yifeng spark-final-public
TRANSCRIPT

Apache Spark の現在Apache Spark – Present
© Hortonworks Inc. 2011 – 2015. All Rights Reserved
Yifeng JiangSolutions Engineer, Hortonworks Japan
2015/10/14

2 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
アジェンダ
• Apache Sparkとは何か?– Introduction– MLlib– Spark SQL– Spark Streaming
• Spark と Hadoop – HDP 2.3
• Hortonworks はSparkにフォーカス

3 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Apache Sparkとは
分散型のコンピューティングエンジン迅速かつ表現が多様なデータ処理に対応反復的、インメモリ向けの設計コンピューティングとインタラクティブデータマイニングApacheオープンソースプロジェクト表現が多様な多⾔語APIJava、Scala、Python、Rに対応強⼒な抽象データワーカーがデータに対して迅速に反復可能: • ETL、機械学習、SQL、ストリーム処理、グラフ処理
Scala Java
Python API
SparkコアエンジンSparkコアエンジン
GraphX Spark SQL
Spark Streaming MLlib

4 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
基本的抽象:RDD(Resilient Distributed Datasets)
RDDプリミティブとして分散コレクションと連携RDDの特性• クラスター全体に分散したオブジェクトの普
遍コレクション• 並列変換(map、filterなど)によって構築• 障害発⽣時に⾃動的に再構築• 制御可能な持続性(例:RAMでのキャッシ
ング)複数⾔語開発者、パートナー、顧客の広範な連携
RDD パーティション1
RDD パーティション2
RDD パーティション3 ワーカーノード
ワーカーノード
ワーカーノード
RDD
論理Spark ドライバ
sc = new SparkContext rDD =sc.textfile(“hdfs://…”) rDD.filter(…) rDD.Cache rDD.Count rDD.map …
開発者
物理
書き込み
RDD
RDDは、クラスタ内に分散し、RAMまたはディスクにキャッシュされるオブジェクトの集合である。これらは並列変換によって作成され、障害発⽣時には⾃動的に再構築され、不変である(変換のたびに新しいRDDが作成される)。

5 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
RDDを利⽤して開発者が実⾏できること
RDDオペレーション変換 • 例:map、filter、groupBy、join• 別のRDDからRDDを構築する簡単なオペ
レーションアクション • 例:count、collect、save• 結果を返す、またはストレージに書き込むその他のプリミティブ• アキュムレーター• ブロードキャスト変数
開発者
書き込み
RDD オペレーション
書き込み
アキュムレーター
アクション
ブロードキャスト変数
変換

6 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
MLlib機械学習ライブラリ
YARN
HDFS
ScalaJava
PythonAPI
SparkコアエンジンSparkコアエンジン
GraphXSpark SQL
Spark Streaming
MLlib

7 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
機械学習とは
機械学習とは、データからコンセプトを学習するアルゴリズムの研究。
データから学習し、明⽰的なプログラムがなくても作動するコンピュータを実現させる科学

8 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
機械学習例: ⾃然グループの検出
ビジネスのユースケース• 顧客セグメンテーション• ニュース記事の分類
クラスタ番号
ID Total$ Age City
101 $200 25 SF 2
102 $350 35 LA 2
103 $25 15 LA 1
… … … … 1
1
2
2
2

9 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
機械学習例:商品のレコメンデーション
嗜好の予測:似通った“好み”の⼈間を特定• この商品を買っている人はこんな商品も買っています

10 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
機械学習の実装
機械学習の実装が複雑• ⾼度なアルゴリズム• ⼤量の繰返し計算が必要:Spark
のインメモリ処理と相性がいい• 分散環境でスケール• パフォーマンスk-means clustering algorithm

11 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
機械学習のプリミティブUnsupervised Learning
Clustering (K-means) Recommendation Collaborative Filtering - alternating least squares
Dimensionality Reductions - Principal component analysis (PCA) and singular
value decomposition (SVD)
Supervised Learning Classification - Naïve Bayes, Decision Tree, Random Forest,
Gradient Boosted Trees
Regression - linear, logistic and Support Vector Machines
(SVMs)

