watson studio & watson machine learning - ibm.com · hadoop, and hdfs. •works with data...
TRANSCRIPT

IBM CloudWatson Studio & Watson Machine Learning 介紹
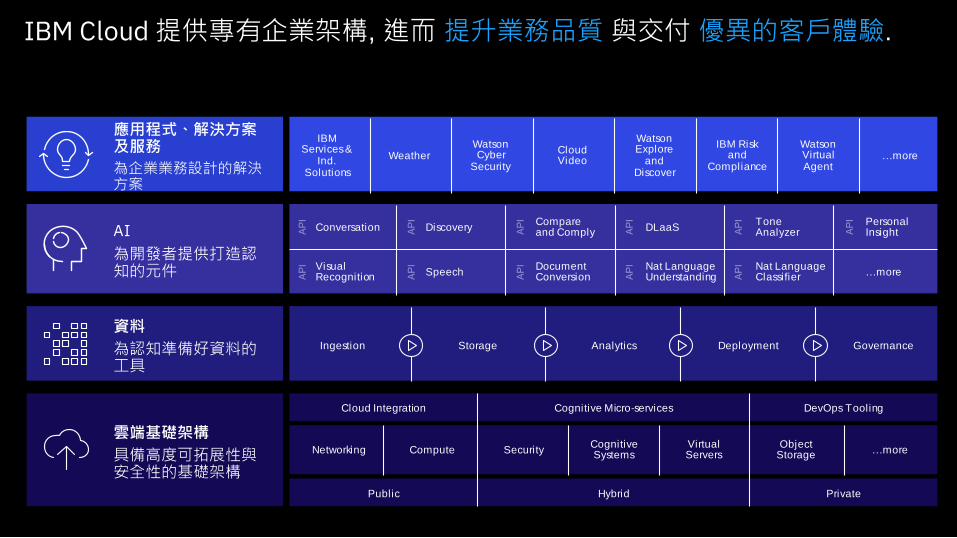
IBM Cloud 提供專有企業架構, 進而 提升業務品質 與交付 優異的客戶體驗.
雲端基礎架構
具備高度可拓展性與安全性的基礎架構
資料
為認知準備好資料的工具
AI
為開發者提供打造認知的元件
應用程式、解決方案及服務
為企業業務設計的解決方案
Ingestion
Conversation
Storage Analytics Deployment Governance
Visual Recognition
Discovery
Speech
Compare and Comply
Document Conversion
DLaaS
Nat Language Understanding
Nat Language Classifier
ToneAnalyzer
PersonalInsight
…more
Cloud Integration
Networking Compute SecurityCognitiveSystems
Virtual Servers …more
Object Storage
Cognitive Micro-services DevOps Tooling
Cloud Video
WatsonCyber
SecurityWeather
IBM Services &
Ind. Solutions
WatsonVirtual Agent
Watson Explore
and Discover
IBM Risk and
Compliance…more
Public Hybrid Private
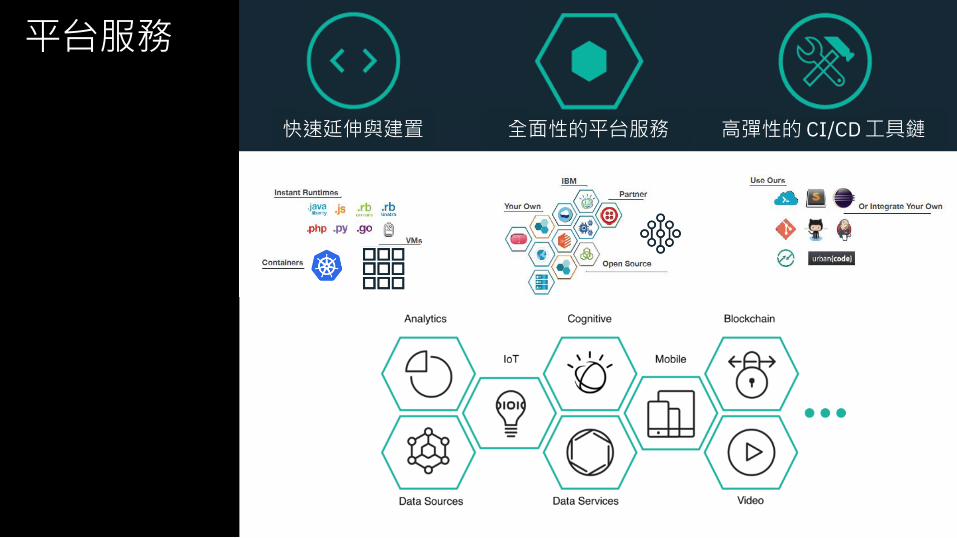
平台服務
