valuepack: value-based scheduling framework for cpu-gpu clusters vignesh ravi, michela becchi, gagan...
TRANSCRIPT

ValuePack: Value-Based Scheduling Framework for CPU-GPU Clusters
Vignesh Ravi, Michela Becchi, Gagan Agrawal, Srimat Chakradhar

2
Context• GPUs are used in supercomputers
– Some of the top500 supercomputers use GPUs• Tianhe-1A
– 14,336 Xeon X5670 processors– 7,168 Nvidia Tesla M2050 GPUs
• Stampede– about 6,000 nodes:
» Xeon E5-2680 8C, Intel Xeon Phi
• GPUs are used in cloud computing
Need for resource managers and scheduling schemes for heterogeneous clusters including many-core GPUs

3
Categories of Scheduling Objectives• Traditional schedulers for supercomputers aim to
improve system-wide metrics: throughput & latency
• A market-based service world is emerging: focus on provider’s profit and user’s satisfaction– Cloud: pay-as-you-go model
• Amazon: different users (On-Demand, Free, Spot, …)
– Recent resource managers for supercomputers (e.g. MOAB) have the notion of service-level agreement (SLA)

Motivation
• Open-source batch schedulers start to support GPUs– TORQUE, SLURM– Users’ guide mapping of jobs to heterogeneous nodes– Simple scheduling schemes (goals: throughput & latency)
• Recent proposals describe runtime systems & virtualization frameworks for clusters with GPUs– [gViM HPCVirt '09][vCUDA IPDPS '09][ rCUDA HPCS’10 ]
[gVirtuS Euro-Par 2010][our HPDC’11, CCGRID’12, HPDC’12]– Simple scheduling schemes (goals: throughput & latency)
• Proposals on market-based scheduling policies focus on homogeneous CPU clusters – [Irwin HPDC’04][Sherwani Soft.Pract.Exp.’04]
4
State of the Art
Our Goal:Reconsider market-based scheduling for heterogeneous clusters including GPUs

5
Considerations• Community looking into code portability between CPU
and GPU– OpenCL– PGI CUDA-x86– MCUDA (CUDA-C), Ocelot, SWAN (CUDA-OpenCL), OpenMPC
→ Opportunity to flexibly schedule a job on CPU/GPU
• In cloud environments oversubscription commonly used to reduce infrastructural costs
→ Use of resource sharing to improve performance by maximizing hardware utilization

6
Problem Formulation• Given a CPU-GPU cluster• Schedule a set of jobs on the cluster
– To maximize the provider’s profit / aggregate user satisfaction
• Exploit the portability offered by OpenCL– Flexibly map the job on to either CPU or GPU
• Maximize resource utilization– Allow sharing of multi-core CPU or GPU
Assumptions/Limitations• 1 multi-core CPU and 1 GPU per node• Single-node, single GPU jobs• Only space-sharing, limited to two jobs per resource

