what is spark? generalcs162/fa17/static/lectures/25.pdf · spark: unified engine across spark sql...
TRANSCRIPT

Page 1
CS162�Operating Systems and�Systems Programming�
Lecture 25 �Apache Spark – Berkeley Data Analytics Stack (BDAS)
November 27th, 2017Prof. Ion Stoica
http://cs162.eecs.Berkeley.edu
Lec 24.211/27/17 CS162 © UCB Fall 2017
A Short History
• Started at UC Berkeley in 2009
• Open Source: 2010
• Apache Project: 2013
• Today: most popular big data processing engine
Lec 24.311/27/17 CS162 © UCB Fall 2017
What Is Spark?
• Parallel execution engine for big data processing
• Easy to use: 2-5x less code than Hadoop MR– High level API’s in Python, Java, and Scala
• Fast: up to 100x faster than Hadoop MR– Can exploit in-memory when available– Low overhead scheduling, optimized engine
• General: support multiple computation models
Lec 24.411/27/17 CS162 © UCB Fall 2017
General
• Unifies batch, interactive computations
Spark Core
Spark SQL

Page 2
Lec 24.511/27/17 CS162 © UCB Fall 2017
General
• Unifies batch, interactive, streaming computations
Spark Core
Spark SQL Spark Streaming
Lec 24.611/27/17 CS162 © UCB Fall 2017
General
• Unifies batch, interactive, streaming computations• Easy to build sophisticated applications
– Support iterative, graph-parallel algorithms– Powerful APIs in Scala, Python, Java
Spark Core
Spark Streaming Spark SQL MLlib GraphX
Lec 24.711/27/17 CS162 © UCB Fall 2017
Easy to Write Code
WordCount in 50+ lines of Java MR
WordCount in 3 lines of Spark
Lec 24.811/27/17 CS162 © UCB Fall 2017
Large-Scale Usage
Largest cluster: 8000 nodes
Largest single job: 1 petabyte
Top streaming intake: 1 TB/hour
2014 on-disk sort record

Page 3
Lec 24.911/27/17 CS162 © UCB Fall 2017
Fast: Time to sort 100TB
2100 machines 2013 Record: Hadoop
2014 Record: Spark
Source: Daytona GraySort benchmark, sortbenchmark.org
72 minutes
207 machines
23 minutes
Also sorted 1PB in 4 hours
Lec 24.1011/27/17 CS162 © UCB Fall 2017
RDD: Core Abstraction
• Resilient Distributed Datasets (RDDs)– Collections of objects distr. across a
cluster, stored in RAM or on Disk– Built through parallel transformations– Automatically rebuilt on failure
Operations• Transformations�
(e.g. map, filter, groupBy)• Actions�
(e.g. count, collect, save)
Write programs in terms of distributed datasets and operations on them
Lec 24.1111/27/17 CS162 © UCB Fall 2017
Operations on RDDs
• Transformations f(RDD) => RDD§ Lazy (not computed immediately)§ E.g. “map”
• Actions:§ Triggers computation§ E.g. “count”, “saveAsTextFile”
Lec 24.1211/27/17 CS162 © UCB Fall 2017
Working With RDDs
RDD
textFile = sc.textFile(”SomeFile.txt”) !

Page 4
Lec 24.1311/27/17 CS162 © UCB Fall 2017
Working With RDDs
RDDRDDRDDRDD
Transformations
linesWithSpark = textFile.filter(lambda line: "Spark” in line) !
textFile = sc.textFile(”SomeFile.txt”) !
Lec 24.1411/27/17 CS162 © UCB Fall 2017
Working With RDDs
RDDRDDRDDRDD
Transformations
Action Value
linesWithSpark = textFile.filter(lambda line: "Spark” in line) !
linesWithSpark.count()!74!!linesWithSpark.first()!# Apache Spark!
textFile = sc.textFile(”SomeFile.txt”) !
Lec 24.1511/27/17 CS162 © UCB Fall 2017
Load error messages from a log into memory, then interactively search for various patterns
Example: Log Mining
Lec 24.1611/27/17 CS162 © UCB Fall 2017
Load error messages from a log into memory, then interactively search for various patterns
Worker
Worker
Worker
Driver
Example: Log Mining