快速延伸與建置 全面性的平台服務 高彈性的 CI/CD 工具鏈
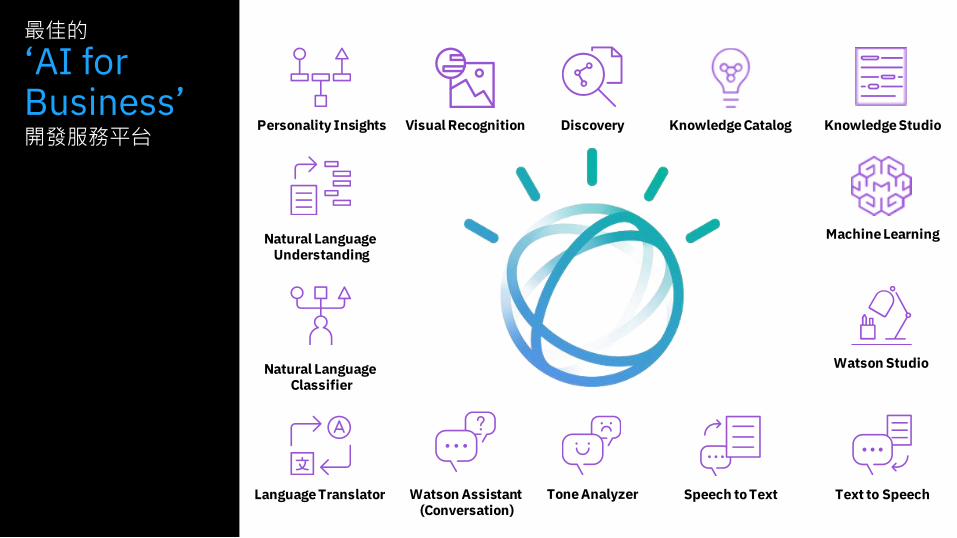
最佳的
‘AI for Business’開發服務平台
Discovery Knowledge Catalog Knowledge Studio
Watson Studio
Machine Learning
Text to SpeechSpeech to TextWatson Assistant(Conversation)
Tone Analyzer
Personality Insights
Natural LanguageUnderstanding
Language Translator
Natural LanguageClassifier
Visual Recognition
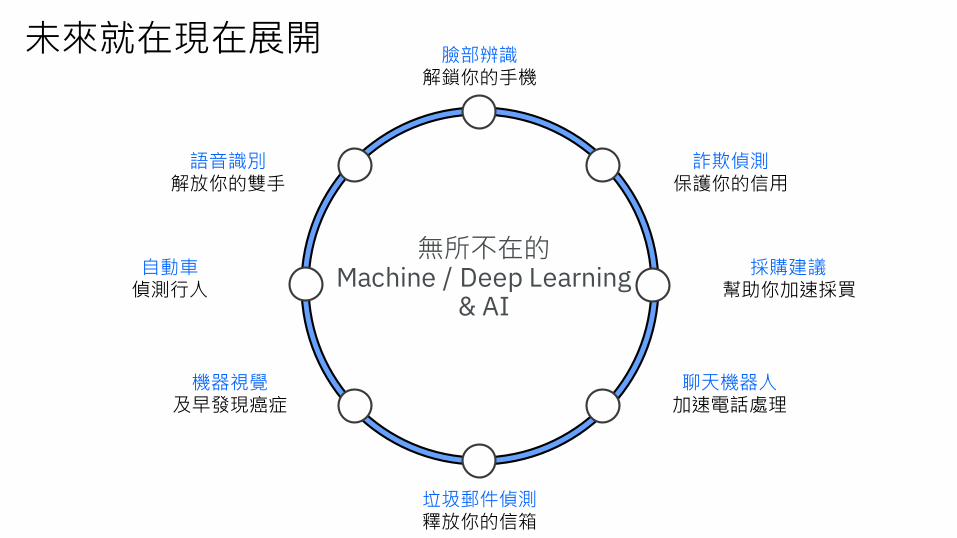
未來就在現在展開
無所不在的Machine / Deep Learning
& AI
臉部辨識解鎖你的手機
詐欺偵測保護你的信用
採購建議幫助你加速採買
語音識別解放你的雙手
聊天機器人加速電話處理
自動車偵測行人
機器視覺及早發現癌症
垃圾郵件偵測釋放你的信箱
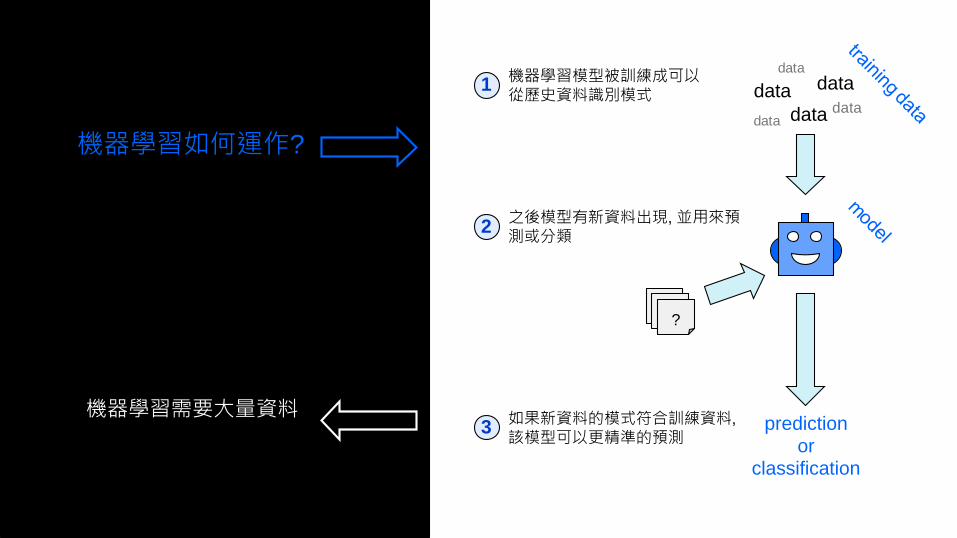
機器學習如何運作?
機器學習模型被訓練成可以從歷史資料識別模式
1data
data data
datadata
data
之後模型有新資料出現, 並用來預測或分類
2
如果新資料的模式符合訓練資料,
該模型可以更精準的預測3 prediction
orclassification
???
機器學習需要大量資料
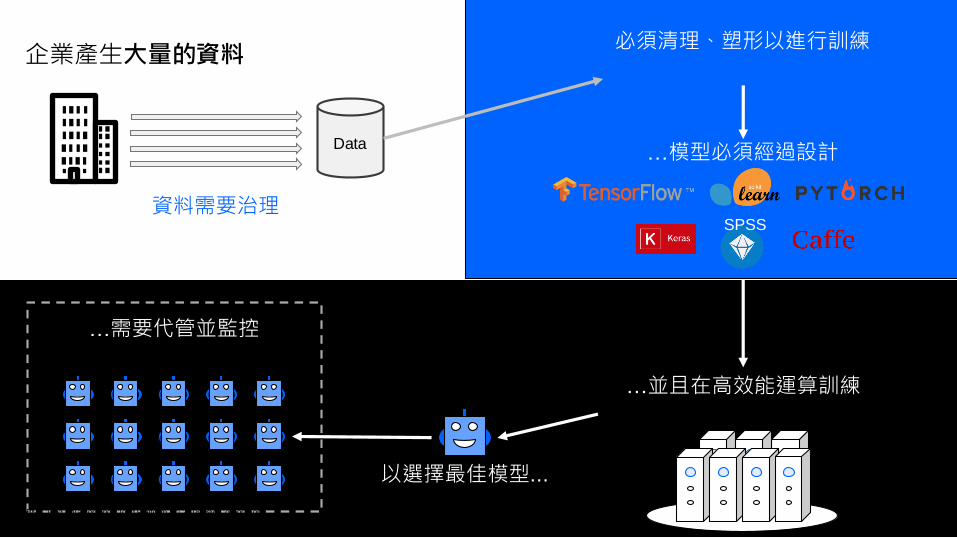
7IBM Cloud / Watson and Cloud Platform / © 2018 IBM Corporation
企業產生大量的資料
Data
資料需要治理
必須清理、塑形以進行訓練
…模型必須經過設計
…需要代管並監控
…並且在高效能運算訓練
SPSS
以選擇最佳模型...
