volumen 3 - noviembre de 2017 - santa...
TRANSCRIPT

ISSN: 2500-6991
Volumen 3 - Noviembre de 2017 - Santa Marta,
CONTENIDO
4 PRESENTACIÓN
5 UN ENFOQUE HEURÍSTICO PARA EL PRE-PROCESAMIENTO DE SUPERFICIES TRIDIMENSIONALES5 Nallig Leal, Esmeide Leal y Germán Sánchez Torres.
12 PROCESAMIENTO DE IMÁGENES SUBACUÁTICAS DE PECES EN CRIADEROS Alberto Ceballos Arroyo, Idanis Diaz Bolaño y Germán Sánchez Torres.
19 CLASIFICACIÓN DE SEGMENTOS DE VIDEO UTILIZANDO REPRESENTACIONES VISUALES Y LINGÜÍSTICAS Pedro Atencio Ortiz, Germán Sánchez Torres y John Branch Bedoya.
27 USO DE TÉCNICAS DE APRENDIZAJE DE MÁQUINAS PARA EL DIAGNÓSTICO DE NÓDULOS PULMONARES Idanis Diaz Bolaño, Germán Sánchez Torres y Pedro E. Romero.
31 SISTEMA DE RIEGO AUTÓNOMO E INTELIGENTE CON CAPACIDAD DE MONITOREAR VARIABLES CLIMÁTICA Amaury Cabarcas, Javier Montoya, Daniel Reyes Betancourt y Cristian Arrieta Pacheco.
38 SISTEMA DE MEDICIÓN AUTOMATIZADA DE VARIABLES AMBIENTALES PARA AGRICULTURA DE PRECISIÓN CON SOFTWARE LIBRE Amaury Cabarcas, Amaury Ortega, David Cermeño, Ariel Arnedo y Astrid Vanegas.
47 SISTEMAS EXPERTOS PARA DETERMINAR LA CALIDAD DE LA MIEL: UNA REVISIÓN BIBLIOGRÁFICA Eliécer Pineda Ballesteros, Alberto Castellanos Riveros y Freddy Reynaldo Téllez Acuña.
53 PROPUESTA PARA LA IMPLEMENTACIÓN DE TECNOLOGÍAS RIFD EN CADENAS DE SUMINISTRO AGRÍCOLA William De la Espriella Avila, Plinio Puello Marrugo y Julio Rodríguez Ribón.
60 UN INTÉRPRETE DE PSEUDO-LENGUAJE EN ESPAÑOL PARA LAS ASIGNATURAS DE PROGRAMACIÓN Y ESTRUCTURAS DE DATOS Jean Benítez Diazgranados y Idanis Diaz B.
66 LA ENSEÑANZA EN INGENIERÍA DE SISTEMAS DESDE UN ENFOQUE VIRTUAL, DOS CASOS DE ESTUDIO Eliécer Pineda Ballesteros y Freddy Reynaldo Téllez Acuña.
75 GUÍA PARA LA INCORPORACIÓN DE LOS CONCEPTOS DE PROTECCIÓN DE DATOS EN EQUIPOS DE DESARROLLO DE SOFTWARE CON BAJOS NIVELES DE MADUREZ Jhon Trespalacios, Andrés Paternina Ariza, Cesar Polo Castro y Alexander Bustamante.
83 INCORPORACIÓN DE PRÁCTICAS ÁGILES EN EQUIPOS DE DESARROLLO CON BAJOS NIVELES DE MADUREZ Camilo Torres, Cesar Polo, Andrés Paternina y Alexander Bustamante.
91 DESARROLLO DEL SISTEMA DE INFORMACIÓN TURÍSTICO DEL MAGDALENA – SITUR MAGDALENA Ernesto Galvis-Lista, Mayda P. González-Zabala, Roberto L. Aguas, Cesar Enrique Polo Castro, Jorge Luis Pineda Montagout, Andrés Eduardo Paternina Ariza, Jhon Alexander Trespalacios, Camilo David Torres Callejas, Jennifer Esther Brequeman Torres, José Gabriel Montero Patiño, Brayan Rene Carbonó Carbonó, Luis Fernando Palmera Escorcia, Joaquín Rodríguez, Mónica Isabel Calderón Solano y Farid Leonardo Rodríguez Pacheco.

CINSIS 2017 - Programa de Ingeniería de Sistemas
COMITÉ ACADÉMICOPhD. Miroslav Svitek - Universidad Técnica de Praga (República Checa)PhD. Javier García - Universidad Complutence de Madrid (España)PhD. Ana Lucila Sandoval - Universidad Complutence de Madrid (España)PhD. Camilo Vieira Mejía - Universidad de Purdue (Estados Unidos)PhD. Idanis Díaz B - Universidad del Magdalena (Colombia)PhD. Germán Sánchez - Universidad del Magdalena (Colombia)MsC. Samuel Prieto Mejía - Universidad del Magdalena (Colombia)PhD. Eduardo Ropaín Munive - Universidad del Magdalena (Colombia)PhD (c). Roberto Aguas Núñez - Universidad del Magdalena (Colombia)
COMITÉ DE PROGRAMAIdanis Diaz Bolaños, Directora de Programa de Ingeniería de Sistemas - Universidad del MagdalenaGermán Sánchez, Docente Tiempo Completo, Líder de Grupo de Investigación y Desarrollo en Tecnologías de la Información y Organizaciones- Universidad del MagdalenaMayda González, Docente Tiempo Completo - Universidad del MagdalenaRoberto Aguas Núñez, Docente Tiempo Completo - Universidad del MagdalenaEduardo Ropain, Docente Tiempo Completo - Universidad del MagdalenaSamuel Prieto Mejía, Docente Tiempo Completo - Universidad del MagdalenaJoaquín Rodríguez, Gerente de Calidad del Centro de Investigación y Desarrollo de Software - Universidad del MagdalenaCesar Polo, Gerente de Proyectos del Centro de Investigación y Desarrollo de Software - Universidad del MagdalenaJorge Luis Pineda Montagu, Diseñador gráfico, Centro de Investigación y Desarrollo de Software - Universidad del MagdalenaAndrés Paternina, Arquitecto de Software del Centro de Investigación y Desarrollo de Software - Universidad del MagdalenaSabina Rada, Técnico Administrativo del Programa de Ingeniería de Sistemas - Universidad del MagdalenaAngélica Manjarrez, contratista del programa de Ingeniería de Sistemas
©EDITORIAL UNIVERSIDAD DEL MAGDALENA
Evento realizado con el apoyo de:Programa de Ingeniería de Sistemas – Facultad de IngenieríasGrupo de Investigación y Desarrollo en Tecnologías de la Información y Organizaciones - Universidad del MagdalenaGrupo de Investigación Desarrollo y Gestión de Tecnologías para las Organizaciones y la Sociedad - Universidad del MagdalenaVicerrectoría de InvestigaciónVicerrectoría Académica
III CONFERENCIA INTERNACIONAL DE INNOVACIÓN EN INGENIERÍA DE SISTEMASVolumen 3Noviembre de 2017 - Santa Marta, ColombiaAnual
ISSN: 2500-6991

CINSIS 2017 - Programa de Ingeniería de Sistemas
CONTENIDO
4 PRESENTACIÓN
5 UN ENFOQUE HEURÍSTICO PARA EL PRE-PROCESAMIENTO DE SUPERFICIES TRIDIMENSIONALES5 Nallig Leal, Esmeide Leal y Germán Sánchez Torres.
12 PROCESAMIENTO DE IMÁGENES SUBACUÁTICAS DE PECES EN CRIADEROS Alberto Ceballos Arroyo, Idanis Diaz Bolaño y Germán Sánchez Torres.
19 CLASIFICACIÓN DE SEGMENTOS DE VIDEO UTILIZANDO REPRESENTACIONES VISUALES Y LINGÜÍSTICAS Pedro Atencio Ortiz, Germán Sánchez Torres y John Branch Bedoya.
27 USO DE TÉCNICAS DE APRENDIZAJE DE MÁQUINAS PARA EL DIAGNÓSTICO DE NÓDULOS PULMONARES Idanis Diaz Bolaño, Germán Sánchez Torres y Pedro E. Romero.
31 SISTEMA DE RIEGO AUTÓNOMO E INTELIGENTE CON CAPACIDAD DE MONITOREAR VARIABLES CLIMÁTICA Amaury Cabarcas, Amaury Ortega, David Cermeño, Ariel Arnedo y Astrid Vanegas.
38 SISTEMA DE MEDICIÓN AUTOMATIZADA DE VARIABLES AMBIENTALES PARA AGRICULTURA DE PRECISIÓN CON SOFTWARE LIBRE Amaury Cabarcas, Javier Montoya, Daniel Reyes Betancourt y Cristian Arrieta Pacheco.
47 SISTEMAS EXPERTOS PARA DETERMINAR LA CALIDAD DE LA MIEL: UNA REVISIÓN BIBLIOGRÁFICA Eliécer Pineda Ballesteros, Alberto Castellanos Riveros y Freddy Reynaldo Téllez Acuña.
53 PROPUESTA PARA LA IMPLEMENTACIÓN DE TECNOLOGÍAS RIFD EN CADENAS DE SUMINISTRO AGRÍCOLA William De la Espriella Avila, Plinio Puello Marrugo y Julio Rodríguez Ribón.
60 UN INTÉRPRETE DE PSEUDO-LENGUAJE EN ESPAÑOL PARA LAS ASIGNATURAS DE PROGRAMACIÓN Y ESTRUCTURAS DE DATOS Jean Benítez Diazgranados y Idanis Diaz B.
66 LA ENSEÑANZA EN INGENIERÍA DE SISTEMAS DESDE UN ENFOQUE VIRTUAL, DOS CASOS DE ESTUDIO Eliécer Pineda Ballesteros y Freddy Reynaldo Téllez Acuña.
75 GUÍA PARA LA INCORPORACIÓN DE LOS CONCEPTOS DE PROTECCIÓN DE DATOS EN EQUIPOS DE DESARROLLO DE SOFTWARE CON BAJOS NIVELES DE MADUREZ Jhon Trespalacios, Andrés Paternina Ariza, Cesar Polo Castro y Alexander Bustamante.
83 INCORPORACIÓN DE PRÁCTICAS ÁGILES EN EQUIPOS DE DESARROLLO CON BAJOS NIVELES DE MADUREZ Camilo Torres, Cesar Polo, Andrés Paternina y Alexander Bustamante.
91 DESARROLLO DEL SISTEMA DE INFORMACIÓN TURÍSTICO DEL MAGDALENA – SITUR MAGDALENA Ernesto Galvis-Lista, Mayda P. González-Zabala, Roberto L. Aguas, Cesar Enrique Polo Castro, Jorge Luis Pineda Montagout, Andrés Eduardo Paternina Ariza, Jhon Alexander Trespalacios, Camilo David Torres Callejas, Jennifer Esther Brequeman Torres, José Gabriel Montero Patiño, Brayan Rene Carbonó Carbonó, Luis Fernando Palmera Escorcia, Joaquín Rodríguez, Mónica Isabel Calderón Solano y Farid Leonardo Rodríguez Pacheco.

CINSIS 2017 - Programa de Ingeniería de Sistemas
4
UN ENFOQUE HEURÍSTICO PARA EL PRE-PROCESAMIENTO DE SUPERFICIES TRIDIMENSIONALES
PRESENTACIÓN
La formación un Ingeniero de Sistemas lleva implícita la innovación. El término innovar se refiere a la proposición e implementación de nuevas soluciones a problemas, que son adoptadas por un grupo o una comunidad como una nueva práctica. En nuestro caso estamos llamados a proponer soluciones a problemas informáticos, siempre con compromiso social.
Par innovar necesitamos conocer el estado del arte, de donde estamos, y que es lo que se ha hecho hasta el momento para solucionar el problema que nos interesa. CINSIS es un evento que hemos venido llevando a cabo con este propósito, en el recopilamos trabajos de investigación que representan una muestra de lo que nuestros grupos de investigación, y otras universidades han venido realizando en aras de resolver problemas informáticos que son de gran interés en diversas áreas que conforman nuestra profesión.
Estas memorias son el producto de un encuentro de científicos de diversas partes del mundo en el compartimos durante varias jornadas nuestras experiencias en investigación, constituyéndose así un legado que dejamos por este medio a disposición de nuestros estudiantes, y de toda la comunidad en general.
Cordialmente, Idanis Diaz BolañosDirectora AcadémicaPrograma Ingeniería de Sistemas

CINSIS 2017 - Programa de Ingeniería de Sistemas
5
Nallig LealUniversidad Autónoma del Caribe
Calle 90 [email protected]
Esmeide LealUniversidad Autónoma del Caribe
Calle 90 No. [email protected]
Germán SánchezUniversidad del Magdalena
Carrera 32 No. 22 - [email protected]
RESUMEN
La reconstrucción tridimensional de formas ha generado un gran interés en los últimos años a la comunidad científica debido a su variedad de aplicaciones en diferentes campos. Sin embargo, los métodos propuestos son aún limitados en su aplicación. Este artículo presenta un enfoque heurístico como solución al problema del pre-procesamiento de datos que describen superficies tridimencionales.
Palabras clave: Reconstrucción 3D, Estrategias Evolutivas, Redes Neuronales Artificiales.
UN ENFOQUE HEURÍSTICO PARA EL PRE-PROCESAMIENTO DE SUPERFICIES TRIDIMENSIONALES
objeto real, y la complejidad computacional misma del proceso, entre otras cosas.
Diferentes soluciones se han presentado a los problemas antes planteados, aunque una forma diferente de atacar estos problemas desde un mismo enfoque, se puede lograr desde las técnicas bioinspiradas o heurísticas como son: los algoritmos genéticos, las estrategias evolutivas y las redes neuronales artificiales, entre otras.
Este artículo está organizado como sigue: en la sección 2 se presentan los fundamentos de la reconstrucción 3D, en la sección 3 se presentan los fundamentos de las técnicas heurísticas propuestas en la solución de los problemas atacados en cada etapa, en la sección 4 las diferentes soluciones planteadas son presentadas. Finalmente, se presentan las conclusiones y el trabajo futuro.
2. RECONSTRUCCIÓN 3D
La reconstrucción 3D consiste en obtener la representación de un objeto real en la memoria de un computador, manteniendo sus características de volumen y forma, partiendo de un conjunto discreto de datos muestreados de la superficie del objeto. Este proceso involucra varias fases, como lo ilustra la Figura 1, las cuales se presentan a continuación
UN ENFOQUE HEURÍSTICO PARA EL PRE-PROCESAMIENTO DE SUPERFICIES TRIDIMENSIONALES
1. INTRODUCCIÓN
Reconstruir un objeto tridimensional, se refiere a obtener su representación en la memoria de un computador, manteniendo sus características de volumen y forma, a partir de un conjunto discreto de datos muestreados de la superficie del objeto. La reconstrucción 3D es una tarea no trivial que, en general, involucra cinco etapas conocidas como: adquisición, registro, integración, segmentación y ajuste, siendo la última etapa la que proporciona el modelo computacional del objeto representado [1] [2].
Durante la ejecución de cada una de las etapas antes mencionadas es común toparse con problemas. Por ejemplo: en la etapa adquisición normalmente la nube de puntos capturada posee el ruido inherente del dispositivo de captura, en la etapa de registro no se logra una alineación perfecta de las caras del objeto 3D por los problemas propios del proceso de adquisición, en la etapa de integración es difícil detectar qué se constituye en un hueco de la superficie real y qué es un hueco debido al proceso de escaneo de dicha superficie, en la etapa de segmentación el cálculo de normales es el principal problema por el ruido y la densidad de muestreo de la superficie del objeto real, y en la etapa de ajuste se presentan problemas como la dificultad en la representación de los detalles finos de la superficie del

CINSIS 2017 - Programa de Ingeniería de Sistemas
6
UN ENFOQUE HEURÍSTICO PARA EL PRE-PROCESAMIENTO DE SUPERFICIES TRIDIMENSIONALES
2.1. Adquisición
El interés en adquirir información geométrica de volúmenes generados a partir de objetos reales ha generado una diversidad de trabajos reportados en la literatura. Cámaras basadas en estereoscopía [3], técnicas basadas en siluetas para recuperar formas tridimensionales basadas en geometría epipolar [4] similar a la utilizada en procesos de tracking, patrones de luz estructurada [5], sistemas de tiempo de vuelo [6], entre otros, constituyen los enfoques principales de esta área, lo que ha resultado en diversidad de dispositivos para dicho fin. Los dispositivos para la adquisición de datos tridimensionales son variados y de diversa naturaleza. Es posible encontrar diferencias notorias en su forma y la metodología de adquisición, desde dispositivos fijos, generalmente acompañados por un dispositivo rotatorio adicional, que gira el objeto alrededor de un sistema coordenado ubicado sobre el centro de masa del objeto, hasta dispositivos versátiles con varios grados de libertad
para su movilidad, lo que permite un desplazamiento del sensor mientras el objeto permanece estático.
Una de las formas clásicas en las que se puede analizar el desarrollo de este tipo de dispositivos es clasificarlos en dos categorías, en relación con la interacción del dispositivo con el objeto a ser medido: sensores pasivos y sensores activos. Uno de los principios comerciales más ampliamente utilizados para la adquisición de puntos 3-D es la triangulación láser, una clase de censado que se clasifica dentro de los dispositivos activos.
El proceso de adquisición por sí sólo, no resulta en un modelo digital final. Éste sólo constituye un paso intermedio del proceso. Tratar problemas de ruido de los datos, alinear los datos sobre un mismo marco de referencia, reparar anomalías y encontrar la representación matemática que reproduzca la geometría del objeto real, es el objetivo de los métodos de reconstrucción de superficies.
Figura 1. Etapas del proceso de reconstrucción 3D
Nallig Leal y Esmeide Leal son profesores titulares del programa de Ingeniería de Sistemas de la Universidad Autónoma del Caribe, Barranquilla Colombia. Ambos pertenecen al grupo de investigación SINT. Germán Sánchez es profesor Asistente del programa de Ingeniería de Sistemas de la Universidad del Magdalena, Santa Marta, Colombia. Pertenece al grupo de investigación TecnIO.

CINSIS 2017 - Programa de Ingeniería de Sistemas
7
UN ENFOQUE HEURÍSTICO PARA EL PRE-PROCESAMIENTO DE SUPERFICIES TRIDIMENSIONALES
2.2. Registro
El problema del registro subyace en transformar múltiples conjuntos de puntos 3D, en un sistema de coordenadas común, solapando las diferentes vistas tomadas por el dispositivo de captura [7]. Cada una de las vistas está asociada a diferentes sistemas de coordenadas. El algoritmo más difundido en el estado del arte es el conocido ICP (Iterative Closest Point Method), este es un método simple y directo [8] para alinear dos vistas de un objeto. El objetivo del ICP es encontrar una transformación entre una nube de puntos y alguna superficie de referencia (u otra nube de puntos), realizando la minimización del error cuadrático entre estas dos.
Desde el punto de vista matemático el ICP se plantea como un problema de minimización, como se muestra en la ecuación 1.
(1)
Donde se asume una transformación lineal con una matriz de rotación R y un vector de traslación t. ui y vi, son puntos correspondientes a las dos vistas que serán registradas. Este algoritmo ha tenido muchas variaciones a lo largo de los años, pero en su núcleo sigue siendo el mismo [9] [10] [11].
2.3. Pre procesamiento
Los escáneres 3D tienen limitaciones relacionadas específicamente con el dispositivo. Entre los problemas típicos que dependen del escáner se encuentran el ruido y la dependencia de las condiciones de luz; especialmente en los escáneres de luz estructurada y en infrarrojo. Otros problemas, derivados de su uso, son: la oclusión de la línea de visión del escáner, que dificulta la adquisición en dichas regiones, y la adquisición de superficies de tipo reflectante o brilloso. Estos problemas pueden producir una ausencia parcial de información o huecos en la nube de datos. Adicionalmente, para muchas aplicaciones, tratar la gran cantidad de información producida por los escáneres 3D representa un problema, debido al costo computacional de su manipulación simultánea, ya sea por limitaciones de memoria, de transmisión o tiempo de procesamiento. Mitigar el efecto de estas limitaciones en la calidad de la información adquirida es el objetivo de un conjunto de técnicas computacionales denominadas métodos de pre procesamiento de nubes de puntos. En resumen, los problemas con los cuales debe tratar el
pre procesamiento de nubes de puntos son: ruido en los datos, huecos o agujeros, problemas de redundancia y simplificación, estimación de normales.
2.4. Ajuste de superficies
El ajuste o reconstrucción de superficies es el proceso mediante el cual se obtiene el modelo digital final a partir de datos censados desde un objeto real. La reconstrucción tridimensional consiste en una serie de etapas, cuyo objetivo es obtener un algoritmo capaz de realizar la conexión del conjunto de puntos representativos del objeto en forma de elementos de superficie, ya sean triángulos, cuadrados o cualquier otra forma geométrica. Una amplia gama de algoritmos para reconstrucción de superficies ha sido propuesta en la literatura reciente [12] [13] [14].
En general, los métodos actuales para reconstrucción de superficies se pueden agrupar desde diferentes puntos de vista, de acuerdo con la forma como los datos sean interpretados. Entre los más comunes se encuentran los métodos basados en interpolación, aproximación, crecimiento de regiones, geométricos, algebraicos y estadísticos.
2.4.1. Interpolación
Esta clase de algoritmos trata de generar puntos intermedios no censados a partir de un conjunto P de datos discretos obtenidos del dispositivo de adquisición, para estimar una superficie continua, de tal forma que la solución final contiene a los datos adquiridos. Estas técnicas no asumen alteraciones en los datos, por lo tanto, son apropiadas para conjuntos de datos libres de ruido.
2.4.2. Aproximación
Este tipo de métodos es el más común en la literatura. A diferencia de los métodos de interpolación, la aproximación incluye un factor adicional de suavidad que no garantiza que los puntos originales estén contenidos como un subconjunto de la solución final. Los puntos iniciales son tomados como referencia para estimar una solución muy cercana o aproximada a los datos de referencia.
2.4.3. Crecimiento de Regiones
Los métodos de crecimiento de regiones propagan información y en consecuencia reconstruyen superficies en un estilo progresivo. Generalmente, estos métodos

CINSIS 2017 - Programa de Ingeniería de Sistemas
8
UN ENFOQUE HEURÍSTICO PARA EL PRE-PROCESAMIENTO DE SUPERFICIES TRIDIMENSIONALES
inician construyendo un triángulo como una región inicial e iteran añadiendo nuevos triángulos en los límites de la región.
2.4.4. Métodos geométricos
Los métodos de geometría computacional dependen de mecanismos como la triangulación de Delaunay y los diagramas de Voronoi [15] [16]. Estos métodos interpolan los puntos originales y básicamente son sensibles a la presencia de ruido. Las triangulaciones o mallas triangulares son una representación simple de la topología del objeto.
2.4.5. Métodos algebraicos
Los métodos algebraicos tratan de ajustar una función a los puntos. A diferencia de las técnicas interpolantes, es posible generar superficies suaves, mediante la incorporación de funciones suaves que restringen la reproducción exacta del conjunto de puntos iniciales. Por lo tanto, es posible generar superficies no ruidosas, continuas y suaves. La superficie reconstruida puede consistir de una sola función global o varias funciones locales, las cuales son unidas.
2.4.6. Métodos estadísticos
Los métodos de reconstrucción mediante un enfoque estadístico están basados fundamentalmente en estimar funciones de densidad de distribución de los datos de referencia. Estos funcionales de densidad pueden utilizarse para la reproducción y la reparación de datos de rango. Sin embargo, dada la característica parcial de los datos, estimar un único funcional a partir de datos discretos es un problema mal planteado. Los problemas mal planteados como la reconstrucción de superficies presentan la dificultad de que múltiples soluciones satisfacen las restricciones. Generalmente, la adición de conocimiento a priori del problema permite restringir el número de soluciones.
3. MÉTODOS HEURÍSTICOS PARA EL PRE PROCESAMIENTO
3.1. Estimación de normales en nubes de puntos usando CNNs
En [22] utilizan una red neuronal convolucional [17]-[18], para la estimación de normales en nubes de puntos, el método propuestos robusto ante los valores atípicos,
el ruido y la variación de densidad de los puntos en presencia de bordes y esquinas, para lo cual ello utilizan una variación de la transformada Hough. El algoritmo toma el vecindario local de cada punto de la nube y lo maneja como si se tratara de una imagen, así un píxel corresponde a una dirección normal, y su intensidad mide el número de votos para esa dirección. Además, la adyacencia de píxeles se relaciona con la cercanía de las direcciones. Esto se puede ver como un mapa plano de la probabilidad empírica de las diferentes direcciones posibles.
Entonces, así como una CNN para imágenes comunes puede explotar la correlación local de píxeles para eliminar la información subyacente, una CNN para estos mapas de dirección basados en Hough también podría manejar el ruido, identificando un pico plano alrededor una sola dirección. Finalmente, para mejorar la robustez y reducir el ajuste de parámetros, se sigue un enfoque de escala múltiple que se adapta automáticamente a diferentes tamaños de vecindarios, que no requieren cambios de la arquitectura de la CNN. La red neuronal fue entrenada usando el error cuadrático medio, con penalización l2 (ecuación 2).
(2)
Donde, p es la normal a estimar, np* es la normal verdadera pero desconocida y np es una primera estimación.
3.2. Simplificación heurística
A continuación, se presenten las tres etapas del método propuesto para la simplificación de nubes de puntos. Estas etapas se realizan de forma que permitan mantener las características de los datos originales [23].
3.2.1. Agrupamiento o Clusterización
El agrupamiento tiene como objetivo determinar regiones de puntos homogéneas; regiones en las cuales, se puede realizar el proceso de reducción sin pérdida de información significativa, gracias a las condiciones de homogeneidad del grupo. El agrupamiento es realizado por medio de una red SOM; aunque, esta etapa es abierta a otras técnicas de agrupamiento. La aplicación de la SOM [19]-[21], encuentra grupos o regiones con características homogéneas, como lo ilustra la Figura 2.

CINSIS 2017 - Programa de Ingeniería de Sistemas
9
UN ENFOQUE HEURÍSTICO PARA EL PRE-PROCESAMIENTO DE SUPERFICIES TRIDIMENSIONALES
Figura 2. Regiones homogéneas encontradas por la SOM
Los puntos de la Figura 1 fueron muestreados a partir de la función 22 yxz += . Se puede apreciar la homogeneidad de las regiones encontradas por la SOM, de ahí que la reducción de puntos realizada en cada uno de ellos no dé lugar a pérdida de información significativa de las mismas.
3.2.2. Estimación de la tendencia de los puntos en cada grupo
Una vez establecidos los grupos, se determina su tendencia (tendencias locales de los puntos sobre la superficie) empleando una nueva variante ponderada del análisis de componentes principales, la cual asigna factores de peso a los datos mediante repartición de pesos inversamente proporcional a la distancia a la media del centro del grupo. Esta nueva variante ponderada no requiere parámetros externos asignados por el usuario (como es el caso de los factores de peso exponenciales que requieren de la especificación del factor de suavidad σ ), ya que los pesos son calculados a partir de los datos mismos. La propuesta de cálculo de pesos consiste en realizar una repartición de la suma total de las distancias de los puntos al centroide, inversamente proporcional a la distancia a que los puntos se encuentran de éste; es decir, los puntos más lejanos tendrán menos influencia sobre el plano de regresión que los puntos más cercanos. Los factores de peso se calculan según la ecuación 3.
∑=
⋅= n
j ji
i
dd
w
1
11
(3)
Donde id es la distancia del esimoi − punto al centroide y n es el número de puntos que participan en el cálculo del plano de regresión. El empleo del análisis de componentes principales ponderado (WPCA), hace al método propuesto robusto al ruido y a los valores atípicos. Se puede apreciar la corrección del bias (Figura 2b) generado por los outliers o valores atípicos (puntos encerrados en círculos) presentes en los datos (Figura 3a). El plano de ajuste dado por el análisis de componentes principales será la referencia de la tendencia local de los datos que se tendrá para el proceso de selección de puntos. Una descripción más completa se detalla en [24].
(a) (b)
Figura 3. Análisis de componentes principales. a) Componentes principales de los datos influenciados
por los valores atípicos. b) Corrección de la tendencia generada por los valores atípicos, luego de aplicar a los puntos factores de pesos calculados con la ecuación 2.
La Figura 3c muestra de tendencia local de los datos dada por los planos WPCA calculados con la variante propuesta. Se aprecia la homogeneidad de los grupos de datos. Gracias a la homogeneidad de los puntos en cada grupo, la reducción realizada en cada uno de ellos no ocasiona la pérdida de información representativa.
3.2.3. Selección de puntos con la misma tendencia del grupo
La selección de puntos con la misma tendencia del grupo se lleva a cabo por medio de un algoritmo genético. El algoritmo genético selecciona puntos cuyo WPCA forme un ángulo menor que ∈ (donde ∈ es un nivel de tolerancia previamente especificado) con el plano WPCA de ese grupo.

CINSIS 2017 - Programa de Ingeniería de Sistemas
10
UN ENFOQUE HEURÍSTICO PARA EL PRE-PROCESAMIENTO DE SUPERFICIES TRIDIMENSIONALES
(a)
(b)
(c)Figura 4. Análisis de tendencia de los datos. a) Nube de puntos. b) Puntos agrupados. c) Planos de ajuste que
describen la tendencia local de los punto
Si el ángulo entre el plano WPCA del grupo original y el de los puntos seleccionados es menor que ε la tendencia de los puntos seleccionados debe ser muy similar a la tendencia de los puntos del grupo original.
El Algoritmo Genético (AG) que realiza la selección se configura de la siguiente manera:
Individuo: puntos seleccionados del grupo original. La Figura 4 ilustra el individuo de la estrategia
Operador de recombinación: Los individuos del AG representan un conjunto de puntos seleccionados a partir de los grupos encontrados. Se seleccionan aleatoriamente los puntos de cruce.
Operador de mutación: la mutación de un individuo se refiere al cambio de uno de sus puntos, por otro no incluido en el, que pertenezca al grupo.
Función de aptitud: ángulo entre el plano WPCA del grupo y el plano WPCA de los puntos seleccionados de éste. El algoritmo genético minimiza el ángulo entre los dos planos, dando como resultado el subconjunto de puntos del grupo que mejor aproxime la distribución de la totalidad de puntos de éste.
Optimización heurística del ajusteEn [2] se plantea la optimización heurística de la fase de ajuste como: Sea { }nPPP ,...,, 21=P un conjunto de puntos en 3R muestreados a partir de la superficie de un objeto físico, nuestro problema consiste en minimizar la ecuación 3.
δ<= ∑ =
n
i SP iid
nSE
1 ,1)( (3)
Donde, ii SPd , representa la distancia entre un punto del
conjunto P de puntos muestreados de la superficie
original, y un punto sobre la superficie aproximada S .
Se pretende conseguir la configuración de la superficie S
que haga E menor que una tolerancia δ dada. Para tal efecto, se manipulan los pesos de los puntos de control de la superficie, de manera que se haga tender ésta, en mayor o menor grado, hacia dichos puntos, para que se alcance el valor deseado en E .
Los valores de los pesos se calculan de manera iterativa mediante una EE ( µ + λ ) – ES. El tamaño de los individuos I de la población está dado por el número de puntos de control que definen la superficie y los
σ asociados a cada peso (ver figura 1); es decir, I =
n2 , donde n es el número de puntos de control. Los
valores iniciales iw , iσ de los alelos de cada individuo se distribuyen uniformemente en el intervalo [0.5, 1.5].
La selección de individuos padres en cada generación, se realiza conforme al ajuste obtenido de cada individuo en la función de aptitud dada por la ecuación 5. El operador de mutación es de tipo no correlacionado con n σ ’s (pasos de mutación). El operador de recombinación es
diferente para las variables objeto iw y los parámetros
de la estrategia iσ .
Para las variables objeto se utilizó una recombinación intermedia global, mientras que, para los parámetros de la estrategia, se empleó una recombinación intermedia local. El número de individuos seleccionados para recombinación, a diferencia de otras estrategias que lo hacen mediante un número fijo, se realiza mediante una distribución uniforme en el intervalo [2, n ), y se escogen según su ajuste en la función de aptitud. El cálculo de la distancia entre la superficie NURBS (Non-
Uniform Rational B-Spline) S y el conjunto de puntos muestreados P , se realiza mediante un esquema iterativo
que calcula los valores de los parámetros ( )kk vu , que
hacen ( )kk vuS , más cercana a cada kP .

CINSIS 2017 - Programa de Ingeniería de Sistemas
11
UN ENFOQUE HEURÍSTICO PARA EL PRE-PROCESAMIENTO DE SUPERFICIES TRIDIMENSIONALES
4. CONCLUSIONES
Se ha descrito un conjunto de aproximaciones basadas en técnicas heurísticas para afrontar el problema del pre procesamiento de datos que representan superficies tridimensionales. Estas técnicas suelen constituir una aproximación que genera niveles de precisión adecuados, de acuerdo con la parametrización establecida por el usuario. Las técnicas basadas en heurísticas permiten mitigar el costo computacional de otras técnicas de optimización y búsqueda de soluciones aplicables a problemas mal planteados (ill-conditioned) que no tienen única solución.
5. REFERENCIAS
[1] G. Sánchez, E. Leal y N. Leal, «Análisis del comportamiento de las propiedades geométricas de los contornos de huecos en nubes de puntos,» Prospectiva, vol. 11, nº 2, pp. 40-45, 2013.
[2] N. Leal, O. Ortega y J. W. Branch, «Improving NURBS Surface Sharp Feature Representation,» International Journal of Computational Intelligence Research, vol. 3, nº 2, pp. 131-138, 2007.
[3] D. Simon, M. Hebert y T. Kanade, «Techniques for fast and accurate intrasurgical registration,» Journal of Image Guided Surgery, vol. 1, nº 1, pp. 17-29, 1995.
[4] W. Matusik, C. Buehler, R. Raskar, S. Gortler y L. McMillan, «Image-based visual hulls,» de SIGGRAPH, New Orleans, Louisiana, USA, 2000.
[5] J. Wang, O. Hall-Holt, P. Konecny y A. E. Kaufman, «Per-pixel camera calibration for 3D range scanning,» de Videometrics VIII, San Jose, California, USA, 2005.
[6] P. Palojärvi, K. Määttä y J. Kostamovaara, «Integrated time-of-flight laser radar,» IEEE Transactions on Instrumentation and Measurement, vol. 46, nº 4, pp. 996 - 999, 1997.
[7] G. Tam, Z.-Q. Cheng, Y.-K. Lai, F. C. Langbein, Y. Liu, D. Marshall, R. R. Martin, X.-F. Sun y P. L. Rosin, «Registration of 3D Point Clouds and Meshes: A Survey From Rigid to Non-Rigid,» IEEE Transactions on Visualization and Computer Graphics, vol. 19, nº 7, pp. 1199-1217, 2013.
[8] P. Besl y N. McKay, «A method for registration of 3-D shapes,» IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 14, nº 2, pp. 239 - 256, 1992.
[9] J. W. Branch, F. Prieto y P. Boulanger, «Correspondence Method for Registration of Range,» de Proceedings of the IEEE International Conference on Industrial Electronics and Control Applications – ICIECA2005, Quito, Ecuador, 2005.
[10] W. Li y P. Song, «A modified ICP algorithm based on dynamic adjustment factor for registration of point cloud and CAD model,» Pattern Recognition Letters, vol. 65, nº C, pp. 88-94, 2015.
[11] Y. Ge, B. Wang y J. Nie, «A point cloud registration method combining enhanced particle swarm optimization and iterative closest point method,» de Chinese Control and Decision Conference (CCDC), Yinchuan, China, 2016.
[12] A. Arge, «Approximation of scattered data using smooth grid functions. Technical Report STF33 A94003,» 1994.
[13] B. J. Charles Baxter, The Interpolation Theory of Radial Basis Functions, Cambridge, Inglaterra, Reino Unido: University of Cambridge, 1992.
[14] H. Hoppe, Surface Reconstruction from Unorganized Points, Seattle, Washington, USA: University of Washington, 1994.
[15] N. Amenta, M. Bern y M. Kamvysselis, «A new Voronoi-based surface reconstruction algorithm,» de Proceedings of the 25th annual conference on Computer graphics and interactive techniques - SIGGRAPH ‘98, Orlando, FL, USA, 1998.
[16] H. Edelsbrunner y E. P. Mücke, «Three-dimensional alpha shapes,» ACM Transactions on Graphics (TOG), vol. 13, nº 1, pp. 43-72, 1994.
[17] C. Szegedy, W. Liu, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke y A. Rabinovich, «Going deeper with convolutions,» de IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 2015.
[18] A. Krizhevsky, I. Sutskever y G. E. Hinton, «ImageNet classification with deep convolutional neural networks,» de Proceedings of the 25th International Conference on Neural Information Processing Systems - NIPS’12, Lake Tahoe, Nevada, USA, 2012.
[19] R. M. Hristev, The ANN Book, 1998. [20] M. Hoffmann, «Local update of B-spline surfaces by
Kohonen neural network,» de 5th International Conference on Computer Graphics and Artificial Intelligence, Limoges, Francia, 2002.
[21] T. Bäck y H. P. Schwefel, «Evolution Strategies I: Variants and their computational implementation,» de Genetic Algorithms in Engineering and Computer Science, John Wiley & Sons Ltd, 1995.
[22] A. Boulch y R. Marlet, «Deep learning for robust normal estimation in unstructured point clouds,» de Proceedings of the Symposium on Geometry Processing - SGP ‘16, Berlin, Germany, 2016.
[23] N. Leal, E. Leal y J. W. Branch, «Simplificación robusta de nubes de puntos usando análisis de componentes principales y algoritmos genéticos,» Avances en Sistemas e Informática, vol. 6, nº 3, pp. 45-50, 2009.
[24] E. Leal y N. Leal, «Point Cloud Denoising using Robust Principal Components Analysis,» de International Conference on Computer Graphics Theory and Applications, Setubal, Portugal, 2006.

CINSIS 2017 - Programa de Ingeniería de Sistemas
12
PROCESAMIENTO DE IMÁGENES SUBACUÁTICAS DE PECES EN CRIADEROS
PROCESAMIENTO DE IMÁGENES SUBACUÁTICAS DE PECES EN CRIADEROS
Alberto Ceballos ArroyoUniversidad del Magdalena
Idanis Diaz BolañoUniversidad del Magdalena
German Sanchez TorresUniversidad del Magdalena
ABSTRACT
En Colombia la industria pesquera se ha constituido en un sector de crecimiento adquiriendo cada vez más una mayor importancia económica. Diferentes políticas han sido establecidas con el interés de incentivar el desarrollo del sector. Es posible encontrar numerosos reportes en literatura sobre el desarrollo de sistemas basados en procesamiento de imágenes para segmentar individuos, sin embargo, la disponibilidad de herramientas software es limitada. La principal dificultad de dichas herramientas se centra en la dificultad para adaptarlos a especies y condiciones de agua locales. La detección de objetos dentro de una imagen es una de las aplicaciones del procesamiento digital de imágenes. La metodología propuesta está orientada a la segmentación del pez en la imagen, la cual divide a la misma según criterios prestablecidos. En particular, la segmentación de imágenes subacuáticas de peces conlleva consideraciones adicionales en cuanto a la forma de los mismos. En este trabajo se exponen los tipos de técnicas de segmentación más recurrentes en el campo, y se describe un conjunto de pasos para segmentar una imagen adquirida.
Palabras clave: Procesamiento de imágenes, Mejoramiento de imágenes subacuáticas, Medición, Segmentación, Peces.
1. INTRODUCCIÓN
En Colombia la industria pesquera se ha constituido en un sector de crecimiento adquiriendo cada vez más una mayor importancia económica (AUNAP, 2014a). Diferentes políticas han sido establecidas con el interés de incentivar el desarrollo del sector (AUNAP, 2014b; Ministerio de Agricultura, 2011), dentro de las principales se encuentra el incentivo de la tecnificación del sector.
Uno de los aspectos de mayor importancia en el contexto de la investigación pesquera lo constituye la recolección y el procesamiento de información de los diferentes individuos de las especies debido a que proveen información relacionada con los parámetros de la población (Ecoutin, Albaret, & Trape, 2005; Niyonkuru & Laleye, 2012). El uso de dicha información es amplio y varía desde la determinación de variables como la cantidad de alimento para la cría de especies en estanques, la clasificación y ordenamiento del pescado capturado para garantizar el tamaño y la especie óptima para su comercialización (Zion, Shklyar, & Karplus, 1999), hasta el desarrollo de estrategias de administración y conservación de especies (Turan, Oral, Öztürk, & Düzgüneş, 2006).
Aunque existe suficiente desarrollo en relación con las técnicas de medición y la instrumentación asociada para realizar la recolección de datos más eficiente (Ovredal & Totland, 2002), las técnicas tradicionales están limitadas por el contacto físico con el individuo. En contextos en los cuales las mediciones son realizadas sobre individuos vivos, este tipo de técnicas invasivas alteran el natural estadio del pez aumentando el riesgo de infringir lesiones o incrementar el nivel de estrés. Es posible encontrar numerosos reportes en literatura sobre el desarrollo de sistemas basados en procesamiento de imágenes para realizar estas mediciones. Sin embargo, la disponibilidad de herramientas software es limitada. La principal dificultad de dichas herramientas se centra en la dificultad para adaptarlos a especies y condiciones de agua locales.
El desarrollo de máquina que no requieren intervención humana para la automatización de procedimientos se ha constituido en una directriz de desarrollo en investigaciones tecnológicas y las aplicaciones de ingeniería (Li & Zhang, 2009). De igual forma el apoyo al desarrollo de estas tecnologías se ha constituido en una estrategia nacional para el incremento de la productividad y la mejora de la competitividad de diferentes sectores. En este trabajo se describe una propuesta para la segmentación automática de peces.