Page 5
Lec 24.1711/27/17 CS162 © UCB Fall 2017
Load error messages from a log into memory, then interactively search for various patterns
Worker
Worker
Worker
Driver
lines = spark.textFile(“hdfs://...”)
Example: Log Mining
Lec 24.1811/27/17 CS162 © UCB Fall 2017
Load error messages from a log into memory, then interactively search for various patterns
Worker
Worker
Worker
Driver
lines = spark.textFile(“hdfs://...”)
Base RDD
Example: Log Mining
Lec 24.1911/27/17 CS162 © UCB Fall 2017
Load error messages from a log into memory, then interactively search for various patterns
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(lambda s: s.startswith(“ERROR”))
Worker
Worker
Worker
Driver
Example: Log Mining
Lec 24.2011/27/17 CS162 © UCB Fall 2017
Load error messages from a log into memory, then interactively search for various patterns
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(lambda s: s.startswith(“ERROR”))
Worker
Worker
Worker
Driver
Transformed RDD
Example: Log Mining

Page 6
Lec 24.2111/27/17 CS162 © UCB Fall 2017
Load error messages from a log into memory, then interactively search for various patterns
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(lambda s: s.startswith(“ERROR”))
messages = errors.map(lambda s: s.split(“\t”)[2])
messages.cache()
Worker
Worker
Worker
Driver
messages.filter(lambda s: “mysql” in s).count()
Example: Log Mining
Lec 24.2211/27/17 CS162 © UCB Fall 2017
Load error messages from a log into memory, then interactively search for various patterns
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(lambda s: s.startswith(“ERROR”))
messages = errors.map(lambda s: s.split(“\t”)[2])
messages.cache()
Worker
Worker
Worker
Driver
messages.filter(lambda s: “mysql” in s).count() Action
Example: Log Mining
Lec 24.2311/27/17 CS162 © UCB Fall 2017
Load error messages from a log into memory, then interactively search for various patterns
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(lambda s: s.startswith(“ERROR”))
messages = errors.map(lambda s: s.split(“\t”)[2])
messages.cache()
Worker
Worker
Worker
Driver
messages.filter(lambda s: “mysql” in s).count()
Block 1
Block 2
Block 3
Example: Log Mining
Lec 24.2411/27/17 CS162 © UCB Fall 2017
Load error messages from a log into memory, then interactively search for various patterns
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(lambda s: s.startswith(“ERROR”))
messages = errors.map(lambda s: s.split(“\t”)[2])
messages.cache()
Worker
Worker
Worker messages.filter(lambda s: “mysql” in s).count()
Block 1
Block 2
Block 3
Driver tasks
tasks
tasks
Example: Log Mining

