white paper rethinking your data retention...
TRANSCRIPT

W H I T E P AP E R
R e t h i n k i n g Y o u r D a t a R e t e n t i o n S t r a t e g y t o B e t t e r E x p l o i t t h e B i g D a t a E x p l o s i o n
Sponsored by: Dell
Richard L. Villars Marshall Amaldas
October 2011
I D C O P I N I O N
The continued generation of business-critical semistructured data (including large
volumes of machine-generated data [MGD] from smart sensors and mobile devices)
is changing the storage dynamic in a wide range of industries and organizations.
Making investments to extract value from this expanding pool of information is fast
becoming a core business mandate, but such efforts can quickly lead to spiraling IT
costs and growing corporate risk without the right data retention and long-term
archiving strategy.
Making the wrong choice in a technology decision (e.g., deciding between an OLTP,
OLAP, or OLDR approach to data storage) can lead to significantly high data
management and retention costs in both the short run and the long run. It can also
jeopardize compliance and privacy standards for data such as call detail records
(CDRs) and trading records. IT organizations need to deploy active archival storage
solutions that address the total cost of ownership (TCO) for archival data at many
layers. Specifically, such a solution:
Provides a semistructured archive platform that's significantly less expensive
than archiving that same information on individual database, data warehouse, or
file systems
Maximizes the utilization of that hardware with intelligent data
management/reduction software
Reduces the ongoing operational burden of the archival storage environment
When selecting a storage and data management partner to help you manage the
"Big Data" challenge, you will need a partner that can address the entire spectrum of
data assessment, data retention, and data use requirements of this new environment.
Dell, as a leading designer and provider of IT solutions optimized for Big Data
analytics, is also providing enterprise-class solutions that address the cost,
performance, and intelligence requirements at the heart of Big Data retention and
active archiving.
Glo
bal H
eadquart
ers
: 5 S
peen S
treet
Fra
min
gham
, M
A 0
1701 U
SA
P
.508.8
72.8
200 F
.508.9
35.4
015
w
ww
.idc.c
om

2 #230747 ©2011 IDC
I N F O R M AT I O N E V E R Y W H E R E , B U T W H E R E ' S T H E K N O W L E D G E ?
For the first 40 years of the IT industry, the main data challenge for most organizations
was enabling/recording more and faster business transactions, often referred to as
structured data. Today, much of the focus is on more and faster exchanges of
information (e.g., documents, medical images, movies, gene sequences, data streams,
tweets) from scale-out cloud clusters to systems, PCs, mobile devices, and living
rooms. This information is often categorized as unstructured data (e.g., image, audio, or
video files) or semistructured data (e.g., emails, logs, call detail records).
Semistructured data is often overlooked, but with the advent of RFID tracking, smart
sensors, mobile devices with geospatial information, and a growing array of data
collection devices, MGD will be a leading driver of the data explosion.
The business challenge for the next decade will be finding ways to better analyze,
monetize, and capitalize on all this MGD (see Figure 1). It will be the age of Big Data.
For the IT organization, the challenge will be to implement an archival storage system
that ensures that this information is reliably and efficiently ingested, protected,
organized, accessed, and preserved.
F I G U R E 1
C h an g i n g B u s i n e s s P r i o r i t i e s i n a F a s t - S h i f t i n g W o r l d
Source: IDC, 2011
MORE
APPLICATIONS
MORE
DEVICES
MORE
CONTENT
MORE
DATA
The range of information created, accessed, and retained affects how
companies organize datacenters and retain information.
Companies rely on a growing range of devices, data sources, and
applications to compete in today's evolving business environment.
salesforce.com
Apple
VMware

©2011 IDC #230747 3
T h e O n g o i n g D a t a E x p l o s i o n
Data creation is occurring at a record rate. In 2010, the world generated over
1 zettabyte (ZB) — that's 1 million petabytes (PB) — of data; by 2014, we will
generate 7ZB a year. While much of this is "unsaved" or highly duplicated data like
personal photos or copies of music/videos, one of the fastest-growing and most
important sources of growth is machine-generated data:
Financial transactions. With the consolidation of global trading environments
and the greater use of programmed trading, the volume of transactions that need
to be collected and analyzed can double or triple in size, while the transaction
volumes can also fluctuate much faster, more widely, and more unpredictably,
and competition among firms forces trading decisions to be made at ever smaller
intervals.