Value Function
7
Market-based Scheduling Formulation• For each job, Linear-Decay Value Function [Irwin HPDC’04]
• Max Value → Importance/Priority of job Decay → Urgency of job• Delay due to:
₋ queuing, execution on non-optimal resource, resource sharing
Execution time
Yiel
d/Va
lue
T
Max Value
Decay rate
Yield = maxValue – decay * delay
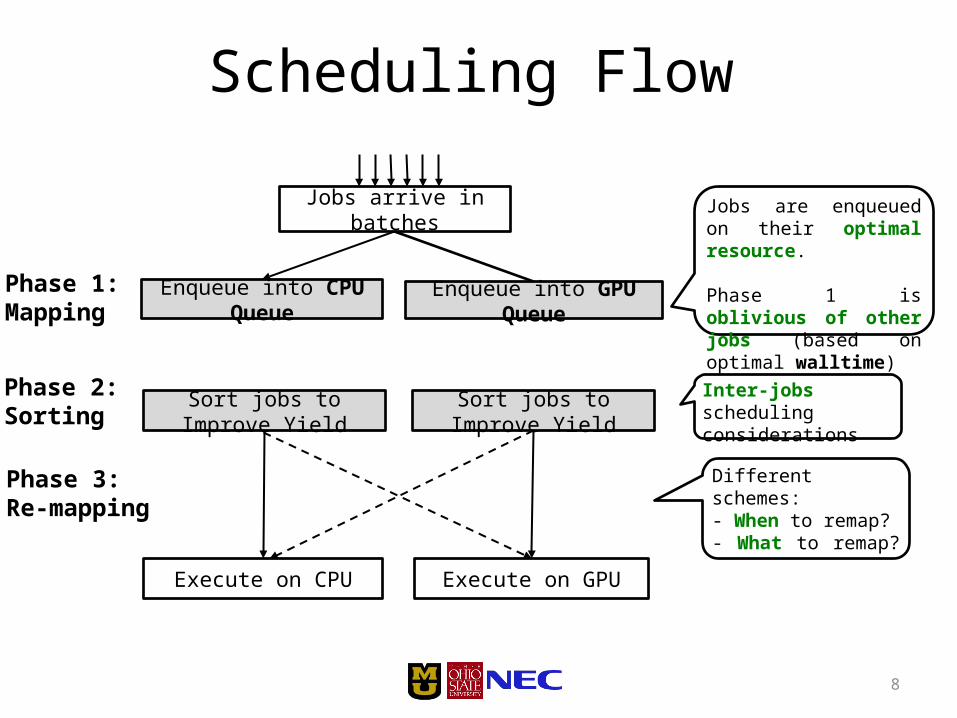
Overall Scheduling Approach
8
Jobs arrive in batches
Execute on CPU Execute on GPU
Scheduling Flow
Enqueue into CPU Queue Enqueue into GPU Queue
Jobs are enqueued on their optimal resource.
Phase 1 is oblivious of other jobs (based on optimal walltime)
Phase 1:Mapping
Sort jobs to Improve YieldInter-jobs scheduling considerationsSort jobs to Improve Yield
Phase 2:Sorting
Phase 3:Re-mapping
Different schemes:- When to remap?- What to remap?

9
Phase 1: Mapping
• Users provide walltime on GPU and GPU– walltime used as indicator of optimal/non optimal
resource– Each job is mapped onto its optimal resourceNOTE: in our experiments we assumed
maxValue = optimal walltime

10
Phase 2: Sorting• Sort jobs based on Reward [Irwin HPDC’04]
• Present Value – f(maxValuei, discount_rate)– Value after discounting the risk of running a job– The shorter the job, the lower the risk
• Opportunity Cost – Degradation in value due to the selection of one among several
alternatives
i
iii Walltime
yCostOpportunituePresentValReward
jijii decaydecayWalltimeyCostOpportunit

11
Phase 3: Remapping
• When to remap:– Uncoordinated schemes
• queue is empty and resource is idle
– Coordinated scheme• When CPU and GPU queues are imbalanced
• What to remap:– Which job will have best reward on non-optimal resource?– Which job will suffer least reward penalty ?

12
Phase 3: Uncoordinated Schemes1. Last Optimal Reward (LOR)
– Remap job with least reward on optimal resource– Idea: least reward → least risk in moving
2. First Non-Optimal Reward (FNOR)– Compute the reward job could produce on non-optimal resource– Remap job with highest reward on non-optimal resource– Idea: consider non-optimal penalty
3. Last Non-Optimal Reward Penalty (LNORP)– Remap job with least reward degradation RewardDegradationi = OptimalRewardi - NonOptimalRewardi

13
Phase 3: Coordinated SchemeCoordinated Least Penalty (CORLP)• When to remap: imbalance between queues
– Imbalance affected by: decay rates and execution times of jobs– Total Queuing-Delay Decay-Rate Product (TQDP)
– Remap if |TQDPCPU – TQDPGPU| > threshold
• What to remap– Remap job with least penalty degradation
j
jji decaydelayqueueingTQDP _

Heuristic for Sharing
• Limitation: Two jobs can space-share of CPU/GPU• Factors affecting sharing
- Slowdown incurred by jobs using half of a resource+ More resource available for other jobs
• Jobs– Categorized as low, medium, high scaling (based on models/profiling)
• When to enable sharing– Large fraction of jobs in pending queues with negative yield
• What jobs share a resource– Scalability-DecayRate factor
• Jobs grouped based on scalability• Within each group, jobs are ordered by decay rate (urgency)
– Pick top K fraction of jobs, ‘K’ is tunable (low scalability, low decay)
14
Resource Sharing Heuristic
15
Master Node
Compute Node
…
Overall System Prototype
Compute Node Compute Node