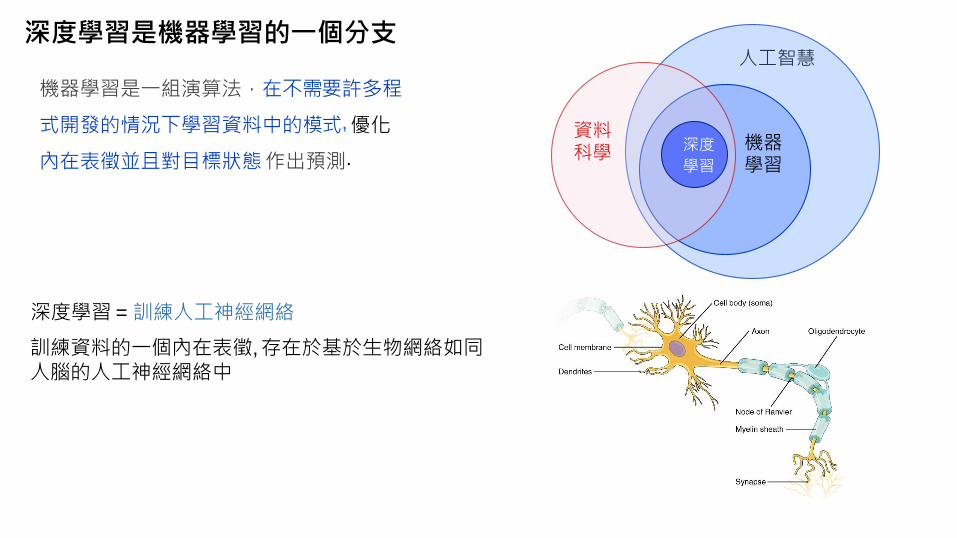
深度學習是機器學習的一個分支
機器學習是一組演算法,在不需要許多程
式開發的情況下學習資料中的模式, 優化
內在表徵並且對目標狀態作出預測.
資料科學 深度
學習
人工智慧
機器學習
深度學習 = 訓練人工神經網絡
訓練資料的一個內在表徵, 存在於基於生物網絡如同人腦的人工神經網絡中
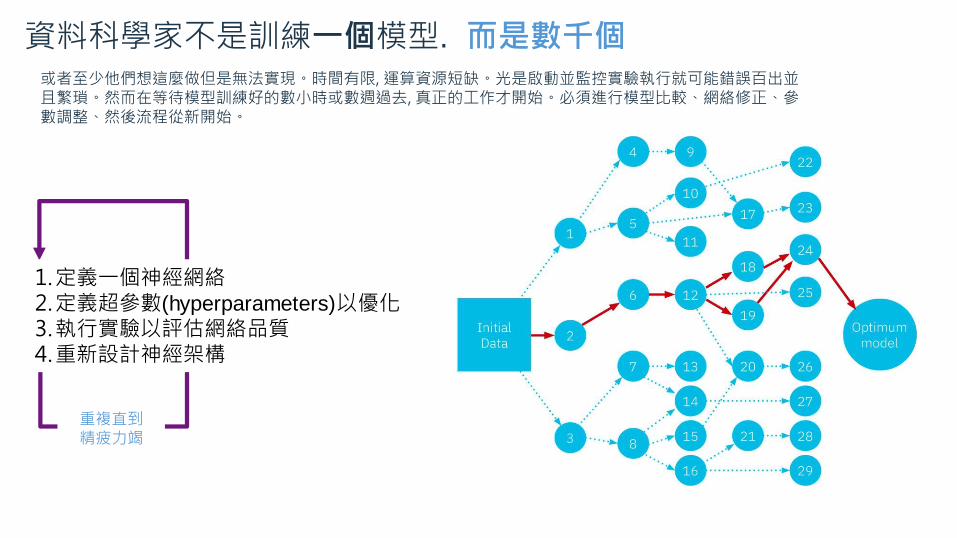
資料科學家不是訓練一個模型. 而是數千個或者至少他們想這麼做但是無法實現。時間有限, 運算資源短缺。光是啟動並監控實驗執行就可能錯誤百出並且繁瑣。然而在等待模型訓練好的數小時或數週過去, 真正的工作才開始。必須進行模型比較、網絡修正、參數調整、然後流程從新開始。
重複直到精疲力竭
1.定義一個神經網絡2.定義超參數(hyperparameters)以優化3.執行實驗以評估網絡品質4.重新設計神經架構

深度學習是神經網絡的設計
機器學習是演算法的選擇
AI 是系統架構

為什麼企業難以獲取 AI 的價值?
工具 & 基礎架構
• 需要一個可以快速實驗的
環境
• 分散的工具阻礙了生產力
治理
• 如果資料不安全, 自助服
務變不能成真
• 難以了解資料脈絡以達成
可信的系統to a system
of truth
技能
• 資料科學技能需求遠高於
供給
• 培養新的資料專家不容易
資料
• 資料分散存放, 難以存取
• 未考慮非結構化和外部資
料

Watson StudioData Science Experience 的進化版
IBM Watson Studio 在雲端提供一套豐富的工具 簡化資料作業, 訓練及管理模型, 和部署AI 驅動的應用程式
關鍵價值:1. 協作式的單一環境– 無須安裝、設定並維護流
程中不同部分的個別工具
2. 可信的資料– 讓團隊可以使用可信的資料來源及分享資源
3. 快速實驗– 一鍵部署, 持續學習
4. 彈性建模選項–可以選擇拖拉式或透過notebook撰寫程式, 深度學習, 從Watson 服務模板開始
5. 雲端! – 隨需並可拓展的資源
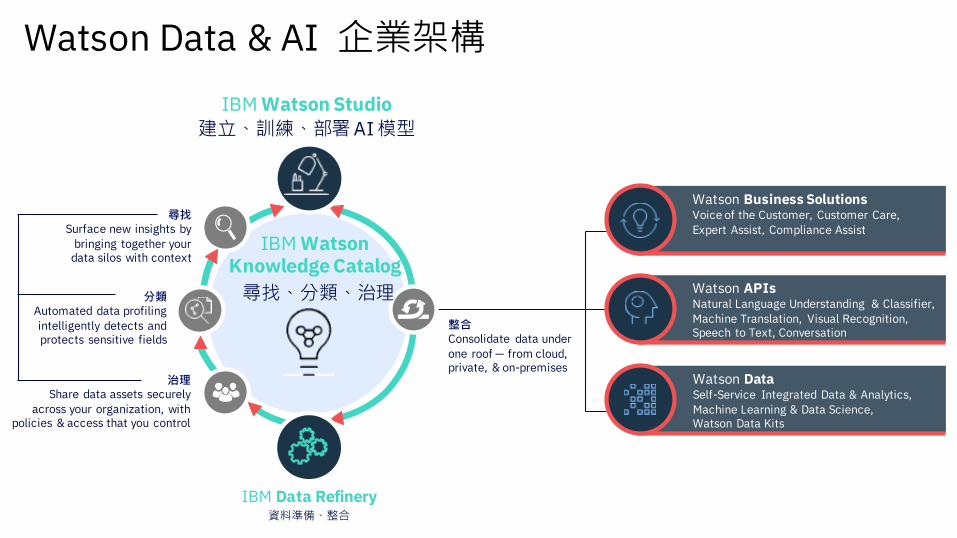
Watson Data & AI 企業架構
IBM Watson Studio
IBM Data Refinery
整合Consolidate data under
one roof — from cloud, private, & on-premises
建立、訓練、部署AI模型
資料準備、整合
尋找Surface new insights by
bringing together your data silos with context
分類Automated data profiling
intelligently detects and protects sensitive fields
治理Share data assets securely
across your organization, with policies & access that you control
IBM WatsonKnowledge Catalog
尋找、分類、治理
Watson DataSelf-Service Integrated Data & Analytics,
Machine Learning & Data Science, Watson Data Kits
Watson Business SolutionsVoice of the Customer, Customer Care,
Expert Assist, Compliance Assist
Watson APIsNatural Language Understanding & Classifier,
Machine Translation, Visual Recognition, Speech to Text, Conversation
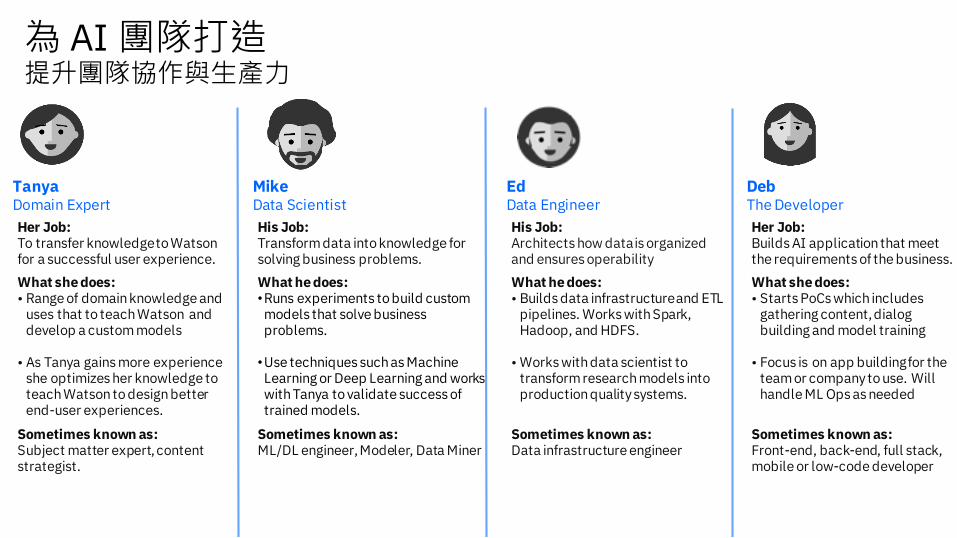
為 AI 團隊打造提升團隊協作與生產力
Her Job: Builds AI application that meet the requirements of the business.
What she does: • Starts PoCs which includes
gathering content, dialog building and model training
• Focus is on app building for the team or company to use. Will handle ML Ops as needed
Sometimes known as:Front-end, back-end, full stack, mobile or low-code developer
TanyaDomain Expert
Her Job: To transfer knowledge to Watson for a successful user experience.
What she does: • Range of domain knowledge and