Page 7
Lec 24.2511/27/17 CS162 © UCB Fall 2017
Load error messages from a log into memory, then interactively search for various patterns
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(lambda s: s.startswith(“ERROR”))
messages = errors.map(lambda s: s.split(“\t”)[2])
messages.cache()
Worker
Worker
Worker messages.filter(lambda s: “mysql” in s).count()
Block 1
Block 2
Block 3
Driver
ReadHDFS Block
ReadHDFS Block
Read HDFS Block
Example: Log Mining
Lec 24.2611/27/17 CS162 © UCB Fall 2017
Load error messages from a log into memory, then interactively search for various patterns
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(lambda s: s.startswith(“ERROR”))
messages = errors.map(lambda s: s.split(“\t”)[2])
messages.cache()
Worker
Worker
Worker messages.filter(lambda s: “mysql” in s).count()
Block 1
Block 2
Block 3
Driver
Cache 1
Cache 2
Cache 3
Process& Cache Data
Process& Cache Data
Process& Cache Data
Example: Log Mining
Lec 24.2711/27/17 CS162 © UCB Fall 2017
Load error messages from a log into memory, then interactively search for various patterns
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(lambda s: s.startswith(“ERROR”))
messages = errors.map(lambda s: s.split(“\t”)[2])
messages.cache()
Worker
Worker
Worker messages.filter(lambda s: “mysql” in s).count()
Block 1
Block 2
Block 3
Driver
Cache 1
Cache 2
Cache 3
results
results
results
Example: Log Mining
Lec 24.2811/27/17 CS162 © UCB Fall 2017
Load error messages from a log into memory, then interactively search for various patterns
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(lambda s: s.startswith(“ERROR”))
messages = errors.map(lambda s: s.split(“\t”)[2])
messages.cache()
Worker
Worker
Worker messages.filter(lambda s: “mysql” in s).count()
Block 1
Block 2
Block 3
Driver
Cache 1
Cache 2
Cache 3 messages.filter(lambda s: “php” in s).count()
Example: Log Mining

Page 8
Lec 24.2911/27/17 CS162 © UCB Fall 2017
Load error messages from a log into memory, then interactively search for various patterns
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(lambda s: s.startswith(“ERROR”))
messages = errors.map(lambda s: s.split(“\t”)[2])
messages.cache()
Worker
Worker
Worker messages.filter(lambda s: “mysql” in s).count()
Block 1
Block 2
Block 3
Cache 1
Cache 2
Cache 3 messages.filter(lambda s: “php” in s).count()
tasks
tasks
tasks
Driver
Example: Log Mining
Lec 24.3011/27/17 CS162 © UCB Fall 2017
Load error messages from a log into memory, then interactively search for various patterns
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(lambda s: s.startswith(“ERROR”))
messages = errors.map(lambda s: s.split(“\t”)[2])
messages.cache()
Worker
Worker
Worker messages.filter(lambda s: “mysql” in s).count()
Block 1
Block 2
Block 3
Cache 1
Cache 2
Cache 3 messages.filter(lambda s: “php” in s).count()
Driver
ProcessfromCache
ProcessfromCache
ProcessfromCache
Example: Log Mining
Lec 24.3111/27/17 CS162 © UCB Fall 2017
Load error messages from a log into memory, then interactively search for various patterns
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(lambda s: s.startswith(“ERROR”))
messages = errors.map(lambda s: s.split(“\t”)[2])
messages.cache()
Worker
Worker
Worker messages.filter(lambda s: “mysql” in s).count()
Block 1
Block 2
Block 3
Cache 1
Cache 2
Cache 3 messages.filter(lambda s: “php” in s).count()
Driver results
results
results
Example: Log Mining
Lec 24.3211/27/17 CS162 © UCB Fall 2017
Load error messages from a log into memory, then interactively search for various patterns
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(lambda s: s.startswith(“ERROR”))
messages = errors.map(lambda s: s.split(“\t”)[2])
messages.cache()
Worker
Worker
Worker messages.filter(lambda s: “mysql” in s).count()
Block 1
Block 2
Block 3
Cache 1
Cache 2
Cache 3 messages.filter(lambda s: “php” in s).count()
Driver
Cache your data è Faster Results Full-text search of Wikipedia • 60GB on 20 EC2 machines • 0.5 sec from mem vs. 20s for on-disk
Example: Log Mining

