uva cs 6316/4501 – fall 2016 machine learning lecture … · – fall 2016 machine learning...
TRANSCRIPT

UVACS6316/4501–Fall2016
MachineLearning
Lecture22:Review
Dr.YanjunQi
UniversityofVirginia
DepartmentofComputerScience
11/30/16
Dr.YanjunQi/UVACS6316/f16
1

Announcements:FinalExam• ClosedNote• Allowingapaper(usleJersize)ofcheatsheet• Nolaptop/NoCellphone/Nointernetaccess/Noelectronicdevices
• RecitalsessionthisFriday(@OSL120,4pm-5pm)forHW7
• Coveringpost-midtermcontents(L12-)Zlltoday– PracZcewithsamplequesZonsinHW7– HW7duenextMondaynoon– Pleasereviewcourseslidescarefully
11/30/16 2
Dr.YanjunQi/UVACS6316/f16

Today
q ReviewofMLmethodscoveredsofarq Regression(supervised)q ClassificaZon(supervised)q Unsupervisedmodelsq Learningtheory
q ReviewofAssignmentscoveredsofar
11/30/16 3
Dr.YanjunQi/UVACS6316/f16

ATypicalMachineLearningPipeline
11/30/16
Low-level sensing
Pre-processing
Feature Extract
Feature Select
Inference, Prediction, Recognition
Label Collection
4
Evaluation
Optimization
e.g. Data Cleaning Task-relevant
Dr.YanjunQi/UVACS6316/f16

11/30/16 5
AnOperaZonalModelofMachineLearning
Learner Reference Data
Model
Execution Engine
Model Tagged Data
Production Data Deployment
Consistsofinput-outputpairs
Dr.YanjunQi/UVACS6316/f16

Machine Learning in a Nutshell
Task
Representation
Score Function
Search/Optimization
Models, Parameters
11/30/16 6
MLgrewoutofworkinAIOp#mizeaperformancecriterionusingexampledataorpastexperience,Aimingtogeneralizetounseendata
Dr.YanjunQi/UVACS6316/f16

Whatwehavecovered
11/30/16
Dr.YanjunQi/UVACS6316/f16
7
Task Regression,classificaZon,clustering,dimen-reducZon
RepresentaIon
Linearfunc,nonlinearfuncZon(e.g.polynomialexpansion),locallinear,logisZcfuncZon(e.g.p(c|x)),tree,mulZ-layer,prob-densityfamily(e.g.Bernoulli,mulZnomial,Gaussian,mixtureofGaussians),localfuncsmoothness,
ScoreFuncIon
MSE,Hinge,log-likelihood,EPE(e.g.L2lossforKNN,0-1lossforBayesclassifier),cross-entropy,clusterpointsdistancetocenters,variance,
Search/OpImizaIon
NormalequaZon,gradientdescent,stochasZcGD,Newton,Linearprogramming,QuadraZcprogramming(quadraZcobjecZvewithlinearconstraints),greedy,EM,asyn-SGD,eigenDecomp
Models,Parameters
RegularizaZon(e.g.L1,L2)

Scikit-learnalgorithmcheat-sheet
11/30/16 8
hJp://scikit-learn.org/stable/tutorial/machine_learning_map/Dr.YanjunQi/UVACS6316/f16

11/30/16 9
hJp://scikit-learn.org/stable/Dr.YanjunQi/UVACS6316/f16

11/30/16 10
ü differentassumpZonsondata
ü differentscalabilityprofilesattrainingZme
ü differentlatenciesatpredicZon(test)Zme
ü differentmodelsizes(embedabilityinmobiledevices)
OlivierGrisel’stalk
Dr.YanjunQi/UVACS6316/f16

Today
q ReviewofMLmethodscoveredsofarq Regression(supervised)q ClassificaZon(supervised)q Unsupervisedmodelsq Learningtheory
q ReviewofAssignmentscoveredsofar
11/30/16 11
Dr.YanjunQi/UVACS6316/f16