uses that to teach Watson and develop a custom models
• As Tanya gains more experience she optimizes her knowledge to teach Watson to design better end-user experiences.
Sometimes known as:Subject matter expert, content strategist.
His Job: Transform data into knowledge for solving business problems.
What he does:•Runs experiments to build custom models that solve business problems.
•Use techniques such as Machine Learning or Deep Learning and works with Tanya to validate success of trained models.
Sometimes known as:ML/DL engineer, Modeler, Data Miner
EdData Engineer
His Job: Architects how data is organized and ensures operability
What he does: • Builds data infrastructure and ETL
pipelines. Works with Spark, Hadoop, and HDFS.
• Works with data scientist to transform research models into production quality systems.
Sometimes known as:Data infrastructure engineer
MikeData Scientist
DebThe Developer
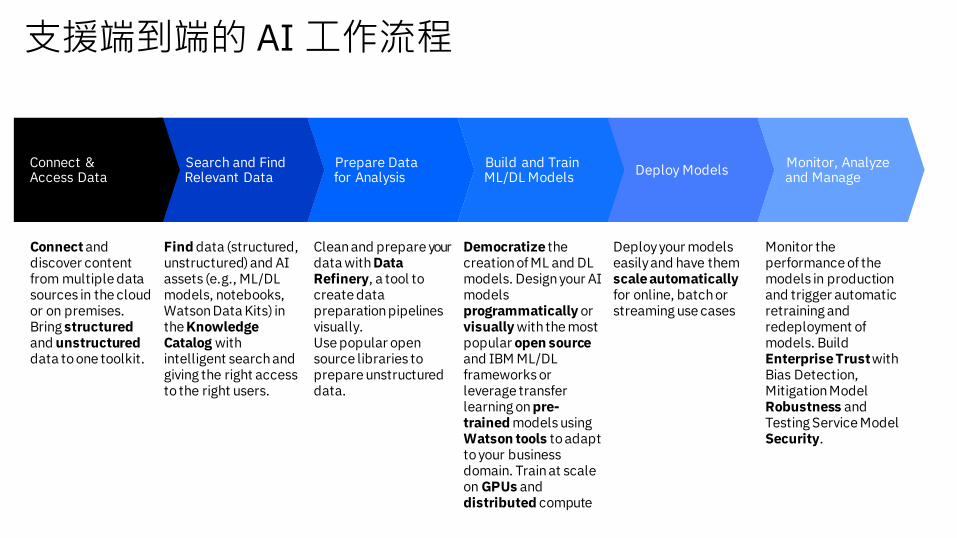
支援端到端的 AI 工作流程
Prepare Data for Analysis
Build and Train ML/DL Models
Deploy ModelsMonitor, Analyze and Manage
Search and Find Relevant Data
Connect & Access Data
Connect and discover content from multiple data sources in the cloud or on premises. Bring structuredand unstructureddata to one toolkit.
Clean and prepare your data with Data Refinery, a tool to create data preparation pipelines visually. Use popular open source libraries to prepare unstructured data.
Democratize the creation of ML and DL models. Design your AI models programmatically or visually with the most popular open source and IBM ML/DL frameworks or leverage transfer learning on pre-trained models using Watson tools to adapt to your business domain. Train at scale on GPUs and distributed compute
Deploy your models easily and have them scale automatically for online, batch or streaming use cases
Monitor the performance of the models in production and trigger automatic retraining and redeployment of models. Build Enterprise Trust with Bias Detection, Mitigation Model Robustness and Testing Service Model Security.
Find data (structured, unstructured) and AI assets (e.g., ML/DL models, notebooks, Watson Data Kits) in the Knowledge Catalog with intelligent search and giving the right access to the right users.