Smart instrumentation. The use of intelligent meters in "smart grid" energy
systems that shift from a monthly meter read to an "every 15 minutes" meter read
can translate into a multi-thousandfold increase in data generated. Similar data
bursts are looming in healthcare, where low-cost gene sequencing will have a
profound impact on medical data volumes.
Mobile devices. Until quite recently, the main data generated on landline and
traditional mobile phones was limited to CDRs with caller, receiver, and length of
call data. With smartphones and tablets, additional CDR data to harvest includes
geographic location, text messages, browsing history, and (thanks to the addition
of accelerometers) even motions.
All of this data creates new opportunities to "extract more value" in sectors such as
energy, human genomics, healthcare, retail, online search, surveillance, and finance,
as well as many other areas. IDC believes that organizations that are best able to
make real-time business decisions based on machine-generated data streams at the
lowest possible cost will thrive, while those that are unable to embrace and make use
of this expanding data source will increasingly find themselves at a competitive
disadvantage in the market. This situation will be particularly true in industries that are
experiencing high rates of business change and aggressive consolidation.
B i g D a t a V a l u e : W h a t ' s i n I t f o r M e ?
Regardless of industry or sector, the ultimate value of Big Data implementations will
be judged based on one or more of three criteria:
Does it provide more useful information? For example, a major retailer might
implement a digital video system throughout its stores, not only to monitor theft
but also to implement a Big Data pattern detection system to analyze the flow of
shoppers — including demographical information such as gender and age —
through the stores at different times of the day, week, and year.

4 #230747 ©2011 IDC
Does it improve the fidelity of the information? For example, a number of
earth science and medical epidemiological research teams are using Big Data
systems to monitor and assess the quality of data being collected from remote
sensor systems; they are using Big Data not just to look for patterns but also to
identify and eliminate false data caused by malfunctions, user error, or temporary
environmental anomalies.
Does it improve the timeliness of the response? Consumer products
companies can use kiosks like Coca-Cola's Freestyle to collect real-time consumer
taste preferences in different regions. This move makes it easier to tune
promotions and control inventory levels on a regional or even store-by-store basis.
Big Data Analytics Versus Retention: Distinct Solutions for Distinct
Needs
Today, a number of Big Data analytics solutions use a combination of open source
software frameworks such as Hadoop and MPP (massively parallel processing)
hardware architectures to support compute- and data-intensive applications that can
consume multiple petabytes of disk storage across thousands of individual server
nodes. Both hardware and software components of such analytics systems are
optimized for performance where the data distributed over multiple nodes is kept
redundant for resiliency and high-availability reasons.
The MPP architecture–based systems are designed such that compute and storage
are tightly coupled to minimize contention for resources. While these solutions are
best suited to run complex large-scale analytics where performance is the prime
objective these systems are not suitable targets for long-term retention of big data
content.
A key element in all these use cases is that organizations must be able to continually
go back and reanalyze the same machine-generated data sets over and over again.
They need to continually look for patterns stretching over hours, days, months, and
years. If it's too expensive to retain the needed historical data or too difficult to
organize the data for timely, ad hoc retrieval, organizations won't be able to capitalize
on their collected information. The key question you need to be asking is whether
your current storage environment can handle this new data explosion and the data
retention challenges it will create. Traditionally, MGD was treated like either
structured or unstructured data sets:
1. It was maintained in a database or data warehouse (leveraging SAN-attached
storage), which is very expensive and can significantly impact performance,
unless an organization used the archiving functions (not also provided) for each
application. In this approach, the data is also trapped in a single application
environment and is difficult to repurpose/reuse.
2. It was pushed down as a blob (sometimes aptly called a TARball) onto a file
system to be retained. In this approach, an organization sacrificed the structure
detail, significantly impacting the querying and analytical ability and, once again,
the ability to repurpose/reuse. Because MGD was often linked to a tape library, it
posed significant data retrieval burdens.
©2011 IDC #230747 5
3. It was kept as a set of personal files on a file server or NAS device and then
either orphaned (when the owner left) or deleted. In both cases, the ability to
access the data and to manage its retention/disposal for regulatory reasons was
severely compromised.