CINSIS 2017 - Programa de Ingeniería de Sistemas
13
PROCESAMIENTO DE IMÁGENES SUBACUÁTICAS DE PECES EN CRIADEROS
suficientes para garantizar que la vista lateral del pez aparezca completamente en por lo menos un fotograma. La cámara se conecta por medio de una capturadora Matrox Imaging Meteor-II a una computadora de modestas prestaciones (1 GB de RAM), la cual una vez calibrada captura imágenes constantemente hasta que el algoritmo implementado detecta un objeto de interés. La cantidad de luz presente en la escena se maximiza ubicando luces del lado de la cámara y un fondo blanco en el lado opuesto a la misma, como se observa en la figura 1.
A continuación, se describe los sistemas de adquisición basados en una única imagen, la técnica de preprocesamiento utilizada y se describe el algoritmo para la segmentación del pez.
2. METODOLOGÍAA continuación, se presenta en un diagrama de flujo la serie de pasos para aplicados desde la adquisición hasta la segmentación.
Figura 2. Esquema general de procedimientos para obtener la segmentacion del pez.
2.1. Adquisición de la imagen
Las configuraciones para la adquisición de imágenes subacuáticas de peces son variadas, pero principalmente se dividen en dos: montajes basados en una única imagen y montajes basados en imágenes estéreo. Se seleccionan los montajes basados en una única imagen ya que utilizan una única imagen como entrada para los algoritmos, reduciendo el costo de procesamiento. Para el propósito de aplicaciones generales como son el conteo o seguimiento de peces, basta con realizar la toma de las imágenes según algún criterio de activación. Sin embargo, para ser de utilidad en el proceso de medición, es necesario que se conozca la distancia entre la cámara y el pez, o que esta pueda ser estimada con base en las propiedades del lente. Es por esto que, en estas implementaciones, generalmente se ubica la cámara a una distancia fija de un conducto o entorno controlado por el que se sabe que transitará el pez.
El entorno de trabajo en (Hardin, 2006)the US Department of Agriculture (USDA son las escaleras de una planta hidroeléctrica estadounidense. En uno de estos conductos se ubicó una cámara monocromática Hitachi KP-F2A de escaneo progresivo. Se establece que la combinación de escaneo progresivo y 30 imágenes por segundo como
Figura 1: El montaje realizado por (Hardin, 2006)the US Department of Agriculture (USDA, las luces ubicadas junto a la cámara y el fondo blanco permiten la toma de imágenes con la mayor cantidad de información
posible.
2.2. Preprocesamiento de la imagen
Las técnicas de mejoramiento de imágenes subacuáticas se pueden definir como procesos en los que, dada una imagen subacuática de baja calidad, se obtiene como salida una imagen mejorada para su posterior utilización (Baajwa, Khan, & Kaur, 2015). Estos métodos mejoran las imágenes mediante el realce de sus características, siendo el contraste y el ruido dos de los atributos recurrentes en la literatura (Singh, Mishra, & Gour, 2011; R. Wang, Wang, Zhang, & Fu, 2015).
En general, las técnicas de mejoramiento de imágenes subacuáticas se pueden clasificar, según el enfoque, como técnicas basadas en la manipulación de histogramas y del contraste, técnicas basadas en el modelo Retinex, técnicas basadas en filtros y técnicas basadas en la polarización o la toma de fotografías estéreo (R. Wang et al., 2015). Dichas clasificaciones no son estrictas, esto da lugar a que existan además metodologías mixtas que combinan varios algoritmos e incluso algoritmos individuales que pueden

CINSIS 2017 - Programa de Ingeniería de Sistemas
14
PROCESAMIENTO DE IMÁGENES SUBACUÁTICAS DE PECES EN CRIADEROS
considerarse pertenecientes a más de una categoría (R. Wang et al., 2015). Así mismo, existen técnicas que por sus peculiaridades no pueden ser clasificadas en ninguna de las categorías anteriores.
2.2.1. Secuencias de filtros para el mejoramiento de imágenes subacuáticas
Estás técnicas utilizan métodos de filtrado de gran efectividad para la reducción del ruido o el tratamiento de otras características con el objeto de mejorar la calidad en las imágenes subacuáticas (R. Wang et al., 2015). Este ruido suele producirse durante el proceso de adquisición de la imagen, y resulta en valores de pixel que no representan la intensidad real de la escena (Sahu, Gupta, & Sharma, 2014). Frecuentemente, estos métodos se usan en secuencia con otros filtros para obtener mejores resultados, e inclusive con técnicas de otras categorías. Se encuentra en esta categoría el Filtrado Homomórfico, el Filtrado Anisotrópico, el Filtrado Bilateral, el Filtrado Lineal, el Filtrado de Mediana y la Reducción de Ruido de Onduleta (Mahiddine, Seinturier, Boï, Drap, & Merad, 2012; Sahu et al., 2014; Sowmyashree, Bekal, Sneha, & Priyanka, 2014; Thakare & Sahu, 2014), entre otros.
En (Prabhakar & Kumar, 2012) implementan un algoritmo basado en distintos métodos de filtrado de imágenes. El primer filtro es el Homomorfico, mediante el cual se corrige la iluminación no uniforme y se mejoran los contrastes en la imagen. Luego, se aplica la técnica de Reducción de Ruido de Onduleta para remover el ruido gaussiano aditivo, usual en las IS. El último paso de filtrado es el Filtrado Bilateral que suaviza la imagen conservando los bordes mediante una combinación no lineal de valores de imagen cercanos entre sí. Finalmente, se aplica Estiramiento de Contraste para mejorar el contraste y Corrección de Color para el balance de los colores. El algoritmo fue probado en imágenes con objetos ubicados a profundidades de entre uno y dos metros de distancia.
La metodología de preprocesamiento implementada se basa en (Ceballos, Bolano, & Sanchez-Torres, 2017), donde se mejoran imágenes subacuáticas por medio de una secuencia de tres pasos: Filtro Homomórfico para corregir la iluminación, Estiramiento Adaptativo de Histogramas Limitado al Contraste (CLAHE) para incrementar el contraste del pez y Filtro Bilateral para la eliminación del ruido y acentuamiento de los bordes.
2.3. Algoritmo para la segmentación del pez
La segmentación de imágenes es uno de los problemas más estudiados en el análisis de imágenes y la visión por computadora, ya que simplifica la comprensión de una imagen de miles de píxeles a unas pocas regiones (X.-Y. Wang, Wu, Chen, Zheng, & Yang, 2016). Con el desarrollo de sensores de imagen y tecnología de procesamiento de imágenes, los métodos de medición basados en procesamiento de imágenes digitales han recibido cada vez más atención y han sido ampliamente utilizados en estudios de ingeniería.
El análisis de imágenes incluye todos los procedimientos orientados a obtener información a partir de una imagen dada. Frecuentemente, se inicia con la etapa de la segmentación que está orientada a la descomposición de la imagen en los diferentes objetos que la conforman, generalmente, los objetos de interés y el fondo, basándose en ciertas características locales que nos permiten distinguir un objeto de otros (Muñóz Pérez, 2010).
Los métodos usados dentro de la segmentación de imágenes de peces pueden ser divididos en tres clases:
• Métodos basados en los histogramas de las imágenes.
• Métodos basados en bordes, gradientes y operaciones morfológicas.
• Métodos basados en vecindarios, apoyados en conceptos geométricos como la proximidad y la homogeneidad.
2.3.1. Métodos basados en los histogramas de las imágenes
Típicamente, una segmentación de imagen basada en histograma comprende tres etapas: reconocer los modos del histograma, encontrar los valles entre los modos identificados y finalmente aplicar umbrales a la imagen basados en los valles. Los métodos basados en umbral de histograma son populares debido a su simplicidad, robustez y precisión. Sin embargo, no pueden separar las áreas que tienen el mismo nivel de gris pero que no pertenecen a la región que se está evaluando. Además, los métodos basados en umbrales no pueden procesar imágenes cuyos histogramas sean casi unimodales, especialmente cuando la región de interés es mucho más pequeña que el área de fondo (X.-Y. Wang et al., 2016).

CINSIS 2017 - Programa de Ingeniería de Sistemas
15
PROCESAMIENTO DE IMÁGENES SUBACUÁTICAS DE PECES EN CRIADEROS
En general, los métodos de umbralización o basados en histogramas pueden clasificarse en métodos paramétricos y no paramétricos. Cuando el enfoque es paramétrico, se supone que la distribución del nivel de grises de cada grupo obedece a una distribución gaussiana, y luego los algoritmos intentan encontrar una estimación de los parámetros de distribución Gaussiana que mejor se ajusten al histograma (Ben Ishak, 2017). Por otro lado, los enfoques no paramétricos encuentran los umbrales que separan las regiones de nivel de gris de una imagen de una manera óptima basándose en criterios discriminantes como la varianza entre clases, la varianza dentro de la clase o el umbral máximo de entropía (Zhang et al., 2014).
Este tipo de segmentación es más usada cuando se tienen imágenes en las que el fondo se diferencia mucho del objeto de interés. Cuando se da tal situación, la imagen se puede segmentar en dos regiones utilizando el operador umbral con parámetro t. La elección del valor umbral t se puede hacer a partir del histograma (Muñóz Pérez, 2010).
2.3.2. Métodos basados en bordes, gradientes y operaciones morfológicas
Estos métodos sirven para simplificar el análisis de las imágenes, al reducir drásticamente los datos que son procesados (Canny, 1986). En las arquitecturas de procesamiento de imágenes la información de los bordes es muy importante para las estructuras de los objetos porque ayudan en el proceso de identificar y localizar las discontinuidades agudas, que aparecen como cambios abruptos en la intensidad de los píxeles (Du, Li, & Meng, 2017).
La detección de bordes se basa en la detección de cambios locales abruptos en los valores de la intensidad de la imagen. El algoritmo de detección de bordes Canny es uno de los métodos más utilizados para la detección de bordes. El detector de bordes Canny primero suaviza la imagen para eliminar el ruido, y luego encuentra el gradiente de la imagen, el cual se usa para detectar los bordes de las imágenes con base en un umbral (Aslam, Khan, & Beg, 2015). Una vez hallados, se suele hacer uso de técnicas morfológicas para rellenarlos y obtener la imagen segmentada.
Cuando se tratan regiones con altos niveles de homogeneidad, las técnicas basadas en bordes resultan apropiadas por lo que la discriminación entre regiones puede realizarse basada en los cambios de la tonalidad de gris. En otro caso resulta más adecuado utilizar técnicas basadas en regiones (Muñóz Pérez, 2010).
2.3.3. Métodos basados en vecindarios
En la segmentación, la información suministrada por el entorno puede ser utilizada con el propósito de obtener regiones más homogéneas. Los anterior aprovechando la similaridad estadísticas presentes en el conjunto de pixeles que pertenecen a una misma región. El agrupamiento por Crecimiento de Regiones inicia con grupos iniciales que van creciendo en la medida que nuevos pixeles se añaden si cumplen un determinado criterio (Muñóz Pérez, 2010). Existe una amplia gama de técnicas de segmentación basadas en regiones, algunas consideradas de uso general y algunas diseñadas para una clase específica de imágenes (Hojjatoleslami & Kittler, 1998). Entre las técnicas de segmentación por vecindarios se pueden encontrar algunos métodos que se basan en la homogeneidad de características espacialmente localizadas, mientras que otros se basan en la determinación de límites, utilizando medidas de discontinuidad. Ambos tipos de métodos explotan dos definiciones diferentes de las regiones que idealmente deberían producir resultados idénticos. La homogeneidad es la característica de una región y la no homogeneidad o discontinuidad es la característica del límite de una región (Hojjatoleslami & Kittler, 1998).
2.4. Algoritmo para determinar ejes principales
2.4.1. Determinación de la orientación de los peces
La forma en la que se determina la orientación del pez es a través de los puntos máximos de X y Y, es decir: si Xmax - Xmin > Ymax - Ymin el pez es clasificado como situado a lo largo del eje X, de lo contrario se clasifica como situado en el eje Y. Para definir en qué dirección apuntan la cabeza y la cola, la computadora mide dos anchos (W1 y W2) del pez, como se muestra en la Fig. 3. La anchura mayor indica la cabeza del pez. Si W2 > W1, las coordenadas en el eje X son invertidas.
2.4.2. Determinar la mejor línea para medir la longitud del pez
Hay que encontrar una línea que:
a. Se extienda desde la nariz del pez hasta la horquilla de la cola.
b. No se vea afectada por las aletas y las aletas del vientre.
c. Se pueda acomodar a la naturaleza flexible del pez.
d. Se pueda acomodar al pez en un ángulo de 45º con respecto al eje x.

CINSIS 2017 - Programa de Ingeniería de Sistemas
16
PROCESAMIENTO DE IMÁGENES SUBACUÁTICAS DE PECES EN CRIADEROS
Para satisfacer las condiciones (c) y (d), los puntos medios de la anchura del pez en varias posiciones a lo largo del eje X se unen creando una línea que representa la longitud. Para satisfacer (b) no se deben tomar medidas entre el 15% y el 50% de la cabeza del pez. Para localizar la horquilla de la cola, los puntos medios de dos líneas verticales en el 10% y el 20% del extremo de la cola se unen y continúan hasta que se encuentra la horquilla de la cola. Las condiciones anteriormente expuestas pueden apreciarse en la Figura 4.
Una vez mejorada la imagen, se probaron separadamente los tres algoritmos de segmentación. En primer lugar, se probó el clásico método de binarización a partir del histograma de Otsu. Posteriormente se utilizó el método planteado por (Costa, Loy, Cataudella, Davis, & Scardi, 2006), basado en el uso de un filtro de convolución por poda, umbralización con un valor de gris fijo y morfología. Finalmente, se plantea la posibilidad de mejorar dicho método haciendo uso de la binarización de Otsu para obtener una segmentación más precisa. En la figura 1 pueden observarse los resultados para una imagen subacuática sin preprocesar, en la figura 2 se aplican los mismos métodos en una imagen mejorada mediante la secuencia de Filtro Homomórfico, CLAHE y Filtro Bilateral.
Figura 5. Aplicación de varios métodos de segmentación sobre imagen preprocesada.
4. CONCLUSIONES
Las imágenes subacuáticas, incluso en entornos controlados, presentan condiciones que dificultan la utilización de técnicas simples de segmentación como la umbralización de Otsu. El algoritmo propuesto por (Costa et al., 2006) demuestra una mayor efectividad a la hora de
Figura 3. Determinación de la orientación de los peces.
3. RESULTADOS EXPERIMENTALES Y EVALUACIÓN
Se realizaron pruebas sobre imágenes del conjunto de datos QUT (Anantharajah et al., 2014) así como otras bases de datos de menor tamaño usadas en trabajos similares (Ancuti, Ancuti, Haber, & Bekaert, 2012; Carlevaris-Bianco, Mohan, & Eustice, 2010; Emberton, Chittka, & Cavallaro, 2015; Fattal, 2008; Galdran, Pardo, Picón, & Alvarez-Gila, 2015; Lu, Li, Zhang, & Serikawa, 2015). Se implementó la secuencia de mejoramiento de imágenes propuesta en (Ceballos et°al., 2017) y tres algoritmos adicionales de segmentación.
a)
b)
Figura 4. Aplicación de varios métodos de segmentación en imagen sin procesar.
Figura 4. Una línea para medir la longitud de un pez (a) recto y (b) deformado.

CINSIS 2017 - Programa de Ingeniería de Sistemas
17
PROCESAMIENTO DE IMÁGENES SUBACUÁTICAS DE PECES EN CRIADEROS
realizar la segmentación del pez, al igual que el método propuesto, pero la calidad de la misma es insuficiente si no se lleva a cabo un preprocesamiento de antemano.
Las secuencias de filtros son útiles para este propósito, al incrementar el contraste y acentuar los bordes antes de llevar a cabo la segmentación, permitiendo obtener una máscara aceptable del pez. Pese a esto, la segmentación continua sin ser perfecta. En futuros trabajos se puede considerar la posibilidad de implementar un montaje en el que se retroilumine el pez para hacer más sencillo el proceso de segmentación. Por otro lado, los avances recientes en aprendizaje profundo permiten intuir que con un conjunto de datos lo suficientemente grande, sería posible entrenar una red profunda para llevar a cabo segmentaciones semánticas de las fotografías capturadas.
5. REFERENCIAS
Anantharajah, K., Ge, Z., McCool, C., Denman, S., Fookes, C., Corke, P., … Sridharan, S. (2014). Local inter-session variability modelling for object classification. En 2014 IEEE Winter Conference on Applications of Computer Vision (WACV) (pp. 309-316). Los Alamitos, CA, USA: IEEE Computer Society. https://doi.org/10.1109/WACV.2014.6836084
Ancuti, C., Ancuti, C. O., Haber, T., & Bekaert, P. (2012). Enhancing underwater images and videos by fusion. En 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (pp. 81-88). https://doi.org/10.1109/CVPR.2012.6247661
Aslam, A., Khan, E., & Beg, M. M. S. (2015). Improved Edge Detection Algorithm for Brain Tumor Segmentation. Procedia Computer Science, 58, 430-437. https://doi.org/10.1016/j.procs.2015.08.057
AUNAP. (2014a). La pesca y la acuicultura en Colombia. Bogotá D.C.: Autoridad nacional de acuicultura y pesca - AUNAP.
AUNAP. (2014b). Plan nacional para el desarrollo de la acuicultura sostenible en Colombia - PlanDAS. Bogotá D.C.: Autoridad nacional de acuicultura y pesca - AUNAP.
Baajwa, D. S., Khan, S. A., & Kaur, J. (2015). Evaluating the Research Gaps of Underwater Image Enhancement Techniques. International Journal of Computer Applications, 117(20). Recuperado a partir de http://search.proquest.com/openview/bacd3a0ca6548b38ad3dd3556336398c/1?pq-origsite=gscholar
Ben Ishak, A. (2017). A two-dimensional multilevel thresholding method for image segmentation. Applied Soft Computing, 52, 306-322. https://doi.org/10.1016/j.asoc.2016.10.034
Carlevaris-Bianco, N., Mohan, A., & Eustice, R. M. (2010). Initial results in underwater single image dehazing (pp. 1-8). IEEE. https://doi.org/10.1109/OCEANS.2010.5664428
Ceballos, A., Bolano, I. D., & Sanchez-Torres, G. (2017). Analyzing pre-processing filters sequences for underwater-image enhancement. Contemporary Engineering Sciences, 10, 751-771. https://doi.org/10.12988/ces.2017.7880
Costa, C., Loy, A., Cataudella, S., Davis, D., & Scardi, M. (2006). Extracting fish size using dual underwater cameras. Aquacultural Engineering, 35(3), 218-227. https://doi.org/10.1016/j.aquaeng.2006.02.003
Ecoutin, J. M., Albaret, J. J., & Trape, S. (2005). Length–weight relationships for fish populations of a relatively undisturbed tropical estuary: The Gambia. Fisheries Research, 72(2), 347-351. https://doi.org/10.1016/j.fishres.2004.10.007
Emberton, S., Chittka, L., & Cavallaro, A. (2015). Hierarchical rank-based veiling light estimation for underwater dehazing (p. 125.1-125.12). British Machine Vision Association. https://doi.org/10.5244/C.29.125
Fattal, R. (2008). Single image dehazing. ACM transactions on graphics (TOG), 27(3), 72.
Galdran, A., Pardo, D., Picón, A., & Alvarez-Gila, A. (2015). Automatic Red-Channel underwater image restoration. Journal of Visual Communication and Image Representation, 26, 132-145. https://doi.org/10.1016/j.jvcir.2014.11.006
Hardin, R. W. (2006). Vision system monitors fish populations. Vision Systems Design, 11(1), 41,43-45.
Hojjatoleslami, S. A., & Kittler, J. (1998). Region growing: a new approach. IEEE Transactions on Image Processing, 7(7), 1079-1084. https://doi.org/10.1109/83.701170
Li, M., & Zhang, X. (2009). Theoretical Analysis on Automatization and Human-Machine Combination. Intelligent Human-Machine Systems and Cybernetics, 2009., 1, 417-422.
Lu, H., Li, Y., Zhang, L., & Serikawa, S. (2015). Contrast enhancement for images in turbid water. Journal of the Optical Society of America. A, Optics, Image Science, and Vision, 32(5), 886-893. https://doi.org/http://dx.doi.org/10.1364/JOSAA.32.000886
Mahiddine, A., Seinturier, J., Boï, J.-M., Drap, P., & Merad, D. (2012). Performances Analysis of Underwater Image Preprocessing Techniques on the Repeatability of SIFT and SURF Descriptors. En WSCG 2012: 20th International Conferences in Central Europe on Computer Graphics, Visualization and Computer Vision. Citeseer.

CINSIS 2017 - Programa de Ingeniería de Sistemas
18
PROCESAMIENTO DE IMÁGENES SUBACUÁTICAS DE PECES EN CRIADEROS
Ministerio de Agricultura. (2011). Decreto 4181 de 2011, por medio del cual se escindieron unas funciones del INCODER y del Ministerio de Agricultura y Desarrollo Rural, y creó la Autoridad Nacional de acuicultura y pesca – AUNAP.
Muñóz Pérez, J. (2010). Procesamiento Digital de Imágenes. Recuperado a partir de http://www.lcc.uma.es/~munozp/
Niyonkuru, C., & Laleye, P. (2012). A Comparative Ecological Approach of the Length–Weight Relationships and Condition Factor of Sarotherodon Melanotheron Rüppell, 1852 and Tilapia Guineensis (Bleeker 1862) in Lakes Nokoué and Ahémé (Bénin, West Africa). International Journal of Business, Humanities and Technology, 2(3), 41–50.
Ovredal, J. ., & Totland, B. (2002). The scantrol fish meter for recording fish length, weight and biological data. Fisheries Research, 55, 325-328.
Prabhakar, C. J., & Kumar, P. U. P. (2012). An Image Based Technique for Enhancement of Underwater Images. arXiv:1212.0291 [cs].
Sahu, P., Gupta, N., & Sharma, N. (2014). A Survey on Underwater Image Enhancement Techniques. International Journal of Computer Applications, 87(13), 19-23.
Singh, B., Mishra, R. S., & Gour, P. (2011). Analysis of contrast enhancement techniques for underwater image. International Journal of Computer Technology and Electronics Engineering, 1(2), 190–194.
Sowmyashree, M. S., Bekal, S. K., Sneha, R., & Priyanka, N. (2014). A Survey on the various underwater image
enhancement techniques. International Journal of Engineering Science Invention, 3(5), 40–45.
Thakare, S. S., & Sahu, A. (2014). Comparative Analysis of Various Underwater Image Enhancement Techniques. International Journal of Computer Science and Mobile Computing (IJCSMC), 3(4), 33–38.
Turan, C., Oral, M., Öztürk, B., & Düzgüne, E. (2006). Morphometric and meristic variation between stocks of Bluefish (Pomatomus saltatrix) in the Black, Marmara, Aegean and northeastern Mediterranean Seas. Fisheries Research, 79(1), 139-147. https://doi.org/10.1016/j.fishres.2006.01.015
Wang, R., Wang, Y., Zhang, J., & Fu, X. (2015). Review on underwater image restoration and enhancement algorithms (pp. 1-6). ACM Press. https://doi.org/10.1145/2808492.2808548
Wang, X.-Y., Wu, Z.-F., Chen, L., Zheng, H.-L., & Yang, H.-Y. (2016). Pixel classification based color image segmentation using quaternion exponent moments. Neural Networks, 74, 1-13. https://doi.org/10.1016/j.neunet.2015.10.012
Zhang, J., Li, H., Tang, Z., Lu, Q., Zheng, X., & Zhou, J. (2014). An Improved Quantum-Inspired Genetic Algorithm for Image Multilevel Thresholding Segmentation. Mathematical Problems in Engineering, 2014, 1-12. https://doi.org/10.1155/2014/295402
Zion, B., Shklyar, A., & Karplus, I. (1999). Sorting fish by computer vision. Computers and Electronics in Agriculture, 23(3), 175-187. https://doi.org/10.1016/S0168-1699(99)00030-7

CINSIS 2017 - Programa de Ingeniería de Sistemas
19
PROCESAMIENTO DE IMÁGENES SUBACUÁTICAS DE PECES EN CRIADEROS
CLASIFICACIÓN DE SEGMENTOS DE VIDEO UTILIZANDO REPRESENTACIONES VISUALES Y LINGÜÍSTICAS
Pedro Atencio Ortiz, M.Sc.Instituto Tecnológico Metropolitano
Medellí[email protected]
Germán Sánchez Torres, Ph.D.Universidad del Magdalena
Santa [email protected]
John Branch Bedoya, Ph.D.Universidad Nacional de Colombia
Medellí[email protected]
RESUMEN
En este trabajo se presenta un método para la clasificación de segmentos de videos a través de las categorías visuales que aparecen en los mismos y la utilización de representaciones vectoriales que permiten capturar la semántica de dichas categorías en un espacio lingüístico. Para ello, el video es segmentado de manera uniforme en segmentos de un segundo y se selecciona un cuadro por cada segmento. Cada cuadro seleccionado es evaluado mediante la red profunda VGG-16 preentrenada con la base de datos ImageNet, la cual retorna un vector one-hot encoding de las categorías visuales que suceden en el cuadro. A continuación, las etiquetas lingüísticas de las categorías visuales detectadas, son representadas mediante GloVe (Global Vectors for Word Representation) preentrenado con las bases de datos Wikipedia 2014+Gigaword 5. Posteriormente, las representaciones vectoriales obtenidas son ingresadas a un clasificador lingüístico basado en redes neuronales previamente entrenado con la base de datos 20_newsgroup para clasificar un texto en una de veinte categorías semánticas. Finalmente, a cada segmento del video se le asignada una categoría semántica. Los resultados obtenidos evidencian que es posible utilizar información lingüística para clasificar segmentos de videos, lo cual puede ser aplicado posteriormente a tareas como resumido de video o búsqueda de videos.
Palabras clave: Redes neuronales convolutivas, análisis de video, análisis lingüístico.
1. INTRODUCCIÓN
En diversas tareas de análisis de video tales como búsqueda de videos (video retrieval) [1]–[3], clasificación de videos (video classification) [4] y generación de resúmenes de video (video summarization) [5], entre otras, es necesaria la segmentación del video para determinar los segmentos homogéneos que conforman el video, esto es, las secuencias de cuadros consecutivos que tienen relación visual o semántica. Es posible pero no necesario que distintos cuadros de un video, los cuales presenten una alta similitud en términos de sus características visuales, presenten una alta correspondencia semántica, es decir, que las temáticas del contenido en dichos segmentos sean similares.
La aproximación más común para segmentar un video, consiste en realizar un muestreo uniforme del mismo basado en tiempo, por ejemplo, creación de segmentos por segundo [6]which captures the parts of the video (or a collection of videos. Es posible también muestreos
más elaborados que implican ventanas deslizantes (sliding-windows) y desplazamientos (shifting) [7]. Otras aproximaciones se basan en el agrupamiento de cuadros consecutivos a partir de características visuales y temporales, por ejemplo, agrupamiento por color [8][9] o por flujo óptico [10][11].
Un enfoque más robusto, consiste en analizar el contenido del video y agrupar cuadros consecutivos de acuerdo a la semántica de los elementos visuales que en ellos suceden (objetos, personas, acciones, etc.). De esta forma, cuadros consecutivos que difieran en términos visuales pero que estén relacionados respecto a un tópico o tema, podrían ser agrupados como un solo segmento del video. Sin embargo, las características visuales por sí mismas, no son suficientes para poder obtener una descripción semántica del contenido de una imagen o un cuadro de un video. Es por ello que se hace necesario explorar representaciones en el espacio lingüístico, en cual suceden relaciones semánticas entre conceptos [6]which captures the parts of the video (or a collection of videos.

CINSIS 2017 - Programa de Ingeniería de Sistemas
20
CLASIFICACIÓN DE SEGMENTOS DE VIDEO UTILIZANDO REPRESENTACIONES VISUALES Y LINGÜÍSTICAS
Figura 1. Segmentos de un video, los cuales consisten en secuencias de cuadros relacionados mediante alguna
característica visual o semántica.
El reciente avance en redes neuronales convolutivas de aprendizaje profundo (CNN) en conjunto con la creación de banco de imágenes de carácter masivo [12][13], ha permitido la creación de potentes arquitecturas de redes neuronales para el análisis de de imágenes y video como VGG-16 [14] y las redes convolutivas 3D (3D-CNN) [15]. Las arquitecturas modernas de redes neuronales han mostrado un alto rendimiento en diversas aplicaciones como detección de objetos [16] [17], y generación de descripciones lingüísticas de escenas visuales [18][19].
En el campo de la lingüística computacional y el procesamiento del lenguaje natural, estas arquitecturas de red también han sido utilizadas. Una aplicación de gran potencia para el análisis lingüístico consiste en la obtención de representaciones vectoriales de palabras [20][21] y sentencias [22] conocidas como embeddings, las cuales presentan la ventaja de que permiten almacenar las relaciones semánticas que existen en un corpus lingüístico.
En este trabajo se presenta un método para clasificar cuadros consecutivos de video utilizando características visuales profundas y representaciones lingüísticas con el objetivo de agrupar los mismos en segmentos que presenten algún grado de relación semántica. Los resultados preliminares obtenidos, muestran que es posible utilizar representaciones lingüísticas para soportar un proceso de segmentación de video.
Este trabajo está organizado de la siguiente forma. En la sección 2 desarrolla el proceso de construcción del método propuesto. En la sección 3 se llevan a cabo los experimentos y resultados visuales y por último en la sección 4 se desarrollan las conclusiones.
2. METODOLOGÍA
La aproximación propuesta puede ser descrita de forma general como la combinación de tres etapas principales
(ver Figura 1). La primera etapa tiene como objetivo describir los cuadros del video en términos de las categorías que en ellos suceden. Esta etapa genera un vector de etiquetas, por cada cuadro analizado, que hace referencia a las categorías detectadas mediante un clasificador visual. En la segunda etapa se clasifica cada cuadro del video mediante un clasificador lingüístico, el cual toma como entrada el vector de etiquetas obtenido para dicho cuadro. Esta clasificación hace referencia al contexto en el que suceden las categorías detectadas en el cuadro. Por ejemplo, si en el cuadro suceden las categorías {cama,habitación,sofa} se espera que el clasificador lingüístico genere una categoría relacionada con la etiqueta hogar. En otro caso, si en el cuadro suceden las categorías {cancha,jugador,balón} se espera que el clasificador lingüístico genere una categoría relacionada con la etiqueta deporte. Finalmente, la última etapa tiene como objetivo agrupar cuadros de video que presenten algún grado de relación semántica, basado en las categorías asignadas por el clasificador lingüístico.
Figura 1. Metodología utilizada para la clasificación de segmentos de videos.
2.1. Preprocesamiento
Inicialmente, es necesario seleccionar los cuadros del video que serán ingresados al clasificador visual. Es posible analizar todos los cuadros del video, sin embargo, el costo computacional es un factor a tener en cuenta en caso de utilizar esta aproximación. Basado en los supuestos que: un segundo de video es la unidad mínima para un segmento y que, para un muestreo promedio de 30 cuadros por segundo, no ocurrirá una variación significativa visual o semántica entre los mismos, se decidió utilizar un muestreo uniforme de un cuadro por segundo (ver Figura 2),
2.2. Detección de categorías visuales
Para la obtención de las categorías de objetos que suceden en la escena visual contenida en cada cuadro del video,

CINSIS 2017 - Programa de Ingeniería de Sistemas
21
CLASIFICACIÓN DE SEGMENTOS DE VIDEO UTILIZANDO REPRESENTACIONES VISUALES Y LINGÜÍSTICAS
se utiliza un clasificador basado en redes neuronales profundas. Particularmente, se utilizó la arquitectura de red VGG-16 [14], preentrenada con la base de datos ImageNet [12]. Esta arquitectura puede reconocer 1000 categorías visuales en una imagen y ha sido utilizada exitosamente por la comunidad científica en diversas aplicaciones.
En la Figura 3, se puede observar el esquema de clasificación mediante la arquitectura VGG-16 para cada cuadro seleccionado en la etapa anterior. La salida de esta arquitectura consiste en un vector one-hot encoding, de dimensión donde cada posición del mismo hace referencia una de 1000 categorías visuales y contiene la probabilidad de que la misma suceda en la imagen de entrada. En este orden de ideas, las posiciones del vector que mayor valor presenten serán las categorías visuales que el clasificador detecta en la imagen. Utilizando la ecuación 1 se pueden obtener las k primeras categorías detectadas en el cuadro de video número Ai, donde i es el vector de tamaño (1,k) que retorna la red.
(1)
Figura 2. Selección de cuadros del video. Los cuadros son seleccionados de manera uniforme con una ventana
temporal de un segundo.
Figura 3. Detección de categorías visuales mediante arquitectura VGG-16. La red toma como entrada una imagen RGB y genera como salida un vector one-hot
encoding de 1000 categorías.
2.3. Representación lingüística
Con el objetivo de poder representar las relaciones semánticas que suceden entre las categorías detectadas en la imagen por el clasificador, es necesario mapear dichos elementos textuales a un espacio vectorial que permita capturar dichas relaciones. La comunidad converge en la utilización de vectores de palabras (word vectors / word embeddings) para este propósito. Una aplicación interesante de este tipo de representaciones, es que permiten operarse algebraicamente, por ejemplo, zuckerberg-facebook+microsoft ~ nadella.
Las dos representaciones más ampliamente utilizadas son Word2Vec [23] y GloVe [21]. Sin embargo, la literatura evidencia que GloVe supera en precisión a las aproximaciones anteriores como word2vec y LSA (Latent Semantic Analysis).
En este trabajo, se usa del modelo GloVe preentrenado mediante un corpus lingüístico, usualmente constituido por grandes colecciones de textos con miles de millones de palabras. El modelo preentrenado consiste en una matriz G de dimensiónes (|V|,nd) donde |V|, se refiere al tamaño del vocabulario o número de palabras únicas en el corpus con el cual fue entrenado y nd es el tamaño de la representación vectorial o embedding.
Utilizando la matriz G, se puede consultar cada palabra contenida en Ci y obtener su representación vectorial Li
de dimensión (k,nd) .
Li=G[Ci] (2)
Nótese que Li es una matriz, ya que cada categoría detectada en el cuadro i es transformado una representación vectorial.

CINSIS 2017 - Programa de Ingeniería de Sistemas
22
CLASIFICACIÓN DE SEGMENTOS DE VIDEO UTILIZANDO REPRESENTACIONES VISUALES Y LINGÜÍSTICAS
2.4. Clasificación
Con el objetivo de asignar una categoría semántica al conjunto de categorías visuales detectadas dentro de un cuadro de video, se diseñó y construyó un clasificador basado en redes neuronales con capas de convolución 1D y capas FCN (fully connected).
En la capa de entrada, este clasificador recibe un vector de palabras , previamente transformadas a índices dentro de un vocabulario y obtiene su representación vectorial utilizando el modelo GloVe preentrenado (Embedding Layer). La representación generada es posteriormente procesada mediante una secuencia de convoluciones 1D y max-pooling con el objetivo de modelar la naturaleza secuencial de las palabras en el vector de entrada. Finalmente, la representación obtenida mediante las capas anteriores es ingresada a una serie capas totalmente conectadas (Fully Connected) cuya capa final tiene una función de activación softmax la cual entrega una representación one-hot encoding para obtener una activación relacionada con la categoría semántica detectada en el cuadro de video.
2.5. Agrupamiento de segmentos
Luego de obtener una categoría semántica por cada cuadro Ci , se agrupan los segmentos del video mediante:
• Filtrado de mediana con ventana de anchura k con el objetivo de reducir la variación en las categorías semánticas detectadas en segmentos consecutivos.
• Generación de grupos de segmentos consecutivos que presente igual categoría semántica.
3. EXPERIMENTOS Y RESULTADOS
Los experimentos fueron realizados en un computador con 30 GB en RAM, CPU de 8 núcleos, GPU Quadro M4000 de 8 GB y almacenamiento de estado sólido.
En la Tabla 1, se pueden observar los detalles técnicos de la arquitectura del clasificador semántico construido.
Este clasificador fue entrenado y validado utilizando la base de datos 20_newsgroup [24], la cual está compuesta de 20.000 documentos de noticias organizados en 20 categorías distintas.
En la Tabla 2, se presentan los resultados del entrenamiento y validación del clasificador sobre la base de datos 20_newsgroup, utilizando distintos valores de tamaño de representación del modelo GloVe utilizado, así como del corpus lingüístico con el cual fue construido.
Figura 4. Arquitectura del clasificador construido. El clasificador combina capas de distinta naturaleza para
mapear un conjunto de palabras en una categoría semántica.

CINSIS 2017 - Programa de Ingeniería de Sistemas
23
CLASIFICACIÓN DE SEGMENTOS DE VIDEO UTILIZANDO REPRESENTACIONES VISUALES Y LINGÜÍSTICAS
Tabla 1. Detalles técnicos de la arquitectura del clasificador semántico.
Capa Tipo Activación
1 Embedding (GloVe)
2 Convolution 1D – filtros = 64 ReLU
3 Max Pooling 1D - pool_size=5
4 Convolution 1D – filtros = 64 ReLU
5 Max Pooling 1D - pool_size=5
6 Convolution 1D – filtros = 64 ReLU
7 Max Pooling 1D - pool_size = 35
8 Flatten
9 Dense – neuronas = 128 ReLU
10 Dense – neuronas = 128 ReLU
11 Dense – neuronas = 20 Softmax
Durante el entrenamiento del clasificador semántico, distintos modelos de GloVe preentrenado fueron utilizados en la capa 1.
Tabla 2. Resultados del entrenamiento del clasificador semántico, utilizando valores diferentes de tamaño de
representación.
Corpus lingüístico
Tamaño de Represent.
()
Precisión (train)
Precisión (test)
Tiempo de entre-namiento
(seg.)
Wikipedia + Giga Word
50 0.9299 0.7237 126.229
100 0.9416 0.7654 164.309
200 0.9554 0.7644 228.464
300 0.9626 0.7552 306.998
50 0.9106 0.7277 126.907
100 0.9460 0.7402 163.160
200 0.9567 0.7462 229.149
Se puede notar en la Tabla 2, que los mejores resultados fueron obtenidos con las representaciones Wikipedia+Gigaword con 6K millones de tokens y con tamaño de representación igual a 100 (WG100) y 300 (WG300), y Twitter con 27K millones de tokens y con tamaño de representación igual a 200 (TW200).
Si bien los resultados de validación (test) del clasificador lingüístico están por debajo de 0.8 es importante aclarar que el propósito de dicha medición no es directamente
clasificar segmentos de videos sino documentos completos, en los cuales es de esperar sucedan mayores variaciones entre palabras y elementos lingüísticos que las que podrían ocurrir en un etiquetado de video. Es por ello que partimos del supuesto que con estos valores de precisión para un clasificador lingüístico es suficiente en una tarea de clasificación semántica a partir de un vector de palabras limitado.
Para la experimentación del método propuesto, se utilizó la base de datos SumMe [25], la cual consiste en 25 videos sin edición con una duración máxima de 5 minutos.
En la Figura 5 se puede observar el resultado de la clasificación semántica de los segmentos del video Cooking de la base de datos SumMe. Los autores de esta base de datos proponen un método para generar resúmenes de videos de forma automática (Figura 5b), cuyo resultado sirve para fines de comparativos a nivel cualitativo con el presente trabajo. En la Figura 5c se observan las clases detectadas por el clasificador semántico utilizando las etiquetas detectadas por el clasificador visual (Figura 5d).
Debido al dataset utilizado para entrenar el clasificador semántico (20_newsgroup), no es necesario que las categorías semánticas detectadas, concuerden con una categoría real de video. Por ejemplo, una categoría detectada en el ejemplo anterior fue “medicine”. Es por ello que solo se utilizan los índices de las categorías semánticas [1,2,3,…,20] para este propósito, ya que la intención es encontrar variaciones semánticas a lo largo del video. Nótese en las categorías detectadas para cada segmento del video, que las variaciones o puntos de cambio mantienen relación con las regiones alta importancia detectadas por el método de Gygli et. al. [25] (Figura 5b).
En las Figuras 6a, 6b y 6c, se puede observar el resultado completo del método propuesto, sobre el video “Cooking”, utilizando en el clasificador semántico, las representaciones WG100, WG300 y TW200, respectivamente, y agrupados mediante los pasos expuestos en la sección 2.5. En estas gráficas, el color indica segmentos diferentes del video.
De forma visual, es posible concluir que los segmentos obtenidos mediante la representación WG300 (Figura 6d) para el video “Cooking” presentan una mayor relación con los segmentos de alta importancia presentados por Gygli et. al. en [25] (Figura 6b), esto es, el centro de los segmentos, coinciden con los picos de los segmentos de alta importancia. Este resultado concuerda con los valores de clasificación presentados en la Tabla 2.

CINSIS 2017 - Programa de Ingeniería de Sistemas
24
CLASIFICACIÓN DE SEGMENTOS DE VIDEO UTILIZANDO REPRESENTACIONES VISUALES Y LINGÜÍSTICAS
Figura 5. Clasificación de segmentos de video mediante el método propuesto. (a) Video “Cooking” obtenido del dataset SumMe [25], (b) resultado del proceso de resumen automático propuesto por Gygli
en [25] (figura tomada de [25]), (c) clasificación semántica segmento a segmento del video mediante
WG300, (d) categorías visuales detectadas por la arquitectura VGG16 preentrenada al inicio, mitad y
final del video.
Un resultado similar es obtenido para el video “Bike Polo” (ver Figura 7). El clasificador con la representación TW200 (Figura 7e) genera mayor cantidad de segmentos, lo cual podría ser de interés en videos que tengan una cantidad alta de variación entre segmentos. Sin embargo, en el caso del video “Bike Polo” el mejor resultado sigue siendo el obtenido con la representación WG300 (Figura 7d).
Figura 6. Resultado del método propuesto para el video “Cooking”, (a) del dataset SumMe, (b) resultado del
proceso de resumen automático propuesto por Gygli en [25] (figura tomada de [25]), (c) resultado del método
propuesto con WG100, (d) resultado del método propuesto con WG300, (e) resultado del método propuesto TW200.
Figura 7. Resultado del método propuesto para el video
“Bike Polo” (a) del dataset SumMe, (b) resultado del proceso de resumen automático propuesto por Gygli en [25] (figura tomada de [25]), (c) resultado del método
propuesto con WG100, (d) resultado del método propuesto con WG300, (e) resultado del método propuesto TW200.

CINSIS 2017 - Programa de Ingeniería de Sistemas
25
CLASIFICACIÓN DE SEGMENTOS DE VIDEO UTILIZANDO REPRESENTACIONES VISUALES Y LINGÜÍSTICAS
4. CONCLUSIONES
En el presente trabajo se propone un método basado en una aproximación visual y lingüística para la estimación de segmentos de video. El carácter modular del método propuesto hace posible la modificación del mismo en sus diferentes etapas variando aspectos como la red de clasificación visual, el modelo de representación lingüística, el clasificador lingüístico o el dataset utilizado para la clasificación semántica.
Los resultados presentados indican que es posible generar resultados interesantes en segmentación de videos utilizando características semánticas extraídas utilizando arquitecturas de redes neuronales modernas (deep learning) preentrenadas, lo cual agiliza la construcción de sistemas de este tipo.
Como trabajo futuro se propone la medición de cuantitativa del método propuesto, utilizando como referencia el resultado de un proceso de generación automática de resúmenes de video, por ejemplo, el método propuesto por Gygli et.al. en [25].
5. REFERENCES
[1]Y. Gong and X. Liu, “Video Summarization and Retrieval Using Singular Value Decomposition,” Multimed. Syst., vol. 9, no. 2, pp. 157–168, 2003.
[2]H. J. Zhang, J. Wu, D. Zhong, and S. W. Smoliar, “An integrated system for content-based video retrieval and browsing,” Pattern Recognit., vol. 30, no. 4, pp. 643–658, Apr. 1997.
[3]D. Lin, S. Fidler, C. Kong, and R. Urtasun, “Visual Semantic Search: Retrieving Videos via Complex Textual Queries,” in 2014 IEEE Conference on Computer Vision and Pattern Recognition, 2014, pp. 2657–2664.
[4]A. Karpathy, G. Toderici, S. Shetty, T. Leung, R. Sukthankar, and L. Fei-Fei, “Large-scale Video Classification with Convolutional Neural Networks,” in CVPR, 2014.
[5]T. Sebastian and J. J. Puthiyidam, “Article: A Survey on Video Summarization Techniques,” Int. J. Comput. Appl., vol. 132, no. 13, pp. 30–32, 2015.
[6]H. Oosterhuis, S. Ravi, and M. Bendersky, “Semantic Video Trailers,” CoRR - ICML 2016 Work. Multi-View Represent. Learn., vol. abs/1609.0, 2016.
[7]M. Otani, Y. Nakashima, E. Rahtu, J. Heikkilä, and N. Yokoya, “Video Summarization using Deep Semantic Features,” CoRR, vol. abs/1609.0, 2016.
[8]Y. J. Lee, J. Ghosh, and K. Grauman, “Discovering important people and objects for egocentric video summarization,” in 2012 IEEE Conference on Computer Vision and Pattern Recognition, 2012, pp. 1346–1353.
[9]Z. Lu and K. Grauman, “Story-Driven Summarization for Egocentric Video,” in 2013 IEEE Conference on Computer Vision and Pattern Recognition, 2013, pp. 2714–2721.
[10]P. Varini, G. Serra, and R. Cucchiara, “Personalized Egocentric Video Summarization for Cultural Experience,” Proc. 5th ACM Int. Conf. Multimed. Retr. - ICMR ’15, vol. PP, no. 99, pp. 539–542, 2015.
[11]P. Varini, G. Serra, and R. Cucchiara, “Personalized Egocentric Video Summarization of Cultural Tour on User Preferences Input,” IEEE Trans. Multimed., vol. PP, no. 99, p. 1, 2017.
[12]J. Deng, W. Dong, R. Socher, L. Li, K. Li, and L. Fei-Fei, “ImageNet: A large-scale hierarchical image database,” in IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2009), 2009.
[13]T. Lin, M. Maire, S. Belongie, and L. Bourdev, “Microsoft: COCO: Common Objects in Context,” Comput. Vis., 2015.
[14]K. Simonyan and A. Zisserman, “Very Deep Convolutional Networks for Large-Scale Image Recognition,” Computer Vision and Pattern Recognition, Sep. 2014.
[15]L. Yao, A. Torabi, K. Cho, N. Ballas, C. Pal, H. Larochelle, and A. Courville, “Describing videos by exploiting temporal structure,” in Proceedings of the IEEE International Conference on Computer Vision, 2015, vol. 2015 Inter, pp. 4507–4515.
[16]R. Girshick, J. Donahue, T. Darrell, and J. Malik, “Rich feature hierarchies for accurate object detection and semantic segmentation,” in Computer Vision and Pattern Recognition (CVPR), 2014.
[17]R. B. Girshick, “Fast {R-CNN},” CoRR, vol. abs/1504.0, 2015.
[18]H. Fang, S. Gupta, F. Landola, and R. Srivastava, “From Captions to Visual Concepts and Back,” in Computer Vision and Pattern Recognition (CVPR), 2015 IEEE Computer Society Conference on, 2015.
[19]K. Xu, J. Lei Ba, R. Kiros, K. Cho, A. Courville, R. Salakhutdinov, R. Zemel, and Y. Bengio, “Show, Attend and Tell: Neural Image Caption Generation with Visual Attention,” 2016.
[20]T. Mikolov, I. Sutskever, K. Chen, G. Corrado, and J. Dean, “Distributed Representations of Words and Phrases and Their Compositionality,” in Proceedings of the 26th International Conference on Neural Information Processing Systems, 2013, pp. 3111–3119.