16
Master Node
Cluster-Level Scheduler
Scheduling Schemes & Policies
TCPCommunicator
Submission Queue
Pending Queues
Execution Queues
Finished Queues
Compute Node
Multi-core CPU GPU
…
Overall System Prototype
Compute Node
Multi-core CPU GPU
Compute Node
Multi-core CPU GPU
CPUGPU
CPUGPU
CPUGPU
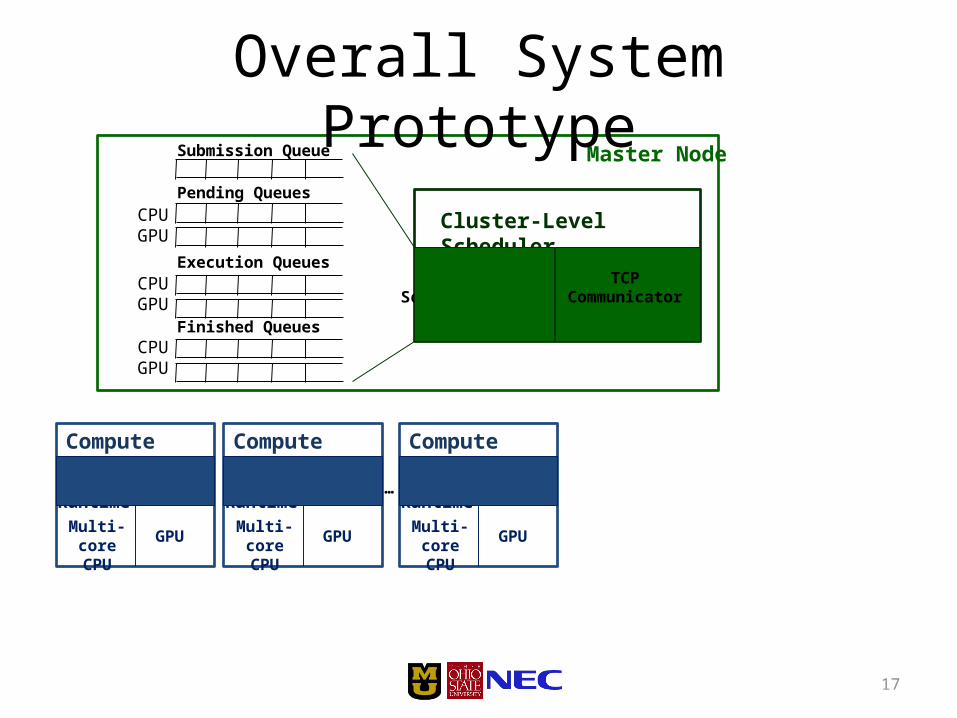
17
Master Node
Cluster-Level Scheduler
Scheduling Schemes & Policies
TCPCommunicator
Submission Queue
Pending Queues
Execution Queues
Finished Queues
Compute Node
Node-Level Runtime
Multi-core CPU GPU
…
Overall System Prototype
Compute Node
Node-Level Runtime
Multi-core CPU GPU
Compute Node
Node-Level Runtime
Multi-core CPU GPU
CPUGPU
CPUGPU
CPUGPU

18
Master Node
Cluster-Level Scheduler
Scheduling Schemes & Policies
TCPCommunicator
Submission Queue
Pending Queues
Execution Queues
Finished Queues
Compute Node
Node-Level Runtime
Multi-core CPU GPU
…
Overall System Prototype
Compute Node
Node-Level Runtime
Multi-core CPU GPU
Compute Node
Node-Level Runtime
Multi-core CPU GPU
CPUGPU
CPUGPU
CPUGPU
TCP Communicator
CPU Execution Processes
GPU Execution Processes
GPU ConsolidationFramework
OS-basedscheduling & sharing