SUPERVISED LEARNING
• Find function to map input space X to output space Y
• Generalisation:learnfuncZon/hypothesisfrompastdatainorderto“explain”,“predict”,“model”or“control”newdataexamples
11/30/16 12KEY
Dr.YanjunQi/UVACS6316/f16

Whatwehavecovered(I)q SupervisedRegressionmodels
– Linearregression(LR)– LRwithnon-linearbasisfuncZons– LocallyweightedLR– LRwithRegularizaZons– FeatureselecZon*
11/30/16 13
Dr.YanjunQi/UVACS6316/f16

ADataset
• Data/points/instances/examples/samples/records:[rows]• Features/a0ributes/dimensions/independentvariables/covariates/
predictors/regressors:[columns,exceptthelast]• Target/outcome/response/label/dependentvariable:special
columntobepredicted[lastcolumn]
11/30/16 14
YisconZnuousOutput Y as
continuous values
Dr.YanjunQi/UVACS6316/f16

(1) Multivariate Linear Regression
Regression
Y = Weighted linear sum of X’s
Least-squares
Linear algebra
Regression coefficients
Task
Representation
Score Function
Search/Optimization
Models, Parameters
y = f (x) =θ0 +θ1x1 +θ2x
2
11/30/16 15θ
Dr.YanjunQi/UVACS6316/f16

(2) Multivariate Linear Regression with basis Expansion
Regression
Y = Weighted linear sum of (X basis expansion)
Least-squares
Linear algebra
Regression coefficients
Task
Representation
Score Function
Search/Optimization
Models, Parameters
y =θ0 + θ jϕ j (x)j=1
m∑ =ϕ(x)θ
11/30/16 16
Dr.YanjunQi/UVACS6316/f16

(3) Locally Weighted / Kernel Regression
Regression
Y = local weighted linear sum of X’s
Least-squares
Linear algebra
Local Regression coefficients
(conditioned on each test point)
Task
Representation
Score Function
Search/Optimization
Models, Parameters
0000 )(ˆ)(ˆ)(ˆ xxxxf βα +=
minα (x0 ),β (x0 )
Kλ (xi, x0 )[yi −α(x0 )−β(x0 )xi ]2
i=1
N
∑11/30/16 17
Dr.YanjunQi/UVACS6316/f16
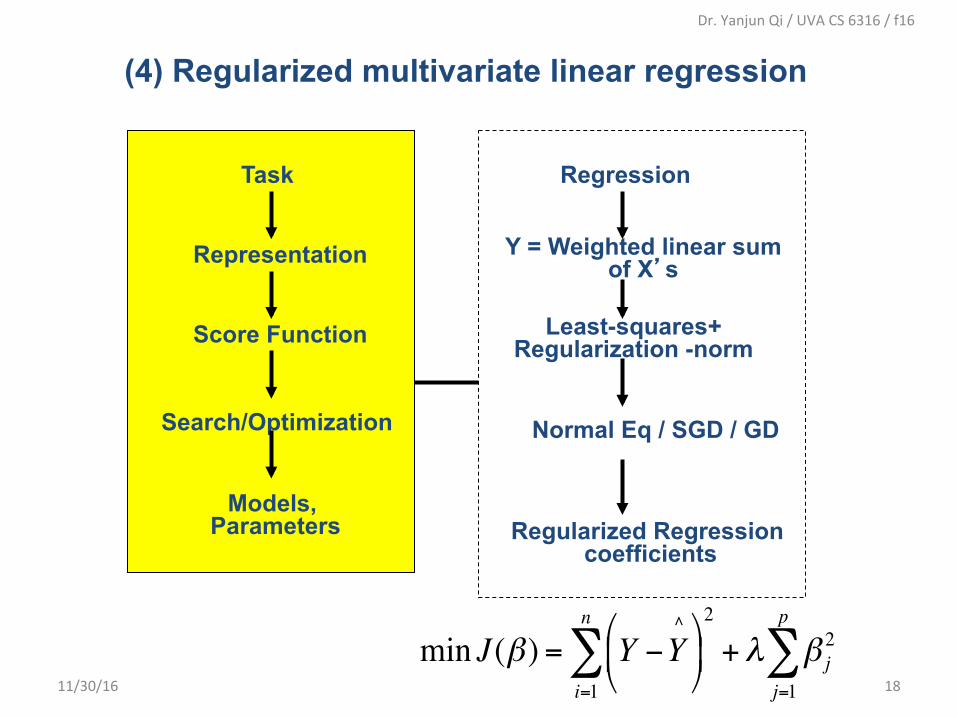
(4) Regularized multivariate linear regression
Regression
Y = Weighted linear sum of X’s
Least-squares+ Regularization -norm
Normal Eq / SGD / GD
Regularized Regression coefficients
Task
Representation
Score Function
Search/Optimization
Models, Parameters
min J(β) = Y −Y^"
#$
%&'2
i=1
n
∑ +λ β j2
j=1
p
∑11/30/16 18
Dr.YanjunQi/UVACS6316/f16