CINSIS 2017 - Programa de Ingeniería de Sistemas
26
CLASIFICACIÓN DE SEGMENTOS DE VIDEO UTILIZANDO REPRESENTACIONES VISUALES Y LINGÜÍSTICAS
[21]J. Pennington, R. Socher, and C. D. Manning, “GloVe: Global Vectors for Word Representation,” in Empirical Methods in Natural Language Processing (EMNLP), 2014, pp. 1532–1543.
[22]R. Kiros, Y. Zhu, R. Salakhutdinov, R. S. Zemel, A. Torralba, R. Urtasun, and S. Fidler, “Skip-Thought Vectors,” CoRR, vol. abs/1506.0, 2015.
[23]T. Mikolov, K. Chen, G. Corrado, and J. Dean, “Efficient Estimation of Word Representations in Vector Space,” CoRR - Comput. Res. Repos., vol. 1301.3781, 2013.
[24]K. Lang, “NewsWeeder: Learning to Filter Netnews,” in in Proceedings of the 12th International Machine Learning Conference (ML95, 1995.
[25]M. Gygli, H. Grabner, H. Riemenschneider, and L. Van Gool, “Creating Summaries from User Videos,” in ECCV, 2014.

CINSIS 2017 - Programa de Ingeniería de Sistemas
27
CLASIFICACIÓN DE SEGMENTOS DE VIDEO UTILIZANDO REPRESENTACIONES VISUALES Y LINGÜÍSTICAS
USO DE TÉCNICAS DE APRENDIZAJE DE MÁQUINAS PARA EL DIAGNÓSTICO DE NÓDULOS PULMONARES
ABSTRACT
In this paper, we describe the formatting guidelines for ACM SIG Proceedings.
Keywords: Nódulos pulmonares, aprendizaje de máquinas, técnicas de clasificación, selección de características.
Idanis Diaz B.Facultad de Ingeniería
Universidad del [email protected]
German Sánchez TorresFacultad de Ingeniería
Universidad del [email protected]
Pedro E. Romero Facultad de Ingeniería
Universidad del [email protected]
1. INTRODUCCIÓN
El cáncer de pulmón además de ser uno de los cánceres más letal que afecta la población mundial, es también uno de las enfermedades más difíciles de diagnosticar en etapas tempranas. La dificultad se presenta debido a que las imágenes de tomografía computarizada (TC), que es la modalidad de imagen médica más utilizada para el estudio, y diagnóstico de afectaciones de los pulmones, presentan apariencia ruidosa, y exceso de información distribuida en diversos cortes o slices que usualmente son inspeccionados visualmente.
Mejorar el diagnóstico de nódulos pulmonares en etapa temprana es de gran interés debido a que incrementa la posibilidad de la detección de cáncer desde su inicio y la aplicación de tratamientos que aumenten la esperanza de vida del paciente. En la literatura existen diversos trabajos para este propósito basados en el procesamiento digital de imágenes. En un trabajo previo se introdujo una técnica de segmentación basada en la localización de un umbral automáticamente para identificar pequeños nódulos pulmonares. El presente trabajo es una extensión del anterior, en el que se lleva a cabo una exploración de posibles características extraídas a partir de los nódulos segmentados para determinar si los nódulos segmentados pueden ser clasificados como benignos o malignos [1].
2. DETECCION DE NÓDULOS PULMONARES
Los métodos de detección de nódulos pulmonares generalmente presentan una estructura específica que se ilustra en la Figura 1.
Figura 1. Etapas en la detección de nódulos pulmonares.
La primera etapa, segmentación del volumen pulmonar consiste en la utilización de alguna técnica de segmentación para separar la cavidad pulmonar del resto de la imagen [2]. La segunda etapa, detección de nódulos candidatos consiste en identificar dentro de la cavidad pulmonar segmentada pequeñas porciones de la imagen que contienen posibles nódulos, que pueden representar estructuras normales de la anatomía del paciente, ruido, o la presencia de un nódulo, esto es, la aparición de una estructura extra que puede ser benigna o maligna. La Figura 2 muestra un slice de una imagen TC tomada de un paciente que presenta algunos nódulos y otras estructuras que lucen como nódulos; pero que realmente no lo son.

CINSIS 2017 - Programa de Ingeniería de Sistemas
28
USO DE TÉCNICAS DE APRENDIZAJE DE MÁQUINAS PARA EL DIAGNÓSTICO DE NÓDULOS PULMONARES
Figura 2. Imagen de un slice pulmonar con la presencia de nódulos encerrados con círculos rojos, y otras estructuras
que lucen como nódulos encerrados con círculos amarillos.
La última etapa, reducción de falsos positivos también es un gran reto no solamente para ser resuelto computacionalmente, sino también para los expertos. La gran cantidad de falsos positivos que se puede encontrar en las imágenes pueden causar confusión en la interpretación del radiólogo, e interferencia de factores tales como la fatiga y la subjetividad [1].
La eliminación de falsos positivos se lleva a cabo a través del análisis de ciertas características extraídas de las regiones segmentadas, tales como, la intensidad de los pixeles, la textura y algunas variables morfológicas, el trabajo presentado por Valente et.al [1], presenta una revisión de algunos de los métodos de aprendizaje de máquinas que se han utilizado sobre bases de datos de nódulos pulmonares, empleando las características mencionadas. Entre estos métodos tenemos máquinas de vector de soporte, redes neuronales, clasificadores bayesianos, y métodos basados en reglas.
A partir de los resultados obtenidos en [3], se extrajo un conjunto de características recopiladas de diferentes trabajos, tales como [3] y [4]. Estas características fueron utilizadas a manera de exploración con diferentes clasificadores para evaluar la bondad de las características en la discriminación de nódulos como falsos positivos, y positivos.
3. CARACTERISITICAS Y METODOS DE APRENDIZAJE DE MAQUINAS
La Tabla 1 lista las características seleccionadas y evaluadas en este trabajo:
Tabla 1. Características para discriminar falsos positivos
Característica Descripción
Máxima áreaÁrea máxima ocupada por el nódulo candidato sobre un slice (corte del volu-men nodular)
Diámetro del área máxima
Diámetro del área máxima ocupada por el nódulo candidato en el slice
Excentricidad del área máxi-
maExcentricidad del área máxima.
Solidez del área máxima
Proporción de píxeles contenidos por el área máxima.
Profundidad Número de slices n los que se encuentra presente el nódulo candidato
Volumen Número de vóxeles pertenecientes al nódulo candidato.
Excentricidad del volumen
en el plano xy
Razón entre las longitudes de los semie-jes del nódulo candidato sobre el plano xy.
Excentricidad del volumen
en eje z
Razón entre el semieje del nódulo del plano z y un semieje trazado sobre el plano xy.
Intensidad media
Valor medio de la intensidad de los vóxeles que pertenecen al nódulo can-didato
EntropíaMedida estadística de la aleatoriedad re-presentativa de la textura de los vóxeles pertenecientes al nódulo candidato.
Estas características fueron evaluadas con tres clasificadores diferentes: redes neuronales con funciones de base radial (RBFnetwork), árboles de decisión (J48), y máquina de vector de soporte (SMO).
Una red neuronal con funciones de base radial es un tipo de red neuronal que generalmente cuenta con una capa de entrada, una capa oculta cuyos nodos contienen funciones radiales no lineales como función de activación y una capa de salida lineal [7]. Generalmente, la función de activación utilizada en la capa de oculta es una función de base radial gaussiana normalizada. La Figura 3 muestra la arquitectura básica de una RBFnetwork.

CINSIS 2017 - Programa de Ingeniería de Sistemas
29
USO DE TÉCNICAS DE APRENDIZAJE DE MÁQUINAS PARA EL DIAGNÓSTICO DE NÓDULOS PULMONARES
Figura 3. Arquitectura de una RBFnetwork
Los árboles de decisión es un tipo de algoritmo de aprendizaje de máquinas que construye un clasificador en forma de árbol, en el que los nodos representan un atributo o característica que divide el conjunto de ejemplos de entrenamiento en subconjuntos tan homogéneos como sea posible en favor de la clase a predecir, de acuerdo a los valores del atributo. Los nodos hojas del árbol representa los ejemplos que pertenecen a una clase que es discriminada por sus valores de atributos desde la raíz hasta la hoja [5].
Por su parte, las máquinas de vector de soporte es un tipo de algoritmos de aprendizaje de máquinas que busca encontrar el hiperplano optimo que divide el conjunto de ejemplos en clases. Para encontrar el hiperplano optimo el método debe solucionar un problema de optimización cuadrático. En [6], se propone un método para resolver el problema de optimización cuadrática basado en una secuencia de optimización mínima, llamado SMO.
4. RESULTADOS
Para evaluar el conjunto de características seleccionados, y los métodos de aprendizaje de máquinas de la sección anterior, se construyó un conjunto de datos de entrenamiento con 78 nódulos tomados de diferentes casos de pacientes disponibles en la base de datos pública: SPIE-AAPM Lung CT Challenge Database (https://wiki.cancerimagingarchive.net/display/Public/SPIE-AAPM+Lung+CT+Challenge). Para cada uno de los 78 casos se registraron los valores de las 10 características listadas en la Tabla 1, más un atributo clase que identifica el nódulo como maligno o benigno. Se seleccionaron casos de ambas clases en igual proporción, 50 casos malignos, y 50 casos benignos. Los algoritmos fueron ejecutados utilizando el software de dominio público WEKA 3.8. La tabla 2 contiene las matrices de confusión obtenidas con los tres clasificadores evaluados:
Tabla 2. Matrices de confusión generadas con WEKA 3.8
RBFnetwork J48
SMO
Método Instancias correctamente clasificadas de 78 casos %
J48 71 91.03
RBFnet-work 68 87.18
SMO 71 91.03
Los porcentajes de clasificaciones correctas de cada clasificador se pueden observar en la Tabla 3. El mejor porcentaje lo obtuvieron el algoritmo J48, y el SMO, frente al RBFnetwork.
Tabla 3. Porcentaje de clasificaciones correcta
Los tres algoritmos fueron ejecutados utilizando la opción de validación cruzada con 10 folds, y los valores de parámetros por defecto que vienen configurados en WEKA.
5. CONCLUSIONES
Podemos observar que el luego de segmentar estructuras dentro de una imagen TC del pulmón incluyendo posibles nódulos pulmonares, es posible discriminar entre nódulos falsos y positivos utilizando un conjunto de características estimables a
partir de las segmentaciones. La extracción de las características se puede llevar a cabo mediante la implementación de técnicas de procesamiento de imágenes digitales, lo que reduce la necesidad de un experto humano para encontrar en un principio los nódulos pulmonares. Adicionalmente, la combinación de técnicas de aprendizaje de máquinas, con técnicas de procesamiento de imágenes digitales, puede ser tomada como una forma para reducir la cantidad de datos que debe ser analizados manualmente.

CINSIS 2017 - Programa de Ingeniería de Sistemas
30
USO DE TÉCNICAS DE APRENDIZAJE DE MÁQUINAS PARA EL DIAGNÓSTICO DE NÓDULOS PULMONARES
Como trabajo futuro se puede repetir la experimentación presentada en este articulo con mas casos de nódulos pulmonares, así como también utilizar otros algoritmos de aprendizaje de máquinas. También se debe hacer un análisis de cada una de las características seleccionadas para determinar su capacidad de discriminación por separado.
6. REFERENCES
1. Valente, I., Cortez, P.C., Neto E.C., Soares, J.M., de Albuquerque, V.H., Tavares, J.M. 2016. Automatic 3D pulmonary nodule detection in CT images: A survey. Comput. Methods Programs Biomed.124 (Feb 2016), 91-107. DOI=10.1016/j.cmpb.2015.10.006.
2. Choi Tae-Sun, Choi Wook-Jin. 2014. Automated pulmonary nodule detection based on three-dimensional shape-based feature descriptor. Computher Methods and Programs in Biomedicine 113, 1 (January 2014), 37-54. DOI= 10.1016/j.cmpb.2013.08.015.
3. Romero, P. Diaz, I, Sánchez, G. Un Método de Segmentación de Nódulos Pulmonares en Imágenes de
Tomografía Computarizada basado en la Localización Automática de un Umbral. In Proceedings of Simposio de Tratamiento de Señales, Imágenes y Visión Artificial (Bucaramanga, Colombia, agosto 31 - septiembre 02, 2016). STSIVA. Universidad Pontificia Bolivariana, Bucaramanga, 50-55.
4. Netto, S. M. B., Silva, A. C., Nunes, R. A., & Gattass, M. 2012. Automatic segmentation of lung nodules with growing neural gas and support vector machine. Computers in biology and medicine, 42, 11(November 2012), 1110-1121. DOI= https://doi.org/10.1016/j.compbiomed.2012.09.003.
5. Quinlan, J. R. 1993. C4.5: Programs for Machine Learning. Morgan Kaufmann Publishers.
6. Platt, J. 1998. Sequential Minimal Optimization: A Fast Algorithm for Training Support Vector Machines. Technical Report. Microsoft Research.
7. Broomhead, D. S.; Lowe, David. 1988. Radial basis functions, multi-variable functional interpolation and adaptive networks. Technical report. RSRE.

CINSIS 2017 - Programa de Ingeniería de Sistemas
31
USO DE TÉCNICAS DE APRENDIZAJE DE MÁQUINAS PARA EL DIAGNÓSTICO DE NÓDULOS PULMONARES
SISTEMA DE RIEGO AUTÓNOMO E INTELIGENTE CON CAPACIDAD DE MONITOREAR VARIABLES CLIMÁTICAS
RESUMEN:
El presente proyecto tiene como objetivo el diseño de un prototipo de sistema de riego autónomo e inteligente con capacidad de medir variables ambientales, que brinde un control en la activación del regado y monitoreo de cultivos o zonas verdes. Se realizó de manera descriptiva y exploratoria la recolección y procesamiento de datos, como punto de partida para la ejecución del sistema. Con lo anterior, se obtendrá la instalación de sensores, la medición de la humedad relativa y temperatura del aire, humedad de suelo y cantidad de luz, las cuales son las variables determinadas en la activación y generación de alertas para el seguimiento y monitoreo del ambiente. Como conclusión, la ejecución de este proyecto permite orientar las actividades de riego al consumo de recursos estrictamente necesario, controlando los tiempos de activación y cantidad de fuente hídrica usada, siendo importante para la toma de decisiones en dichos entornos ambientales.
Palabras Clave: Sistema de riego. Sistema embebido, Internet de las cosas, Sistema de Riego, Arduino.
Amaury CabarcasUniversidad de Cartagena
Piedra de Bolívar Av. del Consulado, Calle 30 No.39B – 192
Amaury OrtegaUniversidad de Cartagena
Piedra de Bolívar Av. del Consulado, Calle 30 No.39B – 192
David CermeñoUniversidad de Cartagena
Piedra de Bolívar Av. del Consulado, Calle 30 No.39B – 192
Ariel ArnedoUniversidad de Cartagena
Piedra de Bolívar Av. del Consulado, Calle 30 No.39B – 192
Astrid VanegasUniversidad de Cartagena
Piedra de Bolívar Av. del Consulado, Calle 30 No.39B – 192
1. INTRODUCCION
Los sistemas de riego para su funcionamiento tienen en cuenta variables que interactúan con el entorno, las cuales miden los cambios climáticos presentes en el ambiente, estos cambios influyen directamente en la formación de los cultivos o zonas verdes, por lo tanto, al darle seguimiento a los valores que se obtienen de estas variables es posible determinar qué tan saludable se encuentra y que medidas de riego debe tomar un agricultor o cuidador. Actualmente en Colombia esta actividad es mayormente dependiente de la intervención humana, por lo tanto, este factor implica que se generan ciertos errores que pueden traer consecuencias leves o permanentes en la preservación de la planta, los errores más comunes se encuentran asociados con la gran diversidad en los tipos de cultivos o plantas, lo que conlleva a cuidados totalmente independientes y variados.
Además, se puede incurrir en un consumo innecesario de los recursos hídricos este desperdicio de agua puede llegar a ser poco o muy considerable, debido a la sobre irrigación. Otro aspecto importante al considerar los sistemas de riego actuales, es la necesidad del fluido eléctrico, en ocasiones estos sistemas consumen mucha energía eléctrica para su funcionamiento, produciendo a largo plazo un costo energético bastante alto si se toma en cuenta que los cuidados a las plantas son diariamente e incluso casi todo el día dependiendo del tipo de planta que se esté interviniendo.
Con la problemática descrita, se propone el desarrollo de un prototipo de sistema de riego para ofrecer un apoyo a la labor realizada por agricultores o cuidadores, de modo que se pueda monitorear y hacer un correcto uso del consumo de agua durante crecimiento del cultivo o zona verde, y al mismo tiempo usar como fuente de

CINSIS 2017 - Programa de Ingeniería de Sistemas
32
SISTEMA DE RIEGO AUTÓNOMO E INTELIGENTE CON CAPACIDAD DE MONITOREAR VARIABLES CLIMÁTICAS
alimentación energías renovables, como lo es la energía solar, considerada una de las más limpias comparadas con las convencionales. Para la implementación de este tipo de sistema, se deben tener en cuenta la medición de variables ambientales como humedad, temperatura y luminosidad que influye directamente en la formación de cultivos y zonas verdes, teniendo en cuenta que estas presentan un comportamiento oportuno para evaluar y analizar, logrando tener la capacidad de medir los cambios que se manifiestan en el ambiente y a través de una actividad adicional como el riego ayudar a conservarlas.
Según estudios, el crecimiento exponencial de la industria debido a su esfuerzo por brindar soluciones rápidas ante las constantes problemáticas y demandas que se están exigiendo en el mercado, se está descuidando al medio ambiente y cuanto le cuesta al bienestar humano el deterioro que a este se le ocasiona. Enfocando la problemática anterior a un sistema de riego, donde el consumo de agua que se utiliza esta entre el 50% y el 85% del total de agua que se encuentra disponible en algunas áreas, tiende a ser el factor de preocupación que necesita ser controlado para satisfacer la necesidad de agua y disminuir la escasez que esta presenta [2]. Por lo anterior es necesario que los sistemas que utilicen este recurso tan importante y demandado se encuentren orientados a su ahorro y conservación.
Considerando la importancia que tiene la preservación de los recursos naturales no renovables, se debe buscar aplicar todas las fuentes de energía renovable para un suministro energético limpio que tiene menos efectos ambientales sobre las usadas convencionalmente. La energía solar es una de las fuentes de energía renovable más popular, gracias a las características que esta posee, su bajo costo operacional, largo ciclo de vida y suministro finito, sus costos de inversión son bastante altos, pero estos son recuperados a largo plazo [1]. A una escala baja, como la que se trabajara inicialmente en el prototipo en construcción, se considera pertinente la aplicación de este tipo de energía, puesto que se contribuye con la concientización del daño que presenta el planeta y el deber que se tiene para mejorar esta problemática.Una investigación llevada a cabo por estudiantes del SENA reafirma lo mencionado en el párrafo anterior, el sistema que crearon era capaz de detectar cuando está lloviendo para que no se active un regado de cultivo innecesario. Esto ofrece un ahorro hídrico y energético bastante oportuno que contribuye directamente con el ambiente [2].
Una característica importante dentro de la creación de sistemas como estos es la automatización de procedimientos, esta es una práctica que está siendo cada vez más aplicada puesto que brinda un proceder efectivo, es claro que hoy en día poco a poco se ha ido pasando de un sistema manual a operaciones automatizadas, esto en busca de ahorrar recursos, tanto en mano de obra como en el control de actividades aumentando su rendimiento [3]. Es importante hacer énfasis en lo anterior, puesto que una variante dentro del sistema es la activación automática de acuerdo a indicadores recolectados del ambiente, factor que agrega valor al sistema de riego y al análisis e interpretación de la toma de datos sobre las variables ambientales guías en la investigación. Un ejemplo de esto fue la creación en el 2015 de un sistema regulador para el funcionamiento de un sistema de riego que responde a la información programada por el usuario, donde aplicando otros componentes o dispositivos, programa la cantidad de agua y tiempo antes de que suspenda el sistema [4]. Esta estrategia es oportuna porque tendrá la autonomía de decidir activarse de acuerdo a un análisis realizado solo a las variables de entorno y dependiendo de estas es que el sistema concluirá cuándo y hasta que tiempo es pertinente que funcione.
Con la creación de un sistema que capture información del entorno, se pretende que esta sea analizada y brinde un apoyo para la toma de decisiones con respecto a cuándo intervenir por medio del riego para reducir el deterioro presente en el cultivo o zona verde a tratar, por lo tanto, a partir de los indicadores o valores que la recolección de datos arroja sobre estas variables, se determinara el estado de la planta para que el operador lleve a cabo un correcto mantenimiento de esta.
En el desarrollo de la investigación se presenta el diseño y elaboración de un sistema de riego automático y auto sostenible energéticamente, para ello se pretende crear un prototipo de riego cuya implementación inicial sea aplicada en la Universidad de Cartagena sede Piedra Bolívar, facilitando el cuidado de las zonas verdes, reduciendo el consumo excesivo de agua, evitando errores humanos, reduciendo el consumo de otros recursos dotados por la universidad como es el caso de la electricidad y por último, la recepción de las diferentes notificaciones que se generen referentes al estado de la vegetación, brindando seguridad y flexibilidad a las actividades relacionadas con jardines o cultivos agrícolas.
El presente artículo se encuentra organizado de la siguiente manera, a continuación se presenta una metodología donde se detallan aspectos relevantes sobre

CINSIS 2017 - Programa de Ingeniería de Sistemas
33
SISTEMA DE RIEGO AUTÓNOMO E INTELIGENTE CON CAPACIDAD DE MONITOREAR VARIABLES CLIMÁTICAS
la construcción del sistema, seguido de unos resultados preliminares o parciales, donde se describen cuáles son los productos de la investigación hasta la fecha y se deja abierta la posibilidad de implementaciones futuras, luego las conclusiones, las cuales manifiestan que se obtiene del trabajo y el impacto que este ocasiona al entorno de aplicación, por ultimo las referencias.
2. METODOLOGIA
Para el cumplimiento de la investigación y de esta manera diseñar y desarrollar un sistema que monitoree las variables ambientales para la toma de decisiones sobre el riego de jardines o plantas, se debe estudiar la aplicabilidad de los sensores y controladores necesarios para plantear una solución, este estudio definirá características con respecto a su uso y salida de datos, logrando concluir costos, diferencia de uso y precisión.
Figura 1. Diagrama de componentes o elementos que forman la arquitectura basada en Internet de las cosas
(IOT) en el sistema de riego
En la figura 1, se puede observar el esquema grafico que explica la arquitectura que compone el sistema de riego, mostrando como se encuentran d istribuidos los objetos y elementos conectados en el entorno, haciendo referencia a que la toma de datos o información es adquirida por dispositivos diferentes, independientes físicamente pero que se encuentran unidos por una red o protocolo de comunicación, la cual, luego es procesada por un servidor para su interpretación y ejecución del sistema
Para la construcción del sistema, se tendrá en cuenta el componente físico, en este caso formado por el hardware donde se usarán sensores, microcontroladores, herramientas para calibración, entre otros, además se usará un componente intangible que ejecutará las reglas o condiciones sobre las que se implementará el riego, este componente será el software o tecnologías de desarrollo software.
Recolección de datos
Lógica de la aplicación
Protocolos HTTP - MQTT
Actualización en tiempo real
Visualización
Datos Almacenamiento
Aplicación Web
2.1. Sistema de recolección de datos de las variables ambientales
Dentro de esta fase se determinan los componentes o elementos necesarios para la toma de datos, dicha recolección se realiza cada cierto tiempo, almacenando la información junto con la anteriormente sincronizada por WIFI.
Para analizar todas las variables ambientales que se involucran en la construcción del sistema, se deben tener en cuenta los siguientes elementos:
• Módulo de interpretación de datos: Es el encargado de conectar los diferentes elementos físicos que componen al sistema.
• Detección de variables ambientales: Para esto es necesaria la implementación de más de un elemento para abarcar las variables de estudio, temperatura y humedad del aire, temperatura del suelo y luminosidad.
2.2. Diseño de un middleware para la conexión entre la adquisición de datos y activación del sistema
La integración de los datos recolectados, como primera medida para la creación de un prototipo funcional básico, se implementara una plataforma web que involucra internet de las cosas usando protocolos como HTTP, protocolo del nivel de aplicación con la agilidad y velocidad necesarias para operar con sistemas de información distribuidos [5] y MQTT, este protocolo está diseñado específicamente para redes de dispositivos Máquina A Máquina, el cual trabaja con el modelo publicador/suscriptor que funciona como una vía de comunicación de uno-a-varios clientes [6]. La plataforma web llamada Ubidots, permite la toma de decisiones en tiempo real al analizar la información almacenada en la nube, logrando visualizar el comportamiento de los datos [7], con la aplicación de estos protocolos se podrá visualizar en tiempo real los cambios de cada una de las variables, en los diferentes nodos de recolección, la elección de este tipo de tecnología es debido a su cómoda implementación para actualizaciones rápidas en ejecución.
Para que la visualización de los datos y generación de alertas se haga correctamente, es necesario la implementación de un enlace que interprete los datos y estos los relacione con los indicadores mínimos que los

CINSIS 2017 - Programa de Ingeniería de Sistemas
34
SISTEMA DE RIEGO AUTÓNOMO E INTELIGENTE CON CAPACIDAD DE MONITOREAR VARIABLES CLIMÁTICAS
cultivos y plantas deben tener para su conservación. En primer lugar, este relacionara la tendencia que tienen los datos leídos, si no son valores estables, el sistema se activara automáticamente o de manera manual, controlando los componentes hídricos que se encuentran enlazados en el sistema eléctrico, cuando se realiza esta acción, se programara el tiempo de riego para que se suspenda o se hace manualmente.
2.3. Diseño de una fuente de alimentación con energía solar para el sistema de riego
El sistema se alimentará con energía solar, esta energía es uno de los métodos más limpios de producción de electricidad, ya que se basa en la conversión de la captación de la radiación solar y su transformación en electricidad (Fotovoltaica) o en calor (térmica) [8].
El ángulo se obtiene multiplicando el número de días transcurridos desde el último Solsticio de invierno por 360° y dividiéndolo es decir 366 si es bisiesto y 365 si no lo es, como Solsticio de invierno se toma el del hemisferio Norte: el 21 de diciembre. El ángulo anual es una medida aproximada de la posición de la Tierra en su órbita alrededor del Sol [9].
Para la implementación de este tipo de alimentación solar, se tiene en cuenta el efecto Fotovoltaico mediante el cual una célula FV convierte la luz solar en electricidad [10], la infraestructura se compone de los paneles Fotovoltaicos o colectores solares fotovoltaicos están formados por un conjunto de celdas (Células fotovoltaicas) que producen electricidad a partir de la luz que incide sobre ellos. La potencia máxima que el módulo puede entregar bajo unas condiciones estandarizadas, que son: Radiación de 1000 W/m2 y Temperatura de célula de 25º C (no temperatura ambiente)
2.4. Prototipo para la recolección de información sobre las variables ambientales
Para la construcción del prototipo se usara el Modulo ESP8266, chip electrónico para dispositivos móviles, electrónica portátil y aplicaciones relacionadas con Internet de Cosas (IoT) [11], éste cuenta con protocolos TCP/IP para obtener el acceso a la red WiFi, este tipo de microcontroladores son esenciales cuando se desea aplicar o construir redes de comunicación entre módulos, lo anterior se presenta en esta investigación, puesto que esta tecnología se ubicara en diferentes sectores de las zonas verdes o cultivos y se realizara la toma de datos desde cada uno de los nodos formados por estos comunicándose entre sí por medio de protocolos de red. [12]
Identificado el microcontrolador que se encargara de la interpretación de los datos, se debe elegir los sensores encargados de la recolección de los datos ambientales, dichos datos o variables de entorno son luminosidad, temperatura, humedad del suelo y del aire. Estos sensores se comunicarán con el microcontrolador por medio de un estándar de comunicación denominado I2C, el cual es un protocolo maestro-esclavo, donde el papel de maestro es iniciar la comunicación mediante la emisión de inicio, solicitar al dispositivo esclavo que se comunique y luego terminar la comunicación a través de una condición de parada [13].
Uno de los sensores aplicados es el SHT21, sensor encargado de la recolección de datos sobre humedad del aire y temperatura, su protocolo de comunicación es el I2C [14]. La variable de luminosidad sera tomada por el sensor TSL2561, este es un convertidor de luz a señal digital que transforma la luz en una salida enviada por su protocolo de comunicación, el cual es, al igual que el anteriormente mencionado I2C [15]. Por último, la variable de entorno humedad del suelo será captada por el YL-69, este consiste en una sonda con dos conexiones que se conectan indistintamente con el módulo YL-38 este último consta de 2 pines para la alimentación VCC (de 3,3V a 5V) y GND; y 2 pines para datos de salida D0 (salida digital) y A0 (salida analógica) [16]. En la figura 2 se encuentra representada la conexión de este sensor
Figura 2. Conexión para el sensor de temperatura del Suelo.
Otro factor importante en la construcción del sistema para medición de variables de riego, es la visualización e interpretación de todos los datos recolectados, para la visualización se implementará una plataforma web aplicando como tecnología para el desarrollo, Angular, esta es una plataforma que combina plantillas, inyección de dependencias y prácticas integradas para un desarrollo integral [17].

CINSIS 2017 - Programa de Ingeniería de Sistemas
35
SISTEMA DE RIEGO AUTÓNOMO E INTELIGENTE CON CAPACIDAD DE MONITOREAR VARIABLES CLIMÁTICAS
En la figura 3, se muestra el diagrama de diseño del sistema de riego, en este se observa cómo se encuentra compuesto un nodo, sensores, modulo interprete de datos y los diferentes componentes que se activaran de acuerdo a como el sistema lo necesite. Los sensores se conectan a un módulo WIFI que captura la información, luego se transmiten los datos que posteriormente son interpretados por el enlace entre lo recolectado y la activación requerida para el riego.
Figura 3. Diseño del prototipo de sistema de riego.
Para la interpretación de datos se implementará un middleware, para realizar el enlace entre la adquisición de datos a través de los sensores y la activación del sistema de riego, con la implementación de este se podrá tener el control sobre los componentes que hacen parte de la hidratación del cultivo (moto bomba, electroválvulas, entre otros)
El prototipo se conforma de bloques como la obtención de datos donde se hace referencia a los sensores de humedad, temperatura y luminosidad, un componente de conexión y procesamiento de los datos recolectados, donde se decide como funciona el sistema y por ultimo un bloque de salida, donde se visualizan todos los datos recolectados y tratados, como se muestra en la figura 4.
Para la realización de peticiones e interpretación de datos se aplicará Node.js, el cual como entorno de ejecución para
JavaScript otorga una facilidad de conexión con el microcontrolador ESP8266. Además, la implementación de Node.js permitirá que el sistema sea liviano y eficiente por su modelo de operación Entrada / Salida y orientado a eventos. [18]
Por ultimo para el almacenamiento de los datos, se trabajará con una base de datos NoSQL llamada MongoDB, esta base de datos es líder en promover la agilidad y escalabilidad de las aplicaciones, mejorando la experiencia del cliente. [19]
La representación del sistema según los flujos o actividades que realiza los módulos hardware conectado se presenta a continuación:
Figura 4. Diagrama de bloques para el prototipo del sistema de Riego con capacidad de monitorear variables climáticas.
OBTENCION DE DATOS
PROCESAMIENTO
SALIDA DE INFORMACION
Sensor d e temperatura y humedad
Sensor d e Temperatura del suelo
Sensor d e luminosidad
Placa de control
(ESP8266)
Visualización (Plataforma Web)
Figura 5. Diagrama de flujo del sistema electrónico para Riego
En la figura 6, primero inicia con los valores de los sensores de humedad, temperatura y luminosidad, el módulo ESP 8266 lee e interpreta los datos de acuerdo a los niveles que son adecuados para las plantas o cultivos que están siendo monitoreados, si los limites no son los adecuados, se activa el sistema de riego mostrando las alertas correspondientes en la plataforma web.
3. RESULTADOS PRELIMINARES O PARCIALES Y DISCUSION
Con la implementación del prototipo se busca generar herramientas que beneficien a los trabajadores involucrados

CINSIS 2017 - Programa de Ingeniería de Sistemas
36
SISTEMA DE RIEGO AUTÓNOMO E INTELIGENTE CON CAPACIDAD DE MONITOREAR VARIABLES CLIMÁTICAS
en el área de jardinería o con lo relacionado al tratamiento de riego de zonas verdes y plantas, manteniendo una constante actualización del estado en el que se encuentran, presentando indicadores que permitan interpretar la necesidad de activación del sistema para su oportuna hidratación, esto último se realizará teniendo en cuenta las variables y datos que se tomen del terreno de riego.
Es importante señalar que el funcionamiento de estos componentes anteriormente definidos se ha desarrollado en un editor de texto orientado a la construcción de aplicaciones llamado Atom [20], y la plataforma PlatformIO [21] para el desarrollo del internet de las cosas por medio del lenguaje de programación C++.
Como resultado parcial de la investigación se planteó un prototipo funcional de software que integra múltiples sensores para medir la humedad relativa o del aire, humedad de suelo promedio, temperatura del aire y cantidad de luz sobre el prototipo situado en una plantación de forma exitosa usando sensores de bajo costo conectados a un ESP8266. Los sensores son los siguientes:
• SHT21 Sensor digital de humedad y temperatura
• TSL2561 Sensor digital de luminosidad
• YL38 con YL69 Sensor de humedad de suelo
Posterior a la medición de estas variables climáticas, se usó una plataforma del internet de las cosas llamada Ubidots las cual nos permite recibir las mediciones previas a través del internet, usando múltiples protocolos como HTTP y MQTT, y visualizarlas o manipularlas en un tablero virtual llamado dashboard. Teniendo en cuenta esta implementación, se plantea usar, como infraestructura, un servidor capaz de recibir información por medio de estos protocolos, en especial MQTT debido a que sigue un patrón de mensajería llamado suscripción-publicación el cual ha sido acogido por grandes empresas como Ubidots.
En la figura 6, se puede observar cómo se da la comunicación entre cada uno de los componentes físicos a través del protocolo MQTT se actualiza la información que inmediatamente se visualiza en la plataforma web.
Trabajando sobre esta plataforma se pueden plantear múltiples soluciones similares pero más acordes a nuestras necesidades, se debe plantear la mejor forma de visualizar la información así como el procesamiento de esta para la toma de decisiones. Dentro de la interfaz de Ubidots se pueden visualizar los datos recolectados por los sensores, donde tambien se administran las herramientas disponibles dentro de esta pagina
Las proximas implementaciones que se realizaran dentro del proyecto, sera la contruccion de la pagina web con angular y node js del lado del servidor, desarrollando los procesos para el analisis de datos que permitira realizar la elaboracion de interpretacion y generacion de indicadores a partir de la recoleccion de las variables de entorno. Ademas dentro de los componenetes que haran parte del prototipo se tiene la fuente de energia a partir de recursos renovables, la infraestructura necesaria para implementar este modulo se encuentra en ejecucion, para una futura aplicación y resultados.
4. CONCLUSIONES
La ejecución de proyectos similares al que se ha descrito, permiten ofrecer alternativas de bajo costo que proporcionan un apoyo a las diferentes áreas laborales presentes en los sectores productivos locales y regionales. Dentro de la investigación se realizaron actividades ordenadas que concretaban el diseño y desarrollo del sistema de riego. Entre estas, se encuentra la conexión los sensores recolectores de información con el microcontrolador ESP8266, dicha conexión se definió en el código que fue compilado en el componente.
Es importante destacar que la aplicación de este proyecto ayuda al actual impacto ambiental que se está haciendo presente hoy en día, el control de riego mediante sensores permite que el consumo de agua sea el estrictamente necesario, generando conciencia sobre el grave problema ambiental que se enfrenta.
En resumen, se realizaron investigaciones detalladas que permitieron establecer las condiciones sobre las que debe trabajar el sistema, los valores que serán el punto de activación y generación de alertas de acuerdo a las entradas a las que el sistema se vea afectado, con Figura 6. Diagrama de comunicación del sistema de Riego
con capacidad de monitorear variables climáticas

CINSIS 2017 - Programa de Ingeniería de Sistemas
37
SISTEMA DE RIEGO AUTÓNOMO E INTELIGENTE CON CAPACIDAD DE MONITOREAR VARIABLES CLIMÁTICAS
lo anterior se hace referencia a que valores reciban los sensores y sobre los cuales el sistema tomara las decisiones para realizar determinada acción. Se considera que el desarrollo de este trabajo investigativo puede estimular el ahorro de recursos, en este caso el sistema se basara en el menor consumo posible de energía, almacenando por medio de los rayos solares la energía suficiente para mantener activo el sistema.
5. AGRADECIMIENTOS
Este proyecto está patrocinado por la Quinta convocatoria para la financiación de proyectos para semilleros de investigación, de la vicerrectoría de investigaciones de la Universidad de Cartagena.
6. REFERENCIAS
1. Deveci, Onur, et al. “Design and development of a low-cost solar powered drip irrigation system using Systems Modeling Language.” Journal of Cleaner Production 102 (2015): 529-544.
2. Víctor, M, “Sistema de riego automatizado, ingenio colombiano” EL UNIVERSAL, 10 10 2013.
3. Yildirim, M., et al. “Drip Irrigation Automation With A Water Level Sensing System In A Greenhouse”. JAPS, Journal of Animal and Plant Sciences, 2016, vol. 26, no 1, p. 131-138.
4. Runge, T.A. and Downie, B.M “Intelligent Environmental Sensor For Irrigation Systems”, Google Patents, 2015. DOI= https://www.google.ch/patents/US20150032274
5. Cabrera Facundo, Ana Margarita, and Adrián Coutín Domínguez. “Las bibliotecas digitales: Parte I. Consideraciones teóricas.” Acimed 13.2 (2005): 1-1.
6. Campoverde, Ariel M., Dixys L. Hernández, and Bertha E. Mazón. “Cloud computing con herramientas open-source para Internet de las cosas.” Maskana 6.Supl. (2015): 173-182.
7. Ubidots. (2017) www.ubidots.com Obtenido de: https://ubidots.com/
8. Garciglia, R. S. (1 de 8 de 2016). Obtenido de Saber más: http://www.sabermas.umich.mx/archivo/secciones-anteriores/tecnologia/133-numero-17/268-paneles-solares-generadores-de-energia-electrica.pdf
9. Instituto Tecnológico Superior de Aranda. (7 de agosto de 2016). Subsecretaria de educación superior tecnologico nacional de méxico. Obtenido de www.tecarandas.edu.mx/descargas/seguidor_solar.pd
10. Universitat politécnica de Catalunya. (7 de agosto de 2016). Obtenido de: http://bibing.us.es/proyectos/abreproy/70271/fichero/02+INTRODUCCI%C3%93N+A+LA+ENERG%C3%8DA+FOTOVOLTAICA%252FIntroducci%C3%B3n+a+la+Energ%C3%ADa+Fotovoltaica.pdf
11. Espressif. (2017) www.espressif.com Obtenido de: http://espressif.com/en/products/hardware/esp8266ex/overview
12. Sensirion. (2017). sensirion.com. Obtenido de: https://www.sensirion.com
13. MANKAR, Jayant, et al. Review of I2C protocol. International Journal, 2014, vol. 2, no 1.
14. Sensirion. (2017). sensirion.com. Obtenido de: https://www.sensirion.com/fileadmin/user_upload/customers/sensirion/Dokumente/2_Humidity_Sensors/Sensirion_Humidity_Sensors_SHT21_Datasheet_V4.pdf
15. TAOS. (2017). alldatasheet. Obtenido de: http://pdf1.alldatasheet.com/datasheet-pdf/view/203054/TAOS/TSL2561.html
16. taloselectronics. (2017). taloselectronics.com. Obtenido de https://www.taloselectronics.com/producto/sensor-de-humedad-del-suelo/
17. Angular (2017). angular.io/. Obtenido de 18. https://angular.io/19. Node.js. (2017). nodejs.org/es/. Obtenido de https://
nodejs.org/es/20. MongoDB. (2017). www.mongodb.com. Obtenido de
https://www.mongodb.com/es21. Atom (2017). www.atom.io. Obtenido de:22. https://atom.io/23. Platform IO (2017). www.platformio.org. Obtenido
de: http://platformio.org/

CINSIS 2017 - Programa de Ingeniería de Sistemas
38
SISTEMA DE MEDICIÓN AUTOMATIZADA DE VARIABLES AMBIENTALES PARA AGRICULTURA DE PRECISIÓN CON SOFTWARE LIBRE
SISTEMA DE MEDICIÓN AUTOMATIZADA DE VARIABLES AMBIENTALES PARA AGRICULTURA DE PRECISIÓN CON SOFTWARE LIBRE
RESUMEN
El objetivo del presente trabajo fue desarrollar un prototipo de un sistema de medición de variables ambientales de bajo costo que permite el monitoreo agrícola automatizado de cultivos. Las principales herramientas utilizadas son el módulo Wi-Fi ESP8266-12F (o posterior), TSL2561, Sensor de humedad de suelo, SHT21, un servidor, un motor de base de datos y un Broker MQTT.
El proyecto está desarrollado bajo la metodología SCRUM, la metodología propuesta permitió obtener varios componentes, tales como recolección de datos, procesamiento, almacenamiento, alimentación, entre otros. Los cuales una vez finalizados, cumplen con los requerimientos que exige un sistema de monitoreo de variables ambientales.
Una breve explicación del cómo funciona el sistema comienza desde la recolección de datos del cultivo, seguida de la comunicación de dicha información a través de una red de microcontroladores, una vez se llega a un punto con acceso a internet la información pasa al servidor y puede ser visualizada por el mundo exterior a través de una página web que facilita la interacción entre el usuario y la red de sensores, brindando la opción de visualizar el sistema en tiempo real a través de internet desde cualquier lugar, manteniendo así informado al usuario final con un alto nivel de flexibilidad.
Como conclusión, se destaca el desarrollo de un sistema basado en arduino con una aplicación software para coordinar de forma eficiente la transmisión de un alto volumen de datos que son provenientes del sistema. Así mismo, en su construcción se utilizan dispositivos de propósito general de fácil consecución y bajo costo, estos elementos, así como su interfaz con el usuario, son programados con Software libre.
Palabras Claves: Monitoreo agrícola, Módulo Wi-Fi ESP8266-12F, Software Libre.
ABSTRACT
In the present project, a prototype of a system of measurement of environmental variables of low cost was developed that allows the agricultural monitoring of crops. The main tools to use are the Wifi module ESP8266-12F (or later), a wide variety of sensors, a server, a database engine, among other components.
The project was developed under the SCRUM development methodology, which, based on this methodology, divided the project into components, such as data collection, processing, storage, food, among others. Once completed, they comply with the requirements of a monitoring system for environmental variables.
Amaury CabarcasUniversidad de Cartagena
Piedra de Bolívar Av. del Consulado, Calle 30 No.39B – 192
Javier MontoyaUniversidad de Cartagena
Piedra de Bolívar Av. del Consulado, Calle 30 No.39B – 192
Daniel Reyes Betancourt Universidad de Cartagena
Piedra de Bolívar Av. del Consulado, Calle 30 No.39B – 192
Cristian Arrieta Pacheco Universidad de Cartagena
Piedra de Bolívar Av. del Consulado, Calle 30 No.39B – 192