Failing to make use of systems that are built specifically for meeting the long-term
retention and compliance needs of MGD data pools will make Big Data analytics
ambitions cost prohibitive and risky. You need a Big Data retention solution like Dell's
Big Data Retention, which recognizes MGD as historic at creation and immediately
commits MGD to an intelligent, long-term, online retention pool. This approach
eliminates much of the high cost associated with databases/SAN storage while
maintaining the critical data context that is lost in NAS environments.
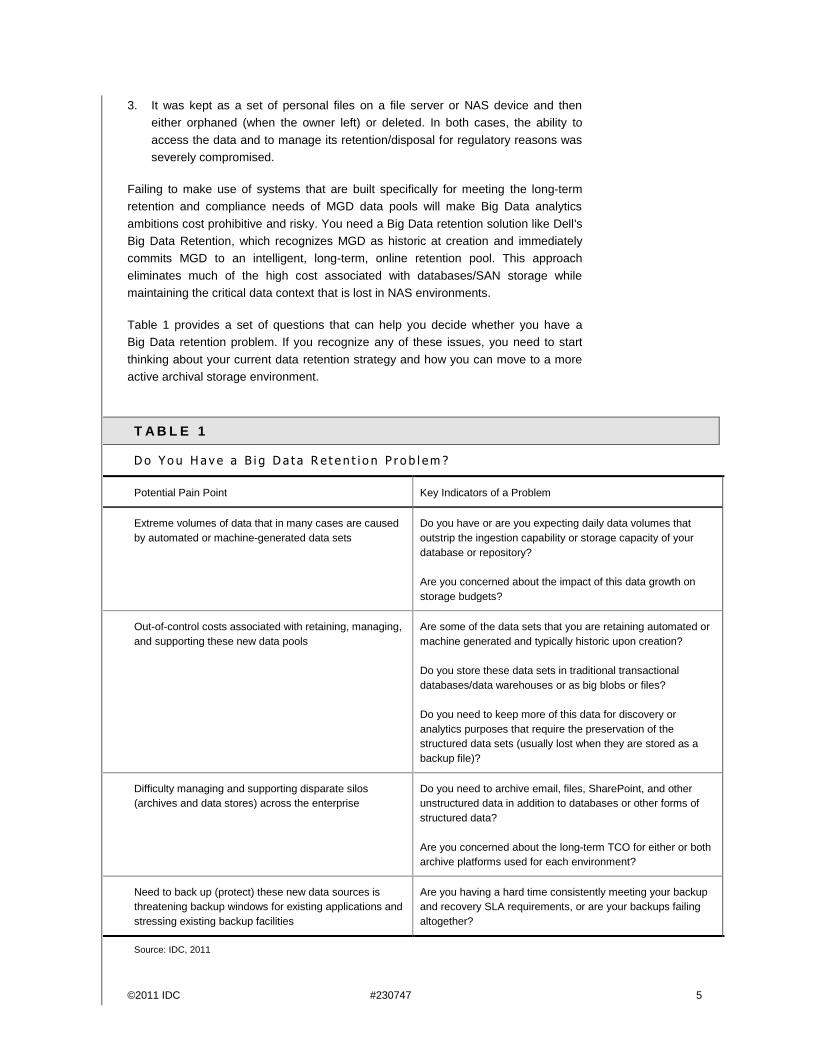
Table 1 provides a set of questions that can help you decide whether you have a
Big Data retention problem. If you recognize any of these issues, you need to start
thinking about your current data retention strategy and how you can move to a more
active archival storage environment.
T A B L E 1
D o Yo u H a v e a B i g D a t a R e t e n t i o n P r o b l em ?
Potential Pain Point Key Indicators of a Problem
Extreme volumes of data that in many cases are caused
by automated or machine-generated data sets
Do you have or are you expecting daily data volumes that
outstrip the ingestion capability or storage capacity of your
database or repository?
Are you concerned about the impact of this data growth on
storage budgets?
Out-of-control costs associated with retaining, managing,
and supporting these new data pools
Are some of the data sets that you are retaining automated or
machine generated and typically historic upon creation?
Do you store these data sets in traditional transactional
databases/data warehouses or as big blobs or files?