(5) Feature Selection
Dimension Reduction
n/a
Many possible options
Greedy (mostly)
Reduced subset of features
Task
Representation
Score Function
Search/Optimization
Models, Parameters
11/30/16 19
Dr.YanjunQi/UVACS6316/f16

(5)FeatureSelecZon• Thousandstomillionsoflowlevelfeatures:selectthemostrelevantonetobuildbeVer,faster,andeasiertounderstandlearningmachines.
X
p
n
p’
FromDr.IsabelleGuyon11/30/16 20
Dr.YanjunQi/UVACS6316/f16

Today
q ReviewofMLmethodscoveredsofarq Regression(supervised)q ClassificaZon(supervised)q Unsupervisedmodelsq Learningtheory
q ReviewofAssignmentscoveredsofar
11/30/16 21
Dr.YanjunQi/UVACS6316/f16

Whatwehavecovered(II)q SupervisedClassificaZonmodels
– SupportVectorMachine– BayesClassifier– LogisZcRegression– K-nearestNeighbor– Randomforest/DecisionTree– NeuralNetwork(e.g.MLP)
11/30/16 22
Dr.YanjunQi/UVACS6316/f16

ThreemajorsecZonsforclassificaZon
• We can divide the large variety of classification approaches into roughly three major types
1. Discriminative - directly estimate a decision rule/boundary - e.g., logistic regression, support vector machine, decisionTree 2. Generative: - build a generative statistical model - e.g., naïve bayes classifier, Bayesian networks 3. Instance based classifiers - Use observation directly (no models) - e.g. K nearest neighbors
11/30/16 23
Dr.YanjunQi/UVACS6316/f16

ADatasetforclassificaZon
• Data/points/instances/examples/samples/records:[rows]• Features/a0ributes/dimensions/independentvariables/covariates/predictors/regressors:[columns,exceptthelast]• Target/outcome/response/label/dependentvariable:specialcolumntobepredicted[lastcolumn]
11/30/16 24
Output as Discrete Class Label
C1, C2, …, CL
C
CDr.YanjunQi/UVACS6316/f16

(1) Support Vector Machine
classification
Kernel Func K(xi, xj)
Margin + Hinge Loss (optional)
QP with Dual form
Dual Weights
Task
Representation
Score Function
Search/Optimization
Models, Parameters
€
w = α ixiyii∑
argminw,b
wi2
i=1p∑ +C εi
i=1
n
∑
subject to ∀xi ∈ Dtrain : yi xi ⋅w+b( ) ≥1−εi
K(x, z) :=Φ(x)TΦ(z)
11/30/16 25
Dr.YanjunQi/UVACS6316/f16

(2) Bayes Classifier
classification
Prob. models p(X|C)
EPE with 0-1 loss, with Log likelihood(optional)
MLE
Prob. Models’ Parameter
Task
Representation
Score Function
Search/Optimization
Models, Parameters
P(X1, ⋅ ⋅ ⋅,Xp |C)
argmaxk
P(C _ k | X) = argmaxk
P(X,C) = argmaxk
P(X |C)P(C)
P(Xj |C = ck ) =1
2πσ jk
exp −(X j−µ jk )
2
2σ jk2
"
#$$
%
&''
P(W1 = n1,...,Wv = nv | ck ) =N !
n1k !n2k !..nvk !θ1kn1kθ2k
n2k ..θvknvk
p(Wi = true | ck ) = pi,kBernoulliNaïve
GaussianNaive
Mul#nomial11/30/16 26
Dr.YanjunQi/UVACS6316/f16