Page 9
Lec 24.3311/27/17 CS162 © UCB Fall 2017
Language Support
Standalone Programs• Python, Scala, & Java
Interactive Shells• Python & Scala
Performance• Java & Scala are faster due to
static typing• …but Python is often fine
Python
lines = sc.textFile(...) lines.filter(lambda s: “ERROR” in s).count()
Scala
val lines = sc.textFile(...) lines.filter(x => x.contains(“ERROR”)).count()
Java JavaRDD<String> lines = sc.textFile(...); lines.filter(new Function<String, Boolean>() { Boolean call(String s) { return s.contains(“error”); } }).count();
Lec 24.3411/27/17 CS162 © UCB Fall 2017
Expressive API
• map reduce
Lec 24.3511/27/17 CS162 © UCB Fall 2017
Expressive API
• map • filter • groupBy • sort • union • join • leftOuterJoin • rightOuterJoin
reduce
count
fold
reduceByKey
groupByKey
cogroup
cross
zip
sample
take
first
partitionBy
mapWith
pipe
save ...
Lec 24.3611/27/17 CS162 © UCB Fall 2017
Fault Recovery
RDDs track lineage information that can be used to efficiently reconstruct lost partitions

Page 10
Lec 24.3711/27/17 CS162 © UCB Fall 2017
Fault Recovery Example
• Two-partition RDD A={A1, A2} stored on disk1) filter and cache à RDD B2) joinà RDD C3) aggregate à RDD D
A1
A2
RDD
A
agg. D
filter
filter B2
B1 join
join C2
C1
Lec 24.3811/27/17 CS162 © UCB Fall 2017
Fault Recovery Example
• C1 lost due to node failure before reduce finishes
A1
A2
RDD
A
agg. D
filter
filter B2
B1 join
join C2
C1
Lec 24.3911/27/17 CS162 © UCB Fall 2017
Fault Recovery Example
• C1 lost due to node failure before reduce finishes• Reconstruct C1, eventually, on different node
A1
A2
RDD
A
agg. D
filter
filter B2
B1
join C2
agg. D
join C1
Lec 24.4011/27/17 CS162 © UCB Fall 2017
• Many important apps must process large data streams at second-scale latencies
– Site statistics, intrusion detection, online ML
• To build and scale these apps users want:– Integration: with offline analytical stack– Fault-tolerance: both for crashes and stragglers
Spark Streaming: Motivation

Page 11
Lec 24.4111/27/17 CS162 © UCB Fall 2017
How does it work?
• Data streams are chopped into batches – A batch is an RDD holding a few 100s ms worth of data
• Each batch is processed in Spark
data streams
rece
iver
s
batches
Lec 24.4211/27/17 CS162 © UCB Fall 2017
Streaming
How does it work?
• Data streams are chopped into batches – A batch is an RDD holding a few 100s ms worth of data
• Each batch is processed in Spark• Results pushed out in batches
data streams
rece
iver
s
batches results
Lec 24.4311/27/17 CS162 © UCB Fall 2017
Streaming Word Count
val lines = context.socketTextStream(“localhost”, 9999)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start() print some counts on screen
count the words
split lines into words
create DStream from data over socket
start processing the stream
Lec 24.4411/27/17 CS162 © UCB Fall 2017
Word Count
object NetworkWordCount { def main(args: Array[String]) { val sparkConf = new SparkConf().setAppName("NetworkWordCount") val context = new StreamingContext(sparkConf, Seconds(1)) val lines = context.socketTextStream(“localhost”, 9999) val words = lines.flatMap(_.split(" ")) val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _) wordCounts.print() ssc.start() ssc.awaitTermination() } }

