viỆn hÀn lÂm khoa hỌc vÀ cÔng nghỆ viỆt nam hỌc …
TRANSCRIPT

VIỆN HÀN LÂM KHOA HỌC VÀ CÔNG NGHỆ VIỆT NAM
HỌC VIỆN KHOA HỌC VÀ CÔNG NGHỆ VIỆT NAM
Lƣu Thị Vân
PHÂN TÍCH CÂU HỎI TIẾNG VIỆT
TRONG HỆ THỐNG ĐÓN TIẾP VÀ PHÂN LOẠI BỆNH NHÂN
LUẬN VĂN THẠC SĨ NGÀNH MÁY TÍNH
HÀ NỘI - 2020

VIỆN HÀN LÂM KHOA HỌC VÀ CÔNG NGHỆ VIỆT NAM
HỌC VIỆN KHOA HỌC VÀ CÔNG NGHỆ VIỆT NAM
Lƣu Thị Vân
PHÂN TÍCH CÂU HỎI TIẾNG VIỆT
TRONG HỆ THỐNG ĐÓN TIẾP VÀ PHÂN LOẠI BỆNH NHÂN
Chuyên ngành: Hệ thống thông tin
Mã số: 8 48 01 04
LUẬN VĂN THẠC SĨ NGÀNH MÁY TÍNH
CÁN BỘ HƢỚNG DẪN KHOA HỌC: TS.Nguyễn Nhƣ Sơn
HÀ NỘI – 2020
Nguyễn Nhƣ Sơn

LỜI CAM ĐOAN
Tôi là Lƣu Thị Vân, học viên khóa I, ngành Công nghệ thông tin, chuyên
ngành Hệ Thống Thông Tin. Tôi xin cam đoan luận văn “Phân tích câu hỏi
Tiếng Việt trong hệ thống đón tiếp và phân loại bệnh nhân” là do tôi nghiên cứu,
tìm hiểu và phát triển dƣới sự hƣớng dẫn của TS. Nguyễn Nhƣ Sơn. Luận văn
không phải sự sao chép từ các tài liệu, công trình nghiên cứu của ngƣời khác mà
không ghi rõ trong tài liệu tham khảo. Tôi xin chịu trách nhiệm về lời cam đoan
này.
Hà Nội, tháng 10 năm 2020
Học viên
Lƣu Thị Vân

LỜI CẢM ƠN
Đầu tiên tôi xin gửi lời cảm ơn tới các thầy cô Học viện Khoa học và
Công nghệ nghệ Việt nam, Viện Hàn lâm Khoa học và Công nghệ Việt Nam đã
tận tình giảng dạy và truyền đạt kiến thức cho tôi trong suốt khóa học cao học
vừa qua.Tôi cũng xin đƣợc gửi lời cảm ơn đến các thầy cô trong Bộ môn Hệ
thống thông tin cũng nhƣ Khoa công nghệ thông tin đã mang lại cho tôi những
kiến thức vô cùng quý giá và bổ ích trong quá trình học tập tại trƣờng.
Đặc biệt xin chân thành cảm ơn thầy giáo, TS. Nguyễn Nhƣ Sơn, ngƣời
đã định hƣớng, giúp đỡ, trực tiếp hƣớng dẫn và tận tình chỉ bảo tôi trong suốt
quá
trình nghiên cứu, xây dựng và hoàn thiện luận văn này.
Tôi cũng xin đƣợc cảm ơn tới gia đình, những ngƣời thân, các đồng
nghiệp và bạn bè đã thƣờng xuyên quan tâm, động viên, chia sẻ kinh nghiệm,
cung cấp các tài liệu hữu ích trong thời gian học tập, nghiên cứu cũng nhƣ trong
suốt quá trình thực hiện luận văn tốt nghiệp.
Hà Nội, tháng 10 năm 2020
Học viên
Lƣu Thị Vân

MỤC LỤC
LỜI CAM ĐOAN .................................................................................................. 2
LỜI CẢM ƠN ....................................................................................................... 3
MỤC LỤC ............................................................................................................. 4
DANH MỤC THUẬT NGỮ VÀ CÁC KÝ HIỆU VIẾT TẮT ............................ 6
DANH MỤC HÌNH VẼ VÀ ĐỒ THỊ ................................................................... 7
DANH MỤC CÁC BẢNG BIỂU ......................................................................... 7
TÓM TẮT ............................................................................................................. 8
MỞ ĐẦU ............................................................................................................. 10
CHƢƠNG 1: GIỚI THIỆU TỔNG QUAN ........................................................ 13
1 Tổng quan về hệ thống trả lời tự động ....................................................... 13
1.1 Hệ thống hƣớng nhiệm vụ và hƣớng hội thoại ....................................... 14
1.2 Tình hình nghiên cứu trong và ngoài nƣớc ............................................ 15
2 Xử lý ngôn ngữ tự nhiên và ứng dụng ....................................................... 17
2.1 Sơ lƣợc về ngôn ngữ tự nhiên ................................................................. 17
2.2 Các ứng dụng xử lý ngôn ngữ tự nhiên .................................................. 18
2.3 Tiền xử lý văn bản .................................................................................. 18
2.3.1 Chuẩn hóa và biến đổi văn bản ........................................................... 18
2.3.2 Biểu diễn văn bản dƣới dạng vector .................................................... 19
3 Bài toán phân loại văn bản ......................................................................... 19
3.1 Bài toán phân loại văn bản ..................................................................... 19
3.2 Một số thuật toán phân loại văn bản ...................................................... 20
3.2.1 Thuật toán Naive Bayes ....................................................................... 20
3.2.2 Thuật toán SVM ................................................................................... 23
3.2.3 Mạng nơ-ron nhân tạo ......................................................................... 31
3.3 Các phƣơng pháp đánh giá một hệ thống phân lớp ................................ 36
3.3.1 Đánh giá theo độ chính xác Accuracy ................................................. 37
3.3.2 Ma trận nhầm lẫn ................................................................................. 37

3.3.3 True/False Positive/Negative .............................................................. 39
3.3.4 Precision và Recall .............................................................................. 40
3.3.5 F1-Score ............................................................................................... 42
CHƢƠNG 2: PHÂN TÍCH CÂU HỎI TRONG HỆ THỐNG TRẢ LỜI TỰ
ĐỘNG ................................................................................................................. 44
1 Vấn đề cơ bản của một hệ thống trả lời tự động ........................................ 44
2 Bài toán phân loại câu hỏi ......................................................................... 46
2.1 Phát biểu bài toán.................................................................................... 46
2.2 Các phƣơng pháp phân loại câu hỏi ....................................................... 46
2.2.1 Phân loại câu hỏi dựa trên luật ............................................................ 47
2.2.2 Phƣơng pháp sử dụng mô hình ngôn ngữ ............................................ 48
2.2.3 Phân loại câu hỏi dựa vào học máy ..................................................... 48
2.3 Trích chọn đặc trƣng cho phân tích câu hỏi ........................................... 51
2.3.1 Đặc trƣng về từ vựng ........................................................................... 51
2.3.2 Đặc trƣng về cú pháp ........................................................................... 53
2.3.3 Đặc trƣng về ngữ nghĩa ....................................................................... 54
3 Sự phân loại câu hỏi Taxonomy ................................................................ 55
3.1 Khái niệm Taxonomy ............................................................................. 55
3.2 Taxonomy câu hỏi .................................................................................. 55
3.3 Mô hình phân lớp đa cấp ........................................................................ 59
4 Một số kết quả nghiên cứu ......................................................................... 60
CHƢƠNG 3: XÂY DỰNG MÔ HÌNH VÀ ĐÁNH GIÁ THỰC NGHIỆM...... 62
1 Kiến trúc ứng dụng .................................................................................... 62
2 Xây dựng và cài đặt mô hình ..................................................................... 63
2.1 Tập dữ liệu thực nghiệm ......................................................................... 63
2.2 Công cụ thực nghiệm .............................................................................. 65
2.3 Lựa chọn đặc trƣng ................................................................................. 66
3 Đánh giá kết quả thực nghiệm ................................................................... 67
KẾT LUẬN ......................................................................................................... 69
TÀI LIỆU THAM KHẢO ................................................................................... 70
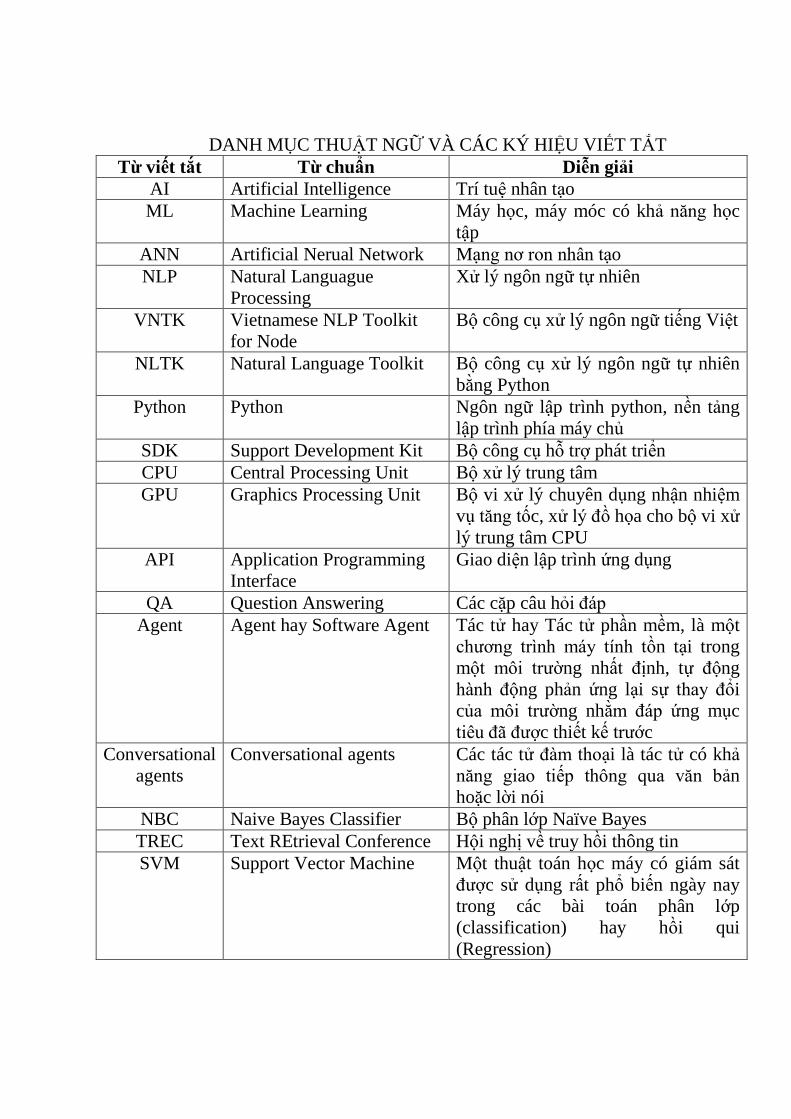
DANH MỤC THUẬT NGỮ VÀ CÁC KÝ HIỆU VIẾT TẮT
Từ viết tắt Từ chuẩn Diễn giải
AI Artificial Intelligence Trí tuệ nhân tạo
ML Machine Learning Máy học, máy móc có khả năng học
tập
ANN Artificial Nerual Network Mạng nơ ron nhân tạo
NLP Natural Languague
Processing
Xử lý ngôn ngữ tự nhiên
VNTK Vietnamese NLP Toolkit
for Node
Bộ công cụ xử lý ngôn ngữ tiếng Việt
NLTK Natural Language Toolkit Bộ công cụ xử lý ngôn ngữ tự nhiên
bằng Python
Python Python Ngôn ngữ lập trình python, nền tảng
lập trình phía máy chủ
SDK Support Development Kit Bộ công cụ hỗ trợ phát triển
CPU Central Processing Unit Bộ xử lý trung tâm
GPU Graphics Processing Unit Bộ vi xử lý chuyên dụng nhận nhiệm
vụ tăng tốc, xử lý đồ họa cho bộ vi xử
lý trung tâm CPU
API Application Programming
Interface
Giao diện lập trình ứng dụng
QA Question Answering Các cặp câu hỏi đáp
Agent Agent hay Software Agent Tác tử hay Tác tử phần mềm, là một
chƣơng trình máy tính tồn tại trong
một môi trƣờng nhất định, tự động
hành động phản ứng lại sự thay đổi
của môi trƣờng nhằm đáp ứng mục
tiêu đã đƣợc thiết kế trƣớc
Conversational
agents
Conversational agents Các tác tử đàm thoại là tác tử có khả
năng giao tiếp thông qua văn bản
hoặc lời nói
NBC Naive Bayes Classifier Bộ phân lớp Naïve Bayes
TREC Text REtrieval Conference Hội nghị về truy hồi thông tin
SVM Support Vector Machine Một thuật toán học máy có giám sát
đƣợc sử dụng rất phổ biến ngày nay
trong các bài toán phân lớp
(classification) hay hồi qui
(Regression)

DANH MỤC HÌNH VẼ VÀ ĐỒ THỊ
Hình 1: Mặt phân cách dữ liệu ............................................................................ 24
Hình 2. Lề siêu phẳng ......................................................................................... 24
Hình 3. Dữ liệu phi tuyến .................................................................................... 27
Hình 4. Không gian dữ liệu phi tuyến ................................................................. 29
Hình 5. Kiến trúc mạng nơ-ron nhân tạo ............................................................ 32
Hình 6. Quá trình xử lý thông tin của một mạng nơ-ron nhân tạo ...................... 33
Hình 7. Minh hoạ unnormalized confusion và normalized confusion matrix .... 39
Hình 8. Cách tính Precision và Recall ................................................................ 41
Hình 9. Các bƣớc cơ bản trong hệ thống trả lời tự động .................................... 44
Hình 10. Mô hình giai đoạn huấn luyện .............................................................. 49
Hình 11. Các bƣớc thực hiện giai đoạn huấn luyện ............................................ 50
Hình 12. Mô hình giai đoạn phân lớp ................................................................. 51
Hình 13. Bộ phân lớp đa cấp của Li và Roth ...................................................... 60
Hình 14. Kiến trúc tổng quan của hệ thống phân loại câu hỏi ............................ 63
Hình 15. Tập dữ liệu huấn luyện ......................................................................... 64
Hình 16. Tập dữ liệu kiểm tra ............................................................................. 64
DANH MỤC CÁC BẢNG BIỂU
Bảng 1. Một vài so sánh các cách sắp xếp trật tự câu ......................................... 18
Bảng 2. Dữ liệu tập mẫu tính xác suất theo phƣơng pháp Naive Bayes ............. 21
Bảng 3. Biểu diễn các đặc trƣng của một câu hỏi ............................................... 52
Bảng 4. Taxonomy câu hỏi ................................................................................. 56
Bảng 5. Độ chính xác phân loại câu hỏi với các thuật toán học máy khác nhau 61
Bảng 6. Thông tin phần cứng thực nghiệm ......................................................... 65
Bảng 7. Các công cụ, thƣ viện sử dụng ............................................................... 65
Bảng 8. Độ chính xác kết quả thực nghiệm SVM với các đặc trƣng khác nhau 67

TÓM TẮT
Sự phát triển mạnh mẽ của Công nghệ thông tin trong những năm gần
đây, đặc biệt trong bối cảnh cuộc cách mạng công nghiệp lần thứ tƣ đang tác
động tới nhiều ngành nghề, nhiều lĩnh vực, trong đó có ngành y tế, đòi hỏi các
bệnh viện và các cơ sở y tế phải không ngừng đổi mới để nâng cao chất lƣợng
dịch vụ khám chữa bệnh, nâng cao hiệu suất làm việc của bác sĩ, giảm chi phí
khám chữa bệnh, giảm thời gian chờ đợi của bệnh nhân.
Ứng dụng những công nghệ mới nhƣ : Trí tuệ nhân tạo (AI), Dữ liệu lớn
(Big Data), Điện toán đám mây (Cloud Computing), Kết nối vạn vật (IOT), Di
động (Mobility), … sẽ giúp các lãnh đạo của bệnh viện và các cơ sở y tế có thể
quản lý toàn bộ hoạt động với các số liệu chính xác, trung thực và trực tuyến.
Việc ứng dụng công nghệ thông tin (CNTT) trong công tác bảo vệ, chăm sóc,
nâng cao sức khỏe ở Việt Nam đã có những bƣớc phát triển quan trọng, đặt nền
móng xây dựng, triển khai và vận hành nền y tế thông minh.
Trí tuệ nhân tạo (AI – Artificial Intelligent) là một ngành của Khoa học
máy tính liên quan đến việc mô phỏng các quá trình suy nghĩ và học tập của con
ngƣời cho máy móc, đặc biệt là cho các hệ thống máy tính. Các quá trình này
bao gồm việc học tập (thu thập thông tin và thiết lập các quy tắc sử dụng thông
tin), lập luận (sử dụng các quy tắc để đạt đƣợc kết luận gần đúng hoặc xác định),
và tự sửa lỗi. AI gần đây trở nên bùng nổ, nhận đƣợc nhiều sự quan tâm là nhờ
Dữ liệu lớn (Big data) phát triển, cho phép xử lý công nghệ AI với tốc độ nhanh
hơn bao giờ hết. Một số ứng dụng điển hình của AI trong lĩnh vực y tế có thể kể
đến nhƣ : (1) Phẫu thuật với sự hỗ trợ của Robot cho phép bác sĩ thực hiện
nhiều quy trình phức tạp cùng với sự kiểm soát tốt hơn ; (2) Trợ lý y tá ảo
hƣớng dẫn và tƣơng tác với bệnh nhân, thực hiện các biện pháp chăm sóc tránh
việc thăm khám không cần thiết ; (3) Hỗ trợ chẩn đoán lâm sàng nhƣ phát hiện
ung thƣ, hay việc hỗ trợ đƣa ra phác đồ điều trị ; (4)Tự động hóa các tác vụ
quản trị giúp tiết kiệm thời gian, giúp giảm bớt khối lƣợng công việc và nhiệm
vụ quản trị ; (5) Phân tích hình ảnh giúp bác sĩ đƣa ra đƣợc kết luận chính xác
về các tổn thƣơng trên các hình ảnh X-Quang, CT, MRI, ....
Đón tiếp và phân loại bệnh nhân là một bài toán quan trọng trong việc

đón tiếp bệnh nhân đến thăm khám và điều trị chữa bệnh tại các cơ sở y tế và
các bệnh viện. Việc đón tiếp liên tục, tự động hóa và nhanh chóng giúp phân
luồng và giảm tải cho cơ sở khám chữa bệnh (KCB) để có thể cứu chữa và thăm
khám đƣợc nhiều bệnh nhân hơn, đồng nghĩa cứu đƣợc nhiều mạng ngƣời hơn.
Từ các yêu cầu thực tế để xây dựng và triển khai một hệ thống có thể tự
động đón tiếp khám bệnh, đón tiếp làm cận lâm sàng, hƣớng dẫn tìm đƣờng,
hƣớng dẫn thủ tục, phân loại khám bệnh cho bệnh nhân dựa vào tập câu hỏi cho
trƣớc thay cho cán bộ đón tiếp. Để xây dựng đƣợc một hệ thống đón tiếp nhƣ
vậy, tôi thực hiện nghiên cứu các phƣơng pháp phân tích câu hỏi tiếng Việt để
tiền xử lý tập lệnh cho hệ thống đón tiếp và phân loại bệnh nhân một cách tự
động.
Phân loại văn bản là quá trình gán nhãn hoặc phân nhóm cho văn bản theo
nội dung của nó. Đây là một trong những nhiệm vụ cơ bản của Xử lý ngôn ngữ
tự nhiên với các ứng dụng rộng rãi nhƣ : Phân tích cảm xúc (Sentiment
analysis), gán nhãn chủ đề (Topic labeling), phát hiện thƣ rác (Spam detection),
và phát hiện ý định (Intent detection).
Trong khuôn khổ của đề tài này, nghiên cứu các phƣơng pháp Phân tích
câu hỏi tiếng Việt và đƣa ra một kiến trúc để xây dựng một hệ thống đón
tiếp và phân loại bệnh nhân đƣợc ứng dụng tại các bệnh viện và cơ sở khám
chữa bệnh.
Kết quả chính của mà tôi đạt đƣợc là một mô hình phân loại văn để xác
định ý định và nhu cầu khám chữa bệnh của ngƣời dân, đối với nhóm đối tƣợng
điều trị bệnh mãn tính, nhóm đối tƣợng tƣ vấn tổng quát. Mô hình ban đầu đã
cho kết quả rất tính cực, có thể giải quyết đƣợc những vấn đề cơ bản về ngữ
nghĩa, ngữ cảnh và tiến tới giải quyết đƣợc những yêu cầu cao hơn về việc phân
loại và hỗ trợ tự động.