19
Master Node
Cluster-Level Scheduler
Scheduling Schemes & Policies
TCPCommunicator
Submission Queue
Pending Queues
Execution Queues
Finished Queues
Compute Node
Node-Level Runtime
Multi-core CPU GPU
…
Overall System Prototype
Compute Node
Node-Level Runtime
Multi-core CPU GPU
Compute Node
Node-Level Runtime
Multi-core CPU GPU
CPUGPU
CPUGPU
CPUGPU
TCP Communicator
CPU Execution Processes
GPU Execution Processes
GPU ConsolidationFramework
Assumption: shared file system
Centralized decision making
Execution & sharing
mechanisms
OS-basedscheduling & sharing
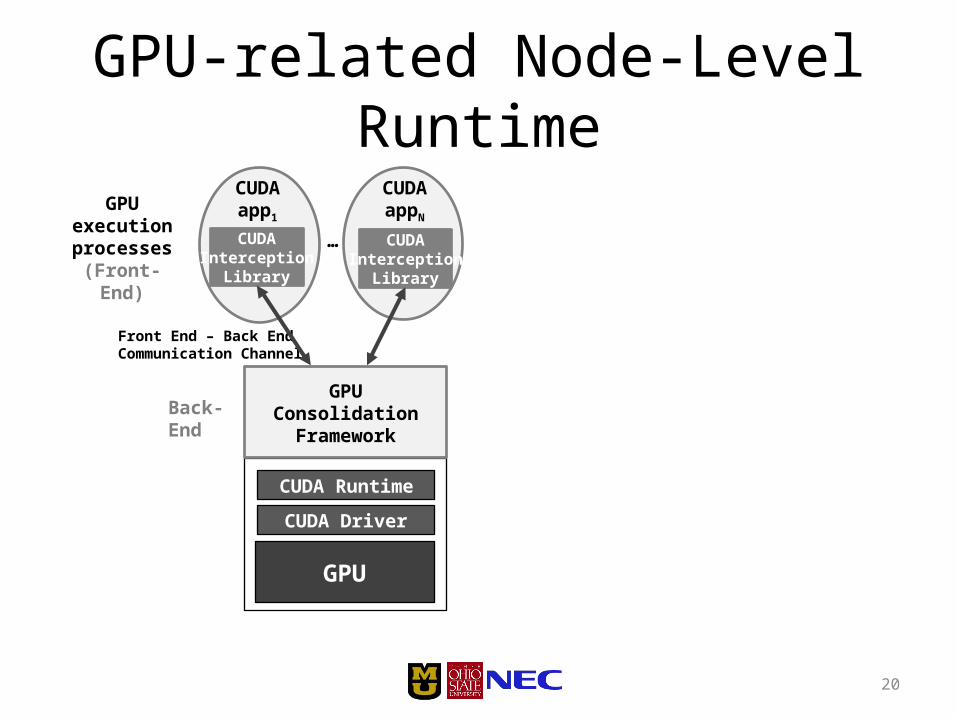
20
GPU
CUDA app1
CUDA Driver
CUDA Runtime
GPU execution processes
(Front-End)
GPU Consolidation Framework
Back-End
GPU Sharing FrameworkGPU-related Node-Level Runtime
CUDA appN
…CUDAInterception
Library
CUDAInterception
Library
Front End – Back End Communication Channel

21
Front End – Back End Communication Channel
GPU
CUDAInterception
Library
CUDA app1
CUDA Driver
CUDA Runtime
GPU Consolidation Framework
GPU execution processes
(Front-End)
Back-End VirtualContext
CUDA calls arrive from Frontend
GPU Sharing FrameworkGPU-related Node-Level Runtime
CUDA appN
… CUDAInterception
LibraryBack-End
Server
CUDA stream1
Manipulates kernel
configurations to allow GPU
space sharing
CUDA stream2CUDA
streamN
Workload Consolidator
Simplified version of our HPDC’11 runtime

