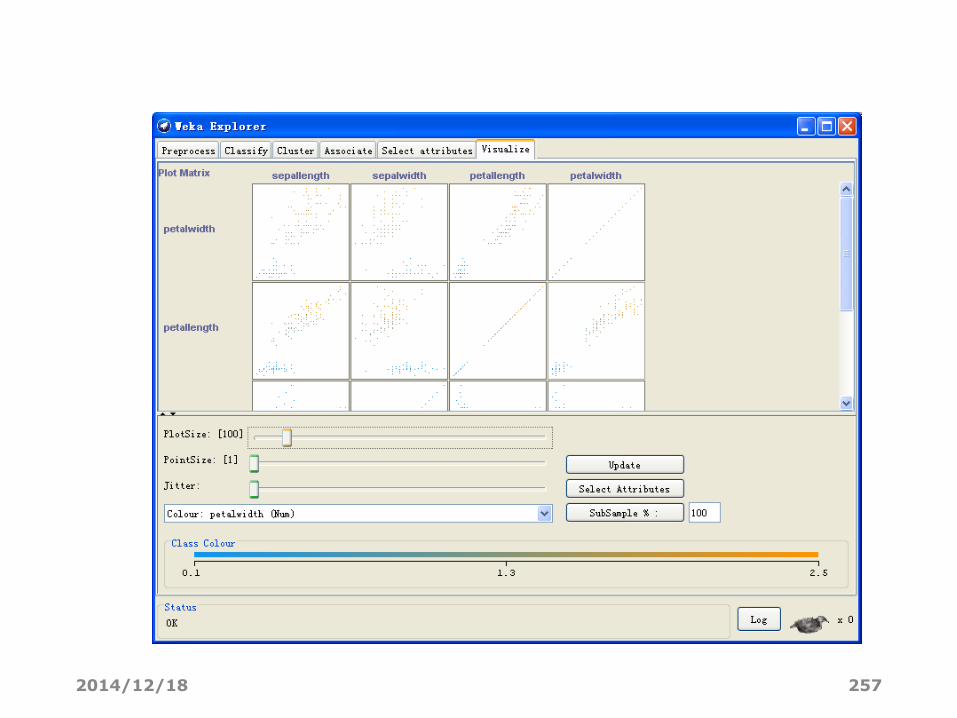
• WEKA 的可视化页面可以对当前的关系作二维散点图式的可视化浏览。
• 散点图矩阵
• 选择了 Visualize 面板后,会为所有的属性给出一个散点图矩阵,它们会根据所选的class 属性来着色。
• 在这里可以改变每个二维散点图的大小,改变各点的大小,以及随机地抖动(jitter)数据(使得被隐藏的点显示出来)。
• 也可以改变用来着色的属性,可以只选择一组属性的子集放在散点图矩阵中,还可以取出数据的一个子样本。
• 注意这些改变只有在点击了Update 了按钮之后才会生效。
2014/12/18 257