Naïve Bayes Classifier
Difficulty: learning the joint probability
• Naïve Bayes classification – Assumption that all input attributes are conditionally independent!
P(X1, ⋅ ⋅ ⋅,Xp |C)
P(X1,X2, ⋅ ⋅ ⋅,Xp |C) = P(X1 | X2, ⋅ ⋅ ⋅,Xp,C)P(X2, ⋅ ⋅ ⋅,Xp |C) = P(X1 |C)P(X2, ⋅ ⋅ ⋅,Xp |C) = P(X1 |C)P(X2 |C) ⋅ ⋅ ⋅P(Xp |C)
11/30/16
AdaptfromProf.KeChenNBslides27
C
X1 X2 X5 X3 X4 X6
Dr.YanjunQi/UVACS6316/f16

(3) Logistic Regression
classification
Log-odds(Y) = linear function of X’s
EPE, with conditional Log-likelihood
Iterative (Newton) method
Logistic weights
Task
Representation
Score Function
Search/Optimization
Models, Parameters
P(c =1 x) = eα+βx
1+ eα+βx11/30/16 28
Dr.YanjunQi/UVACS6316/f16

LogisZcRegression—when?
LogisZcregressionmodelsareappropriatefortargetvariablecodedas0/1.
Weonlyobserve“0”and“1”forthetargetvariable—butwethinkofthetargetvariableconceptuallyasaprobabilitythat“1”willoccur.
This means we use Bernoulli distribution to model the target variable with its Bernoulli parameter p=p(y=1|x) predefined. The main interest è predicting the probability that an event occurs (i.e., the probability that p(y=1|x) ).
11/30/16 29
Dr.YanjunQi/UVACS6316/f16

0.0
0.2
0.4
0.6
0.8
1.0e.g.Probabilityofdisease
x
P (C=1|X)
11/30/16 30
DiscriminaZve LogisZcregressionmodelsforbinarytargetvariablecoded0/1.
P(c =1 x) = eα+βx
1+ eα+βx
ln P(c =1| x)P(c = 0 | x)!
"#
$
%&= ln
P(c =1| x)1−P(c =1| x)!
"#
$
%&=α +β1x1 +β2x2 +...+βpxp
logisZcfuncZon
LogitfuncZon
DecisionBoundaryèequalstozero
Dr.YanjunQi/UVACS6316/f16

Discriminative vs. Generative GeneraZveapproach-ModelthejointdistribuZonp(X,C)using p(X|C=ck)andp(C=ck)DiscriminaZveapproach-ModelthecondiZonaldistribuZonp(c|X)directly
Classprior
e.g.,

Discriminative vs. Generative
● Empirically,generaZveclassifiersapproachtheirasymptoZcerrorfasterthandiscriminaZveones○ Goodforsmalltrainingset○ Handlemissingdatawell(EM)
● Empirically,discriminaZveclassifiershavelowerasymptoZcerrorthangeneraZveones○ Goodforlargertrainingset

(4) K-Nearest Neighbor
classification
Local Smoothness
EPE with L2 loss è conditional mean
NA
Training Samples
Task
Representation
Score Function
Search/Optimization
Models, Parameters
11/30/16 33
Dr.YanjunQi/UVACS6316/f16

• k-Nearest neighbor classifier is a lazy learner – Does not build model explicitly. – Unlike eager learners such as decision tree
induction and rule-based systems. – Classifying unknown samples is relatively
expensive. • k-Nearest neighbor classifier is a local model,
vs. global model of linear classifiers.
Nearest neighbor classification
11/30/16 34
Dr.YanjunQi/UVACS6316/f16

(5) Decision Tree / Random Forest
Greedy to find partitions
Split Purity measure / e.g. IG / cross-entropy / Gini /
Tree Model (s), i.e. space partition
Task
Representation
Score Function
Search/Optimization
Models, Parameters
11/30/16 35
Classification
Partition feature space into set of rectangles, local smoothness
Dr.YanjunQi/UVACS6316/f16