MỞ ĐẦU
1. Động lực nghiên cứu và tính cấp thiết của bài toán thực tế
Trong bối cảnh mạng Internet đã trở lên rất phổ biến nhƣ hiện nay, con
ngƣời kết nối với con ngƣời thông qua mạng xã hội, bất cứ thời gian nào và ở
bất cứ nơi đâu. Sẽ thật tốt hơn nếu có một hệ thống tự động thông minh hỗ trợ
con ngƣời bằng cách trò chuyện, có khả năng nhắc nhở, làm trợ lý công việc và
có thể theo dõi tình trạng sức khỏe cá nhân mọi lúc, mọi nơi.
Hệ thống trả lời tự động hay trợ lý ảo đang là chủ đề rất nóng từ đầu năm
2016, khi chính thức các công ty lớn nhƣ Microsoft, Google, Facebook, Apple,
Samsung, WeChat, Slack đã giới thiệu các trợ lý ảo của mình, là các hệ thống
trả lời tự động. Chính thức đặt cƣợc lớn vào cuộc chơi tạo những những thế hệ
trợ lý ảo, với mong muốn tạo ra một trợ lý ảo thực sự thông minh tồn tại trong
hệ sinh thái các sản phẩm của mình.
Trong nƣớc, một số công ty nhƣ ERM và Vietcare đã phát triển tạo ra hệ
thống trả lời tự động về kiến thức y khoa, hỏi đáp về sức khỏe thông tin y tế, hay
Subiz, Messnow, Harafunnel, Chatbot Vietnam, … cũng đang cố gắng tạo ra
cho mình một hệ thống hỗ trợ, chăm sóc khách hàng và bán hàng tự động.
Trong lĩnh vực y tế, một số công ty cũng đã ứng dụng Robot Đón tiếp nhƣ
một sản phẩm của Trí tuệ nhân tạo, Robot là một sản phẩm của quá trình chuyển
đổi số y tế, là nhân tố không thể thiếu trong một bệnh viện thông minh. Hỗ trợ
hƣớng dẫn toàn bộ các quy trình từ khám chữa bệnh đến chỉ dẫn, có thể kết nối
với hệ thống thông tin y tế khác.
Nhiều nhà nghiên cứu đang có hi vọng phát triển các trợ lý ảo có thể hiểu
đƣợc ngôn ngữ tự nhiên của con ngƣời, có thể đối thoại và tƣơng tác đƣợc với
con ngƣời một cách tự nhiên. Nhiều ngƣời cho rằng việc sử dụng kỹ thuật xử lý
ngôn ngữ tự nhiên NLP và các kỹ thuật học sâu Deep Learning để làm tăng
đƣợc chất lƣợng và hiệu quả của hệ thống. Nhƣng từ lý thuyết đến thực tế là cả
một chặng đƣờng dài và nhiều thách thức, bằng cách nào đó, con ngƣời có thể
tích hợp Trí tuệ nhân tạo vào các sản phẩm công nghiệp của mình.

Có thể thấy, hệ thống trả lời tự động có những nhiệm vụ và vai trò quan
trọng, có thể trợ giúp đƣợc con ngƣời rất nhiều trong rất nhiều lĩnh vực: y tế,
giáo dục, thƣơng mại điện tử, …, là động lực to lớn để nghiên cứu và đƣa ra các
sản phẩm phù hợp ứng dụng vào thực tế.
2. Mục tiêu của luận văn
Với cơ sở thực tiễn trên, luận văn này đặt ra mục tiêu nghiên cứu một số
phƣơng pháp xử lý ngôn ngữ tự nhiên để phân tích câu hỏi, câu mệnh lệnh, cho
phép phân loại các văn bản đầu vào là các câu nói tiếng Việt có tính chất sai
khiến, yêu cầu ra lệnh. Nhằm giải quyết một phần nhỏ trong một hệ thống Hỏi
đáp và Đón tiếp bệnh nhân tại các cơ sở y tế.
Từ đó, xây dựng một mô hình phân loại văn bản để dự đoán đƣợc ý định
của văn bản đầu vào. Từ kết quả thu đƣợc, sẽ đƣợc sử dụng để ứng dụng vào bài
toán Đón tiếp và phân loại bệnh nhân đến phòng khám phù hợp tại các cơ sở
khám chữa bệnh.
3. Cấu trúc của luận văn
Các nghiên cứu và kết quả đƣợc mô tả trong luận văn đƣợc chia thành bố
cục với các nội dung nhƣ sau:
CHƢƠNG 1: Giới thiệu tổng quan; Giới thiệu tổng quan về hệ thống trả
lời tự động, tình hình nghiên cứu trong và ngoài nƣớc; Nghiên cứu về cơ sở xử
lý ngôn ngữ tự nhiên và các ứng dụng;tìm hiểu bài toán phân loại văn bản và
Các phƣơng pháp phân loại văn bản.
CHƢƠNG2: Phân tích câu hỏi trong hệ thống trả lời tự dộng; Nghiên
cứu các vấn đề cơ bản của hệ thống trả lời tự động, tìm hiểu các phƣơng pháp
xác định ý định ngƣời dùng bằng phƣơng pháp học máy; Nghiên cứu phƣơng
pháp đánh giá một hệ thống thống phân lớp ý định.
CHƢƠNG3: Xây dựng mô hình và đánh giá thực nghiệm; Đề xuất mô
hình học máy và kiến trúc của ứng dụng, trình bày các kỹ thuật tiền xử lý dữ liệu
đầu vào là các câu nói Tiếng Việt có tính chất sai khiến, yêu cầu ra lệnh.Liệt kê
các vấn đề và giải pháp khắc phục khi huấn luyện mô hìnhdữ liệu.

KẾT LUẬN VÀ KIẾN NGHỊ: Phần này đƣa ra các kết luận và đánh giá
kết quả đạt đƣợc của luận văn, một số đề xuất để cải tiến mô hình, cũng nhƣ khả
năng ứng dụng vào bài toán thực tế.
TÀI LIỆU THAM KHẢO: Đƣa ra danh sách các bài báo đƣợc sử dụng
làm tham khảo, tham chiếu cho luận văn.

13
CHƢƠNG 1: GIỚI THIỆU TỔNG QUAN
Xây dựng hệ thống trả lời tự động là một bài toán khó thuộc lĩnh vực xử
lý ngôn ngữ tự nhiên. Bởi vì tính nhập nhằng, đa nghĩa, đa ngữ cảnh của ngôn
ngữ tự nhiên. Bài toán đặt ra nhiều thách thức để phát hiện ra đƣợc câu trả lời
phù hợp nhất, thông tin hữu ích nhất.
Chƣơng này sẽ giới thiệu tổng quan về hệ thống đối thoại ngƣời máy, các
nghiên cứu ở trong và ngoài nƣớc để thấy đƣợc các phƣơng pháp tiếp cận là rất
phong phú, sau đó tổng quan và phân loại các mô hình trả lời tự động. Tìm hiểu
và giới thiệu bài toán phân loại văn bản, các lý thuyết về học máy, các phƣơng
pháp đánh giá một hệ thống phân lớp.
1 Tổng quan về hệ thống trả lời tự động
Hệ thống hộp thoại (Dialogue systems), còn đƣợc gọi là trợ lý tƣơng tác
hội thoại, trợ lý ảo và đôi khi đƣợc gọi với thuật ngữ là chatbot, đƣợc sử dụng
rộng rãi trong các ứng dụng khác nhau, từ các dịch vụ kỹ thuật cho đến các công
cụ có thể học ngôn ngữ và giải trí [22]. Các hệ thống đối thoại có thể đƣợc chia
thành các hệ thống hướng mục tiêu, ví dụ nhƣ các dịch vụ hỗ trợ kỹ thuật, và
các hệ thống không có định hướng mục tiêu, ví dụ nhƣ các công cụ học ngôn
ngữ hoặc các nhân vật trò chơi máy tính [23]. Trong luận văn này tập trung vào
trƣờng hợp thứ nhất, thiết kế một hệ thống hƣớng tới các nhiệm vụ có mục tiêu,
tức là đi xây dựng một mô hình phân tích ý định của ngƣời dùng cho tiếng Việt
trên tập dữ liệu đƣợc xây dựng theo kịch bản.
Một trong những thách thức chính trong phát triển của hệ thống đối thoại
ngƣời máy hƣớng nhiệm vụ, và trong việc mở rộng chúng trong nhiều miền ứng
dụng, đƣợc nhắc đến trong [24], là sự sẵn có của dữ liệu trên một miền hội thoại
cụ thể. Hệ thống đối thoại cần kết hợp và khai thác nhiều thành phần, ví dụ nhƣ
nhận dạng giọng nói, hiểu ngôn ngữ tự nhiên, giám sát hội thoại, phát sinh ngôn
ngữ tự nhiên, và mỗi thành phần này yêu cầu sẵn có nguồn dữ liệu trên miền cụ
thể, tài nguyên và các mô hình. Bao gồm các mô hình ngôn ngữ, mô hình ngữ
âm, mô hình hiểu ngôn ngữ, các miền bản thể Ontology, các kịch bản tƣơng tác,
các mô hình sinh ngôn ngữ, …
Mặc dù, nhiều vấn đề AI đã đƣợc hƣởng lợi ích từ các nguồn dữ liệu ngày
càng lớn, thu thập dữ liệu end-to-end cho các hệ thống đối thoại hƣớng nhiệm

14
vụ vẫn còn là một vấn đề khó khăn. Phƣơng pháp tiếp cận hiện tại để thu thập
dữ liệu thoại dẫn đến chi phí phát triển cao và tiêu tốn thời gian cho các nhà phát
triển hệ thống. Trừ khi các nguồn lực bên ngoài đã có sẵn trong miền tập dữ liệu
yêu cầu phải có một hệ thống triển khai có khả năng duy trì một cuộc đối thoại
với ngƣời dùng. Điều này dẫn đến một vấn đề khởi đầu: do thiếu dữ liệu để huấn
luyện hệ thống ban đầu, các nhà phát triển hệ thống mang gánh nặng về việc
phát triển văn phạm và các mô hình ngôn ngữ, hoặc là thủ công [24]. Thu thập
dữ liệu hội thoại với phiên bản đầu tiên của một hệ thống đƣợc triển khai thƣờng
có thiếu sót: chất lƣợng dữ liệu thu thập có thể phải chịu những bất cập của hệ
thống chính nó, và ngƣời dùng có thể chịu ảnh hƣởng ngôn ngữ của chúng để
điều chỉnh cho những khuyết điểm của hệ thống trong việc theo hết một cuộc
đối thoại. Kết quả là, tốc độ của tập dữ liệu có thể chậm hơn so với mong muốn.
Cuối cùng, quá trình phát triển tốn kém này phải đƣợc lặp đi lặp lại trên một lần
nữa cho mỗi miền hoặc hệ thống mới, hoặc ngay cả khi chức năng mới đƣợc
thêm vào.
1.1 Hệ thống hƣớng nhiệm vụ và hƣớng hội thoại
Các hệ thống trả lời tự động giao tiếp với ngƣời dùng bằng ngôn ngữ tự
nhiên (văn bản, giọng nói, hoặc cả hai) thƣờng đƣợc chia vào hai nhóm chính:
Hƣớng nhiệm vụ hoặc hƣớng hội thoại:
Các hệ thống hƣớng nhiệm vụ đƣợc thiết kế cho một tác vụ cụ thể và
đƣợc thiết lập để có các cuộc hội thoại ngắn (từ một tƣơng tác đơn lẻ đến các
hàng loạt các tƣơng tác liên tiếp) để lấy thông tin từ ngƣời dùng để giúp hoàn
thành tác vụ.
Ngày nay mà chúng ta có thể thấy sự hiện diện của chúng trên các thiết bị
di động hoặc trên bộ điều khiển gia đình (Siri, Cortana, Alexa, Google Home,
v.v.) mà các hệ thốnghội thoại có thể đƣa ra chỉ dẫn tìm đƣờng, điều khiển thiết
bị gia đình, tìm nhà hàng hoặc giúp gọi điện thoại hoặc gửi văn bản. Các công ty
triển khai các tác tử đàm thoại trên trang web của họ để giúp khách hàng trả lời
các câu hỏi hoặc giải quyết các vấn đề một cách tự động. Tác tử đàm thoại đóng
một vai trò quan trọng nhƣ một giao diệncho robot để có thể giao tiếp.
Hệ thống hƣớng hội thoại là các hệ thống đƣợc thiết kế cho các cuộc hội
thoại mở rộng, đƣợc cài đặt để mô phỏng các cuộc hội thoại không có cấu trúc

15
hoặc mô phỏng lại đặc trƣng của sự tƣơng tác giữa ngƣời và ngƣời, thay vì tập
trung vào một nhiệm vụ cụ thể nhƣ đặt vé máy bay. Các hệ thống này thƣờng có
giá trị giải trí, chẳng hạn nhƣ hệ thống Microsoft Xiao XiaoIce (Little Bing)
(Microsoft, 2014), trò chuyện với mọi ngƣời trên nền tảng nhắn tin văn bản.
Trên phƣơng tiện truyền thông và trong công nghiệp, các tác tử đàm thoại
ngƣời-máy thƣờng đƣợc gọi bằng thuật ngữ Chatbots, và các chƣơng trình này,
cũng thƣờng cố gắng vƣợt qua các bài kiểm tra thử nghiệm Turing khác nhau.
Tuy nhiên, một hệ thống đầu tiên rất sớm, ELIZA (Weizenbaum, 1966),
những Chatbots cũng đã đƣợc sử dụng cho các mục đích thực tế, chẳng hạn nhƣ
kiểm tra các lý thuyết về tƣ vấn tâm lý.
1.2 Tình hình nghiên cứu trong và ngoài nƣớc
Việc nghiên cứu vềhệ thống trả lời tự động có ý nghĩa trong khoa học và
thực tế. Đã có rất nhiều các hội nghị thƣờng niên về xử lý ngôn ngữ tự nhiên,
khai phá dữ liệu, xử lý dữ liệu lớn, tƣơng tác ngƣời máy, … nhƣ TREC, CLEF,
tại Việt Nam có KSE, RIVF, ATC, …
Theo ý tƣởng của Russellvà cộng sự [25], thì một hệ thống AI phải đƣợc
kiểm tra (hành động dƣới sự ràng buộc hình thức và phù hợp với các điều kiện
kỹ thuật); phải đƣợc xác nhận (không theo đuổi các hành vi không mong muốn
dƣới sự ràng buộc trƣớc); phải an toàn (ngăn chặn các thao tác có chủ ý của các
bên thứ ba, hoặc bên ngoài hoặc bên trong); và phải đƣợc kiểm soát (con ngƣời
cần phải có cách để thiết lập lại kiểm soát nếu cần thiết).
Thiết kế hệ thống đối thoại là một nhiệm vụ đầy thách thức và là một
trong những mục tiêu ban đầu của trí tuệ nhân tạo (Turing, 1950) [26]. Trong
nhiều thập kỷ, việc thiết kế tác nhân đối thoại đã giúp các hệ thống dựa trên cơ
sở tri thức và cơ chế dựa trên luật Rule-based để hiểu các thông điệp đầu vào
của con ngƣời và tạo ra các phản hồi đáp ứng hợp lý [27,28,29]. Phƣơng pháp
tiếp cận hƣớng dữ liệu nhấn mạnh vào việc học trực tiếp từ các tập ngữ liệu của
các cuộc đối thoại tiếng nói hoặc văn bản chữ viết. Gần đây, phƣơng pháp này
đã đạt đƣợc hiệu quả vì lợi thế dữ liệu phong phú [23], sức mạnh tính toán, và
các thuật toán học tốt hơn [30,31].