2014/12/18 258
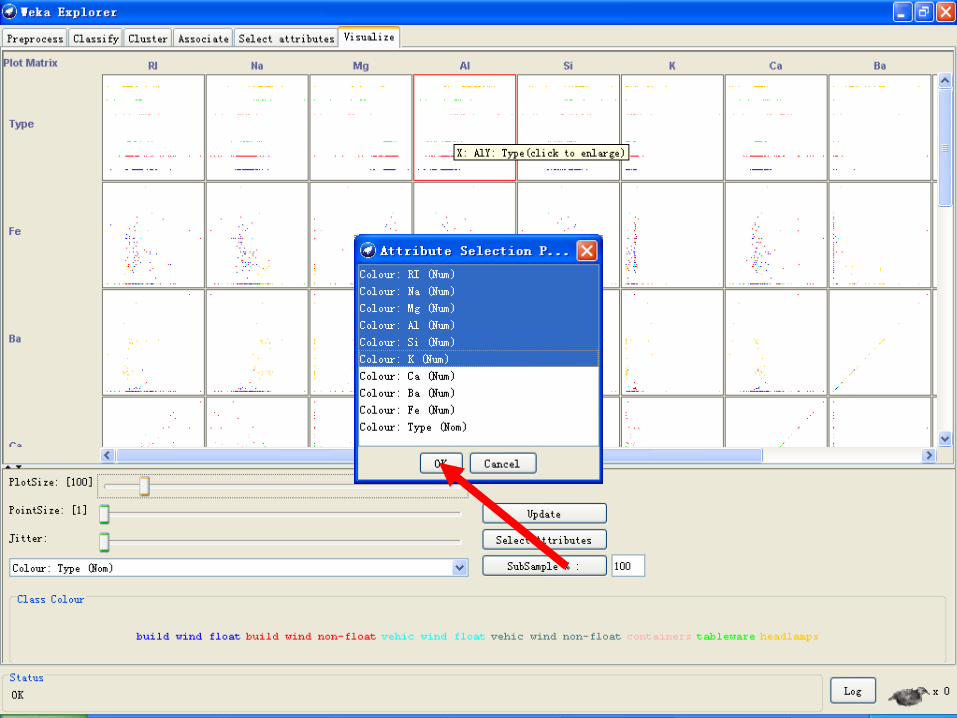
• 选择单独的二维散点图
• 在散点图矩阵的一个元素上点击后,会弹出一个单独的窗口对所选的散点图进行可视化。
• 数据点散布在窗口的主要区域里。上方是两个下拉框选择用来选择打点的坐标轴。左边是用作 x 轴的属性;右边是用作 y 轴的属性。
• 在 x 轴选择器旁边是一个下拉框用来选择着色的方案。它可以根据所选的属性给点着色。
• 在打点区域的下方,有图例来说明每种颜色代表的是什么值。如果这些值是离散的,可以通过点击它们所弹出的新窗口来修改颜色。

2014/12/18 259
• 打点区域的右边有一些水平横条。每一条代表着一个属性,其中的点代表了属性值的分布。这些点随机的在竖直方向散开,使得点的密集程度能被看出来。
• 在这些横条上点击可以改变主图所用的坐标轴。左键点击改变 x 轴的属性;右键点击改变 y 轴的。横条旁边的“X”和“Y”代表了当前的轴用的那个属性(“B”则说明 x 轴和 y 轴都是它)。
• 属性横条的上方是一个标着 Jitter 的游标。它能随机地使得散点图中各点的位置发生偏移,也就是抖动。把它拖动到右边可以增加抖动的幅度,这对识别点的密集程度很有用。
• 如果不使用这样的抖动,几万个点放在一起和单独的一个点看起来会没有区别。

2014/12/18 260

2014/12/18 261
• 在y轴选择按钮的下方是一个下拉按钮,它决定选取数据点的方法。

2014/12/18 262
• 可以通过以下四种方式选取数据点:
• Select Instance. 点击各数据点会打开一个窗口列出它的属性值,如果点击处的点超过一个,则更多组的属性值也会列出来。
• Rectangle. 通过拖动创建一个矩形,选取其中的点。
• Polygon. 创建一个形式自由的多边形并选取其中的点。左键点击添加多边形的顶点,右键点击完成顶点设置。起始点和最终点会自动连接起来因此多边形总是闭合的。
• Polyline. 可以创建一条折线把它两边的点区分开。左键添加折线顶点,右键结束设置。折线总是打开的(与闭合的多边形相反)。

2014/12/18 263
• 使用 Rectangle,Polygon 或 Polyline 选取了散点图的一个区域后,该区域会变成灰色。
• 这时点击 Submit按钮会移除落在灰色区域之外的所有实例。
• 点击Clear按钮会清除所选区域而不对图形产生任何影响。如果所有的点都被从图中移除,则 Submit 按钮会变成Reset 按钮。这个按钮能使前面所做的移除都被取消,图形回到所有点都在的初始状态。
• 最后,点击Save按钮可把当前能看到的实例保存到一个新的 ARFF 文件中。

2014/12/18 264
数据可视化举例

2014/12/18 265

2014/12/18 266

2014/12/18 267

2014/12/18 268

2014/12/18 269
2014/12/18 270

2014/12/18 271

2014/12/18 272

2014/12/18 273

2014/12/18 274

2014/12/18 275
2014/12/18 276

2014/12/18 277
使用 WEKA 探索数据的环境
提供了一个简单的命令行界面
和 Explorer 功能相同的可以拖放 界 面环境
试验算法的统计检验环境