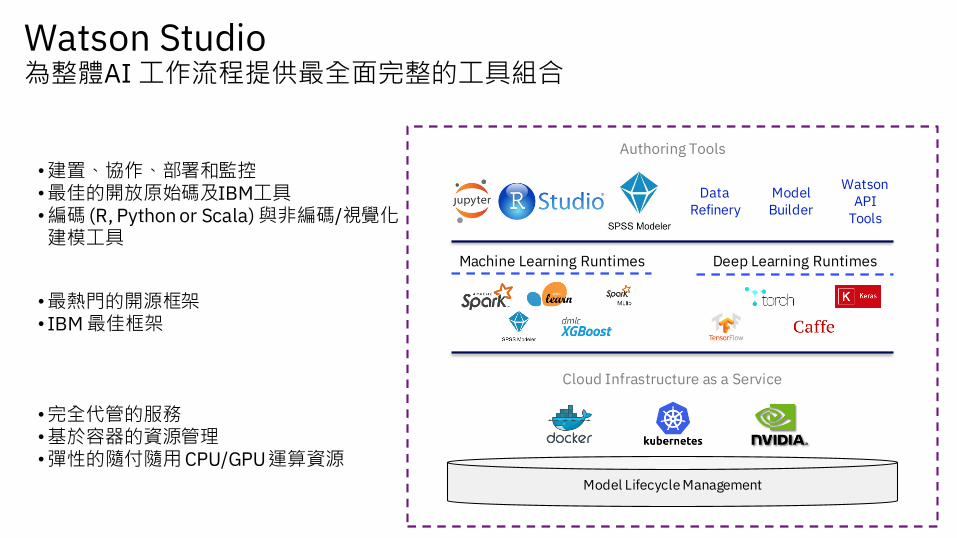
Model Lifecycle Management
Machine Learning Runtimes Deep Learning Runtimes
Authoring Tools
Cloud Infrastructure as a Service
Watson API
Tools
Model Builder
•最熱門的開源框架• IBM 最佳框架
•建置、協作、部署和監控•最佳的開放原始碼及IBM工具•編碼 (R, Python or Scala) 與非編碼/視覺化建模工具
•完全代管的服務•基於容器的資源管理•彈性的隨付隨用CPU/GPU 運算資源
Data Refinery
Watson Studio為整體AI 工作流程提供最全面完整的工具組合
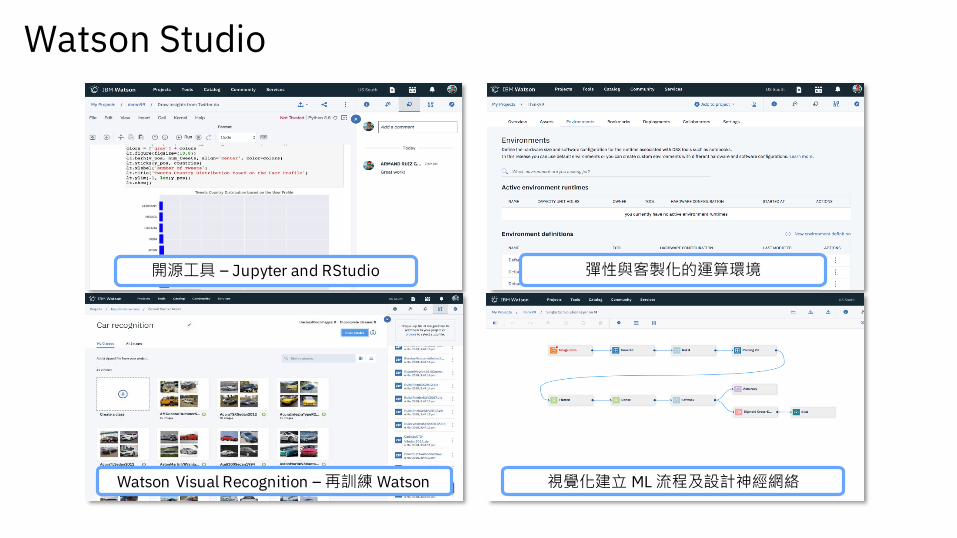
Watson Studio
開源工具 – Jupyter and RStudio
Watson Visual Recognition – 再訓練 Watson
彈性與客製化的運算環境
視覺化建立 ML 流程及設計神經網絡
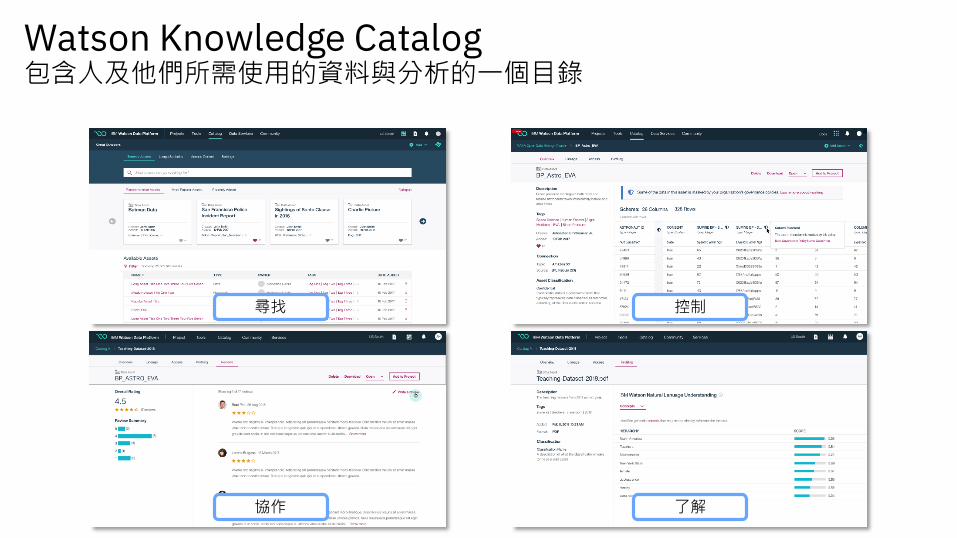
Watson Knowledge Catalog包含人及他們所需使用的資料與分析的一個目錄
尋找 控制
協作 了解
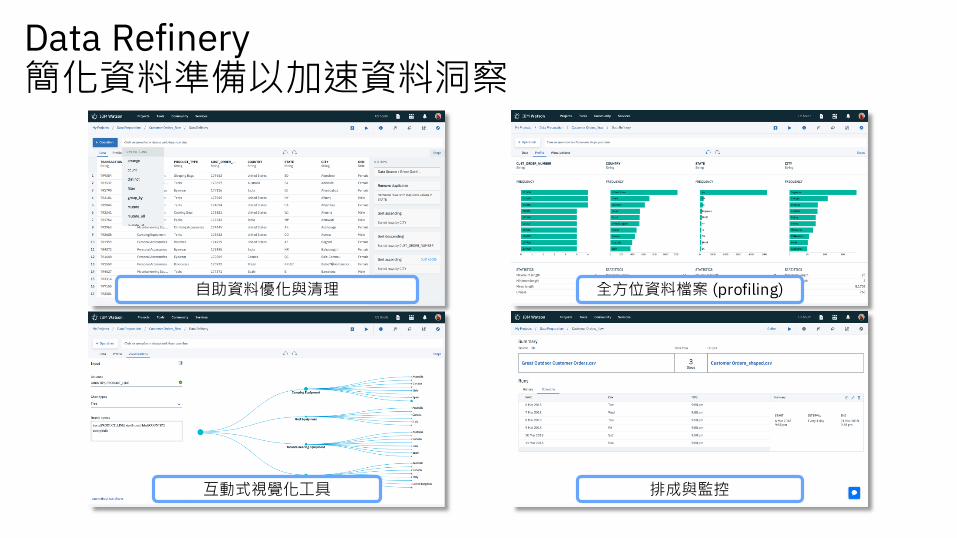
Data Refinery簡化資料準備以加速資料洞察
自助資料優化與清理 全方位資料檔案 (profiling)
互動式視覺化工具 排成與監控
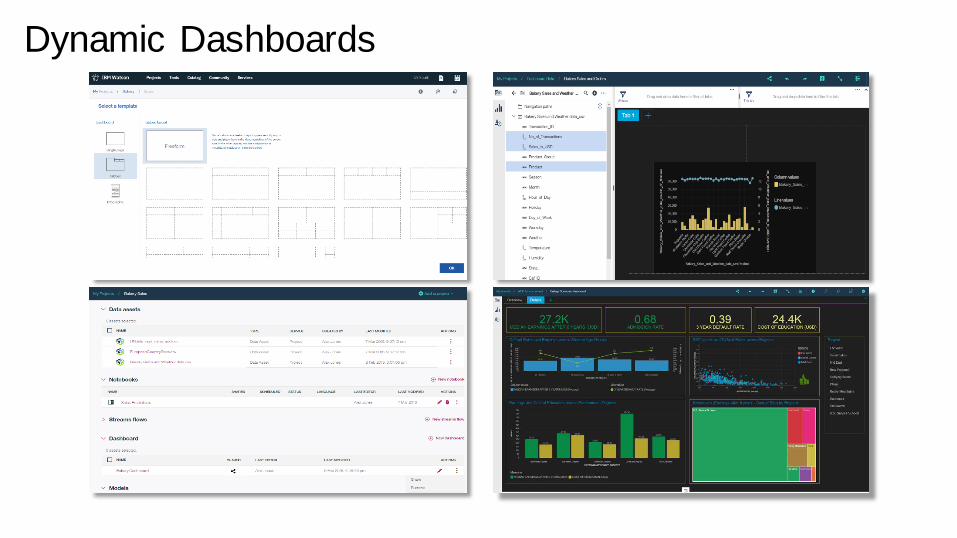
Dynamic Dashboards
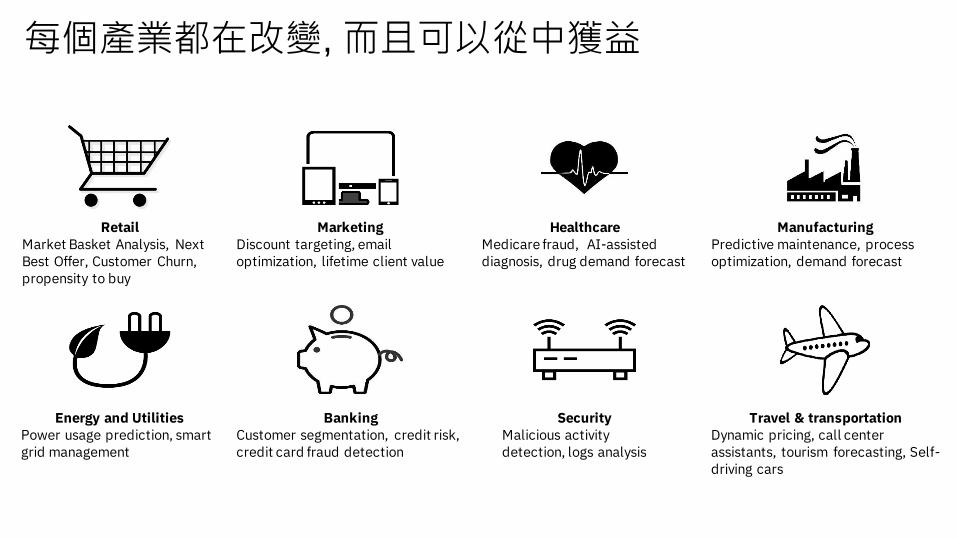
每個產業都在改變, 而且可以從中獲益
Retail High Tech Healthcare Industrial
Energy Finance Communication Transportation
RetailMarket Basket Analysis, Next Best Offer, Customer Churn, propensity to buy
HealthcareMedicare fraud, AI-assisted diagnosis, drug demand forecast
Travel & transportationDynamic pricing, call center assistants, tourism forecasting, Self-driving cars
ManufacturingPredictive maintenance, process optimization, demand forecast
MarketingDiscount targeting, email optimization, lifetime client value
BankingCustomer segmentation, credit risk, credit card fraud detection
SecurityMalicious activity detection, logs analysis