CINSIS 2017 - Programa de Ingeniería de Sistemas
39
SISTEMA DE MEDICIÓN AUTOMATIZADA DE VARIABLES AMBIENTALES PARA AGRICULTURA DE PRECISIÓN CON SOFTWARE LIBRE
A brief explanation of how the system works starts from the collection of crop data, followed by the communication of that information through a network of microcontrollers, once you reach a point with access to the internet the information passes to the server and can be viewed by the outside world through a web page that facilitates interaction between the user and the sensor network, providing the option of visualizing the system in real time through the internet from anywhere, thus keeping the end user informed with a high level of flexibility.
With respect to novel aspects, the development of a system with circuits and software of its own authorship and with algorithms designed to coordinate efficiently the transmission of a high volume of data that comes from the system. Likewise, in its construction are used general purpose devices of easy attainment and low cost, these elements, as well as its interface with the user, are programmed with free software.
Keywords: Agricultural monitoring, Wi-Fi module ESP8266-12F, Free Software.
1. INTRODUCCIÓN
La necesidad de mejorar la producción agrícola de los campos en Colombia hace que se necesiten herramientas tecnológicas de apoyo en la toma de decisiones orientadas a la mejora de la producción de cultivos. Como herramienta orientada a este aspecto hemos visto de manera creciente el uso de la agricultura de precisión, la cual busca la mejora de los procesos productivos en el agro. La agricultura de precisión es el manejo diferenciado de los cultivos utilizando para ello diferentes herramientas tecnológicas (GPS, sensores planta-clima-suelo e imágenes multiespectrales provenientes tanto de satélites como de UAS/RPAS), a partir de este manejo diferenciado del cultivo podremos detectar la variabilidad que tiene una determinada explotación agrícola, así como realizar una gestión integral de dicha explotación. [2]
La Unidad de Planificación Rural Agropecuaria de Colombia (UPRA) tiene cifras que preocupan, este ente establece que más de la mitad de los predios en Colombia tienen un tamaño menor a 5 hectáreas y que 82% de la tierra productiva está en manos de 10% de los propietarios. Dicho de otro modo, las tierras son pequeñas y las áreas productivas no están siendo totalmente usadas y son abarcadas por pocos propietarios, por lo que muchos agricultores están trabajando bajo tierras no prosperas. Por otra parte, para el presidente de la sociedad de agricultores de Colombia, independiente del tamaño de la explotación agropecuaria, los productores colombianos deben tener un enfoque empresarial, que implica conocer los costos de producción, tener claros sus gastos y proyectar su rentabilidad [3]. Siguiendo esta idea, la implementación de la agricultura de precisión en las tierras suena como una solución real a este inconveniente.
La Organización de las Naciones Unidas para la Alimentación y la Agricultura estipula que Latinoamérica se establece como el granero del mundo y por lo tanto afirma que: “Para el año 2050 en el mundo habrá 9.300 millones de personas para alimentar y se requerirá un 50% o 60% más de los alimentos disponibles en el planeta, de los cuales el 85% proviene de la agricultura” [4]. Sin embargo, los agricultores en Latinoamérica presentan impedimentos a la hora de generar su desarrollo a nivel industrial, dentro de los cuales están, la poca investigación del terreno, las cadenas de comercialización ineficientes, la falta de financiamiento y asesoría, educación inadecuada en el tema y escasa inversión en infraestructura para el terreno, entre otros.
Como muestra de los resultados obtenidos al aplicar la agricultura de precisión, podemos situarnos en la provincia de Xin-jiang, China, donde se implementó un sistema compuesto por una red de sensores inalámbricos para monitorear la humedad del suelo en un cultivo de algodón. En dichos proyectos una red de sensores envía datos a un servidor el cual los recibía, almacena y analiza. Después de seis meses de su implementación se pudo apreciar que el sistema permitió determinar riesgos razonables, reduciendo considerablemente el consumo de agua y aumentando el crecimiento de la raíz de la planta [5].
Investigaciones como Precision Farming Technologies for Weed Control in the Mississippi Delta de James E. Hanks y Charles T. Bryson, en donde se buscó la comparación de dos tecnologías enfocadas a la agricultura de precisión en una cuenca del Mississippi, los cuales fueron relacionados a sistemas de gestión de área de evaluación (MDMSEA). Este proyecto consistía en rociar sólo cuando se presenta malezas, esto por medio de sensores de tipo reflectancia, la prueba ocurrió durante tres años en la cuenca del Lago

CINSIS 2017 - Programa de Ingeniería de Sistemas
40
SISTEMA DE MEDICIÓN AUTOMATIZADA DE VARIABLES AMBIENTALES PARA AGRICULTURA DE PRECISIÓN CON SOFTWARE LIBRE
Deep Hollow. Se Redujo en promedio en los 3 año en el uso de pesticidas con cada sistema en un 73% y 49%, respectivamente, para el algodón (43 ha) y la soja (47 ha). Evento confirmado por la evaluación de los sistemas de posicionamiento global (GPS) y sistemas de información geográfica (GIS) para el mapeo de malezas confirmó que reducciones significativas en el uso de herbicidas se pueden obtener con esta tecnología. []
Otro ejemplo es Precision Farming: Technologies and Information as Risk-Reduction Tools, en el cual se pretendía reducir los riesgos ambientales que se producen por el uso de plaguicidas con la mejora de la gestión ambiental y una mayor rentabilidad económica a través de un uso más eficiente de los recursos escasos. La información puede ayudar a los agricultores a reducir el uso de pesticidas, reducir la necesidad de aerosoles, reducir los costos de entrada y llevar la racionalidad ambiental y económica. Esto con el fin de explotar el potencial de la agricultura de precisión para localizar con exactitud las variables de población de plagas/malezas espacialmente, con lo que se requiere un sistema de aplicación selectiva [].
Ahora bien, Precision farming using unmanned aerial and ground vehicles, se basa en el diseño de un UAV (Vehículo aéreo no tripulado) completamente autónomo para la agricultura de precisión destinado al manejo de fincas. Dicho UAV proporciona imágenes espectrales de alta resolución. Como objetivo secundario del proyecto, se tuvo el desarrollo de un UGV (Vehículo terrestre no tripulado) equipado con múltiples sensores para proporcionar un alto nivel de autonomía para el modelado ambiental y obtener imágenes en tiempo real. Al trabajar los dos vehículos en conjunto se tendrán imágenes que se procesarán con índices específicos tales como: Índice de Vegetación de Diferencia Normalizada [NDVI], Índice de Vegetación de Diferencia Renormalizada [RDVI], Índice de Vegetación Ajustada al Suelo Optimizado [OSAVI], Índice de Vegetación de Diferencia Normalizada Mejorada [ENDVI] y Índice de Vegetación Ajustada al Suelo [SAVI] para obtener resultados útiles para el manejo de la finca [].
En el agro, otro componente clave es el uso de fertilizantes, por eso el uso óptimo del mismo es de gran interés para los agricultores. En la investigación nombrada Variable Rate Fertilizer Distributor in Precision Farming Based on PLC Technology, para lograr mejorar la racionalidad de la fertilización de los cultivos y disminuir la contaminación y los residuos, se usaron sensores ópticos sobre la base de
la tecnología PLC. El valor NDVI (Índice Vegetativo de Diferencia Normalizada) fue una escala para medir el estado de salud del cultivo. Según los datos en tiempo real del equipo NDVI, en conjunto con el algoritmo fuzzy aplicado en este proyecto, y un tractor que aplicó fertilizante a través del operador eléctrico, se indicó que el NDVI podría instruir fertilizante de tasa variable, y podría satisfacer con los requisitos planteados y con un margen de error permisivo [].
En Colombia existen proyectos con fines similares al anterior, pero no han tenido un alto impacto, un ejemplo de ello está en la Universidad del Cauca, dicho proyecto consistía en una red de sensores inalámbricos para el monitoreo de variables ambientales en un campo de café, pero se encontraron algunos problemas técnicos en la transmisión de los datos y el proyecto quedó en estudio [5].
Pero en términos generales la capacidad que tiene el país en materia de investigación en aspectos relacionados con las ciencias agrícolas es menor que en otras disciplinas. De acuerdo con Colciencias, en Colombia se registran en la Plataforma ScienTI 4.304 grupos reconocidos según lo establecido en la Convocatoria 640/2013 de Colciencias, concentrados en las áreas de ciencias sociales (36%), ciencias naturales (20%), ciencias médicas y de la salud (15%), ingenierías y tecnologías (15%), humanidades (9%) y en menor proporción ciencias agrícolas (5%). Para este último caso, se clasificaron 32 investigadores como sénior, 118 como asociado y 278 como junior [6].
La presente investigación contribuye en el desarrollo del material de investigación en el ámbito agrícola, ayudando al mejoramiento en este medio e incentivando a otros jóvenes a incursionar en este campo que aún no ha sido totalmente explotado.
Por último, el presente artículo está organizado de la siguiente manera, primero la metodología en la cual se mostrará que modelos y herramientas que se están usando para la realización del proyecto, y a su vez una breve explicación del cómo se están desglosando las actividades para el cumplimiento del proyecto. Seguidamente se tocará el apartado de resultados preliminares o parciales y discusión de los mismos, en el cual se exponen los resultados que se tienen hasta el momento del proyecto. Una vez abordado los anteriores temas, se procederá a dar conclusiones del proyecto y comentarios derivados de la investigación. Para dar finalización al documento se anexan las referencias que se usaron.

CINSIS 2017 - Programa de Ingeniería de Sistemas
41
SISTEMA DE MEDICIÓN AUTOMATIZADA DE VARIABLES AMBIENTALES PARA AGRICULTURA DE PRECISIÓN CON SOFTWARE LIBRE
2. METODOLOGÍA
Para la creación del proyecto se utilizó la metodología SCRUM, la cual suele introducirse en los procesos de desarrollo de software y presupone un conjunto de prácticas que agilizan los métodos de creación del proyecto, por lo tanto permite una mayor adaptabilidad a factores externos e impredecibles [17], en dicha metodología se dividive el proyecto en tareas y dichas tareas en actividades, partiendo de eso, se consideró factible dividir el proyecto en componentes, los cuales serán presentados más adelante en el texto.
2.1. Sistema de Medición de variables ambientales para agricultura de precisión
La agricultura de precisión está basada en el reconocimiento de la variabilidad espacial y temporal del clima, los suelos y los cultivos, y consecuentemente, de la importancia de proporcionar un manejo agronómico específico que tenga en cuentas esas diferencias [7]. A partir de este concepto se entiende que es de vital importancia obtener datos del espacio y que los sistemas puedan notar los cambios que se presentan en este. Pero que no es suficiente con que el sistema sea capaz de notificar dichos cambios, también se busca que les de un enfoque específico para tener un manejo del agro.
Por otra parte para entender el concepto medición de variables ambientales es preciso comenzar con el concepto de estaciones meteorológicas, las cuales sirven para captar diferentes variables físicas del entorno, tales como la luz, la velocidad del viento, humedad, entre otros, lo cual comprende el estudio de la agrometeorología [8].
La agrometeorología es la ciencia que estudia las condiciones meteorológicas, climáticas, hidrológicas y el papel que estos juegan en los procesos de la producción agrícola. La agrometeorología observa dichas variables y ayuda a predecir cuándo se acercan sequías, tornados, precipitaciones, etc [8].
De acuerdo con lo anterior, se entiende que las estaciones meteorológicas son un resultado de la agrometeorología, y estas se han convertido en referencia mundial de monitorización de datos atmosféricos, por consiguiente, es utilizada en todos los continentes y en casi todos los países. Son conocidas por su precisión, robustez, fiabilidad, su amplio rango de temperaturas de funcionamiento, y su bajo consumo [9]. Las estaciones meteorológicas ofrecen la flexibilidad para cambiar fácilmente la configuración
de los sensores, procesado de datos, almacenamiento y obtención de datos, pero no tienen como enfoque al proceso agrícola en sí, sino más bien al medio ambiente que lo rodea, esto debido a que sus datos no son para este fin.
Por lo tanto un sistema de medición de variables ambientales para agricultura de precisión es un sistema que no solo contempla la toma de datos sino también su procesamiento. Por otra parte las estaciones usualmente tienen un lugar específico para operar, pero al contemplar la necesidad de múltiples zonas es necesario la implementación de un sistema más complejo y que cubra dicha área.
Ilustración 1: Componentes generales del sistema de medición (Imagen creada por los autores).
Un bosquejo general de los componentes que se presentan en un sistema como el que se trabaja en el presente proyecto se instruye en la ilustración 1, la cual menciona que en estos sistemas es necesario tener componentes que se encarguen de la obtención de datos, procesamiento de estos, su almacenamiento y una manera de visualizarlos.
2.2. Diseño del sistema del Sistema de Medición de variables ambientales.
2.2.1. Obtención de datos
Se realizó una búsqueda y comparación de sensores, con el fin de establecer diferencias en cuanto al uso, precio y la precisión que puedan tener estos. Dentro de los sensores que se pretenden implementar están los sensores de: humedad del ambiente, temperatura del ambiente, intensidad lumínica, humedad del suelo y velocidad del viento.
Las medidas tomadas por los sensores vendrán en forma de corriente eléctrica y son transformadas en lenguaje

CINSIS 2017 - Programa de Ingeniería de Sistemas
42
SISTEMA DE MEDICIÓN AUTOMATIZADA DE VARIABLES AMBIENTALES PARA AGRICULTURA DE PRECISIÓN CON SOFTWARE LIBRE
natural por el código que se implementa en el controlador del sensor. Siguiendo con la idea anterior la humedad del aire se mide en %, esta varía entre 0% (cuando el aire está completamente seco) y 100% (cuando está completamente saturado), la humedad del suelo hace referencia a la cantidad de agua por volumen de tierra que hay en un terreno, la temperatura se mide en grados Celsius, la intensidad lumínica tiene como unidad de medida la candela (Cd) y por último la unidad de medida del viento es velocidad (Km/h).
2.2.2. Procesamiento
Los procesos investigativos en el sector agrícola, como los programas de mejoramiento de cultivos, no son ajenos a la necesidad de la intervención de las tecnologías de la información y las comunicaciones, como herramientas para la gestión de los grandes volúmenes de información que generan los mismos [15].
Teniendo en cuenta la diversidad de información que se recibe de los cultivos, es necesario elegir cuidadosamente las herramientas que permitirán el análisis de los grandes volúmenes de información que se recibirán de los cultivos. Para ello es necesario contar con una plataforma capaz de procesar de manera sencilla y rápida la información.
El procesamiento erróneo de la información recaería en un fallo catastrófico del sistema, quedando casi inutilizado el mismo, por ello es necesario una investigación previa antes de seleccionar una herramienta de procesamiento de datos.
En otro aspecto, como se es mencionado en la ilustración 1, en el apartado de procesamiento es necesario un servidor, este último debe cumplir con las necesidades antes mencionadas.
2.2.3. Almacenamiento
Para el almacenamiento en este tipo de sistemas es necesario tener en cuenta dos situaciones. La primera recae en cuando el sistema se encuentra caído o sin acceso a internet, en este contexto el sistema propuesto debe ofrecer una manera en la cual se pueda almacenar la información y ser reenviada a los servidores para que no haya pérdida de datos, se implementa una funcionalidad
del ESP8266, llamada SPIFF, consiste en un sistema de archivos común, que permite ser usado como microSD.La segunda situación se presenta cuando hay acceso a internet, en este caso el sistema no tiene por qué almacenar información de forma local, más bien debe concentrarse en el envió de paquetes para que estos sean posteriormente almacenados en la base de datos que utilice el sistema de almacenamiento.
2.2.4. Alimentación energética del sistema
Un aspecto que no se menciona en la ilustración 1, es el apartado de la energía del sistema. El sistema se divide en una parte de recolección de datos, compuesta por módulos y otra “virtual”, que está compuesta por el servidor en la nube. La primera debe poder ser auto sostenible, para llevar a cabalidad este propósito es necesario la implementación de baterías recargables por energía solar o por otro medio de energía renovable que aproveche las cualidades del lugar en donde fue instalado el sistema.
2.2.5. Comunicación entre componentes
Este apartado tampoco se encuentra contemplado en la ilustración 1, y hace referencia al cómo se intercomunican los elementos del sistema. Los nodos que se encargan de la recolección de información deben enviar esa información a través de otros nodos hasta llegar a uno que tenga acceso a internet, para esto se implementa una especie de malla entre los nodos para que estos se comuniquen entre sí, luego una vez se llegue al nodo encargado del envió se necesita que esta información llegue al servidor, y para ello se implementan protocolos de comunicación máquina a máquina. Por último, el servidor se encargará del procesamiento de esa información y la mostrará en formato HTML.
3. PROTOTIPO DEL SISTEMA DE MEDICIÓN DE VARIABLES AMBIENTALES.
Para el prototipo del Sistema de Medición de variables ambientales se requiere crear un “empaque” para los sensores y el microcontrolador, el cual los protege de los cambios climáticos que serán sometidos una vez se encuentre en el campo. Y dicho prototipo debe cumplir con los componentes presentes en el diagrama de la ilustración 2.

CINSIS 2017 - Programa de Ingeniería de Sistemas
43
SISTEMA DE MEDICIÓN AUTOMATIZADA DE VARIABLES AMBIENTALES PARA AGRICULTURA DE PRECISIÓN CON SOFTWARE LIBRE
Ilustración 2 : Componentes definidos del Sistema de medición de variables ambientales (Imagen creada por los
autores).
El diseño del proyecto está basado en una red de nodos conectados por WIFI, en la que los datos deberán viajar por dicha red y cumplir con el procedimiento ya antes mencionado en los anteriores apartados.
3.1. Diagrama de Bloques
El diagrama de bloques que se encuentra en la ilustración 3, representa los subsistemas que conforman el prototipo de medición de variables ambientales, éste consta de tres partes: la obtención de datos que se realiza a través del sensor de temperatura, humedad del aire, humedad del suelo y luminosidad, el procesamiento que se realiza a través de una placa de control que para este caso es el módulo ESP8266-12F y la salida de información que se realiza a través de la visualización de estadísticas de dichas variables en un portal web.
Ilustración 3 : Diagrama de bloques del Sistema de medición de variables ambientales (Imagen creada por los
autores).
4. RESULTADOS PRELIMINARES
Para el control de la obtención de datos se determinó que el ESP8266-12F es el encargado de coordinar y comunicar los datos obtenidos por los sensores. En particular en este proyecto se usa el Módulo ESP8266, el cual es un SOC (System on chip) autónomo, con pila de protocolos TCP / IP integrado que puede dar acceso a cualquier microcontrolador a la red WiFi. El ESP8266 es capaz de alojar una aplicación o descargar todas las funciones de red Wi-Fi desde otro procesador de aplicaciones. [1]. El ESP8266-12F es un chip altamente integrado, diseñado para las necesidades de un nuevo mundo interconectado, este microcontrolador se encarga de dirigir el funcionamiento de cada uno de los sensores que se utilizarán en el diseño del prototipo, ofrece una solución completa y autónoma de las redes Wi-Fi gracias a su arquitectura interna, la cual se puede apreciar en la ilustración 4, dicha estructura para fines del proyecto ahorraría recursos económicos en cuanto a la conectividad que se quiere tener, además, su programación a nivel software es compatible con lenguajes de programación abiertos de alto nivel como C, C++ y Lua.
Ilustración 4: Módulo WiFi ESP8266-12F (Microcontrolador)[18]
Seguidamente, se realizaron comparaciones preliminares de sensores y se decidieron los siguientes para poder censar las variables de luminosidad, temperatura, humedad del suelo y del ambiente. Los cuales corresponden a los sensores SHT21, TSL2561 y YL-69.
Ahora bien, el sensor SHT21, es un sensor de humedad y temperatura de Sensirion, con un chip diseñado por CMOSens® y se comunica por medio del protocolo I2C de manera digital. Cuenta con un sensor de humedad de tipo capacitivo reelaborado y sensor de temperatura de

CINSIS 2017 - Programa de Ingeniería de Sistemas
44
SISTEMA DE MEDICIÓN AUTOMATIZADA DE VARIABLES AMBIENTALES PARA AGRICULTURA DE PRECISIÓN CON SOFTWARE LIBRE
banda ancha que mejora el rendimiento e incluso más allá del nivel sobresaliente de la generación de sensor anterior (SHT1x y SHT7x) [10]. Su estructura se puede observar en la ilustración 5.
al aumentar la humedad la corriente crece y al bajar la corriente disminuye. Para entender su estructura vea la ilustración 7.
Consiste en una sonda YL-69 con dos terminales separados adecuadamente y un módulo YL-38 que contiene un circuito comparador LM393 SMD (de soldado superficial) muy estable, un led de encendido y otro de activación de salida digital. Este último presenta 2 pines de conexión hacia el módulo YL-69, 2 pines para la alimentación y 2 pines de datos. VCC, GND, D0, A0 [12].
Ilustración 5 : Esquema electrónico del módulo del sensor de humedad y temperatura SHT21 (Imagen Creada por
los autores)
Por otra parte el TSL2561 es un convertidor de luz a señal digital que transforma la intensidad de la luz en una salida y es enviada por medio del protocolo I2C. Este dispositivo combina un fotodiodo de banda ancha (visible más en infrarrojo) y un fotodiodo de respuesta infrarroja en un solo circuito integrado CMOS capaz de proporcionar una respuesta casi fotópica sobre un rango dinámico efectivo de 20 bits (resolución de 16 bits) [11]. Su estructura se puede ver en la ilustración número 6.
Ilustración 6 : Esquema electrónico del módulo del sensor de luminosidad TSL2561 (Imagen creada por los autores)
No menos importante tenemos al YL-69, el cual tiene la capacidad de medir la humedad del suelo, aplicando una pequeña tensión entre los terminales del módulo, y esto hace pasar una corriente que depende básicamente de la resistencia que se genera en el suelo y el cual obedece mucho a la cantidad de humedad. Por lo tanto,
Ilustración 7 : Esquema electrónico del módulo del sensor de humedad de suelo YL-69 (Imagen creada por los
Autores)
Para la creación del servidor se pretende usar Node.js, el cual es un entorno de ejecución para JavaScript construido con el motor de JavaScript V8 de Chrome, se elige esta plataforma gracias a la facilidad de conexión que tiene con el microcontrolador ESP8266, Node.js usa un modelo de operaciones E/S sin bloqueo y orientado a eventos, que lo hace liviano y eficiente [13].
Y para el almacenamiento de información se cuenta con MongoDB que es la base de datos NoSQL líder y permite a las empresas ser más ágiles y escalables. Organizaciones de todos los tamaños están usando MongoDB para crear nuevos tipos de aplicaciones, mejorar la experiencia del cliente, acelerar el tiempo de comercialización y reducir costes [14].
En otra instancia, la comunicación entre la obtención de datos y el procesamiento se hace por medio del protocolo MQTT, se decidió este protocolo por su fácil implementación y manejo. El protocolo está pensado para ser utilizado en redes inalámbricas y con bajo ancho de banda. Una aplicación móvil que utiliza MQTT envía y recibe mensajes llamando a una biblioteca de MQTT. Los mensajes se intercambian a través de un servidor de mensajería de MQTT. El cliente y el servidor de MQTT manejan las complejidades de entregar mensajes de forma fiable para la aplicación móvil y mantener bajo el precio de la gestión de red. [16]

CINSIS 2017 - Programa de Ingeniería de Sistemas
45
SISTEMA DE MEDICIÓN AUTOMATIZADA DE VARIABLES AMBIENTALES PARA AGRICULTURA DE PRECISIÓN CON SOFTWARE LIBRE
5. CONCLUSIONES
En conclusión, el sistema que se desarrolla siguiendo esta propuesta puede analizar en tiempo real el estado de las zonas donde se encuentran las plantas de un cultivo, para ello será necesario que un potencial usuario final decida dividir el terreno en cuadrículas lo más pequeñas que sea posible. En una situación ideal se tendría un nodo de sensores por cada planta, el cual nos proporciona un índice de humedad del suelo en el sitio donde está sembrada la planta, la temperatura y humedad de esa planta en específico, también determinaría si está siendo golpeada y con qué intensidad por lo rayos del sol y, por último, nos diría si está siendo sometida a vientos fuertes o moderados.
De lo anterior es importante aclarar que no se espera que haya señales o elementos que entorpezcan la comunicación de los nodos. Además, la presente investigación en un estado ideal daría suficiente información, como para no tener que optar con otras tecnologías, pero dado que este es un prototipo es necesario brindarle soporte con otros medios, tales como drones, fotografías, expertos, etc.
En síntesis, este proyecto se enfoca en implementar el prototipo en un terreno de siembra, pero al no contar con uno propio se pretende usar las instalaciones de la Universidad de Cartagena, más específico sus zonas verdes como lugares de prueba, en esas zonas se tendrá un arreglo denso cuadriculado de nodos con sensores de medición, cada uno con capacidad de comunicar los datos recolectados vía inalámbrica.
Es importante considerar que la implementación de un sistema completo de monitoreo para plantas o agros específicos va más allá del alcance del presente proyecto, esto debido a las diferentes necesidades que se presentan por particularidades específicas del agro y por el momento no se cuenta con suficiente información para anexarlas en el proyecto.
Pero se establecerán colaboraciones con grupos de investigación que hoy en día realizan recorridos semanales de cultivos y que aplican en ellos técnicas avanzadas de fotografía aérea de amplio espectro, quienes podrán complementar más adelante sus actividades con el análisis de la información registrada por los sensores que se desarrollarán en este proyecto e incluirán esa información en discusiones que involucran a todo un equipo de expertos.
Finalmente, en cuanto se esté en una etapa posterior al prototipo, y ya se tenga una versión preliminar del proyecto, el equipo de expertos con quienes se buscará colaboración, ayudará a definir líneas guías sobre qué hacer en cada situación no esperada y con estos parámetros el personal técnico encargado del monitoreo de un cultivo particular podrá ofrecer un dictamen sobre cómo se encuentra el cultivo y qué medidas tomar.
6. REFERENCIAS
[1]Dinero, «www.Dinero.com,» [En línea]. Available: http://www.dinero.com/edicion-impresa/pais/articulo/sociedad-de-agricultores-busca-empresarizar-el-campo/244551.
[2]Dinero, «Dinero.com,» 2017. [En línea]. Available: http://www.dinero.com/economia/articulo/agricultura-en-america-latina-segun-foro-de-alianza-del-pacifico/244481.
[3]mikrocontroller, «https://www.mikrocontroller.net,» 23 08 2015. [En línea]. Available: https://www.mikrocontroller.net/attachment/286085/ESP8266-12F_Tronixlabs_Australia.pdf.
[4]D. C. García y J. José, Estudio de Índices de vegetación a partir de imágenes aéreas tomadas desde UAS/RPAS y aplicaciones de estos a la agricultura de precisión, MADRID: UNIVERSIDAD COMPLUTENSE DE MADRID, 2015.
[5]J. C. Suárez Barón y M. J. Suárez Barón, «Monitoreo de variables ambientales en invernaderos usando tecnología Zigbee,» Revista Ingeneria al Dia, 2014.
[6]CORPOICA,-«colaboracion.dnp.gov.co,» -4-2015. [En-línea].Available: https://colaboracion.dnp.gov.co/CDT/Agriculturapecuarioforestal%20y%20pesca/Diagn%C3%B3st ico%20de%20la%20Ciencia,%20Tecnolog%C3%ADa%20e%20Innovaci%C3%B3n%20en%20el%20Sector%20Agropecuario-CORPOICA.pdfhttps://colaboracion.dnp.gov.co/CDT/Agriculturapecuario.
[7]I. A. Lizarazo Salcedo y O. A. A. Carvajal, «Aplicaciones de la agricultura de precisíon en palma de aceite “Elaeis Guineensis” e hibrido O x G,» 2011.
[8]Departamento de Agronomía Universidad Nacional del sur, «http://agrometeorologia.criba.edu.ar/,» 18 Octubre 2001. [En línea]. Available: http://agrometeorologia.criba.edu.ar/.
[9]Campbell, «ftp.campbellsci.com,» 4 Mayo 2001. [En línea]. Available: ftp://ftp.campbellsci.com/pub/csl/outgoing/es/leaflets/estaciones_meteo_campbell_high_res.pdf.

CINSIS 2017 - Programa de Ingeniería de Sistemas
46
SISTEMA DE MEDICIÓN AUTOMATIZADA DE VARIABLES AMBIENTALES PARA AGRICULTURA DE PRECISIÓN CON SOFTWARE LIBRE
[10]Sensirion,«staging1.unep.org,»Diciembre2011.[Enlínea]. Available:http://staging1.unep.org/uneplive/media/docs/air_quality/aqm_document_v1/Blue%20Print/Components/Microcomputer%20a n d % 2 0 s e n s o r s / D . % 2 0 S u p p o r t i n g % 2 0Sensors/D.1%20Temp%20&%20Humid i ty/Datasheet%20SHT21.pdf.
[11]TAOS, «Alldatasheet,» [En línea]. Available:http://pdf1.alldatasheet.com/datasheet-pdf/view/203054/TAOS/TSL2561.html.
[12]Taloselectronics, «www.taloselectronics.com,»[En línea].Available: https://www.taloselectronics.com/producto/sensor-de-humedad-del-suelo/.
[13]Node.js, «www.nodejs.org,» 2017. [En línea]. Available:https://nodejs.org/es/.
[14]MongoDB, «www.mongodb.com/es,» [En línea].Available: https://www.mongodb.com/es.
[15]R. Morejon Rivera, F. A. Camara, D. E. Jimenezy S. H. Diaz, «SISDAM: aplicacion web para el procesamiento de datos segun un Diseno AumentadoModificado,» Editorial Universitaria de la Republicade Cuba, 2016.
[16]IBM,«www.ibm.com,»[Enlínea].-Available: https://www.ibm.com/support/knowledgecenter/es
/SS9D84_1.0.0/com.ibm.mm.tc.doc/tc00000_.htm.[17]Fokina, A. (2016). Scrum Methodology and Sales Force
in the tourism sector: a project developed at Ubiwhere ; Metodologia Scrum e Força de Vendas no setor do Turismo: um projeto desenvolvido na Ubiwhere. Universidade de Aveiro: PROA-UA (Plataforma de Revistas em Open Access da Universidade de Aveiro).
[18]WATTEROTT,«www.watterott.com»[Enlínea].-Available:http://www.watterott.com/en/ESP8266-ESP-12F-WiFi/WLAN-Module

CINSIS 2017 - Programa de Ingeniería de Sistemas
47
SISTEMAS EXPERTOS PARA DETERMINAR LA CALIDAD DE LA MIEL: UNA REVISIÓN BIBLIOGRÁFICA
SISTEMAS EXPERTOS PARA DETERMINAR LA CALIDAD DE LA MIEL: UNA REVISIÓN BIBLIOGRÁFICA
RESUMEN
En esta ponencia se presenta un rastreo bibliográfico sobre la posibilidad de usar sistemas expertos para la determinación de la calidad de la miel, encontrándose en general, que no existe experiencias previas de uso de sistemas expertos con este propósito y además se evidenció también la ausencia de protocolos de seguimiento de la calidad de la miel de abejas, que se destina al consumo humano en Colombia. Se tiene como propósito construir un sistema experto que podrá ser aprovechado por gran parte de los actores de la cadena productiva de la miel, especialmente por los productores apícolas, los consumidores, los organismos de control sanitario y los diseñadores de la política pecuaria, pues se generará una herramienta informática útil para la determinación de la calidad de la miel de abejas, basada en propiedades fisicoquímicas. Se usará la metodología de desarrollo de sistemas expertos conocida como metodología IDEAL. Al momento de la escritura de esta ponencia se ha avanzado en la revisión bibliográfica acerca de la manera en que se determina la calidad de la miel, a partir de sus propiedades fisicoquímicas, y la forma en que los sistemas expertos son usados en el campo agro-pecuario.
Palabras Clave: Sistema Experto, Calidad, Miel.
Eliécer Pineda BallesterosUNAD
BucaramangaCarrera 27 # 40-4357+037-6358577
Alberto Castellanos RiverosUNAD
BucaramangaCarrera 27 # 40-4357+037-6358577
Freddy Reynaldo Téllez AcuñaUNAD
BucaramangaCarrera 27 # 40-4357+037-6358577
1. INTRODUCCIÓN
La agenda prospectiva de investigación en la cadena productiva agroindustrial de las abejas y la apicultura de Colombia [1] establece que el mundo se encuentra en la mega-tendencia de los alimentos naturales, sostenibles ambientalmente, lo que hace que los productos y servicios de la apicultura se encuentren en una dinámica de mercado en crecimiento. Es una interesante y nueva oportunidad para la apicultura colombiana, no solo de cubrir y llegar a nuevos mercados internacionales sino, sobre todo, de atender el mercado interno, con amplias perspectivas de crecimiento. Para [1] Colombia ocupa el puesto 70 a nivel internacional en la producción de miel de abejas, su consumo interno per cápita es muy bajo, solo 35 gramos al año, comparado con el internacional que es de 205 gramos.
Según el IFE [2], la demanda a nivel internacional aumenta, pero la producción de algunos países disminuye, ya sea por enfermedades o por ausencia de recursos. En
este contexto se presenta una gran oportunidad para los productores nacionales de miel, quienes podrían acceder a la cualificación que los habilita para determinar y garantizar, de forma científica, la calidad de la miel. Lo anterior se constituye en un valor agregado, que se podría reflejar en un incremento de la oferta, en respuesta a una demanda mayor, lo que finalmente se podría traducir en un mejoramiento del ingreso de los productores y la generación de nuevos estilos de vida. La miel certificada permitiría aportar en aspectos tan diversos como la alimentación sana, la cosmética, el tratamiento de enfermedades, que, entre otros usos, se pueden constituir en factores que determinan un gran potencial para el sector apícola en Colombia.
A partir del rastreo bibliográfico se encontró que en Santander no hay información de seguimiento sobre la calidad de la miel de abejas, vista esta como producto comercial; sin embargo, en Colombia sí se realizan actividades en este sentido en la apicultura, pero el desarrollo de ese potencial no se ve reflejado en la

CINSIS 2017 - Programa de Ingeniería de Sistemas
48
SISTEMAS EXPERTOS PARA DETERMINAR LA CALIDAD DE LA MIEL: UNA REVISIÓN BIBLIOGRÁFICA
práctica. Evidencia de lo antes señalado está en que el bajo consumo interno parece obedecer a la desconfianza del consumidor frente a la calidad de la miel. En parte, la calidad de la miel se manifiesta en términos de su legitimidad de origen; pero al momento de escribir este artículo no existe ningún ente a nivel regional o nacional que garantice dicha legitimidad. Otro aspecto a considerar lo constituye el hecho que las entidades de control, como el Invima o las secretarías de agricultura, no poseen protocolos que permitan a los productores garantizar la calidad de su miel y formalizar de esta manera su goodwill.
Con lo antes expuesto se podría señalar que la apicultura en Colombia adolece de un estímulo a su consumo interno, [3] y que este obedece, entre otras causas, a que no se garantiza la oferta de una miel de calidad. En este contexto la universidad está llamada a implementar los protocolos normativos que permitan determinar de manera científica, la calidad de la miel, a partir de un reconocimiento inicial de esa calidad mediante el uso de herramientas de corte tecnológico como los sistemas expertos.
La existencia de protocolos que permitan la determinación de la calidad de la miel, puede contribuir a que se resuelvan los problemas de producción y por tanto de consumo en el país; necesariamente la determinación de los protocolos de calidad y el uso de sistemas expertos requiere del acompañamiento a los productores, que debería ser realizado por los organismos de control, aplicando los resultados de investigación, inicialmente en relación a la garantía que tiene la miel que se comercializa en Santander.
2. MATERIALES Y MÉTODOS
2.1. La revisión bibliográfica
Se usó el método de revisión bibliográfica, tomando como referente conceptual lo expuesto por autores como [4] [5] [6] y [7]. Señala [8] que no hay reglas con respecto al número óptimo de referencias bibliográficas que deban incluirse en una revisión de estado del arte.
La selección de artículos de investigación para su análisis se realizó tomando como referencia el sistema Scopus, contemplando los siguientes criterios de selección:
• Fechas de publicación: 2010 en adelante, sin dejar de revisar textos clásicos.
• El artículo presenta una experiencia relacionada con el análisis de la calidad de la miel.
• El artículo describe el uso de sistemas expertos en la agroindustria.
• Se seleccionan solo artículos disponibles a texto completo.
• El artículo profundiza sobre la determinación de la calidad de la miel y/o el uso de TI en el proceso.
• Palabras clave utilizadas: Sistemas Expertos AND Expert Systems AND Quality AND Honey AND Físico-Químico AND Organoléctica AND Physical-Chemical AND Organoleptic AND Calidad de la Miel
Las referencias recuperadas se organizaron por fecha de publicación para realizar un proceso de selección y posteriormente por relevancia. Con cada referencia que cumplía con los criterios de selección se procedía a realizar la búsqueda del artículo completo en las bases de datos Academic Search Complete (EbscoHost), Journal Storage, Compendex, Elsevier Directory of Open Access Journals e Internet, en caso de que no se encontrara el artículo a texto completo se excluía la referencia. Los artículos seleccionados se revisaron completamente y se procedió a sintetizar los aspectos más relevantes de cada uno de los mismos registrándolos en una matriz de análisis que contiene los siguientes aspectos: Palabras de búsqueda, Base de datos, Palabras claves, Referencia, Tipos de miel, Pregunta o problema de investigación, Materiales y métodos, Parámetros de análisis, Análisis estadístico usado, Software o tecnología usada y Conclusiones.
2.2. La construcción de Sistemas Expertos
Para la construcción de un sistema experto, actualmente se pueden emplear varias metodologías, entre las que se puede mencionar la metodología del Ciclo de Vida del Software la cual consta de 6 etapas: análisis previo, análisis de la tarea, construcción del prototipo, desarrollo del sistema, pruebas de campo e instalación y mantenimiento. El Método de Grover [9] se concentra en la definición del dominio, el cual consiste en realizar una cuidadosa interpretación del problema y documentarla, elaborando un manual de definiciones del dominio; y la formulación del conocimiento fundamental, esta etapa tiene como objetivo examinar los escenarios ejemplo a partir de criterios de evaluación y reclasificarlos.
En el Método de Buchanan y Duda [10] se destacan 6 etapas fundamentales que son Identificación: seleccionar al experto, fuentes y medios de conocimiento y clara

CINSIS 2017 - Programa de Ingeniería de Sistemas
49
SISTEMAS EXPERTOS PARA DETERMINAR LA CALIDAD DE LA MIEL: UNA REVISIÓN BIBLIOGRÁFICA
definición del problema; Conceptualización: encontrar los conceptos claves y las relaciones necesarias para caracterizar el problema; Formalización; Implementación; Testeo y Revisión del Prototipo: rediseño y refinamiento del sistema implementado. El Método de Grover es, junto con el de Buchanan, uno de los más importantes para el diseño de una base de conocimiento. El método de Grover, además de definir una serie de etapas, propone un énfasis en la documentación de los procesos, los cuales reemplazarían parcialmente al experto y servirían de medio de comunicación y referencia entre los usuarios y los diseñadores.
La Metodología de Weiss y Kulikowski [11] se basa en las siguientes etapas: Planteamiento del problema, Encontrar expertos humanos que puedan resolver el problema, Diseño de un sistema experto, Elección de la herramienta de desarrollo, Desarrollo y prueba de un prototipo, Refinamiento y generalización, Mantenimiento y puesta al día. En la Metodología Proceso Unificado, el proceso se repite a lo largo de una serie de ciclos que constituyen la vida del sistema. Cada ciclo constituye una versión del producto. Consta de cuatro fases (Inicio, Elaboración, Construcción y Transición), atendiendo al momento en que se realizan.
La metodología IDEAL [12], presenta un ciclo de vida en tres dimensiones. Su base es un modelo en espiral y la tercera dimensión representa el mantenimiento perfectivo una vez implementado el Sistema Experto (S.E.). La metodología IDEAL consta de cinco fases, a saber: Identificación de la tarea, Desarrollo de los prototipos, Ejecución de la construcción del sistema integrado, Actuación para conseguir el mantenimiento perfectivo y Lograr una adecuada transferencia tecnológica.
3. ANÁLISIS DE LA LITERATURA
3.1. Antecedentes en la determinación de la calidad de la miel
En [1] se señala que la apicultura colombiana es una actividad económica en consolidación, caracterizada por la presencia de un gran número de apicultores, que generan productos de las abejas de interés para los mercados, principalmente, la miel de abejas y otros productos como el polen, los propóleos y la jalea real. Más adelante mencionan que en el diagnóstico llevado a cabo, a partir de la consulta hecha a los actores sociales sobre la prioridad en cuanto al mercado objetivo, dio como resultado unánime que es la atención del mercado interno
la mayor prioridad de los apicultores, entendida como la sustitución parcial de las importaciones de miel, el logro de nuevos consumidores colombianos y la captación de un porcentaje del mercado de mieles que hoy es atendido con sustitutos edulcorados.
Con respecto de la calidad de la miel, existe suficiente reglamentación, la más reconocida es el Codex Standar For Honey [13], que define técnicas aceptadas para certificar la calidad de una miel de origen apícola. Adicional a lo anterior existe la comisión internacional de la miel (International Honey Commission) que define los requerimientos de calidad y determina los criterios de aplicación de procedimientos de evaluación específicos. En Colombia se tienen las normas NTC (1273 de 2007) [14] y la resolución 1057 de 2010 [15] en donde se estableció el reglamento técnico sobre los requisitos sanitarios que debe cumplir la miel de abejas para el consumo humano en Colombia y en particular, los requisitos fisicoquímicos.
El departamento de Bolívar, según [16], cuenta con algunos sistemas de producción apícola no tecnificados, carentes de controles reglamentarios que garanticen la calidad de las mieles cosechadas. Los autores citados evaluaron también la aceptabilidad y presencia de adulterantes en mieles de Apis mellifera comercializadas en 6 zonas de Cartagena.
En un trabajo realizado por [17] para determinar la calidad de la miel en la provincia de Huesca – España, en muestras tomadas entre 1997 y 1998, encontraron que los valores medidos de las muestras tomadas no superaron los niveles máximos permitidos por las legislaciones aragonesa y española, por lo que dedujeron en su momento que la miel allí producida era de excelente calidad, excepto para el HMF (Hidroximetilfurfural) en algunas muestras.
En otro estudio [18] se analizaron las características organolépticas, físico-químicas y biológicas de las mieles de Santiago del Estero, Argentina. Una investigación hecha en Cuba por [19] determinó las características organolépticas y físico-químicas de la miel producida por Melipona beecheii. En este mismo sentido investigadores de la Provincia de La Pampa – Argentina [20], evaluaron miel de abejas en función de sus características físico-químicas y microbiológicas. En México [21] realizaron una investigación que tenía como propósito evaluar la calidad fisicoquímica de las mieles de las abejas melíferas producidas en el estado de Yucatán. Finalmente se refiere un trabajo realizado en Venezuela sobre las mieles de abejas sin aguijón, producidas por abejas de la subfamilia

CINSIS 2017 - Programa de Ingeniería de Sistemas
50
SISTEMAS EXPERTOS PARA DETERMINAR LA CALIDAD DE LA MIEL: UNA REVISIÓN BIBLIOGRÁFICA
Meliponini y según [22] existen pocos estudios sobre su composición y ningún país ha elaborado estándares para su control de calidad.
La caracterización de la miel es un tema importante en la industria alimentaria y de interés para los consumidores, investigadores como [23] [24] [25] [26] [27] [28] y [29] orientaron su trabajo en determinar las propiedades antiinflamatorias, antibacterianas, sus propiedades antioxidantes y bioquímicas de la miel. Estos estudios se concentraron en determinar los usos de la miel teniendo en cuenta sus propiedades terapéuticas, su gran valor nutricional y sabor, el cual puede ser usado para reemplazar otros edulcorantes. Los autores también refieren que, frente a la creciente aparición de cepas bacterianas resistentes a los antibióticos, la miel aparece como apropiada para realizar tratamientos alternativos sobre úlceras, quemaduras y heridas a partir de su efecto protector contra el estrés oxidativo.
Antecedente sobre Sistemas Expertos
Durante la búsqueda bibliográfica, no se encontraron trabajos directamente relacionados con la determinación de la calidad de la miel usando sistemas expertos (SE), por esta razón se procedió a indagar sobre antecedentes que dieran cuenta del uso de los SE para determinar la calidad de algún producto o que ilustrara sobre su uso.
En la Argentina [30] desarrollaron un sistema experto para clasificar la calidad de muestras de granos pulidos de arroz empleando procesamiento de imágenes y así determinar las características morfológicas y de aspecto de cada grano, con la finalidad de evaluar el tipo y la calidad de una muestra. La determinación de las características morfológicas se basó en la forma del contorno de la superficie expuesta de los granos y para las características de aspecto empleó un análisis estadístico de la distribución de niveles gris de los pixeles.
Otro sistema experto en el entorno agrícola [31], fue desarrollado para el diagnóstico del estado nutrimental de naranjos, empleando información sistematizada de especialistas, referencias bibliográficas, fórmulas elaboradas para la interpretación del análisis foliar y fotografías de deficiencias [32]. El sistema experto puede diagnosticar deficiencias cuando el usuario introduce la sintomatología visual, a través de preguntas y respuestas, mientras interactúa con el sistema.
Siguiendo en el ambiente agrícola [33] construye un sistema experto para el diagnóstico de plagas insectiles de maíz en Centro América, buscando poner a disposición el conocimiento técnico para el diagnóstico de insectos y plagas, y facilitar el manejo integrado de plagas en este cultivo. El trabajo se hizo con base al conocimiento adquirido de expertos del proyecto de manejo integrado de plagas. El sistema experto puede diagnosticar hasta 52 insectos y plagas del maíz, por medio de seis módulos de inferencia. En dicho S. E. se usan como criterios: la fenología de la planta, el órgano de la planta dañado, la forma general del insecto, la forma específica de insecto, el daño general, el daño específico, el orden del insecto y la familia del insecto.
En este sentido [34], construyen un sistema experto para el diagnóstico de las plagas y enfermedades del espárrago, usando la técnica de propagación de certeza, la cual permite la actualización de nodos dentro de la red, alcanzando resultados con un margen de diferencia de centésimas con respecto al cálculo exacto de la Tabla de distribución conjunta completa usando un algoritmo de enumeración. El sistema experto permite establecer resultados coherentes de acuerdo a los patrones convencionales de cada germen patógeno y sus manifestaciones. El sistema también es adaptable a cualquier entorno, con el estudio estadístico de síntomas y enfermedades dentro de dicho entorno, como información a priori para el sistema experto.
De otra parte en [35] dan cuenta de un sistema experto diseñado para apoyar a los cultivadores, en el proceso de toma de decisiones sobre el proceso de irrigación del cultivo de maíz en Aguascalientes, México, constituyéndose este en una alternativa real para los productores de maíz en la medida en que considera, para sugerir acciones, las condiciones de clima y suelo de cada municipio, los sistemas y equipos de riego con que cuentan los agricultores.
4. CONCLUSIONES
Existen evidencias, en la revisión bibliográfica, de que el uso de las tecnologías de la información y en especial de técnicas de la inteligencia artificial, como los sistemas expertos, aporta herramientas que pueden contribuir para la efectiva toma de decisiones, por parte de los agentes de la cadena productiva de la miel, en este caso, y fomenta además la promoción de buenas prácticas en la producción y comercialización de la miel de abeja.