Anatomyofadecisiontree
overcast
high normal falsetrue
sunny rain
No NoYes Yes
Yes
Outlook
HumidityWindy
Eachnodeisatestononefeature/aVribute
PossibleaJributevaluesofthenode
Leavesarethedecisions
11/30/16 36
Dr.YanjunQi/UVACS6316/f16

Decisiontrees• DecisiontreesrepresentadisjuncZonofconjuncZonsofconstraintsontheaJributevaluesofinstances.
• (Outlook ==overcast) • OR • ((Outlook==rain) and (Windy==false)) • OR • ((Outlook==sunny) and (Humidity=normal)) • => yes play tennis
11/30/16 37
Dr.YanjunQi/UVACS6316/f16

InformaIongain
• IG(X_i,Y)=H(Y)-H(Y|X_i)ReducZoninuncertaintybyknowingafeatureX_i
InformaZongain:=(informaZonbeforesplit)–(informaZonawersplit)=entropy(parent)–[averageentropy(children)]
Fixed thelower,thebeJer(childrennodesarepurer)
– ForIG,thehigher,thebeJer=
11/30/16 38
Dr.YanjunQi/UVACS6316/f16

RandomForestClassifierNexamples
....…
....…
Takehemajorityvote
Mfeatures
11/30/16 39
Dr.YanjunQi/UVACS6316/f16

(6) Neural Network
conditional Log-likelihood , Cross-Entropy / MSE
SGD / Backprop
NN network Weights
Task
Representation
Score Function
Search/Optimization
Models, Parameters
11/30/16 40
Classification / Regression
Multilayer Network topology
Dr.YanjunQi/UVACS6316/f16

Logistic regression
Logistic regression could be illustrated as a module
On input x, it outputs ŷ:
where
Draw a logisticregression unit as:
Σ
x1
x2
x3
+1
ŷ=P(Y=1|X,Θ)wT !x + b
11+ e− z
Bias
Summing function
Activation function
Output
11/30/16 41
Dr.YanjunQi/UVACS6316/f16

MulZ-LayerPerceptron(MLP)String a lot of logistic units together. Example: 3 layer network:
x1
x2
x3
+1 +1
a3
a2
a1
Layer1 Layer2
Layer3
hiddeninput output
y
11/30/16 42
Dr.YanjunQi/UVACS6316/f16

Backpropagation
● Back-propagaZontrainingalgorithm
Network activation Forward Step
Error propagation Backward Step
11/30/16 43
Dr.YanjunQi/UVACS6316/f16

DeepLearningWay:Learningfeatures/RepresentaIonfromdata
Feature Engineering ü Most critical for accuracy ü Account for most of the computation for testing ü Most time-consuming in development cycle ü Often hand-craft and task dependent in practice
Feature Learning ü Easily adaptable to new similar tasks ü Layerwise representation ü Layer-by-layer unsupervised training ü Layer-by-layer supervised training 4411/30/16
Dr.YanjunQi/UVACS6316/f16

Today
q ReviewofMLmethodscoveredsofarq Regression(supervised)q ClassificaZon(supervised)q Unsupervisedmodelsq Learningtheory
q ReviewofAssignmentscoveredsofar
11/30/16 45
Dr.YanjunQi/UVACS6316/f16

Whatwehavecovered(III)
q Unsupervisedmodels– DimensionReducZon(PCA)– Hierarchicalclustering– K-meansclustering– GMM/EMclustering
11/30/16 46
Dr.YanjunQi/UVACS6316/f16

AnunlabeledDatasetX
• Data/points/instances/examples/samples/records:[rows]• Features/a0ributes/dimensions/independentvariables/covariates/predictors/regressors:[columns]
11/30/16 47
a data matrix of n observations on p variables x1,x2,…xp
Unsupervisedlearning=learningfromraw(unlabeled,unannotated,etc)data,asopposedtosuperviseddatawherealabelofexamplesisgiven
Dr.YanjunQi/UVACS6316/f16