Energy and UtilitiesPower usage prediction, smart grid management

Watson Studio: 加速AI企業的價值
Watson Studio 加速您企業引入AI 以創新所需的機器及深度學習, 為資料科學家、程式開發人員及領域專家提供一組工具, 簡單、合作地處理資料, 並使用資料大規模地建立、訓練並部署模型
AI 需要團隊合作
• AI 不是魔術• AI 是 演算法 + 資料 + 團隊
IBM Cloud
Support for most popular deep learning frameworks
Tensorf low, Caf f e, Py Torch, and Keras.
Latest NVIDIA GPUs
Train deep learning models on a cluster of V100 and P100 GPUs
Kubernetes Container-based training orchestration
Training run are securely allocated resources and run in parallel on an elastic GPU compute cluster
End-to-end support for deep learning
Prepare data and prototy pe neural networks using Jupy ter notebooks then ref ine the network’s hy perparameters using
HPO-enabled batch training. Host the models as prediction endpoints with monitoring and continuous learning.
Manage and deploy your models
Watson Machine Learning is f ully integrated into DLaaS and prov ides a f ull suite of model management tools.
Distributed training (beta)
IBM’s Distributed Deep Learning (DDL) now av ailable in the cloud plus support f or Uber’s Horov od f or TensorFlow.
Neural Network Modeler (beta)
An intuitiv e drag-and-drop, no-code interf ace f or designing neural network srtuctures using the most popular deep
learning f rameworks.
Built by IBM. Used by IBM. And Now Available to you.
DSX and WML are the platf orm f or deep learning across IBM. Customers can now access the same inf rastructure
used to train deep learning models in WDC and across IBM.