16
Ritter và cộng sự (2010) [32] đã đề xuất phƣơng pháp tiếp cận hƣớng dữ
liệu cho việc xây dựng hệ thống đối thoại, và họ đã trích xuất ra 1,3 triệu cuộc
hội thoại từ Twitter với mục đích là phát hiện ra các hành động trong cuộc hội
thoại. Bằng việc xây dựng dựa trên sự tƣơng đồng về phân phối trong khuôn khổ
mô hình không gian vector, Banchs và Li (2012) [33] đã xây dựng một công cụ
tìm kiếm để lấy câu trả lời thích hợp cho bất kỳ một thông điệp đầu vào. Phƣơng
pháp tiếp cận khác tập trung vào nhiệm vụ trên một lĩnh vực cụ thể nhƣ các trò
chơi [34], và các nhà hàng ăn uống (2016) [35,36].
Việc xây dựng các chƣơng trình Trả lời tự động và Tác tử đàm thoại
(conversational agents) đã đƣợc theo đuổi bởi nhiều nhà nghiên cứu trong nhiều
thập kỷ qua, và rất nhiều nghiên cứu khác không đƣợc đề cập trong danh mục
tham khảo. Tuy nhiên, hầu hết các hệ thống hội thoại này đòi hỏi một quy trình
xử lý khá phức tạp qua nhiều giai đoạn [37, 38].

17
2 Xử lý ngôn ngữ tự nhiên và ứng dụng
2.1 Sơ lƣợc về ngôn ngữ tự nhiên
Xử lý ngôn ngữ tự nhiên (Natural Language Processing - NLP), là một
lĩnh vực khoa học máy tính, kỹ thuật thông tin và trí tuệ nhân tạo tập trung vào
nghiên cứu các tƣơng tác về mặt ngôn ngữ giữa máy tính và con ngƣời, cụ thể
hơn là làm thế nào để lập trình cho máy tính xử lý và phân tích một lƣợng lớn
dữ liệu ngôn ngữ tự nhiên.
Theo cách hiểu khác, NLP quan tâm đến việc làm thế nào để máy tính
hiểu và tận dụng đƣợc các tập dữ liệu sẵn có dƣới dạng ngôn ngữ tự nhiên. NLP
đã đƣợc ứng dụng rộng rãi trong thực tế nhằm: tiết kiệm sức lao động, thúc đẩy
các ngành nghề kinh doanh mới, và giúp các nhà hoạch định chiến lƣợc trong
việc đƣa ra quyết định, …
Ngôn ngữ tự nhiên không giống với ngôn ngữ nhân tạo nhƣ ngôn ngữ
máy tính (C, PHP, …). Trên thế giới hiện nay có khoảng 7000 loại ngôn ngữ.
Có nhiều cách để phân loại, một số cách phân loại ngôn ngữ phổ biến nhƣ dựa
vào: nguồn gốc, đặc điểm, …
Phân loại ngôn ngữ theo nguồn gốc:
1. Ấn – Âu : Dòng Ấn độ, Hy lạp, German, …
2. Xê-mít (Semite): Dòng Semite, Do Thái, Ả Rập, Ai cập, Kusit, …
3. Thổ: Thổ Nhĩ Kỳ
4. Hán Tạng (Tạng-Miến): Dòng Hán, Tạng-Miến, …
5. Nam Phƣơng: Dòng Nam-Thái, Nam Á (Tiếng Việt).
Phân loại ngôn ngữ theo đặc điểm:
1. Hòa kết (Flexional): Đức, Anh, Nga…
2. Chắp dính (Agglutinate): Thổ Nhĩ Kỳ, Nhật Bản, Triều Tiên, …
3. Đơn lập (Isolate): Tiếng Việt, Hán, …
4. Tổng hợp (Polysynthetic): Chukchi, Aniu…
Do đó tiếng Việt đƣợc xếp vào loại đơn lập – tức phi hình thái, không
biến hình. Cùng với đó, tiếng Việt đƣợc viết theo trật tự S – V – O. (subject (S),
verb (V) and object (O)).

18
Bảng 1. Một vài so sánh các cách sắp xếp trật tự câu
Ngôn ngữ Câu ví dụ Trật tự
Tiếng Việt Tôi đọc sách SVO
Tiếng Anh I read a book SVO
Tiếng Nhật 私は本を読みます SOV
2.2 Các ứng dụng xử lý ngôn ngữ tự nhiên
Các ứng dụng phổ biến của NLP bao gồm: ứng dụng giám sát mạng xã
hội, chatbot, và tổng đài trả lời tự động.
2.3 Tiền xử lý văn bản
Văn bản trƣớc khi đƣợc vector hoá, tức là trƣớc khi sử dụng văn bản cần
phải đƣợc tiền xử lý, để loại bỏ nhiễu và làm sạch dữ liệu. Quá trình tiền xử lý
sẽ giúp nâng cao hiệu suất phân loại và giảm độ phức tạp của thuật toán huấn
luyện.
Tuỳ vào mục đích bộ phân loại mà chúng ta sẽ có những phƣơng pháp
tiền xử lý văn bản khác nhau, nhƣ :
1. Chuyển vẳn bản về chữ thƣờng.
2. Loại bỏ dấu câu (nếu không thực hiện tách câu).
3. Loại bỏ các kí tự đặc biệt biệt, các chữ số, phép tính toán số học.
4. Loại bỏ các từ dừng stopword (những từ xuất hiện hầu hết trong các
văn bản) không có ý nghĩa khi tham gia vào phân loại văn bản
5. Các kỹ thuật tinh chỉnh khác dựa trên kinh nghiệm
2.3.1 Chuẩn hóa và biến đổi văn bản
Một trong những nhiệm vụ đầu tiên trong việc xử lý phân loại văn bản là
chọn đƣợc một mô hình biểu diễn văn bản thích hợp. Một văn bản ở dạng thô
(dạng chuỗi) cần đƣợc chuyển sang một mô hình khác để tạo thuận lợi cho việc
biểu diễn và tính toán.
Tuỳ thuộc vào từng thuật toán phân loại khác nhau mà chúng ta có mô
hình biểu diễn riêng. Một trong những mô hình đơn giản và thƣờng đƣợc sử
dụng trong nhiệm vụ này là mô hình không gian vector. Một văn bản trong

19
nhiệm vụ này đƣợc biểu diễn theo dạng , với là một vector n chiều để
đo lƣờng giá trị của phần tử văn bản.
2.3.2 Biểu diễn văn bản dƣới dạng vector
Mô hình không gian vector là một trong những mô hình đƣợc sử dụng
rộng rãi nhất cho việc tìm kiếm (truy hồi) thông tin. Nguyên nhân chính là bởi vì
sự đơn giản của nó.
Trong mô hình này, các văn bản đƣợc thể hiện trong một không gian có
số chiều lớn, trong đó mỗi chiều của không gian tƣơng ứng với một từ trong văn
bản. Phƣơng pháp này có thể biểu diễn một cách hình tƣợng nhƣ sau : mỗi văn
bản D đƣợc biểu diễn dƣới dạng (vector đặc trƣng cho văn bản D). Trong đó,
, và n là số lƣợng đặc trƣng hay số chiều của vector văn bản,
là trọng số của đặc trƣng thứ i (với 1≤ i ≤n).
Nhƣ vậy, nếu trong kho ngữ liệu của quá trình huấn luyện nhiều văn bản,
ta kí hiệu Dj, là văn bản thứ j trong tập ngữ liệu, và vector
là vector đặc trƣng cho văn bản Dj, và là trọng số thứ i của vector văn bản j.
3 Bài toán phân loại văn bản
3.1 Bài toán phân loại văn bản
Trong lĩnh vực xử lý ngôn ngữ tự nhiên, phân loại văn bản là một bài toán
xử lý văn bản cổ điển, có nhiệm vụ là ánh xạ một văn bản vào một chủ đề đã
biết trong một tập hữu hạn các chủ đề dựa trên ngữ nghĩa của văn bản. Theo
Yang & Xiu (1999)[1] “Phân loại văn bản tự động là việc gán các nhãn phân
loại lên một văn bản mới dựa trên mức độ tương tự của văn bản đó so với các
văn bản đã được gán nhãn trong tập huấn luyện”. Ví dụ một bài viết trong một
tờ báo có thể thuộc một (hoặc một vài) chủ đề nào đó (nhƣ thể thao, sức khỏe,
công nghệ thông tin,…). Việc tự động phân loại văn bản vào một chủ đề nào đó
giúp cho việc sắp xếp, lƣu trữ và truy vấn tài liệu dễ dàng hơn về sau.
Bài toán phân loại văn bản, thực chất, có thể xem là bài toán phân lớp.
Phân loại văn bản tự động là việc gán các nhãn phân loại lên một văn bản mới
dựa trên mức độ tƣơng tự của văn bản đó so với các văn bản đã đƣợc gán nhãn
trong tập huấn luyện. Các ứng dụng của phân lớp văn bản thƣờng rất đa dạng

20
nhƣ: lọc email spam, phân tích cảm xúc (sentiment analysis), phân loại tin tức,
…
Đã có nhiều công trình nghiên cứu đạt những kết quả khả quan, nhất là
đối với phân loại văn bản tiếng Anh. Tuy vậy, các nghiên cứu và ứng dụng đối
với văn bản tiếng Việt còn nhiều hạn chế do khó khăn về tách từ và câu. Một số
công trình nghiên cứu trong nƣớc với các hƣớng tiếp cận khác nhau cho bài toán
phân loại văn bản, nhƣ: phân loại với máy học vectơ hỗ trợ [39], cách tiếp cận
sử dụng lý thuyết tập thô [40], cách tiếp cận thống kê hình vị [41], cách tiếp cận
sử dụng phƣơng pháp học không giám sát và đánh chỉ mục [42], cách tiếp cận
theo luật kết hợp [43]. Theo các kết quả trình bày trong các công trình đó thì
những cách tiếp cận nêu trên đều cho kết quả khá tốt.
3.2 Một số thuật toán phân loại văn bản
3.2.1 Thuật toán Naive Bayes
Naive Bayes đã đƣợc nghiên cứu rộng rãi từ những năm 1950. Đƣợc dùng
lần đầu tiên trong lĩnh vực phân loại vào đầu những năm 1960. Sau đó nó trở
nên phổ biến và đƣợc sử dụng rộng rãi trong lĩnh vực này cho đến ngày nay.
Ý tƣởng cơ bản của cách tiếp cận này là sử dụng xác suất có điều kiện
giữa từ hoặc cụm từ và chủ đề để dự đoán xác suất chủ đề của một tập tin cần
phân loại. Điểm quan trọng của phƣơng pháp này chính là ở chỗ giả định rằng
sự xuất hiện của tất cả các từ trong tập tin đều độc lập với nhau. Ví dụ một loại
trái cây có thể đƣợc cho là quả táo nếu nó đỏ, tròn và đƣờng kính là 10cm. Giải
thuật Naïve Bayes sẽ cho rằng mỗi tính năng này đều đóng góp một cách độc lập
để xác suất trái cây này là quả táo bất kể sự hiện diện hay vắng mặt của các tính
năng khác.
Thuật toán Naive Bayes dựa trên định lý Bayes đƣợc phát biểu nhƣ sau :
|
|
Trong đó:
P(Y|X) là xác suất X thuộc lớp Y.

21
P(X|Y) xác suất một phần tử thuộc lớp Y, và phần từ đó có đặc điểm
X.
P(Y) xác suất xảy ra lớp Y, mức độ thƣờng xuyên lớp Y xuất hiện
trong tập dữ liệu
P(X) xác suất xảy ra X.
Ví dụ 1: Giả sử ta có hai lớp Y1 = Nam, Y2 = nữ. Và một ngƣời không
biết giới tính là Phƣơng, X = Phƣơng. Việc xác định Phƣơng là Nam hay Nữ
tƣơng đƣơng với việc so sánh xác suất P(Nam/Phƣơng) và P(Nữ/Phƣơng). Theo
thuật toán Naïve Bayes ta có công thức nhƣ sau:
| |
Trong đó: P(Nam|Phƣơng): Xác suất Phƣơng là Nam
P (Phƣơng|Nam): xác suất những ngƣời phái nam đƣợc gọi
Phƣơng (có tên Phƣơng).
P(Nam): xác suất phái nam trong tập dữ liệu.
P(Phƣơng): xác suất tên Phƣơng trong tập dữ liệu.
Tƣơng tự ta có:
| |
Giả sử ta có bảng dữ liệu tên và giới tính nhƣ sau :
Bảng 2.Dữ liệu tập mẫu tính xác suất theo phương pháp Naive Bayes
Tên Giới tính
Phƣơng Nam
Nga Nữ
Hồng Nữ
Nam Nam
Phƣơng Nữ
Phƣơng Nữ
Tiến Nam
Giang Nữ
Tùng Nam

22
Đài Nữ
|
|
Nhƣ vậy Phƣơng là Nữ có xác suất cao hơn nên Phƣơng đƣợc phân vào
lớp nữ khi phân loại.
Thuật toán Naive Bayes Classification đƣợc áp dụng vào các loại ứng
dụng sau:
Real time Prediction: NBC chạy khá nhanh nên nó thích hợp áp dụng
ứng dụng nhiều vào các ứng dụng chạy thời gian thực, nhƣ hệ thống
cảnh báo, các hệ thống trading …
Multi class Prediction: Nhờ vào định lý Bayes mở rộng ta có thể ứng
dụng vào các loại ứng dụng đa dự đoán, tức là ứng dụng có thể dự
đoán nhiều giả thuyết mục tiêu.
Text classification/ Spam Filtering/ Sentiment Analysis: NBC cũng rất
thích hợp cho các hệ thống phân loại văn bản hay ngôn ngữ tự nhiên vì
tính chính xác của nó lớn hơn các thuật toán khác. Ngoài ra các hệ
thống chống thƣ rác cũng rất ƣu chuộng thuật toán này. Và các hệ
thống phân tích tâm lý thị trƣờng cũng áp dụng NBC để tiến hành phân
tích tâm lý ngƣời dùng ƣu chuộng hay không ƣu chuộng các loại sản
phẩm nào từ việc phân tích các thói quen và hành động của khách
hàng.
Recommendation System: Naive Bayes Classifier và Collaborative
Filtering đƣợc sử dụng rất nhiều để xây dựng cả hệ thống gợi ý, ví dụ
nhƣ xuất hiện các quảng cáo mà ngƣời dùng đang quan tâm nhiều nhất
từ việc học hỏi thói quen sử dụng internet của ngƣời dùng, hoặc nhƣ ví

23
dụ đầu bài viết đƣa ra gợi ý các bài hát tiếp theo mà có vẻ ngƣời dùng
sẽ thích trong một ứng dụng nghe nhạc
3.2.2 Thuật toán SVM
SVM (Support Vector Machine) là một thuật toán học máy có giám sát
đƣợc sử dụng rất phổ biến ngày nay trong các bài toán phân lớp (classification)
hay hồi qui (Regression).
SVM đƣợc đề xuất bởi Vladimir N. Vapnik [5] và các đồng nhiệp của ông
vào năm 1963 tại Nga dựa trên lý thuyết học thống kê và sau đó trở nên phổ biến
trong những năm 90 nhờ ứng dụng giải quyết các bài toán phi tuyến tính
(nonlinear) bằng phƣơng pháp Kernel Trick [4]. Có nhiều tiềm năng phát triển
về mặt lý thuyết cũng nhƣ ứng dụng trong thực tiễn.
Ý tƣởng của phƣơng pháp này là cho trƣớc một tập huấn luyện đƣợc biểu
diễn trong không gian véc-tơ, trong đó mỗi văn bản đƣợc xem nhƣ là một điểm
trong không gian này. Phƣơng pháp này tìm ra một mặt siêu phẳng h quyết định
tốt nhất có thể chia các điểm trên không gian này thành hai lớp riêng biệt tƣơng
ứng, tạm gọi là lớp + (dƣơng) và lớp – (âm). Nhƣ vậy, bộ phân loại SVM là một
mặt siêu phẳng tách các mẫu thuộc lớp dƣơng ra khỏi cách mẫu thuộc lớp âm
với độ chênh lệch lớn nhất. Độ chênh lệch này hay còn gọi là khoảng cách biên
đƣợc xác định bằng khoảng cách giữa mẫu dƣơng và mẫu âm gần mặt siêu
phẳng nhất (hình).
Khoảng cách này càng lớn các mẫu thuộc hai lớp càng đƣợc phân chia rõ
ràng, nghĩa là sẽ đạt đƣợc kết quả phân loại tốt. Mục tiêu của thuật toán SVM là
tìm đƣợc khoảng cách biên lớn nhất để tạo đƣợc kết quả phân loại tốt.
Với bài toán phân loại nhị phân tuyến tính ta cần vẽ đƣợc mặt phân tách
(với không gian 2 chiều thì mặt phẳng này là đƣờng phân tách):
để phân biệt đƣợc dữ liệu. Khi đó dấu của hàm ƣớc lƣợng
sẽ thể hiện đƣợc điểm dữ
liệu x nằm ở cụm dữ liệu nào.