Do you need to keep more of this data for discovery or
analytics purposes that require the preservation of the
structured data sets (usually lost when they are stored as a
backup file)?
Difficulty managing and supporting disparate silos
(archives and data stores) across the enterprise
Do you need to archive email, files, SharePoint, and other
unstructured data in addition to databases or other forms of
structured data?
Are you concerned about the long-term TCO for either or both
archive platforms used for each environment?
Need to back up (protect) these new data sources is
threatening backup windows for existing applications and
stressing existing backup facilities
Are you having a hard time consistently meeting your backup
and recovery SLA requirements, or are your backups failing
altogether?
Source: IDC, 2011

6 #230747 ©2011 IDC
T H E C H AN G I N G N A T U R E O F AR C H I V AL S T O R AG E I N T H E W O R L D O F B I G D AT A
Data retention via archiving has a long history as an IT practice, stretching back
decades. Archiving of structured data was required for regulatory/contractual
purposes or as a method of maintaining high levels of system performance (removing
inactive data to free up capacity and I/O performance on databases). The archive
data was rarely, if ever, accessed again and was stored on inactive media (e.g.,
tapes). Moving the data was expensive, time consuming, and often tied to the backup
process, which made retrieval after a relatively short time (e.g., 30 to 90 days) time
consuming and difficult.
The rapid growth in digital data triggered by the arrival/explosion of the Internet, along
with a series of business scandals, increased the scope of the data
retention/disposition problem. For IT managers in the past decade, regulation and
compliance requirements mandated that organizations retain semistructured data
(e.g., CDR and trading records) for even longer periods of time. They also mandated
that this archived material be more quickly accessible for eDiscovery purposes.
Concurrently, the move to online collaboration began to generate larger amounts of
emails, office documents, and rich media data, which must also be retained and
archived. These mandates added a further layer of complexity because just storing
the data was not enough. Organizations also needed to preserve the data in context.
Both of these developments drove organizations to greater reliance on active
(HDD-based) storage for their long-term data storage needs. IDC estimates that in
2010, organizations around the world deployed 4,465 petabytes of new disk storage
capacity just to store copies of their data for availability and retention purposes; by
2015, they will be deploying 16,538 petabytes (see Figure 2). While solving the
access time issue, this addition of another disk storage tier often poses even greater
storage asset management challenges.

©2011 IDC #230747 7
F I G U R E 2
W o r l dw i d e E n t e r p r i s e D i s k S t o r a g e C o n s u m p t i o n , 2 0 1 0– 2 0 1 5
Source: IDC's Enterprise Disk Storage Consumption Model, September 2011
M a c h i n e - G e n e r a t e d D a t a a n d B i g D a t a
R e f r a m e t h e D a t a R e t e n t i o n C h a l l e n g e
Today, the rate of data growth and the diversity of data types are reaching
unprecedented levels. The traditional archiving jobs of preservation and active
application offload remain daunting challenges. At the most basic level, the sheer
data volume increase associated with new and fast-growing machine-generated
environments can pose significant archival challenges. The shift to intelligent meters
as part of a smart grid energy system would lead to a 3,000-fold increase in machine-
generated data that a utility would be collecting on a monthly basis.
Certain industries such as financial services (market, trading, and tick data) and
telecommunications (logs, CDRs for lawful intercept) are continuously generating vast
quantities of data at a rate of billions of MGD records a day. With retention
requirements ranging from a few years to indefinitely, the demand for raw storage will
only accelerate unless we figure out how to be smarter about how data is retained.
What's different in the new world of machine-generated data and Big Data analytics is
the need to continually go back and mine this data over and over again. You're not
just retaining it; you're continually reusing it.
Standard database and data warehouse applications aren't optimized to handle
ingestion of such volumes of data, and they are even less suitable platforms from a
cost and performance standpoint when it comes to archiving. At the same time, the
0
10,000
20,000
30,000
40,000
50,000
60,000
70,000
80,000
2010 2011 2012 2013 2014 2015
(Peta
byte
s s
hip
ped
)
Structured data
Replicated data
Unstructured and semistructured data

8 #230747 ©2011 IDC
previously mentioned utility can't just park the data on some tapes. Organizations are
constantly deploying new sets of analytic applications that continually go back and
analyze behaviors (and then make real-time adjustments) on an hourly, daily, weekly,
monthly, and even yearly basis.