12 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
MLlibによるレコメンデーション
MLlibを使ったレコメンデーション• ライブラリを利⽤• MLlibがSpark上に分散実⾏• よいパフォーマンス

13 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
SQLSQLアクセスとデータフレーム
YARN
HDFS
Scala Java
Python API
SparkコアエンジンSparkコアエンジン
GraphX Spark Streaming MLlib Spark
SQL

14 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
YARN
HDFS
Spark SQL
テーブル構造テーブルおよび⾏との連携のために統合
SparkによるHiveクエリーSpark SQL ContextはHiveに接続してHiveをクエリー可能
バインドPython、Scala、Java、Rが対象
DataFrameSQL処理を合理化 / 迅速化する新しい抽象
Sparkコアエンジン
Spark SQL データフレームDSL Spark SQL
データフレームAPI
データソースAPI

15 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
スト
レー
ジ
DataFrameとはデータフレームは、RDD内のデータをテーブルとして表現する
RDDは低レベルの抽象である– RDDはバイトコード、DataFrameはJavaコードとして考える
データフレームのプロパティ– データフレームはRDDにスキーマを追加する– ユーザーによる積極的なクエリー最適化を可能にする
– SQLのパワーをRDDに提供する
部門 名前 年齢 Bio H Smith 48
CS A Turing 54
Bio B Jones 43
Phys E Witten
61
タプル
リレーショナルビュー
カラム指向ストレージ
ORCFile Parquet
非構造化データ
JSON CSV
テキスト Avro
カスタム
ブログ

16 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
データフレームは直感的
RDDの例
同等データフレームの例
部門 名前 年齢 Bio H Smith 48
CS A Turing 54
Bio B Jones 43
Phys E Witten
61
部門別の平均年齢を求める

17 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Sparkデータフレームは⾼速

18 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Streamingリアルタイムストリーム処理
YARN
HDFS
Scala Java
Python API
SparkコアエンジンSparkコアエンジン
GraphX Spark SQL MLlib Spark
Streaming

19 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Spark Streamingストリーミングへの対応ライブマイクロバッチの⾼スループット、フォールトトレラントな処理
複数の取り込みソースKafka、Flume、Twitter、ZeroMQ、Kinesis、TCPソケット
Spark APIの再利⽤マップ、削減、結合、ウィンドウなどの⾼レベル機能による複雑なアルゴリズムの処理
データの持続性ファイルシステム、データベース、ライブダッシュボードへの処理済みデータのプッシュ