24
Hình 1: Mặt phân cách dữ liệu
Ta có thể thấy có nhiều mặt phân tách thoả mãn đƣợc việc này và đƣơng
nhiên là nếu chọn đƣợc mặt mà phân tách tốt thì kết quả phân loại của ta sẽ tốt
hơn. Một lẽ rất tự nhiên là dƣờng nhƣ mặt nằm vừa khít giữa 2 cụm dữ liệu sao
cho nằm xa các tập dữ liệu nhất là mặt tốt nhất.
Hình 2. Lề siêu phẳng

25
SVM chính là một biện pháp để thực hiện đƣợc phép lấy mặt phẳng nhƣ
vậy.
Để xác định mặt phẳng kẹp giữa đó, trƣớc tiên ta cần phải xác định đƣợc
2 mặt biên gốc nhƣ 2 đƣờng nét đứt ở trên. Các điểm dữ liệu gần với mặt biên
gốc này nhất có thể xác định bằng:
Để dễ dàng cho việc tính toán thì ngƣời ta sẽ chọn w và b sao cho các
điểm gần nhất (mặt biên gốc) thoả mãn: , tức là:
Đƣơng nhiên là có thể tồn tại nhiều cặp đôi mặt biên gốc nhƣ vậy và tồn
tại nhiều mặt phân đôi kẹp giữa các mặt biên gốc đó. Nên ta phải tìm cách xác
định đƣợc mặt kẹp giữa tốt nhất bằng cách lấy cặp có khoảng cách xa nhau nhất.
Lẽ này là đƣơng nhiên bởi cặp có khoảng cách xa nhất đồng nghĩa với chuyện
tập dữ liệu đƣợc phân cách xa nhất.
Nhƣ vậy, ta có thể thiết lập thông số tính khoảng cách đó bằng phép lấy
độ rộng biên từ mặt biên gốc tới mặt phân tách cần tìm.
Bài toán của ta bây giờ sẽ là cần xác định w và b sao cho ρ đạt lớn nhất và
các điểm dữ liệu . ρ đạt lớn nhất đồng nghĩa với
việc ∥w∥ đạt nhỏ nhất. Tức là:

26
Ở đây, m là số lƣợng các điểm dữ liệu còn việc lấy bình phƣơng
và chia đôi nhằm dễ dàng tính toán và tối ƣu lồi.
Bài toán này có thể giải thông qua bài toán đối ngẫu của nó và sử dụng
phƣơng pháp nhân tử Lagrance. Lúc này, ta sẽ cần tìm các giá trị λ nhƣ sau:
Việc giải λ có thể đƣợc thực hiện bằng phƣơng pháp quy hoạch động bậc
2 (Quadratic Programing). Sau khi tìm đƣợc λ thì ta có các tham số :
Ở đây, là một điểm dữ liệu bất kì nào đó nằm trên đƣờng biên
gốc. Điểm dữ liệu này còn đƣợc gọi là Support Vector. Tên của phƣơng pháp
SVM cũng từ đây mà ra. Tuy nhiên, thƣờng ngƣời ta tính b bằng phép lấy trung
bình tổng của tất cả các bi. Giả sử, ta có tập các Support Vectors thì:
Khi đó, một điểm dữ liệu mới sẽ đƣợc phân loại dựa theo:

27
Nhƣ vậy, chỉ cần các điểm Support Vector trên đƣờng biên gốc là ta có
thể ƣớc lƣợng đƣợc các tham số tối ƣu cho bài toán. Việc này rất có lợi khi tính
toán giúp phƣơng pháp này tiết kiệm đƣợc tài nguyên thực thi
Dữ liệu chồng nhau và phƣơng pháp biên mềm
Trong thực tế tập dữ liệu thƣờng không đƣợc sạch nhƣ trên mà thƣờng có
nhiễu. Nhiễu ở đây là dạng dữ liệu chồng chéo lên nhau nhƣ hình bên dƣới
Hình 3. Dữ liệu phi tuyến
Với dạng dữ liệu nhƣ vậy thì mặt phân tách tìm đƣợc sẽ khó mà tối ƣu
đƣợc, thậm chí là không tìm đƣợc mặt phân tách luôn. Giờ vấn đề đặt ra là làm
sao triệt đƣợc các nhiễu này. Tức là tính toán bỏ qua đƣợc các nhiễu này khi
huấn luyện.
Một cách hình thức, các điểm nhiễu là những điểm mà không đảm bảo
điều kiện . Khi đó bằng phép thêm biến lùi (Slack
Variables) sao cho ra có đƣợc ràng buộc:
Giờ, hàm mục tiêu tối ƣu đƣợc viết lại nhƣ sau :

28
C ở đây là hệ số cân bằng giữa nhiễu và không nhiễu. Nếu C càng lớn thì
các nhiễu càng nhiều điểm đƣợc coi là nhiễu hơn tức là nhiễu đƣợc coi trọng
hơn.
Giải bài toán này, nghiệm tƣơng tự nhƣ cách tính ở trên chỉ khác một điều
là tập các điểm support vectors đƣợc mở rộng thêm tới các điểm ra
miễn sao nó thoả mãn điều kiện:
Tức là :
Khi đó, tham số đƣợc ƣớc lƣợng nhƣ sau:
Với tập mở rộng nhƣ vậy ngƣời ta gọi phƣơng pháp này là phƣơng
pháp biên mềm (Soft-Margin SVM). Còn phƣơng pháp truyền thống là biên
cứng (Hard-Margin SVM).

29
Dữ liệu phân tách phi tuyến và phƣơng pháp kernel
Hình 4. Không gian dữ liệu phi tuyến
Đối với các bài toán có không gian dữ liệu là phi tuyến tính (non-linear)
chúng ta không thể tìm đƣợc một siêu phẳng thỏa mãn bài toán.
Để giải quyết bài toán trong trƣờng hợp này chúng ra cần biểu diễn (ánh
xạ) dữ liệu từ không gian ban đầu X sang không gian F bằng một hàm ánh xạ
phi tuyến:
Trong không gian F tập dữ liệu có thể phân tách tuyến tính. Nhƣng nảy
sinh một vẫn đề lớn đó là trong không gian mới này số chiều của dữ liệu tăng
lên rất nhiều so với không gian ban đầu làm cho chi phí tính toán vô cùng tốn
kém. Rất may trong bài toán SVM ngƣời ta đã tìm ra một cách không cần phải

30
tính , và hàm ánh xạ mà vẫn tính đƣợc . Phƣơng pháp
này gọi là Kernel Trick.
Khi đó tối ƣu biên mềm đƣợc viết dƣới dạng:
Đặt hàm Kernel: , ta có:
Khi đó tham số tƣơng ứng sẽ là :
Điểm dữ liệu mới đƣợc phân lớp với:
Nhƣ vậy, chỉ cần hàm Kernel để tính tích vô hƣớng giữa các điểm
dữ liệu trong không gian mới là ta có thể ƣớc lƣợng đƣợc một điểm mới nằm
trong phân lớp nào.
Việc sử dụng hàm Kernel ở đây sẽ giúp giảm đƣợc công số tính từng hàm Φ và
tích vô hƣớng giữa chúng. Nó có thể tính đƣợc cho bất kì không gian nào rất

31
hiệu quả. Kể cả các không gian với số chiều vô hạn. Bởi nó chỉ cần tính tích vô
hƣơng giữa các điểm dữ liệu mà thôi. Tất nhiên để làm đƣợc điều đó thì Kernel
phải thoả mãn điều kiện Mercer [7].
Khi làm việc ngƣời ta thƣờng chọn một hàm Kernel thông dụng sau:
Phƣơng pháp SVM là một cách hiệu quả cho bài toán phân lớp mà chỉ sử
dụng một lƣợng ít dữ liệu là các điểm support vectors nằm trên đƣờng biên gốc
và phần mở rộng.
3.2.3 Mạng nơ-ron nhân tạo
Mạng nơ ron nhân tạo (Artificial Neural Network – ANN) là một mô hình
xử lý thông tin đƣợc mô phỏng dựa trên hoạt động của hệ thống thần kinh của
sinh vật, bao gồm số lƣợng lớn các Nơ-ron đƣợc gắn kết để xử lý thông tin.
ANN hoạt động giống nhƣ bộ não của con ngƣời, đƣợc học bởi kinh nghiệm
(thông qua việc huấn luyện), có khả năng lƣu giữ các tri thức và sử dụng các tri
thức đó trong việc dự đoán các dữ liệu chƣa biết (unseen data).
Một mạng nơ-ron là một nhóm các nút nối với nhau, mô phỏng mạng nơ-
ron thần kinh của não ngƣời. Mạng nơ ron nhân tạo đƣợc thể hiện thông qua ba
thành phần cơ bản: mô hình của nơ ron, cấu trúc và sự liên kết giữa các nơ ron.
Trong nhiều trƣờng hợp, mạng nơ ron nhân tạo là một hệ thống thích ứng, tự
thay đổi cấu trúc của mình dựa trên các thông tin bên ngoài hay bên trong chạy
qua mạng trong quá trình học.

32
Hình 5. Kiến trúc mạng nơ-ron nhân tạo
Kiến trúc chung của một ANN gồm 3 thành phần đó là Input Layer,
Hidden Layer và Output Layer.
Trong đó, lớp ẩn (Hidden Layer) gồm các nơ-ron, nhận dữ liệu input từ
các Nơ-ron ở lớp (Layer) trƣớc đó và chuyển đổi các input này cho các lớp xử lý
tiếp theo. Trong một mạng ANN có thể có nhiều Hidden Layer.
Lợi thế lớn nhất của các mạng ANN là khả năng đƣợc sử dụng nhƣ một
cơ chế xấp xỉ hàm tùy ý mà “học” đƣợc từ các dữ liệu quan sát. Tuy nhiên, sử
dụng chúng không đơn giản nhƣ vậy, một số các đặc tính và kinh nghiệm khi
thiết kế một mạng nơ-ron ANN.
Chọn mô hình: Điều này phụ thuộc vào cách trình bày dữ liệu và các
ứng dụng. Mô hình quá phức tạp có xu hƣớng dẫn đền những thách
thức trong quá trình học.
Cấu trúc và sự liên kết giữa các nơ-ron
Thuật toán học: Có hai vấn đề cần học đối với mỗi mạng ANN, đó là
học tham số của mô hình (parameter learning) và học cấu trúc
(structure learning). Học tham số là thay đổi trọng số của các liên kết
giữa các nơ-ron trong một mạng, còn học cấu trúc là việc điều chỉnh

33
cấu trúc mạng bằng việc thay đổi số lớp ẩn, số nơ-ron mỗi lớp và cách
liên kết giữa chúng. Hai vấn đề này có thể đƣợc thực hiện đồng thời
hoặc tách biệt.
Nếu các mô hình, hàm chi phí và thuật toán học đƣợc lựa chọn một cách
thích hợp, thì mạng ANN sẽ cho kết quả có thể vô cùng mạnh mẽ và hiệu quả.
Hoạt động của mạng nơ-ron nhân tạo:
Hình 6. Quá trình xử lý thông tin của một mạng nơ-ron nhân tạo
Inputs: Mỗi Input tƣơng ứng với 1 đặc trƣng của dữ liệu. Ví dụ nhƣ trong
ứng dụng của ngân hàng xem xét có chấp nhận cho khách hàng vay tiền hay
không thì mỗi input là một thuộc tính của khách hàng nhƣ thu nhập, nghề
nghiệp, tuổi, số con,…
Output: Kết quả của một ANN là một giải pháp cho một vấn đề, ví dụ
nhƣ với bài toán xem xét chấp nhận cho khách hàng vay tiền hay không thì
output là yes hoặc no.
Connection Weights (Trọng số liên kết) : Đây là thành phần rất quan
trọng của một ANN, nó thể hiện mức độ quan trọng, độ mạnh của dữ liệu đầu
vào đối với quá trình xử lý thông tin chuyển đổi dữ liệu từ Layer này sang layer
khác. Quá trình học của ANN thực ra là quá trình điều chỉnh các trọng số
Weight của các dữ liệu đầu vào để có đƣợc kết quả mong muốn.

34
Summation Function (Hàm tổng): Tính tổng trọng số của tất cả các input
đƣợc đƣa vào mỗi Nơ-ron. Hàm tổng của một Nơ-ron đối với n input đƣợc tính
theo công thức sau:
∑
Transfer Function (Hàm chuyển đổi): Hàm tổng của một nơ-ron cho biết
khả năng kích hoạt của nơ-ron đó còn gọi là kích hoạt bên trong. Các nơ-ron này
có thể sinh ra một output hoặc không trong mạng ANN, nói cách khác rằng có
thể output của 1 Nơ-ron có thể đƣợc chuyển đến layer tiếp trong mạng Nơ-ron
theo hoặc không. Mối quan hệ giữa hàm tổng và kết quả output đƣợc thể hiện
bằng hàm chuyển đổi.
Việc lựa chọn hàm chuyển đổi có tác động lớn đến kết quả đầu ra của
mạng ANN. Hàm chuyển đổi phi tuyến đƣợc sử dụng phổ biến trong mạng
ANN là hoặc sigmoid hoặc tanh.
Trong đó, hàm tanh là phiên bản thay đổi tỉ lệ của sigmoid , tức là khoảng
giá trị đầu ra của hàm chuyển đổi thuộc khoảng [-1, 1] thay vì [0,1] nên chúng
còn gọi là hàm chuẩn hóa (Normalized Function).
Kết quả xử lý tại các nơ-ron (Output) đôi khi rất lớn, vì vậy hàm chuyển
đổi đƣợc sử dụng để xử lý output này trƣớc khi chuyển đến layer tiếp theo. Đôi
khi thay vì sử dụng Transfer Function ngƣời ta sử dụng giá trị ngƣỡng
(Threshold value) để kiểm soát các output của các neuron tại một layer nào đó
trƣớc khi chuyển các output này đến các Layer tiếp theo. Nếu output của một
neuron nào đó nhỏ hơn Threshold thì nó sẻ không đƣợc chuyển đến Layer tiếp
theo.
Mạng nơ-ron của chúng ta dự đoán dựa trên lan truyền thẳng (forward
propagation) là các phép nhân ma trận cùng với activation function để thu đƣợc

35
kết quả đầu ra. Nếu input x là vector 2 chiều thì ta có thể tính kết quả dự đoán
bằng công thức sau
Trong đó, là input của layer thứ , là output của layer thứ sau khi áp
dụng activation function. là các thông số (parameters) cần tìm của
mô hình mạng nơ-ron.
Huấn luyện để tìm các thông số cho mô hình tƣơng đƣơng với việc tìm
các thông số , sao cho độ lỗi của mô hình đạt đƣợc là thấp nhất. Ta
gọi hàm độ lỗi của mô hình là loss function. Đối với softmax function, ta
dùng cross-entropy loss (còn gọi là negative log likelihood).
Nếu ta có N dòng dữ liệu huấn luyện, và C nhóm phân lớp (trƣờng hợp
này là hai lớp nam, nữ), khi đó loss function giữa giá trị dự đoán và đƣợc
tính nhƣ sau
∑∑
Ý nghĩa công thức trên nghĩa là: lấy tổng trên toàn bộ tập huấn luyện và
cộng dồn vào hàm loss nếu kết quả phân lớp sai. Độ dị biệt giữa hai giá
trị và càng lớn thì độ lỗi càng cao. Mục tiêu của chúng ta là tối thiểu hóa
hàm lỗi này. Ta có thể sử dụng phƣơng pháp gradient descent để tối tiểu hóa
hàm lỗi. Có hai loại gradient descent, một loại với fixed learning rate đƣợc gọi
là batch gradient descent, loại còn lại có learning rate thay đổi theo quá trình
huấn luyện đƣợc gọi là SGD (stochastic gradient descent) hay minibatch
gradient descent.
Gradient descent cần các gradient là các vector có đƣợc bằng cách lấy đạo
hàm của loss function theo từng thông số , , , . Để tính các gradient
này, ta sử dụng thuật toán backpropagation (lan truyền ngược). Đây là cách hiệu
quả để tính gradient khởi điểm từ output layer.

36
Áp dụng backpropagation ta có các đại lƣợng:
3.3 Các phƣơng pháp đánh giá một hệ thống phân lớp
Khi xây dựng một mô hình phân lớp, chúng ta cần một phƣơng pháp đánh
giá để xem mô hình sử dụng có hiệu quả không và để so sánh khả năng của các
mô hình. Trong phần này sẽ giới thiệu các phƣơng pháp đánh giá các mô hình
phân lớp.
Hiệu năng của một mô hình thƣờng đƣợc đánh giá dựa trên tập dữ liệu
kiểm thử (test data). Cụ thể, giả sử đầu ra của mô hình khi đầu vào là tập kiểm
thử đƣợc mô tả bởi vector y_pred - là vector dự đoán đầu ra với mỗi phần tử là
class đƣợc dự đoán của một điểm dữ liệu trong tập kiểm thử. Ta cần so sánh
giữa vector dự đoán y_pred này với vector class thật của dữ liệu, đƣợc mô tả bởi
vector y_true.
Ví dụ với bài toán có 3 lớp dữ liệu đƣợc gán nhãn là 0, 1, 2. Trong bài
toán thực tế, các class có thể có nhãn bất kỳ, không nhất thiết là số, và không
nhất thiết bắt đầu từ 0. Chúng ta hãy tạm giả sử các class đƣợc đánh số
từ 0 đến C-1 trong trƣờng hợp có C lớp dữ liệu. Có 10 điểm dữ liệu trong tập
kiểm thử với các nhãn thực sự đƣợc mô tả bởi y_true = [0, 0, 0, 0, 1, 1, 1, 2, 2,
2]. Giả sử bộ phân lớp chúng ta đang cần đánh giá dự đoán nhãn cho các điểm
này là y_pred = [0, 1, 0, 2, 1, 1, 0, 2, 1, 2].
Có rất nhiều cách đánh giá một mô hình phân lớp. Tuỳ vào những bài
toán khác nhau mà chúng ta sử dụng các phƣơng pháp khác nhau. Các phƣơng
pháp thƣờng đƣợc sử dụng là:

37
Độ chính xác – Accuracy score
Ma trận nhầm lẫn – Confusion matrix
Precision & Recall
F1 score
ROC curve
Top R error
3.3.1 Đánh giá theo độ chính xác Accuracy
Cách đơn giản và hay đƣợc sử dụng nhất là Accuracy (độ chính xác).
Cách đánh giá này đơn giản tính tỉ lệ giữa số điểm đƣợc dự đoán đúng và tổng
số điểm trong tập dữ liệu kiểm thử.
Trong ví dụ trên, ta có thể đếm đƣợc có 6 điểm dữ liệu đƣợc dự đoán
đúng trên tổng số 10 điểm. Vậy ta kết luận độ chính xác của mô hình là 0.6 (hay
60%). Để ý rằng đây là bài toán với chỉ 3 class, nên độ chính xác nhỏ nhất đã là
khoảng 1/3, khi tất cả các điểm đƣợc dự đoán là thuộc vào một class nào đó.
3.3.2 Ma trận nhầm lẫn
Ma trận nhầm lẫn là một trong những kỹ thuật đo lƣờng hiệu suất phổ
biến nhất và đƣợc sử dụng rộng rãi cho các mô hình phân loại.
Cách tính sử dụng độ chính xác Accuracy nhƣ ở trên chỉ cho chúng ta
biết đƣợc bao nhiêu phần trăm lƣợng dữ liệu đƣợc phân loại đúng mà không chỉ
ra đƣợc cụ thể mỗi loại đƣợc phân loại nhƣ thế nào, lớp nào đƣợc phân loại đúng
nhiều nhất, và dữ liệu thuộc lớp nào thƣờng bị phân loại nhầm vào lớp khác. Để
có thể đánh giá đƣợc các giá trị này, chúng ta sử dụng một ma trận đƣợc gọi là
confusion matrix.
Về cơ bản, confusion matrix thể hiện có bao nhiêu điểm dữ liệu thực
sự thuộc vào một class, và đƣợc dự đoán là rơi vào một class. Để hiểu rõ hơn,
hãy xem bảng dƣới đây:
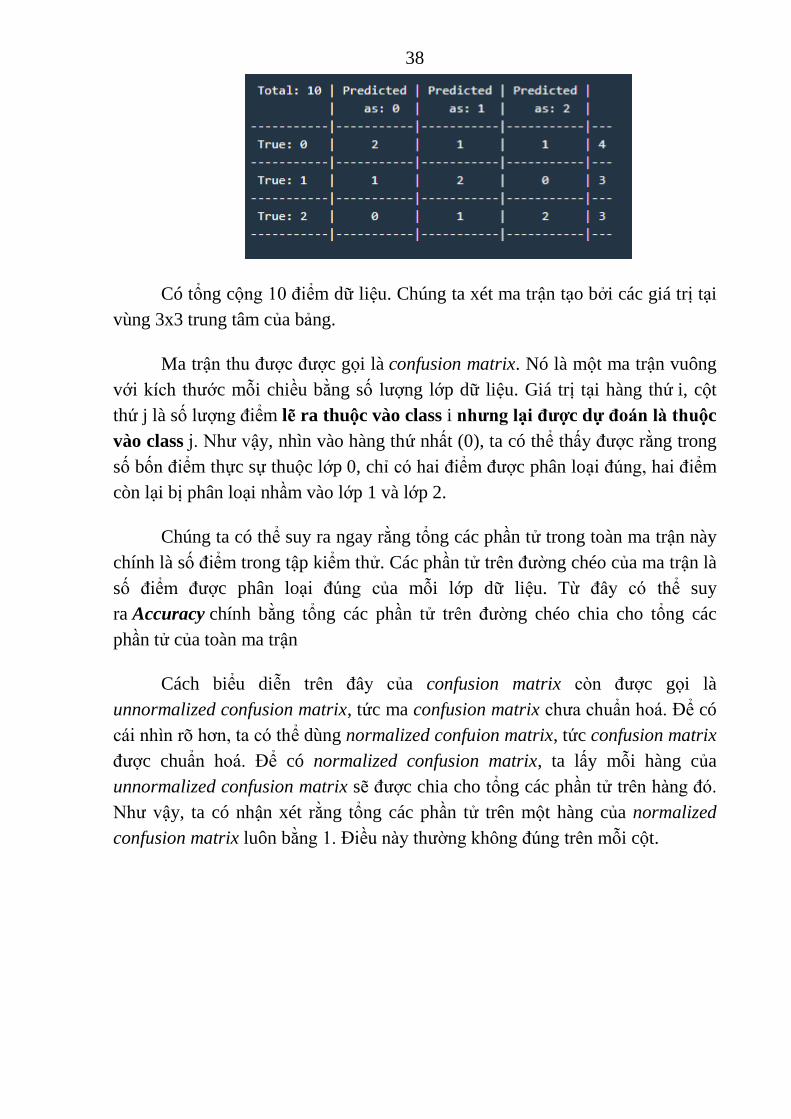
38
Có tổng cộng 10 điểm dữ liệu. Chúng ta xét ma trận tạo bởi các giá trị tại
vùng 3x3 trung tâm của bảng.
Ma trận thu đƣợc đƣợc gọi là confusion matrix. Nó là một ma trận vuông
với kích thƣớc mỗi chiều bằng số lƣợng lớp dữ liệu. Giá trị tại hàng thứ i, cột
thứ j là số lƣợng điểm lẽ ra thuộc vào class i nhƣng lại đƣợc dự đoán là thuộc
vào class j. Nhƣ vậy, nhìn vào hàng thứ nhất (0), ta có thể thấy đƣợc rằng trong
số bốn điểm thực sự thuộc lớp 0, chỉ có hai điểm đƣợc phân loại đúng, hai điểm
còn lại bị phân loại nhầm vào lớp 1 và lớp 2.
Chúng ta có thể suy ra ngay rằng tổng các phần tử trong toàn ma trận này
chính là số điểm trong tập kiểm thử. Các phần tử trên đƣờng chéo của ma trận là
số điểm đƣợc phân loại đúng của mỗi lớp dữ liệu. Từ đây có thể suy
ra Accuracy chính bằng tổng các phần tử trên đƣờng chéo chia cho tổng các
phần tử của toàn ma trận
Cách biểu diễn trên đây của confusion matrix còn đƣợc gọi là
unnormalized confusion matrix, tức ma confusion matrix chƣa chuẩn hoá. Để có
cái nhìn rõ hơn, ta có thể dùng normalized confuion matrix, tức confusion matrix
đƣợc chuẩn hoá. Để có normalized confusion matrix, ta lấy mỗi hàng của
unnormalized confusion matrix sẽ đƣợc chia cho tổng các phần tử trên hàng đó.
Nhƣ vậy, ta có nhận xét rằng tổng các phần tử trên một hàng của normalized
confusion matrix luôn bằng 1. Điều này thƣờng không đúng trên mỗi cột.

39
Hình 7. Minh hoạ unnormalized confusion và normalized confusion matrix
Với các bài toán với nhiều lớp dữ liệu, cách biểu diễn bằng màu này rất
hữu ích. Các ô màu đậm thể hiện các giá trị cao. Một mô hình tốt sẽ cho một
confusion matrix có các phần tử trên đƣờng chéo chính có giá trị lớn, các phần
tử còn lại có giá trị nhỏ. Nói cách khác, khi biểu diễn bằng màu sắc, đƣờng chéo
có màu càng đậm so với phần còn lại sẽ càng tốt. Từ hai hình trên ta thấy rằng
confusion matrix đã chuẩn hoá mang nhiều thông tin hơn. Sự khác nhau đƣợc
thấy ở ô trên cùng bên trái. Lớp dữ liệu 0 đƣợc phân loại không thực sự tốt
nhƣng trong unnormalized confusion matrix, nó vẫn có màu đậm nhƣ hai ô còn
lại trên đƣờng chéo chính.
3.3.3 True/False Positive/Negative
Cách đánh giá này thƣờng đƣợc áp dụng cho các bài toán phân lớp có hai
lớp dữ liệu, trong hai lớp dữ liệu này có một lớp nghiêm trọng hơn lớp kia và
cần đƣợc dự đoán chính. Trong y khoa, còn đƣợc gọi là Dƣơng tính / Âm tính
Thật/Giả. Ví dụ, trong bài toán xác định có bệnh ung thƣ hay không thì việc
không bị sót (miss) quan trọng hơn là việc chẩn đoán nhầm âm tính thành dương
tính. Trong bài toán xác định có mìn dƣới lòng đất hay không thì việc bỏ sót
nghiêm trọng hơn việc báo động nhầm rất nhiều. Hay trong bài toán lọc email
rác thì việc cho nhầm email quan trọng vào thùng rác nghiêm trọng hơn việc xác
định một email rác là email thƣờng.
Trong những bài toán này, ngƣời ta thƣờng định nghĩa lớp dữ liệu quan
trọng hơn cần đƣợc xác định đúng là lớp Positive (P-dƣơng tính), lớp còn lại
đƣợc gọi là Negative (N-âm tính). Ta định nghĩa True Positive (TP), False

40
Positive (FP), True Negative (TN), False Negative (FN) dựa trên confusion
matrix chƣa chuẩn hoá nhƣ sau:
Ngƣời ta thƣờng quan tâm đến TPR, FNR, FPR, TNR (R - Rate) dựa
trên normalized confusion matrix nhƣ sau:
False Positive Rate còn đƣợc gọi là False Alarm Rate (tỉ lệ báo động
nhầm), False Negative Rate còn đƣợc gọi là Miss Detection Rate (tỉ lệ bỏ sót).
Trong bài toán dò mìn, thà báo nhầm còn hơn bỏ sót, tức là ta có thể chấp
nhận False Alarm Rate cao để đạt đƣợc Miss Detection Rate thấp.
Việc biết một cột của confusion matrix này sẽ suy ra đƣợc cột còn lại vì
tổng các hàng luôn bằng 1 và chỉ có hai lớp dữ liệu. Với các bài toán có nhiều
lớp dữ liệu, ta có thể xây dựng bảng True/False Positive/Negative cho mỗi
lớp nếu coi lớp đó là lớp Positive, các lớp còn lại gộp chung thành lớp Negative
3.3.4 Precision và Recall
Với bài toán phân loại mà tập dữ liệu của các lớp là chênh lệch nhau rất
nhiều, có một phép đo hiệu quả thƣờng đƣợc sử dụng là Precision-Recall.
Trƣớc hết xét bài toán phân loại nhị phân. Ta cũng coi một trong hai lớp
là positive, lớp còn lại là negative. Xem xét Hình dƣới đây:

41
Hình 8. Cách tính Precision và Recall
Với một cách xác định một lớp là positive, Precision đƣợc định nghĩa là tỉ
lệ số điểm true positive trong số những điểm đƣợc phân loại là positive (TP +
FP).
Recall đƣợc định nghĩa là tỉ lệ số điểm true positive trong số những
điểm thực sự là positive (TP + FN).
Một cách toán học, Precison và Recall là hai phân số có tử số bằng nhau
nhƣng mẫu số khác nhau:
Có thể nhận thấy rằng TPR và Recall là hai đại lƣợng bằng nhau. Ngoài
ra, cả Precision và Recall đều là các số không âm nhỏ hơn hoặc bằng một.

42
Precision cao đồng nghĩa với việc độ chính xác của các điểm tìm đƣợc là
cao. Recall cao đồng nghĩa với việc True Positive Rate cao, tức tỉ lệ bỏ sót các
điểm thực sự positive là thấp.
Khi Precision = 1, mọi điểm tìm đƣợc đều thực sự là positive, tức không
có điểm negative nào lẫn vào kết quả. Tuy nhiên, Precision = 1 không đảm bảo
mô hình là tốt, vì câu hỏi đặt ra là liệu mô hình đã tìm đƣợc tất cả các
điểm positive hay chƣa. Nếu một mô hình chỉ tìm đƣợc đúng một
điểm positive mà nó chắc chắn nhất thì ta không thể gọi nó là một mô hình tốt.
Khi Recall = 1, mọi điểm positive đều đƣợc tìm thấy. Tuy nhiên, đại
lƣợng này lại không đo liệu có bao nhiêu điểm negative bị lẫn trong đó. Nếu mô
hình phân loại mọi điểm là positive thì chắc chắn Recall = 1, tuy nhiên dễ nhận
ra đây là một mô hình cực tồi.
Một mô hình phân lớp tốt là mô hình có cả Precision và Recall đều cao,
tức càng gần một càng tốt. Có một cách đo chất lƣợng của bộ phân lớp dựa vào
Precision và Reall, đó là: F-score.
3.3.5 F1-Score
F score, hay F1-score, là số trung bình điều hòa (harmonic mean) của
precision và recall (giả sử rằng hai đại lƣợng này khác không):
F1 có giá trị nằm trong nửa khoảng (0,1]. F1 càng cao, bộ phân lớp càng
tốt. Khi cả recall và precision đều bằng 1 (tốt nhất có thể), F1=1. Khi cả recall
và precision đều thấp, ví dụ bằng 0.1, F1=0.1. Dƣới đây là một vài ví dụ về F1.

43
Nhƣ vậy, một bộ phân lớp với precision = recall = 0.5 tốt hơn một bộ
phân lớp khác với precision = 0.3, recall = 0.8 theo cách đo này.
Trƣờng hợp tổng quát:
F1 chính là một trƣờng hợp đặc biệt của Fβ khi β=1. Khi β>1, recall đƣợc
coi trọng hơn precision, khi β<1, precision đƣợc coi trọng hơn. Hai đại
lƣợng β thƣờng đƣợc sử dụng là β=2 và β=0.5.

44
CHƢƠNG 2: PHÂN TÍCH CÂU HỎI TRONG HỆ THỐNG TRẢ LỜI TỰ
ĐỘNG
Chƣơng này nghiên cứu lý thuyết cụ thể cho bài toán phân loại câu hỏi
Tiếng Việt, nghiên cứu các phƣơng pháp phân loại câu hỏi, các đặc trƣng của
ngôn ngữ khi tiến hành phân loại. Tìm hiểu các nghiên cứu trong bài toán phân
loại câu hỏi, các mô hình đã đƣợc nghiên cứu và xây dựng cũng nhƣ kết quả mới
nhất đạt đƣợc. Từ đó, định hƣớng mô hình ứng dụng cho phần thực nghiệm,
cũng nhƣ đề xuất đƣợc kiến trúc phân tích câu hỏi cho hệ thống trả lời tự động.
1 Vấn đề cơ bản của một hệ thống trả lời tự động
Các hệ thống hỏi đáp tự động hiện nay có kiến trúc rất đa dạng, tuy nhiên
chúng đều bao gồm ba phần cơ bản: Phân tích câu hỏi; Trích chọn tài liệu; Trích
xuất câu trả lời [3,10,11,18].
Hình 9. Các bước cơ bản trong hệ thống trả lời tự động
Sự khác nhau chính giữa các hệ thống là ở quá trình xử lý trong từng
bƣớc, đặc biệt là ở cách tiếp cận trong việc xác định câu trả lời, trong đó:

45
Bƣớc 1 - Phân tích câu hỏi: Tạo truy vấn cho bƣớc trích chọn tài liệu
liên quan và tìm ra những thông tin hữu ích cho bƣớc trích xuất câu trả lời
Bƣớc 2 - Trích chọn tài liệu: Bƣớc này sử dụng câu truy vấn đƣợc tạo ra
ở bƣớc phân tích câu hỏi để tìm các tài liệu liên quan đến câu hỏi.
Bƣớc 3 - Trích xuất câu trả lời: Bƣớc này phân tích tập tài liệu trả về từ
bƣớc 2 và sử dụng các thông tin hữu ích do bƣớc phân tích câu hỏi cung cấp để
đƣa ra câu trả lời chính xác nhất.
Cách tiếp cận theo trích chọn thông tin thuần túy (pure IR) là: chia nhỏ
một tài liệu trong tập dữ liệu thành chuỗi các tài liệu con, trích chọn các tài liệu
con có độ tƣơng đồng lớn nhất với câu truy vấn (do bƣớc phân tích câu hỏi tạo
ra) và trả lại chúng cho ngƣời dùng.Thách thức lớn nhất ở đây là làm sao chia
nhỏ đƣợc tài liệu thành các phần với kích cỡ tƣơng ứng với kích cỡ của câu trả
lời mà vẫn đủ lớn để có thể đánh chỉ mục đƣợc (nếu chia quá nhỏ thì số lƣợng
tài liệu để đánh chỉ mục sẽ rất lớn, gây gánh nặng cho hệ thống trích chọn thông
tin).
Cách tiếp cận theo xử lý ngôn ngữ tự nhiên (pure NLP) là: so khớp giữa
biểu diễn ngữ pháp và (hoặc) biểu diễn ngữ nghĩa của câu hỏi với dạng biểu diễn
ngữ pháp, ngữ nghĩa của các câu trong các tài liệu liên quan trả về. Khó khăn
của cách tiếp cận này là hệ thống phải thực hiện việc phân tích ngữ pháp, ngữ
nghĩa và so khớp đủ nhanh để đƣa ra câu trả lời trong thời gian chấp nhận đƣợc,
bởi số lƣợng các tài liệu cần xử lý là rất lớn trong khi các bƣớc phân tích trên lại
phức tạp và tốn nhiều thời gian.
Sự khác nhau trong cách trích xuất câu trả lời dẫn đến việc phân tích câu
hỏi cũng trở nên đa dạng. Trong hƣớng tiếp cận theo trích xuất thông tin thuần
túy, phân tích câu hỏi chỉ cần làm tốt việc tạo truy vấn, trong khi với hƣớng tiếp
cận theo xử lý ngôn ngữ tự nhiên, câu hỏi cần đƣợc phân tích ngữ pháp, ngữ
nghĩa một cách chính xác. Các hệ thống hiện nay thƣờng là sự kết hợp giữa hai
hƣớng tiếp cận, sử dụng hệ thống trích chọn thông tin để thu hẹp không gian tìm
kiếm câu trả lời, đồng thời phân tích câu hỏi để tìm ra các thông tin về ngữ pháp,
ngữ nghĩa nhằm tìm ra câu trả lời chính xác nhất.
Kết quả của bƣớc phân tích câu hỏi là đầu vào cho cả hai bƣớc trích chọn
tài liệu liên quan và trích xuất câu trả lời. Bƣớc phân tích câu hỏi có ý nghĩa rất

46
quan trọng, bởi nó ảnh hƣởng đến hoạt động của các bƣớc sau và do đó quyết
định đến hiệu quả của toàn hệ thống
2 Bài toán phân loại câu hỏi
2.1 Phát biểu bài toán
Theo định nghĩa chính thức của phân loại văn bản (Sebastiani 2002 và
Yang & Xiu 1999). Håkan Sundblad [6] đã đƣa ra một định nghĩa phân loại câu
hỏi nhƣ sau:
Định nghĩa: Phân loại câu hỏi là nhiệm vụ gán một giá trị kiểu boolean
cho mỗi cặp , trong đó Q là miền chứa các câu hỏi và
| | là tập các phân loại cho trước.
Cặp (qj,ci) đƣợc gán cho giá trị là T chỉ ra rằng câu hỏi qj thuộc phân loại
ci và đƣợc gán cho giá trị là F nếu qj không thuộc phân loại ci.
Trong bối cảnh học máy, nhiệm vụ của phân loại câu hỏi là làm cho hàm
mục tiêu từ chƣa rõ ràng trở nên gần đúng với hàm mục tiêu lý tƣởng , nhƣ
vậy và Ф trùng nhau càng nhiều càng tốt.
Bài toán phân loại câu hỏi có thể đƣợc phát biểu nhƣ sau:
Input:
- Cho trƣớc một tập các câu hỏi
- Tập các chủ đề (phân loại) đƣợc định nghĩa
Output:
- Nhãn của câu hỏi .
2.2 Các phƣơng pháp phân loại câu hỏi
Theo [3,6] có 2 cách tiếp cận để phân loại câu hỏi: dựa trên luật (rule-
based) và dựa trên học máy (machine learning based). Ngoài ra, có một vài cách
tiếp cận lai là sự kết hợp của tiếp cận dựa trên luật và học máy.