(0) Principal Component Analysis
Dimension Reduction
Gaussian assumption
Direction of maximum variance
Eigen-decomp
Principal components
Task
Representation
Score Function
Search/Optimization
Models, Parameters
11/30/16 48
Dr.YanjunQi/UVACS6316/f16

Whatwehavecovered(III)
q Unsupervisedmodels– DimensionReducZon(PCA)– Hierarchicalclustering– K-meansclustering– GMM/EMclustering
11/30/16 49
Dr.YanjunQi/UVACS6316/f16

• Find groups (clusters) of data points such that data points in a group will be similar (or related) to one another and different from (or unrelated to) the data points in other groups
Whatisclustering?
Inter-cluster distances are maximized
Intra-cluster distances are
minimized
11/30/16 50
Dr.YanjunQi/UVACS6316/f16

11/30/16
Issuesforclustering• Whatisanaturalgroupingamongtheseobjects?
– DefiniZonof"groupness"• Whatmakesobjects“related”?
– DefiniZonof"similarity/distance"• RepresentaZonforobjects
– Vectorspace?NormalizaZon?• Howmanyclusters?
– Fixedapriori?– Completelydatadriven?
• Avoid“trivial”clusters-toolargeorsmall• ClusteringAlgorithms
– ParZZonalalgorithms– Hierarchicalalgorithms
• FormalfoundaZonandconvergence51
Dr.YanjunQi/UVACS6316/f16

11/30/16
ClusteringAlgorithms
• ParZZonalalgorithms– Usuallystartwitharandom(parZal)parZZoning
– RefineititeraZvely• Kmeansclustering• Mixture-Modelbasedclustering
• Hierarchicalalgorithms– BoJom-up,agglomeraZve– Top-down,divisive
52
Dr.YanjunQi/UVACS6316/f16

(1) Hierarchical Clustering
Clustering
Distance measure
No clearly defined loss
greedy bottom-up (or top-down)
Dendrogram (tree)
Task
Representation
Score Function
Search/Optimization
Models, Parameters
11/30/16 53
Dr.YanjunQi/UVACS6316/f16

Example: single link
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
04507
0
54)3,2,1(
54)3,2,1(
12 3 4
5
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
0458079
030
543)2,1(
543)2,1(
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
0458907910
03602
0
54321
54321
5},min{ 5),3,2,1(4),3,2,1()5,4(),3,2,1( == ddd
11/30/16 54
Dr.YanjunQi/UVACS6316/f16

(2) K-means Clustering
Clustering
Spherical clusters
Sum-of-square distance to centroid
K-means (special case of EM) algorithm
Cluster membership &
centroid
Task
Representation
Score Function
Search/Optimization
Models, Parameters
11/30/16 55
Dr.YanjunQi/UVACS6316/f16

11/30/16
56
K-meansClustering:Step2-Determinethemembershipofeachdatapoints
Dr.YanjunQi/UVACS6316/f16

(3) GMM Clustering
Clustering
Likelihood
EM algorithm
Each point’s soft membership &
mean / covariance per cluster
Task
Representation
Score Function
Search/Optimization
Models, Parameters
11/30/16 57
MixtureofGaussians
Dr.YanjunQi/UVACS6316/f16
log p(x = xi )i=1
n
∏i∑ = log p(µ = µ j )
1
2π( )p/2Σ j
1/2e−1
2!x−!µ j( )T Σ j
−1 !x−!µ j( )
µ j
∑⎡
⎣
⎢⎢⎢
⎤
⎦
⎥⎥⎥i
∑

11/30/16
58
ExpectaZon-MaximizaZonfortrainingGMM
• Start:– "Guess"thecentroidmkandcovarianceSkofeachoftheKclusters
• Loop each cluster, revising both the mean (centroid position) and covariance (shape)
Dr.YanjunQi/UVACS6316/f16
For each point, revising its proportions belonging to each of the K clusters