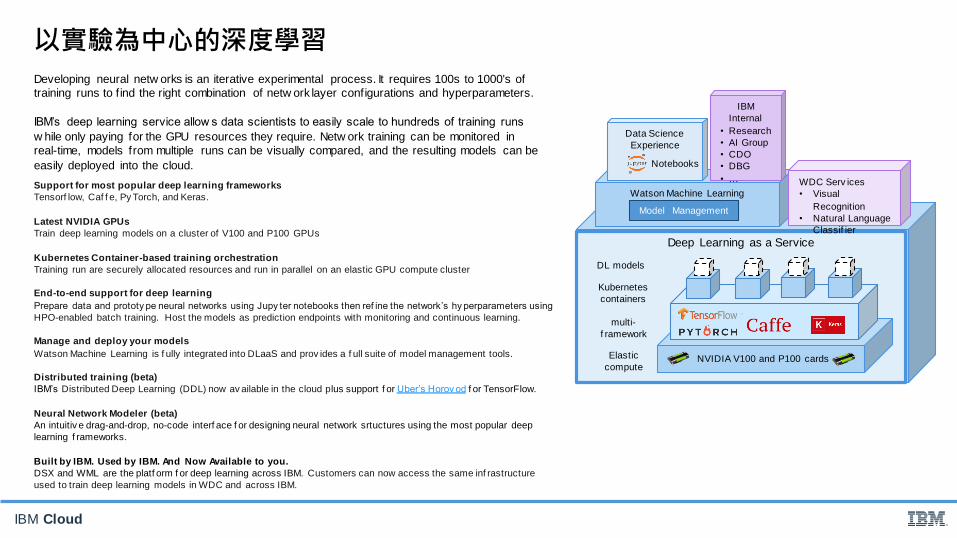
Deep Learning as a Service
Watson Machine Learning
WDC Serv ices
• Visual
Recognition
• Natural Language
Classif ier
Model Management
Data Science
Experience
Notebooks
DL models
multi-
f ramework
Kubernetes
containers
Elastic
compute
IBM
Internal
• Research
• AI Group
• CDO
• DBG
• …
NVIDIA V100 and P100 cards
以實驗為中心的深度學習Developing neural netw orks is an iterative experimental process. It requires 100s to 1000's of
training runs to f ind the right combination of netw ork layer configurations and hyperparameters.
IBM’s deep learning service allow s data scientists to easily scale to hundreds of training runs
w hile only paying for the GPU resources they require. Netw ork training can be monitored in
real-time, models from multiple runs can be visually compared, and the resulting models can be
easily deployed into the cloud.
IBM Cloud
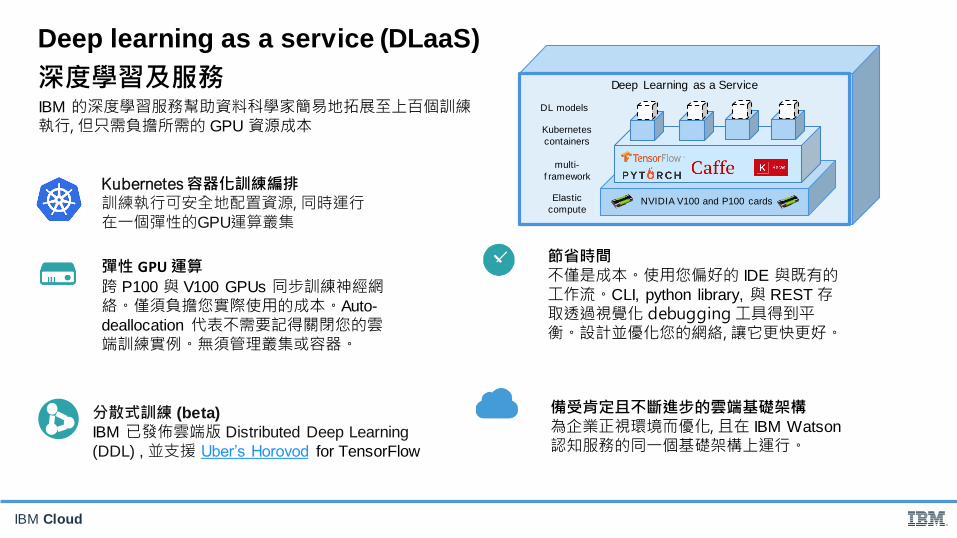
Deep learning as a service (DLaaS)
深度學習及服務 Deep Learning as a Service
DL models
multi-
f ramework
Kubernetes
containers
Elastic
computeNVIDIA V100 and P100 cards
分散式訓練 (beta)
IBM 已發佈雲端版 Distributed Deep Learning
(DDL) , 並支援 Uber’s Horovod for TensorFlow
備受肯定且不斷進步的雲端基礎架構為企業正視環境而優化, 且在 IBM Watson
認知服務的同一個基礎架構上運行。
彈性 GPU運算
跨 P100 與 V100 GPUs 同步訓練神經網絡。僅須負擔您實際使用的成本。Auto-
deallocation 代表不需要記得關閉您的雲端訓練實例。無須管理叢集或容器。
IBM 的深度學習服務幫助資料科學家簡易地拓展至上百個訓練執行, 但只需負擔所需的 GPU 資源成本
Kubernetes 容器化訓練編排訓練執行可安全地配置資源, 同時運行在一個彈性的GPU運算叢集
節省時間不僅是成本。使用您偏好的 IDE 與既有的工作流。CLI, python library, 與 REST 存取透過視覺化 debugging 工具得到平衡。設計並優化您的網絡, 讓它更快更好。

IBM Cloud
使用您個人的 IDE 或在DSX代管的 Jupyternotebook, 同時使用最熱門的深度學習框架
Hyperparameter Optimization有效地自動搜尋您的神經網絡中的超參數空間以確保在最少的訓練執行下得到最佳模型效能。
Experimentation Assistant啟動並監控批次訓練實驗,無須擔心日誌轉移及腳本,比較跨模型效能以呈現結果。您專注於設計您的神經網絡, 我們管理並追蹤您的資產。
Neural Network Modeler (beta)視覺化方式設計您的神經網絡。拖拉您的神經架構層, 然後使用最受歡迎的深度學習框架配置並部署。