47
2.2.1 Phân loại câu hỏi dựa trên luật
Đây là cách tiếp cận đƣợc cho là đơn giản nhất để phân loại câu hỏi.
Trong cách tiếp cận này thì việc phân loại câu hỏi dựa vào các luật ngữ pháp
viết tay. Các luật này có đƣợc là do đề xuất từ các chuyên gia. Đối với cách tiếp
cận này, một loạt các biểu thức chính quy (regular expression) đƣợc tạo ra để so
khớp với câu hỏi từ đó quyết định phân loại của câu hỏi và loại câu trả lời.
Nhóm tác giả Singhal (1999) dựa trên các quy tắc hoạt động của từ đã
giới thiệu một số luật nhƣ sau [6]:
Truy vấn bắt đầu bằng “Who” hoặc “Whom” đƣợc đƣa đến loại
“person”.
Truy vấn bắt đầu bằng “Where”, “Whence”, hoặc “Whither” đƣợc
đƣa về loại “location”.
Truy vấn bắt đầu với “How few”, “How great”, “How little”, “How
many” hoặc “How much” đƣợc đƣa về loại “quantity”.
Truy vấn bắt đầu bằng “Which” hoặc “What” thì tìm kiếm danh từ
chính (head noun) trong từ điển để xác định loại câu trả lời.
Tuy nhiên, cách tiếp cận nàythể hiện một số hạn chế nhƣ:
Sự phân loại dựa trên các luật viết gặp nhiều khó khăn và tốn nhiều
thời gian xử lý, do dựa trên kiến thức chủ quan của con ngƣời trên
một tập dữ liệu câu hỏi .
Có sự giới hạn về mức độ bao quát và phức tạp trong việc mở rộng
phạm vi của các loại câu trả lời .
Khi một phân loại mới xuất hiện, nhiều quy tắc trƣớc đó phải đƣợc
sửa đổi hoặc viết mới hoàn toàn.
Li và Roth đã cung cấp ví dụ để chỉ ra khó khăn của cách tiếp cận dựa
trên luật.Tất cả các câu hỏi dƣới đây đều có cùng một câu trả lời nhƣng chúng
đƣợc viết trong những định dạng cú pháp khác nhau.
What tourist attractions are there in Reims?
What are the names of the tourist attractions in Reims?
What do most tourist visit in Reims?
What attracts tourists to Reims?

48
What is worth seeing in Reims?
Tất cả các câu hỏi trên cùng đề cập đến một lớp trong khi chúng có định
dạng cú pháp khác nhau và do đó chúng cần so khớp với các luật khác nhau. Vì
vậy với sự giới hạn về số lƣợng các luật dẫn đến việckhó để phân loại.
2.2.2 Phƣơng pháp sử dụng mô hình ngôn ngữ
Phƣơng pháp này xây dựng một mô hình ngôn ngữ thốngkê [44] để ƣớc
lƣợng đƣợc phân phối của ngôn ngữ tự nhiên chính xác nhất có thể. Cụ thể
vớibài toán phân lớp câu hỏi là việc ƣớc lƣợng xác suất có điều kiệnP(a|b) của
“loại câu hỏi”a xuất hiện trong “ngữ cảnh” câu hỏi tự nhiên b. Bài toán đặt ra là
chúng ta phải tìm mộtphƣơng pháp ƣớc lƣợng (có thể tin tƣởng đƣợc) mô hình
xác suất có điều kiện p(a|b).
2.2.3 Phân loại câu hỏi dựa vào học máy
Đây là cách tiếp cận đƣợc sử dụng phổ biến để giải quyết bài toán phân
loại câu hỏi. Cách tiếp cận này sẽ thay thế các kiến thức chuyên môn bằng một
tập lớn các câu hỏi đƣợc gán nhãn (tập dữ liệu mẫu). Sử dụng tập này, một bộ
phân lớp sẽ đƣợc huấn luyện có giám sát. Một số thuật toán thƣờng đƣợc sử
dụng nhƣ: Mạng nơ-ron (Neural NetWork), tính xác suất Naïve Bayes,
Maximum Entropy, cây quyết định (Decision Tree), Máy Vector hỗ trợ (Support
Vector machine-SVM) ... Cách tiếp cận bằng học máy đã giải quyết đƣợc các
hạn chế trong cách tiếp cận dựa trên luật.
Một số thuận lợi trong cách tiếp cận này bao gồm:
Thời gian tạo dựng ngắn vì không phải tốn thời gian đề ra các luật.
Bộ phân loại đƣợc tạo ra tự động thông qua việc học từ một tập dữ
liệu huấn luyện, việc cung cấp các luật giờ không cần thiết nữa.
Độ bao phủ rộng hơn, và có thể mở rộng độ bao phủ bằng cách thu
đƣợc từ các ví dụ huấn luyện.
Nếu có yêu cầu , bộ phân loại có thể tái cấu trúc lại (học lại) một
cách linh hoạt để phù hợp với quy luật mới.
Trong hội nghị TREC các nhà nghiên cứu đã phát triển một phƣơng pháp
học máy tiếp cận để phân loại câu hỏi. Mục đích của phƣơng pháp này là phân

49
loại các câu hỏi vào trong các lớp ngữ nghĩa khác nhau mà đã đƣợc gợi ý về khả
năng trả lời, để chúng có thể đƣợc sử dụng trong các giai đoạn sau của hệ thống
hỏi đáp. Một trong những giai đoạn quan trọng trong tiến trình này là việc phân
tích câu hỏi đến một cấp độ cho phép xác định “loại” câu trả lời sau khi đƣợc
tìm kiếm .
Cách tiếp cận bài toán phân loại câu hỏi theo phƣơng pháp học máy đƣợc
sử dụng phổ biến hơn cả. Vấn đề phân loại câu hỏi theo phƣơng pháp thống kê
dựa trên kiểu học có giám sát đƣợc đặc tả bao gồm 2 giai đoạn: giai đoạn huấn
luyện và giai đoạn phân lớp.
Giai đoạn huấn luyện:
Đầu vào: tập dữ liệu huấn luyện và thuật toán huấn luyện.
Đầu ra: mô hình phân loại (bộ phân loại – classifier)
Hình 10. Mô hình giai đoạn huấn luyện
Giai đoạn huấn luyện bộ phân loại về cơ bản có thể có nhiều kỹ thuật,
tổng quát đều thực hiện các bƣớc sau:
Thu thập dữ liệu huấn luyện: một tập dữ liệu huấn luyện đƣợc thu
thập từ nhiều nguồn khác nhau.
Tiền xử lý: chuyển đổi các dữ liệu trong tập huấn luyện thành một
hình thức phù hợp để phân loại.
Vector hóa: các câu hỏi trong tập dữ liệu cần đƣợc mã hóa bởi mô
hình không gian vector.
Trích chọn đặc trƣng: loại bỏ những từ (đặc trƣng) không mang ý
nghĩa thông tin nhằm nâng cao hiệu suất phân loại và giảm độ phức
tạp của thuật toán huấn luyện.
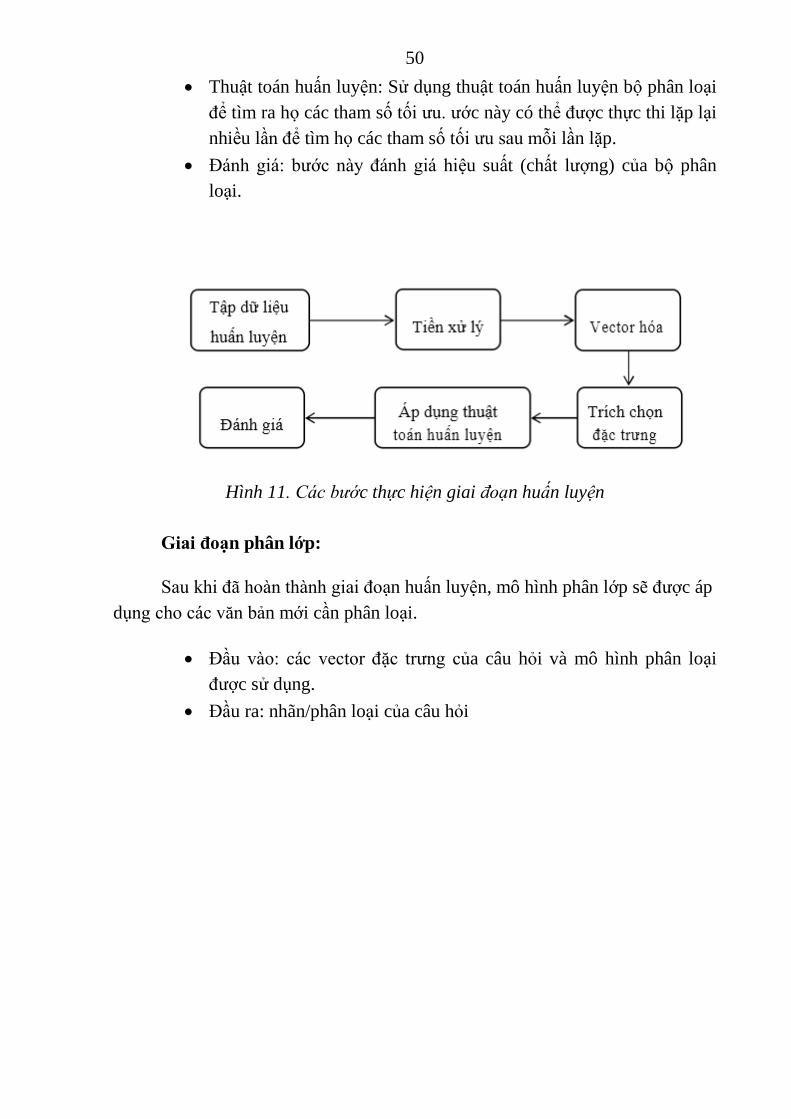
50
Thuật toán huấn luyện: Sử dụng thuật toán huấn luyện bộ phân loại
để tìm ra họ các tham số tối ƣu. ƣớc này có thể đƣợc thực thi lặp lại
nhiều lần để tìm họ các tham số tối ƣu sau mỗi lần lặp.
Đánh giá: bƣớc này đánh giá hiệu suất (chất lƣợng) của bộ phân
loại.
Hình 11. Các bước thực hiện giai đoạn huấn luyện
Giai đoạn phân lớp:
Sau khi đã hoàn thành giai đoạn huấn luyện, mô hình phân lớp sẽ đƣợc áp
dụng cho các văn bản mới cần phân loại.
Đầu vào: các vector đặc trƣng của câu hỏi và mô hình phân loại
đƣợc sử dụng.
Đầu ra: nhãn/phân loại của câu hỏi

51
Hình 12. Mô hình giai đoạn phân lớp
2.3 Trích chọn đặc trƣng cho phân tích câu hỏi
Trích chọn đặc trƣng có ý nghĩa quan trọng, ảnh hƣởng trực tiếp đến kết
quả phânlớp. Các loại đặc trƣng chính thƣờng đƣợc sử dụng là tập từ (bag-of-
word) và tập các cặptừ/nhãn từ loại (bag-of-word/POS tag). Việc phân loại câu
hỏi có điểm khác với phân loạivăn bản đó là câu hỏi chỉ chứa một số ít từ trong
khi văn bản có số lƣợng từ rất lớn. Trọngsố từ (TF – term frequency) góp phần
quan trọng trong nâng cao độ chính xác của phânlớp văn bản, trong khi với câu
hỏi các từ hầu nhƣ chỉ xuất hiện một lần duy nhất, do đóviệc biểu diễn câu hỏi
theo trọng số từ không có ý nghĩa nhiều trong phân lớp câu hỏi.
Trong Tiếng Anh việc biểu diễn câu hỏi dƣới dạng bag-of-word là khá
đơn giản bởiđặc trƣng của tiếng Anh là các từ phân cách nhau bởi khoảng trắng.
Do đó việc sử dụngunigram cũng chính là bag-of-word. Trong khi với tiếng
Việt, một từ có thể đƣợc ghép lạitừ nhiều âm tiết, do đó không thể dùng khoảng
trắng làm ranh giới phân cách các từ. Cầnthiết phải có một công cụ tách từ hiệu
quả cho tiếng Việt.
Các đặc trƣng trong phân loại câu hỏi có thể đƣợc chia thành 3 loại
khácnhau: các đặc trƣng về từ vựng, các đặc trƣng về cú pháp và các đặc trƣng
về ngữnghĩa.
2.3.1 Đặc trƣng về từ vựng
Các đặc trƣng từ vựng của một câu hỏi thƣờng đƣợc rút trích dựa trên ngữ
cảnhcủa các từ của câu hỏi, nghĩa là, các từ đó xuất hiện trong một câu hỏi. Tần

52
số xuất hiện của các từ trong câu hỏi (các giá trị của đặc trƣng) có thể đƣợcxem
nhƣ là giá trị trọng số, nó biểu thị cho tầm quan trọng của một từ trong câu hỏi.
Không gian đặc trƣng bag-of-word còn đƣợc gọi là unigram.Unigram là
mộttrƣờng hợp đặc biệt của các đặc trƣng n-gram.Để trích xuất các đặc trƣng n-
gram, bấtkỳ n từ liên tiếp nhau trong một câu hỏi sẽ đƣợc xem nhƣ là một đặc
trƣng.Ngoàiunigram, còn có thêm 2 loại n-gram thƣờng đƣợc sử dụng là bigram,
trigram. Cụ thể:
Bigram: lấy lần lƣợt 2 từ liên tiếp nhau trong câu.
Trigram : lấy lần lƣợt 3 từ liên tiếp nhau trong câu.
Ngoài các đặc trƣng trên, nhóm tác giả Huang đã giới thiệu đặc trƣng từ hỏi wh-
word.Đặc trƣng wh-word đƣợc hiểu các câu hỏi bắt đầu bằng “wh”.Chẳng hạn
wh-word của câu hỏi “What is the longest river in the world?” là what.Đã có 8
loại wh-word đƣợc đƣa ra [39]: what, which, when, where, who, how, why, và
rest, với restđƣợc hiểu là các loại câu hỏi còn lại không thuộc 8 loại trên. Ví dụ
câu hỏi “Name a food high in zinc” là một câu hỏi thuộc loại rest.
Nhóm tác giả Huang [39] còn giới thiệu một đặc trƣng từ vựng khác là
word-shapes (khuôn dạng từ). Loại đặc trƣng này dùng để chỉ tính chi tiết của
các đơn từ. Đãcó 5 loại đặc trƣng word shapes đƣợc giới thiệu: all digits, all
lower case, all upper case, mixed case and other.
Blunsom cùng các đồng nghiệp (2006) đã giới thiệu chiều dài của câu hỏi
nhƣ làđặc trƣng về từ vựng. Nó đơn giản là số từ trong một câu hỏi.
Các đặc trƣng của câu hỏi: How many Grammys did Michael Jackson win
in 1983 ? đƣợc biểu diễn nhƣ bảng dƣới đây.
Bảng 3. Biểu diễn các đặc trưng của một câu hỏi
Không gian đặc
trƣng Đặc trƣng
Unigram {(How,1) (many,1) (Grammys,1) (did,1) (Michael,1)(
Jackson,1) (win,1) (in,1) (1983,1) (?,1) }
Bigram {(How-many, 1) (many-Grammys,1) (Grammys-did,1)
(didMichael,1) (Michael-Jackson,1) (Jackson-win,1) (win-
in,1)(in-1983,1) (1983-?,1)}

53
Trigram {(How-many-Grammys,1) (many-Grammys-
did,1)(Grammys-did-Michael,1) (did-Michael-Jackson,1)
(MichaelJackson-win,1) (Jackson-win-in,1) (win-in-
1983,1) (in-1983-?,1)}
Wh-word {(How,1)}
Word-shapes {(lowercase,4) (mixed,4) (digit,1) (other,1)}
Question-length {(question-len, 10)}
2.3.2 Đặc trƣng về cú pháp
Một vài loại đặc trƣng khác có thể đƣợc trích rút từ cấu trúc cú pháp của
câuhỏi. Có 2 loại đặc trƣng thƣờng đƣợc sử dụng nhất:
POS tags cho biết nhãn từ loại của mỗi từ trong câu hỏi nhƣ NN
(Noun- danh từ), JJ (adjective- tính từ), RB (Adverb – trạng từ).
Việc gán nhãn từ loại cũng đóng một vai trò quan trọng trong việc
phân loại câu hỏi. Các danh từ trong câu hỏi đại diện cho các đối
tƣợng hay các thực thể cần hỏi tới. Vì thế, ta cần xác định từ loại
của các từ trong câu hỏi
Từ đầu (head word): Huang [39] đã đề xuất đặc trƣng head word
dựa trên ý tƣởng một từ trong câu hỏi đại diện cho một đối tƣợng
cần hỏi đến. Xác định chính xác từ đầu có thể cải thiện đáng kể độ
chính xác của việc phân loại do nó là từ chứa thông tin nhất trong
câu hỏi. Ví dụ cho câu hỏi “What is the oldest city in Canada ?” từ
đầu là “city”. Từ “city” trong câu hỏi này có thể có đóng góp cao
cho bộ phân loại để phân loại câu hỏi này là LOC: city.
Trong thực tế, một số câu hỏi vốn không có từ đầu. Chẳng hạn nhƣ với
câu hỏi“What is biosphere ?”, không có từ đầu nào phù hợp để góp phần phân
loại nhƣ là“definition”. Vấn đề tƣơng tự cũng xuất hiện trong câu hỏi “Why does
the moon turn orange ?”, không có các từ nào trong câu hỏi này ngoại trừ từ để
hỏi giúp bộ phân loạiphân loại câu hỏi này là “reason”.
Để định nghĩa một đặc trƣng thay thế cho từ đầu của câu hỏi, nhóm tác
giảHuang đã giới thiệu một vài mẫu biểu thức chính quy để ánh xạ các kiểu của
câu hỏitới một mẫu và sau đó sử dụng mẫu tƣơng ứng nhƣ là đặc trƣng. Danh
sách các mẫucủa Huang [15] nhƣ sau:

54
DESC:def pattern 1 Các câu hỏi bắt đầu bằng what is/are, không
bắt buộc theo sau nó là a, an, hoặc the và tiếp theo là 1 hoặc nhiều
từ.
DESC:def pattern 2 Các câu hỏi bắt đầu bằng what do/does và kết
thúc là mean.
ENTY:substance pattern Các câu hỏi bắt đầu là what is/are và kết
thúc là composed of/made of/made out of.
DESC:desc pattern Các câu hỏi bắt đầu với what does và kết thúc
là do.
ENTY:term Các câu hỏi bắt đầu là what do you call.
DESC:reason pattern 1 Các câu hỏi bắt đầu là what causes/cause.
DESC:reason pattern 2 Các câu hỏi bắt đầu bằng What is/are và
kết thúc là used for.
ABBR:exp pattern Các câu hỏi bắt đầu bằng What does/do và kết
thúc với stand for.
HUM:desc pattern Các câu hỏi bắt đầu với Who is/was và theo
sau nó là một từ bắt đầu là một kí tự viết hoa
Nếu một câu hỏi so khớp với một vài các luật trên thì đặc trƣng tƣơng ứng
sẽđƣợc sử dụng.Ví dụ cho câu hỏi “What is biosphere ?”, các đặc trƣng có thể
đƣợc biểudiễn nhƣ sau:
{(DESC:def-pattern1, 1)}
2.3.3 Đặc trƣng về ngữ nghĩa
Các đặc trƣng ngữ nghĩa đƣợc trích rút dựa trên ngữ nghĩa của các từ
trong câu hỏi. Hầu hết các đặc trƣng ngữ nghĩa đòi hỏi nguồn dữ liệu thứ 3 nhƣ
là mạng từ WordNet (Fellbaum, 1998), hoặc là một từ điển để trích rút thông tin
ngữ nghĩa cho các câu hỏi.
Sử dụng WordNet để phân loại câu hỏi thông qua hypernyms: Y là một
hypernyms của X nếu ý nghĩa của Y bao hàm ý nghĩa của một hoặc nhiều từ
khác cùng loại của X. Ví dụ, hypernyms của từ “city” là “municipality”,
hypernyms của “municipality” là “urban area” và cứ nhƣ vậy, cấu trúc đi từ
nghĩa cụ thể đến nghĩa khái quát hơn.