2014/12/18 278
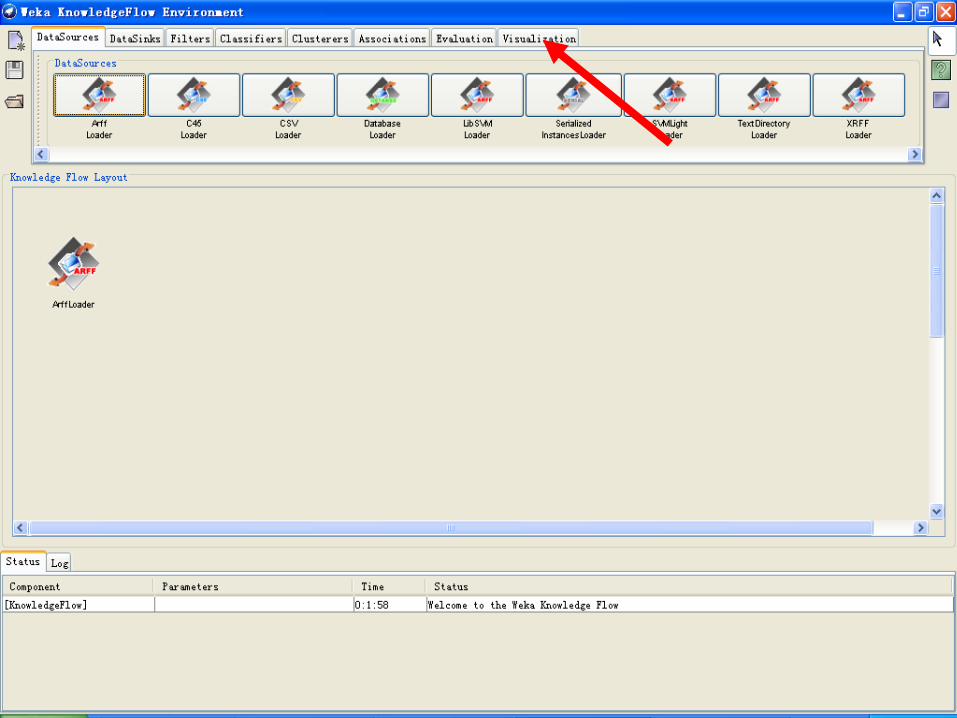
10、知识流图形界面 KnowledgeFlow
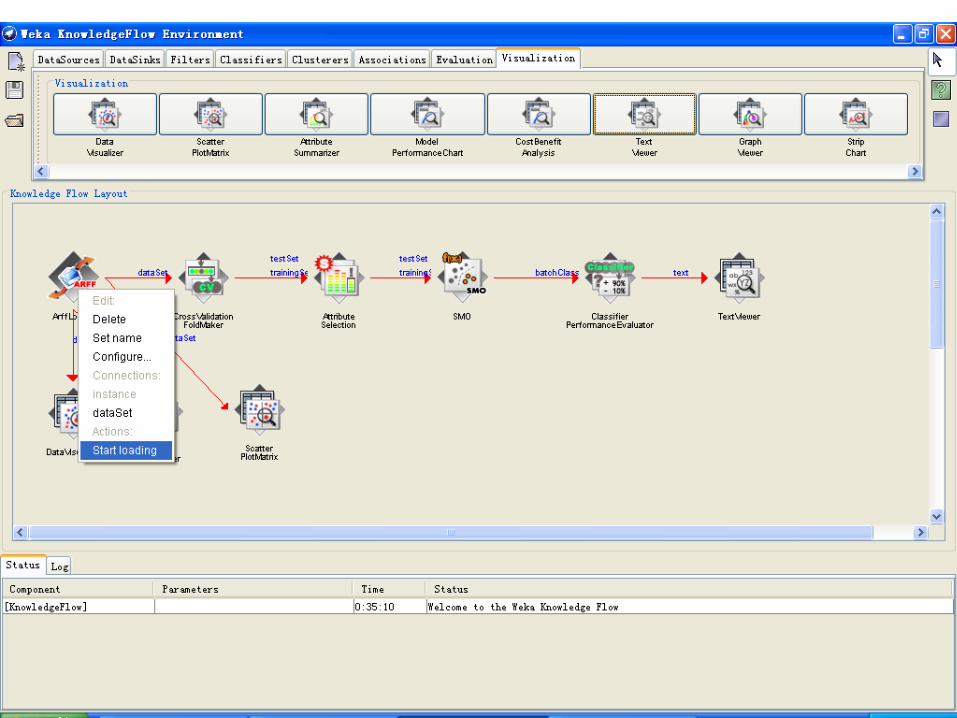
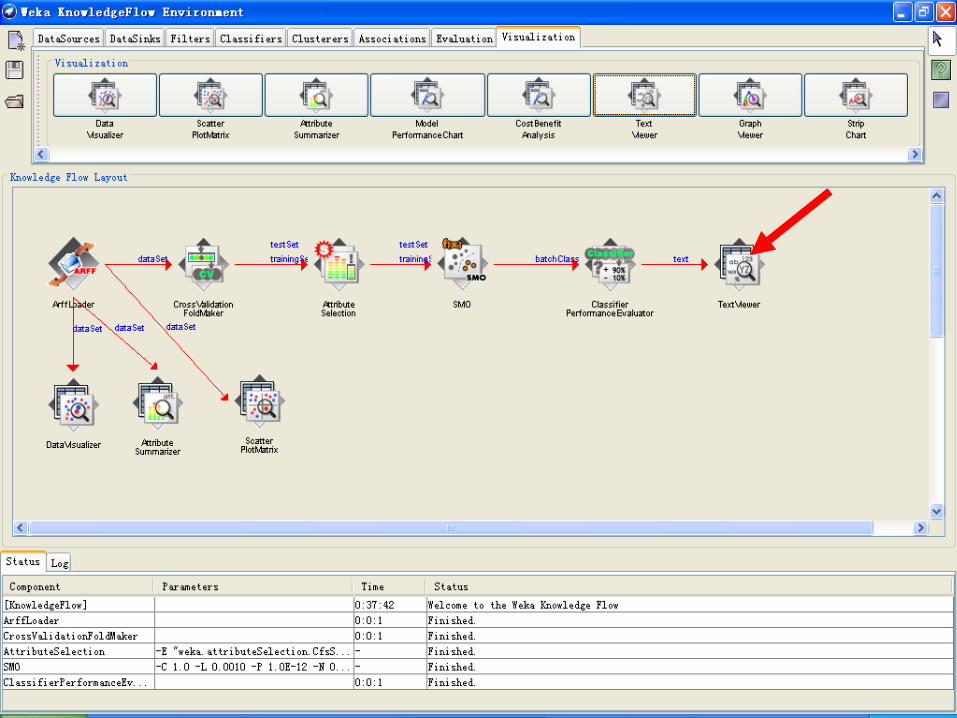
• KnowledgeFlow 为Weka 提供了一个图形化的“知识流”形式的界面。
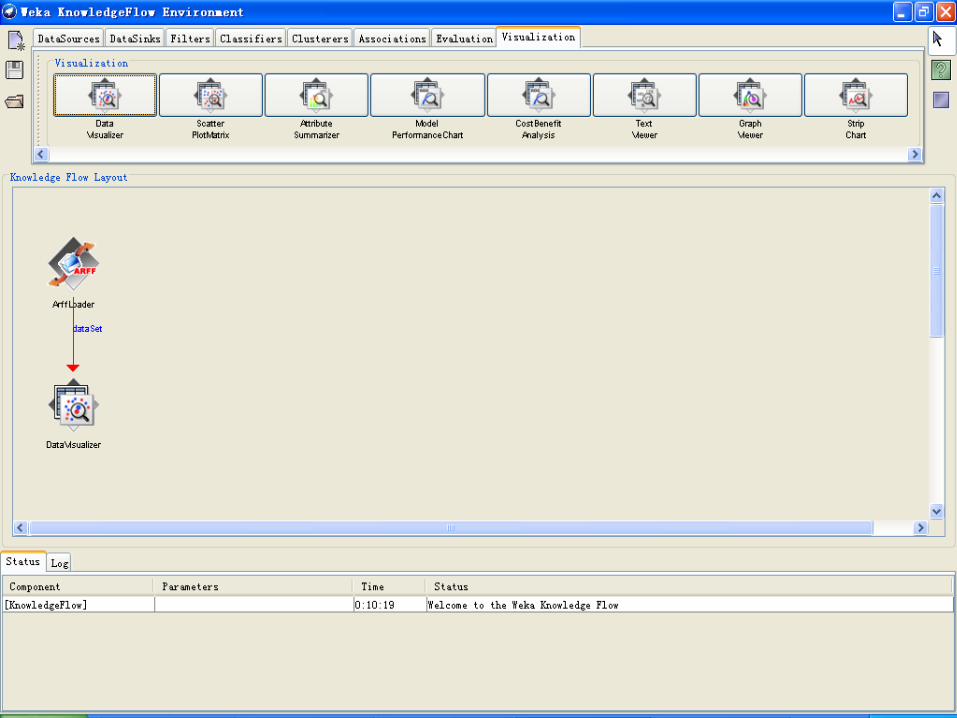
• 用户可以从一个工具栏中选择组件,把它们放置在面板上并按一定的顺序连接起来,这样组成一个“知识流”(KnowledgeFlow)来处理和分析数据。
• 例如 :“数据源” -> “筛选” -> “分类” -> “评估”
• Weka 分类器(classifier)、筛选器(Filter)、聚类器(clusterers)、载入器(loader)、保存器(saver),以及一些其他的功能可以在KnowledgeFlow 中使用。
• 可以保存“知识流”布局,并重新加载。