CINSIS 2017 - Programa de Ingeniería de Sistemas
51
SISTEMAS EXPERTOS PARA DETERMINAR LA CALIDAD DE LA MIEL: UNA REVISIÓN BIBLIOGRÁFICA
Al momento de la escritura de este texto se han hecho valoraciones en el laboratorio de más de 10 muestras de diferentes tipos de miel comercializada en Santander, hecho que permitirá aportar el conocimiento necesario para la construcción de la respectiva base de conocimientos, que se será elaborada usando las reglas de producción y posteriormente se implementará con el software Visual Prolog. Este conocimiento se obtiene en el laboratorio, debido a la especificidad del mismo, pues no se dispone de información formal a nivel local, salvo la documentación de referencia europea y alguna regulación en países de América del sur y en Colombia.
Uno de los análisis que con mayor frecuencia se encuentra en la literatura, es el que se basa en el análisis de los parámetros fisicoquímicos más comunes, a saber: humedad, conductividad eléctrica, acidez libre, carbohidratos, HMF, color, rotación óptica y pH.
Luego de hecha la revisión de antecedentes, relacionada con la construcción de sistemas expertos para la determinación de calidad de productos agropecuarios, se encontró que la literatura no reporta antecedentes relacionados con la determinación de la calidad de la miel, por lo que se identifica un vacío en el conocimiento que requiere abordarse y que da plena justificación a la ejecución de esta propuesta.
5. REFERENCIAS
[1] J. C. Laverde, L. M. Egea, D. M. Rodríguez y J. E. Peña, Agenda prospectiva de investigación y desarrollo tecnológico para la cadena productiva de las abejas y la apicultura en Colombia con énfasis en miel de abejas, Bogotá: Ministerio de Agricultura y Desarrollo Rural, 2010.
[2] L. Haberle y A. Zarratea, Informe Internacional de la Miel –Quinquenio 2009-2013, Corrientes: Instituto de Fomento Empresarial, 2014.
[3] O. A. Sánchez, P. C. Castañeda, G. Muños y G. Tellez, «Aportes para el análisis del sector apícola Colombiano,» CienciAgro, vol. 2, nº 4, pp. 469-483 , 2013.
[4] J. W. Barbosa, J. C. Barbosa y M. Rodríguez, «Revisión y análisis documental para estado del arte: una propuesta metodológica desde el contexto de la sistematización de experiencias educativas,» Investigación Bibliotecológica, vol. 27, nº 61, pp. 83-105, 2013.
[5] N. Molina, «Herramientas Para Investigar, ¿Qué Es El Estado Del Arte?,» Revista: Ciencia Y Tecnología Para La Salud Visual Y Ocular, nº 5, pp. 73-75, 2005.
[6] M. d. P. Jiménez, «Comunicación y lenguaje en la clase de ciencias,» de Enseñar Ciencias, Barcelona, Graó, 2007, pp. 55-71.
[7] S. Rojas, «El Estado Del Arte Como Estrategia De Formación En La Investigación,» Revista Studiositas, vol. 2, nº 3, pp. 5-10, 2007.
[8] L. B. López, «La Búsqueda bibliográfica: Componente clave del proceso de investigación,» DIAETA, vol. 24, nº 115, pp. 31-37, 2006.
[9] M. Grover, «A Pragmatic Knowledge Aquisition Methodology,» de Proceedings of the 8th International Joint Conference on Artificial Intelligence, Karlsruhe, 1983.
[10] B. G. Buchanan y R. O. Duda, «Principles of Rule-Based Expert Systems,» Advances in Computers, pp. 163-216, 1982.
[11] S. M. Weiss y C. A. Kulikowski, «A Practical Guide to Designing Expert Systems,» AI Magazine, pp. 84-86, 1985.
[12] B. McFeeley, IDEALSM: A User’s Guide for Software Process Improvement, Pittsburgh: Carnegie Mellon University, 1996.
[13] FAO, «Codex Alimentarius Standard for Honey,» FAO and WHO, Roma, 1993.
[14] ICONTEC, «Norma Técnica Colombia NTC 1273, Miel de abejas,» ICONTEC, Bogotá, 2007.
[15] D. Palacio y INVIMA, «Resolución 1057 de 2010,» Bogotá.
[16] Y. Aguas, R. Olivero y C. Cury, «Determinación de adulteración y aceptabilidad de mieles (apis mellifera) comercializadas en Cartagena, Bolívar, Colombia,» Revista Colombiana de Ciencia Animal - Recia, vol. 2, nº 2, pp. 349-354, 2010.
[17] R. C. Díaz y D. Fernández, «Determinación de algunos aprámetros de calidad de la miel en la provincia de Huesca,» Lucas Mallada, nº 10, pp. 107-122, 1998.
[18] J. F. Maidana, H. Herrera, A. Rojas, M. Mazzola, R. Fontanellaz y M. Rodríguez, «Determinación de las características Fisico-Químicas de mieles de Santiago del Estero,» CEDIA, Santiago del Estero, 2010.
[19] L. Fonte, M. Díaz, R. Machado, J. Demedio, A. García y D. Blanco, «Caracterización físico-química y organoléptica de miel de Melipona beecheii obtenida en sistemas agroforestales,» Pastos y Forrajes, vol. 36, nº 3, pp. 345-349, 2013.

CINSIS 2017 - Programa de Ingeniería de Sistemas
52
SISTEMAS EXPERTOS PARA DETERMINAR LA CALIDAD DE LA MIEL: UNA REVISIÓN BIBLIOGRÁFICA
[20] M. Noia, C. Cárdenas, M. Villat, G. Laporte, D. Sereno, R. Otrosky y N. Mestorino, «Características físico-Químicas y Microbiológicas de mieles de la Pampa,» Ciencia Veterinaria, vol. 11, nº 1, pp. 32-36, 2009.
[21] Y. B. Moguel, C. Echazarreta y R. Mora, «Calidad fisicoquímica de la miel de abeja Apis mellifera producida en el estado de Yucatán durante diferentes etapas del proceso de producción y tipos de floración,» Revista Mexicana de Ciencias Pecuarias, vol. 43, nº 3, pp. 323-334, 2005.
[22] P. Vit, E. Enriquez, M. O. Barth, A. H. Matsuda y L. B. Almeida, «Necesidad del control de calidad de la miel de abejas sin aguijón,» MedULA, vol. 15, nº 2, pp. 89-95, 2006.
[23] L. C. Cruz, J. E. S. Batista, A. P. P. Zemolin, M. E. M. Nunes, D. B. Lippert, L. F. F. Royes, F. A. Soares, A. B. Pereira, T. Posser y J. L. Franco, «A Study on the Quality and Identity of Brazilian Pampa Biome Honey: Evidences for Its Beneficial Effects against Oxidative Stress and Hyperglycemia,» Hindawi Publishing Corporation International Journal of Food Science, pp. 1-11, 2014.
[24] M. Moniruzzaman, S. A. Sulaiman, I. Khalil y S. H. Gan, «Evaluation of physicochemical and antioxidant properties of sourwood and other Malaysian honeys: a comparison with manuka honey,» Moniruzzaman et al. Chemistry Central Journal, pp. 1-12, 2013.
[25] S. Saxena, S. Gautam y A. Sharma, «Physical, biochemical and antioxidant properties of some Indian honeys,» Food Chemistry 118, pp. 391-397, 2010.
[26] M. Dardón y E. Enríquez, «Caracterización físicoquímica y antimicrobiana de la miel de nueve especies de abejas sin aguijón (Meliponini) de Guatemala,» Interciencia, Vol 33 No 12, pp. 916-922, 2008.
[27] G. Montenegro, R. Pizarro, G. Avila, R. Castro, C. Ríos, O. Muñoz, F. Bas y M. Gómez, «Origen Botánico y Propiedades Químicas de las Mieles de la Región Mediterránea Árida de Chile,» Ciencia e Investigación Agraria, Vol 30 Nº 3, pp. 161-174, 2003.
[28] L. Zamora y M. Arias, «Calidad microbiológica y actividad antimicrobiana de la miel de abejas sin aguijón,» Revista Biomédica Vol 22, pp. 59-66, 2011.
[29] S. Shafieea, S. Minaeia, N. Moghaddam, M. Ghasemi y M. Barzegar, «Potential application of machine vision
to honey characterization,» Trends in Food Science & Technology 30, pp. 174-177, 2013.
[30] G. Sampallo, C. Acosta, A. González y M. Cleva, «Sistema experto para clasificación de granos de arroz,» de Congreso Argentino de AgroInformatica, CAI 2013, Córdoba, 2013.
[31] T. Corona, G. Almaguer y R. Maldonado, «Sistema computarizado experto en diagnostico nutrimental en naranjo,» terra, vol. 18, nº 2, pp. 173-178, 2000.
[32] K. B. Lazarevic´, F. Andric´, J. Trifkovic´, Z. Tešic´ y D. Milojkovic´ Opsenica, «Characterisation of Serbian unifloral honeys according to their physicochemical parameters,» Food Chemistry, vol. 132, p. 2060–2064, 2012.
[33] F. L. Merino, «Sistema experto para diagnóstico de plagas insectiles de maíz (Zea mays L.) en Centro América,» Agronomía Mesoamericana, vol. 2, pp. 80-88, 1991.
[34] P. N. Shiguihara y J. C. Valverde, «SEDFE: Un Sistema Experto para el Diagnóstico Fitosanitario del Espárrago usando redes Bayesianas,» de Proceedings de Congreso de Inteligencia Computacional Aplicada (CICA 2009), Buenos Aires, 2009.
[35] F. Ramos, V. E. Ortiz, J. M. Mora, F. Padilla, F. Patlán y J. E. Macías, «Desarrollo y Evaluación de un Sistema Experto (prototipo) que Auxilie en el Proceso de Irrigación del cultivo de maíz (Zea mays L.) en Aguascalientes,» Investigación y Ciencia, vol. 14, nº 36, pp. 15-24, 2006.
[36] S. Popek, «A procedure to identify a honey type,» Food Chemistry, vol. 79, pp. 401-406, 2002.
[37] A. Soria, M. Gonzalez, . C. de Lorenzo, I. Martınez Castro y . J. Sanz, «Characterization of artisanal honeys from Madrid (Central Spain) on the basis of their melissopalynological, physicochemical and volatile composition data,» Food Chemistry, vol. 85, p. 121–130, 2004.
[38] P. Missio, C. Gauche, L. V. Gonzaga, A. C. Oliveira y R. Fett, «Honey: Chemical composition, stability and authenticity,» Food Chemistry, pp. 309-323, 2016.
[39] M. S. Finola, M. C. Lasagno y J. M. Mariol, «Microbiological and chemical characterization of honeys from central Argentina,» Food Chemistry, pp. 1649-1653, 2007.

CINSIS 2017 - Programa de Ingeniería de Sistemas
53
PROPUESTA PARA LA IMPLEMENTACIÓN DE TECNOLOGÍAS RIFD EN CADENAS DE SUMINISTRO AGRÍCOLA
PROPUESTA PARA LA IMPLEMENTACIÓN DE TECNOLOGÍAS RIFD EN CADENAS DE SUMINISTRO AGRÍCOLA
RESUMEN
El presente trabajo tiene como objetivo proponer la implementación de una solución basada en tecnologías de Identificación por Radio Frecuencia aplicada a cadenas de suministro agrícola. Se utilizó una metodología de desarrollo por fases que abarca la recolección, análisis de información y diseño de una propuesta de implementación para este sector. Como principal resultado se propuso una solución utilizando esta tecnología que permite realizar labores de seguimiento orientadas a mejorar la recolección de la carga, reducir los inconvenientes presentados en las centrales de acopio en procesos de almacenamiento e inventario al descargar o cargar los productos. La conclusión más relevante es que con la implementación de esta solución se podrán gestionar eficientemente procesos operativos en la cadena de suministro agrícola generando una disminución de tiempos de cargue y descargue del producto, gestionar adecuadamente actividades, ahorrando recursos por la reducción de inconvenientes que atrasan y perjudican cada una de estas.
Palabras Clave: Cadena de suministro agrícola, código de barras, código electrónico del producto, identificador por radio frecuencia.
ABSTRACT
The present work objective is to propose the implementation of a solution based on Radio Frequency Identification technologies applied to agricultural supply chains. A phased development methodology was used that covers the collection and analysis of information. And using the design of an implementation proposal in this sector. As a main result, a solution was proposed using this technology, which allows for follow-up work aimed at improving the collection of the cargo and reducing the inconveniences presented in the collection centers in storage and inventory processes when loading or loading the products. The most relevant conclusion is that, with the implementation of this solution it will be possible the efficient management of operational processes in the agricultural supply chain, generating a reduction in loading and unloading times of the product. Thus adequately managing activities and saving resources for the reduction or drawbacks which hamper each one of them.
Keywords: Agricultural supply chain, barcode, electronic code product, radio frecuency identificator.
William De la Espriella AvilaEstudiante Universidad de Cartagena
Sede Piedra de Bolívar Av. del Consulado, Calle 30 No.39B - 192
Plinio Puello MarrugoDocente Universidad de Cartagena
Sede Piedra de Bolívar Av. del Consulado,Calle 30 No.39B - 192
Julio Rodríguez RibónDocente Universidad de Cartagena
Sede Piedra de Bolívar Av. del Consulado,Calle 30 No.39B - 192
1. INTRODUCCION
Las cadenas de suministro se han convertido en algo fundamental para el desarrollo de las empresas, debido a que mejoran las relaciones generadas entre clientes y proveedores con el fin de alcanzar ventajas competitivas. Las cadenas
de suministro se definen como un conjunto de actividades repetitivas a lo largo del canal de flujo de producto, en el que se convierte la materia prima en productos terminados y se le suma un valor para el consumidor [1], en la figura 1 se puede visualizar una relación entre la cadena de suministro, la logística y su gestión.

CINSIS 2017 - Programa de Ingeniería de Sistemas
54
PROPUESTA PARA LA IMPLEMENTACIÓN DE TECNOLOGÍAS RIFD EN CADENAS DE SUMINISTRO AGRÍCOLA
Figura 1. Gestión de la Cadena de suministro.
Fuente. “Tecnologías de la información en la cadena de suministro” [1]
En las cadenas de suministro se realizan muchas actividades entre las cuales se encuentran procesar pedidos, controlar inventarios, almacenamiento de productos perecederos, tratamiento de mercancía entre otras. Estas son parte fundamental de la misma, por lo que su mejoramiento puede ayudar a su desarrollo, ya sea en reducción de tiempos de ejecución, capacidad productiva, oferta y/o demanda de productos perecederos.
Si nos centramos en el control de inventarios y almacenamiento de productos, los cuales se encargan de: manejar la disponibilidad de los mismos con relación a las solicitudes de demanda y la toma decisiones como por ejemplo el determinar los espacios requeridos para el almacenamiento, configuración de almacenes y la disposición de los productos al interior de los mismos [5]. Tener un mal control de lo anteriormente mencionado, puede llevar a la reducción de ganancias por pérdidas en la cantidad de productos, ya sea por un mal conteo de empaques o porque los mismos fueron mal empacados y mal distribuidos en un espacio determinado.
El correcto manejo de inventario y almacenamiento lleva una disminución de tiempos de entrega y recepción de los distribuidores que entregan o reciben productos de la cadena de suministro agrícola lo que también se ve reflejado en sus ganancias. La caracterización del producto es un buen punto de referencia para la gestión eficiente del almacenamiento e inventario, debido a que permite una mejor organización en los procesos de compra y venta del mismo, teniendo en cuenta la característica del peso para apoyar estas actividades.
Por medio de este trabajo se presenta una solución tecnológica para el control de inventario y almacenamiento utilizando la identificación por radiofrecuencia (RFID -
Radio Frequency Identification) aplicada al producto logrando una mejor disponibilidad, autenticidad, integridad y privacidad de la información [5].
La tecnología RFID se basa en la captura de información sin un enlace directo ni contacto, está conformada por radio frecuencias y su objetivo fundamental es obtener información serializada de una forma ágil, referente a productos, personas, vehículos entre otros [1]. Esta tecnología utiliza etiquetas especiales o Tags, las cuales tienen un microchip que almacena los datos de identificación del producto al que se adjunta conectado a una antena que envía estos datos a través de radiofrecuencias. También cuenta con un lector, el cual mantiene la funcionalidad del envío de radiofrecuencias inducida a la etiqueta para transmitir los datos contenidos en su chip. El lector recibe la información, la convierte en ondas de radio, la envía de regreso a la etiqueta en datos digitales y las transmite a un sistema informático [1].
Esta tecnología posee gran potencial debido a que reduce tiempos de revisión, facilita la ubicación y extracción de los productos que la apliquen, además se convierte en la base para implementación del estándar ECP (Código Electrónico de Producto) [1], constituido por un código numérico para identificar productos con más detalles, puede contener información sobre los mismos, la cual se guarda en dispositivos de radiofrecuencia como los RFID [3]. A continuación se observa un comparativo entre la tecnología RFID y la de código de barras convencional.
Tabla 1. Comparación entre tecnologías [12]
Fuente: Comparación entre tecnologías de RFID y código de barras [11]
Características Código de Barras RFID
Capacidad / Identificación
Espacio limitado/Estandarizado
Mayor cantidad de información/ uni-voca por producto
Actualización de lectura
Solo una lectura a la vez
Lectura / escritura simultanea
Tipos de lec-tura Solo en superficie A través de diver-
sos materiales
FlexibilidadRequiere línea de visión para la lec-tura
No requiere con-tacto directo
Precisión de Durabilidad
Requiere interven-ción humana/ pue-de estropearse con facilidad
100% automático / soporta ambien-tes agresivos

CINSIS 2017 - Programa de Ingeniería de Sistemas
55
PROPUESTA PARA LA IMPLEMENTACIÓN DE TECNOLOGÍAS RIFD EN CADENAS DE SUMINISTRO AGRÍCOLA
Los ECP no representan un reemplazo de los códigos de barras, pero si son un camino para que las empresas puedan migrar a tecnologías de radiofrecuencia. Los códigos de barras son una herramienta que permite la captura de información referente a los números de identificación de productos, unidades logísticas y localizaciones, de manera automática e inequívoca en cualquier punto de la red de valor [2]. A pesar de ser uno de los métodos más utilizados su existencia se está viendo afectada por tecnologías de radio frecuencias. Puesto que estas ofrecen una mayor capacidad de memoria de almacenamiento de datos con respecto a los códigos de barras; también debido a que la información contenida en los Tags es variable y los mismos son reutilizables, lo que no sucede con los códigos de barras; los Tags pueden ser identificados de manera simultánea debido al beneficio de no necesitar contacto visual entre el lector y la etiqueta [1].
Los Tag RFID se clasifican en pasivos, semipasivos y activos. En los tag pasivos, la energía se dirige al chip y es redistribuida de vuelta. Una etiqueta pasiva no posee fuente de energía, una tag activo se alimenta de una batería incorporada, este puede transmitir su señal sin que el lector se dirija hacia él. Entre los Tag pasivos y activos están los semipasivos que tienen una batería incluida, para impulsar la señal, no transmite la misma hasta que sea alcanzada y activada por las ondas electromagnéticas de un lector. El ambiente en el cual se encuentran las tecnologías RFID afecta de manera sustancial la implementación. Un ejemplo sería que los metales reflejan ondas de radio mientras los líquidos absorben las mismas, por esto la presencia de estos entre un lector y el tag puede afectar en que la energía de la Radio Frecuencia alcance al receptor. Los Tag RFID también se diseñan para trabajar a frecuencias diferentes [4]:
• VLF 3 a 30 kHz Ondas miriamétricas.
• LF 30 a 300 kHz Ondas kilométricas.
• MF 300 a 3000 kHz Ondas hectométricas.
• HF 3 a 30 MHz Ondas decamétricas.
• VHF 30 a 300 MHz Ondas métricas.
• UHF 300 a 3000 MHz Ondas decimétricas.
• SHF 3 a 30 GHz Ondas centimétricas.
• EHF 30 a 300 GHz Ondas decimilimétricas.
En la cadena de suministro agrícola se presentan inconvenientes a nivel de inventario y almacenamientos, debido a que los productos perecederos generalmente son de forma irregular y no se acoplan uniformemente a su empaque, por lo que estimar una capacidad o cantidad promedio para todos es complicado. Para solucionar este inconveniente se hace necesario la utilización de una variable general como el peso de los mismos los cuales serían pesados al estar llenos de producto que se desea transportar en la cadena de suministro. Teniendo en cuenta lo anterior, si a estos empaques se les identifica adicionando un Tag se puede asegurar la integridad del mismo a través de los procesos de recepción y distribución. Por lo que la aplicación de un RFID contribuiría a:
• Adicionar un nuevo nivel de seguridad, verificación y autenticidad del producto al complementar su información con el peso del mismo para su correcta comercialización y almacenamiento [1].
• Facilitar los procesos de recogida y trasbordo de producto, debido a la fácil detección de la cantidad que poseen los camiones y la bodega por medio de los tag y lectores RFID especializados.
• Reducir los tiempos de entrega y clasificación del producto agrícola, como también su venta y distribución
2. METODOLOGIA
El alcance de la investigación será enfocado en la fase de distribución de la cadena de suministro, localizada en el municipio de María la Baja perteneciente de los Montes de María. La investigación tomará como enfoque el almacenamiento y manejo de inventario a nivel de la cadena de suministro agrícola, centrándose en la caracterización de los productos por su peso, de manera que se tenga una balanza electrónica con conexión Ethernet y cada vez que se realice este proceso se asocie el Tag con el peso del empaque en una base de datos. Esto permite tener un control de la cantidad de producto que se posee en inventario y almacenamiento. Como también saber la cantidad de producto que se entrega en un camión y se evitan las pérdidas de mismos a nivel de la entrega esto gracias a que los lectores RFID no necesitan contacto con el Tag. Otro ámbito a abarcar es la capacidad de asegurar la cantidad (en este caso en peso) del producto, al llegar al cliente este puede comparar y asegurase de la integridad de la carga transportada.

CINSIS 2017 - Programa de Ingeniería de Sistemas
56
PROPUESTA PARA LA IMPLEMENTACIÓN DE TECNOLOGÍAS RIFD EN CADENAS DE SUMINISTRO AGRÍCOLA
Serán relevantes aspectos como el control de inventario y almacenamiento en los sistemas de información y la utilización de software que permitan la integración con tecnologías RFID, para contribuir con el desarrollo de las cadenas de suministro agrícolas. Para ello, se utilizará una metodología distribuida en las siguientes fases:
2.1. Recopilación de información
Se realizará un estudio detallado de logística de transporte en las cadenas de suministro agrícola en el municipio de María La Baja perteneciente a los Montes de María, sus principales fuentes y causales. Indagando en la estructura de cómo funciona y se llevan a cabo etapas como: recepción de productos, el almacenamiento, la gestión de riesgos, el envío o cargue del producto a los camiones y otros aspectos pertenecientes al desarrollo de esta actividad. También se investigará sobre tecnologías RFID que ofrece el mercado, aplicadas al control de inventario y almacenamiento de productos en las cadenas de suministro agrícola.
2.2. Análisis de la Información
Se procederá a estudiar toda la información previamente recogida, de manera que se pueda realizar un análisis entre las soluciones tecnológicas existentes para llevar a cabo el control de inventario y almacenamiento, permitiendo crear un ambiente seguro para la ejecución de las labores. Basados en estos análisis se sustentará las ventajas de las soluciones que se propondrán con tecnologías de radio frecuencia. Del mismo modo, en esta fase se analizó de forma breve el impacto que tiene a nivel financiero para las compañías que gestionan cadenas de suministro agrícola.
2.3. Diseño de solución basada en RFID
Basados en la fase de análisis de la información, se procede a la creación de modelos que representen una solución tecnológica viable para realizar el control de inventario y almacenamiento en las cadenas de suministro agrícola a partir de un análisis de requisitos. Para luego plantear soluciones formales que aumenten la eficiencia a partir de una adecuada identificación del producto en la cadena de suministro.
3. RESULTADOS
Los procesos agrícolas en las cadenas de suministro demandan una gran labor de seguimiento puesto que se tienden a cometer errores que atrasan y perjudican cada uno de las actividades dentro de esta.
Los resultados se describen principalmente para el almacenamiento e inventario dentro de los centros de acopio o asociaciones orientados a los beneficios supuestos gracias a la tecnología RFID:
3.1. Recepción y descargue del producto
Dentro de la cadena de suministro, el transportador realiza el recorrido hasta el productor o agricultor que tiene disponible cierta cantidad de producto para ser enviado a la central de acopio, donde se realizan los procedimientos de almacenamiento e inventario, en la cual se organiza la carga para ser distribuida a los clientes.
En este punto, el transportista continua en su labor de distribución hasta la descarga en el punto que el centro de acopio le asigno, mientras tanto el empleado encargado de la recepción del producto debe buscar el lugar donde esta carga debe ser acomodada dependiendo de la categorización correspondiente de cada producto, con el objetivo de tener el registro y la ubicación dentro de la bodega, donde luego será procesada, es decir, dentro de esta actividad se caracteriza la carga de acuerdo a su peso, instalando un RFID donde se encuentre toda la información referente a esto. Este proceder dentro del almacenamiento de los acopiadores, debe realizar pasos rigurosos que identifican el producto y luego lo registran en la base de datos, para obtener un control de las cantidades y mantener un historial de las cargas recibidas.
El flujo de actividades que se deben tener en cuenta para registrar e identificar el producto que ha llegado al centro de acopio se encuentra detalladas en la figura 2, enfatizando en el proceder que implica la actividad de pesaje e implementación de RFID, aunque estas sean actividades independientes, se relacionan una con la otra, puesto que el pesaje determinara la medida del producto dentro del inventario que se relacionara al momento de registrar en el sistema, asociando las cantidades disponibles que se tienen en almacenamiento de un centro de acopio en específico.
El seguimiento que se brinda a la carga cuando se descarga en las terminales de acopio, facilita y agiliza la localización de cada carga dentro del almacén o bodega, puesto que en esta labor tiende a perderse el tiempo por poca precisión de la ubicación. El beneficio más importante que se obtiene al implementar sistemas de este tipo, es el ahorro en tiempos de negociación y realización de las tareas, puesto que el flujo de ejecución de estas no tendrá mayor perturbación por inconsistencias en la información porque esta se encuentra registrada de acuerdo a los

CINSIS 2017 - Programa de Ingeniería de Sistemas
57
PROPUESTA PARA LA IMPLEMENTACIÓN DE TECNOLOGÍAS RIFD EN CADENAS DE SUMINISTRO AGRÍCOLA
datos tomados en los pesajes realizados, obteniendo las medidas específicas que tiene cada producto, ayudando al mejoramiento de los procedimientos de pago por producto e inventario.
Figura 3. Sistema RFID en el manejo de almacén e inventarios de la cadena de suministro agrícola.
Fuente. De los autores
Las cadenas de suministro a grandes rasgos se componen de actividades como producción, transporte, almacenamiento, inventario y distribución, esto se aprecia en la figura 3, donde en la parte superior de esta, se destacan las actividades del cultivador, cosechando lo que será la carga a transportar a las centrales de acopio, luego en esta se realizarán un conjunto de actividades internas que darán como resultado un producto final que se distribuirá a empresas o industrias transformadoras próximas al cliente final.
La serie de actividades internas que se realizan en el centro de acopio es el punto donde se considera pertinente aplicar un sistema con tecnologías como las RFID que ayuden a monitorear y controlar las diferentes transacciones o movimientos que se hagan con la carga, su cantidad distribuida y la que se encuentra aún almacenada, para esto como se aprecia en la parte inferior de la figura 3, se determinaron los componentes que son necesarios para una correcta comunicación y registro en la base de datos. En este caso se puede observar que, en el almacén la carga tiene unos círculos azules, estos hacen alusión a los tags RFID, donde en la zona de evaluación de la carga con los lectores RFID se identificarán de acuerdo a los que necesiten para determinada orden de pedido o situación, estos lectores usarán como medio de interacción los tags, las antenas RFID, puesto que
Figura 2. Flujo de procedimientos de caracterización de la carga en almacenamiento.
Fuente. De los autores
3.2. Problemas en almacenamiento e inventarios
La instalación de los tags RFID a los empaques que llegan a la central de acopio, ayudan a referenciar el producto que llega a bodega. Con estos dispositivos (Tags y lectores) se facilitaría determinar cuándo llegan a la central de acopio, cómo fueron comercializados y el momento de salida del almacén, logrando controlar rápidamente y con un grado de eficacia mayor el inventario, puesto que este se va ir actualizando automáticamente y continuamente la cantidad de empaques que han sido procesados.
El sistema RFID en conjunto, es decir, la instalación de los tags y los lectores, facilitan el trabajo de los encargados en el centro de acopio sobre el inventario y almacenamiento del producto, puesto que brinda soluciones a inconsistencias y tiempos muertos, producidos por falta de información, puesto que esta tecnología permite marcar o etiquetar todo tipo de producto bajo diferentes entornos y circunstancias.
En la figura 3, se puede apreciar a grandes rasgos como inicia y termina la cadena de suministro, identificando el foco de la investigación.

CINSIS 2017 - Programa de Ingeniería de Sistemas
58
PROPUESTA PARA LA IMPLEMENTACIÓN DE TECNOLOGÍAS RIFD EN CADENAS DE SUMINISTRO AGRÍCOLA
serán las encargadas de recibir la información que se transmitirá al servidor donde se correlacionan los pesos correspondientes a cada empaque.
3.3. Reducción de errores en los procedimientos que demanda la cadena de suministro
En el proceder de las asociaciones debido a los diferentes productores que manejan, además de las otras actividades que deben realizar, muchas veces puede suceder que se agreguen pedidos, pero de agricultores erróneos o no registrados, este aspecto se puede evitar aplicando tecnologías RFID, ya que el transportista tendrá el punto exacto de recolección al que fue asignado, sin dar cabida a que se produzcan inconvenientes en su gestión.
Ahora bien, dentro de la industria muchos han intentado aplicar este tipo de tecnologías llegando a una conclusión común, la implementación de RFID beneficia en gran medida la ejecución de los procesos, ya sea que la idea de negocio se encuentre orientada al almacenamiento e inventario o incluso para el tratado que los productos perecederos en frio necesitan. Lo anterior se encuentra sustentado con proyectos realizados utilizando esta herramienta.
Una investigación aplicada en el sector cárnico, obtuvo como resultado un control y monitoreo de las etapas del proceso productivo, donde lograban minimizar el riesgo de contaminación por mala salubridad de los alimentos, ya que su objetivo era optimizar el tiempo de vida que estos presentan, puesto que su propuesta para el mercado es entregar al consumidor un producto de alta gama. Su énfasis en la investigación se orientaba a la gestión en la trazabilidad del producto logrando tener un historial de los datos registrados sobre este, que luego con ayuda de otras herramientas tener la posibilidad de generar conclusiones inteligentes que mejorarán los procedimientos que llevan a cabo [8].
Otra investigación abordó la importancia de usar RFID en la gestión de inventario para herramientas de mantenimiento, la cual permitía poder llevar un seguimiento de la ubicación y de los repuestos con los que se contaba en bodega, con el objetivo de reducir tiempo de trabajo, reducción en el uso de recursos energéticos y minimización de tiempos de espera entre búsquedas, manteniendo la mejora continua de sus procesos, los cuales agregan rentabilidad y un factor diferenciador en el mercado [9].
Una investigación que es importante destacar y la cual es bastante novedosa, es la aplicada a una empresa que trabaja con cebaderos de ganado, donde se implementaban tecnologías RFID para el registro y acceso sobre las reses, identificándolas. El historial que se registra en esta actividad está compuesto de información sobre vacunación, alimentación, entre otras, esto con la finalidad de componer una base de datos centralizada que permita tener una trazabilidad manteniendo todos los datos sobre la vida del producto para el cliente final [10].
Todos los resultados obtenidos por las investigaciones realizadas son el indicador que asegura que la aplicación y correcta introducción de RFID puede apoyar muchos de los procesos y por lo tanto el ahorro de tiempo y dinero en la cadena logística de abastecimiento, los investigadores hacían énfasis en que no solo proporcionaba indicadores cuantificables con respecto a beneficios económicos, sino que agrega valor a las empresas que lo implementen, puesto que incluyen en sus procesos métodos innovadores, sobre todo porque el sector agrícola a pesar de ser el más productivo y que genera mayores movimientos comerciales, se encuentra atrasado en la aplicación de sistemas que optimicen su labor.
A pesar de sus grandes ventajas, las investigaciones no dejaban de lado uno de sus principales problemas, el cual es que RFID es una tecnología que requiere de inversiones en capital altas, puesto que sus mayores costos están en el equipamiento que implica su implementación (impresoras, lectores, tags y antenas) sumado a esto, se encuentra el costo por contratación de personal para la supervisión e instalación. Por lo tanto, la conclusión sobre esto es que la inversión de esta tecnología se justifica cuando se trata de empresas grandes que trabajen con un volumen mayor de procesos y de clientes comerciales.
4. CONCLUSIONES
El desarrollo de las cadenas de suministro agrícola es una parte esencial en el crecimiento estructural del país, por lo que la implantación de tecnologías que contribuyan ya sea, al desarrollo integral, al fortalecimiento de infraestructura, o simplemente colaboren con el crecimiento de una de las fases de esta actividad, ayudan al mejoramiento productivo nacional, debido a que el desarrollo de las cadenas de suministro agrícola, contribuye al crecimiento económico de las regiones porque que se mueve la economía, generando empleo ya sea para transportistas u otros actores presentes en el sector.

CINSIS 2017 - Programa de Ingeniería de Sistemas
59
PROPUESTA PARA LA IMPLEMENTACIÓN DE TECNOLOGÍAS RIFD EN CADENAS DE SUMINISTRO AGRÍCOLA
Al ubicarse en las actividades que involucra el almacenamiento o inventarios de las cadenas de suministro agrícolas, con la finalidad de generar trazabilidad dentro de esta, es totalmente aplicable la adopción de RFID como herramienta que aumente la productividad y desempeño en los trabajadores, permitiendo controlar y monitorear las cantidades disponibles que apoyen la gestión en el cumplimiento de la demanda que se manifiesta en el sector, orientada a aumentar el impacto en toda la cadena de abastecimiento.
La utilización del peso como medida complementaria a las Tag RFID para identificar los empaques de productos ayuda a incrementar la exactitud en el registro de entradas y salidas del producto aumentando el mejoramiento de los procesos y la calidad en el cubrimiento de órdenes demandadas, lo que mejora la trazabilidad y disponibilidad de las herramientas en la gestión de inventarios.
5. REFERENCIAS
1. A. Correa Espinal, and A. Gomez Montoya, ”TEGNOLOGÍAS DE LA INFORMACIÓN EN LA CADENA DE SUMINISTRO”,2008
2. Beneficios de RFID, (2017). http://www.gs1mexico.org Obtenido de: http://www.gs1mexico.org/nuestros-servicios/servicios/codigo-electronico-de-productos/que-es
3. J. A. .Chuquimarca Moreira, and Ing. J. Caicedo Salazar,” desarrollo e implementacion de un sistema para manejo y control de inventarios utilizando tecnología rfid”, Universidad de guayaquil 2015
4. J. Bateman, C. Cortés, P. Cruz, and H.paz-Penagas, “Diseño de un protocolo de identificación por radiofrecuencia (RFID) propietario para una aplicación específica”, Ing. Univ. Bogotá (Colombia) 2009.
5. Comparación entre tecnologías de RFID y código de barras. (2017). www.evaluandoerp.com. Obtenido de: http://www.evaluandoerp.com/comparacion-tecnologias-rfid-codigo-barras/
6. Diana P. Jaramillo, and Valentina G. “Reseña del software disponible para la Gestion de inventarios en cadenas de abastecimiento”, 2009.
7. Lagares, Josep, et al. “Identificación por radiofrecuencia: inteligencia rentable para el sector cárnico.” Eurocarne 185 (2010): 126-134.
8. Rosero, Andrade, and Henry Bolivar. Diseño de un sistema de gestión de mantenimiento basado en almacenamiento virtual de información en tags RFIDS y lectura por radiofrecuencia para los buques de la comandancia de escuadra de la Armada del Ecuador. BS thesis. Espol, 2017.
9. Santana, Alejandro Escudero, et al. “Análisis de posibles aplicaciones de la tecnología RFID en la cadena de suministros del sector agroalimentario: caso del control de expediciones.” II International Conference on Industrial Engineering and Industrial Management. 2008.
10. D.Gregor Recalde, and DR. D. S.Toral Martin. “Desarrollo de un servicio middleware de ontologías cooperativas aplicado a sistemas embebidos de transportes inteligentes”, 2013.
11. “Comparación entre tecnologías de RFID y código de barras”, 2017. Obtenido de : http://www.evaluandoerp.com/comparacion-tecnologias-rfid-codigo-barras/

CINSIS 2017 - Programa de Ingeniería de Sistemas
60
UN INTÉRPRETE DE PSEUDO-LENGUAJE EN ESPAÑOL PARA LAS ASIGNATURAS DE PROGRAMACIÓN Y ESTRUCTURAS DE DATOS
UN INTÉRPRETE DE PSEUDO-LENGUAJE EN ESPAÑOL PARA LAS ASIGNATURAS DE PROGRAMACIÓN Y ESTRUCTURAS DE DATOS
ABSTRACT
En detalle se describe el desarrollo de una solución informática, enfocada a apoyar a estudiantes de Ingeniería de Sistemas, en temas relacionados a algoritmos, programación y estructura de datos, la cual proporciona características capaces de ilustrar mediante animaciones la forma en la que se comportan los datos en la memoria al momento de ejecutar una instrucción en la máquina, con una interfaz y un diseño amigable. El desarrollo de la misma fue soportado a partir de investigaciones en el área y fue comprobado mediante pruebas y evaluaciones.
Keywords: Software educativo, Programación, Estructura de datos, Listas, Algoritmo, Intérprete, Memoria, Pseudolenguaje, Español, Accesibilidad, Ingeniería.
Jean Benítez DiazgranadosIngeniero de Sistemas
Universidad del Magdalena
Idanis Diaz B.Facultad de Ingeniería
Universidad del [email protected]
1. INTRODUCTION
Los fundamentos de la programación son enseñados a estudiantes universitarios en los primeros semestres, en programas de Ingeniería de Sistemas, informática o afines, a través de asignaturas en las que se imparten elementos básicos de algoritmos, estructuras de datos, y/o estructuras de la información.
Si bien es cierto que estas asignaturas son esenciales en el desarrollo de la disciplina del diseño de algoritmos y la programación, también es cierto que presentan quizás uno de los niveles de dificultad más elevado en lo que se refiere a materias propias de las carreras de informática y ciencias de la computación, ocasionando una alta deserción académica en los primeros semestres, y un gran número de fracasos en la asignatura.
En sus investigaciones, Casas & Vanoli (2007) identificaron que en el proceso de enseñanza-aprendizaje de los cursos de algoritmos y programación, los estudiantes encuentran dificultades en la realización de la traza o prueba de escritorio manual, el manejo de memoria dinámica y la identificación de errores. Conceptos que son claves en la comprensión de algoritmos y estructuras de datos, tales como la abstracción, la representación de memoria dinámica, no son fácilmente captados a través de solo
código en un lenguaje de programación, sin ninguna ayuda visual.
A pesar de que existen cantidades de compiladores de pseudolenguaje en español y herramientas para diagramas de flujo, tanto de uso comercial como de código libre, los cuales son bastante usados para complementar y ayudar a la pedagogía en cursos de algoritmos, programación y estructuras de datos, (Orellano, Nieva, & Solar, 2012), muchas de estas herramientas se limitan a funciones específicas que no soportan tipos de datos abstractos, ni tampoco cuentan con un componente didáctico enfocado a explicar el comportamiento de la memoria cuando se utilizan dichos tipos de dato abstractos, y por esto no alcanzan a cubrir las necesidades puntuales que existen en la asignatura de estructuras de datos.
En este trabajo se describe el desarrollo de una herramienta para que los estudiantes puedan captar más fácilmente el concepto abstracto que hay en la manera en que se representan los tipos de datos complejos. La herramienta permite a los estudiantes ingresar sus propios algoritmos, realizar pruebas e identificar errores, utilizando como entrada un pseudolenguaje en español de fácil entendimiento, y que además representa de manera gráfica el manejo de memoria realizado por las

CINSIS 2017 - Programa de Ingeniería de Sistemas
61
UN INTÉRPRETE DE PSEUDO-LENGUAJE EN ESPAÑOL PARA LAS ASIGNATURAS DE PROGRAMACIÓN Y ESTRUCTURAS DE DATOS
distintas estructuras de datos que haya implementado en sus algoritmos.
En las siguientes secciones
2. DESARROLLO DE LA HERRAMIENTA
El desarrollo de este proyecto se llevó a cabo siguiendo la metodología de software educativo propuesta por el Dr. Pere Marques (1996). Los elementos principales del desarrollo de la herramienta se describen a continuación:
2.1. Análisis y Diseño
El software desarrollado es una herramienta orientada a apoyar al estudiante en el proceso de aprendizaje de estructuras de datos, viendo cómo se comportan los espacios de memorias a medida que se va ejecutando un algoritmo dado, pero que también es bastante útil para aquellos que apenas van a empezar en el mundo de algoritmos y programación. Durante el análisis y diseño de esta herramienta se tuvieron en cuenta las siguientes actividades didácticas de enseñanza, para cumplir con el objetivo de la herramienta:
• Ejecuta y aprende: Se le hace entrega a los estudiantes de un proyecto desarrollado en el software, con el fin de que vean la ejecución del mismo y su comportamiento, para que puedan entender el concepto explicado en clase.
• Ejercicio práctico: Entregar un proyecto empezado en el software, donde se le da un panorama/estado inicial del problema presentado, y se le pide que a partir de allí desarrolle una solución algorítmica.
• Desafío en clase: Se le propone al estudiante un ejercicio donde él deba pensar la lógica de su solución para posteriormente crear y probar sus propios algoritmos en la herramienta.
• El diseño de todas las funcionalidades necesarias para permitir la realización de estas actividades didácticas de enseñanza se puede observar en la Figura 1.
Figura 1. Diagrama casos de usos de la herramienta desarrollada.
2.2. Procesamiento del Pseudolenguaje
La gramática abordada por el pseudolenguaje es una gramática libre del contexto. Un ejemplo de este tipo de gramática es el lenguaje C, en el que un tipo de agrupación son las llamadas ‘expresión’. Una regla para hacer una expresión podría ser: “Una expresión puede estar formado por un signo menos y otra expresión”. Otra