與團隊成員協作分享您的深度學習實踐、debug 您的神經網絡架構、在受管的物件儲存空間存取共通資料、轉發標示版本的模型給您的開發團隊然後讓他們送出新資料到您持續進行的學習流
以您最愛的框架與工具編寫程式
圖像而非日誌文件
當您可以比對精確及損失圖來深入您的神經網絡訓練, 就無須再盯著文字日誌。追蹤並檢視模型超參數, 您便可以開始了解您的網絡中訓練各層級的進展。
別受限。依您的問題領域和您的團隊技能挑選最適框架來應付您的獨特需求。或是嘗試簡單的方式或使用高階meta-framework 如Keras來加速模型探勘, 避免低階的複雜性。
IBM Cloud
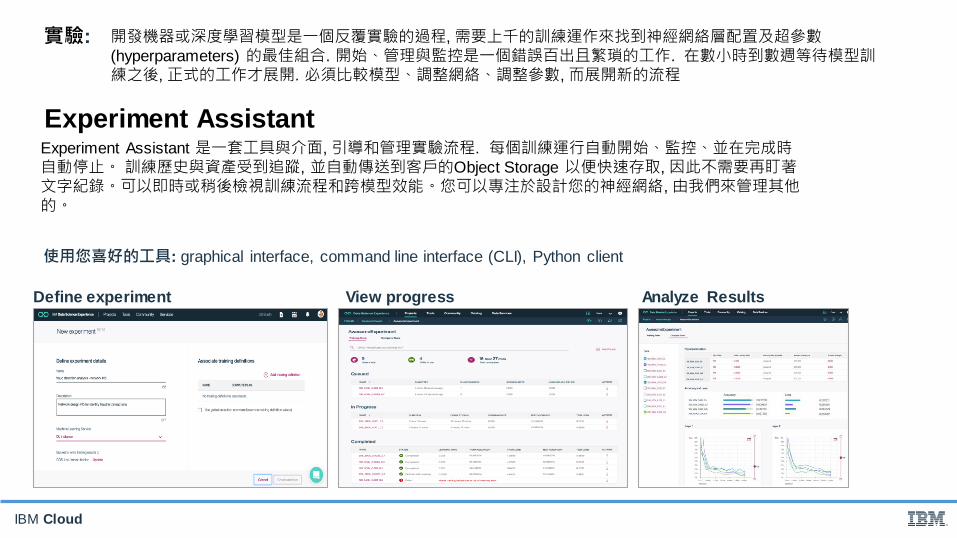
Experiment AssistantExperiment Assistant 是一套工具與介面, 引導和管理實驗流程. 每個訓練運行自動開始、監控、並在完成時自動停止。 訓練歷史與資產受到追蹤, 並自動傳送到客戶的Object Storage 以便快速存取, 因此不需要再盯著文字紀錄。可以即時或稍後檢視訓練流程和跨模型效能。您可以專注於設計您的神經網絡, 由我們來管理其他的。
實驗: 開發機器或深度學習模型是一個反覆實驗的過程, 需要上千的訓練運作來找到神經網絡層配置及超參數(hyperparameters) 的最佳組合. 開始、管理與監控是一個錯誤百出且繁瑣的工作. 在數小時到數週等待模型訓練之後, 正式的工作才展開. 必須比較模型、調整網絡、調整參數, 而展開新的流程
Define experiment View progress
使用您喜好的工具: graphical interface, command line interface (CLI), Python client
Analyze Results
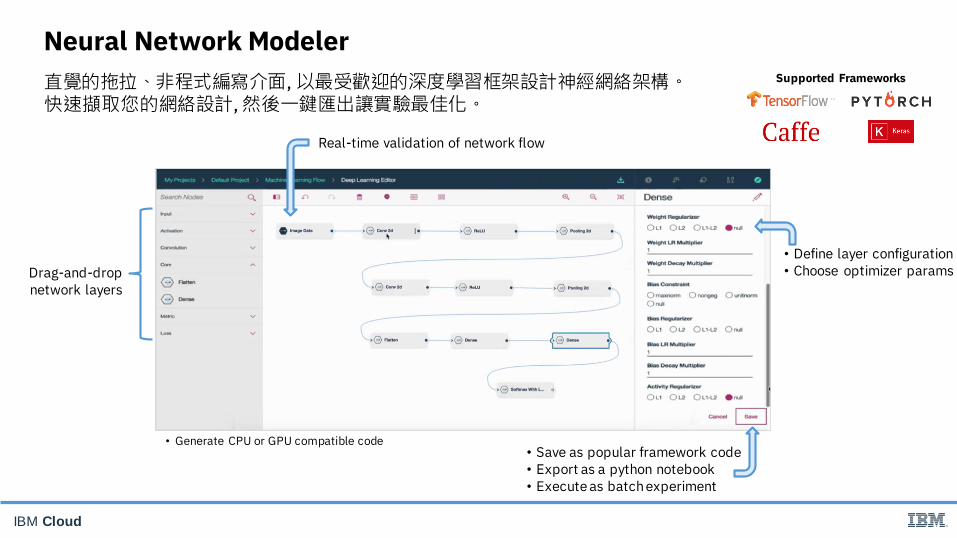
IBM Cloud
Neural Network Modeler
Real-time validation of network flow
Drag-and-dropnetwork layers
• Define layer configuration• Choose optimizer params
• Save as popular framework code• Export as a python notebook• Execute as batch experiment
• Generate CPU or GPU compatible code
Supported Frameworks直覺的拖拉、非程式編寫介面, 以最受歡迎的深度學習框架設計神經網絡架構。快速擷取您的網絡設計, 然後一鍵匯出讓實驗最佳化。
IBM Cloud
MNIST model builder tutorial
Model builder
Machine Learning
Sample Model Deployment
IBM Cloud
MNIST flow editor tutorial
Modeler flow Sample Model Deployment
Object Storage
Experiment
Machine Learning
IBM Cloud
MNIST flow editor tutorial
Modeler flow Sample Model DeploymentExperiment
IBM Cloud
MNIST experiment builder HPO tutorial
Experiment
Model.zip
Model DeploymentTraining
Definition
Machine Learning
Object Storage
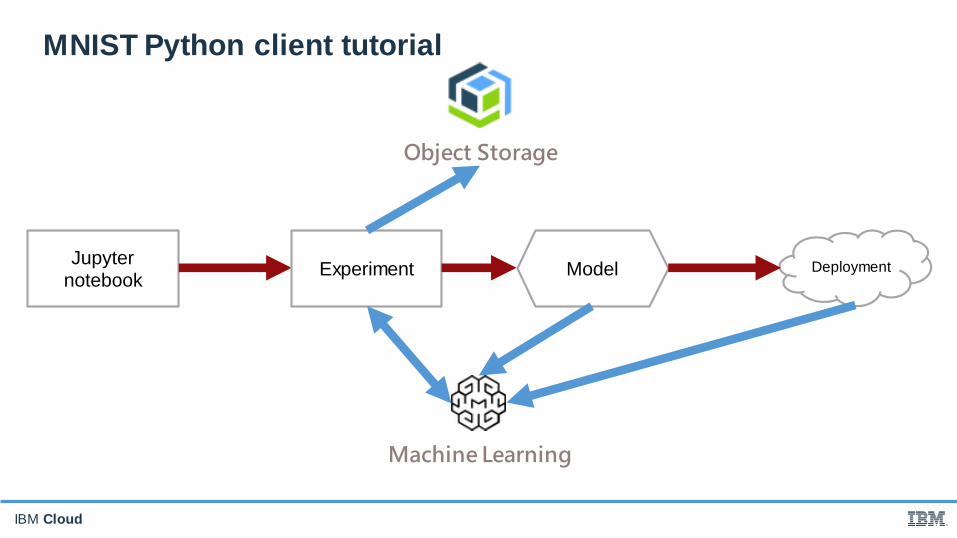
IBM Cloud
MNIST Python client tutorial
Jupyternotebook
Machine Learning
Model Deployment
Object Storage
Experiment

Let’s get started.
www.ibm.com/cloud