20 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Hortonworks Data Platform
& Hadoop 完璧な組み合わせ
21 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
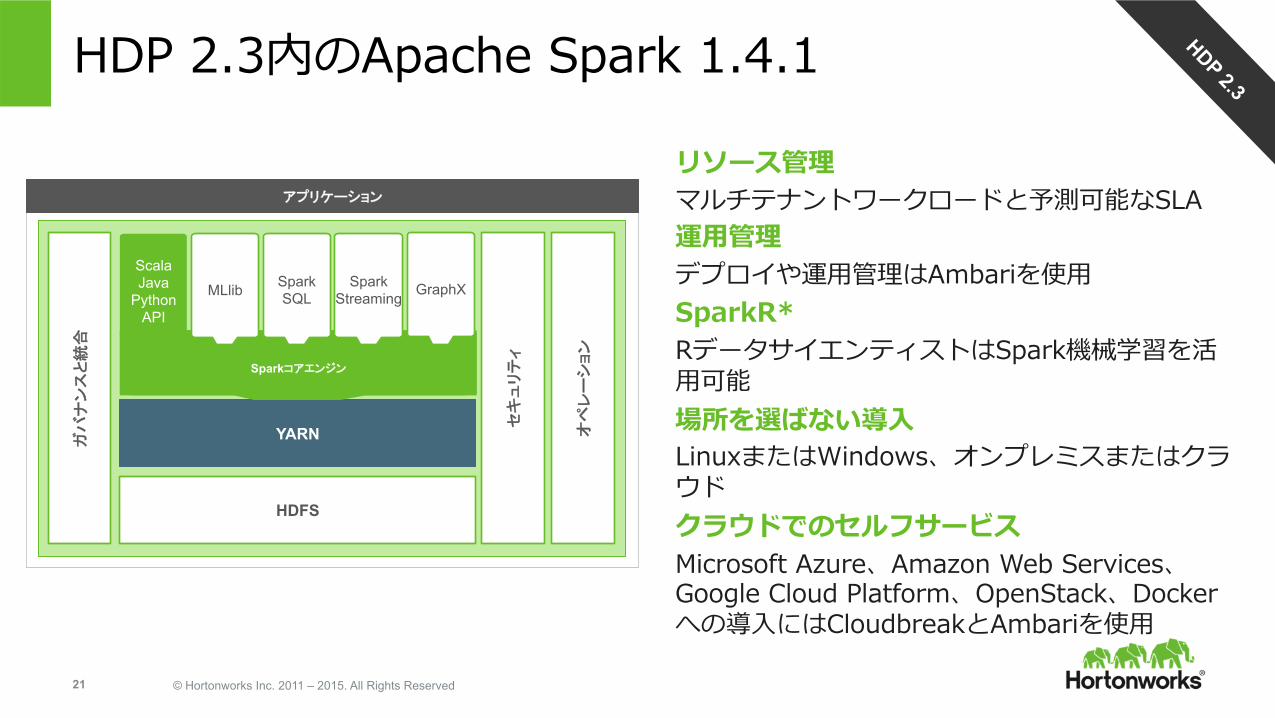
HDP 2.3内のApache Spark 1.4.1
リソース管理マルチテナントワークロードと予測可能なSLA運⽤管理デプロイや運⽤管理はAmbariを使⽤SparkR*RデータサイエンティストはSpark機械学習を活⽤可能場所を選ばない導⼊LinuxまたはWindows、オンプレミスまたはクラウドクラウドでのセルフサービスMicrosoft Azure、Amazon Web Services、Google Cloud Platform、OpenStack、Dockerへの導⼊にはCloudbreakとAmbariを使⽤
アプリケーション
ガバ
ナン
スと
統合
セキ
ュリ
ティ
オペ
レー
ショ
ン
YARN
HDFS
Scala Java
Python API
SparkコアエンジンSparkコアエンジン
Spark SQL
Spark Streaming MLlib GraphX

22 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
SparkセキュリティSpark on YARNだけが Kerberos をサポートKerberos 認証を活⽤Spark は HDFS and ORC からデータを読込みHDFS ファイル パーミッション (またはRanger連携) は Spark ジョブにも適⽤Spark がジョブを YARN キュー に投⼊
YARN キュー ACL (またはRanger連携) が Spark ジョブにも適⽤転送中のデータの暗号化Spark は⼀定のカバーがあるが、すべてのチャンネルではない
LDAP 認証Spark UIでの直接サポートはまだない, LDAPに接続するフィルターを使⽤

23 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Ambariによるインストール
Select Spark
Assign nodes for
Spark History
Server & Spark Client
Add Servic
e
Go to a node with
Spark Client
Submit spark jobs
Hadoop Admin
Spark is
Ready
Spark User

24 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Spark on YARNSpark が YARN を クラスタマネージャーとして利⽤
2つのモード: YARN-client か YARN-cluster
YARN-client
• ドライバがクライアント ノードに
• 開発、デバッギングに有効
YARN-cluster
• ドライバが YARN application master (left)に
• バッチや⾃動化したジョブに有効
Spark in HDP
Task Task
Cache Executor
Spark Content
Driver Program
App Master
Monitoring UI
YARN RM
Worker Nodes
Task Task
Cache Executor

25 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
ORCサポートORC• Hadoopワークロード向けの最⼩、最速のカラ
ム指向ストレージ
ORC in Spark• SparkからORCデータの読み書き
• パーティション、フィルタプッシュダウンなどの最適化もサポート
• DataFrame サポートYARN:データオペレーティングシステム
HDFS
Sparkコア
Scala Java
Python ライブラリ
MLlib
(機械学習)
Spark SQL*
Spark
Streaming*
Hive
HBase