CINSIS 2017 - Programa de Ingeniería de Sistemas
62
UN INTÉRPRETE DE PSEUDO-LENGUAJE EN ESPAÑOL PARA LAS ASIGNATURAS DE PROGRAMACIÓN Y ESTRUCTURAS DE DATOS
sería, “Una expresión puede ser un entero”. (Donnelly & Richard , 1995)
El sistema formal más común para la presentación de dichas normas, para que los seres humanos podamos leer, es Backus-Naur Form o “BNF”, el cual fue desarrollado con el fin de especificar el lenguaje Algol 60. Cualquier gramática expresada en BNF es una gramática libre de contexto.
Dado a que la mayoría de los lenguajes de programación siguen dichas reglas, y por las circunstancias de que nuestro pseudolenguaje no es más que una simple imitación de lenguajes como C, PHP, JavaScript, etc., en este trabajo se siguió el mismo lineamiento. Las siguientes tablas contienen las principales palabras reservadas y operadores de la gramática en español diseñada para este trabajo:
Tabla 1. Palabras reservadas del pseudolenguaje
SI PARA ROMPER
ENTONCES CADA CONTINUAR
SINO HASTA FIN FUNCION
FIN SI FIN PARA DEVOLVER
MIENTRAS FUNCION VERDADERO
FIN MIENTRAS SEGÚN FALSO
HACER CASO LEER
REPETIR POR DEFECTO IMPRIMIR
QUE FIN SEGÚN
Para desarrollar el analizador léxico-sintáctico se utilizó Jison, el cual toma una gramática libre de contexto como entrada y genera un archivo JavaScript capaz de analizar léxica y sintácticamente el lenguaje descrito por esa gramática. Luego se puede utilizar el script generado para analizar entradas y aceptar, rechazar o realizar acciones basadas en la entrada. (Jison JavaScript parser generator, 2013). La siguiente figura muestra los pasos que sigue la herramienta desde el recibimiento de una entrada, instrucciones en el pseudolenguaje definido, hasta la interpretación y ejecución de dicha entrada.
Tabla 2. Operadores del pseudolenguaje
Relacionales Lógicos Algebraicos
Mayor que > Conjunción && Suma +
Menor que < Disyunción || Resta -
Igual que == Negación ! Multiplicación *
Menor o igual que <= División /
Mayor o igual que >= Potenciación ^
Diferente != Módulo %
Figura 2. Pasos a seguir para desarrollar el compilador
La herramienta con la que se desarrolló el analizador léxico-sintáctico también facilitó la creación del traductor sintáctico, el cual permite ir definiendo la representación que debe tener cada regla de la gramática que hemos definido, y así se obtiene en la raíz del árbol sintáctico el código generado.
En este trabajo se optó por desarrollar un tipo especial de compilador: un transpilador, también conocido como compilador código a código, transcompilador o simplemente transpilador. Este es un tipo de compilador que toma el código fuente de un programa escrito en un lenguaje de programación como entrada y produce el código fuente equivalente en otro lenguaje de programación. Un

CINSIS 2017 - Programa de Ingeniería de Sistemas
63
UN INTÉRPRETE DE PSEUDO-LENGUAJE EN ESPAÑOL PARA LAS ASIGNATURAS DE PROGRAMACIÓN Y ESTRUCTURAS DE DATOS
transpilador funciona cuando el lenguaje fuente y el lenguaje objetivo operan en aproximadamente un mismo nivel de abstracción, mientras que un compilador común traduce a partir de un lenguaje de programación de alto nivel a un lenguaje de programación de nivel inferior (Compiler code-to-code, 2016).
El transpilador desarrollado en este trabajo convierte instrucciones escritas en un pseudolenguaje en español a Javascript. Para esto, se utiliza la librería JS-Interpreter.
2.3. Interfaz de Usuario
La interfaz de usuario cuenta con paneles bien definidos, los cuales brinda al usuario final un entorno amigable para el uso de la herramienta. Se implementaron paneles tales como: una barra de menú que presenta opciones para crear un nuevo archivo, guardar el actual, o cargar uno ya elaborado. Un editor en el que el usuario de la herramienta puede ingresar instrucciones en pseudo código en español, el cual fue desarrollado utilizando la librería Ace Editor. Esta librería facilita el realce de código o highlight, para garantizar al estudiante que está utilizando las palabras reservadas correctamente. También, es posible definir una serie de fragmentos de códigos o snippets para ayudar al estudiante a escribir código ágilmente le enseña la sintaxis del pseudolenguaje. La Figura 2, ilustra el diseño de este editor:
la estructura por parte del usuario. La Figura 3 es una ilustración de una lista simplemente ligada diseñada a través del tablero de la herramienta.
Figura 3. Interfaz gráfica, editor de pseudolenguaje en español.
La herramienta también cuenta con un tablero en el cual se modela y visualiza la estructura de datos definida por las instrucciones escritas en el editor. A medida que se ejecuta o realiza la prueba de escritorio del algoritmo en este panel se puede observar los cambios en la estructura de datos. También permite la modificación directa de
Figura 4. Tablero para modelar y visualizar estructuras de datos en la herramienta.
Otro panel disponible en la herramienta es una terminal para hacer seguimiento a las entradas y salidas de texto llevadas a cabo, en tiempo de ejecución, por las instrucciones ingresadas en pseudocódigo. El terminal no es más que un espacio que está a la espera de ser manipulado por la ejecución de las instrucciones del usuario.
También se cuenta con una tabla de símbolos que indica qué valor tienen las variables en dicho momento de la ejecución, y en qué ámbito de la ejecución se encuentra. Los ámbitos de ejecución son apilados a medida que una función está siendo llamada dentro de la función principal, y así se va incrementando a medida que se ejecutan funciones una dentro de otra.
3. EVALUACION Y PRUEBAS
El software educativo se evaluó para determinar si cumple con los mínimos requisitos para ser un sistema viable en la enseñanza de las Estructuras de datos y/o de la información. El objetivo principal de las pruebas realizadas, la cual fue llevada a cabo con estudiantes que ya habían cursado Estructuras de datos o Estructuras de la información, fue evaluar un software educativo orientado a la enseñanza de la asignatura misma, comparando los resultados obtenidos con la realización de los algoritmos a mano, con las pruebas de escritorio y con el primitivo manejo de la memoria que se realiza comúnmente en papel.
4. EVALUACION Y PRUEBAS
Las siguientes gráficas son los resultados obtenidos del desarrollo de las pruebas, donde medimos el grado de completitud del ejercicio desarrollado por cada estudiante, así como la duración del mismo.

CINSIS 2017 - Programa de Ingeniería de Sistemas
64
UN INTÉRPRETE DE PSEUDO-LENGUAJE EN ESPAÑOL PARA LAS ASIGNATURAS DE PROGRAMACIÓN Y ESTRUCTURAS DE DATOS
Figura 5. Grado de completitud pruebas de usuario
El grado de completitud de los ejercicios desarrollados en las pruebas por los estudiantes dio un promedio de 47% a mano, el cual subió a 55% en el software (ESTRUCTURATOR). En la gráfica de barras vemos que los picos están en el desarrollo en el software, y también hay unos picos en las soluciones dadas a mano.
Cabe resaltar que hubo estudiantes capaces de resolver el ejercicio a mano a la perfección pero que en el software tuvieron un poco de retraso, esto es, por la sintaxis fija en el software, la cual no tuvo restricción en la respuesta entregada a mano. Otro punto a rescatar es que hubo muchos estudiantes que tuvieron problemas en la lógica a mano, pero en el software pudieron realizar pruebas y corregir rápidamente, que a pesar del poco manejo de la sintaxis del pseudolenguaje, la restricción les sirvió para ser creativos.
y 17 minutos en la respuesta en el software, la diferencia de tiempos fue excelente teniendo en cuenta que los estudiantes están más familiarizados con las pruebas a mano que con las pruebas en un nuevo software que tiene una sintaxis definida.
Un factor que influyó mucho en la duración fue el hecho de que el pseudolenguaje era desconocido y no había sido utilizado por ninguno anteriormente, a pesar de ser sencillo, tiene estrictas reglas de gramática libre del contexto, como cualquier lenguaje. A esto hay que sumarle el hecho de que la mayoría no prestaba la suficiente atención a los mensajes e instrucciones del sistema. Esto ocasionaba que los usuarios muchas veces tuvieran que adivinar o preguntar al no saber qué hacer en determinados puntos del proceso y esto obviamente consumió tiempo.
5. CONCLUSIONES
El conocimiento adquirido en el desarrollo del software permite dar hincapié a grandes proyectos enfocados al desarrollo de elementos tales como: Software educativo, componentes gráficos para representar conceptos abstractos y complejos, desarrollo de herramientas CASE avanzadas y de intérpretes especializados. Como todo software, éste desarrollo está abierto a ser escalado, a dar soporte a nuevas estructuras de datos, a mejorar la usabilidad y a desarrollar una mejor representación gráfica de dichos elementos abstractos.
Es conveniente continuar con el desarrollo e implementación de herramientas pedagógicas computacionales tales como la creación de objetos virtuales de aprendizajes interactivos que puedan incorporarse a la herramienta para fortalecer su base conceptual y la base de conocimiento, y de este modo permitir la adquisición de los conocimientos de diferentes formas. También es posible utilizar el software para crear nuevos caminos pedagógico, que ayuden al cuerpo docente de las asignaturas relacionadas a programación, para que inviten a sus estudiantes a utilizar la herramienta y no tener inconvenientes de instalación, restricción de sistema, u otros problemas que pueden surgir a la hora de utilizar un compilador o intérprete de un lenguaje de programación como C/C++, Javas, etc.
Para concluir, se debe entender que el impacto del uso del software se verá evidenciado en la disminución del tiempo y del esfuerzo realizado por los docentes de asignaturas relacionadas a Estructura de Datos y/o Información, en cuanto a las posibles dudas sobre el manejo y la implementación de las diferentes estructuras de datos que
Figura 6. Duración promedio en minutos de Pruebas de usuario
En cuanto a la duración del desarrollo de los ejercicios por parte de los estudiantes, se puede ver en la Ilustración 2 que demoraron un poco menos en el software, en promedio demoraron 20 minutos en la solución a mano

CINSIS 2017 - Programa de Ingeniería de Sistemas
65
UN INTÉRPRETE DE PSEUDO-LENGUAJE EN ESPAÑOL PARA LAS ASIGNATURAS DE PROGRAMACIÓN Y ESTRUCTURAS DE DATOS
les pueden surgir a sus estudiantes, ya que el software facilita al docente presentar los conceptos, las operaciones, las aplicaciones y los algoritmos de ejemplos de una forma más legible y clara a los estudiantes que se les dificulta captar conceptos abstractos, disminuyendo así las inquietudes que se podían plantear antes y que ahora con el intérprete se han facilitado resolver, y además, ayudando a la disminución de la deserción estudiantil en los programas relacionados a Ingeniería del software, informática y computación, en las universidades de habla hispana.
6. REFERENCIAS
1. Carrillo Siles, B. (2009). Dificultades en el Aprendizaje Matemático. Recuperado el 08 de Abril de 2016, de Sitio web de CSIF Andalucía: http://www.csi-csif.es/andalucia/modules/mod_ense/revista/pdf/Numero_16/BEATRIZ_CARRILLO_2.pdf
2. Casas, S., & Vanoli, V. (2007). Programación y Algoritmos: Análisis y Evaluación de Cursos Introductorios. Recuperado el 2 de Juinio de 2016, de Universidad Nacional de la Patagonia Austral: http://sedici.unlp.edu.ar/bitstream/handle/10915/20502/Documento_completo.pdf?sequence=1
3. Orellano, J., Nieva, O., & Solar, R. (Diciembre de 2012). Software para la enseñanza-aprendizaje. Oaxaca, Mexico.
4. Marqués, P. (1996). Metodología de Software Educativo. Recuperado el Octubre de 2015, de Software Educativo, Ed. Madrid: http://salonvirtual.upel.edu.ve/pluginfile.php/18099/mod_resource/content/0/PERE_MARQUES.doc
5. Donnelly , C., & Richard , S. (1995). Concepts of Bison. Obtenido de Bison: http://dinosaur.compilertools.net/bison/bison_4.html#SEC7
6. Carter, Z. (2013). Jison JavaScript parser generator. Obtenido de Jison: http://zaa.ch/jison/
7. Wikipedia. (2016). Compiler code-to-code. Obtenido de Wikipedia: https://en.wikipedia.org/wiki/Source-to-source_compiler
8. Cairó, O., & Guardati, S. (s.f.). Estrucura de datos 3ra Edición. McGrawHill.

CINSIS 2017 - Programa de Ingeniería de Sistemas
66
LA ENSEÑANZA EN INGENIERÍA DE SISTEMAS DESDE UN ENFOQUE VIRTUAL, DOS CASOS DE ESTUDIO
LA ENSEÑANZA EN INGENIERÍA DE SISTEMAS DESDE UN ENFOQUE VIRTUAL, DOS CASOS DE ESTUDIO
RESUMEN
En este artículo se presenta un par de experiencias de uso de las Tecnologías de la Información (TI) en procesos de formación en ingeniería de sistemas, en la Universidad Nacional Abierta y a Distancia - UNAD. Inicialmente se hace una presentación de la manera en que se diseña y gestiona un curso de ingeniería, partiendo de la descripción del esquema tradicional educativo para llegar al curso implementado bajo la metodología de la educación a distancia. Seguidamente se presentan dos casos de estudio mediante la descripción del acompañamiento de un grupo típico, mostrándose cómo se van desarrollando una serie de trabajos colaborativos alrededor de un proyecto de curso. Finalmente se expone una serie de conclusiones en términos de lo que implica el uso de las TI para el aprendizaje en ingeniería.
Palabras Clave: Física Electrónica, Dinámica de Sistemas, Modelado, Circuitos Eléctricos, Entornos Virtuales de Aprendizaje, Tecnologías de la Información.
Eliécer Pineda BallesterosUNAD
BucaramangaCarrera 27 # 40-43 - 57+037-6358577
Freddy Reynaldo Téllez AcuñaUNAD
BucaramangaCarrera 27 # 40-4357+037-6358577
1. INTRODUCCIÓN
En las dos primeras décadas del siglo XXI ha habido un elevado interés, por parte de los centros de educación superior, por hacer uso de las TI como instrumentos que permitan acercar las instituciones de educación a la mayor cantidad posible de personas [1] [2] [3].
Históricamente la manera como se ha enseñado en las universidades ha sido usando el método tradicional de la presencialidad cuya principal característica es el papel preponderante y activo de un maestro que expone los conocimientos a sus alumnos, constituyéndose estos en receptores de información que deben estar atentos para dar cuenta de lo aprendido a través de los métodos tradicionales de evaluación.
Figura 1. Educación Tradicional, Tomado de [4].
Los modelos tradicionales de educación fueron inspirados en las propuestas teóricas de autores como Skinner y otros que atribuían a la repetición y a la estimulación de los alumnos, mediante condicionamientos, la forma en que estos aprendían. Parte de las contribuciones de los principios skinnerianos son la definición y delimitación de objetivos educativos, la enseñanza personalizada, la modificación de conducta e incluso la instrucción asistida por computador; a este método se le conoce como la enseñanza bancaria [5].
En este sentido [6] plantean la existencia de cuatro principios didácticos identificados en este modelo: Aprendizaje dirigido por el profesor; aprendizaje de una clase relativamente estandarizada adaptada al alumno “promedio”; aprendizaje temáticamente orientado; y silencio de los que aprenden para que se oiga la voz del profesor. Estos modelos de educación tradicional requieren de ambientes de aprendizaje caracterizados por requerimientos como la sala de clases relativamente pequeña, el orden frontal de los asientos de los alumnos que permite al profesor una visión general, sobretodo, cuando su asiento está puesto en una tarima; y permite a los alumnos dirigir la mirada hacia la pizarra o hacia un telón o pantalla de proyección.

CINSIS 2017 - Programa de Ingeniería de Sistemas
67
LA ENSEÑANZA EN INGENIERÍA DE SISTEMAS DESDE UN ENFOQUE VIRTUAL, DOS CASOS DE ESTUDIO
Siguiendo esta lógica, ha habido intentos relatados en artículos que muestran cómo es posible fomentar, a través del uso de un ambiente virtual de aprendizaje, el desarrollo de competencias de toma de decisiones, apoyándose en modelos de dinámica de sistemas [7]. Si bien hay una pregunta por el efecto de usar la dinámica de sistemas para desarrollar ciertas habilidades, no hay una pregunta específica por cómo aprenderla, específicamente, en un ambiente virtual.
La Universidad Nacional Abierta y a Distancia (UNAD), ofrece la mayor parte de sus cursos en entornos virtuales denominados AVA (Ambientes Virtuales de Aprendizaje). Dentro del programa de ingeniería de sistemas se oferta el curso de Dinámica de Sistemas el cual tiene un promedio semestral de 300 estudiantes atendidos por un tutor y un director de curso y el curso de Física Electrónica, perteneciente a ciencias básicas, que al semestre tiene alrededor de 1000 estudiantes matriculados.
La UNAD [8] ha diseñado un modelo pedagógico mediado por las TI, que promueve el aprendizaje autónomo, significativo y colaborativo, fundamentado teóricamente en el constructivismo social [9] y los paradigmas crítico social y ecológico formativo, materializado este a través del uso de la plataforma de aprendizaje Moodle.
Los cursos AVA se componen de 6 entornos de interacción e interactividad sincrónica y asincrónica, que permiten a los actores educativos aumentar el uso flexible de los materiales didácticos, emplear diferentes metodologías y estrategias pedagógicas, optimizar los recursos educativos y con ello, mejorar sus resultados académicos [10].
En el primero de ellos, el Entorno de Información Inicial, se tienen todos los referentes del curso como las agendas, los foros de noticias, la presentación del curso, indicaciones para navegar en el curso, etc.
En segunda instancia se tiene el Entorno de Conocimiento, en donde se pone a disposición del estudiante contenidos académicos digitalizados en múltiples formatos que le llegan mediante multicanales estructurados y centrados en el elemento curricular medular del problema cognitivo que se concreta en el Syllabus, las Guías, las Agendas, etc.
Luego se tiene el Entorno de Aprendizaje Colaborativo, escenario que posibilita la realimentación e interacción sincrónica y asincrónica de los estudiantes, organizados en pequeños grupos, y el tutor. De este trabajo académico realizado a través de foros, chats y redes sociales y de la afirmación del aprendizaje empleando Web-Conferencias,
radio, televisión IP, etc., se genera la construcción social del conocimiento produciéndose de esta manera un aprendizaje significativo y auto gestionado [11].
El siguiente es el Entorno de Aprendizaje Práctico, contexto educativo creado para el ejercicio guiado del estudiante donde aplica los conocimientos adquiridos durante el proceso formativo. En este escenario se posibilita incorporar laboratorios remotos accesibles a los estudiantes que usan simuladores de eventos reales, realidad aumentada, televisión IP, etc.
En el Entorno de Seguimiento y Evaluación del Aprendizaje se realiza el acompañamiento sincrónico y asincrónico del proceso formativo del estudiante mediante la tutoría y la consejería virtual; este ambiente está diseñado para la evaluación continua, formativa y sumativa del aprendizaje.
Finalmente está el Entorno de Gestión del estudiante, que es un contexto de vital importancia para él, pues le facilita realizar todos los trámites propios del proceso educativo [12].
Figura 2. Ambiente Virtual de Aprendizaje.
2. CARACTERÍSTICAS DEL CURSO VIRTUAL EN LA UNAD
Como se señaló en el apartado anterior, los cursos virtuales en la UNAD cuentan con 6 ambientes, de los cuales se presentarán en este artículo básicamente tres, que son los de mayor impacto en el proceso de aprendizaje de los estudiantes.
El primer entorno es el de conocimiento el cual está organizado por unidades de conocimiento, para el caso del curso de dinámica de sistemas, estas son: unidad 1, conceptualización sobre sistemas y modelos, unidad 2, diagramas de Forrester y unidad 3, toma de decisiones apoyada con simulación. Además de los contenidos que deben ser estudiados por los estudiantes, estos tienen a

CINSIS 2017 - Programa de Ingeniería de Sistemas
68
LA ENSEÑANZA EN INGENIERÍA DE SISTEMAS DESDE UN ENFOQUE VIRTUAL, DOS CASOS DE ESTUDIO
su disposición el syllabus del curso, la guía integradora de actividades y la rúbrica analítica de evaluación, dispositivos diseñados para facilitar la auto-gestión del aprendizaje.
Figura 3. Entorno de Conocimiento.
En el entorno de conocimiento el estudiante tiene a su disposición una serie de materiales, en diferentes formatos, que deben ser estudiados y apropiados de tal forma que luego pueda usar, los conceptos apropiados, en la realización de los trabajos colaborativos y en la resolución de exámenes en línea. Si una vez consultados los materiales de estudio el estudiante tiene alguna inquietud, este tiene la posibilidad de hacer la consulta a su tutor, ya sea de forma sincrónica, a través de chats o web-conferencias, o de forma asincrónica, usando para ello los correos electrónicos o los foros.
El siguiente entorno es el de evaluación y seguimiento en el cual los estudiantes presentan, en línea, los diferentes tipos de evaluación que el curso les plantee. Para el caso de dinámica de sistemas los estudiantes deben presentar tres pruebas objetivas cerradas y para ello tienen unos tiempos establecidos que se incluyen en la agenda del curso. En este entorno se le informa al estudiante del resultado de los trabajos colaborativos. Las pruebas son cuestionarios que buscan determinar qué tanto se ha apropiado los conceptos fundamentales de la dinámica de sistemas, esenciales luego en el abordaje del proceso de modelado.
Figura 4. Entorno de Evaluación.
El tercero y más importante de los entornos es el de aprendizaje colaborativo. En este entorno se pone en práctica la estrategia de aprendizaje que el docente director de curso haya escogido; entre ellas la basada en proyectos que es la que se usa en este curso. Este curso propone la formulación de un proyecto de modelado y simulación que aborde una problemática local, acorde a la orientación social y comunitaria de la UNAD.
En este entorno se desarrolla uno de los pilares fundamentales de los cursos de la UNAD, los trabajos colaborativos, espacios diseñados bajo los postulados del aprendizaje autónomo, el aprendizaje significativo y el constructivismo social, posibilitando así que el estudiante alcance la construcción social del conocimiento.
En lo que sigue se ilustrará con un par de ejemplos ejemplo la manera en que se desarrolla la interacción entre estudiantes y docente en el proceso de construir el conocimiento orientado bajo la estrategia de aprendizaje basado en proyectos y basada en problemas [13] [14]. El aprendizaje basado proyectos se caracteriza porque se centra en los conceptos y principios de una disciplina, implica a los estudiantes en investigaciones de solución de problemas y otras tareas significativas, esto les permite trabajar de manera autónoma para construir su propio conocimiento y culmina en productos objetivos y realistas. En este aprendizaje los estudiantes planean, implementan y evalúan proyectos que tienen aplicación en el mundo real, mediante actividades de aprendizaje interdisciplinarias, de largo plazo y centradas en el estudiante [15].
3. CASOS DE ESTUDIO
3.1. Curso de Dinámica de Sistemas
En esta Sección se muestra un caso de estudio, en donde un grupo de estudiantes desarrollan un proyecto semestral relacionado con el modelado del problema de la disposición de basuras.
Los estudiantes deben abordar la solución de un problema mediante la estrategia de aprendizaje basado en proyectos en cinco momentos durante el semestre. El primero de ellos es la construcción de un anteproyecto en donde el grupo de manera colaborativa, usando principalmente el foro, construyen la propuesta, la cual va siendo realimentada por el tutor y al final del tiempo establecido se hará una valoración del mismo y se realizará una realimentación en procura del mejoramiento de la propuesta.

CINSIS 2017 - Programa de Ingeniería de Sistemas
69
LA ENSEÑANZA EN INGENIERÍA DE SISTEMAS DESDE UN ENFOQUE VIRTUAL, DOS CASOS DE ESTUDIO
Figura 5. Momento 1, Elaboración del Anteproyecto.
En el segundo momento los estudiantes comienzan el diseño del diagrama de influencias que debe representar el fenómeno modelado, también usando el foro y las realimentaciones tanto del tutor como de los demás compañeros del grupo; en este momento se insiste a los estudiantes para que escojan variables que sean cuantificables y que incluyan en sus descripciones los ciclos de realimentación. Se supone que los estudiantes van haciendo la lectura de los materiales dispuestos en el entorno de conocimiento y lo que hacen en los foros es ir construyendo sobre la base de lo leído y las orientaciones del tutor. Este momento finaliza con la entrega del diagrama de influencias, que luego de ser revisado por el tutor, lo regresa al grupo con las observaciones del caso y una valoración numérica del trabajo.
Una de las situaciones recurrentes en los estudiantes es la no inclusión de los ciclos de realimentación y la dificultad que presentan para identificar relaciones de material de las relaciones de información. A medida que el tutor hace las observaciones sobre la construcción del diagrama comienzan a prestar atención y van logrando identificar qué tipo de relación es y por tanto aumentan su capacidad para ir identificando los ciclos de realimentación en el modelo.
Al final el grupo de aprendizaje colaborativo, luego de las interacciones entre los miembros del grupo y el tutor, logra desarrollar un diagrama de influencias como el que sigue.
Figura 6. Momento 2, Construcción del Diagrama Causal.
Figura 7. Diagrama Causal entregado por los Estudiantes.
En este diagrama se nota el trabajo del grupo colaborativo. Es evidente que el diagrama aún no está completo, pues le faltan ciclos de realimentación por identificar, pero resulta siendo un buen trabajo de estudiantes neófitos en el asunto del modelado y más aún si se tiene en cuenta que gran parte del conocimiento requerido es apropiado por el estudiante de forma auto-gestionada.
En el tercer foro colaborativo los estudiantes construyen el diagrama de Forrester, esto se hace de la misma manera que han venido trabajando en los dos foros previos. En este caso los estudiantes se enfrentan al desafío de convertir el diagrama de influencias en el diagrama de Forrester. Es habitual encontrar que los estudiantes tienen problemas en comprender las nociones de acumulación y razón de cambio, incluso suele suceder que en ocasiones las comprenden y usan de forma contraria. Otra situación muy frecuente es que no son conscientes de respetar la ley de la conservación de la materia siendo habitual en ellos que conecten niveles que contienen diferentes cosas. Los estudiantes en este curso no alcanzan a utilizar conceptos como retardos y tablas, evidentemente esto los limita como modeladores, pero se ha optado por no incluirlos dado la complejidad que para ellos implica comprender los conceptos de flujo y nivel y usarlos de forma adecuada para representar de manera adecuada los fenómenos que están modelando. Es bastante común también que conecten de forma lineal una serie de variables auxiliares cuando esto usualmente no tiene sentido; igualmente se les dificulta hacer que el modelo sea consistente desde el punto de vista dimensional.

CINSIS 2017 - Programa de Ingeniería de Sistemas
70
LA ENSEÑANZA EN INGENIERÍA DE SISTEMAS DESDE UN ENFOQUE VIRTUAL, DOS CASOS DE ESTUDIO
Figura 8. Momento 3, Construcción del Diagrama de Forrester.
El trabajo colaborativo requiere de un ejercicio continuo de parte de los estudiantes. Suele suceder que un buen número de los estudiantes dejan para participar a última hora, esto naturalmente trae las consecuencias consabidas, es decir, que la calidad de los modelos construidos es muy pobre, al igual que la apropiación de los conceptos básicos. Frente a esta situación se opta por enviar correos electrónicos invitándolos a participar en el foro; de hecho, hay una normatividad institucional que regula el trabajo colaborativo y establece como mínimo que un estudiante debe participar en el foro al menos cuatro días antes que el foro cierre, so pena de no considerársele como autor del trabajo.
No obstante, hay grupos de estudiantes que entran en la dinámica del trabajo colaborativo y a partir de la realimentación a los trabajos entregados, ellos logran los propósitos del curso.
La siguiente figura muestra claramente una serie de imprecisiones que cometen los estudiantes a la hora de construir los modelos; las realimentaciones buscan generar en los estudiantes conflictos cognitivos, pues al mostrarles los errores en el diagrama y sugerir el origen, mediante preguntas, hace que ellos de alguna manera intenten resolver la situación. No siempre funciona la estrategia de hacer preguntas y básicamente ocurre porque el estudiante, al no haber apropiado los conceptos, no posee estructuras cognoscitivas que le permitan caer en la cuenta del error, luego de haber reflexionado ante las preguntas planteadas.
Figura 9. Realimentación del Diagrama de Forrester.
La figura 10 muestra que ha habido progresos en la comprensión de los útiles de la dinámica de sistemas y su uso más cercano a lo que debería ser. Es evidente que la distancia estudiante-tutor en este caso hace que los procesos de aprendizaje vayan siendo más lentos, pero no por ello menos efectivos. Aunque es notorio el progreso en la construcción del diagrama de Forrester, aún el diagrama debe ser perfeccionado.
Una vez se ha logrado que construyan un buen diagrama de Forrester viene el problema, para los estudiantes, que consiste en la comprensión de qué tipo de funciones matemáticas han de usar asociado a cada uno de los elementos de la dinámica de sistemas. En estos casos ayuda que hayan aprendido que hay una relación entre dX/dt y el flujo y otra relación entre X y el nivel. Resulta ser que, en muchos de los casos, los estudiantes encuentran en el diseño e inclusión de las ecuaciones una de las partes más difíciles, lo que hace que un proceso como la validación de los modelos resulte dificultoso a la hora de realizarlo.
Una consulta que es muy frecuente en los estudiantes es: ¿Cómo hago para generar las ecuaciones?, ¿Qué parte del software hace eso? En esta circunstancia hay que citar a los estudiantes, generalmente, a una web-conferencia en la que se les muestra mediante ejemplos que no hay una fórmula mágica para generar las ecuaciones, que ello depende básicamente del conocimiento que el modelador

CINSIS 2017 - Programa de Ingeniería de Sistemas
71
LA ENSEÑANZA EN INGENIERÍA DE SISTEMAS DESDE UN ENFOQUE VIRTUAL, DOS CASOS DE ESTUDIO
tenga del fenómeno que está siendo modelado y de conocimientos mínimos de matemática que se suponen presentes en estudiantes de séptimo nivel.
El siguiente foro es el de toma de decisiones; en este foro los estudiantes revisan material sobre el uso de los modelos dinámicos para el apoyo de la toma de decisiones, el diseño de escenarios de simulación y la realización de pruebas de validación de los modelos. La idea de este foro es que puedan hacer estos ejercicios sobre el modelo de tal forma que los prepare para el siguiente trabajo colaborativo. En el curso se asume la toma de decisiones como lo plantea [16], es decir, como los mecanismos de realimentación, capaces de convertir información en acción.
El último foro en el que trabajan los estudiantes es el de la experimentación simulada en el cual ellos deben plantear, ciertos experimentos simulados, a partir de los escenarios diseñados, naturalmente, relacionados con el problema que inicialmente se propusieron abordar. El grupo al cual se le estaba haciendo el seguimiento logró refinar el modelo según se ve en la siguiente figura, pero por falta de trabajo de grupo no lograron calibrarlo para realizar el ejercicio asociado a la simulación experimentada para luego formular las políticas de interrvención, criterios o reglas que rige la forma de tomar decisiones, conducentes a la resolución del problema inicialmente planteado.
Figura 10. Realimentación del Diagrama de Forrester.
El grupo hizo la entrega del modelo que se puede ver en la figura 11, este modelo se realimentó de la siguiente manera: “Modelo basuras. Bien identificados los niveles y los flujos, pero los valores están produciendo comportamientos que no son coherentes, deben revisar las ecuaciones y las unidades. Las tasas de producción de basura de las industrias no pueden ser las mismas que las de las empresas. La capacidad del relleno debería servir para determinar cuándo se llena y por tanto deberían implementar un nivel llamado relleno y usar ese dato de la capacidad para indicar en que momento hay problemas por estar sin donde llevar la basura.”
Figura 11. Diagrama de Forrester entregado por el grupo.
A partir de esta realimentación y del modelo, los estudiantes abordan la siguiente actividad colaborativa.
Figura 12. Diagrama de Forrester Final.
No en todos los casos se logran resultados exitosos pues el hecho de haber desarrollado una de las tareas previas de forma incorrecta, en uno de los foros anteriores, naturalmente hace casi imposible que puedan desarrollar los propósitos del último foro de manera apropiada. En el caso revisado el grupo tuvo un desempeño promedio; hay grupos que desde el primer colaborativo no son capaces de formular bien el problema, mientras que hay otros grupos que debido a su trabajo y al acompañamiento del tutor logran desarrollar competencias mínimas esperadas en el curso.
3.2. Curso de Física Electrónica
A continuación, se presenta el trabajo desarrollado por los estudiantes del curso Física Electrónica, relacionado con la Unidad 1: Fundamentos de Electricidad.

CINSIS 2017 - Programa de Ingeniería de Sistemas
72
LA ENSEÑANZA EN INGENIERÍA DE SISTEMAS DESDE UN ENFOQUE VIRTUAL, DOS CASOS DE ESTUDIO
Esta temática se desarrolló bajo la estrategia Aprendizaje Basado en Problemas y contó como herramienta de apoyo para la realización del trabajo con un software simulador, buscando con ello facilitar la comprensión de los principales conceptos, leyes y aplicaciones de la electricidad en situaciones y experiencias muy similares a las existentes en la realidad.
La actividad propuesta parte de un macro-problema, que consiste en el análisis de diferentes circuitos susceptibles a ser implementados en una vivienda. El primer paso es presentarle a los estudiantes el plano arquitectónico de un apartamento de dos pisos, para que cada estudiante del grupo colaborativo seleccione una de las siguientes ubicaciones para su trabajo individual: Cocina, Garaje, Sala-Comedor, Dormitorio o Sala de Estar.
En este punto el estudiante debía detectar una conexión en serie entre los tomacorrientes 3 y 4 y proponer la mejora del circuito, la cual sería un circuito con todos los tomacorrientes conectados en paralelo.
La siguiente tarea asignada fue el cálculo matemático de algunas magnitudes eléctricas en el circuito mejorado y su verificación por medio de la respectiva simulación.
Figura 13. Plano Arquitectónico de Apartamento.
De acuerdo a la ubicación seleccionada y a la potencia eléctrica que consume cada uno de los electrodomésticos o cargas eléctricas asignadas a cada estudiante, debían determinar el consumo en Kwh y su valor en pesos, tomando como referencia su factura de energía eléctrica.
Posteriormente se solicita que analice un circuito eléctrico conformado por varios tomacorrientes, que conecte a cada tomacorriente un electrodoméstico y que realice el análisis sobre si el circuito era el recomendado para una vivienda o no.
Figura 14. Evidencia de Aporte de un Estudiante.
Figura 15. Medición de Magnitudes Eléctricas por medio del Software Simulador.
Hasta este punto de la actividad y de acuerdo a los aportes realizados por los estudiantes, el docente puede evidenciar la comprensión de importantes temas de la unidad en estudio como: el circuito serie, el circuito paralelo, la ley de Ohm, la potencia eléctrica y las habilidades desarrolladas para el cálculo matemático y la medición de algunas magnitudes eléctricas como el voltaje y la corriente eléctrica.
El trabajo individual finaliza con un ejercicio de asociación de las resistencias eléctricas del circuito en el que se tienen todos loselectrodomésticos en paralelo, para obtener así un circuito eléctrico equivalente conformado por: la fuente de alimentación, la resistencia total equivalente y un medidor de corriente.
Para el trabajo colaborativo del grupo se proponen dos tareas de síntesis muy importantes, a saber: (1) la conexión en paralelo de los cinco circuitos equivalentes, los cuales representarán el circuito eléctrico completo del apartamento, siempre y cuando se hayan realizado los aportes respectivos sobre cada una de las ubicaciones asignadas y (2) el análisis de los resultados y las conclusiones de la experiencia.

CINSIS 2017 - Programa de Ingeniería de Sistemas
73
LA ENSEÑANZA EN INGENIERÍA DE SISTEMAS DESDE UN ENFOQUE VIRTUAL, DOS CASOS DE ESTUDIO
Figura 16. Circuito Eléctrico Unificado del Apartamento.
Esta parte de la actividad presentó en varios grupos dificultades, pues algunos estudiantes no cumplieron con su trabajo individual o dejaron para muy tarde el análisis de resultados y la elaboración de las conclusiones. Sin embargo en la mayoría de grupos a cargo se obtuvieron trabajos de muy buena calidad que evidencian el logro de los objetivos propuestos y la comprensión de los temas de estudio.
4. REFLEXIONES FINALES
Una de las principales ventajas que tiene el uso de las TI, para mediar procesos de aprendizaje, consiste en hacer accesible el conocimiento a un número mayor de personas; pues al desvanecerse el espacio físico, se crea un otro espacio en el cual quien desea aprender y quien puede acompañar dicho aprendizaje, se pueden encontrar de forma sincrónica o asincrónica para hacerlo posible. A nivel de dinámica de sistemas, esta estrategia de aprendizaje podría ser aprovechada como una posibilidad para incrementar la base de sus practicantes, trayendo con ello las consabidas consecuencias, promoviendo de esta forma una corriente de pensamiento dinámico sistémica.
La principal dificultad que puede entrañar la educación mediada por TI es que algunos hablan de la desnaturalización de la educación a causa del uso intensivo de las tecnologías; pero finalmente parecen ser más las bondades del uso de las TI en educación, una de ellas es que puede surgir como un elemento democratizador de la educación. Consecuencia de lo anterior, esta dejaría de ser privilegio de unas ciertas élites que pueden asistir a los centros de educación tradicional, para convertirse en una forma de pensar asequible a todos.
5. CONCLUSIONES
La educación tradicional ofrece a los estudiantes la posibilidad de resolver las dudas de forma inmediata una vez estas aparecen, cosa que no es posible en la educación a distancia mediada virtualmente; este hecho puede hacer un poco más lento el proceso de aprendizaje en la virtualidad.
En educación tradicional quien no asiste a clase pierde la posibilidad de recibir la orientación del docente; esto no ocurre en la educación a distancia pues el estudiante dispone de los materiales diseñados para que afronte su proceso de aprendizaje y tiene la opción de formular sus inquietudes, a la vez que estas aparecen, con la posibilidad de que sean luego resueltas.
El uso de las TI en el proceso de aprendizaje en ingeniería implica que haya docentes que estén preparados para establecer comunicación sincrónica y asincrónica a través de las TI y no solo que estén preparados en el aspecto disciplinar; de hecho, es deseable que haya sido un estudiante en este sistema de aprendizaje.
El estudiante de entornos virtuales, en gran proporción, suele procrastinar el proceso de apropiación de conceptos, por la flexibilidad que en estos entornos se tiene para decidir en qué momentos se accede a la plataforma de estudio; naturalmente eso influye de manera negativa en el proceso de aprendizaje. No se debe confundir la flexibilidad con facilidad.
Tanto el estudiante tradicional como el virtual enfrentan los problemas clásicos de ver lo que no es visible, específicamente, las relaciones de información, a la hora de diseñar los diagramas de influencias y suelen cometer los mismos errores en cuanto a la distinción de las relaciones de material y el desconocimiento de la ley de la conservación de la materia, en sus representaciones.
6. REFERENCIAS
[1] J. Salinas, «Innovación docente y uso de las TIC,» Revista Universidad y Sociedad del Conocimiento, pp. 1-16, 2004.
[2] Á. M. Molina, «Las TIC en la educación superior como vía de formación y desarrollo competencial en la sociedad del conocimiento,» Revista electrónica de investigación Docencia Creativa, pp. 106-114, 2012.
[3] J. E. Padilla, P. L. Vega y D. A. Rincón, «Tendencias y dificultades para el uso de las TIC en educación superior,» Revista Entramado, pp. 272-295, 2014.

CINSIS 2017 - Programa de Ingeniería de Sistemas
74
LA ENSEÑANZA EN INGENIERÍA DE SISTEMAS DESDE UN ENFOQUE VIRTUAL, DOS CASOS DE ESTUDIO
[4] PNAS, «Investigación y Ciencia,» 23 05 2014. [En línea]. Available: http://www.investigacionyciencia.es/noticias/los-lmites-de-la-enseanza-tradicional-12128. [Último acceso: 17 10 2017].
[5] G. Sotomayor, «De la educación bancaria en el Aula, a la educación problematizadora en la Red,» Revista Didáctica, Innovación y Multimedia, pp. 1-7, 2011.
[6] K.-H. Flechsig y E. Schiefelbein, «Enseñanza frontal o Tradicional (Enseñanza cara a cara),» de Veinte Modelos Didácticos para América Latina, Washington, OAS Cataloging-in-Publication Data, 2003, pp. 17-22.
[7] H. H. Andrade, G. Maestre y G. López, «Desarrollando competencias en la toma de decisiones con dinámica de sistemas: una experiencia de aula,» de La Dinámica de Sistemas: Un Paradigma de Pensamiento 9° Encuentro Colombiano de Dinámica de Sistemas, Bogotá, 2011.
[8] C. Abadía, P. Vela y J. H. Guerrero, «Lineamientos generales del Currículo en la UNAD,» Unad, Bogotá, 2014.
[9] L. Vigotsky, El Desarrollo de los Procesos Psicológicos Superiores, Barcelona: Editorial Crítica - 1979, 1932.
[10] G. C. Herrera, «Ambientes virtuales de aprendizaje. Documento de trabajo. Vicerrectoría de medios y mediaciones pedagógicas (VMMEP),» Unad, Bogotá, 2011.
[11] G. C. Herrera y C. E. Riaño, «Redes académicas fractales de la universidad nacional abierta y a distancia,» Revista de Investigaciones UNAD, pp. 243-252, 2010.
[12] UNAD, «Proyecto académico pedagógico solidario. PAP solidario. Versión 3.0.,» Unad, Bogotá, 2011.
[13] A. Badia y C. García, «Incorporación de las TIC en la enseñanza y el aprendizaje basados en la elaboración colaborativa de proyectos,» Revista de Universidad y Sociedad del Conocimiento, pp. 42-54, 2006.
[14] J. A. Martí, M. Heydrich, M. Rojas y A. Hernández, «Aprendizaje basado en proyectos: una experiencia de innovación docente,» REVISTA Universidad EAFIT, pp. 11-21, 2010.
[15] L. Galeana, «Aprendizaje basado en proyectos,» CEUPROMED, 2006.
[16] Y. Álvarez y R. M. García, «Aprendizaje de la organización, juegos de empresa y dinámica de sistemas,» de Anales de Economía Aplicada. XIV Reunión ASEPELT, Oviedo, 2000.