55
3 Sự phân loại câu hỏi Taxonomy
3.1 Khái niệm Taxonomy
Khái niệm Taxonomy đƣợc sử dụng trong nhiều lĩnh vực khác nhau, vì
vậy mà có rất nhiều định nghĩa khác nhau. Các chuyên gia đầu tiên phát triển
cấu trúc hệ thống Web đã dùng thuật ngữ taxonomy để nói về tổ chức nội dung
các trang web.Trong lĩnh vực công nghệ thông tin, Taxonomy đƣợc định nghĩa
nhƣ sau[2]:
Định nghĩa: Taxonomy là sự phân loại của toàn bộ thông tin trong một
hệ phân cấp theo một mối quan hệ có trước của các thực thể trong thế giới thực
mà nó biểu diễn.
Một taxonomy thƣờng đƣợc mô tả với gốc ở trên cùng, mỗi nút của
taxonomy (bao gồm cả gốc) là một thực thể thông tin đại diện cho một thực thể
trong thế giới thực. Giữa các nút trong taxonomy có một mối quan hệ đặc biệt
gọi là is subclassification of nếu hƣớng liên kết từ nút con lên nút cha hoặc là is
superclassification of nếu hƣớng liên kết từ nút cha xuống nút con. Đôi khi
những quan hệ này đƣợc xác định một cách chặt chẽ hơn là is subclass of hoặc is
superclass of, nếu thực thể thông tin là một lớp đối tƣợng.
3.2 Taxonomy câu hỏi
Taxonomy theo kiểu câu trả lời có thể đƣợc chia thành 2 loại [6]:
taxonomy phẳng (flat) và taxonomy phân cấp (hierarchical). Taxonomy phẳng
chỉ có duy nhất một mức phân loại, do đó không phân loại theo đúng nghĩa của
từ. Taxonomy phân cấp bao gồm các phân loại lớn và tập các phân loại nhỏ bên
trong.
Một số hệ thống (Srihari & Li 1999) sử dụng các taxonomy bắt nguồn từ
các loại đƣợc sử dụng trong các đánh giá tại Message Understanding Conference
(MUC).MUC đã phân biệt giữa các thực thể đặt tên (organization, person, và
location), biểu thức thời gian (date và time), và các biểu thức số (money và
percentage).
Một giải pháp khác đƣợc sử dụng để xây dựng các taxonomy đó là sử
dụng WordNet (Fellbaum 1998).Nhóm tác giả Kim (2000) đã sử dụng cách tiếp
cận này để xây dựng một taxonomy cho 46 phân loại khác nhau về ngữ nghĩa

56
khác nhau. Ngoài ra còn có các taxonomy câu hỏi nổi tiếng khác sử dụng để
phân loại câu hỏi.Taxonomy đƣợc đề xuất bởi Hermjakob (2002) bao gồm 180
lớp, đó cũng là nguyên tắc phân loại câu hỏi rộng nhất đƣợc đề xuất đến bây giờ.
Hầu hết các tiếp cận dựa trên học máy gần đây đều sử dụng taxonomy
đƣợc đề xuất bởi Li và Roth[2] từ khi các tác giả công bố một tập các giá trị là
6000 câu hỏi đã gán nhãn. Tập dữ liệu này bao gồm hai tập riêng rẽ là 5500 và
500 câu hỏi trong đó tập đầu tiên sử dụng nhƣ một tập dữ liệu huấn luyện và tập
thứ hai sử dụng nhƣ một tập kiểm tra độc lập. Tập dữ liệu này đƣợc xuất bản lần
đầu tiên ở University of Illinois Urbana-Champaign (UIUC), thƣờng đƣợc gọi là
tập dữ liệu UIUC và thỉnh thoảng đƣợc coi nhƣ là tập dữ liệu TREC kể từ khi nó
đƣợc mở rộng sử dụng trong hội nghị về truy hồi thông tin (Text REtrieval
Conference-TREC).
Taxonomy câu hỏi do Li và Roth đƣa ra gồm 2 cấp theo sự phân loại ngữ
nghĩa tự nhiên của câu trả lời trong hội nghị TREC. Cấu trúc phân cấp bao gồm
6 lớp thô: ABBREVIATION (viết tắt), ENTITY (thực thể),DESCRIPTION (mô
tả), HUMAN (con ngƣời), LOCATION (địa điểm) và NUMERIC VALUE (giá
trị số) cùng với 50 lớp con (fine class).Mỗi lớp thô lại chứa một tập khác nhau
các lớp nhau.Taxonomy câu hỏi của Li và Roth đƣợc trình bày trong bảng dƣới
đây.
Bảng 4. Taxonomy câu hỏi
Nhãn Định nghĩa ABBREVIATION Dạng viết tắt
abb Dạng viết tắt
exp Ý nghĩa của từ viết tắt
ENTITY Thực thể
animal Động vật
body Các bộ phận cơ thể
color Màu sắc
creative Phát minh, sách và các sáng tạo khác
currency Tiền tệ

57
dis.med. Bệnh tật và y học
event Sự kiện
food Đồ ăn
instrument Dụng cụ âm nhạc
lang Ngôn ngữ
letter Chữ cái (các kí tự từ a-z)
other Các thực thể khác
plant Thực vật
product Sản phẩn
religion Tôn giáo, tín ngƣỡng
sport Thể thao
substance Nguyên tố, vật chất
symbol Biểu tƣợng và ký hiệu
technique Kỹ thuật và phƣơng pháp
term Thuật ngữ tƣơng đƣơng
vehicle Phƣơng tiện giao thông
word Từ với tính chất đặc biệt
DESCRIPTION Mô tả và các khái niệm trừu tƣợng
definition Định nghĩa về cái gì đó
description Mô tả về cái gì đó
manner Cách thức của hành động
reason Lý do
HUMAN Con ngƣời

58
group Một nhóm ngƣời hoặc một tổ chức
ind Một cá nhân riêng lẻ
title Tƣ cách, danh nghĩa, chức vụ của một ngƣời
description Mô tả về ngƣời nào đó
LOCATION Địa điểm
city Thành phố
country Đất nƣớc
mountain Núi
other Các địa điểm khác
state Bang, tỉnh thành
NUMERIC Giá trị số
code Mã thƣ tín và các mã khác
count Số lƣợng của cái gì đó
date Ngày tháng
distance Khoảng cách, đo lƣờng tuyến tính
money Giá cả
order Thứ hạng
other Các số khác
period Khoảng thời gian
percent Phần trăm
speed Tốc độ
temp Nhiệt độ
size Kích thƣớc, diện tích, thể tích

59
weight Cân nặng
3.3 Mô hình phân lớp đa cấp
Theo Li và Roth [2], một khó khăn trong nhiệm vụ phân loại câu hỏi đó là
không có một ranh giới rõ ràng nào giữa các lớp. Do đó, việc phân loại một câu
hỏi cụ thể có thể khá mơ hồ. Hãy cùng xem xét ví dụ sau:
(1) What is bipolar disorder?
(2) What do bats eat?
(3) What is the PH scale?
Câu hỏi thứ nhất có thể thuộc lớp definition hoặc disease medicine; câu
hỏi thứ 2 có thể thuộc lớp food, plant hoặc animal; còn câu hỏi thứ 3 có thể là
numeric hoặc definition. Với những câu hỏi nhƣ trên sẽ gặp khó khăn trong việc
phân loại câu hỏi vào một lớp duy nhất.Để giải quyết vấn đề này, với câu hỏi
đơn sẽ cho phép các lớp đƣợc gán nhiều nhãn lớp.Điều này sẽ tốt hơn so với
việc chỉ cho phép gán 1 nhãn lớp duy nhất vì ta có thể áp dụng tất cả các lớp đó
trong tiến trình xử lý sau này.
Li và Roth đã xây dựng bộ phân lớp đa cấp (hình 13), trong suốt giai đoạn
huấn luyện, một câu hỏi sẽ đƣợc xử lý theo chiều từ trên xuống để có đƣợc phân
loại.Theo mô hình, ta có một bộ phân loại thô .Câu hỏi ban
đầu đƣợc phân loại bởi bộ phân loại thô Coarse_Classifiercho ra một tập các lớp
thô.
| | | |
Sau đó, các nhãn của loại thô đƣợc mở rộng bởi các nhãn con tƣơng
ứng.Cụ thể, mỗi nhãn thô ci đƣợc ánh xạ vào một tập nhãn lớp con
và sau đó đƣợc tổng hợp lại thành .
Bộ phân lớp mịn sẽ xác định tập các nhãn lớp con
C3 = Fine_Classifier(C2) với |C3| <=5.
C1 và C3 là kết quả đầu ra đƣợc sử dụng cho quá trình tìm câu trả
lời.

60
Hình 13. Bộ phân lớp đa cấp của Li và Roth
Kết quả mà Li và Roth đạt đƣợc khá tốt, độ chính xác là 84.2% cho 50 lớp
mịn và 91% cho 6 lớp thô với thuật toán SnoW.
4 Một số kết quả nghiên cứu
Bộ dữ liệu do Li và Roth sử dụng đã đƣợc công bố và đƣợc nhiều nhóm
nghiên cứu sử dụng để so sánh kết quả khi thực nghiệm với các thuật toán hoặc
các đặc trƣng mới để nâng cao kết quả đạt đƣợc của phân lớp câu hỏi. Hacioglu
và Ward [10] sử dụng SVM với đặc trƣng là bigram và mã sửa lỗi đầu ra (error-
correcting output code-ECOC ) đã đạt kết quả 80.2% và 82.0%.
Dell Zhang và Wee Sun Lee [16] đã tiến hành thử nghiệm năm thuật toán
khác nhau theo hƣớng học máy khi xây dựng bộ phân lớp câu hỏi. Năm thuật
toán đƣợc nhóm tác giả sử dụng thực nghiệm là: Nearest Neighbors (NN), Naïve
Bayes (NB), Decision Tree (DT), Sparse Network of Winnows (SNoW) và
Support Vector Machine (SVM).
Thực nghiệm của nhóm tác giả cụ thể nhƣ sau:
Nguyên tắc phân loại đƣợc sử dụng trong thực nghiệm là nguyên
tắc phân loại hai lớp bao gồm 6 lớp thô và 50 lớp mịn của Li và
Roth đã đƣợc trình bày trong Bảng 3.

61
Tập dữ liệu huấn luyện và kiểm thử đƣợc cung cấp bởi USC, UIUC
và TREC. Có khoảng 5.500 câu hỏi đƣợc dán nhãn phân chia ngẫu
nhiên thành 5 tập dữ liệu huấn luyện có kích thƣớc 1.000, 2.000,
3.000, 4.000 và 5.500 tƣơng ứng. Tập dữ liệu này đƣợc gán nhãn
thủ công. Mỗi một câu hỏi chỉ thuộc một lớp nhất định. Tập dữ liệu
kiểm thử bao gồm 500 câu hỏi đã đƣợc gán nhãn.
Lựa chọn đặc trƣng: các tác giả đã sử dụng hai đặc trƣng là bag-of-
words và bag-of-ngrams trong thực nghiệm của mình.
Sau 5 lần thử nghiệm với 5 tập dữ liệu có số lƣợng câu hỏi khác nhau, kết
quả thực nghiệm (độ chính xác) lớn nhất đạt đƣợc là 80.2% trên phân lớp mịn
với đặc trƣng đƣợc là bag-of-word.
Bảng 5. Độ chính xác phân loại câu hỏi với các thuật toán học máy khác nhau
Thuật toán 1000 2000 3000 4000 5500
NN 57.4% 62.8% 65.2% 67.2% 68.4%
NB 48.8% 52.8% 56.5% 56.2% 58.4%
DT 67.0% 70.0% 73.6% 75.4% 77.0%
SNoW 42.2% 66.2% 69.0% 66.6% 74.0%
SVM 68.0% 75.0% 77.2% 77.4% 80.2%
Từ kết quả thực nghiệm ở trên, ta nhận thấy rằng:
Tập dữ liệu huấn luyện lớn sẽ cho ra kết quả phân loại tốt hơn.
Thuật toán SVM mang lại độ chính xác cao hơn so với các phƣơng
pháp còn lại.

62
CHƢƠNG 3: XÂY DỰNG MÔ HÌNH VÀ ĐÁNH GIÁ THỰC NGHIỆM
Chƣơng này tiến hành thực nghiệm mô hình phân loại câu hỏi cho Tiếng
Viết bằng phƣơng pháp học máy SVM đa lớp. Mô tả về kiến trúc ứng dụng, mô
hình cài đặt, công cụ sử dụng và dữ liệu thực nghiệm. Từ đó đánh giá kết quả
đạt đƣợc và đề xuất hƣớng áp dụng cho thực tiễn đạt đƣợc mục tiêu của luận
văn, xây dựng hệ thống đón tiếp và phân loại bệnh nhân.
1 Kiến trúc ứng dụng
Bài toán phân lớp câu hỏi cũng có thể coi là bài toán phân lớp văn bản,
trong đó mỗi câu hỏi đƣợc xem là một văn bản. Tuy nhiên phân lớp câu hỏi có
một số đặc trƣng riêng so với phân lớp văn bản:
Số lƣợng từ trong một câu hỏi ít hơn nhiều trong một văn bản, do
đó dữ liệu câu hỏi là rất rời rạc. Việc biểu diễn câu hỏi theo tần suất
từ (TF, IDF) hầu nhƣ không tăng hiệu quả phân lớp vì các từ
thƣờng chỉ xuất hiện một lần trong câu hỏi.
Các từ dừng trong phân lớp văn bản là quan trọng với phân lớp câu
hỏi.
Số lƣợng nhãn lớp thƣờng rất lớn. Đối với các thuật toán phân lớp,
khi số lƣợng lớp tăng thì hiệu quả sẽ giảm [36].
Nhiều hệ thống Q&A đã áp dụng phân lớp đa cấp nhằm giảm số
lƣợng lớp tại mỗi bộ phân lớp ở từng cấp.
Cho đầu vào một câu hỏi, bộ phân loại sẽ trích rút ra các đặc trƣng từ câu
hỏi, kết hợp các đặc trƣng và phân loại câu hỏi vào một trong các lớp đã đƣợc
định nghĩa trƣớc. Giả sử rằng không gian đặc trƣng kết hợp là d chiều. Một câu
hỏi có thể đƣợc biểu diễn nhƣ là , trong đó là đặc trƣng thứ
i trong không gian kết hợp. Bộ phân loại là một hàm trong đó ánh xạ một câu
hỏi tới một lớp ci từ một tập các lớp . Hàm này đƣợc học
trên một tập dữ liệu huấn luyện là các câu hỏi đã gán nhãn.

63
Hình 14. Kiến trúc tổng quan của hệ thống phân loại câu hỏi
Hình 14 minh họa kiến trúc tổng thể của hệ thống phân loại câu hỏi mà tôi
sử dụng để thực nghiệm ứng dụng. Đầu tiên hệ thống trích rút các tập đặc trƣng
khác nhau từ câu hỏi và sau đó kết hợp chúng lại. Kết hợp của các đặc trƣng sẽ
đƣa vào bộ phân loại huấn luyện và dự báo nhãn lớp có khả năng nhất.
2 Xây dựng và cài đặt mô hình
2.1 Tập dữ liệu thực nghiệm
Dựa theo các kết quả nghiên cứu về phân lớp câu hỏi đƣợc trình bày trong
CHƢƠNG 2,bộ phân loại SVM-đa lớp đƣợc chứng minh là vƣợt trội hơn so với
các bộ phân loại khác.Do đó, tôi sử dụng kỹ thuật này,tập trung xây dựng SVM
để làm bộ phân lớp cho hệ thống Đón tiếp và Phân loại bệnh nhân:
Taxonomy câu hỏi: Sử dụng taxonomy của Li và Roth bao gồm 6
lớp thô: ABBREVIATION (viết tắt), ENTITY (thực thể),
DESCRIPTION (mô tả), HUMAN (con ngƣời), LOCATION (địa
điểm) và NUMERIC VALUE (giá trị số) và 50 lớp mịn. Tập
taxonomy câu hỏi theo loại ngữ nghĩa của câu trả lời này đƣợc xem
là có khả năng bao phủ hầu hết các trƣờng hợp về ngữ nghĩa của
câu trả lời.
Dữ liệu: Sử dụng tập 5500 câu hỏi tiếng Anh đã đƣợc công bố bởi
UIUC (bộ dữ liệu đã đƣợc gán nhãn chuẩn), tiến hành chuẩn hóa và
dịch sang Tiếng Việt. Quá trình dịch đƣợc tiến hành theo tiêu chí:
hiểu nghĩa và phân lớp của câu tiếng Anh, từ đó đặt câu hỏi với nội
dung tƣơng tự trong tiếng Việt theo văn phong tự nhiên của ngƣời
Việt, đảm bảo rằng không có sự gƣợng ép.