The context and techniques for mining that data will change and evolve. Any data
retention solution that locks the retained data into a traditional hierarchical database
or file structure severely impacts the long-term cost of storing the MGD. More
important, it greatly reduces the long-term value of the data.
A c t i v e A r c h i v i n g f o r B i g D a t a
The primary data management challenge associated with Big Data is to ensure that
the data is retained (to satisfy compliance needs at the lowest possible costs) while
also keeping up with the unique and fast-evolving scaling requirements associated
with new business analytics efforts. Organizations that strike this balance will boost
efficiency, drive down cost, and be in a far better position to capitalize on Big Data
innovations.
Firms must be able to mine their historical data to analyze and extract data for market
intelligence, product planning, and inventory planning. In R&D environments, reuse of
historical information can yield vast savings in time and effort, which in turn saves
money and in some cases provides competitive advantage by shrinking the time
required to bring products to market.
Today, many of these Big Data projects are best described as "junior science
projects" with a small core of servers and storage assets. From a business and an IT
governance standpoint, however, these kinds of "junior science projects" can quickly
turn into the next "Manhattan project" with companywide and industrywide business,
organizational, and legal consequences. IT organizations need to deploy active
archival storage solutions that address three major requirements:
Rapid, continuous, and intelligent movement of "instantly historical" data
from the data-generating devices/applications onto the active archive
system. This ability ensures that the source application continues to run at
maximum efficiency in terms of performance and reliability and that the
underlying IT assets (servers and primary storage systems) aren't compromised
by having to support multiple, incompatible workloads.
Flexibility in data ingest capability. The amount of machine-generated
data can vary significantly from time to time, depending on the amount of
activity that is experienced by a monitoring system. Financial trade
monitoring systems can experience very high levels of activity due to an
external event that causes panic, which in turn could trigger a sudden surge
in the number of trades. The active archive target should be able to
accommodate such variation and be able to ingest data at different rates as
required.

©2011 IDC #230747 9
Rapid, nondisruptive scalability of archival storage capacity and I/O
performance. This modularity makes it easier to launch initial, limited machine-
generated data mining capabilities, without jeopardizing the ability to meet rapidly
expanding requirements for capacity and performance. You may outgrow a
specific module, but you never want to outgrow the archival platform. When
you're talking about hundreds of terabytes (TB) to multiple petabytes of
information, migrating to a new platform should not be a necessary option.
Built-in efficiency. Unchecked data growth is bound to become a burden
over the course of time, even on an archive tier. IT organizations need to
look for solutions that take full advantage of proven efficiency technologies
that are purpose designed to make the most out of machine-generated data
to achieve targets.
Flexible, nonhierarchical data organization based on an object-based
storage foundation. This flexibility is critical because one of the key tenets of
Big Data applications is the ability to deal with new and unpredictable data
patterns. Machine-generated data required for one purpose today may prove
absolutely critical for enabling some new analytic algorithm tomorrow. An object-
based approach to storing information eliminates the risk that a data-organizing
approach that makes sense now doesn't render the data difficult to extract or
useless in the future.
Preserve metadata. The metadata attributes of machine-generated data are
much richer than those of other content types, which makes them very
useful for analytical purposes. Having the ability to make sense of
relationships between different data sets using common metadata and
attributes is a key analytical value of the data. IT acquisition decision makers
need to make sure that their choice of storage system does not depreciate
this value.
Because most organizations are new to the subject of active archiving for machine-
generated content, purchase decision makers need to look for solutions and vendors
that place a high emphasis on providing complete service and support throughout the
implementation.
Don't Overlook Data/Information Security/Privacy
As in the case of other content types, regulation and compliance is also an important
consideration of machine-generated data. For example, the USA PATRIOT Act
stipulates strict retention requirements on CDR. Telecommunications organizations
need to make sure that this information is stored such that it is not modified from the
time it is created.
If the data involved is sensitive for reasons of privacy, enterprise security, or
regulatory requirement, then misplacement or misuse of retained data can represent
a serious security breach. More traditional database management systems support
security policies that are quite granular, protecting data at both the coarse-grained
level and the fine-grained level from inappropriate access.

