using ceph for large hadron collider data
TRANSCRIPT

Lincoln Bryant • University of Chicago Ceph Day ChicagoAugust 18th, 2015
Using Ceph for Large Hadron Collider Data

about us
● ATLAS at the Large Hadron Collider at CERN
○ Tier2 center at UChicago, Indiana, UIUC/NCSA:
■ 12,000 processing slots, 4 PB of storage
○ 140 PB on disk in 120 data centers worldwide + CERN
● Open Science Grid: high throughput computing
○ Supporting “large science” and small research labs on
campuses nationwide
○ >100k cores, >800M CPU-hours/year, ~PB transfer/day
● Users of Ceph for 2 years
○ started with v0.67, using v0.94 now
○ 1PB, more to come
ATLAS site
5.4 miles(17 mi circumference)
⇐ Standard Model of Particle Physics
Higgs boson: final piece discoved in 2012⇒ Nobel Prize
2015 → 2018:Cool new physics searches underway at 13 TeV
← credit: Katherine Leney (UCL, March 2015)
LHC

ATLAS detector
● Run2 center of mass energy = 13 TeV (Run1: 8 TeV)● 40 MHz proton bunch crossing rate
○ 20-50 collisions/bunch crossing (“pileup”) ● Trigger (filters) reduces raw rate to ~ 1kHz ● Events are written to disk at ~ 1.5 GB/s
LHC

ATLAS detector100M active sensors
torroidmagnets
inner tracking
person(scale)
Not shown:Tile calorimeters (electrons, photons)Liquid argon calorimeter (hadrons) Muon chambersForward detectors

ATLAS data & analysis
Primary data from CERN globally processed (event reconstruction and analysis)
Role for Ceph:
analysis datasets & object store for single events
3x100 Gbps

Ceph technologies used
● Currently:○ RBD○ CephFS
● Future:○ librados○ RadosGW

Our setup
● Ceph v0.94.2 on Scientific Linux 6.6● 14 storage servers● 12 x 6 TB disks, no dedicated journal devices
○ Could buy PCI-E SSD(s) if the performance is needed● Each connected at 10 Gbps● Mons and MDS virtualized● CephFS pools using erasure coding + cache
tiering

Ceph Storage Element

● ATLAS uses the Open Science Grid middleware in the US○ among other things: facilitates data management and
transfer between sites● Typical sites will use Lustre, dCache, etc as the
“storage element” (SE)● Goal: Build and productionize a storage
element based on Ceph

XRootD
● Primary file access protocol for accessing files within ATLAS
● Developed by Stanford Linear Accelerator (SLAC)
● Built to support standard high-energy physics analysis tools (e.g., ROOT)○ Supports remote reads, caching, etc
● Federated over WAN via hierarchical system of ‘redirectors’

Ceph and XRootD
● How to pair our favorite access protocol with our favorite storage platform?

Ceph and XRootD
● How to pair our favorite access protocol with our favorite storage platform?
● Original approach: RBD + XRootD○ Performance was acceptable○ Problem: RBD only mounted on 1 machine
■ Can only run one XRootD server○ Could create new RBDs and add to XRootD cluster to
scale out■ Problem: NFS exports for interactive users become
a lot trickier

Ceph and XRootD
● Current approach: CephFS + XRootD○ All XRootD servers mount CephFS via kernel client
■ Scale out is a breeze○ Fully POSIX filesystem, integrates simply with existing
infrastructure● Problem: Users want to r/w to the filesystem
directly via CephFS, but XRootD needs to own the files it serves ○ Permissions issues galore

Squashing with Ganesha NFS
● XRootD does not run in a privileged mode○ Cannot modify/delete files written by users○ Users can’t modify/delete files owned by XRootD
● How to allow users to read/write via FS mount?● Using Ganesha to export CephFS as NFS and
squash all users to the XRootD user○ Doesn’t prevent users from stomping on each other’s
files, but works well enough in practice