CINSIS 2017 - Programa de Ingeniería de Sistemas
75
GUÍA PARA LA INCORPORACIÓN DE LOS CONCEPTOS DE PROTECCIÓN DE DATOS EN EQUIPOS DE DESARROLLO DE SOFTWARE CON BAJOS NIVELES DE MADUREZ
GUÍA PARA LA INCORPORACIÓN DE LOS CONCEPTOS DE PROTECCIÓN DE DATOS EN EQUIPOS DE DESARROLLO DE SOFTWARE CON BAJOS NIVELES
DE MADUREZ
RESUMEN
El presente documento tiene como objetivo ofrecer una guía para el tratamiento de datos personales dentro de un proyecto de desarrollo de software, con base en la normatividad colombiana. La guía está dirigida a grupos de trabajo pequeños e innovadores, conformados principalmente por estudiantes y recién egresados de instituciones de educación superior, con poco conocimiento jurídico en general y con respecto al manejo de datos personales en particular. La elaboración estuvo motivada en que dada la creciente proliferación en la transmisión y almacenamiento de datos personales por parte de aplicaciones software, la normativa concerniente a las restricciones en el manejo de este grupo de datos ha cambiado, imponiendo unas nuevas restricciones al momento de desarrollar software, las cuales deben ser conocidas y manejadas con audacia. Para la construcción de la guía se siguió una metodología de cuatro pasos, donde el primer paso fue la formulación de preguntas de interés para iniciar la búsqueda de la información, luego se prosiguió con la revisión de la normatividad vigente con la finalidad de responder esas interrogantes, posteriormente se revisó sus aplicaciones en el campo de desarrollo de software y por último se diseñó la guía. Este proceso arrojó como resultado una guía que contiene de manera estructurada el proceso que una pequeña empresa, o un grupo de desarrollo, puede seguir para establecer unas políticas de manejo de datos y privacidad claros, ajustados con la normatividad vigente.
ABSTRACT
This document aims to provide a guide for the processing of personal data within a software development project, based on Colombian regulations. The guide is aimed at small and innovative work groups, consisting mainly of students and recent graduates of institutions of higher education, with little legal knowledge in general and little knowledge regarding the management of personal data in particular. The elaboration was motivated in that given the growing proliferation in the transmission and storage of personal data by software applications, the regulations concerning the restrictions in the management of this data group has changed, imposing new restrictions when developing software, which must be known and managed with audacity. For the construction of the guide, a four-step methodology was followed, where the first step was the formulation of questions of interest to start the search for information, then continued with the revision of the current regulations in order to answer those questions , Later its applications in the field of software development were revised and finally the guide was designed. This process resulted in a guide that contains in a structured way the process that a small company or a development group can follow in order to establish clear data and privacy management policies, adjusted with current regulations.
Palabras Claves: Protección de datos; Privacidad de datos del usuario; Políticas de tratamiento de datos
Keywords: Data Protection; Privacy of user data; Data processing policies
Jhon TrespalaciosLíder de modelado de base
Andrés Paternina ArizaSubgerente y líder de desarrollo
Cesar Polo CastroGerente generalSoftSimulation
Alexander BustamanteArquitecto

CINSIS 2017 - Programa de Ingeniería de Sistemas
76
GUÍA PARA LA INCORPORACIÓN DE LOS CONCEPTOS DE PROTECCIÓN DE DATOS EN EQUIPOS DE DESARROLLO DE SOFTWARE CON BAJOS NIVELES DE MADUREZ
1. INTRODUCCIÓN
En la actualidad se está experimentando un crecimiento acelerado en el uso del internet, se estima que del año 2012 al 2016 hubo un aumento de más del 60% en la cantidad de usuarios conectados, pasando de 2.1 a 3.1 billones [1]. Este crecimiento también se evidencia en el tráfico de información, donde las grandes empresas enfrentan, además del desafío de tener la capacidad de soportar las visitas de los usuarios, gestionar la información que se genera en cada una de las transacciones [2]. Se estima que durante un minuto del día, una compañía como Amazon obtiene $ 222.283 USD en ventas, en Twitter se envía 9.678 tweets, en Dropbox los usuarios suben 833.333 documentos, en redes sociales como Instagram existen 2.430.555 likes en publicaciones y en Facebook 216.302 personas comparten sus fotos [1]. De acuerdo con The Software Alliance (BSA) [2], el 90 % de los datos que existen en internet desde el año 2014 se generaron hace dos años; por lo cual, se puede afirmar que se vive en la era de revolución de los datos.
Sumando a lo anteriormente descrito, el bajo precio tanto en capacidad de almacenamiento como de procesamiento ha creado un escenario para que las compañías, no solo las grande sino también las pequeñas y medianas, vean rentable la recolección, el tratamiento y el análisis de datos con la finalidad de producir conocimientos valiosos que permitan optimizar procesos, ahorrar tiempo y dinero dentro de la organización [2]. Sin embargo, muchos de los datos recolectados son de carácter personal, los cuales son almacenados transgrediendo barreras o procesados y difundidos sin considerar los efectos. Incluso en las grandes empresas se han presentado casos de fugas de información, por ejemplo, la red social más grande del mundo, Facebook, en el año 2013 reporto una fuga de información de más de 6 millones de usuarios, por medio de la herramienta “Descarga tu información” [3], donde se podría encontrar la información de contactos que no se habían compartido por la plataforma, incluso si alguna vez no se hubiera compartido un dato que no se encontraba en la red, Facebook podría obtenerlo a través de tu lista de amigos. Otro caso fue el de Adobe, donde se reportó 38 millones de cuentas afectadas por el robo de las credenciales, debido que contaban con un sistema deficiente al momento del cifrar contraseñas. Incluso, Google ha recibido denuncias por vulnerar la ley de protección de datos por su servicio de Street View, debido que poseen la capacidad de capturar, difundir y emplear bajo sus propios fines multitud de imágenes que no han sido consentidas con anticipación [4]. Estas denuncias
han llegado al menos por 30 países, incluyendo a España, Alemania, Argentina, Holanda, entre otros [5].
Casos como los citados han llevado a la necesidad de mejorar la normatividad con respecto al manejo de datos personales. Los gobiernos a nivel mundial han establecido medidas para garantizar que las personas pueden tener garantías que protejan la privacidad de su información, además de velar de su derecho de solicitar la revisión y supresión de ella al momento que lo desee [6].
En este contexto, la Unión Europea como primera medida instauró la directiva 95/46/CE en 24 de octubre de 1995, la que crea un marco regulador destinado a establecer un equilibrio entre un nivel elevado de protección de la vida privada de las personas y la libre circulación de datos personales dentro de la Unión Europea (UE) [7], donde cada Estado miembro establece un ente para supervisión de actividades relacionadas con el tratamiento de la información. Sin embargo, dado que la directiva no se ajustaba a la realidad digital actual, creó el Reglamento General de Protección de Datos (RGPD) el 25 de mayo del 2016, que entrará en vigor en mayo del 2018. El RGPD establece explícitamente la necesidad de un consentimiento inequívoco por parte del titular de los datos, es decir, debe haber una manifestación afirmativa del interesado, además, la información debe ser sencilla y concisa, igualmente, se crea la figura de delegado de protección de datos, siendo este el encargado de cumplir de la normatividad, sin tener la responsabilidad jurídica [8].
En Estados Unidos el panorama es diferente, solo existe el Privacy Act of 1974, que establece un código para el manejo de información contenida en bases de datos federales, exceptuando de unas pocas leyes que tratan de la información personal financiera y médica, Estados Unidos no cuenta con una legislación que rija el procesamiento de datos personales por entidades privadas, al contrario prevé la auto regulación por parte de los sectores económicos en materia de datos personales manejados por entidades privada [9].
En Colombia, como primera medida se instauró en el año 2008 la ley 1266 denominada “Habeas Data”, el cual busca velar por el derecho consagrado en el artículo 15 de la constitución 1991 como “Todas las personas tienen derecho a su intimidad personal y familiar y a su buen nombre, y el Estado debe respetarlos y hacerlos respetar. De igual modo, tienen derecho a conocer, actualizar y rectificar las informaciones que se hayan recogido sobre ellas en los bancos de datos y en archivos de entidades

CINSIS 2017 - Programa de Ingeniería de Sistemas
77
GUÍA PARA LA INCORPORACIÓN DE LOS CONCEPTOS DE PROTECCIÓN DE DATOS EN EQUIPOS DE DESARROLLO DE SOFTWARE CON BAJOS NIVELES DE MADUREZ
públicas y privadas.” [10]. Esta legislación estaba orientada en la protección de la información en bases de datos, financieras, crediticia, comercial, de servicios, reportadas en agencias de riesgo, por ejemplo data crédito. No obstante, la protección de los datos debe ir a un nivel superior, por lo tanto la ley 1581 de 2012 donde se establece un marco general aplicable a todas las bases de datos de entidades públicas y privadas que almacenen y lo utilicen. Además, establece como autoridad a la Superintendencia de Industria y Comercio como entidad encargada de investigar y sancionar el incumplimiento, regula la seguridad, confidencialidad de los datos, finalidad en el tratamiento de los datos y se crea el Registro Nacional de Base de Datos (Rdnb).
En el marco de la construcción de un proyecto de desarrollo de software, el equipo de desarrollo debe garantizar el cumplimiento del marco legal establecido dentro del contexto anteriormente descrito. Pero, muy frecuentemente, unas veces por desconocimiento y muchas otras por falta de claridad no se posee el conocimiento de qué y cómo cumplir, no existe una fase donde se tenga en cuenta el marco legal de los datos, por tal motivo en el presente documento se establecerá una guía para el tratamiento de datos con base a la legislación colombiana dirigida a grupos de trabajo pequeños e innovadores principalmente emergentes de instituciones de educación superior que tienen poco conocimiento jurídico concerniente al tema. Para dicho fin el documento continúa presentando los antecedentes y fundamentación teórica, luego se procede con el proceso metodológico seguido; posteriormente se presenta el diseño de la guía y se ilustra su aplicación dentro del proceso de desarrollo de software; para finalmente, presentar las conclusiones y los trabajos futuros.
2. ANTECEDENTES
La evolución normativa relacionada con el tratamiento de datos personales por parte de las empresas ha empezado a cobrar mucha relevancia tanto en el plano internacional como en el nacional, esto se evidencia desde el artículo 12 la declaración universal de los derechos de hombre [11] en el año de 1948, donde garantiza como derecho fundamental la privacidad de la información privada de las personas. Teniendo lo anterior como base, cada país dentro de sus normatividades, deberían garantizar la privacidad de cada persona, por lo tanto cada uno desarrolla sus legislaciones aplicables ajustadas a su realidad, por lo tanto en los años 70 Estados Unidos elabora “Fair Information Practice” [12] donde establece
principios básicos para proteger los datos personales y sirvió de base para la construcción de las legislaciones posteriores. Sin embargo, con el aumento de tráfico de datos a nivel mundial, la creciente demanda de recolección de información, países pioneros como los miembros de la Unión Europea, crearon una directiva que sirve de un marco regulador destinado a establecer un equilibrio entre un nivel elevado de protección de la vida privada de las personas y la libre circulación de datos personales dentro de ella que se ajuste directamente a las normas ya establecidas por ella.
La principal referencia a la fecha tanto en términos de robustez como de claridad conceptual y procedimental es el RGPD creado por la Unión Europea el 25 de mayo del 2016 [7] . El documento busca ofrecer más control a los ciudadanos sobre su información personal en el contexto de la era digital, además de reducir las cargas administrativas y facilitar la aplicación por partes de las compañías. En esta legislación se destaca unos puntos importantes como:
• El consentimiento debe ser expresado de manera afirmativa, además debe solicitarse cuando se realiza tratamientos de datos sensibles, transferencias internacionales y adopción de decisiones automatizadas.
• Se incluyeron nuevos derechos: como ejercer los derechos del interesado serán de manera gratuitas, exceptuando cuando se realicen solicitudes excesivas, también el interesado de puede obtener una copia de la información almacenada en un formato estructurado de uso común.
El gobierno buscando qué el periodo de transición en la normatividad vigente elaboró una guía denominada “Guía del reglamento general de protección de datos para responsable de tratamiento” [8], se explica conceptos claves de la normatividad vigente dirigida a los que son responsables de tratamiento. Otro documento que se publicó fue “Guía para el cumplimiento del deber informar” [13], la cual tiene como objetivo orientar acerca de las mejores prácticas para dar cumplimiento a la obligación de informar a los interesados, en virtud del principio de transparencia, acerca de las circunstancias y condiciones del tratamiento de datos a efectuar, así como de los derechos que les asisten.
En Argentina, la Dirección Nacional de Protección de Datos Personales del Ministerio de Justicia y Derechos Humanos de la Nación y la fundación Sadosky, debido

CINSIS 2017 - Programa de Ingeniería de Sistemas
78
GUÍA PARA LA INCORPORACIÓN DE LOS CONCEPTOS DE PROTECCIÓN DE DATOS EN EQUIPOS DE DESARROLLO DE SOFTWARE CON BAJOS NIVELES DE MADUREZ
a los nuevos desafíos en el ámbito de la protección de datos crearon la guía “Guía de Buenas Prácticas para el Desarrollo de Aplicaciones” [14], un documento dirigidos a desarrolladores de aplicaciones, quienes tienen la responsabilidad de velar por la privacidad de los datos personales que utiliza su software, en el marco de la ley 25.326 (Ley de Protección de Datos Personales) que establece principios y obligaciones sobre el tratamiento de los datos [15]. De esta guía se puede destacar:
• Establece una serie de procedimientos, desde el inicio del proceso de desarrollo con el fin de establecer política de datos para el usuario sea clara y transparente que permita conocer el tratamiento que se están realizando a los datos suministrados.
• Incluye, aspectos metodológicos y técnicos en el ámbito de seguridad para amparar la cantidad y calidad de datos que se manejan. Un aspecto importante de la legislación para la protección de datos, en el año 2003 la Unión Europea realizo la adecuación de los términos establecidos con la directiva N° 95/46/CE, por lo tanto cumplen los estándares europeos.
En Estados Unidos a diferencia de la Unión Europea no está altamente legislada, no existe una ley que rija la adquisición, almacenado y uso información personal, que aplique para toda la nación, solamente la información que es objeto de protección son los de registro de salud por la ley de Transferibilidad y Responsabilidad del Seguro Sanitario (HIPAA, por sus siglas en inglés), la cual establece quien puede tener acceso a la información médica. La información de crédito de los ciudadanos está regulada por la Ley Federal de Transacciones Crediticias Justas y Exactas (FACTA, por sus siglas en inglés) la cual está diseñada para proteger los datos financieros de los consumidores asociados por el robo de datos. Sin embargo, la protección de datos a nivel comercial es autorregulada por cada uno de los estados, donde se caracteriza California tiene más de 25 leyes para la privacidad y seguridad de la información, además de los pocos estados que reconoce el derecho de la privacidad de los individuos descrita en su constitución. La mayoría de las grandes compañías comerciales son reguladas por la Comisión Federal de Comercio (FTC, por sus siglas en inglés) ha utilizado esta autoridad para perseguir a las empresas que no implementan la seguridad mínima
de datos o medidas que no cumplan con las promesas en las políticas de privacidad [16].
3. METODOLOGÍA
Para la construcción de la presente guía se siguió un
proceso de 4 pasos, tal como se puede observar en la Ilustración 1 y es descrito a continuación.
Ilustración 1 Proceso metodológico
4. FORMULACIÓN DE PREGUNTAS DE INTERÉS.
En esta primera fase se formularon las preguntas de interés o guía, con la finalidad de realizar una búsqueda de información orientada a identificar elementos claves que posteriormente fueran útiles en la construcción de la guía. Además, busca clarificar las ideas, dando un alcance delimitado de lo que se desea transmitir, en el marco de desarrollo de un proyecto de software. Dichas interrogantes se describirán a continuación:
P1. ¿Cuál es la normatividad vigente respecto a la protección de datos en Colombia?
P2. ¿Cuáles son las leyes que regulan la protección de datos a nivel mundial y que puede ser de utilidad en la construcción de la guía?
P3. ¿Existen guías para el desarrollo de proyectos de software teniendo en cuenta la protección de datos?
P4. ¿Existe una estructura para establecer políticas de privacidad cumpliendo la normatividad vigente colombiana?
P5. Si P3 es verdadera, ¿cuáles son esas guías?

CINSIS 2017 - Programa de Ingeniería de Sistemas
79
GUÍA PARA LA INCORPORACIÓN DE LOS CONCEPTOS DE PROTECCIÓN DE DATOS EN EQUIPOS DE DESARROLLO DE SOFTWARE CON BAJOS NIVELES DE MADUREZ
4.1. Revisión de la normatividad vigente
En esta fase se realizó un proceso de recolección de documentos con la finalidad de resolver los interrogantes de lo descrito anteriormente. En la información encontrada se puede destacar, la ley 1266 del año 2008 la cual fue el primer intento de legislación en Colombia para cumplir el derecho de privacidad de conocer, actualizar y rectificar la información que se encuentre almacena, lo cual que se conoce como “Habeas Data” [17]. En el marco de la legislación de colombiana, esta ley se actualizo por la 1581 del año 2012, en esta se describe la cual es la normatividad vigente que dicta las disposiciones generales con respecto a la protección de datos personales. A pesar que la ley fue expedida en el 2012, se necesitaba que fuera complementada para que se pudiera aplicar de forma efectiva para esto en el año 2013 se creó el decreto 1377 que tenía como finalidad facilitar la implementación y el cumplimiento de la ley 1581 reglamentando aspectos relacionados con la autorización del titular de la información para el tratamiento de sus datos personales, las políticas de tratamiento de los responsables y encargados, el ejercicio de los derechos de los titulares de la información, entre otros [18].
Adicionalmente, para tener una visión de las leyes a nivel mundial en materia de protección de datos, se consultó el portal DLA Piper, que ofrece un compilado de normatividad de múltiples países denominado “Data protection law of the world” [16], donde describe a detalle en cada nación la ley vigente, la autoridad encargada, las sanciones aplicables, el proceso de recolección y tratamiento correspondiente a la normatividad. Además, en la búsqueda de documentos a nivel internacional, se revisó el “Reglamento General de protección de datos” el cual es el marco de trabajo legal con respecto a la protección de la información de las personas que entrara en vigencia en el año 2018, asimismo, la misma agencia reguladora en aras de ofrecer un proceso de adaptación a la nueva legislación para las organizaciones, publicó una guía llamada “Guía para el cumplimiento del deber informar” que tiene como objetivo orientar acerca de las mejores prácticas para dar cumplimiento a la obligación de informar a los interesados de las políticas de tratamiento de datos.
4.2. Revisión de sus aplicaciones en el desarrollo de software
Con relación a privacidad de la información de los usuarios en el ámbito del desarrollo de software, se revisó el documento publicado por el Ministerio de Ciencia, Tecnología e Innovación Productiva, y la Dirección Nacional de Protección de Datos Personales de Argentina llamado “Guía de buenas prácticas para el desarrollo de apps” que contiene una serie de procedimientos, teniendo en cuenta desde el inicio de desarrollo de un proyecto de software, además de establecer una política de uso de datos transparente y clara que el usuario pueda saber el tratamiento que se realiza a su información.
4.3. Diseño de la guía
Finalmente luego de tener identificada la normatividad vigente en el territorio nacional y las referencias nivel internacional como es el caso de Argentina con su llamado “Guía de buenas prácticas para el desarrollo de apps” [15] orientada directamente a equipos de desarrolladores y la de España con sus publicaciones de “Guía del reglamento general de protección de datos para responsable de tratamiento” [8] y “Guía para el cumplimiento del deber informar” [13] cuyo objetivo es informar a los organizaciones responsables de recolección de datos , se procedió con el diseño de la guía.
5. RESULTADOS
5.1. Diseño de la guía
Con base en lo anterior, se construyó la guía con el fin de resolver algunos de estos interrogantes, además de brindar información clara y sencilla al equipo de desarrolladores con el fin de establecer una política de datos que cumpla con la normatividad vigente. El diseño que tiene la guía, se elaboró teniendo como base, documentos que son publicados en países que son referentes a nivel internacional en la protección de datos, además teniendo en cuenta conceptos descritos en la normatividad vigente colombiana. En la Tabla 1, se relaciona los capítulos que tiene y la descripción que se encuentra en cada uno de ellos.

CINSIS 2017 - Programa de Ingeniería de Sistemas
80
GUÍA PARA LA INCORPORACIÓN DE LOS CONCEPTOS DE PROTECCIÓN DE DATOS EN EQUIPOS DE DESARROLLO DE SOFTWARE CON BAJOS NIVELES DE MADUREZ
Tabla 1 Estructura de secciones de la guía
5.2. Aplicación en el contexto del desarrollo de software
En el marco de desarrollo de un proyecto de software, se utilizan metodologías que tienen la finalidad de seguir una serie de pasos planteados para estructurar, planificar y controlar el proceso que tenga el producto resultante. Dentro de estas existen modelos tradicionales, como el modelo en cascada, modelo lineal, incremental, entre otros, donde se caracteriza que el ciclo básico de vida de un software que son análisis, diseño, codificación e implementación, donde se caracterizaba con documentación que resultaba tediosa y poca flexibilidad para generar cambios durante su transcurso. Sin embargo, debido a la aparición de nuevas tecnologías que no se acoplaban a las metodologías tradicionales y la expansión del internet, a finales de los noventa apareció las metodologías agiles, el cual buscaba solucionar los problemas de su predecesor, ofreciendo rápida respuesta al cambio, entrega de producto incrementables y la inclusión del cliente como parte vital en el proceso, dentro de estos se caracteriza el Scrum, XP, Kanban, entre otras [19]. No obstante, ninguno de estos marcos de trabajo, no establecen una fase para revisar el aspecto legal de la normatividad vigente que existen en cuanto a la protección de datos de los usuarios que debe realizarse.
Capítulos Descripción
Definición
En esta parte se establece unas definiciones básicas que están en el marco de la norma colombiana
Principios del tratamiento de datos personales
En esta sección se establecen unas nociones básicas que deben seguir al momento de crear una política de protección de datos.
Metodologías para proteger la privacidad del
usuario
En esta sección se puede encontrar metodologías, herramientas y medidas que permitan a los desarrolladores la construcción de software teniendo en cuenta la privacidad como un punto clave en transcurso del proyecto.
Establecimiento de una política de tratamientos
de datos.
En esta sección se realiza una propuesta de la estructura que tendría que tener una política de datos que se ajuste a la normatividad colombiana vigente.
Teniendo en cuenta la búsqueda de información recolectada en la metodología, la guía definida y disponible en [20] y tomando como base las fases de la metodología de SCRUM, se plantearon una serie de preguntas, que tienen como finalidad que durante en el marco de un proyecto se aplique la protección de datos desde el diseño, el desarrollo e implementación y no sea un apartado que se trate al final. En la Tabla 2, se relaciona en cada fase del SCRUM, con los interrogantes que deben plantearse además de resolverlos para que se elabore un producto que tenga como prioridad la protección de los datos y los derechos que tienen los usuarios. Las preguntas están perfectamente alineadas con la guía elaborada.
Tabla 2 Implementación de preguntas usando la metodología SCRUM
Fases Sub Fases Preguntas
Preg
ame
Plan
ifica
ción
• ¿Cuál es la normatividad vigente en cuanto a la protección de datos en Colombia?
• ¿Cuál es el objetivo de la información que voy a recolectar?
• ¿Quién es el responsable del tratamiento de datos?
• ¿De qué nacionalidad serán los usuarios que usaran el sistema?
• ¿Qué leyes internacionales debo cumplir si aplicaría el proceso de transferencia de información?
Arq
uite
ctur
a
• ¿Qué datos necesito recolectar?
• ¿Los datos que estoy recolectando pertenecen a personas menores de edad?
• ¿Cuántas bases de datos mi proyecto está generando?
• ¿Cuál es el proceso de suprimir un dato a nivel de desarrollo?
• ¿Cómo será el proceso que se le aplicará al tratamiento de datos?
• ¿Qué protocolo debo usar para solicitudes de supresión de datos?
Desarrollo
• ¿Qué métodos o herramientas puedo implementar para evitar el uso de datos personales en el tratamiento de datos?
PostGame
• ¿Dónde debo registrar las bases de datos generadas?
• ¿Por cuál canal de comunicación debo presentar las políticas de tratamiento?

CINSIS 2017 - Programa de Ingeniería de Sistemas
81
GUÍA PARA LA INCORPORACIÓN DE LOS CONCEPTOS DE PROTECCIÓN DE DATOS EN EQUIPOS DE DESARROLLO DE SOFTWARE CON BAJOS NIVELES DE MADUREZ
La alineación de la guía orienta en la resolución de las preguntas planteadas, por ejemplo, necesito autorización inequívoca para los datos qué estoy solicitando, y de ser positiva la respuesta, la guía provee un instrumento modelo que puede ser utilizado. Este, la versión completa de la guía y los demás instrumentos están disponibles en el repositorio [20].
6. CONCLUSIONES
La protección de datos en la actualidad ha tomado un gran protagonismo a nivel mundial, donde países de la Unión Europea están en la vanguardia en el tema y buscando que la privacidad de los ciudadanos de los estados miembros este resguardada, sin embargo, con la búsqueda de información realizada para la construcción del documento arrojó que en Colombia no le ha dado la prioridad a la privacidad de datos que es necesaria, donde no existen documentos que ofrezcan una guía a esos pequeños grupos de trabajos emergentes acerca de cómo establecer una políticas de tratamiento que puedan cuidar los intereses los usuarios, ni como desarrollar productos de software que tenga como prioridad la privacidad en todas las fases de su construcción.
Con esta guía se da un primer paso hacia explicar de una manera clara, transparente y sencilla el proceso que es necesario en la construcción de políticas de tratamiento de datos desde la perspectiva del proceso de desarrollo de software, teniendo en cuenta elementos que son referentes a nivel internacional y que son ajustados a la normatividad colombiana vigente. Sin olvidar que el público objetivo es, principalmente, pequeños grupos emergentes de trabajo que no cuentan con la capacitación del aspecto legal del tratamiento de datos.
Colombia con la normatividad 1581 del 2012 la protección de datos se actualizó, debido al auge que ha tenido las miles de transacciones que realizan los colombiano a diario vía internet, obligando que las empresas tenga políticas de tratamiento y solicitar consentimiento de los datos recolectados, sin embargo, el gobierno colombiano no ofrece mecanismo de divulgación efectivos de la legislación, además no incita a pequeños desarrolladores tener en cuenta la privacidad como parte fundamental en el proceso de desarrollo.
7. REFERENCIAS
[1] DOMO, “Data Never Sleeps 4.0,” 28 Junio 2016. [Online]. Available: https://www.domo.com/blog/data-never-sleeps-4-0/. [Accessed 17 07 2017].
[2] BSA The Software Alliance, “BSA The Software Alliance,” [Online]. Available: http://data.bsa.org/wp-content/uploads/2015/10/BSADataStudy_es.pdf. [Accessed 27 Julio 2017].
[3] Sophos Iberia, “Sophos Iberia,” 27 12 2013. [Online]. Available: https://sophosiberia.es/los-principales-casos-de-perdida-de-datos-y-robo-de-informacion-de-2013/. [Accessed 17 Julio 18].
[4] D. Clavero, “Google Street View: nueva denuncia por vulnerar la ley de protección de datos,” [Online]. Available: https://www.diariomotor.com/tecmovia/2012/05/08/google-street-view-nueva-denuncia-por-vulnerar-la-ley-de-proteccion-de-datos/. [Accessed 31 Julio 2017].
[5] El Pais, “Google, denunciado ante Protección de Datos, por Street View,” [Online]. Available: https://elpais.com/tecnologia/2012/05/07/actualidad/1336391180_245016.html. [Accessed 31 Julio 2017].
[6] S. Michael McFarland, “Santa Clara University,” 01 Junio 2012. [Online]. Available: https://www.scu.edu/ethics/focus-areas/internet-ethics/resources/privacy-and-the-law/. [Accessed 31 Julio 2017].
[7] Access to European Union law, “Access to European Union law,” [Online]. Available: http://eur-lex.europa.eu/legal-content/ES/TXT/?uri=LEGISSUM:l14012.
[8] Agencia de proteccion de datos Española, “Guia de reglamento general de protección de datos,” [Online]. Available: https://www.agpd.es/portalwebAGPD/temas/reglamento/common/pdf/guia_rgpd.pdf. [Accessed 31 Julio 2017].
[9] Departamento de Derecho Internacional de la Secretaría de Asuntos, “Organization of American States,” [Online]. Available: http://www.oas.org/dil/esp/cp-cajp-2921-10_rev1_corr1_esp.pdf. [Accessed 21 Junio 2017].
[10] Constitución Politca de Colombia, “Constitución Politca de Colombia,” [Online]. Available: http://www.constitucioncolombia.com/titulo-2/capitulo-1/articulo-15. [Accessed 4 Junio 2017].
[11] NACIONES UNIDAS, “NACIONES UNIDAS,” [Online]. Available: http://www.ohchr.org/EN/UDHR/Documents/UDHR_Translations/spn.pdf.
[12] M. Rouse, “WhatIs.com,” TechTarget, [Online]. Available: http://whatis.techtarget.com/definition/Fair-Information-Practices-FIP. [Accessed 31 Julio 2017].
[13] Agencia de proteccion de datos Española, “Agencia de proteccion de datos Española,” [Online]. Available: https://www.agpd.es/portalwebAGPD/temas/reglamento/common/pdf/modeloclausulainformativa.pdf. [Accessed 22 Julio 2017].

CINSIS 2017 - Programa de Ingeniería de Sistemas
82
GUÍA PARA LA INCORPORACIÓN DE LOS CONCEPTOS DE PROTECCIÓN DE DATOS EN EQUIPOS DE DESARROLLO DE SOFTWARE CON BAJOS NIVELES DE MADUREZ
[14] Direccion Nacional de Proteccion de datos, “Ministerio de Ciencia, Tecnología e Innovación Productiva,” 14 Octubre 2015. [Online]. Available: http://www.jus.gob.ar/media/3075908/guiabpsoftware.pdf. [Accessed 22 Julio 2017].
[15] Ministerio de Ciencia, Tecnologia e Innovacion Productiva, “Ministerio de Ciencia, Tecnologia e Innovacion Productiva,” [Online]. Available: http://www.mincyt.gob.ar/noticias/la-proteccion-de-datos-personales-en-el-desarrollo-de-aplicaciones-11552. [Accessed 23 Julio 2017].
[16] DLA Piper, “DLA Piper,” 06 Diciembre 2015. [Online]. Available: http://winnersfdd.com/wp-content/uploads/2015/12/DLA-Piper-Data-protection-Laws-of-the-World3.pdf. [Accessed 22 Julio 2017].
[17] J. Pérez Porto and A. Gardey, “Definición de,” 2012. [Online]. Available: http://definicion.de/habeas-data/. [Accessed 26 Julio 2017].
[18] Certicámara, “ABC para proteger los datos personales, Ley 1581 de 2012 Decreto 1377 de 2013,” 29 Agosto 2013. [Online]. Available: https://colombiadigital.net/actualidad/articulos-informativos/item/5543-abc-para-proteger-los-datos-personales-ley-1581-de-2012-decreto-1377-de-2013.html. [Accessed 31 Julio 2017].
[19] OK HOSTING, “Metodologías del Desarrollo de Software,” [Online]. Available: https://okhosting.com/blog/metodologias-del-desarrollo-de-software/. [Accessed 31 Julio 2017].
[20] SoftSimulation, “Guia de protección de datos,” 31 Julio 2017. [Online]. Available: https://drive.google.com/drive/folders/0B_jTbNEvYz0mSUpwQ1J1TWNxYk0?usp=sharing.

CINSIS 2017 - Programa de Ingeniería de Sistemas
83
INCORPORACIÓN DE PRÁCTICAS ÁGILES EN EQUIPOS DE DESARROLLO CON BAJOS NIVELES DE MADUREZ
INCORPORACIÓN DE PRÁCTICAS ÁGILES EN EQUIPOS DE DESARROLLO CON BAJOS NIVELES DE MADUREZ
RESUMEN
El siguiente artículo presenta el enfoque seguido por la empresa de desarrollo de software SoftSimulation S.A.S para la incorporación dentro de su equipo de desarrollo los principios, valores y prácticas agiles. Dicho enfoque está inspirado en la guía definida por Mike Cohn “ADAPTing to Agile for Continued Success”, el pensamiento blando de sistemas y la estrategia top-down; en conjunto estos tres proporcionaron un marco apropiado para solventar inconvenientes como la falta de entrenamiento del equipo, el temor al cambio y los bajos niveles de organización intrínsecos de este tipo de equipos, permitiendo abarcar prácticas como planificación y seguimiento de proyectos, pruebas de funcionalidades y definición de procesos dentro de la organización de una manera organizada y con un alto nivel de aceptación por parte del equipo. Todo este planteamiento, fundamentado en que la agilidad deseada en el equipo se asumió como una propiedad emergente resultado de la sinergia entre las prácticas, los valores, los principios, las herramientas y los miembros de equipo, permitiendo así una mejora continua de los procesos internos de la organización sin dejar de lado la orientación de la calidad de todos estos.
ABSTRACT
The following article presents the approach followed by software development firm SoftSimulation S.A.S for the incorporation within its development team of agile principles, values and practices. This approach is inspired by the guide defined by Mike Cohn “ADAPTing to Agile for Continued Success,” soft systems thinking and top-down strategy; Together, these three provided an appropriate framework to overcome problems such as the lack of training of the team, the fear of change and the low levels of organization intrinsic of this type of equipment. Allowing to cover practices such as planning and monitoring projects, functional tests and definition of processes within the organization in an organized manner and with a high level of acceptance by the team. All this approach, based on the fact that the desired agility in the team was assumed as an emerging property resulting from the synergy between practices, values, principles, tools and team members, thus allowing a continuous improvement of internal processes of the organization without leaving aside the orientation of the quality of all these.
PALABRAS CLAVES: Metodologías agiles, manifiesto ágil, proceso de desarrollo.
KEYWORDS: Agile methodologies, agile manifestó, development process.
Camilo Torres [email protected]
Cesar Polo [email protected]
Andrés [email protected]
Alexander [email protected]
1. INTRODUCCIÓN
Para lograr el éxito en el desarrollo de software no es suficiente tener un equipo de desarrollo experimentado con un grupo de actividades definidas a realizar en un tiempo estipulado, para alcanzar un proceso de desarrollo
equilibrado y que ofrezca buenos resultados hace falta un elemento clave, una metodología de desarrollo [1]. La metodología provee la orientación a seguir basada en diferentes prácticas de desarrollo como la gestión del proyecto, control de versiones, pruebas de unidad y demás.

CINSIS 2017 - Programa de Ingeniería de Sistemas
84
INCORPORACIÓN DE PRÁCTICAS ÁGILES EN EQUIPOS DE DESARROLLO CON BAJOS NIVELES DE MADUREZ
En la actualidad ha sido de gran estudio e interés la implementación de las diferentes metodologías de desarrollo como se demuestra en [2]. Dentro de metodologías se distinguen varios subgrupos, algunos solapados entre sí, a saber, secuenciales, tradicionales, ligeras, robustas, agiles, orientadas al proceso, orientado desarrollo, entre muchas más. Todas ellas dependiendo de la variable con la cual se analicen. En el presente trabajo se enfocará en un grupo, el conocido como métodos ágiles para el desarrollo de software.
Los métodos agiles surgen como opuesto al enfoque tradicional, donde existe una representación marcada del control de los procesos mediante definiciones rigurosas de componentes como lo son los roles, actividades, modelados, basándose en documentaciones detalladas [2]. Esta metodología ha dado buenos frutos en proyectos grandes en los que se hace necesario llevar nota de todo lo que ocurre en los diferentes procesos, para así tener una amplia visión de todo lo que ocurre en diferentes orientaciones de un proyecto. Pese a todo esto, los resultados no son del todo satisfactorio en proyectos donde los requisitos y demás componentes del desarrollo están sujetos a cambios y/o modificaciones en cualquier momento dado, en donde además toma gran preponderancia la capacidad de adaptarse y ser flexible. Siendo este último grupo el tipo de proyectos que la empresa SoftSimulation S.A.S desarrolla. Proyectos con entornos cambiantes donde la innovación y satisfacción del cliente juega un rol preponderante a la hora de marcar el rumbo dentro del flujo de trabajo.
No obstante pese al auge y aceptación de los métodos agiles en la actualidad se han identificado problemas y restricciones como las siguientes: métodos dirigidos a equipos pequeños o medianos, necesidad de un entorno físico que garantice la comunicación y colaboración de miembros del equipo en todo el tiempo de desarrollo, cualquier resistencia del cliente o del equipo hacia las practicas puede llevar al fracaso, la elección de una metodología la cual no soporte fácilmente cambios [3]. Lo cual es particularmente cierto para equipos de desarrollo con bajos niveles de madurez caracterizados por: procesos ad hoc los cuales tienden a ser caóticos y sin un orden definido, en los que además se excede con frecuencia en presupuesto y tiempos estipulados [4]. Este era el caso de SoftSimulation donde el equipo se caracteriza por no tener experiencia en la implementación de metodologías de desarrollo, no realizar un buen seguimiento de proyecto y otros inconvenientes en todo el proceso de diseño y construcción del producto, todo lo anterior puede apreciarse en la Ilustración 1.
Ilustración 1 Proceso inicial de desarrollo de software.
En la Ilustración 1 se puede observar todo el proceso de desarrollo de un producto en SoftSimulation S.A.S., partiendo desde el inicio del proyecto en donde una persona o cliente tiene una necesidad y/o idea la cual es transmitida al gerente mediante una interacción continua en la que este define una solución tecnológica para la necesidad presentada. Luego de tener claro el producto que se quiere realizar el gerente pasa a discutirlo con el equipo de trabajo designado, en este momento es donde se ven los primeros requisitos del sistema y se toma nota de esto en físico por uno de los integrantes de la reunión. Posteriormente se da inicio del proceso de desarrollo codificando los primeros componentes de la solución, desde ese mismo instante inicia el caos e incertidumbre puesto que no se generan documentos y soportes almacenados para verificar lo que se tiene que hacer en un tiempo estipulado de trabajo. Como consecuencia de lo anterior al momento de hacer una revisión del progreso no se cumple con lo establecido lo que conlleva con retrasos en fechas pactadas haciendo que se empiece a trabajar contra reloj trayendo consigo que no se puedan realizar otras actividades como control de versiones, pruebas y demás. Al terminar el producto pese a los retrasos se le es entregada la versión al cliente sin realizar las pruebas requeridas, permitiendo que este sea quien asuma el rol de tester dejando una actividad importante en manos de este.
Las metodologías ágiles tienen dos diferencias fundamentales con las metodologías tradicionales; la primera es que los métodos ágiles son adaptativos no predictivos. La segunda diferencia es que las metodologías ágiles son orientadas a las personas no orientadas a los procesos [5]. Las metodologías ágiles son adaptativas;

CINSIS 2017 - Programa de Ingeniería de Sistemas
85
INCORPORACIÓN DE PRÁCTICAS ÁGILES EN EQUIPOS DE DESARROLLO CON BAJOS NIVELES DE MADUREZ
este hecho es de gran importancia ya que contrasta con la predictibilidad buscada por las metodologías tradicionales. Con el enfoque de las metodologías ágiles los cambios son eventos esperados que generan valor para el cliente [6]. Implementar metodologías agiles en una organización no es una tarea sencilla, este enfoque se ha difundido de manera exponencial en el mercado generando un gran debate acerca de las mismas. ¿Cuál es el tipo de metodología ágil que se debe usar?, ¿Se debe adoptar de manera integral, es decir utilizando todas las practicas propuestas?, ¿Al utilizar metodologías agiles garantizo la calidad de mis servicios?, estos interrogantes son presentados normalmente a la hora de iniciar a implementar enfoques agiles para el desarrollo de software, la agilidad funciona correctamente no al llevar una documentación a la par de los formatos de una metodología escogida, sino cuando se empiezan a llevar sus principios de manera adecuada, cuando cada uno de los integrantes del equipo tiene claro y realiza adecuadamente su rol siendo claro en la forma de comunicación con sus compañeros de equipos. Puede decirse que no es necesario demandar demasiado tiempo para lograr avances en la agilidad de los procesos de desarrollo de software, lo que se requiere es compromiso del equipo y una buena organización para ejecutar de manera adecuada las practicas recomendadas.
Este documento está motivado por la necesidad de encontrar y reflejar aquellas prácticas comprendidas en las diferentes metodologías agiles, las cuales acompañadas de conceptos básicos del pensamiento y teoría general de sistemas permitan evolucionar ese conjunto de competencias a propiedades emergentes que apunten al mejoramiento de la calidad en los procesos de la organización. Para todo lo anterior, inicialmente, se llevó a cabo una revisión de la literatura sobre metodologías agiles partiendo de una fundamentación teórica, tipos e implementación de las diferentes prácticas que estas recomiendan, para luego así describir la experiencia de la incorporación del grupo de actividades escogidas en la organización, terminando con las conclusiones sobre todos los resultados obtenidos mediante estas prácticas.
2. FUNDAMENTACIÓN TEÓRICA
2.1. Metodologías agiles
Las metodologías ágiles son flexibles, sus proyectos son subdivididos en proyectos más pequeños, incluyen comunicación constante con el cliente, son altamente colaborativos y se adaptan mejor a los
cambios. De hecho, el cambio en los requerimientos es una característica esperada al igual que las entregas constantes al cliente y la retroalimentación por parte de él. Tanto el producto como el proceso son mejorados frecuentemente [7].
En una reunión celebrada en febrero de 2001 en Utah – USA, nace el término ágil aplicado al desarrollo de software. En esta reunión participa un grupo de expertos, incluyendo algunos de los creadores e impulsores de las metodologías de software. Su objetivo fue esbozar los valores y principios que deberían permitir a los equipos desarrollar rápidamente software de calidad capaz de responder, en forma ágil y eficaz a las necesidades de cambios que puedan surgir a lo largo de los proyectos. Se pretendía ofrecer una alternativa a los procesos tradicionales de desarrollo, caracterizados por ser rígidos y cautivos de condiciones de uso severas plasmadas en una documentación extensa a generar en cada una de las etapas de desarrollo. Varias de las denominadas metodologías ágiles ya estaban siendo utilizadas con éxito en proyectos reales.
Tras esta reunión se creó The Agile Alliance, una organización sin ánimo de lucro dedicado a promover los conceptos relacionados con el desarrollo ágil de software y ayudar a las organizaciones para que adopten dichos conceptos. El punto de partida fue el Manifiesto Ágil, un documento en el cual se sintetiza la filosofía ágil. El Manifiesto Ágil establece los valores que rigen a los métodos ágiles así [8]:
1. Individuos y su interacción sobre los procesos y herramientas
2. Software funcional sobre documentación comprensiva
3. Colaboración de cliente sobre la negociación del contrato
4. Respuesta al cambio sobre seguir un plan
Existen varias metodologías ágiles en la actualidad, entre las cuales se pueden citar aquellas que llevan la vanguardia en el enfoque ágil del desarrollo de software, algunas de estas son XP (Programación extrema), Crystal y el Desarrollo orientado a funcionalidades (FDD), SCRUM, Método de desarrollo de sistemas dinámicos (DSDM) y el Desarrollo adaptativo de software (ASD).
De igual manera, todos estos estos tipos de metodologías agiles proponen dentro de su marco de trabajo la implementación de diferentes prácticas que tienen en