10 #230747 ©2011 IDC
Today, Big Data applications generally have no such safeguards. Enterprises that
include any sensitive data in Big Data operations must ensure that the data itself is
secure and that the same data security policies that apply to the data when it exists in
databases or files are also enforced in the Big Data context. Failure to do so can have
serious negative consequences.
The archival storage environment, as the common retention point for all machine-
generated data, must enable advanced, yet easy-to-leverage, data/information
security capabilities. It must include:
The ability to automatically place specified records on disks that have WORM
capability
Monitoring and reporting capabilities, which will help IT administrators make
informed infrastructure and policy decisions proactively
The remainder of this white paper examines how well Dell's Big Data Retention
solution addresses the need for compliant, enterprise-class Big Data/MGD retention
and on-demand access.
D E L L ' S B I G D A T A R E T E N T I O N A N D A C T I V E A R C H I V E S T O R A G E S O L U T I O N
Dell is a leading provider of IT products and services for organizations around the
world. It provides the computing systems at the heart of machine-generated data
devices. It is also a leader in designing and deploying servers optimized for Big Data
analytics compute platforms that play a key role in monetizing the value of machine-
generated data.
Now, Dell is also providing enterprise-class solutions that will be at the heart of Big
Data retention and active archiving.
Dell set a goal of creating a complete archival solution (hardware, software, and
professional services) that cost-effectively solves the "Big Data" retention/archive
problem and enables a better way to retire and archive legacy applications. For Dell,
cost-effectiveness means addressing the TCO of archival data at many layers:
Providing an MGD/Big Data–optimized archive platform that is significantly less
expensive (and more useful) than archiving that same information on individual
database, data warehouse, or file systems
Leveraging the least expensive hardware (without compromising
performance/reliability)
Maximizing the utilization of that hardware with intelligent data
management/reduction software
Reducing the ongoing operational burden (provisioning, migrating, and
administrating) of the archival storage environment

©2011 IDC #230747 11
The company introduced the Big Data Retention solution in 2011. It's designed to
provide a low-cost, standard foundation for data reduction, long-term retention, and
on-demand data retrieval of historical data (machine generated and all other forms of
semistructured data). Big Data Retention is a single platform for retaining structured,
unstructured, and semistructured data across an unlimited number of data sources,
formats, and types. It is based on a clustered Web storage service that utilizes a
peer-scaling design that can start at 1TB and extend to exabytes. The DX Object
Storage Platform abstracts underlying technology by integrating compute, network,
and storage resources into one delivery unit.
Key characteristics of the Big Data Retention solution include:
Fast deployment with minimal administration overhead and no special tuning:
Minimal administration required compared with specialized DBA requirements
associated with many traditional repositories and ability to rapidly search and
retrieve data using native SQL for seamless integration with existing systems
within the enterprise
Scalable performance with high data ingestion rates and fast queries: Ability to
load big data volumes (billions of records/day, petabytes/month)
Scalable, intelligent archival storage capacity to handle big data volumes: Ability
to dedupe at the structured data value and pattern level, leveraging the resulting
40 to 1+ compression ratio (97%+ reduction in size)
Integrated compliance features such as configurable retention rules and audits:
Ability to set flexible configurable retention and expiry rules for the life cycle of
the data with guaranteed read-only immutability and audited access
Dell provides customers with multiple deployment options for the Big Data Retention
solution. IT organizations can deploy Big Data Retention as an on-premise system
within their own datacenter. In addition, Dell will be providing a cloud-based solution
running in Dell's cloud datacenters.
D e l l D X O b j e c t S t o r a g e P l a t f o r m I s A r c h i v a l
S t o r a g e a t t h e C o r e o f B i g D a t a R e t e n t i o n
One of the key components of the Big Data Retention solution is the Dell DX Object
Storage Platform. The DX allows IT organizations to effectively archive both structured
data (e.g., from RDBMSs) and semistructured data (e.g., logs, call data records, other
MGD) while still supporting reliable query via SQL or any business intelligence tool
using ODBC/JDBC. IT organizations can archive terabytes to petabytes of
semistructured data on the Dell DX Object Storage Platform while minimizing TCO
through the use of advanced data reduction capabilities built into the DX.