2014/12/18 279
KnowledgeFlow 的可用组件
• 在KnowledgeFlow 窗口顶部有八个标签:
• DataSources--数据载入器
• DataSinks--数据保存器
• Filters--筛选器
• Classifiers--分类器
• Clusterers--聚类器
• Associations—关联器
• Evaluation—评估器
• Visualization—可视化

2014/12/18 280
评估器 Evaluation• TrainingSetMaker--使一个数据集成为训练集
• TestSetMaker--使一个数据集成为测试集
• CrossValidationFoldMaker--把任意数据集,训练集或测试集分割成若干折以供交叉验证使用
• TrainTestSplitMaker--把任意数据集,训练集或测试集分割成一个训练集和一个测试集
• ClassAssigner --把某一列作为任意数据集,训练集或测试集的class 属性
• ClassValuePicker--选择某个类别作为“positive”的类。这在为ROC形式的曲线生成数据时会有用
• ClassifierPerformanceEvaluator --评估批处理模式下训练过或测试过的分类器的表现
• IncrementalClassi erEvaluator--评估增量模式下训练过的分类器的表现
• ClustererPerformanceEvaluator--评估批处理模式下训练过或测试过的聚类器的表现
• PredictionAppender--往测试集中添加分类器的预测值。对于离散的分类问题,可以添加预测的类标志或者概率分布

2014/12/18 281
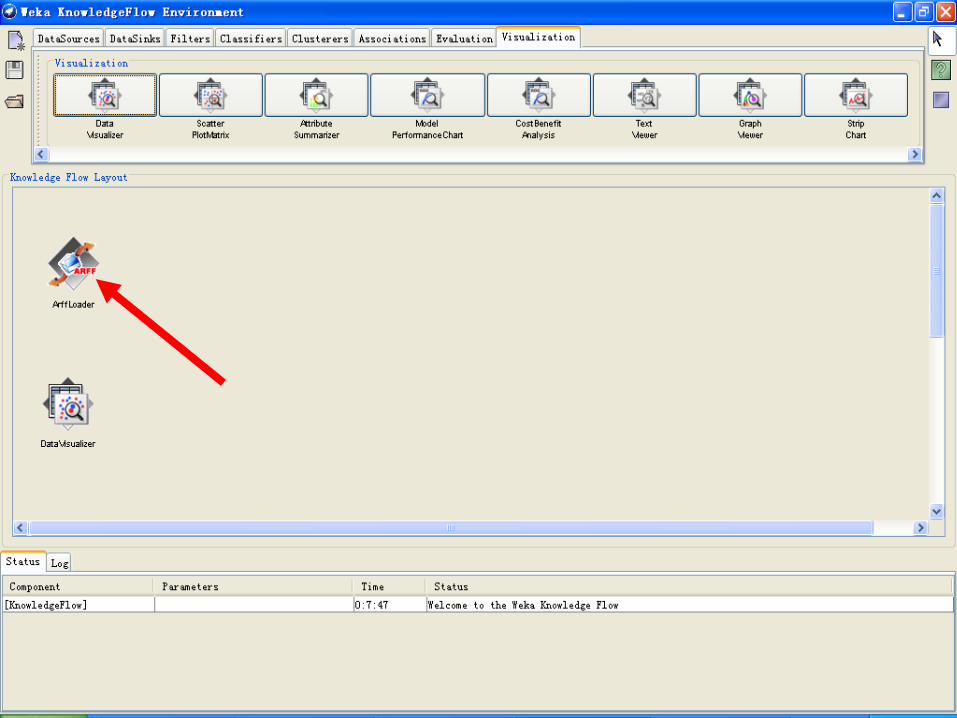
可视化 Visualization
• DataVisualizer--该组件可弹出一个面板,使得可以在一个单独的较大的散点图中对数据进行可视化
• ScatterPlotMatrix--该组件可弹出一个面板,其中有一个由一些小的散点图构成的矩阵(点击各小散点图会弹出一个大的散点图)
• AttributeSummarizer --该组件可弹出一个面板,其中有一个直方图构成的矩阵,每个直方图对应输入数据里的一个属性
• ModelPerformanceChart --该组件能弹出一个面板来对阈值曲线(例如ROC 曲线)进行可视化
• TextViewer--该组件用来显示文本数据,可用来显示数据集以及衡量分类表现的统计量等
• GraphViewer --该组件能弹出一个面板来对基于树的模型进行可视化
• StripChart --该组件能弹出一个面板,其中显示滚动的数据散点图(用来即时观察增量分类器的表现)