Transfers from CERN to Chicago
● Using Ceph as the backend store for data from the LHC
● Analysis input data sets for regional physics analysis
● Easily obtain 200 MB/s from Geneva to our Ceph storage system in Chicago
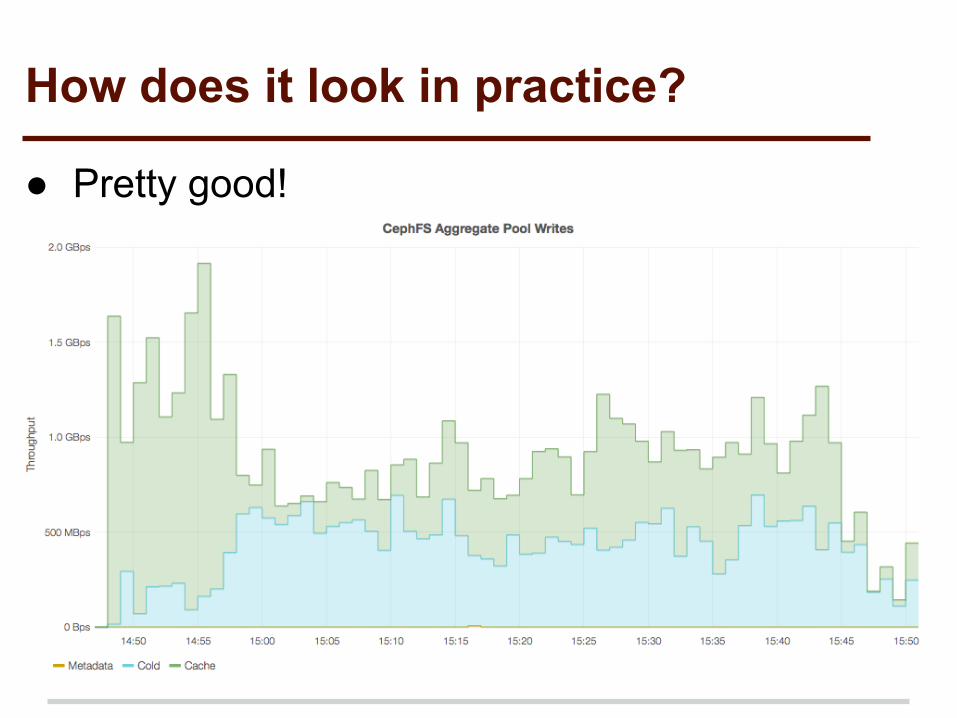
How does it look in practice?
● Pretty good!

Potential evaluations
● XRootD with librados plugin○ Skip the filesystem, write directly to object store○ XRootD handles POSIX filesystem semantics as a
pseudo-MDS○ Three ways of accessing:
■ Directly access files via XRootD clients■ Mount XRootD via FUSE client■ LD_PRELOAD hook to intercept system calls to
/xrootd

Cycle scavenging Ceph servers

Ceph and the batch system
● Goal: Run Ceph and user analysis jobs on the same machines
● Problem: Poorly defined jobs can wreak havoc on the Ceph cluster○ e.g., machine starts heavily swapping, OOM killer starts
killing random processes including OSDs, load spikes to hundreds, etc..

Ceph and the batch system
● Solution: control groups (cgroups)● Configured batch system (HTCondor) to use
cgroups to limit the amount of CPU/RAM used on a per-job basis
● We let HTCondor scavenge about 80% of the cycles○ May need to be tweaked as our Ceph usage increases.

Ceph and the batch system
● Working well thus far:

Ceph and the batch system
● Further work in this area:○ Need to configure the batch system to immediately kill
jobs when Ceph-related load goes up ■ e.g., disk failure
○ Re-nice OSDs to maximum priority○ May require investigation into limiting network saturation

ATLAS Event Service and RadosGW
Higgs boson detection

ATLAS Event Service
● Deliver single ATLAS events for processing○ Rather than a complete dataset - “fine grained”
● Able to efficiently fill opportunistic resources like AWS instances (spot pricing), semi-idle HPC clusters, BOINC
● Can be evicted from resources immediately with negligible loss of work
● Output data is streamed to remote object storage

ATLAS Event Service
● Rather than pay for S3, RadosGW fits this use case perfectly
● Colleagues at Brookhaven National Lab have deployed a test instance already○ interested in providing this service as well○ could potentially federate gateways
● Still in the pre-planning stage at our site

Final thoughts
June 2015 event
17 p-p collisionsin one event

Final thoughts
● Overall, quite happy with Ceph○ Storage endpoint should be in production soon○ More nodes on the way: plan to expand to 2 PB
● Looking forward to new CephFS features like quotas, offline fsck, etc
● Will be experimenting with Ceph pools shared between data centers with low RTT ping in the near future
● Expect Ceph to play important role in ATLAS data processing ⇒ new discoveries

Questions?
cleaning up inside ATLAS :)