Key design characteristics of the DX platform include:
System persistence. Adding/replacing hardware components (e.g., disks or
controllers) is automated and nondisruptive and doesn't require any data
organization changes. Only one physical migration (the original one) on the DX
platform is necessary.

12 #230747 ©2011 IDC
System resiliency. The system is self-healing. If a hardware element fails, you
just plug in a replacement and the system automatically restores what needs to
be restored.
System flexibility. The system supports highly granular file-level management
to enable great effectiveness of data reduction services and employs an open
API so that your data won't be trapped in a single, proprietary environment.
The DX Object Storage Platform makes it possible for IT organizations to ingest
billions of records per day, accumulating petabytes of data per month. More
important, it ensures that this data is properly retained based on legal/governance or
business analytics requirements.
C h a l l e n g e s / O p p o r t u n i t i e s f o r D e l l
Given the continued rapid growth of machine-generated data and the increasing role
of big data analysis in organizations' new application and services plans, the storage
and information management challenges posed by Dell's data-driven customers and
prospects will only increase in the coming years. Dell needs to address a number of
requirements as it expands its role in organizations' active archiving and data analysis
environments:
Continue to improve underlying storage hardware capacity, performance, and
power management efficiencies through more tunable/intelligent automated data
movement and support for even denser/more power-efficient HDD solutions
Establish closer technical and business ties with leading analytics (Big Data)
application suppliers that will make it easier for customers to fully exploit the
information stored within the Big Data Retention archive
Extend the reach of the Big Data Retention solution to better address the active
archive and data mining needs of medium-sized and small businesses through
further expansion of Dell's cloud-based offering
F I N AL T H O U G H T S
When assessing the impact of machine-generated data and supporting analytic
applications on your IT infrastructure, you'll find that the challenges extend from data
creation, to data collection, to data retention, and, finally, to ongoing analysis. This
new environment represents both big opportunities and big challenges for CIOs.
Almost every CIO dreams about making IT a more valued asset to the organization.
Big Data projects are at the frontier of the business, where the majority of the most
significant business expansion or cost reduction opportunities lie. Taking a lead in
leveraging machine-generated data provides the CIO with a chance to be a strategic
partner with business unit leaders.
Because speed is strategically important in many early efforts, it will be tempting for
business unit teams to move forward without IT support. You will find, however, that Big
Data issues emerge at surprisingly low data volumes. They manifest themselves when
the balance between the value of data and the cost of retention becomes an issue.

©2011 IDC #230747 13
Making the wrong choice in a technology decision (e.g., deciding between an OLTP,
OLAP, or OLDR approach to data storage) will lead to significantly high data
management and retention costs in both the short run and the long run.
It will also expose the organization to greater risks when it comes to IT and corporate
governance. Your IT team needs to recognize that it must think differently (as well as
quickly) and fight for a seat at the table as analytic and data archiving strategies are
developed. You need to ensure that the solution:
Reduces infrastructure cost by ingesting and querying large volumes of data on
commodity infrastructure while cutting demand for physical storage through
compression
Retains huge volumes of records without a need to roll up or aggregate while
managing record life cycles through configurable retention policies, preserving a
secure and immutable data model
Retrieves information speedily using standard SQL over ODBC/JDBC, enabling
enterprises to leverage existing business information, reporting, and analytics
investments
When selecting a storage and data management partner to help you, picking the best
product isn't enough. You will need a partner that can address the entire spectrum of
data assessment, data retention, and data use requirements of this new environment.
IDC believes that building successful business cases around the intersection of
machine-generated data and Big Data analysis can be accomplished only through a
tight alignment of critical thinking across both IT and the business. You will need a
partner that can help you capitalize on new initiatives quickly and cost-effectively.
As a CIO, you want to be more involved in the business; creating the right data
management infrastructure for the retention and active archiving of machine-
generated data can bring your IT organization front and center in the next major
business effort.
C o p y r i g h t N o t i c e
External Publication of IDC Information and Data — Any IDC information that is to be
used in advertising, press releases, or promotional materials requires prior written
approval from the appropriate IDC Vice President or Country Manager. A draft of the
proposed document should accompany any such request. IDC reserves the right to
deny approval of external usage for any reason.
Copyright 2011 IDC. Reproduction without written permission is completely forbidden.