Page 12
Lec 24.4511/27/17 CS162 © UCB Fall 2017
Word Count
object NetworkWordCount { def main(args: Array[String]) { val sparkConf = new SparkConf().setAppName("NetworkWordCount") val context = new StreamingContext(sparkConf, Seconds(1)) val lines = context.socketTextStream(“localhost”, 9999) val words = lines.flatMap(_.split(" ")) val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _) wordCounts.print() ssc.start() ssc.awaitTermination() } }
Spark Streaming
public class WordCountTopology { public static class SplitSentence extends ShellBolt implements IRichBolt { public SplitSentence() { super("python", "splitsentence.py"); } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("word")); } @Override public Map<String, Object> getComponentConfiguration() { return null; } } public static class WordCount extends BaseBasicBolt { Map<String, Integer> counts = new HashMap<String, Integer>(); @Override public void execute(Tuple tuple, BasicOutputCollector collector) { String word = tuple.getString(0); Integer count = counts.get(word); if (count == null) count = 0; count++; counts.put(word, count); collector.emit(new Values(word, count)); } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("word", "count")); } }
Storm
public static void main(String[] args) throws Exception { TopologyBuilder builder = new TopologyBuilder(); builder.setSpout("spout", new RandomSentenceSpout(), 5); builder.setBolt("split", new SplitSentence(), 8).shuffleGrouping("spout"); builder.setBolt("count", new WordCount(), 12).fieldsGrouping("split", new Fields("word")); Config conf = new Config(); conf.setDebug(true); if (args != null && args.length > 0) { conf.setNumWorkers(3); StormSubmitter.submitTopologyWithProgressBar(args[0], conf, builder.createTopology()); } else { conf.setMaxTaskParallelism(3); LocalCluster cluster = new LocalCluster(); cluster.submitTopology("word-count", conf, builder.createTopology()); Thread.sleep(10000); cluster.shutdown(); } } }
Lec 24.4611/27/17 CS162 © UCB Fall 2017
119
57 56 58 5881
57 59 57 59
020406080100120140
1 2 3 4 5 6 7 8 9 10
Iteratrion
time(s)
Iteration
Failurehappens
Fault Recovery Example
Lec 24.4711/27/17 CS162 © UCB Fall 2017
Administrivia (1/2)
• Midterm 3 coming up on Wen 11/29 6:30-8PM– All topics up to and including Lecture 24
» Focus will be on Lectures 17 – 24 and associated readings, and Projects 3
» But expect 20-30% questions from materials from Lectures 1-16
– Closed book– 2 sides hand-written notes both sides
Lec 24.4811/27/17 CS162 © UCB Fall 2017
Administrivia (2/2)
• Exam location: Assigned based on Cal student ID number: – ends in 0, 1, 2, 3, 4: Li Ka Shing 245– ends in 5, 6, 7: GPB 100– ends in 8, 9: Kroeber 160
• Rest of today– 7:45pm: HKN class survey– 8-9:30pm Review (VLSB 2050)

Page 13
Lec 24.4911/27/17 CS162 © UCB Fall 2017
BREAK
Lec 24.5011/27/17 CS162 © UCB Fall 2017
From RDDs to DataFrames
Spark early adopters
Data Engineers Data Scientists Statisticians R users PyData …
Users
Understands MapReduce
& functional APIs
Lec 24.5111/27/17 CS162 © UCB Fall 2017 Lec 24.5211/27/17 CS162 © UCB Fall 2017
DataFrames in Spark
Distributed collection of data grouped into named columns �(i.e. RDD with schema)Domain-specific functions designed for common tasks
– Metadata– Sampling– Project, filter, aggregation, join, …– UDFs
Available in Python, Scala, Java, and R

Page 14
Lec 24.5311/27/17 CS162 © UCB Fall 2017
Spark DataFrame
• >head(filter(df,df$waiting<50))#anexampleinR• ##eruptionswaiting• ##11.75047• ##21.75047• ##31.86748
Similar APIs as single-node tools like Pandas, R, i.e., easy to learn
*Old Faithful geyser data from http://www.stat.cmu.edu/~larry/all-of-statistics/=data/faithful.dat
Lec 24.5411/27/17 CS162 © UCB Fall 2017
Spark RDD Execution
Java/Scala frontend
JVM backend
Python frontend
Python backend
opaque closures (user-defined functions)
Lec 24.5511/27/17 CS162 © UCB Fall 2017
Spark DataFrame Execution
DataFrame frontend
Logical Plan
Physical execution
Catalyst optimizer
Intermediate representation for computation
Lec 24.5611/27/17 CS162 © UCB Fall 2017
Spark DataFrame Execution
Python DF
Logical Plan
Physical execution
Catalyst optimizer
Java/Scala DF
R DF
Intermediate representation for computation
Simple wrappers to create logical plan