22
Experimental Setup• 16-node cluster
– CPU: 8-core Intel Xeon E5520 (2.27 GHz), 48 GB memory– GPU: Nvidia Tesla C2050 (1.15 GHz), 3GB device memory
• 256-job workload– 10 benchmark programs– 3 configurations: small, large, very large datasets– Various application domains: scientific computations, financial analysis,
data mining, machine learning
• Baselines– TORQUE (always optimal resource)– Minimum Completion Time (MCT) [Maheswaran et.al, HCW’99]
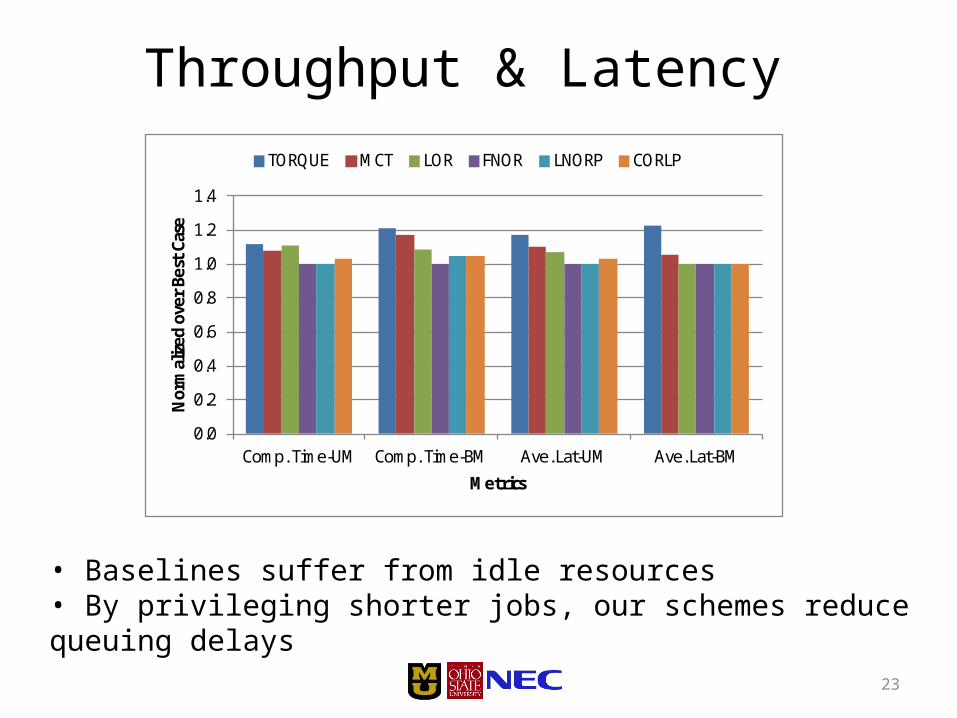
Comparison with Torque-based Metrics
23
0.0
0.2
0.4
0.6
0.8
1.0
1.2
1.4
Comp. Time-UM Comp. Time-BM Ave. Lat-UM Ave. Lat-BM
Nor
mal
ized
ove
r Be
st C
ase
Metrics
TORQUE MCT LOR FNOR LNORP CORLP
• Baselines suffer from idle resources• By privileging shorter jobs, our schemes reduce queuing delays
Throughput & Latency
COMPLETION TIME AVERAGE LATENCY
10-20% better
~ 20% better

Results with Average Yield Metric
24
0
2
4
6
8
10
25C/75G 50C/50G 75C/25G
Rela
tive
Ave
. Yie
ld
CPU/GPU Job Mix Ratio
Torque MCT FNOR LNORP LOR CORLP
up to 8.8x better
Yield: Effect of Job Mix
Skewed-GPU Skewed-CPUUniform
up to 2.3x better
• Better on skewed job mixes:− More idle time in case of baseline schemes− More room for dynamic mapping