CINSIS 2017 - Programa de Ingeniería de Sistemas
86
INCORPORACIÓN DE PRÁCTICAS ÁGILES EN EQUIPOS DE DESARROLLO CON BAJOS NIVELES DE MADUREZ
común la finalidad en el acercamiento al paradigma ágil del desarrollo de software. Estas prácticas comunes son presentadas a continuación.
Tabla 1 Practicas utilizadas en las metodologías agiles
Luego de haber descrito lo anterior podemos preguntarnos ¿cómo se logra la agilidad en los procesos de desarrollo de software de una organización? Para responder dicha inquietud podemos partir del siguiente supuesto “la agilidad es una propiedad emergente”. Según O’Connor y McDermott, se hace especial referencia al concepto de propiedad emergente; si un sistema funciona como un todo, entonces tiene propiedades distintas a las de las partes que lo componen y que “emergen” de él cuando está en acción. Estas propiedades no se encuentran si el sistema se divide en sus componentes y se analiza cada uno de ellos por separado. Para lograr la agilidad no basta con integrar al cliente en ciclos de trabajos y llevar un registro documentado de lo que ocurre día a día, ser ágil demanda utilizar patrones de desarrollo integrando distintas áreas de proceso como lo son la automatización de pruebas, gestión del conocimiento, gestión de la calidad, integración, verificación, validación del producto y demás, las cuales pueden ser analizadas y aplicadas por separado, pero cuando estas son acopladas y orientadas hacia un mismo fin se convierten en propiedades emergentes que empiezan a acercarnos a la agilidad dentro del desarrollo de software.
En los últimos años las metodologías agiles han gozado de mucha popularidad lo que ha llevado a que hayan sido incorporadas en muchas organizaciones en donde encontramos muchos casos de éxitos en donde la incorporación de estos métodos dan como resultados beneficios como efectividad en las entregas frecuentes
Método Prácticas Desarrollo Gestión
XP
Planificación x
Diseño simple X
Pruebas y refactorización X
Propiedad colectiva X
Integración continua X
Estándares de codificación X
Clientes en el lugar de trabajo
X
Scrum
Equipos de trabajo pequeños
X
Reuniones cortas x
Incrementos frecuentes x
Pruebas constantes x
Backlog del Producto x
Cliente in-situ x
Historias de usuario x
Retrospectiva x
Crystal
Mejora reflexiva x
Comunicación osmótica x
Fácil acceso a usuarios expertos
x
Pruebas automatizadas x
DSDM
Desarrollo iterativo e incremental
x
Pruebas durante el ciclo del proyecto
x
Cambios reversibles x
Alcance de alto nivel (Requerimientos antes de iniciar desarrollo)
x
Comunicación y cooperación
x
Método Prácticas Desarrollo Gestión
ASD
Iteraciones x
Objetivos de iteración x
Asignaciones de funcionalidades
x
Revisión de estados con criterios del cliente
x
FDD
Proceso simple y bien definido
x
División del dominio general
x
Agrupación de funcionalidades
x
Inspección de código x
Pruebas de unidad x
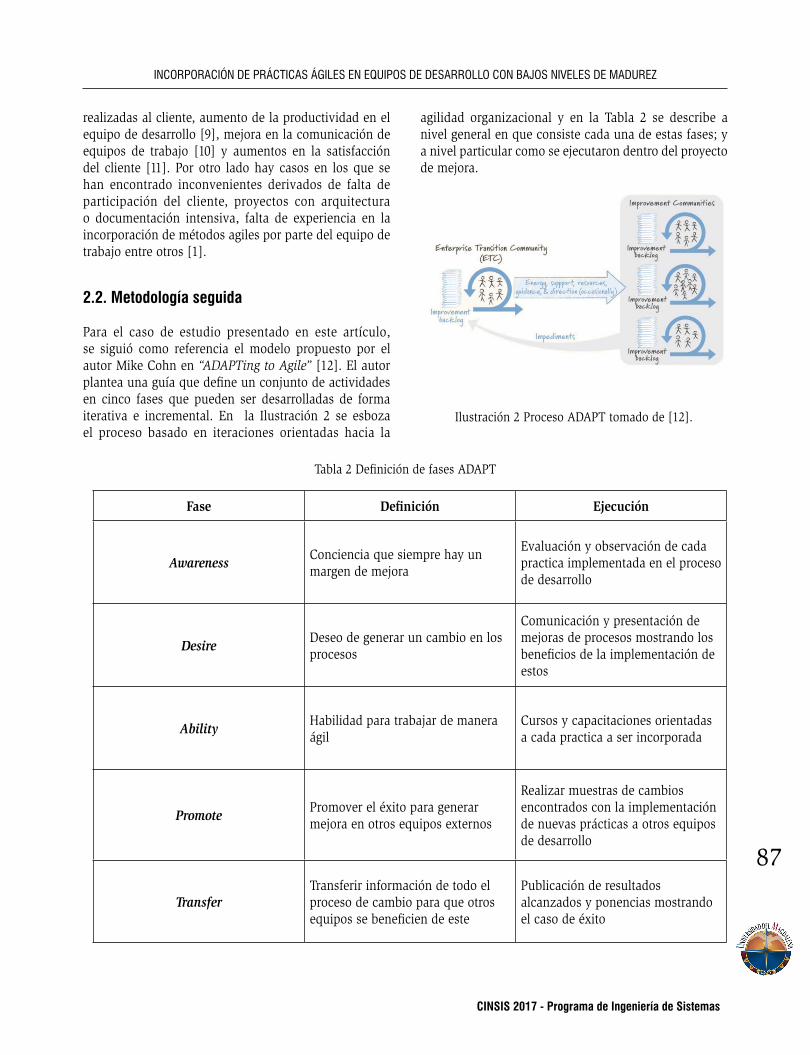
CINSIS 2017 - Programa de Ingeniería de Sistemas
87
INCORPORACIÓN DE PRÁCTICAS ÁGILES EN EQUIPOS DE DESARROLLO CON BAJOS NIVELES DE MADUREZ
realizadas al cliente, aumento de la productividad en el equipo de desarrollo [9], mejora en la comunicación de equipos de trabajo [10] y aumentos en la satisfacción del cliente [11]. Por otro lado hay casos en los que se han encontrado inconvenientes derivados de falta de participación del cliente, proyectos con arquitectura o documentación intensiva, falta de experiencia en la incorporación de métodos agiles por parte del equipo de trabajo entre otros [1].
2.2. Metodología seguida
Para el caso de estudio presentado en este artículo, se siguió como referencia el modelo propuesto por el autor Mike Cohn en “ADAPTing to Agile” [12]. El autor plantea una guía que define un conjunto de actividades en cinco fases que pueden ser desarrolladas de forma iterativa e incremental. En la Ilustración 2 se esboza el proceso basado en iteraciones orientadas hacia la
agilidad organizacional y en la Tabla 2 se describe a nivel general en que consiste cada una de estas fases; y a nivel particular como se ejecutaron dentro del proyecto de mejora.
Fase Definición Ejecución
AwarenessConciencia que siempre hay un margen de mejora
Evaluación y observación de cada practica implementada en el proceso de desarrollo
DesireDeseo de generar un cambio en los procesos
Comunicación y presentación de mejoras de procesos mostrando los beneficios de la implementación de estos
AbilityHabilidad para trabajar de manera ágil
Cursos y capacitaciones orientadas a cada practica a ser incorporada
PromotePromover el éxito para generar mejora en otros equipos externos
Realizar muestras de cambios encontrados con la implementación de nuevas prácticas a otros equipos de desarrollo
TransferTransferir información de todo el proceso de cambio para que otros equipos se beneficien de este
Publicación de resultados alcanzados y ponencias mostrando el caso de éxito
Ilustración 2 Proceso ADAPT tomado de [12].
Tabla 2 Definición de fases ADAPT

CINSIS 2017 - Programa de Ingeniería de Sistemas
88
INCORPORACIÓN DE PRÁCTICAS ÁGILES EN EQUIPOS DE DESARROLLO CON BAJOS NIVELES DE MADUREZ
3. RESULTADOS
El llevar a cabo la incorporación de prácticas agiles dentro del proceso de desarrollo durante alrededor de seis meses no ha sido fácil, a medida que ha pasado el tiempo se ha ganado experiencia en todo lo relacionado con estas metodologías, en donde se puede afirmar que se han logrado acoplar un cierto grupo de competencias las cuales han mejorado el rendimiento y calidad de los productos ofrecidos por SoftSimulation S.A.S., en la Tabla 3 podemos encontrar un mapa de todo lo que se ha logrado y lo que se está trabajando actualmente en términos de mejoras de procesos a nivel interno.
Tabla 3 Comparativo de progreso en el tiempo
Es importante resaltar que cada una de las áreas y actividades citadas en la tabla anterior se encuentran definidas por la alianza ágil en su “mapa de rutas de prácticas agiles” [13] las cuales son comúnmente aplicadas en las metodologías descritas en la Tabla 1.
En primera instancia se hizo necesario obtener un diagnóstico sobre el estado actual de la organización en términos de que proceso sigue, que herramientas utiliza, que roles tiene definidos, que procedimientos sigue, junto
Que se ha logrado
Que se está trabajando
Que se quiere lograr a futuro
Diagnóstico sobre el estado inicial de la organización en términos de procesos encontrando áreas que presentaban oportunidades de mejoras como las siguientes:
• Definición de procesos
• Planificación de proyectos
• Monitorización y control de proyecto
• Pruebas de funcionalidades
Implementación de prácticas agiles como:
• Historias de usuario
• Tablero kanban
• Backlog
• Reuniones periódicas
• Desarrollos iterativos
• Diseño simple
• Control de versiones
• Criterios de aceptación
Promover la experiencia y el conocimiento adquirido en métodos agiles.
Incorporación de área de gestión y transferencia de conocimiento dentro de la organización.
Afianzar en la consolidación de las prácticas escogidas en el equipo de desarrollo.
con la calidad y efectividad de sus productos y artefactos. Para cumplir con esto se realizó una evaluación de todos los procesos que llevaba SoftSimulation en donde se observó cómo era el flujo de trabajo mediante una acompañamiento a todos los proyectos que se encontraban desplegados, además para esta evaluación inicial se siguió como modelo los procesos que describe el CMMI en sus etapas de madurez.
Lo anterior, posibilitó establecer oportunidades de mejoras en la gestión documental, en la organización de todo lo que rodea a los proyectos y en el control de la calidad de los productos, las cuales luego de ser discutidas y analizadas con el equipo, tanto de desarrollo como de gestión, se establecieron consensos, se priorizaron y se estableció el alcance del proyecto dentro de las siguientes áreas y actividades: planificación de proyectos, control de tareas mediantes historias de usuario, estandarización de código, control de versiones y pruebas unitarias.
En ese mismo orden se identificaron un conjunto de prácticas las cuales dan solución a los problemas encontrados anteriormente, se optó por concientizar al equipo de la necesidad de implementar estas soluciones esto se dio mediante un conjunto de charlas y presentaciones en las que se logró hacer ver a este la urgencia de cambio que se tenían en las áreas que presentaban un alto grado de incertidumbre.
Una vez establecido el alcance, se procedió a la elaboración de los planes de mejoras que dieron inicio al proceso de generar habilidad en el equipo para implementar las prácticas citadas en la Tabla 3. En la Ilustración 3 se pueden detallar las fases de dicho plan de mejora; es importante aclarar que este mismo proceso se realizó para cada una de las prácticas incorporadas.
Ilustración 3 Plan de implementación de competencias agiles.

CINSIS 2017 - Programa de Ingeniería de Sistemas
89
INCORPORACIÓN DE PRÁCTICAS ÁGILES EN EQUIPOS DE DESARROLLO CON BAJOS NIVELES DE MADUREZ
En la ilustración anterior se puede identificar que inicialmente se realizó una definición de tareas a implementar dentro de esta se establecían calendarios para incorporación de cada una de estas, seguido de esto se asignaba un responsable de incorporación el cual se apropiaba y familiarizaba del componente para luego realizar talleres con todos los integrantes de la organización. Estos talleres o capacitaciones estaban orientados hacia diferentes competencias como es el caso de la planificación, control y seguimiento de proyectos en donde como primera medida se mostró al equipo la necesidad de poder llevar un orden en todo lo relacionado con el estado de un proyecto el control de requisitos, funcionalidades y demás; para esto se decidió manejar el concepto de historia de usuario para las funcionalidades y la definición de iteraciones para los ciclos de trabajos, como soporte en esta práctica se utilizó la herramienta Trello la cual permite almacenar y compartir toda esta información en un mismo sitio.
En ese mismo orden se hicieron capacitaciones y/o talleres para prácticas como las pruebas unitarias en la que se manejó phpunit como herramienta de trabajo para las pruebas, manejo y control de versiones la cual se apoyó en bitbucket como repositorio de código fuente, y por ultimo cursos en los que se definieron estándares para la codificación y nomenclaturas en bases de datos.
Luego de realizar las capacitaciones respectivas, se inició con la incorporación de cada una de las actividades seleccionadas en donde se definió un plan de trabajo el cual se priorizó según el impacto que generaba la integración de cada practica en el equipo, por lo que se estipularon fechas para el uso de las mismas. Al concluir lo anterior, se realizaron retroalimentaciones en las cuales se dieron a conocer propuestas de mejoras por parte del equipo.
Como resultado de todo el plan de trabajo anterior se puede resumir en términos de cifras que se logró implementar un total de seis prácticas en seis meses de trabajo continúo con todo el equipo de la organización. Como consecuencia de esto se presentó una reducción del 25% en los tiempos de entrega de versiones de productos, en la que se pudo identificar que se cumplían con los tiempos y requisitos establecidos inicialmente generando una mayor satisfacción por parte del cliente.
4. CONCLUSIONES
Hoy en día los métodos agiles constituyen uno de los temas de más actualidad y debate dentro de la ingeniería del software. Estos métodos emergen como una necesidad a la hora de satisfacer los requisitos cambiantes del desarrollo de sistemas de información, pero con la virtud de mantener la calidad del producto resultante. Este enfoque ha sido adoptado por muchas organizaciones de desarrollo de software, esto se debe a que funcionan bien dentro de un contexto especifico caracterizado por pequeños grupos de trabajo ubicados en un mismo sitio, clientes que pueden tomar decisiones sobre los requerimientos y con alcances de proyectos variables. Pese a todo esto incorporar agilidad en una organización no es una tarea sencilla se necesita de mucho compromiso por parte de todos los actores en el proceso de desarrollo para generar consciencia de cambio y mejora, acompañado de cierto grado de organización en la ejecución de actividades encaminadas hacia la calidad de los productos.
De la incorporación de prácticas agiles en SoftSimulation S.A.S. se obtuvieron muchos logros como lo fue la mejora en todo el proceso de organización de proyectos en el cual se pudo dar una correcta incorporación de competencias para el control y monitoreo de tareas asignadas; en temas de gestión documental se dio un avance significativo se pasó de tener escasa documentación a contar con formatos de actas de reuniones, planillas de asistencias, planes de mercadeos etc. En términos de control de versiones se logró habituar al equipo a usar la herramienta para generar copias periódicas de proyectos, para las pruebas de unidad se ha encargado a un líder de área el cual verifica que en los proyectos se cumplan con las verificaciones necesarias. Como inconvenientes presentados hay que denotar, que la poca madurez del equipo en temas agiles hizo que el trabajo fuese inicialmente lento mientras este mismo se acoplaba a estos cambios y adoptaba estas nuevas prácticas las cuales eran de completo desconocimiento.
Por último, como trabajo a futuro se espera seguir afianzando en la adopción y consolidación de todas estas prácticas agiles en el equipo de trabajo, que sea un hábito la realización de cada actividad para así seguir logrando un acercamiento en la calidad de los productos de la organización. Además, se espera empezar con la incorporación del área de gestión y transferencia de conocimiento dentro de la organización la cual no pudo ser integrada en este primer acercamiento por limitaciones de tiempos y del personal encargado de esta área.

CINSIS 2017 - Programa de Ingeniería de Sistemas
90
INCORPORACIÓN DE PRÁCTICAS ÁGILES EN EQUIPOS DE DESARROLLO CON BAJOS NIVELES DE MADUREZ
5. REFERENCIAS
[1] G. Bioul, F. Escobar, M. Alvarez, A. Nardin y E. R. Aparicio, «Metodologías Ágiles, análisis de su implementación y,» XVI CONGRESO ARGENTINO DE CIENCIAS DE LA COMPUTACIÓN, 2010.
[2] R. Figueroa, C. Solís y A. Cabrera, «Meotodlogías tradicionales vs Metodologías ágiles,» Universidad Técnica Particular de Loja, Escuela de Ciencias de en Computación, 2008.
[3] C. José, P. Letelier y P. Carmen, «Métodologías Ágiles en el Desarrollo de Software,» vol. V, nº 26, 2006.
[4] Software Engineering Institute, Mejora de los procesos para el desarrollo de mejores productos y servicios, Editorial Universitaria Ramón Areces, 2010.
[5] M. Fowler, «The new methodology,» 4 Julio 2017. [En línea]. Available: https://www.martinfowler.com/articles/newMethodology.html.
[6] P. Ahmed, S. Ali, T. Mona, W. Christopher, N. Liu, L. Rodziah y M. Sanjay, «A COMPARATIVE STUDY OF AGILE, COMPONENT-BASED, ASPECT-ORIENTED AND,» Technical Gazette, 2012, pp. 175-189.
[7] S. Ghosh, «Systemic Comparison of the Application of EVM in Traditional and Agile Software Project,» PM World Journal, vol. IV, nº 8, 2015.
[8] B. Kent, B. Mike, v. B. Arie, C. Alistair y otros, «Manifiesto por el Desarrollo Ágil de Software,» 2001. [En línea]. Available: http://agilemanifesto.org/iso/es/manifesto.html. [Último acceso: 2017].
[9] J. Gamboa, «Aumento de la productividad en la gestión de proyectos, utilizando una metodología ágil aplicada en una fábrica de software en la ciudad de Guayaquil.,» Revista Tecnológica ESPOL, vol. 27, nº 2, 2014.
[10] L. Echeverry y L. Delgado, «Caso práctico de la metodología XP al desarrollo de software,» Pereira, 2007.
[11] J. Navarro, «Experiencia en la implantación de CMMI-DEV v1.2 en una micropyme con metodologías ágiles y software libre,» Revista Española de Innovación, Calidad e Ingeniería del Software, vol. 6, nº 1, 2010.
[12] M. Cohn, Mountain Goat Software, 7 Junio 2010. [En línea]. Available: https://www.mountaingoatsoftware.com/presentations/adapting-to-agile. [Último acceso: Julio 2017].
[13] Agile Alliance, 2015. [En línea]. Available: https://www.agilealliance.org/agile101/subway-map-to-agile-practices/. [Último acceso: 2017].
[14] P. García y C. Sánchez, «Teoría de sistemas y propiedades emergentes en las organizaciones. Una aproximación al estudio de la consistencia interna en los sistemas de gestión de recursos humanos,» Revista internacional de organizaciones, p. 29, 2006.
[15] J. O’Connor y I. McDermott, Introducción al pensamiento sistemico, Barcelona: Urano, 1998.

CINSIS 2017 - Programa de Ingeniería de Sistemas
DESARROLLO DEL SISTEMA DE INFORMACIÓN TURÍSTICO DEL MAGDALENA – SITUR MAGDALENA
DESARROLLO DEL SISTEMA DE INFORMACIÓN TURÍSTICO DEL MAGDALENA – SITUR MAGDALENA
RESUMEN
El presente documento presenta el desarrollo del Sistema de Información Turística del Magdalena – SITUR Magdalena, el cual tiene por objeto crear un portal web que permita integrar la información estadística para turismo del departamento del Magdalena y hacer la promoción turística del mismo. Para su desarrollo se utilizó la metodología ágil SCRUM y se utilizó la tecnología de Microsoft MVC.NET y un motor de base de datos SQL SERVER. Entre los principales resultados fue el desarrollo del sistema de información conformado por módulos orientados a la promoción de la oferta turística y al reporte de estadísticas del sector turismo en el departamento del Magdalena.
Palabras Clave: Sistema de información, desarrollo, turismo, Magdalena.
Ernesto Galvis-Lista, Mayda P. González-Zabala, Roberto L. Aguas, Cesar Enrique Polo Castro, Jorge Luis Pineda Montagout, Andrés Eduardo Paternina Ariza, Jhon Alexander Trespalacios, Camilo David Torres Callejas, Jennifer Esther Brequeman Torres, José Gabriel Montero Patiño, Brayan Rene Carbonó Carbonó,
Luis Fernando Palmera Escorcia, Joaquín Rodríguez, Mónica Isabel Calderón Solano y Farid Leonardo Rodríguez [email protected], [email protected], [email protected], [email protected], [email protected].
co, [email protected], [email protected], [email protected], [email protected], [email protected], [email protected], [email protected], [email protected], [email protected]
Universidad del Magdalena Carrera 32 No 22 – 08, Bloque 3
Santa Marta, Colombia
1. INTRODUCCIÓN
La gestión de la información turística de un territorio es un aspecto esencial para la promoción de los destinos y experiencias turísticas ofertadas, así como para el soporte a la toma de decisiones a nivel organizacional, gremial o gubernamental. En esta línea, el Ministerio de Comercio, Industria y Turismo (MINCIT) a través de FONTUR ha venido desarrollando plataformas de tecnología de información (TI) que permiten: la construcción y divulgación de contenidos
relacionados con promoción turística, la recolección de datos de caracterización de la oferta existente y del turismo receptor, interno y emisor, y la generación de estadísticas y cálculo de indicadores que facilitan el seguimiento y la toma de decisiones sobre este importante sector de la economía.
En la Tabla 1 se describen cuatro experiencias de desarrollo de plataformas de TI que ilustran el estado actual de la línea de trabajo y constituyen los principales antecedentes [1].
Plataforma Descripción
Centro de información turística de Colombia
CITUR
El centro de información turística de Colombia CITUR es un sistema integral para el manejo de las estadísticas de turismo de Colombia, que facilita el seguimiento del comportamiento del turismo y genera datos para la formulación, evaluación, seguimiento y coordinación de políticas dirigidas al desarrollo del sector. Su lanzamiento se realizó en noviembre de 2016. http://www.citur.gov.co/
Visita Santander y SITUR Santander
Plataforma de TI que ofrece un sitio web promocional de los distintos eventos y atractivos turísticos de Santander y una plataforma virtual que tiene como finalidad brindar información turística y medir el impacto económico de este renglón económico en Santander. http://www.sitursantander.co/
SITUR Villavicencio Plataforma de TI que cuenta con un portal web con información real actualizada sobre el Turismo en Villavicencio, que brinda información a: Turistas, Prestadores de Servicios Turísticos (PST), Entidades del Gobierno Nacional, Departamental, Municipal y población en general. http://www.siturvillavicencio.com/
Sistema de indicadores y estadísticas del sector del turismo SITUR Antioquia
SITUR es el Sistema de Indicadores y Estadísticas del Sector Turismo de Antioquia y Medellín. Creado en el año 2007, nace como propuesta de la Secretaria de Productividad y Competitividad de la Gobernación de Antioquia y la Secretaria de Cultura Ciudadana del Municipio de Medellín, administrado desde la fecha por el Medellín Convention & Visitors Bureau. http://www.situr.gov.co/
Tabla 1. Referentes de plataformas de turísmo

CINSIS 2017 - Programa de Ingeniería de Sistemas
DESARROLLO DEL SISTEMA DE INFORMACIÓN TURÍSTICO DEL MAGDALENA – SITUR MAGDALENA
En este contexto de trabajo surge la iniciativa de construcción del Sistema de Información Turística para el Magdalena (SITUR MAGDALENA), liderada y ejecutada por COTELCO Magdalena, cuyo objetivo es implementar un sistema estratégico de información turística, con un alto componente tecnológico e innovador, que permita el seguimiento de las variables asociadas a la oferta y demanda de productos y servicios turísticos del Departamento del Magdalena; en armonía con el plan estadístico sectorial de turismo –PST, DANE-MINCIT y con las recomendaciones metodológicas propuestas por la organización mundial del turismo (OMT) y los equipos ejecutores de otras iniciativas regionales y nacionales, principalmente SITUR Santander y CITUR Colombia. En este orden de ideas, el objetivo de este documento es presentar el desarrollo del sistema software para la Web que constituye el componente tecnológico de SITUR Magdalena.
2. METODOLOGÍA
Como metodología se trabajó bajo el marco de trabajo colaborativo SCRUM para proyectos de Software. SCRUM es una metodología ágil orientada a la interacción con el cliente y al desarrollo incremental del software, mostrando versiones parcialmente funcionales del mismo al cliente en intervalos cortos de tiempo, para que pueda evaluar y sugerir cambios en el producto según se va desarrollando [2]. Se escogió esta metodología porque:
• El cliente tiene la oportunidad de ver los resultados desde el inicio del proyecto.
• Se ahorra tiempo en dedicación para conseguir especificaciones y documentación exhaustiva que se deben llevar en metodologías tradicionales.
• Se hace comunicación continua con el equipo reportando seguidamente los éxitos conseguidos.
• El cliente tiene la oportunidad de participar y opinar en el desarrollo del proyecto.
• No es una metodología restrictiva y permite ser integrada con otras.
• Permite adaptar cambios en el software con mayor facilidad
SCRUM se puede dividir en tres fases, que se pueden entender como reuniones. Las reuniones forman parte de los artefactos de esta metodología junto con los roles y elementos que lo forman. Dentro de las reuniones se
realizará la planificación del Product Backlog donde se reflejarán los requisitos del sistema por prioridades, el seguimiento al Sprint (entregable funcional para mostrar al cliente) y la revisión del Sprint, todo esto de forma iterativa entregando un Sprint o versión parcial hasta cumplir todos los objetivos del proyecto.
3. RESULTADOS
3.1. Aspectos Generales
El trabajo de esta plataforma estadística e informativa permite obtener indicadores mediante la aplicación de encuestas a turistas que visitan el departamento, personas residentes en el Magdalena y proveedores de servicios turísticos legalmente constituidos. Los datos resultantes de la información recolectada en campo generan, mediante unas reglas de cálculos definidas por el Ministerio de Comercio, Industria y Turismo – MinCIT, indicadores de turismo receptor, interno y emisor. Además de una completa caracterización de la oferta y empleo del sector turístico del departamento, lo cual permite a quienes acceden al sistema de información tener conocimiento del estado actual de dicho gremio y de sus principales indicadores de medición de una forma fiable, sistematizada y totalmente en línea las 24 horas del día durante los 365 días del año. Para la realización del proyecto se contó con el respaldo de MinCIT, FONTUR y COTELCO, teniendo en cuenta la apuesta en firme del gobierno nacional por el turismo en Colombia, y en especial la consideración de posicionar al departamento del Magdalena como un punto estratégico para la consolidación del turismo nacional [3].
El portal web SITUR MAGDALENA, ha sido construido con la finalidad de ofrecer a sus visitantes información de los componentes turísticos representativos del departamento del Magdalena. En la Tabla 2 se presentan en detalle las principales funcionalidades del sistema.
Tabla 2. Módulos del sistema y principales funcionalidades
Módulo Principales funcionalidades
Administración de contenidos
para la promoción
de atractivos turísticos
• Acerca de la región.
• Actividades por realizar en la región.
• Requisitos del viaje.
• Últimas noticias.
• Lugares sugeridos.
• Contenidos y galerías de la región.

CINSIS 2017 - Programa de Ingeniería de Sistemas
DESARROLLO DEL SISTEMA DE INFORMACIÓN TURÍSTICO DEL MAGDALENA – SITUR MAGDALENA
3.2. Módulos Estadísticas
Este módulo le permite al usuario observar indicadores respecto al comportamiento del sector turístico en el Departamento del Magdalena. Aquí se permite observar seis componentes que hacen referencia a las mediciones que pueden ser utilizadas para el análisis referente a la caracterización del turismo en el departamento, las cueles son: Turismo receptor, Turismo interno, Turismo emisor, Oferta turística, Impacto en el empleo y Estadísticas secundarias.
Módulo Principales funcionalidades
Recolección estandarizada de datos de
caracterización
• Turismo receptor y características del viaje al Departamento del Valle del Cauca.
• Caracterización de la oferta turística. (Museos, Sitios Turísticos, Ocupación Hotelera, entre otros).
• Caracterización de los viajes internos y emisores de los hogares del departamento del Valle del Cauca.
• Impacto de la industria turística en la generación de empleo en el departamento del Valle del Cauca.
• Turismo sostenible
Bodega de datos y ETL
• Procedimientos de extracción, transformación y carga de datos desde el módulo de recolección estandarizada.
Presentación de indicadores y generación de
reportes
• Indicadores de turismo receptor y características del viaje al departamento del Valle del Cauca.
• Indicadores de la oferta turística. (museos, sitios turísticos, ocupación hotelera, entre otros).
• Indicadores de caracterización de viajes internos y emisores de los hogares del Valle del Cauca.
• Indicador del Impacto de la industria turística en la generación de empleo en el Valle del Cauca.
• Indicador del impacto del turismo en la calidad ambiental del departamento (Turismo Sostenible)
Administración del sistema software
• Creación de nuevos Usuarios
• Eliminación de usuarios
• Edición de Usuarios
• Edición de Roles
• Asignación de Vistas a Usuarios
3.3. Módulos Experiencias, qué hacer y servicios
Los componentes Experiencias, Qué hacer y Servicios, son módulos que se enfocan principalmente en la promoción turística del departamento del Magdalena, debido a que muestra al usuario los atractivos turísticos del departamento, las actividades que puede realizar y pone a su disposición la información que necesita para hacer de su visita al departamento una experiencia única.
Figura 1. Módulo experiencias
En estos módulos, el usuario tiene acceso a información relacionada con las experiencias que puede obtener como turista en el departamento del Magdalena, las actividades que puede realizar y los atractivos turísticos que tiene el departamento. Se hace una descripción de los lugares que puede visitar en busca de aventuras según los gustos y preferencias de cada persona.
Además, se ofrece información de los proveedores de servicios turísticos en el departamento del Magdalena, tales como Alojamientos, Establecimientos de gastronomía, Agencias de viaje, Establecimientos de esparcimiento y similares y Transporte especializado, todo con el fin de que el usuario tenga la información que necesita para hacer de su visita en el departamento una experiencia agradable y, así mismo, lograr aumentar la competitividad y desarrollo del sector turístico en el departamento.

CINSIS 2017 - Programa de Ingeniería de Sistemas
DESARROLLO DEL SISTEMA DE INFORMACIÓN TURÍSTICO DEL MAGDALENA – SITUR MAGDALENA
Figura 2. Módulo Qué hacer
Cuando es escogido el módulo Mapa, se aprecia la posición geográfica de los diferentes destinos, atracciones y proveedores turísticos del Magdalena que se encuentran registrados en el sistema, con el objetivo de que los turistas o personas que deseen obtener conocimientos acerca de un sitio turístico logren referenciar la ubicación de dicho sitio de manera más fácil y práctica.
Figura 3. Módulo servicios
3.4. Módulos Planifica tu viaje y Mapa
El módulo Planifica tu viaje, le permite al usuario establecer un cronograma con las actividades que desea realizar durante su visita en el departamento del Magdalena. Aquí, el usuario puede elegir de la lista de experiencias, actividades y atractivos, cuáles son sus favoritos, de tal manera, que puede organizar por días, los lugares a visitar y actividades a realizar, para así mismo, lograr una experiencia más completa y satisfactoria.
Figura 5. Módulo Mapa
3.5. Tecnologías utilizadas
Técnicamente, para el desarrollo de la Plataforma SITUR Magdalena se utilizó la tecnología de Microsoft MVC.NET, la cual permitió la creación de un sistema de información seguro y robusto, que cumpliera con las expectativas del COTELCO y MinCIT y se utilizó un motor de base de datos SQL SERVER, el cual permite crear la estructura de almacenamientos de datos de la plataforma, además, cuenta con una bodega de datos para el almacenamiento de los indicadores. También se utilizó la biblioteca de JavaScript JQUERY, el framework estrucural para páginas web dinámicas MVC de código abierto ANGULARJR. Para los gráficos se utilizó la API de Google, Google CHART API, así mismo, para la visualizar los datos tabulados para ser manipulados por el usuario se uso JQGRID, que es un plugin de JQuery de la librería JavaScript.
4. CONCLUSIONES
En síntesis, la Plataforma SITUR Magdalena permite consolidar información base para la planificación turística y la toma de decisiones por parte de las entidades gubernamentales, gremios, empresarios e inversionistas. La Plataforma también contribuye al desarrollo sectorial, proporcionando a los públicos de interés, información continua, oportuna y actualizada de la actividad turística en el Departamento.
Figura 4. Módulo Planifica tu viaje

CINSIS 2017 - Programa de Ingeniería de Sistemas
DESARROLLO DEL SISTEMA DE INFORMACIÓN TURÍSTICO DEL MAGDALENA – SITUR MAGDALENA
La implementación de la Plataforma SITUR Magdalena, traerá consigo múltiples beneficios, debido a que contará con información oficial y confiable sobre la ocupación hotelera, la cantidad de turistas que visitan el Departamento, características sociodemográficas, comportamiento y gasto, entre otros.
El lanzamiento de la Plataforma SITUR Magdalena se llevó a cabo en la Rueda “Turismo Negocia Santa Marta” organizada por el Ministerio de Comercio, Industria y Turismo (MinCIT). En este espacio, se mostró los resultados del trabajo realizado en la Plataforma Virtual de SITUR Magdalena ante la Viceministra de Turismo, Gerente de FONTUR, Presidente Ejecutivo Nacional de COTELCO, Gobernadora, Alcaldes, Secretario de Turismo Departamental, Gerente de Proyectos Turísticos Distrital, representantes de gremios, entidades públicas y privadas locales, proveedores turísticos y 60 compradores e inversionistas interesados en conocer la oferta turística regional, quienes hicieron un reconocimiento al excelente trabajo realizado y resaltaron la importancia de la Plataforma para el sector turístico del Magdalena.
Además, el Proyecto SITUR Magdalena, ha sido socializado en otros espacios como Villavicencio, siendo siempre exaltado por el gremio turístico colombiano como uno de los mejores del país. Así mismo COTELCO Valle del Cauca, extendió una invitación a COTELCO Magdalena, para conocer la experiencia del desarrollo de la Plataforma SITUR Magdalena.
5. REFERENCIAS
[1]Equipo SITUR Magdalena - Unimagdalena, Propuesta de desarrollo - Revisión de Antecedentes. Universidad del Magdalena - Documento interno, 2015.
[2]K.Schowaber y J. Sutherland. La guía definitiva de Scrum. 2013. Disponible: http://www.scrumguides.org/docs/scrumguide/v1/scrum-guide-es.pdf .
[3]Equipo SITUR Magdalena - Unimagdalena, Informe de avance - diciembre 2016. Universidad del Magdalena - Documento interno, 2016.
[4]Equipo SITUR Magdalena - Unimagdalena, Informe de avance - Informe Final. Universidad del Magdalena - Documento interno, 2017.

ISSN: 2500-6991
Volumen 3 - Noviembre de 2017 - Santa Marta,
CONTENIDO
4 PRESENTACIÓN
5 UN ENFOQUE HEURÍSTICO PARA EL PRE-PROCESAMIENTO DE SUPERFICIES TRIDIMENSIONALES5 Nallig Leal, Esmeide Leal y Germán Sánchez Torres.
12 PROCESAMIENTO DE IMÁGENES SUBACUÁTICAS DE PECES EN CRIADEROS Alberto Ceballos Arroyo, Idanis Diaz Bolaño y Germán Sánchez Torres.
19 CLASIFICACIÓN DE SEGMENTOS DE VIDEO UTILIZANDO REPRESENTACIONES VISUALES Y LINGÜÍSTICAS Pedro Atencio Ortiz, Germán Sánchez Torres y John Branch Bedoya.
27 USO DE TÉCNICAS DE APRENDIZAJE DE MÁQUINAS PARA EL DIAGNÓSTICO DE NÓDULOS PULMONARES Idanis Diaz Bolaño, Germán Sánchez Torres y Pedro E. Romero.
31 SISTEMA DE RIEGO AUTÓNOMO E INTELIGENTE CON CAPACIDAD DE MONITOREAR VARIABLES CLIMÁTICA Amaury Cabarcas, Javier Montoya, Daniel Reyes Betancourt y Cristian Arrieta Pacheco.
38 SISTEMA DE MEDICIÓN AUTOMATIZADA DE VARIABLES AMBIENTALES PARA AGRICULTURA DE PRECISIÓN CON SOFTWARE LIBRE Amaury Cabarcas, Amaury Ortega, David Cermeño, Ariel Arnedo y Astrid Vanegas.
47 SISTEMAS EXPERTOS PARA DETERMINAR LA CALIDAD DE LA MIEL: UNA REVISIÓN BIBLIOGRÁFICA Eliécer Pineda Ballesteros, Alberto Castellanos Riveros y Freddy Reynaldo Téllez Acuña.
53 PROPUESTA PARA LA IMPLEMENTACIÓN DE TECNOLOGÍAS RIFD EN CADENAS DE SUMINISTRO AGRÍCOLA William De la Espriella Avila, Plinio Puello Marrugo y Julio Rodríguez Ribón.
60 UN INTÉRPRETE DE PSEUDO-LENGUAJE EN ESPAÑOL PARA LAS ASIGNATURAS DE PROGRAMACIÓN Y ESTRUCTURAS DE DATOS Jean Benítez Diazgranados y Idanis Diaz B.
66 LA ENSEÑANZA EN INGENIERÍA DE SISTEMAS DESDE UN ENFOQUE VIRTUAL, DOS CASOS DE ESTUDIO Eliécer Pineda Ballesteros y Freddy Reynaldo Téllez Acuña.
75 GUÍA PARA LA INCORPORACIÓN DE LOS CONCEPTOS DE PROTECCIÓN DE DATOS EN EQUIPOS DE DESARROLLO DE SOFTWARE CON BAJOS NIVELES DE MADUREZ Jhon Trespalacios, Andrés Paternina Ariza, Cesar Polo Castro y Alexander Bustamante.
83 INCORPORACIÓN DE PRÁCTICAS ÁGILES EN EQUIPOS DE DESARROLLO CON BAJOS NIVELES DE MADUREZ Camilo Torres, Cesar Polo, Andrés Paternina y Alexander Bustamante.
91 DESARROLLO DEL SISTEMA DE INFORMACIÓN TURÍSTICO DEL MAGDALENA – SITUR MAGDALENA Ernesto Galvis-Lista, Mayda P. González-Zabala, Roberto L. Aguas, Cesar Enrique Polo Castro, Jorge Luis Pineda Montagout, Andrés Eduardo Paternina Ariza, Jhon Alexander Trespalacios, Camilo David Torres Callejas, Jennifer Esther Brequeman Torres, José Gabriel Montero Patiño, Brayan Rene Carbonó Carbonó, Luis Fernando Palmera Escorcia, Joaquín Rodríguez, Mónica Isabel Calderón Solano y Farid Leonardo Rodríguez Pacheco.
ISSN: 2500-6991
Volumen 3 - Noviembre de 2017 - Santa Marta,
CONTENIDO
4 PRESENTACIÓN
5 UN ENFOQUE HEURÍSTICO PARA EL PRE-PROCESAMIENTO DE SUPERFICIES TRIDIMENSIONALES5 Nallig Leal, Esmeide Leal y Germán Sánchez Torres.
12 PROCESAMIENTO DE IMÁGENES SUBACUÁTICAS DE PECES EN CRIADEROS Alberto Ceballos Arroyo, Idanis Diaz Bolaño y Germán Sánchez Torres.
19 CLASIFICACIÓN DE SEGMENTOS DE VIDEO UTILIZANDO REPRESENTACIONES VISUALES Y LINGÜÍSTICAS Pedro Atencio Ortiz, Germán Sánchez Torres y John Branch Bedoya.
27 USO DE TÉCNICAS DE APRENDIZAJE DE MÁQUINAS PARA EL DIAGNÓSTICO DE NÓDULOS PULMONARES Idanis Diaz Bolaño, Germán Sánchez Torres y Pedro E. Romero.
31 SISTEMA DE RIEGO AUTÓNOMO E INTELIGENTE CON CAPACIDAD DE MONITOREAR VARIABLES CLIMÁTICA Amaury Cabarcas, Javier Montoya, Daniel Reyes Betancourt y Cristian Arrieta Pacheco.
38 SISTEMA DE MEDICIÓN AUTOMATIZADA DE VARIABLES AMBIENTALES PARA AGRICULTURA DE PRECISIÓN CON SOFTWARE LIBRE Amaury Cabarcas, Amaury Ortega, David Cermeño, Ariel Arnedo y Astrid Vanegas.
47 SISTEMAS EXPERTOS PARA DETERMINAR LA CALIDAD DE LA MIEL: UNA REVISIÓN BIBLIOGRÁFICA Eliécer Pineda Ballesteros, Alberto Castellanos Riveros y Freddy Reynaldo Téllez Acuña.
53 PROPUESTA PARA LA IMPLEMENTACIÓN DE TECNOLOGÍAS RIFD EN CADENAS DE SUMINISTRO AGRÍCOLA William De la Espriella Avila, Plinio Puello Marrugo y Julio Rodríguez Ribón.
60 UN INTÉRPRETE DE PSEUDO-LENGUAJE EN ESPAÑOL PARA LAS ASIGNATURAS DE PROGRAMACIÓN Y ESTRUCTURAS DE DATOS Jean Benítez Diazgranados y Idanis Diaz B.
66 LA ENSEÑANZA EN INGENIERÍA DE SISTEMAS DESDE UN ENFOQUE VIRTUAL, DOS CASOS DE ESTUDIO Eliécer Pineda Ballesteros y Freddy Reynaldo Téllez Acuña.
75 GUÍA PARA LA INCORPORACIÓN DE LOS CONCEPTOS DE PROTECCIÓN DE DATOS EN EQUIPOS DE DESARROLLO DE SOFTWARE CON BAJOS NIVELES DE MADUREZ Jhon Trespalacios, Andrés Paternina Ariza, Cesar Polo Castro y Alexander Bustamante.
83 INCORPORACIÓN DE PRÁCTICAS ÁGILES EN EQUIPOS DE DESARROLLO CON BAJOS NIVELES DE MADUREZ Camilo Torres, Cesar Polo, Andrés Paternina y Alexander Bustamante.
91 DESARROLLO DEL SISTEMA DE INFORMACIÓN TURÍSTICO DEL MAGDALENA – SITUR MAGDALENA Ernesto Galvis-Lista, Mayda P. González-Zabala, Roberto L. Aguas, Cesar Enrique Polo Castro, Jorge Luis Pineda Montagout, Andrés Eduardo Paternina Ariza, Jhon Alexander Trespalacios, Camilo David Torres Callejas, Jennifer Esther Brequeman Torres, José Gabriel Montero Patiño, Brayan Rene Carbonó Carbonó, Luis Fernando Palmera Escorcia, Joaquín Rodríguez, Mónica Isabel Calderón Solano y Farid Leonardo Rodríguez Pacheco.
ISSN: 2500-6991
Volumen 3 - Noviembre de 2017 - Santa Marta,
CONTENIDO
4 PRESENTACIÓN
5 UN ENFOQUE HEURÍSTICO PARA EL PRE-PROCESAMIENTO DE SUPERFICIES TRIDIMENSIONALES5 Nallig Leal, Esmeide Leal y Germán Sánchez Torres.
12 PROCESAMIENTO DE IMÁGENES SUBACUÁTICAS DE PECES EN CRIADEROS Alberto Ceballos Arroyo, Idanis Diaz Bolaño y Germán Sánchez Torres.
19 CLASIFICACIÓN DE SEGMENTOS DE VIDEO UTILIZANDO REPRESENTACIONES VISUALES Y LINGÜÍSTICAS Pedro Atencio Ortiz, Germán Sánchez Torres y John Branch Bedoya.
27 USO DE TÉCNICAS DE APRENDIZAJE DE MÁQUINAS PARA EL DIAGNÓSTICO DE NÓDULOS PULMONARES Idanis Diaz Bolaño, Germán Sánchez Torres y Pedro E. Romero.
31 SISTEMA DE RIEGO AUTÓNOMO E INTELIGENTE CON CAPACIDAD DE MONITOREAR VARIABLES CLIMÁTICA Amaury Cabarcas, Javier Montoya, Daniel Reyes Betancourt y Cristian Arrieta Pacheco.
38 SISTEMA DE MEDICIÓN AUTOMATIZADA DE VARIABLES AMBIENTALES PARA AGRICULTURA DE PRECISIÓN CON SOFTWARE LIBRE Amaury Cabarcas, Amaury Ortega, David Cermeño, Ariel Arnedo y Astrid Vanegas.
47 SISTEMAS EXPERTOS PARA DETERMINAR LA CALIDAD DE LA MIEL: UNA REVISIÓN BIBLIOGRÁFICA Eliécer Pineda Ballesteros, Alberto Castellanos Riveros y Freddy Reynaldo Téllez Acuña.
53 PROPUESTA PARA LA IMPLEMENTACIÓN DE TECNOLOGÍAS RIFD EN CADENAS DE SUMINISTRO AGRÍCOLA William De la Espriella Avila, Plinio Puello Marrugo y Julio Rodríguez Ribón.
60 UN INTÉRPRETE DE PSEUDO-LENGUAJE EN ESPAÑOL PARA LAS ASIGNATURAS DE PROGRAMACIÓN Y ESTRUCTURAS DE DATOS Jean Benítez Diazgranados y Idanis Diaz B.
66 LA ENSEÑANZA EN INGENIERÍA DE SISTEMAS DESDE UN ENFOQUE VIRTUAL, DOS CASOS DE ESTUDIO Eliécer Pineda Ballesteros y Freddy Reynaldo Téllez Acuña.
75 GUÍA PARA LA INCORPORACIÓN DE LOS CONCEPTOS DE PROTECCIÓN DE DATOS EN EQUIPOS DE DESARROLLO DE SOFTWARE CON BAJOS NIVELES DE MADUREZ Jhon Trespalacios, Andrés Paternina Ariza, Cesar Polo Castro y Alexander Bustamante.
83 INCORPORACIÓN DE PRÁCTICAS ÁGILES EN EQUIPOS DE DESARROLLO CON BAJOS NIVELES DE MADUREZ Camilo Torres, Cesar Polo, Andrés Paternina y Alexander Bustamante.
91 DESARROLLO DEL SISTEMA DE INFORMACIÓN TURÍSTICO DEL MAGDALENA – SITUR MAGDALENA Ernesto Galvis-Lista, Mayda P. González-Zabala, Roberto L. Aguas, Cesar Enrique Polo Castro, Jorge Luis Pineda Montagout, Andrés Eduardo Paternina Ariza, Jhon Alexander Trespalacios, Camilo David Torres Callejas, Jennifer Esther Brequeman Torres, José Gabriel Montero Patiño, Brayan Rene Carbonó Carbonó, Luis Fernando Palmera Escorcia, Joaquín Rodríguez, Mónica Isabel Calderón Solano y Farid Leonardo Rodríguez Pacheco.