Page 15
Lec 24.5711/27/17 CS162 © UCB Fall 2017
Performance
0 2 4 6 8 10
Java/Scala
Python
Runtime for an example aggregation workload (sec)
RDD
Lec 24.5811/27/17 CS162 © UCB Fall 2017
Benefit of Logical Plan: �Performance Parity Across Languages
0 2 4 6 8 10
Java/Scala
Python
Java/Scala
Python
R
SQL
Runtime for an example aggregation workload (sec)
DataFrame
RDD
Lec 24.5911/27/17 CS162 © UCB Fall 2017
Further Optimizations
• Whole-stage code generation– Remove expensive iterator calls– Fuse across multiple operators
Spark 1.6 14M rows/s
Spark 2.0 125M
rows/s
Parquet in 1.6
11M rows/s
Parquet in 2.0
90M rows/s
Optimized input / output • Parquet + built-in cache
Automatically applies to SQL, DataFrames, Datasets Lec 24.6011/27/17 CS162 © UCB Fall 2017
0
100
200
300
400
500
600
q1 q11
q13
q15
q17
q19
q2
q21
q25
q26
q28
q29 q3
q3
1 q3
4 q3
7 q3
8 q3
9a q3
9b
q4
q40
q42
q43
q46
q48
q50
q52
q55
q59 q6
1 q6
2 q6
6 q6
8 q7
q71
q73
q74
q75
Runt
ime
(sec
onds
)
TPC-DS Spark 2.0 vs 1.6 – Lower is Better
Time (1.6)
Time (2.0)

Page 16
Lec 24.6111/27/17 CS162 © UCB Fall 2017
Processing Business logic change & new ops
(windows, sessions)
From Streaming to Structured Streaming
Output How do we define
output over time & correctness?
Data Late arrival, varying distribution over time, …
Lec 24.6211/27/17 CS162 © UCB Fall 2017
The simplest way to perform streaming analytics is not having to reason about streaming
Lec 24.6311/27/17 CS162 © UCB Fall 2017
Spark 2.0 Infinite DataFrames
Spark 1.3 Static DataFrames
Single API ! Lec 24.6411/27/17 CS162 © UCB Fall 2017
Structured Streaming
High-level streaming API built on DataFrames• Event time, windowing, sessions, sources & sinks
Also supports interactive & batch queries• Aggregate data in a stream, then serve using JDBC• Change queries at runtime• Build and apply ML models
Not just streaming, but “continuous applications”