Dr.YanjunQi/UVACS6316/f16
59
Compare:K-means
• TheEMalgorithmformixturesofGaussiansislikea"sowversion"oftheK-meansalgorithm.
• IntheK-means“E-step”wedohardassignment:
• IntheK-means“M-step”weupdatethemeansastheweightedsumofthedata,butnowtheweightsare0or1:
11/30/16

Today
q ReviewofMLmethodscoveredsofarq Regression(supervised)q ClassificaZon(supervised)q Unsupervisedmodelsq Learningtheory
q ReviewofAssignmentscoveredsofar
11/30/16 60
Dr.YanjunQi/UVACS6316/f16

Whatwehavecovered(IV)
q Learningtheory/ModelselecZon– K-foldscrossvalidaZon– ExpectedpredicZonerror– Biasandvariancetradeoff
11/30/16 61
Dr.YanjunQi/UVACS6316/f16

CV-basedModelSelecZonWe’retryingtodecidewhichalgorithm/
hyperparametertouse.• Wetraineachmodelandmakeatable...
11/30/16
Dr.YanjunQi/UVACS6316/f16
62
Hyperparametertuning….

Dr.YanjunQi/UVACS6316/f16
63
Whichkindofcross-validaZon?
11/30/16

Whatwehavecovered(IV)
q Learningtheory/ModelselecZon– K-foldscrossvalidaZon– ExpectedpredicZonerror– Biasandvariancetradeoff
11/30/16 64
Dr.YanjunQi/UVACS6316/f16

StaZsZcalDecisionTheory
• Random input vector: X • Random output variable:Y • Joint distribution: Pr(X,Y ) • Loss function L(Y, f(X))
• Expected prediction error (EPE): •
€
EPE( f ) = E(L(Y, f (X))) = L(y, f (x))∫ Pr(dx,dy)
e.g. = (y − f (x))2∫ Pr(dx,dy)Consider
population distribution
e.g. Squared error loss (also called L2 loss )
11/30/16 65
Dr.YanjunQi/UVACS6316/f16

Bias-VarianceTrade-offforEPE:
EPE (x_0) = noise2 + bias2 + variance
Unavoidable error
Error due to incorrect
assumptions
Error due to variance of training
samples
Slidecredit:D.Hoiem11/30/16 66
Dr.YanjunQi/UVACS6316/f16

Bias-Variance Tradeoff / Model Selection
67
underfit region overfit region
11/30/16
Dr.YanjunQi/UVACS6316/f16

Model “bias” & Model “variance”
• Middle RED: – TRUE function
• Error due to bias: – How far off in general
from the middle red
• Error due to variance: – How wildly the blue
points spread
11/30/16 68
Dr.YanjunQi/UVACS6316/f16

needtomakeassumpZonsthatareabletogeneralize
• Components of generalization error – Bias: how much the average model over all training sets differ from
the true model? • Error due to inaccurate assumptions/simplifications made by the
model – Variance: how much models estimated from different training sets
differ from each other • Underfitting: model is too “simple” to represent all the
relevant class characteristics – High bias and low variance – High training error and high test error
• Overfitting: model is too “complex” and fits irrelevant characteristics (noise) in the data – Low bias and high variance – Low training error and high test error
Slidecredit:L.Lazebnik11/30/16 69
Dr.YanjunQi/UVACS6316/f16

Today
q ReviewofMLmethodscoveredsofarq Regression(supervised)q ClassificaZon(supervised)q Unsupervisedmodelsq Learningtheory
q ReviewofAssignmentscoveredsofar
11/30/16 70
Dr.YanjunQi/UVACS6316/f16

Task
Machine Learning in a Nutshell
Representation
Score Function
Search/Optimization
Models, Parameters
11/30/16 71
MLgrewoutofworkinAIOp#mizeaperformancecriterionusingexampledataorpastexperience,Aimingtogeneralizetounseendata
Dr.YanjunQi/UVACS6316/f16