25
0
1
2
3
4
5
6
7
8
Linear Decay Step Decay
Rela
tive
Ave
. Yie
ld
Value Decay Function
TORQUE MCT LOR FNOR LNORP CORLP
up to 3.8x better
up to 6.9x better
Results with Average Yield MetricYield: Effect of Value Function
• Adaptability of our schemes to different value functions
Results with Average Yield Metric
26
0
2
4
6
8
10
128 256 384 512
Re
lati
ve A
ve.
Yie
ld
Total No. of Jobs
TORQUE MCT LOR FNOR LNORP CORLP
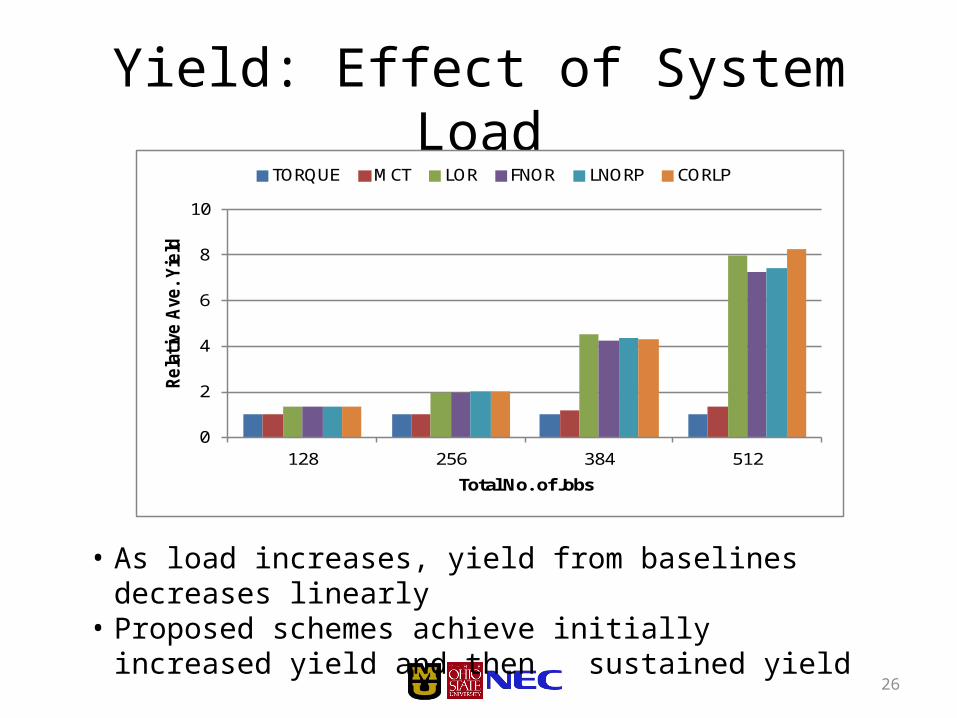
up to 8.2x better
Yield: Effect of System Load
• As load increases, yield from baselines decreases linearly
• Proposed schemes achieve initially increased yield and then sustained yield
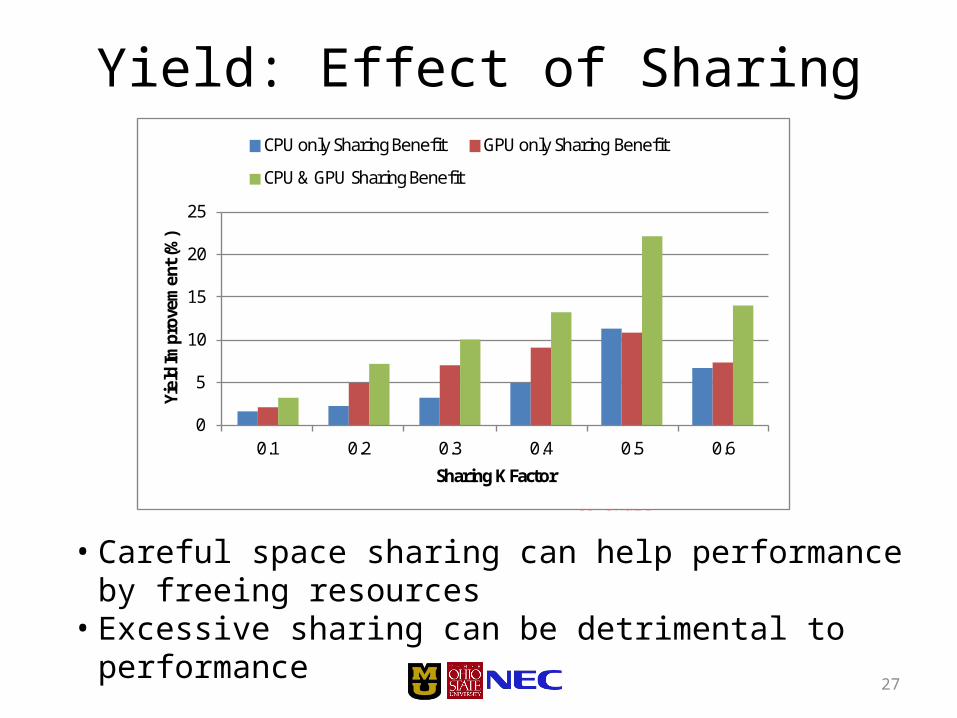
Yield Improvements from Sharing
27
0
5
10
15
20
25
0.1 0.2 0.3 0.4 0.5 0.6
Yiel
d Im
prov
emen
t (%
)
Sharing K Factor
CPU only Sharing Benefit GPU only Sharing Benefit
CPU & GPU Sharing Benefit
Fraction of jobs to share
• Careful space sharing can help performance by freeing resources
• Excessive sharing can be detrimental to performance
Yield: Effect of Sharing
up to 23x improvement

Summary
28
• Value-based Scheduling on CPU-GPU clusters- Goal: improve aggregate yield
• Coordinated and uncoordinated scheduling schemes for dynamic mapping
• Automatic space sharing of resources based on heuristics
• Prototypical framework for evaluating the proposed schemes
• Improvement over state-of-the-art- Based on completion time & latency- Based on average yield
Conclusion