2014/12/18 282
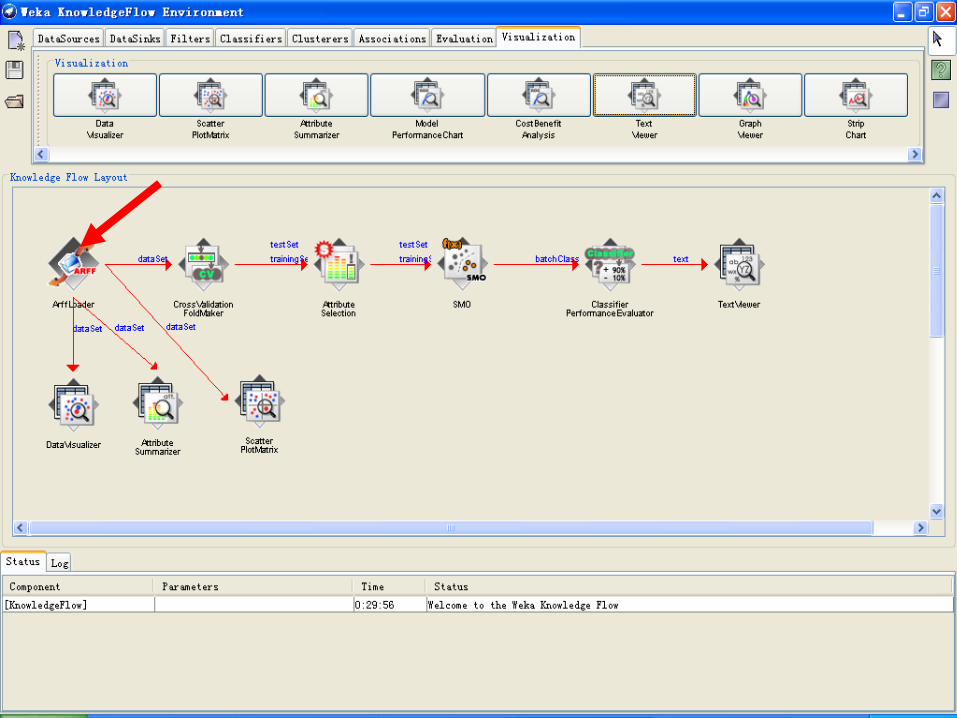
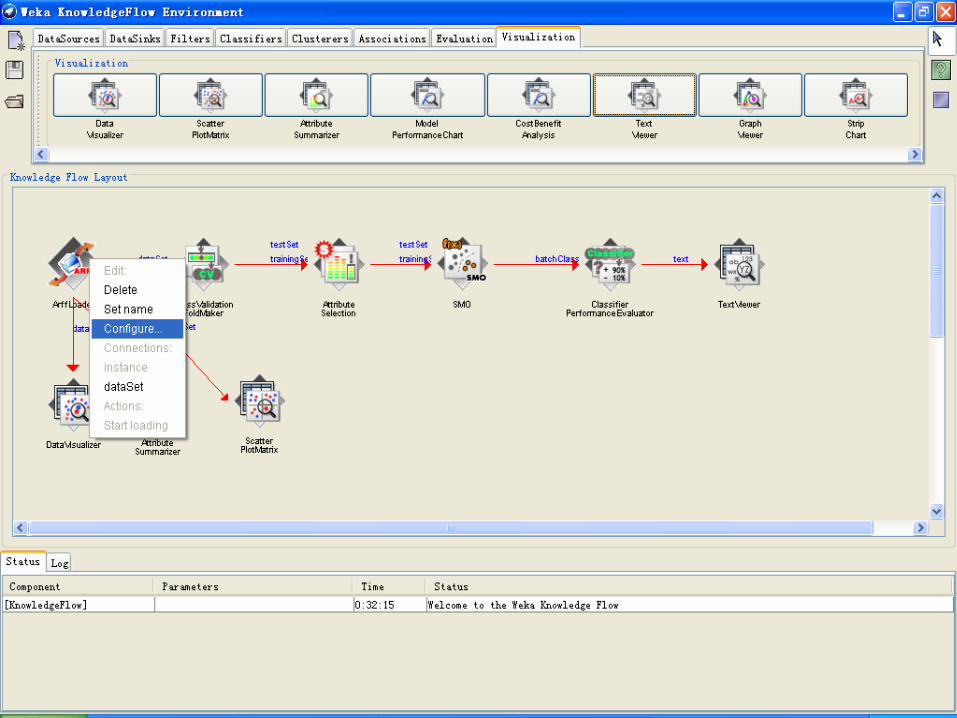
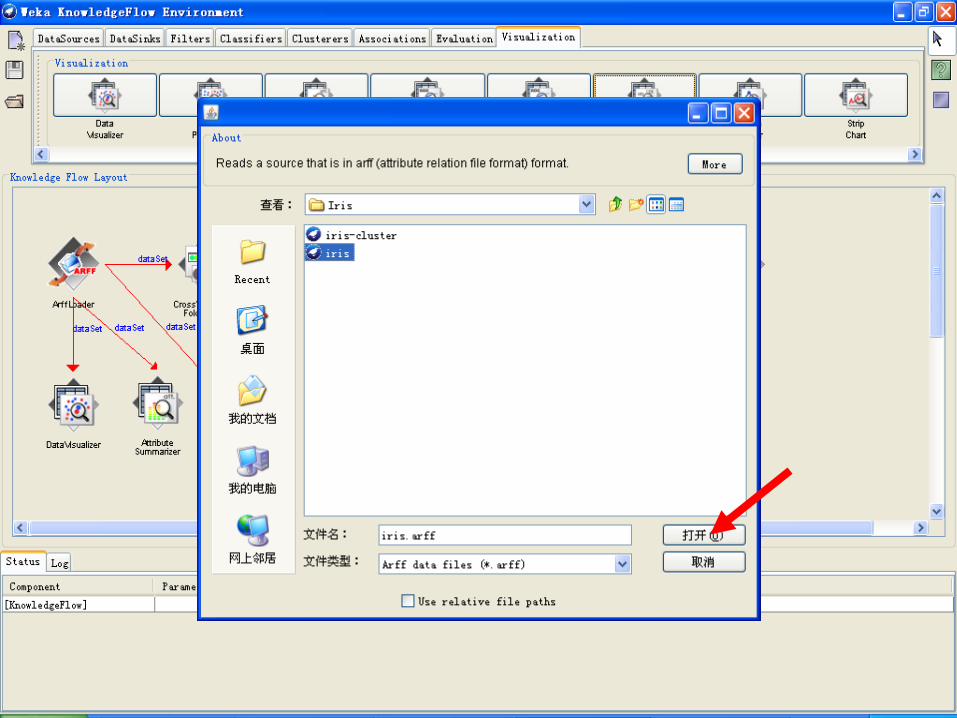
示例:建立IRIS数据集分类模型的知识流

2014/12/18 283
2014/12/18 284

2014/12/18 285

2014/12/18 286
2014/12/18 287

2014/12/18 288
2014/12/18 289
2014/12/18 290
2014/12/18 291
2014/12/18 292
2014/12/18 293

2014/12/18 294
2014/12/18 295
2014/12/18 296

2014/12/18 297
2014/12/18 298

2014/12/18 299

2014/12/18 300

2014/12/18 301
2014/12/18 302

2014/12/18 303