Whatwehavecoveredforeachcomponent
11/30/16
Dr.YanjunQi/UVACS6316/f16
72
Task Regression,classificaZon,clustering,dimen-reducZon
RepresentaIon
Linearfunc,nonlinearfuncZon(e.g.polynomialexpansion),locallinear,logisZcfuncZon(e.g.p(c|x)),tree,mulZ-layer,prob-densityfamily(e.g.Bernoulli,mulZnomial,Gaussian,mixtureofGaussians),localfuncsmoothness,kernelmatrix,localsmoothness,parZZonoffeaturespace,
ScoreFuncIon
MSE,Margin,log-likelihood,EPE(e.g.L2lossforKNN,0-1lossforBayesclassifier),cross-entropy,clusterpointsdistancetocenters,variance,condiZonallog-likelihood,completedata-likelihood,regularizedlossfunc(e.g.L1,L2),
Search/OpImizaIon
NormalequaZon,gradientdescent,stochasZcGD,Newton,Linearprogramming,QuadraZcprogramming(quadraZcobjecZvewithlinearconstraints),greedy,EM,asyn-SGD,eigenDecomp,backprop
Models,Parameters
Linearweightvector,basisweightvector,localweightvector,dualweights,trainingsamples,tree-dendrogram,mulZ-layerweights,principlecomponents,member(sow/hard)assignment,clustercentroid,clustercovariance(shape),…

Today
q ReviewofMLmethodscoveredsofarq Regression(supervised)q ClassificaZon(supervised)q Unsupervisedmodelsq Learningtheory
q ReviewofAssignmentscoveredsofar
11/30/16 73
Dr.YanjunQi/UVACS6316/f16

HW1
• Q1:Linearalgebrareview• Q2:Linearregression+LOOCV
– Regression– EvaluaZonpipeline
• Q3:MachinelearningpipelinepracZce– Basicpipeline– GUIToolbox– EvaluaZon
11/30/16
Dr.YanjunQi/UVACS6316/f16
74
Task
Representation
Score Function
Search/Optimization
Models, Parameters

HW2
• Q1:Linearregressionmodelfi~ng– Dataloading– Basiclinearregression– Threewaystotrain:NormalequaZon/SGD/BatchGD
– Polynomialregression
• Q2:Ridgeregression– MathderivaZonofridge– Understandwhy/howRidge– ModelselecZonofRidgewithK-CV11/30/16
Dr.YanjunQi/UVACS6316/f16
75
Task
Representation
Score Function
Search/Optimization
Models, Parameters

HW3
• Q1:SupportVectorMachineswithScikit-Learn– Datapreprocessing– HowtouseSVMpackage– ModelselecZonforSVM– ModelselecZonpipelinewithtrain-vali,ortrain-CV;thentest
11/30/16
Dr.YanjunQi/UVACS6316/f16
76
Task
Representation
Score Function
Search/Optimization
Models, Parameters

HW5
• Q1:NaiveBayesClassifierforText-baseMovieReviewClassificaZon– Preprocessingoftextsamples– BOWDocumentRepresentaZon– MulZnomialNaiveBayesClassifier
• BOWway• Languagemodelway
– MulZvariateBernoulliNaiveBayesClassifier
11/30/16
Dr.YanjunQi/UVACS6316/f16
77
Task
Representation
Score Function
Search/Optimization
Models, Parameters

HW6
• Q1:NeuralNetworkTensorflowPlayground– InteracZvelearningofMLP– Featureengineeringvs.– Featurelearning
• Q2:ImageClassificaZon– Toolusing– DT/KNN/SVM– PCAeffectforimageclassificaZon
11/30/16
Dr.YanjunQi/UVACS6316/f16
78
Task
Representation
Score Function
Search/Optimization
Models, Parameters

HW6
• Q3:UnsupervisedClusteringofaudiodataandconsensusdata– Dataloading– K-meanclustering– GMMclustering– HowtofindK:knee-findingplot– Howtomeasureclustering:purityMetric
11/30/16
Dr.YanjunQi/UVACS6316/f16
79
Task
Representation
Score Function
Search/Optimization
Models, Parameters

References
q HasZe,Trevor,etal.TheelementsofstaZsZcallearning.Vol.2.No.1.NewYork:Springer,2009.
q Prof.M.A.Papalaskar’sslidesq Prof.AndrewNg’sslides
11/30/16 80
Dr.YanjunQi/UVACS6316/f16