64
Hình 15. Tập dữ liệu huấn luyện
Hình 16. Tập dữ liệu kiểm tra

65
2.2 Công cụ thực nghiệm
Để xây dựng bộ phân loại SVM, thƣ viện LIBSVM đƣợc áp dụng trong
quá trình huấn luyện và kiểm thử.
Bảng 6. Thông tin phần cứng thực nghiệm
STT Thành phần Chỉ số
1 CPU Intel Core i7 2.4 GHZ
2 RAM 8GB
3 Hệ điều hành Windows 10
Bảng 7. Các công cụ, thư viện sử dụng
STT Công cụ Chức năng Nguồn
1 LIBSVM 3.24 Phân loại câu hỏi sử
dụng thuật toán SVM
Multi-class
https://www.csie.ntu.edu.tw
/~cjlin/libsvm/
2 Underthe Sea NLP Công cụ xử lý ngôn
ngữ tự nhiên Tiếng
Việt
https://github.com/underthes
eanlp/underthesea
3 VNTK Các tiện ích xử lý
ngôn ngữ tự nhiên
Tiếng Việt
https://www.npmjs.com/pac
kage/vntk
4 Visual Studio Code Công cụ lập trình https://code.visualstudio.co
m/
5 Python 2.7.18 Ngôn ngữ lập trình https://www.python.org/do
wnloads/release/python-
2718/

66
2.3 Lựa chọn đặc trƣng
Trong phần thực nghiệm nàysử dụng đặc trƣng unigram và bigram để tiến
hành phân loại.Tiến hành thử nghiệm và đánh giá ảnh hƣởng của các đặc trƣng
khác nhau của câu hỏi tới việc phân lớp câu hỏi.
Đặc trƣng đầu tiên đƣợc sử dụng là bag-of-unigram và bag-of-
word. Để sử dụng bag-of-word, sử dụng công cụ mã nguồn mở tách
từ Tiếng Việt Underthesea, tiện ích xử lý dữ liệu VNTK.
Trong tiếng Việt, nhiều khi chỉ cần dựa trên các từ để hỏi nhƣ ở
đâu, khi nào, ai,.. là có thể xác định đƣợc câu hỏi thuộc loại nào. Vì
vậy, trong tập dữ liệu đã điều chỉnh bổ sung thêm các từ để hỏi
trong tiếng Việt làm đặc trƣng cho phân lớp câu hỏi.
Nhƣ đƣợc trình bày trong Chƣơng 2, câu hỏi đƣợc biểu diễn dƣới dạng
vector. Các đặc trƣng trích rút từ các câu hỏi sẽ đƣợc bổ sung vào vectơ đặc
trƣng với một cặp (đặc trƣng, giá trị). Nếu chỉ trích rút các đặc trƣng unigram,
với câu hỏi “Bệnh_viện tốt nhất cho chỉnh_hình ở đâu ?”,sẽ đƣợc chuyển thành
vector đặc trƣng:
{(Bệnh_viện, 1)(tốt, 1)(nhất, 1)(cho, 1)(chỉnh_hình, 1)(ở, 1)(đâu, 1)(?, 1)}
Tuy nhiên thay vì sử dụng chuỗi, mỗi phần tử (đặc trƣng) sẽ đƣợc ánh xạ
tới một số duy nhất, chỉ số đặc trƣng. Hơn nữa tên của lớp cũng đƣợc ánh xạ tới
một số duy nhất. Mẫu định dạng dƣới đây là tƣơng tự bộ dữ liệu TREC, nó đƣợc
chuyển qua hình thức mà có thể đƣợc chấp nhận bởi thƣ viện LIBSVM.
Để sử dụng đƣợc thƣ viện LIBSVM, chúng ta phải đƣa dữ liệu huấn luyện
và kiểm tra theo cấu trúc tiêu chuẩn mà bộ thƣ viện quy định nhƣ sau:
[label] [index1]:[value1] [index2]:[value2] ...
[label] [index1]:[value1] [index2]:[value2] ...
Trong đó:
Mỗi dòng là một dữ liệu quan sát

67
label: nhãn lớp câu hỏi, là giá trị đích của tập huấn luyện, vì SVM
chỉ hiểu đƣợc số liệu số nên mỗi nhãn phải "số hóa" nó bằng cách
đặt cho các giá trị số khác nhau.
index1, index2,... là các chỉ số đại diện của các đặc trƣng có trong
từ điển. Là một số nguyên bắt đầu từ 1.
value1,value2,... là giá trị kiểu số thực ứng với các vị trí của các đặc
trƣng.Giá trị này thể hiện mức độ liên quan của đặc trƣng đối với
một phân loại nằm trong khoảng [-1,1]. Do các đặc trƣng trong
phân loại câu hỏi đều là đặc trƣng nhị phân nên lúc huấn luyện giá
trị này sẽ là 1.
3 Đánh giá kết quả thực nghiệm
Sau khi thử nghiệm với nhiều giá trị khác nhau, tham số trade off giữa tỉ
lệ sai của dữ liệu học và kích thƣớc biên của bộ phân lớp SVM đƣợc đặt giá trị c
= 10000. Kết quả tốt nhất với SVM khi sử dụng đặc trƣng unigram kết hợp từ để
hỏi với độ chính xác là 82.08%.
Bảng 8. Độ chính xác kết quả thực nghiệm SVM với các đặc trưng khác nhau
Đặc trƣng Độ chính xác
Unigram 81.26%
Tách từ 80.12%
Unigram + từ hỏi 82.08%.
Tách từ + từ hỏi 81.10%
Đặc trƣng từ để hỏi có tác dụng nâng cao độ chính xác của phân lớp câu
hỏi. Khi áp dụng với SVM, đặc trƣng từ để hỏi giúp tăng độ chính xác 0.82 %
và 0.98% tƣơng ứng khi kết hợp với đặc trƣng unigram và tách từ. Độ tăng này
không lớn có thể đƣợc giải thích nhƣ sau: Trong các đặc trƣng bag-of-unigram
và bag-of-word cũng đã xét đến các từ hỏi này với vai trò giống với các từ khác
trong câu hỏi. Việc xuất hiện các từ hỏi này với tần suất lớn theo từng loại câu
hỏi khác nhau cũng đã giúp SVM nhận diện đƣợc các từ này là từ quan trọng
trong phân lớp.
Ảnh hƣởng của tách từ trong phân lớp câu hỏi khi áp dụng triển khai với
SVM dƣờng nhƣ không hiệu quả. Kết quả này có thể diễn giải nhƣ sau: Với
SVM, dữ liệu đƣợc biểu diễn dƣới dạng các điểm trong không gian vec-tơ đặc

68
trƣng, SVM cố gắng tìm ra các siêu phẳng ngăn cách dữ liệu của từng lớp câu
hỏi, việc tách từ đã ảnh hƣởng đến sự phân bố của dữ liệu trong không gian, dẫn
đến siêu phẳng phân cách các lớp không tốt nhƣ siêu phẳng tìm đƣợc khi dùng
unigram.

69
KẾT LUẬN
Nhu cầu có đƣợc một hệ thống hỏi đáp Tiếng Việt là rất lớn và đang nhận
đƣợc sự quan tâm đặc biệt của các nhà nghiên cứu và doanh nghiệp trong các
ngành nghề có ứng dụng công nghệ thông tin.
Phân tích câu hỏi có vai trò đặc biệt quan trọng trong hệ thống hỏi đáp tự
động. Khóa luận khảo sát các phƣơng pháp phân tích câu hỏi và lựa chọn một
phƣơng pháp tối ƣu phù hợp cho việc giải quyết bài toán xây dựng hệ thống Đón
tiếp và Phân loại bệnh nhân tại một số cơ sở khám chữa bệnh, đặc biệt trong các
Bệnh Viện tuyến đầu, nơi thƣờng xuyên xảy ra ùn tắc trong việc đón tiếp ngƣời
bệnh.
Phân loại câu hỏi là một vấn đề khó. Thực tế là máy cần phải hiểu đƣợc
câu hỏi và phân loại nó vào loại chính xác. Điều này đƣợc thực hiện bởi một loạt
các bƣớc phức tạp. Luận văn này đã đƣa ra các lý thuyết và vấn đề trong quá
trình thiết lập, huấn luyện và xây dựng một hệ thống hỏi đáp tự động cho Tiếng
Việt.
Qua những kết quả đạt đƣợc ban đầu, chúng nhận thấy còn rất nhiều việc
phải làm, cần phải tối ƣu. Với cách tiếp cận này ban đầu đã cho những kết quả
rất tích cực và đúng đắn, có thể giải quyết đƣợc những vấn đề ngữ nghĩa, ngữ
cảnh trong hệ thống trả lời tự động. Ứng dụng hiệu quả vào các bài toán thực tế
nhƣ Hỗ trợ đón tiếp và phân loại bệnh nhân, tra cứu kết quả xét nghiệm, tra cứu
kết quả chẩn đoán hình ảnh, hỏi đáp quy trình khám chữa bệnh và thăm khám
BHYT, tìm đƣờng trong bệnh viện, … một cách tự động trong hệ thống mô hình
khám chữa bệnh, chăm sóc sức khỏe thông minh, đáp ứng phù hợp với nhu cầu
đổi mới công nghệ thông tin ngành y tế.

70
TÀI LIỆU THAM KHẢO
Tiếng Anh:
1. Yang & Xiu (1999), “A re-examination of text categorization methods”,
Proceedings ofACM SIGIR Conference on Research and Development in
Information Retrieval (SIGIR’ 99)
2. Xin Li, Dan Roth, “Learning Question Classifier”, In Proceedings of the
19th International Conference on Computational Linguistics
(COLING’02), 2002.
3. Sanda M. Harabagiu, Marius A. Paşca, Steven J. Maiorano. Experiments
with open-domain textual Question Answering. International Conference
On Computational Linguistics Proceedings of the 18th conference on
Computational linguistics – Volume 1, 2000, tr. 292 - 298.
4. Boser, B.E., Guyon, I.M., Vapnik, V.N., (1992), A training algorithm for
optimal margin classifiers, in Proceedings of the fifth annual workshop on
Computational learning theory - COLT, 92, 144-152.
5. Vapnik V. N., (1995), The nature of statistical learning theory. Springer.
6. Håkan Sundblad,2007. Question Classification in Question Answering
Systems. Thesis No. 1320.
7. R. Courant, D. Hilbert, Methods of Mathematical Physics. Wiley, New
York (1953).
8. Saxena A., Sambhu G., Kaushik S., Subramaniam L. IITD-IBMIRL
System for Question Answering Using Pattern Matching, Semantic Type
and Semantic Category Recognition. TREC 2007.
9. Clark S., Steedman M., Curran R. Object-Extraction and Question-
Parsing using CCG. Proceedings of the SIGDAT Conference on
Empirical Methods in Natural Language Processing, pp.111-118, 2004.
10. Kadri Hacioglu, Wayne Ward. 2003. Question Classification with Support
Vector Machines and Error Correcting Codes. The Association for
Computational Linguistics on Human Language Technology, vol. 2,
tr.28–30.
11. Harabagiu H., Maiorano J., Pasca A. Open-Domain Textual Question
Answering Techniques. Natural Language Engineering, 1(1):1-38, 2003.

71
12. Kocik K. Question classification using maximum entropy models.
Honours thesis, University of Sydney, 2004.
13. Li W. Question Classification Using Language Modeling. In CIIR
Technical Report: University of Massachusetts, Amherst, 2002
14. Nguyen M.L., Shimazu A., Nguyen T.T. Subtree mining for question
classification problem. Twentieth International Joint Conference on
Artificial Intelligence (IJCAI 2007) Hyderabad, India, January 6-12,
2007.
15. Nguyen T.T., Nguyen L.M., Shimazu A. Using Semi-supervised Learning
for Question Classification. Information and Media Technologies, Vol. 3,
No. 1, pp.112-130, 2008.
16. Zhang D., Lee W. S. Question classification using support vector
machines. Proceedings of SIGIR2003, 2003.
17. Chen, Z., Lin, F., Liu, H., Liu, Y., Ma, W. Y., & Wenyin, L. (2002). User
intention modeling in web applications using data mining. World Wide
Web, 5(3), 181-191.
18. Bernardo Magnini. Open Domain Question Answering: Techniques,
Resources and Systems. RANLP 2005.
19. Zamora, Juan, Marcelo Mendoza, and Héctor Allende. "Query Intent
Detection Based on Query Log Mining." J. Web Eng. 13.1&2 (2014): 24-
52
20. Frumkina R. M., Mikhejev A. V. Meaning and Categorization. New York:
Nova Science Publishers, Inc, 1996.
21. Yang and Xin Liu. “A re-examination of text categorization methods”,
Proceedings of ACM SIGIR Conference on Research and Development in
Information Retrieval (SIGIR’99), 1999
22. Young, M. Gasic, B. Thomson, and J. D. Williams, 2013. “POMDP-based
statistical spoken dialog systems: A review. Proceedings of the IEEE”,
101(5):1160–1179.
23. Iulian V. Serban, Alessandro Sordoni, Yoshua Bengio, Aaron Courville,
Joelle Pineau, 6 Apr 2016. “Building End-To-End Dialogue Systems
Using Generative Hierarchical Neural Network Models”.

72
24. Walter S. Lasecki, Ece Kamar, Dan Bohus, January 2013. “Conversations
in the Crowd: Collecting Data for Task-Oriented Dialog Learning”, pp1-
10.
25. Russell, S., Dewey, D., Tegmark, M. (2015). “Research Priorities for
Robust and Beneficial Artificial Intelligence”. AI Magazine, 36 (4):105–
114.
26. Alan M Turing. 1950. “Computing machinery and intelligence”. Mind,
59(236):433–460.
27. Joseph Weizenbaum. 1966. “Elizaa computer program for the study of
natural language communication between man and machine”.
Communications of the ACM, 9(1):36–45.
28. Roger C Parkinson, Kenneth Mark Colby, and William S Faught. 1977.
“Conversational language comprehension using integrated pattern-
matching and parsing”. Artificial Intelligence, 9(2):111–134.
29. Richard S Wallace. 2009. “The anatomy of ALICE”. Springer.
30. Jurgen Schmidhuber. 2015. “Deep learning in neural networks: An
overview. Neural Networks”, 61:85–117.
31. Yann LeCun, Yoshua Bengio, and Geoffrey Hinton. 2015. Deep learning.
Nature, 521(7553):436–444.
32. Alan Ritter, Colin Cherry, and Bill Dolan. 2010. “Unsupervised
modeling of twitter conversations”. In Human Language Technologies:
The 2010 Annual Conference of the North American Chapter of the
Association for Computational Linguistics, HLT ’10, pages 172–180,
Stroudsburg, PA, USA. Association for Computational Linguistics.
33. Rafael E. Banchs and Haizhou Li. 2012. “Iris: a chat-oriented dialogue
system based on the vector space model”. In Proceedings of the ACL
2012 System Demonstrations, pages 37–42, Jeju Island, Korea, July.
Association for Computational Linguistics.
34. Karthik Narasimhan, Tejas Kulkarni, and Regina Barzilay. 2015.
“Language understanding for text-based games using deep reinforcement
learning”. In Proceedings of the 2015 Conference on Empirical Methods
in Natural Language Processing, pages 1–11, Lisbon, Portugal,
September. Association for Computational Linguistics.

73
35. T.-H. Wen, D. Vandyke, N. Mrksic, M. Gasic, L. M. Rojas-Barahona, P.-
H. Su, S. Ultes, and S. Young. 2016. A Network-based End-to-End
Trainable Task-oriented Dialogue System. ArXiv eprints, April.
36. Heriberto Cuayahuitl. 2016. Simpleds: “A simple deep reinforcement
learning dialogue system”. CoRR, abs/1601.04574.
37. Lester, J., Branting, K., and Mott, B, 2004. “Conversational agents. In
Handbook of Internet Computing. Chapman & Hall”.
38. Will, T, 2007. “Creating a Dynamic Speech Dialogue”. VDM Verlag Dr.
39. Zhiheng Huang, Marcus Thint, Zengchang Qin (2008), Question
Classification Using Head Words and Their Hypernyms, In Proceedings
of the Conference on Empirical Methods in Natural Language Processing,
Honolulu, Hawaii, Association for Computational Linguistics, pp. 927–
936
Tiếng Việt:
40. Nguyễn Linh Giang, Nguyễn Mạnh Hiển, Phân loại văn bản tiếng Việt
với bộ phân loại vectơ hỗ trợ SVM. Tạp chí CNTT&TT, Tháng 6 năm
2006.
41. Nguyễn Ngọc Bình, “Dùng lý thuyết tập thô và các kỹ thuật khác để phân
loại, phân cụm văn bản tiếng Việt”, Kỷ yếu hội thảo ICT.rda’04. Hà nội
2004.
42. Nguyễn Linh Giang, Nguyễn Duy Hải, “Mô hình thống kê hình vị tiếng
Việt và ứng dụng”, Chuyên san “Các công trình nghiên cứu, triển khai
Công nghệ Thông tin và Viễn thông, Tạp chí Bƣu chính Viễn thông, số 1,
tháng 7-1999, trang 61-67. 1999
43. Huỳnh Quyết Thắng, Đinh Thị Thu Phƣơng, “Tiếp cận phƣơng pháp học
không giám sát trong học có giám sát với bài toán phân lớp văn bản tiếng
Việt và đề xuất cải tiến công thức tính độ liên quan giữa hai văn bản trong
mô hình vectơ”, Kỷ yếu Hội thảo ICT.rda’04, trang 251-261, Hà Nội
2005.
44. Đỗ Phúc, Nghiên cứu ứng dụng tập phổ biến và luật kết hợp vào bài toán
phân loại văn bản tiếng Việt có xem xét ngữ nghĩa, Tạp chí phát triển
KH&CN, tập 9, số 2, pp. 23-32, năm 2006

74
45. Nguyễn Minh Tuấn. Phân lớp câu hỏi hƣớng tới tìm kiếm ngữ nghĩa tiếng
việt trong lĩnh vực y tế. Khóa luận tốt nghiệp đại học, Đại học Công nghệ,
2008.