26 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
レファレンス アーキテクチャ
バッチ ソース
ストリーミング ソース
レファレンス データ
ストリーミング処理 Storm/Spark-Streaming
データ パイプライン Hive/Pig/Spark
長期保存データウェアハウス Hive + ORC
データ ディスカバリー
レポーティング
ビジネス インテリジェンス (BI)
アドホック/オンデマンド ソース
データサイエンス Spark-ML, Spark-SQL
高度な分析
データ ソース データ処理、保存や分析 データ アクセス
27 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
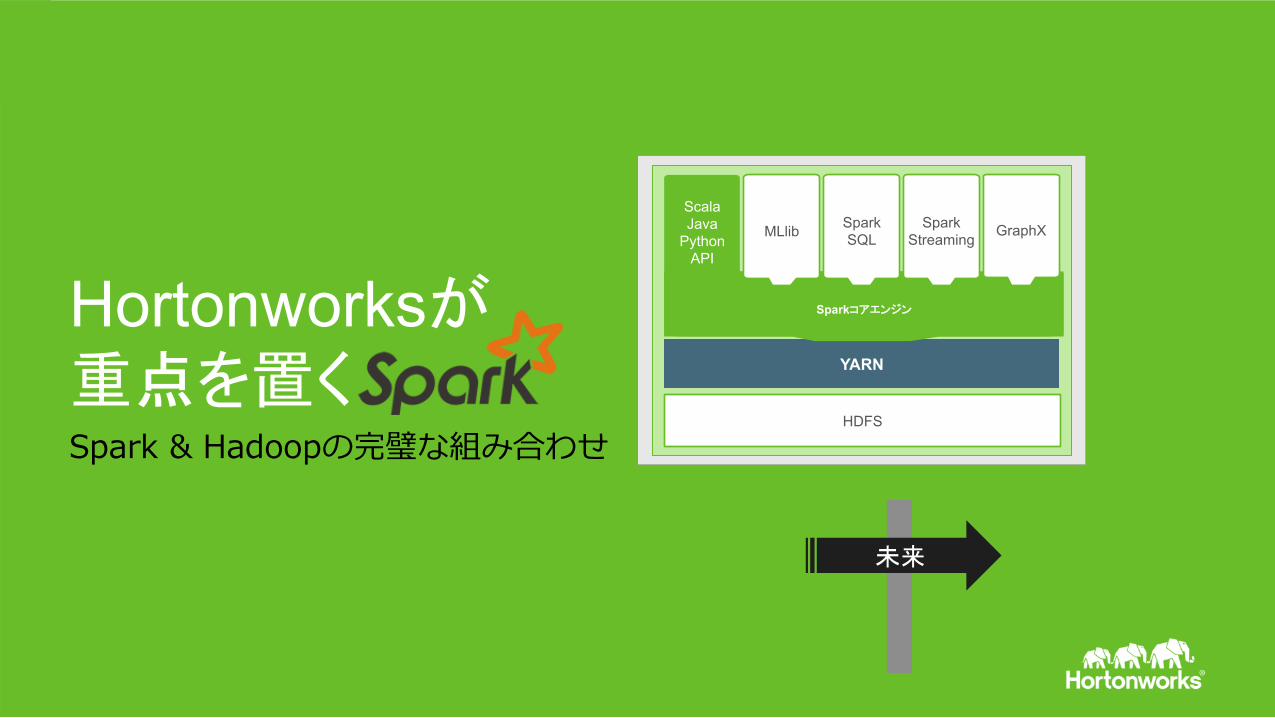
Hortonworksが重点を置くSpark & Hadoopの完璧な組み合わせ
YARN
HDFS
Scala Java
Python API
Sparkコアエンジン Sparkコアエンジン
Spark SQL
Spark Streaming MLlib GraphX
未来

28 © Hortonworks Inc. 2011 – 2015. All Rights Reserved 28 © Hortonworks Inc. 2011 – 2015. All Rights Reserved Tweet: #hadooproadshow
詳細情報:
hortonworks.com/hadoop/spark

29 © Hortonworks Inc. 2011 – 2015. All Rights Reserved 29 © Hortonworks Inc. 2011 – 2015. All Rights Reserved Tweet: #hadooproadshow
Thank You