Page 17
Lec 24.6511/27/17 CS162 © UCB Fall 2017
logs = ctx.read.format("json").open("s3://logs")
logs.groupBy(“userid”, “hour”).avg(“latency”)
.write.format("jdbc")
.save("jdbc:mysql//...")
Example: Batch Aggregation
Lec 24.6611/27/17 CS162 © UCB Fall 2017
logs = ctx.read.format("json").stream("s3://logs")
logs.groupBy(“userid”, “hour”).avg(“latency”)
.write.format("jdbc")
.startStream("jdbc:mysql//...")
Example: Continuous Aggregation
Lec 24.6711/27/17 CS162 © UCB Fall 2017
Goal: end-to-end continuous applications
Example
Reporting
Applications
ML Model
Ad-hoc Queries
Traditional streaming Other processing types
Kafka Database ETL
Lec 24.6811/27/17 CS162 © UCB Fall 2017
Apache Spark Today
• > 1,500 contributors• > 400K meetup members world wide• > 300K students trained world wide
• 1,000s deployments in productions– Virtually every large enterprise– Available in all clouds (e.g., AWS, Google Compute Engine, MS
Azure, IBM, …)– Distributed by IBM, Cloudera, Hortonworks, MapR, Oracle, …
• Databricks, startup to commercialize Apache Spark
Page 18
Lec 24.6911/27/17 CS162 © UCB Fall 2017
{JSON}
Data Sources
Spark Core
DataFrames ML Pipelines
Spark Streaming
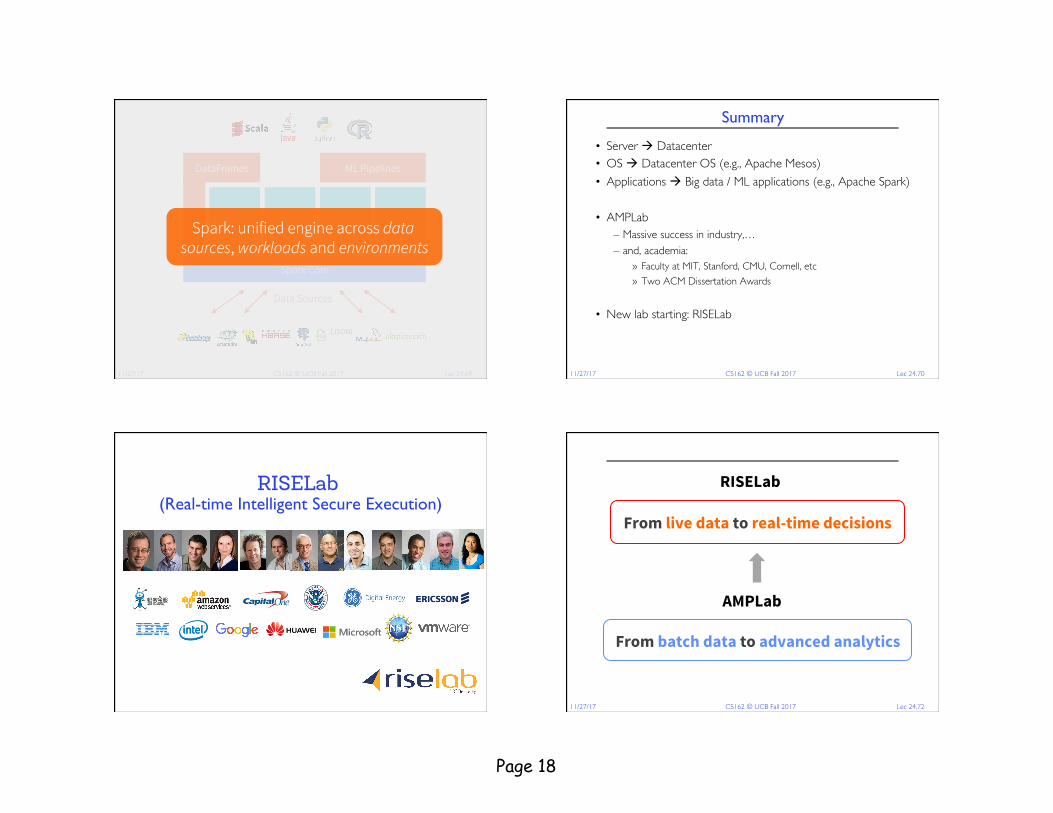
Spark SQL MLlib GraphX Spark: unified engine across data sources, workloads and environments
Lec 24.7011/27/17 CS162 © UCB Fall 2017
Summary
• Server à Datacenter• OS à Datacenter OS (e.g., Apache Mesos)• Applications à Big data / ML applications (e.g., Apache Spark)
• AMPLab– Massive success in industry,…– and, academia:
» Faculty at MIT, Stanford, CMU, Cornell, etc» Two ACM Dissertation Awards
• New lab starting: RISELab
RISELab �(Real-time Intelligent Secure Execution)
Lec 24.7211/27/17 CS162 © UCB Fall 2017
From batch data to advanced analytics
AMPLab
From live data to real-time decisions
RISELab

Page 19
Lec 24.7311/27/17 CS162 © UCB Fall 2017
RISE stack
scheduler object store RISE μkernel
Ray Clipper …
Ground (data context service)
Tegra
optimizer
Secure Analytics &
ML
Tim
e M
achi
ne
SGX